
Adaptive Fuzzy Predictive Approach in Control


Abstract
:1. Introduction
- The principle of the control object decomposition: The management of a complex object is based on analysis of a large volume and the various types of data. It is necessary to ensure management models have sustainable functioning when choosing and adapting them. One solution is the formulation of restrictions on input data and its types and on operation modes of management models. First, this task must be solved successfully at the lowest level. Then, decision makers can build models for higher levels.
- The principle of dynamic indicators: We must analyze the attributes of objects over the time (in dynamic states) to track tendencies in their values for successful analysis. Such an analysis allows us to consider a greater number of dependencies.
- The principle of abstraction: It is necessary to conceptualize abstractions from the features of the analyzed objects in the modeling process.
- The principle adaptability: The context of analyzed objects allows us to adapt models to features and restrictions of the current problem area.
2. Related Works
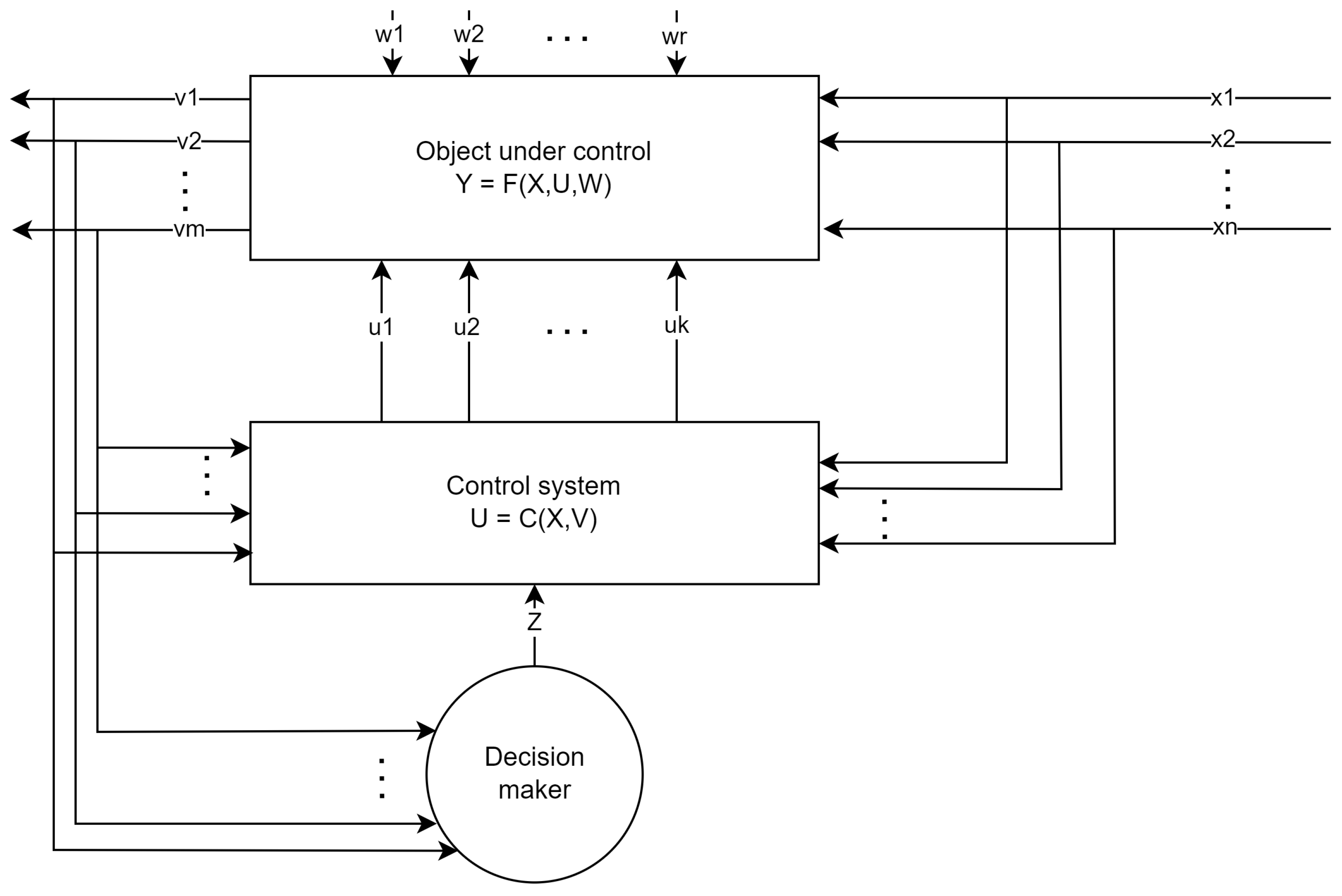
- The input of the control object is the vector .
- The control object is also regulated by the vector . The values of the vector W cannot be determined.
- The output of the control object is the vector .
- The feedback vector from the control system also comes to the input of the control object.
- The expansion of the set of analyzed data;
- The complication of the applied models;
- The increase in the interpretability of the results;
- The explainability of the result.
3. The Problem Statement
- Input to obtain external information about the control context D of a control object;
- Input to accumulate the dynamics of a control object attributes (vector V);
- Management recommendations as the output (recommendations for decision maker and/or numerical values to regulate the behavior of a control object).
4. Control Models
- The state and reliable trends of changes in the values of attributes of one object are known. It is possible to predict the value of the attribute associated with the source object by the presented functional dependence: , where is the predicted value of i-th attribute j-th object, or in the form of a time series forecast:
- We do not know the trends in the values of related objects, but there are predictive values. Using these values, it is possible to diagnose the values of the attributes .
5. Analysis Algorithm
- Form an ontology D that describes the relationships between objects and attributes.
- Generate time series of values of indicators of the studied objects . Instead of a single output vector of the control object, it is necessary to present the history of each indicator .
- Describe the context in the ontology D as rules for performing fuzzy inference when working with predictive , their parameters, and types.
- Select and train fuzzy predictive to adapt to the features of the selected objects. The results are presented in more detail in [14].
- Make a forecast based on incoming data and context.
- Evaluate the result on test data .
- If the quality is satisfactory, make a forecast for the next management period and adjust the management parameters based on the forecasts; otherwise, choose other predictive models.
6. Quality Assessment
6.1. Time Series Quality Assessment
6.2. Total Quality Assessment
7. Ontology for Representing the Context of a Control Problem
7.1. Description Logic
7.2. Model of the Proposed Ontology
7.3. Terminology of the Proposed Ontology ()
- The terminology contains a set of classes for describing:
- –
- Analyzed objects—;
- –
- Properties (attributes) of an object—;
- –
- The time series of values of an object attribute—;
- –
- Dependencies between attributes of objects—;
- –
- Types of dependencies: positive, negative—:
- The classes , , , , and are declared as disjoint:
- The class has the role to specify a tie between some object and a set of its attributes:
- The class has:
- –
- Functional roles and to define the minimum and maximum value of an attribute;
- –
- The role to specify a tie between attributes of analyzed objects;
- –
- The functional role to define a tie between an attribute and time series that contains a dynamic of an attribute:
- The class has the functional role to define a source of time series data:
- The class has:
- –
- The functional role to organize dependencies between object attributes;
- –
- The functional role to define the dependency between attributes;
- –
- The functional role to determine a weight of dependency between attributes:
- The terminology contains a set of classes for describing:
- –
- Methods for time series modeling—;
- –
- The features of time series that a method supports: fuzziness, periodicity, smoothing, trends—:
- The classes and are declared as disjoint:
- The class has:
- –
- The role to define a tie between the method and its features;
- –
- Functional roles and to determine the minimum and maximum lengths of time series that the method supports:
- In addition, the additional role is defined for the class in the terminology . The role allows declaring a tie between time series and its features:
- The terminology contains a set of classes for describing:
- –
- Expert knowledge—;
- –
- A value of some attribute of the object at a certain point of a time series—;
- –
- States in which an object is located—. A set of states of an object is based on a value of some object attributes. The class extends the class;
- –
- Actions to correct a value of some object attribute—. The class extends the class:
- The classes , , and are declared as disjoint:
- The class has the functional role common to all classes of expert knowledge:
- The class has:
- –
- The functional role to associate a value of some attribute with a specific point of a time series,;
- –
- The functional role to define actions to correct a value of some object attribute;
- –
- The functional role to define a value of an attribute at some point in a time series;
- –
- The functional role to associate some point of a time series with an object attribute:
7.4. Axioms of the Proposed Ontology ()
- Specification of objects:
- Specification of the attributes for each object. Each attribute specifies a data source and a valid range of values:Currently, only one-dimensional time series in CSV format are supported.
- Specification of dependencies between object attributes:
- Specification of a set of states for some attribute and a membership function to make fuzzification of attribute values [23]:A more detailed description of the fuzzy inference module is presented in the Section 7.5.
- Specification of a set of actions to correct a value of some object attribute:
- Specification of a set of SWRL-rules for transition from states to results:The rules are based on the states of the attributes at a certain point in time (a point in a time series) through the ‘forAttribute’ role.
7.5. Fuzzy Inference
- Membership functions;
- Linguistic variables;
- Fuzzy implication methods.
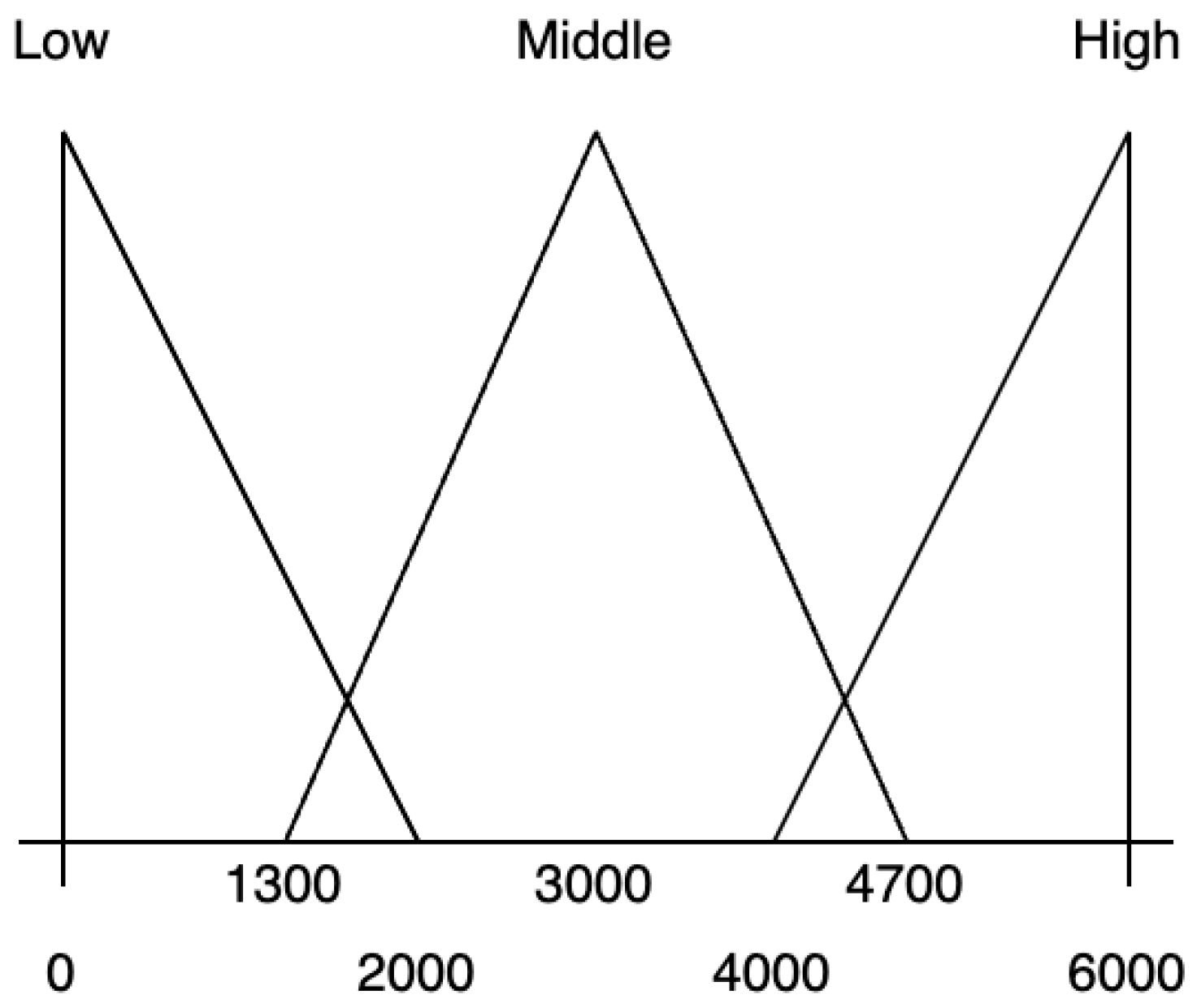
- x is an employees number;
- X a set of integers from the range [0, 6000];
- is a set of fuzzy variables: ‘low’, ‘middle’, ‘high’. It is necessary to set a membership function that specifies information about what employees number should be considered ‘low’, ‘middle’, or ‘high’;
- G is a set of additional features: ‘less than’, ‘more than’. Additional features are used to create new fuzzy variables. For example, ‘less than middle’ and ‘more than low’, etc.
- Fuzzification. Fuzzification is used to switch from numerical indicators of object properties to linguistic variables. The values of all input variables are associated with specific values of the membership functions of linguistic terms from antecedents of fuzzy rules at the fuzzification stage.A set of attribute states is formed in the process of fuzzy inference based on the values of time series points (‘hasValue’ role). Each point of a time series is associated through the ‘hasState’ role with a corresponding linguistic term in the process of fuzzy inference [23]. The ‘hasState’ role describes a membership of some time series point to a certain fuzzy set with some degree of membership:
- Aggregation. A truth degree of antecedents for each rule is determined at the aggregation stage. If an antecedent of a fuzzy rule contains one atom, then a truth degree of an antecedent is a truth degree of this atom. A truth degree of an atom is calculated based on the value of a membership function of a linguistic variable term. If an antecedent of a rule contains several atoms, then a truth degree is calculated based on the truth degrees of the antecedent atoms using fuzzy logic AND () operator.
- Activation. A truth degree of each consequent atom of the fuzzy rule is determined at the stage of activation. A truth degree of each consequent atom is equal to the algebraic product of a rule weight and a truth degree of a rule antecedent. If weights of production rules are not specified, then their default values are equal to one. Minimum is used to calculate truth degrees.A Set of results for object control is formed as a result of the inference. It is possible to obtain results for each point of a time series or for the individual points. Fuzzy inference allows obtaining a set of solutions ordered by their degree of truth. The degree of truth is calculated at the stages of aggregation and activation of the fuzzy inference [23]. For example:
Attribute Result Result description Truth degree attr1 result1 Some result 0.356 attr1 result2 Another result 0.047 - Accumulation. A membership function is formed for each linguistic variable from the consequent fuzzy rules at the accumulation stage. Accumulation is based on the union of fuzzy sets of all consequent atoms for some linguistic variable using fuzzy logic OR () operator.
- Defuzzification. The result of defuzzification is quantitative (crisp) values for each output linguistic variable based on the results of the accumulation of all output linguistic terms from the consequences of fuzzy rules using the center of gravity method.
- A set of recommendations for decision makers ordered by truth degree. The result is formed at the aggregation step, the accumulation and defuzzification steps are not required.
- A set of numerical values to regulate the behavior of the object. All steps must be completed.
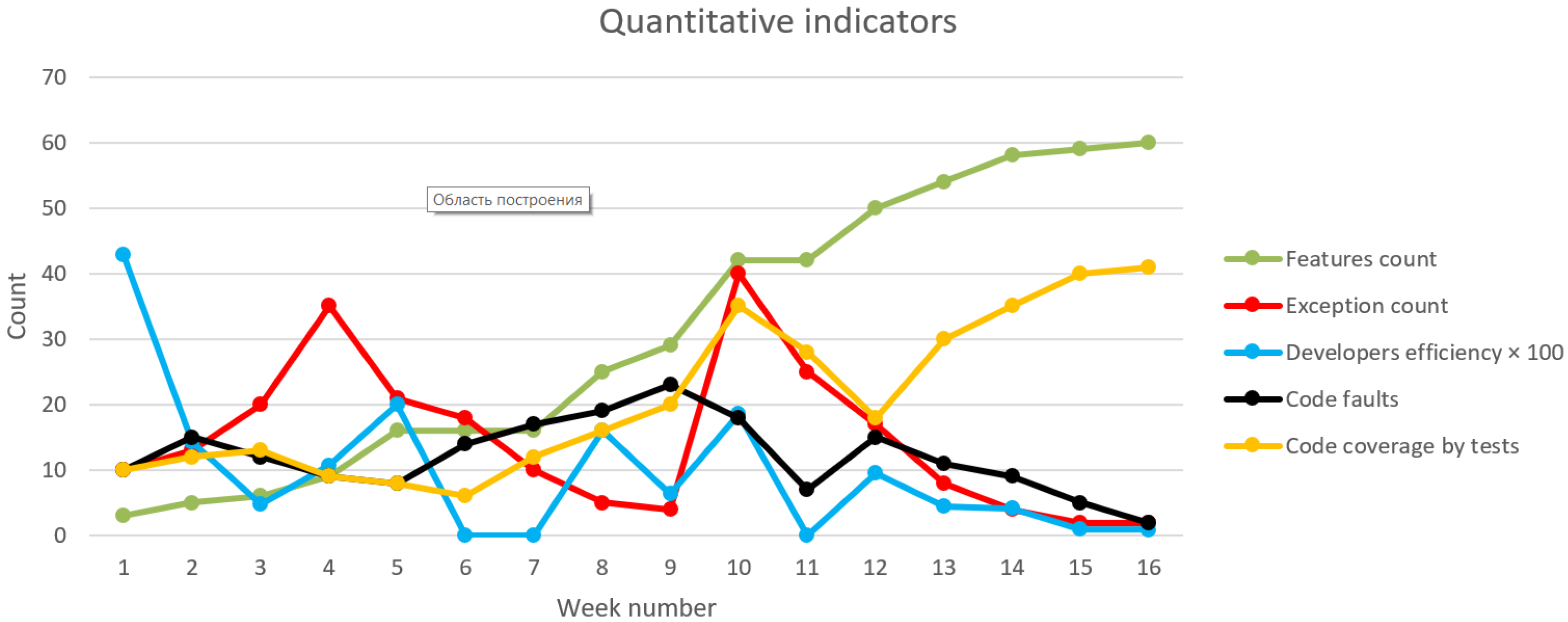
8. Results
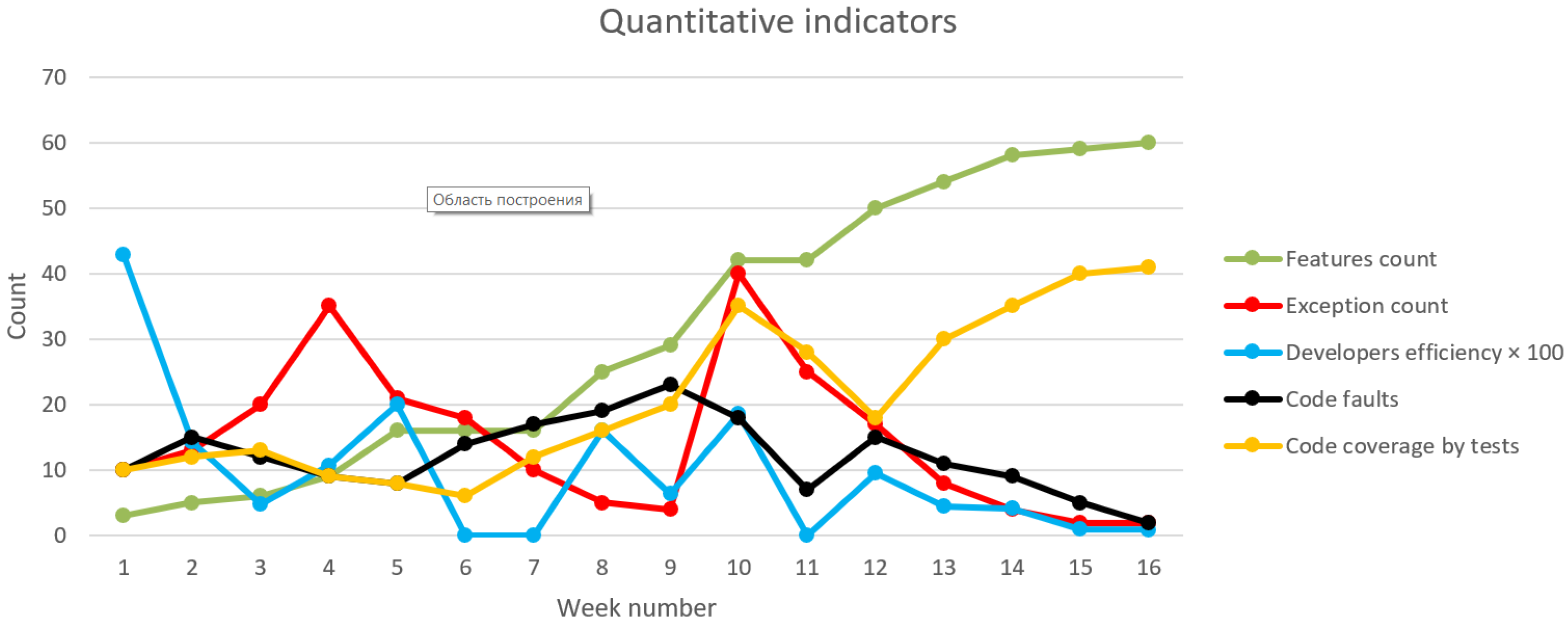
- The number of features is determined by the number of issues (issue) in the “Implemented” state.
- Feature execution time is determined by the cumulative execution time of automated tests.
- Exception count is the sum of all exceptions found during testing.
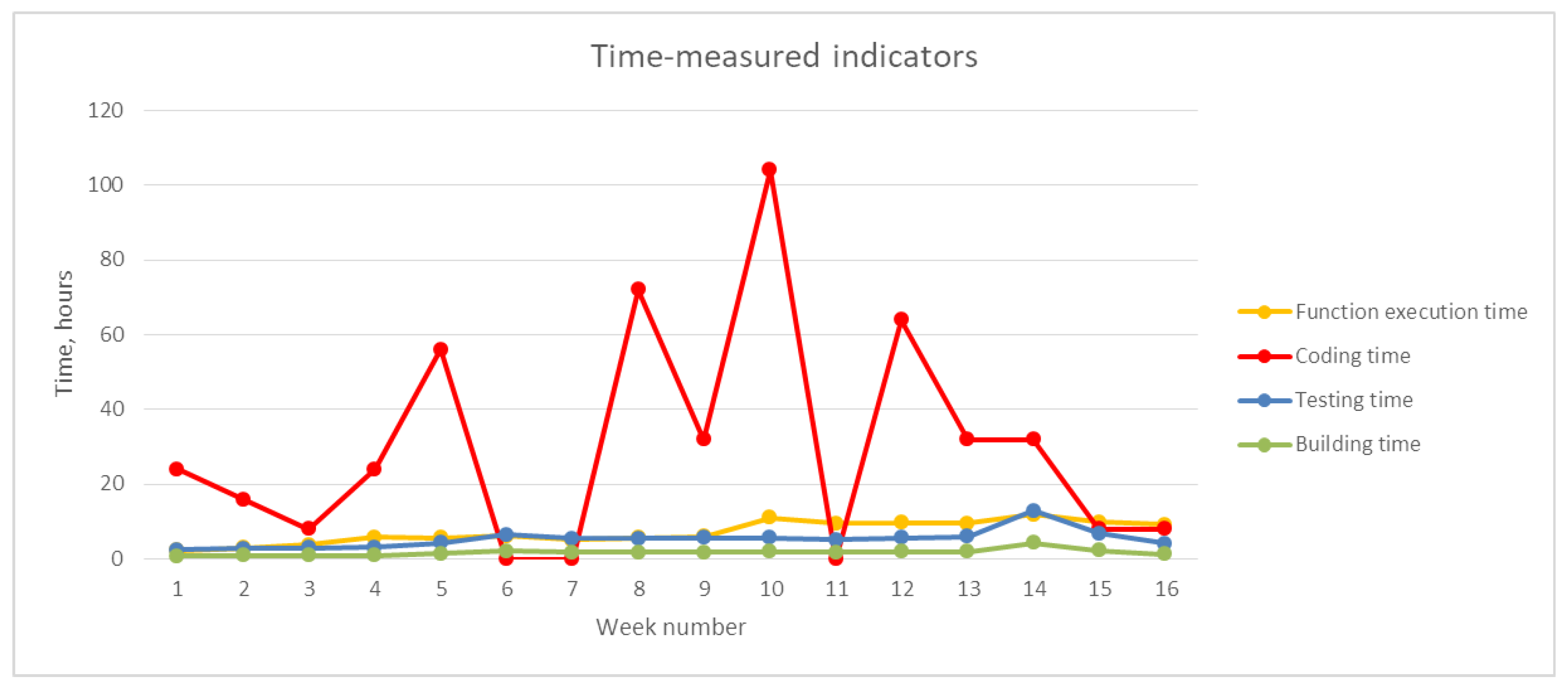
- Test time is the cumulative runtime of unit tests.
- Project build time is the average time of compilation of a project and running in automatic mode to check if it works.
- Efficiency of developers is determined by the number of completed tasks in a weekly interval.
- Bugs in the code are determined using the SonarQube service to obtain an indicator of the static code analysis system.
- Code test coverage shows the measure of checking all the implemented functionality with unit tests.
- Code writing time reflects a measure similar to developer efficiency, the time developers spend on tasks. However, unlike the first indicator, the measurement of this indicator does not include such overhead costs as task management, life cycle changes, discussion, and testing costs.
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pospelov, D.A. Situational Management: Theory and Practice; Fizmatlit: Moscow, Russia, 1986. (In Russian) [Google Scholar]
- Xu, J.; Wang, Q.; Lin, Q. Parallel robot with fuzzy neural network sliding mode control. Adv. Mech. Eng. 2018, 10, 1687814018801261. [Google Scholar] [CrossRef]
- Nguyen, A.-T.; Taniguchi, T.; Eciolaza, L.; Campos, V.; Palhares, R.; Sugeno, M. Fuzzy Control Systems: Past, Present and Future. IEEE Comput. Intell. Mag. 2019, 14, 56–68. [Google Scholar] [CrossRef]
- Tabbussum, R.; Dar, A.Q. Performance evaluation of artificial intelligence paradigms—Artificial neural networks, fuzzy logic, and adaptive neuro-fuzzy inference system for flood prediction. Environ. Sci. Pollut. Res. 2021, 28, 25265–25282. [Google Scholar] [CrossRef]
- Frazzon, E.M.; Kück, M.; Freitag, M. Data-driven production control for complex and dynamic manufacturing systems. CIRP Ann. 2018, 67, 515–518. [Google Scholar]
- Bejarano, G.; Alfaya, J.A.; Rodríguez, D.; Morilla, F.; Ortega, M.G. Benchmark for PID control of refrigeration system based on vapour compression. IFAC PapersOnLine 2018, 51, 497–502. [Google Scholar]
- Márquez-Vera, M.A.; Ramos-Fernández, J.C.; Cerecero-Natale, L.F.; Lafont, F.; Balmat, J.F.; Esparza-Villanueva, J.I. Temperature control in a MISO greenhouse by inverting its fuzzy model. Comput. Electron. Agric. 2016, 124, 168–174. [Google Scholar] [CrossRef]
- Kotenko, I.; Saenko, I.; Ageev, S. Hierarchical fuzzy situational networks for online decision-making: Application to telecommunication systems. Knowl.-Based Syst. 2019, 185, 104935. [Google Scholar] [CrossRef]
- Petrushevskaya, A.A. Control model of technological operations of mounting automatic printed circuit boards based on a multiparameter fuzzy classifier. J. Phys. Conf. Ser. 2019, 1333, 042026. [Google Scholar]
- Morales Escobar, L.; Aguilar, J.; Garcés-Jiménez, A.; Gutierrez De Mesa, J.A.; Gomez-Pulido, J.M. Advanced Fuzzy-Logic-Based Context-Driven Control for HVAC Management Systems in Buildings. IEEE Access 2020, 8, 16111–16126. [Google Scholar] [CrossRef]
- Novák, V.; Mirshahi, S. On the Similarity and Dependence of Time Series. Mathematics 2021, 9, 550. [Google Scholar] [CrossRef]
- What Is Scrum. Available online: https://www.scrum.org/resources/what-is-scrum (accessed on 30 December 2022).
- ISO/IEC 25010:2011. Systems and Software Engineering—Systems and Software Quality Requirements and Evaluation (SQuaRE)—System and Software Quality Models. Available online: https://www.iso.org/ru/standard/35733.html (accessed on 30 December 2022).
- Romanov, A.; Filippov, A.; Yarushkina, N. An Approach to Contextual Time Series Analysis. In Proceedings of theArtificial Intelligence and Soft Computing: 20th International Conference, ICAISC 2021, Virtual Event, 21–23 June 2021. [Google Scholar]
- SMAPE Criterion by Computational Intelligence in Forecasting (CIF). Available online: http://irafm.osu.cz/cif/main.php (accessed on 30 December 2022).
- Perfilieva, I.G.; Yarushkina, N.G.; Afanasieva, T.V.; Romanov, A.A. Web-Based System for Enterprise Performance Analysis on the Basis of Time Series Data Mining. In Proceedings of the First International Scientific Conference “Intelligent Information Technologies for Industry” (IITI-16), Rostov-on-Don, Russia, 16–21 May 2016; pp. 75–86. [Google Scholar]
- Romanov, A.; Filippov, A.; Yarushkina, N. Extraction and Forecasting Time Series of Production Processes. In Proceedings of the International Conference on Information Technologies, Paris, France, 23–26 April 2019; pp. 173–184. [Google Scholar]
- Guarino, N.; Musen, M.A. Ten years of applied ontology. Appl. Ontol. 2015, 10, 169–170. [Google Scholar]
- Horrocks, I.; Patel-Schneider, P.F.; Boley, H.; Tabet, S.; Grosof, B.; Dean, M. SWRL: A semantic web rule language combining OWL and RuleML. W3C Memb. Submiss. 2004, 21, 1–31. [Google Scholar]
- Baader, F.; Calvanese, D.; McGuinness, D.; Nardi, D.; Patel-Schneider, P.F. The Description Logic Handbook: Theory, Implementation, and Applications; Cambridge University Press: New York, NY, USA, 2003. [Google Scholar]
- Bonatti, P.; Tettamanzi, A. Some complexity results on fuzzy description logics. In Proceedings of the WILF 2003 International Workshop on Fuzzy Logic and Applications, Naples, Italy, 9–11 October 2003; Volume 2955. [Google Scholar]
- Grosof, B.; Horrocks, I.; Volz, R.; Decker, S. Description logic programs: Combining logic programs with description logics. In Proceedings of the WWW 2003, Budapest, Hungary, 20–24 May 2003; pp. 48–57. [Google Scholar]
- Romanov, A.; Stroeva, J.; Filippov, A.; Yarushkina, N. An Approach to Building Decision Support Systems Based on an Ontology Service. Mathematics 2021, 9, 2946. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy logic. Computer 1988, 21, 83–93. [Google Scholar] [CrossRef]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning—I. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Automation of Scientific Group Activities. Available online: https://gitlab.com/romanov73/ng-tracker (accessed on 30 December 2022).
- Romanov, A.A.; Filippov, A.A.; Voronina, V.V.; Guskov, G.; Yarushkina, N.G. Modeling the Context of the Problem Domain of Time Series with Type-2 Fuzzy Sets. Mathematics 2021, 9, 2947. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | DL | OWL |
|---|---|---|
| top (a special class with every individual as an instance) | ⊤ | owl:Thing |
| bottom (an empty class) | ⊥ | owl:Nothing |
| class inclusion axiom | A owl:SubClassOf B | |
| disjoint classes axiom | [A, B] owl:DisjointClasses | |
| equivalence classes axiom (or defining classes with necessary and sufficient conditions) | [A, B] owl:equivalentClasses | |
| intersection or conjunction of classes | A and B | |
| universal restriction axiom | R only A | |
| existential restriction axiom | R some A | |
| cardinality restrictions axiom | R exactly n A | |
| concept assertion axiom (a is an instance of class A) | a: A | |
| role assertion axiom | aRb |
| Indicator Name | Relation Weight | |
|---|---|---|
| Product quality | Features count | 5 |
| Features execution time | −3 | |
| Exception count | −1 | |
| Testing time | −2 | |
| Project quality | Building time | −1 |
| Developers efficiency | 5 | |
| Code faults | −4 | |
| Code coverage by tests | 3 | |
| Coding time | −5 |
| Indicator Name | Actual Value | Forecast Tendency Value | Smape, % |
|---|---|---|---|
| Features count | 60 | 63 | 1.28 |
| Features execution time | 9.1 | 10 | 4.35 |
| Exception count | 1.9 | 1.7 | 10.79 |
| Testing time | 8.81 | 4.4 | 15.83 |
| Building time | 3.55 | 1.42 | 15.65 |
| Developers efficiency | 0.14 | 0.72 | 0.01 |
| Code faults | 1.99 | 1.91 | 4.67 |
| Code coverage by tests | 40.8 | 45.1 | 3.83 |
| Coding time | 8 | 9 | 0.1 |
| Indicator Name | Weight × Normalized Value | Weight × Normalized Forecast | |
|---|---|---|---|
| Product quality | Features count | 4.7 | 5 |
| Features execution time | −1.72 | −1.89 | |
| Exception count | −0.03 | −0.02 | |
| Total | 2.95 | 3.09 | |
| Project quality | Testing time | −1.11 | −0.55 |
| Building time | −0.22 | −0.08 | |
| Developers efficiency | 0.01 | 0.057 | |
| Code faults | −0.12 | −0.12 | |
| Code coverage by tests | 1.94 | 2.14 | |
| Coding time | −2.52 | −2.84 | |
| Total | −1.02 | −1.48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Romanov, A.A.; Filippov, A.A.; Yarushkina, N.G. Adaptive Fuzzy Predictive Approach in Control. Mathematics 2023, 11, 875. https://doi.org/10.3390/math11040875
Romanov AA, Filippov AA, Yarushkina NG. Adaptive Fuzzy Predictive Approach in Control. Mathematics. 2023; 11(4):875. https://doi.org/10.3390/math11040875
Chicago/Turabian StyleRomanov, Anton A., Aleksey A. Filippov, and Nadezhda G. Yarushkina. 2023. "Adaptive Fuzzy Predictive Approach in Control" Mathematics 11, no. 4: 875. https://doi.org/10.3390/math11040875
APA StyleRomanov, A. A., Filippov, A. A., & Yarushkina, N. G. (2023). Adaptive Fuzzy Predictive Approach in Control. Mathematics, 11(4), 875. https://doi.org/10.3390/math11040875