

Recent Advances in Optimization Methods for Machine Learning: A Systematic Review

Abstract
1. Introduction
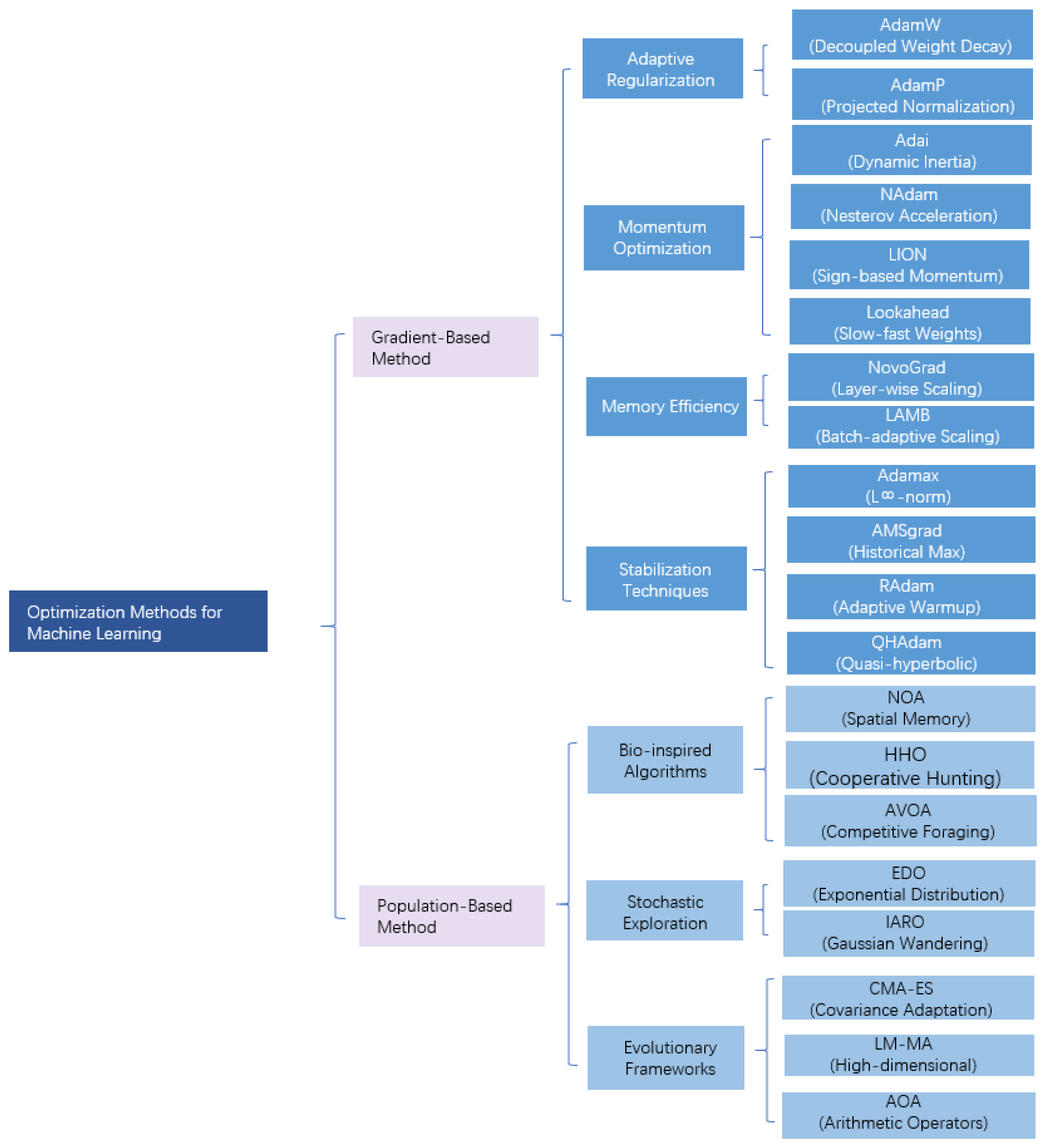
2. Optimization Methods for Machine Learning
2.1. Gradient-Based Methods
2.1.1. AdamW Algorithm
2.1.2. AdamP Algorithm
2.1.3. Adai Algorithm
2.1.4. NAdam Algorithm
2.1.5. LION Optimization Algorithm
2.1.6. Look-Ahead Algorithm
2.1.7. NovoGrad Algorithm
2.1.8. LAMB Algorithm
2.1.9. Adamax Algorithm
2.1.10. AMSgrad Algorithm
2.1.11. RAdam Algorithm
2.1.12. QHAdam ALgorithm
2.2. Population-Based Methods
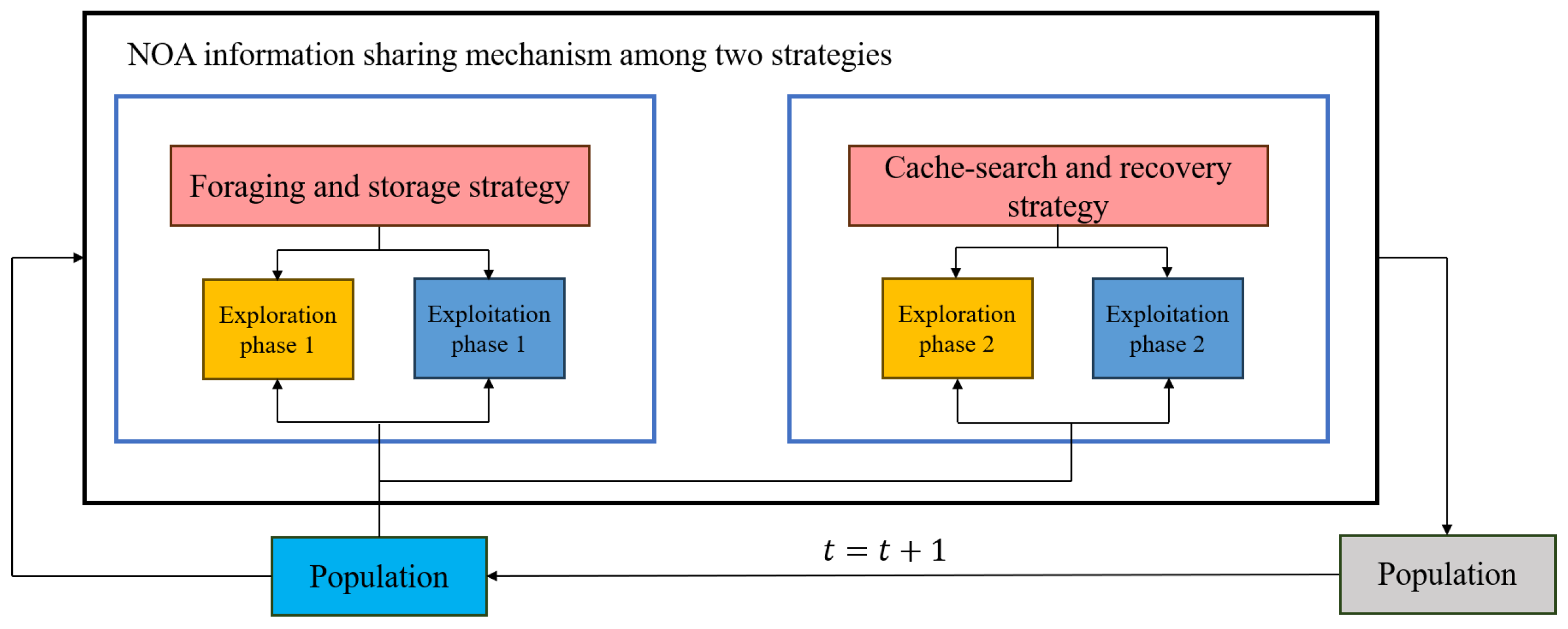
2.2.1. Nutcracker Optimization Algorithm
2.2.2. HHO Algorithm
- Soft Besiege ( and )
- Hard Besiege ( and )
- Soft Besiege with Progressive Dives ( and )
- Hard Besiege with Progressive Dives ( and )where is the Lèvy flight function.
2.2.3. AVOA Algorithm
- Exploration phase ():where .
- Primary exploitation phase ():with , and selected via the leader probability .
- Advanced exploitation phase ():Here the advanced exploitation phase uses Lévy vector L to enhance local search.
2.2.4. EDO Algorithm
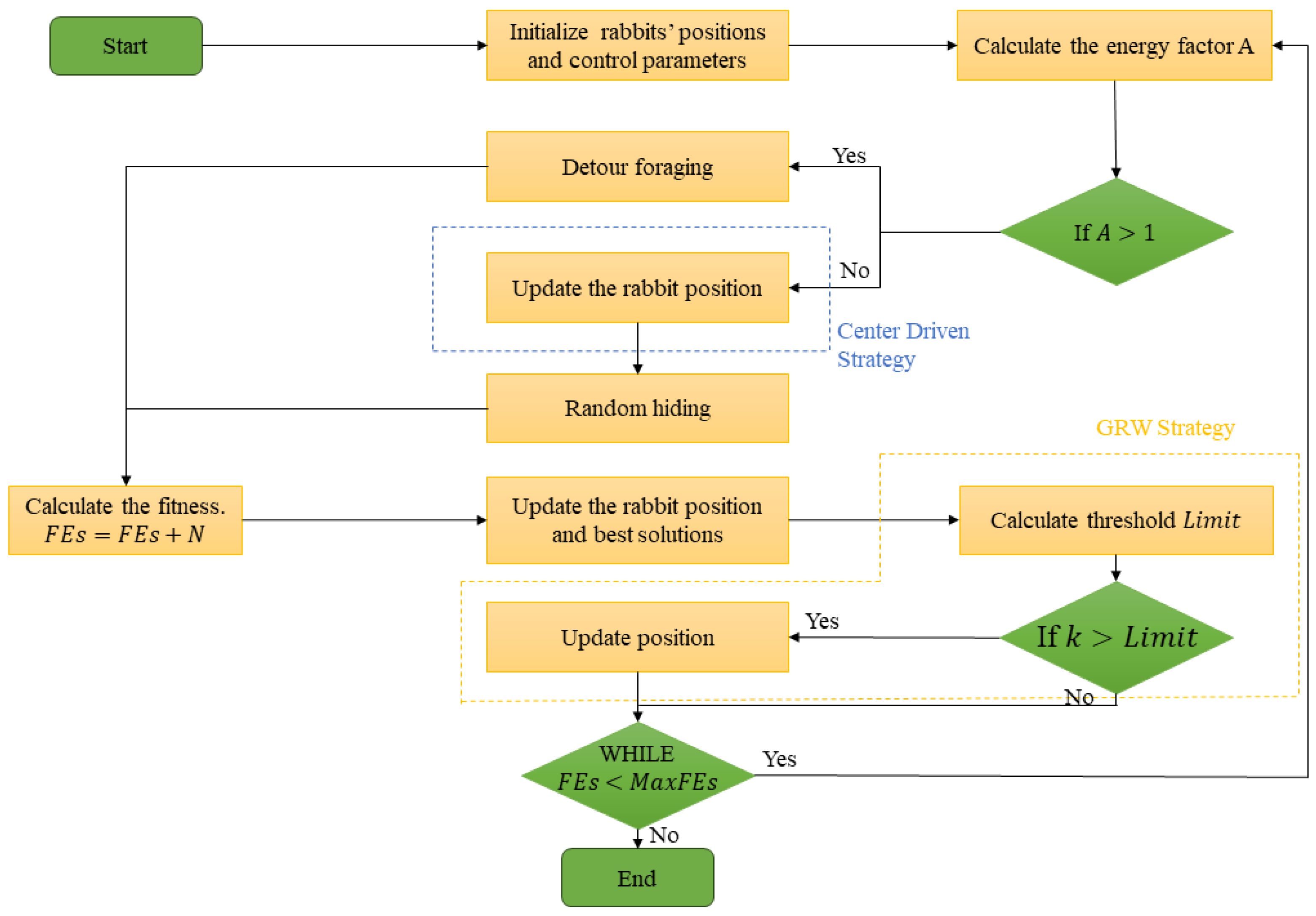
2.2.5. IARO Algorithm
2.2.6. CMA-ES Algorithm
2.2.7. LM-MA Algorithm
2.2.8. AOA Algorithm
3. Application of State-of-the-Art Optimization Methods
3.1. Deep Learning and Natural Language Processing
3.2. Reinforcement Learning and Online Learning
3.3. Feature Selection and Dimensionality Reduction
3.4. Hyperparameter Optimization
3.5. Operations Research
4. Challenges and Innovations of Optimization Methods
4.1. Key Challenges
- High-Dimensional Optimization: Scaling optimization to billion-parameter models creates computational bottlenecks:
- Memory constraints limit traditional gradient methods like Adam [16].
- Multimodal Landscapes: Non-convex optimization landscapes present local optima trapping risks:
- Dynamic Environments: Real-world applications demand continuous adaptation:
4.2. Innovations in Existing Methods
- Decoupled Regularization: AdamW [15] resolves the incompatibility between adaptive gradients and weight decay by applying regularization directly to parameters rather than scaling it with gradient magnitudes. This approach consistently improves generalization across deep learning tasks.
- Memory-Efficient Updates: LION [26] reduces memory requirements by 50% through sign-based momentum updates, eliminating the need for second-moment estimation while maintaining competitive performance in large-scale training, leveraging automatic differentiation advances [85]. Recent advances in sparse optimization frameworks like SparseProp [86] further enhance this direction.
- Hybrid Exploration Strategies: IARO [34] combines centroid-driven position updates with Gaussian Randomized Wandering to escape the local optima, demonstrating 20% faster convergence in complex optimization landscapes like image segmentation.
- Dynamic Constraint Handling: Nutcracker optimizer [32] employs adaptive phase transition mechanisms that automatically shift between exploration and exploitation based on iterative progress, particularly effective in engineering design problems with changing constraints.
- Population Covariance Adaptation: CMA-ES [27] continuously reshapes its search distribution using successful evolution paths, enabling the efficient navigation of high-dimensional non-convex spaces where gradient information is unavailable.
4.3. Emerging Paradigms
- Bio-Inspired Hybrid Algorithms: Methods like Nutcracker optimizer [32] and Harris Hawks Optimization (HHO) [29] integrate biological behaviors into optimization frameworks. Nutcracker mimics seasonal foraging–caching strategies, while HHO simulates energy-driven prey pursuit. These approaches demonstrate superior performance in engineering design problems, with HHO achieving 15% cost reduction in supply chain routing applications.
- Mathematically Grounded Frameworks: Algorithms such as EDO [33] and AOA [31] leverage mathematical principles rather than biological metaphors. EDO utilizes exponential distribution properties to balance exploration–exploitation trade-offs, while AOA combines arithmetic operators with Genetic Algorithm concepts. These frameworks show particular strength in maintaining robustness under noisy conditions and dynamic environments.
- AutoML-Integrated Optimization: The integration of optimization methods with automated machine learning represents a frontier innovation. LION [26] was discovered through symbolic program search in algorithm space, while LM-MA [28] incorporates knowledge-preserving restart strategies. This paradigm enables the automatic discovery of optimization rules tailored to specific problem domains, significantly reducing manual design efforts.
4.4. Evidence-Based Research Prioritization
5. Conclusions
- Developing scalable second-order methods for billion-parameter models;
- Enhancing theoretical guarantees for population-based algorithms in non-convex settings;
- Bridging optimization and robustness through adversarial training frameworks.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: http://arxiv.org/abs/1706.03762 (accessed on 30 June 2025).
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Vapnik, V. Statistical Learning Theory; Wiley-Interscience: Hoboken, NJ, USA, 1998. [Google Scholar]
- Rumelhart, D.; Hinton, G.; Williams, R. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A survey on bias and fairness in machine learning. ACM Comput. Surv. 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef]
- Amari, S.I. Natural gradient works efficiently in learning. Neural Comput. 1998, 10, 251–276. [Google Scholar] [CrossRef]
- Rajbhandari, S.; Rasley, J.; Ruwase, O.; He, Y. Zero: Memory optimizations toward training trillion pa- rameter models. In Proceedings of the SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, Atlanta, GA, USA, 9–19 November 2020. [Google Scholar]
- Krizhevsky, A. One weird trick for parallelizing convolutional neural networks. arXiv 2014, arXiv:1404.5997. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feed- forward neural networks. J. Mach. Learn. Res. Proc. Track 2010, 9, 249–256. [Google Scholar]
- Bubeck, S. Convex optimization: Algorithms and complexity. Found. Trends® Mach. Learn. 2015, 8, 231–357. [Google Scholar] [CrossRef]
- Hardt, M.; Recht, B.; Singer, Y. Train faster, generalize better: Stability of stochastic gradient descent. In International Conference on Machine Learning (ICML); PMLR: New York, NY, USA, 2016; pp. 1225–1234. Available online: http://proceedings.mlr.press/v48/hardt16.html (accessed on 20 May 2025).
- Ilya, L.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Reddi, S.J.; Kale, S.; Kumar, S. On the convergence of adam and beyond. arXiv 2019, arXiv:1904.09237. [Google Scholar]
- Xie, Z.; Wang, X.; Zhang, H.; Sato, I.; Sugiyama, M. Adaptive inertia: Disentangling the effects of adaptive learning rate and momentum. In International Conference on Machine Learning; PMLR: New York, NY, USA, 2022. [Google Scholar]
- Ginsburg, B.; Castonguay, P.; Hrinchuk, O.; Kuchaiev, O.; Lavrukhin, V.; Leary, R.; Li, J.; Nguyen, H.; Zhang, Y.; Cohen, J.M. Stochastic gradient methods with layer-wise adaptive moments for training of deep networks. arxiv 2020, arXiv:1905.11286. [Google Scholar]
- Heo, B.; Chun, S.; Oh, S.J.; Han, D.; Yun, S.; Kim, G.; Uh, Y.; Ha, J.W. AdamP: Slowing Down the Slowdown for Momentum Optimizers on Scale-invariant Weights. International Conference on Learning Representations (ICLR). arXiv 2020, arXiv:2006.08217. [Google Scholar]
- Dozat, T. Incorporating Nesterov Momentum into Adam. ICLR Workshop Proceedings. 2016. Available online: https://openreview.net/forum?id=OM0jvwB8jIp57ZJjtNEZ (accessed on 20 May 2025).
- Shazeer, N.; Stern, M. Adafactor: Adaptive learning rates with sublinear memory cost. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; PMLR: New York, NY, USA, 2018; Volume 80, pp. 4596–4604. [Google Scholar]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the Variance of the Adaptive Learning Rate and Beyond. arXiv 2019, arXiv:1908.03265. [Google Scholar]
- You, Y.; Li, J.; Reddi, S.; Hseu, J.; Kumar, S.; Bhojanapalli, S.; Song, X.; Demmel, J.; Keutzer, K.; Hsieh, C.-J. Large batch optimization for deep learning: Training bert in 76 minutes. arXiv 2019, arXiv:1904.00962. [Google Scholar]
- Zhang, M.R.; Lucas, J.; Hinton, G.; Ba, J. Lookahead Optimizer: K Steps Forward, 1 Step Back. Adv. Neural Inf. Process. Syst. (Neurips) 2019, 32. [Google Scholar] [CrossRef]
- Chen, X.; Liang, C.; Huang, D.; Real, E.; Wang, K.; Liu, Y.; Pham, H.; Dong, X.; Luong, T.; Hsieh, C.-J.; et al. Symbolic Discovery of Optimization Algorithms. arXiv 2023, arXiv:2302.06675. [Google Scholar]
- Khouzani, F.F.; Mirzaei, A.; Plante, P.L.; Gewali, L. CMA-ES with Radial Basis Function Surrogate for Black-Box Optimization; Springer: Cham, Switzerland, 2025; pp. 367–379. [Google Scholar]
- Loshchilov, I.; Glasmachers, T.; Beyer, H.-G. Large Scale Black-Box Optimization by Limited-Memory Matrix Adaptation. IEEE Trans. Evol. Comput. 2019, 23, 353–358. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Abdollahzadeh, B.; Gharehchopogh, F.S.; Mirjalili, S. African vultures optimization algorithm: A new nature-inspired metaheuristic algorithm for global optimization problems. Comput. Indus. Trial Eng. 2021, 158, 107408. [Google Scholar] [CrossRef]
- Yao, Q. Dayang Jiang Improved AOA Algorithm to Optimize Image Entropy for Image Recognition Model. Aut. Control Comp. Sci. 2024, 58, 441–453. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Mohamed, R.; Jameel, M.; Abouhawwash, M. Nutcracker optimizer: A novel nature inspired metaheuristic algorithm for global optimization and engineering design problems. Knowl. Based Syst. 2023, 262, 110248. [Google Scholar] [CrossRef]
- Kalita, K.; Ramesh, J.V.N.; Cepova, L.P.; Ya, S.B.; Jangir, P.; Abualigah, L. Multi-objective exponential distribution optimizer (MOEDO): A novel math-inspired multi-objective algorithm for global optimization and real-world engineering design problems. Sci. Rep. 2024, 14, 1816. [Google Scholar] [CrossRef]
- Jia, H.; Su, Y.; Rao, H.; Liang, M.; Abualigah, L.; Liu, C.; Chen, X. Improved artificial rabbits algorithm for global optimization and multi-level thresholding color image segmentation. Artif. Intell. Rev. 2025, 58, 55. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. (Neurips) 2019, 32, 8026–8037. [Google Scholar]
- Holland, J.H. Adaptation in Natural and Artificial Systems; University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Bottou, L.; Curtis, F.E.; Nocedal, J. Optimization methods for large-scale machine learning. Siam Rev. 2018, 60, 223–311. [Google Scholar] [CrossRef]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Nocedal, J.; Wright, S.J. Numerical Optimization, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Fletcher, R. Practical Methods of Optimization, 2nd ed.; Wiley: Hoboken, NJ, USA, 1987. [Google Scholar]
- Polyak, B.T. Some methods of speeding up the convergence of iteration methods. Ussr Comput. Math. Math. Phys. 1964, 4, 1–17. [Google Scholar] [CrossRef]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Liu, Y.; Gao, Y.; Yin, W. An Improved Analysis of Stochastic Gradient Descent with Momentum. Adv. Neural Inf. Process. Syst. 2020, 33, 18261–18271. [Google Scholar]
- Chrabaszcz, P.; Loshchilov, I.; Hutter, F. A downsampled variant of ImageNet as an alternative to the CIFAR datasets. arXiv 2017, arXiv:1707.08819. [Google Scholar]
- Frankle, J.; Carbin, M. The lottery ticket hypothesis: Training pruned neural networks. arXiv 2019, arXiv:1803.03635. [Google Scholar]
- Nesterov, Y. A method of solving a convex programming problem with convergence rate O(1/*k*2). Sov. Math. Dokl. 1983, 27, 372–376. [Google Scholar]
- Luo, L.; Xiong, Y.; Liu, Y.; Sun, X. Adaptive gradient methods with dynamic bound of learning rate. arXiv 2019, arXiv:1902.09843. [Google Scholar]
- Ma, J.; Yarats, D. Quasi-hyperbolic momentum and adam for deep learning. arXiv 2018, arXiv:1810.06801. [Google Scholar]
- Zhuang, J.; Tang, T.; Ding, Y.; Tatikonda, S.; Dvornek, N.; Papademetris, X.; Duncan, J.S. Adabelief optimizer: Adapting stepsizes by the belief in observed gradients. Adv. Neural Inf. Process. Syst. 2020, 33, 18795–18806. [Google Scholar]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization, and Machine Learning; Addison-Wesley: Boston, MA, USA, 1989. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. Proc. IEEE Int. Conf. Neural Netw. 1995, 4, 1942–1948. [Google Scholar]
- Poli, R.; Kennedy, J.; Blackwell, T. Particle swarm optimization: An overview. Swarm Intell. 2007, 1, 33–57. [Google Scholar] [CrossRef]
- Dorigo, M.; Stützle, T. Ant Colony Optimization; MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- Storn, R.; Price, K. Differential evolution—A simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Tanabe, R.; Fukunaga, A. Success-history based parameter adaptation for Differential Evolution. In Proceedings of the 2013 IEEE Congress on Evolutionary Computation, Cancun, Mexico, 20–23 June 2013; pp. 71–78. [Google Scholar] [CrossRef]
- Wang, L.; Cao, Q.; Zhang, Z.; Mirjalili, S.; Zhao, W. Artificial rabbits optimization: A new bio-inspired meta-heuristic algorithm for solving engineering optimization problems. Eng. Appl. Artif. Intell. Int. J. Intell. Real Time Autom. 2022, 114, 105082. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Mirjalili, S.; Gandomi, A.H.; Mirjalili, S.Z.; Saremi, S.; Faris, H.; Mirjalili, S.M. Salp swarm algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 2017, 114, 163–191. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Yang, X.-S.; Deb, S. Cuckoo Search via Lévy flights. In Proceedings of the 2009 World Congress on Nature Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009; pp. 210–214. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; El-Shahat, D.; Jameel, M.; Abouhawwash, M. Exponential distribution optimizer (EDO): A novel math-inspired algorithm for global optimization and engineering problems. Artif. Intell. Rev. 2023, 56, 1–72. [Google Scholar] [CrossRef]
- Durrett, R. Essentials of Stochastic Processes; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Zhang, Y.; Jin, Z.; Mirjalili, S. Generalized normal distribution optimization and its applications in parameter extraction of photovoltaic models. Energy Convers. Manag. 2020, 224, 113301. [Google Scholar] [CrossRef]
- Awad, N.H.; Ali, M.Z.; Suganthan, P.N.; Reynolds, R.G. An ensemble sinusoidal parameter adaptation incorporated with L-SHADE for solving CEC2014 benchmark problems. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; pp. 2958–2965. [Google Scholar] [CrossRef]
- Arbeláez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour Detection and Hierarchical Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 898–916. [Google Scholar] [CrossRef]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. International Conference on Pattern Recognition. In Proceedings of the 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010. [Google Scholar]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A Feature Similarity Index for Image Quality Assessment. Trans. Img. Proc. 2011, 20, 2378–2386. [Google Scholar] [CrossRef] [PubMed]
- Alacaoglu, A.; Malitsky, Y.; Cevher, V. Convergence of adaptive algorithms for weakly convex constrained optimization. arXiv 2020, arXiv:2006.06650. [Google Scholar]
- Rao, A.R.M.; Shyju, P.P. Development of a hybrid meta-heuristic algorithm for combinatorial optimisation and its application for optimal design of laminated composite cylindrical skirt. Comput. Struct. 2008, 86, 796–815. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Artificial Intelligence and Statistics (AISTATS); PMLR: New York, NY, USA, 2017; pp. 1273–1282. Available online: http://proceedings.mlr.press/v54/mcmahan17a.html (accessed on 20 May 2025).
- Goyal, P.; Doll´ar, P.; Girshick, R.B.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, large minibatch SGD: Training imagenet in 1 hour. arXiv 2017, arXiv:1706.02677. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv 2016, arXiv:1612.03928. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. Autoaugment: Learning augmentation policies from data. arXiv 2018, arXiv:1805.09501. [Google Scholar]
- Schulman, J.; Levine, S.; Moritz, P.; Jordan, M.I.; Abbeel, P. Trust region policy optimization. In International Conference on Machine Learning (ICML); PMLR: New York, NY, USA, 2015; pp. 1889–1897. [Google Scholar]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive representation distillation. arXiv 2019, arXiv:1910.10699. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian optimization of machine learning algorithms. Adv. Neural Inf. Process. Syst. (Neurips) 2012, 25, 2951–2959. [Google Scholar]
- He, X.; Zhao, K.; Chu, X. Automl: A survey of the state-of-the-art. Knowl.-Based Syst. 2021, 212, 106622. [Google Scholar] [CrossRef]
- Hansen, N. The CMA evolution strategy: A tutorial. arXiv 2016, arXiv:1604.00772. [Google Scholar]
- Hardt, M.; Ma, T. Identity matters in deep learning. arXiv 2016, arXiv:1611.04231. [Google Scholar]
- Li, Z.; Arora, S. An exponential learning rate schedule for deep learning. arXiv 2019, arXiv:1910.07454. [Google Scholar]
- Baydin, A.G.; Pearlmutter, B.A.; Radul, A.A.; Siskind, J.M. Automatic differentiation in machine learning: A survey. J. Mach. Learn. Res. 2018, 18, 1–43. [Google Scholar]
- Nikdan, M.; Pegolotti, T.; Iofinova, E.; Kurtic, E.; Alistarh, D. Sparseprop: Efficient sparse backpropagation for faster training of neural networks. arXiv 2023, arXiv:2302.04852. [Google Scholar]
- Aitchison, L. A unified theory of adaptive stochastic gradient descent as Bayesian filtering. arXiv 2018, arXiv:1507.02030. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | Gradient-Based Methods | Population-Based Methods |
|---|---|---|
| Core Mechanism | Derivative-driven local search | Stochastic population evolution |
| Key Algorithms | AdamW [15], LION [26], RAdam [23], LAMB [24], AMSGrad [17], NovoGrad [19], Adai [18], NAdam [21], QHAdam [22], AdamP [20], Adamax [16], Look-ahead [25] | AOA [31], NOA [32], IARO [34], EDO [33], CMA-ES [27], LM-MA [28], HHO [29], AVOA [30] |
| Computational Efficiency | High efficiency | Moderate efficiency |
| Global Search Ability | Local convergence guarantees | Global exploration capability |
| Memory Requirements | Moderate state storage | High population maintenance |
| Optimal Use Cases | Deep network parameter optimization | Hyperparameter tuning, non-convex problems |
| Domain | Method | Key Contribution |
|---|---|---|
| DL & NLP | AdamW [15], LION [26], Adamax [16] RAdam [23], AdamP [20], NAdam [21] LAMB [24], AOA [31] | Improved generalization, memory efficiency Training stability, large-batch scaling Hyperparameter tuning |
| RL & Online | QHAdam [51], CMA-ES [27] AMSGrad [17], Look-ahead [25] NovoGrad [19] | 30% variance reduction, gradient-free opt Learning rate stability, 40% less oscillation Memory-efficient RNN training |
| Feature Selection | IARO [34], LION [26] EDO [33] | 9.2% Dice improvement, feature selection Efficient subspace exploration |
| Hyperparameter | NOA [32], EDO [33] AOA [31] Adai [18] | Bio-inspired tuning, RL optimization Bayesian-evolutionary search Oscillation reduction |
| Operations Research | LM-MA [28], AVOA [30] HHO [29], NOA [32] | Large-scale allocation, scheduling 15% cost reduction, constraint handling |
| Research Vector | Evidence Source | Urgency Metric |
|---|---|---|
| High-dimensional regularization | Temporal prevalence | 78% failure rate (2024–2025) |
| Fairness-non-convex integration | Co-occurrence gap | , 12% coverage |
| Differentiable fairness audits | ORL maturity | 1.2 vs. 3.7 baseline |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Qi, H.; Jia, S.; Guo, Y.; Liu, Y. Recent Advances in Optimization Methods for Machine Learning: A Systematic Review. Mathematics 2025, 13, 2210. https://doi.org/10.3390/math13132210
Liu X, Qi H, Jia S, Guo Y, Liu Y. Recent Advances in Optimization Methods for Machine Learning: A Systematic Review. Mathematics. 2025; 13(13):2210. https://doi.org/10.3390/math13132210
Chicago/Turabian StyleLiu, Xiaodong, Huaizhou Qi, Suisui Jia, Yongjing Guo, and Yang Liu. 2025. "Recent Advances in Optimization Methods for Machine Learning: A Systematic Review" Mathematics 13, no. 13: 2210. https://doi.org/10.3390/math13132210
APA StyleLiu, X., Qi, H., Jia, S., Guo, Y., & Liu, Y. (2025). Recent Advances in Optimization Methods for Machine Learning: A Systematic Review. Mathematics, 13(13), 2210. https://doi.org/10.3390/math13132210