


A Lightweight YOLOv5-Based Model with Feature Fusion and Dilation Convolution for Image Segmentation

Abstract
:1. Introduction
2. Related Work
3. The Proposed Segmentation Approach
3.1. Improved YOLOv5s Model Based on Feature Fusion
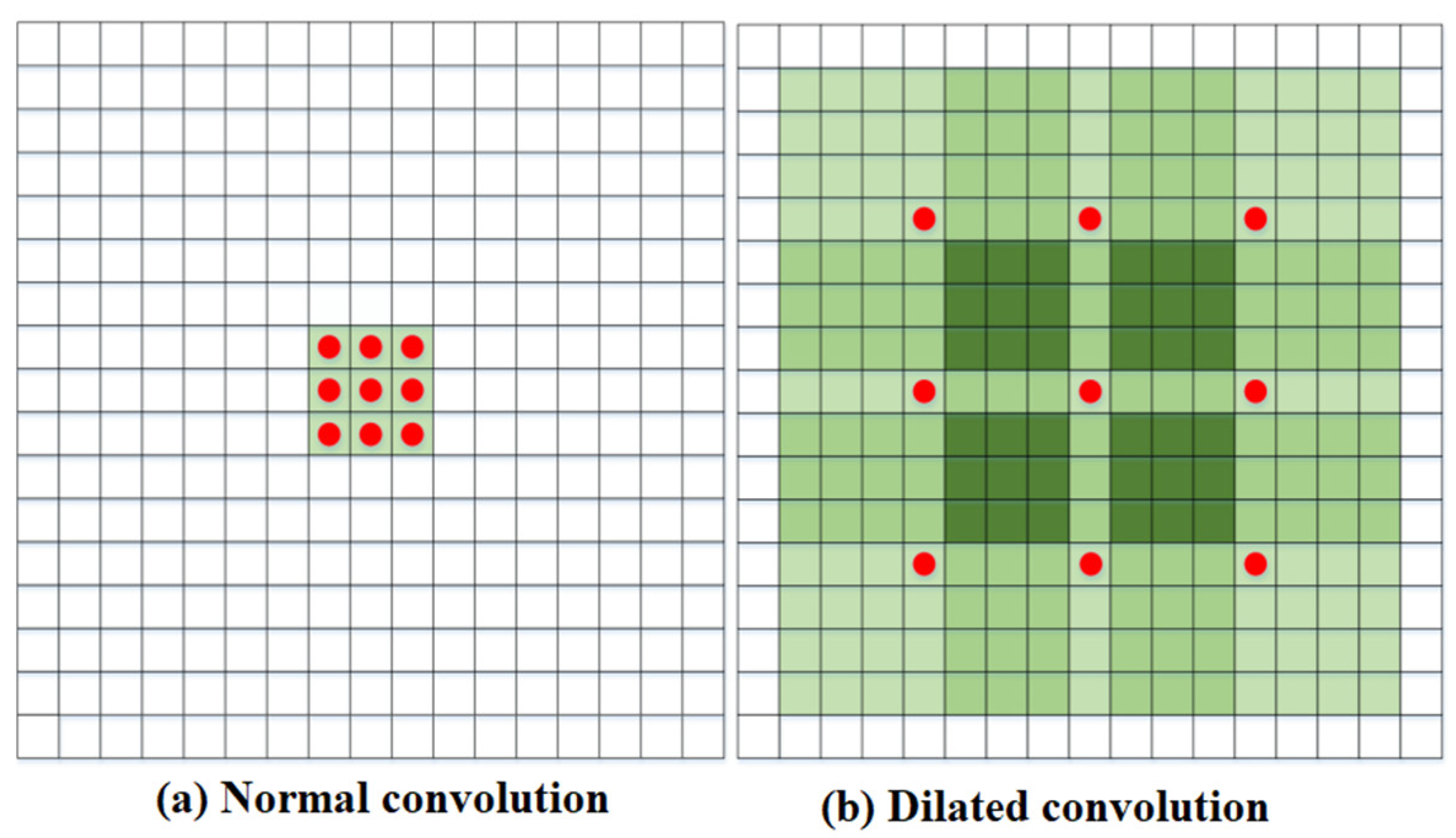
3.2. Addition of Dilated Convolution Module
3.3. DM-YOLOv5s Model Based on MobileViT Lightweight
| Algorithm 1: The Flow of MobileViT-DM-YOLOv5s Algorithm |
| Begin |
| // Define inputs and outputs |
| Input: image |
| Output: segmentation_result |
| // Defining M-YOLOv5s Algorithm for Multi-Level Feature Fusion |
| // Define feature pyramid structure |
| X1, X2, X3 = feature_pyramid(image) |
| // Define multi-layer feature fusion network structure |
| F1 = X1 |
| F2 = fuse_features(X2, F1) |
| F3 = fuse_features(X3, F2) |
| // Defining top-down convolutional neural networks |
| U1 = upsample(F3) |
| U2 = fuse_features(U1, F2) |
| U3 = fuse_features(U2, F1) |
| // Define DM-YOLOv5s model |
| M-YOLOv5s = YOLOv5s(feature=F3) |
| DM-YOLOv5s = DilatedConvolution(M-YOLOv5s) |
| // Defining the MobileViT Network |
| MobileViT = MobileViT(feature=U3) |
| // Performing image segmentation tasks |
| segmentation_result = MobileViT(DM-YOLOv5s(image)) |
| End |
4. Experiment Section
4.1. Experimental Setup
4.1.1. Experimental Platform
4.1.2. Dataset
4.1.3. Mean Average Precision
4.2. Ablation Experiments
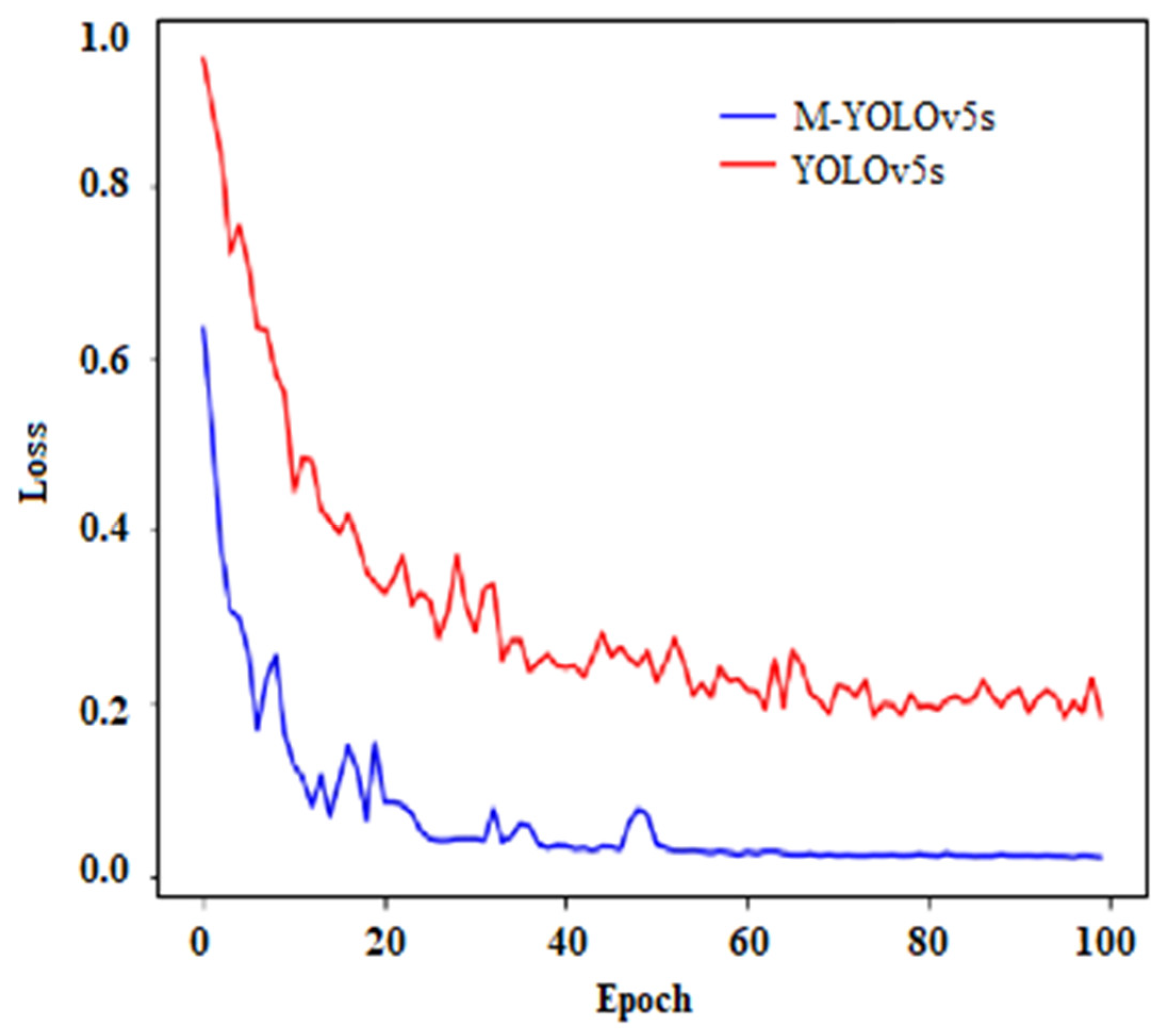
4.2.1. Ablation Experiment of Feature Fusion
- (1)
- Loss comparison
- (2)
- Accuracy comparison
4.2.2. Ablation Experiment of Dilated Convolutional
- (1)
- Loss comparison
- (2)
- Accuracy comparison
4.2.3. Ablation Experiment of Lightweight Model
4.3. Comparison Experiment
- Feature fusion technique: The MDM-YOLOv5s model uses the feature fusion technique to fuse features at different levels, thus improving the model’s understanding of images and segmentation accuracy;
- Dilated convolution technique: The MDM-YOLOv5s model adopts the dilated convolution technique, which can effectively expand the perceptual field and improve the model’s ability to capture image details, thus improving the segmentation accuracy;
- MobileViT technology: The MDM-YOLOv5s model also adopts MobileViT technology, which can effectively reduce the model parameters and computation volume, thus improving the model operation speed and efficiency;
- YOLOv5s structure: The MDM-YOLOv5s model is improved based on the YOLOv5s structure, and YOLOv5s itself is an efficient target detection algorithm with a simple structure, small computation, and fast speed, and these advantages also provide the basis for the high accuracy of the MDM-YOLOv5s model.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kurban, T.; Civicioglu, P.; Kurban, R.; Besdok, E. Comparison of evolutionary and swarm based computational techniques for multi-level color image thresholding. Appl. Soft Comput. 2014, 23, 128–143. [Google Scholar] [CrossRef]
- Liu, X.; Deng, Z.; Yang, Y. Recent progress in semantic image segmentation. Artif. Intell. Rev. 2019, 52, 1089–1106. [Google Scholar] [CrossRef]
- Pal, N.R.; Pal, S.K. A review on image segmentation techniques. Pattern Recognit. 1993, 26, 1277–1294. [Google Scholar] [CrossRef]
- Patra, S.; Gautam, R.; Singla, A. A novel context sensitive multi-level thresholding for image segmentation. Appl. Soft Comput. 2014, 23, 122–127. [Google Scholar] [CrossRef]
- Dutta, P.K. Image segmentation based approach for the purpose of developing satellite image spatial information extraction for forestation and river bed analysis. Int. J. Image Graph. 2019, 19, 1950002. [Google Scholar] [CrossRef]
- Wen, J.; Fang, X.Z.; Cui, J.R.; Fei, L.K.; Yan, K.; Chen, Y.; Xu, Y. Robust sparse linear discriminant analysis. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 390–403. [Google Scholar] [CrossRef]
- Bao, X.; Jia, H.; Lang, C. A novel hybrid harris hawks optimization for color image multi-level thresholding segmentation. IEEE Access 2019, 7, 76529–76546. [Google Scholar] [CrossRef]
- Khan, A.; Irtaza, A.; Javed, A.; Nazir, T.; Malik, H.; Malik, K.; Khan, M. Defocus blur detection using novel local directional mean patterns (LDMP) and segmentation via KNN matting. Front. Comput. Sci. 2022, 16, 104–116. [Google Scholar] [CrossRef]
- Nanda, N.; Kakkar, P.; Nagpal, S. Computer-aided segmentation of liver lesions in CT scans using cascaded convolutional neural networks and genetically optimised classifier. Arab. J. Sci. Eng. 2019, 44, 4049–4062. [Google Scholar] [CrossRef]
- Thyreau, B.; Taki, Y. Learning a cortical parcellation of the brain robust to the MRI segmentation with convolutional neural networks. Med. Image Anal. 2020, 14, 101639. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Han, L.; Chen, Y.H.; Li, J.M.; Zhong, B.; Sun, M. Liver segmentation with 2.5 D perpendicular UNets. Comput. Electr. Eng. 2021, 91, 107118. [Google Scholar] [CrossRef]
- Huynh, C.; Tran, A.T.; Luu, K.; Hoai, M. Progressive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16750–16759. [Google Scholar] [CrossRef]
- Fan, H.; Sun, Y.; Zhang, X.J.; Zhang, C.C.; Li, X.J.; Wang, Y. Magnetic-resonance image segmentation based on improved variable weight multi-resolution Markov random field in undecimated complex wavelet domain. Chin. Phys. B 2021, 30, 748–761. [Google Scholar] [CrossRef]
- Kotte, S.; Kumar, P.R.; Injeti, S.K. An efficient approach for optimal multi-level thresholding selection for gray scale images based on improved differential search algorithm. Ain Shams Eng. J. 2018, 9, 1043–1067. [Google Scholar] [CrossRef]
- Huang, J.Y.; Cui, H.; Ma, J.; Hao, Y. Research on an aerial object detection algorithm based on improved YOLOv5. In Proceedings of the 2022 3rd International Conference on Computer Vision, Image and Deep Learning & International Conference on Computer Engineering and Applications (CVIDL & ICCEA), Changchun, China, 20–22 May 2022; pp. 396–400. [Google Scholar] [CrossRef]
- Zhou, Q.; Wang, R.; Hu, H.M.; Tan, Q.; Zhang, W.J. Referring image segmentation with attention guided cross modal fusion for semantic oriented languages. Front. Comput. Sci. 2022, 16, 175–177. [Google Scholar] [CrossRef]
- Li, Z.L.; Zhang, Q.J.; Long, T.; Zhao, B.J. A parallel pipeline connected-component labeling method for on-orbit space target monitoring. Syst. Eng. Electron. 2022, 33, 1095–1107. [Google Scholar] [CrossRef]
- Xia, H.; Sun, W.; Song, S.; Mou, X. Md-net: Multi-scale dilated convolution network for CT images segmentation. Neural Process Lett. 2020, 51, 2915–2927. [Google Scholar] [CrossRef]
- Wu, Y.; Lin, L. Automatic lung segmentation in CT images using dilated convolution based weighted fully convolutional network. J. Phys. Confer. Ser. 2022, 1646, 012032. [Google Scholar] [CrossRef]
- Dong, X.; Yan, S.; Duan, C. A lightweight vehicles detection network model based on YOLOv5. Eng. Appl. Artif. Intell. 2022, 113, 104914. [Google Scholar] [CrossRef]
- Liu, H.; Sun, F.; Gu, J.; Deng, L.J. Sf-yolov5: A lightweight small object detection algorithm based on improved feature fusion mode. Sensors 2022, 22, 5817. [Google Scholar] [CrossRef]
- Zhou, L.; Wei, S.Y.; Cui, Z.M.; Fang, J.Q.; Yang, X.T.; Ding, W. Lira-YOLO: A lightweight model for ship detection in radar images. Syst. Eng. Electron. Technol. 2020, 31, 950–956. [Google Scholar] [CrossRef]
- Wen, J.; Liu, C.L.; Deng, S.J.; Liu, Y.C.; Fei, L.K.; Yan, K.; Xu, Y. Deep double incomplete multi-view multi-label learning with incomplete labels and missing views. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–13. [Google Scholar] [CrossRef]
- Yang, G.H.; Feng, W.; Jin, J.T.; Lei, Q.J.; Li, X.H.; Gui, G.C.; Wang, W.J. Face mask recognition system with YOLOV5 based on image recognition. In Proceedings of the 2020 IEEE 6th International Conference on Computer and Communications (ICCC), Chengdu, China, 11–14 December 2020; pp. 1398–1404. [Google Scholar] [CrossRef]
- Wang, Z.; Jin, L.; Wang, S.; Xu, H. Apple stem/calyx real-time recognition using YOLO-v5 algorithm for fruit automatic loading system. Postharvest Biol. Technol. 2022, 185, 111808. [Google Scholar] [CrossRef]
- Lei, F.; Tang, F.F.; Li, S.H. Underwater target detection algorithm based on improved YOLOv5. J. Mar. Sci. Eng. 2022, 10, 310. [Google Scholar] [CrossRef]
- Mathew, M.P.; Mahesh, T.Y. Leaf-based disease detection in bell pepper plant using YOLOv5. Signal Image Video Process 2022, 16, 841–847. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.C.; Jiang, X.; Yu, H. Deep convolutional neural network for enhancing traffic sign recognition developed on yolov4. Multimed Tools Appl. 2022, 81, 37821–37845. [Google Scholar] [CrossRef]
- Zhou, L.; Gao, R.; Wang, J. A self-supervised, few-shot semantic segmentation study based on mobileViT model structure. In Proceedings of the 2023 IEEE International Conference on Control, Electronics and Computer Technology (ICCECT), Jilin, China, 28–30 April 2023; pp. 917–921. [Google Scholar] [CrossRef]
- Aiadi, O.; Khaldi, B. A fast lightweight network for the discrimination of COVID-19 and pulmonary diseases. Biomed. Signal Process Control 2022, 78, 103925. [Google Scholar] [CrossRef]
- Csurka, G.; Larlus, D.; Perronnin, F.; Meylan, F. What is a good evaluation measure for semantic segmentation? In Proceedings of the British Machine Vision Conference, Meylan, France, 16–19 January 2013; pp. 1–11. [Google Scholar] [CrossRef]
- Zhang, Y.; David, P.; Foroosh, H.; Gong, B. A curriculum domain adaptation approach to the semantic segmentation of urban scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1823–1841. [Google Scholar] [CrossRef]
- Chen, J.N.; Lu, Y.Y.; Yu, Q.H.; Luo, X.D.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y.Y. TransUNet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Operator | #Out | L | s |
|---|---|---|---|---|
| 2562 × 3 | conv2d | 16 | - | 2 |
| 1282 × 16 | MV2 | 32 | - | 1 |
| 1282 × 32 | MV2 | 64 | - | 2 |
| 642 × 64 | MV2 | 64 | - | 1 |
| 642 × 64 | MV2 | 64 | - | 1 |
| 642 × 64 | MV2 | 96 | - | /2 |
| 322 × 96 | MVIT | 96 | 2 | 1 |
| 322 × 96 | MV2 | 128 | - | 2 |
| 162 × 128 | MVIT | 128 | 4 | 1 |
| 162 × 128 | MV2 | 160 | - | 2 |
| 82 × 160 | MVIT | 160 | 3 | 1 |
| 82 × 160 | Conv2d | 640 | - | 1 |
| 82 × 640 | Avgpool 8 × 8 | - | - | - |
| 12 × 640 | FC | - | - | - |
| 12 × k | Conv2d\ | K< | - | - |
| Backbone Networks | Feature Pyramid Network | mPA (%) |
|---|---|---|
| YOLOv5s | FPN | 92.12 |
| M-YOLOv5s | M- FPN | 93.70 |
| Image Segmentation Model | Dilated Convolution Module | mPA (%) |
|---|---|---|
| M-YOLOv5s | - | 93.70 |
| DM-YOLOv5s | V | 95.91 |
| Image Segmentation Model | MobileviT | mAP (%) | Size/MB | Time/s |
|---|---|---|---|---|
| DM-YOLOv5s | - | 95.91 | 317 | 0.045 |
| MDM-YOLOv5s | V | 95.32 | 302 | 0.035 |
| Image Segmentation Model | COCO Precision (%) | PASCAL-VOC Precision (%) | mAP (%) | Model Size/MB |
|---|---|---|---|---|
| U-Net | 89.78 | 85.76 | 87.77 | 418 |
| SegNet | 90.82 | 89.76 | 90.29 | 354 |
| Mask R-CNN | 91.85 | 92.49 | 92.17 | 378 |
| MDM-YOLOv5s | 95.32 | 96.02 | 95.67 | 302 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, L.; Yang, J. A Lightweight YOLOv5-Based Model with Feature Fusion and Dilation Convolution for Image Segmentation. Mathematics 2023, 11, 3538. https://doi.org/10.3390/math11163538
Chen L, Yang J. A Lightweight YOLOv5-Based Model with Feature Fusion and Dilation Convolution for Image Segmentation. Mathematics. 2023; 11(16):3538. https://doi.org/10.3390/math11163538
Chicago/Turabian StyleChen, Linwei, and Jingjing Yang. 2023. "A Lightweight YOLOv5-Based Model with Feature Fusion and Dilation Convolution for Image Segmentation" Mathematics 11, no. 16: 3538. https://doi.org/10.3390/math11163538
APA StyleChen, L., & Yang, J. (2023). A Lightweight YOLOv5-Based Model with Feature Fusion and Dilation Convolution for Image Segmentation. Mathematics, 11(16), 3538. https://doi.org/10.3390/math11163538