
Optimization of Task-Scheduling Strategy in Edge Kubernetes Clusters Based on Deep Reinforcement Learning


Abstract
:1. Introduction
- A Markov process for pod scheduling in edge heterogeneous environments using the k3s framework is modeled. A custom Kubernetes scheduler based on deep reinforcement learning is designed and implemented.
- The PPO-LRT algorithm is proposed by combining PPO with LRT. The reward function is designed to emphasize load balancing within the cluster and includes a mechanism to guard against excessively high workloads. Additionally, the algorithm incorporates a response time calculation, leading to more balanced loads on different nodes in the Kubernetes edge cluster and controlling resource utilization within a more reasonable range. This adaptive optimization addresses the resource constraints and low-latency requirements of the edge environment.
- The proposed PPO-LRT algorithm is implemented as a custom Kubernetes scheduler and interacts with the cluster. Different types and quantities of task sets are used to test the algorithm’s load-balancing adjustment capabilities and high-load bearing capacity in a heterogeneous and resource-limited cluster during task-scheduling peaks.
2. Scheduling System Design
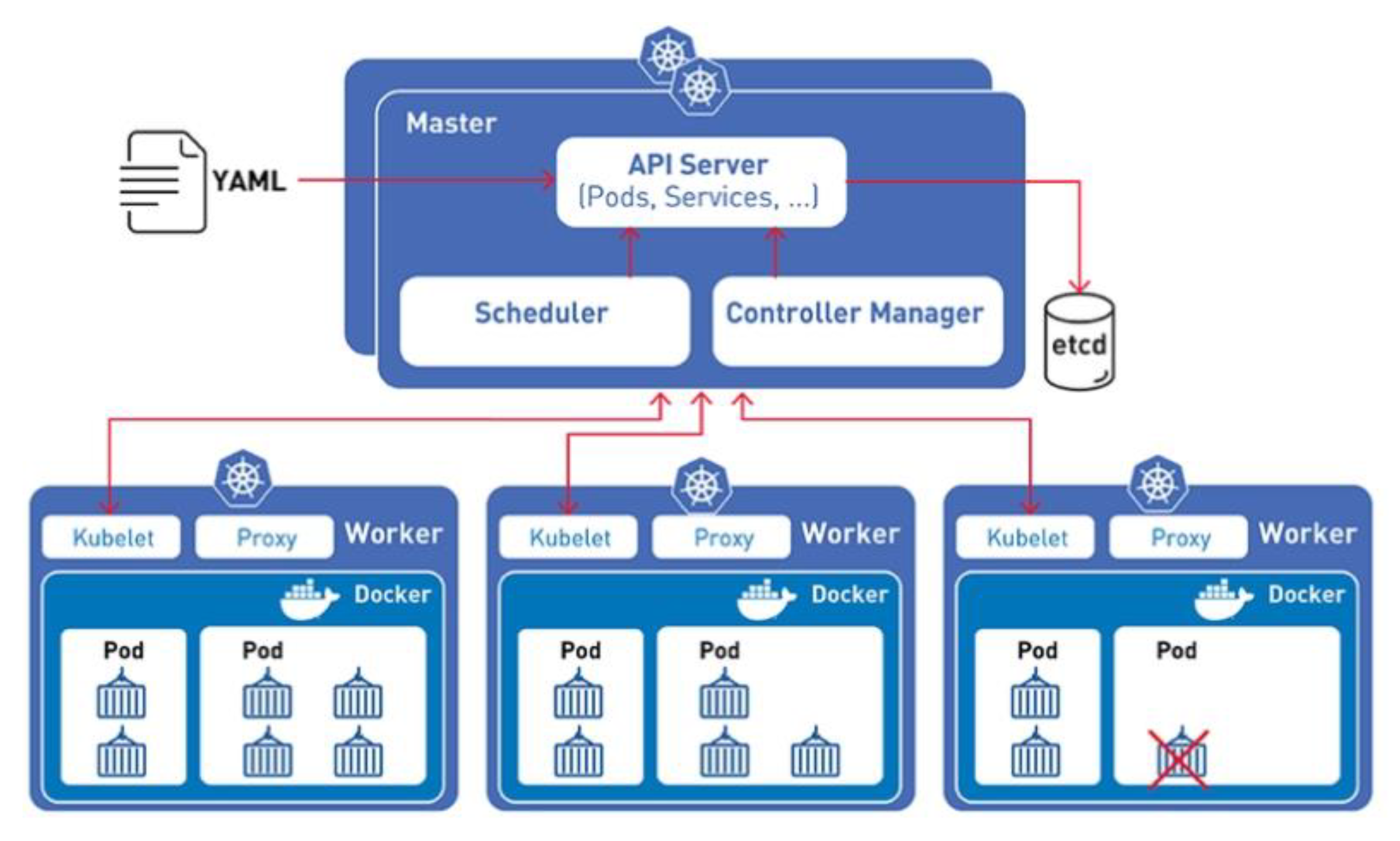
2.1. Kubernetes Cluster Architecture
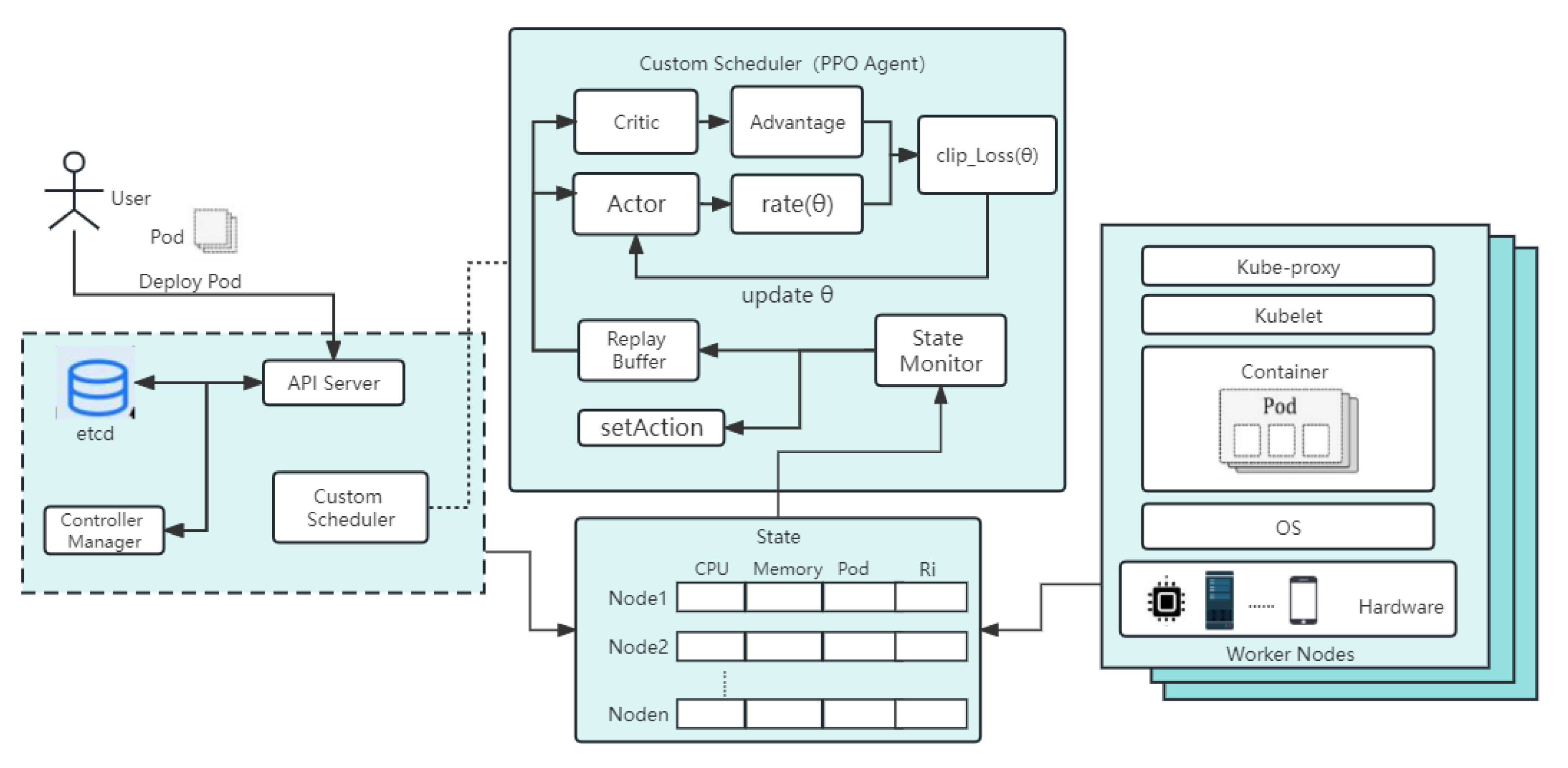
2.2. Custom Scheduler Design Based on DRL
3. PPO-LRT Algorithm
3.1. PPO Algorithm
3.2. Least Response Time (LRT)
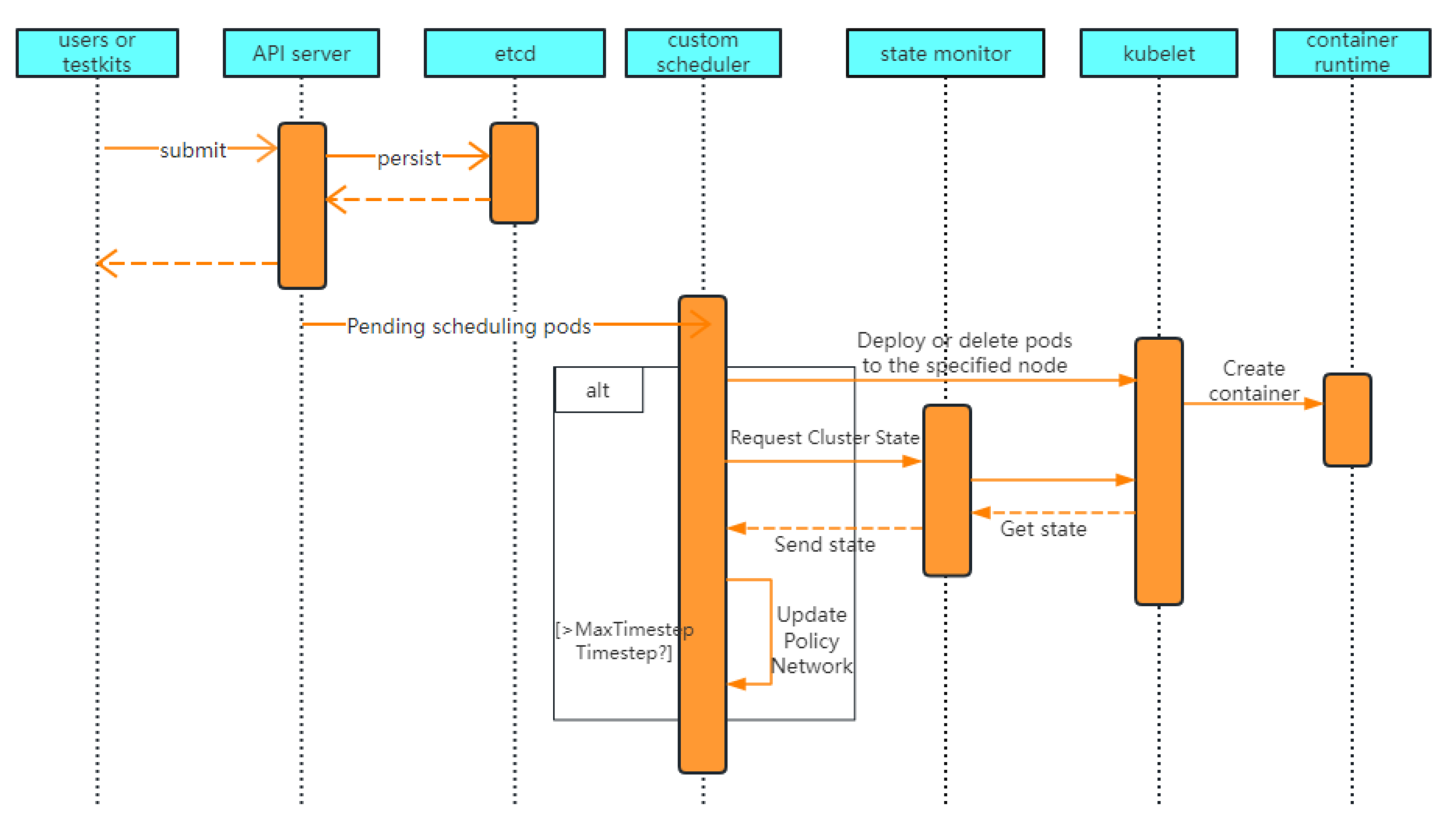
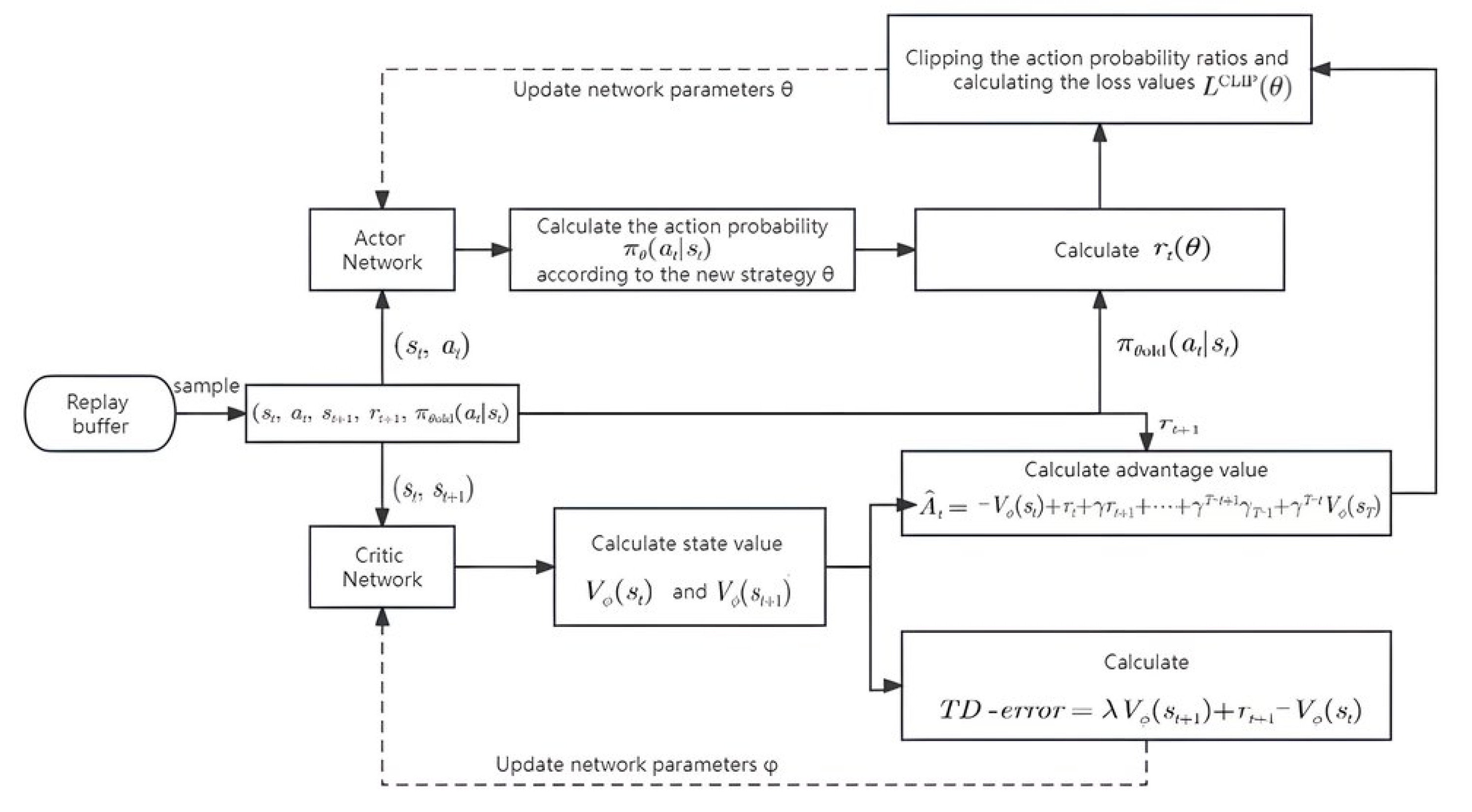
3.3. Scheduling Problem Modeling and PPO-LRT Algorithm Flow
| Algorithm 1 Pod Scheduling Algorithm Based on PPO-LRT |
| Initialize the policy parameters θ. |
| Initialize the value function network parameters ϕ. |
| for i in range(t): |
| Perform the scheduling of a certain number of pods based on the current policy and obtain trajectories . |
| Calculate the rewards-to-go using Equation (5). |
| Obtain the current state data of all nodes in the cluster, including CPU, memory, resource requirements of the previous pod, and its response time. Then, use the current value function to estimate the advantage values of the trajectory data. |
| Updating the policy by maximizing the clipped surrogate objective function: |
| where , is a hyperparameter. |
| The value function is updated by minimizing the mean squared error between the predicted values and the observed returns: |
| . |
| Use the updated policy to repeat the process. |
4. Evaluation
4.1. Experimental Environment Setup
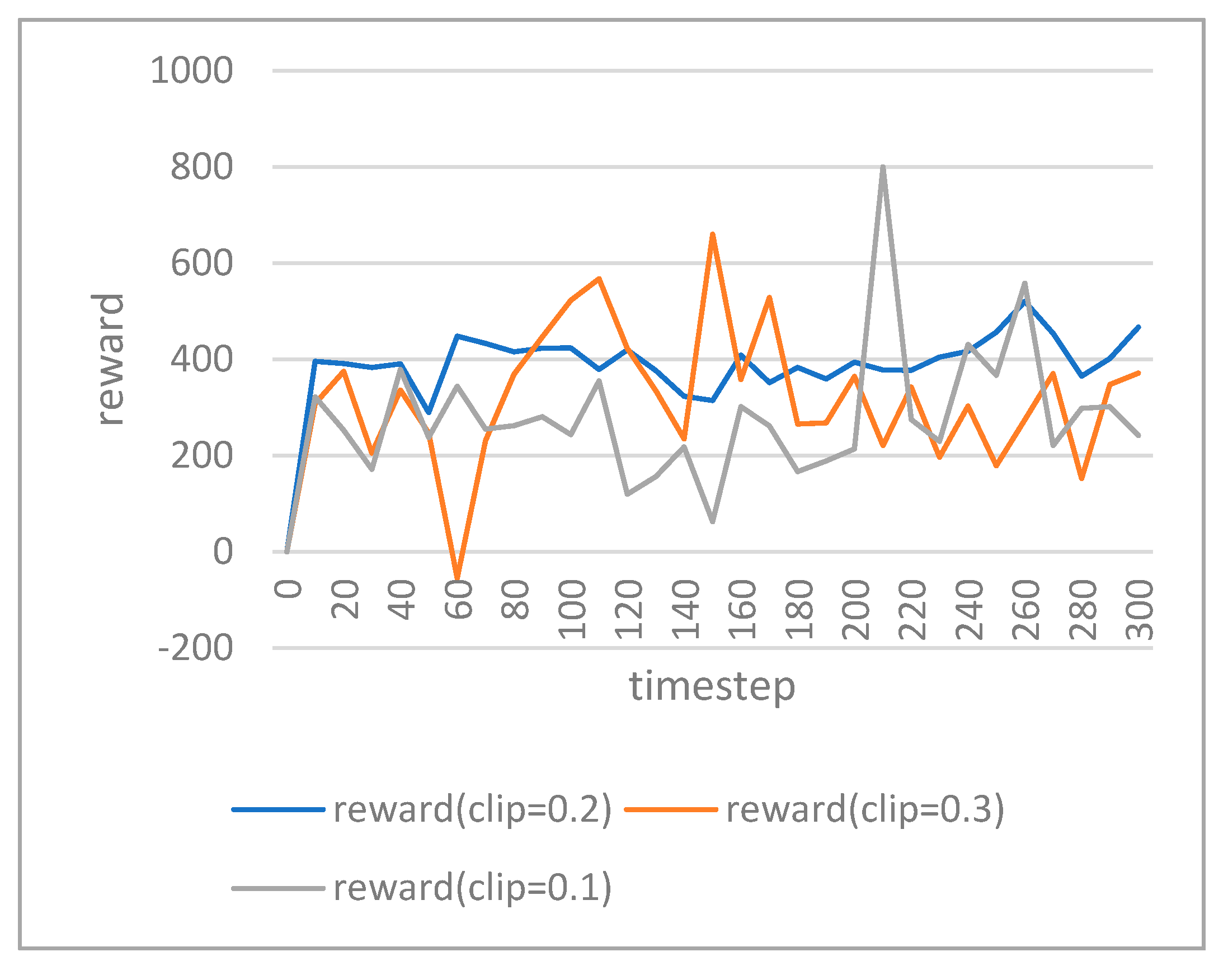
4.2. Training Performance
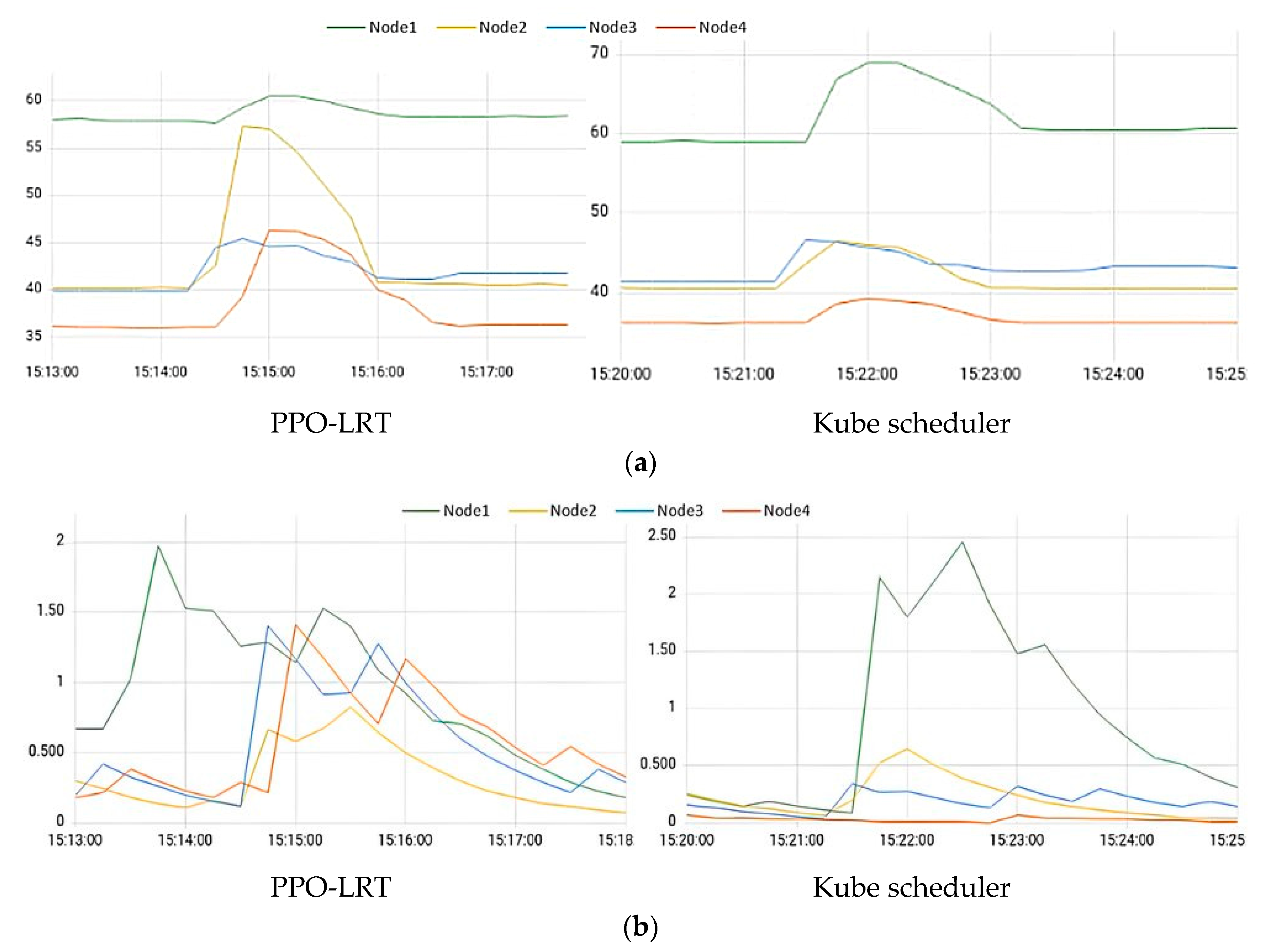
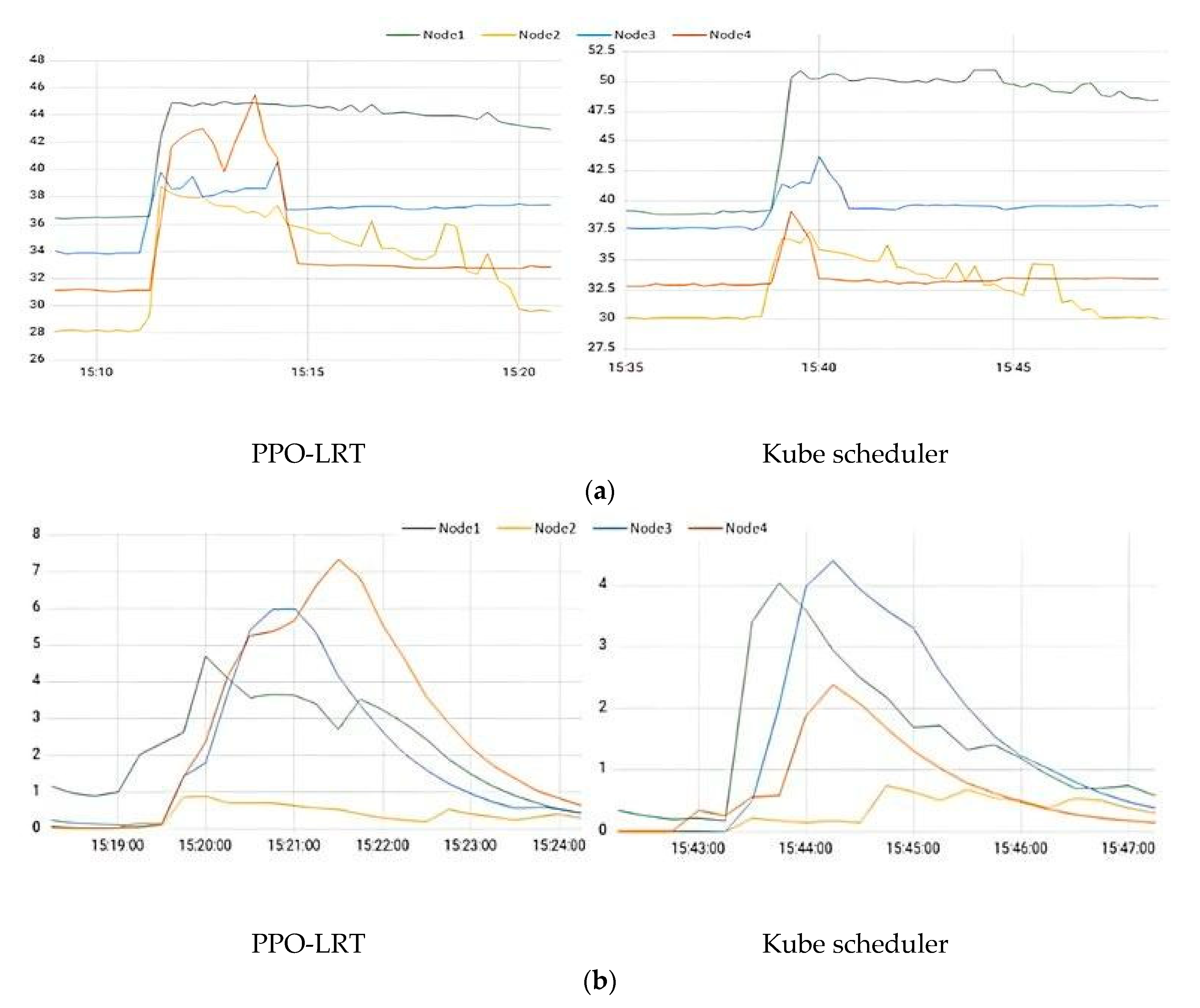
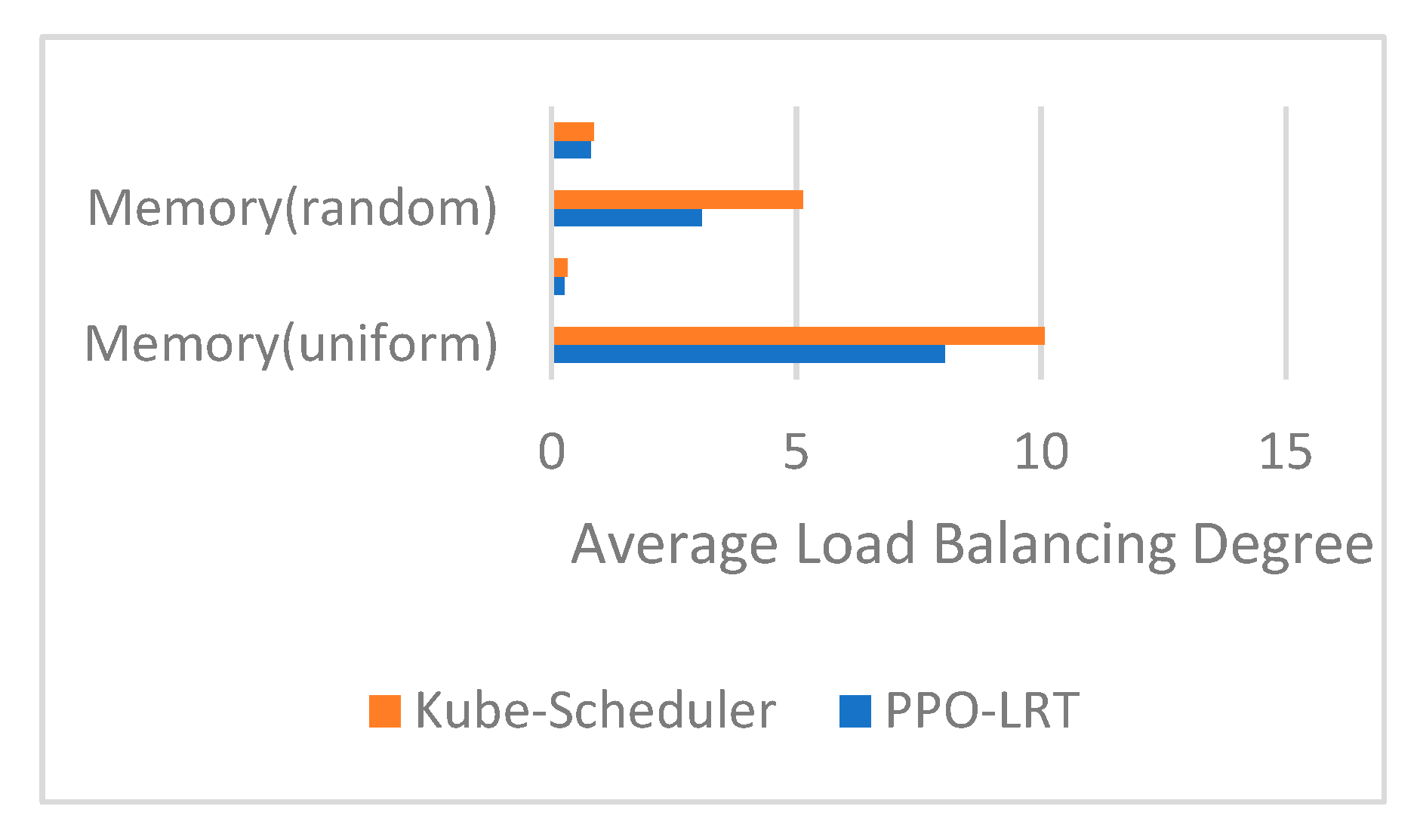
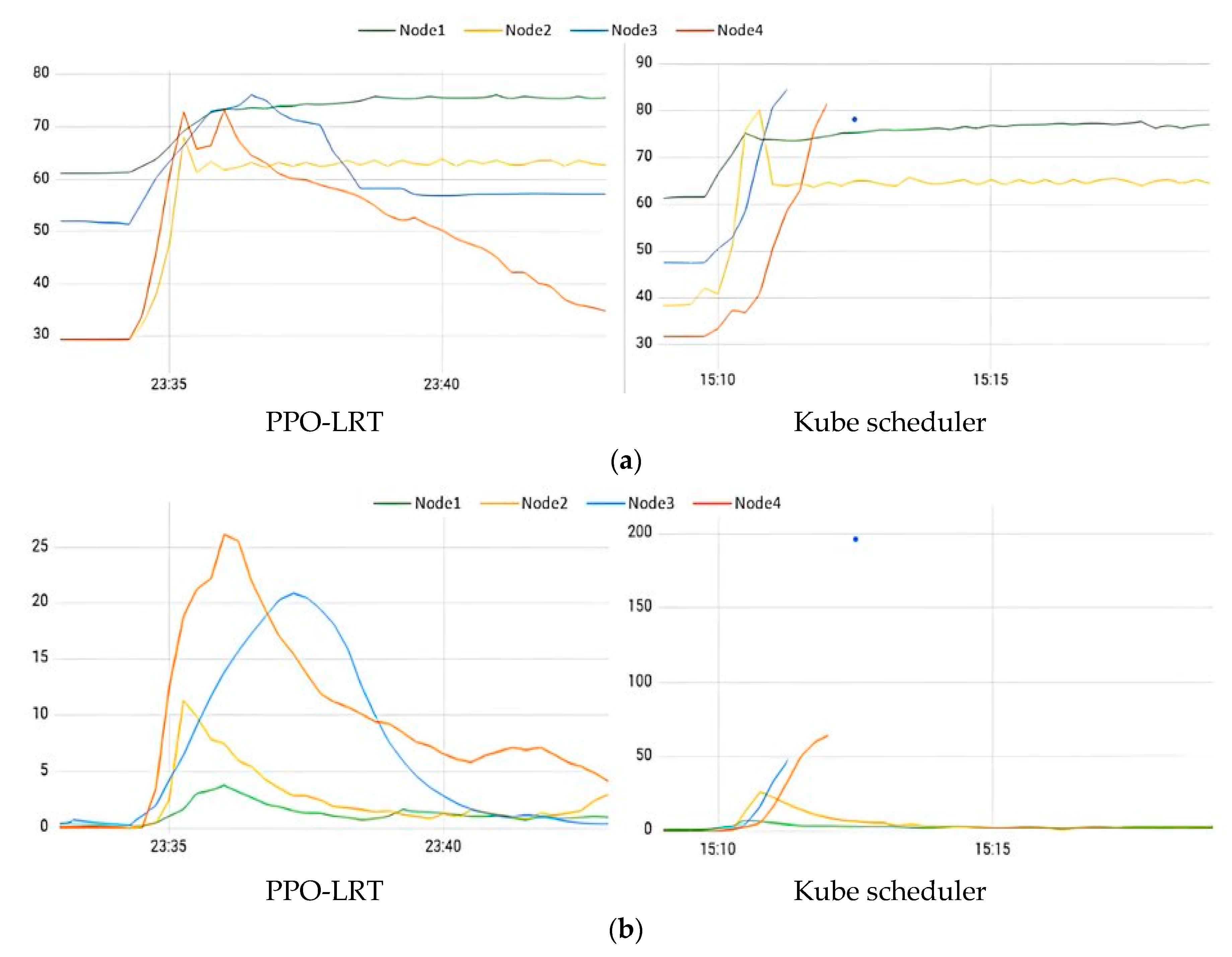
4.3. Load Balancing Test
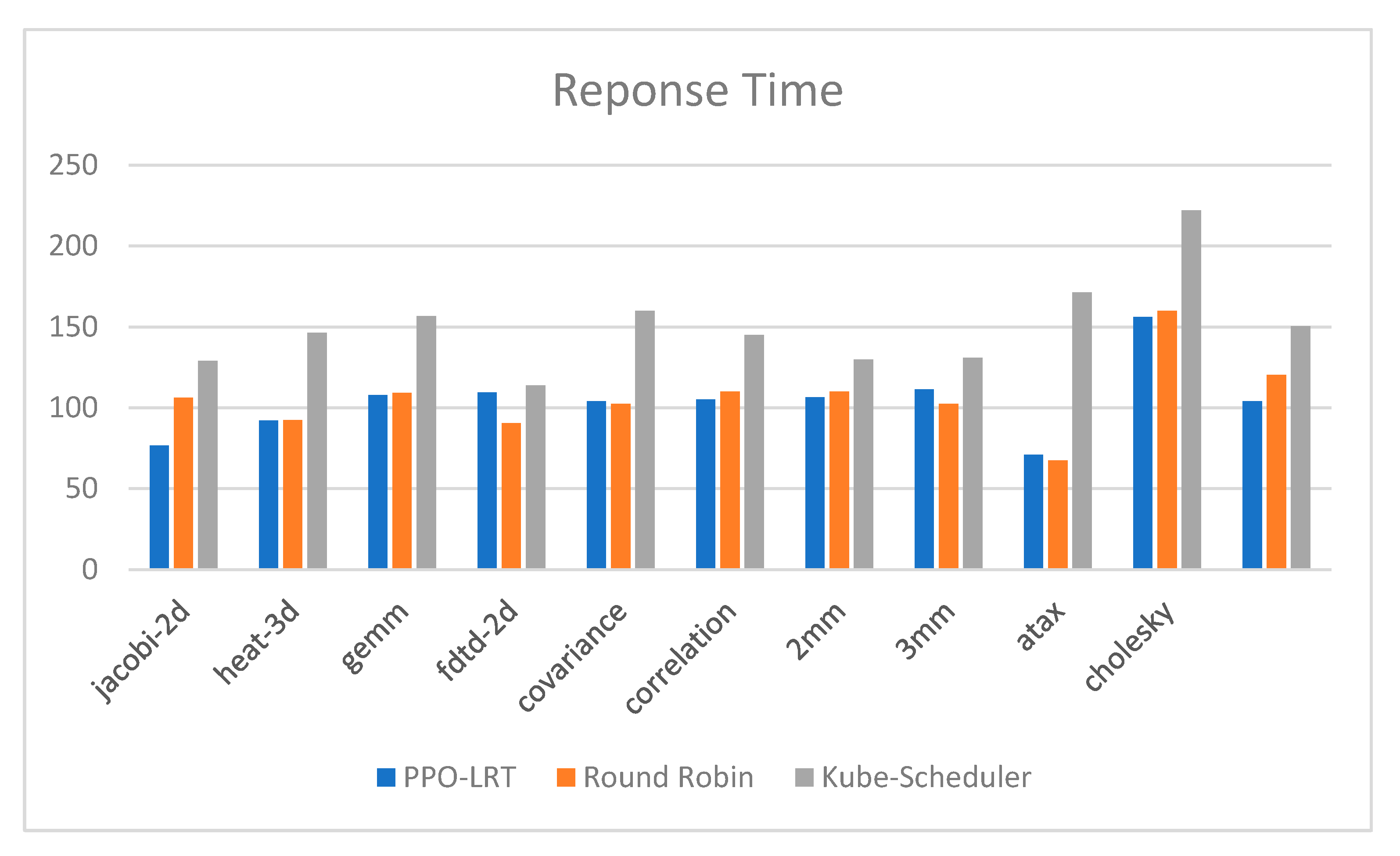
4.4. Response Time
4.5. Results and Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wöbker, C.; Seitz, A.; Mueller, H.; Bruegge, B. Fogernetes: Deployment and management of fog computing applications. In Proceedings of the NOMS 2018—2018 IEEE/IFIP Network Operations and Management Symposium, Taipei, Taiwan, 23–27 April 2018; pp. 1–7. [Google Scholar]
- Medel, V.; Tolón, C.; Arronategui, U.; Tolosana-Calasanz, R.; Bañares, J.Á.; Rana, O.F. Client-side scheduling based on application characterization on Kubernetes. In Proceedings of the Economics of Grids, Clouds, Systems, and Services: 14th International Conference, GECON 2017, Biarritz, France, 19–21 September 2017; Proceedings 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 162–176. [Google Scholar]
- Lai, W.K.; Wang, Y.C.; Wei, S.C. Delay-Aware Container Scheduling in Kubernetes. IEEE Internet Things J. 2023, 10, 11813–11824. [Google Scholar] [CrossRef]
- Amirteimoori, A.; Tirkolaee, E.B.; Simic, V.; Weber, G.W. A parallel heuristic for hybrid job shop scheduling problem considering conflict-free AGV routing. Swarm Evol. Comput. 2023, 79, 101312. [Google Scholar] [CrossRef]
- Goli, A.; Ala, A.; Hajiaghaei-Keshteli, M. Efficient multi-objective meta-heuristic algorithms for energy-aware non-permutation flow-shop scheduling problem. Expert Syst. Appl. 2023, 213, 119077. [Google Scholar] [CrossRef]
- Kchaou, H.; Kechaou, Z.; Alimi, A.M. A PSO task scheduling and IT2FCM fuzzy data placement strategy for scientific cloud workflows. J. Comput. Sci. 2022, 64, 101840. [Google Scholar] [CrossRef]
- Park, S.; Jeon, J.; Jeong, B.; Park, K.; Baek, S.; Jeong, Y.S. Actual Resource Usage-Based Container Scheduler for High Resource Utilization. In Proceedings of the International Conference on Computer Science and Its Applications and the International Conference on Ubiquitous Information Technologies and Applications, Vientiane, Laos, 19–21 December 2022; Springer Nature Singapore: Singapore, 2022; pp. 611–614. [Google Scholar]
- Harichane, I.; Makhlouf, S.A.; Belalem, G. KubeSC-RTP: Smart scheduler for Kubernetes platform on CPU-GPU heterogeneous systems. Concurr. Comput. Pract. Exp. 2022, 34, e7108. [Google Scholar] [CrossRef]
- Menouer, T. KCSS: Kubernetes container scheduling strategy. J. Supercomput. 2021, 77, 4267–4293. [Google Scholar] [CrossRef]
- Shi, B.; Chen, F.; Tang, X. Deep Reinforcement Learning Based Task Offloading Strategy Under Dynamic Pricing in Edge Computing. In Proceedings of the International Conference on Service-Oriented Computing, Online. 22–25 November 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 578–594. [Google Scholar]
- Yamansavascilar, B.; Baktir, A.C.; Sonmez, C.; Ozgovde, A.; Ersoy, C. Deepedge: A deep reinforcement learning based task orchestrator for edge computing. IEEE Trans. Netw. Sci. Eng. 2022, 10, 538–552. [Google Scholar] [CrossRef]
- Xiao, L.; Lu, X.; Xu, T.; Wan, X.; Ji, W.; Zhang, Y. Reinforcement learning-based mobile offloading for edge computing against jamming and interference. IEEE Trans. Commun. 2020, 68, 6114–6126. [Google Scholar] [CrossRef]
- Lim, D.; Joe, I. A DRL-Based Task Offloading Scheme for Server Decision-Making in Multi-Access Edge Computing. Electronics 2023, 12, 3882. [Google Scholar] [CrossRef]
- Xu, X.; Liu, K.; Dai, P.; Jin, F.; Ren, H.; Zhan, C.; Guo, S. Joint task offloading and resource optimization in noma-based vehicular edge computing: A game-theoretic drl approach. J. Syst. Archit. 2023, 134, 102780. [Google Scholar] [CrossRef]
- Zhao, N.; Ye, Z.; Pei, Y.; Liang, Y.C.; Niyato, D. Multi-agent deep reinforcement learning for task offloading in UAV-assisted mobile edge computing. IEEE Trans. Wirel. Commun. 2022, 21, 6949–6960. [Google Scholar] [CrossRef]
- Agarwal, S.; Rodriguez, M.A.; Buyya, R. A reinforcement learning approach to reduce serverless function cold start frequency. In Proceedings of the 2021 IEEE/ACM 21st International Symposium on Cluster, Cloud and Internet Computing (CCGrid), Melbourne, Australia, 10–13 May 2021; pp. 797–803. [Google Scholar]
- Huang, J.; Xiao, C.; Wu, W. Rlsk: A job scheduler for federated kubernetes clusters based on reinforcement learning. In Proceedings of the 2020 IEEE International Conference on Cloud Engineering (IC2E), Sydney, Australia, 21–24 April 2020; pp. 116–123. [Google Scholar]
- Peng, Y.; Bao, Y.; Chen, Y.; Wu, C.; Meng, C.; Lin, W. Dl2: A deep learning-driven scheduler for deep learning clusters. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 1947–1960. [Google Scholar] [CrossRef]
- Burns, B.; Beda, J.; Hightower, K.; Evenson, L. Kubernetes: Up and Running; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2022. [Google Scholar]
- Carrión, C. Kubernetes scheduling: Taxonomy, ongoing issues and challenges. ACM Comput. Surv. 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Rejiba, Z.; Chamanara, J. Custom scheduling in Kubernetes: A survey on common problems and solution approaches. ACM Comput. Surv. 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Kakade, S.; Langford, J. Approximately optimal approximate reinforcement learning. In Proceedings of the 19th International Conference on Machine Learning, Sydney, Australia, 8–12 July 2002. [Google Scholar]
- Arshad, A. What Is the Least Response Time Load Balancing Technique. Available online: https://www.educative.io/answers/what-is-the-least-response-time-load-balancing-technique (accessed on 30 December 2021).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Definition | Description |
|---|---|
| Ratio of the new and old policies | |
| Loss function based on clip function | |
| Policy network parameter | |
| The action at the moment t | |
| The state at the moment t | |
| Hyperparameter between 0 and 1 | |
| A value function in state that estimates the expected return of following a strategy in that state, where φ is a parameter of the value function, usually a neural network or other learning model | |
| Probability of executing state |
| Node | OS | CPU Cores | Memory |
|---|---|---|---|
| Master (Node1) | Centos7 | 8 | 8 GB |
| Node2 | Centos7 | 2 | 3 GB |
| Node3 | Ubuntu | 2 | 4 GB |
| Node4 | Redhat | 2 | 4 GB |
| Name | Type | Description |
|---|---|---|
| Jacobi-2d | Linear Algebra | 2D Jacobi stencil computation |
| 3 mm | Linear Algebra | Three matrix multiplications |
| 2 mm | Linear Algebra | Two matrix multiplications |
| Gemm | Linear algebra | Matrix multiplication |
| Atax | Linear Algebra | Matrix transpose and vector multiplication |
| Cholesky | Linear Algebra | Cholesky decomposition |
| heat-3d | Physics simulation | Heat equation over 3D data domain |
| Fdtd-2d | Physics simulation | 2D finite-difference time-domain kernel |
| Covariance | Data mining | Covariance computation |
| Correlation | Data mining | Correlation computation |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Zhao, K.; Qin, B. Optimization of Task-Scheduling Strategy in Edge Kubernetes Clusters Based on Deep Reinforcement Learning. Mathematics 2023, 11, 4269. https://doi.org/10.3390/math11204269
Wang X, Zhao K, Qin B. Optimization of Task-Scheduling Strategy in Edge Kubernetes Clusters Based on Deep Reinforcement Learning. Mathematics. 2023; 11(20):4269. https://doi.org/10.3390/math11204269
Chicago/Turabian StyleWang, Xin, Kai Zhao, and Bin Qin. 2023. "Optimization of Task-Scheduling Strategy in Edge Kubernetes Clusters Based on Deep Reinforcement Learning" Mathematics 11, no. 20: 4269. https://doi.org/10.3390/math11204269
APA StyleWang, X., Zhao, K., & Qin, B. (2023). Optimization of Task-Scheduling Strategy in Edge Kubernetes Clusters Based on Deep Reinforcement Learning. Mathematics, 11(20), 4269. https://doi.org/10.3390/math11204269