
Asymptotic Results of Some Conditional Nonparametric Functional Parameters in High-Dimensional Associated Data


Abstract
:1. Introduction
2. Model and Estimator
3. The Consistency and Asymptotic Normality of the Kernel Estimators
3.1. Assumptions and Necessary Background Knowledge
- (P1)
- and the function is a differentiable at 0.There exists a function such that:
- (P2)
- The conditional distribution function satisfies the Holder condition, that is:Here, is a fixed compact subset of .
- (P3)
- The kernel, denoted by H, is a differentiable function, and its inverse, denoted by , is a positive, bounded, and Lipschitzian continuous function:
- (P4)
- For K, we have the necessary conditions for it to be a bounded continuous Lipschitz function, which are:Here, is referred to as an indicator function.
- (P5)
- A quasi-association exists between the sequence of random pairings , where , and the covariance coefficient , as long as the conditions are met.
- (P6)
- The joint distribution functions are defined so that they hold for each and every pair .satisfy:
- (P7)
- The frequencies , verified:(i)(ii)(iii) for
3.2. Brief Comment on the Conditions
3.3. Almost Complete Convergence of
3.4. Almost Complete Convergence of
3.5. Asymptotic Normality of the Conditional Hazard Function Estimate
4. Confidence Bands
5. A Simulation Study
6. Conclusions and Perspectives
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Aneiros, G.; Cao, R.; Fraiman, R.; Genest, C.; Vieu, P. Recent advances in functional data analysis and high-dimensional statistics. Multivar. Anal. 2019, 170, 3–9. [Google Scholar] [CrossRef]
- Araujo, A.; Giné, E. The Central Limit Theorem for Real and Banach Valued Random Variables; Wiley Series in Probability and Mathematical Statistics; John Wiley and Sons: New York, NY, USA; Chichester, UK; Brisbane, Australia, 1980; p. xiv+233. [Google Scholar]
- Gasser, T.; Hall, P.; Presnell, B. Nonparametric estimation of the mode of a distribution of random curves. J. R. Stat. Society. Ser. B 1998, 60, 681–691. [Google Scholar] [CrossRef]
- Ferraty, F.; Vieu, P. Nonparametric Functional Data Analysis: Theory and Practice; Springer Series in Statistics; Springer: New York, NY, USA, 2006. [Google Scholar]
- Ferraty, F.; Laksaci, A.; Tadj, A.; Vieu, P. Rate of uniform consistency for nonparametric estimates with functional variables. J. Stat. Plan. Inference 2010, 140, 335–352. [Google Scholar] [CrossRef]
- Kara-Zaitri, L.; Laksaci, A.; Rachdi, M.; Vieu, P. Uniform in bandwidth consistency for various kernel estimators involving functional data. J. Non Parametr. Stat. 2017, 29, 85–107. [Google Scholar] [CrossRef]
- Ferraty, F.; Peuch, A.; Vieu, P. Modèle à indice fonctionnel simple. Comptes Rendus Math. 2003, 336, 1025–1028. [Google Scholar] [CrossRef]
- Ezzahrioui, M.; Ould-Saïd, E. Asymptotic Results of a Nonparametric Conditional Quantile Estimator for Functional Time Series. Commun. Stat. Theory Methods 2008, 37, 2735–2759. [Google Scholar] [CrossRef]
- Ezzahrioui, M.; Ould-Said, E. On the asymptotic properties of a nonparametric estimator of the conditional mode for functional dependent data. J. Nonparametr. Stat. 2008, 20, 3–18. [Google Scholar] [CrossRef]
- Laksaci, A. Convergence en moyenne quadratique de l’estimateur à noyau de la densité conditionnelle avec variable explicative fonctionnelle. Ann. L’Institut Stat. L’Université Paris 2007, 51, 69–80. [Google Scholar]
- Laksaci, A.; Maref, F. Estimation non paramétrique de quantiles conditionnels pour des variables fonctionnelles spatialement dépendantes. Comptes Rendus Math. 2009, 347, 1075–1080. [Google Scholar] [CrossRef]
- Matula, P. A note on the almost sure convergence of sums of negatively dependent random variables. Stat. Probab. Lett. 1992, 15, 209–213. [Google Scholar] [CrossRef]
- Newman, C.M. Asymptotic independence and limit theorems for positivelyand negatively dependent random variables: In Inequalities in Statistics and Probability. IMS Lect. Notes Monogr. Ser. 1984, 5, 127–140. [Google Scholar]
- Roussas, G.G. Positive and negative dependence with some statistical applications. In Asymptotics, Nonparametrics and Time Series; Ghosh, S., Ed.; Marcell Dekker, Inc.: New York, NY, USA, 1999; pp. 757–788. [Google Scholar]
- Doukhan, P.; Louhichi, S. A new weak dependence condition andapplications to moment inequalities. Stoch. Process. Their Appl. 1999, 84, 313–342. [Google Scholar] [CrossRef]
- Bulinski, A.; Suquet, C. Normal approximation for quasi-associated random fields. Stat. Probab. Lett. 2001, 54, 215–226. [Google Scholar] [CrossRef]
- Douge, L. Théorèmes limites pour des variables quasi-associées hilbertiennes. Ann. L’Institut Stat. L’Université Paris 2010, 54, 51–60. [Google Scholar]
- Attaoui, S.; Laksaci, A.; Ould-Said, E. Asymptotic Results for an M-estimator of the Regression Function for Quasi-Associated Processes. In Functional Statistics and Applications. Contributions to Statistics; Springer International Publishing: Cham, Switzerland, 2015; pp. 3–28. [Google Scholar] [CrossRef]
- Tabti, H.; Ait Saïdi, A. Estimation and simulation of conditionalhazard function in the quasi-associated framework when the observationsare linked via a functional single-index structure, Commun. Stat. Theory Methods 2017, 47, 816–838. [Google Scholar]
- Hamza, D.; Mechab, B.; Chikr Elmezouar, Z. Asymptotic normality of a conditional hazard function estimate in the single index for quasi-associated data. Commun. Stat. Theory Methods 2020, 49, 513–530. [Google Scholar] [CrossRef]
- Laksaci, A.; Mechab, W. Nonparametric relative regression for associatedrandom variables. Metron 2016, 74, 75–97. [Google Scholar]
- Daoudi, H.; Mechab, B. Asymptotic Normality of the Kernel Estimate of Conditional Distribution Function for the quasi-associated data. Pak. J. Stat. Oper. Res. 2019, 15, 999–1015. [Google Scholar]
- Daoudi, H.; Mechab, B.; Benaissa, S.; Rabhi, A. Asymptotic normality of the nonparametric conditional density function esti-mate with functional variables for the quasi-associated data. Int. J. Stat. Econ. 2019, 20, 94–106. [Google Scholar]
- Allaoui, S.; Bouzebda, S.; Chesneau, C.; Liu, J. Uniform almost sure convergence and asymptotic distribution of the wavelet-based estimators of partial derivatives of multivariate density function under weak dependence. J. Nonparametr. Stat. 2021, 33, 170–196. [Google Scholar] [CrossRef]
- Mohammedi, M.; Bouzebda, S.; Laksaci, A.; Bouanani, O. Asymptotic normality of the k-NN single index regression estimator for functional weak dependence data. Commun. Stat. Theory Methods 2022, 33, 1–26. [Google Scholar] [CrossRef]
- Bouzebda, S.; Laksaci, A.; Mohammedi, M. The k-nearest neighbors method in single index regression model for functional quasi-associated time series data. Rev. Mat. Complut. 2023, 36, 361–391. [Google Scholar] [CrossRef]
- Bouzebda, S.; Laksaci, A.; Mohammedi, M. Single Index Regression Model for Functional Quasi-Associated Times Series Data. REVSTAT Stat. J. 2023, 20, 605–631. [Google Scholar]
- Bouaker, I.; Belguerna, A.; Daoudi, H. The consistency of the kernel estimation of the Function conditional density for associated Data in high-dimensional statistics. J. Sci. Arts 2022, 22, 247–256. [Google Scholar] [CrossRef]
- Kallabis, R.S.; Neumann, M.H. An exponential inequality under weakdependence. Bernoulli 2006, 12, 333–350. [Google Scholar] [CrossRef]
- Doob, J.L. Stochastic Processes; John Wiley and Sons: New York, NY, USA, 1953. [Google Scholar]
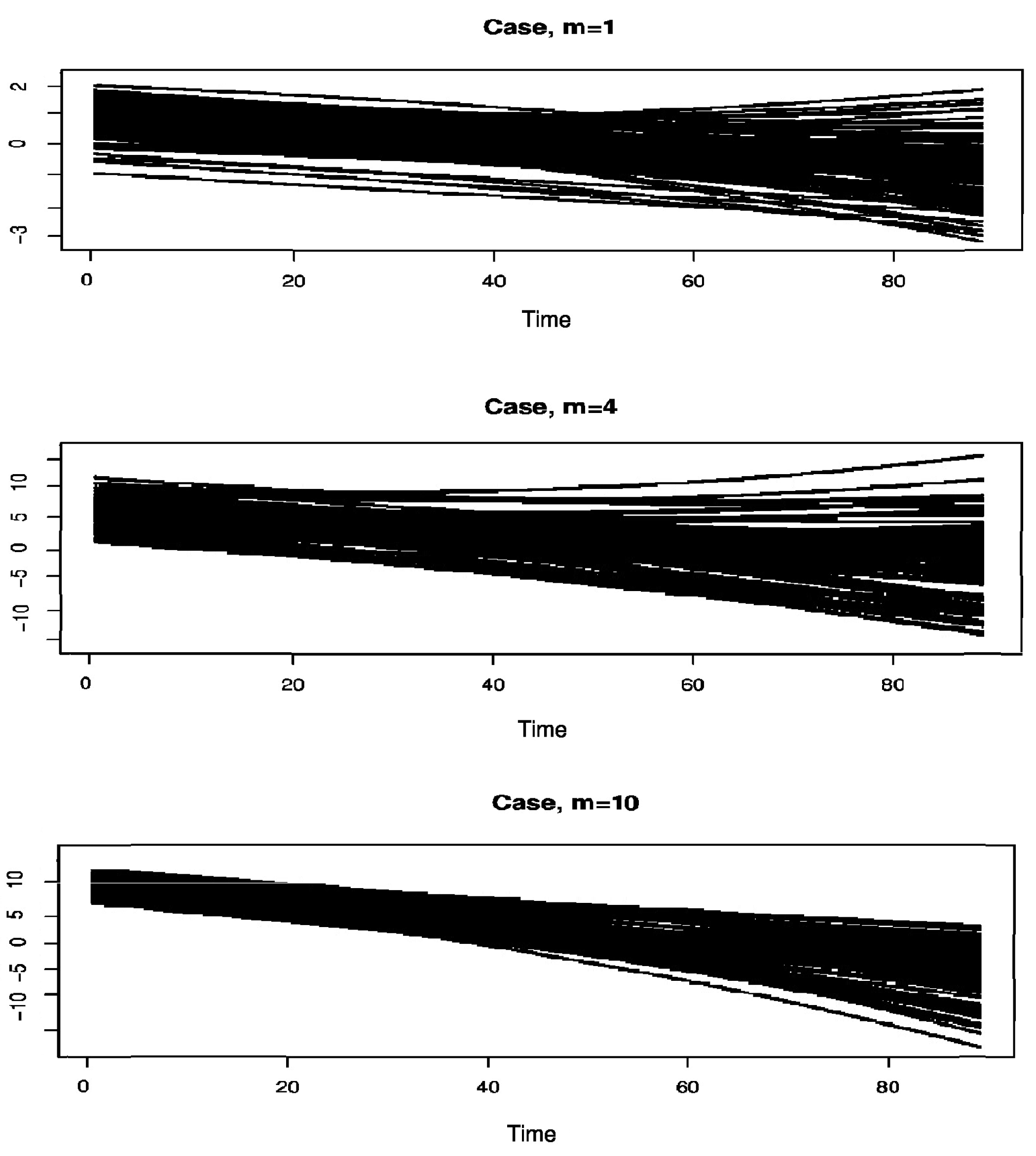
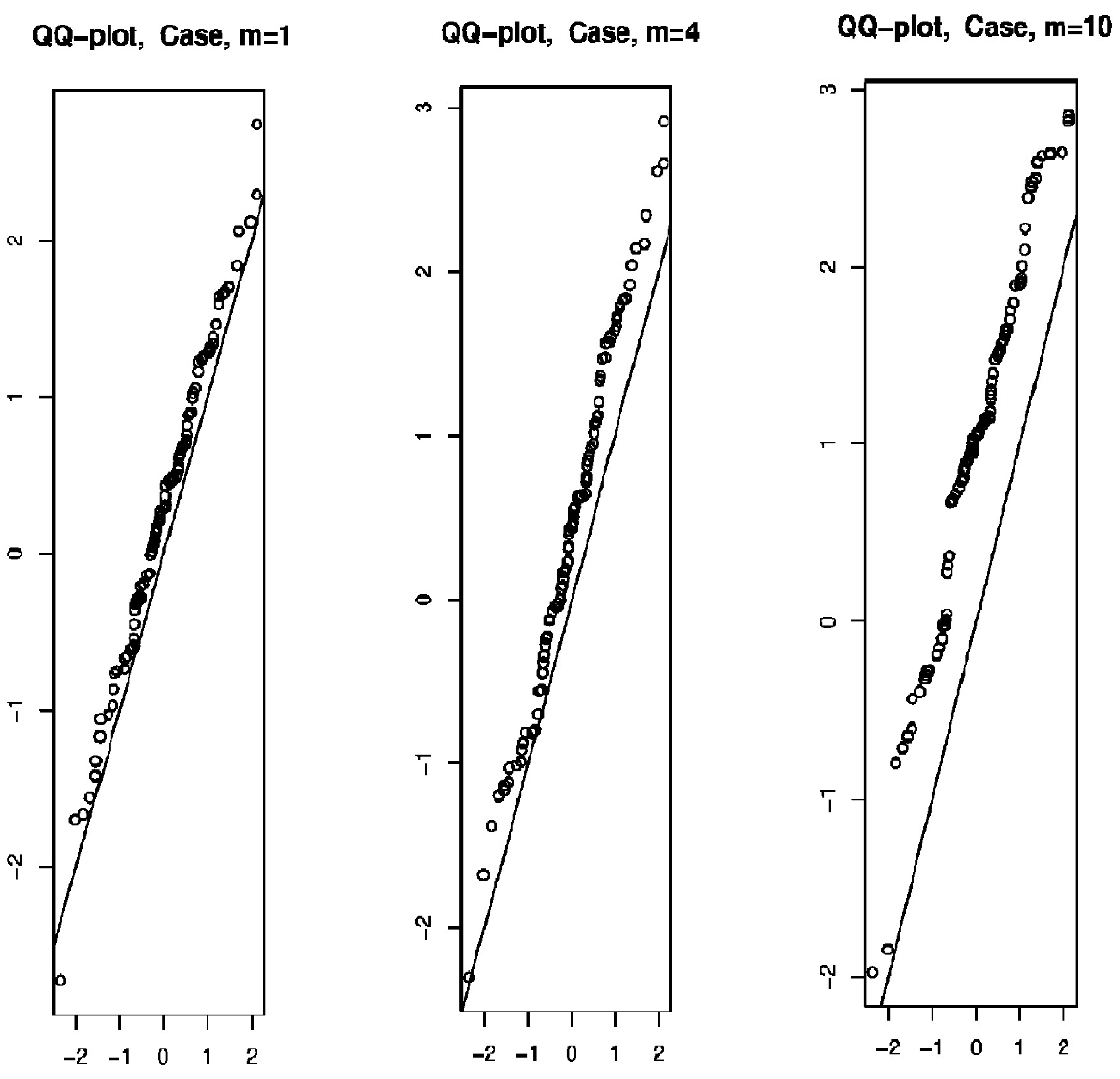

{kind=link}
{kind=link}
| m | 1 | 4 | 10 |
|---|---|---|---|
| p-value | 0.88 | 0.67 | 0.43 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Daoudi, H.; Elmezouar, Z.C.; Alshahrani, F. Asymptotic Results of Some Conditional Nonparametric Functional Parameters in High-Dimensional Associated Data. Mathematics 2023, 11, 4290. https://doi.org/10.3390/math11204290
Daoudi H, Elmezouar ZC, Alshahrani F. Asymptotic Results of Some Conditional Nonparametric Functional Parameters in High-Dimensional Associated Data. Mathematics. 2023; 11(20):4290. https://doi.org/10.3390/math11204290
Chicago/Turabian StyleDaoudi, Hamza, Zouaoui Chikr Elmezouar, and Fatimah Alshahrani. 2023. "Asymptotic Results of Some Conditional Nonparametric Functional Parameters in High-Dimensional Associated Data" Mathematics 11, no. 20: 4290. https://doi.org/10.3390/math11204290
APA StyleDaoudi, H., Elmezouar, Z. C., & Alshahrani, F. (2023). Asymptotic Results of Some Conditional Nonparametric Functional Parameters in High-Dimensional Associated Data. Mathematics, 11(20), 4290. https://doi.org/10.3390/math11204290