1. Introduction
Researchers and scholars have applied various statistical methods and econometric models to the prediction of exchange rate fluctuations. The most-popular methods in current research mainly include the single-integer auto-regressive moving average (ARIMA) model [
1], the auto-regressive conditional heteroskedasticity (ARCH) model [
2], the generalized auto-regressive conditional heteroskedasticity (GARCH) model [
3], and the threshold auto-regressive (TAR) model [
4], among others. These methods mostly utilize a single model to complete predictions while paying more attention to local information. It is easy for them to fit a standard time series when dealing with smoother and fewer data, thus allowing them to reach a prediction. However, for complex nonlinear exchange rates, these models cannot achieve accurate predictions. Existing research shows that foreign exchange market returns do not obey a normal distribution, as they typically have sharp peaks and thick tails. In foreign exchange time series, the fluctuations are very significantly non-stationary, nonlinear, and history-dependent [
5]. Therefore, when forecasting foreign exchange, the assumptions of traditional linear models cannot be satisfied. So, the application of forecasting with a traditional model may cause significant deviations [
6]. Based on this, machine learning models began to be gradually used in exchange rate forecasting. In the existing literature, most studies proposed either the combination of linear models and machine learning models [
7] or combinations of several machine learning algorithms for stacked optimization [
8]. The research was biased towards improving the models from the technical point of view, but few studies were conducted to improve the models in terms of the characteristics of the financial market. Deep learning models have many advantages over machine learning for the forecasting of nonlinear time series [
9]. Without any assumptions about the time structure, they can find highly nonlinear and complex dependencies in a time series and have the advantage of processing and memorizing nonlinear feature data themselves, which has caused them to quickly attract much attention. Wenhui Dai (2017) built a VAR estimation model by combining deep learning LSTM, DBN, and ARMA-GARCH models, and they used seven common types of exchange rate data to confirm that the model was accurate and reliable [
10]. Huang Jiahui (2022) optimized their model by constructing a composite network that decomposed raw serial data on the exchange rate before training it using an LSTM-based model, and the results showed the model’s better prediction capabilities and optimization [
11]. Zhang Lei (2021) added the VIX index, which represented sentiment, to an LSTM neural network for exchange rate prediction, and the results showed that the model was able to improve the prediction accuracy to a certain extent compared with the traditional volatility prediction method [
12]. Another way to improve a prediction model consists of using an attention mechanism. This mechanism can automatically obtain the input time point that best determines the forecast value at the current moment. This can optimize the neural network structure to better take the temporal dependence into account, thus allowing further improvement of the prediction accuracy in long-term forecasting [
13]. The aforementioned research results laid the foundation for this work. However, research gaps exist when attempting to answer the following question: How can one effectively decompose the exchange rate in these kinds of non-smooth, nonlinear serial-data time series containing some noise to improve the accuracy of forecasting?
In order to address the drawbacks of the use of a single model, a new EMD-LSTM-SVR model is proposed. It was formed to draw on the advantages of EMD and LSTM models. The empirical modal decomposition (EMD) method not only has the advantages of good resolution, directness, adaptability, and a posteriori function, but its basis function can also be derived from its own decomposition of the data. So, there is no need to pre-compute and pre-specify the basis function [
14]. The LSTM, an improved recurrent neural network, can learn long-term memory information and optimize a problem through gradient disappearance [
15]. The proposed model should portray a stronger generalization ability, simpler structure, greater ability to fit nonlinear features, and better prevention of gradient vanishing and overfitting, which should improve the learning ability to achieve a higher degree of prediction accuracy.
In order to verify and confirm the efficiency of the proposed model, we selected more than 30,000 units of data on the USD/CNY exchange rate opening price from 2 January 2015 to 30 April 2022, for model measurement. We show through experiments that the use of a deep-learning-based LSTM model in the exchange rate series prediction was able to effectively improve the prediction accuracy. The prediction results showed that, relative to the BP and LSTM models, the average absolute percentage errors of the prediction results of the EMD-LSTM-SVR model were reduced by 21.03% and 14.72%, respectively, thus improving the effect by 43.93% and 33.08%, respectively. Moreover, the standard deviation was closer to the average error than that of the BP and LSTM models. So, the proposed EMD-LSTM-SVR model for the prediction of exchange rate fluctuations not only had higher prediction accuracy, but also ensured that most of the predicted positions deviated less from the actual ones.
The research results in this work relate to the traditional methods of forecasting nonlinear exchange rate fluctuations, which is a more-complex prediction task, and a sequence prediction method using deep learning was optimized, as this can increase the complexity of a neural network model for the achievement of the function of accurate prediction. In addition, sequence prediction based on deep learning is an existential supervised learning technique that does not require the creation of time series features through human labeling, so it saves much of the workload in comparison with traditional methods. It goes without saying that the research results in this work are also of great significance for the effective prevention of economic risks due to exchange rate fluctuations.
The rest of this paper is organized into six sections: First, in
Section 2, we introduce the related technologies involved in this work and establish the foundation for the next step of building the framework of the proposed model. Then, in
Section 3, we present the idea behind establishing a new model according to the characteristics of exchange rate fluctuations through the construction of related technology. The model parameters are optimized, and the exchange rate prediction model is established. After that, in
Section 4, we describe the dataset used in the experiments and present the accuracy of the model as empirical evidence. Later, in
Section 5, we select and present the evaluation indexes and analyze, discuss, and compare the obtained results. Finally, in
Section 6, we summarize the findings of this work and discuss the possible further improvement of the model.
3. Construction of the Proposed Model
In this section, we describe the idea behind the proposed model and its construction. First, we characterize times series of exchange rate fluctuations. Then, we present the modeling ideas, followed by the modeling steps.
3.1. Characterization of Exchange Rate Fluctuations
The original exchange rate series used in this study were constructed from data that did not undergo any data processing.
Figure 3 shows a chart of the real exchange rate of the U.S. dollar with the Chinese yuan from 2 January 2015 to 30 April 2022, through which it can be seen that the statistical characteristics of the exchange rate data changed dynamically over time and were both high and low.
Under normal circumstances, original exchange rate series have considerable non-stationarity. As indicated by complexity theory, the lower the complexity of the observed data, the greater the likelihood that they will follow some fixed pattern of change, which, in turn, is more likely to be mined and predicted. Conversely, the lower the complexity of a time series, the lower the irregularity and the easier it is to forecast it [
20].
3.2. Modeling Ideas
According to the non-stationarity of exchange rate fluctuations, if a whole series is divided into a number of small segments and the shape of each small segment is required to move in a way that approximates a normal curve, it can be found that the overall trend between the small segments that make up the whole exchange rate time series is more or less the same; only the specific distributions within them are not the same.
An analogy can be made with the characterization of exchange rate series based on the concept of
CovariateShift [
21]. This is commonly interpreted as a case in which the marginal probability distributions are different and the conditional distributions are the same, i.e., a situation in which a dataset consisting of two sets of features and labels—a training set and a test set—is defined; when the features of the training set are not the same as the features of the test set,
, and when the labels of the training set are the same as the labels of the test set,
. The same goes for exchange rate series, where the exchange rate series for a period of time are split into a number of segments, and the value of the exchange rate series at two different times is also the same. After discovering that an exchange rate series has this feature, the model can be improved based on it to improve its prediction accuracy. The model can be improved with the following two steps:
The first step is determining the worst distribution. First, the overall exchange rate series is divided into any number of segments, and this requires the most-skillful segmentation method, that is to say, it is necessary to make the worst-case scenario between the divided segments, and the worst-case scenario can be interpreted as the largest difference in the internal distributions between the segments because, only by making the distributions of the segments particularly different from each other can we obtain the best performance in the training of the model afterward (description of the temporal distribution).
In the second step, the differences are reduced. The two segments corresponding to the largest differences among the segments divided in the previous step are found to be connected as a group, and the differences in several groups such as this one are minimized to obtain the model with the best learning effect (matching of temporal distributions).
3.3. Modeling
Considering the aforementioned idea, the next step is to improve the model. Thus, firstly, the EMD model is used to decompose the original exchange rate sequence into several sub-sequences to enhance the non-stationarity of the original exchange rate sequence, and then, an LSTM neural network is used to separately predict each sub-sequence; finally, the prediction results of each sub-sequence are combined, and the SVR operation is used to reduce the error. The model structure is shown in
Figure 4.
As can be seen in
Figure 4, there are two core components: the description of the time distribution and the matching of the time distribution. The description of the time distribution is a step used to characterize the distribution information in the time series, and the matching of the time distribution is the pairing of the time distribution periods for the their subsequent fitting to build a time series forecasting model.
In the process of time distribution description, it is possible to distribute the original time series in the form of the worst case, i.e., the distribution of the individual sequence segments (i.e., the cycles that can characterize the distribution information) obtained after performing this step has a large gap because, only by maximizing the distributional differences between them and subsequently fitting these differences can we finally obtain the model with the best performance. In temporal distribution matching, the distributions are matched by using the LSTM network with regularization terms. This process uses the knowledge learned from the training set sequences to make accurate predictions for the test set.
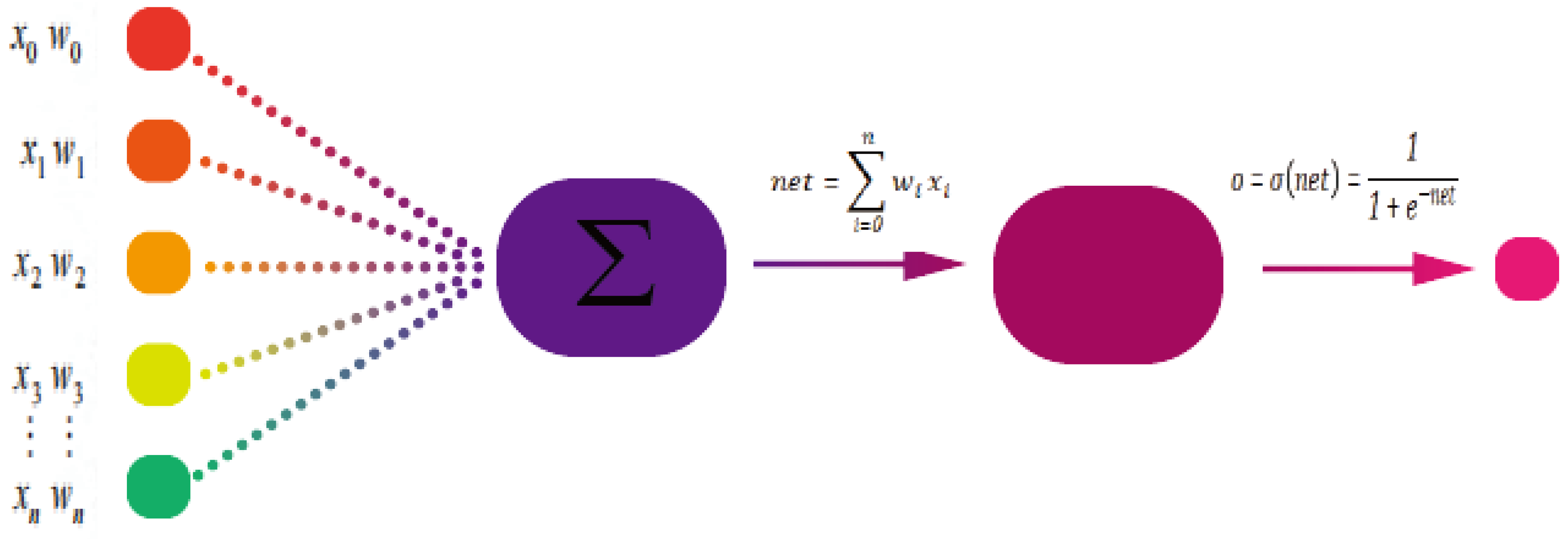
The LSTM-based exchange rate prediction model consists of an LSTM layer, dropout layer, and dense layer; the input of the model is the exchange rate data after data preprocessing. Through the LSTM neural network model, this model is first placed in an LSTM layer with 80 neural units and returns a 3D tensor; in order to avoid overfitting, a randomly ignored rate of 0.2 is then chosen. An LSTM layer with 100 neural units is used next, and a dropout layer with a ratio of 0.2 is added; finally, a network with one-dimensional output is defined by the dense layer. This model uses a dropout network in the LSTM layer, which prevents overfitting during model training, as it controls the random disconnection of some of the nodes connected to the neural network. The operational formula is given in Equation (
9):
where
D stands for the operation of the dropout layer and
p is an adjustable hyperparameter that indicates the value set for the ratio of disconnected neural network units in advance.
Because the dense layer can output the result as a number, it is suitable for problems of sequence prediction, and the final prediction is obtained through the dense output layer.
3.3.1. Description of the Time Distribution
According to the principle of maximum entropy, in the case of covariate transfer, the maximization of the shared knowledge of a time series can be achieved by finding the periods that are least similar to each other. This process is illustrated in
Figure 5.
The time distribution describes this objective of segmenting the original time series by solving an optimization problem, which can be formulated as shown in Equation (
10).
where
d is the distance unit,
and
are predefined parameters for avoiding very small values or very large values that may not capture distributional information, and
is a hyperparameter for avoiding over-segmentation;
d in Equation (
10) can be an arbitrary distance function, e.g., Euclidean or some distributional-based distances, such as the MMD or KL difference.
The learning objective of the optimization problem is to maximize the difference between the average distributions of the cycles based on the determination of the value of
K and the corresponding cycles so that the distributions of each cycle are as diverse as possible and the learned prediction model has a better generalization ability. The principle of segmentation can be explained in detail using the principle of maximum entropy [
22]. First of all, it is necessary to find the most-different periods instead of the most-similar ones, and in the absence of prior assumptions about the segmentation of time series data, the entropy of the total distribution can only be maximized by diversifying the distribution of each period as much as possible so that a model can be built to flexibly cope with future data. At the same time, since there is no prior information about the data in the test set because the model is not visible during training, a more-reasonable approach is to train the model in the worst-case scenario, where different cycles can be simulated and the distributions of these cycles can be learned. If the model is able to learn from the worst-case scenario, then it will have a better ability to generalize to test data that it has never seen before. This assumption has also been validated in the theoretical analysis of time series models, as data diversity is very important in time series modeling.
In general, the time series segmentation optimization problem in Equation (
10) is computationally very cumbersome and may not have a definite solution. However, by choosing a suitable distance metric, this optimization problem can be solved using dynamic programming. Because of the value of scalability in large-scale data and considering the goal of improving the efficiency as much as possible, a greedy algorithm can also be used to solve this optimization problem. Specifically, in order to more efficiently compute and avoid uncertain solutions, the actual exchange rate time series is divided into 10 equal parts, and each part must meet the minimum unit period. Subsequently, a value of
k is randomly chosen from among the 10 segments, and each segment is of length
. In order to optimize the model,
A and
B are set as the beginning and the end of the time series, e.g.,
, and one of the candidate segmentation points (denoted as
C) is randomly chosen by maximizing the distributional variance
. After determining
C, the same method can be used to derive another point
D when
. A similar method is applied for different values of
k. Experiments have shown that this method can be used to select a more-appropriate segmentation period than that selected with the algorithm of random segmentation, and it has also been shown that the final performance of the predictive model deteriorates when
k is very large or very small.
3.3.2. Time Distribution Matching
Based on the time series segments to be learned, a time series distribution matching module was designed to learn the common knowledge of the different periods by matching the distributions of the different periods, and this knowledge is used to match their distributions for the unknown sequences. As a result, the model trained in this step is able to generalize well to never-before-seen test sets in comparison with methods that rely only on local or statistical information. The structure is shown in
Figure 6.
The loss function
for the prediction of time distribution matching can be formulated as in Equation (
11):
where the pair
denotes the
i-th labeled segment from period
;
L is a loss function, which can be a mean-squared error (MSE) loss function, and
is a model parameter with learning capabilities.
Nonetheless, these steps can only cause the predictive knowledge for each period to be learned, and they cannot narrow down the diversity of distributions across different time periods in order to utilize their common knowledge. This problem can be solved using a simple approach, i.e., by employing some generalized distribution matching distances
as a regularization term to match the distributions of
and
in each period. In contrast to existing distribution matching methods, where the regularization term is often performed at a higher level, in this model, the regularization term is applied to the final output of the LSTM cellular units.
is used to denote the hidden state
V of the LSTM with feature dimension
q. The pair
of periodic distribution matching in the final hidden state can be expressed as in Equation (
12):
However, the above regularization term does not fully capture the time dependence of each hidden state in the LSTM network. Since each hidden state contains only part of the distributional information of the input sequence, each hidden state of the LSTM network should also be considered when constructing the distributional matching regularization term.
It can be seen in the temporal distribution matching schematic in
Figure 6 that it is possible to capture the temporal dependency while matching the distributions of two LSTM cells. An importance vector is introduced so that the relative importance of the
V hidden states inside the LSTM can be learned, and all of the hidden states are weighted with the normalized
. Of course, for each pair of corresponding period segments, there is a corresponding
. By doing so, the difference in the distribution of each pair of corresponding period segments can be dynamically reduced. Given a pair of period segments
, the loss of temporal distribution matching can be expressed as in Equation (
13):
where
denotes the similarity of the distribution between the
period segments and the
period segments for state
t.
All hidden states in an LSTM network can be easily computed by following the standard LSTM computation.
denotes the computation of the next hidden state based on the previous state. The computation of this state can be formulated as Equation (
14):
The final goal of the time distribution matching is achieved with the computation defined in Equations (
13) and (
14):
where
in Equation (
15) is a hyperparameter used to balance the reduction in the prediction loss in training and the fitting of cycle pairs for migration learning; in addition, the average of the distributional differences in all corresponding cycle pairs is also calculated. To facilitate this calculation, small portions of
and
are selected to perform a forward operation in the recurrent neural network layer to concatenate all of the hidden features. Temporal distribution matching is then performed.
3.3.3. Learning on
A boosting-based importance assessment algorithm is used to learn
[
23]. Prior to this, the network parameter
is first pre-trained using all cycle-to-cycle data, i.e., using Equation (
13). This is to train the model to be able to better characterize the hidden state to facilitate the learning of
. In addition, by representing the pre-trained parameters as
, the importance of the hidden state can become progressively more realistic as the training progresses. Initially, for each LSTM layer, all weights are initialized to the same value, i.e.,
. The difference in the distribution of the corresponding cycle pair is chosen as the indicator for boosting, and if the distribution difference in the ephemeral
is larger than the distribution difference in the ephemeral
n, we increase the value of
to reduce the distribution difference; otherwise, the value of
is kept unchanged. This can be expressed as in Equation (
16):
where
can be expressed as in Equation (
17):
The update function
is computed with the distribution matching loss at different learning stages, while
is the distribution difference at the
t-th time step of the
n-th period of iteration;
is the sigmoid function. It is easy to see that
; therefore, the proof’s importance increases again. Similar to the plain method, this can be simplified to Equation (
18):
Note that, by using Equations (
16) and (
18), the trained
-value can be obtained.
4. Data Collection and Organization
Monthly data on the USD/CNY exchange rate published by the Wind database were selected, and these data were used as the basic data for this experiment; the style of the data series is shown in
Figure 3. The exchange rate data released on this platform were the most-complete, and at the same time, the exchange price was accurate to the unit of minutes, so these data can meet the needs of researchers and investors in their study and analysis of short-term high-frequency exchange rate series in the international market. In this study, the real exchange rate price data from 2 January 2015 to 30 April 2022 were selected, and these data were split into training data and test data, respectively; each group of exchange rate price data contained 30,000 units, and the opening price was selected as the experimental object. The training data accounted for 80% of the total time series (24,000 articles), and the test data accounted for 20% of the total time series (a total of 6000 articles).
The main currency pair in Forex is the U.S. dollar currency pair. The U.S. dollar is currently the major currency in circulation in the world, occupying more than 80% of the global foreign exchange trading volume, which is mainly due to the United States of America’s economic strength, as it has a wide range of global trade as a result of its core position. The main reasons for this are as follows:
- ①
At present, almost all of the world’s national central banks use the dollar in foreign exchange reserves, although many countries’ central banks are currently reducing their proportions of foreign exchange reserves in dollars.
- ②
At present, the world’s major commodities, such as gold, are denominated in dollars. Therefore, global commodity transactions use them as a settlement currency, and borrowing and lending between countries are also denominated in U.S. dollars.
- ③
The U.S. dollar is the main medium of trade before cross-border transactions. The most-common example is that of oil, as oil is priced in dollars, so all international trade in oil must occur through the U.S. dollar.
- ④
Settlements of currency exchange rates between countries are all calculated through the dollar rate, and all other exchange rates are converted through the dollar.
Although USD/CNY was chosen as the research object in this study, the research results can be applied to other currencies.
The first step in the pre-construction of the neural network prediction model was that of data preprocessing, and among the various forms of methods used in the field of time series, the most widely used are normalization and standardization methods; the final prediction effect is different depending on the processing method used. Normalization and standardization methods can map time series data to a certain region, effectively reducing the time taken by a neural network to establish a construction process, but due to large gaps in the distributions of time series data, the prediction effect cannot be optimized, which is important for the realization of the task of the effective prediction of a time series through a neural network. In this study, a standardized method was used to preprocess the data, as defined in Equation (
19):
where
is the normalized data,
x is the original data,
is the standard deviation of the data, and
is the mean of the data. The logical relationship between the processed data remained unchanged, and the results after the completion of the prediction were still standardized data, which needed to be back-normalized to obtain the actual size of the data.
6. Conclusions and Discussion
With a focus on exchange rate time series with non-stationary characteristics, the analysis and decomposition of a time series were used to reduce its complexity and, thus, improve the prediction accuracy. EMD was used to perform experiments; a sequence was first decomposed through EMD into several IMFs and a segment of signal Res components, and then, these segments were input into a previous LSTM model for exchange rates to train it for prediction. Next, these predictions were weighed and summed up; finally, in order to be more accurate, a layer of SVR was passed to reduce the noise and arrive at the final prediction value. The experimental results showed that the EMD-LSTM-SVR model for exchange rate fluctuation prediction not only had a high prediction accuracy, but it also ensured that most of the predicted positions deviated less from the actual positions.
Although this research on the prediction of actual exchange rates made some progress, there are still some deficiencies and areas for further study based on existing research: First, for the exchange rate forecasting model, the next step of research should be the comparison of the EMD-LSTM-SVR model with more time series forecasting models so as to better forecast exchange rates. Second, a set of empirical modal decompositions (EEMDs) should be used for the complexity reduction algorithm used on the exchange rate data sequence when performing forecasting experiments on the exchange rate, and EMD-based sequence decomposition should be used for a comparison of the complexity after the decomposition of the two algorithms in order to further improve the forecasting accuracy and increase the practical value.
The EMD algorithm can continuously decompose the original signal to obtain IMF components that meet certain conditions. These IMF components often have different frequencies, which provides a way of thinking about their use in the direction of harmonic detection. The EMD algorithm is widely used in the field of signal processing due to its orthogonality and convergence, but it does not have a fixed mathematical model like a wavelet analysis or neural network does, so some of its important properties have not been proven with careful mathematical methods. Moreover, the definition of the IMFs’ modal components has not been unified, and they can only be described using the connection between the zero point and the extreme value point of a signal, the local characteristics of a signal, etc. EMD still has a long way to go from theory to practical application, and the specific deficiencies of EMD are reflected in the following aspects:
There is modal overlapping in IMF decomposition, that is to say, an IMF will contain feature components of different time scales. On the one hand, this is due to the signal itself, and on the other hand, this is a defect of the EMD algorithm itself.
In the process of decomposing IMFs, many iterations are needed, and there is a lack of a standard for stopping the iterations, so IMFs obtained with different stopping conditions are different.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}