Abstract
This study investigates whether analyzing the code comments available in the source code can effectively reveal functional similarities within software. The authors explore how both machine-readable comments (such as linter instructions) and human-readable comments (in natural language) can contribute towards measuring the code similarity. For the former, the work is relying on computing the cosine similarity over the one-hot encoded representation of the machine-readable comments, while for the latter, the focus is on detecting similarities in English comments, using threshold-based computations against the similarity measurements obtained using models based on Levenshtein distances (for form-based matches), Word2Vec (for contextual word representations), as well as deep learning models, such as Sentence Transformers or Universal Sentence Encoder (for semantic similarity). For evaluation, this research has analyzed the similarities between different source code versions of the open-source code editor, VSCode, based on existing ESlint-specific directives, as well as applying natural language processing techniques on incremental releases of Kubernetes, an open-source system for automating containerized application management. The experiments outlines the potential for detecting code similarities solely based on comments, and observations indicate that models like Universal Sentence Encoder are providing a favorable balance between recall and precision. This research is integrated into Project Martial, an open-source project for automatic assistance in detecting plagiarism in software.
Keywords:
code similarity; linter analysis; comments analysis; software plagiarism; plagiarism detection; universal sentence encoder MSC:
68T20
1. Introduction
The research aims to expand automated methods for detecting software code similarities, designing tools that facilitate collaboration between human experts and software. This will support informed plagiarism decisions through an interactive process where the broader context of the code, including comments and coding style, is automatically analyzed. To this end, this research introduces two novel models for identifying code similarities based solely on source code comments: one targeting machine-readable comments and the other focusing on human-readable comments.
There are several methods that have been used for detecting software code similarities, with the most common being fingerprint-based techniques [1,2,3,4], which aim to create distinctive “signatures” of code sections, allowing for automatic comparison. The main downside of these is that they lack the ability to fully explain flagged similarities, thus necessitating in-depth human review. Software birthmarks aim to address these limitations by extracting more robust identifying features and can work on both source code [4,5,6,7] and binary code [6,8,9,10]. Advanced birthmark techniques may incorporate machine learning to improve accuracy in complex programs. Finally, code embeddings-based solutions are another promising technique, as they are able to capture semantic meaning, as well as enabling similarity detection based on functionality. While these have primarily been applied to source code [11,12,13], they hold potential for binary code [14] analysis as well.
Ultimately, even if these techniques offer varying degrees of automation and explainability, human judgment remains essential for determining true plagiarism [15,16]. The current research focuses solely on the detection part of code similarities.
This paper continues with Section 2, which aims to classify and analyze comments in code, based on the target audience. Section 3 underscores the importance of comments as part of software development, and Section 4 proposes a formal method to represent comments within the source code as multisets, allowing analysis of comment structures within their local context. Later, Section 5 investigates whether code comments alone can reveal similarities between programs. It demonstrates how to analyze machine-readable comments, to detect similarities across different releases, with examples from ESLint instructions available in VSCode, and it explores the successful application of natural language processing techniques to human-readable comments, highlighting the superior balance of recall and precision achieved by the Universal Sentence Encoder [17] model. Section 6 discusses the implementation of the techniques in Project Martial, an open-source project for detecting software plagiarism. Section 7 discusses the interpretation of the results presented in this paper and finally, Section 8 summarizes the contributions of this paper, draws some conclusions and outlines potential future research directions.
2. Classification of Comments
Donald Knuth concluded in [18] that computer programming is an art, because it applies accumulated knowledge to the world, which requires skill and ingenuity, and especially because it produces objects of beauty. Such a powerful statement uplifts the merits of software developers but comes with a not-so-obvious pitfall when viewing software in the context of continuous development with contributions from a set of ever-changing engineers. In order to help the readers and reviewers comprehend the structure and purpose of the code, developers would provide lasting explanations, in the form of code comments, to the main program’s source code. Programming languages all agreed on the importance of providing such mechanisms, and for pioneer programming languages such as Fortran, the convention was that any line beginning with either the C character or an * in the first column is a comment. The Fortran basics guide states that well-written comments are crucial to program readability. Even in assembly languages, comments have been introduced to allow the developers explain, in a human-readable statement, the outcome. In x86 assembly, comments are usually denoted by the use of the semicolon (;) symbol, but variations also allow for shell-like (#) or C-like (//, /*) structures.
While often perceived as elements irrelevant to the computer, comments were historically only dropped from automatic analysis due to language specification limitations. For example, in early Fortran, when punch cards were prevalent, a comment character in the first column would designate the entire card as a comment, causing the execution to completely ignore it.
Kernighan and Ritchie reinforced this notion in their influential book [19] describing C specifications, which stated that any characters between /* and */ are ignored by the compiler; they may be used freely to make a program easier to understand. An example of a grammar implementation of this statement is presented in the appendix, Code Listing A.1.
Predictably, programming languages and software development technologies have evolved, introducing new complexities and requirements. Consequently, “code comments” have gained significance in various stages of the life-cycle of a program, moving beyond their traditionally overlooked role. For instance, in some languages including Python, specifying a custom encoding requires adding a special comment line at the very beginning of the file, as illustrated in Code Listing A.2. Another example, presented in Code Listing A.3, covers operating system directives, but there are also cases where code comments, while not directly affecting program execution or interpretation, provide guidance for external analysis tools, such as instructions for linters (Code Listings A.4 and A.5) or static analyzers (Code Listing A.6). Nonetheless, they can also provide hints, instructing compilers or interpreters to alter the behavior of the program.
Therefore, even if the primary use of comments was and remains to indicate explanations for software engineers that are reviewing existing codebases, there are quite a few exceptional cases where it is reasonable for commentaries to be designed in a way that they are machine-readable, in order to allow actions to be automatically performed, by various systems.
Moreover, there are other machine-readable expressions, besides comment statements, that do not directly influence the functionality of the executable code. Pragma statements within libraries or languages are an example; they modify the binary only if the compiler supports them. Consider OpenMP: if the compiler does not support its pragmas, they are discarded, ensuring the resulting binary still functions as intended (Code Listing A.7). While analyzing such pragmas could potentially assist in determining code similarities, that analysis is outside of the scope of this paper.
3. Statistics on Open-Source Projects
Because open-source projects promote transparency, by releasing the source code within a project, they are a good source of analysis, as opposed to proprietary software provided in binary format, where past traces of comments have already been eliminated. This paper analyzed the evolution of the commentary in code, for notable open-source projects, such as, but not limited to, Kubernetes [20] (Go), Visual Studio Code (TypeScript) and Linux [21] (C). Table 1 summarizes quantitative data for all the analyzed projects, with the ratio of total lines of comments to code varying anywhere between 8% and 22% across different projects, but the percentages increases even further if the reporting switches towards counting the total number of characters (between 16% and 33%) or words (between 21% and 43%), that are contained in the comments against the total corpus.

Table 1.
Quantitative analysis of comment distribution for various open-source projects (including projects written in Go, TypeScript, Java, C and C++), employing code analysis tools to measure comment density, length and the ratio of English words (defined as words composed entirely of alphabetical characters from the English alphabet).
Kubernetes v1.1.1 was released in 2015, and in January 2023, v1.26.1 has been released. Figure 1 presents the ratio of comments w.r.t. the total lines of code. Between these versions, comments have been ranging between and of the total number of lines in the source code, peaking to about M of lines of comments (out of a total of M) in the last analysed release. Even if the proportion of comments to total lines of code fluctuates within consecutive versions, the overall long-term trend is ascendant, which could indicate an increased emphasis on code readability, maintainability, or collaboration within the Kubernetes development community. If the investigation is char-wise (counting the ratio of characters appearing in comments against the total number of characters appearing in the source code) or word-wise (counting the ratio of space-separated words) focused, the percentages are even bigger; for chars and for the words. Figure 2 captures the evolution of these percentages against different versions of Kubernetes. Moreover, these data suggest a clear upward trend in the use of code comments within large-scale open-source projects, with both the relative and absolute amounts of comment words increasing over time, and indicate that comments are becoming essential tools for navigating and comprehending the complexities of large-scale open-source projects to make the source code more accessible and understandable.
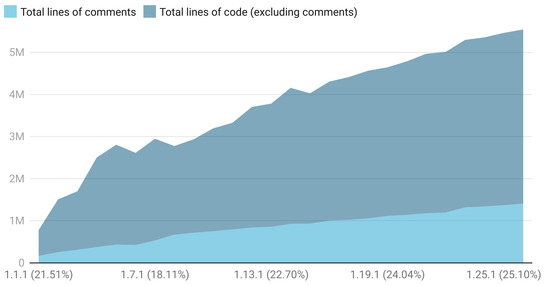
Figure 1.
The evolution of the total number of lines of comments and lines of code across different versions of Kubernetes. In parentheses, it is captured the proportion of lines of comments within the total source code corpus. This analysis spans roughly 10 years of continuous development, between the first release in 2013 and the first available release from 2023. Kubernetes releases currently happen approximately three times per year. The ratio trend over time is important because commenting practices within the Kubernetes project might have changed over time, converging towards the idea of offering insights into the maintainability, collaboration dynamics and code readability within this complex open-source system.
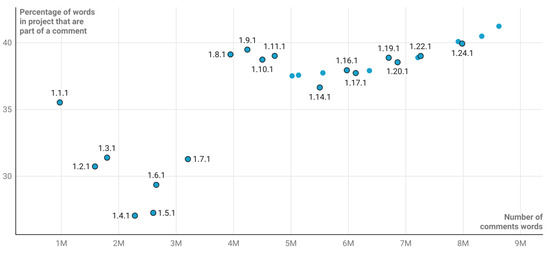
Figure 2.
This figure shows the percentage of words in different Kubernetes versions that are part of comments out of the total corpus. These data offer insights into how commenting practices evolve within large-scale open-source software projects, showing an increasing trend in the amount of words part of comments out of the total corpus, across releases, as well as an ever increasing trend in the absolute number of comment words.
4. Formalizing Code Comments Analysis
Let be the text representation of the source code. By it is denoted the set of all blocks of comments from . All single-line comments are mapped to an element of . For languages that support multi-line comments, for simplicity, multi-line blocks are also modelled as a single element of .
An important statement is that is finite. Given that all source codes are finite sets of instructions of the programming language, is also finite. As is built exclusively as a subset of , is also finite.
Let be the multiset of all blocks of comments from , where provides the multiplicity of the element in . The multiset representation helps in capturing the count of duplicated comments.
There is one aspect that is yet not covered, regarding the fact that a logical comment may not spawn over one single line. One proposal would be to aim to concatenate multiple line-independent comments when performing the analysis.
Let , and denote by the multiset of all concatenated blocks of comments from , where .
While provides the most extensive set to search in, it is impractical to analyze all possible concatenations, as the cardinality grows over powers rule. To allow room for a meaningful analysis, the cardinality of this set can be reduced by analyzing multi-line comments based on their locality.
Let the function return a set of lines where comment was found in , and let , and denote by the multiset of all locally concatenated blocks of comments from . It is important to note that exists, and it is equal to the total number of possible combinations of .
In practice, the cardinality of is a scaling issue for automatic detection, so let the subset be defined, with the additional constraint from that allows for maximum r single line comments concatenation, i.e., any element must have . Likewise, let be the multiset of all locally concatenated blocks of comments of maximum length of r from and be the total number of possible combinations of .
By convention, .
An important note to make is that, for any given finite , will also be finite.
To prove this, let . Therefore, the set will contain the maximum possible length concatenation of comments, , this set representing the concatenation of all comments from the source code. Therefore, and .
Modeling Repetitive Comments
Because duplicated comments are a frequent phenomenon in code (Code Listing A.9 presents such an example), a worthwhile analysis would investigate the necessity of both repetition detection and locality context searching for code similarity analysis. This property will be explicitly used in subsequent sections related to the investigation of machine-readable comments, where the multiplicity of lint comments has a key role in computing the similarity.
To address situations where duplicate comments appear in different locations and to better capture the importance of locality context, the model requires an extension for repetitive comments.
The multiplicity is covered in the model via the multiplicity function of the multiset . Code Listing A.8 demonstrates how seemingly isolated single-line comments, when considered together, form a cohesive explanation requiring locality context for accurate analysis.
Locality context searching will be enforced in the models via the r-parameter of . Due to computational constraints, the research will only focus on , with a finite r. To pick an appropriate value of r, the authors have empirically evaluated the capabilities of detecting similarities with respect to r. Choosing a finite smaller value for r makes the approach prone to missing true positives, as well as not defending against willful changes between the analyzed versions. An improvement can be made if more computational resources are available by increasing the value of r, or using . The proposed models runs two main algorithms: one algorithm is optional and it is only applied for generating the embeddings for models that need one, such as transformers and sentence encoders, and the other algorithm is mandatory and it process the comments (or their associated embeddings) from different sources, one pair at a time. The complexity of the former algorithm grows linearly with r, while the latter algorithm is quadratic in r. Figure 3 presents some practical results, which outline the two dependencies of these algorithms with respect to the increase in r.
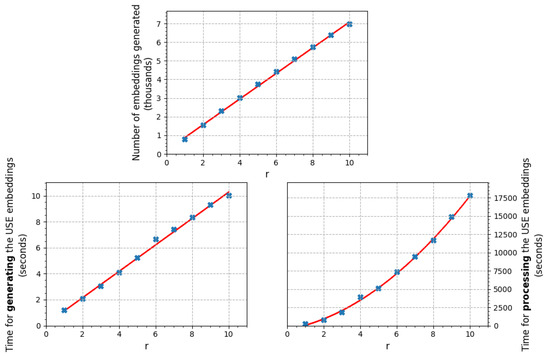
Figure 3.
The performance of the Universal Sentence Encoder, when tested against different values of r, based on a subset of Kubernetes v1.2.1 and v1.3.1 code, analyzing a corpus of 6000 lines of code.
Choosing this particular value was, in this research, based on empirical tests on Kubernetes releases, where was considered to be the right trade-off. For any , the numbers of similarities identified remained constant, and large chunks of similar comments identified were also covered by analyzing subsets. When evaluating the model, the increase from to led to several more matches, but the the growth from to slowed considerably. Because the only downside of choosing a larger value for r is the increase in the computational expense, it is recommended to adopt a value that fits the available physical resources, as well as potential time constraints of the application. Please consult Figure 3 for the performance implications associated with choosing , for the scenario analysed in this paper.
5. Analyzing Code Similarity
Section 2 and Section 3 have emphasized the importance of comments to any non-trivial software project and, given their relevance, this research investigates if whether analyzing the comments from a source code can provide sufficient information to perform relevant measurements of code similarity. The presented approach would involve combining natural language processing techniques with the analysis of comment structure and their placement within the code. This paper will separately treat machine- and human-readable comments in the next two subsections.
5.1. Machine-Readable Comments
In order to validate whether machine-readable comments may help in measuring code similarity to some degree, the research presents the evolution of ESlint [22] traces for the VSCode Project [23]. It is worth noting that because currently VScode releases happen monthly, with the notable exception that there is no release in December, this provides plenty of resources to analyse.
Figure 4 captures a subset of ESlint-identified issues in the VSCode Project, where some similarities between incremental versions of this software will be analysed. For analyzing the similarity for a particular use case, suffices for identifying all the ESlint suppressions.
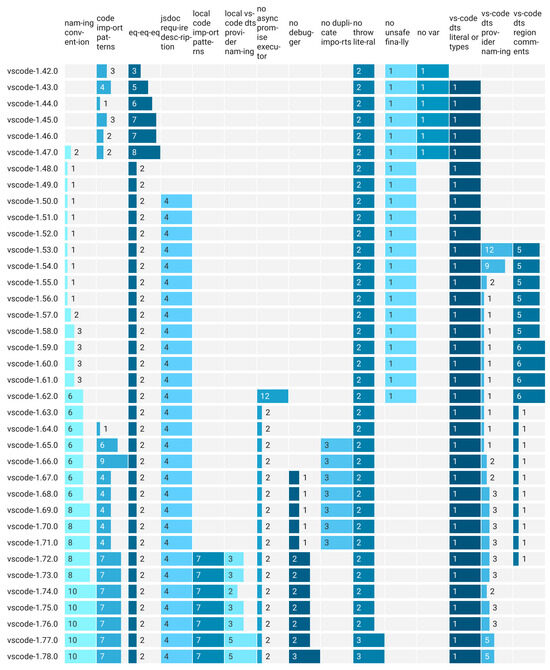
Figure 4.
Subset of ESlint issues signaled on incremental VSCode versions, later than 1.42. Versions prior to this had no ESlint suppressing expressions.
Let be the set of all lint overrides identified in . , such that l appears in . The occurrences of l are tracked by modeling the multiset , where , such that l appears in .
In order to compute a metric that captures the similarity of the two algorithms, defined by and , based on the linter findings, the research uses the cosine similarity. Let and be the multisets that describe the lint overrides identified in and and let . The method attaches to each algorithm a vector embedding that corresponds to the hot-encoding of the set of lint issues present in an , weighted by their occurrence.
, where
Figure 5 presents the results of computing the cosine-based similarity based on ESlint suppressions in various VSCode releases by computing the value . This score contains more linter issues (27) than the ones presented in Figure 4 (a subset of 15 linter issues).
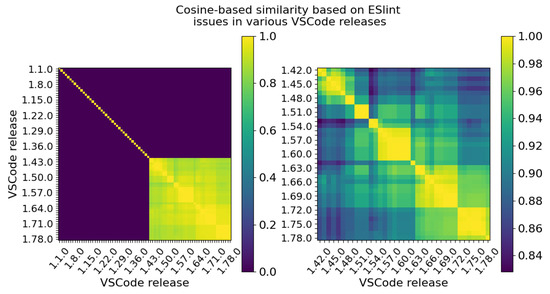
Figure 5.
Similarity calculation based on ESlint data for various releases of VSCode. In the left heatmap, all the VScode releases are being presented, ranging from: 1.1 -> 1.78, and on the right, only a relevant subset of analyzed versions with ESlint reported issues are captured, versions: 1.42 -> 1.78. By convention, let if . The left image presents a limitation of the current model (for versions 1.1 -> 1.41) in the absence of machine-readable comments, for which the model is not able to produce meaningful similarity detection, while the right heatmap outlines cases where the model performs well and is able to create a relevant similarity measurement.
Of particular note are the similarity scores presented in Figure 5 are built entirely based on the cosine similarity of the resulting one-hot encodings obtained from the data available in Figure 4, and each square in the heatmap obtained in Figure 5 corresponds to the cosine similarity between the vectors available in the latter. For example, as the vectors defining the lint issues in VSCode versions v and v are equal, their cosine similarity score will be 1 and, therefore, matched with the highest intensity square in the heat-map.
It is worth mentioning that the closer the versions are, in general, the higher the similarity observed by this algorithm. Comparing v with v, the similarity score obtained is around , while v with v, the similarity is 0.947. Finally, v with v yields a similarity score of 0.867. The similarity is, however, not described by a strictly monotonic function. For example, v with v yields a similarity score of , greater than the one obtained against v.
Please note that earlier than v, there were no lint issues in the code of VSCode, so is a nil-vector and, therefore, cosine similarity is nil for each comparison. This research therefore excludes versions below v from the analysis, for which the current method does not provide any meaningful inputs. This is a known limitation of this model model, which is irrelevant for similarity analysis for any two source codes that lack machine-readable comments.
5.2. Human Comments
Because the intend is to leverage established natural language processing technologies for computing code similarity through comment analysis, as a prerequisite, the research aims to evaluate the applicability of such techniques to code comments. by analyzing the percentage of actual English words found within comments. To approximate whether a word belongs to the English lexicon, it will be cross-referenced against the nltk’s corpus of words, enchant’s US_en dictionary and wordnet’s corpus.
Figure 6 shows that for Kubernetes, between 91 and 93 percent of all the alpha (contains only a–z letters) words from comments are words belonging to the English lexicon. Some coding style guides may actually enforce the proper use of grammar and vocabulary in the code-base. For example, the Google Style Guide for writing code in languages such as C++, Go or Java state that comments that are complete sentences should be capitalized and punctuated like standard English sentences [24] and comments should be as readable as narrative text, with proper capitalization and punctuation [25].
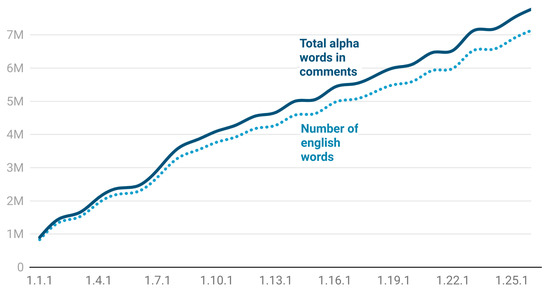
Figure 6.
The evolution of the number of English identified words against the total number of alphabetical comment words identified in different versions of Kubernetes.
English dominates open-source software development as the most frequently used human-readable language. This simplifies the analysis, as understanding the percentage of meaningful English words provides a close approximation of the total percentage of words belonging to the lexicon of a human-spoken language. This concept is illustrated in Listing A.10. However, comments might not always adhere strictly to natural language syntax, even when intended to convey meaning similar to spoken language, which may be a limitation of the presented solution. In Listing A.11, even if the name of the flag is not part of any lexicon, it is easier for humans to understand the meaning of that value.
To analyze the similarity between two algorithms, defined by and , the model will investigate and , the multiset containing locally concatenated blocks of comments of maximum length of 6 from and . The models are detecting similarities in code comments by computing a similarity function against each two elements of these sets and a threshold value . If , the model considers , to have a similarity and labels the pair accordingly.
There are trade-offs in choosing an appropriate value of t. At limit cases, will make all comments look similar, while will enforce that only exact comments are labeled with similarities.
The choice of similarity function is crucial to this approach. Since obtaining definitively similar code samples is challenging [26], this study constructs the analysis dataset using incremental versions of the same program. The assumption is that recent versions represent a high degree of similarity. To validate whether comments can indicate similarity between different releases, this model is evaluated against the evolution of comments in various Kubernetes versions. The research explores a wide range of techniques: from basic string matching and fuzzy matching with rapidfuzz [27], to advanced NLP approaches. These include cosine similarity calculations based on word2vec embeddings [28], as well as models based on deep contextualized of word representations, which aim to create vector embeddings from the code comments.
A Levenshtein-based similarity function will typically provide higher precision scores but will be prone not to detect changes of form without substance, while a contextualized word representation may be able to generalize for more complex cases but is at risk of triggering false positives. More details backing up this statement will be available in Section 7 and Section 8.
It is important to consider that the model treats consecutive comments as potentially connected and analyzes them accordingly (up to r). In reality, they could be related, or they may not be related at all. That is not a limitation of the approach, because if the model matches the entire group as similar, with a distinct group of consecutive comments obtained from the analyzed source, related or not locally, they result in a similarity that is worth analyzing. In the context of plagiarism detection, as per the argument of [15], “after specific sections of the programs have been flagged as similar, it shouldn’t matter whether the questionable code was initially uncovered by software or by a person” and that “the argument for plagiarism should stand on its own”.
Another consideration in choosing the optimal model is the associated complexity of the method. In Table 2, it is presented the total time required to perform the two tasks (generating and processing the similarities) on a dataset of over 12 thousands lines of Go code. The total time of the analysis is the sum of these intervals. Simpler models like Word2Vec are faster for both generating and processing embeddings, while more complex models (such as ELMo or RoBERTa) are computationally demanding. The Universal Sentence Encoder demonstrates significant efficiency in embedding generation but incurs a longer computational cost during the subsequent processing stage. Levenshtein-based models are notable outliers in the presented table, as their extremely good performance in terms of speed, but come with the trade-off of missing broader semantic understanding.
Table 2.
Time statistics (obtained on a 2.3 GHz Dual-Core Intel Core i5 processor) for generating and processing embeddings on over 12,000 Go lines, obtained from a subset of Kubernetes v1.2.1 and v1.3.1 and v1.25.1 repositories. The Levenshtein-based models require no prior work for generating embeddings, and the processing step simply involves evaluating the text-based similarity of the two analyzed comments.
For analyzing the performance of the models, the authors have compared the predictions of similarity of the models against a human-labeled dataset obtained from over 12,000 lines of Go code from the source code of Kubernetes “/pkg/api” directories versions v1.2.1 (April, 2016), v1.3.1 (July 2016) and v1.25.1 (September 2021). The dataset contains 3594 comments, and the ground truth contains 49573 identified similarities between pairs of comments (including 3594 identity similarities). This dataset has a big class imbalance: the total number of ‘not similar’ matches on the code comments is nearly 6 million, compared to ‘similar’ classes, which are on the order of 50 thousands. As a result, to obtain the most reliable assessment of the model’s performance, in this analysis the evaluation based on the F1-Score will be prioritize. This is because a high F1-Score indicates the model performs well in both minimizing both false positives and false negatives, even if the dataset is unbalanced.
The performance of the models on this dataset is also summarized in Table 3 by evaluating the models using precision, recall and F1-Score as metrics. It also computes the macro and weighted average, as well as the accuracy. The model based on the Universal Sentence Encoder seems to achieve the best quantitative results, maintaining a good balance between precision and recall on the analyzed Kubernetes-based test dataset described above.
Table 3.
A performance comparison of different models tested against around 35 thousand comments from three versions of Kubernetes source code. The presence of numerous trivial similarity examples within the dataset, such as identical or nearly identical comments, can lead to artificially inflated performance metrics, even for relatively simplistic models. Optimizing for the long tail provides a more realistic measure of a model’s capabilities in real-world code analysis. The ELMo-based model is being ignored when computing the most appropriate model for optimizing a certain metric because of the low F1-Score.
Because the dataset contains many comments that are either identical or have very minor changes across consecutive versions, even simple models will easily identify them as similar. This artificially inflates accuracy, precision and recall. It is therefore critical to optimize the long tail of misses in the data presented in Table 3, as spotting trivial similarities is far less valuable than pinpointing the more subtle similarities that require a deeper understanding of the natural language used.
5.2.1. Levenshtein-Based Models
Rapidfuzz [27] is an implementation of an approximate string matching algorithm, which aims to only approximately find strings that match a given pattern based on Levenshtein distance. While matches in this approach are high quality and clear indications on similarity [29,30,31], produced by making a variety of minor changes of inserting, deleting or substituting words, the method has a low hit rate [32] on more advanced cases, where structural changes are involved.
The results seem to be of high quality due to the number of false positive matches being minimal compared to other methods. For high values of t, the number of false positive matches is almost nonexistent (for , only exact matching will be performed). Some qualitative examples are described in Appendix B.1, in Examples B1 towards B6. However, overall, the match perspective is bounded in identifying true positives. It works really well in identifying form changes, such as typos, refactoring or (almost) duplicated code comments.
5.2.2. Word2Vec-Based Models
Spacy’s approach to computing similarity involves assigning each word a vector representation derived from a pre-trained model. This model has been trained on large corpora using the Word2Vec technique [28], enabling the creation of contextual embeddings. To calculate the similarity between full sentences, Spacy averages the word embeddings and computes the cosine difference. While generally useful [33], this method can yield unexpected results. False positives may arise due to the “canceling out” effect within the averaged embeddings or from the model misinterpreting similarities between unrelated words.
This method can identify the very vast majority of similarities that Levenshtein-based models can, as seen in Appendix B.2, example B7, but it can also find more complex sequence paraphrases, as seen in examples B8 and B9. Examples B10 and B11 capture more cases, including complete rephrases and rewording of the original statements. Example B12 is a debatable case if the similarity is correctly identified by the current model. While the two comments refer to similar things (bind addresses, IP addresses, 0.0.0.0, servers and serving), it is rather difficult to state their exact similarity, even for a human expert.
5.2.3. ELMo-Based Models
ELMo [34] is a model that computes the embeddings from the states of a two-layer bi-directional language model [35]. In practice, running the ELMo-based model for large projects is expensive computationally. The risk of false positives can be addressed either by increasing the value of t, or by human judgement. Even when performing the detection with a very high value for the threshold (), in the presented experiments, the model identified a really high number of false positive matches, consequently leading to inefficiency.
The suitability of ELMo-based models for this specific task appears questionable. Analysis of the examples reveals shortcomings, as presented by the qualitative analysis on the examples from Appendix B.3. The only similarity in example B13 is that both comments reference the same GenericAPIServer, but the context in which it is referenced appears to be completely different (creation | usage of IP). Examples B14–B16 seem completely unrelated, and the matches are not particularly helpful in helping the manual labor involved by the operators.
5.2.4. Sentence Transformers
In the research, the authors have used the RoBERTa [36] model implementation from the SentenceTransformers framework, which is a BERT [37]-based model to create embeddings from text, as developed in [38]. These neural networks use Siamese structures to convert semantically meaningful embeddings from sentences. Given the output embeddings generated from , the research computed the cosine similarity and chose for the experiments. Overall, the quality of the matches is pretty high.
As shown in examples B17–B19 from Appendix B.4, the model has thus proven good capabilities of identifying similarities, as it can identify pretty well changes in the phrases, as well as similar meaning within multiple different statements.
5.2.5. Universal Sentence Encoder
The Universal Sentence Encoder [17] is yet another model that the authors have selected for evaluating for encoding sentences into embedding vectors. The model (available online, open-source, at: https://tfhub.dev/google/universal-sentence-encoder/4, accessed on 16 March 2024) has been trained with a deep averaging network encoder [35]. Similar to the Sentence Transformers model, the use of the Universal Sentence Encoder seems to provide a better balance concerning the ratio of true to false positives than the rest of the analyzed methods. Examples B20–B22, referenced in Appendix B.5, show several qualitative similarities identified by the model.
Qualitatively, the most notable misclassifications of this model, which are not observed in simpler methods such as Levenshtein or Word2vec models, happens in comments that contain numerical values. For example, between Kubernetes v1.2.1 and v1.25.1, a change observed around the code-base is that “Copyright 2016” comments got replaced by “Copyright 2021”. The model fails to identify in many cases such similarities, as exemplified in example B23.
This paper evaluated the performance of the algorithm for multiple values of r and summarized the results in Figure 3. According to the results displayed, the generation part of the embeddings is very fast for this particular model, as it can generate more than 700 embeddings per second on a 2.3 GHz Dual-Core Intel Core i5 processor, and the time efficacy grows linearly with larger inputs. In terms of the processing, as mentioned in Section 4, the performance is quadratic because the required number of evaluations is quadratic in the total number of embeddings, and practical experiments have observed that, on the same architecture, it executes about 2800 similarity evaluations per second.
6. Implementation Details and Reproducibility
The techniques presented in this paper have been incorporated into Project Martial, an open-source initiative for automated software plagiarism detection (source code available at https://github.com/raresraf/project-martial, accessed on 16 March 2024). The implementation includes a user interface that visually highlights potentially similar code sections, as identified by the similarity functions described within the presented models. The authors acknowledge the valuable insights provided by the work in [35] for the analysis of human-readable comments, as well as the detailed implementation details that have been provided.
The natural language processing components of the models are being implemented in Python, utilizing libraries such as scikit-learn and Matplotlib for the presentation of the data and frameworks such as TensorFlow and PyTorch for importing, loading and running the transformer-based models presented in this paper. A review of the dependencies used for the processing of human-based comments can be consulted within the project-martial code, under the comments drivers from the “modules/”.
For syntactic and semantic code parsing, the software stack uses ANTLR (ANother Tool for Language Recognition), a parser generator that uses a top-down LL-based algorithm for parsing.
The data presented in Table 1 and in Figure 1, Figure 2 and Figure 6 are reproducible using the modules associated with the project-martial code, under “grammars/”. The data presented in Figure 4 and Figure 5 are reproducible using the modules under “parsers/”. The raw data numbers are also available under “dataset/”. Figure 3 is reproducible running the executables provided under “scripts/”.
For the plots, Figure 1, Figure 2, Figure 5 and Figure 6 are built using datawrapper, an online data visualization product. Figure 3 and Figure 5 are generated using the Matplotlib library.
The web-based user interface is developed in TypeScript, providing a responsive and intuitive experience for code review. Figure 7 illustrates how the software highlights potentially similar comments identified, aiding users in identifying areas of interest for code similarity. For a review of the implementation, please consult the resources under ui/.
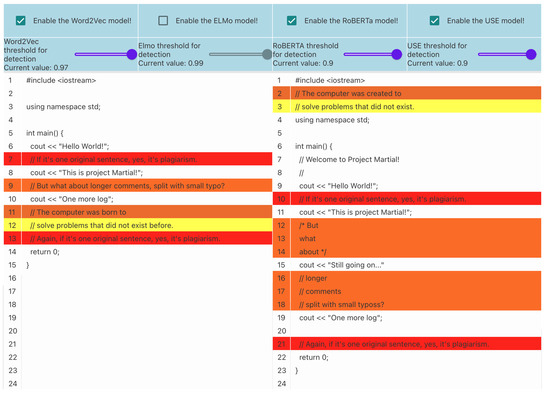
Figure 7.
The web-based interface of Project Martial, highlighting potentially similar comments to visually guide users towards areas where code similarities might exist.
The back-end server is built in Python, using the Flask framework, which is capable of serving API requests over HTTP, and the source code is accessible in the root directory of the project, under main.py.
7. Discussion
For the proposed solutions, this research observed that Levenshtein-based models offer excellent precision but may miss broader semantic similarities, while contextualized word embeddings such as Word2Vec or Universal Sentence Encoders perform better by capturing some of these complexities. However, these models might have some more false positives than Levenshtein-based, which minimizes almost to zero this metric.
The dataset used for evaluation was extracted from a subset of three Kubernetes versions, accumulating over 12 thousands lines of code and around 50 thousands identified similarities in comments. The best (Based on the F1-Score achieved on the dataset presented in this paper, from collected commentaries from three Kubernetes versions) model was based on the Universal Sentence Encoder [17], achieving a strong balance between precision and recall, but it showed some limitations when operating with sentences containing numerical values.
In addition, the Universal Sentence Encoder-based model stands out with efficient embedding generation, though processing of the embeddings is slower, due to their increased size. As expected, simpler models such as Levenshtein- and Word2Vec-based are significantly faster (see Table 2). Due to their still good performance, Word2Vec-based models can provide feasible alternatives to Universal Sentence Encoders, as they only use a fraction of the computational power required to run the analysis.
8. Conclusions and Future Work
This study aimed to develop practical methods for detecting code similarities by analyzing various types of software comments, and the results confirm the valuable contribution of comments in revealing code similarities.
Machine-readable comments (like ESlint directives) proved surprisingly effective when using techniques like cosine similarity and one-hot encoding, while the investigation of human-readable English comments demonstrated the power of semantic similarity models (Sentence Transformers, Universal Sentence Encoder) over form-based matching techniques (Levenshtein-based approaches). The former model can be classified in the collection of software birthmarks approaches, while the latter is an embedding-based model.
The research, performed on a diverse set of open-source projects, confirms the predominance of English in open-source code comments, making NLP methods highly applicable. However, a further area of research can be analyzing the potential deviations from strict natural language syntax, which should be considered when analyzing non-machine-readable comments, as this case exists in software projects, as pointed out in Table 1 and Figure 2. The quantitative analysis of comment distribution has been captured in Table 1 for various open-source projects (including projects written in Go, TypeScript, Java, C and C++), aiming to uncover language-specific commenting practices, readability trends and potential correlations with project maturity.
Integrating this research into Project Martial adds practical value by enhancing the capabilities of software plagiarism detection tools. The two proposed models are used in an ensemble manner, meaning that their predictions are combined in the score of similarity to achieve a more accurate and robust outcome.
As future work, it would be useful to extend this analysis beyond the analyzed datasets of Kubernetes and VSCode repositories in order to capture a larger variety of software languages and project types. This assesses the wider applicability of comment-based similarity detection, as well as performing further human-assisted validations, on the utility of these tools, to make the right trade-offs between precision and recall while fine-tuning the parameters. Nonetheless, as the state-of-the-art pre-trained language models improve, it becomes possible to update detectors to generate more sophisticated sentence-level representations for similarity checks than the capabilities of the current models.
Additionally, future work could explore the fine-tuning of models like RoBERTa or other Sentence Transformers on large-scale code comment datasets. This fine-tuning has the potential to improve the models’ sensitivity to the nuances of programming language and domain-specific terminology often found in comments.
Finally, the model’s reliance on comments presents a clear limitation, hindering its use on code-bases which have minimal documentation or for which comments have been intentionally removed. Future research, as part of the development of Project Martial, will investigate hybrid approaches that synergistically combine comment-based analysis with structural code analysis techniques. This would provide a more robust similarity detection solution applicable to a wider range of software.
Author Contributions
Conceptualization: R.F. and E.S.; Methodology: R.F. and E.S.; Software: R.F.; Validation: R.F. and E.S.; Writing: R.F. and E.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
All the datasets used and the experiment code are available online at https://github.com/raresraf/project-martial, accessed on 16 March 2024.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Code Listings: Classification Model
This appendix contains relevant code listings that offer detailed examples illustrating the context in which certain statements in the paper are made.
| Listing A.1. This language specification of the C programming language is exemplified by the ANTLR’s implementation of the language grammar in the open-source examples [39]. Skip statements instruct the lexer to discard a given token, implying that a skipped lexer rule cannot be later used in a parser rules. |
BlockComment: ’/*’ .*? ’*/’ -> skip; LineComment: ’//’ [\r\n]* -> skip; |
| Listing A.2. To support the Greek alphabet in a python program, the cp869 codec may be used. This is indicated to the interpreter by specifying a first-line comment. |
# -*- coding: cp869 -*-
|
| Listing A.3. A well-known method for making scripts directly executable is the UNIX ‘shebang’ line. For example, this “comment” line appears at the start of a Python script and indicates what interpreter should be used (in this case, version 3.9). Python interpreters themselves will ignore the shebang line since it is not relevant to the code’s logic, but it provides valuable information to the operating system in order to be able to launch it in execution. |
#!/usr/bin/env python3.9
|
| Listing A.4. pylint is a tool specific for Python. In order to enable or disable a message for a particular module, a comment-like statement should be added. |
# pylint: disable=wildcard-import, method-hidden, line-too-long
|
| Listing A.5. For TypeScript, the disabling of the type checking for a source file may be accomplished with a two-line comment. |
// ESlint-disable-next-line @typescript-ESlint/ban-ts-comment // @ts-nocheck |
| Listing A.6. Cppcheck is a static analysis tool that checks C/C++ code for various errors and style issues, including potential buffer access out-of-bounds errors. This comment tells Cppcheck to ignore the “bufferAccessOutOfBounds” warning on the line of code where this comment appears. |
// cppcheck-suppress bufferAccessOutOfBounds array[index] = value; // This line might trigger the warning |
| Listing A.7. An OpenMP example that showcases the “pragma omp parallel for” syntax, a core OpenMP directive. It instructs the compiler to create a parallel region where the following for loop will be executed by multiple threads. In the absence of parallel support for a given architecture, the directive will simply be ignored, and the program will be able to (correctly) proceed and execute the statements in a serial manner. |
int sum = 0; #pragma omp parallel for reduction(+:sum) for (int i = 0; i < N; i++) { sum += a[i]; } |
| Listing A.8. Sample (Kubernetes) comment that needs to be analyzed in context to capture the correct meaning. Individually reading and interpreting single lines of comments is not enough for a complete understanding. For example, comment line 4 has no standalone meaning, but in context, it connects the first three blocks, as well as with the fifth line of comment. |
// teststale checks the staleness of a test binary. go test -c builds a test // binary but it does no staleness check. In other words, every time one runs // go test -c, it compiles the test packages and links the binary even when // nothing has changed. This program helps to mitigate that problem by allowing // to check the staleness of a given test package and its binary. |
| Listing A.9. Example (Kubernetes) of situations where duplicated comments may occur. |
// In host_config.go. type Resources struct { … // Kernel memory limit (in bytes) KernelMemory int64 ‘json:“kernel_memory”‘ … } // In cgroup_unix.go. type Resources struct { // Applicable to UNIX platforms … KernelMemory int64 // Kernel memory limit (in bytes) … } |
| Listing A.10. Sample comment from Kubernetes project, written in compliant English grammar. |
// Package leaderelection implements leader election of a set of endpoints. // It uses an annotation in the endpoints object to store the record of the election state. // This implementation does not guarantee that only one client is acting as a leader (a.k.a. fencing). // A client observes timestamps captured locally to infer the state of the leader election. |
| Listing A.11. Example for Linux Kernel where a comment is used to point the reader from the hexadecimal number 0x00400000 to the EXT4_EOFBLOCKS_FL flag. ext4 is pointing to the Linux journaling file system (fourth extended filesystem) and EOFBLOCKS is indicating the number of blocks allocated beyond the end-of-file (EOF). This is how the EXT4_EOFBLOCKS_FL block can have a natural language equivalent, while at first glance, it was not composed of parts from lexicon. |
0x00400000 /* EXT4_EOFBLOCKS_FL */
|
Appendix B. Code Listings: Qualitative Analysis
This appendix section presents a qualitative analysis of comments identified as similar using the proposed models. To provide context, examples of similar comments are included, along with an in-depth discussion of their characteristics in Section 5.
Appendix B.1. Qualitative Analysis of the Identified Similarities for the Levenshtein-Based Model
This section contains some sample similarities, identified in comment snippets between releases Kubernetes 1.2.1 and 1.3.1, using a similarity score with the matching threshold and a Levenshtein-based model:
| Example B1 |
| Copyright 2015 The Kubernetes Authors All rights reserved |
| Copyright 2016 The Kubernetes Authors All rights reserved |
| Example B2 |
| For maximal backwards compatibility if no subnets are tagged it will fallback to the current subnet |
| For maximal backwards compatibility if no subnets are tagged it will fallback to the current subnet |
| Example B3 |
| Canonicalize returns the canonical form of q and its suffix see comment on Quantity |
| CanonicalizeBytes returns the canonical form of q and its suffix see comment on Quantity |
| Example B4 |
| May also be set in SecurityContext If set in both SecurityContext and |
| May also be set in PodSecurityContext If set in both SecurityContext and |
| Example B5 |
| If the affinity requirements specified by this field are not met at |
| If the anti-affinity requirements specified by this field are not met at |
| Example B6 |
| URISchemeHTTP means that the scheme used will be http |
| URISchemeHTTPS means that the scheme used will be https |
Appendix B.2. Qualitative Analysis of the Identified Similarities for the Word2vec-Based Model
This section identifies comments sections with high similarity scores between releases Kubernetes 1.2.1 and 1.3.1 using Spacy’s word2vec-based similarity score with a threshold of :
| Example B7 |
| InstanceID returns the cloud provider ID of the specified instance |
| ExternalID returns the cloud provider ID of the specified instance deprecated |
| Example B8 |
| Produces a path that etcd understands to the resource by combining the namespace in the context with the given prefix |
| Produces a path that etcd understands to the root of the resource by combining the namespace in the context with the given prefix |
| Example B9 |
| Because in release 11 apisextensionsv1beta1 returns response with empty APIVersion we use StripVersionNegotiatedSerializer to |
| Because in release 11 api returns response with empty APIVersion we use StripVersionNegotiatedSerializer to keep the response backwards |
| Example B10 |
| Scans all managed zones to return the GCE PD Prefer getDiskByName if the zone can be established |
| zone can be provided to specify the zone for the PD if empty all managed zones will be searched |
| Example B11 |
| leaseDuration is the duration that nonleader candidates will wait after observing a leadership renewal until attempting to acquire leadership of a led but unrenewed leader slot This is effectively the maximum duration that a leader can be stopped before it is replaced by another candidate This is only applicable if leader election is enabled |
| renewDeadline is the interval between attempts by the acting master to renew a leadership slot before it stops leading This must be less than or equal to the lease duration This is only applicable if leader election is enabled |
| Example B12 |
| healthzBindAddress is the IP address for the health check server to serve on defaulting to 127.0.0.1 set to 0.0.0.0 for all interfaces |
| bindAddress is the IP address for the proxy server to serve on set to 0.0.0.0 |
Appendix B.3. Qualitative Analysis of the Identified Similarities for the ELMo-Based Model
This appendix presents several qualitative examples of identified comments similarities between releases Kubernetes 1.2.1 and 1.3.1 using an ELMo-based model with a very high threshold value ().
| Example B13 |
| Select the first valid IP from ServiceClusterIPRange to use as the GenericAPIServer service IP |
| New returns a new instance of GenericAPIServer from the given config |
| Example B14 |
| is because the forwarding rule is used as the indicator that the load |
| what its IP address is if it exists and any error we encountered |
| Example B15 |
| Map storing information about all groups to be exposed in discovery response |
| Used to customize default proxy dialtls options |
| Example B16 |
| Unless required by applicable law or agreed to in writing software |
| EnsureLoadBalancer creates a new load balancer name or updates the existing one Returns the status of the balancer |
Appendix B.4. Qualitative Analysis of the Identified Similarities for the RoBERTa-Based Model
The RoBERTa-based model detected comment sections with high similarity scores between Kubernetes releases 1.2.1 and 1.3.1. These findings are presented in this section.
| Example B17 |
| a mustache is an eligible helper if |
| a mustache is definitely a helper if it is an eligible helper and |
| Example B18 |
| target average CPU utilization represented as a percentage of requested CPU over all the pods |
| current average CPU utilization over all pods represented as a percentage of requested CPU |
| Example B19 |
| Available represents the storage space available bytes for the Volume For Volumes that share a filesystem with the host eg emptydir hostpath this is the available |
| Capacity represents the total capacity bytes of the volumes underlying storage For Volumes that share a filesystem with the host eg emptydir hostpath this is the size of the underlying storage |
Appendix B.5. Qualitative Analysis of the Identified Similarities for the Universal Sentence Encoder-Based Model
This section presents some qualitative analysis on comments exhibiting high similarity scores between Kubernetes releases 1.2.1 and 1.3.1, as detected by the Universal Sentence Encoder-based model.
| Example B20 |
| This is a simple passthrough of the ELB client interface which allows for testing |
| This is a simple passthrough of the Autoscaling client interface which allows for testing |
| Example B21 |
| so this implementation always returns nil false |
| LoadBalancer always returns nil false in this implementation |
| Example B22 |
| Returns resources allocated to system cgroups in the machine |
| SystemCgroupsLimit returns resources allocated to system cgroups in the machine |
While the quantitative analysis shows that this model performs well, qualitatively, a common misclassification that this model encounters when needing to handle numerical values can be observed. The example presented below was not observed by the model as a potential similarity:
| Example B23 |
| Copyright 2016 The Kubernetes Authors. |
| Copyright 2021 The Kubernetes Authors. |
References
- Schleimer, S.; Wilkerson, D.S.; Aiken, A. Winnowing: Local algorithms for document fingerprinting. In Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data, San Diego, CA, USA, 10–12 June 2003; pp. 76–85. [Google Scholar]
- Chilowicz, M.; Duris, E.; Roussel, G. Syntax tree fingerprinting for source code similarity detection. In Proceedings of the 2009 IEEE 17th International Conference on Program Comprehension, Vancouver, BC, Canada, 17–19 May 2009; pp. 243–247. [Google Scholar]
- Narayanan, S.; Simi, S. Source code plagiarism detection and performance analysis using fingerprint based distance measure method. In Proceedings of the 2012 7th International Conference on Computer Science & Education (ICCSE), Melbourne, VIC, Australia, 14–17 July 2012; pp. 1065–1068. [Google Scholar]
- Cesare, S.; Xiang, Y. Software Similarity and Classification; Springer: Cham, Switzerland, 2012. [Google Scholar]
- Myles, G.; Collberg, C. K-gram based software birthmarks. In Proceedings of the 2005 ACM symposium on Applied Computing, Santa Fe, NM, USA, 13–17 May 2005; pp. 314–318. [Google Scholar]
- Tian, Z.; Zheng, Q.; Liu, T.; Fan, M.; Zhuang, E.; Yang, Z. Software Plagiarism Detection with Birthmarks Based on Dynamic Key Instruction Sequences. IEEE Trans. Softw. Eng. 2015, 41, 1217–1235. [Google Scholar] [CrossRef]
- Myles, G.; Collberg, C. Detecting software theft via whole program path birthmarks. In Proceedings of the Information Security: 7th International Conference, ISC 2004, Palo Alto, CA, USA, 27–29 September 2004; Proceedings 7. Springer: Cham, Switzerland, 2004; pp. 404–415. [Google Scholar]
- Ullah, F.; Wang, J.; Farhan, M.; Habib, M.; Khalid, S. Software plagiarism detection in multiprogramming languages using machine learning approach. Concurr. Comput. Pract. Exp. 2021, 33, e5000. [Google Scholar] [CrossRef]
- Lu, B.; Liu, F.; Ge, X.; Liu, B.; Luo, X. A software birthmark based on dynamic opcode n-gram. In Proceedings of the International Conference on Semantic Computing (ICSC 2007), Irvine, CA, USA, 17–19 September 2007; pp. 37–44. [Google Scholar]
- Tian, Z.; Wang, Q.; Gao, C.; Chen, L.; Wu, D. Plagiarism detection of multi-threaded programs via siamese neural networks. IEEE Access 2020, 8, 160802–160814. [Google Scholar] [CrossRef]
- Chen, Z.; Monperrus, M. A literature study of embeddings on source code. arXiv 2019, arXiv:1904.03061. [Google Scholar]
- Alon, U.; Brody, S.; Levy, O.; Yahav, E. code2seq: Generating sequences from structured representations of code. arXiv 2018, arXiv:1808.01400. [Google Scholar]
- Alon, U.; Zilberstein, M.; Levy, O.; Yahav, E. code2vec: Learning distributed representations of code. Proc. ACM Program. Lang. 2019, 3, 1–29. [Google Scholar] [CrossRef]
- Folea, R.; Iacob, R.; Slusanschi, E.; Rebedea, T. Complexity-Based Code Embeddings. In Proceedings of the International Conference on Computational Collective Intelligence; Springer: Cham, Switzerland, 2023; pp. 256–269. [Google Scholar]
- Plagiarism Detection. Available online: https://theory.stanford.edu/~aiken/moss/ (accessed on 23 September 2023).
- Wahle, J.P.; Ruas, T.; Kirstein, F.; Gipp, B. How large language models are transforming machine-paraphrased plagiarism. arXiv 2022, arXiv:2210.03568. [Google Scholar]
- Cer, D.; Yang, Y.; Kong, S.y.; Hua, N.; Limtiaco, N.; John, R.S.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal sentence encoder. arXiv 2018, arXiv:1803.11175. [Google Scholar]
- Knuth, D.E. The Art of Computer Programming; Pearson Education: London, UK, 1997; Volume 3. [Google Scholar]
- Kernighan, B.W.; Ritchie, D.M. The C PROGRAMMING Language; Prentice hall: London, UK, 1988. [Google Scholar]
- Burns, B.; Grant, B.; Oppenheimer, D.; Brewer, E.; Wilkes, J. Borg, omega, and kubernetes. Commun. ACM 2016, 59, 50–57. [Google Scholar] [CrossRef]
- Torvalds, L. The linux edge. Commun. ACM 1999, 42, 38–39. [Google Scholar] [CrossRef]
- Find and Fix Problems in Your JavaScript Code—ESLint—Pluggable JavaScript Linter. Available online: https://eslint.org/ (accessed on 27 October 2023).
- Visual Studio Code—Code Editing. Redefined. Available online: https://code.visualstudio.com/ (accessed on 27 October 2023).
- styleguide|Style Guides for Google-Originated Open-SOURCE Projects. Available online: https://google.github.io/styleguide/go/decisions (accessed on 26 March 2023).
- Google C++ Style Guide. Available online: https://google.github.io/styleguide/cppguide.html (accessed on 26 March 2023).
- Chae, D.K.; Ha, J.; Kim, S.W.; Kang, B.; Im, E.G. Software plagiarism detection: A graph-based approach. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 1577–1580. [Google Scholar]
- rapidfuzz · PyPI. Available online: https://pypi.org/project/rapidfuzz/ (accessed on 8 December 2023).
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Su, Z.; Ahn, B.R.; Eom, K.Y.; Kang, M.K.; Kim, J.P.; Kim, M.K. Plagiarism detection using the Levenshtein distance and Smith-Waterman algorithm. In Proceedings of the 2008 3rd International Conference on Innovative Computing Information and Control, Dalian, China, 18–20 June 2008; p. 569. [Google Scholar]
- Scerbakov, N.; Schukin, A.; Sabinin, O. Plagiarism detection in SQL student assignments. In Proceedings of the Teaching and Learning in a Digital World: Proceedings of the 20th International Conference on Interactive Collaborative Learning—Volume 2; Springer: Cham, Switzerland, 2018; pp. 110–115. [Google Scholar]
- Soyusiawaty, D.; Rahmawanto, F. Similarity Detector on the Student Assignment Document Using Levenshtein Distance Method. In Proceedings of the 2018 International Seminar on Research of Information Technology and Intelligent Systems (ISRITI), Yogyakarta, Indonesia, 21–22 November 2018; pp. 656–661. [Google Scholar] [CrossRef]
- Greenhill, S.J. Levenshtein distances fail to identify language relationships accurately. Comput. Linguist. 2011, 37, 689–698. [Google Scholar] [CrossRef]
- Stan, A.I.; Truică, C.O.; Apostol, E.S. SimpLex: A lexical text simplification architecture. Neural Comput. Appl. 2023, 35, 6265–6280. [Google Scholar]
- Sarzynska-Wawer, J.; Wawer, A.; Pawlak, A.; Szymanowska, J.; Stefaniak, I.; Jarkiewicz, M.; Okruszek, L. Detecting formal thought disorder by deep contextualized word representations. Psychiatry Res. 2021, 304, 114135. [Google Scholar] [CrossRef] [PubMed]
- Ultimate Guide to Text Similarity with Python—NewsCatcher. Available online: https://www.newscatcherapi.com/blog/ultimate-guide-to-text-similarity-with-python (accessed on 16 September 2023).
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]
- Parr, T. The definitive ANTLR 4 reference. In The Definitive ANTLR 4 Reference. Sample Grammars; Torrosa: Barcelona, Spain, 2013; Available online: https://github.com/antlr/grammars-v4 (accessed on 23 September 2023).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).