1. Introduction
Current status data generally arise in demographic, tumorigenic, and epidemiological fields [
1,
2,
3]. One significant feature of the current status data is that the failure time cannot be accurately observed. On the contrary, it is known that the failure time is less than or greater than the observation or examination time. One common feature of studies that produce such data is that participants are only observed once, perhaps due to the limitation of resources. In this manuscript, we consider the semiparametric regression analysis of current status data with left truncation and informative censoring. In addition, an SMLE method is proposed.
Several methods have been developed to study the current status data. For example, under the proportional hazards (PH) model, ref. [
1] considered the efficiency problem and established asymptotic properties of maximum likelihood estimators of regression parameters and baseline cumulative hazard functions. Ref. [
4] studied this problem under the additive hazard model and proposed an estimation equation approach to estimate the regression coefficient. Ref. [
5] discussed the regression analysis problem under the proportional odds model.
Note that all the literature above assume that the failure time is independent of the examination or observation time. When the two are not independent, the data obtained are generally referred to as current status data with informative observation times or dependent current status data. Currently, some literature studies have discussed the regression analysis of current status data under the assumption of informative censoring. For example, ref. [
2] discusses the regression analysis of the current status with informative examination times under the additive hazards regression model. Ref. [
6] developed a class of semiparametric transformation models for dependent current status data. The above literature studies introduced frailty to depict the correlation between failure time and examination time. It is well-known that this method needs to assume the specific distribution of the latent variable, which makes the application of this method limited. An alternative way to describe the correlation between the failure time and the examination time is by introducing the copula function. For example, ref. [
7] employed this method and discussed the regression analysis of current status data under the PH model. Note that the copula method has been applied in many types of dependent data analyses [
8,
9,
10].
In addition to censoring, truncation is another statistical phenomenon that arises in various fields, including survival analysis, astronomy, epidemiology, and economics [
11,
12,
13,
14,
15]. Subjects whose failure times were truncated were unable to provide any information to researchers. When only the data of individuals whose event times exceeded a certain random time (i.e., left truncation time) are recorded, left truncation will occur. Under left truncation, individuals with smaller event times are less likely to be observed, leading to bias in the research sample toward larger event times. Currently, some literature studies have developed regression analyses of current status data with left truncation [
16,
17]. In the following, we will discuss the regression analyses of current status data with left truncation and informative censoring.
The remainder of the article is structured as follows: We introduce the models and assumptions in
Section 2. In
Section 3, we introduce the SMLE method, including the estimation procedure and asymptotic properties. In
Section 4, we conduct simulation studies to evaluate the practical performance of the developed approach. In
Section 5, we apply the established approaches to a real dataset. Our discussions and concluding remarks are presented in
Section 6.
2. Notation, Assumptions, and Models
Suppose that a failure time study consists of n independent subjects. For subject i, let represent the failure time and be the p-dimensional vector of the covariate associated with the subject. As mentioned above, truncation is also very common in practice. For this, assume that, for every subject, there exists a left truncation time , such that . The examination time is denoted by . It is possible that Y is dependent on the failure time . Define . The observed data can be represented as follows: . In other words, for the failure time , we only have current status data with the left truncation available.
We assume that
follows a Cox model given by
where
is the hazard function of
given
,
denotes an unspecified baseline hazard function, and
denotes a
vector of regression coefficients.
In practice, the covariate may also affect the observation time
. So, we suppose that the hazard function of
has the following form
where
represents an unknown baseline hazard function, and
represents the regression parameter.
To show the correlation between
and
, we next introduce the Copula function. Let
represent the joint distribution function of
and
given
. Thus, according to Theorem 2.3.3 in [
9], there exists a copula function
, satisfying
where
and
denote the marginal distribution function of
and
, respectively,
is the association parameter representing the correlation between
and
.
satisfies
,
, and
. We then have the conditional distribution function of
given
and
, as follows:
Let
,
and
. We define
to be the marginal density function of
, given the covariate, so we can obtain
and
When
, we have
For
, we have
Therefore, the likelihood function based on
is
Thus, the full likelihood function based on the i.i.d. sample
has the following form
In the next part, we will consider the maximization of the above likelihood function. It should be noted that, as mentioned by [
3], given a specified parametric copula family, the associated parameter
cannot be identified without prior or additional information. Hence, in the next section, we assume that both the copula functions and the associated parameters are necessary.
3. Maximum Likelihood Estimation
Now, we discuss how to maximize the full likelihood function
. In fact, it is difficult to directly maximize the likelihood function because this likelihood function contains not only finite-dimensional parameters but also infinite-dimensional parameter functions,
and
. In order to maximize the likelihood function, we intend to approximate
and
by linear combinations of some basic functions. Specifically, we intend to use the
I-spline function to accomplish this task [
18]. Let
represent the
I-spline base function, where
k and
are the order of the spline and the number of interior knots, respectively. Additionally,
and
. Then, we define
as the sieve space,
, and
denote the range of
. Thus, the functions in
are all non-negative and non-decreasing on the interval
[
18]. Therefore, we can employ
to approximate or replace
in the likelihood function, and estimate the regression parameters
,
and coefficients
simultaneously by maximizing the
subject to
,
.
One issue when using splines is how to choose k and . An easy way to do this for a given problem is to try several different values for k and and compare the results. Furthermore, we can employ the Bayesian information criteria (BIC) to choose k and , which give the smallest BIC values.
Let represent the estimator of described above and be the true value of . To establish the asymptotic properties, we need to describe the regularity conditions first.
- (C1)
The copula functions are differentiable and the partial derivatives satisfy the Lipschitz condition.
- (C2)
The covariate Z has bounded support in .
- (C3)
(i) If a constant and the constant vector satisfy almost surely, then and . (ii) Assume that for any open set B in , , where represents the probability measure generated by the copula function .
- (C4)
For
, suppose that the Fisher matrix
is positive-definite, where
is defined in
Appendix A.
- (C5)
Let denote the kth derivative of , . Assume they are Holder-continuous with exponent . In other words, there exists a positive constant K and some , such that for all . In the following, let
According to [
19,
20], the aforementioned conditions are typically moderate and meet in practical situations. The following theorems provide the large sample properties of the estimators. Here, for function
g, let
, where
is the probability measure generated by
X.
Theorem 1. Assume that the regularity conditions C1–C4 are satisfied. Then, almost surely.
Theorem 2. Assume that the regularity conditions C1–C4 are satisfied. Then Theorem 3. Assume that conditions C1–C5 are satisfied and . Then, as , we have ; the definition of Σ is in Appendix A. We provide the proof of the above theorems in the appendix. In order to estimate the covariance matrix, we recommend a common and direct method based on the sieve likelihood function, i.e., using the inverse of the observed information matrix. The observed information may be poorly conditioned or high-dimensional, so this method might be computationally demanding. Nevertheless, the simulation results shown in the following section suggest that it typically performs effectively, particularly when k and are not very big.
4. Simulation Study
In this section, simulation studies are conducted to evaluate the performance of the developed procedure. We suppose that the
covariates are Bernoulli (0.5). We first generate the left truncation time
from the exponential distribution with parameters
a, where constant
a is selected to provide a suitable percentage of the left truncation. We set
, and
is generated from model (
1). To generate the examination time
, we consider the following three copula models:
They are the FGM, Frank, and Gumbel models, respectively. As mentioned above, the association parameter here indicates the correlation between T and Y. Since the range of in the above three copula models are not the same, one needs a uniform measure of association between T and Y, such as Kendall’s . For the FGM model, , and for the Frank model, and . Under the Gumbel model, the relationship is .
Based on a fixed copula function, we set
, then the examination time
is generated from the conditional distribution, given
. Specifically, we first generate a random number
; given
and
b, we can solve the following equation for
,
For the spline functions, we employ the quadratic splines with the quantiles of the pooled set of all ’s and ’s as three interior knots. The results shown below are based on 1000 replications.
Table 1 and
Table 2 report the simulation results under the FGM model with sample sizes
and 400. The results show the estimated bias (bias, empirical average of the parameter estimator minus the true value), the standard error of the parameter estimator (SSE), the empirical average of the standard error estimator (SEE), and the empirical coverage percentage of the 95% confidence interval (CP).
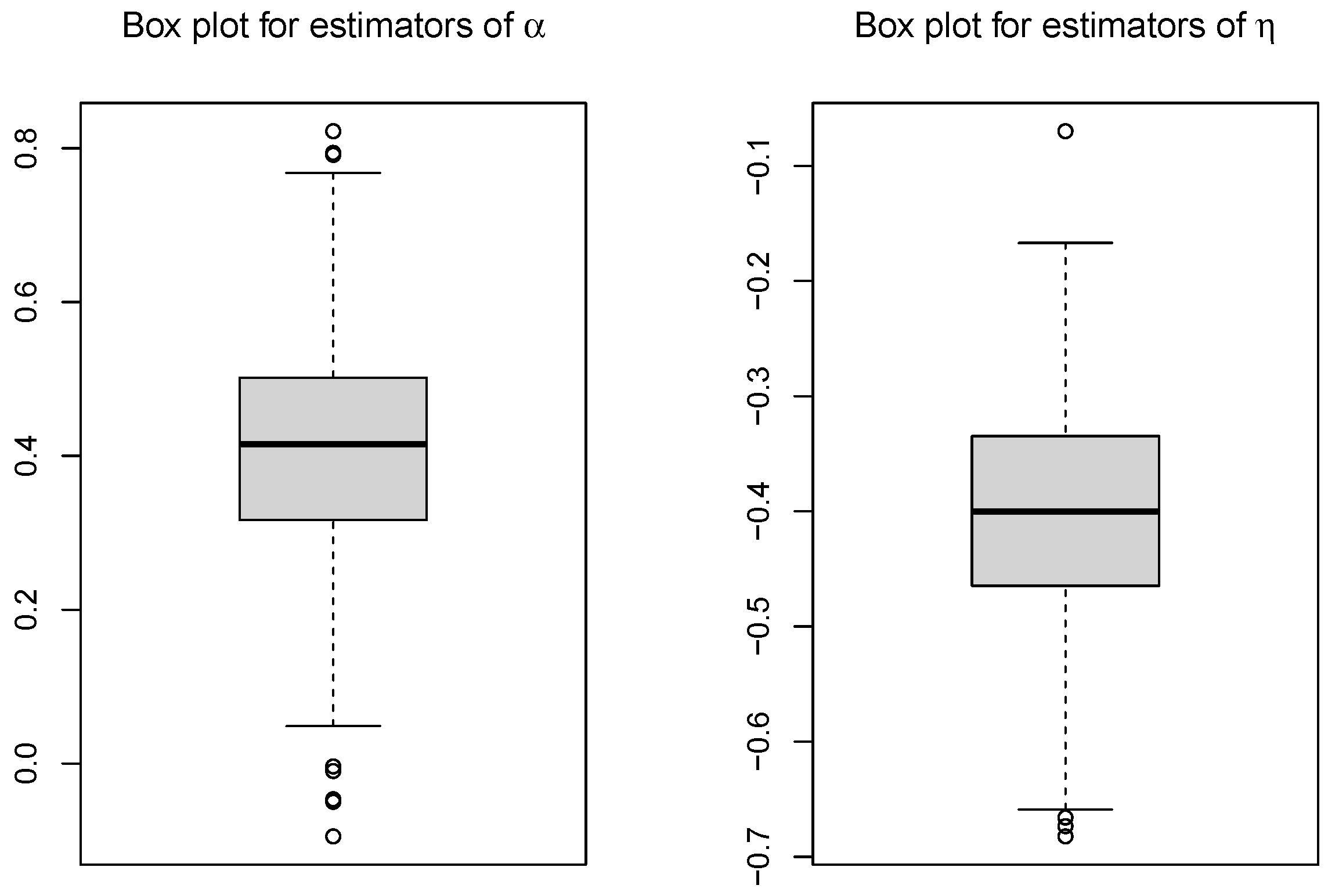
Figure 1 presents the boxplots of estimators of
and
with
and
under the FGM copula. It can be seen that the estimators have a slight bias, and the bias becomes smaller as
n increases. The true variabilities are accurately reflected by the variance estimators, and the confidence intervals have proper coverage probabilities, i.e., the normal approximation to the distribution of the estimated regression parameters seems reasonable. The estimation results based on the Frank and Gumbel copulas are presented in
Table 3,
Table 4,
Table 5 and
Table 6; they yield comparable conclusions to those given in
Table 1.
Regarding model misspecification,
Table 7 shows the estimation results of the simulated data generated under the Frank model but obtained from the FGM model. In the table,
presents Kendall’s
for the estimation. This table suggests that the estimator of
may be biased when copula is specified correctly but
is specified wrong. When
is specified correctly but the copula model is misspecified, the estimator seems relatively reasonable. In addition, the estimator of
seems to be less sensitive to the choice of the association parameter
or the copula model. We attempted other set-ups and acquired comparable conclusions.
5. An Application
Now, we apply our method to an AIDS cohort study of hemophiliacs, as analyzed by [
21], among others. This study included 257 hemophilia patients receiving treatment at medical centers in France since 1978. Due to the potential contamination of blood factors used for treatment, these patients were in danger of contracting HIV-1. In this study, the failure time represents the duration from HIV-1 infection to the AIDS diagnosis. Patients were divided into two groups—heavily and lightly treated groups—based on the blood volume they received. Here, the primary objective was to evaluate the effect of the treatment on the total time to HIV diagnosis from the beginning of the treatment.
HIV-1 contraction and the time of AIDS diagnosis cannot be accurately observed since the patients were only examined regularly; only the time intervals that include HIV-1 contraction and AIDS diagnosis can be observed. Here, the left truncation time is taken as the midpoint of the examination interval for HIV-1 infection, and the observation time is taken as the right endpoint of the examination interval for AIDS diagnosis [
21]. For our analysis, we focus on the 188 patients identified as HIV-1-infected during the study. Of these, 41 had been diagnosed with AIDS.
Let the covariate
be 1 if the
ith subject is in the heavily treated groups, and 0, otherwise. Following the simulation part, we still use the quadratic spline functions with
, or 8 for approximation, and use FGM, Frank, and Gumbel copulas for dependent censoring. In the following, the BIC values were calculated to find the smallest one, which is given by the FGM copula model with
and
. We present the results obtained under the FGM model in
Table 8 with
and 7, and several
values. The table shows the estimated treatment effect
, the estimated effect on the examination time
, the estimated standard error (SE), and the
p-value for testing the absence of treatment effects. The results indicate that the patients in the heavily treated group had a higher hazard of being diagnosed with AIDS, which is similar to the conclusions presented in [
16].
6. Discussion and Concluding Remarks
In the previous sections, we discussed the regression analysis of dependent current status data with left truncation and developed an SMLE method for inference. The developed procedure uses the copula function to depict the correlation between the failure time and the examination time, and the spline function is used to approximate the known nonparametric function in the model. Simulation studies suggest that the considered approach works well in practice.
For the presented approach, one may consider other statistical models, like the linear transformation model and accelerated failure model, and develop comparable estimation procedures. In our approach, we applied the copula model to construct the joint distribution. One future study direction will be to apply the frailty methods to describe the connection between the two and establish corresponding statistical methods. Furthermore, in our method, while we adopted the I-splines to approximate unknown functions in our approach, other basis functions can also be utilized, such as monotone B-splines, Bernstein polynomials, and even step functions.





{kind=link}