Abstract
To better fit the actual data, this paper will consider both spatio-temporal correlation and heterogeneity to build the model. In order to overcome the “curse of dimensionality” problem in the nonparametric method, we improve the estimation method of the single-index model and combine it with the correlation and heterogeneity of the spatio-temporal model to obtain a good estimation method. In this paper, assuming that the spatio-temporal process obeys the mixing condition, a nonparametric procedure is developed for estimating the variance function based on a fully nonparametric function or dimensional reduction structure, and the resulting estimator is consistent. Then, a reweighting estimation of the parametric component can be obtained via taking the estimated variance function into account. The rate of convergence and the asymptotic normality of the new estimators are established under mild conditions. Simulation studies are conducted to evaluate the efficacy of the proposed methodologies, and a case study about the estimation of the air quality evaluation index in Nanjing is provided for illustration.
Keywords:
spatio-temporal correlation; spatio-temporal heterogeneity; reweighting estimation; local linear method; single-index models MSC:
62H11
1. Introduction
Recently, statistical analysis of spatio-temporal data has been widely used in environmental science, economics and social science, and other fields, and it plays an important role in both academic and industrial circles. Spatio-temporal data estimation methods have also been developed. Spatio-temporal correlation and spatio-temporal heterogeneity are two significant features of spatio-temporal data.
In the process of solving practical problems, spatio-temporal data models usually consider these two properties. Various spatio-temporal modeling methods have been applied to explore the effect of spatio-temporal correlation and heterogeneity. For example, ref. [1] proposed multiscale geographically weighted regression (MGWR). The authors of [2] extended geographically and temporally weighted regression (GTWR) ([3]) to multiscale geographically and temporally weighted regression (MGTWR) in consideration of scale effects. The authors of [4] proposed the hetero-convolutional long short-term memory model based on the convolutional long short-term memory (ConvLSTM) neural network model. The authors of [5] adopted a local linear method to model spatio-temporal heterogeneity. A new nonparametric spatio-temporal inversion model was proposed by [6] for the gas emission problem considering both spatio-temporal heterogeneity and atmospheric inversion. Ref. [7] proposed to estimate the variance–covariance structure of the residuals by variography and removed the correlation by spatial filtering residuals.
In addition, the spatio-temporal trend is more complex, and spatio-temporal data can be regarded as a time series dataset with spatial information, which has the characteristics of being dynamic, massive, and high-dimensional. In order to accurately predict the change in the spatio-temporal trend function, this paper combines the idea of a semi-parametric model, adds the influence behavior of multidimensional independent variables on dependent variables, and considers the spatio-temporal error model. The single-index model is one of the most popular semi-parametric models. The spatio-temporal single-index model that we are interested in here is:
where , , represents the spatial location, t represents the time, , is an unknown link function, is an unknown coefficient with and the first component of is positive [8], and is a random error which has almost surely.
The single-index model is one of the most popular semi-parametric models in applied statistics. Many authors have studied the estimation of the index coefficient , focusing on issues of estimability and efficiency. The methods include the average derivative method [9,10], the local linear method [11,12], the least squares method [13,14], the functional additive regression [15], and the empirical likelihood method [16,17]. Most regressions in single-index models assume that the random variables are independently and identically distributed. However, spatio-temporal correlation and heterogeneity are often found in the model error terms. For spatio-temporal correlation, we portray it through an -mixing condition that is consistent with the spatio-temporal characterization. There are usually two types of assumptions for heterogeneity: the first assumption is that the variance function is purely nonparametric, and the second requires that the variance function has a dimension reduction structure like the mean function. This is often the case with models with a dimensionality reduction structure, such as generalized linear models. The second case holds in more general semiparametric settings for the central subspace and the central mean subspace, which have the same dimensions; see [18,19,20].
This work mainly deals with the estimation problem of spatio-temporal heterogeneity. By combining the idea of the local linear method and Nadaraya–Watson smoothing techniques, we propose a method for estimating the variance function in the single index model with heteroscedastic errors, and the resulting estimator based on a fully nonparametric variance function or a dimensionality reduction structure is proved to be consistent. For the parametric part, we use an efficient estimator of the parametric component by applying the iterative generalized least squares method in heteroscedastic generalized linear models and taking into account the estimated heteroscedasticity. We call this model fitting method reweighting estimation, and it is shown that the resulting constant coefficient estimators have smaller asymptotic variances than the rMAVE estimators, which neglect error heteroscedasticity but retain the same biases.
Throughout the rest of the paper, the symbols ‘’ and ‘’ denote convergence in probability and convergence in distribution, respectively. The symbol indicates the Moore–Penrose inverse of the symmetric matrix A. The notation denotes the Euclidean distance.
This article is structured as follows. In Section 2, the estimation process of the rMAVE method is briefly described. In Section 3, two estimators for variance are proposed, namely, a nonparametric estimator of kernel smoothing type and a nonparametric estimator integrated with the dimensionality reduction structure. In Section 4, a reweighting estimation method and its asymptotic properties are given. In Section 5, the effectiveness of the proposed method is verified through simulations. The analyses for Nanjing air quality data are found in Section 6. Conclusions are presented in Section 7. The assumptions required for the theorem and the proof are in Appendix A and Appendix B.
2. A Brief Description of the rMAVE
Consider the regression model (1). Let be the random variable in model (1). The parameter is obtained by minimizing the expectation of the joint distribution ; see [21],
For any , the conditional variance given is:
It follows that:
Therefore, minimizing Expression (2) is equivalent to minimizing, with respect to ,
Suppose that is a random sample from Formula (2). Let . For any given , a local linear expansion of at is:
where , , and . Following the idea of local linear smoothing estimation, we can estimate by exploiting the approximation:
where , , is a bandwidth, and is an univariate symmetric density function. Therefore, the estimator of at is just the minimum value of expression (6), namely:
Under some mild conditions, we have . On the basis of Expressions (2), (4), and (7), we can estimate by solving the minimization problem:
Let . The estimation algorithm for and can be described as follows.
- Step 0.
- Give the calculation of the initial value of .
- Step 1.
- Calculate:and:
- Step 2.
- Calculate:where , and is a trimming function.
- Step 3.
- Repeat steps 1–3 with , where denotes the Euclidean distance, until convergence. The vector obtained in the last iteration is defined as the rMAVE estimator of , denoted by .
- Step 4.
- Put into step 1 and obtain the estimators of and , denoted by .
Combining , and model (1) leads to the residuals
Remark 1.
The calculation of the initial value can refer to [10,13,22]. To deal with the large deviation of the boundary points, a suitable trimming function is introduced; see [11], which is of the form:
where and .
3. Estimation of the Variance Function
In this section, we focus on estimating the variance function in single-index heteroscedastic models. The estimation methods and the convergence properties of their estimations are given respectively.
3.1. Estimation of the Variance Function with Fully Nonparametric Function
For any given point and the estimation , an estimation of at is:
where are the residuals calculated by (9), , is a d-dimensional symmetric density function such that and , and is a bandwidth. Taking (()), the estimations at all the designed points can be obtained, i.e., ().
The following theorems are about the asymptotic result for the estimator .
Theorem 1.
According to the assumptions (C1)–(C4), we have:
Theorem 1 shows that the estimator is consistent, and the proof is found in the Appendix B.
3.2. Estimation of the Variance Function with Dimension Reduction Structure
If the dimension of the covariates is large, the core estimates given in the previous section suffer from the curse of dimensionality and, furthermore, the proposed test statistic may not be very informative. If the model contains a dimensionality reduction structure, we should use it to make the test more powerful. Let us assume the following model structure:
Formula (11) notes that, given , Y and X are conditionally independent. According to [18,19,20], this is a general dimension reduction structure that includes the model as its special case.
If the above structure holds for model (1), the mean and variance have the same index . For any given point and the estimated , the variance function at is:
where can also be denoted by , are the residuals of the rMAVE, , is a univariate kernel function, and is a bandwidth. Particularly, taking , (), we can obtain the estimations of the variance function at , i.e., .
For the estimate of the variance function, the consistency can be proven.
Theorem 2.
According to the assumptions (C1)–(C3) and (C5), we have:
The proof of Theorem 2 is given in the Appendix B.
4. Reweighting Estimation and Asymptotic Properties
In this section, we provide the estimation method for the spatio-temporal single-index model and provide the asymptotic properties of the proposed estimator.
4.1. Reweighting Estimation
If the model exhibits heteroscedasticity, the usual approach can be taken by considering weighted estimates. In particular, we describe a reweighting procedure of the single-index model with heteroscedastic errors with the estimated values of the variance function at all designed points. For model (1), weighted versions of the proposed estimation methods following the idea of [23] can be considered. When calculating, we only need to modify the algorithms in Step 2, by replacing with
where is defined in (10) or (12). In terms of the modified algorithms, the reweighted estimators for the parameter vector and the link function can be obtained, denoted by and , respectively.
4.2. Asymptotic Properties
In this subsection, under the assumption of the mixing condition, we provide the asymptotic distributions of two type estimators of and show that the reweighted estimator has no greater asymptotic variance than the rMAVE estimator . Then, the asymptotic distributions of and are shown.
There are some notations to determine asymptotic results. Let , , , and .
Theorem 3.
Assuming , according to the assumptions (C1)–(C3), we have:
where and .
Theorem 4.
Assuming , according to the assumptions (C1)–(C3) and (C4) or (C5), we have:
where .
Theorem 5.
In addition to the assumptions (C1)–(C3) and (C4) or (C5), if ε is independent of X, then we have,
Remark 2.
From the result of Theorem 5, a conclusion can be obtained that is asymptotically more efficient than in terms of asymptotic variance.
For the rMAVE estimator and reweighted estimator of the link function at , their asymptotic distributions are also derived. These are the following theorems.
Theorem 6.
According to the assumptions (C1)–(C3), for any , as ,
Theorem 7.
According to the assumptions (C1)–(C3), for any , as ,
Remark 3.
By comparing Theorems 6 and 7, the asymptotic distributions obtained by rMAVE and reweighting methods are the same, which reflects the characteristic of local regression in nonparametric models.
5. Monte Carlo Study
We use the spectral method to simulate the spatio-temporal process:
where are i.i.d. from a standard normal distribution, independent of i.i.d. uniform random variables on As , converges to a Gaussian ergodic process (see [24]). Additionally, the are i.i.d. from a standard normal distribution. We conducted 100 simulation studies with and a sample size of , . Comparisons were made between the rMAVE estimator and two reweighted estimators. For the convenience of expression, we use RWEFN and RWEDR respectively to represent reweighting estimation of a fully nonparametric function and reweighting estimation by the dimensionality reduction structure.
For simplicity, the rule of thumb [25] is used to select the bandwidth for the rMAVE and reweighted methods. To verify the performance of the proposed methods, we design the following two examples. We take the Gaussian kernel functions and with . The trimming function with and is considered. In the example, we also take , and the samples are simulated by the spectral method on the 4-dimensional cube .
Example 1.
We consider the following model:
Example 2.

We consider the following example:
The simulated results of Example 1 are reported in Table 1 and Table 2, and the results of Example 2 are shown in Table 3 and Table 4.
Table 1.
Sample means, standard deviations, and relative efficiencies in Example 1 when .
Table 2.
Sample means, standard deviations, and relative efficiencies in Example 1 when .
Table 3.
Sample means, standard deviations, and relative efficiencies in Example 2 when .
Table 4.
Sample means, standard deviations, and relative efficiencies in Example 2 when .
We assume the value of to evaluate the influence of error heteroscedasticity on coefficient estimates. To show the performance of the estimators , (RWEFN), and (RWEDR), two indices are defined: the sampling standard deviation (SSD) and the relative sampling efficiency (SRE), respectively. In particular, for rMAVE, RWEFN, or RWEDR, let be estimates of in M replicates. The SSD for is defined by:
and the SRE for is defined by:
where , and has the same form as that of or , except that the weighting uses the true variance function. The calculation in different sample size results of , and , in terms of the sample mean, sample standard deviation, and relative sampling efficiency, are shown in Table 1 and Table 2.
The following conclusions can be obtained from Table 1, Table 2, Table 3 and Table 4. First, in all cases, the values of the sample mean are reasonably close to their true values, suggesting that , , and are asymptotically unbiased. Second, for , the values of SSD and SRE for the RWEFN and RWEDR methods are smaller than those for the rMAVE method. Third, from tables, the values of slightly outperform when error heteroscedasticity exists. This is also explainable because the example has a dimensionality reduction structure. Fourth, and have better performance when the error heteroscedasticity is larger, which implies that the improvement in and over becomes obvious with the growth of errors. Overall, and work much better than , and is the best. Finally, because the composition of Example 2 is more complex, the average value of the obtained estimators is worse than that of Example 1.
6. Real Data Analysis
Based on the reweighting method proposed in this article, the air pollution data of Nanjing were studied, with the data coming from the China Meteorological Data Network and the real air data from the Environment Big Data Center. The data contain the air quality index (AQI) PM (g/m), PM (g/m), CO (mg/m), SO(g/m), NO(g/m), and ozone eight-hour O3_8h (g/m) of Nanjing from 23 October 2020 to 23 October 2022, including the AQI in response to a variable Y and the rest of the variables as covariate .
When the data were estimated using the rMAVE method, the value of the estimated parameter was . The results obtained by reweighting the data are as follows: first, was obtained by adopting a dimensional-reduction structure. The other difference is estimated by taking the kernel regression, resulting in . The fitting result is shown in Figure 1, which contains the true values as well as the values fitted by the three methods, where , , . Due to the four lines being too close to distinguish, the right side of Figure 1 is the enlarged part. The estimators obtained by the reweighting method have a better fitting effect.
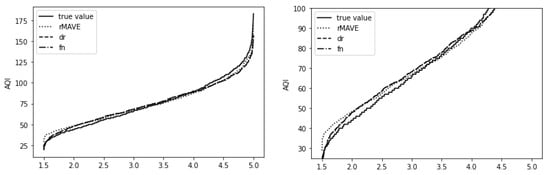
Figure 1.
Air pollution data fitting.
7. Conclusions
This work considers an estimation problem in single-index models with spatio-temporal correlation and heterogeneity. We propose a parametric component reweighting estimated method based on the variance function of the error. Theoretical results show that the proposed reweighting estimators have smaller asymptotic variances while maintaining the same biases. Numerical simulations show that the estimators revealed that heterogeneity is closer to the true value. A real data analysis was conducted to illustrate the proposed methods.
Author Contributions
Methodology, H.H.; Formal analysis, Z.Z.; Writing—original draft, H.W.; Writing—review & editing, C.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Social Science Fund of China under Grant No. 22BTJ021.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Assumptions
In order to obtain asymptotic results, we will assume throughout the paper that at any fixed moment satisfies the following mixing condition: there exists a function as , , such that whenever with finite cardinals
where (resp, ) denotes the Borel —field generated by (resp,), Card E (resp, Card ) is the cardinality of E(resp, ) and is the ordinary Euclidean distance. is a symmetric positive function that is nondecreasing in each variable.
Similarly, we assume that at any fixed location satisfies the following mixing condition: there exists a function as , , such that whenever with finite cardinals
where (resp, ) denote the Borel —field generated by (resp,), is a symmetric positive function that is nondecreasing in each variable. Furthermore, the random field also satisfies the above assumption.
The following conditions are imposed to obtain the asymptotic properties of the resulting estimators. They are not the weakest, but they are introduced to make the evidence easier.
- (C1)
- The density function of and its derivatives up to the third order are bounded on R for all : where is a constant, , and .
- (C2)
- The conditional mean and its derivatives up to the third order are bounded for all : where .
- (C3)
- is a symmetric univariate density function with finite moments of all orders and a bounded derivative. Bandwidth and .
- (C4)
- is a symmetric multivariate density function with finite moments and bounded derivatives. Bandwidth and . , such that .
- (C5)
- is a symmetric univariate density function with finite moments and bounded derivatives. Bandwidth and . , such that .
According to (C1), covariate X can have discrete components provided that is continuous for in a small neighbor of ; see also [23]. In order to be able to use the optimal bandwidth, there needs to be a moment of order higher than the second order moment for the variable Y. The smoothness requirement of the link function in hypothesis (C2) can be relaxed to the existence of a bounded second-order derivative but requires a more complex proof process and a smaller bandwidth. The hypotheses (C3)–(C5) are common hypotheses in kernel regression; see [13].
Let , , and . For any k, denotes a k-dimension vector with all elements equal to 1, and denotes a matrix with all elements equal to 1. For any vector of functions of v, we define . Recall that is a symmetric density function. Thus, and . For ease of exposition, we assume that . Otherwise, . Let , where , . In order to prove the result of the theorems, we first present the following lemmas.
Appendix B. Proof
Lemma A1.
Suppose , are measurable functions of Z with index , where d is any integer number, such that with for some , and increases with n such that ; with , where and are two constants (without loss of generality, we assume ); and that with some , and exists. Suppose is a random sample from Z. Then, for any positive , we have:
Proof of Lemma A1.
For the “continuity argument” approach, see [13,25]. For simplicity, let denote . Let be bounded and its Borel measure be less than . There are balls centered at with a diameter smaller than , so that . Then,
By , we have:
By assumption ,
Let , , and ; then, we have:
where . Because of and , for all sufficiently large , with probability 1, for . This implies that the first term on the right-hand side of (A5) is eventually 0. By assumption , we have:
By , we can obtain:
Let , . According to Theorem 2.1 of [26],
According to the mixing condition, when N is large enough. Hence,
By the Borel-Cantelli lemma, we have:
Combining (A4) and (A9), we have:
Therefore, Lemma A1 follows. □
Lemma A2 ([11]).
Assume that and are two measurable functions of such that , , with for some , and for all . Suppose that , , and , are random copies of , and , respectively. If (C1), (C3), and (C4) hold, then:
Lemma A3.
Suppose and its derivatives up to the second order are bounded for all , and suppose that exists for some . Let be a sample from and . If conditions (C1), (C3), and (C4) hold, then:
where , .
Proof of Lemma A3.
Since:
where , combining it with Lemma A1, we complete the proof of Lemma A3. □
Lemma A4.
Let
and
Under conditions (C1)–(C4), we have:
where:
and
Proof of Lemma A4.
By the Taylor expansion of at and , we have:
where . By Equation (A11), it follows that:
According to Lemma A3, we have:
If , we have:
It is easy to check that
According to Lemma A3 and Equation (A11), we have:
By Lemma A3, we have:
For the noise term, we have:
It follows from Lemma A2 that:
Then, we have:
Thus, Lemma A4 follows from (A13)–(A17). □
Lemma A5.
Under conditions (C1)–(C4), we have:
where and .
Proof of Lemma A5.
According to condition (C1), we have:
By the Borel–Cantelli lemma, we have:
Let . Similarly, we have:
Hence, we can exchange summations over , , in the sense of almost sure consistently. By Lemma A3 and condition (C1), we have:
By Equation (A19) and the smoothness of with for some , we have:
Denote by an orthogonal matrix. According to Lemma A3, we have:
where , . It follows from (A19) that:
where . According to (A20), we have: . Note that . Thus,
where . Therefore, by the matrix inversion formula in blocks [27], we have:
where . Note that . Then, . By the definition of the Moore–Penrose inverse, we have:
Combining the facts that and , we complete the proof. □
Lemma A6.
Under conditions (C1)–(C4), we have:
Proof of Lemma A6.
According to Lemma A4, we have:
Denote by . We have . Note that and . By Lemmas A1 and A2, we have:
According to Lemma A3, (A18) and (A19), we have:
By Lemmas A3 and A4, we have:
Letting , then we have . Note that . According to Lemma A2, we have:
By Lemma A1 and Corollary 2 in [28] ( p. 122), we have:
Combining (A21)–(A25), we complete the proof of this lemma. □
Lemma A7.
According to Theorem 3 in [29], for , we have:
Lemma A8.
Under conditions (C1)–(C5), we have:
where:
Proof of Theorem 1.
Proof of Theorem 2.
Theorem 2 can be proven in the same way as Theorem 1, so it is omitted here. □
Proof of Theorem 3.
After one iteration, by Lemmas A5 and A6, we have that the new is:
the last equation holds because , , , and
It is easy to check that , so then . Let be the value of after k iterations. We have:
Recursing the preceding equation, we have, as the iteration :
The following lemmas are used to prove Theorem 3. □
Lemma A9.
Lemma A10.
Lemma A11.
Under assumptions (C1) and (C2), one has:
Proof of Lemma A11.
□
Lemma A12.
Under assumptions (C1)–(C5), one has:
where and .
Proof of Lemma A12.
By the boundedness of for , and then by the mixing condition, and similar to the proof of in Lemma 4.4 in [5],
□
Lemma A13.
Under assumptions (C1)–(C5), one has:
Proof of Lemma A13.
To simplify, let , . Then, let
Let us now introduce a space–time block decomposition, which has been used by [30]. Fix integers , and assume that, for some integer r,
The random variables are now set into blocks of different sizes. Let:
and so on. Note that:
Finally,
Setting , we define for each integer ,
Then, with this notation, we obtain the decomposition
Note that is the sum of the random variables over “large” blocks, whereas are sums over “small” blocks. If it is not the case that for r, then an additional term , say, containing all the terms that are not included in the big or small blocks, can be considered. This term will not change the proof much.
The main idea is to show that, as :
□
Proof of (A42)).
The proof is similar to the proof of (5.42) in [31]. □
Proof of (A43).
According to assumption (C1), if for each exists, (A43) can be proven. Without loss of generality, it suffices to prove that, for . Enumerate the r.v’s in an arbitrary manner and refer to them as where . □
Now,
If and can be shown, is obvious.
Similar to (A47), we have:
Then, by Equations (A47) and (A49), we have:
By Lemma A9, the above inequality continues as:
Consequently,
which tends to zero by the definition of and .
Let:
Then, is the sum of with sites in . Since , if and belong to the two distinct sets and , then for some , and . To simplify, denoting , then we obtain:
by Lemma A9, we have the following equation:
which tends to 0 by the definition of and q. Hence, (A43) holds.
Proof of (A44).
Let , and . Then, is the sum of terms over the “large” blocks, and is over the "small" ones. Lemmas A11 and A12 imply that ; this, combined with (A43), entails . Now,
If the last term of Equation (A51) tends to zero as , then Equation (A44) can be obtained. By the same argument used in obtaining , the last term of (A51) is bounded by:
which tends to 0 by the assumptions and the definition of and q. □
Proof of (A45).
We need a truncation argument, so set , , , and define . Set
Clearly, ; therefore, . Hence,
Now, by the definition of . Thus, at all for sufficiently large n, so for large n. Hence,
Define , and we know that . By Equation (A52), to prove the lemma, it suffices to prove . Similar to Lemma A12, we can show that . According to the above lemmas, we have:
Additionally, by Lemma A11, we have , and then we obtain □
Proof of Theorem 4.
By Theorems 1 and 2, similar to Lemma A5, under conditions (C1)–(C4), we have:
where . Similar to Lemma A6, under conditions (C1)–(C4), we have:
Similar to Theorem 3, , , recursing the preceding equation, and we have, as the iteration :
Similar to the proof of Theorem 3, as , Theorem 4 holds. □
Proof of Theorem 5.
Set , , . According to the definitions of , and , we have:
and
For any d-dimensional vector , let . Since is a positive matrix, then is a norm of space . Therefore, we have:
By the universality of the column vector c, we can obtain Theorem 5. □
Proof of Theorem 6.
For simplicity, set , by Lemma A4; then, we have:
Thus,
After some simple computations, by Lemma A1, we have:
Similar to the proof of Theorem 3, as , Theorem 6 holds. □
References
- Fotheringham, A.S.; Yang, W.; Kang, W. Multiscale geographically weighted regression (MGWR). Ann. Am. Assoc. Geogr. 2017, 107, 1247–1265. [Google Scholar] [CrossRef]
- Wu, C.; Ren, F.; Hu, W.; Du, Q. Multiscale geographically and temporally weighted regression: Exploring the spatio-temporal determinants of housing prices. Int. J. Geogr. Inf. Sci. 2019, 33, 489–511. [Google Scholar] [CrossRef]
- Chu, H.J.; Huang, B.; Lin, C.Y. Modeling the spatio-temporal heterogeneity in the PM10-PM2.5 relationship. Atmos. Environ. 2015, 102, 176–182. [Google Scholar] [CrossRef]
- Yuan, Z.; Zhou, X.; Yang, T. Hetero-ConvLSTM: A deep learning approach to traffic accident prediction on heterogeneous spatio-temporal data. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 984–992. [Google Scholar]
- Wang, H.; Wang, J.; Huang, B. Prediction for spatio-temporal models with autoregression in errors. J. Nonparametric Stat. 2012, 24, 1–28. [Google Scholar] [CrossRef]
- Wang, H.; Zhao, Z.; Wu, Y.; Luo, X. B-spline method for spatio-temporal inverse model. J. Syst. Sci. Complex. 2022, 35, 2336–2360. [Google Scholar] [CrossRef]
- Římalovȧ, V.; Fišerováa, E.; Menafogliob, A.; Pinic, A. Inference for spatial regression models with functional response using a permutational approach. J. Multivar. Anal. 2022, 189, 104893. [Google Scholar] [CrossRef]
- Lin, W.; Kulasekera, K.B. Identifiability of single-index models and additive-index models. Biometrika 2007, 94, 496–501. [Google Scholar] [CrossRef]
- Stoker, T.M. Consistent estimation of scaled coefficients. Econometrica 1986, 54, 1461–1481. [Google Scholar] [CrossRef]
- Powell, J.L.; Stock, J.H.; Stoker, T.M. Semiparametric estimation of index coefficients. Econometrica 1989, 57, 1403–1430. [Google Scholar] [CrossRef]
- Xia, Y. Asymptotic distributions for two estimators of the single-index model. Econom. Theory 2006, 22, 1112–1137. [Google Scholar] [CrossRef]
- Xia, Y. A constructive approach to the estimation of dimension reduction directions. Ann. Stat. 2007, 35, 2654–2690. [Google Scholar] [CrossRef]
- Härdle, W.; Hall, H.; Ichimura, H. Optimal smoothing in single-index models. Ann. Stat. 1993, 21, 157–178. [Google Scholar] [CrossRef]
- Li, G.; Peng, H.; Dong, K.; Tong, T. Simultaneous confidence bands and hypothesis testing for single-index models. Stat. Sin. 2014, 24, 937–955. [Google Scholar] [CrossRef]
- Fan, Y.; James, G.M.; Radchenko, P. Functional additive regression. Ann. Stat. 2015, 43, 2296–2325. [Google Scholar] [CrossRef]
- Xue, L. Estimation and empirical likelihood for single-index models with missing data in the covariates. Comput. Stat. Data Anal. 2013, 52, 1458–1476. [Google Scholar] [CrossRef]
- Xue, L.; Zhu, L. Empirical likelihood for single-index model. J. Multivar. Anal. 2006, 97, 1295–1312. [Google Scholar] [CrossRef][Green Version]
- Cook, R.D.; Li, B. Dimension reduction for conditional mean in regression. Ann. Stat. 2002, 30, 455–474. [Google Scholar] [CrossRef]
- Zhu, L.; Ferré, L.; Wang, T. Sufficient dimension reduction through discretization-expectation estimation. Biometrika 2010, 97, 295–304. [Google Scholar] [CrossRef]
- Ma, Y.; Zhu, L. A review on dimension reduction. Int. Stat. Rev. 2013, 81, 134–150. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, J.; Wang, H.; Zhao, H.; Chen, X. Efficient estimation in heteroscedastic single-index models. J. Nonparametric Stat. 2021, 33, 273–298. [Google Scholar] [CrossRef]
- Horowitz, J.L.; Härdle, W. Direct semiparametric estimation of single-index models with discrete covariates. J. Am. Stat. Assoc. 1996, 91, 1632–1640. [Google Scholar] [CrossRef]
- Ichimura, H. Semiparametric least squares (SLS) and weighted SLS estimation of single-index models. J. Econom. 1993, 58, 71–120. [Google Scholar] [CrossRef]
- Cressie, N.A.C. Statistics for Spatial Data; John Wiley & Sons: New York, NY, USA, 1993. [Google Scholar]
- Mack, Y.P.; Silverman, B.W. Weak and strong uniform consistency of kernel regression estimates. Zeitschrift für Wahrscheinlichkeitstheorie Und Verwandte Geb. 1982, 61, 405–415. [Google Scholar] [CrossRef]
- Liebscher, E. Strong convergence of sums of α-mixing random variables with applications to density estimation. Stoch. Process. Their Appl. 1996, 65, 69–80. [Google Scholar] [CrossRef]
- Schott, J.R. Matrix Analysis for Statistics; Wiley: Hoboken, NJ, USA, 1997. [Google Scholar]
- Chow, Y.S.; Teicher, H. Probability Theory: Independence, Interchangeability, Martin-Gales; Springer: Berlin/Heidelberg, Germany, 1978; p. 122. [Google Scholar]
- Lu, Z.; Arvid, L.; Dag, T.; Yao, Q. Exploring spatial nonlinearity using additive approximation. Bernoulli 2007, 13, 447–472. [Google Scholar] [CrossRef]
- Wang, H.; Wang, J. Estimation of the trend function for spatio-temporal models. J. Nonparametric Stat. 2009, 21, 567–588. [Google Scholar] [CrossRef]
- Lu, Z.; Linton, O. Local linear fitting under near epoch dependence. Econ. Theory 2007, 23, 37–70. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).