

Optical Flow Magnification and Cosine Similarity Feature Fusion Network for Micro-Expression Recognition

Abstract
1. Introduction
- To capture subtle motion variations in micro-expression datasets, this work pioneers the application of optical flow estimation to motion-magnified micro-expression images, marking a significant advancement in the field.
- A novel method is proposed that leverages FAU segmentation to enhance input preprocessing, thereby improving the efficacy of conventional optical flow techniques.
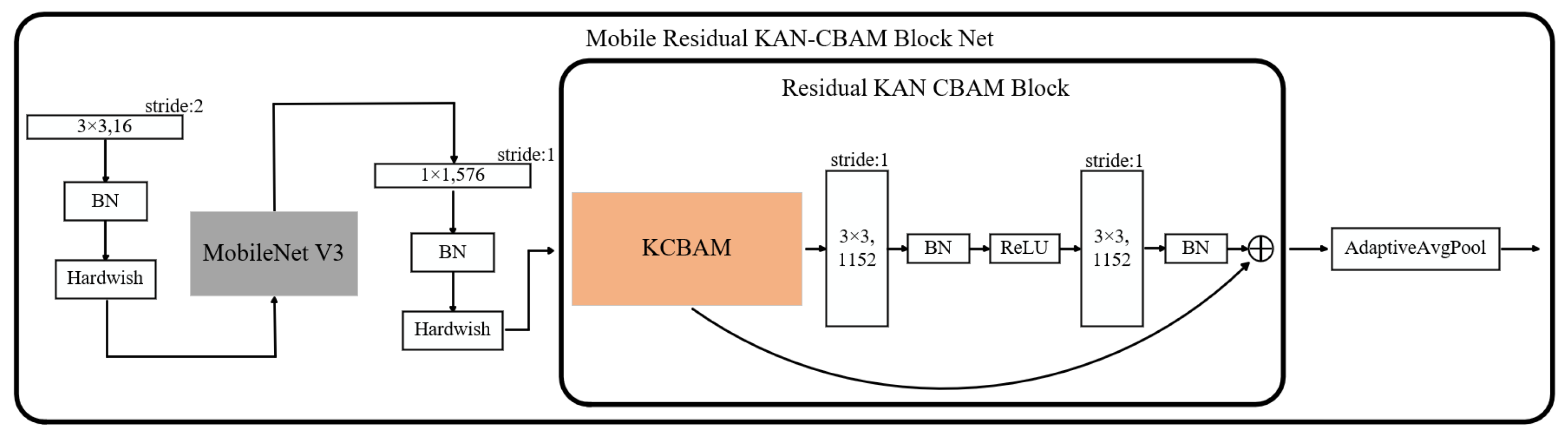
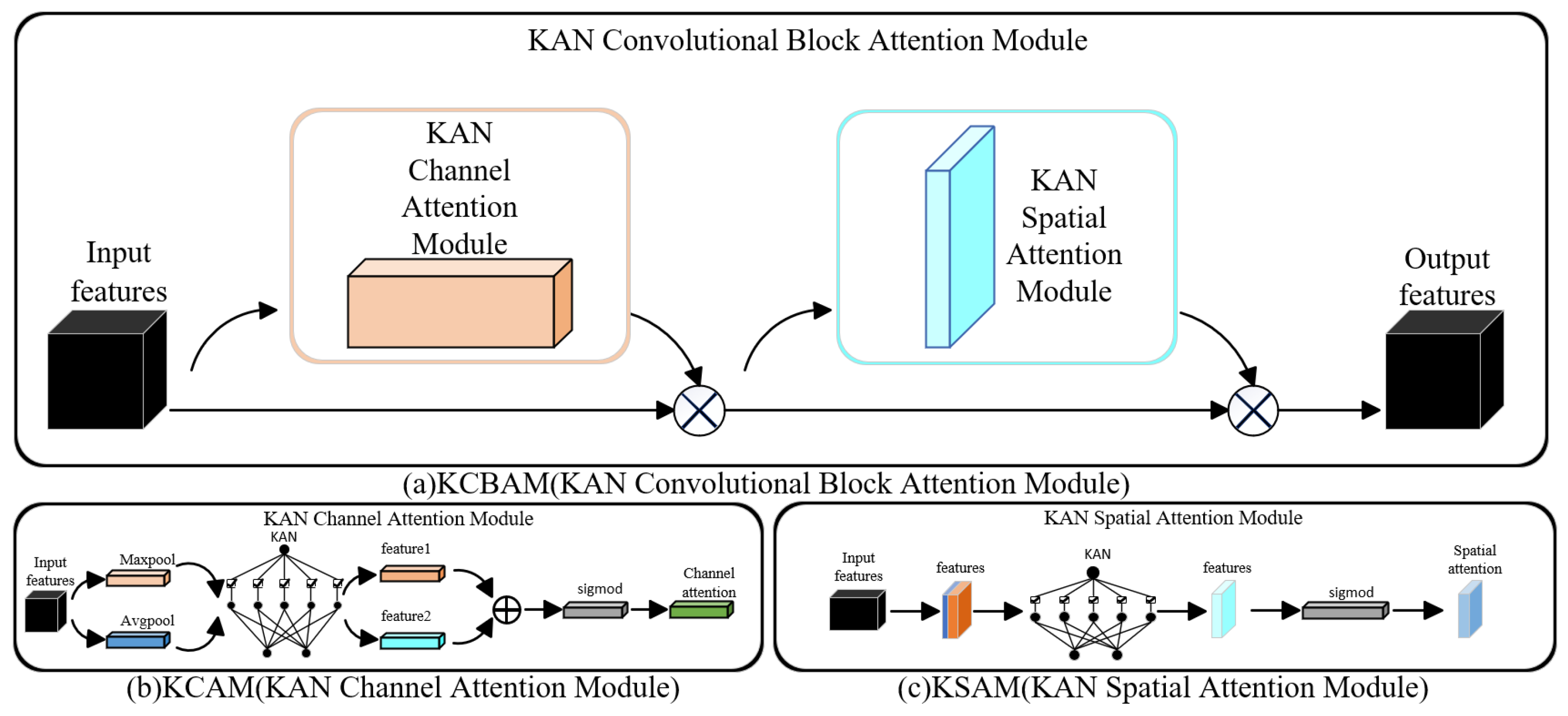
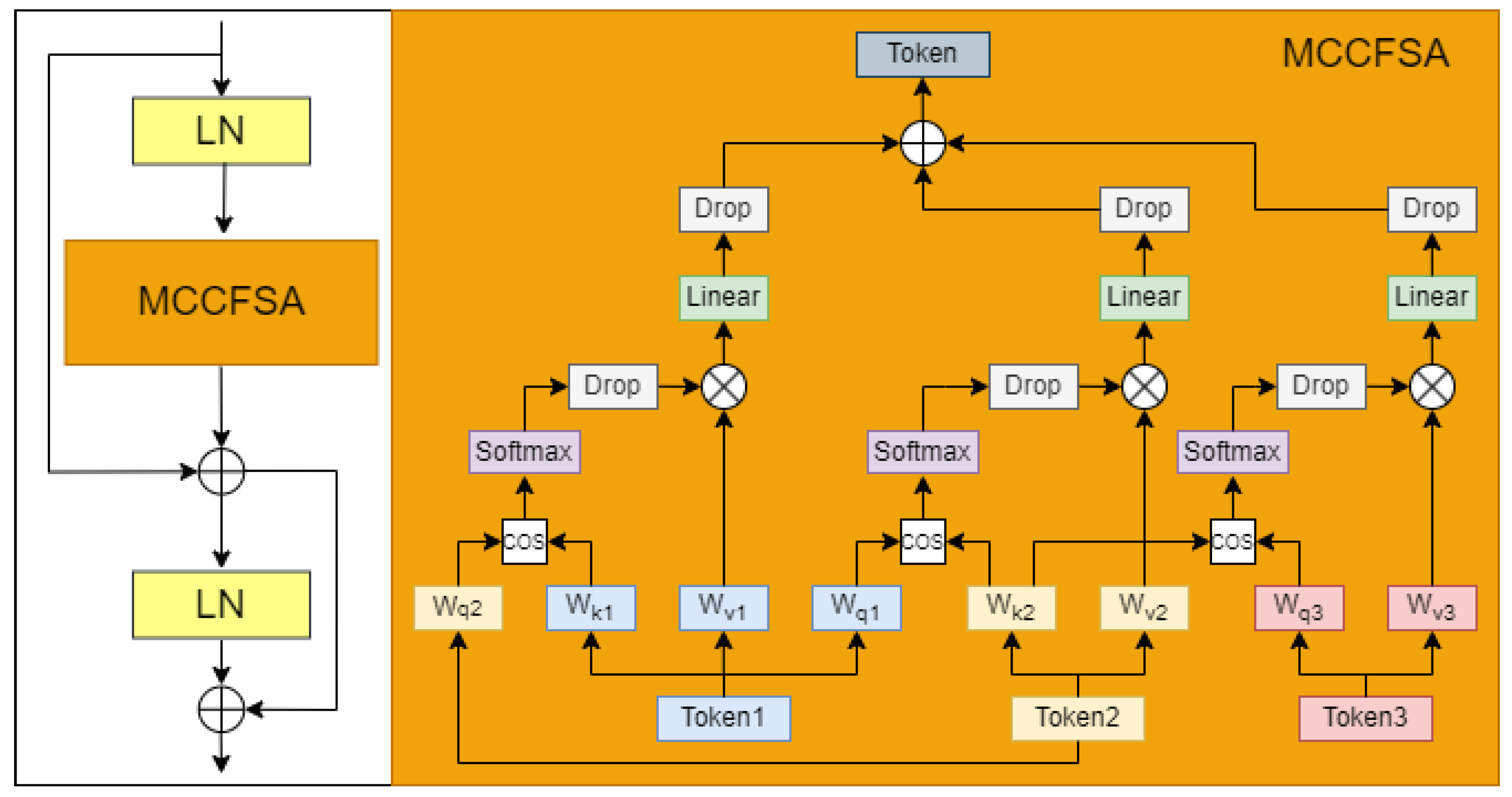
- Two innovative modules are introduced for feature extraction and fusion: the Mobile Residual KAN CBAM Block Net (MRKCBN) and the Multi-Channel Cosine Fusion Module (MCCFM). The MRKCBN enhances feature learning by substituting traditional weight parameters with learnable univariate functions, facilitating the extraction of highly discriminative features. Concurrently, the MCCFM captures subtle yet critical features often overlooked, thereby elevating micro-expression recognition performance.
2. Related Work
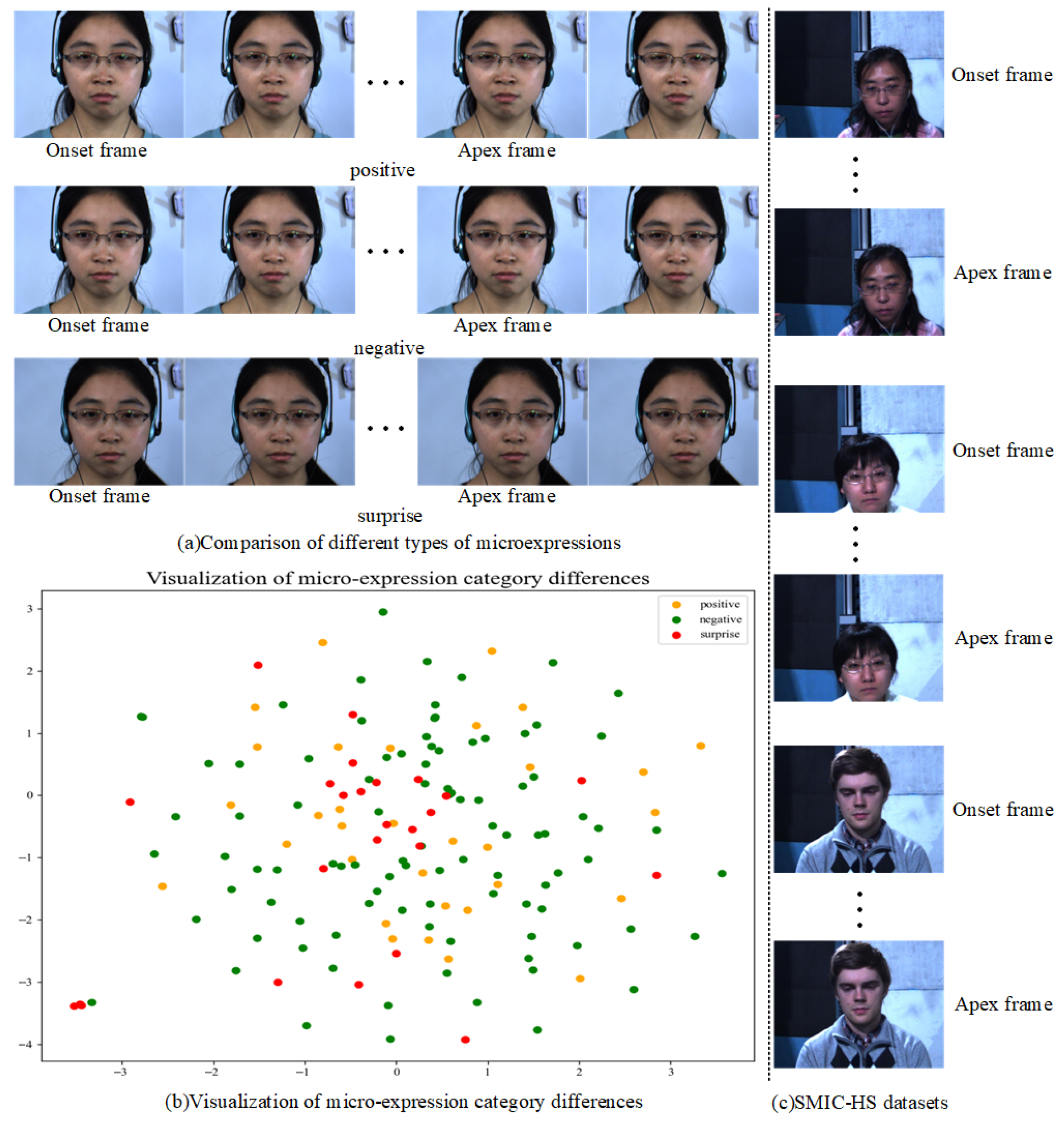
2.1. Micro-Expression Recognition
2.2. KAN (Kolmogorov–Arnold Networks)
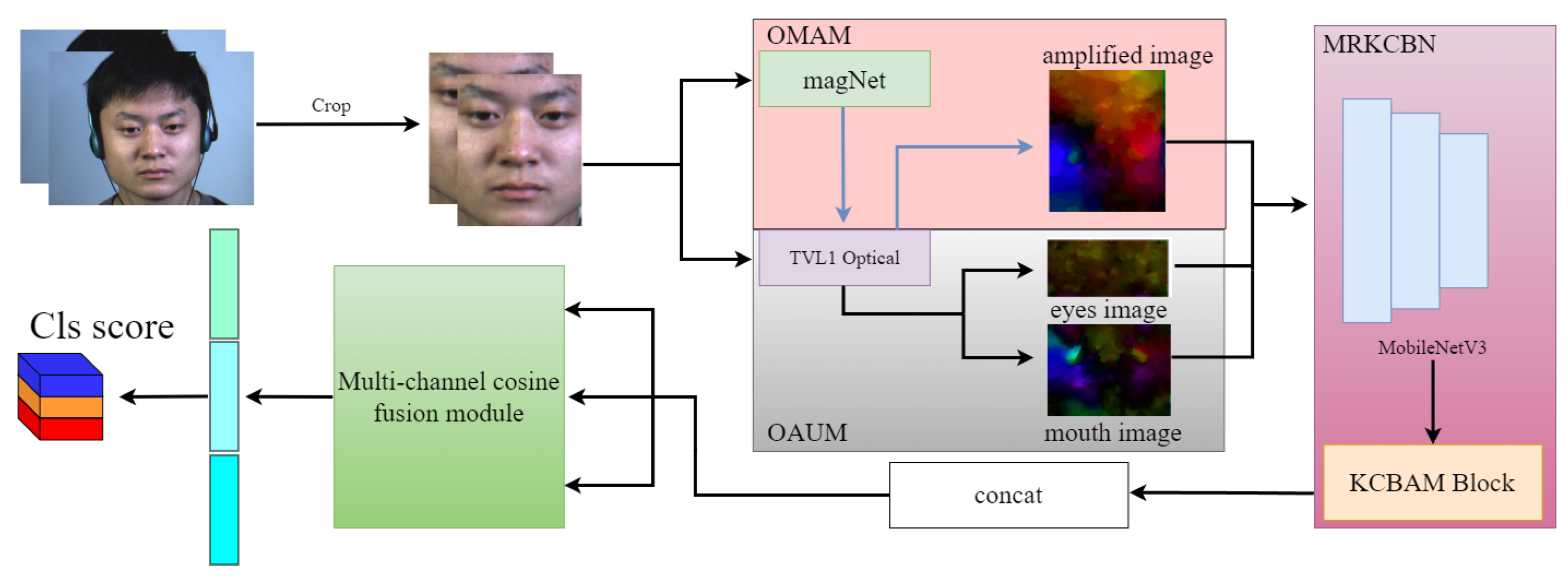
3. The Optical Flow Magnification and Cosine Similarity Feature Fusion Network
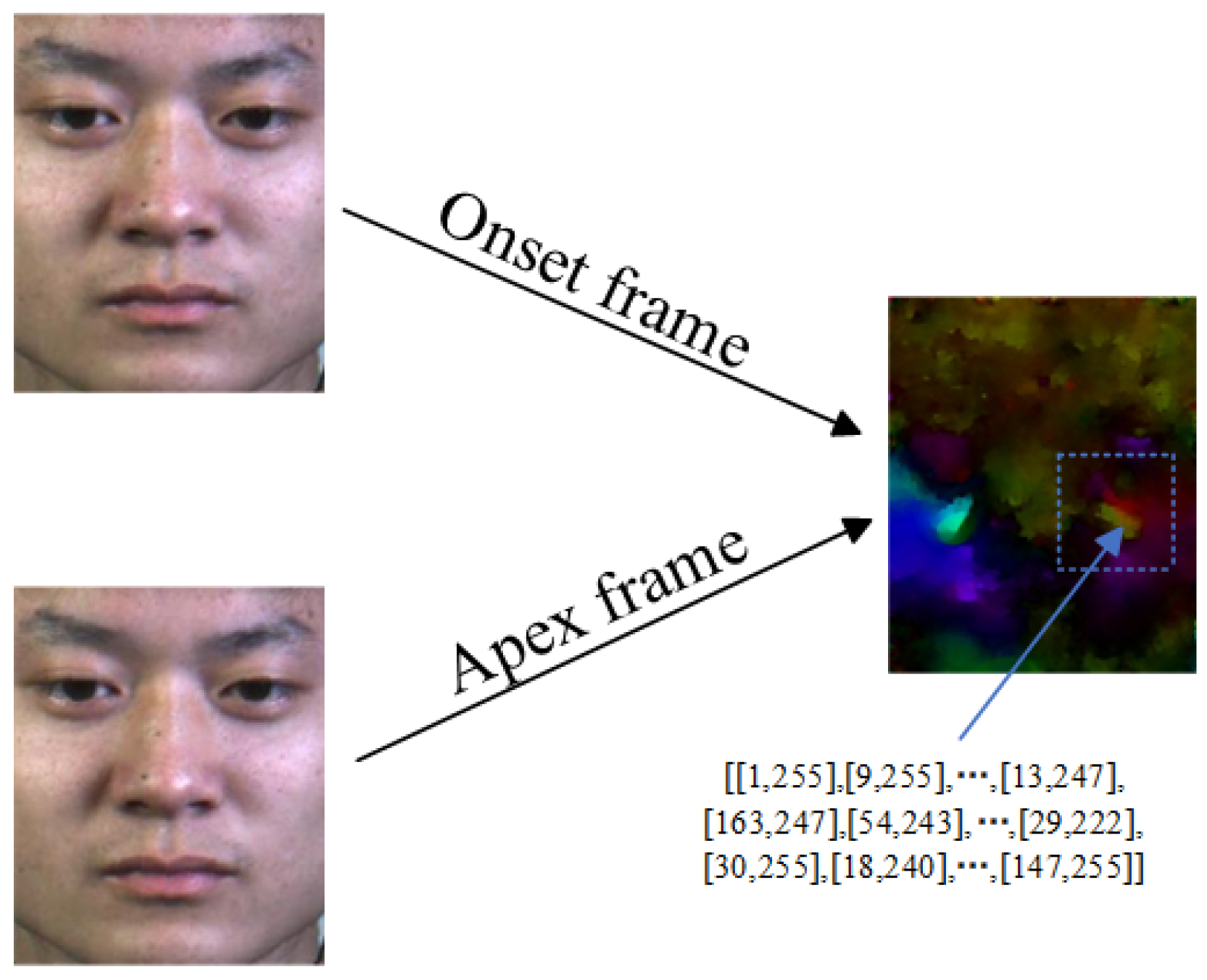
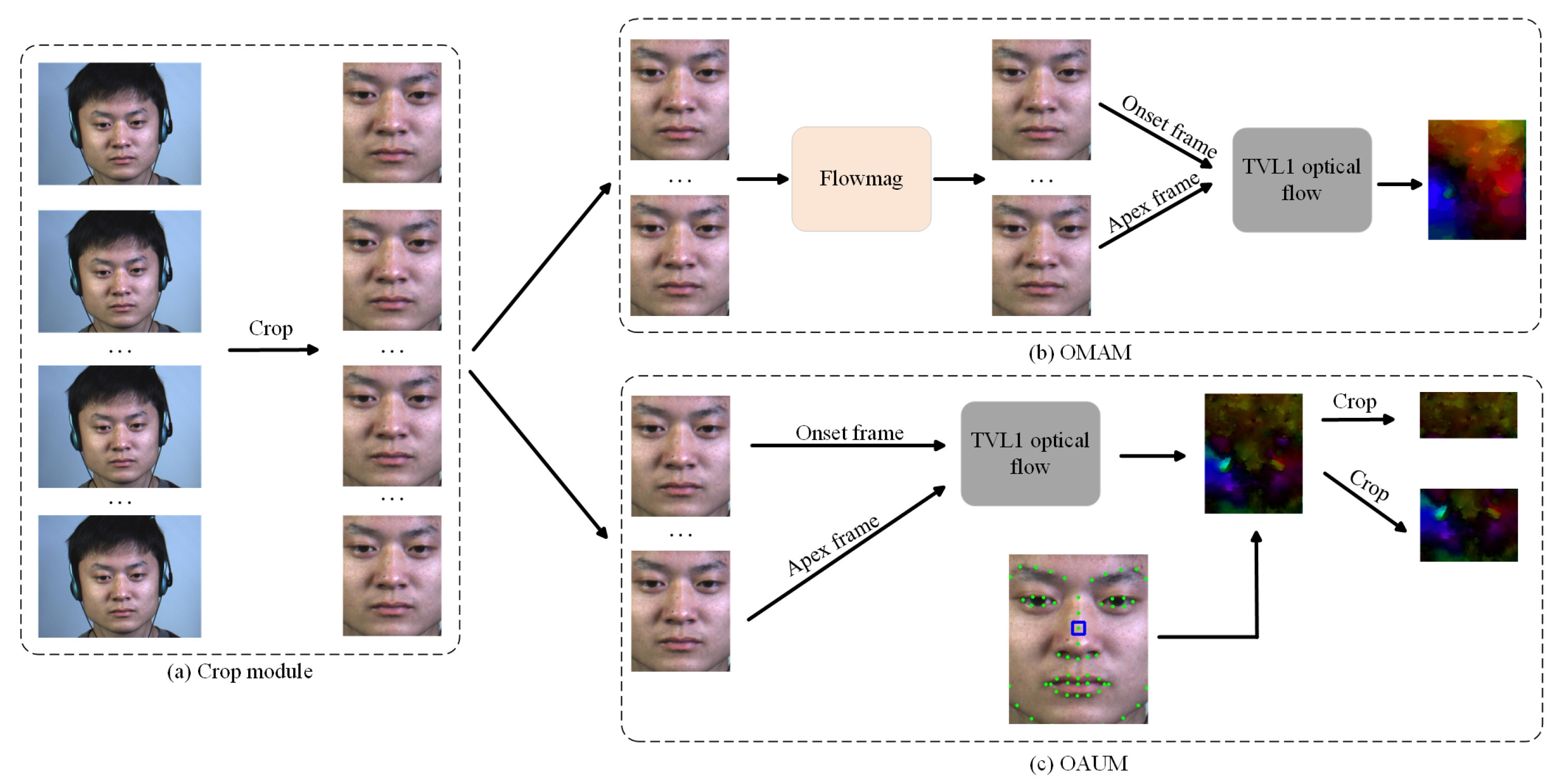
3.1. The Optical Flow Processing Module
3.2. The Mobile Residual KAN CBAM Block Net
3.3. The Multi-Channel Cosine Fusion Module
3.4. Loss Function
4. Experimental Results and Analysis
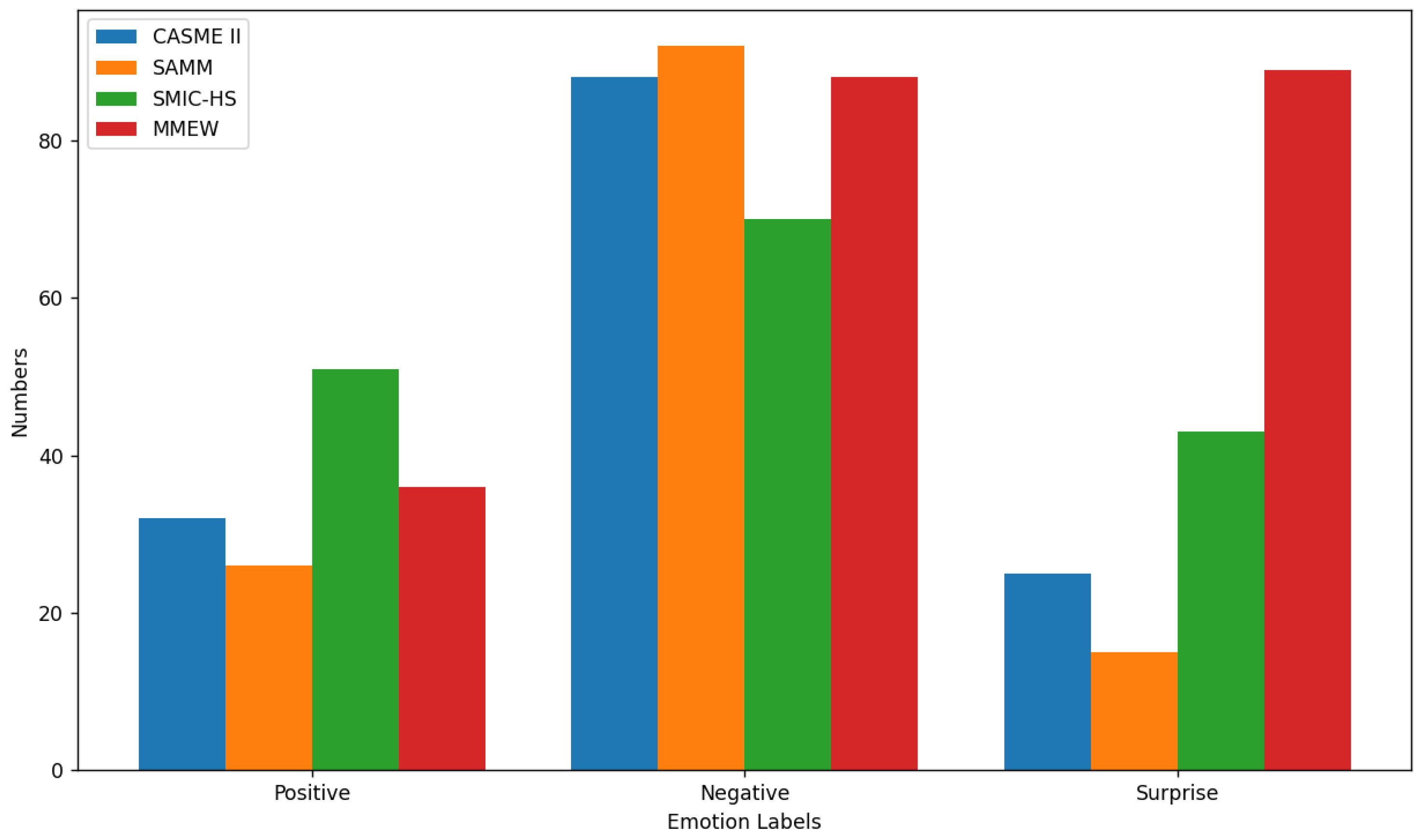
4.1. Experimental Dataset
4.2. Experimental Settings
4.3. Experimental Results
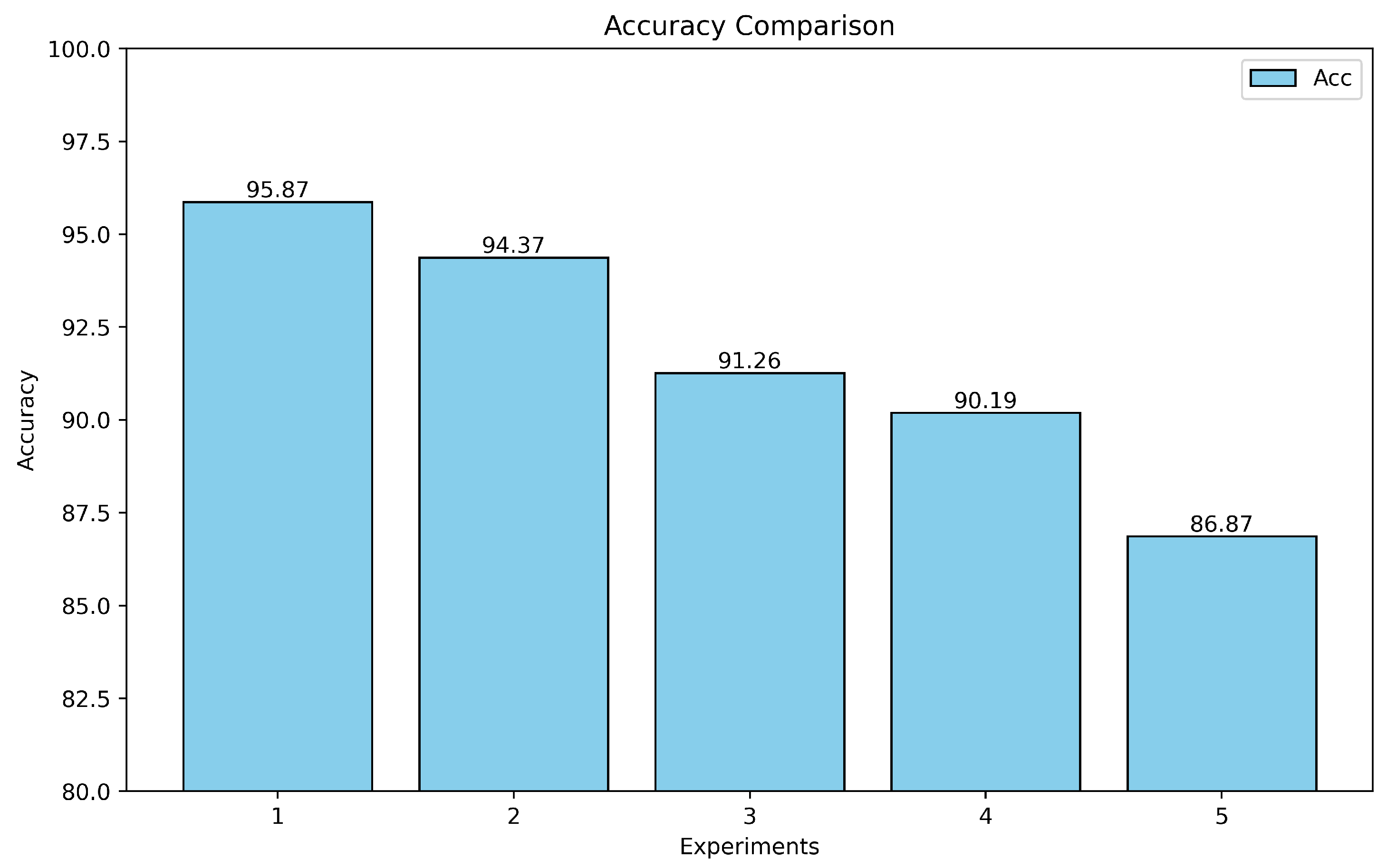
4.4. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zheng, H.; Wang, R.; Ji, W.; Zong, M.; Wong, W.K.; Lai, Z.; Lv, H. Discriminative deep multi-task learning for facial expression recognition. Inf. Sci. 2020, 533, 60–71. [Google Scholar] [CrossRef]
- Zheng, H.; Geng, X.; Tao, D.; Jin, Z. A multi-task model for simultaneous face identification and facial expression recognition. Neurocomputing 2016, 171, 515–523. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, H.; Bo, L.L.; Li, H.R.; Xu, S.; Yuan, D.Q. Subspace transform induced robust similarity measure for facial images. Front. Inf. Technol. Electron. Eng. 2020, 21, 1334–1345. [Google Scholar] [CrossRef]
- Huang, X.; Wang, S.J.; Liu, X.; Zhao, G.; Feng, X.; Pietikäinen, M. Discriminative spatiotemporal local binary pattern with revisited integral projection for spontaneous facial micro-expression recognition. IEEE Trans. Affect. Comput. 2017, 10, 32–47. [Google Scholar] [CrossRef]
- Verma, M.; Vipparthi, S.K.; Singh, G.; Murala, S. LEARNet: Dynamic imaging network for micro expression recognition. IEEE Trans. Image Process. 2019, 29, 1618–1627. [Google Scholar] [CrossRef]
- Zhao, S.; Tang, H.; Liu, S.; Zhang, Y.; Wang, H.; Xu, T.; Guan, C. ME-PLAN: A deep prototypical learning with local attention network for dynamic micro-expression recognition. Neural Netw. 2022, 153, 427–443. [Google Scholar] [CrossRef]
- Zhao, G.; Pietikainen, M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 915–928. [Google Scholar] [CrossRef]
- Liu, Y.J.; Zhang, J.K.; Yan, W.J.; Wang, S.J.; Zhao, G.; Fu, X. A main directional mean optical flow feature for spontaneous micro-expression recognition. IEEE Trans. Affect. Comput. 2015, 7, 299–310. [Google Scholar] [CrossRef]
- Li, G.H.; Yuan, Y.F.; Ben, X.Y.; Zhang, J. Spatiotemporal attention network for micro-expression recognition. J. Image Graph. 2020, 25, 2380–2390. [Google Scholar] [CrossRef]
- Chang, H.; Zhang, F.; Ma, S.; Gao, G.; Zheng, H.; Chen, Y. Unsupervised domain adaptation based on cluster matching and Fisher criterion for image classification. Comput. Electr. Eng. 2021, 91, 107041. [Google Scholar] [CrossRef]
- Gan, Y.S.; Liong, S.T.; Yau, W.C.; Huang, Y.C.; Tan, L.K. OFF-ApexNet on micro-expression recognition system. Signal Process. Image Commun. 2019, 74, 129–139. [Google Scholar] [CrossRef]
- Nguyen, X.B.; Duong, C.N.; Li, X.; Gauch, S.; Seo, H.S.; Luu, K. Micron-bert: Bert-based facial micro-expression recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–14 June 2023; Volume 1482–1492. [Google Scholar]
- Xie, Z.; Zhao, C. Dual-Branch Cross-Attention Network for Micro-Expression Recognition with Transformer Variants. Electronics 2024, 13, 461. [Google Scholar] [CrossRef]
- Cai, W.; Zhao, J.; Yi, R.; Yu, M.; Duan, F.; Pan, Z.; Liu, Y.J. MFDAN: Multi-level Flow-Driven Attention Network for Micro-Expression Recognition. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 12823–12836. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Liong, S.T.; See, J.; Phan, R.C.W.; Le Ngo, A.C.; Oh, Y.H.; Wong, K. Subtle expression recognition using optical strain weighted features. In Proceedings of the Computer Vision-ACCV 2014 Workshops, Singapore, 1–2 November 2014; Revised Selected Papers, Part II 12. pp. 644–657. [Google Scholar]
- Wei, M.; Zheng, W.; Zong, Y.; Jiang, X.; Lu, C.; Liu, J. A novel micro-expression recognition approach using attention-based magnification-adaptive networks. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 2420–2424. [Google Scholar]
- Wang, Z.; Zhang, K.; Luo, W.; Sankaranarayana, R. HTNet for micro-expression recognition. Neurocomputing 2024, 602, 128196. [Google Scholar] [CrossRef]
- Tang, J.; Li, L.; Tang, M.; Xie, J. A novel micro-expression recognition algorithm using dual-stream combining optical flow and dynamic image convolutional neural networks. Signal Image Video Process. 2023, 17, 769–776. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, Y.; Vaidya, S.; Ruehle, F.; Halverson, J.; Soljačić, M.; Tegmark, M. Kan: Kolmogorov-arnold networks. arXiv 2024, arXiv:2404.19756. [Google Scholar]
- Bresson, R.; Nikolentzos, G.; Panagopoulos, G.; Chatzianastasis, M.; Pang, J.; Vazirgiannis, M. KAGNNs: Kolmogorov-arnold networks meet graph learning. arXiv 2024, arXiv:2406.18380. [Google Scholar]
- Genet, R.; Inzirillo, H. TKAN: Temporal Kolmogorov-arnold networks. arXiv 2024, arXiv:2405.07344. [Google Scholar] [CrossRef]
- Pan, Z.; Geng, D.; Owens, A. Self-supervised motion magnification by backpropagating through optical flow. Adv. Neural Inf. Process. Syst. 2024, 36, 253–273. [Google Scholar]
- Zach, C.; Pock, T.; Bischof, H. A duality based approach for realtime TV-L1 optical flow. In Proceedings of the Pattern Recognition: 29th DAGM Symposium, Heidelberg, Germany, 12–14 September 2007; pp. 214–223. [Google Scholar]
- Howard, M.A.; Sandler, G.; Chu, L.C.; Chen, B.; Chen, M.; Tan, W.; Wang, Y.; Zhu, R.; Pang, V.; Vasudevan, Q.V.; et al. Adam: Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Bodner, A.D.; Tepsich, A.S.; Spolski, J.N.; Pourteau, S. Convolutional Kolmogorov-Arnold Networks. arXiv 2024, arXiv:2406.13155. [Google Scholar] [PubMed]
- Yan, W.J.; Li, X.; Wang, S.J.; Zhao, G.; Liu, Y.J.; Chen, Y.H.; Fu, X. CASME II: An improved spontaneous micro-expression database and the baseline evaluation. PLoS ONE 2014, 9, e86041. [Google Scholar] [CrossRef] [PubMed]
- Davison, A.K.; Lansley, C.; Costen, N.; Tan, K.; Yap, M.H. SAMM: A spontaneous micro-facial movement dataset. IEEE Trans. Affect. Comput. 2016, 9, 116–129. [Google Scholar] [CrossRef]
- Davison, A.K.; Li, J.; Yap, M.H.; See, J.; Cheng, W.H.; Li, X.; Wang, S.J. MEGC2023: ACM Multimedia 2023 ME Grand Challenge. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 9625–9629. [Google Scholar]
- Ben, X.; Ren, Y.; Zhang, J.; Wang, S.J.; Kpalma, K.; Meng, W.; Liu, Y.J. Video-based facial micro-expression analysis: A survey of datasets, features and algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5826–5846. [Google Scholar]
- Liong, S.T.; See, J.; Wong, K.; Phan, R.C.W. Less is more: Micro-expression recognition from video using apex frame. Signal Process. Image Commun. 2018, 62, 82–92. [Google Scholar] [CrossRef]
- Van Quang, N.; Chun, J.; Tokuyama, T. CapsuleNet for micro-expression recognition. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–7. [Google Scholar]
- Liong, S.T.; Gan, Y.S.; See, J.; Khor, H.Q.; Huang, Y.C. Shallow triple stream three-dimensional CNN (STSTNet) for micro-expression recognition. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–5. [Google Scholar]
- Liu, Y.; Du, H.; Zheng, L.; Gedeon, T. A neural micro-expression recognizer. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–4. [Google Scholar]
- Xia, Z.; Peng, W.; Khor, H.Q.; Feng, X.; Zhao, G. Revealing the invisible with model and data shrinking for composite-database micro-expression recognition. IEEE Trans. Image Process. 2020, 29, 8590–8605. [Google Scholar] [CrossRef]
- Zhou, L.; Mao, Q.; Huang, X.; Zhang, F.; Zhang, Z. Feature refinement: An expression-specific feature learning and fusion method for micro-expression recognition. Pattern Recognit. 2022, 122, 108275. [Google Scholar] [CrossRef]
- Xu, F.; Zhang, J.; Wang, J.Z. Microexpression Identification and Categorization Using a Facial Dynamics Map. IEEE Trans. Affect. Comput. 2017, 8, 254–267. [Google Scholar] [CrossRef]
- Hu, C.; Jiang, D.; Zou, H.; Zuo, X.; Shu, Y. Multi-task Micro-expression Recognition Combining Deep and Handcrafted Features. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 946–951. [Google Scholar] [CrossRef]
- Wang, S.-J.; Li, B.-J.; Liu, Y.-J.; Yan, W.-J.; Ou, X.; Huang, X.; Fu, X. Micro-expression recognition with small sample size by transferring long-term convolutional neural network. Neurocomputing 2018, 312, 251–262. [Google Scholar] [CrossRef]
- Tang, H.; Chai, L. Facial micro-expression recognition using stochastic graph convolutional network and dual transferred learning. Neural Netw. 2024, 178, 106421. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Input_Size | Output_Size | Core |
|---|---|---|---|
| Conv2d | 3 × 224 × 224 | 16 × 112 × 112 | 3 |
| BatchNorm2d | 16 × 112 × 112 | 16 × 112 × 112 | |
| Hardswish | 16 × 112 × 112 | 16 × 112 × 112 | |
| MobileNetV3 | 16 × 112 × 112 | 96 × 7 × 7 | |
| Conv2d | 96 × 7 × 7 | 576 × 7 × 7 | 1 |
| BatchNorm2d | 576 × 7 × 7 | 576 × 7 × 7 | |
| Hardswish | 576 × 7 × 7 | 576 × 7 × 7 | |
| RKCB | 576 × 7 × 7 | 1152 × 7 × 7 |
| Method | CASME II | SAMM | SMIC | Full | ||||
|---|---|---|---|---|---|---|---|---|
| UF1 (%) | UAR (%) | UF1 (%) | UAR (%) | UF1 (%) | UAR (%) | UF1 (%) | UAR (%) | |
| LBP-TOP | 70.26 | 74.29 | 39.54 | 41.02 | 20.00 | 52.80 | 58.82 | 57.85 |
| Bi-WOOF | 78.05 | 80.26 | 52.11 | 51.39 | 57.27 | 58.29 | 62.96 | 62.27 |
| CapsuleNet | 70.68 | 70.18 | 62.09 | 59.89 | 58.20 | 58.77 | 65.20 | 65.06 |
| FDCN | 73.09 | 72.00 | 58.07 | 57.00 | – | – | – | – |
| STSTNet | 83.82 | 86.86 | 65.88 | 68.10 | 68.01 | 70.13 | 73.53 | 76.05 |
| OFFApexNet | 87.64 | 86.81 | 54.09 | 53.92 | 68.17 | 66.95 | 71.96 | 70.96 |
| EMR | 82.93 | 82.09 | 77.54 | 71.52 | 74.61 | 75.30 | 78.85 | 78.24 |
| RCN | 85.12 | 81.23 | 76.01 | 67.15 | 63.26 | 64.41 | 74.32 | 71.90 |
| FeatRef | 89.15 | 88.73 | 73.72 | 71.55 | 70.11 | 70.83 | 78.38 | 78.32 |
| MFDAN | 91.34 | 93.26 | 78.71 | 81.96 | 68.15 | 70.83 | 84.53 | 86.88 |
| MCNet (ours) | 94.34 | 96.89 | 81.88 | 92.24 | 86.05 | 90.55 | 86.30 | 92.88 |
| Methods | Recognition Rate (%) |
|---|---|
| FDM [37] | 34.6 |
| Handcrafted features + deep learning [38] | 36.6 |
| MDMO [8] | 65.7 |
| TLCNN [39] | 69.4 |
| SGCN [40] | 73.0 |
| MCNet (ours) | 76.2 |
| Experiments | OMAM | OAUM | KAN | RKCB | MCCFM | UF1 (%) |
|---|---|---|---|---|---|---|
| 1 | × | ✓ | ✓ | ✓ | ✓ | 83.77 |
| 2 | ✓ | × | ✓ | ✓ | ✓ | 89.18 |
| 3 | ✓ | ✓ | × | ✓ | ✓ | 87.31 |
| 4 | ✓ | ✓ | ✓ | × | ✓ | 92.70 |
| 5 | ✓ | ✓ | ✓ | ✓ | × | 91.60 |
| 6 | ✓ | ✓ | ✓ | ✓ | ✓ | 94.34 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, H.; Yang, J.; Huang, K.; Xu, W.; Zhang, J.; Zheng, H. Optical Flow Magnification and Cosine Similarity Feature Fusion Network for Micro-Expression Recognition. Mathematics 2025, 13, 2330. https://doi.org/10.3390/math13152330
Chang H, Yang J, Huang K, Xu W, Zhang J, Zheng H. Optical Flow Magnification and Cosine Similarity Feature Fusion Network for Micro-Expression Recognition. Mathematics. 2025; 13(15):2330. https://doi.org/10.3390/math13152330
Chicago/Turabian StyleChang, Heyou, Jiazheng Yang, Kai Huang, Wei Xu, Jian Zhang, and Hao Zheng. 2025. "Optical Flow Magnification and Cosine Similarity Feature Fusion Network for Micro-Expression Recognition" Mathematics 13, no. 15: 2330. https://doi.org/10.3390/math13152330
APA StyleChang, H., Yang, J., Huang, K., Xu, W., Zhang, J., & Zheng, H. (2025). Optical Flow Magnification and Cosine Similarity Feature Fusion Network for Micro-Expression Recognition. Mathematics, 13(15), 2330. https://doi.org/10.3390/math13152330