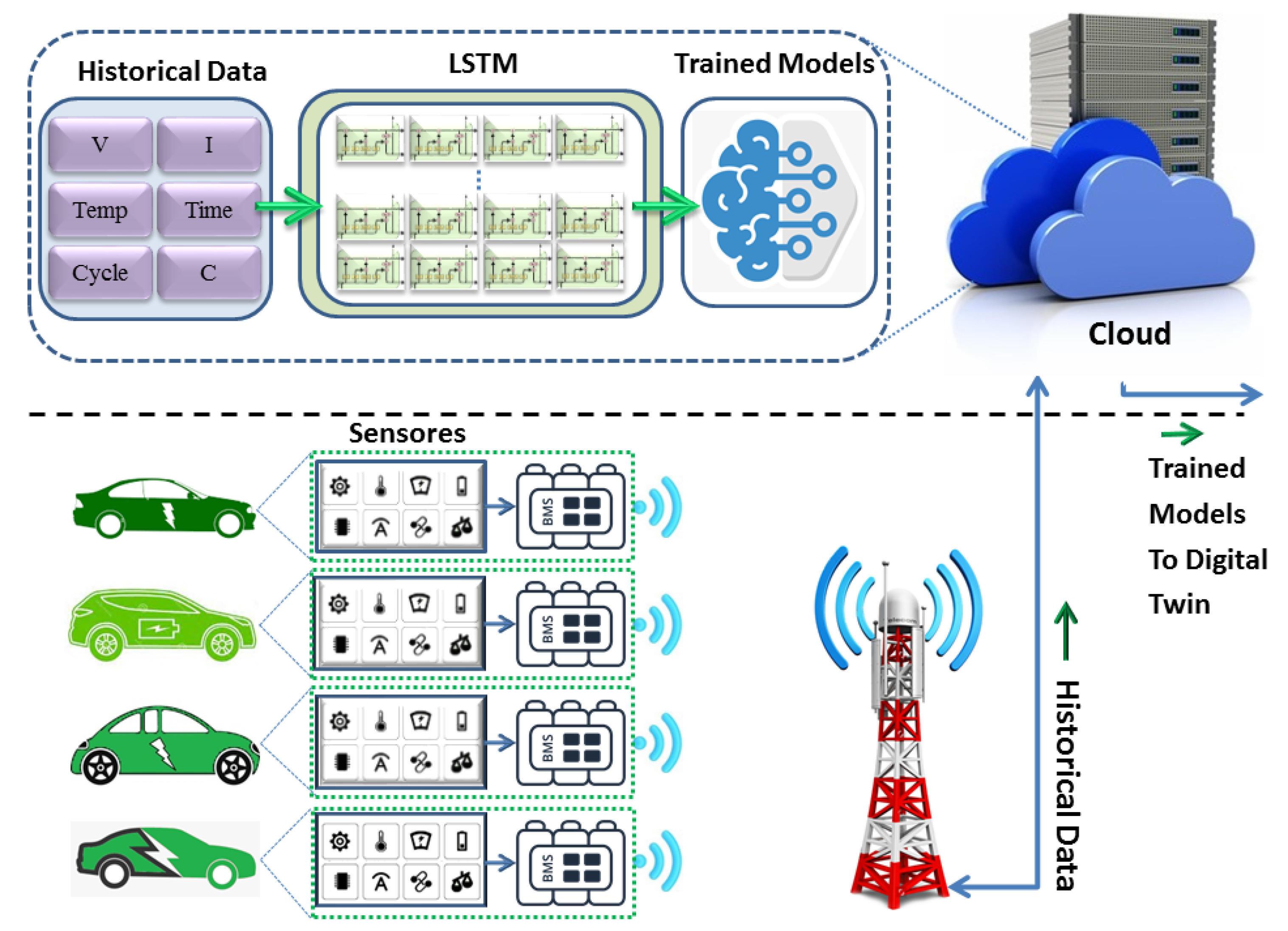
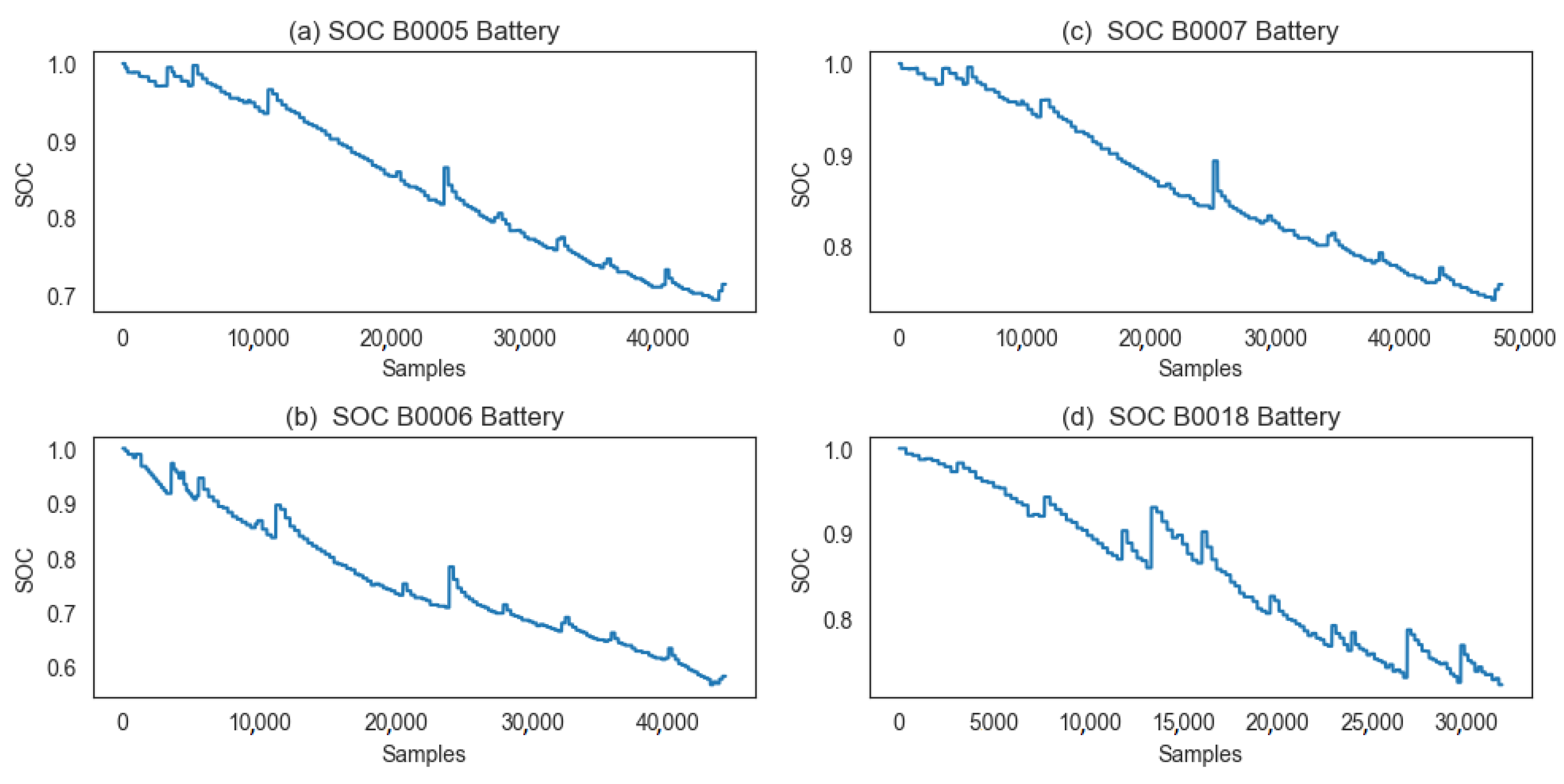
In this study, a dataset comprising four LIBs (labeled #5, #6, #7, and #18) was utilized.This type of data is known as historical or physical data, and the experimental setup closely followed the methodology outlined in [
44]. At room temperature (25
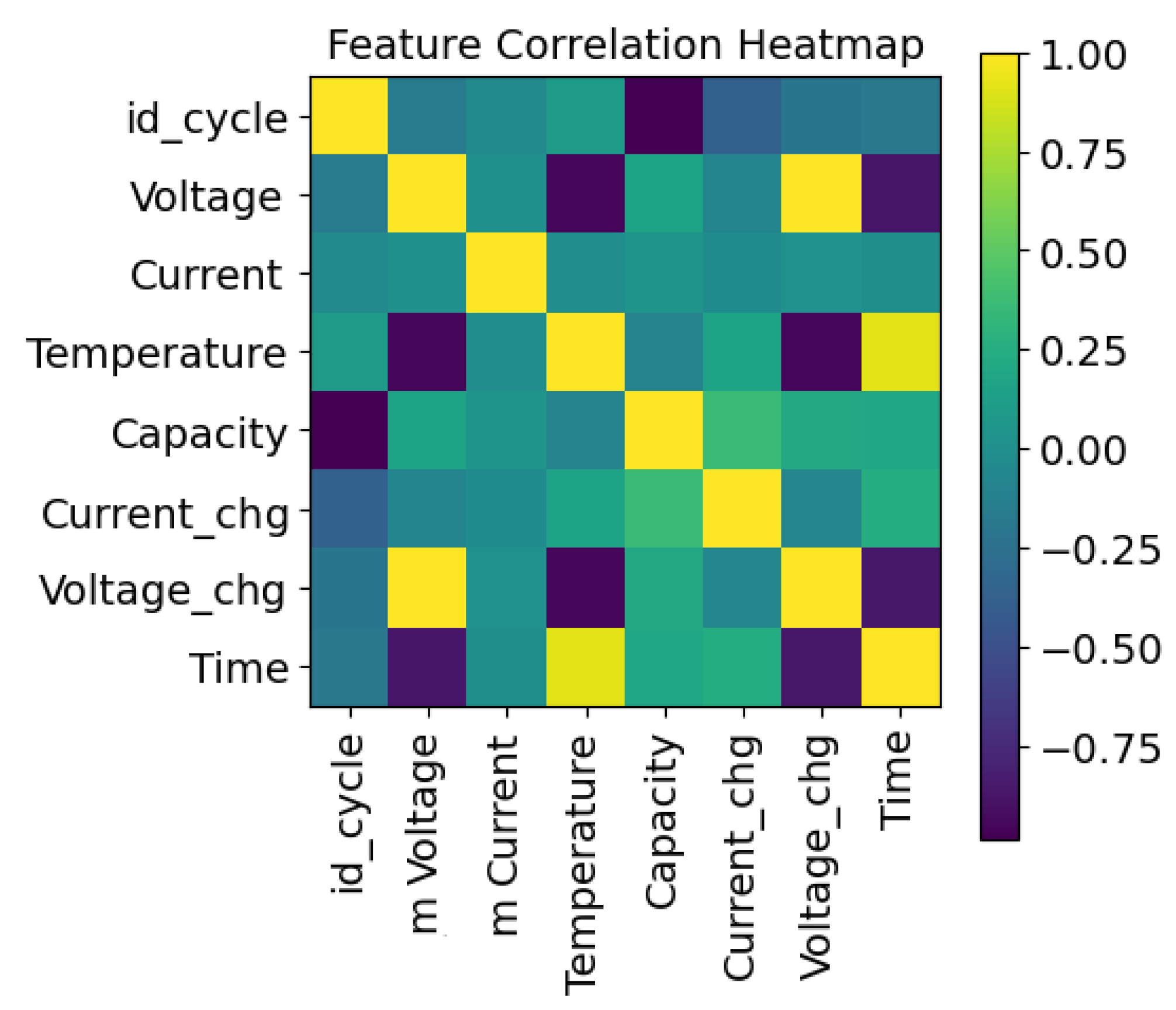
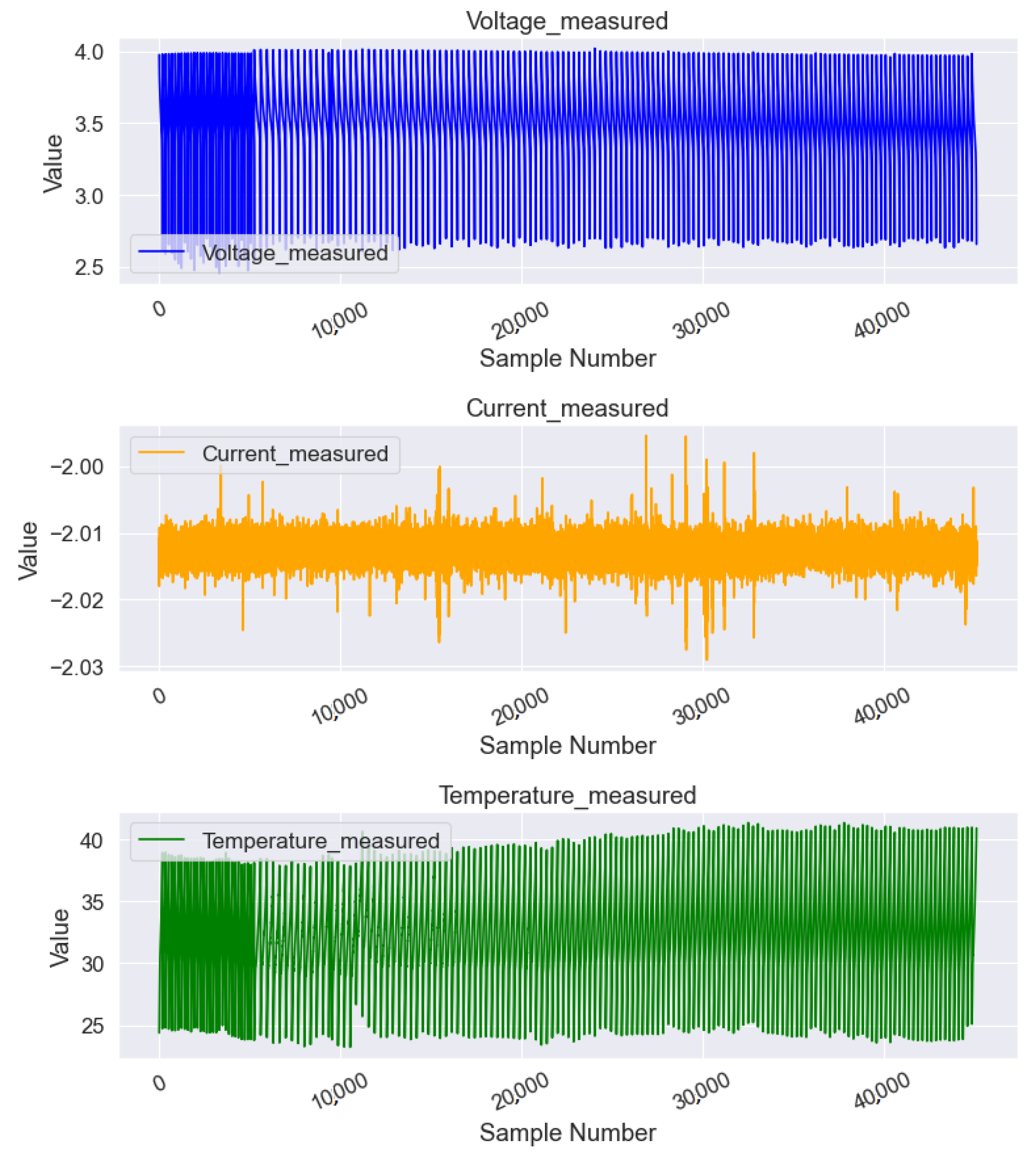
C), batteries were subjected to three distinct operational profiles: charge, discharge, and impedance measurements. Charging was accomplished by applying a constant current of 1.5 A until the voltage reached 4.2 V and then switching to a constant voltage until the charge current dropped to 20 mA. In order to discharge, a constant current of 2 A was applied until specific voltage thresholds were reached. In addition, electrochemical impedance spectroscopy was performed. During repeated cycles, batteries were exposed to accelerated aging, allowing for the observation of changes in internal battery parameters until the end-of-life criteria were met, which were defined as a 30% decrease in the rated capacity. Finally, the dataset included the battery capacity for discharge until 2.7 V, which was recorded and analyzed. The multivariate time-series data obtained from Li-ion batteries included 45,122 samples and eight features, namely, the ID cycle, measured voltage, measured current, measured temperature, capacity, charging current, charging voltage, and time. Additionally, temperature is a crucial factor that significantly affects the performance and overall health of battery systems. Our framework addressed this by incorporating temperature as an important aspect in the following ways.
4.1.3. Problem Formulation with Physical Batteries and Simulation Results
Overall, the SOC is an important factor when it comes to overseeing and controlling the energy of a battery, as it indicates the present amount of charge that it holds. The SOC can be obtained for time
t as follows:
where
and
are the state of charge of the battery at the starting time
and the present time
t, respectively,
C is the capacity of the battery,
is the Coulomb efficiency, and
I represents the current that passes through the voltage source. Accurate prediction of SOC values is crucial for efficient energy utilization and optimization of battery performance, and the LSTM utilizes sequential patterns in battery data to achieve this goal. Each LSTM unit uses a memory
at time
t. Here,
is an output or LSTM unit activation determined by
where
is the output gate that controls the amount of content that is provided through memory.
The output gate is calculated through the following:
where
is the sigmoid activation function,
is the weight matrix,
is the input at time
t,
is a model parameter, and
is the hidden state from the previous time step.
With the partial forgetting of the current memory and addition of new memory content as
, memory cell
is updated to
where
is the activation vector of the forget gate, and
is the activation vector of the input/update gate. The amount of current memory that should be forgotten is controlled by the forgetting gate (
), and the amount of new memory content that should be added to the memory cell is controlled by the update gate (
) which is sometimes known as the input gate. This is done with the following calculations:
The new memory content is expressed through the following:
At every time step, an LSTM is provided with details regarding the battery, such as its voltage, current, temperature, and so on. Additionally, the LSTM takes the previous hidden state
, as well as the previous cell state
from the previous time step
, into account. Through a particular formulation, an LSTM makes predictions of the SOC. So, we can define SOC at time t as
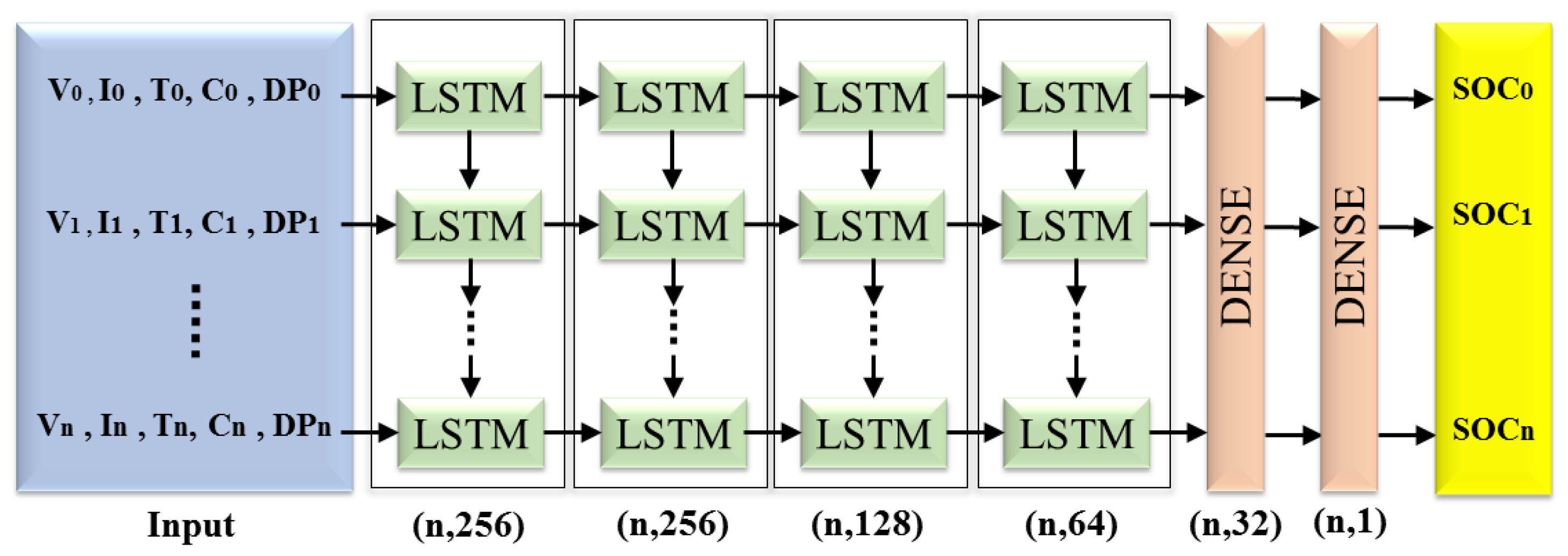
The problem of estimating the SOC was approached as a supervised learning problem in this study, wherein the model was provided with numerous input–output pairs from which to learn. An offline model was trained using a dataset with historical information obtained from the battery manufacturer. The dataset consisted of 45,122 samples of multivariate time-series data with eight characteristics, including the cycle ID, measured voltage, measured current, measured temperature, capacity, charging current, charging voltage, and time. The objective of the offline model was to utilize the known SOC values to compare and evaluate them against the digital twin’s SOC predictions. During the offline model’s training, five essential input features, namely, the measured voltage, measured current, cycle ID, measured temperature, and time, were selected to capture the battery’s behavior over time. The output vector for the offline model was the known SOC values. In a given sample, the input vector
X comprised concatenated values of five selected input features, and it was represented by
. The output vector
Y, which was represented by
, corresponded to the SOC value
for the input sample. The goal was to train the LSTM model to accurately map the input vector
X to the output vector
Y. The LSTM neural network used in the offline model comprised four hidden layers, as shown in
Figure 8. The LSTM’s hidden layers sequentially processed the input and passed the hidden state to the following layer. This model received sequential input data at the input layer, where each time step’s features were processed. Each LSTM unit in a layer comprised an input gate, a forget gate, and an output gate, which determined what information to store in the cell state, what information to discard, and what part of the cell state to output as the hidden state to the next layer or the final output. The activation functions utilized by the LSTM units were sigmoid and hyperbolic tangent (
) functions. The input, forget, and output gates utilized the sigmoid function to regulate the flow of information based on relevance and importance, and the values were limited to a range of 0 to 1. On the other hand, tanh was employed to compute new candidate values that could be included in the memory cell; values were compressed between
and 1 while taking the magnitude and significance of new data into account. The output layer processed the final hidden state or cell state to produce the desired output, that is, the prediction of the next value or the estimation of the SOC of a battery. During training, backpropagation through time (BPTT) was used to compute gradients and update the weights. To prevent overfitting, the L1/L2 regularization technique was included in the LSTM model by adding a penalty term to the loss function. Furthermore, two dense layers were used in the output layer to take the sequence of hidden states produced by the LSTM layers and transform them into a meaningful prediction of the state of charge.
Figure 8 illustrates that the input was a matrix with dimensions of
and a batch size of 256. After passing through the LSTM and dense layers, the output was transformed into a matrix of dimensions
.
The LSTM model was trained using three different types of optimizers, namely, SWATS, Adam, and SGD, with different learning rates. This approach provided several benefits, such as the ability to choose the most effective optimizer, ensuring good generalization and convergence, adapting to various data characteristics and learning rates, being robust against local minima, and gaining insights for future optimization strategies. Despite the presence of L1/L2 regularization, overfitting could still occur in the LSTM model, particularly if the learning rate was high. This was because a high learning rate could lead to the model learning the training data too well, including the noise, and consequently, the model may not have performed well on unseen data. To mitigate this problem, one can use the SWATS optimizer. The SWATS optimizer is a new optimizer that prevents overfitting by adaptively adjusting the learning rate during training. It is based on the Adam optimizer but adds features such as a moving average of gradients and a decay factor to gradually decrease the learning rate over time. It can be used with any machine learning model but is particularly useful for LSTM models that are prone to overfitting. The Switching Adam to SGD optimizer is a variant that improves the convergence speed of the optimizer by switching to SGD after a certain number of epochs. The SWATS optimizer has shown promising results in preventing overfitting in LSTM models.
In This study, the SWATS optimizer was used to train the LSTM model with different learning rates. The results showed that the SWATS optimizer was able to achieve better performance than that of the other optimizers, including Adam and SGD. The SWATS optimizer prevented overfitting while still achieving good accuracy on the training data.
The LSTM model was trained using the battery manufacturer’s past data to create an offline model that could be used as a benchmark to measure the reliability and precision of the digital twin’s SOC forecasts. This enabled a quantitative assessment of the digital twin’s effectiveness by comparing its predictions with the actual SOC values.
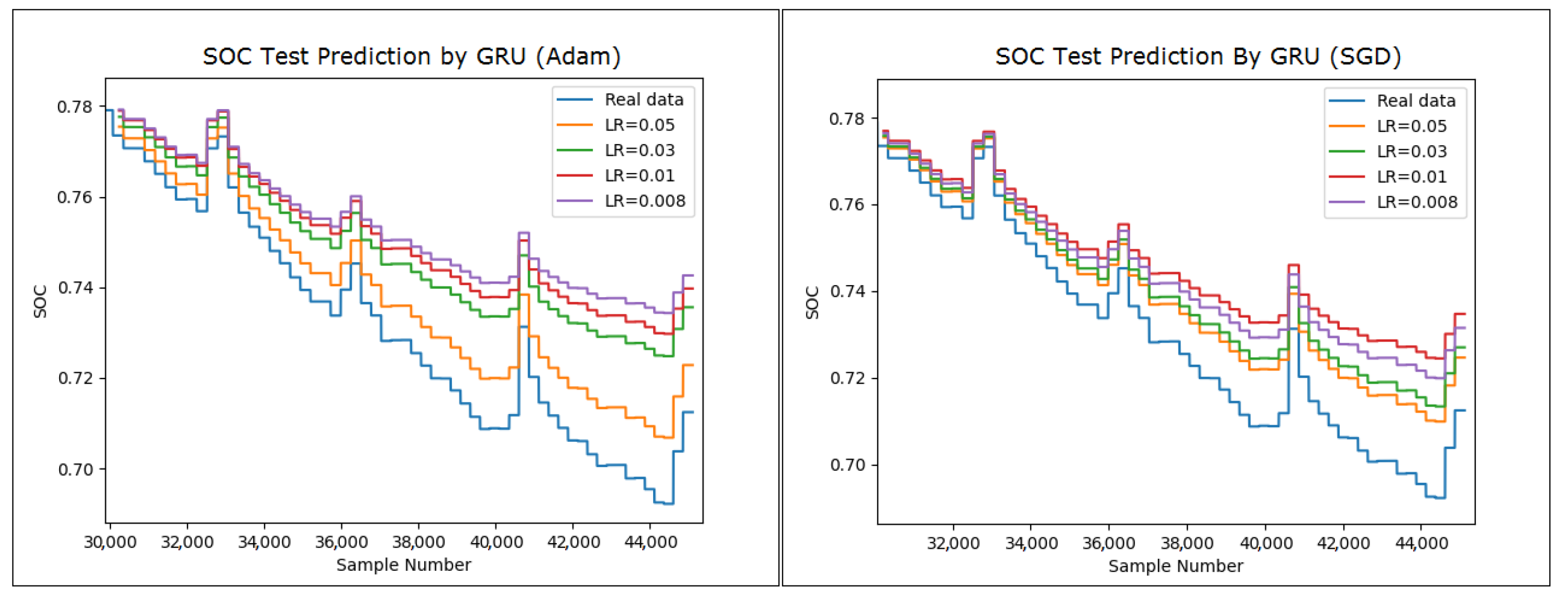
Additionally, we compared the LSTM models trained with different optimizers (SWATS, Adam, and SGD) with a GRU network to understand their strengths and weaknesses in LIB behavior forecasting. LSTM and GRU are both RNN variants but differ in their architecture, which impacts their ability to capture temporal dependencies and handle long-term sequences. GRU networks have a simplified architecture compared to that of LSTM [
48]. GRU networks have a reset gate and an update gate, which control the flow of information within the network. The reset gate determines which parts of the past information should be forgotten, while the update gate decides which parts of the new information should be incorporated. By comparing the performance of both models, we evaluated their suitability for accurate battery behavior forecasting while considering factors such as prediction accuracy, convergence speed, generalization capabilities, and computational efficiency. Two different evaluation metrics, the root mean square error (RMSE), and mean absolute error (MAE), were utilized to evaluate the effectiveness of the proposed model. The formulas for calculating these metrics are presented below.
Following every forward propagation, the model loss was computed as the mean square error (MSE), which involved assessing the deviation between the predicted SOC value and the actual SOC value.
Table 1 presents a summary of the MAE and RMSE outcomes obtained from the LSTM and GRU models while utilizing three distinct optimizers with learning rates of
,
,
, and
. Compared to the other two optimization techniques, the SWATS optimizer exhibited superior performance, effectively mitigating issues related to overfitting and gradient instability. Furthermore, it was evident that the choice of learning rate significantly impacted the accuracy and quality of the predictions. To assess their impacts, we used a range of learning rate values in our simulations. Notably, for battery B0005, the employment of a learning rate of
in conjunction with the SWATS optimizer yielded the most optimal results in terms of SOC calculations. This particular configuration proved to be highly effective for estimating the SOC in this battery model. Moreover, we provide similar simulation results for battery B0006 in
Table 2, battery B0007 in
Table 3, and battery B0018 in
Table 4.
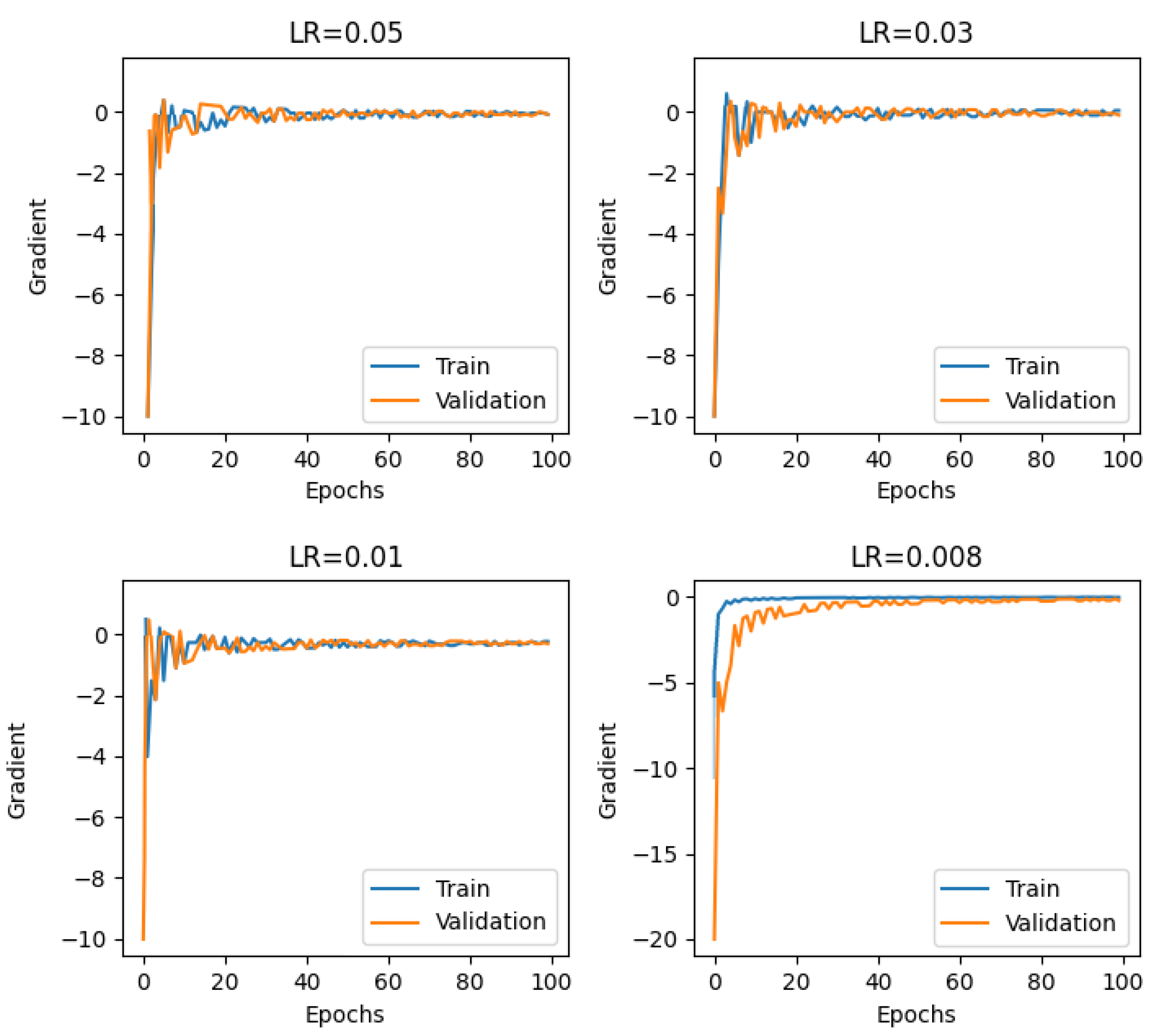
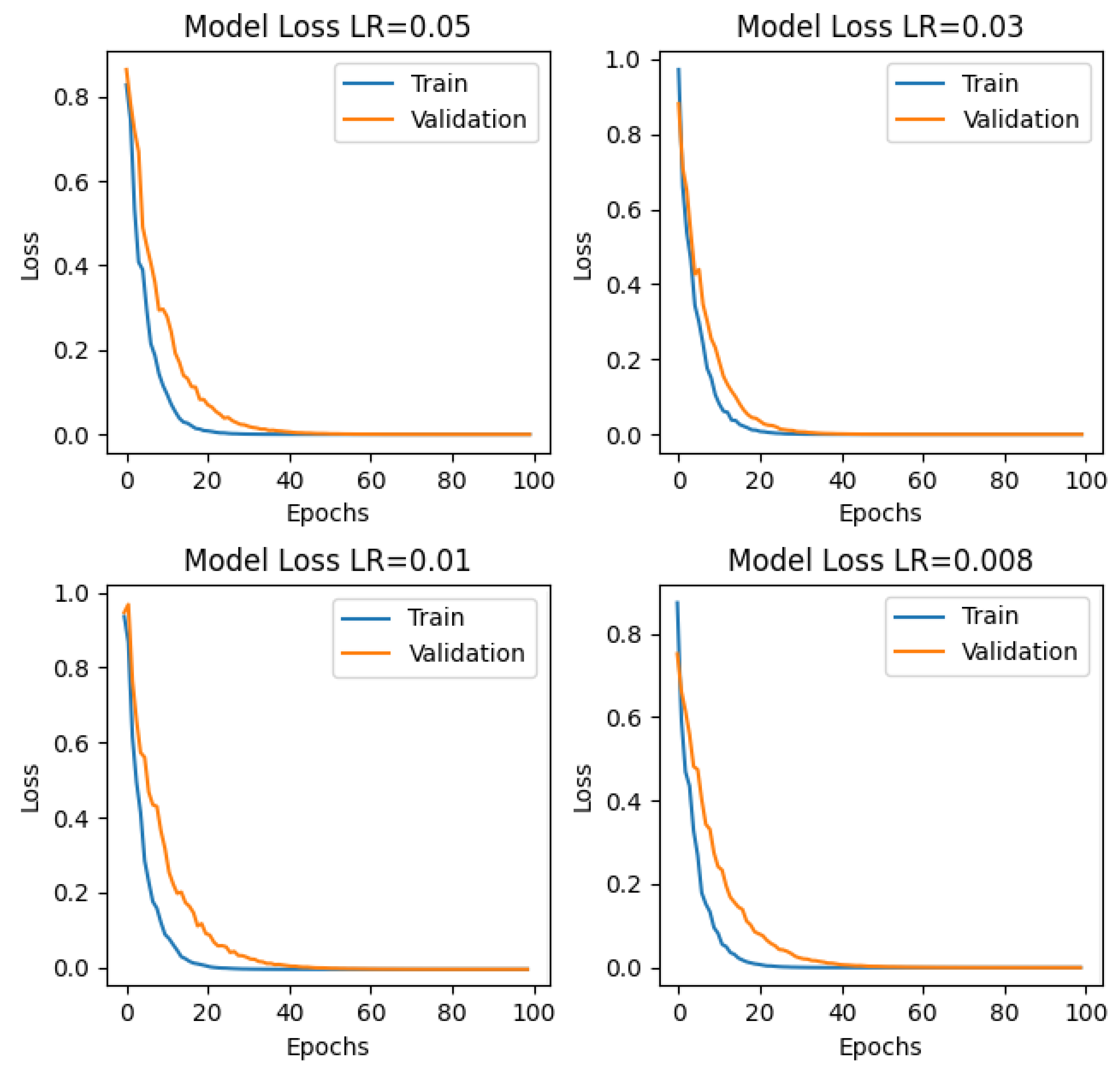
This gives a thorough understanding of how our suggested method performs with and adjusts to different battery models. Finally, the loss function results for the initial 100 epochs of LSTM with the SWATS optimizer are shown in
Table 5. Based on the results that were obtained, the optimal learning rate for battery B0006 with the SWATS optimizer was
, while for battery B0007, it was
, and for battery B0018, it was
. The simulations using the SWATS optimizer yielded the most favorable outcomes and the lowest loss function values for SOC calculation in these batteries. The analysis of the results obtained from battery B0006 indicated that the SWATS optimizer worked best with a learning rate of
. For battery B0007, after careful experimentation, it was found that the most favorable outcomes were achieved with a learning rate of
when used alongside the SWATS optimizer. On the other hand, a learning rate of
was the most effective value, highlighting the adaptability of the SWATS optimizer in B0018 across various battery models. It was noteworthy that the utilization of the SWATS optimizer consistently yielded superlative outcomes across these battery types, which were characterized by the lowest loss function values in the SOC calculation process. In
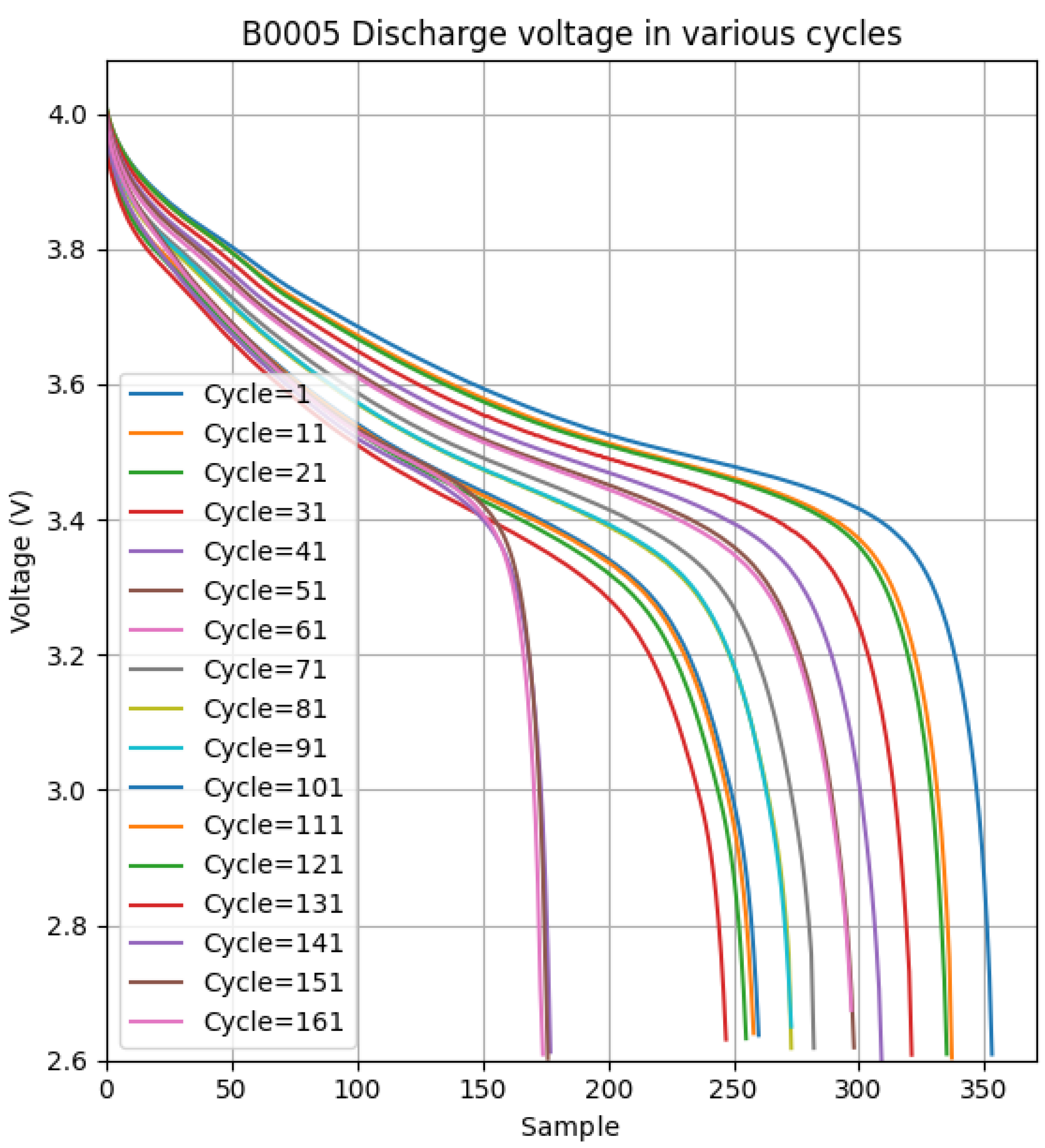
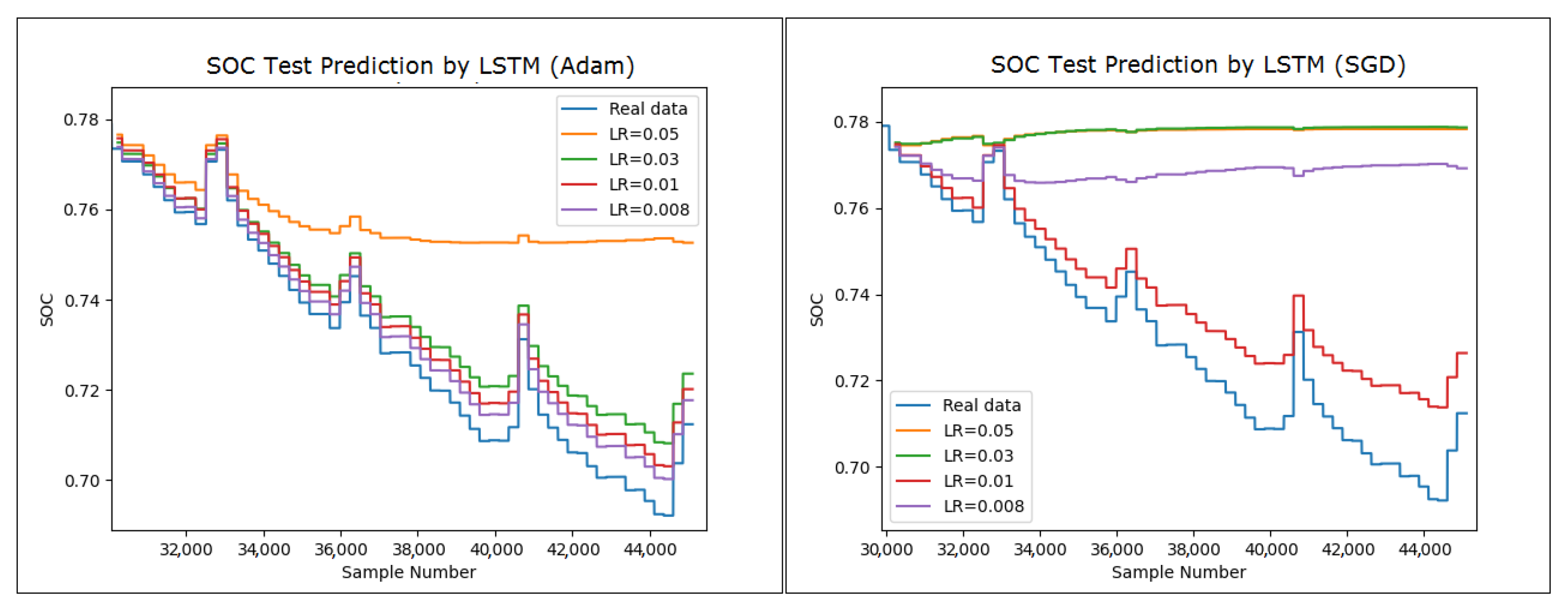
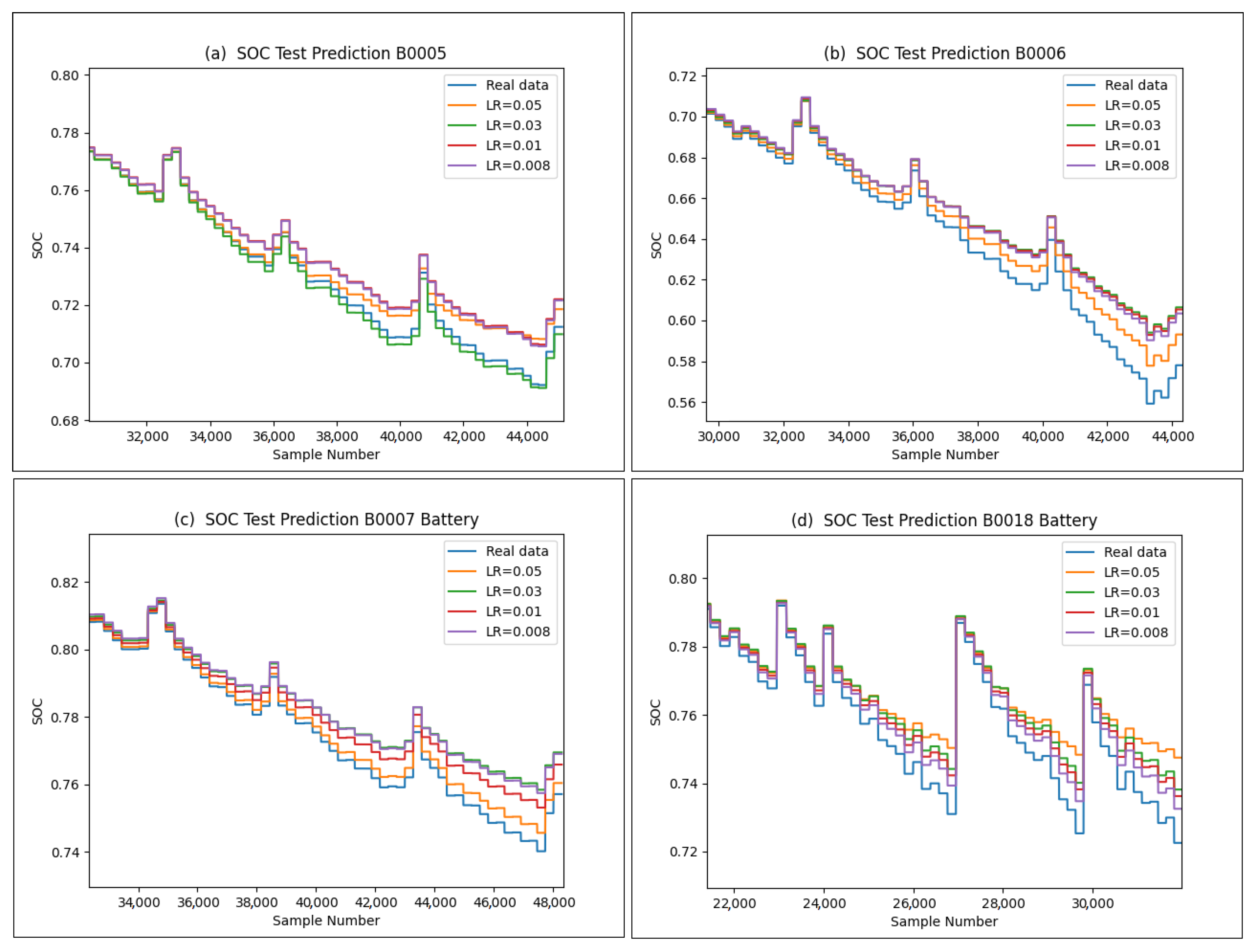
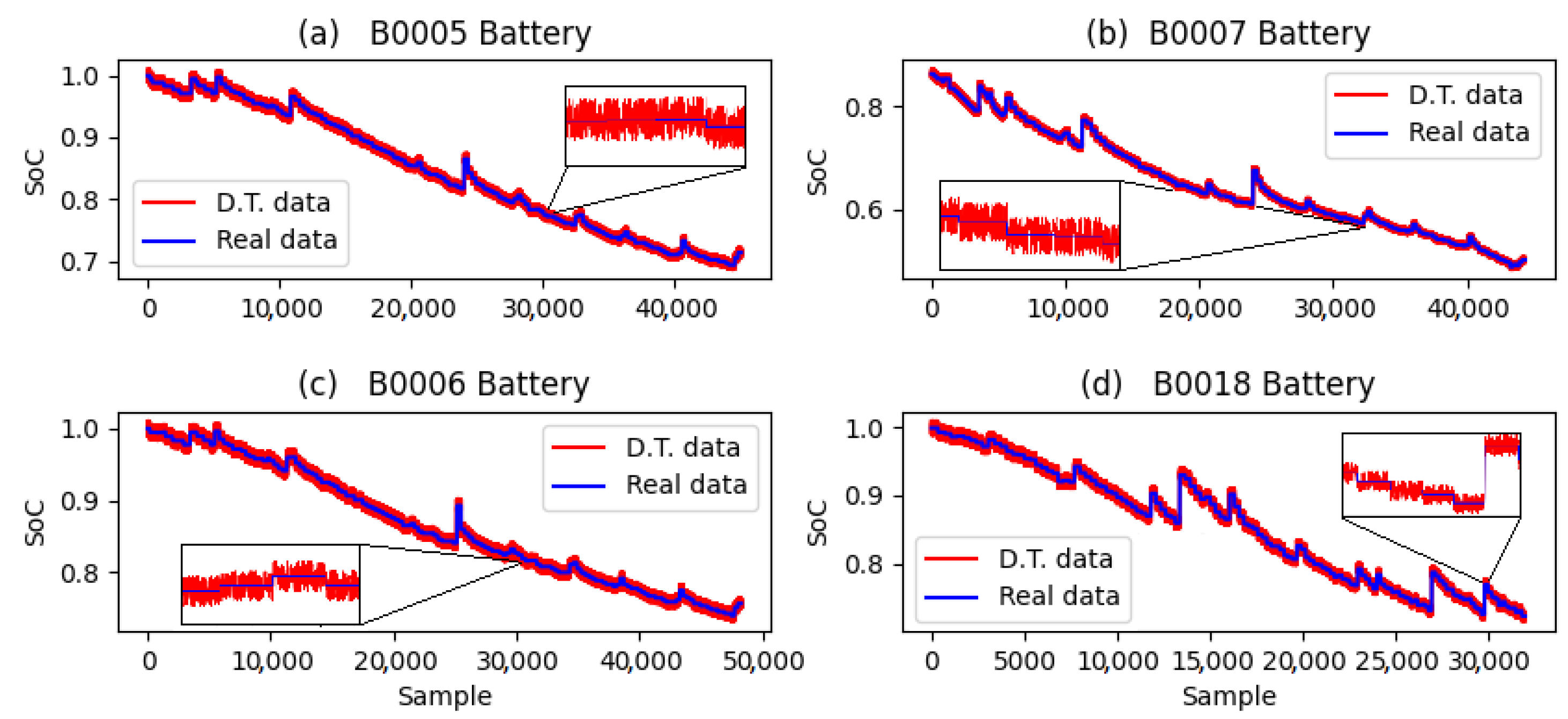
Figure 9, we show in great detail the results of our thorough simulations of the B0005 battery. The findings are summarized in
Figure 10, which showcases the use of the SWATS optimizer for batteries B0005, B0006, B0007, and B0018. In addition, we expanded our investigation to encompass the assessment of the effectiveness of the LSTM network in conjunction with the GRU network. The results of the SOC estimation for the B0005 battery are depicted in
Figure 11, where we utilized different optimizers and learning rates to gain insights into the performance behavior of the network. We will specifically examine the outcomes of our LSTM modeling efforts that were conducted offline with a particular focus on forecasting the SOC using various learning rates in
Section 5.
4.1.4. Problem Formulation for the Generation of Real Data and Simulation Results
GANs were introduced in 2014 [
49] and have proven effective in producing high-quality outputs via a mutual game-learning process between two modules: a generative model and a discriminative model. Generative models—or generators—are responsible for recovering real data distributions. The algorithm takes a random noise vector
Z as an input and generates an output,
, which can be an image or other data format. On the other hand, the discriminator is a type of discriminative model that has the job of differentiating between data samples that come from the training set and those that are created by the generator. It receives input in the form of
x, which can either be actual training data or data that have been generated by the generator. The output score produced by the discriminator is either 1 or 0. If the score is 1, it means that the input is real data, while a score of 0 indicates that the input is false or generated data. The aim of the generative model
G is to understand a distribution
of the data
x. This is achieved by using a function
that maps a prior noise distribution
to the data space, where
represents the model’s parameters. These parameters can be the weights of a multilayer perceptron that is used in
G. On the other hand, the discriminative model
is created as a binary classifier that gives a scalar output that shows the probability of input
x coming from the training data instead of
.
The training process involves a game between two models, which continues until they reach a stable balance point. This ensures that the generator can produce realistic data samples, while the discriminator can accurately distinguish between real and generated data. Both the generator and discriminator networks are trained simultaneously using min–max adversarial loss functions. The generation module’s objective function is stated as follows:
where
D represents the discriminator,
G represents the generator,
V is the adversarial loss function, the real data distribution is denoted by
, and the latent space distribution is represented by
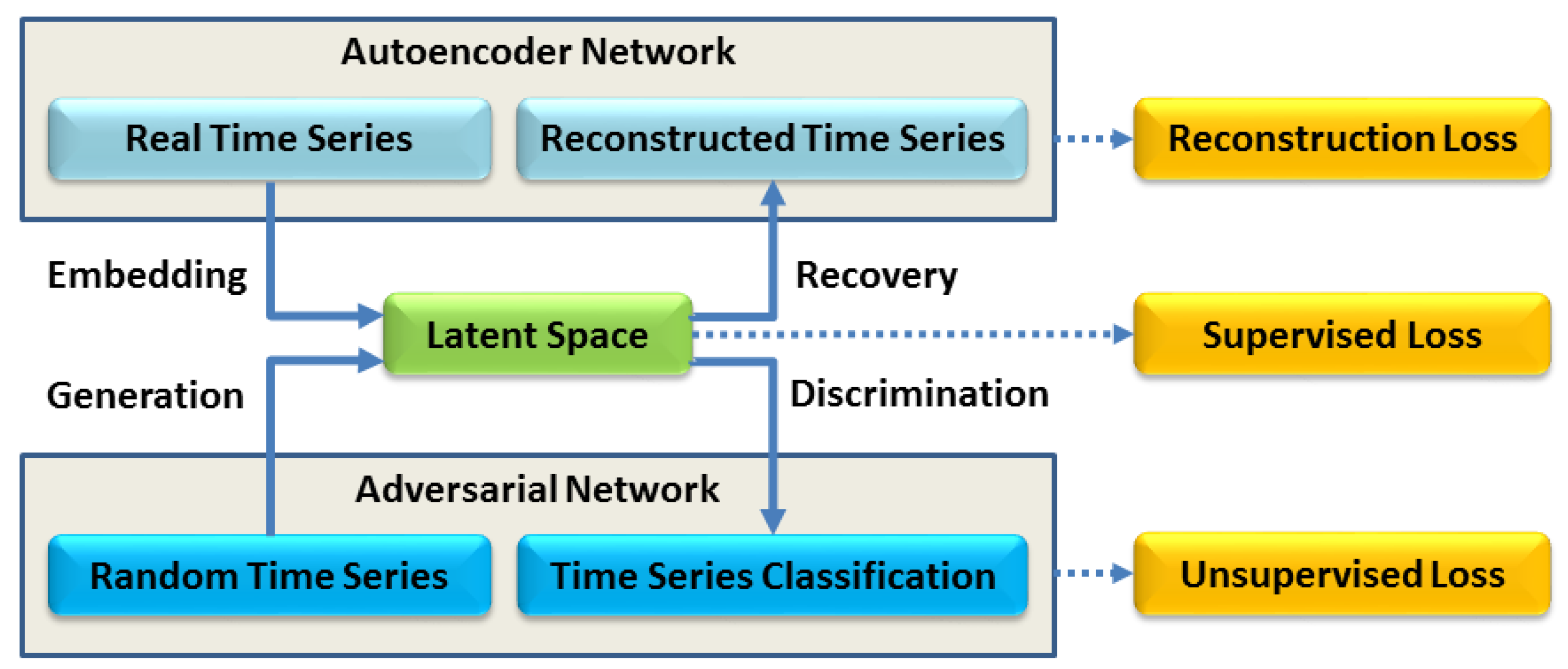
. In order to transform a traditional GAN into a TS-GAN, some modifications in the architecture and training process have to be made. The following is a step-by-step guide for accomplishing this task. The TS-GAN architecture comprises two main components: an autoencoder and an adversarial network (
Figure 12).
The autoencoder is responsible for learning a time-series embedding space that can capture the underlying patterns in the data, while the adversarial network generates artificial time-series data and distinguishes them from real data. The TS-GAN uses both supervised and unsupervised learning objectives during training, and it applies the adversarial loss to both real and synthetic sequences [
43]. In addition, TS-GAN includes a stepwise supervised loss that rewards the model for accurately learning the distribution over transitions from one time point to the next, as observed in historical data.
To implement the TS-GAN architecture, several steps are required; firstly, real historical time-series data, such as EV battery system data, are collected and made ready for training. Alongside this, random time-series data are generated to be used as a benchmark for comparison with the synthetic data that are produced. Next, the key components of the TS-GAN model, which include the autoencoder, sequence generator, and sequence discriminator, are established.
The TS-GAN architecture is made up of various components such as an Embedder, a Recovery, a Generator, a Discriminator, and a Supervisor. Its training involves 10,000 iterations. The Embedder is an RNN-based model that maps real data sequences
to a lower-dimensional space
and captures temporal dependencies.
The Recovery (another RNN-based model) maps embeddings
back to the original data space to reconstruct the time-series data:
The Generator is an RNN-based model that generates synthetic data sequences
from random noise sequences
:
while the Discriminator distinguishes between real time-series data
and generated data
:
represents the probability that is real;
represents the probability that is fake.
The Supervisor acts as an intermediary between the Embedder and the Generator to enhance the quality of the generated sequences. There are two main objectives in the training process: adversarial loss and supervised loss. The adversarial loss can be defined as
The supervised loss can be defined as
The combined adversarial and supervised losses make up the following overall objective:
where
is an objective-balanced hyperparameter. During the initialization phase of the TS-GAN model, an autoencoder is employed to integrate the Generator and the Embedder. The main objective of this approach is to reconstruct genuine data sequences and obtain significant embeddings of the real data. During training, the Generator and Embedder are trained twice as often as the Discriminator to maintain balance. After training, the Generator generates synthetic data sequences, which are transformed back to the original data space using the Recovery model and inverse-scaled to obtain realistic-looking synthetic data. The results of the data generated by the TS-GAN algorithm are shown in
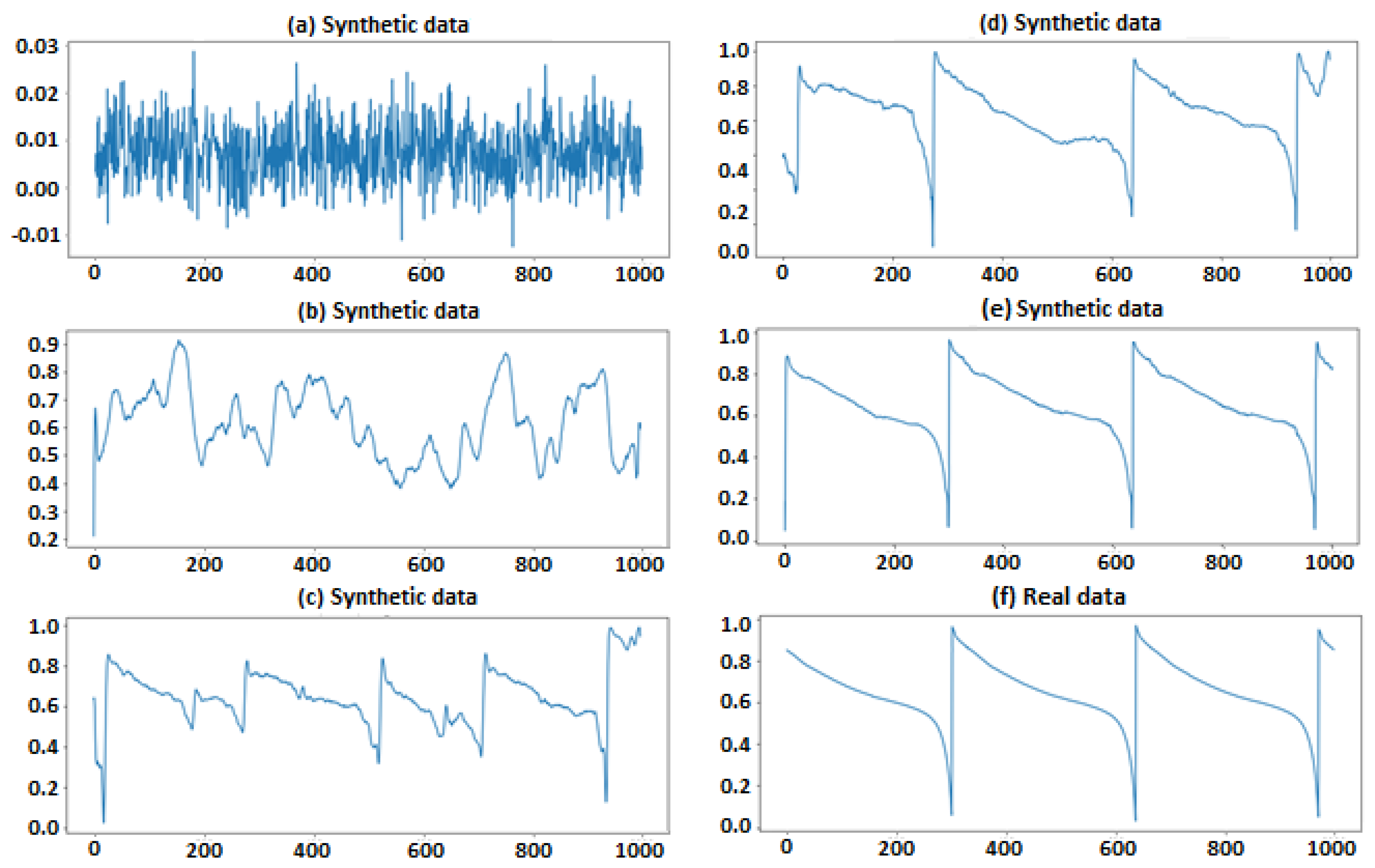
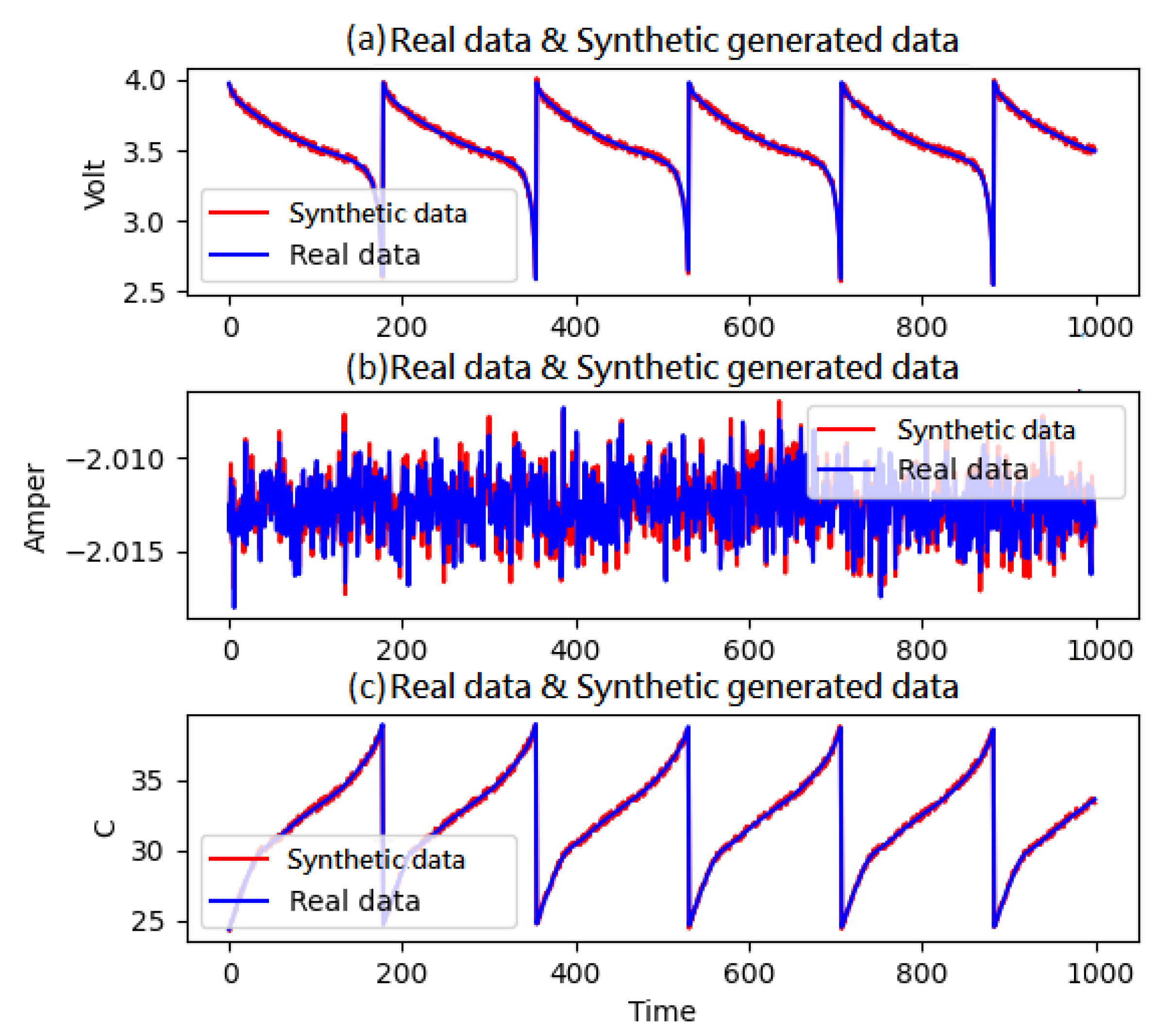
Figure 13.
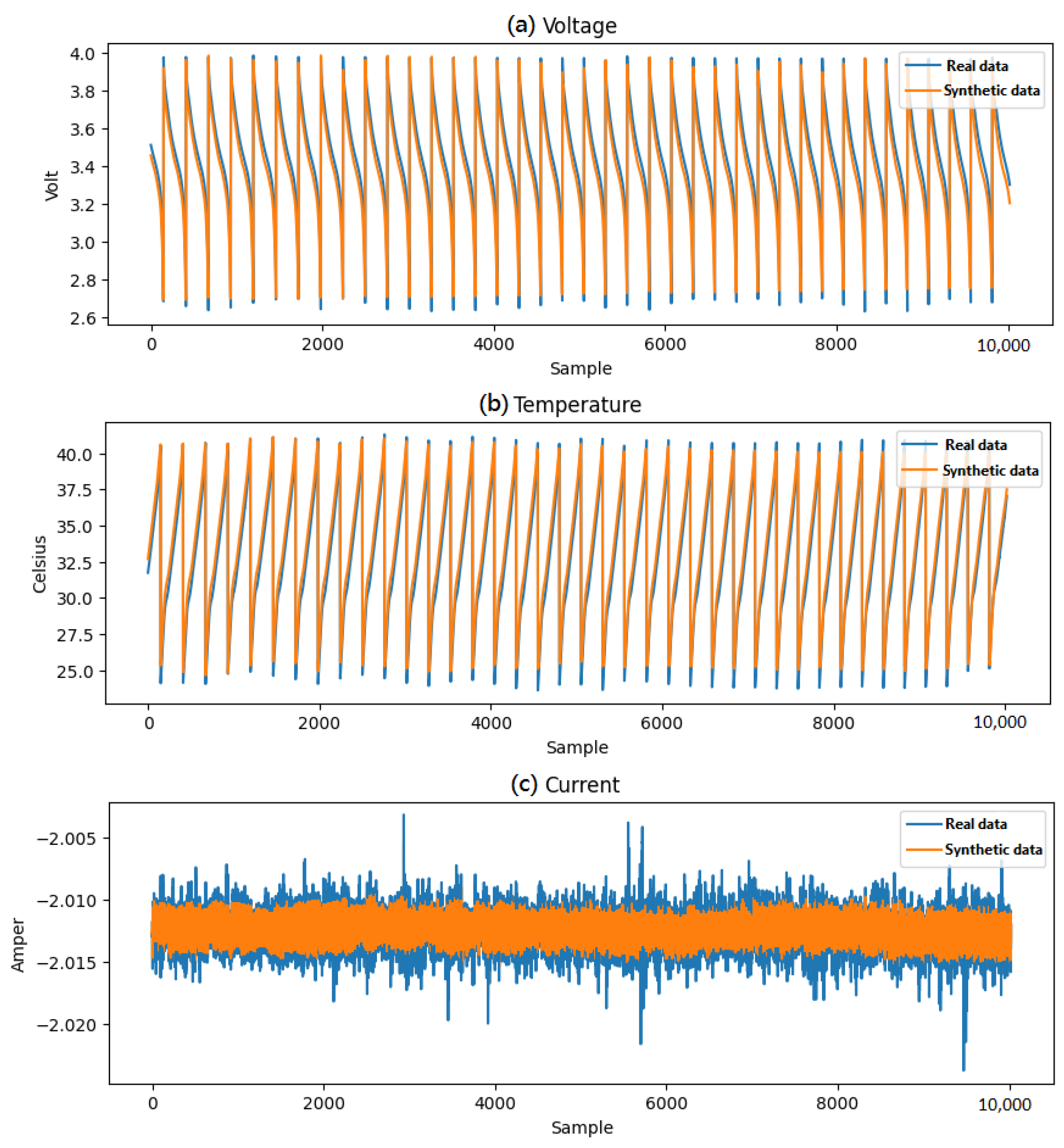
Furthermore, the battery time-series data for B0018 and B0005 are compared in
Figure 14 and
Figure 15 to show the differences between the actual and generated data.
4.1.5. Evaluation of the Synthetic Data
The next step after synthesizing our data was to verify that the new data accurately reproduced the initial battery data. Using evaluation metrics is one of the best ways to compare real and synthetic data. In order to ensure the TS-GAN’s reliability and applicability in real-world scenarios, it was important to accurately evaluate the data generated by it. It is important for the evaluation metric to be carefully selected when dealing with multivariate time-series data, such as those obtained from LIBs. A model’s performance or predictive capabilities may not be significantly affected by small changes in time-series data. Hence, it is crucial to strike a balance between capturing meaningful differences in the generated data and being robust enough to tolerate minor variations. These requirements can be met by the Fréchet inception distance (FID). An objective measure of similarity between a generated data distribution and a real distribution is provided without being excessively influenced by minor fluctuations in the data distribution.
When evaluating data from a TS-GAN—especially historical data instead of real-time data—it is imperative to use an accurate evaluation metric, such as the FID. The FID approach provides objective and quantitative insights into the performance and generalization capabilities of a TS-GAN model, despite the fact that historical data are not ideal for evaluation. As a result, potential overfitting can be detected, generalization can be validated, and the model can be iteratively improved. Through the use of the FID, one can obtain significant insights into the TS-GAN model’s ability to learn from past data and the similarity between the generated data and the actual data distribution, even without real-time data.
Formulation of the Fréchet inception distance: The Fréchet inception distance (FID) is a popular metric used in generative modeling, including for time-series data. The authors of [
50] employed the FID metric to evaluate the performance of a new update rule called the two-time-scale update rule (TTUR) on various datasets. The TTUR is a strategy used in training generative adversarial networks (GANs) with stochastic gradient descent. It is designed to address convergence issues and enhance learning for GANs, leading to improved results in tasks such as image generation. The evaluation involves deep learning and feature extraction to gauge the dissimilarity between two probability distributions. In order to evaluate the accuracy of the data produced by TS-GAN, we utilized the FID to measure the disparity between the feature representations of the generated time-series data and the original time-series data. This was achieved by utilizing a pre-trained neural network, which is usually an Inception-v3 network (a deep convolutional neural network architecture), to extract high-level features from both types of time-series data. The FID is calculated as follows:
is the mean of the feature representations of the real data samples;
is the mean of the feature representations of the generated data samples;
is the covariance matrix of the feature representations of the real data samples;
is the covariance matrix of the feature representations of the generated data samples;
denotes the matrix transposition operation.
By taking the multivariate nature of time-series data into account, the FID metric captures the relevant relationships and patterns for precise evaluation. It offers a reliable and informative measure of the similarity between the two distributions. A lower FID score suggests a higher similarity, indicating that the generated data closely resemble the actual data. This demonstrates the effectiveness of the TS-GAN model in replicating the underlying dynamics of the target system. In conclusion, the FID metric is a valuable tool for impartial and precise evaluation of TS-GAN-generated data, contributing to the advancement and application of this technology in real-world scenarios involving LIBs and beyond. Based on the FID metric,
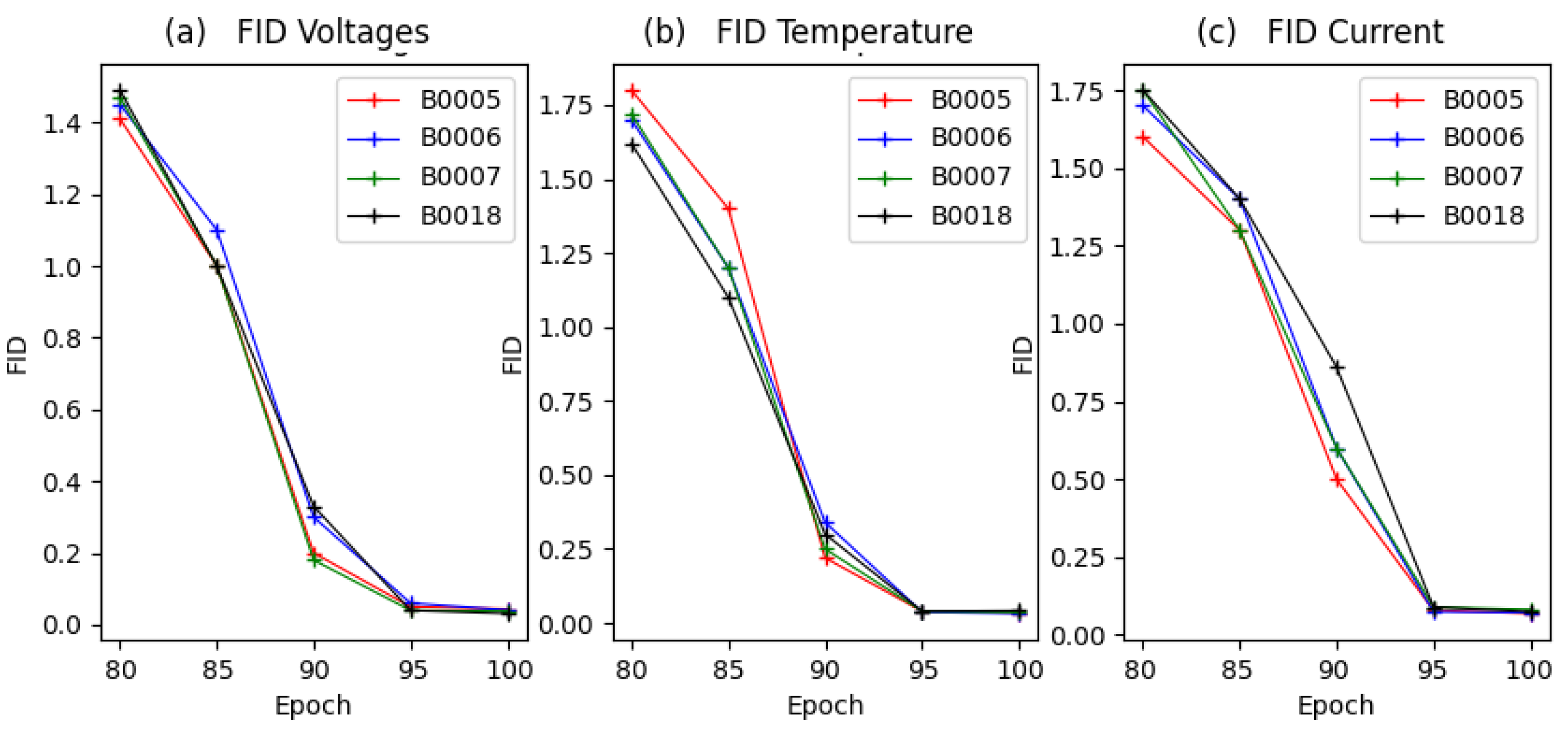
Figure 16 illustrates the results of the evaluation of the TS-GAN data.
To apply the FID on two distinct datasets, namely, a historical dataset and a real-time dataset of lithium-ion batteries produced by the TS-GAN, we utilized TensorFlow. The process involved loading and preprocessing the pre-trained Inception-v3 model, extracting features from both datasets using the same pre-trained Inception-v3 model, computing the mean and covariance matrix for each dataset, and, finally, computing the FID score based on the mean and covariance matrix of the two datasets. The results are shown in
Table 6.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}