

Web-Informed-Augmented Fake News Detection Model Using Stacked Layers of Convolutional Neural Network and Deep Autoencoder

 ,
,  , , and
, , and 
Abstract
:1. Introduction
- An augmented information-gathering algorithm is proposed to support the news sentences by enriching the representative features. The augmented information is retrieved from reliable sources using Google search techniques, and only the relevant news features are utilized as new knowledge to reduce the sparsity and improve the detection accuracy.
- A model based on probabilistic deep-learning architecture has been developed for detecting fake news. The model involves stacking convolutional neural network layers with deep autoencoder layers. The last layer’s probabilistic output serves as a new representative feature for the second stage of learning, which involves stacking multilayer perceptron layers into the CNN and the autoencoder layers.
2. Related Work
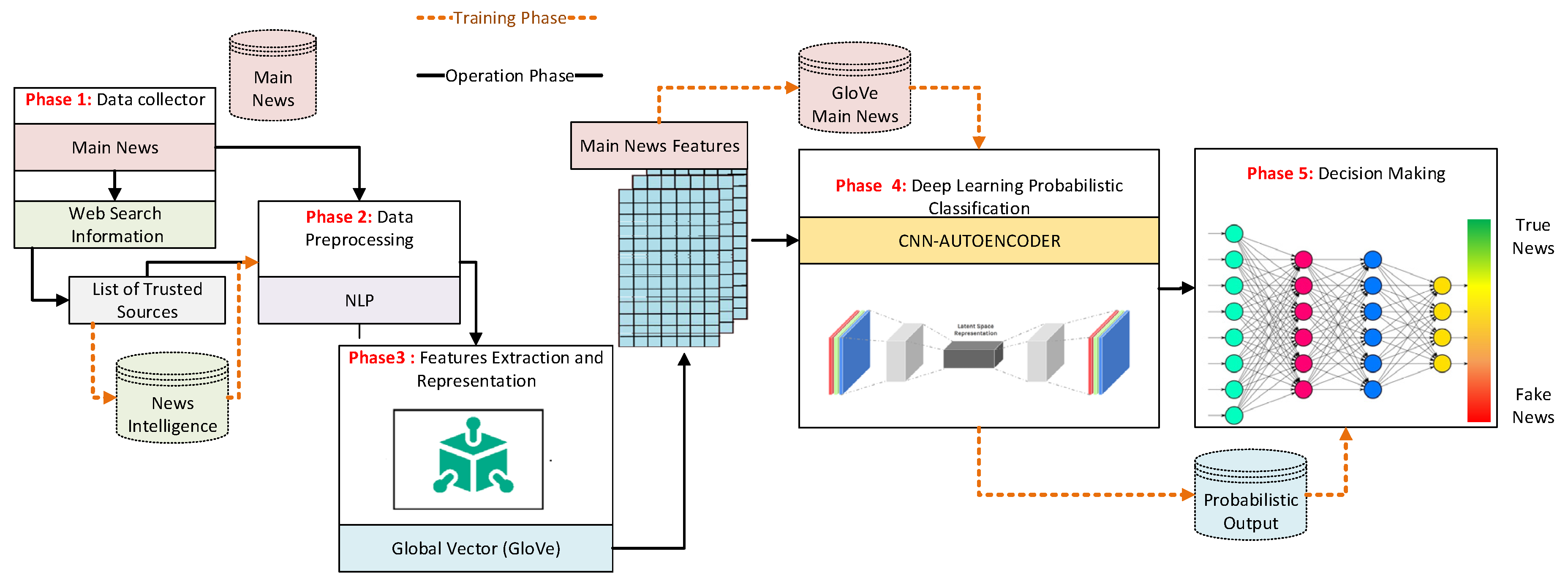
3. The Proposed Fake News Detection Model
3.1. Augmented Information-Gathering Phase
| Algorithm 1: Augmented Information Collecting Algorithm |
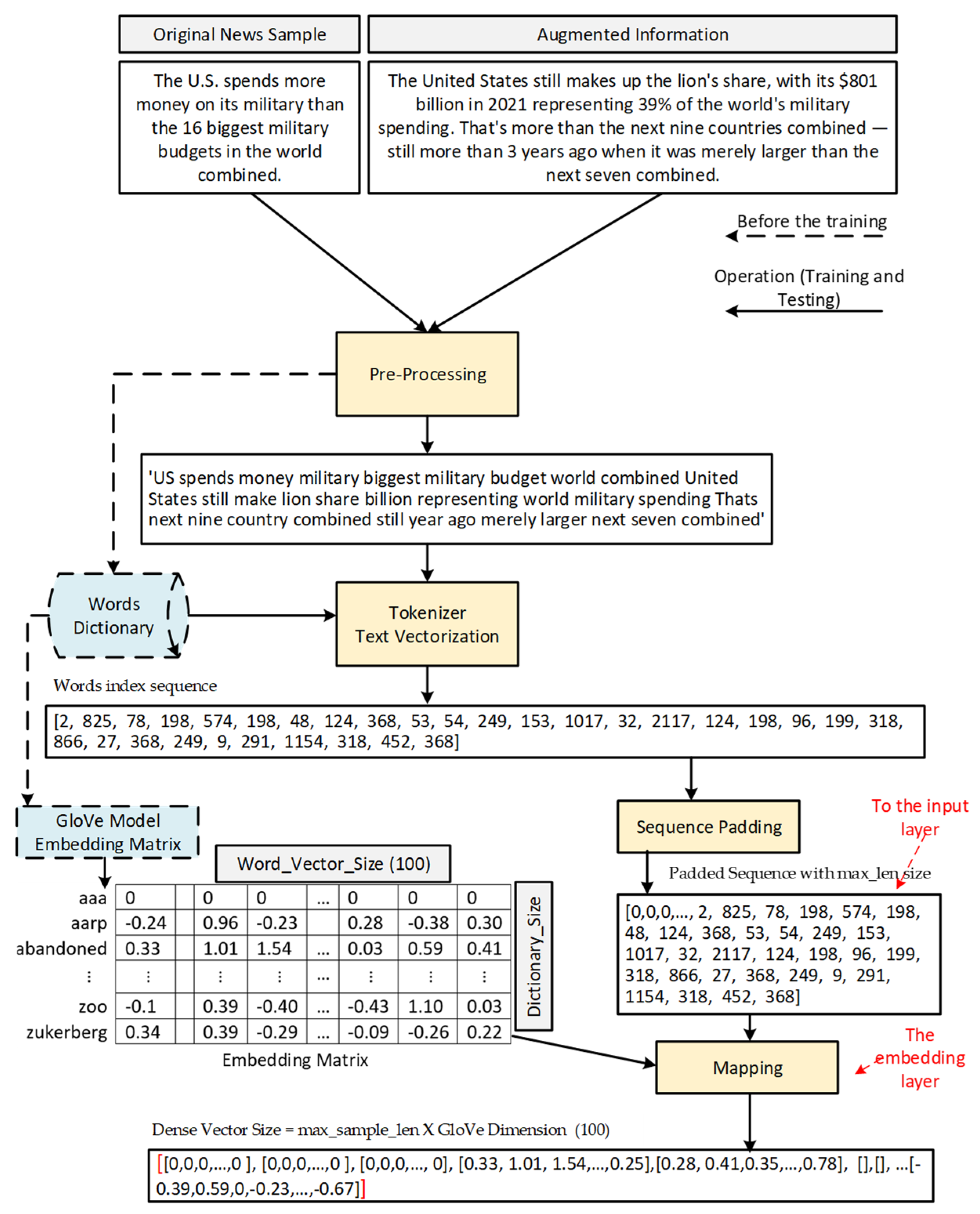
3.2. Data Pre-Processing Phase
3.3. Word Embedding Phase
3.4. Probabilistic Classification Phase
3.5. Decision Making
4. Performance Evaluation
4.1. Datasets
4.1.1. LIAR Dataset
- Pants-Fire: also referred to Pants on Fire: The statement is not true, and it’s ridiculous. Examples of the pants on fire class include, “Evidence shows Zika virus turns fetus brains to liquid,” and “In the 2012 election, there were more votes cast than registered voters in St. Lucie County, and Palm Beach County had 141 percent turnout.”
- False: The statement is not true, and evidence exists that proves it false. For example, the sentence, “Wisconsin is on pace to double the number of layoffs this year,” is known to be false.
- Barely-true: The statement contains an element of truth but is still mostly false. For example, the sentence, “The majority of people traveling to these resort destinations are not going for the primary purpose of gambling,” is barely-true.
- Half True: The statement is partially true, but also partially false. An example of a half-true sentence is, “Studies have shown that in the absence of federal reproductive health funds, we are going to see the level of abortion in Georgia increase by about 44 percent.”
- Mostly True: The statement contains an element of falsehood but is still mostly true. An example of the mostly true sentence is, “The sex-offender registry has been around for a long time, and the research that’s out there says that it has no positive impact on public safety.”
- True: The statement is true, and evidence exists that proves it true. An example of true sentence is, “Before World War II, very few people had health insurance.”
4.1.2. ISOT Dataset
4.2. Performance Measure
4.3. Evaluation Procedure
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, X.; Zafarani, R. A survey of fake news: Fundamental theories, detection methods, and opportunities. ACM Comput. Surv. 2020, 53, 1–40. [Google Scholar] [CrossRef]
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef] [PubMed]
- Silverman, C. This Analysis Shows How Viral Fake Election News Stories Outperformed Real News on Facebook. Available online: https://www.buzzfeednews.com/article/craigsilverman/viral-fake-election-news-outperformed-real-news-on-facebook (accessed on 18 February 2023).
- Nistor, A.; Zadobrischi, E. The Influence of Fake News on Social Media: Analysis and Verification of Web Content during the COVID-19 Pandemic by Advanced Machine Learning Methods and Natural Language Processing. Sustainability 2022, 14, 10466. [Google Scholar] [CrossRef]
- Alhakami, H.; Alhakami, W.; Baz, A.; Faizan, M.; Khan, M.W.; Agrawal, A. Evaluating Intelligent Methods for Detecting COVID-19 Fake News on Social Media Platforms. Electronics 2022, 11, 2417. [Google Scholar] [CrossRef]
- Choudhary, A.; Arora, A. Linguistic feature based learning model for fake news detection and classification. Expert Syst. Appl. 2021, 169, 114171. [Google Scholar] [CrossRef]
- Sahoo, S.R.; Gupta, B.B. Multiple features based approach for automatic fake news detection on social networks using deep learning. Appl. Soft Comput. 2021, 100, 106983. [Google Scholar] [CrossRef]
- Samadi, M.; Mousavian, M.; Momtazi, S. Deep contextualized text representation and learning for fake news detection. Inf. Process. Manag. 2021, 58, 102723. [Google Scholar] [CrossRef]
- Sheikhi, S. An effective fake news detection method using WOA-xgbTree algorithm and content-based features. Appl. Soft Comput. 2021, 109, 107559. [Google Scholar] [CrossRef]
- Hakak, S.; Alazab, M.; Khan, S.; Gadekallu, T.R.; Maddikunta, P.K.R.; Khan, W.Z. An ensemble machine learning approach through effective feature extraction to classify fake news. Future Gener. Comput. Syst. 2021, 117, 47–58. [Google Scholar] [CrossRef]
- Koloski, B.; Perdih, T.S.; Robnik-Šikonja, M.; Pollak, S.; Škrlj, B. Knowledge Graph informed Fake News Classification via Heterogeneous Representation Ensembles. Neurocomputing 2022, 496, 208–226. [Google Scholar] [CrossRef]
- Chauhan, T.; Palivela, H. Optimization and improvement of fake news detection using deep learning approaches for societal benefit. Int. J. Inf. Manag. Data Insights 2021, 1, 100051. [Google Scholar] [CrossRef]
- Kumari, R.; Ekbal, A. AMFB: Attention based multimodal Factorized Bilinear Pooling for multimodal Fake News Detection. Expert Syst. Appl. 2021, 184, 115412. [Google Scholar] [CrossRef]
- Song, C.; Ning, N.; Zhang, Y.; Wu, B. A multimodal fake news detection model based on crossmodal attention residual and multichannel convolutional neural networks. Inf. Process. Manag. 2021, 58, 102437. [Google Scholar] [CrossRef]
- Song, C.; Ning, N.; Zhang, Y.; Wu, B. Knowledge augmented transformer for adversarial multidomain multiclassification multimodal fake news detection. Neurocomputing 2021, 462, 88–100. [Google Scholar] [CrossRef]
- Zeng, J.; Zhang, Y.; Ma, X. Fake news detection for epidemic emergencies via deep correlations between text and images. Sustain. Cities Soc. 2021, 66, 102652. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wang, L.; Yang, Y.; Lian, T. SemSeq4FD: Integrating global semantic relationship and local sequential order to enhance text representation for fake news detection. Expert Syst. Appl. 2021, 166, 114090. [Google Scholar] [CrossRef]
- Kirn, H.; Anwar, M.; Sadiq, A.; Zeeshan, H.M.; Mehmood, I.; Butt, R.A. Deepfake Tweets Detection Using Deep Learning Algorithms. Eng. Proc. 2022, 20, 2. [Google Scholar]
- Sastrawan, I.K.; Bayupati, I.P.A.; Arsa, D.M.S. Detection of fake news using deep learning CNN–RNN based methods. ICT Express 2022, 8, 396–408. [Google Scholar] [CrossRef]
- Ali, A.M.; Ghaleb, F.A.; Al-Rimy, B.A.S.; Alsolami, F.J.; Khan, A.I. Deep Ensemble Fake News Detection Model Using Sequential Deep Learning Technique. Sensors 2022, 22, 6970. [Google Scholar] [CrossRef]
- Souza Freire, P.M.; Matias da Silva, F.R.; Goldschmidt, R.R. Fake news detection based on explicit and implicit signals of a hybrid crowd: An approach inspired in meta-learning. Expert Syst. Appl. 2021, 183, 115414. [Google Scholar] [CrossRef]
- Meel, P.; Vishwakarma, D.K. HAN, image captioning, and forensics ensemble multimodal fake news detection. Inf. Sci. 2021, 567, 23–41. [Google Scholar] [CrossRef]
- Shim, J.-S.; Lee, Y.; Ahn, H. A link2vec-based fake news detection model using web search results. Expert Syst. Appl. 2021, 184, 115491. [Google Scholar] [CrossRef]
- Yuan, H.; Zheng, J.; Ye, Q.; Qian, Y.; Zhang, Y. Improving fake news detection with domain-adversarial and graph-attention neural network. Decis. Support Syst. 2021, 151, 113633. [Google Scholar] [CrossRef]
- Abu Salem, F.K.; Al Feel, R.; Elbassuoni, S.; Ghannam, H.; Jaber, M.; Farah, M. Meta-learning for fake news detection surrounding the Syrian war. Patterns 2021, 2, 100369. [Google Scholar] [CrossRef]
- Gupta, A.; Li, H.; Farnoush, A.; Jiang, W. Understanding patterns of COVID infodemic: A systematic and pragmatic approach to curb fake news. J. Bus. Res. 2022, 140, 670–683. [Google Scholar] [CrossRef]
- Nasir, J.A.; Khan, O.S.; Varlamis, I. Fake news detection: A hybrid CNN-RNN based deep learning approach. Int. J. Inf. Manag. Data Insights 2021, 1, 100007. [Google Scholar] [CrossRef]
- Goldani, M.H.; Safabakhsh, R.; Momtazi, S. Convolutional neural network with margin loss for fake news detection. Inf. Process. Manag. 2021, 58, 102418. [Google Scholar] [CrossRef]
- Probierz, B.; Stefański, P.; Kozak, J. Rapid detection of fake news based on machine learning methods. Procedia Comput. Sci. 2021, 192, 2893–2902. [Google Scholar] [CrossRef]
- Kaliyar, R.K.; Goswami, A.; Narang, P.; Sinha, S. FNDNet—A deep convolutional neural network for fake news detection. Cogn. Syst. Res. 2020, 61, 32–44. [Google Scholar] [CrossRef]
- Vishwakarma, D.K.; Varshney, D.; Yadav, A. Detection and veracity analysis of fake news via scrapping and authenticating the web search. Cogn. Syst. Res. 2019, 58, 217–229. [Google Scholar] [CrossRef]
- Agarwal, V.; Sultana, H.P.; Malhotra, S.; Sarkar, A. Analysis of Classifiers for Fake News Detection. Procedia Comput. Sci. 2019, 165, 377–383. [Google Scholar] [CrossRef]
- Chiang, T.H.C.; Liao, C.-S.; Wang, W.-C. Investigating the Difference of Fake News Source Credibility Recognition between ANN and BERT Algorithms in Artificial Intelligence. Appl. Sci. 2022, 12, 7725. [Google Scholar] [CrossRef]
- Ansar, W.; Goswami, S. Combating the menace: A survey on characterization and detection of fake news from a data science perspective. Int. J. Inf. Manag. Data Insights 2021, 1, 100052. [Google Scholar] [CrossRef]
- Meel, P.; Vishwakarma, D.K. Fake news, rumor, information pollution in social media and web: A contemporary survey of state-of-the-arts, challenges and opportunities. Expert Syst. Appl. 2020, 153, 112986. [Google Scholar] [CrossRef]
- Saquete, E.; Tomás, D.; Moreda, P.; Martínez-Barco, P.; Palomar, M. Fighting post-truth using natural language processing: A review and open challenges. Expert Syst. Appl. 2020, 141, 112943. [Google Scholar] [CrossRef]
- Zhang, X.; Ghorbani, A.A. An overview of online fake news: Characterization, detection, and discussion. Inf. Process. Manag. 2020, 57, 102025. [Google Scholar] [CrossRef]
- Wang, W.Y. “liar, liar pants on fire”: A new benchmark dataset for fake news detection. arXiv 2017, arXiv:1705.00648. [Google Scholar]
- Ahmed, H.; Traore, I.; Saad, S. Detection of online fake news using n-gram analysis and machine learning techniques. In Proceedings of the Intelligent, Secure, and Dependable Systems in Distributed and Cloud Environments: First International Conference, ISDDC 2017, Vancouver, BC, Canada, 26–28 October 2017; pp. 127–138. [Google Scholar]
- Khan, T.; Michalas, A.; Akhunzada, A. Fake news outbreak 2021: Can we stop the viral spread? J. Netw. Comput. Appl. 2021, 190, 103112. [Google Scholar] [CrossRef]
- Bondielli, A.; Marcelloni, F. A survey on fake news and rumour detection techniques. Inf. Sci. 2019, 497, 38–55. [Google Scholar] [CrossRef]
- Domenico, G.D.; Sit, J.; Ishizaka, A.; Nunan, D. Fake news, social media and marketing: A systematic review. J. Bus. Res. 2021, 124, 329–341. [Google Scholar] [CrossRef]
- Rastogi, S.; Bansal, D. A review on fake news detection 3T’s: Typology, time of detection, taxonomies. Int. J. Inf. Secur. 2022, 22, 177–212. [Google Scholar] [CrossRef]
- Xu, J.; Zadorozhny, V.; Zhang, D.; Grant, J. FaNDS: Fake News Detection System using energy flow. Data Knowl. Eng. 2022, 135, 101985. [Google Scholar] [CrossRef]
- Ko, H.; Hong, J.Y.; Kim, S.; Mesicek, L.; Na, I.S. Human-machine interaction: A case study on fake news detection using a backtracking based on a cognitive system. Cogn. Syst. Res. 2019, 55, 77–81. [Google Scholar] [CrossRef]
- Trueman, T.E.; Kumar, A.; Narayanasamy, P.; Vidya, J. Attention-based C-BiLSTM for fake news detection. Appl. Soft Comput. 2021, 110, 107600. [Google Scholar] [CrossRef]
- Shu, K.; Wang, S.; Liu, H. Understanding user profiles on social media for fake news detection. In Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 430–435. [Google Scholar]
- Silva, A.; Han, Y.; Luo, L.; Karunasekera, S.; Leckie, C. Propagation2Vec: Embedding partial propagation networks for explainable fake news early detection. Inf. Process. Manag. 2021, 58, 102618. [Google Scholar] [CrossRef]
- Hakim, A.A.; Erwin, A.; Eng, K.I.; Galinium, M.; Muliady, W. Automated document classification for news article in Bahasa Indonesia based on term frequency inverse document frequency (TF-IDF) approach. In Proceedings of the 2014 6th International Conference on Information Technology and Electrical Engineering (ICITEE), Yogyakarta, Indonesia, 7–8 October 2014; pp. 1–4. [Google Scholar]
- Alghamdi, J.; Lin, Y.; Luo, S. A Comparative Study of Machine Learning and Deep Learning Techniques for Fake News Detection. Information 2022, 13, 576. [Google Scholar] [CrossRef]
- Ozbay, F.A.; Alatas, B. Fake news detection within online social media using supervised artificial intelligence algorithms. Phys. A Stat. Mech. Its Appl. 2020, 540, 123174. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Douze, M.; Jégou, H.; Mikolov, T. Fasttext. zip: Compressing text classification models. arXiv 2016, arXiv:1612.03651. [Google Scholar]
- Jadhav, S.S.; Thepade, S.D. Fake news identification and classification using DSSM and improved recurrent neural network classifier. Appl. Artif. Intell. 2019, 33, 1058–1068. [Google Scholar] [CrossRef]
- Goldani, M.H.; Momtazi, S.; Safabakhsh, R. Detecting fake news with capsule neural networks. Appl. Soft Comput. 2021, 101, 106991. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | Validation | Testing | Total | |
|---|---|---|---|---|
| Pants-fire | 839 | 116 | 92 | 1047 |
| FALSE | 1994 | 263 | 249 | 2506 |
| Barely-true | 1654 | 236 | 212 | 2102 |
| Half-true | 2114 | 248 | 265 | 2627 |
| Mostly-true | 1962 | 251 | 241 | 2454 |
| TRUE | 1676 | 169 | 207 | 2052 |
| Total | 10,239 | 1283 | 1266 | 12,788 |
| News Category | Training | Validation | Testing | Total |
|---|---|---|---|---|
| FAKE | 12,850 | 2142 | 6425 | 21,417 |
| TRUE | 14,089 | 2348 | 7044 | 23,481 |
| Total | 26,939 | 4490 | 13,469 | 44,898 |
| Model | Notes | Accuracy | Precession | Recall | F-Measure |
|---|---|---|---|---|---|
| RoBERTa [28] | GloVe.6B.300d + CNN | 63.00% | 62.00% | 62.00% | 62.00% |
| Conv-HAN [39] | GloVe + LSVM | 59.00% | 59.00% | 59.00% | 59.00% |
| DEFNDM [20] | Capsule neural networks | 51.05% | 85.86% | 45.47% | 60.90% |
| EFNDM [10] | Statistical + RF | 51.05% | 85.86% | 45.47% | 42.50% |
| The proposed | ICNN-AEN-DM | 89.59% | 68.59% | 69.09% | 69.09% |
| Author and Year | F-Measure | Notes |
|---|---|---|
| Goldani, et al. [28], 2021, | 99.90% | Glove.6B.300d + CNN |
| Ahmed, et al. [39], 2017, | 92.00% | GloVe + LSVM |
| Goldani, et al. [56], 2021, | 99.80% | Word2Vec + Capsule neural networks |
| Hakak, et al. [10], 2021, | 100% | Statistical + RF |
| Samadi, et al. [8], et al., 2021, | 99.96% | Funnel + CNN |
| Marish et al. [20], 2022 | 100% | TF/IDF,+ SDL + MLP |
| CNN-Autoencoder | 100% | CNN-Autoencoder |
| The proposed | 100% | Glove.6B.100d, ICNN-AEN-DM |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, A.M.; Ghaleb, F.A.; Mohammed, M.S.; Alsolami, F.J.; Khan, A.I. Web-Informed-Augmented Fake News Detection Model Using Stacked Layers of Convolutional Neural Network and Deep Autoencoder. Mathematics 2023, 11, 1992. https://doi.org/10.3390/math11091992
Ali AM, Ghaleb FA, Mohammed MS, Alsolami FJ, Khan AI. Web-Informed-Augmented Fake News Detection Model Using Stacked Layers of Convolutional Neural Network and Deep Autoencoder. Mathematics. 2023; 11(9):1992. https://doi.org/10.3390/math11091992
Chicago/Turabian StyleAli, Abdullah Marish, Fuad A. Ghaleb, Mohammed Sultan Mohammed, Fawaz Jaber Alsolami, and Asif Irshad Khan. 2023. "Web-Informed-Augmented Fake News Detection Model Using Stacked Layers of Convolutional Neural Network and Deep Autoencoder" Mathematics 11, no. 9: 1992. https://doi.org/10.3390/math11091992
APA StyleAli, A. M., Ghaleb, F. A., Mohammed, M. S., Alsolami, F. J., & Khan, A. I. (2023). Web-Informed-Augmented Fake News Detection Model Using Stacked Layers of Convolutional Neural Network and Deep Autoencoder. Mathematics, 11(9), 1992. https://doi.org/10.3390/math11091992