
A Convolutional Neural Network-Based Auto-Segmentation Pipeline for Breast Cancer Imaging
 , , ,
, , ,
Abstract
1. Introduction
- (1)
- A prediction pipeline is proposed, utilizing a 3D U-Net architecture for image segmentations in 3D CT scan images. The developed pipeline consists of a series of algorithms for data pre-processing to generalize and normalize the CT scan data. A 3D U-Net architecture is customized to cater to the requirements of accurate segmentations and volumetric predictions of breast tumors. The designed pipeline can become a complementary supporting tool for radiologists to increase the productivity and efficiency of their jobs.
- (2)
- For the U-Net architecture in the developed pipeline, a hybrid Tversky–cross-entropy loss function is utilized, which combines the advantages of the binary cross-entropy (BCE) loss function and the Tversky focal loss. A Nesterov-accelerated adaptive moment estimation (Nadam) optimization algorithm is leveraged to achieve better optimization performance.
- (3)
- Three types of 3D U-net architecture models are designed and compared in this research. Their performance is evaluated based on the Dice coefficient metric [16].
2. Background Knowledge
2.1. CNN and U-Net
2.2. Image Segmentation
3. Methodology
3.1. Proposed Structure of the Volumetric Prediction Pipeline
- (1)
- An algorithm is developed to extract the number of slices in the axial plane for each patient.
- (2)
- The model training in the pipeline requires tumor labels, i.e., masks to be assigned to each slice. The slices without masks are filtered out from the training. Another algorithm is designed to identify which slices of each patient have associated masks. The indexes of such slices with masks are sorted out for each patient.
- (3)
- To ensure consistent training and better prediction performance, the pipeline requires the same ranges of slice spatial locations in the z-axis for all patients. The patients are classified into three categories based on the threshold value of the slice indexes at the z-axis. Only the slices from the patient category whose slice indexes are all smaller than or equal to the threshold value are selected for further processing.
- (4)
- The selected patient category is further classified into two groups based on the CT scan thickness.
- (5)
- The values of CT scan image matrices are normalized into the range of 0 to 1.
- (6)
- The 3D volumes with large dimensions require a large amount of GPU resources in the model training. They are divided by an algorithm into a set of cuboids with smaller dimensions to reduce computation complexity.
- (7)
- A 3D U-Net architecture is customized and trained for the image segmentation tasks with a hybrid loss function and a hybrid optimizer.
- (8)
- The results of 2D and 3D prediction results are visualized.
3.2. Detailed Data Pre-Processing Steps
- (1)
- The List with all indexes ≤ 96: All indexes of the slices with masks are lesser than or equal to 96. As shown in Figure 6, most patients, e.g., patients 1, 2, 4, 5, and 7, satisfy this condition.
- (2)
- The List with all indexes > 96: All indexes of the slices with 96 masks or more. As shown in Figure 6, patient 6 and patient 8 are some examples.
- (3)
- The overlap list: Indexes of the slices with masks across all 96 indexes, where some indexes are lesser than or equal to 96, and the others are more than 96. As shown in Figure 6, patient 3 is the only patient that satisfies this condition.
3.3. Data Normalization
- (1)
- Not all patients have 96 slices. For example, the scan dimensions of a few patients are 512 × 512 × 87.
- (2)
- There are many empty cuboids without masks (i.e., tumor labels). If empty cuboids are fed into the training model, the loss function will become erratic, resulting in inaccurate model predictions.
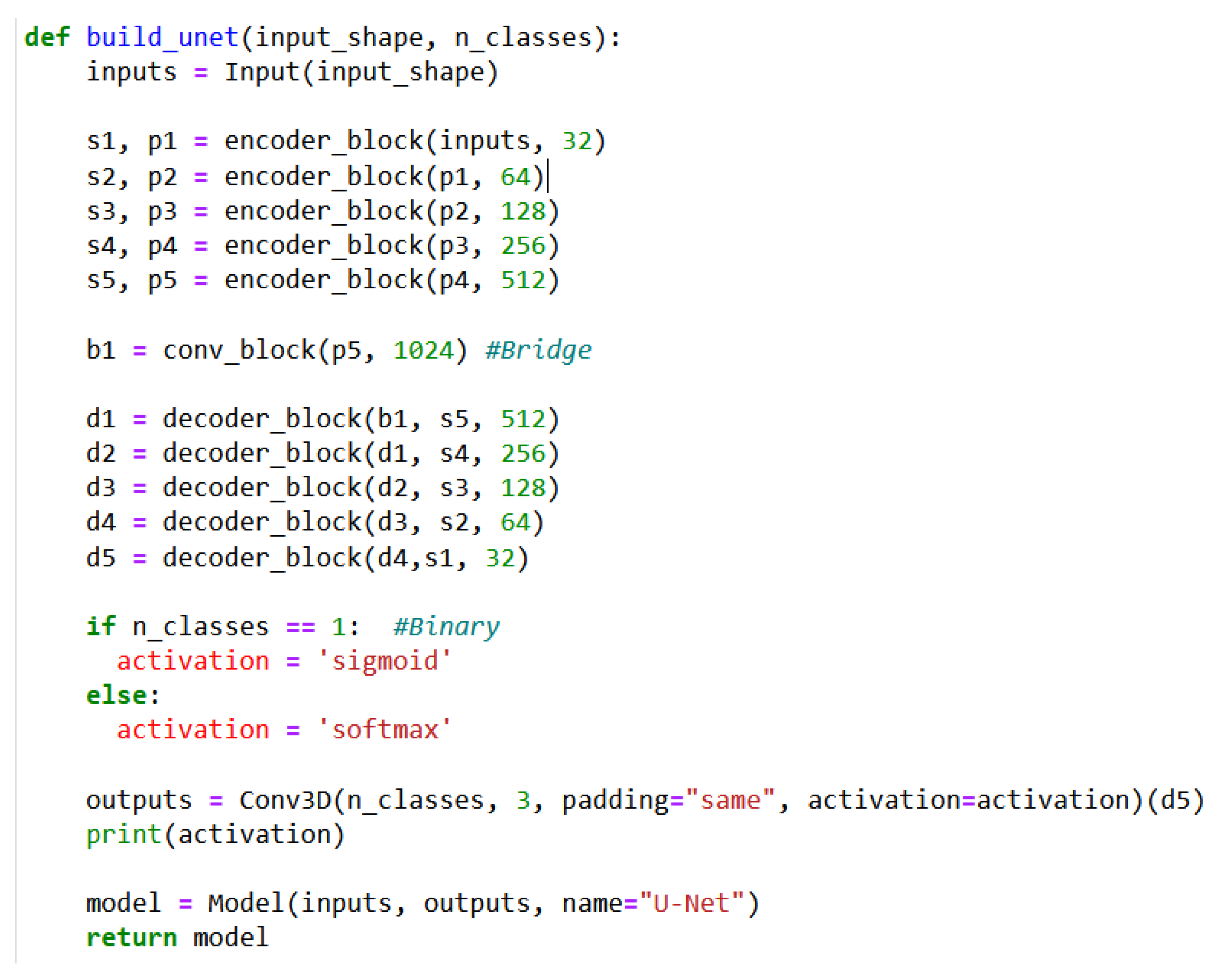
3.4. Set-Up of 3D U-Net Architecture in the Pipeline
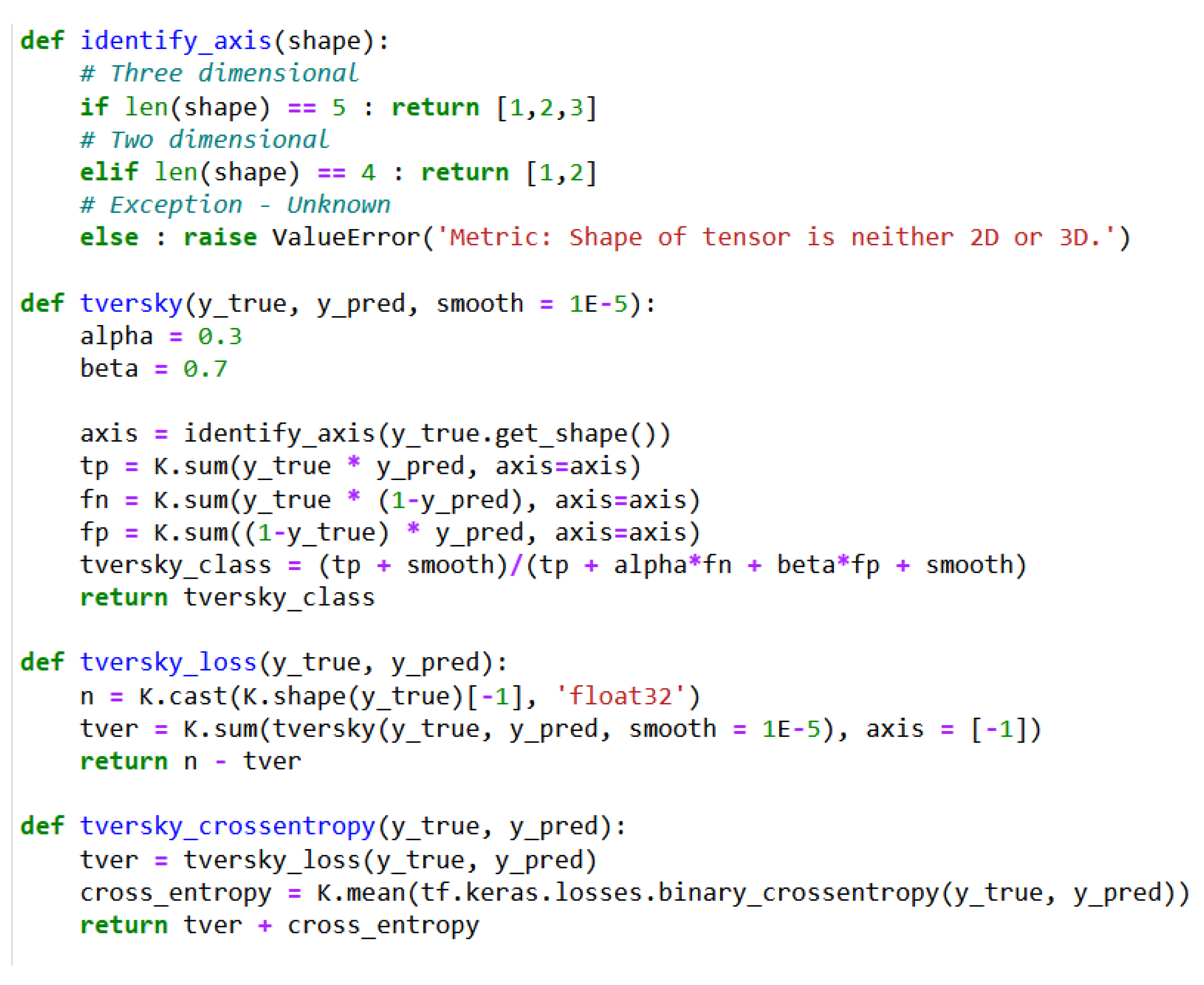
3.5. U-Net Performance Metrics
3.6. Hybrid U-Net Loss Function
3.7. Hybrid Optimizer for the U-Net in the Pipeline
4. Experiment Results and Discussions
4.1. Model 1 Configuration and Experiment Results
4.2. Model 2 Configuration and Experiment Results
4.3. Model 3 Configuration and Experiment Results
4.4. Discussions and Comparisons of Three Models
5. Conclusions
Limitations and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Anyoha, R. The History of Artificial Intelligence. 2017. Available online: https://sitn.hms.harvard.edu/flash/2017/history-artificial-intelligence/ (accessed on 10 November 2023).
- Joksimovic, S.; Ifenthaler, D.; Marrone, R.; Laat, M.D.; Siemens, G. Opportunities of artificial intelligence for supporting complex problem-solving: Findings from a scoping review. Comput. Educ. Artif. Intell. 2023, 4, 100138. [Google Scholar] [CrossRef]
- Zakaryan, V. How ML Will Disrupt the Future of Clinical Radiology. 2021. Available online: https://postindustria.com/computer-vision-in-radiology-how-ml-will-disrupt-the-future-of-clinical-radiology-healthcare/ (accessed on 10 November 2023).
- Yue, W.; Zhang, H.; Zhou, J.; Li, G.; Tang, Z.; Sun, Z.; Cai, J.; Tian, N.; Gao, S.; Dong, J.; et al. Deep learning-based automatic segmentation for size and volumetric measurement of breast cancer on magnetic resonance imaging. Front. Oncol. 2022, 12, 984626. [Google Scholar] [CrossRef] [PubMed]
- Jafari, Z.; Karami, E. Breast Cancer Detection in Mammography Images: A CNN-Based Approach with Feature Selection. Information 2023, 14, 410. [Google Scholar] [CrossRef]
- Liu, Z.; Liu, F.; Chen, W.; Liu, X.; Hou, X.; Shen, J.; Guan, H.; Zhen, H.; Wang, S.; Chen, Q.; et al. Automatic Segmentation of Clinical Target Volumes for Post-Modified Radical Mastectomy Radiotherapy Using Convolutional Neural Networks. Front. Oncol. 2021, 10, 581347. [Google Scholar] [CrossRef]
- Gaudez, S.; Slama, M.B.H.; Kaestner, A.; Upadhyay, M.V. 3D deep convolutional neural network segmentation model for precipitate and porosity identification in synchrotron X-ray tomograms. J. Synchrotron Radiat. 2022, 29, 1232–1240. [Google Scholar] [CrossRef]
- Xie, L.; Liu, Z.; Pei, C.; Liu, X.; Cui, Y.-Y.; He, N.-A.; Hu, L. Convolutional neural network based on automatic segmentation of peritumoral shear-wave elastography images for predicting breast cancer. Front. Oncol. 2023, 13, 1099650. [Google Scholar] [CrossRef]
- Zhang, Y.; Chan, S.; Park, V.Y.; Chang, K.-T.; Mehta, S.; Kim, M.J.; Combs, F.J.; Chang, P.; Chow, D.; Parajuli, R.; et al. Automatic Detection and Segmentation of Breast Cancer on MRI Using Mask R-CNN Trained on Non–Fat-Sat Images and Tested on Fat-Sat Images. Acad. Radiol. 2020, 29, S135–S144. [Google Scholar] [CrossRef]
- Raimundo, J.N.C.; Fontes, J.P.P.; Magalhães, L.G.M.; Lopez, M.A.G. An Innovative Faster R-CNN-Based Framework for Breast Cancer Detection in MRI. J. Imaging 2023, 9, 169. [Google Scholar] [CrossRef] [PubMed]
- Qi, T.H.; Hian, O.H.; Kumaran, A.M.; Tan, T.J.; Cong, T.R.Y.; Su-Xin, G.L.; Lim, E.H.; Ng, R.; Yeo, M.C.R.; Tching, F.L.L.W. Multi-center evaluation of artificial intelligent imaging and clinical models for predicting neoadjuvant chemotherapy response in breast cancer. Breast Cancer Res. Treat. 2022, 193, 121–138. [Google Scholar] [CrossRef]
- Buelens, P.; Willems, S.; Vandewinckele, L.; Crijns, W.; Maes, F.; Weltens, C. Clinical evaluation of a deep learning model for segmentation of target volumes in breast cancer radiotherapy. Radiother. Oncol. 2022, 171, 84–90. [Google Scholar] [CrossRef]
- Sreenivasu, S.V.N.; Gomathi, S.; Kumar, M.J.; Prathap, L.; Madduri, A.; Almutairi, K.M.A.; Alonazi, W.B.; Kali, D.; Jayadhas, S.A. Dense Convolutional Neural Network for Detection of Cancer from CT Images. BioMed Res. Int. 2022, 2022, 1293548. [Google Scholar] [CrossRef]
- Shehmir, J. Computer Vision in Radiology: Benefits & Challenges. 19 July 2022. Available online: https://research.aimultiple.com/computer-vision-radiology (accessed on 11 November 2023).
- Esteva, A.; Chou, K.; Yeung, S.; Naik, N.; Madani, A.; Mottaghi, A.; Liu, Y.; Topol, E.; Dean, J.; Socher, R. Deep learning-enabled medical computer vision. NPJ Digit. Med. 2021, 4, 5. [Google Scholar] [CrossRef] [PubMed]
- Costa, M.G.F.; Campos, J.P.M.; Aquino, G.d.A.e.; Pereira, W.C.d.A.; Filho, C.F.F.C. Evaluating the performance of convolutional neural networks with direct acyclic graph architectures in automatic segmentation of breast lesion in US images. BMC Med. Imaging 2019, 19, 85. [Google Scholar] [CrossRef]
- Al Bataineh, A.; Kaur, D.; Al-Khassaweneh, M.; Al-Sharoa, E. Automated CNN Architectural Design: A Simple and Efficient Methodology for Computer Vision Tasks. Mathematics 2023, 11, 1141. [Google Scholar] [CrossRef]
- Taye, M.M. Theoretical Understanding of Convolutional Neural Network: Concepts, Architectures, Applications, Future Directions. Computation 2023, 11, 52. [Google Scholar] [CrossRef]
- Soffer, S.; Ben-Cohen, A.; Shimon, O.; Amitai, M.M.; Greenspan, H.; Klang, E. Convolutional Neural Networks for Radiologic Images: A Radiologist’s Guide. Radiology 2019, 290, 590–606. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Rosebrock, A. LeNet: Recognizing Handwritten Digits. 22 May 2021. Available online: https://pyimagesearch.com/2021/05/22/lenet-recognizing-handwritten-digits/ (accessed on 8 November 2023).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Han, X.; Zhong, Y.; Cao, L.; Zhang, L. Pre-Trained AlexNet Architecture with Pyramid Pooling and Supervision for High Spatial Resolution Remote Sensing Image Scene Classification. Remote Sens. 2017, 9, 848. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Computer Vision—ECCV 2014. ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2014; Volume 8689. [Google Scholar] [CrossRef]
- Abdelhafiz, D.; Yang, C.; Ammar, R.; Nabavi, S. Deep convolutional neural networks for mammography: Advances, challenges and applications. BMC Bioinform. 2019, 20, 281. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A.; Liu, W.; et al. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2015, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015. MICCAI 2015; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9351. [Google Scholar] [CrossRef]
- Zhang, J. Unet—Line by Line Explanation. 18 October 2019. Available online: https://towardsdatascience.com/unet-line-by-line-explanation-9b191c76baf5 (accessed on 10 November 2023).
- Azad, R.; Aghdam, E.K.; Rauland, A.; Jia, Y.; Avval, A.H.; Bozorgpour, A.; Karimijafarbigloo, S.; Cohen, J.P.; Adeli, E.; Merhof, D. Medical Image Segmentation Review: The Success of U-net. arXiv 2022, arXiv:2211.14830. [Google Scholar] [CrossRef]
- Luo, L.; Wang, X.; Lin, Y.; Ma, X.; Tan, A.; Chan, R.; Vardhanabhuti, V.; Chu, W.C.; Cheng, K.-T.; Chen, H. Deep Learning in Breast Cancer Imaging: A Decade of Progress and Future Directions. arXiv 2024, arXiv:2304.06662. [Google Scholar] [CrossRef] [PubMed]
- Kodipalli, A.; Fernandes, S.L.; Gururaj, V.; Rameshbabu, S.V.; Dasar, S. Performance Analysis of Segmentation and Classification of CT-Scanned Ovarian Tumours Using U-Net and Deep Convolutional Neural Networks. Diagnostics 2023, 13, 2282. [Google Scholar] [CrossRef] [PubMed]
- Sakshi; Kukreja, V. Image Segmentation Techniques: Statistical, Comprehensive, Semi-Automated Analysis and an Application Perspective Analysis of Mathematical Expressions. Arch. Comput. Methods Eng. 2022, 30, 457–495. [Google Scholar] [CrossRef]
- Barrowclough, O.J.; Muntingh, G.; Nainamalai, V.; Stangeby, I. Binary segmentation of medical images using implicit spline representations and deep learning. Comput. Aided Geom. Des. 2021, 85, 101972. [Google Scholar] [CrossRef]
- Qian, Q.; Cheng, K.; Qian, W.; Deng, Q.; Wang, Y. Image Segmentation Using Active Contours with Hessian-Based Gradient Vector Flow External Force. Sensors 2022, 22, 4956. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Wang, C.; Fu, Q.; Kou, R.; Huang, F.; Yang, B.; Yang, T.; Gao, M. Techniques and Challenges of Image Segmentation: A Review. Electronics 2023, 12, 1199. [Google Scholar] [CrossRef]
- Huo, Y.; Tang, Y.; Chen, Y.; Gao, D.; Han, S.; Bao, S.; De, S.; Terry, J.G.; Carr, J.J.; Abramson, R.G.; et al. Stochastic tissue window normalization of deep learning on computed tomography. J. Med. Imaging 2019, 6, 044005. [Google Scholar] [CrossRef]
- Abraham, N.; Khan, N.M. A Novel Focal Tversky Loss Function with Improved Attention U-Net for Lesion Segmentation. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 683–687. [Google Scholar] [CrossRef]
- Haji, S.H.; Abdulazeez, A.M. Comparison of optimization techniques based on gradient descent algorithm: A review. Palarch’s J. Archaeol. Egypt/Egyptol. 2021, 18, 2715–2743. [Google Scholar]
- TensorFlow. tf.keras.applications.inception_v3.InceptionV3. Available online: https://www.tensorflow.org/api_docs/python/tf/keras/applications/inception_v3/InceptionV3 (accessed on 15 January 2024).
- Keras. MobileNet, MobileNetV2, and MobileNetV3. Available online: https://keras.io/api/applications/mobilenet/ (accessed on 25 January 2024).
- TensorFlow. tf.keras.applications.inception_resnet_v2.InceptionResNetV2. Available online: https://www.tensorflow.org/api_docs/python/tf/keras/applications/inception_resnet_v2/InceptionResNetV2 (accessed on 25 January 2024).
- Wang, H.; Cao, P.; Wang, J.; Zaiane, O.R. UCTransNet: Rethinking the skip connections in u-net from a channel-wise perspective with transformer. Proc. AAAI Conf. Artif. Intell. 2022, 36, 2441–2449. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Le Folgoc, L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Huang, X.; Deng, Z.; Li, D.; Yuan, X. Missformer: An Effective Medical Image Segmentation Transformer. arXiv 2021, arXiv:2109.07162. [Google Scholar] [CrossRef]
- Khaled, R.; Vidal, J.; Vilanova, J.C.; Martí, R. A U-Net Ensemble for breast lesion segmentation in DCE MRI. Comput. Biol. Med. 2021, 140, 105093. [Google Scholar] [CrossRef]
- Galli, A.; Marrone, S.; Piantadosi, G.; Sansone, M.; Sansone, C. A Pipelined Tracer-Aware Approach for Lesion Segmentation in Breast DCE-MRI. J. Imaging 2021, 7, 276. [Google Scholar] [CrossRef]






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Properties |
|---|---|
| LeNet [20,21] |
|
| AlexNet [22,23] |
|
| ZFNet [24,25] |
|
| GoogLeNet [25,26] |
|
| VGGNet [25,27] |
|
| ResNet [25,28] |
|
| MobileNets [29] |
|
| U-Net [30,31] |
|
| Mask Slice Presence | No. of Patients | Train Patients | Valid Patients | Test Patients |
|---|---|---|---|---|
| Index ≤ 96 | 191 | 109 | 43 | 39 |
| Index > 96 | 91 | 58 | 9 | 24 |
| The overlap | 64 | 42 | 8 | 14 |
| Total | 346 | 210 | 60 | 77 |
| CT Scan Thickness | Train Patients | Valid Patients | Test Patients | Total Patients |
|---|---|---|---|---|
| 3 mm | 74 | 26 | 27 | 127 |
| 5 mm | 35 | 17 | 12 | 64 |
| Total | 109 | 43 | 39 | 191 |
| Patient Category | Patient Index |
|---|---|
| Patients for Training | 4, 5, 9, 10, 15, 16, 18, 19, 20, 21, 22, 23, 28, 29, 33, 34, 35, 37, 44, 51, 52, 58, 64, 68, 69, 72, 73, 76, 77, 79, 82, 83, 90, 91, 92, 93, 94, 95, 97, 103, 104, 116, 123, 126, 129, 131, 134, 136, 139, 142, 149, 151, 155, 157, 159, 162, 163, 164, 169, 170, 171, 179, 180, 186, 188, 191, 192, 198, 200, 201, 206, 207, 208, 209 |
| Patients for Valid | 213, 214, 215, 217, 219, 220, 221, 224, 226, 227, 228, 231, 237, 238, 240, 243, 248, 249, 250, 254, 255, 256, 257, 264, 266, 270 |
| Patients for Test | 271, 272, 274, 277, 280, 283, 286, 287, 288, 293, 294, 296, 297, 298, 300, 303, 305, 306, 314, 315, 317, 320, 322, 340, 342, 345, 347 |
| Parameter | Value |
|---|---|
| Training Data | 9450 |
| Validation Data | 1575 |
| Train Array Size | 7875 × 64 × 64 × 96 × 1 |
| Validation Array Size | 1350 × 64 × 64 × 96 × 1 |
| Approximated Memory Usage | 62.7 GB |
| Learning Rate at the Start | 0.001 |
| Optimizer | Nadam |
| Performance Metric | Dice coefficient |
| Activation Function | Sigmoid |
| Loss Function | hybrid Tversky-Cross Entropy loss |
| ReduceLROnPlateau | Factor: 0.1 Patience: 10 |
| Batch Size | 5 |
| Epochs | 300 |
| Time used per epoch | 1st Epoch: 265 s Subsequent Epochs: 250 s |
| Parameter | Value |
|---|---|
| Training Data | 1112 |
| Validation Data | 225 |
| Train Array Size | 1112 × 64 × 64 × 96 × 1 |
| Validation Array Size | 225 × 64 × 64 × 96 × 1 |
| Approximated Memory Usage | 25.5 GB |
| Learning Rate at the Start | 0.0001 |
| Optimizer | Nadam |
| Metric | Dice coefficient |
| Activation Function | Sigmoid |
| Loss Function | hybrid Tversky-Cross Entropy loss |
| ReduceLROnPlateau | Factor: 0.2 Patience: 7 |
| Batch Size | 4 |
| Epochs | 300 |
| Time used per epoch | 1st Epoch: 42 s Subsequent Epochs: 31 s |
| Parameter | Value |
|---|---|
| Training Data | 5560 |
| Validation Data | 1125 |
| Train Array Size | 5560 × 64 × 64 × 96 × 1 |
| Validation Array Size | 1125 × 64 × 64 × 96 × 1 |
| Approximated Memory Usage | 53.9 GB |
| Learning Rate at the Start | 0.001 |
| Optimizer | Nadam |
| Metric | Dice coefficient |
| Activation Function | Sigmoid |
| Loss Function | hybrid Tversky-Cross Entropy loss |
| ReduceLROnPlateau | Factor: 0.5 Patience: 8 |
| Batch Size | 5 |
| Epochs | 300 |
| Time used per epoch | 1st Epoch: 194 s Subsequent Epochs: 178 s |
| Parameter | Model 1 | Model 2 | Model 3 |
|---|---|---|---|
| Training Data | 9450 | 1112 | 5560 |
| Approximated Memory Usage | 62.7 GB | 25.5 GB | 53.9 GB |
| Learning Rate at the Start | 0.001 | 0.0001 | 0.001 |
| ReduceLROnPlateau | Factor: 0.1 Patience: 10 | Factor: 0.2 Patience: 7 | Factor: 0.5 Patience: 8 |
| Batch Size | 5 | 4 | 5 |
| Epochs | 300 | 300 | 300 |
| Time used for the 1st epoch (second) | 265 | 42 | 194 |
| Time used for subsequent epoch (second) | 250 | 31 | 178 |
| Dice Score on test data | 91.44% | 85.18% | 89.84% |
| Model | Dice Scores | Test Data Used for Experiments |
|---|---|---|
| Model 1 | 91.44% | Test data from this paper |
| Model 2 | 85.18% | Test data from this paper |
| Model 3 | 89.84% | Test data from this paper |
| InceptionV3 model [42] | 91.20% | Pretrained model using test data from this paper |
| SM MobileNetV2 [43] | 90.30% | Pretrained model using test data from this paper |
| InceptionResNetV2 [44] | 88.10% | Pretrained model using test data from this paper |
| UCTransNet [32,45] | 91.74% | SegPC 2021 cell segmentation dataset |
| 78.23% | Synapse multi-organ CT segmentation dataset | |
| Attention U-Net [32,46] | 91.58% | SegPC 2021 cell segmentation dataset |
| Multi Res-Unet [32,47] | 86.94% | ISIC 2018 skin lesion segmentation dataset |
| TransUNet [32,48] | 84.99% | ISIC 2018 skin lesion segmentation dataset |
| MISSFormer [32,49] | 86.57% | ISIC 2018 skin lesion segmentation dataset |
| 81.96% | Synapse multi-organ CT segmentation dataset | |
| Res-Unet [4,33] | 89.4% | MRI dataset for breast cancer |
| U-Net [33,50] | 80.2% | MRI dataset for breast cancer |
| Pipelined U-Net [33,51] | 70.37% | MRI dataset for breast cancer |
| DenseNet [13] | 94% | 10-fold cross-validation for CT scan images |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leow, L.J.H.; Azam, A.B.; Tan, H.Q.; Nei, W.L.; Cao, Q.; Huang, L.; Xie, Y.; Cai, Y. A Convolutional Neural Network-Based Auto-Segmentation Pipeline for Breast Cancer Imaging. Mathematics 2024, 12, 616. https://doi.org/10.3390/math12040616
Leow LJH, Azam AB, Tan HQ, Nei WL, Cao Q, Huang L, Xie Y, Cai Y. A Convolutional Neural Network-Based Auto-Segmentation Pipeline for Breast Cancer Imaging. Mathematics. 2024; 12(4):616. https://doi.org/10.3390/math12040616
Chicago/Turabian StyleLeow, Lucas Jian Hoong, Abu Bakr Azam, Hong Qi Tan, Wen Long Nei, Qi Cao, Lihui Huang, Yuan Xie, and Yiyu Cai. 2024. "A Convolutional Neural Network-Based Auto-Segmentation Pipeline for Breast Cancer Imaging" Mathematics 12, no. 4: 616. https://doi.org/10.3390/math12040616
APA StyleLeow, L. J. H., Azam, A. B., Tan, H. Q., Nei, W. L., Cao, Q., Huang, L., Xie, Y., & Cai, Y. (2024). A Convolutional Neural Network-Based Auto-Segmentation Pipeline for Breast Cancer Imaging. Mathematics, 12(4), 616. https://doi.org/10.3390/math12040616