To enhance the accuracy of the evaluation model, which is a function of federated learning, this subsection proposes a dynamic communication algorithm and an adaptive aggregation algorithm. Subsequently, the federated deep learning model (FL-DL) is constructed based on the two aforementioned algorithms.
3.1. Dynamic Communication Algorithm Design
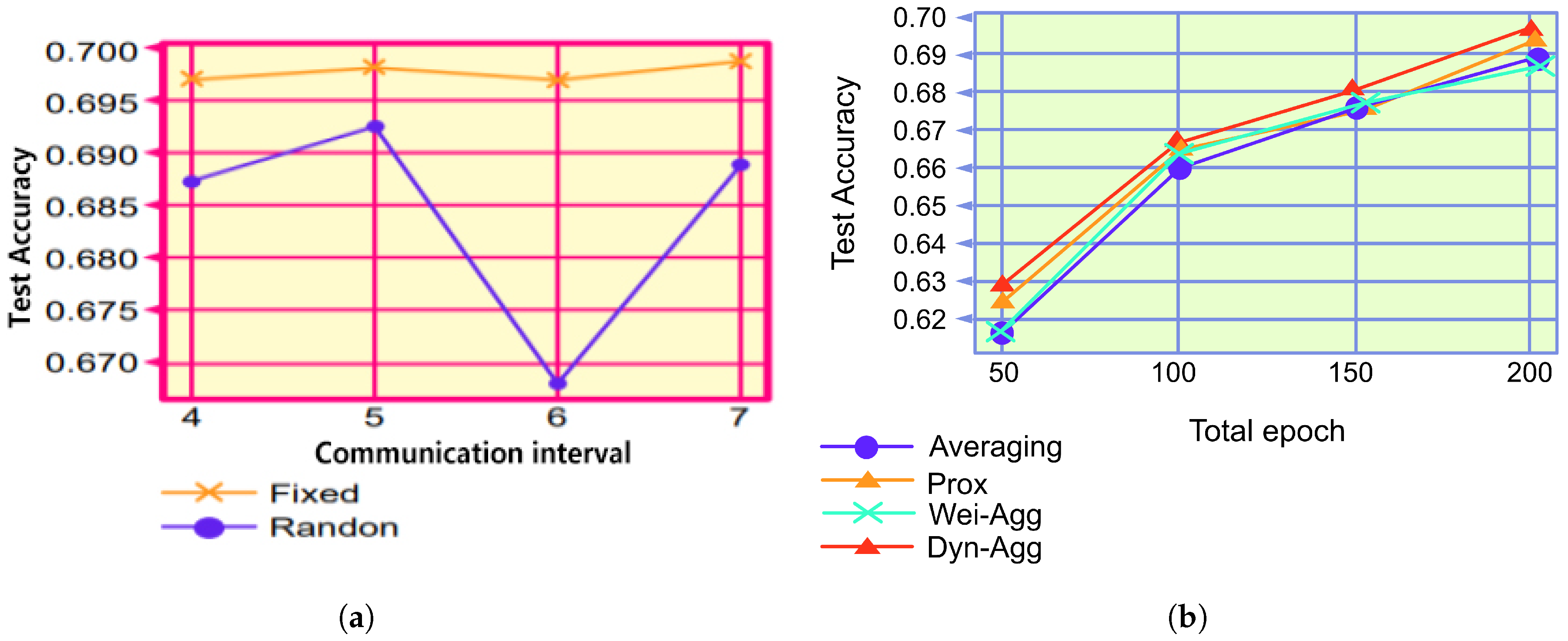
It is difficult to predict and utilize a suitable communication interval before training, and an inappropriate communication interval can adversely affect model performance [
19]; therefore, a dynamic communication interval is considered. With respect to the federated learning system, we utilize a fixed communication interval in the first half-cycle of the training. Therefore, the system follows a fixed communication scheme. Subsequently, it utilizes a variable communication interval in the second half cycle. Larger communication intervals can lead to a decrease in task accuracy [
20]; to address this problem, the dynamic communication algorithm adds a constraint to the variable communication interval. Thus, it prevents the communication interval from becoming immensely large. By using the constrained variable communication interval, the federated learning system follows the dynamic communication scheme in the second half cycle of training. This combination (i.e., making the federated learning system utilize a fixed communication scheme in the first half-cycle of training and a dynamic communication scheme in the second half-cycle) constitutes the dynamic communication algorithm proposed herein.
Let the total number of system training wheels be E, the fixed communication interval be f, the set of training wheels be , the set of communication occurring wheels be , and the set of communication intervals be . The dynamic communication algorithm is described as follows:
Step 1: Divide set into three subsets of training wheels based on the fixed communication interval f and the midpoint of the total training period. Because f is not necessarily divisible by E in practical applications, the three divided subsets are as follows: , set, and .
Step 2: Construct the communication interval set based on the three training wheel subsets.
For , for each , and for , an f is added to . It is apparent that by this operation, the algorithm adds a total number of s to at .
For
, for each
, and for
, the algorithm randomly selects an integer in the interval
of length
f; thus, it replaces the original communication-generating wheel
and adds it to
. After each addition of the randomly selected communication-generating wheel to set
, the algorithm computes the difference between the value of the last element in set
that is not 0 and the value of its predecessor element, and it adds the computed difference to
. Let the value of the predecessor element pertaining to the first element in
be 0. By restricting the selection of the alternative communication-generating wheels to the left side of the replaced original communication-generating wheel (i.e., the
-th wheel) to a left-open–right-closed position of length
f, the interval between the two alternative communication-generating wheels (i.e., the variable communication interval) is made to be no more than
and no less than 1; thus, a constraint is added to the variable communication interval to prevent it from varying considerably and from occasioning the degradation of the model performance. As per
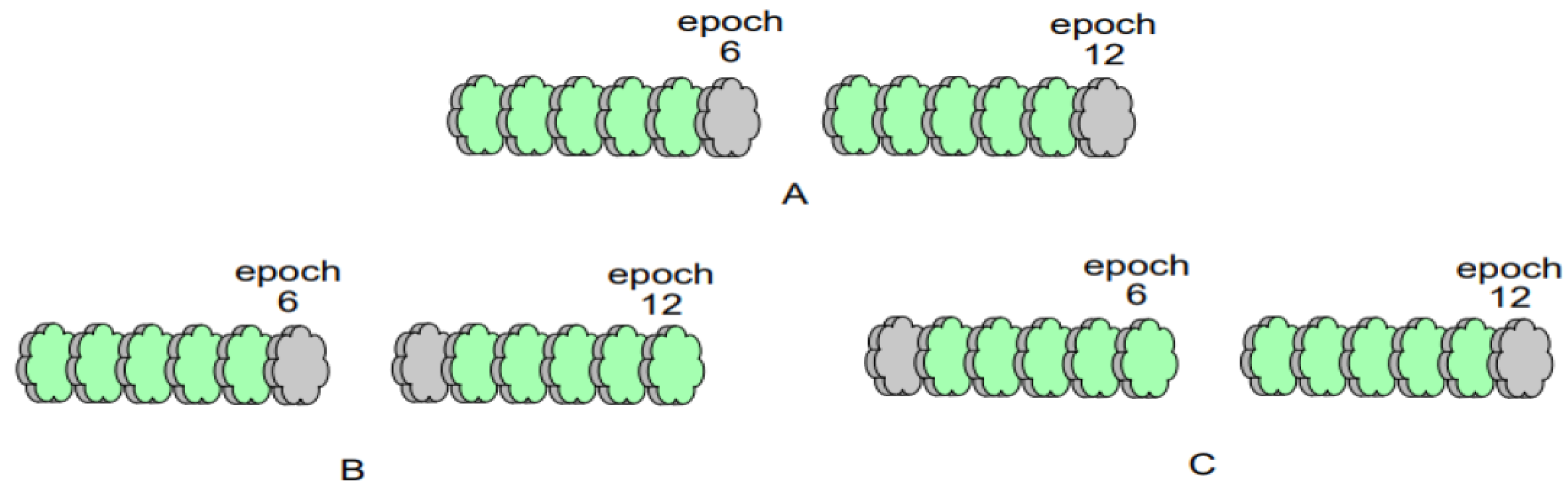
Figure 4, let the fixed communication interval be 6.
Figure 4A depicts the communication generation wheels of rounds 6 and 12 when the fixed communication interval is utilized,
Figure 4B indicates the minimum interval case when the variable communication interval is utilized, and
Figure 4C indicates the maximum interval case when the variable communication interval is utilized.
For , it is apparent that if f is divisible by E, then it will not exist. If f is not divisible by E, for any , the federated learning system that follows the fixed communication scheme is not communicating. Therefore, to accurately compare the dynamic communication algorithm proposed herein with the federated learning algorithm that follows the original fixed communication scheme, the dynamic communication algorithm does not treat .
Step 3: Apply the constructed to the server side. The server side takes one element from and broadcasts it sequentially and without putting it back each time it broadcasts global model parameters to the clients. Subsequently, each client sets the value of the broadcasted element to the number of local training rounds, and the local private data set is utilized to train the global model.
Using the three aforementioned steps, the federated learning system that applies the dynamic communication algorithm will follow a fixed communication scheme during the first half-cycle of training, and it will follow a dynamic communication scheme during the second half-cycle of training. The dynamic scheme can optimally combine the two schemes; thus, an enhanced model performance is obtained. This combined approach is the dynamic communication approach (Algorithm 2).
In the scenario in which the total number of training rounds is
E and the fixed communication interval is
f, the dynamic communication algorithm first initializes the “midpoint” round
, the set of communication occurring rounds
, the set of communication intervals
, and the two self-increasing variables
i and
j. Subsequently,
and
are calculated as per the preceding three steps and the corresponding three scenarios contained in Algorithm 2. Finally,
is output.
| Algorithm 2 Dynamic communication algorithm |
- 1:
Input: total number of training rounds of System E, fixed communication interval f - 2:
Initialize the “midpoint” round for division, for the set of communication occurring rounds, for the set of communication intervals, and self-incrementing variables and - 3:
for t in range (1, E) do: - 4:
if and : - 5:
elif # “randint” means to choose a random integer in the interval - 6:
elif and : - 7:
Output:
|
3.2. Adaptive Aggregation Algorithm Design
Because it has been demonstrated that averaging the weights of the model parameters as per the size of the data set is not the most efficient aggregation method [
21], herein, the algorithm that constructs a new aggregation weight formula and automatically updates the aggregation weights is referred to as the adaptive aggregation algorithm. The basic principle of this algorithm is as follows: the automatic updating of aggregation weights is achieved by making the aggregation weights back-propagate and optimize according to the loss of the global model before each use.
First, based on the formula provided by the standard aggregation algorithm FedAvg [
22] (i.e., row 6 of Algorithm 1), a novel aggregation weight formula is proposed:
where
denotes the global model,
n denotes the number of clients,
denotes the size of the local data set
of client
denotes the size of the whole data set,
denotes the local model of client
k, and
denotes the aggregation weights proposed for use in
. The weight
will be initialized as follows:
where
denotes the task accuracy of
at the current communication round
e. Thus, the adaptive aggregation algorithm extends the impact of the better-performing local model on the global model.
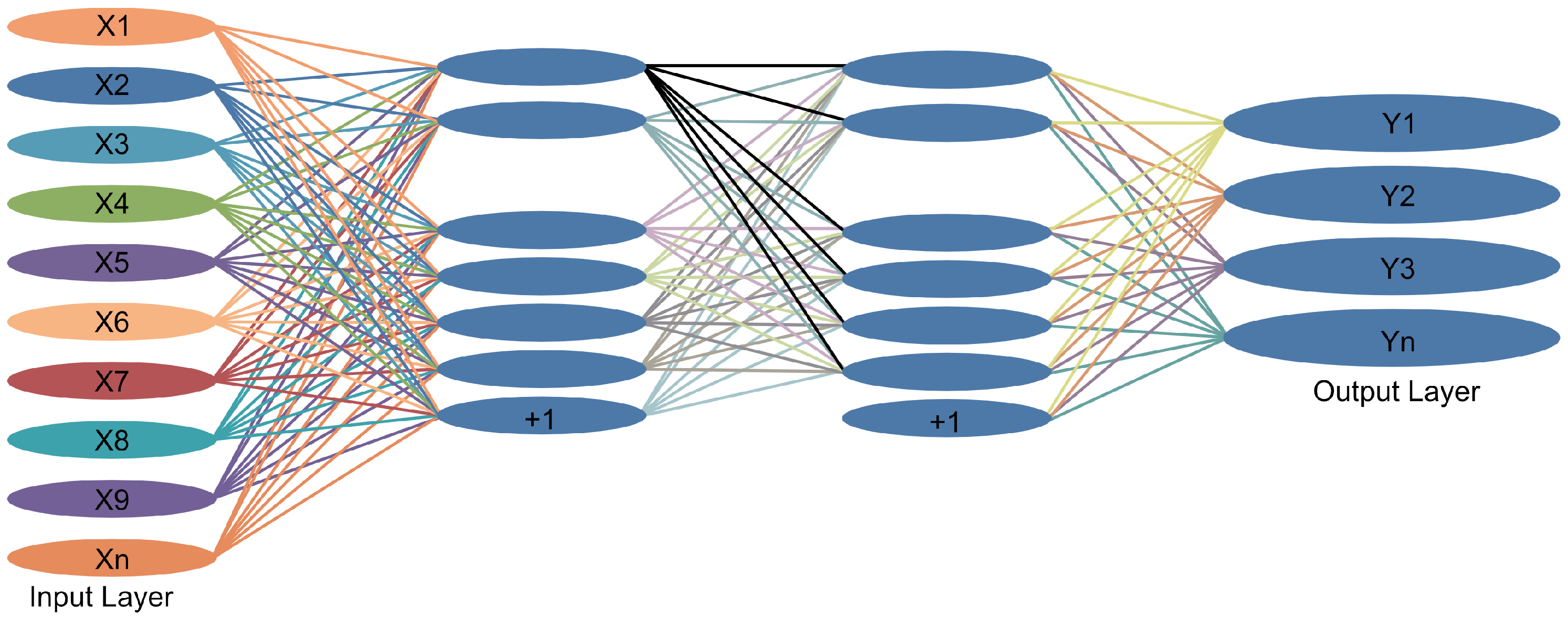
Subsequently, because the feedback mechanism of artificial neural networks enables self-learning [
23], a small two-layer neural network, NeuNet (
Figure 5), is utilized; thus, the aggregation weights can optimize themselves.
This study considers the manner in which the optimization goal can be set. Because the optimization goal of NeuNet is aligned with the optimization goal of the entire federated learning system, which entails reducing task loss, this study achieves NeuNet self-learning. Therefore, the output layer of NeuNet should be connected to the server side, and this connection is utilized to pass a loss value
from the server side to the output layer of NeuNet in one direction; thus,
can be utilized as the loss applied by NeuNet for back propagation. This passed loss value is the average loss of the global model at the end of the last communication (i.e., the average loss of each local model tested on the test set before each local model was trained locally with the global model). This method exhibits the following advantage: it is not necessary to collect the privacy data of each client on the server side to test the global loss, and the method does not add immense computational effort to each client [
24]. In summary, the adaptive aggregation algorithm utilizes
as the input to NeuNet and SysLoss as the back-propagation loss; subsequently, the new
for client k after automatic optimization is:
where Equation (
3) represents the weight update formula of the neural network and
denotes the learning rate of NeuNet.
Thus, the adaptive aggregation algorithm complementarily applies the influence of the global model to the local model while expanding the influence of the partial local model on the global model through Equation (
2).
The pseudo-code description of the algorithm is depicted in Algorithm 3. The inputs to the adaptive aggregation algorithm are the task accuracy set
for each local model, the parameter set
for each local model, and the task loss rate set
for the global model. First, the algorithm initializes a two-layer neural network model and the global average loss variable. Subsequently, the global average loss is calculated as per the preceding algorithm description, and the calculated loss is utilized as a feedback for the neural network to automatically update the aggregation weights. Finally, a new global model
calculated from the new aggregation weights is output.
| Algorithm 3 Adaptive aggregation algorithm. |
- 1:
Inputs: task accuracy set for each local model, parameter set for each local model, and global model task loss set . - 2:
Initialize a two-layer neural network model with global model average loss - 3:
for k in range do: - 4:
- 5:
- 6:
- 7:
Set as the feedback loss of the neural network to obtain the automatically optimized - 8:
- 9:
Output:
|
3.3. FL-DL Model Design
Based on the dynamic communication algorithm and adaptive aggregation algorithm, this study proposes a new federated learning model (FL-DL), whose framework is depicted in
Figure 5.
FL-DL is based on the architecture of a typical federated learning system, which comprises a server side and multiple clients. Herein, the same model is utilized for the global model on the server side and for the local model on each client (i.e., both models utilize AlexNet)[
25]. It can be observed from the server-side module depicted in
Figure 5 that both algorithms proposed herein are applied on the server side, which exhibits the advantage of placing the additional but small computation on the server side instead of on the client side, where computational resources are strained. The pseudo-code description of the model is depicted in Algorithm 4.
| Algorithm 4 FL-DL algorithm. |
Server side: 1: : 2: Initialize 3: Interval ← Dynamic communication algorithm 4: : 5: Receive the transmitted by each client to build to build , and to build 6: G M ⟵ Adaptive aggregation 7: Broadcast the global model or and to each client Client k: 8: Initialize , 9: Test the local test set on the global model and obtain the global model loss 10: Train the local training set on the global model for e rounds and test it to obtain the accuracy of the local model 11: Communicate with the server side to transmit
|
Here, t represents the training round the system is in; represents the global model; Interval represents the set of communication intervals; E represents the total number of training rounds; f represents the fixed communication interval; i represents the self-incrementing variable initialized to zero; represents the local model; represents the local training set of client k; and represents the local test set of client k.
The description of the working steps of FL-DL can be summarized as follows:
Step 1: the server side broadcasts a global model to each client, along with a communication interval generated by a dynamic communication algorithm;
Step 2: The client first tests the global model on a local test set to obtain the loss of the global model; subsequently, they train the local training set in rounds on the global model, and they test it with the local test set to obtain the local model as well as the task accuracy of the local model;
Step 3: Each client reports the trained local model parameters, the global model loss, and the local task accuracy to the server side;
Step 4: The server side aggregates the local model parameters into a new global model as per the adaptive aggregation algorithm, and it returns to Step 1.
The aforementioned four steps are repeated from round 1, and the new global model is utilized in the next iteration until the number of iterations is .







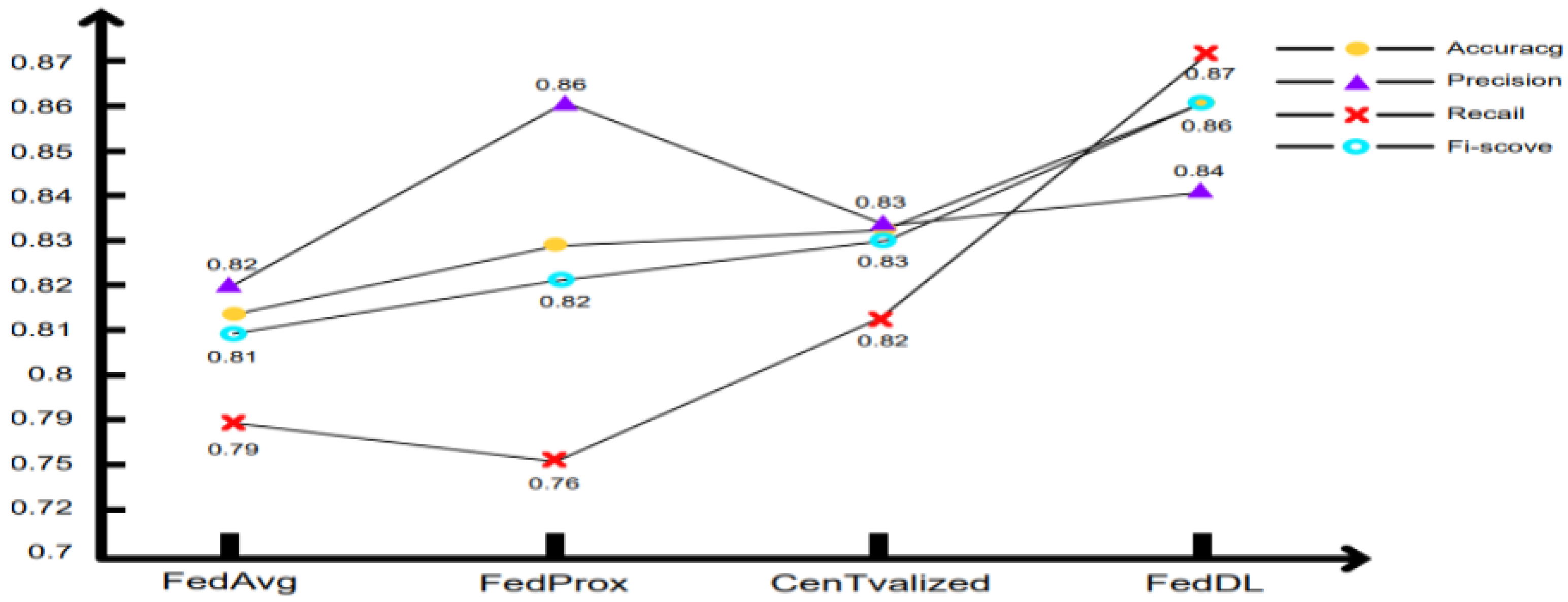

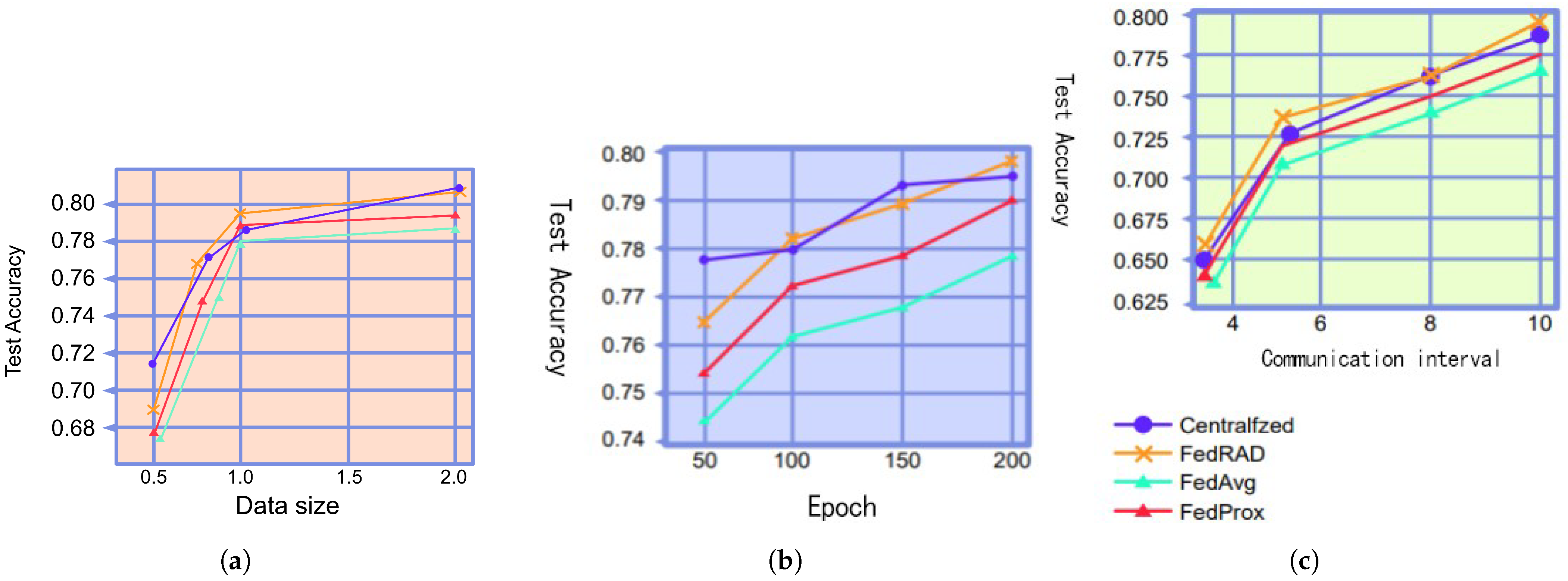

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}