

Sim-to-Real Reinforcement Learning for a Rotary Double-Inverted Pendulum Based on a Mathematical Model


Abstract
1. Introduction
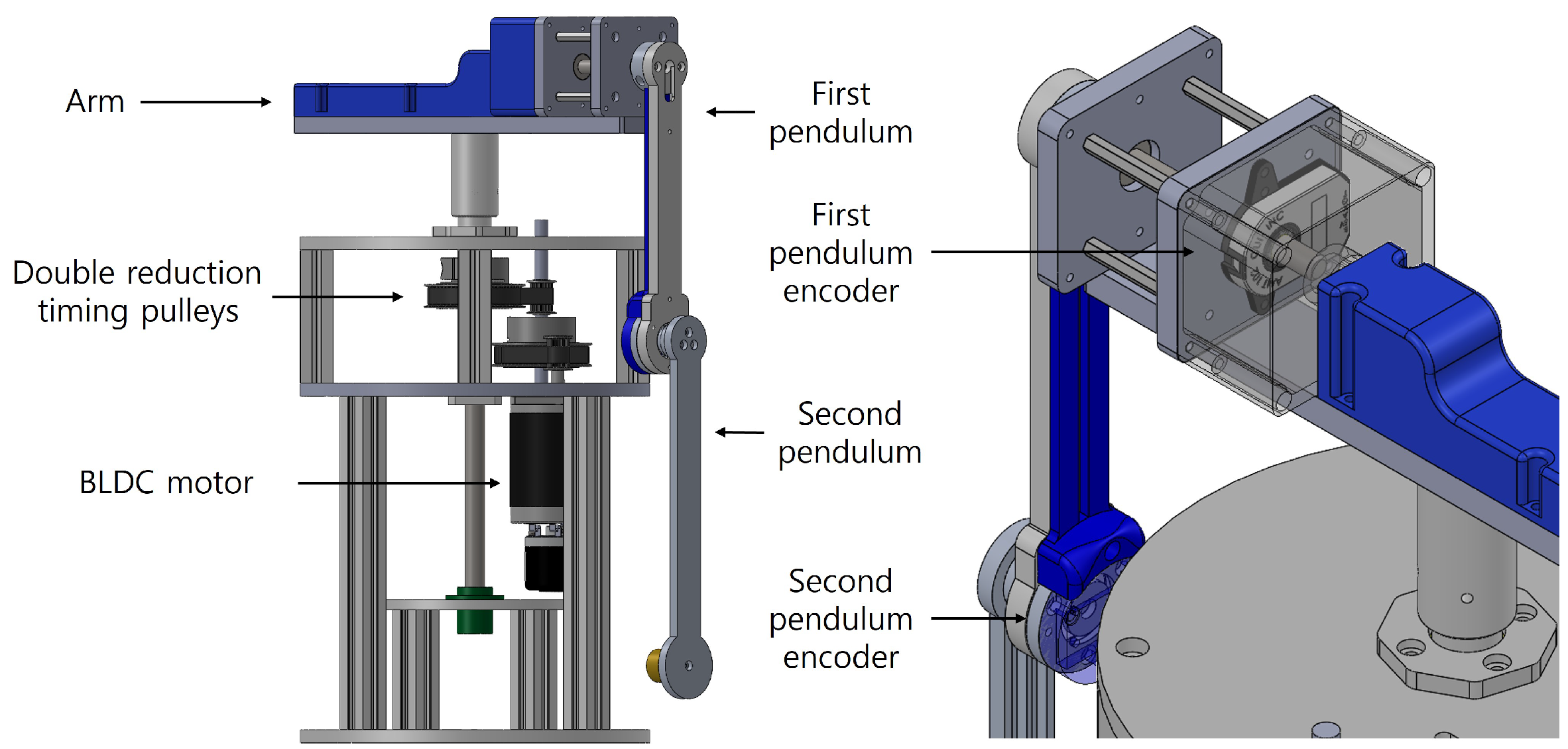
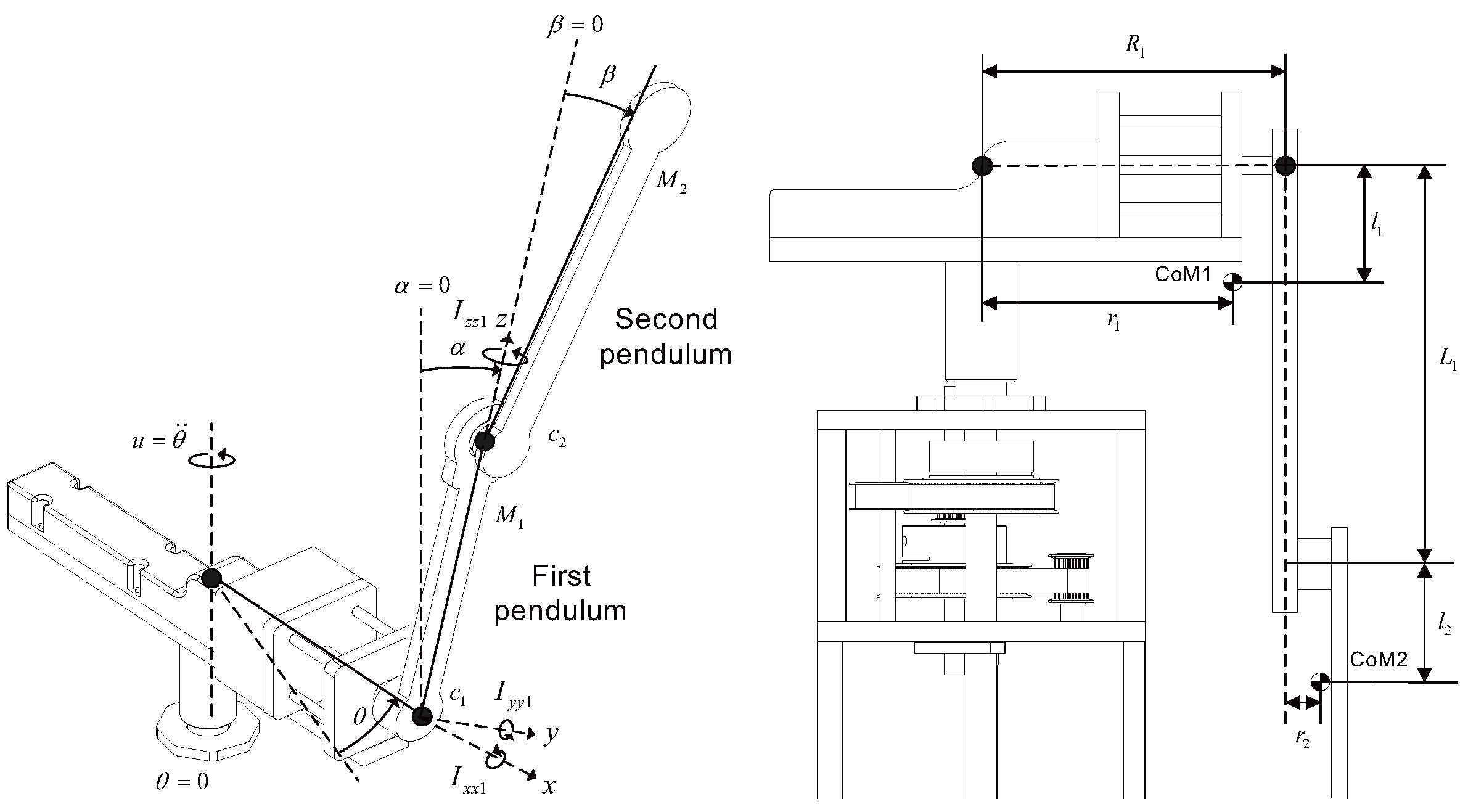
2. System Modeling and Parameter Identification
2.1. Dynamic Modeling
2.2. Parameter Identification
3. Reinforcement-Learning-Based Simulation
3.1. Training Environment
3.2. Learning Algorithm
3.3. Training Settings
3.3.1. Experimental Environment
3.3.2. Reward Function
4. Reinforcement-Learning-Based Transition Control Using Sim-to-Real Transfer
4.1. Simulation
4.2. Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Izutsu, M.; Pan, Y.; Furuta, K. Swing-up of Furuta Pendulum by Nonlinear Sliding Mode Control. Sice J. Control Meas. Syst. Integr. 2008, 1, 12–17. [Google Scholar] [CrossRef]
- Glück, T.; Eder, A.; Kugi, A. Swing-up control of a triple pendulum on a cart with experimental validation. Automatica 2013, 49, 801–808. [Google Scholar] [CrossRef]
- Rigatos, G.; Abbaszadeh, M.; Siano, P.; Cuccurullo, G.; Pomares, J.; Sari, B. Nonlinear Optimal Control for the Rotary Double Inverted Pendulum. Adv. Control Appl. 2024, 6, e140. [Google Scholar] [CrossRef]
- Zied, B.H.; Mohammad, J.F.; Zafer, B. Development of a Fuzzy-LQR and Fuzzy-LQG stability control for a double link rotary inverted pendulum. J. Frankl. Inst. 2020, 357, 10529–10556. [Google Scholar]
- Graichen, K.; Treuer, M.; Zeitz, M. Swing-up of the double pendulum on a cart by feedforward and feedback control with experimental validation. Automatica 2007, 43, 63–71. [Google Scholar] [CrossRef]
- Ju, D.; Lee, T.; Lee, Y.S. Transition Control of a Rotary Double Inverted Pendulum Using Direct Collocation. Mathematics 2025, 13, 640. [Google Scholar] [CrossRef]
- Turcato, N.; Calì, M.; Dalla Libera, A.; Giacomuzzo, G.; Carli, R.; Romeres, D. Learning Global Control of Underactuated Systems with Model-Based Reinforcement Learning. arXiv 2025, arXiv:2504.06721. [Google Scholar]
- Taets, J.; Lefebvre, T.; Ostyn, F.; Crevecoeur, G. Energy-Based Exploration for Reinforcement Learning of Underactuated Mechanical Systems. IEEE Access 2025, 13, 98847–98859. [Google Scholar] [CrossRef]
- Kormushev, P.; Calinon, S.; Saegusa, R.; Metta, G. Learning the skill of archery by a humanoid robot iCub. In Proceedings of the 2010 10th IEEE—RAS International Conference on Humanoid Robots, Nashville, TN, USA, 6–8 December 2010; pp. 417–423. [Google Scholar]
- Kormushev, P.; Calinon, S.; Caldwell, D.G. Reinforcement Learning in Robotics: Applications and Real-World Challenges. Robotics 2013, 2, 122–148. [Google Scholar] [CrossRef]
- Haarnoja, T.; Ha, S.; Zhou, A.; Tan, J.; Tucker, G.; Levine, S. Learning to Walk via Deep Reinforcement Learning. arXiv 2019, arXiv:1812.11103. [Google Scholar]
- Rupam Mahmood, A.; Korenkevych, D.; Komer, B.J.; Bergstra, J. Setting up a Reinforcement Learning Task with a Real-World Robot. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4635–4640. [Google Scholar]
- Sun, C.; Orbik, J.; Devin, C.M.; Yang, B.H.; Gupta, A.; Berseth, G.; Levine, S. Fully Autonomous Real-World Reinforcement Learning with Applications to Mobile Manipulation. In Proceedings of the 5th Conference on Robot Learning; Faust, A., Hsu, D., Neumann, G., Eds.; Publishing PMLR: London, UK, 2021; pp. 308–319. [Google Scholar]
- Dang, K.N.; Van, L.V. Development of deep reinforcement learning for inverted pendulum. Int. J. Electr. Comput. Eng. 2023, 13, 3895–3902. [Google Scholar]
- Zhao, W.; Queralta, J.P.; Westerlund, T. Sim-to-Real Transfer in Deep Reinforcement Learning for Robotics: A Survey. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, ACT, Australia, 1–4 December 2020; pp. 737–744. [Google Scholar]
- Kalapos, A.; Gór, C.; Moni, R.; Harmati, I. Sim-to-real reinforcement learning applied to end-to-end vehicle control. In Proceedings of the 2020 23rd International Symposium on Measurement and Control in Robotics (ISMCR), Budapest, Hungary, 15–17 October 2020; pp. 1–6. [Google Scholar]
- Kaspar, M.; Osorio, J.D.M.; Bock, J. Sim2real transfer for reinforcement learning without dynamics randomization. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 4383–4388. [Google Scholar]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain randomization for transferring deep neural networks from simulation to the real world. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 23–30. [Google Scholar]
- Matas, J.; James, S.; Davison, A.J. Sim-to-real reinforcement learning for deformable object manipulation. In Proceedings of The 2nd Conference on Robot Learning; Billard, A., Dragan, A., Peters, J., Morimoto, J., Eds.; Publishing PMLR: London, UK, 2018; pp. 734–743. [Google Scholar]
- Arndt, K.; Hazara, M.; Ghadirzadeh, A.; Kyrki, V. Meta Reinforcement Learning for Sim-to-real Domain Adaptation. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 2725–2731. [Google Scholar]
- James, S.; Wohlhart, P.; Kalakrishnan, M.; Kalashnikov, D.; Irpan, A.; Ibarz, J.; Levine, S.; Hadsell, R.; Bousmalis, K. Sim-To-Real via Sim-To-Sim: Data-Efficient Robotic Grasping via Randomized-To-Canonical Adaptation Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 11–15 June 2019; pp. 12627–12637. [Google Scholar]
- Tong, D.; Choi, A.; Qin, L.; Huang, W.; Joo, J.; Jawed, M.K. Sim2Real Neural Controllers for Physics-Based Robotic Deployment of Deformable Linear Objects. Int. J. Robot. Res. 2023, 6, 791–810. [Google Scholar] [CrossRef]
- Wang, K.; Johnson, W.R.; Lu, S.; Huang, X.; Booth, J.; Kramer-Bottiglio, R.; Aanjaneya, M.; Bekris, K. Real2Sim2Real Transfer for Control of Cable-Driven Robots Via a Differentiable Physics Engine. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023; pp. 2534–2541. [Google Scholar]
- Wiberg, V.; Wallin, E.; FA¨lldin, A.; Semberg, T.; Rossander, M.; Wadbro, E.; Servin, M. Sim-to-real transfer of active suspension control using deep reinforcement learning. Robot. Auton. Syst. 2024, 179, 104731. [Google Scholar] [CrossRef]
- Rai, A.; Bhushan, B.; Jaint, B. Stabilization and Performance Analysis of Double Link-Rotary Inverted Pendulum Using LQR-I Controller. In Proceedings of the 2025 3rd IEEE International Conference on Industrial Electronics: Developments & Applications (ICIDeA), Bhubaneswar, India, 21–22 February 2025; pp. 1–5. [Google Scholar]
- Lee, T.; Ju, D.; Lee, Y.S. Transition Control of a Double-Inverted Pendulum System Using Sim2Real Reinforcement Learning. Machines 2025, 13, 186. [Google Scholar] [CrossRef]
- Bo¨hm, P.; Pounds, P.; Chapman, A.C. Low-cost Real-world Implementation of the Swing-up Pendulum for Deep Reinforcement Learning Experiments. arXiv 2025, arXiv:2503.11065. [Google Scholar]
- Ho, T.-N.; Nguyen, V.-D.-H. Model-Free Swing-Up and Balance Control of a Rotary Inverted Pendulum Using the TD3 Algorithm: Simulation and Experiments. Eng. Technol. Appl. Sci. Res. 2025, 15, 19316–19323. [Google Scholar] [CrossRef]
- Lee, Y.S.; Jo, B.; Han, S. A light-weight rapid control prototyping system based on open source hardware. IEEE Access 2017, 5, 11118–11130. [Google Scholar] [CrossRef]
- Chukwurah, N.; Adebayo, A.S.; Ajayi, O.O. Sim-to-Real Transfer in Robotics: Addressing the Gap Between Simulation and Real-World Performance. Int. J. Robot. Simul. 2024, 6, 89–102. [Google Scholar] [CrossRef]
- Kuznetsov, A.; Shvechikov, P.; Grishin, A.; Vetrov, D. Controlling overestimation bias with truncated mixture of continuous distributional quantile critics. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 5556–5566. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Dabney, W.; Rowland, M.; Bellemare, M.; Munos, R. Distributional reinforcement learning with quantile regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Lower Bound (Min) | Upper Bound (Max) |
|---|---|---|
| 0 | ||
| 0 | ||
| Parameter | Value |
|---|---|
| 0.187 kg | |
| 0.132 kg | |
| 1.0415 × kgm2 | |
| 8.8210 × kgm2 | |
| 4.3569 × kgm2 | |
| 4.9793 × kgm2 | |
| 3.3179 × kgm2 | |
| 4.8178 × kgm2 | |
| 3.7770 × kgm2 | |
| 1.9823 × kgm2 | |
| 0.072 m | |
| 0.133 m | |
| 2.4100 × | |
| 1.0900 × | |
| 0.1645 m | |
| 0.1625 m | |
| 0.1597 m | |
| 0.0209 m |
| Equilibrium Point (EP) | Target Angle | |
|---|---|---|
| 0 | − | 0 |
| 1 | − | − |
| 2 | 0 | − |
| 3 | 0 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ju, D.; Lee, J.; Lee, Y.S. Sim-to-Real Reinforcement Learning for a Rotary Double-Inverted Pendulum Based on a Mathematical Model. Mathematics 2025, 13, 1996. https://doi.org/10.3390/math13121996
Ju D, Lee J, Lee YS. Sim-to-Real Reinforcement Learning for a Rotary Double-Inverted Pendulum Based on a Mathematical Model. Mathematics. 2025; 13(12):1996. https://doi.org/10.3390/math13121996
Chicago/Turabian StyleJu, Doyoon, Jongbeom Lee, and Young Sam Lee. 2025. "Sim-to-Real Reinforcement Learning for a Rotary Double-Inverted Pendulum Based on a Mathematical Model" Mathematics 13, no. 12: 1996. https://doi.org/10.3390/math13121996
APA StyleJu, D., Lee, J., & Lee, Y. S. (2025). Sim-to-Real Reinforcement Learning for a Rotary Double-Inverted Pendulum Based on a Mathematical Model. Mathematics, 13(12), 1996. https://doi.org/10.3390/math13121996