
A Data-Driven Convolutional Neural Network Approach for Power Quality Disturbance Signal Classification (DeepPQDS-FKTNet)

 , , and
, , and 
Abstract
:1. Introduction
- An intelligent computer method for classifying PQDs has been developed.
- A constructive method is proposed for automatically constructing a data-driven CNN model with a custom-designed architecture by utilizing clustering, FKT, and the ratio of the traces of the between-class scatter matrix and the within-class scatter matrix to extract discriminative information from the 1D PQD dataset.
- The obtained results reveal that the proposed PQDs classification scheme is quick, accurate, and performs well.
2. Proposed Method
2.1. Adaptive CNN Model
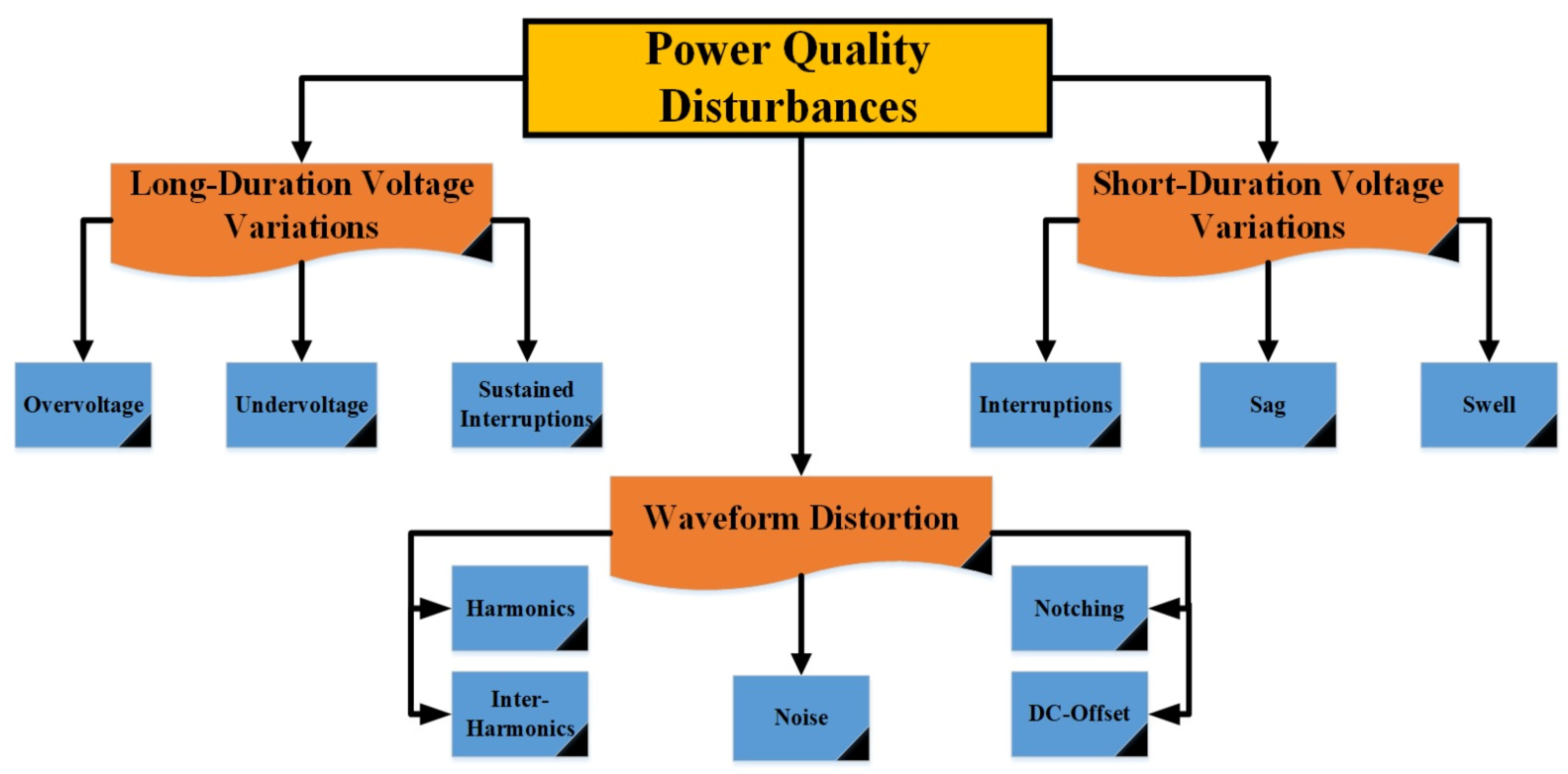
2.1.1. Selection of Representative PQDs
| Algorithm 1: Design of the main DeepPQDS-FKTNet architecture |
| Input: The set PS = (PS1, PS2, …, PSC), where c is the number of classes and PSi = (PQDj, j = 1, 2, 3, …, ni) is the set of PQD signals of the ith class. |
| Output: The main DeepPQDS-FKTNet architecture. |
|

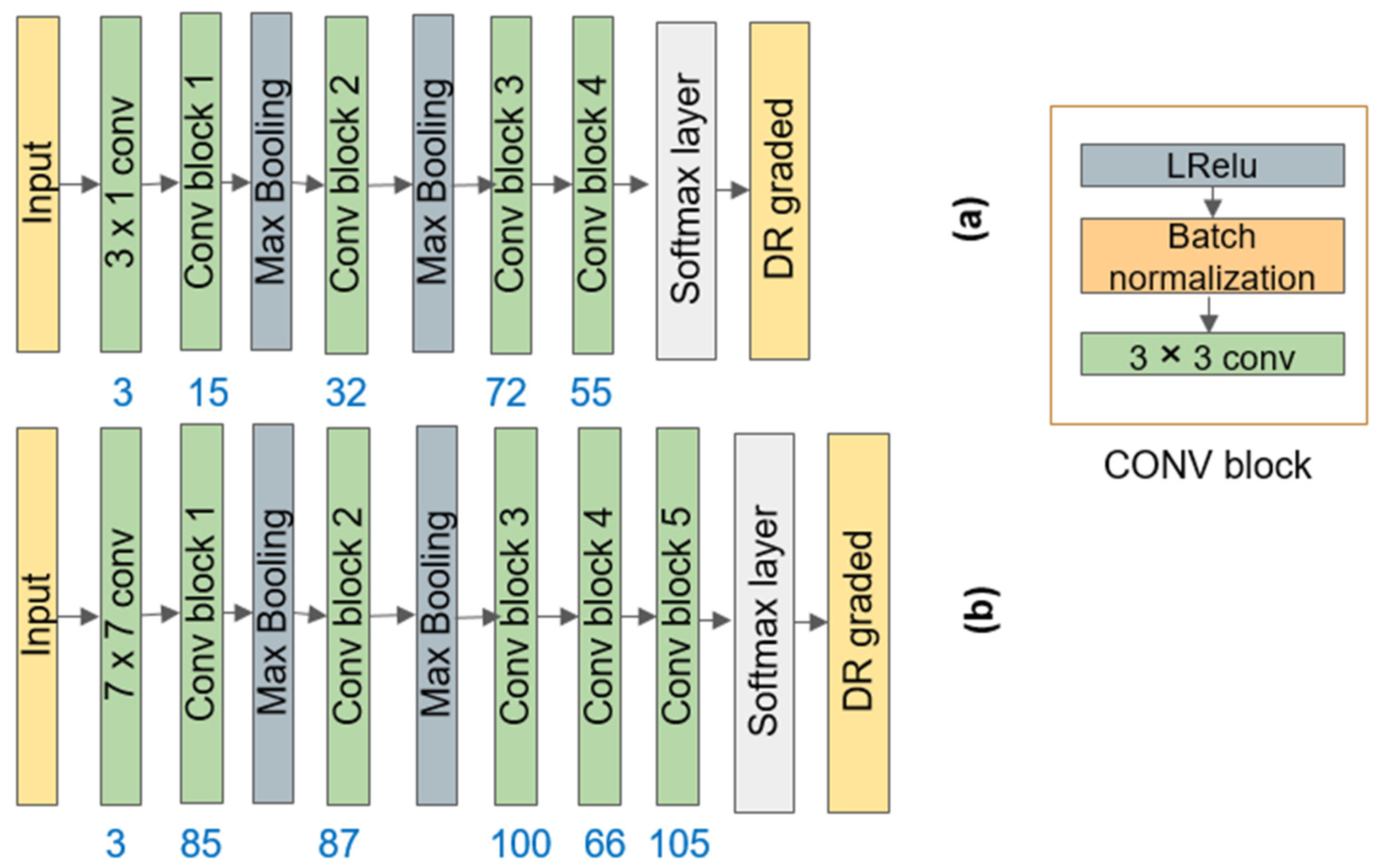
2.1.2. Design of the Main DeepPQDS-FKTNet Architecture
2.2. Problem Formulation
2.3. Fine Tuning the Model
Evaluation Procedure
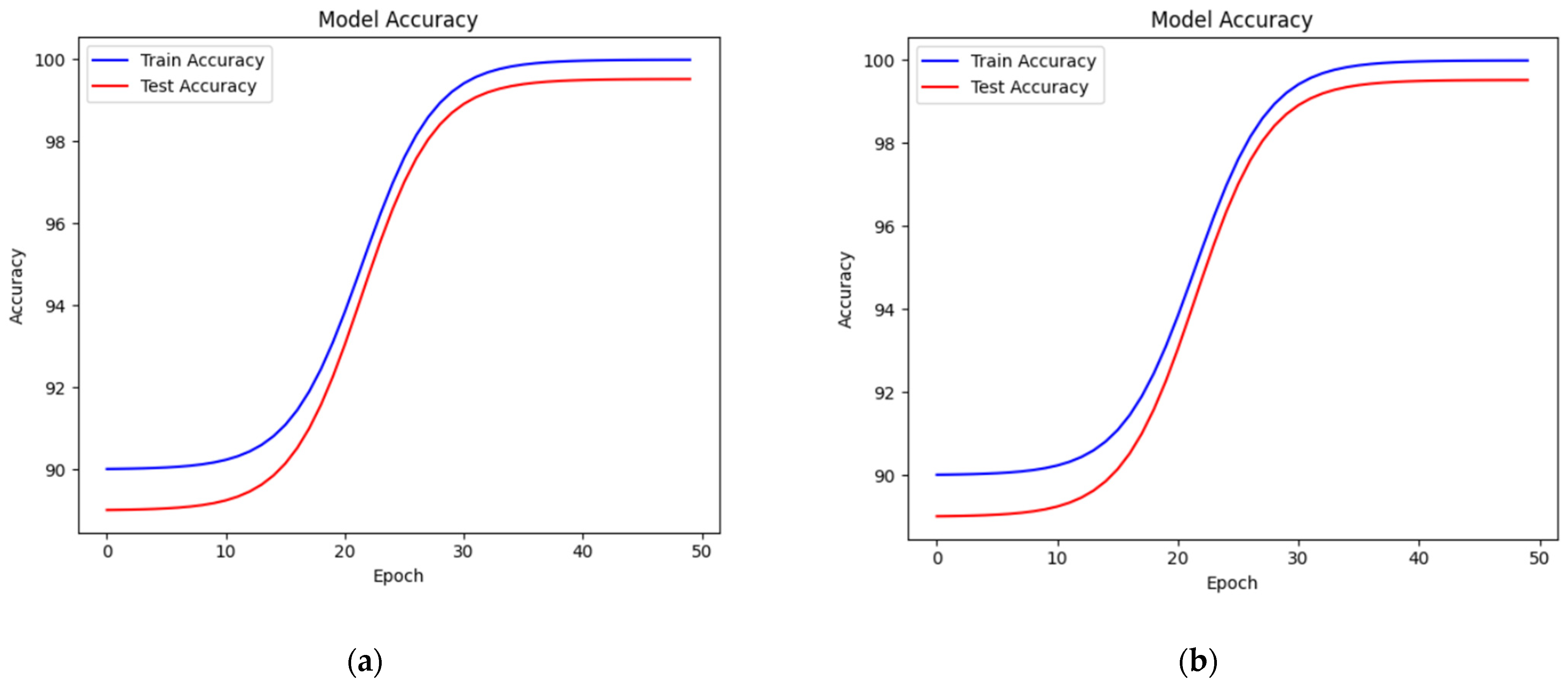
3. Experimental Results
Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, C.; Ju, P.; Wu, F.; Pan, X.; Wang, Z. A systematic review on power system resilience from the perspective of generation, network, and load. Renew. Sustain. Energy Rev. 2022, 167, 112567. [Google Scholar] [CrossRef]
- Afonso, J.L.; Tanta, M.; Pinto, J.G.O.; Monteiro, L.F.C.; Machado, L.; Sousa, T.J.C.; Monteiro, V. A Review on Power Electronics Technologies for Power Quality Improvement. Energies 2021, 14, 8585. [Google Scholar] [CrossRef]
- Alam, M.R.; Bai, F.; Yan, R.; Saha, T.K. Classification and visualization of power quality disturbance-events using space vector ellipse in complex plane. IEEE Trans. Power Deliv. 2020, 36, 1380–1389. [Google Scholar] [CrossRef]
- Vazquez, S.; Zafra, E.; Aguilera, R.P.; Geyer, T.; Leon, J.I.; Franquelo, L.G. Prediction model with harmonic load current components for FCS-MPC of an uninterruptible power supply. IEEE Trans. Power Electron. 2021, 37, 322–331. [Google Scholar] [CrossRef]
- Sharma, A.; Rajpurohit, B.S.; Singh, S.N. A review on economics of power quality: Impact, assessment and mitigation. Renew. Sustain. Energy Rev. 2018, 88, 363–372. [Google Scholar] [CrossRef]
- Khaleel, M.; Abulifa, S.A.; Abulifa, A.A. Artificial Intelligent Techniques for Identifying the Cause of Disturbances in the Power Grid. Brill. Res. Artif. Intell. 2023, 3, 19–31. [Google Scholar] [CrossRef]
- Caicedo, J.E.; Agudelo-Martínez, D.; Rivas-Trujillo, E.; Meyer, J. A systematic review of real-time detection and classification of power quality disturbances. Prot. Control Mod. Power Syst. 2023, 8, 3. [Google Scholar] [CrossRef]
- Chawda, G.S.; Shaik, A.G.; Shaik, M.; Padmanaban, S.; Holm-Nielsen, J.B.; Mahela, O.P.; Kaliannan, P. Comprehensive Review on Detection and Classification of Power Quality Disturbances in Utility Grid with Renewable Energy Penetration. IEEE Access 2020, 8, 146807–146830. [Google Scholar] [CrossRef]
- Mishra, M.; Nayak, J.; Naik, B.; Abraham, A. Deep learning in electrical utility industry: A comprehensive review of a decade of research. Eng. Appl. Artif. Intell. 2020, 96, 104000. [Google Scholar] [CrossRef]
- Gunawan, T.S.; Husodo, B.Y.; Ihsanto, E.; Ramli, K. Power Quality Disturbance Classification Using Deep BiLSTM Architectures with Exponentially Decayed Number of Nodes in the Hidden Layers. In Recent Trends in Mechatronics Towards Industry 4.0: Selected Articles from iM3F 2020, Malaysia; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Li, Z.; Liu, H.; Zhao, J.; Bi, T.; Yang, Q. A Power System Disturbance Classification Method Robust to PMU Data Quality Issues. IEEE Trans. Ind. Inform. 2021, 18, 130–142. [Google Scholar] [CrossRef]
- Eikeland, O.F.; Holmstrand, I.S.; Bakkejord, S.; Chiesa, M.; Bianchi, F.M. Detecting and Interpreting Faults in Vulnerable Power Grids with Machine Learning. IEEE Access 2021, 9, 150686–150699. [Google Scholar] [CrossRef]
- Hong, W.; Liu, Z.; Wu, X. Power quality disturbance recognition based on wavelet transform and convolutional neural network. In Proceedings of the 2021 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 28–30 June 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Li, J.; Liu, H.; Wang, D.; Bi, T. Classification of Power Quality Disturbance Based on S-Transform and Convolution Neural Network. Front. Energy Res. 2021, 9, 708131. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, X. Classification of power quality disturbances using visual attention mechanism and feed-forward neural network. Measurement 2022, 188, 110390. [Google Scholar] [CrossRef]
- Reddy, K.R. Power quality classification of disturbances using discrete wavelet packet transform (DWPT) with adaptive neuro-fuzzy system. Turk. J. Comput. Math. Educ. TURCOMAT 2021, 12, 4892–4903. [Google Scholar]
- IEEE 1159-2009; IEEE Recommended Practice for Monitoring Electric Power Quality. IEEE: New York, NY, USA, 2009.
- Huo, X. A Statistical analysis of Fukunaga–Koontz transform. IEEE Signal Process. Lett. 2004, 11, 123–126. [Google Scholar] [CrossRef]
- Saeed, F.; Hussain, M.; Aboalsamh, H.A. Automatic Fingerprint Classification Using Deep Learning Technology (DeepFKTNet). Mathematics 2022, 10, 1285. [Google Scholar] [CrossRef]
- Saeed, F.; Hussain, M.; Aboalsamh, H.A. Method for Fingerprint Classification. U.S. Patent 9530042, 13 June 2016. [Google Scholar]
- Zhang, Q.; Couloigner, I. A new and efficient k-medoid algorithm for spatial clustering. In Proceedings of the International Conference on Computational Science and Its Applications, Singapore, 9–12 May 2005; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. CVPR 2017. arXiv 2016, arXiv:1608.06993. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Mika, S.; Ratsch, G.; Weston, J.; Scholkopf, B.; Mullers, K.R. Fisher discriminant analysis with kernels. In Neural Networks for Signal Processing IX: Proceedings of the 1999 IEEE Signal Processing Society Workshop (Cat. No. 98th8468); IEEE: Piscataway, NJ, USA, 1999. [Google Scholar]
- Machlev, R.; Chachkes, A.; Belikov, J.; Beck, Y.; Levron, Y. Open source dataset generator for power quality disturbances with deep-learning reference classifiers. Electr. Power Syst. Res. 2021, 195, 107152. [Google Scholar] [CrossRef]
- Cook, A. Global Average Pooling Layers for Object Localization. 2017. Available online: https://alexisbcook.github.io/2017/globalaverage-poolinglayers-for-object-localization/ (accessed on 19 August 2019).
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Gao, Z.; Li, J.; Guo, J.; Chen, Y.; Yi, Z.; Zhong, J. Diagnosis of Diabetic Retinopathy Using Deep Neural Networks. IEEE Access 2018, 7, 3360–3370. [Google Scholar] [CrossRef]
- Quellec, G.; Charrière, K.; Boudi, Y.; Cochener, B.; Lamard, M. Deep image mining for diabetic retinopathy screening. Med. Image Anal. 2017, 39, 178–193. [Google Scholar] [CrossRef] [PubMed]
- Chowdhury, A.R.; Chatterjee, T.; Banerjee, S. A Random Forest classifier-based approach in the detection of abnormalities in the retina. Med. Biol. Eng. Comput. 2019, 57, 193–203. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Zhong, J.; Yang, S.; Gao, Z.; Hu, J.; Chen, Y.; Yi, Z. Automated identification and grading system of diabetic retinopathy using deep neural networks. Knowl. Based Syst. 2019, 175, 12–25. [Google Scholar] [CrossRef]
- Haghighi, S.; Jasemi, M.; Hessabi, S.; Zolanvari, A. PyCM: Multiclass confusion matrix library in Python. J. Open Source Softw. 2018, 3, 729. [Google Scholar] [CrossRef]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2011, arXiv:2010.16061. [Google Scholar]
- Fleiss, J.L.; Cohen, J.; Everitt, B.S. Large sample standard errors of kappa and weighted kappa. Psychol. Bull. 1969, 72, 323. [Google Scholar] [CrossRef]
- Li, J.; Teng, Z.; Tang, Q.; Song, J. Detection and classification of power quality disturbances using double resolution S-transform and DAG-SVMs. IEEE Trans. Instrum. Meas. 2016, 65, 2302–2312. [Google Scholar] [CrossRef]
- Qiu, W.; Tang, Q.; Liu, J.; Yao, W. An automatic identification framework for complex power quality disturbances based on multifusion convolutional neural network. IEEE Trans. Ind. Inform. 2019, 16, 3233–3241. [Google Scholar] [CrossRef]
- Liu, M.; Chen, Y.; Zhang, Z.; Deng, S. Classification of Power Quality Disturbance Using Segmented and Modified S-Transform and DCNN-MSVM Hybrid Model. IEEE Access 2023, 11, 890–899. [Google Scholar] [CrossRef]
- Mozaffari, M.; Doshi, K.; Yilmaz, Y. Real-Time Detection and Classification of Power Quality Disturbances. Sensors 2022, 22, 7958. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Disturbance | Characteristics Equation | Parameters |
|---|---|---|
| 1 Normal | [1 ± α(u(t − t1) − u(t − t2))] sin(ωt) | α < 0.4, T ≤ (t2 − t1) ≤ 9T |
| 2 Sag | [1 − α(u(t − t1) − u(t − t2))] sin(ωt) | 0.1 ≤ α < 0.9, T ≤ (t2 − t1) ≤ 9T |
| 3 Swell | [1 + α(u(t − t1) − u(t − t2))] sin(ωt) | 0.1 ≤ α ≤ 0.8, T ≤ (t2 − t1) ≤ 9T |
| 4 Interruption | [1 − α(u(t − t1) − u(t − t2))] sin(ωt) | 0.9 ≤ α ≤ 1, T ≤ (t2 − t1) ≤ 9T |
| 5 Flicker | [1 + αf sin(βωt)] sin(ωt) | 0.1 ≤ αf < 0.2, 5 ≤ β < 20 Hz |
| 6 Sag with harmonics | [1 − α(u(t − t1) − u(t − t2))] × [α1 sin(ωt) + α3 sin(3ωt) + α5 sin(5ωt) + α7 sin(7ωt)] | 0.1 ≤ α ≤ 0.9, T ≤ (t2 − t1) ≤ 9T, |
| 7 Swell with harmonics | [1 + α(u(t − t1) − u(t − t2))] × [α1 sin(ωt) + α3 sin(3ωt) + α5 sin(5ωt) + α7 sin(7ωt)] | 0.1 ≤ α ≤ 0.8, T ≤ (t2 − t1) ≤ 9T, |
| 8 Interruption with harmonics | [1 − α(u(t − t1) − u(t − t2))] × [α1 sin(ωt) + α3 sin(3ωt) + α5 sin(5ωt) + α7 sin(7ωt)] | 0.9 ≤ α ≤ 1, T ≤ (t2 − t1) ≤ 9T, |
| 9 Flicker with harmonics | [1 + αf sin(βωt)] × [α1 sin(ωt) + α3 sin(3ωt) + α5 sin(5ωt) + α7 sin(7ωt)] | 0.1 ≤ αf < 0.2, 5 ≤ β < 20, |
| Dataset | Activation Function | Learning Rate | Patch’s Size | Optimizer | Dropout |
|---|---|---|---|---|---|
| Synthetic dataset without noise | Relu6 | 0.001 | 8 | RMSprop | 0.25 |
| Synthetic dataset with noise | Relu6 | 0.0002 | 8 | RMSprop | 0.35 |
| Dataset | Model | # FLOPs | # Parameters | ACC % | SE % | SP % | Kappa % |
|---|---|---|---|---|---|---|---|
| Noiseless | GoogleNet | 1.44 G | 7.3 M | 94.4 | 92.41 | 96.61 | 91.12 |
| ResNet50 | 0.089 G | 0.64 M | 95.23 | 92.87 | 97.12 | 90.82 | |
| DeepPQDS-FKTNet-5 | 0.003 G | 55.4 K | 99.51 | 94.38 | 98.18 | 93.13 | |
| Noisy | GoogleNet | 1.44 G | 7.3 M | 93.1 | 91.5 | 94.99 | 91.12 |
| ResNet50 | 0.089 G | 0.64 M | 94.12 | 91.38 | 95.37 | 90.82 | |
| DeepPQDS-FKTNet-6 | 0.0035 G | 55.9 K | 98.5 | 93.98 | 99.28 | 92.43 |
| Paper | Method | Noise (dB) | Number of PQDs | ACC (%) |
|---|---|---|---|---|
| Cai et al., 2019 [38] | DRST + DAG + SVM | 20 | 9 | 97.77 |
| Qiu et al., 2019 [39] | Multifusion convolutional neural network (MFCNN) | - | 24 | 99.26 |
| Liu et al., 2023 [40] | SMST + DCNN + MSVM | 20 | 21 | 98.86 |
| Mozaffari et al., 2022 [41] | Vector-ODIT | 20 30 | 5 | 98.38 100 |
| DeepPQDS-FKTNet-6 | FKTNet model (six layers and one softmax layer) | 50 | 9 | 98.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saeed, F.; Aldera, S.; Alkhatib, M.; Al-Shamma’a, A.A.; Hussein Farh, H.M. A Data-Driven Convolutional Neural Network Approach for Power Quality Disturbance Signal Classification (DeepPQDS-FKTNet). Mathematics 2023, 11, 4726. https://doi.org/10.3390/math11234726
Saeed F, Aldera S, Alkhatib M, Al-Shamma’a AA, Hussein Farh HM. A Data-Driven Convolutional Neural Network Approach for Power Quality Disturbance Signal Classification (DeepPQDS-FKTNet). Mathematics. 2023; 11(23):4726. https://doi.org/10.3390/math11234726
Chicago/Turabian StyleSaeed, Fahman, Sultan Aldera, Mohammad Alkhatib, Abdullrahman A. Al-Shamma’a, and Hassan M. Hussein Farh. 2023. "A Data-Driven Convolutional Neural Network Approach for Power Quality Disturbance Signal Classification (DeepPQDS-FKTNet)" Mathematics 11, no. 23: 4726. https://doi.org/10.3390/math11234726
APA StyleSaeed, F., Aldera, S., Alkhatib, M., Al-Shamma’a, A. A., & Hussein Farh, H. M. (2023). A Data-Driven Convolutional Neural Network Approach for Power Quality Disturbance Signal Classification (DeepPQDS-FKTNet). Mathematics, 11(23), 4726. https://doi.org/10.3390/math11234726