


High-Efficiency and High-Precision Ship Detection Algorithm Based on Improved YOLOv8n

Abstract
1. Introduction
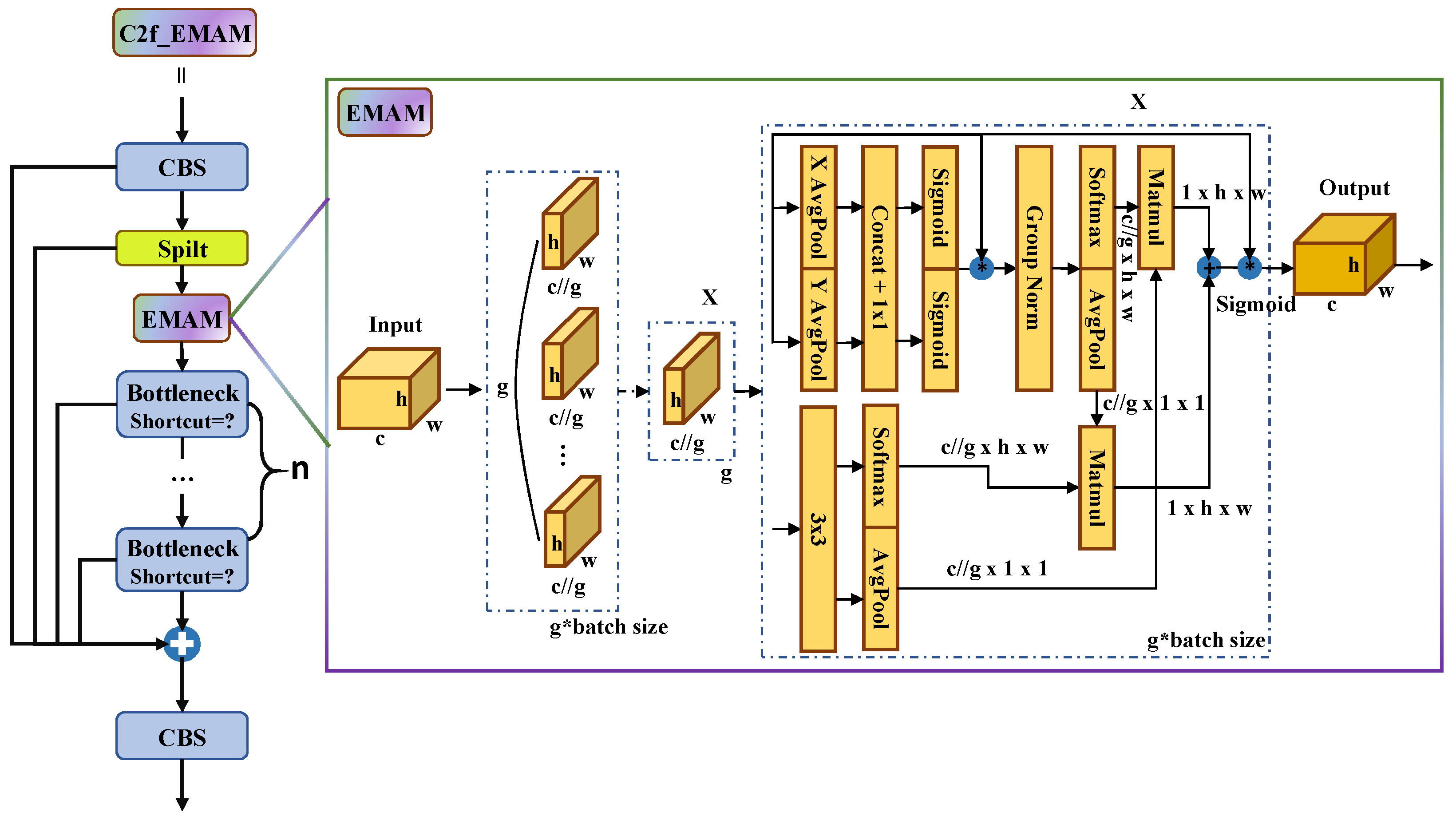
- The proposed efficient multi-scale attention module (C2f_EMAM) achieves the fusion of contextual information at different scales and significantly improves the attention of high-level feature maps;
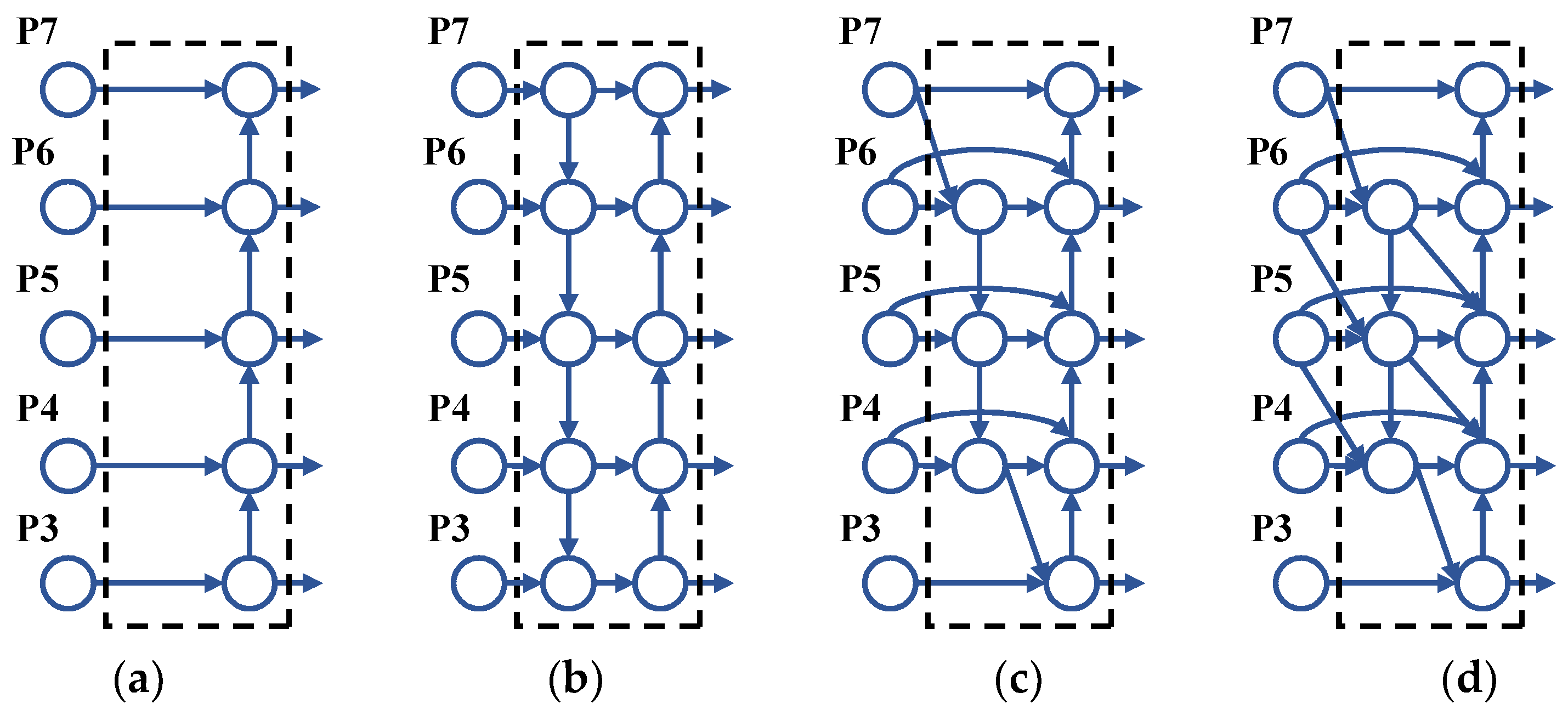
- The fully-concatenate bi-directional feature pyramid network (Concatenate_FBiFPN) is used to optimize the classification and regression structure to better solve the problem of feature propagation and information flow in target detection;
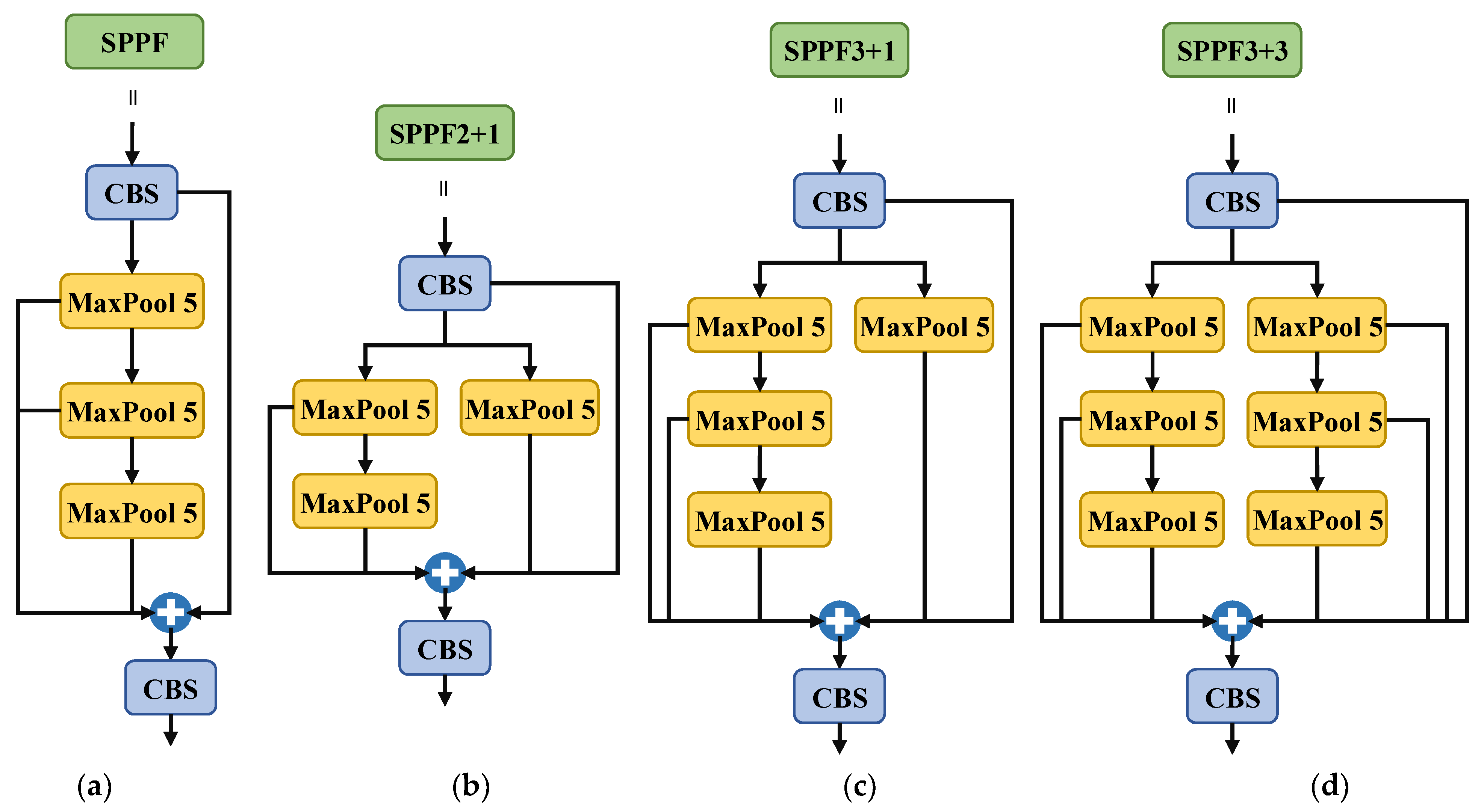
- The spatial pyramid pooling fast structure (SPPF2+1) is redesigned to emphasize the low-level pooling features and learn the target features more comprehensively;
- The ablation study of C2f_EMAM, Concatenate_FBiFPN, and SPPF2+1 is conducted, and the experimental results verified the feasibility and effectiveness of these modules.
2. Materials and Methods
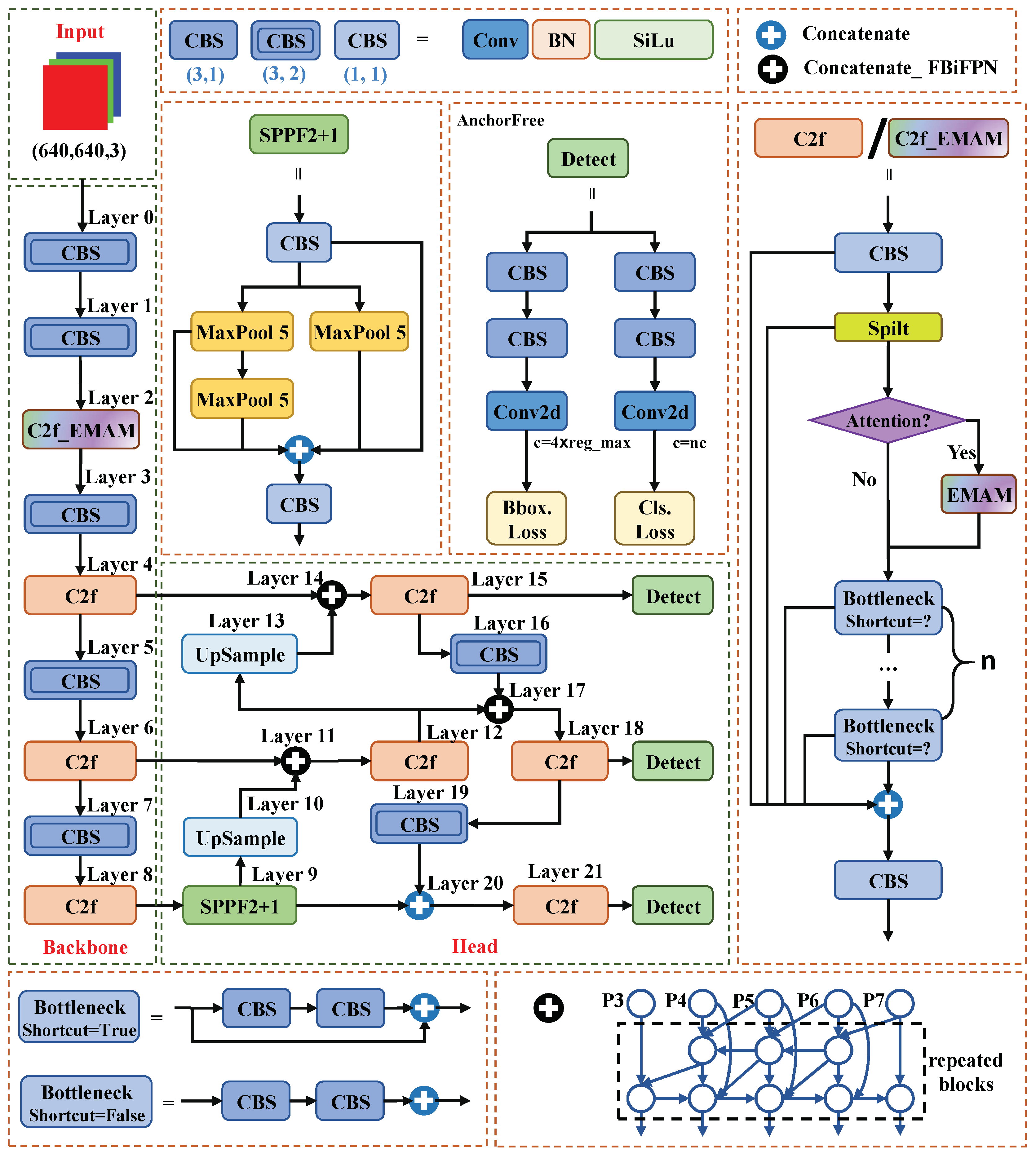
2.1. Overview of the Improved YOLOv8n
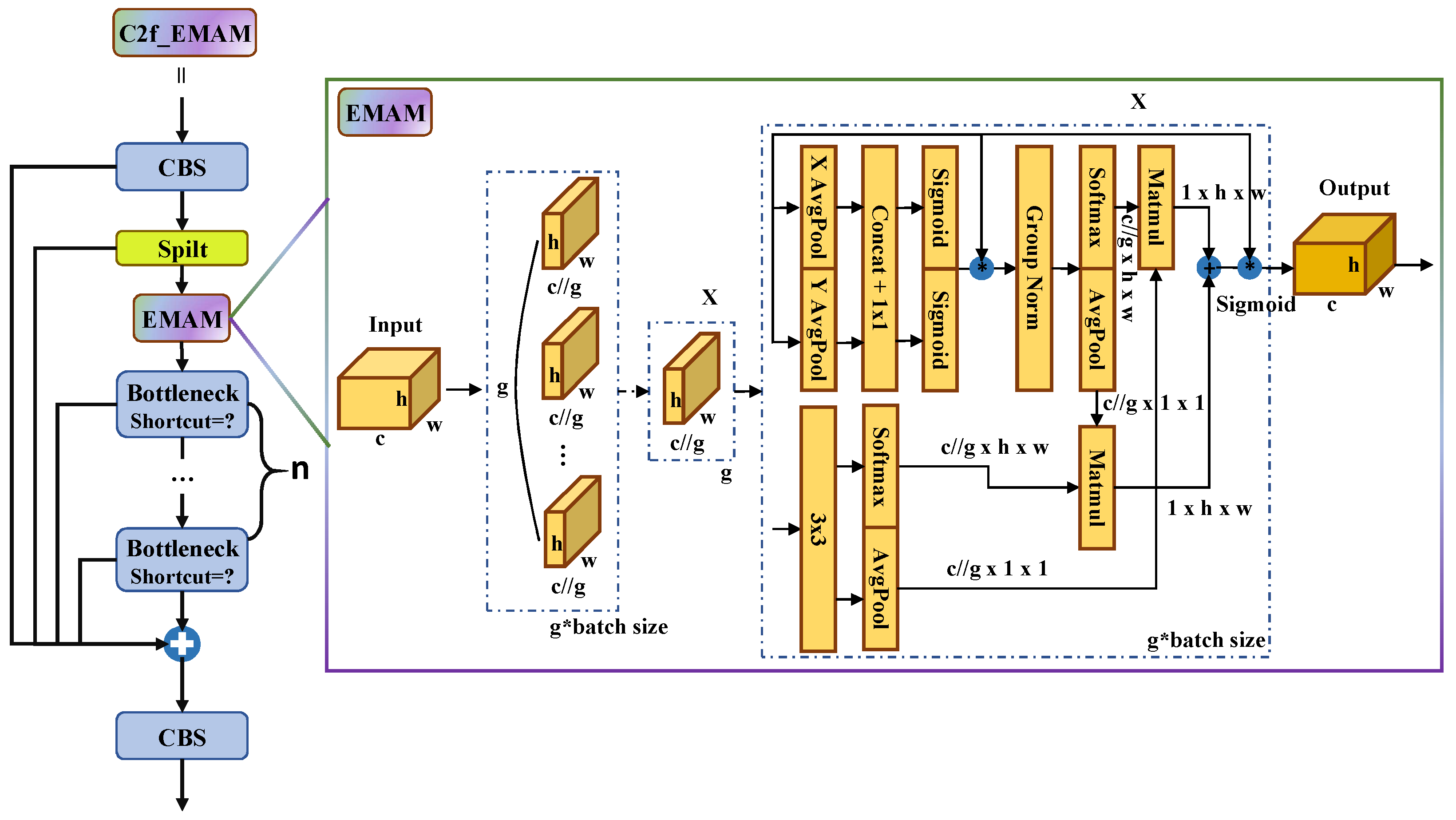
2.2. Architecture of C2f_EMAM
2.3. Architecture of Concatenate_FBiFPN
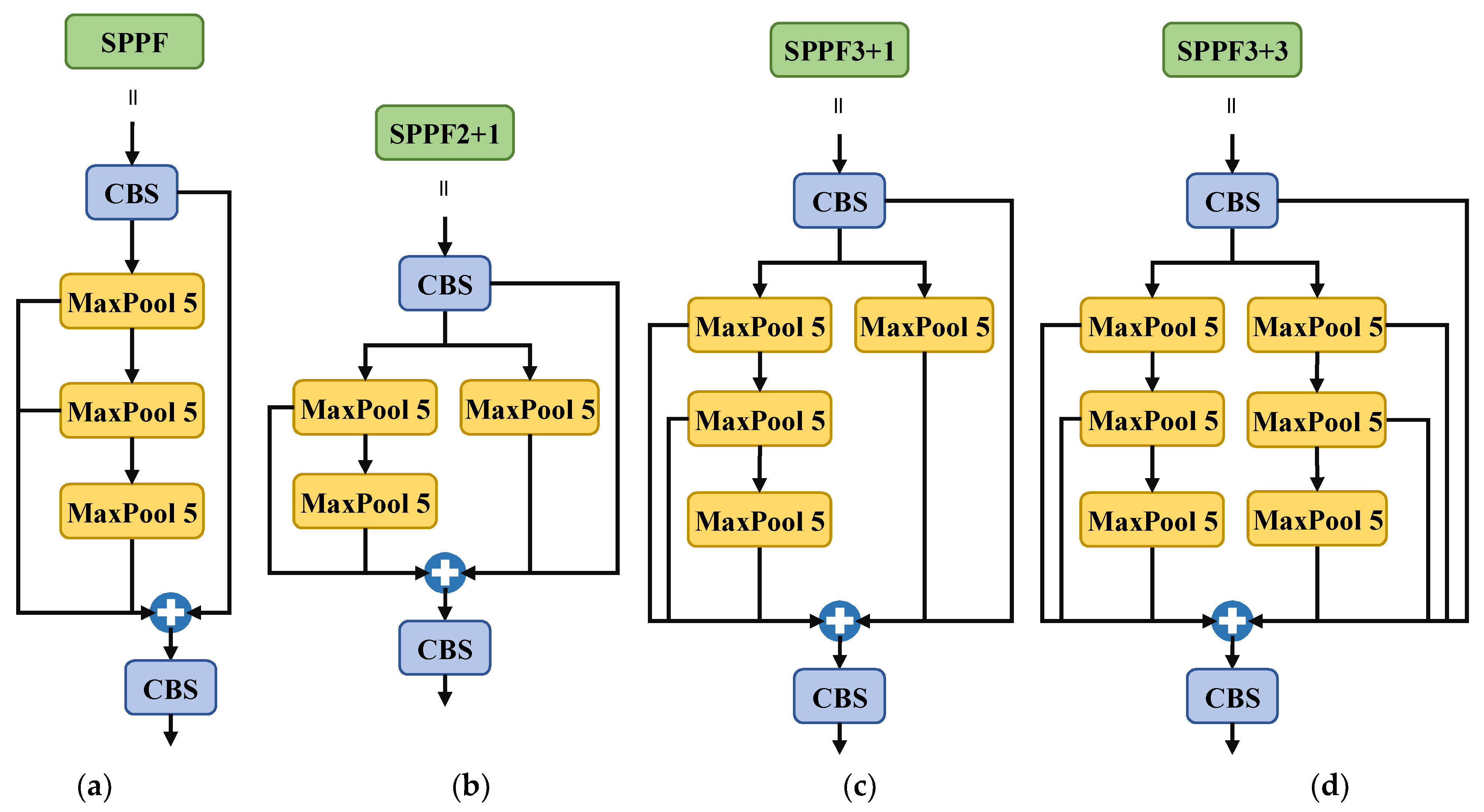
2.4. Architecture of SPPF2+1
3. Results
3.1. Evaluation Metrics
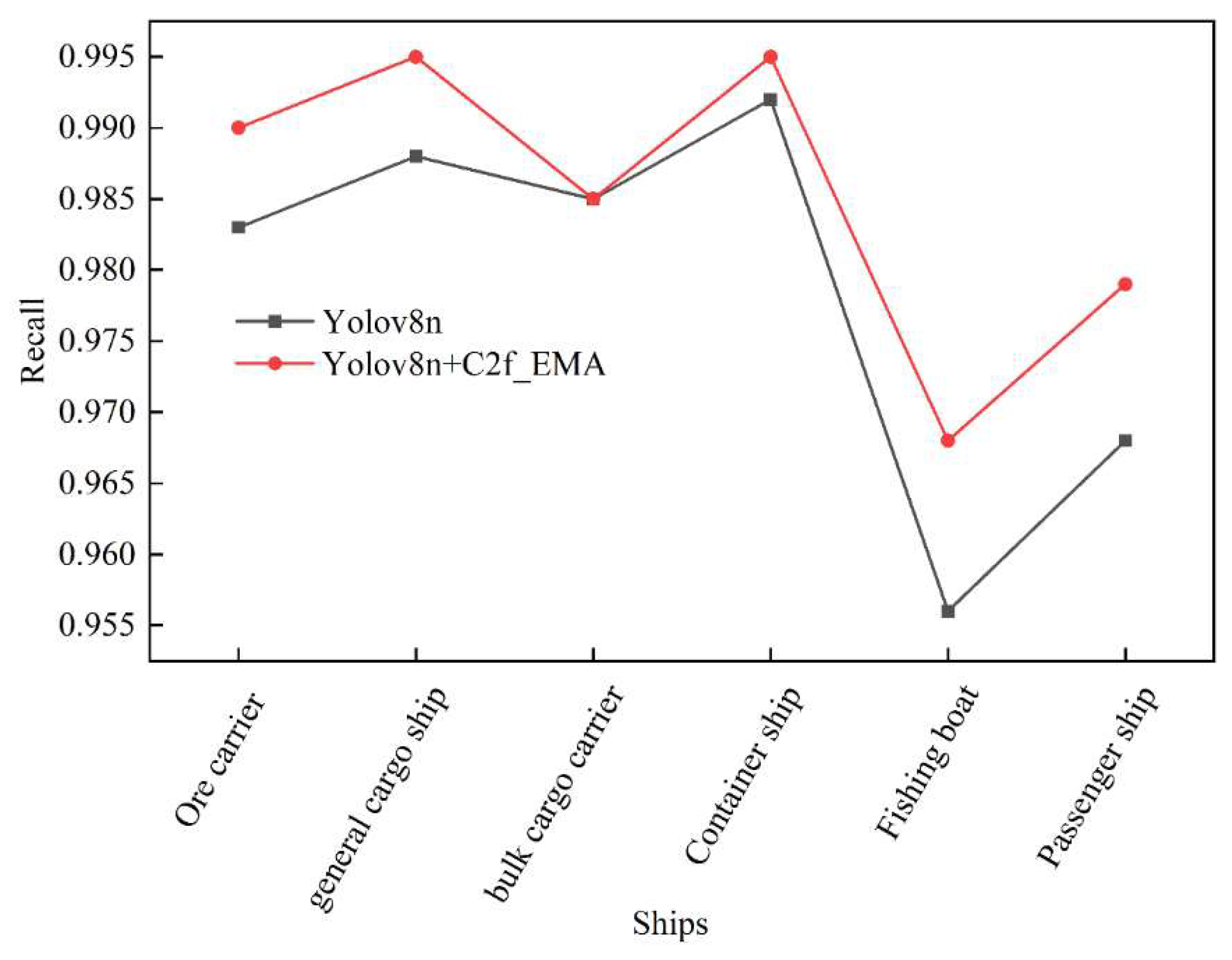
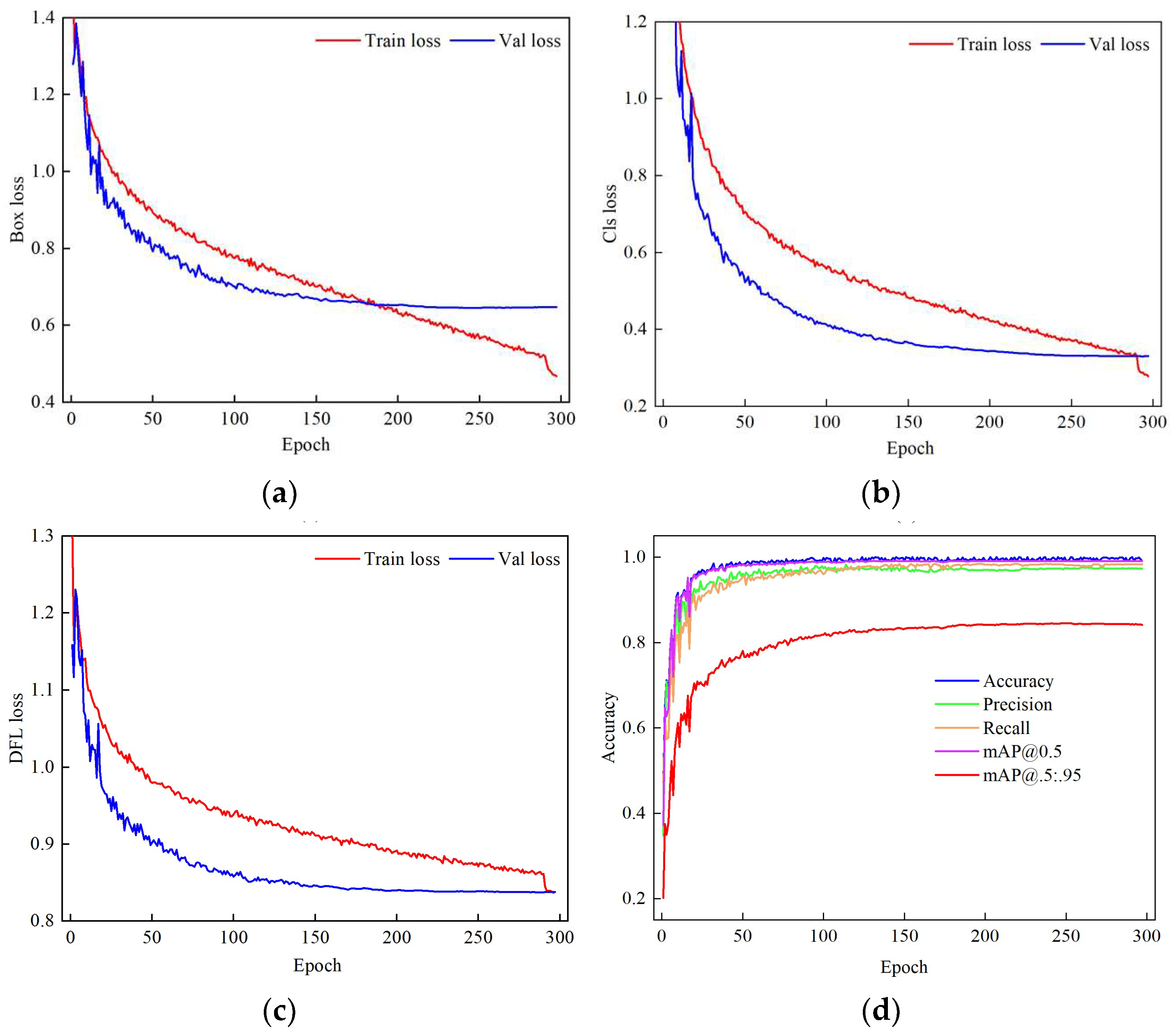
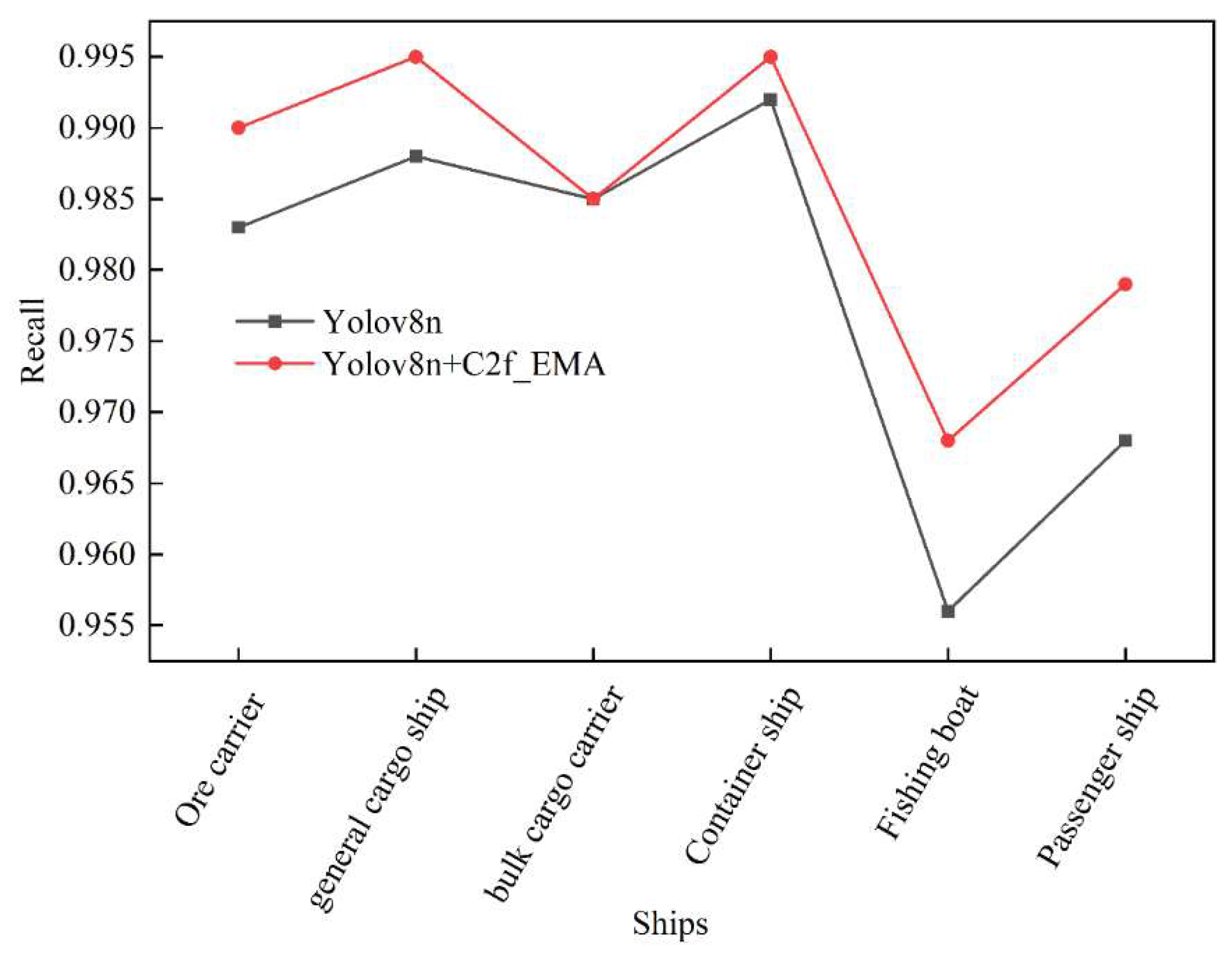
3.2. Results of the Improved YOLOv8n
3.3. Ablation Experiment
3.3.1. C2f_EMAM
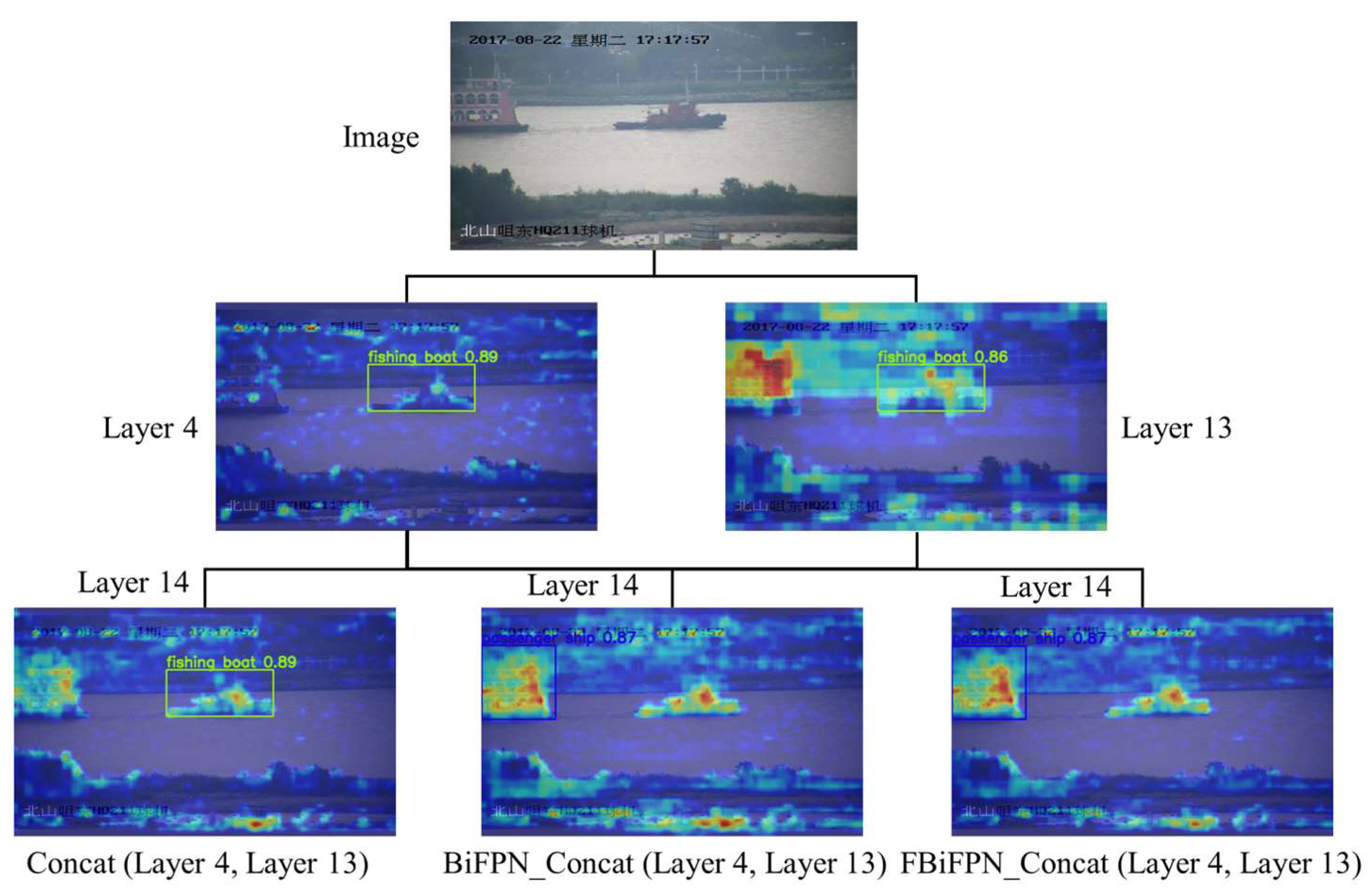
3.3.2. Concatenate_FBiFPN
3.3.3. SPPF2+1
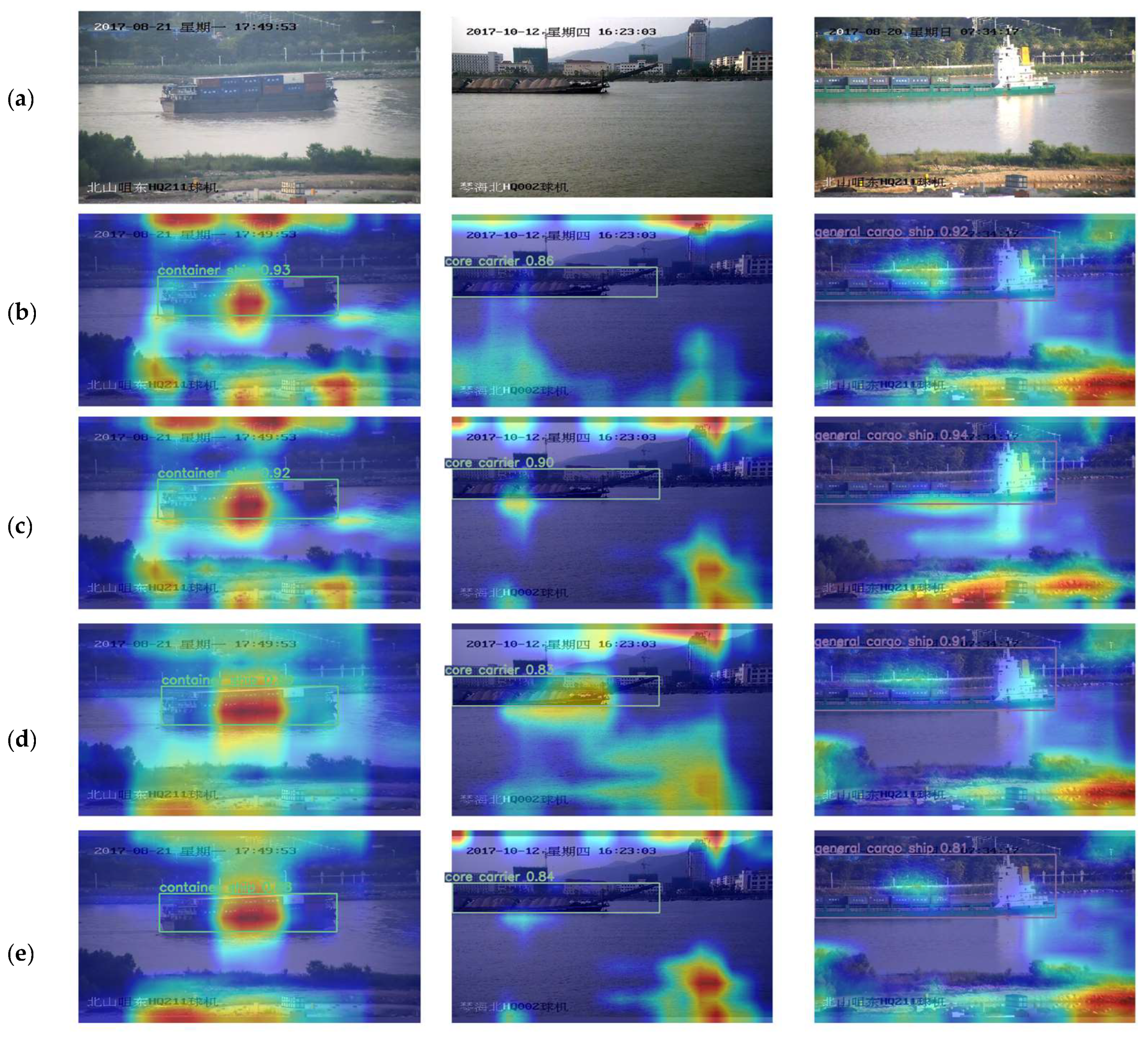
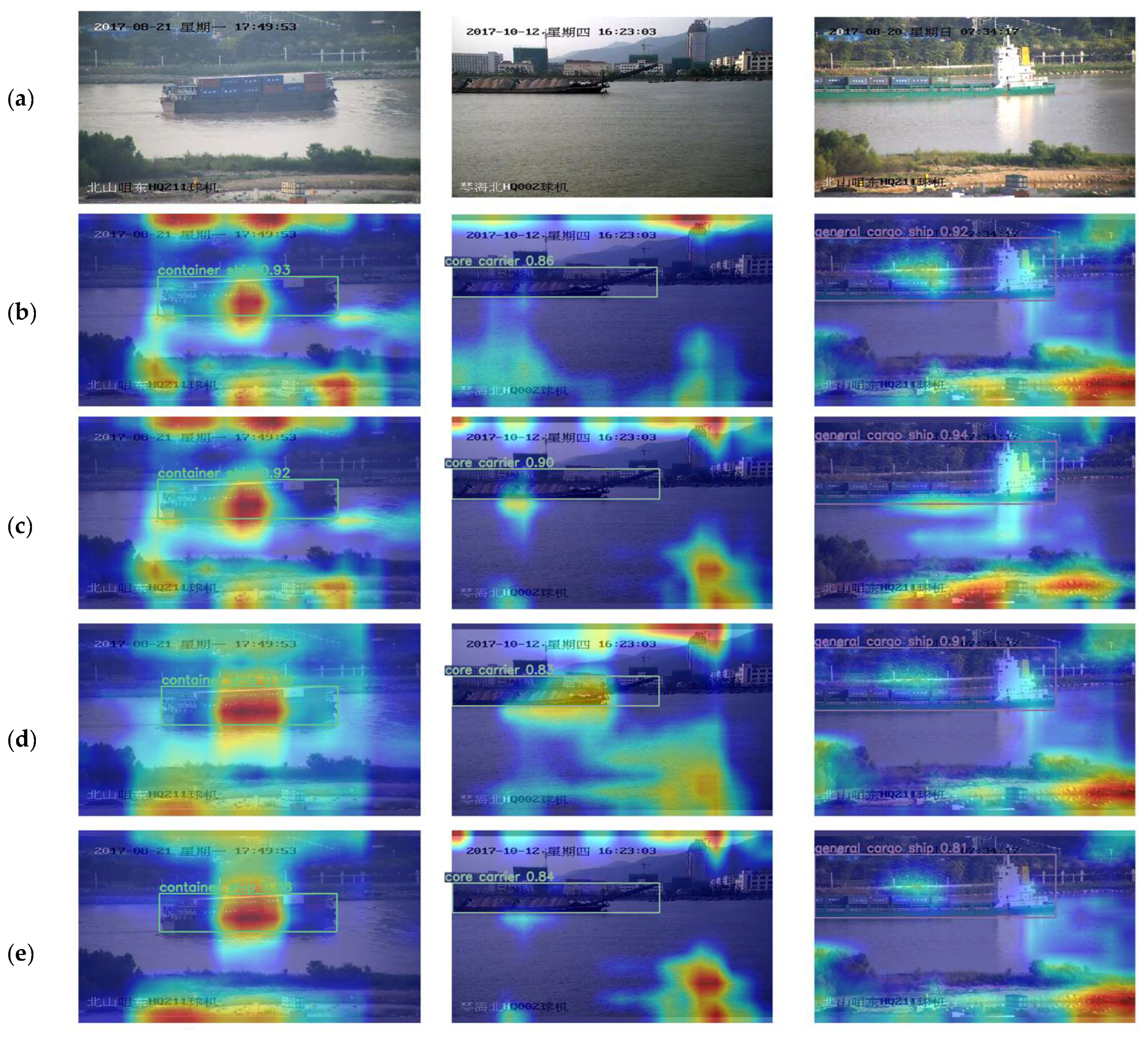
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhou, A.; Xie, W.; Pei, J. Background modeling combined with multiple features in the Fourier domain for maritime infrared target detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 4202615. [Google Scholar] [CrossRef]
- Zhou, A.; Xie, W.; Pei, J. Maritime infrared target detection using a dual-mode background model. Remote Sens. 2023, 15, 2354. [Google Scholar] [CrossRef]
- Yoshida, T.; Ouchi, K. Improved Accuracy of Velocity Estimation for Cruising Ships by Temporal Differences Between Two Extreme Sublook Images of ALOS-2 Spotlight SAR Images with Long Integration Times. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11622–11629. [Google Scholar] [CrossRef]
- Yao, S.; Chang, X.; Cheng, Y.; Jin, S.; Zuo, D. Detection of moving ships in sequences of remote sensing images. ISPRS Int. J. Geo-Inf. 2017, 6, 334. [Google Scholar] [CrossRef]
- Larson, K.M.; Shand, L.; Staid, A.; Gray, S.; Roesler, E.L.; Lyons, D. An optical flow approach to tracking ship track behavior using GOES-R satellite imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 6272–6282. [Google Scholar] [CrossRef]
- Bahrami, Z.; Zhang, R.; Wang, T.; Liu, Z. An end-to-end framework for shipping container corrosion defect inspection. IEEE Trans. Instrum. Meas. 2022, 71, 5020814. [Google Scholar] [CrossRef]
- He, H.; Lin, Y.; Chen, F.; Tai, H.-M.; Yin, Z. Inshore ship detection in remote sensing images via weighted pose voting. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3091–3107. [Google Scholar] [CrossRef]
- Chen, X.; Qiu, C.; Zhang, Z. A Multiscale Method for Infrared Ship Detection Based on Morphological Reconstruction and Two-Branch Compensation Strategy. Sensors 2023, 23, 7309. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and excitation rank faster R-CNN for ship detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 751–755. [Google Scholar] [CrossRef]
- Guo, H.; Yang, X.; Wang, N.; Song, B.; Gao, X. A rotational libra R-CNN method for ship detection. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5772–5781. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, S.; Wang, W.-Q. A lightweight faster R-CNN for ship detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2020, 19, 4006105. [Google Scholar] [CrossRef]
- Wen, G.; Cao, P.; Wang, H.; Chen, H.; Liu, X.; Xu, J.; Zaiane, O. MS-SSD: Multi-scale single shot detector for ship detection in remote sensing images. Appl. Intell. 2023, 53, 1586–1604. [Google Scholar] [CrossRef]
- Yang, Y.; Chen, P.; Ding, K.; Chen, Z.; Hu, K. Object detection of inland waterway ships based on improved SSD model. Sh. Offshore Struct. 2023, 18, 1192–1200. [Google Scholar] [CrossRef]
- Long, Z.; Suyuan, W.; Zhongma, C.; Jiaqi, F.; Xiaoting, Y.; Wei, D. Lira-YOLO: A lightweight model for ship detection in radar images. J. Syst. Eng. Electron. 2020, 31, 950–956. [Google Scholar] [CrossRef]
- Xu, Q.; Li, Y.; Shi, Z. LMO-YOLO: A ship detection model for low-resolution optical satellite imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4117–4131. [Google Scholar] [CrossRef]
- Sun, S.; Xu, Z. Large kernel convolution YOLO for ship detection in surveillance video. Math. Biosci. Eng. 2023, 20, 15018–15043. [Google Scholar] [CrossRef]
- Karthi, M.; Muthulakshmi, V.; Priscilla, R.; Praveen, P.; Vanisri, K. Evolution of yolo-v5 algorithm for object detection: Automated detection of library books and performace validation of dataset. In Proceedings of the 2021 International Conference on Innovative Computing, Intelligent Communication and Smart Electrical Systems (ICSES), Chennai, India, 24–25 September 2021; pp. 1–6. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 1 March 2024).
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Ji, M.; Wu, Z. Automatic detection and severity analysis of grape black measles disease based on deep learning and fuzzy logic. Comput. Electron. Agric. 2022, 193, 106718. [Google Scholar] [CrossRef]
- Shao, Z.; Wu, W.; Wang, Z.; Du, W.; Li, C. Seaships: A large-scale precisely annotated dataset for ship detection. IEEE Trans. Multimed. 2018, 20, 2593–2604. [Google Scholar] [CrossRef]
- Zhang, L.; Ding, G.; Li, C.; Li, D. DCF-Yolov8: An Improved Algorithm for Aggregating Low-Level Features to Detect Agricultural Pests and Diseases. Agronomy 2023, 13, 2012. [Google Scholar] [CrossRef]
- Yang, G.; Wang, J.; Nie, Z.; Yang, H.; Yu, S. A lightweight YOLOv8 tomato detection algorithm combining feature enhancement and attention. Agronomy 2023, 13, 1824. [Google Scholar] [CrossRef]
- Li, S.; Wang, S.; Wang, P. A small object detection algorithm for traffic signs based on improved YOLOv7. Sensors 2023, 23, 7145. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Li, P.; Xu, T.; Xue, H.; Wang, X.; Li, Y.; Lin, H.; Liu, P.; Dong, B.; Sun, P. Detection of cervical lesions in colposcopic images based on the RetinaNet method. Biomed. Signal Process. Control 2022, 75, 103589. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ships | Accuracy | Precision | Recall | mAP@.5 | mAP@.5:.95 |
|---|---|---|---|---|---|
| Ore carrier | 0.996 | 0.986 | 0.989 | 0.994 | 0.863 |
| general cargo ship | 0.995 | 0.987 | 0.994 | 0.993 | 0.875 |
| bulk cargo carrier | 0.992 | 0.968 | 0.979 | 0.989 | 0.873 |
| Container ship | 0.996 | 0.993 | 0.995 | 0.995 | 0.886 |
| Fishing boat | 0.992 | 0.970 | 0.965 | 0.989 | 0.801 |
| Passenger ship | 0.991 | 0.989 | 0.988 | 0.988 | 0.818 |
| Average | 0.994 | 0.982 | 0.985 | 0.991 | 0.854 |
| Structure | Accuracy | Precision | Recall | mAP@.5 | mAP@.5:.95 |
|---|---|---|---|---|---|
| Yolov8n-C2f | 0.990 | 0.982 | 0.979 | 0.988 | 0.848 |
| Yolov8n-C2f_EMAM | 0.993 | 0.981 | 0.982 | 0.990 | 0.950 |
| Structure | Accuracy | Precision | Recall | mAP@.5 | mAP@.5:.95 |
|---|---|---|---|---|---|
| Yolov8n-Concatenate | 0.989 | 0.982 | 0.979 | 0.988 | 0.848 |
| Yolov8n-Concatenate_BiFPN | 0.991 | 0.981 | 0.980 | 0.989 | 0.851 |
| Yolov8n-Concatenate_FBiFPN | 0.992 | 0.983 | 0.981 | 0.990 | 0.852 |
| Structure | Accuracy | Precision | Recall | mAP@.5 | mAP@.5:.95 |
|---|---|---|---|---|---|
| Yolov8n-SPPF | 0.989 | 0.982 | 0.979 | 0.988 | 0.848 |
| Yolov8n-SPPF2+1 | 0.992 | 0.980 | 0.982 | 0.990 | 0.951 |
| Yolov8n-SPPF3+1 | 0.987 | 0.979 | 0.978 | 0.985 | 0.837 |
| Yolov8n-SPPF3+3 | 0.988 | 0.978 | 0.979 | 0.985 | 0.838 |
| Models | mAP@.5 | mAP@.5:.95 | Parameters (M) | GFLOPs (G) | FPS |
|---|---|---|---|---|---|
| Faster RCNN | 0.850 | 0.698 | 39.56 | 101.80 | 20.40 |
| EfficientDet-D1 | 0.950 | 0.761 | 6.67 | 12.43 | 19.62 |
| Yolov5s | 0.960 | 0.754 | 6.74 | 16.50 | 78.56 |
| Yolov5m | 0.975 | 0.760 | 20.10 | 50.70 | 64.40 |
| Yolov5l | 0.983 | 0.767 | 44.50 | 114.60 | 41.50 |
| Yolov7 | 0.986 | 0.821 | 35.50 | 105.53 | 73.58 |
| Yolov8n | 0.988 | 0.848 | 2.87 | 8.21 | 83.33 |
| Yolov8s | 0.990 | 0.851 | 10.62 | 28.71 | 71.42 |
| Yolov8m | 0.991 | 0.854 | 24.66 | 79.1 | 47.62 |
| Improved Yolov8n | 0.991 | 0.854 | 2.87 | 8.30 | 83.33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lan, K.; Jiang, X.; Ding, X.; Lin, H.; Chan, S. High-Efficiency and High-Precision Ship Detection Algorithm Based on Improved YOLOv8n. Mathematics 2024, 12, 1072. https://doi.org/10.3390/math12071072
Lan K, Jiang X, Ding X, Lin H, Chan S. High-Efficiency and High-Precision Ship Detection Algorithm Based on Improved YOLOv8n. Mathematics. 2024; 12(7):1072. https://doi.org/10.3390/math12071072
Chicago/Turabian StyleLan, Kun, Xiaoliang Jiang, Xiaokang Ding, Huan Lin, and Sixian Chan. 2024. "High-Efficiency and High-Precision Ship Detection Algorithm Based on Improved YOLOv8n" Mathematics 12, no. 7: 1072. https://doi.org/10.3390/math12071072
APA StyleLan, K., Jiang, X., Ding, X., Lin, H., & Chan, S. (2024). High-Efficiency and High-Precision Ship Detection Algorithm Based on Improved YOLOv8n. Mathematics, 12(7), 1072. https://doi.org/10.3390/math12071072