1. Introduction
In today’s rapidly evolving technological landscape driven by the Industry 4.0 revolution, security has become a crucial aspect of any reliable system. As industries increasingly adopt innovative solutions, the integration of smart IoT devices has evolved from being merely advantageous to absolutely essential for modern businesses. These IoT devices offer diverse benefits, including enhanced connectivity, seamless communication, and improved decision-making capabilities, which have made them indispensable in contemporary enterprise ecosystems. The number of IoT devices continues to grow exponentially and is projected to reach 25.1 billion by 2025 as per the researchers’ estimation; the devices also introduce a host of security challenges that cannot be overlooked [
1,
2]. Unlike traditional computers, IoT devices often use simplified security protocols or weak encryption algorithms to reduce power consumption and cost. Also, these devices typically have limited storage capacity, making it difficult to implement complex security measures that require large amounts of data. These factors combined make it challenging to implement traditional security measures on IoT devices. This security challenge is particularly critical as these devices often handle sensitive data and control critical infrastructure components, which makes them attractive targets for cybercriminals. As a result, they are more vulnerable to various types of cyberattacks.
While creating more advanced systems, the integration of IoT devices with Cyber-Physical Systems (CPSs) significantly amplifies security risks. In an integrated system, CPSs utilize IoT components to interact with the physical world, monitoring and controlling various processes in industries [
3]. IoT devices collect and transmit data about machinery performance, contributing to the overall functionality of the system. However, this increased complexity also exposes CPSs to a wider range of cyberattacks [
4]. Attackers can exploit vulnerabilities in the physical or digital components of a CPS to gain unauthorized access to the system. Sensitive data collected or processed by CPSs can be compromised if the system’s security is breached. These risks can have significant consequences, including disruptions to operations, financial losses, and potential physical harm. Therefore, it is essential to implement robust security measures to protect CPSs and the IoT devices integrated with them. The combination of IoT and CPS technologies has created the ‘cyber-physical-social systems’ (CPSs), where the interconnections between digital, physical, and human elements occur. This evaluation further complicates security considerations and demands new ways to protect the systems in multiple domains simultaneously while maintaining efficiency.
Given the growing threats and vulnerabilities in IoT networks, there is a critical need for advanced IDSs capable of effectively identifying and mitigating various cyberattacks. While traditional Machine Learning (ML) and Deep Learning (DL) approaches have been used for intrusion detection, DL shows greater potential as a solution to secure the ever-growing IoT landscape [
5]. Most existing IDSs frequently focus on detecting a limited number of cyberattacks and profiling specific devices, often neglecting automated attack type categorization and overall system reliability. Furthermore, these models typically require extensive training data, and their accuracy can significantly diminish when training data are insufficient. Additionally, traditional IDSs often struggle with the ‘curse of dimensionality’ when processing high-dimensional IoT data streams. It leads to increased computational overhead and reduced detection accuracy. The heterogeneous nature of IoT devices also presents unique challenges in terms of data standardization and model generalization.
To address these issues, the growing IoT ecosystem requires more adaptable and reliable solutions. In this case, FL models have shown promising results in managing large-scale datasets from diverse IoT devices, offering a potential path forward. Some traditional Intrusion Detection Systems (IDSs) may effectively detect known attack patterns, but due to their centralized training mechanism, they pose risks related to data centralization, including privacy violations and single points of failure. These systems struggle to adapt to the decentralized nature and heterogeneity of IoT networks, which generate diverse and massive amounts of data. Unlike traditional models, FL can train on decentralized data from various sources while minimizing computational overhead, thus maintaining system efficiency [
6]. When evaluating the attack detection capabilities of the IDS, three key metrics are considered: accuracy, efficiency, and adaptability. Accuracy refers to the system’s ability to correctly identify and differentiate between normal and malicious activities, which minimizes false positives and false negatives. Efficiency refers to the IDS’s capability to perform intrusion detection with minimal computational overhead, which ensures quick response times and low resource consumption. Adaptability is the system’s ability to handle an increasing number of data sources from a wide range of IoT sensors, which allows it to maintain high detection rates even as the network scales and evolves. Considering all the challenges, we propose five Deep Learning (DL) architectures, each utilizing the Flower-based FL framework, to enable efficient intrusion detection in IoT environments.
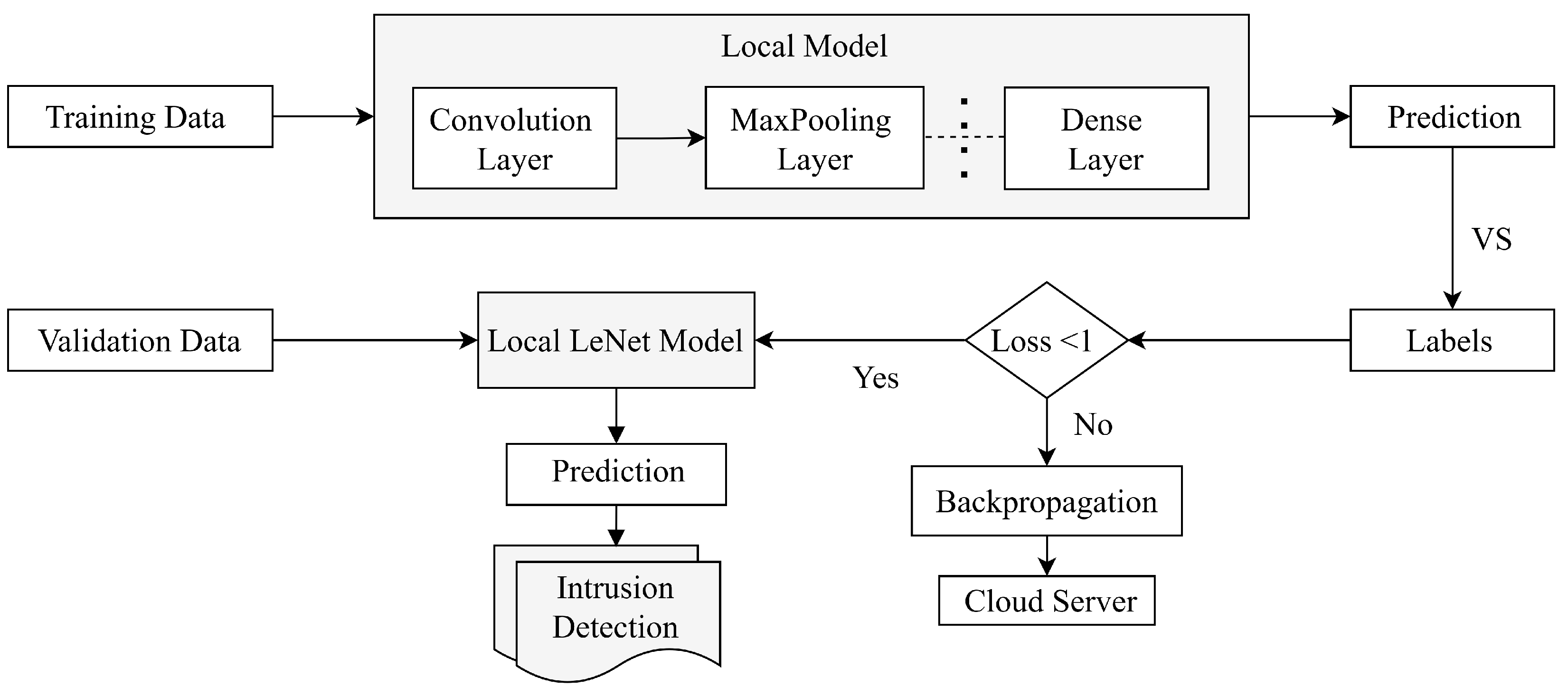
Figure 1 illustrates our proposed approach, an FL-based intrusion detection technique for CPSs. Here, the final model is selected based on optimal prediction performance on the set of heterogeneous IoT sensor data. We trained all five DL models on an unbiased training dataset and validated them using a separate validation dataset. We then comprehensively compared the models’ detection capabilities across various discrete parameter types.
Our proposed approach utilizes seven IoT devices, which are equipped with local clients trained on diverse sensor data. During training, local clients generate weights, which are then sent to the cloud server via a secure communication channel using Secure Sockets Layer (SSL). These weights are then aggregated by the cloud server using the FedAvg algorithm. The resulting global updates are then distributed to local clients, enhancing their detection capabilities. This iterative process continues until the global model ensures optimal accuracy in classifying normal and attack data. Compared to the existing approaches, our model achieves competitive results across several key performance metrics. The overall accuracy of the proposed detection model exceeds 90% while maintaining low computational demands. In addition, the model significantly improves other performance metrics. Our approach outperforms all baseline approaches, achieving top-performing metrics across the five DL algorithms with a precision score of 0.87%, a recall score of 0.87%, and an F1 score of 0.87%, while also reducing training loss by 20%. While traditional FL-based IDS frameworks are effective at preserving privacy by keeping data local, our research improves on this by offering a more adaptable and scalable solution. Our approach supports the detection of a wide range of intrusions in real-world, diverse IoT environments, which is backed by a comparative analysis of different architectures to achieve higher accuracy. Furthermore, our approach demonstrates remarkable resilience against concept drift, meaning it can effectively adapt to changes in the underlying data distribution. This is crucial in real-world scenarios where data patterns can evolve over time. For example, in attack detection, our method can continuously adjust its decision boundaries to accommodate new types of attacks that may appear. This adaptability ensures that the model remains effective even in dynamic and unpredictable environments. These evaluations have proven that the proposed model is robust and more efficient and performs better. This paper makes significant contributions to the field of intrusion detection for heterogeneous IoT networks. The main contributions of this paper are outlined as follows:
In this work, a DL architecture based on FL has been proposed for efficient intrusion detection. This proposed IDS extends traditional FL-based systems by detecting a broad spectrum of attacks against heterogeneous IoT networks, such as Scanning, Denial of Service (DoS), Distributed Denial of Service (DDoS), ransomware, backdoor, data injection, Cross-Site Scripting (XSS), the Password Cracking Attack (PCA), and the Man in the Middle (MITM) attack. The feature extraction mechanism and adaptive learning capabilities of this architecture enable it to identify continuously evolving attack patterns with minimal false positives. It addresses a critical gap in existing FL-based IoT security solutions.
We adapted the SSL mechanism to implement lightweight cryptographic protocols specifically chosen for IoT constraints. It utilizes the optimized handshake process, which reduces computational overhead and maintains security while minimizing energy consumption through selective encryption.
The tests have been carried out by using real-world heterogeneous data collected from seven different IoT sensors, which provide a diverse and realistic training dataset. This includes various types of data such as environmental data, location data and movement data, binary state data, control system data, and temperature regulation data. By analyzing real-world sensor data streams, we identified optimal features for our supervised learning framework, which helped to speed up the training and improve performance metrics.
Finally, a broad variety of DL architectures have been employed in performance evaluation within a comparative analysis between all the architectures in terms of higher attack detection accuracy. This demonstrates that the proposed model is more sustainable and effective than similar models developed previously.
This research paper is further structured as follows. First,
Section 2 presents an overview of Privacy Preserving in FL, addressing key privacy challenges in FL and exploring possible solutions. This includes understanding FL in terms of Privacy Preservation and categories of FL.
Section 3 provides the background and related work in this field. In
Section 4, we describe the methodology for our proposed privacy-preserving FL-based IDS, which includes the problem statement, SSL mechanism, the workflow of the proposed model, aggregation functions, and the proposed architecture. The model workflow is further broken down and each stage is explored: initialization, local training on sensor data, parameter encryption, parameter aggregation, local model update, and overall computational complexity. Model implementation and model evaluation are discussed in
Section 5. Furthermore, an analysis of the results is provided in
Section 6.
Section 7 presents a summary and possible future research directions.
2. Privacy-Preserving FL
FL is an advanced ML model recommended by the Google developer team that prioritizes privacy preservation and the security of user data. It protects user data by enabling collaborative model training across decentralized devices, such as sensors and smartphones, without centralizing raw data. This method addresses the challenges associated with a central server or device to train a shared global model, thus enhancing the privacy and security of user data [
7,
8].
Initially, FL was implemented to train the ML model based on data distributed across various mobile devices. In this approach, each client (e.g., sensors, smartphones) independently trains models on their local datasets, ensuring the security of user data during the training process [
6,
9]. With the continuous increase in sensor devices, a large amount of data has been generated in recent years. As a result, it is recommended to store data locally and perform computations directly on these devices using edge computing, which ensures privacy and security issues as well as the problems of increasing the extensible computing capabilities of the cloud server [
10,
11]. Advances in local device storage and processing capabilities have further enabled the efficient implementation of this mechanism [
8]. To maximize this potential, FL acts as a promising approach that can enable direct analysis of data on local or remote devices [
12]. Traditional ML typically involves centralizing data from various sources for model training. In contrast, the FL mechanism can be widely applicable to large-scale applications in artificial intelligence AI, medical technology, and IoT, primarily to enhance data privacy and security [
9,
13].
Studies have shown that most large-scale service providers have already incorporated FL technology [
4,
11]. Various types of devices are increasingly equipped with numerous sensors, enabling real-time acquisition, aggregation, response, and adaptation to new sensitive sensor data in a real-time environment [
14,
15]. To accurately predict the intrusion, sensor devices require the latest models trained on a large dataset of attack and non-attack data to operate safely and make real-time predictions. However, building aggregate models in such scenarios is challenging due to privacy and security concerns surrounding sensitive data and limited device connectivity [
16].
Due to the heightened sensitivity of sensor data, it is necessary to ensure the privacy and security of sensor data when analyzing this information. FL technology facilitates model training in this context, allowing for the rapid adaptation of models while ensuring user privacy and security [
17]. In this approach, data are stored securely on local devices [
18,
19]. This makes FL an ideal approach for instruction detection, which often involves managing large volumes of sensitive data [
16,
19]. This FL technique also enables secure and private collaborative learning among organizations where sensor data privacy is a primary concern.
3. Related Work
While exploring the latest related literature, we found several projects that had similar motivations but used different strategies. The following discussion highlights these works before presenting our proposed approach.
FL is emerging as the leading solution for intrusion detection in Industrial Internet of Things (IIoT) networks, surpassing the capabilities of centralized models. This approach not only enhances data privacy and security but also provides overall performance improvements. The IDS proposed for the Industrial Internet (IoT) by Pedro Ruzafa-Alcázar et al. also uses this dataset to address privacy concerns when updated gradients/weights are exchanged during the training period; the analysis uses differential privacy techniques (DP). The model is built upon Multinomial Logistic Regression, and evaluated using the FedAvg and Fed+ aggregation methods [
20].
Chatterjee and Hanawal [
21] introduced a Probabilistic hybrid ensemble model (PHEC) for IDSs in the context of IoT security. Their model demonstrated good performance in centralized environments, and its extension to an FL framework retained comparable effectiveness, confirming its promise to address challenges in decentralized and privacy-sensitive IoT environments. Additionally, they introduced a noise-tolerant version of PHEC to handle label noise. Their model demonstrated exceptional performance, effectively distinguishing genuine threats while minimizing false alarms, even in noisy conditions.
Lazzarini et al. [
22] conducted a sophisticated study using FL for IDSs in IoT environments. Their work supports the effectiveness of FL in preserving data privacy while achieving competitive accuracy, precision, recall, and F1 scores compared to centralized approaches using shallow artificial neural network (ANN) and FedAvg.
Zhang et al. [
23] introduced FeDIoT, a platform that uses FL directly on devices to detect anomalies in IoT traffic. Using the N-BaIoT and LANDER datasets, their study demonstrated that FL could be used to effectively identify and detect network attacks. This technique involved clients within the network running a specific FL model that used a method called Auto-Encoder.
An outstanding contribution by Chen et al. [
24] proposed a FL-based Attention Gated Recurrent Unit (FedAGRU) for intrusion detection within wireless edge networks. This approach outperformed the FedAvg aggregation model in terms of communication efficiency during model updates, while achieving higher accuracy in detecting attacks compared to a centralized Convolutional Neural Network (CNN) model.
Aashmi and Jaya [
25] introduced an intrusion detection system (IDS) utilizing FL within Jungle Computing (JC), integrating various computing platforms. This system effectively detects intrusion attacks without human intervention, achieving 96% accuracy with low False Positive Rates. The authors emphasized JC’s adaptability to diverse computing paradigms, which enhances the system’s efficiency and robustness.
Truong Thu Huong et al. [
26] presented FedeX, a FL-based architecture for Explainable Anomaly Detection in Industrial Control Systems (ICS) within Smart Manufacturing. Outperforming 14 existing solutions, FedeX excels in detection metrics, run-time efficiency (7.5 min), and lightweight deployment on resource-constrained edge devices (14% memory consumption). The architecture integrates the Variational Autoencoder (VAE) and Support Vector Data Description (SVDD) with FL. It ensures distributed anomaly detection in smart factories while addressing interpretability through Explainable Artificial Intelligence (XAI).
Popoola et al. [
27] introduced Federated Deep Learning (FDL), a method for detecting zero-day botnet attacks on IoT edge devices, to address data privacy concerns. FDL, employing a deep neural network (DNN) architecture with a FedAvg algorithm, proved to besuperior to Centralized Deep Learning (CDL), Localized Deep Learning (LDL) and Distributed Deep Learning (DDL) methods. The results demonstrated high classification performance, guaranteed data privacy, low communication overhead, minimal memory space requirements, and low network latency.
Kun Li et al. [
28] introduced a distributed Network Intrusion Detection System (NIDS) using FL to address security and privacy challenges in satellite-terrestrial integrated networks (STINs). They designed a typical STIN topology and developed security datasets for satellite and terrestrial networks. To increase resistance to attack and resource allocation, the authors introduced a satellite network topology optimization algorithm and a FL adaptation algorithm for STIN. Their distributed NIDS outperformed traditional methods in detecting malicious traffic, reducing packet loss, and optimizing Central Processing Unit (CPU) utilization.
Fangyu Li et al. [
29] proposed a federated sequence learning (FSL) approach to address the challenges of modeling varying time series data in IIoT while prioritizing data security. FSL, under a federated framework, constructs a collaborative global model without compromising local data integrity, capturing intrinsic industrial time-series responses and considering data heterogeneity among distributed clients. Experiments on classic distributed datasets and real IIoT attack detection scenarios demonstrate FSL’s capability to accurately model data heterogeneity and improve performance in attack detection for industrial time-series sensory data compared to existing methods, making it promising for real IIoT applications.
Mohanad Sarhan et al. [
30] proposed a collaborative cyber threat intelligence sharing scheme that uses FL to allow multiple organizations to train and evaluate an ML-based IDS. The framework was tested with two key datasets, NF-UNSW-NB15-v2 and NF-BoT-IoT-v2, and evaluated under centralized and localized training scenarios. The results show the framework’s effectiveness in creating a robust ML model that accurately classifies various network traffic types from multiple organizations, all while preserving data privacy.
Roberto Doriguzzi-Corin et al. [
31] introduced FLAD (Adaptive FL Approach to DDoS Attack Detection), a novel FL solution for cybersecurity that addresses the challenge of updating DL models with new attack profiles without sharing test data. Unlike traditional FL, which requires test data to monitor model performance, FLAD dynamically allocates more computational resources to members with harder-to-learn attack profiles. The authors demonstrated that FLAD outperforms existing FL algorithms in terms of convergence time and accuracy across diverse, unbalanced datasets. Additionally, FLAD’s robustness is validated in a realistic scenario where the model is repeatedly re-trained to incorporate new attack profiles, enhancing detection capabilities for all federation members.
Table 1 shows a summary of recent research on FL-based IDSs for IoT applications.
Considering the specifics of different IoT applications, this paper significantly enhances the existing FL model. The architecture of our proposed model ensures data privacy by applying a privacy-preserving FL framework along with encrypting the local model parameters. The FL framework allows us to train the data on local devices without exposing sensitive information, and the SSL connection between clients and servers contributes to the process of transmitting encrypted model weights. These ensure that our model can provide robust data security by adopting a decentralized architecture, unlike the centralized systems used by Ruzafa-Alcázar et al. [
20] and Chatterjee and Hanawal [
21]. Additionally, models like Zhang et al. [
23] and Aashmi and Jaya [
25] used shallow learning techniques, which are less effective in detecting complex attack patterns. Our model utilizes a multilayer CNN with three convolutional layers, followed by pooling and dropout layers. These layers contribute to optimized feature extraction and improved detection accuracy in a variety of cyber threats. Furthermore, we introduce a novel contribution ratio mechanism, which is the FedAvg algorithm, to aggregate client parameters. It improves the representation of local models in global updates, which is often neglected in existing models. This feature allows better adaptability and performance across heterogeneous IoT environments. The primary aim is to strengthen the model’s performance in effectively detecting a diverse array of complex cyberattacks.
4. Proposed Privacy-Preserving FL-Enabled IDS for IoT/IIoT
4.1. Problem Statement
The traditional IDSs have several limitations, such as limited concerns about data privacy and security, challenges in scalability and efficiency, issues with data heterogeneity in network environments, and difficulties with resource constraints in IoT networks, particularly in providing efficient real-time intrusion detection. Furthermore, IoT networks are the heterogeneity of data produced by sensor devices with different types, formats, and distributions.
This research is motivated by those key factors driving the need for an advanced IDS that overcomes the constraints of traditional techniques. Most centralized IDSs compromise the privacy and security of client data because they require sensitive data to be aggregated into a centralized repository. To address this, we develop an FL-based IDS, where our system explores a decentralized approach to mitigate these limitations by keeping data localized.
Traditional IDSs often fail to identify new and emerging cyberattacks because they are designed to identify only a limited set of known cyberattack patterns. In this situation, the goal of our proposed model is to efficiently detect and classify a broad spectrum of cyberattacks, including DoS, DDoS, data injection, MITM, backdoor, PCA, scanning, and ransomware. These attacks are particularly difficult to detect while maintaining low computational complexity. Traditional IDSs face challenges of scalability and efficiency due to the increase in data volume and network traffic [
26]. Our FL-based model addresses these issues by distributing the learning process, thus enhancing scalability and efficiency. In a network, different types of sensor devices generate different types of data with a variety of features and distributions. The proposed FL model is designed to solve the problem of heterogeneity by letting each IoT device train its model locally over its own data subset before contributing to the global model. This approach makes sure that changes in input data or data fluctuations, including time series data from GPS and binary from Modbus, are taken into account during training. Taking use of this variability helps the FL framework generalize better across different IoT devices.
Networks with limited resources, such as IoT networks, need vast data to build complex and efficient IDSs. However, with limited resources, IoT networks cannot run complex IDS [
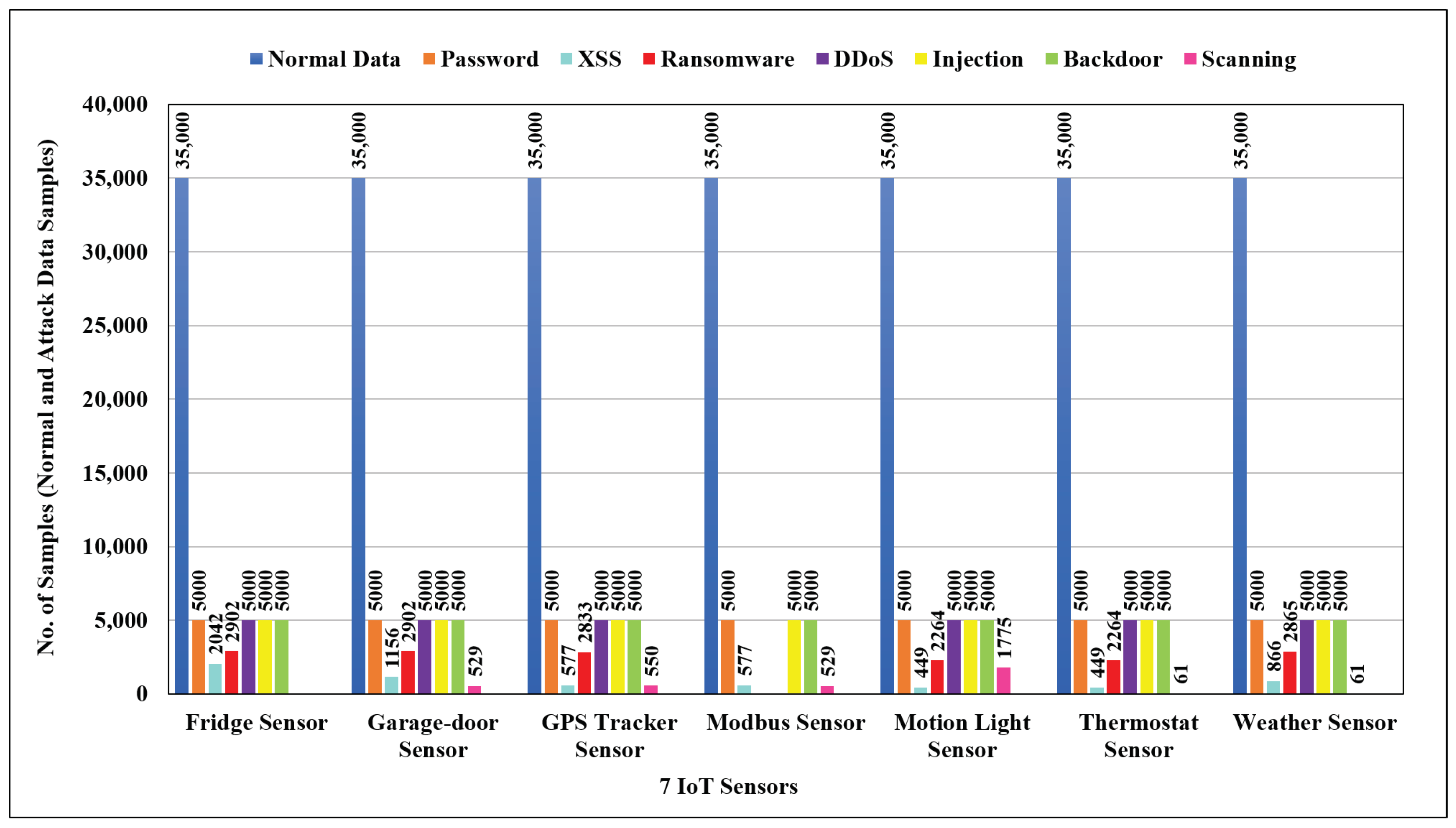
32]. Our proposed system leverages FL as a resource-efficient and lightweight alternative to overcome these limitations. To build a network with effective security, a real-time IDS is needed. Our proposed model provides this capability without compromising accuracy. Existing research has yet to do much profiling of devices. Our approach takes into account the behavior of seven IoT devices, such as a fridge, GPS tracker, motion light, garage door, Modbus, thermostat, and weather sensor. The integrity of the proposed FL-based model is enhanced for these considerations.
Most suggested IDSs did not consider reliability. Our FL-based model provides reliability and does not compromise the accuracy of classifying different types of attacks. IoT applications typically operate on lightweight communication protocols, as well as on limited computing and storage capacity [
33]. However, traditional security systems require complex computing power with massive storage; as a result, this system can not be used directly for IoT applications [
32]. In addition, new threats and vulnerabilities to the IoT increase rapidly due to traditional IDSs not being able to handle this new attack. IoT applications run inside the network, and IoT applications are different from each other by their nature of work in the environment [
33,
34]. Traditional IDSs can only identify attacks outside the network; as a result, these old systems are not strong enough to fight targeted attacks and related anomalies. In contrast, our proposed FL-based IDS efficiently addresses these challenges.
Many earlier IDS proposals did not focus on strengthening the performance for diverse attack detection. To address these issues, we propose a privacy-preserving FL-based intrusion detection technique for CPS. In this approach, local models are trained on each IoT device, which can detect whether the data are normal or an attack. Then, the local models generate weights based on their data, which are sent to the server via a secure connection where the global model resides. The global model aggregates these weights to produce a new set of weights, which is sent back to the local models for the next round of training. This process continues iteratively until the global model converges to a set of weights that can accurately detect both normal and attack data.
4.2. Federated Averaging (FedAvg)
In FL, FedAvg is a primary aggregation method that allows decentralized devices to collaboratively train a model without transferring raw data [
35]. This method plays a vital role in combining the knowledge gathered from various sources and constructing an improved global model.
Each participating device in FL uses its own local data to train the local model without sharing the raw data with the central server. The local dataset of each device can be different in terms of how it is distributed, size, and data quality, allowing the local model to learn from different perspectives. To be more specific, each participating device
i trains a local intrusion detection model using its locally available data, where the local model parameters
are optimized to minimize a local loss function
, which is specific to the data available on that device. Local training can be expressed as
After local model training, each device computes a model update
based on the changes in its local model parameters. These model updates are sent to the central server, which is crucial for preserving data privacy, as raw data remains on the local devices and is not directly shared. The central server collects these model updates from all participating devices to create global updates for the local model. The server then aggregates these local model updates and creates the global updates using the FedAvg algorithm. FedAvg is a weighted averaging technique that gives each model update an appropriate weight based on factors like how much data the device has and how well the local model performs [
36]. The aggregated update
is computed as,
Here,
N is the total number of participating devices. In this aggregation technique, devices with more data or better local models may have more impact on global updates or the model [
36]. In each round, after the central server aggregates the model updates, it applies the aggregated update to the global model parameters
to obtain the updated global model parameters
,
The updated global model is sent back to the participating devices. These devices use the updated global model as a starting point for their local model training in the next round. The process of local training, model update sharing, and aggregation using FedAvg is repeated for a predefined number of rounds to refine the global model.
4.3. SSL Mechanism
SSL ensures a secure communication channel between the central server and decentralized devices during FL model updates. SSL encrypts data using strong encryption methods, making it unreadable to anyone without the decryption key [
37]. This encryption protects sensitive data from unauthorized access. SSL also authenticates the central server and decentralized clients to verify that only authorized clients can engage in FL. SSL uses a system of digital certificates and public and private keys to ensure that the central server and the decentralized devices are who they say they are. The digital certificate is issued by an authentic organization called Certificate Authorities (CAs). During the SSL handshake process, this digital certificate allows local clients and cloud servers to participate in FL. This method of authentication prevents unauthorized clients from accessing the system and manipulation with global updates to the model [
38]. Furthermore, SSL verifies the integrity of model updates during transmission to ensure that they have not been altered. SSL uses cryptographic hashes and algorithms to ensure the integrity of the data. To ensure that data are not altered while in transmission, each segment of data is converted into a unique code called a hash. The hash is then sent along with the data itself. When the data arrive at their destination, they are hashed again, and the new hash is compared to the original hash. If the hashes match, it means that the data have not been changed [
39]. This is necessary to ensure the accuracy of the FL model.
4.4. Workflow of the Proposed Model
The proposed model aims to create a reliable and privacy-preserving FL-based IDS. The model’s complete workflow includes model initialization, local model training by sensor clients, model parameter encryption by sensor clients, model parameter aggregation by cloud server, local model update by sensor clients, and overall computational complexity of the model. This framework follows a step-by-step procedure where, initially, a reliable key management authority (KMA) creates a secure communication channel by generating cryptographic keys, and the cloud server sets the initial parameters for the FL algorithm. Then, each client trains a local model using unique local datasets that differ in size, distribution, and quality while keeping its data decentralized to ensure privacy. During the local training phase, the client further optimized the model parameters by minimizing the loss function associated with their local data. Once local training is completed, the client uses the public key to encrypt the model parameters’ updates and send them to the cloud server. The server fetches these updates and applies the FedAvg mechanism to update the global model according to the weighted contributions of each client. The clients then receive the new global model back and decrypt it. After decryption, each client adjusts their model as per the new update. The global model is improved through the repetition of this process over a number of predetermined communication rounds until convergence is attained. To provide a detailed understanding of the model’s complete workflow, each key stage is described below.
4.4.1. Model Initialization
At first, a trusted KMA generates a pair of cryptographic keys, which are the public key and the private key. These keys are generated by using the key generation method with a security parameter. The trusted KMA then establishes a secure and protected communication channel between the cloud server and each sensor client. The cloud server also selects an array and sets its initial parameters for the FL algorithm. Next, each sensor client reports the size of its personal data resource to the cloud server, and then the cloud server calculates each sensor client’s contribution ratio. Finally, the cloud server sets the index of the first communication round at one, which specifies the beginning of the iterative FL process. In subsequent rounds, the model parameters are updated using data from decentralized clients.
4.4.2. Local Model Training by Sensor Clients
Every sensor client trains a DL framework locally, utilizing their own data resource while keeping everything personal. It starts with the cloud server distributing the parameters of the initial model, which consist of learning rate, moments estimators, numerical factorization for stabilization, loss function, batch size, previous model parameters, a constant, and data for training. The local model is trained until the loss function converges. In this stage, the first and second-moment variables are initialized to zero. Then, The dataset is divided into batches of equal size, and the local model parameters are set based on the previous round’s parameters. Furthermore, for each batch of data resources, compute the gradient-biased first and second-moment estimates, respectively. Later on, the one moment bias-corrected estimate and the second moment are obtained along with the bias-corrected learning rate. Finally, the local model parameters are further modified, and the new model parameters are sent to the cloud server. To avoid computational complexity and impacts on real-time demands, this training process is performed offline.
4.4.3. Encryption of Model Parameters by Sensor Clients
This process ensures the privacy of the parameters of the local DL model, encrypting these parameters before sending them to the cloud server. Once a sensor client has trained its local DL model and generated the model parameters, it encrypts these parameters using the public key with the encryption method. Then, the encrypted parameters of the local DL model are uploaded to the cloud server by each sensor client.
4.4.4. Aggregation of Model Parameters by Cloud Server
The cloud server computes each client contribution ratio and aggregates these ratios with the encrypted parameters. Finally, the aggregated parameters are sent back to all the clients through a secure channel by the cloud server so that all the clients are in a position to modify their local parameters with the new global model parameters.
4.4.5. Local Model Updating by Sensor Clients
This process shows how the sensor clients perform local model updates with the aggregated parameters provided by the cloud server. In the first step, each client decrypts the encrypted parameters with the help of a private key corresponding to the public key used for encryption. Once clients decrypt the encrypted parameters, they modify their local model to take into account global changes. The index value is increased one by one after the completion of each successful update operation. The process repeats between the cloud server and the clients for a selected number of rounds (an empirically determined threshold), resulting in an efficient DL-based model.
4.4.6. Overall Computational Complexity of the Model
At every communication round that has been completed, all the clients are required to perform both parameter encryption and parameter decryption operations. These two tasks involve a certain number of exponentiations and several multiplication operations. The level of computation for each client corresponds to the parameter in the local DL model. Moreover, the server needs to perform various multiplication operations on every communication round that is successfully completed when it is aggregating the model parameters as well as the contribution ratios from the clients who took part.
4.5. Proposed Architecture
The block diagram in
Figure 2 shows that the proposed model has two main parts: the local clients and the cloud server. The local clients are further divided into two subcomponents: the model training part and the model validation part.
After preprocessing the raw sensor data, it is applied to the local client model for training. Subsequent empirical investigations identify the most important parameters of this model. Randomly selected training and validation datasets are utilized to train and validate the local client model. At the training stage, the local model parameters have been back-propagated to the cloud server if the local model loss is not negligible. After collecting each of the local model parameters, the cloud server aggregates the weights, averages the parameters, and then sends them back to all local clients’ models so that they can update their parameters’ weight to minimize the loss. The process is repeated until the loss is as small as possible; at this point, the best performance indicators are used to choose the final model.
Table 2 shows the hyperparameters of the proposed model.
Local client devices consist of multiple layers with hyperparameters, including the input layer. In this layer, we give sensor data as input to our model. This layer contains a number of neurons that correspond to the total number of features. The input data are preprocessed, which is identical for all clients. This input is then fed into subsequent layers for further processing. Following the input layer, a convolution layer transforms the encoded sensor data into a vector of features [
2]. This trainable layer applies a sliding window across the encoded sensor data [
40]. The model uses three convolution layers in our model. The first layer combines 32 filters with a kernel size of 5, followed by the second layer with 64 filters, and the third with 256 filters, all having the same kernel size of 5. Each of these layers is a one-dimensional convolutional layer, followed by BatchNormalization() and a Rectified Linear Unit (ReLU) activation function, collectively referred to as the feature smoothing layer. Following each convolution layer, a BatchNormalization() function is applied to address the heterogeneity of the input data, ensuring that the model can process diverse sensor data effectively by regularizing the input data from different IoT devices. By normalizing the activations, limiting internal covariate shifts, and promoting faster convergence, this layer enhances the generalization of the model. Following the convolution layer, a non-trainable pooling layer is incorporated to modify the feature map’s dimensions. Various pooling techniques exist, including maximum pooling and average pooling. We implemented max-pooling layers, identifying the neuron with the most significant activation value. This process significantly reduces the number of parameters in a DL model while facilitating a class activation map generation [
34], which allows an interpretation of the learned features.
A dropout layer is added after the second max pooling layer to enhance the model’s robustness and prevent overfitting. This layer randomly deactivates a specified percentage of neurons or connections during training, as defined by a dropout ratio of 0.10 [
1]. The data must undergo a flattening process to facilitate its incorporation into the subsequent layer, transforming the multidimensional output into a one-dimensional array. This layer reshapes the preceding layers’ output into a single, elongated feature vector, which is then connected to the next layer. The next layer is a fully connected layer (FCL) that combines information from all the previous layers. This layer helps to learn complex relationships between features, making final prediction easier. A dense layer is used to classify attacks based on the information extracted from the preceding layers. This layer establishes direct connections with the preceding layer, effectively combining and extracting higher-order features from the input sequence. The ReLU activation function, which introduces non-linearity into the model, is utilized within this layer. Finally, the softmax layer is connected to a dense layer. This layer serves the crucial function of determining the probability of each classification or label, effectively predicting whether a new attack is present or not. In this layer, the number of neurons corresponds to the total classes present in the dataset [
41,
42].
6. Result Analysis
This section presents the evaluation results of the performance of DL models mentioned above to the FL training scenario that incorporates the SSL mechanism on the ToN_IoT dataset. The key performance evaluation parameters include Accuracy, Precision, Recall, F1 score, Loss, and the application of the FedAvg aggregation algorithm. In our experimental setup, each model was applied to seven different IoT sensor datasets individually. The evaluation metrics for these selected models for the seven clients are presented in
Table 4.
6.1. Model Performance Analysis
Each DL model was applied to seven chosen IoT sensor datasets in such a way that each sensor was viewed individually as a client. These models were trained for 50 rounds on the data provided by each sensor. These sensors have been denoted as follows: C1 for the fridge sensor, C2 for the GPS tracker sensor, C3 for the motion light sensor, C4 for the garage door sensor, C5 for the Modbus sensor, C6 for the thermostat sensor, and C7 for the weather sensor.
Table 4 provides a detailed overview of the optimal metric outcomes for each sensor dataset across various models.
The LeNet model demonstrated exceptional performance by achieving very high results, especially in the case of the fridge sensor (C1), where the highest accuracy was achieved. LeNet’s convolutional layers capture spatial features in order, so it is most suitable for detecting intrusions based on unusual spatial patterns. This capability is evident in its superior performance on the fridge sensor (C1), where it outperformed other models. It also performed well in the garage door sensor (C4) with respect to precision, recall, and F1 score with the least loss recorded, which means that this model was able to capture patterns in this dataset with a minimal number of errors.
The FCN model also performed well, particularly with the weather sensor (C7), where it obtained the highest precision, recall, and F1 score at the lowest loss. This shows that FCN is able to perform at predicting accurate outcomes while maintaining class balance, particularly for the weather sensor (C7). FCN is less likely to skew its predictions toward one class over another, ensuring that it does not falsely identify normal sensor readings as intrusions. The weather sensor might have a unique distribution of intrusion and non-intrusion patterns. For example, sudden and extreme weather events might be more likely to trigger intrusion alarms. FCN’s ability to balance predictions helps ensure that the model does not become overly sensitive to these events, leading to false alarms.
The GRU model achieved excellent precision, recall, and F1 score for the fridge sensor (C1) and highest accuracy for the GPS tracker sensor (C2). The GPS tracker sensor generates location data over time. Due to the capabilities of learning temporal dependencies in these data, GRU was able to detect unusual movement patterns that might indicate an intrusion. For the garage door sensor (C4), the least loss was recorded, which means that GRU was quite accurate in its predictions with only minimal errors. Data heterogeneity is a significant factor that contributed to the differences in the performance of models on the IoT devices. For instance, the GRU model has the ability to capture the temporal dependencies which help this model to perform exceptionally well on GPS sensor data. However, the GRU model’s performance is not good enough with the categorical dataset. As a result, this model’s performance on the Modbus and thermostat sensor is not as good as the GPS sensor because both Modbus and thermostat sensors have categorical data. In particular, further work could aim to enhance model robustness by overcoming these issues with newly developed models. It confirms that the GRU’s gating mechanism enables it to learn long-term dependencies in the sequential data, rendering it suitable for the time-series data.
The LSTM model was able to minimize the loss percentage for the GPS tracker sensor (C2) and achieved the highest accuracy among all models for both the motion light (C3) and weather (C7) sensors, suggesting its effectiveness in predicting the behavior of these sensors based on historical patterns. Motion patterns often have temporal dependencies, and weather patterns are highly dependent on past conditions and exhibit both short-term and long-term dependencies. LSTM’s ability to remember information for long periods of time makes it well-suited for tasks that require understanding the context of temporal and past events.
On the other hand, the DNN model ranked best as it exhibited an overall superior performance for the garage door sensor (C4), obtaining the highest metrics across the board. DNNs are a versatile architecture that can be applied to a wide range of tasks. While they may not have the specialized strengths of other models, they often provide a robust baseline for intrusion detection tasks.
The performance variation across different DL models can be attributed to the specific characteristics of the data produced by each IoT sensor. Within our analysis,
Table 4 depicts that both LeNet and FCN displayed effectiveness with the fridge sensor dataset (C1). The fridge sensor generates relatively simple and low-dimensional data that typically includes time, temperature readings and conditions, etc. LeNet’s architecture is well-suited for processing simpler and pattern-based data streams like this type of household appliance. This model is traditionally known for handling low-dimensional data efficiently. On the other hand, FCN is known for handling complex and high-dimensional data. Despite of that, FCN’s architecture also proves effective for the fridge sensor data due to the richness of this dataset’s temporal and correlational patterns. The convolutional layers in FCN have been successful in capturing the temporal patterns of the cycling behavior in this dataset. While having the ability to handle higher dimensions, FCN’s architecture does not suffer from overhead when processing this type of structured, multi-feature data. It proves that convolutional architectures (LeNet, FCN) perform best with devices generating regular, pattern-based data. LSTM excelled in having similar accuracy with motion light and weather sensor datasets because both sensors generate data with significant long-term, short-term, and temporal dependencies like irregular patterns in light changes (short-term) or weather changes (long-term), which align with LSTM’s architectural strengths. Based on the metrics, GRU slightly outperformed LSTM in terms of accuracy and loss for the GPS tracker sensor. This is because its simplified gating mechanism is more efficient for regular sampling intervals and also better for handling the sequential nature of location data with fewer parameters. This demonstrates that Recurrent architectures (LSTM, GRU) excel with sequential data (GPS tracker and weather sensor). DNN model demonstrated proficiency with the garage door sensor dataset because its multi-layer architecture handles the combination of discrete states (open/closed) and continuous sensor readings. The model’s adaptability suits the periodic nature of garage door operations, which proves that simpler architectures like DNN work well with devices having clear state transitions. However, none of the models achieved the pinnacle of accuracy for the Modbus (C5) and thermostat (C6) sensor datasets. This comprehensive analysis underscores the sophisticated strengths of each model across diverse IoT and IIoT sensors. It means that the choice of the best ML or DL model for a particular IoT sensor application may depend on the specific sensor characteristics.
Table 5 highlights the top performance metrics for the seven clients in the chosen models. LeNet stands out with the highest overall performance, achieving an impressive 91.68% accuracy, 87.77% precision, 87.79% recall, 87.78% F1 score, and a loss of just 20.31%—the lowest recorded for any model. This indicates that the LeNet performs best overall in terms of both attack detection capability and minimizing errors. FCN performs almost as well as LeNet, with a very close accuracy of 91.53% and a relatively low loss (20.92%). Its precision, recall, and F1 score are also high, making it one of the top performers in terms of balancing accuracy and error minimization. DNN is slightly behind LeNet and FCN in terms of accuracy (91.31%), with a slightly higher loss of 21.51%, indicating a marginally higher rate of error compared to LeNet. LSTM shows relatively lower performance compared to other models and has a higher loss of 23.76%, suggesting more errors in predictions. The GRU and LSTM algorithms exhibit similar performance, with GRU having a marginally higher accuracy of 90.73% compared to LSTM’s 90.62%.
6.2. Server Accuracy and Loss Trajectory
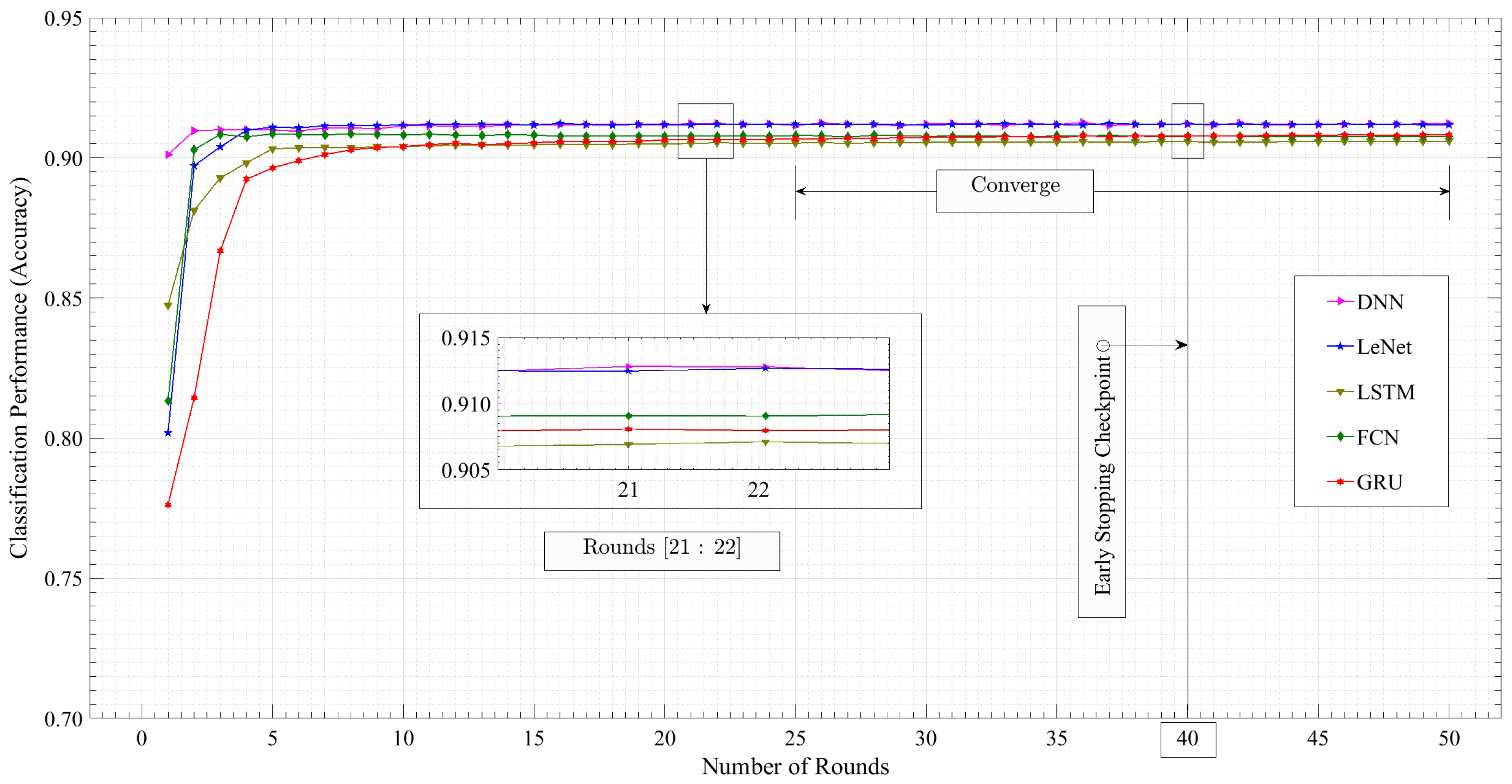
Figure 7 shows the server accuracy of all five models over the number of rounds, where the x-axis shows the number of rounds, and the y-axis shows the classification accuracy. The vertical line at round 40 marks the early stopping checkpoints for the models. Early stopping is a regularization technique used to prevent overfitting, where a model learns the training data too well and fails to generalize to unseen data.
The server accuracy for all five models increases over time, indicating that the models are learning. However, the rate of learning is different for each model. The DNN model demonstrates the fastest convergence, reaching the highest server accuracy at the end of 50 rounds, approximately 0.912188. The DNN’s strong performance can be attributed to its ability to learn complex patterns and relationships within the data. However, it may be prone to overfitting if not carefully regularized. The LSTM model reaches a plateau in accuracy after around 20 rounds. While this model excels in capturing long-term dependencies, its performance stabilized early at a high level. This indicates that the model has effectively learned the patterns in the data and is not overfitting. LeNet and GRU models continue to improve up to round 30. The FCN model will likely overfit the training data by round 40, so its accuracy will likely decrease on new data. By halting training at round 40, this model is prevented from overfitting, ensuring better performance on new data.
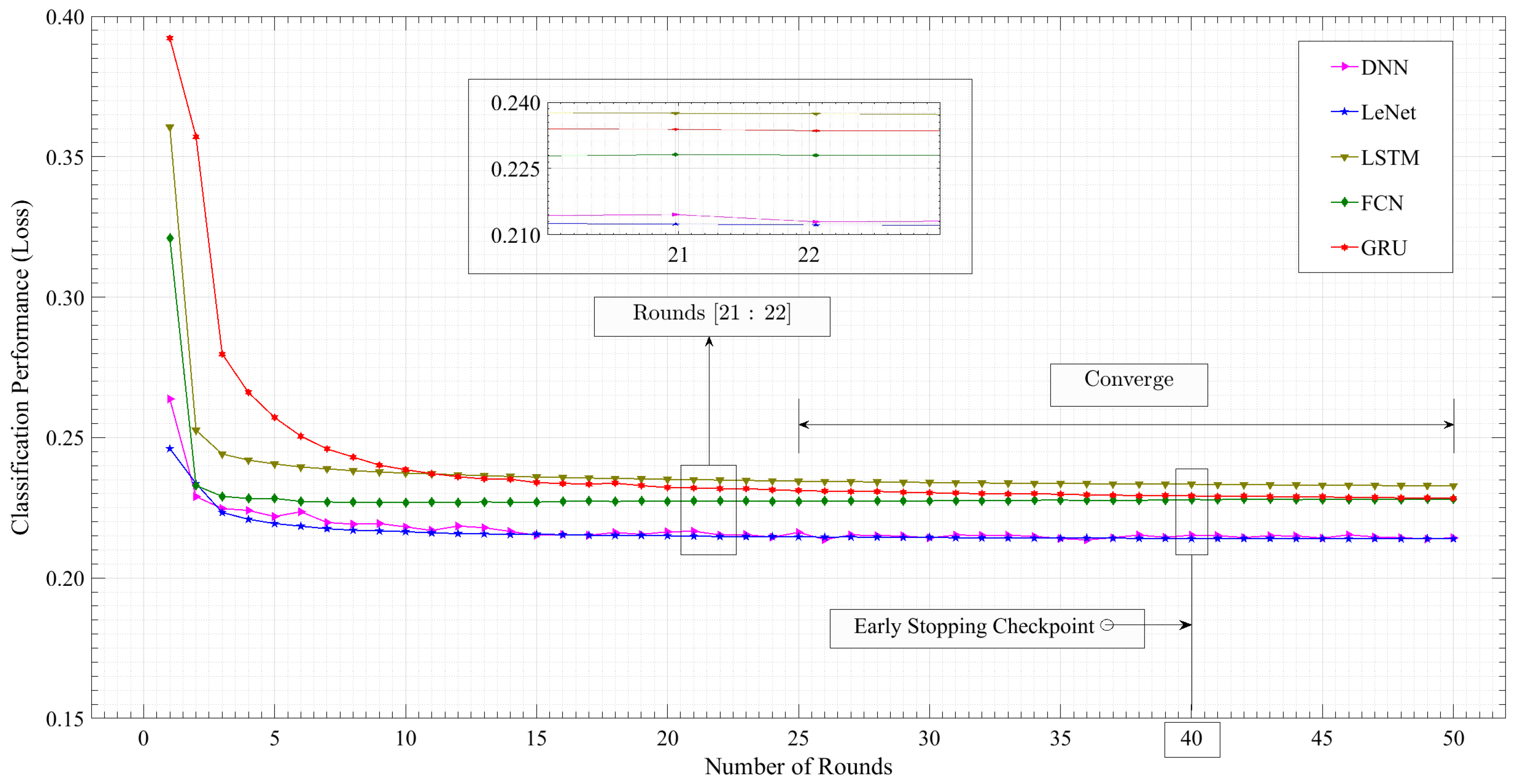
Figure 8 provides a graphical representation of the server loss trajectory across multiple rounds for the five models. The x-axis denotes the progression of rounds, while the y-axis captures the classification loss incurred during each corresponding round. Notably, a vertical demarcation line at round 40 serves as a significant point, indicating the early stopping checkpoints for the respective models. This visual depiction offers a comprehensive overview of the models’ loss dynamics and the strategic decision to halt training at a specific juncture, shedding light on the convergence patterns and optimization strategies employed.
As time progresses, the server loss of all five models gradually decreases. The LeNet model exhibits the lowest server loss at the end of 50 rounds, approximately 0.213967. The FCN and LSTM models reach a point where their loss stabilizes after about 20 rounds, whereas the LeNet and GRU models continue to improve up to round 30. From round 5 to round 22, the DNN model shows notable variations in loss. However, following round 22, these fluctuations become less pronounced, and the loss value stabilizes.
7. Conclusions
This study represents a novel privacy-preserving FL-based approach for detecting intrusion in heterogeneous IoT networks. By utilizing the collective insights of distributed IoT devices without putting data privacy at risk, our approach addresses the critical drawbacks of existing IDSs. The proposed architecture contains seven diverse IoT sensors as clients and a cloud server for global model aggregation, thus demonstrating the effectiveness of FL in increasing the security of IoT ecosystems. Our comprehensive evaluation compares five DL models across various types of IoT sensors, highlighting the potential of this approach. Among all these DL architectures we evaluated, the LeNet model achieved the highest accuracy of 91.68% and the lowest loss of 20.31%, with balanced precision and recall. This indicates the capability of FL to effectively detect and classify a wide range of cyber threats. Moreover, different models showed variability in their performance in different sensor scenarios. It emphasizes the importance of tailored approaches for specific IoT applications. The integration of SSL for secure communication and the FedAvg algorithm for model aggregation further strengthens the robustness and reliability of our system. By maintaining data locality and enabling collaborative learning, this approach enhances scalability and efficiency in handling the growing complexity of IoT networks, along with preserving data privacy. One limitation of this research is that few clients (seven sensors) are used to evaluate the model performance, which may not fully represent the larger and heterogeneous IoT situations. In the future, many IoT sensors will be considered, and the hyperparameters of the proposed models will be improved to achieve better results. Additionally, the approaches of this study concentrate on supervised learning models. However, large-scale labeled datasets may be difficult to gather in real-world situations. Lastly, while new attack types are constantly developing, this research is only centered on recognized attacks. Future work in this domain can build on these findings to further refine and expand FL applications in IoT security, contributing to safer and more reliable smart environments. The system will be modified to include unsupervised or semi-supervised learning techniques to deal with situations where labeled data are unavailable. Also, future work should focus on enhancing the model’s ability to recognize previously unknown attacks and withstand manipulation by adversaries.




 and
and 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}