1. Introduction
Convolutional neural networks (CNNs) have become top-rated tools in recent years in digital image processing for pattern recognition tasks like detection, localization, segmentation, and classification [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11]. They have the capability to learn parameters of convolutional filters to extract those significant, higher-order features, which can be used to distinguish images belonging to different classes. The training phase requires thousands of manually labeled images and large-scale computational capacity. The proposed CNNs are sufficiently general to apply them to various classification problems with high accuracy. However, if we intend to improve the classification performance, we may consider the composition of an ensemble from these networks.
Several papers can be found in the literature that consider ensembles of deep learning-based classifiers. Especially, ensemble-based techniques are rather popular to handle regression [
12,
13], classification [
14,
15,
16], segmentation [
17] and metric learning [
18] tasks. A pioneer work is [
19], where the authors showed that an ensemble of neural networks could achieve higher accuracy than a single one. When we use an ensemble of CNNs or other machine learning-based methods, we have to take into account the following two critical issues: first, how to merge the outputs of the members, and second, how to achieve their diverse behavior to raise accuracy.
There are several ways to aggregate the outputs of the ensemble members. We can calculate, for example, their simple average, arithmetic mean [
20] or weighted average. In a weighted aggregation scheme, the weights are usually determined based on the performances of the ensemble members [
12,
17,
21] or by some learning algorithm [
14]. We might as well apply voting, where the most common method is the majority-based one [
22,
23,
24]. Moreover, there exist methods which involve also the confidence of the members [
25] or assign weights to the voters [
26]. In general, the weighting approaches perform better than the unweighted ones because they have extra parameters, which usually lead to a better fit.
Applying a machine learning method for merging the outputs is also quite common, including support vector machine [
14], random forest [
26], simulated annealing [
27], or multi-layer perceptron (MLP) [
14]. The main benefit of these learning-based methods is the capability to find the best combination of the members. The cited methods also have a common property: they are used in an offline manner. That is, the members of the ensemble learn their parameters separately before their aggregation. Training the members separately is time consuming and also much harder to make them less correlated, which helps to increase the diversity. On the other hand, we can incorporate the aggregation in the neural architecture to set up an online ensemble with considering fusion layers and concatenation to merge the member outputs. When we use such an ensemble, the members simultaneously can learn their parameters [
18,
28,
29,
30], as well. This simultaneous learning shortens the training time, which is a critical issue in deep learning.
Besides the aggregation scheme, another important question is how to achieve large diversity among the members. A corresponding early work [
31] recognized that without diversity, the performance of the ensemble becomes limited. There are several methods which could be applied to rise of the diversity of the members. Since offline ensembles are more widespread currently, we start with them first. A possible way is to apply different pre-processing methods [
15,
23] to make the input more diverse, thus the members also learn different parameters to recognize the various patterns. Others proposed different model architectures [
20,
25,
26] or various kernel sizes and model depth [
12]. With the same model architecture but cyclic change of the learning rate, we can also obtain diverse models. This approach is called SnapShot learning [
32,
33,
34] and is able to find different local minima of the loss function that makes the members more diverse. In [
22], diversity is raised by splitting an inner layer’s outputs to feed them into other networks. Another possibility is to use custom class weights in the loss function during training [
17,
23]. With these custom weights, the learning algorithm can be forced to focus on different classes in the training data.
Some of the methods listed so far can be also used online, including, for example, using different pre-processing techniques [
29] or different model architectures [
35]. However, the simplest and most efficient way for online ensembles is to incorporate the diversity constraints directly into the loss function. The first work that inserted a correlation penalty term in the loss function to force the gradient descent algorithm to learn more diverse ensembles was [
13]. This so-called negative correlation learning (NCL) was successfully applied to regression with MLP and used mean square error to calculate the loss. In [
28], the same NCL technique was considered for CNN in crowd counting, age estimation, personality analysis and single-image super-resolution tasks. An inner layer of the CNN was split, and the separated outputs were fed into three “sub-networks”. The NCL method was combined with AdaBoost for MLPs in [
36] to solve classification problems. In [
18], a custom loss function was presented to achieve a diverse and less correlated embedding for image metric learning. The cosine similarity also can be used as a penalty term to raise diversity [
29]. The cooperative ensemble was also investigated here by KL-divergence and was combined with differently pre-processed images and network dropout to make it more diverse.
In the current work, we propose an online ensemble technique for image classification. As our main contribution, we introduce a new, more refined penalty term than NCL for a loss function dedicated to classification purposes. Namely, we use the Pearson-correlation penalty term instead of the simple one of NCL, which is able to simultaneously support the correlation for correct decisions, while supporting uncorrelated behaviors of the members for false decisions. On the other hand, instead of using MSE like in the former works related to NCL, we use categorical cross entropy, which is currently a better accepted loss function for classification scenarios. Nevertheless, notice that though we use our penalty term with a cross-entropy loss, it can be applied to any other one in the same way. Finally, as a supplementary step, we also adopt the strategy to include different types of member architectures.
In our former work [
35], we combined different individual CNN architectures that have already proven their efficiencies in pattern recognition scenarios. We elaborated on an ensemble-based framework, which can be successfully applied to improve the accuracy of individual CNNs if the expansion of the training image set is not possible. We trained the four CNN architectures GoogLeNet [
37], AlexNet [
38], ResNet [
39] and VGGNet [
40] and aggregated their outputs. We showed how to train different CNNs in parallel and fuse their outputs based on specific mathematical and statistical models to improve the final classification accuracy. This solution can be considered a rather loosely connected ensemble-based system since the members are trained completely independently from each other.
As an improvement, we proposed the fusion of the CNNs at the architecture level in a later work. Thus, we composed a much more complex, combined super-network and trained the involved members as a whole [
41]. More specifically, we interconnected the members with inserting a joint fully connected layer followed by the classic softmax/classification ones for the final prediction. In this way, we created a single network architecture from the member CNNs, which can be trained by backpropagation in a standard way.
In this work, we improve the final classification accuracy of the composed ensemble further by forcing the members to adjust their parameters during backpropagation to increase the diversity in their decisions. More specifically, we join the member CNNs via a fully connected layer and introduce a new term in the loss function as a correlation penalty, which rises when the individual neural networks misclassify at the same time. With this approach, we implement the traditional common guideline to increase the diverse behaviors of the members also for ensembles of CNNs. As an additional theoretical contribution, we properly determine the derivative of the introduced loss function to be able to implement the backpropagation procedure efficiently. The benefits of our general method is demonstrated on four classification problems related to natural images and medical ones. Besides the theoretical considerations and foundations, our experimental results suggest that the proposed approach is a highly competitive one.
The rest of the paper is organized as follows. In
Section 2, we introduce our methodology for creating an ensemble of CNNs. We also present how a term penalizing the correlation of the member CNNs on the false decisions is added to the loss function. To highlight our main contribution, we also give a formal derivation to prove the positive effects of our penalty term for the ensemble diversity. We also provide the partial derivatives of the penalty term in a closed form to be able to integrate it seamlessly to the backpropagation process to adjust the corresponding weights in the joint network.
Section 3 is dedicated to our experimental results in classification tasks related to the automatic recognition of skin cancer and the severity of diabetic retinopathy (DR) from several aspects and evaluating our method on well-known natural image data sets, as well. We also compare our method with some state-of-the-art ensemble-based techniques suggested for the same type of classification tasks. Finally, some conclusions are drawn in
Section 4.
2. Learning Methodology
Recently, in the field of natural image classification, several CNN architectures have been released, like GoogLeNet [
37], AlexNet [
38], ResNet [
39], VGGNet [
40], DensNet [
42], and MobileNet [
43], besides others. Some of these architectures are available as pre-trained models initially trained on approximately 1.28 million natural images from the data set ImageNet [
44]. Thus, as a transfer learning approach [
45], we can use the weights and biases from these pre-trained models. That is, if we fine-tune all the layers of these models by going on with the backpropagation using our data, they can be applied to our specific classification task, as well. On the other hand, if we have sufficiently many annotated images to train from scratch, we can initialize the parameters of the CNNs randomly.
This study considers both randomly initialized and pre-trained networks also designed for deep learning purposes. We fuse these networks during the creation of the ensemble and produce a directed acyclic graph, where layers can have inputs from multiple ones. In practice, we combine the outputs of the members using a concatenation layer, which is a dense one. The general aim of an ensemble system is to benefit from the members’ strengths while overcoming their weaknesses. Unfortunately, some critical problems may arise during the combination of members’ outputs. The worst situation is when more than one member predicts the same wrong class label for the same input because member classifiers are trained on the same data set to minimize the same loss function. To improve the final accuracy in image classification, we elaborated a method that ensures that the outputs of the members will be combined efficiently, and their diversity (regarding the wrongly classified cases) is also aimed to be increased.
As a realization of this idea, we create an ensemble of some well-known CNNs to increase classification accuracy via a new network architecture. The interconnection of the member CNNs is solved with an additional fully connected (FC) layer inserted after the last FC layers of the original CNNs. We initialize/load the weights of this layer and extend the categorical/binary cross-entropy loss function with an extra term, which can be considered a correlation penalty to enforce more diverse behavior of the participating CNNs. In this study, cross entropy is considered, as it has been widely used as a single loss function and also to construct a hybrid loss function particularly for object classification [
46,
47,
48,
49]. However, our approach also supports any other loss functions. As the main contribution of this work, we implement the common guideline with adding a new term to diversify the members for the ensemble of CNNs. In this way, the constructed ensemble architecture can train the weights of the combination of two or more networks according to their diversity.
2.1. The Fusion of the Member Networks
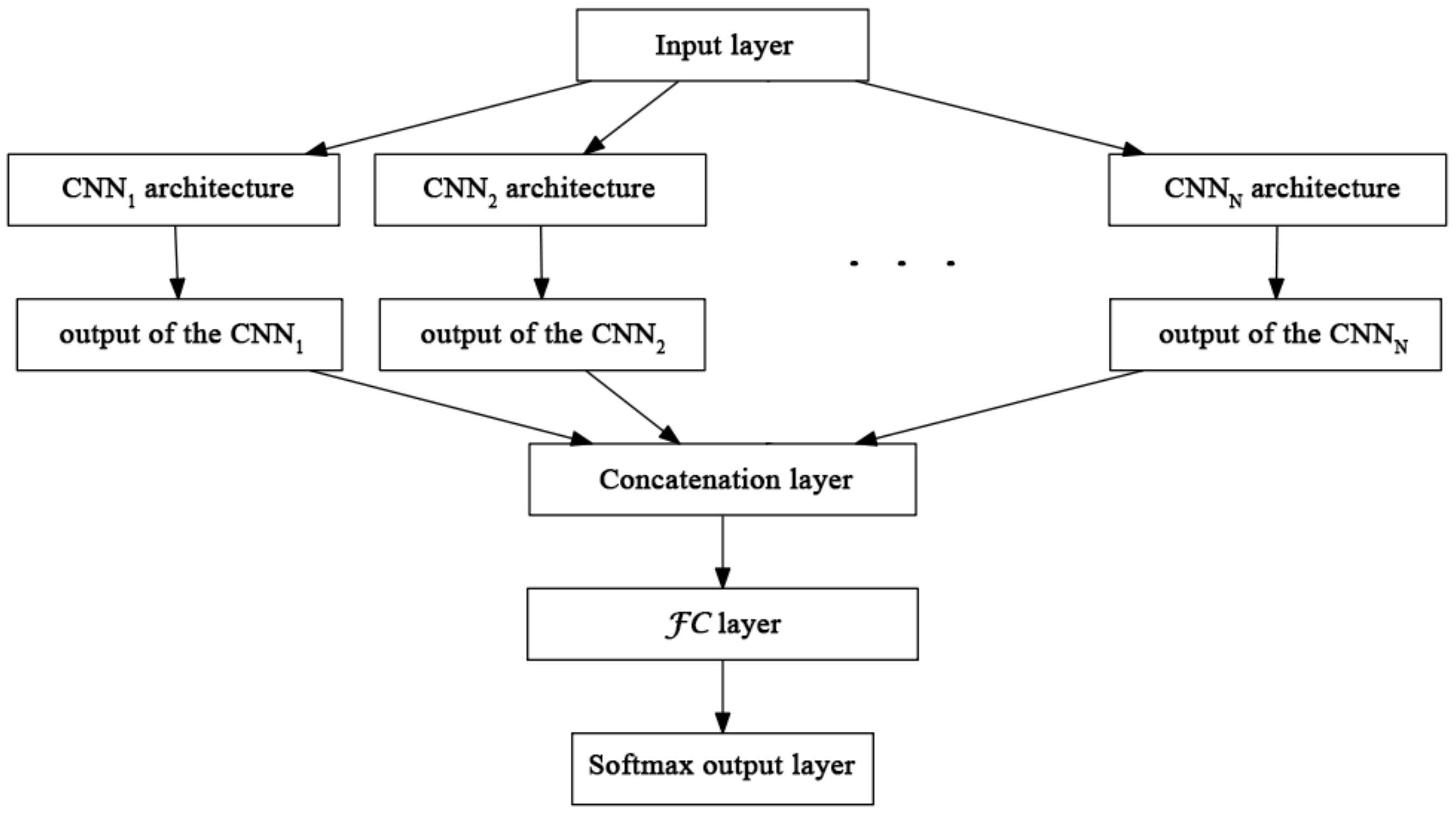
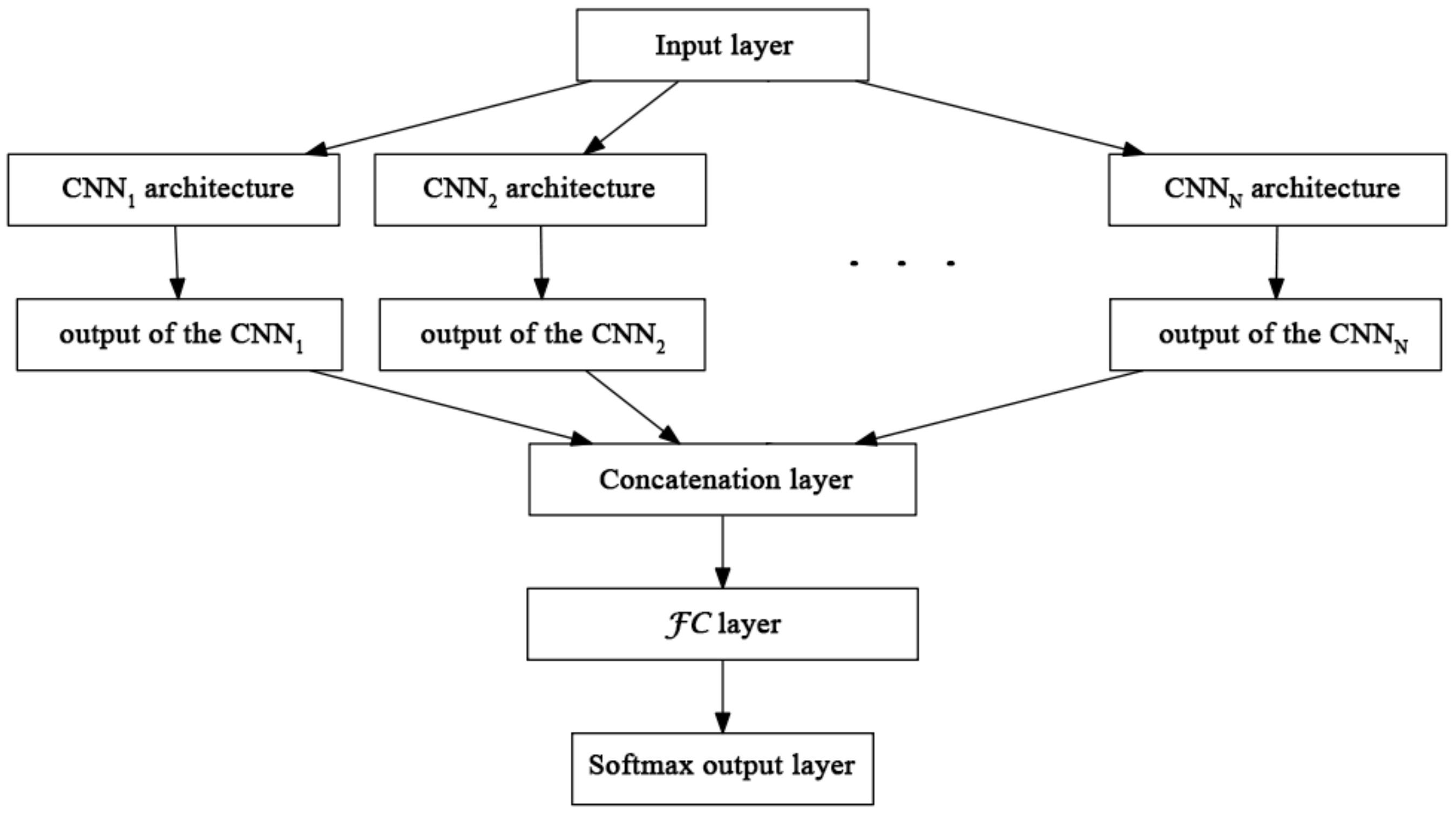
This section presents how we produce a single neural network architecture as an ensemble of
N member CNNs. For this aim, we remove their softmax output layers. To prepare the member CNNs for the current classification task, we replace their last FC layers with other ones, whose output sizes are set to the required number of classes. We connect the CNNs via these FC layers with a concatenation one and combine them with an additional fully connected layer
. The input of
is a concatenated vector built from the outputs of the member CNNs, and the
layer creates its output as a weighted combination of these values, as it can be seen in
Figure 1.
To give the proper formal description of our approach, let us denote the training set by
where the given true labels are
Here,
M denotes the number of samples in the training set, while
L is the number of classes (typically
) and the labels
are
L-dimensional one-hot vectors. For the
n-th training sample, let
be the output of the softmax layer of the
i-th CNN (
), which is a probability distribution vector of dimension
L, where the
i-th coordinate gives the probability that the given training sample corresponds to the
i-th class. As an ensemble of the member networks, the
layer computes the linear combination
where the coefficients
are initialized as
matrices close to a diagonal one with equal weights in their diagonals and small (
) values outside the diagonal:
Practically, that means that we take approximately the arithmetical mean of the outputs of the members initially. However, the weights of these vectors are trainable parameters of the network, so these parameters are also changed during the backpropagation steps of the training phase. To follow the common principles, at the end of this ensemble, we also insert a softmax layer to convert the vector to a probability distribution .
2.2. The Loss Function
To increase the diversity of the member networks and avoid the jointly misclassified items, we introduce a new loss function to achieve higher final classification accuracy. We supply the cross-entropy loss function with our proposed penalty term, penalizing when the member networks work similarly wrong and simultaneously supporting correct decisions.
For this aim, we define the penalty function
E with the help of the Pearson correlation coefficient. If
and
are
K-dimensional vectors, then their Pearson correlation coefficient can be calculated as
where
and
are the means of
X and
Y, while
and
denote the corresponding standard deviations, respectively.
Using the notation introduced in
Section 2.1, let
be the correlation matrix of the vectors
,
and
:
which is a symmetric one of dimension
.
Then, the penalty term
E is defined as
That is, we consider the upper-left part of the matrix , take the sum of the entries in the upper triangular part of this latter matrix, and add the sum of elements in the last column of with weight N. Finally, we calculate the mean of the values for . Note that the values standing in the main diagonal of are equal to 1, which means a constant term in the penalty function.
As a next step, we give a formal proof that the penalty term
E introduced in (
2) owns the properties to improve the ensemble performance.
Proposition 1. Including the penalty term (2) provides a loss function, having increasing values according to the order of the following cases: All the experts (member networks) classify the n-th training sample correctly;
Some of the experts do not assign the n-th training sample to the true class, but their outputs are different classes;
Some of the experts classify the n-th training sample in the same false class;
All experts assign the n-th training sample to false classes, but these classes differ;
All experts assign the n-th training sample to the same false class.
We use the penalty term
E with a
weight in the final loss function:
where
is the original cross-entropy loss function. The role of
is to control the effect of the penalty term: increasing its value means that we try to increase the diversity of the member networks. Naturally, a too-high
value has a negative effect, because in this case, the diversity operates against the accuracy.
Finally, to help the implementation of the backpropagation process, we describe the partial derivative of the penalty term with respect to the coordinates of
for
. Denoting by
the
m-th coordinate of
, we obtain that
where the partial derivatives of the correlation coefficients can be calculated as
3. Application to Image Classification Problems
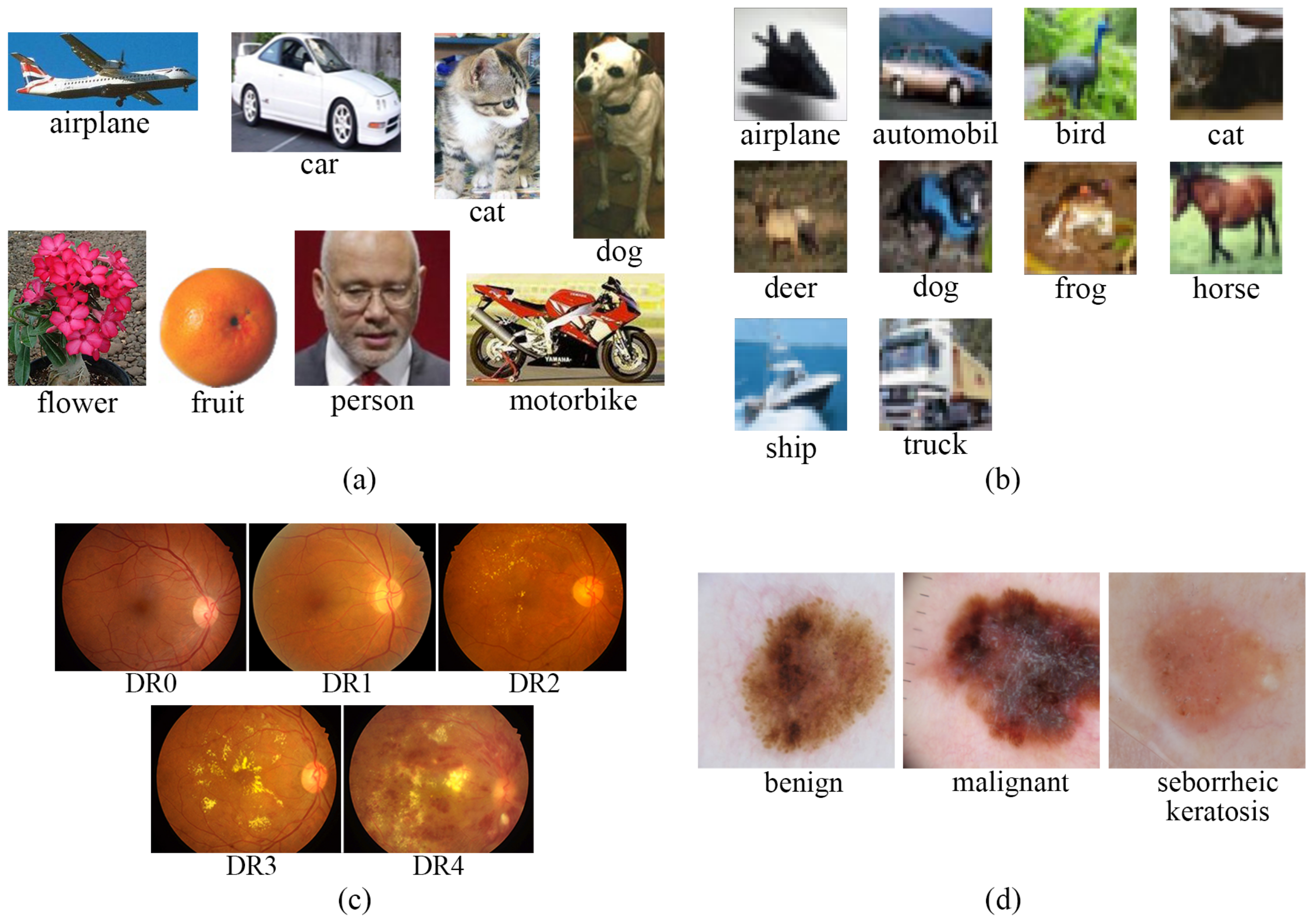
For the experimental evaluation of our approach, we used some different well-known CNNs and composed their ensembles to show the usability of our proposed solution. We also demonstrate the positive effects of our penalization term on the classification accuracy by reducing the correlation of the members’ outputs. We involved four different image sets (see
Figure 2) for the comprehensive evaluation and used them to train the models and evaluate their performances.
3.1. Data Sets and Preparations
To show the improvement obtained by using the proposed penalty term, we evaluated our approach on the natural image sets ISINI [
50], and CIFAR-10 [
51], which are the commonly used ones in the related literature. Moreover, as a special field currently investigated by us, we also involved the skin lesion data set [
52] and the DR ones [
53,
54,
55] to see the possible classification accuracy gain provided by greater diversity.
3.1.1. ISINI Image Set
The ISINI data set is published by Prasun et al. in [
50], and it contains 6899 images classified into eight classes: airplane, car, cat, dog, flower, fruit, motorbike, and person (see sample images in
Figure 2a). All the classes contain almost the same number of items (727, 968, 885, 702, 843, 1000, 788, and 986 samples from the eight classes, respectively), which supports the efficient training of the CNNs for each class. The images have different resolutions varying from
to
pixels, hence we resized them to the same size of
pixels to overcome these differences. To train the neural networks, we split the set into training (5519) and test (1380) parts with keeping up the original ratio among the classes.
3.1.2. CIFAR-10 Image Set
The CIFAR-10 natural image set is published in [
51] by Krizhevsky et al. in 2009, and it is one of the most commonly used data sets for the evaluation of different CNNs. The CIFAR-10 data set consists of 60,000
color images in 10 classes, with 6000 images per class. The low resolution of these images can also be observed in
Figure 2b. In total, 50,000 training and 10,000 test images are provided, and we also used this original partitioning. The class labels are airplane, automobile, bird, cat, deer, dog, frog, horse, ship, and truck. As for this data set, the original image resolution was kept and instead of resizing the images, we replaced the input layers of the architecture with the appropriate ones.
3.1.3. DR Image Set
To prove the usability of the proposed ensemble model and the penalty term, we considered a DR image classification task to check whether the performance can be increased in this application as well. We merged the data sets Kaggle DR [
54], Messidor [
55], and the Indian Diabetic Retinopathy Image Dataset (IDRiD) [
53] into a single one and split it into a training and test part. Each of the three data sets contains digital retinal images of different resolutions (400 × 315, 1440 × 960, 2240 × 1488, 2304 × 1536, 4288 × 2848, and 5184 × 3456 pixels) and different fields of view. Each image is categorized according to the severity of DR (5 classes), which means the images are labeled as no (DR0), mild (DR1), moderate (DR2), severe (DR3), and proliferative DR (DR4). Some sample images from these classes can be seen in
Figure 2c. The DR grading score is provided for 18,127/4529 training/test images, among which 9975/2493 are categorized as DR0, 2085/520 as DR1, 4537/1134 as DR2, 757/189 as DR3, and 773/193 as DR4.
3.1.4. ISIC Image Set
To have an even more reliable evaluation for the clinical domain as our primary target, we considered a skin lesion image set as well. The ISIC image set was published by Codella et al. in [
52], which has a training part containing 2000 images (samples can be seen in
Figure 2d) with manual annotations regarding three different classes in the following compounds: 1372 images with nevus, 254 with seborrheic keratosis, and 374 ones with malignant skin tumors. The images from this training set were used to fine tune the constructed ensemble network, and the evaluation was performed on the test set. The test set consists of 393 nevus, 90 melanoma, and 117 seborrheic keratosis images, respectively.
3.1.5. Image Augmentation
Regarding the ISINI, ISIC, and DR data sets, the volumes of images in certain classes are not sufficiently large to train CNNs and their ensembles [
44] without overfitting. To overcome this issue, we followed the common recommendation regarding the augmentation of the training data set. There are several possibilities for data augmentation, like image shearing with randomly selected angle (max:
) in the counter-clockwise direction, random zooming from range [
–
], flipping horizontally, and rotating with different random angles. Using such transformations, we made some minor modifications to the training images, which helps to avoid the overfitting of the models.
3.2. Convolution Neural Networks and Their Ensemble
As for the design of the ensemble network architecture, our main motivation was to use reliable classifiers as backbone architectures and compare the aggregated results to their original individual accuracies. In the field of natural image classification, several CNN architectures have been released, like AlexNet, VGG16, GoogLeNet Inception-v3, MobileNetV2 and ResNet50, which were reported to show solid performances.
AlexNet consists of five convolutional layers some of which are followed by max-pooling layers and three FC layers with a final softmax one. The FC layer before the last one has 4096 neurons, which means that it extracts the same number of features from each input image and uses them to predict the class label at the last FC layer. VGGNet has a depth between 16 and 19 layers and consists of small-sized convolutional filters. In VGG16, we used the configuration consisting of 13 convolutional layers with filters of size
pixels. A stack of convolutional layers is followed by three FC layers, where the last one has the same number of neurons as the class labels required. For the medical image classification tasks, some deeper and newer architectures are also involved in our ensembles, such as MobileNetV2, ResNet50, and GoogLeNet Inception-v3. The MobileNetV2 is based on an inverted residual structure, and its intermediate expansion layer uses lightweight convolutions to extract important features of the image. This CNN contains initial fully convolution layer with 32 filters, followed by 19 residual bottleneck layers. ResNet50 has 48 convolution layers along with 1 max-pool layer and 1 average-pool layer. This network architecture can handle the problem of vanishing/exploding gradients with the benefit of shortcut identity mapping, which is known as the deep residual learning technique. Finally, we considered GoogLeNet Inception-v3 for our ensemble regarding the dermatology image classification task, as GoogLeNet is reported to show a solid performance in skin lesion classification [
56], as well.
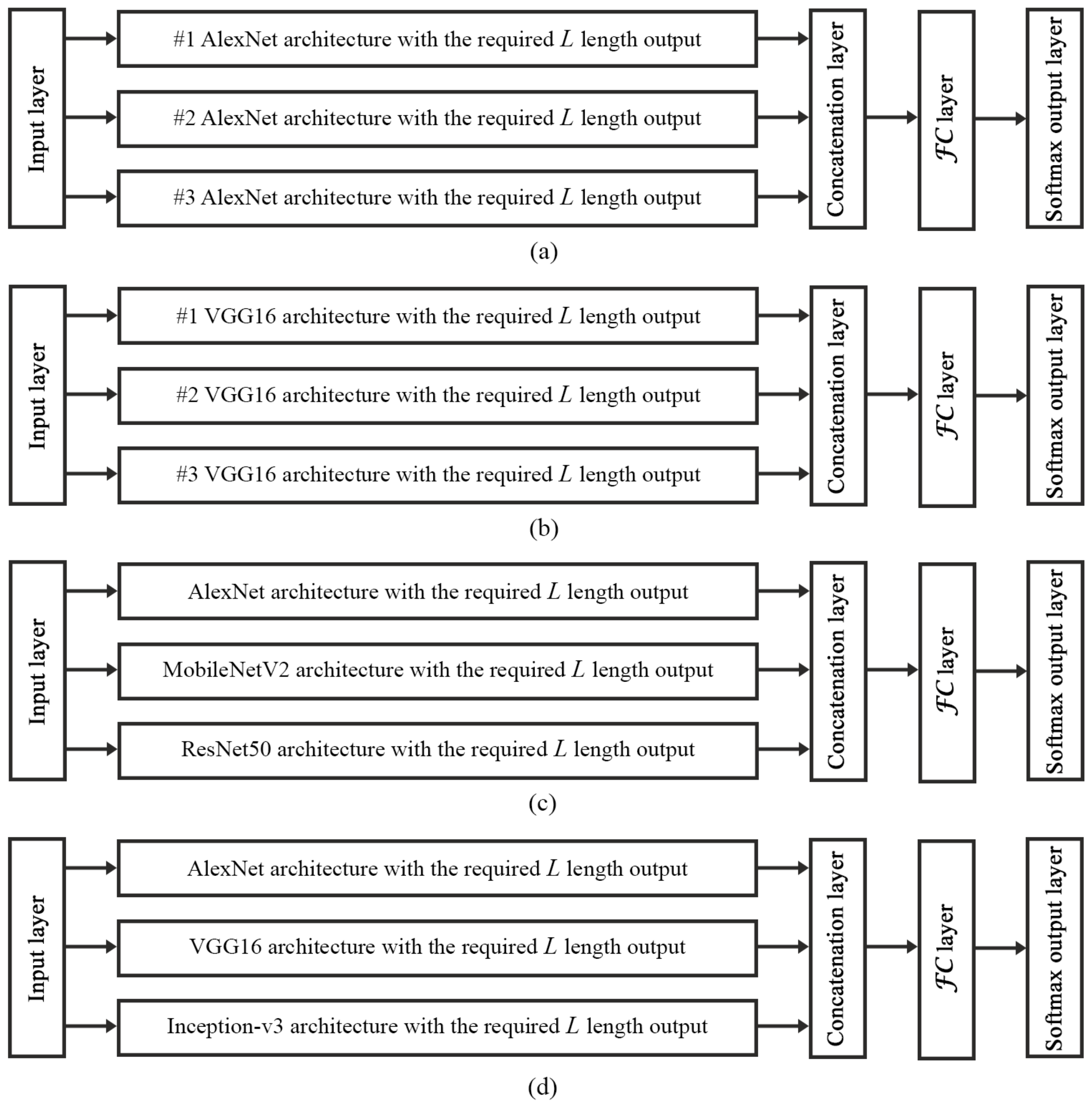
To create an ensemble architecture from these CNNs, we prepared the members for the given image classification task. Thus, we replaced their last FC layers with other ones having the length of the number of classes, and connected these FC layers with an additional fully connected layer
as described in
Section 2.1. Altogether, we composed four different ensemble networks to make an exhaustive evaluation and show that the proposed methodology for connecting CNNs and training them simultaneously by using the
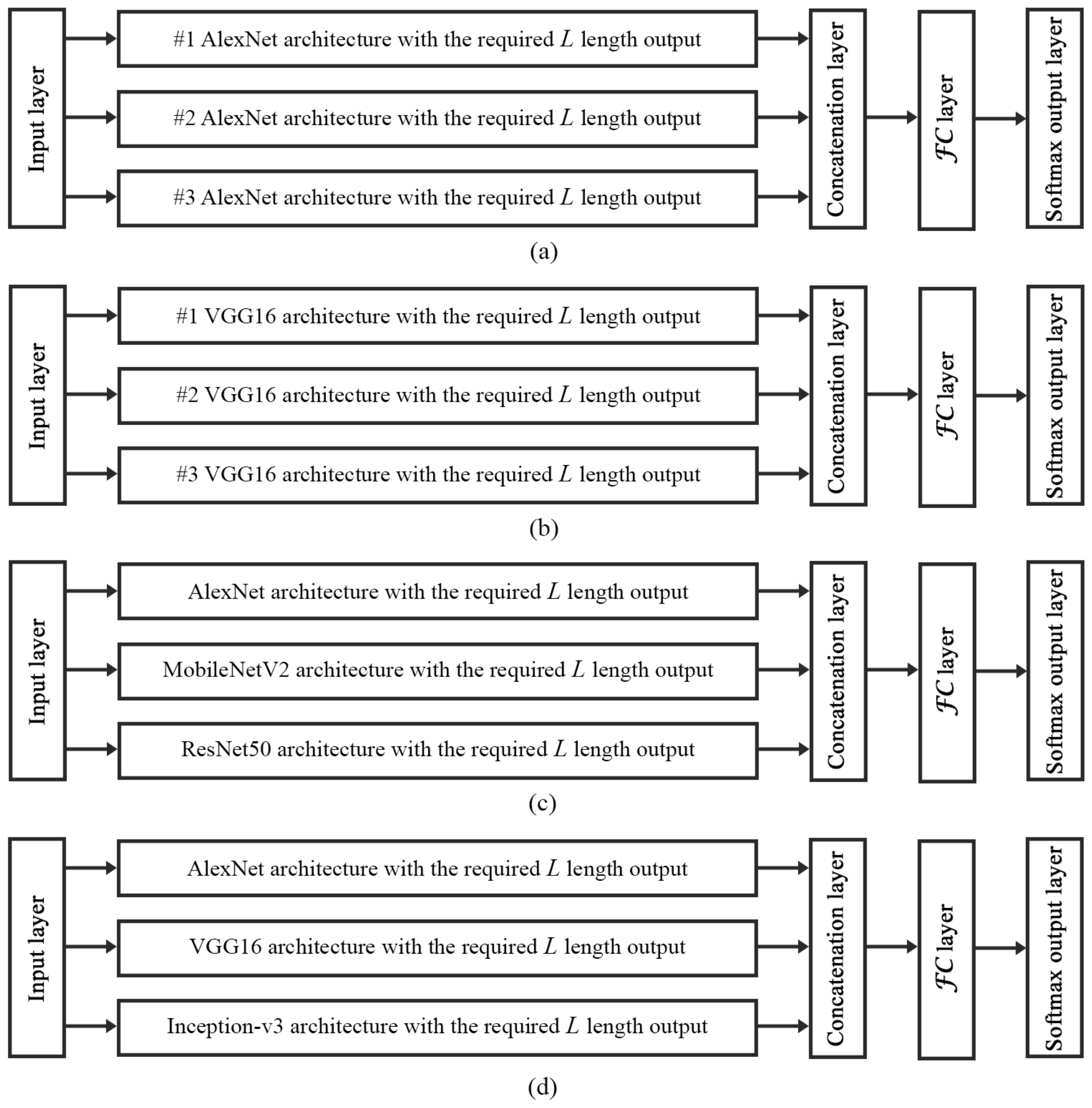
penalty term has a capability to improve the accuracy with increasing the diversity between the members. There are two types of ensembles. The first one contains the same architecture multiple times to demonstrate how the penalty term makes the similar architectures more diverse (see
Figure 3a,b). In the second one, we combine some different CNN models to make an initially diverse ensemble architecture (see
Figure 3c,d) and to train them simultaneously. Our aim was to show that if we considered the state-of-the-art models and fused them, we can outperform their individual accuracies. The ensemble network is optimized on different data sets with applying the penalized loss function with different
values.
3.3. Experimental Results
We used the four data sets introduced in
Section 3.1.1–
Section 3.1.4 and four different setups of the ensembles of the CNNs to validate the benefit of the proposed penalty term regarding the final accuracy. Moreover, to exclude any random noise and confirm the achieved results, we repeated each experiment five times and calculated the mean accuracies and standard deviations.
In the first scenario, to measure the effects of the penalization term on the ensemble architecture during the training stage, we considered the simplest ensemble to avoid any unexpected effects derived from the complexity of the member CNNs. Accordingly, we included only the AlexNet network three times to compose the ensemble, as it can be seen in
Figure 3a. To ensure a reliable comparison, we evaluated the classification performance of a single AlexNet and its ensemble with and without (
) using the proposed penalization term. Moreover, we applied different
values in (
3) to show how the members become more diverse as
increases.
To have also a comparison with other approaches, we considered some frequently applied state-of-the-art ensemble methods to show the superiority of the proposed combination framework, where the members can be trained simultaneously. As we described in the introduction, there are some well-known aggregation methods, which can be applied successfully to increase the global accuracy. One of them is simple majority voting (SMV) when we check the outputs of the members and select the label supported by the largest number of votes as in [
22,
23]. SMV could provide false labels when none of the members finds the correct class or when more members predict the same wrong class than the correct one. If we have some information about the reliability or the individual accuracies of the members, we can exploit this knowledge for weighting the votes accordingly to realize weighted majority voting (WMV) as in [
26]. As a last method for comparison, we include the simple averaging (AVE) when the member outputs are merged by calculating the arithmetic mean of their softmax outputs as it is proposed in [
20].
The details of these evaluations can be seen in
Table 1, where AlexNet multi stands for the ensemble architecture trained by different strength penalization
terms.
Table 1 shows the accuracies and the number of misclassified images regarding the single AlexNet and its different ensembles with and without (
) applying the penalization term. If we check the accuracy values, a
improvement can be observed over all the investigated state-of-the-art combination methods and the individual member accuracies. Our aim was to improve the classification accuracy and make the members more diverse to reduce the chance of simultaneous mistakes. To show how the proposed penalization term reduced the number of simultaneously misclassified items, we considered the outputs of the members and evaluated their individual accuracies with increasing the value of
, as well. Moreover, we checked how many images are classified wrongly by at least two members. Accordingly, the last two columns of
Table 1 show the average number of images which were classified wrongly by two members (double missed) and three members (triple missed). We can see that the number of jointly missed images decreases when
increases, and in this way, the proposed penalty term
E is applied during training. So it can be used efficiently to reduce the incidence of joint mistakes of the members. Notice that if we set
to a higher value, the penalty term becomes stronger, resulting in lower classification accuracy, as the optimization process focuses better on the more diverse members.
To further check the usability and efficiency of the proposed penalty term, we trained and evaluated AlexNet and its ensemble on the CIFAR-10 image set (see
Table 2 for the results). In this scenario, we can observe a slight improvement considering the accuracy (
), which means that more 253 images were classified correctly. Even more importantly, the double/triple misses dropped remarkably, showing that higher diversity is reached. Raising
above a given point could have harmful effect on the global classification accuracy just in our previous setup and all the further experiments.
For the sake of completeness, VGG16 is also involved in the same type of evaluation using the CIFAR-10 data set. So, we trained the single VGG16, composed its ensemble in the same way as AlexNet and measured the classification accuracies with and without applying the proposed penalization term. The results enclosed in
Table 3 show a
rise in classification accuracy when we compose an ensemble using more VGG16 networks by only concatenating and training them together instead of combining their outputs after a separate training. The performance is increased with an additional
when the proposed penalization term is applied. Moreover, the number of jointly missed images is reduced dramatically.
To demonstrate the efficiency of the proposed combination and the penalty term also for medical image classification tasks, we considered an ensemble network composed from AlexNet, MobileNetV2, and ResNet50 as it can be seen in
Figure 3c. As a first step, we trained the members separately as individual architectures and calculated their accuracies. Then, we took their outputs and combined them using SMV, WMV, and AVE, respectively. Finally, we connected these member CNNs to form a single architecture and trained them simultaneously using the proposed concatenation layer and the penalty term with different
values. As we can see in
Table 4, the model composed by the proposed combination framework after training with the penalty term
E reached 2–
higher accuracy than SMV/WMV/AVE, and the number of the simultaneously misclassified fundus images decreased as well.
As our final use case, we checked the usability and effectiveness of our proposed combination technique in skin lesion classification. We have already made substantial efforts in this field to improve classification accuracy, e.g., in an ensemble-based manner. In [
35], we considered four different CNN architectures, and after training them in parallel, we fused their outputs using statistical models. In [
41], we interconnected the CNNs by inserting a joint fully connected layer and composed a super-network in which all the members are trained together. Now, we use the same CNNs and data set [
52] and show how the proposed penalization term can help the members to become more diverse to make the ensemble-based system reach higher classification accuracy.
At this point, we have composed an ensemble-based system (see
Figure 3d) from AlexNet, VGG16 and GoogLeNet Inception-v3 as we described in
Section 2.1 and
Section 3.2. The classification performances of the individual models and their ensembles using different
values can be seen in
Table 5, where
can be considered the result of a previous approach published in [
41].
We can see a more than
improvement in classification regarding our previous ensemble-based method and a remarkable growth in diversity based on the drops of the double/triple misses at
. In one of the five runs with
, the ensemble network reached its best performance when it missed only 151 images, so its accuracy was
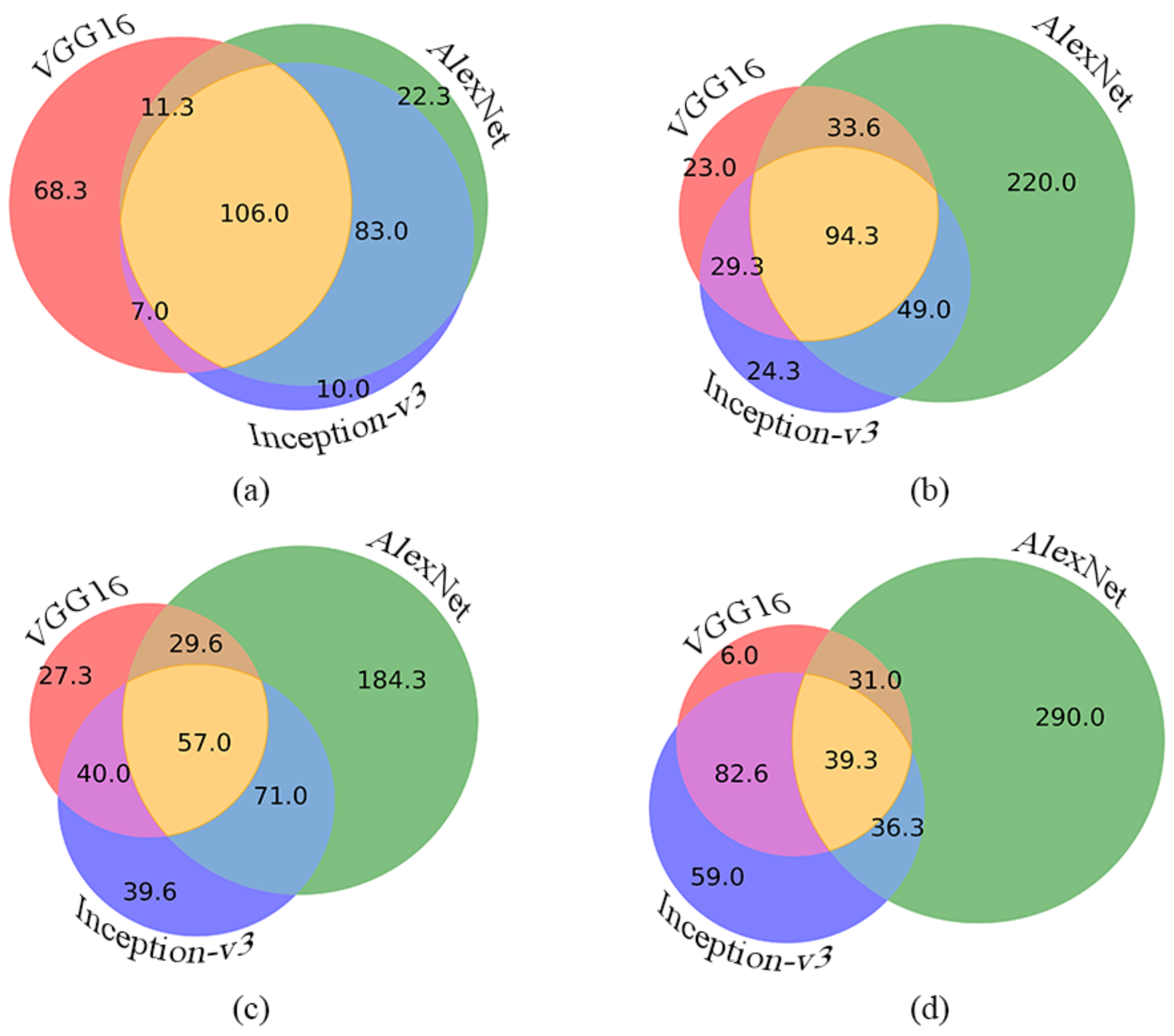
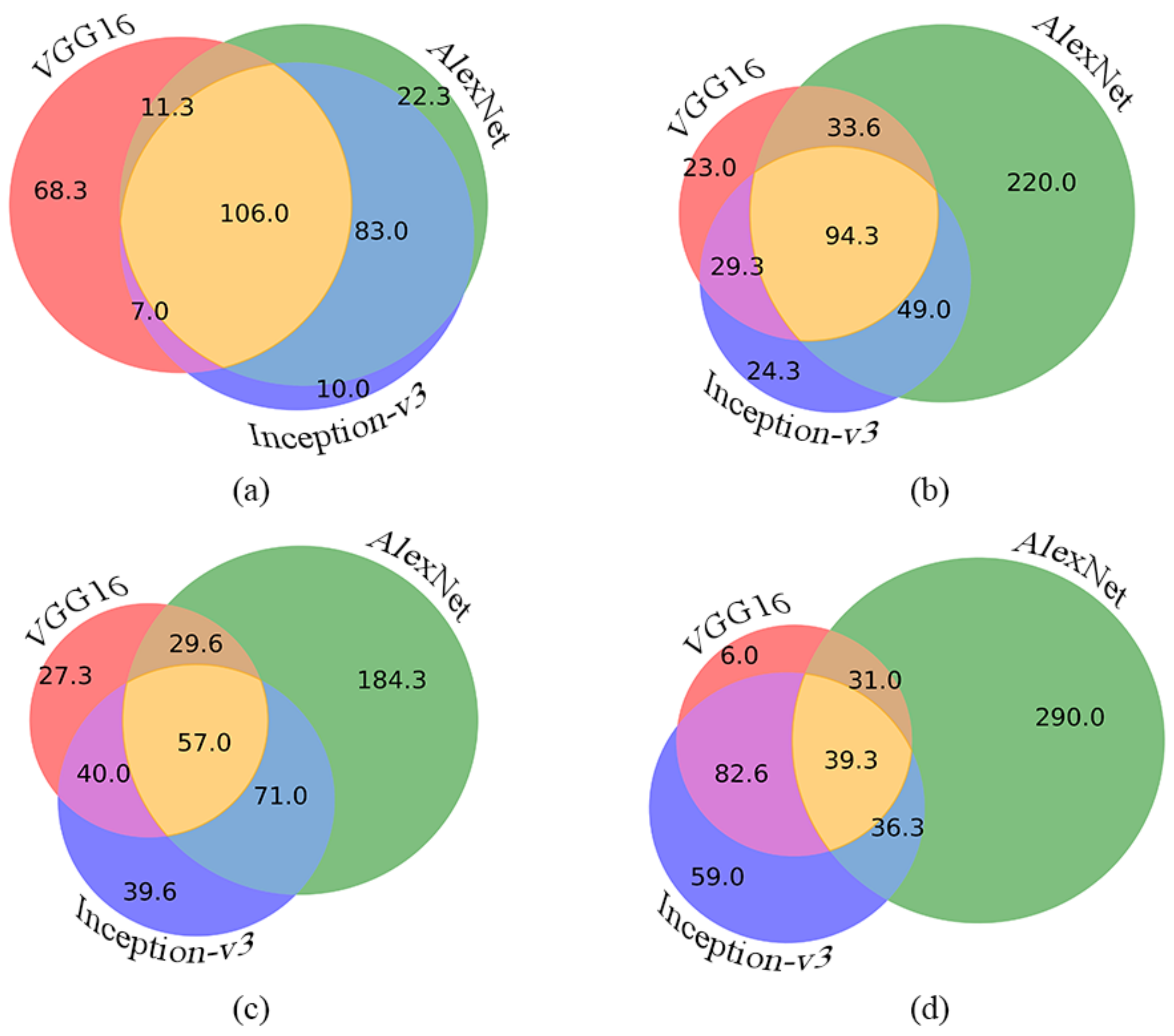
. For a better interpretation, we also give a visual representation on how the ratios of the single, double, and triple misses change for
,
,
, and
(see
Figure 4a,b,c,d, respectively). In these charts, each disc contains the average number of the missed images by the given member. The intersecting parts contain the average numbers of the double and triple missed images.
To make our comparative study more comprehensive, we also applied the evaluation protocol of the ISBI 2017 challenge [
52]. Namely, we converted the originally three-classes task to three binary classification problems using the one-vs-all approach. Then, the performance was evaluated as the average of the three binary classification accuracies. In this test, the best current model reached
, while our previous approach with
only reached
as it was originally published in [
41].
3.4. Discussion
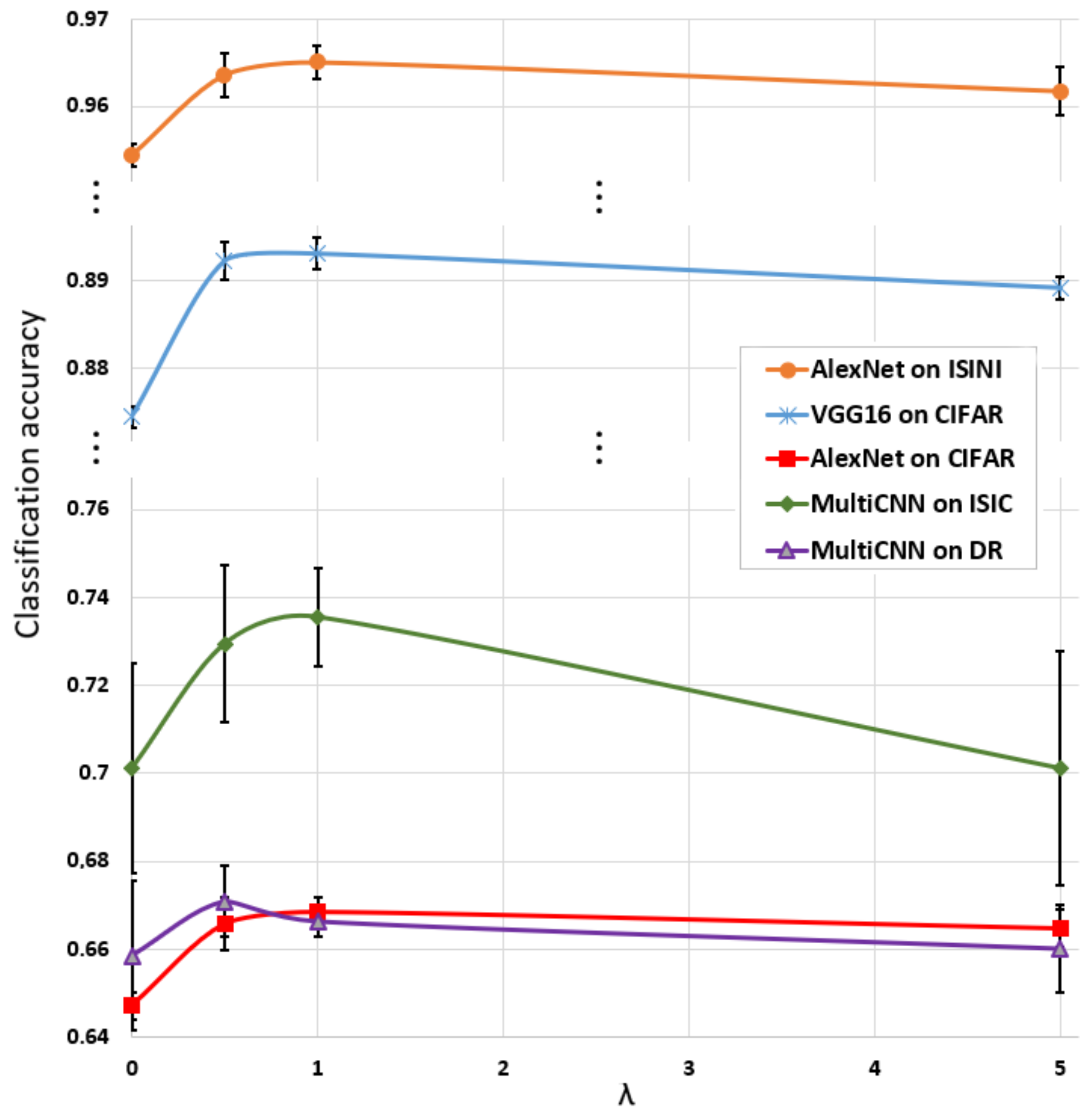
As we saw in
Section 3.3, the proposed penalization term makes the outputs of the members more diverse, which improves the final classification accuracy. Higher diversity is reflected in the number of jointly missed images. That is, double/triple misses reduce when the value of
increases. However, when the value of
goes over an optimal level, the overall accuracy of the ensemble starts to drop. The reason is that the approach focuses more on making the members more diverse than on the overall classification performance as we can see it, for example, in
Figure 5. So we can consider
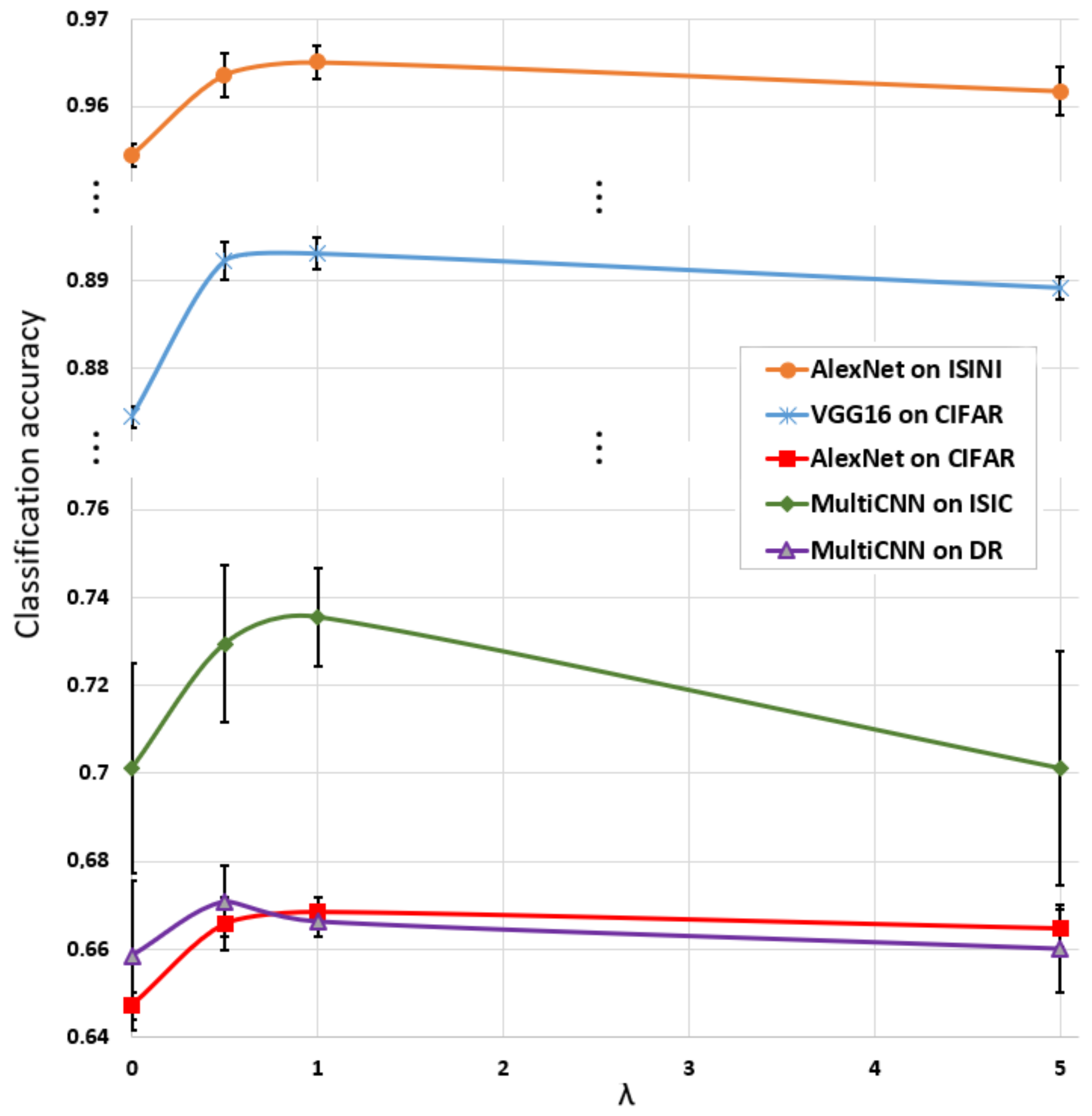
as a hyperparameter which should also be optimized similarly, for example, to the learning rate; thus, it should be carefully adjusted.
Regarding the details of implementation, several open-source libraries are available for machine learning and deep learning purposes, such as CNTK, Caffe2, PyTorch, TensorFlow, and Keras, which can be considered an API for the previously mentioned backend libraries. Our implementation was developed using TensorFlow (ver = 2.2.0) and TensorFlow-GPU (ver = 2.3.1) as backend for Keras. The CNNs VGG16, ResNet50, MobileNetV2 and GoogLeNet Inception-v3 were available as pre-trained models in Keras to build up our ensembles. The required AlexNet was not available in the core Keras library, so we composed this architecture from the necessary layers as published and trained it from scratch.
A general bottleneck of ensemble-based methods, especially in the case of CNN members, is that the number of model parameters increases to a large extent that requires the expansion of the training data set to avoid overfitting. Though we have not directly encountered this problem, a remedy can be to not fully pre-train the members, a solution which should leave some space for them to become diverse during their simultaneous training.Another common limitation of complex ensemble-based systems is that the training and optimization require high computational capacity. To mitigate this issue, we considered CUDA-based implementations running on GPU cards.
The fine-tuning and training steps were performed on a computer equipped with an NVIDIA TITAN RTX, and a GeFroce RTX 2080 Ti GPU card with 24 GB and 11 GB memories, respectively. The TITAN RTX (RTX 2080 Ti) has 16.31 (13.45) TFLOPs computational performance at single precision, 672.0 (616.0) GB/s of memory bandwidth, and 4608 (4352) CUDA cores. This 35 GB available memory was necessary when the ensemble networks were trained, and the total number of trainable and non-trainable parameters was 526,439,818. We used the mirrored strategies of TensorFlow for the complete ensemble network, which is typically used for training on one machine with multiple GPUs. The member CNNs were placed into the different GPU memories, so we shared the available memory among the network branches. The training time highly depends on the complexity of the model. For the individual networks, it is varied between 2 and 5 h, while the complex ensemble-based networks are trained for more than 16 h.
For a reliable evaluation, we fixed the same hyperparameter settings during the training stage of each setup. Namely, for optimizing the parameters of the individual CNNs and their ensembles, we trained the models over 100 epochs using the Adam optimizer with a learning rate of . To avoid overfitting, we used of each training set as a cross-validation set. For each model, we preserved the parameters, reaching the highest accuracy on the validation set during the 100 epochs.
4. Conclusions
In this work, we introduced a new correlation penalty term to increase the diversity of individual CNN members to build up efficient ensembles from them. During training, the new term penalizes the cases when the members make wrong decisions simultaneously. In this way, our approach is technically similar to regularization, offering a trade-off between accuracy and diversity in the cost function. Accordingly, a parameter is also introduced for weighing the correlation penalty consideration; the setting completely switches it off. We gave a proper theoretical derivation of the new term and its derivative to support the efficient integration in the backpropagation process.
With this completion, we were able to remarkably improve the performance of previously proposed ensemble-based methods by generalizing them with the possible consideration of the new penalty term. Namely, our approach was evaluated on natural image classification problems with a specific interest on the clinical domain, including dermatology and retinal images as well. Accordingly, we fused popular CNN architectures by incorporating them into a super-network and adding the penalty term to the classification cost function. The ensembles trained using the new penalty term remarkably outperformed all the individual member CNNs and also the ensembles ignoring it. Moreover, a comparison with other state-of-the-art ensemble-based methods for the same classification task confirmed the efficiency of our approach.
Though our method was introduced for CNNs with corresponding image processing problems, the framework is sufficiently general for its possible applicability in other domains, too.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}