
Reliability Estimation of XLindley Constant-Stress Partially Accelerated Life Tests using Progressively Censored Samples



Abstract
:1. Introduction
2. Model Description
2.1. Testing Procedure
- The experimenter divides the n test products into two sets: The first set contains products that are randomly picked from the n test products and placed in normal operating conditions. The second set contains remaining products that are placed in an accelerated situation.
- Let denote the number of products tested using PT-IIC with progressive censoring plans under normal and accelerated conditions, respectively, and denote the number of failures actually observed under normal and accelerated configurations, respectively. In this case, one can observe the following example
2.2. Basic Assumptions
- The HRF of a product working under accelerated conditions is determined by the following formulawhere is specified by (4) and is an acceleration factor.
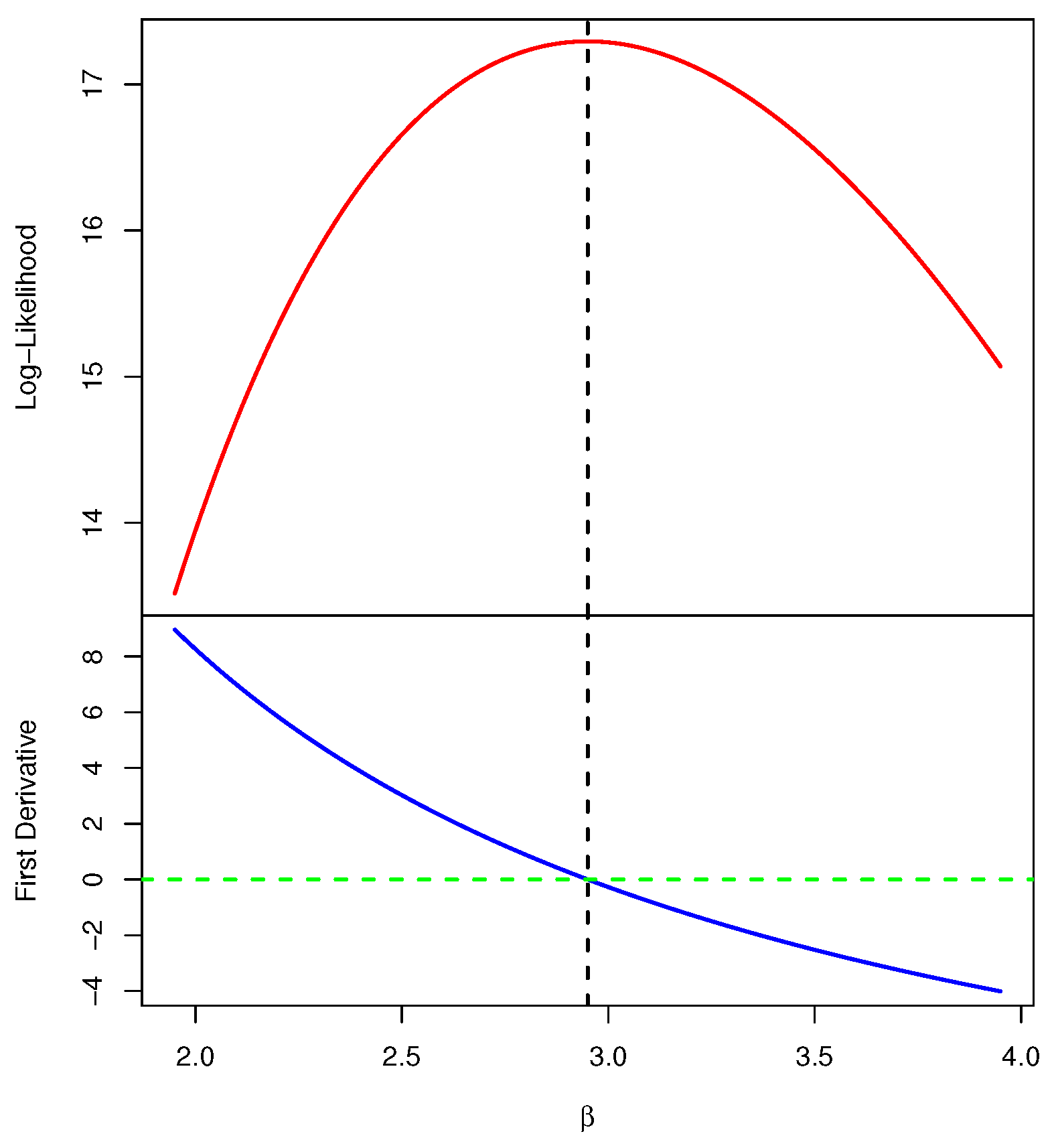
3. Maximum Likelihood Estimation
- Step 1.
- Set the initial value of , say .
- Step 2.
- Put .
- Step 3.
- Compute .
- Step 4.
- Proceed in this way to obtain .
- Step 5.
- Stop the iteration at , where is a pre-assigned tolerance bound.
- Step 6.
- Put .
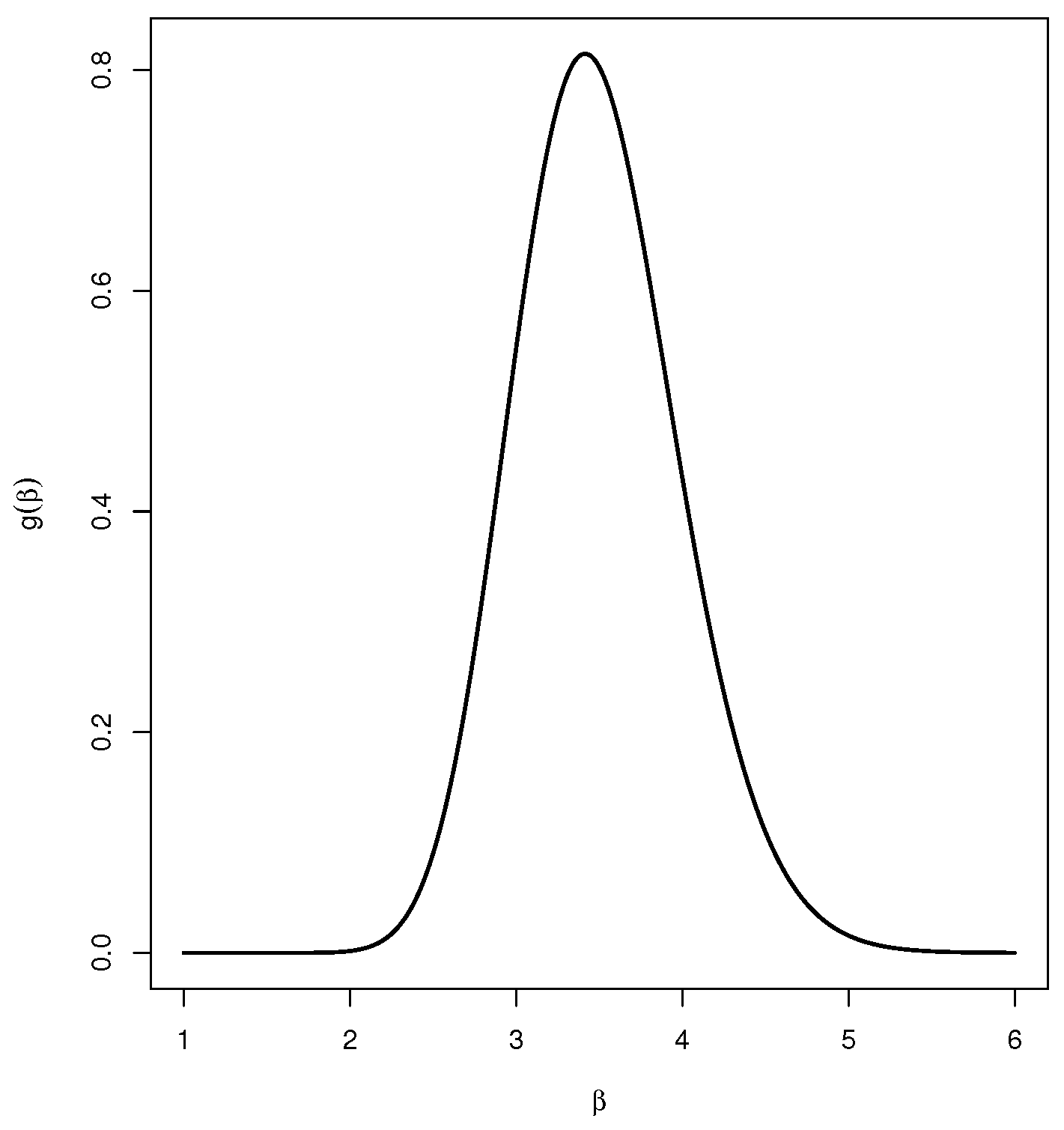
4. Bayesian Estimation
- Step 1.
- Set and put the initial guesses of and as .
- Step 2.
- Generate from using .
- Step 3.
- Generate using the M-H procedure from (22) with .
- Step 4.
- Use and to compute .
- Step 5.
- Set .
- Step 6.
- Repeat steps 2 to 5, M times to acquire .
5. Monte Carlo Simulations
- For Set-1: Prior-1=(1.5,1.5,3,3) and Prior-2=(3,3,6,6);
- For Set-2: Prior-1=(7.5,7.5,5,5) and Prior-2=(15,15,10,10).
- Step 1
- Set the values of and .
- Step 2
- Set the values of , and .
- Step 3
- Generate two PT-IIC samples using the same approach of Balakrishnan and Cramer [25].
- Step 4
- Obtain the observations with .
- Step 5
- Generate random samples of and from and distributions, respectively.
- Step 6
- Redo Steps 2–5 1000 times and use them to simulate 12,000 MCMC samples and ignore the first 2000 variates as burn-in.
- Step 7
- Compute the MLEs and Bayes estimates of the unknown parameters.
- Step 8
- Compute the two bounds of ACI (from NA and NL methods) and of credible interval (from BCI and HPD methods) of each parameter.
- Step 9
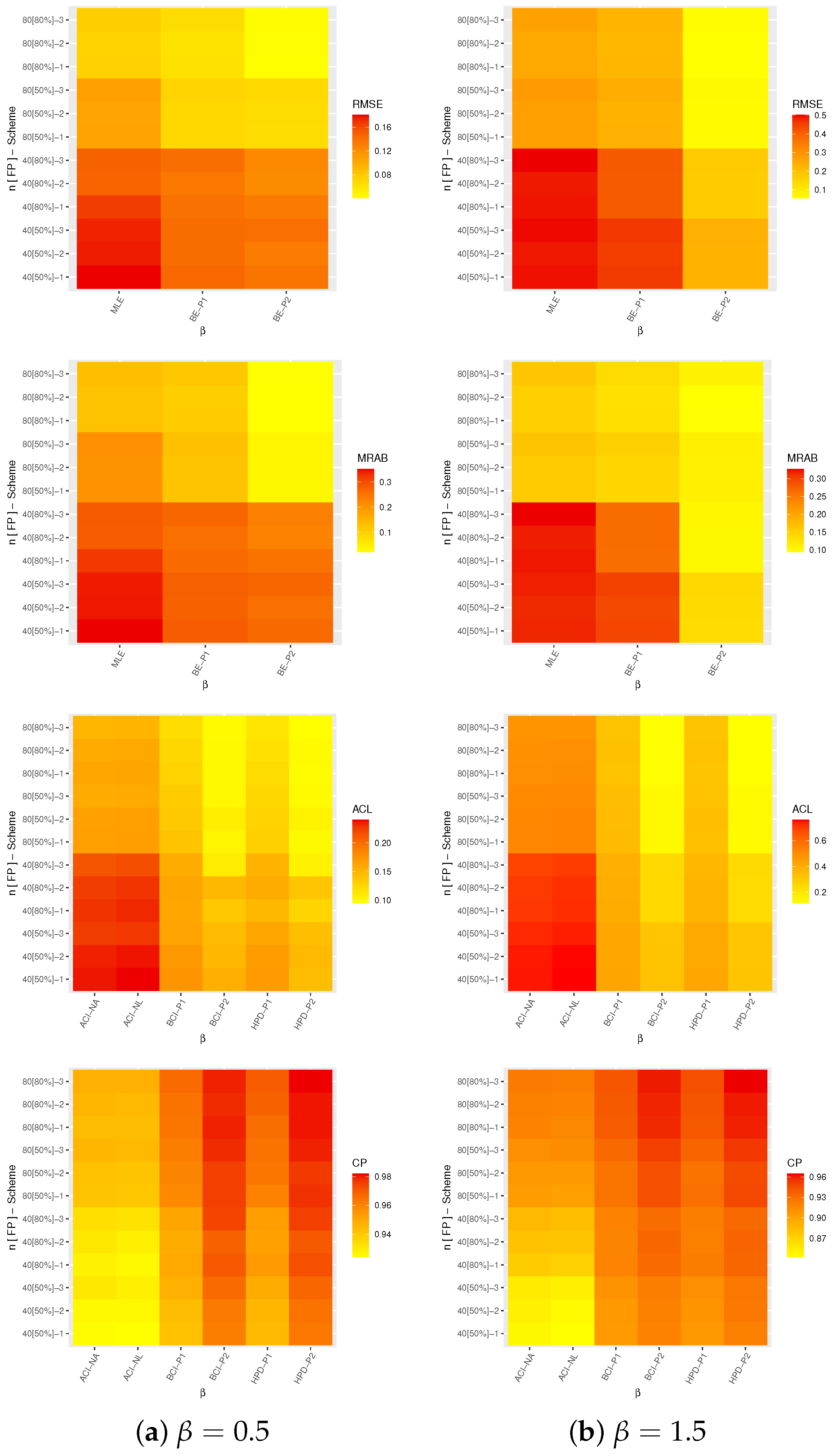
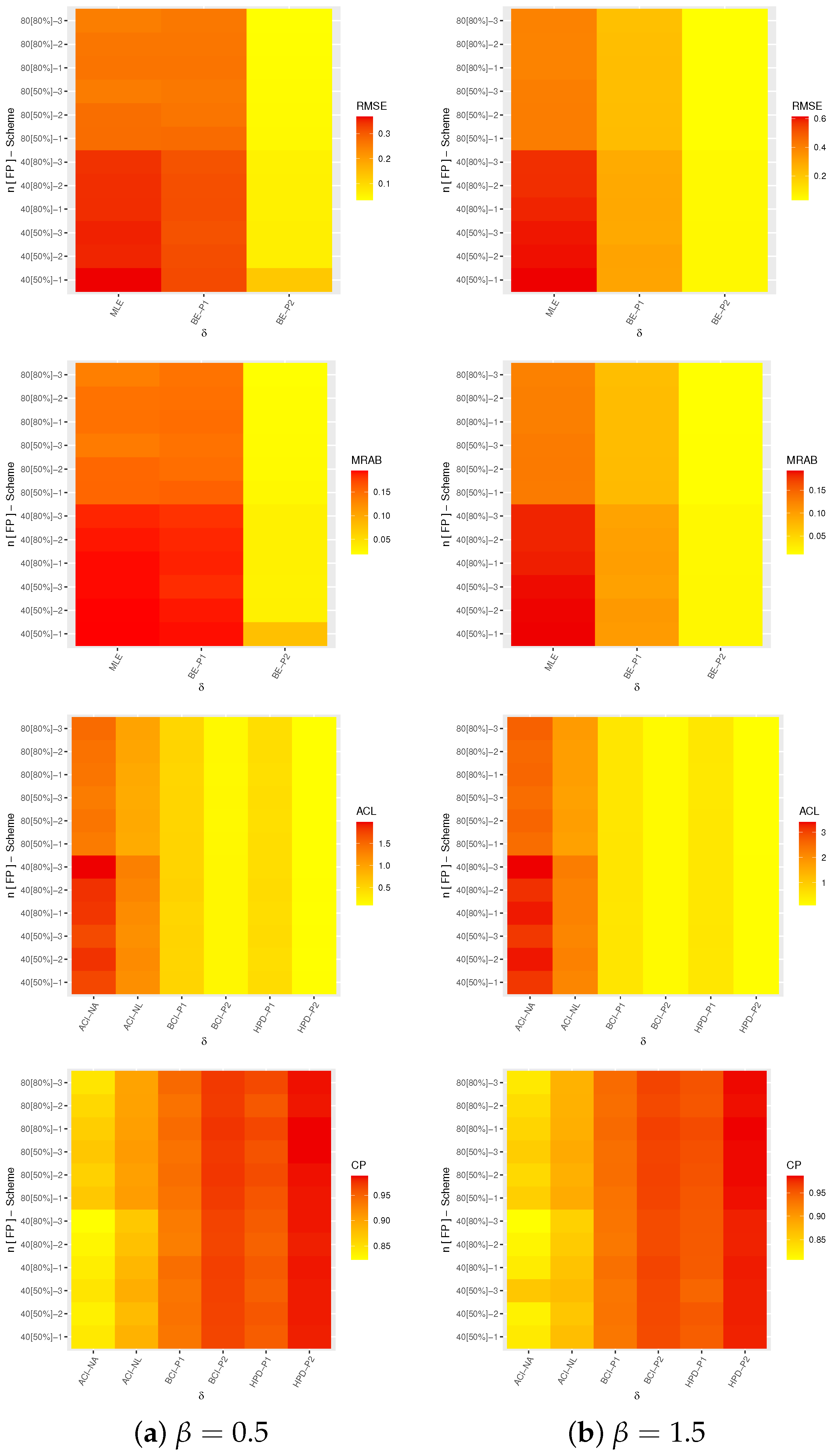
- Compute the root mean square error (RMSE) and mean relative absolute bias (MRAB) as:andrespectively, where is the calculated estimate at the sample of such , and .
- Step 10
- Compute the average confidence length (ACL) and coverage probability (CP) as:andrespectively, where is the indicator function, and is the two-sided interval estimate.
- Step 11
- Redo Steps 1–10 for various choices of , , , and .
- The proposed point (or interval) estimates of , and , for both given sets 1 and 2 perform well.
- As (or ) increases, all estimates operate effectively, produce superior outcomes and hold the consistency property. Equivalent behavior is also observed when the total of decreases.
- As and increase, the RMSEs and MRABs of all estimates of , and increase except for the Bayes estimates of .
- As and increase, the ACLs of all estimates of , and increase, but their CPs decrease.
- Since the Bayes point/interval estimates included more priority information on the unknown parameters, for each setting, the Bayes estimates of , or provide more accurate results compared to those obtained from the maximum likelihood estimation method.
- Since the variance of Prior-1 is higher than that of Prior-2, as anticipated, the estimates from Prior-2 are more accurate than those based on Prior-1.
- Comparing the proposed interval estimation approaches, for both sets 1 and 2, the estimates of and derived from the ACI-NA and HPD interval methods behave preferably to the others, while the estimates of derived from the ACI-NL and BCI methods behave better than others.
- Comparing the proposed censoring plans 1, 2 and 3, for both sets 1 and 2, it is observed that (i) the point estimates of and perform better based on Scheme-2 (middle censoring) while those associated with the acceleration factor perform better based on Scheme-3 (right censoring) than others; and (ii) the interval estimates of perform better based on Scheme-3 (right censoring) while those associated with and perform better based on Scheme-2 (middle censoring) than others.
- Based on the Markov chain Monte Carlo algorithm, the Bayes estimation approach is the best choice for estimating the XL distribution parameter, its acceleration factor, and its reliability function under normal use conditions for CSPALT in the presence of PT-IIC data.
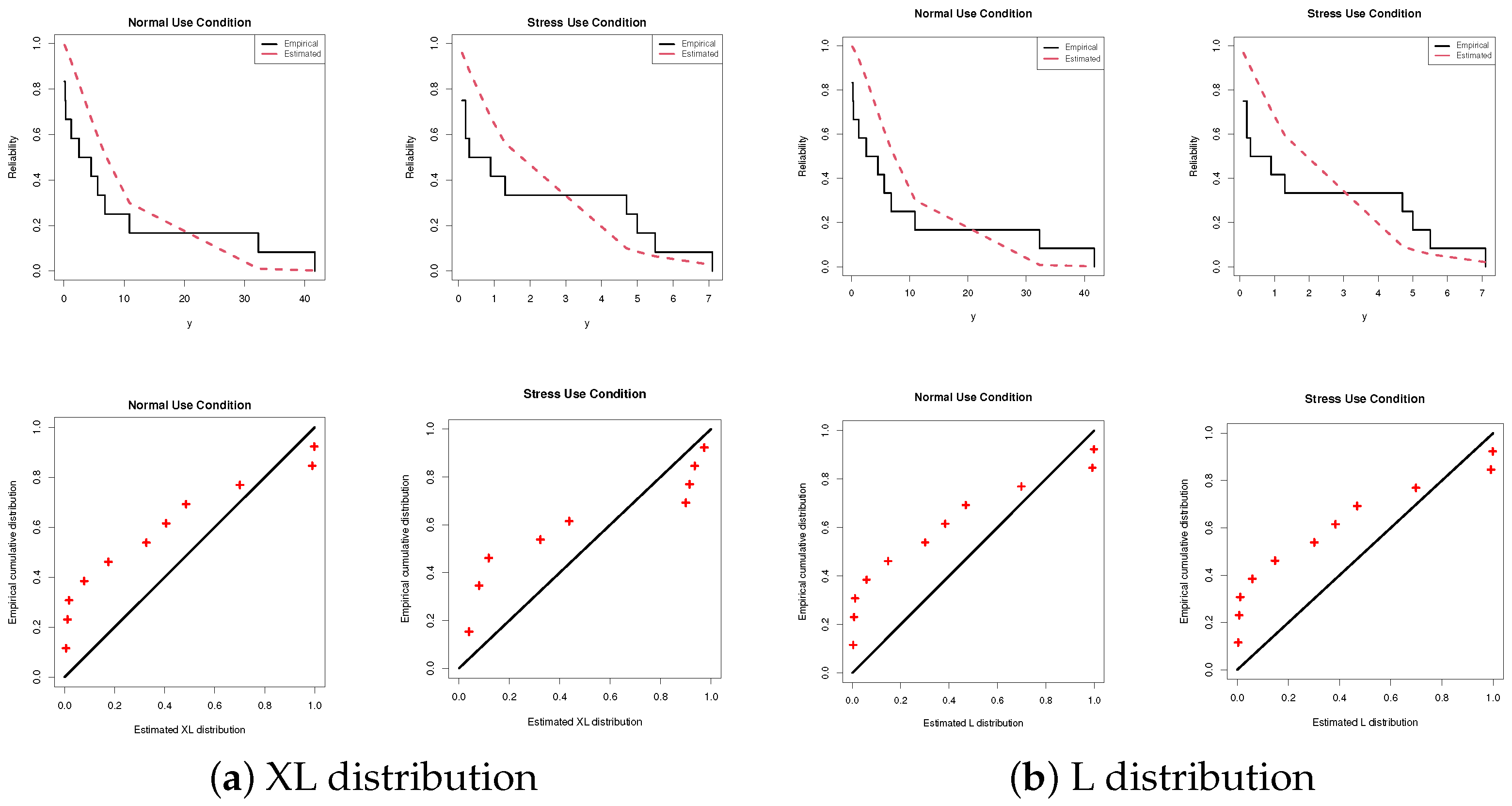
6. Applications
6.1. Insulating Fluid
6.2. Light-Emitting Diode
7. Concluding Remarks
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- El-Din, M.M.; Abu-Youssef, S.E.; Ali, N.S.; El-Raheem, A.A. Estimation in constant-stress accelerated life tests for extension of the exponential distribution under progressive censoring. Metron 2016, 74, 253–273. [Google Scholar] [CrossRef]
- Samanta, D.; Ganguly, A.; Kundu, D.; Mitra, S. Order restricted Bayesian inference for exponential simple step-stress model. Commun.-Stat.-Simul. Comput. 2017, 46, 1113–1135. [Google Scholar] [CrossRef]
- Wang, L. Inference of constant-stress accelerated life test for a truncated distribution under progressive censoring. Appl. Math. Model. 2017, 44, 743–757. [Google Scholar] [CrossRef]
- Cui, W.; Yan, Z.; Peng, X. Statistical analysis for constant-stress accelerated life test with Weibull distribution under adaptive Type-II hybrid censored data. IEEE Access 2019, 7, 165336–165344. [Google Scholar] [CrossRef]
- Nassar, M.; Okasha, H.; Albassam, M. E-Bayesian estimation and associated properties of simple step–stress model for exponential distribution based on type-II censoring. Qual. Reliab. Eng. Int. 2021, 37, 997–1016. [Google Scholar] [CrossRef]
- Kumar, D.; Nassar, M.; Dey, S.; Alam, F.M.A. On estimation procedures of constant stress accelerated life test for generalized inverse Lindley distribution. Qual. Reliab. Eng. Int. 2022, 38, 211–228. [Google Scholar] [CrossRef]
- Hyun, S.; Lee, J. Constant-stress partially accelerated life testing for log-logistic distribution with censored data. J. Stat. Appl. Probab. 2015, 4, 193–201. [Google Scholar]
- Mohamed, N.M. Estimation on kumaraswamy-inverse Weibull distribution with constant stress partially accelerated life tests. Appl. Math. Inf. Sci. 2021, 15, 503–510. [Google Scholar]
- Dey, S.; Wang, L.; Nassar, M. Inference on Nadarajah–Haghighi distribution with constant stress partially accelerated life tests under progressive type-II censoring. J. Appl. Stat. 2022, 49, 2891–2912. [Google Scholar] [CrossRef]
- Eliwa, M.S.; Ahmed, E.A. Reliability analysis of constant partially accelerated life tests under progressive first failure type-II censored data from Lomax model: EM and MCMC algorithms. AIMS Math. 2023, 1, 29–60. [Google Scholar] [CrossRef]
- Almarashi, A.M. Inferences of generalized inverted exponential distribution based on partially constant-stress accelerated life testing under progressive Type-II censoring. Alex. Eng. J. 2023, 63, 223–232. [Google Scholar] [CrossRef]
- Rastogi, M.K.; Tripathi, Y.M. Estimating the parameters of a Burr distribution under progressive type II censoring. Stat. Methodol. 2012, 9, 381–391. [Google Scholar] [CrossRef]
- Sultan, K.S.; Alsadat, N.H.; Kundu, D. Bayesian and maximum likelihood estimations of the inverse Weibull parameters under progressive type-II censoring. J. Stat. Comput. Simul. 2014, 84, 2248–2265. [Google Scholar] [CrossRef]
- Wu, M.; Gui, W. Estimation and prediction for Nadarajah-Haghighi distribution under progressive type-II censoring. Symmetry 2021, 13, 999. [Google Scholar] [CrossRef]
- Alotaibi, R.; Nassar, M.; Rezk, H.; Elshahhat, A. Inferences and engineering applications of alpha power Weibull distribution using progressive type-II censoring. Mathematics 2022, 10, 2901. [Google Scholar] [CrossRef]
- Bedbur, S.; Mies, F. Confidence bands for exponential distribution functions under progressive type-II censoring. J. Stat. Comput. Simul. 2022, 92, 60–80. [Google Scholar] [CrossRef]
- Balakrishnan, N. Progressive censoring methodology: An appraisal. Test 2007, 16, 211–259. [Google Scholar] [CrossRef]
- Lindley, D.V. Fiducial distributions and Bayes’ theorem. J. R. Stat. Soc. Ser. B 1958, 20, 102–107. [Google Scholar] [CrossRef]
- Chouia, S.; Zeghdoudi, H. The XLindley Distribution: Properties and Application. J. Stat. Theory Appl. 2021, 20, 318–327. [Google Scholar] [CrossRef]
- Pareek, B.; Kundu, D.; Kumar, S. On Progressively censored competing risks data for Weibull distributions. Comput. Stat. Data Anal. 2009, 53, 4083–4094. [Google Scholar] [CrossRef]
- Maiti, K.; Kayal, S.; Kundu, D. Statistical Inference on the Shannon and Rényi Entropy Measures of Generalized Exponential Distribution Under the Progressive Censoring. SN Comput. Sci. 2022, 3, 1–21. [Google Scholar] [CrossRef]
- Nassar, M.; Elshahhat, A. Statistical Analysis of Inverse Weibull Constant-Stress Partially Accelerated Life Tests with Adaptive Progressively Type I Censored Data. Mathematics 2023, 11, 370. [Google Scholar] [CrossRef]
- Henningsen, A.; Toomet, O. maxLik: A package for maximum likelihood estimation in R. Comput. Stat. 2011, 26, 443–458. [Google Scholar] [CrossRef]
- Plummer, M.; Best, N.; Cowles, K.; Vines, K. CODA: Convergence diagnosis and output analysis for MCMC. R News 2006, 6, 7–11. [Google Scholar]
- Balakrishnan, N.; Cramer, E. The Art of Progressive Censoring; Spriger: New York, NY, USA; Birkhäuser: Basel, Switzerland, 2014. [Google Scholar]
- Nelson, W.B. Accelerated Testing: Statistical Model, Test Plan and Data Analysis; Wiley: New York, NY, USA, 2004. [Google Scholar]
- Cheng, Y.F.; Wang, F.K. Estimating the Burr XII parameters in constant–stress partially accelerated life tests under multiple censored data. Commun. Stat. -Simul. Comput. 2012, 41, 1711–1727. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Normal Use (40 kV) | |||||||||||
| 0.1 | 0.1 | 0.2 | 0.3 | 1.2 | 2.5 | 4.5 | 5.6 | 6.8 | 10.9 | 32.3 | 41.7 |
| Accelerated Stress (45 kV) | |||||||||||
| 0.1 | 0.1 | 0.1 | 0.2 | 0.2 | 0.3 | 0.9 | 1.3 | 4.7 | 5.0 | 5.5 | 7.1 |
| Model | Estimate(St.E) | NL | A | CA | B | HQ | KS(p-Value) |
|---|---|---|---|---|---|---|---|
| Normal Use Data | |||||||
| XL | 0.1942(0.0401) | 41.954 | 85.908 | 86.308 | 86.393 | 85.728 | 0.3382(0.1284) |
| L | 0.2066(0.0425) | 43.983 | 89.966 | 90.366 | 90.451 | 89.787 | 0.3574(0.0931) |
| Stress Use Data | |||||||
| XL | 0.6507(0.1431) | 21.675 | 45.351 | 45.751 | 45.836 | 45.172 | 0.3815(0.0607) |
| L | 0.7408(0.1586) | 22.859 | 47.719 | 48.119 | 48.204 | 47.540 | 0.4029(0.0406) |
| Sample | Censored Data | |
|---|---|---|
| 1 | 0.1, 0.2, 0.3, 1.2, 4.5, 6.8 | |
| 0.1, 0.2, 0.3, 0.9, 1.3, 5.0 | ||
| 2 | 0.1, 0.1, 0.2, 0.3, 2.5, 10.9 | |
| 0.1, 0.1, 0.1, 0.2, 0.9, 5.0 | ||
| 3 | 0.1, 0.1, 0.2, 0.3, 1.2, 2.5 | |
| 0.1, 0.1, 0.1, 0.2, 0.2, 0.3 |
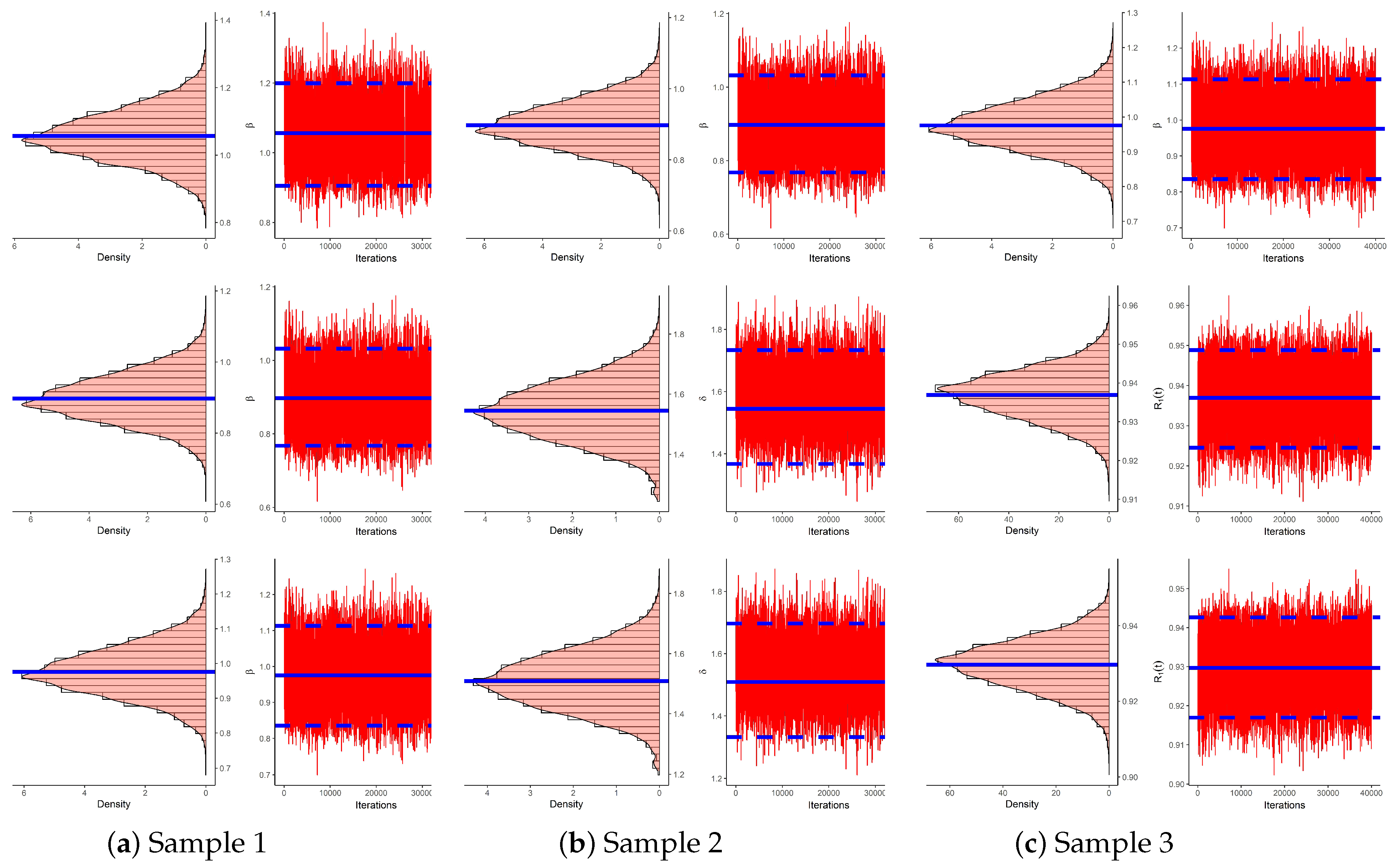
| Sample | Par. | MLE | MCMC | ||
|---|---|---|---|---|---|
| Est. | St.E | Est. | St.E | ||
| 1 | 0.6285 | 0.1904 | 0.5658 | 0.0991 | |
| 1.5970 | 0.9144 | 1.4849 | 0.1506 | ||
| 0.8169 | 0.0718 | 0.8405 | 0.0373 | ||
| 2 | 0.2316 | 0.0613 | 0.2179 | 0.0379 | |
| 2.2039 | 1.2641 | 2.1514 | 0.0869 | ||
| 0.9586 | 0.0181 | 0.9622 | 0.0108 | ||
| 3 | 0.4988 | 0.1420 | 0.4635 | 0.0656 | |
| 7.5727 | 4.4921 | 7.5226 | 0.0856 | ||
| 0.8658 | 0.0532 | 0.8788 | 0.0243 | ||
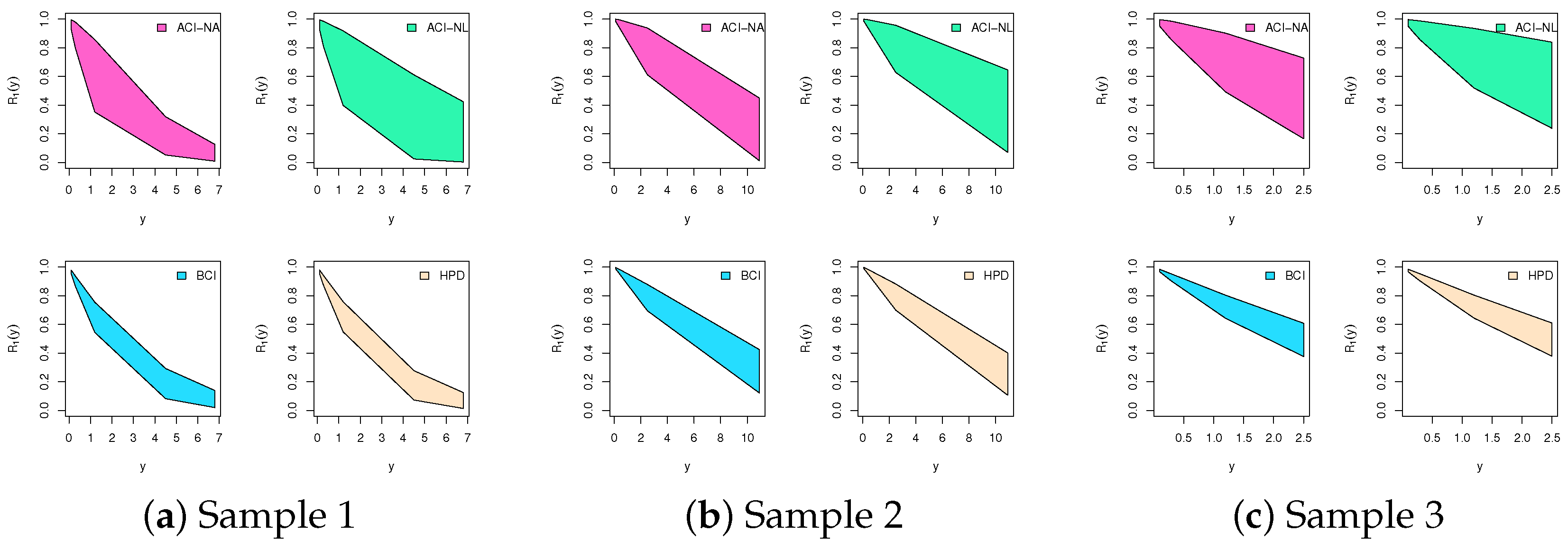
| Sample | Par. | ACI-NA | BCI | ||||
|---|---|---|---|---|---|---|---|
| ACI-NL | HPD | ||||||
| Lower | Upper | Length | Lower | Upper | Length | ||
| 1 | 0.2553 | 1.0017 | 0.7463 | 0.4204 | 0.7208 | 0.3004 | |
| 0.3471 | 1.1380 | 0.7909 | 0.4152 | 0.7137 | 0.2985 | ||
| 0.0000 | 3.3892 | 3.3892 | 1.2884 | 1.6811 | 0.3927 | ||
| 0.5200 | 4.9053 | 4.3853 | 1.2961 | 1.6841 | 0.3881 | ||
| 0.6762 | 0.9576 | 0.2814 | 0.7823 | 0.8949 | 0.1126 | ||
| 0.6876 | 0.9704 | 0.2828 | 0.7849 | 0.8968 | 0.1118 | ||
| 2 | 0.1116 | 0.3517 | 0.2401 | 0.1532 | 0.2906 | 0.1374 | |
| 0.1379 | 0.3890 | 0.2511 | 0.1506 | 0.2875 | 0.1369 | ||
| 0.0000 | 4.6815 | 4.6815 | 2.0222 | 2.2885 | 0.2663 | ||
| 0.7161 | 6.7830 | 6.0669 | 2.0186 | 2.2839 | 0.2653 | ||
| 0.9231 | 0.9942 | 0.0711 | 0.9402 | 0.9796 | 0.0394 | ||
| 0.9237 | 0.9949 | 0.0711 | 0.9415 | 0.9805 | 0.0390 | ||
| 3 | 0.2204 | 0.7771 | 0.5567 | 0.3573 | 0.5742 | 0.2169 | |
| 0.2854 | 0.8715 | 0.5860 | 0.3561 | 0.5717 | 0.2156 | ||
| 0.0000 | 16.377 | 16.377 | 7.3921 | 7.6590 | 0.2669 | ||
| 2.3676 | 24.221 | 21.853 | 7.3874 | 7.6538 | 0.2664 | ||
| 0.7615 | 0.9702 | 0.2087 | 0.8373 | 0.9175 | 0.0801 | ||
| 0.7675 | 0.9767 | 0.2092 | 0.8403 | 0.9199 | 0.0796 | ||
| Sample | Par. | Mean | Mode | St.D | Skewness | |||
|---|---|---|---|---|---|---|---|---|
| 1 | 0.56582 | 0.50241 | 0.51437 | 0.56481 | 0.61539 | 0.07681 | 0.12627 | |
| 1.48493 | 1.20282 | 1.41684 | 1.48423 | 1.55349 | 0.10058 | 0.00933 | ||
| 0.84050 | 0.86443 | 0.82182 | 0.84093 | 0.85994 | 0.02883 | –0.13522 | ||
| 2 | 0.21794 | 0.22567 | 0.19290 | 0.21625 | 0.24110 | 0.03536 | 0.25698 | |
| 2.15143 | 1.94905 | 2.10374 | 2.14982 | 2.19832 | 0.06928 | 0.06757 | ||
| 0.96221 | 0.96039 | 0.95581 | 0.96312 | 0.96960 | 0.01020 | –0.49041 | ||
| 3 | 0.46348 | 0.38443 | 0.42646 | 0.46216 | 0.50003 | 0.05536 | 0.10422 | |
| 7.52261 | 7.37523 | 7.47489 | 7.52122 | 7.57016 | 0.06935 | 0.05224 | ||
| 0.87879 | 0.90788 | 0.86532 | 0.87946 | 0.89264 | 0.02049 | –0.15533 |
| Normal Use Condition |
| 0.18, 0.19, 0.19, 0.34, 0.36, 0.40, 0.44, 0.44, 0.45, 0.46, 0.47, 0.53, 0.57, 0.57, 0.63, |
| 0.65, 0.70, 0.71, 0.71, 0.75, 0.76, 0.76, 0.79, 0.80, 0.85, 0.98, 1.01, 1.07, 1.12, 1.14, |
| 1.15, 1.17, 1.20, 1.23, 1.24, 1.25, 1.26, 1.32, 1.33, 1.33, 1.39, 1.42, 1.50, 1.55, 1.58, |
| 1.59, 1.62, 1.68, 1.70, 1.79, 2.00, 2.01, 2.04, 2.54, 3.61, 3.76, 4.65, 8.97 |
| Accelerated Stress Condition |
| 0.13, 0.16, 0.20, 0.20, 0.21, 0.25, 0.26, 0.28, 0.28, 0.30, 0.31, 0.33, 0.35, 0.35, 0.35, |
| 0.39, 0.50, 0.52, 0.58, 0.60, 0.60, 0.62, 0.63, 0.67, 0.71, 0.73, 0.75, 0.75, 0.78, 0.80, |
| 0.80, 0.86, 0.90, 0.91, 0.93, 0.93, 0.94, 0.98, 0.99, 1.01, 1.03, 1.06, 1.06, 1.10, 1.22, |
| 1.22, 1.24, 1.28, 1.39, 1.39, 1.46, 1.48, 1.52, 1.74, 1.95, 2.46, 3.02, 5.16 |
| Sample | Censored Data | |
|---|---|---|
| 1 | 0.18, 0.19, 0.19, 0.34, 0.36, 0.40, 0.44, 0.44, 0.45, 0.46, 0.47, 0.53, 0.57, 0.71, 0.71, | |
| 0.75, 0.85, 1.14, 1.17, 1.20, 1.32, 1.33, 1.50, 1.55, 1.58, 1.59, 1.62, 1.79, 2.00, 2.01 | ||
| 0.13, 0.16, 0.20, 0.25, 0.26, 0.28, 0.28, 0.30, 0.35, 0.35, 0.60, 0.62, 0.63, 0.67, 0.71, | ||
| 0.73, 0.75, 0.75, 0.80, 0.80, 0.86, 0.90, 0.98, 0.99, 1.01, 1.22, 1.24, 1.28, 1.39, 1.39 | ||
| 2 | 0.18, 0.19, 0.19, 0.34, 0.36, 0.40, 0.44, 0.44, 0.45, 0.46, 0.47, 0.53, 0.57, 0.57, 0.63, | |
| 0.65, 0.70, 0.71, 0.71, 0.75, 0.76, 0.76, 1.23, 1.26, 1.32, 1.42, 1.55, 1.59, 1.68, 1.70 | ||
| 0.13, 0.16, 0.20, 0.20, 0.21, 0.25, 0.26, 0.28, 0.28, 0.30, 0.31, 0.33, 0.35, 0.35, 0.35, | ||
| 0.39, 0.50, 0.60, 0.60, 0.62, 0.71, 0.73, 0.75, 0.78, 0.90, 0.91, 0.98, 1.01, 1.03, 1.28 | ||
| 3 | 0.18, 0.19, 0.19, 0.34, 0.36, 0.40, 0.44, 0.44, 0.45, 0.46, 0.47, 0.53, 0.57, 0.57, 0.63, | |
| 0.65, 0.70, 0.71, 0.71, 0.75, 0.76, 0.76, 0.79, 0.80, 0.85, 0.98, 1.01, 1.07, 1.12, 1.14 | ||
| 0.13, 0.16, 0.20, 0.20, 0.21, 0.25, 0.26, 0.28, 0.28, 0.30, 0.31, 0.33, 0.35, 0.35, 0.35, | ||
| 0.39, 0.50, 0.52, 0.58, 0.60, 0.60, 0.62, 0.63, 0.67, 0.71, 0.73, 0.75, 0.75, 0.78, 0.80 |
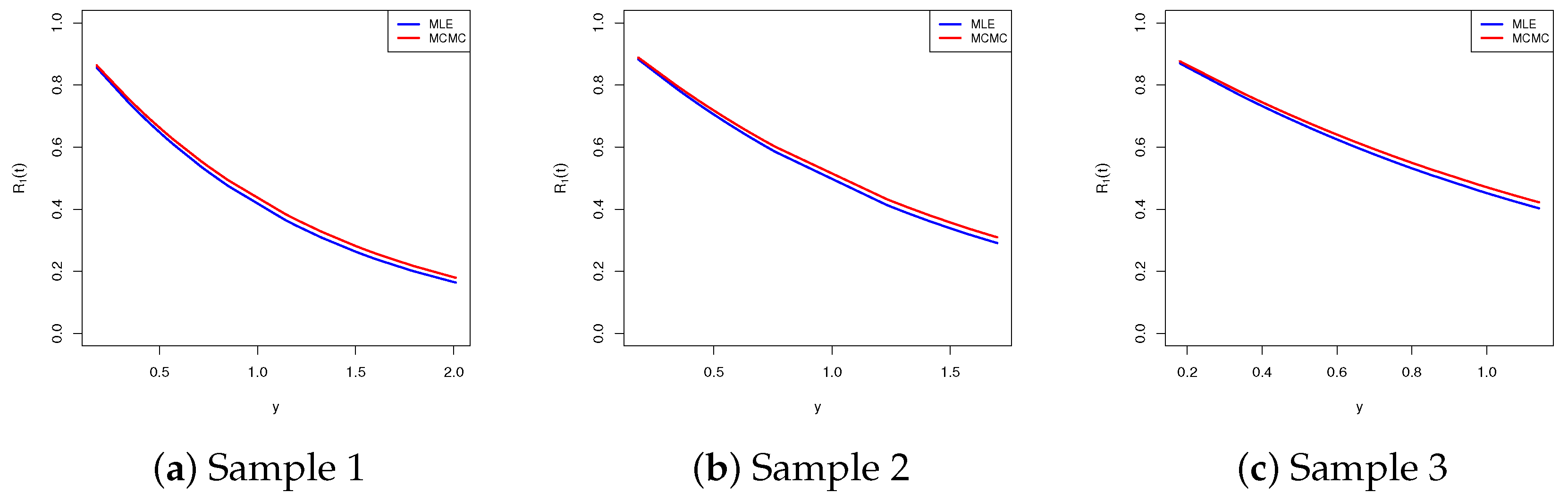
| Sample | Par. | MLE | MCMC | ||
|---|---|---|---|---|---|
| Est. | St.E | Est. | St.E | ||
| 1 | 1.1011 | 0.1637 | 1.0566 | 0.0867 | |
| 1.4019 | 0.3687 | 1.2951 | 0.1462 | ||
| 0.9181 | 0.0152 | 0.9222 | 0.0080 | ||
| 2 | 0.9338 | 0.1334 | 0.8975 | 0.0765 | |
| 1.6411 | 0.4316 | 1.5452 | 0.1354 | ||
| 0.9336 | 0.0123 | 0.9369 | 0.0071 | ||
| 3 | 1.0167 | 0.1468 | 0.9757 | 0.0815 | |
| 1.6052 | 0.4213 | 1.5092 | 0.1351 | ||
| 0.9259 | 0.0136 | 0.9297 | 0.0075 | ||
| Sample | Par. | ACI-NA | BCI | ||||
|---|---|---|---|---|---|---|---|
| ACI-NL | HPD | ||||||
| Lower | Upper | Length | Lower | Upper | Length | ||
| 1 | 0.7802 | 1.4220 | 0.6418 | 0.9118 | 1.2071 | 0.2953 | |
| 0.8228 | 1.4737 | 0.6509 | 0.9055 | 1.1993 | 0.2939 | ||
| 0.6792 | 2.1246 | 1.4454 | 1.0933 | 1.4869 | 0.3936 | ||
| 0.8372 | 2.3475 | 1.5102 | 1.1046 | 1.4916 | 0.3870 | ||
| 0.8883 | 0.9478 | 0.0595 | 0.9083 | 0.9356 | 0.0274 | ||
| 0.8888 | 0.9483 | 0.0596 | 0.9090 | 0.9362 | 0.0272 | ||
| 2 | 0.6723 | 1.1953 | 0.5230 | 0.7681 | 1.0323 | 0.2642 | |
| 0.7057 | 1.2356 | 0.5299 | 0.7680 | 1.0319 | 0.2638 | ||
| 0.7952 | 2.4870 | 1.6918 | 1.3678 | 1.7345 | 0.3667 | ||
| 0.9801 | 2.7479 | 1.7677 | 1.3678 | 1.7334 | 0.3656 | ||
| 0.9094 | 0.9578 | 0.0484 | 0.9245 | 0.9488 | 0.0244 | ||
| 0.9097 | 0.9581 | 0.0484 | 0.9245 | 0.9488 | 0.0243 | ||
| 3 | 0.7290 | 1.3044 | 0.5754 | 0.8378 | 1.1165 | 0.2787 | |
| 0.7661 | 1.3493 | 0.5831 | 0.8357 | 1.1134 | 0.2776 | ||
| 0.7795 | 2.4310 | 1.6520 | 1.3311 | 1.6965 | 0.3653 | ||
| 0.9597 | 2.6850 | 1.7250 | 1.3319 | 1.6970 | 0.3651 | ||
| 0.8992 | 0.9526 | 0.0534 | 0.9166 | 0.9424 | 0.0258 | ||
| 0.8996 | 0.9530 | 0.0534 | 0.9169 | 0.9426 | 0.0257 | ||
| Sample | Par. | Mean | Mode | St.D | Skewness | |||
|---|---|---|---|---|---|---|---|---|
| 1 | 1.05659 | 0.97503 | 1.00675 | 1.05321 | 1.10589 | 0.07440 | 0.10953 | |
| 1.29506 | 1.00769 | 1.22867 | 1.29564 | 1.36308 | 0.09972 | –0.07161 | ||
| 0.92221 | 0.92977 | 0.91763 | 0.92252 | 0.92683 | 0.00690 | –0.10999 | ||
| 2 | 0.89753 | 1.00956 | 0.85154 | 0.89513 | 0.94278 | 0.06733 | 0.11433 | |
| 1.54519 | 1.26645 | 1.47943 | 1.54308 | 1.61046 | 0.09559 | 0.06226 | ||
| 0.93693 | 0.92657 | 0.93276 | 0.93717 | 0.94118 | 0.00621 | –0.12847 | ||
| 3 | 0.97569 | 1.09249 | 0.92824 | 0.97360 | 1.02265 | 0.07043 | 0.10148 | |
| 1.50918 | 1.23056 | 1.44375 | 1.50729 | 1.57402 | 0.09507 | 0.05070 | ||
| 0.92970 | 0.91888 | 0.92536 | 0.92991 | 0.93411 | 0.00652 | –0.10833 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nassar, M.; Alotaibi, R.; Elshahhat, A. Reliability Estimation of XLindley Constant-Stress Partially Accelerated Life Tests using Progressively Censored Samples. Mathematics 2023, 11, 1331. https://doi.org/10.3390/math11061331
Nassar M, Alotaibi R, Elshahhat A. Reliability Estimation of XLindley Constant-Stress Partially Accelerated Life Tests using Progressively Censored Samples. Mathematics. 2023; 11(6):1331. https://doi.org/10.3390/math11061331
Chicago/Turabian StyleNassar, Mazen, Refah Alotaibi, and Ahmed Elshahhat. 2023. "Reliability Estimation of XLindley Constant-Stress Partially Accelerated Life Tests using Progressively Censored Samples" Mathematics 11, no. 6: 1331. https://doi.org/10.3390/math11061331
APA StyleNassar, M., Alotaibi, R., & Elshahhat, A. (2023). Reliability Estimation of XLindley Constant-Stress Partially Accelerated Life Tests using Progressively Censored Samples. Mathematics, 11(6), 1331. https://doi.org/10.3390/math11061331