1. Introduction
This study is devoted to developing numerical methods for solving complex tasks in control theory, namely, the control synthesis problem. To implement the optimal control problem solution for a real control object, solving the control synthesis problem is necessary, which is a highly time-consuming computational task. Previous studies have proposed automatically solving this problem using effective machine learning (ML) methods [
1].
Solving the optimal control problem in a classical statement leads to obtaining control as a time function. This control cannot be directly implemented for a real control object because the model of this optimal control problem was formulated and solved, as it is sensitive to the initial state and perturbations. To directly implement the optimal control problem solution in a real control object, a stabilisation system must be built for the control object’s motion along the optimal trajectory, in order to compensate for deviation from the optimal trajectory [
2,
3,
4].
Trajectory tracking is a common motion control problem in which the control object moves with the time-parameterised reference [
5,
6]. Trajectory tracking is widely applied in autonomous driving [
7,
8], robotics [
9], high-precision agriculture [
10,
11], and so on. Effective methods for trajectory tracking include model predictive control [
12], backstepping [
13], PID regulators [
14], and neural network PID control [
15], among others.
It should be noted that the stabilisation system should provide trajectory tracking in the expanded space of states, taking into account the time; otherwise, the value of the quality criterion obtained from solving the optimal control problem will change.
Building a trajectory motion stabilisation system is not any easier than solving the optimal control problem. It requires searching for a control function that depends on the control object’s state deviation from a given trajectory. For example, if this problem is defined as optimisation (i.e., the minimisation of deviation from a given trajectory), then its solution generally involves finding the structure and parameters of the stabilisation system function.
The search for mathematical expressions occurs in various tasks, such as experimental data approximation, inverse function searches, common differential equation solutions, control object model identification, control synthesis, and so on, and includes determining the mathematical expression in the following form:
where
is a vector of variables, and
is a vector of parameters searched for with the structure of Expression (
1).
Machine learning methods to search for mathematical expressions, including symbolic regression, are described in [
1,
16,
17,
18]. Symbolic regression methods allow us to determine mathematical expressions, including their parameters, using a computational evolutionary approach. The mathematical expressions are iteratively composed of alphabets of elementary functions, and the evolutionary technique is used to search for the most suitable equation to satisfy the given quality criteria. In our research, symbolic regression was applied to the control synthesis problem solution.
1.1. Relation to the Literature
The classical statement of the optimal control problem has been expanded [
19], and additional optimal trajectory conditions have been introduced as the classical statement does not address stabilisation system construction for control object motion along the optimal trajectory, and creating such a stabilisation system or similar solutions is necessary to implement the optimal control problem solution. In the extended statement, obtaining an optimal control and trajectory in the state space is followed by creating a system that stabilises the control object motion along the obtained optimal trajectory. The obtained stabilisation system should ensure the attraction property in the vicinity of the optimal trajectory. However, a quality problem arises when synthesising a motion stabilisation system, as the criterion of reducing the motion error along a given trajectory is usually used.
The main issue in solving the extended optimal control problem is that the stabilisation system for object motion along the optimal trajectory significantly changes the mathematical model of the control object. Initially, the optimal control problem was deemed to be solved for one mathematical model of the control object. In reality, the object moving along the trajectory had another mathematical model that was overlooked at first. Another issue is that the motion stabilisation system cannot be synthesised on the on-board processor of the control object in real time. If the optimal control problem can be solved via the direct method on the on-board processor of the control object within a few seconds, then synthesis of the motion stabilisation system requires much more time due to its computational complexity.
The authors of [
20] presented a universal stabilisation system for motion along a given trajectory. Initially, several trajectories were set in the state space, and one universal stabilisation system was sought, which ensured control object motion in the vicinity of all given trajectories. Furthermore, when the optimal control problem is solved, the universal stabilisation system is used. In this study, the optimal control problem is solved in real time with a possible deterioration in the stabilisation quality of the motion along the optimal trajectory, as the obtained optimal trajectory is not guaranteed to belong to the class of trajectories that the universal stabilisation system stabilises. In addition, the second problem remains. The optimal control problem is solved for a mathematical model of the control object that does not include a stabilisation system, and a real control object contains a stabilisation system.
In the work of [
21], the problem of stabilising the motion along a given trajectory was considered. The trajectory was given in space in the form of straight-line segments. A reference model of motion was created to calculate the deviation from the trajectory. For this purpose, the motion speed along each segment was calculated and considered constant. The deviation of the object from the reference motion of the point along the trajectory was calculated at each segment. To solve the control synthesis problem, the network operator method was used and a stabilisation system was obtained.
1.2. Contribution
In this study, we searched for a feasible optimal control problem solution. The search space includes a class of feasible optimal trajectories.
An advanced mathematical model of the control object was used to solve the extended optimal control problem. Initially, a universal stabilisation system was built. Furthermore, the stabilisation system was input into the mathematical model of the control object. An object trajectory vector in an extended state space in the right part of the control object model was obtained, instead of a free control vector. The mathematical model of the control object includes a reference model, which contains a free control vector in the right part. As a result, the advanced control object model was obtained. The dimension of the advanced model is twice as large as the original control object model. The advanced mathematical model allowed us to solve the optimal control problem in the classical statement, in an on-board and online manner. The optimal control problem was solved for an object with a mathematical model that includes a stabilisation system for motion along a given trajectory.
The rest of this study is organised as follows: The advanced model and problem statement of the control object are presented in
Section 2; a network operator method, as one of the symbolic regression methods, is outlined in
Section 3; computational experiments focused on solving the optimal control, control synthesis, and stabilisation system synthesis problems for two-wheeled robots are described in
Section 4, followed by a discussion in
Section 5, a conclusion in
Section 6, and potential avenues for future studies in
Section 7.
2. Advanced Control Object Model and Problem Statement
In the classical statement of the optimal control problem, the mathematical model of the control object is given as follows:
where
is a state vector,
,
is a control vector,
, and
is a compact set that, as a rule, determines constraints on the control.
The terminal state is
where
is a terminal time,
, and
is a given limitation.
The quality criterion in an integral form is
We created a universal stabilisation system of motion along a given trajectory to develop an advanced model. For this purpose, we formulated the problem of a universal stabilisation system synthesis. The initial state domain is given as a deviation from the specified initial state as follows:
where
.
A set of diverse control functions is
where
The diversity of functions should be enough to consider all control object features. Functions in (
7) may include simple discontinuities.
If we substitute the control functions in (
7) into the right parts of the control object model (
2), we can then obtain a set of program trajectories as particular solutions of the ODE system from a given initial state, as shown in the following equation:
where
is a particular solution of the ODE system (
2) from an initial state (
3) with the control function
in the right part.
Then, we searched for control in (
2) as a function of state
To minimise the following quality criterion:
where
is a particular solution of the ODE system,
from the initial state of
where
is a binary code of the number
k of
n bit, and ⊙ is a Hadamard product of vectors.
The obtained stabilisation system (
11) is inserted into the mathematical model of the control object. Then, the original model (
2) is added. As a result, the advanced mathematical model of the control object is obtained:
The structure of the advanced model (
15) (see
Figure 1) consists of two subsystems: the reference model, which is usually realised on the on-board processor, and a model of the control object with a trajectory tracking stabilisation system.
The first subsystem is related to the open-loop control, while the second subsystem is related to the closed-loop control. Therefore, the control quality depends on the stabilisation formula
previously found for a class of trajectories (
9) and the initial state domain (
6).
For the advanced model (
15), the optimal control problem can be solved in the classical statement. A control function is found as a time function, using the quality criterion of reaching the terminal state and avoiding collisions with obstacles, namely, satisfying the phase constraints in terms of control theory. Phase constraints may be static and dynamic in nature. Static phase constraints are obstacles in the environment, and dynamic phase constraints are possible collisions between interacting objects.
The two-step scheme for designing a control system based on the proposed advanced control object model is shown in
Figure 2. In the first step, a universal stabilisation system for trajectory tracking is obtained using a machine-learning symbolic regression method. In the second step, an optimal control problem is solved using an evolutionary algorithm for the advanced model. The obtained solution belongs to the class of feasible control functions.
For the advanced model, it is possible to build a Hamiltonian system of differential equations for conjugate variables and use the maximum principle
where
and
are vectors of conjugate variables as shown in the following equations:
3. Machine Learning for Stabilisation System Synthesis
To solve the control synthesis problems (
2), (
11), (
12), and (
14) and obtain a stabilisation formula
for a class of trajectories (
9), machine learning control via symbolic regression was used.
Symbolic regression encodes mathematical expressions as special codes and searches for the solution in the code space. The space of mathematical expression codes is not numerical, and it is rather difficult to determine the search direction as it does not have the metrics to estimate the distance between possible solutions nor a possible solution to evaluate the gradient. The convergence of symbolic regression algorithms is the main problem in this optimisation class. Let us call this class non-numeric. It contains the most difficult optimisation problems. A developed search algorithm should, at least, guarantee more efficient performance than a simple random search.
To assess the distance between two possible solutions in the space of mathematical expression codes, the concept of small variation in the mathematical expression code is defined in [
22]. As most codes of mathematical expressions are integer mathematical constructions, vectors, matrices, sets, and so on, a small variation in code means the smallest number of integer changes in a mathematical construction code (i.e., their positions and values). With this small change in code, the correct code of another mathematical expression should be obtained. Any symbolic regression method has its own set of small variations.
Any mathematical expression may have an infinite number of representations if any other expression that can be added to the outlined expression is also equal to zero. However, as a rule, mathematical expressions are written in the most compact form possible, without adding identical expressions equal to zero or multiplying by mathematical expressions with identical unit values.
When searching for a mathematical expression in the code space, it is difficult to state that the found code does not contain insignificant additives. Therefore, it is necessary to limit the length of the searched code. Small variations must possess the property of completeness. This means that any mathematical expression described using symbolic regression code from a set of codes of limited length can be transformed using a finite number of small variations into any other mathematical expression with code belonging to the same set.
where
is a code of initial mathematical expression,
is a code of small variation,
d is a number of small variations,
is a code of a new mathematical expression, and ∘ denotes an operator of the variation application.
We considered an example of encoding a mathematical expression and applying small variations. To code mathematical expressions, we used a graph-based structure of a network operator (for more details, see [
18]). Then, we needed to code and vary the following mathematical expression:
where
,
are variables, and
,
are constant parameters.
To code the mathematical expression, an alphabet of unary and binary functions was used.
Unary functions include the following:
Binary functions include the following:
The identity function
is obligatory in Equation (
21). Binary functions in Equation (
22) should be commutative and associative and have a unit element: 0 for addition and 1 for multiplication.
In the PC memory, the network operator is represented as the following integer matrix:
In the matrix, rows that have zeroes on the main diagonal are connected to source nodes (variables and parameters). Other elements on the main diagonal are numbers from (
22). The elements above the main diagonal are numbers from (
21). For coding and decoding algorithms, see [
18].
Let us apply the principle of small variations and varied expression (
20) using two small variations,
and
, as outlined in the following equation:
The first component in the vector of variation is a code of small variation types: 0—alternation of unary function; 1—alternation of binary function; 2—addition of unary function; 3—deletion of unary function. The second and third components are numbers of rows and columns in the matrix. The fourth component is a number of the unary or binary function depending on the type of variation.
Having performed two variations, we obtained a new matrix of the network operator and, thus, a new mathematical expression as follows:
4. Computational Experiment
A series of computational experiments were carried out.
4.1. Optimal Control Problem
We considered the optimal control problem for two-wheeled differential drive robots.
The mathematical model of control object is given as follows:
where
j is an index of the robot
,
,
, and
is a compact set that is determined by constraints on control:
The initial states of both robots are given as follows:
The terminal states are given as follows:
where
is a time to reach the terminal states by each of the robots,
is not given but limited by
, and
is a given limited time. If two robots reach their terminal states at different times
,
, then a maximal time is considered as follows:
Static phase constraints are given in the form of circular obstacles as follows:
where
,
,
,
,
, and
.
Dynamic phase constraints consider collision avoidance conditions as follows:
where
.
It is necessary to find a control function with respect to constraints (
28) in order to reach the terminal states and minimise the following quality criterion:
Firstly, the optimal control problem is solved in the classical statement, and the control function is a function of time. For this purpose, the direct approach is used. According to this approach, phase constraints and the accuracy of reaching the terminal states are included in the quality criterion as follows:
where
,
, and
are penalty coefficients.
, and
,
is a Heaviside function
The control function is found in the form of a piece-wise linear approximation of the time function. The time axis is divided into equal intervals
and on the borders of intervals; the values of constant parameters are found for the respective control of both robots. Within the intervals, the parameter values are linked by straight lines. The control function is truncated at the top and bottom according to the specified control constraints in the following:
where
,
,
m is a number of components in the control vector,
,
N is a number of robots,
,
is a time interval,
, and
L is a number of intervals.
Thus, an optimal control problem solution (
27)–(
30), (
35) includes a vector of constant parameters
To numerically solve the optimal control problem, a hybrid evolutionary algorithm was used [
23]. The algorithm includes evolutionary transformations from three evolutionary algorithms: the genetic algorithm, particle swarm optimisation, and the grey wolf optimiser.
The hybrid algorithm determined the following solution:
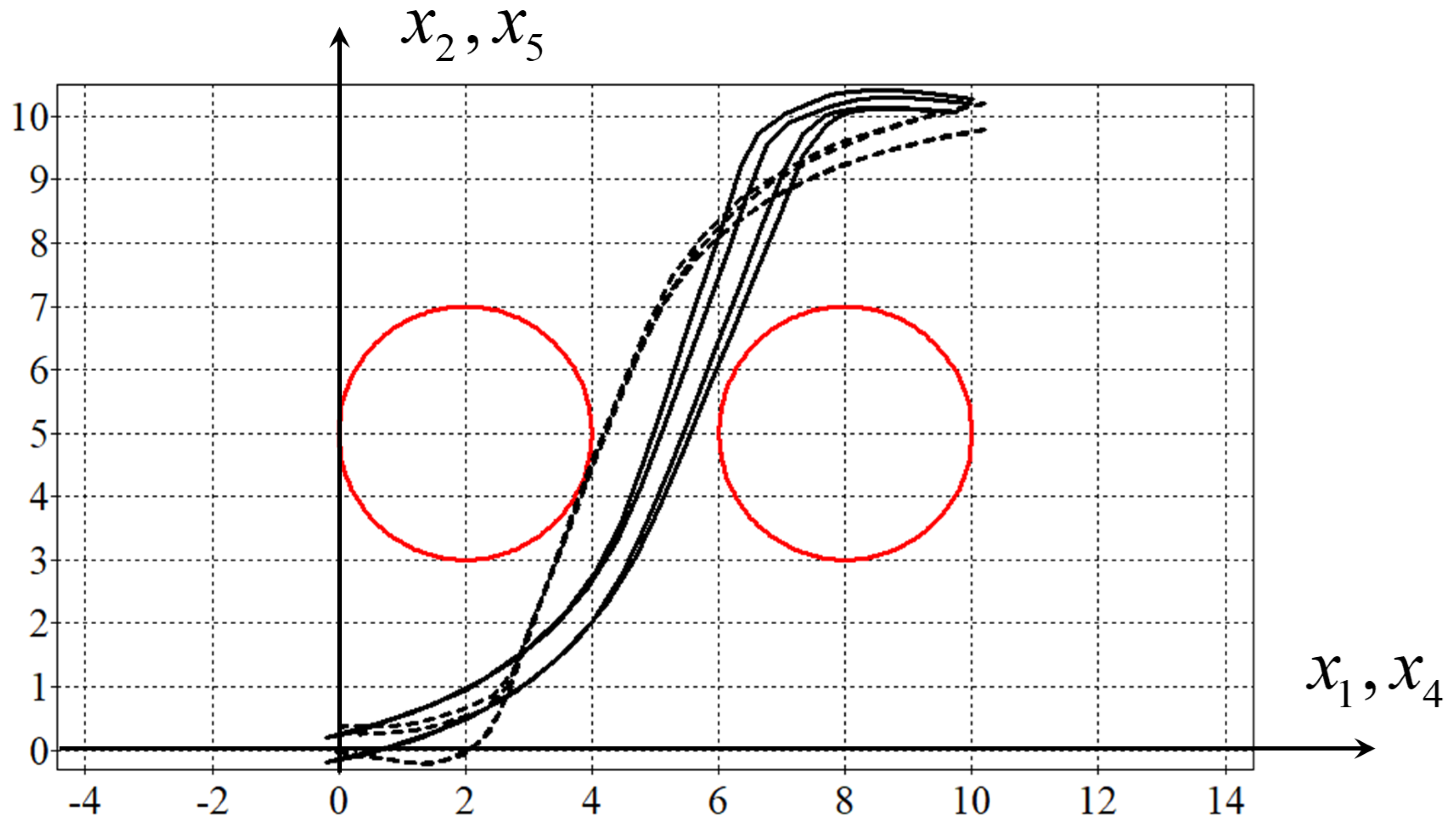
Figure 3 shows the optimal trajectories of two robots. The red circles are obstacles or static phase constraints in terms of control theory. As shown in
Figure 3, the found solution is almost optimal because both robots avoided collisions, satisfied the phase constraints, and reached the given terminal states. The quality criterion value of (
35) was
.
The solution in the form of the control function of time cannot be implemented in real objects since the control system is open-loop. If the initial conditions change, the obtained optimal control will no longer remain optimal even in a small domain.
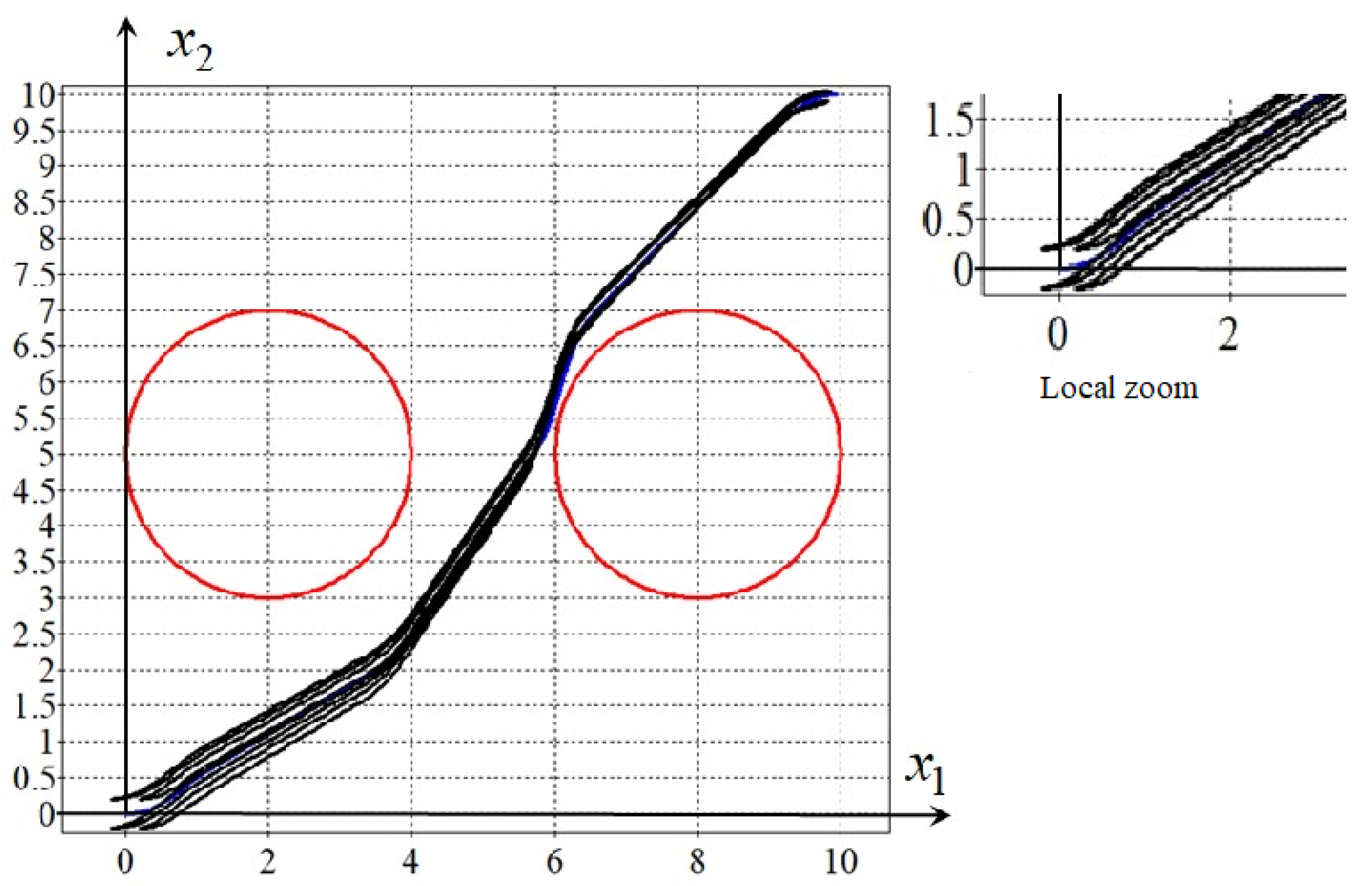
Figure 4 shows robots trajectories from four randomly disturbed initial states in the range of
, as shown in the following:
where
is a generator of random numbers that returns a random value from 0 to 1 at every call. Small disturbances of the initial states essentially change the trajectories. The robots violate phase constraints and do not reach terminal states. The average value of (
35) in a series of 10 experiments was
. To deal with this problem, we proposed to solve the optimal control problem as a control synthesis problem.
4.2. Control Synthesis Problem
In the control synthesis problem, mathematical models of two robots should be considered as a model of one control object because a control function of one robot depends on the state vector of the other.
The mathematical model of control object is
where
,
, and
are coordinates of the state vector of the first robot;
,
, and
are coordinates of the state vector of the second robot;
and
are components of the control vector of the first robot; and
and
are components of the control vector of the second robot.
The constraints on control are
The terminal state is
where
is not given but limited
.
A set of initial states is given in the form of the
neighbourhood of the original initial state for the optimal control problem
where
For the numerical solution of the synthesis problem, the domain of initial states is replaced by a set of points
where
is an integer binary vector of two binary vectors, three bits each, as shown in the following equation:
is a three bit binary code of the number
, and ⊙ is a Hadamard or element-wise product of vectors.
The quality criterion is
where
is a particular solution of the ODE system (
44) from the initial state
,
, and
,
, and
are penalty coefficients.
,
,
,
,
,
,
,
,
,
.
In the control synthesis problem, it is necessary to find a control function as a function of the state space vector as follows:
If the control function (
57) is placed in the right part of the ODE system (
44), then the system will have a particular solution from any initial state of (
47) that will reach the given terminal state (
46) with an optimal value of the quality criterion (
52).
The control synthesis problem may be effectively solved using symbolic regression methods. Here, the network operator method was applied.
The network operator method was performed with the following parameters: an NOP matrix size of , 12 source nodes for the NOP graph, including 6 nodes for variables and 6 nodes for searched parameters, and 4 sink nodes for the output components of the control vector. The variational genetic algorithm parameters were as follows: the number of possible solutions in the initial population—1024; the number of crossover operations in one generation—128; the number of generations—128; the depth of variation—7; the number of generations between change in the basic solution—20; the number of bits for coding a parameter—16.
Computations were performed on a CPU Intel core i7, 2.8 GHz. The computational time was approx. 10 min. Any change in the obstacle position required recalculation. It could be completed offline on on-board processors but not in real time.
The following solution was obtained using the network operator method as follows:
where
,
,
,
,
,
.
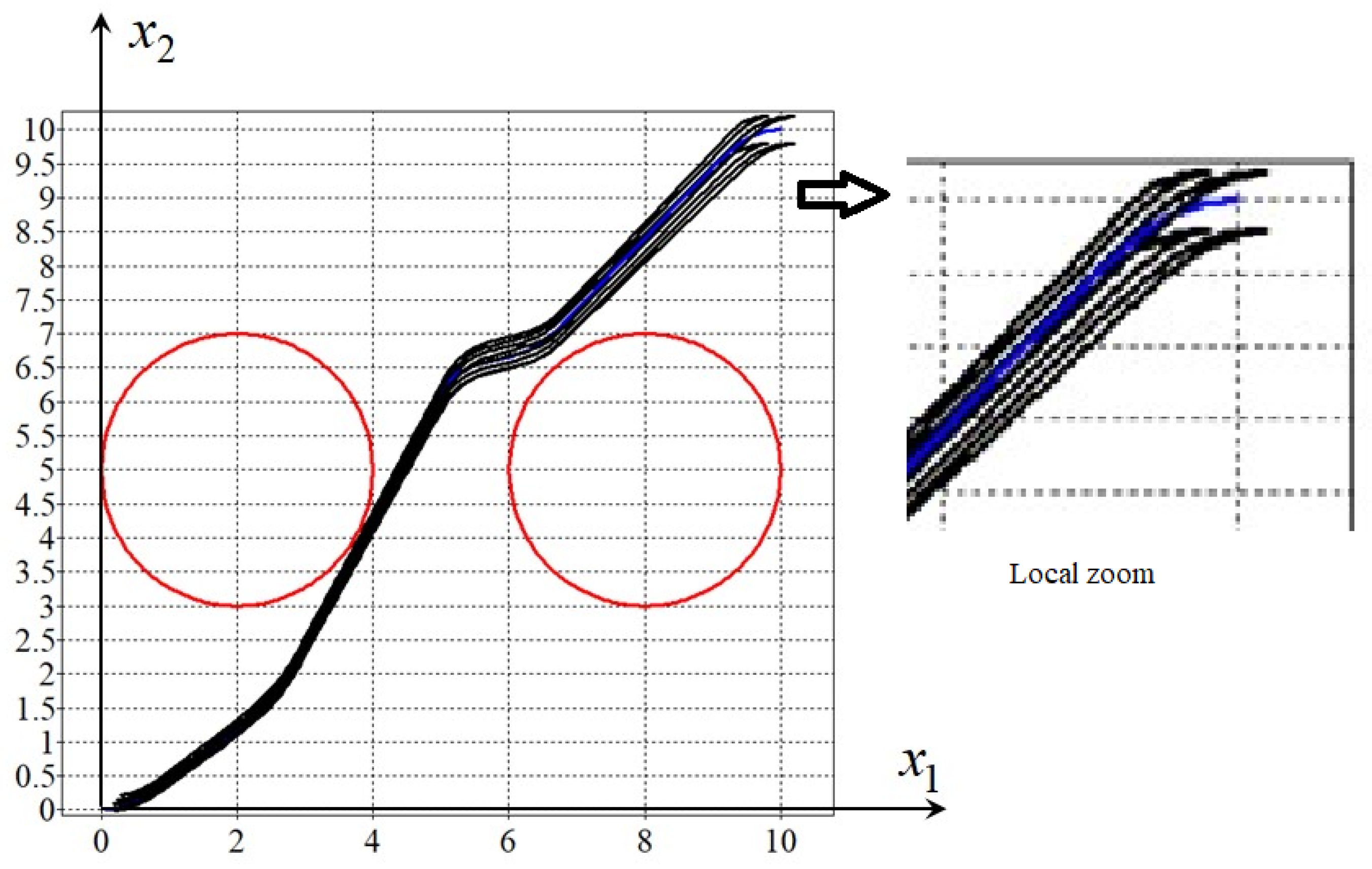
Figure 5 shows the trajectories of two robots with the control system (
58) from some initial states. None of the trajectories violate the phase constraints and they almost reach terminal states. The average value of the quality criterion (
52) was
.
If we solved the optimal control problem in the classical statement and then synthesised the control system for motion stabilisation along the optimal trajectory, then the control synthesis problem for motion stabilisation took too much time.
4.3. Stabilisation System Synthesis
It was proposed to first solve the synthesis problem of the universal stabilisation system. Universal means that the stabilisation system stabilises the motion along a class of trajectories. Then, the optimal control problem is solved in a class of optimal trajectories that can be stabilised using an already obtained stabilisation system of motion along the trajectory.
We considered the synthesis problem of the universal stabilisation system for motion along the given trajectories. For this purpose, we created one stabilisation system for one robot to work in tandem with the two optimal trajectories, obtained upon solving the optimal control problem and starting from two different initial states.
In the stabilisation synthesis problem, the mathematical model of one robot is considered as follows:
Control constraints are given as follows:
Two sets of initial states are given as follows:
where
and
are the initial states of each robot (
29),
, and
is a three-bit binary code of
number,
.
Two program trajectories are given as follows:
which are particular solutions of the reference model:
from the initial states (
29) with the program control in the form of a piece-wise linear function
where
,
,
j is the trajectory number,
,
Both program trajectories have the last points in the terminal states of
It necessary to find a control function in the form of
where
j is the program trajectory number.
The quality criterion is given as follows:
To solve the control synthesis problem, machine learning control via the network operator method was used. The network operator method was performed with the following parameters: an NOP matrix size of , six source nodes for the NOP graph, including three nodes for variables and three nodes for searched parameters, and two sink nodes for the output components of the control vector. The variational genetic algorithm parameters were as follows: the number of possible solutions in initial population—512; the number of crossover operations in one generation—128; the number of generations—128; the depth of variation—7; the number of generations between change in the basic solution—20; the number of bits for coding a parameter—16.
The following solution was obtained:
where
,
,
. A network operator matrix is given in
Appendix A. Here, the trajectory number is not indicated since it is assumed that the stabilisation system provides the control object motion along any given program trajectory from some class.
If the obtained motion stabilisation system (
75) was inserted into the mathematical models of the control objects (
27), and the system was simulated without disturbances to the program trajectories obtained via the control (
42) applied to the reference model (
68). Then, the quality criterion for the optimal control problem was
, instead of
, which was obtained upon solving the origin optimal control problem. This result was expected, as the optimal control problem was solved for objects without a motion stabilisation system.
4.4. Optimal Control Problem with Advanced Control Object Model
Let us consider the same optimal control problem, but for the advanced mathematical model of the control object. There are two control objects described using the advanced mathematical model, including reference models for program trajectory generation.
where
.
A hybrid evolutionary algorithm was used. The previously found optimal solution (
42) was included in the initial population as one of the possible solutions. This solution is the best in the initial population as other possible solutions are generated randomly, which makes it possible to not look for a completely new solution but to improve the previously found one for a problem with the advanced control object model.
The following solution for the piece-wise linear approximation of the control function (
38) was obtained:
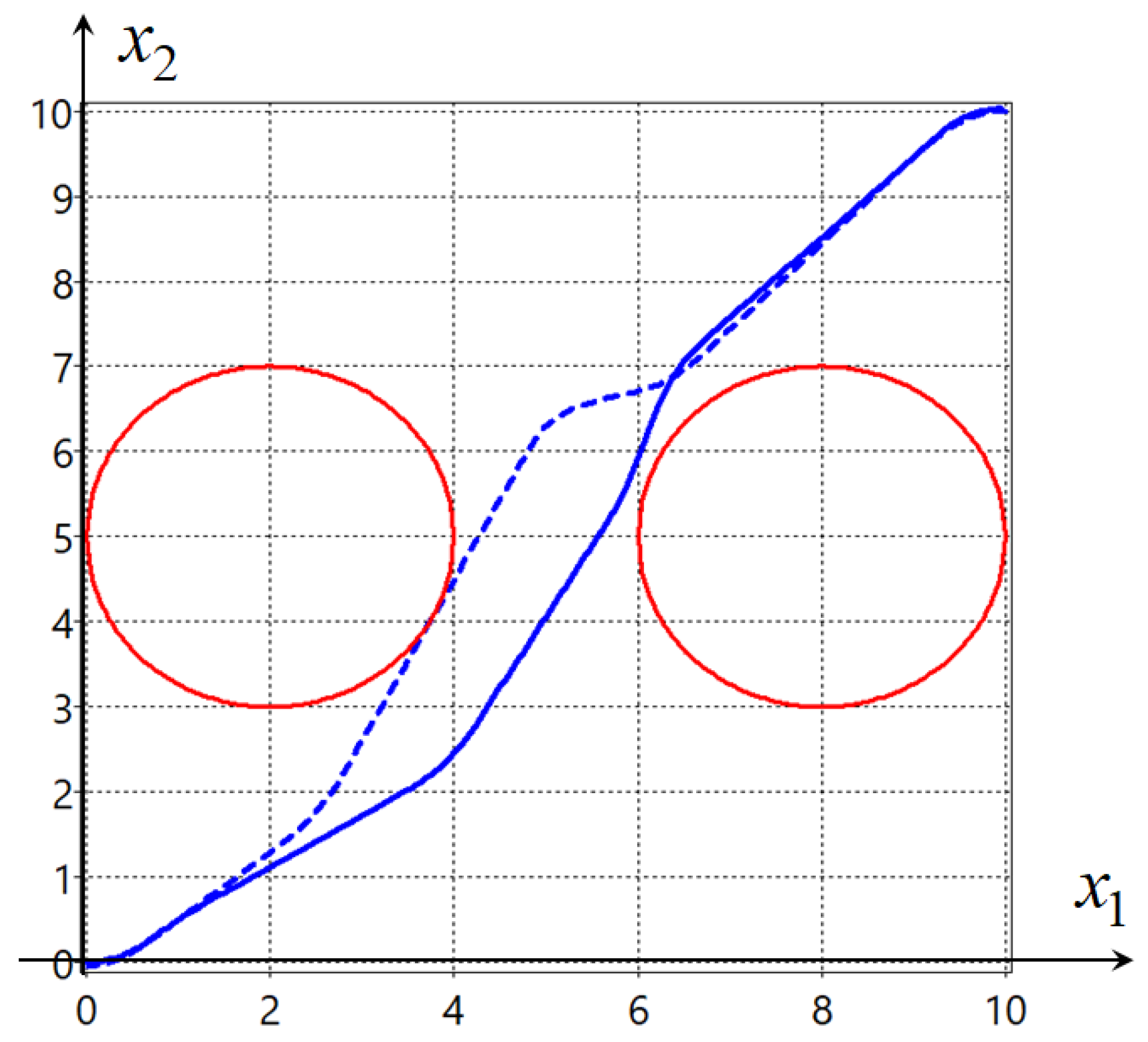
Figure 8 shows the optimal trajectories (
79) for robots with the advanced mathematical model with a quality criterion value
. Optimal trajectories are marked with blue lines, and obstacles are marked with red circles.
5. Discussion
At present, obtaining the optimal control problem solution for multi-functional objects, such as robots in their functioning process, is highly desirable. This is even the case for an approximate solution that is fast and can be obtained on-board. Modern on-board processors allow us to solve problems in short periods of time, albeit in the classical statement, when the control function is searched for as a time function. It is well known and has been demonstrated in our computational experiments that such solutions obtained for original mathematical models are not feasible in practice as they lead to significant errors when the control object experiences small perturbations. The proposed approach of using the advanced method allows us to obtain optimal control problem solutions from the class of feasible control functions. The quality criterion includes penalties for violating both static and dynamic phase constraints. It should be noted that if the number and size of obstacles change, then the optimal control problem should be solved again for the same advanced model and another number of obstacles, and so on, and new optimal trajectories should be obtained, which will also belong to the class of trajectories that are stabilised via the trajectory motion stabilisation system.
The key factor in creating an advanced model is a set of control functions (
7) that generate a class of trajectories (
9). If the set (
7) is sufficient, then the optimal control problem solution with the advanced model with a quality criterion value of (
5) will be close to the optimal solution obtained solely for the reference model.
Creating an advanced model is always possible for tasks where the optimal control problem is stated for the model without uncertainties and stochastics in the right parts.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}