1. Introduction
Graph neural networks (GNNs) are considered the intersection of deep learning and graph theory [
1,
2]. Originally designed to handle data with graph structures, they capture relationships between nodes and propagate information through the graph structure [
2]. In recent years, the application of graph neural networks (GNNs) in computer vision tasks has been extensively explored. The fusion of visual networks with GNNs has led to significant improvements in model comprehension and breakthroughs in various visual tasks, including image classification [
3,
4,
5], object detection [
6,
7], and semantic segmentation [
8,
9]. However, the integration of these networks results in larger model sizes and higher computational costs, limiting their practical application on resource-constrained devices [
10]. To address these challenges, several compression and acceleration methods have been proposed, including pruning [
11,
12,
13], quantization [
14,
15,
16,
17], kernel decomposition [
18], and efficient inference backends [
19,
20,
21].
Among these methods, quantization has emerged as one of the most effective approaches. It uses quantization functions to reduce the bit width of network weights and activations, leading to faster inference and reduced memory usage [
14,
22]. For instance, LSQ [
23] sets a learnable scale factor in the quantization function, achieving adaptive fine-grained quantization through backpropagation. N2UQ [
24] realizes a better adaptation to distribution by learning non-uniform input thresholds to quantize inputs into equidistant output levels. AdaQP [
25] applies stochastic quantization to message vectors transmitted across devices, thereby reducing communication traffic. WGCN [
26] proposes the integration of Haar wavelet transforms and quantization functions to compress graph channels, achieving computational savings through channel shrinkage. CoGNN [
27] introduces the concept of reuse-aware sampling, performing node-level parallel-aware quantization to reduce the overhead of feature aggregation.
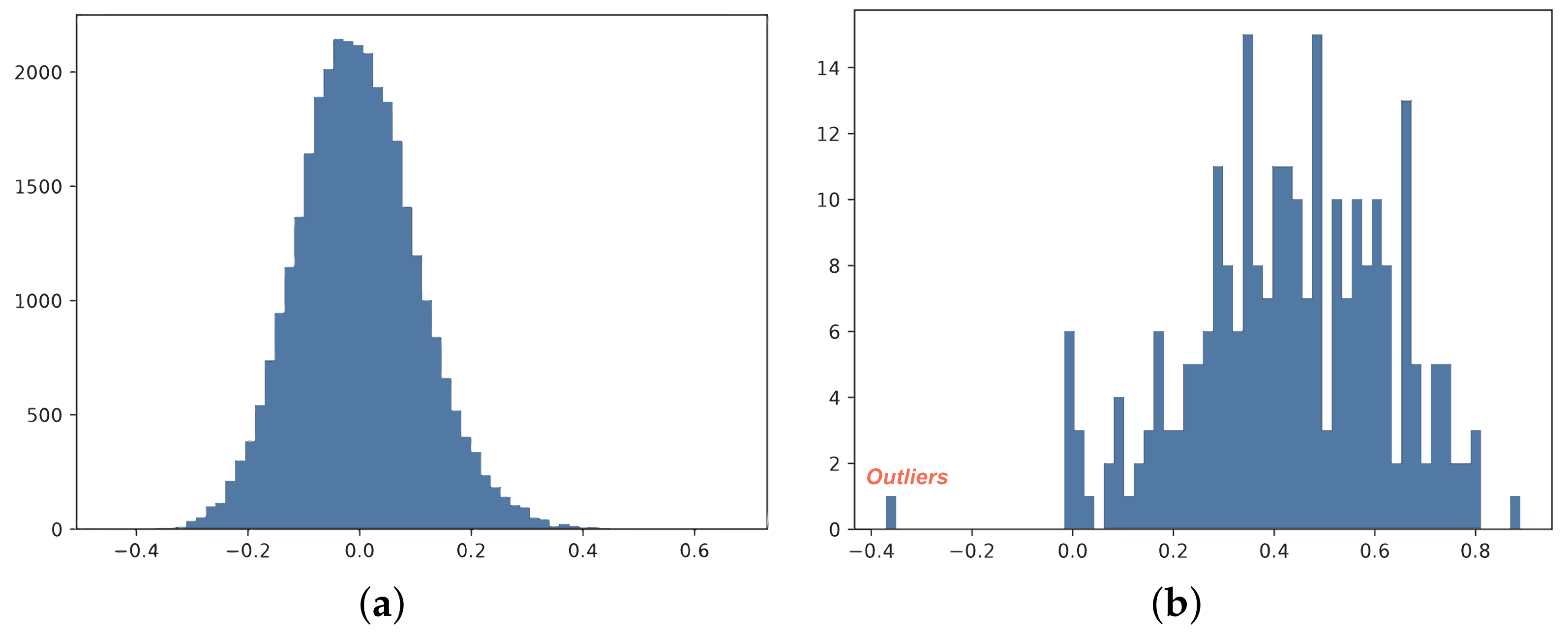
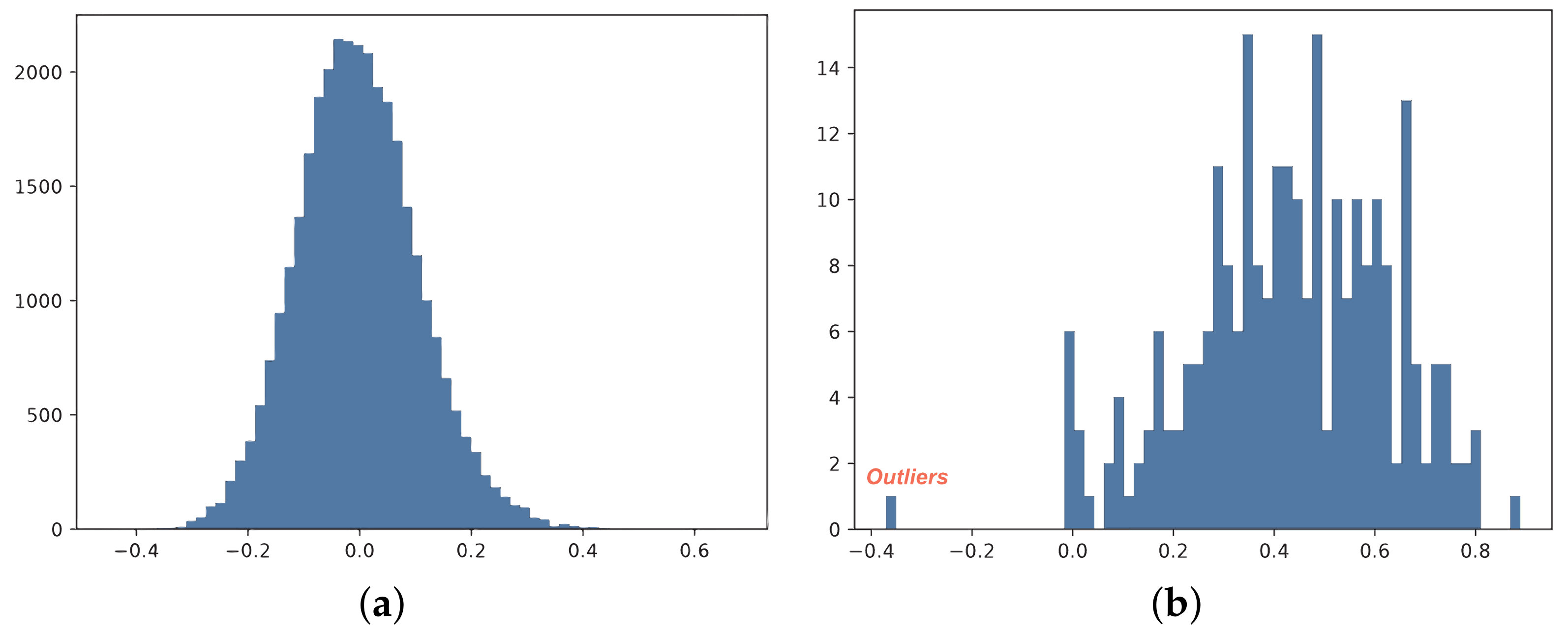
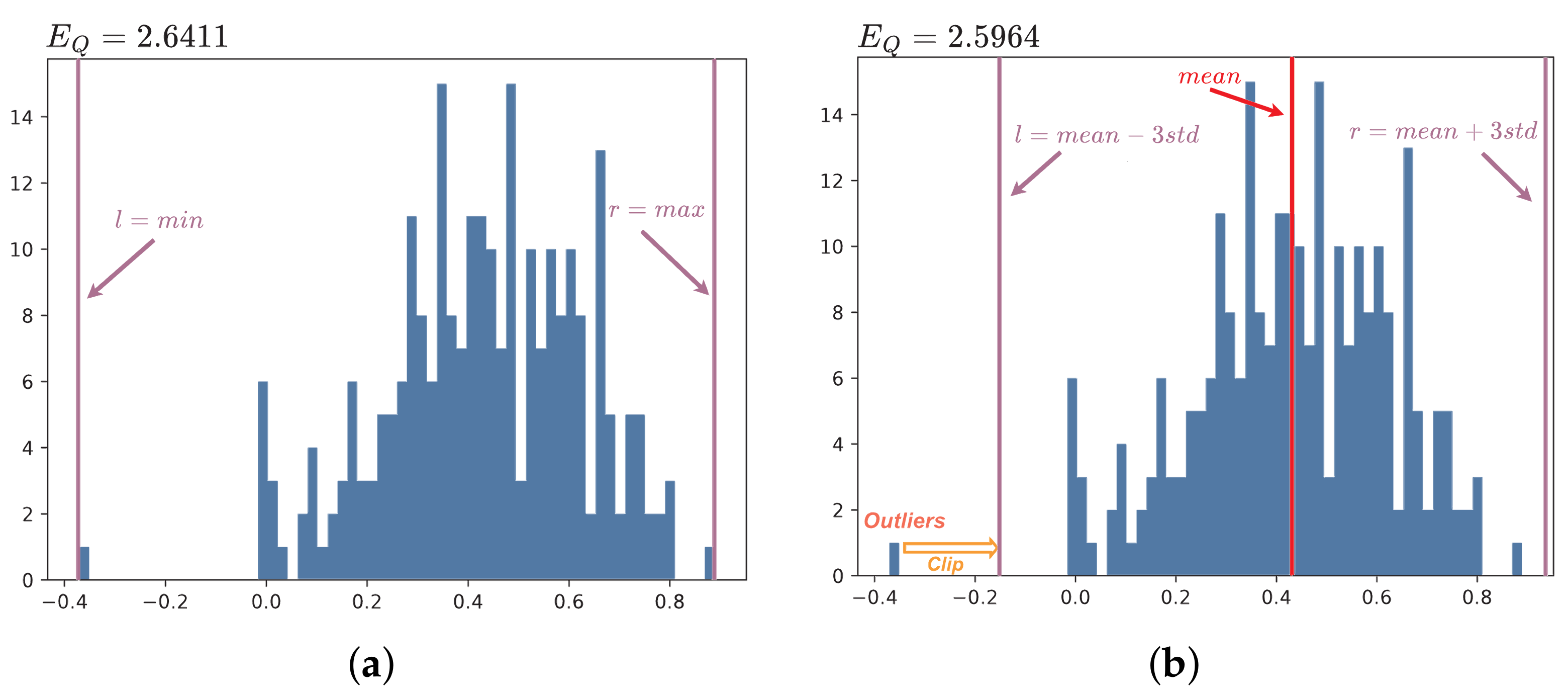
Despite advancements in designing better quantization methods, quantized GNNs for visual tasks still face significant challenges. The GNNs for visual tasks can be divided into two parts: visual networks for extracting semantic features from images and graph networks for identifying image relationships through message-passing mechanisms. In visual networks, weights often approximate a Gaussian distribution with a mean close to zero [
28,
29]. However, in graph networks, weights tend to deviate from zero and introduce outliers (see
Figure 1b). These outliers expand the quantization range, leading to coarse-grained quantization and higher quantization errors. Consequently, the performance of quantized models significantly deteriorates. Although researchers have employed knowledge distillation (KD) [
30,
31,
32], this approach has not fundamentally solved the problem of outliers. Moreover, KD introduces an additional teacher model, resulting in higher computational and memory costs for training, contradicting the intention of quantization to improve model efficiency.
To address these challenges, this paper explores the mechanisms of quantized GNNs used for image classification. We propose the quantized graph neural networks for image classification (QGNN-IC), which incorporates a novel quantization function called Pauta Quantization (PQ) and two plug-and-play self-distillation methods: attention quantization distillation (AQD) and stochastic quantization distillation (SQD). Specifically, PQ utilizes the mean and standard deviation of the input distribution to remove outliers, enabling fine-grained quantization and consequently reducing quantization errors, thereby enhancing the accuracy of the quantized model. AQD utilizes attention mechanisms to transfer more beneficial information to the quantized network, enhancing the visual network’s ability to extract semantic information. SQD enhances the robustness of the model to quantization by minimizing the information discrepancy between the randomly quantized branch and the fully quantized branch. AQD and SQD significantly improve the performance of quantized models without external teacher models, resulting in minimal additional computational and memory overhead during the training phase. Experimental results indicate that the 2-bit quantized model exhibits enhancements in accuracy of 1.92% and 0.95% on CIFAR-FS and CUB-200-2011, respectively. Moreover, the experiments also validate the generalizability of QGNN-IC.
The remainder of this paper is organized as follows:
Section 2 describes some related works to facilitate comprehension.
Section 3 clarifies the details of QGNN-IC, including quantization functions, self-distillation methods, loss functions, etc.
Section 4 reports the experimental results of the quantized models across different datasets and provides an analysis of the results. Finally,
Section 5 discusses the results and summarizes the article.
3. Methodology
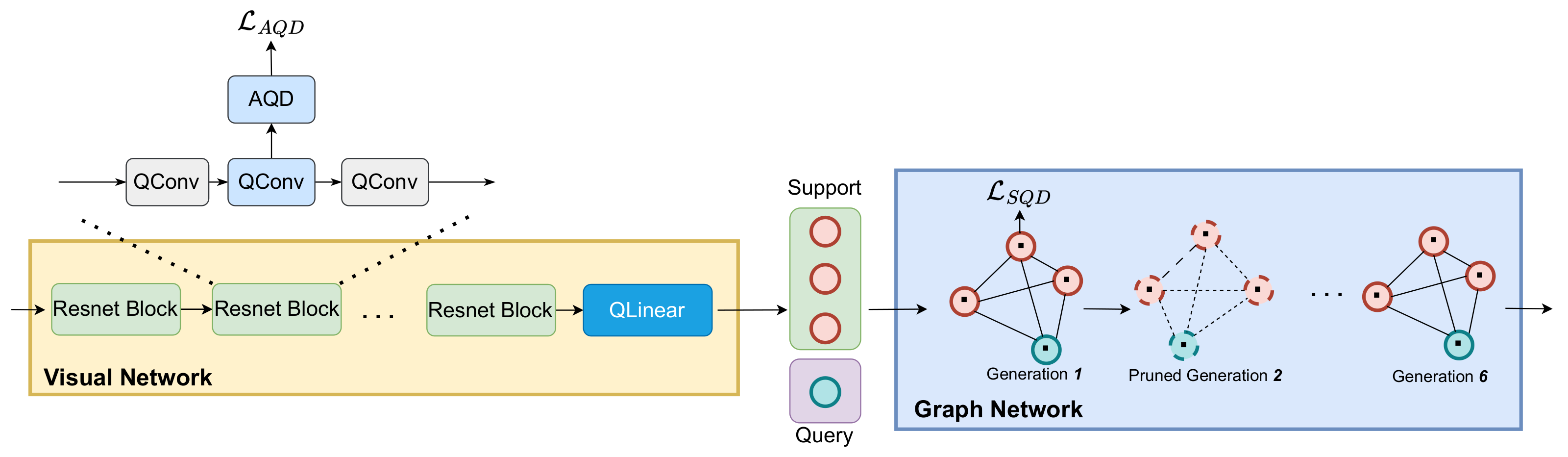
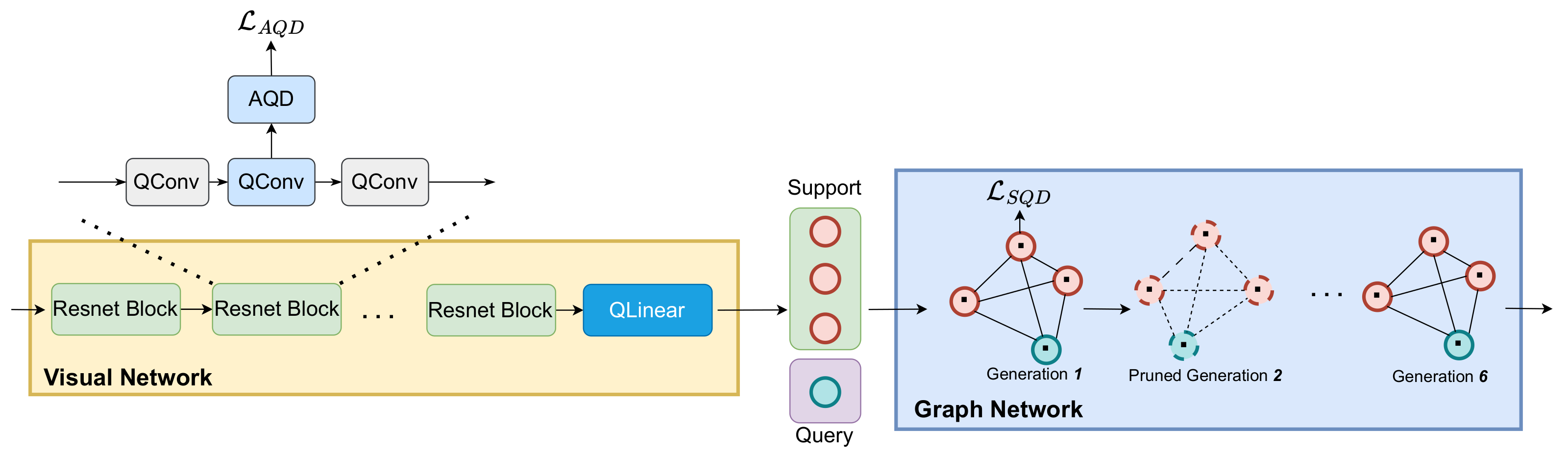
This section provides a comprehensive overview of the proposed QGNN-IC (see
Figure 2). Initially, we introduce the symbols and typical formulas used in model quantization (
Section 3.1). Subsequently, we propose a novel quantization function, PQ, designed to minimize the quantization error caused by outliers (
Section 3.2). In
Section 3.3 and
Section 3.4, we present two distinct self-distillation methods: AQD and SQD. AQD aims to enhance the semantic representation capability of quantized visual networks, while SQD seeks to improve the quantization robustness of quantized graph networks. Lastly, in
Section 3.5, we apply all the proposed methods to a graph neural network for image classification.
3.1. Preliminary
Model quantization converts the full-precision (32-bit) weights and activations to lower bit-width values, such as 8-bit fixed-point integers, using a quantization function. The n-bit quantization function is defined as follows:
where
X represents the weights or activations,
z is the zero-point,
denotes the rounding function,
is a clipping function that limits the lower bound of the values to
and the upper bound to
, and
is the scaling factor, with
and
being the maximum and minimum values of
X. The corresponding dequantized value
can be calculated as:
During backpropagation, the straight-through estimator (STE) [
47] is used to mitigate the gradient vanishing problem caused by the rounding function.
Finally, we define the quantization error with respect to
X as:
Generally, a smaller quantization error corresponds to a lesser decrease in model performance.
3.2. Pauta Quantization
GNNs for computer vision comprise two components: visual networks that extract semantic features from images and graph networks that identify image relationships using message-passing mechanisms. As depicted in
Figure 1, the weights in visual networks are typically approximated by Gaussian distributions with a mean close to zero [
28,
29]. On the other hand, in the graph network, the weights often have means far from zero and may include some outliers. These outliers can expand the quantization range, leading to a larger scaling factor
s and coarser quantization. Coarse quantization induces a high quantization error near the means, which impairs the performance of the quantized model. Therefore, the identification and management of outliers are crucial for enhancing the quantized models.
The Pauta criterion, a method for identifying outliers in sample data, utilizes the mean and standard deviation as thresholds to detect significant errors. If the error exceeds this threshold, it is deemed a significant error rather than a random error. These outliers should be removed as they are deemed unacceptable.
Inspired by the above analysis and the Pauta criterion, we propose Pauta quantization (PQ). Specifically, we first calculate the mean and standard deviation of the distribution and determine the quantization range
:
where
is the mean function, and
is the standard deviation function. Then, we perform precise quantization by excluding outliers. The formula for n-bit PQ is as follows:
where
is a clipping function that limits the lower bound of the values to 0 and the upper bound to
.
l and
r are set as learnable parameters.
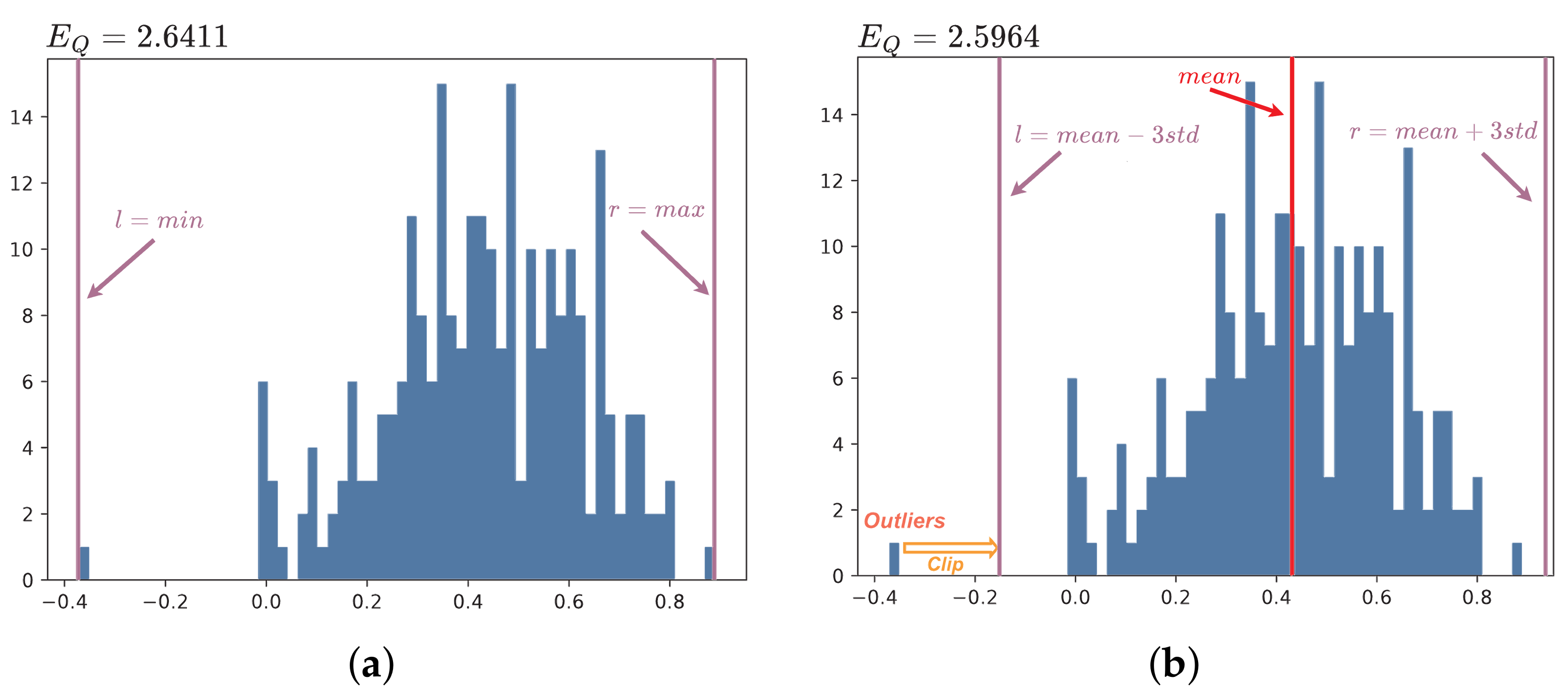
As shown in
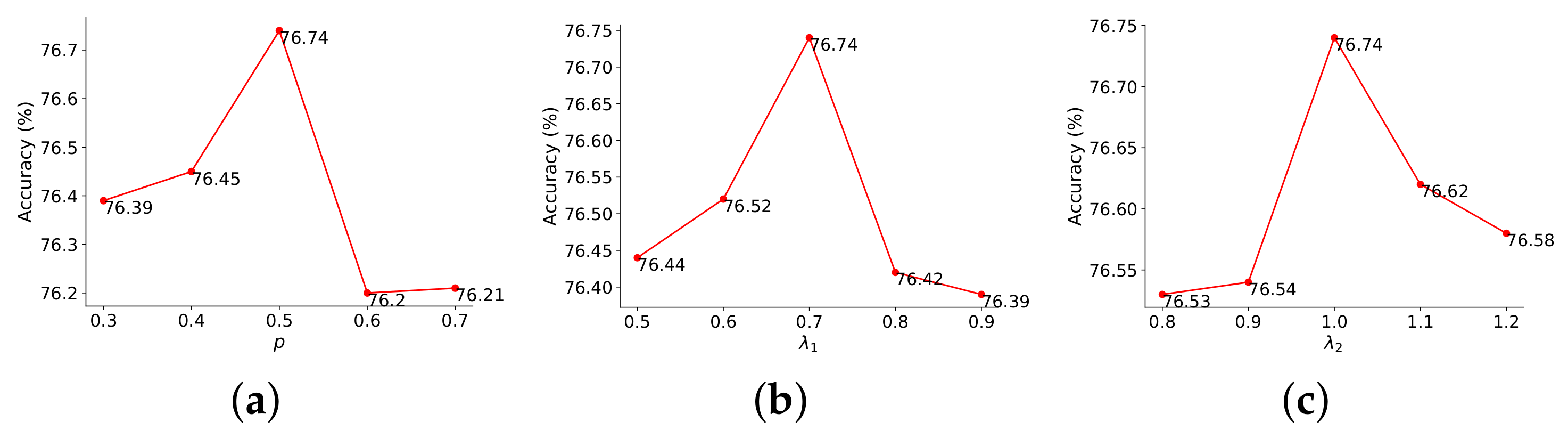
Figure 3, PQ analyzes the data distribution and estimates the quantization range appropriately, resulting in fine-grained quantization. This allows a large number of values distributed around the mean to be quantized to more suitable integers. Compared to the original quantization function, PQ reduces the quantization error by approximately 1.7%.
3.3. Attention Quantization Distillation
In visual tasks, GNNs leverage visual networks to extract rich semantic information from images and then use graph networks to perform message passing based on feature similarity. However, quantization compresses the data into low bit widths, leading to a loss of semantic information in visual networks. Knowledge distillation is a common method to assist in training quantized models, using a full-precision teacher model to enhance the semantic information extraction capability of the quantized model. However, the additional teacher model introduces greater computational and memory burdens during the training phase.
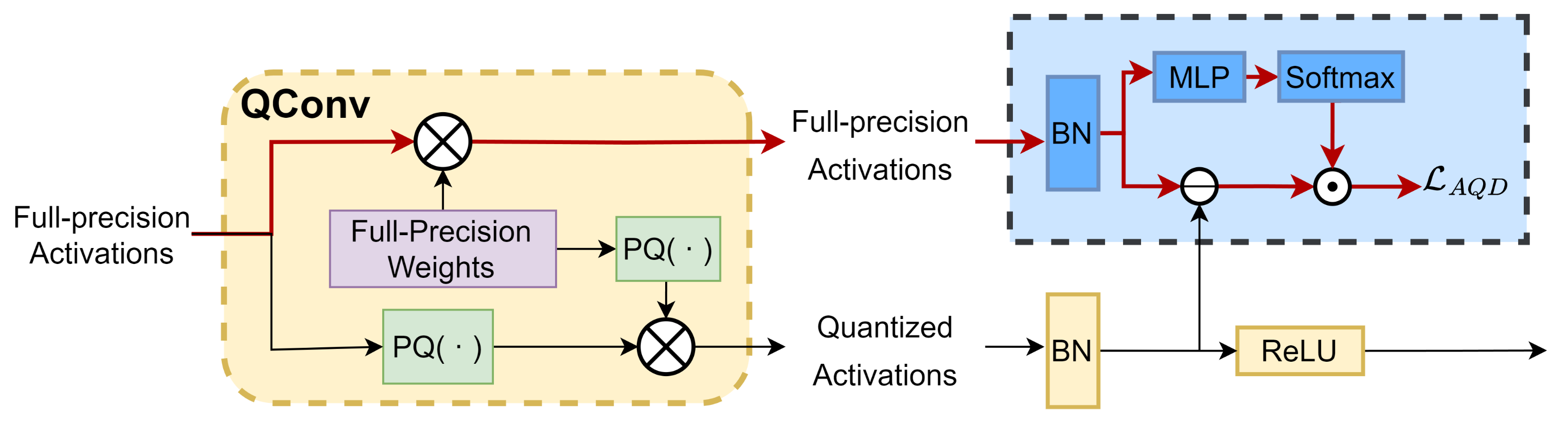
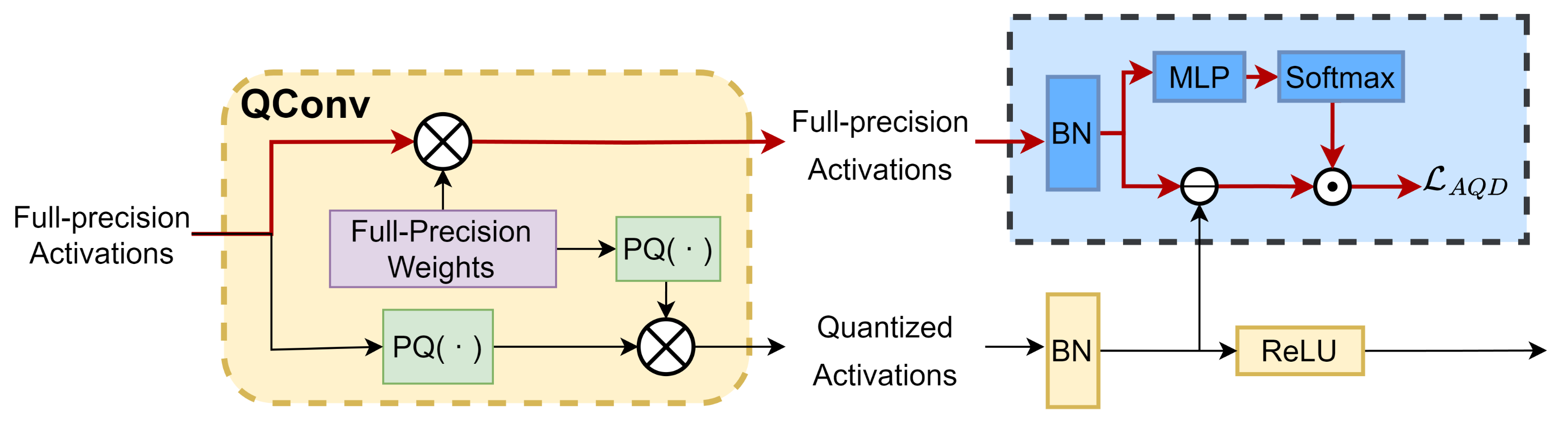
To mitigate this, we propose AQD specifically for visual networks. AQD aims to enhance the semantic feature extraction capability of the quantized visual network by identifying beneficial high-level feature information from the latent full-precision activations. As shown in
Figure 4, we allow the quantized convolutional layer (Qconv) to output both full-precision and quantized activations:
where
A represents the activations, subscripts
f and
q indicate whether it is full-precision or quantized;
W represents the weights; ⊗ denotes the convolution operation;
is the quantization function proposed in
Section 3.2. Considering the distribution shift caused by the precision difference, it is necessary to normalize these two types of activations:
where
:
flattens the activations after normalization;
H,
W, and
C are the height, width, and the number of channels, respectively;
denotes the batch normalization layer.
Since different channels have different importance, it is crucial to further evaluate the importance of channels using a multi-layer perceptron (MLP) so that AQD can adaptively focus on channels with more discriminative features. We define the importance
of different channels as:
where
,
. With
, AQD emphasizes channels with more discriminative capabilities by minimizing the loss function
, which can be expressed as:
where
C represents the number of channels in the activations.
As shown in
Figure 2, AQD is deployed in the shallow layers of the entire model, which not only improves the ability to extract semantic information but also alleviates the problem of gradient vanishing. Moreover, AQD does not require any additional teacher models and only introduces relatively low computational and memory overhead during the training phase.
3.4. Stochastic Quantization Distillation
Quantization for neural networks, especially below 4-bit, results in a significant degradation of model performance [
23,
48]. As shown in
Table 1, this problem is more severe in GNNs used for computer vision. The quantization of weights and activations introduces quantization errors and gradient errors, resulting in degraded model performance. Furthermore, as the model becomes deeper, these negative effects further accumulate in graph networks. Therefore, improving the robustness of graph networks to quantization is crucial for enhancing model performance.
Dropout [
49] is a widely used strategy that randomly drops some neurons during the model training process to enhance the model’s robustness. If we randomly quantize, i.e., randomly discard the quantization functions during the training process, can we obtain a more robust quantized model? Wei et al. [
34] have shown that quantizing part of modules during PTQ can flatten the loss landscape. Therefore, it is feasible to enhance the robustness of quantized models through stochastic quantization.
Based on the above challenges and analysis, we propose SQD, which extracts more robust information from randomly quantized activations to guide the training of fully quantized activations. The formula for stochastic quantization is defined as:
where
is a random sampling variable following a uniform distribution within the range (0,1);
p is a hyperparameter;
is the proposed quantization function in
Section 3.2;
X is a 32-bit full-precision tensor.
The matrix operation results of weights and activations are randomly quantized by
to obtain
. Simultaneously,
is obtained by using the function
. The equations are as follows:
Compared with
,
contains more accurate and robust visual semantic information. Therefore, two special similarity pattern matrices can be constructed to help improve the visual characteristics of
:
We distill the semantic matrix
to enhance the performance of quantized graph networks:
As shown in
Figure 2, SQD is deployed on the nodes of the graph network to alleviate the cumulative effects of quantization errors. Furthermore, SQD serves as a self-distillation module, which does not require an additional teacher model and only incurs a small amount of computational and memory overhead during the training phase.
3.5. Quantized Graph Neural Networks for Image Classification
Without loss of generality, we apply the proposed methods to the distribution propagation graph network (DPGN) [
5], which is a GNN used for image classification tasks, and obtain the QGNN-IC. As shown in
Figure 2, QGNN-IC extracts image features through a visual network, initializes the nodes of the graph network with these features, and then utilizes message-passing mechanisms to compute the similarity between unlabeled and labeled samples for classification. Since the first layer in the visual network is directly related to the input and the last convolutional layer in each generation of the graph network is directly related to the prediction, we maintain these in full precision and quantize all other layers. AQD is inserted into the quantized convolutional layers (QConv) of the visual network, while SQD is deployed on the graph nodes of the graph network.
To further compress the model and improve training and inference speed, we need to strike a balance between accuracy and efficiency. Focusing on the graph network, we find that this part incurs significant computational overhead, so we perform generation-level pruning on the graph network. While this approach slightly reduces the performance of the quantized model, it greatly reduces the computational and parameter overhead. We believe this will facilitate the deployment of state-of-the-art graph neural networks in more real-world computer vision applications.
The overall training loss of
can be defined as:
where
is the classification loss of DPGN;
and
are hyperparameters used to balance the loss function.
5. Discussion and Conclusions
In this paper, we propose QGNN-IC, a method for quantizing GNNs for visual tasks. It consists of a quantization function, PQ, along with two self-distillation methods, AQD and SQD. PQ eliminates outliers based on data distribution, allowing for fine-grained quantization. SQD and AQD guide the learning of low-bit activations by extracting information from the quantized model itself.
The concept of PQ shares similarities with PAMS [
59] and EWGS [
29], both of which establish a learnable truncation threshold, thus enabling the model to autonomously determine its own quantization range. Nevertheless, PQ takes into account the distribution discrepancies between visual networks and graph neural networks, initializing the quantization range using mean and standard deviation and reducing quantization errors by truncating outliers. Experimental outcomes and statistical data reveal that PQ effectively reduces quantization errors by nearly 1.7%, significantly enhancing the accuracy of quantized models.
The essence of AQD and SQD is to utilize modules that contain rich knowledge to assist in training quantized models. This is similar to some previous methods that use knowledge distillation to aid quantization, such as the approach proposed by Zhuang et al. [
60], which utilizes full-precision auxiliary modules to assist in training binary networks, and the approach proposed by Xie et al. [
45], which uses an attentive transfer module to train quantized models under a knowledge distillation system. However, in comparison, AQD and SQD are self-knowledge distillation modules that fully consider the quantization mechanism and utilize their own implicitly stored full-precision activation values to assist in training the quantized models themselves. They introduce only a small amount of training overhead while significantly enhancing the performance of the quantized models.
This work conducts a focused investigation into quantized graph neural networks applied to image classification tasks. The effectiveness of the proposed approaches has been substantiated on both DPGN and EGNN. However, its suitability for other tasks, such as point cloud classification, remains unexplored. In the future, we will study the performance of our methods in more tasks.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}