1. Introduction
Blockchain technology has emerged as a game-changer in the wake of the success of Bitcoin and other cryptocurrencies. Decentralized application developers tend to instead focus on finding a solution that best meets their needs and the needs of their decentralized applications market rather than developing a new blockchain platform from scratch as the number of existing ones grows. Decentralization-based technologies guarantees the ownership and transferability of digital financial assets to a certain extent. The upsurge in market value and popularity of cryptocurrencies raises several global issues and concerns for business and industrial economics. Distributed ledger has gained traction over the years and refers to the technological infrastructure and protocols to meet the very objectives of transparency and traceability. For each secure transaction, a separate secure location has to be maintained over the internet by the participants, who are essentially the users of the distributed ledger technology. Blockchain makes it possible to maintain a widely dispersed network through cooperative efforts to establish mechanisms for coordination, communication, and motivation [
1]. The term “blockchain finance” refers to how this technology has been implemented. This has given rise to several digital platforms, such as TRON, which has its own digital coin, called the TRX coin. The usage of blockchain technology in the finance sector reduces costs and improves service quality in a safe and flexible manner [
2]. The Blockchain distributed database is nearly impossible to alter, whereas traditional credit models rely on third parties to process payment information. As a result of peer-to-peer innovation and decentralization in the financial sector, there has been rapid global expansion and a trustworthy database.
The basis of a blockchain is an immutable, tamper-proof chain of linked blocks. Sets are recorded in each block, and the metadata are associated with a transaction. It was launched as a peer-to-peer currency exchange system. Blockchain topologies act as a critical parameter in developing a blockchain application by classifying the nodes that will be a part of it. Permissioned, private, and hybrid blockchain systems are the most recent subdivisions of blockchain technology [
3,
4]. Transactions on the Blockchain have the same effect on both parties; each node has its ledger [
5]. The role of digital currency tokens, often referred to as crypto-tokens, have a unique role in transforming the way people make transactions over the web. This has become more useful since the introduction of the first crypto-currencies such as Bitcoin [
6] and Ethereum [
7] that have nodes that can generate the next valid block without consensus [
8]. TRX serves a similar function fundamentally, to make safe and secure transactions digitally. The TRON Protocol, one of the biggest operating systems based on blockchain, provides scalability, availability, and high throughput for the Decentralized Applications (Daps) in the TRON environment [
9,
10]. TRON Protobuf is a serialization mechanism for structured data, similar to JSON or XML but significantly faster and smaller [
11]. A custom-built blockchain network, such as TRON, may be more efficient, convenient, secure, and stable for millions of global developers [
12]. For now, it is impossible to predict how high TRON (TRX Token) will rise. The primary goal of the TRON network is to decentralize the distribution and content creation industry, which has been criticized for censorship and revenue distribution unfairly. Without a doubt, as individuals, it is our own responsibility to act ethically when it comes to digital media and always take responsibility for the content we post online or on any digital media platform. Additionally, TRON provides a few other tools to help ensure more democratic content creation. TRON was reasonably conceived as an innovative solution to address robust scalability issues and appears to be like its competitors on the surface. All of them could just as easily create Daps that further motivate the increase in the adoption of TRON. Quite a few of them already have. That being said, TRON still has the potential to succeed better in this market if its adoption increases over time. It is possible that the growing importance of interoperability in the blockchain industry will help TRON maintain its position as one of the leading networks for the distribution of original digital content. TRON’s unique selling point is that anyone, anywhere, with an internet connection, can access data on the network. Several researchers have made useful attempts in the blockchain and cryptocurrency sphere leading up to the present, where these works validate the usefulness of various Artificial Intelligence techniques in the technology. Very few attempts, if any, have been made to study TRON as a cryptocurrency by applying Artificial Intelligence to predict profit the next day, prices in the future, and address transaction success and failure rates. The scope and flexibility of the research and a framework that can be applied when analyzing digital tokens, as well as other cryptocurrencies having a relatively good standing in the market.
The followings are highlights of the contributions of the paper:
We checked the potential capabilities of regression models such as Catboost, Xgboost and Light GBM for predicting the future price of cryptocurrencies.
We have proposed classification models for TRX transaction success rate powered by machine learning techniques.
Finally, we have estimated the earnings from the profit made by the TRX tokens.
The rest of this paper is organized as follows:
Section 2 is about the literature review pertaining to blockchain technology and cryptocurrency price prediction.
Section 3 is about the dataset, visualizations and discussion about the detailed methodology involved in this research.
Section 4 exhibits the experimental results obtained by individual classifiers as well as ensemble methods along with its analysis. The paper is concluded in
Section 5.
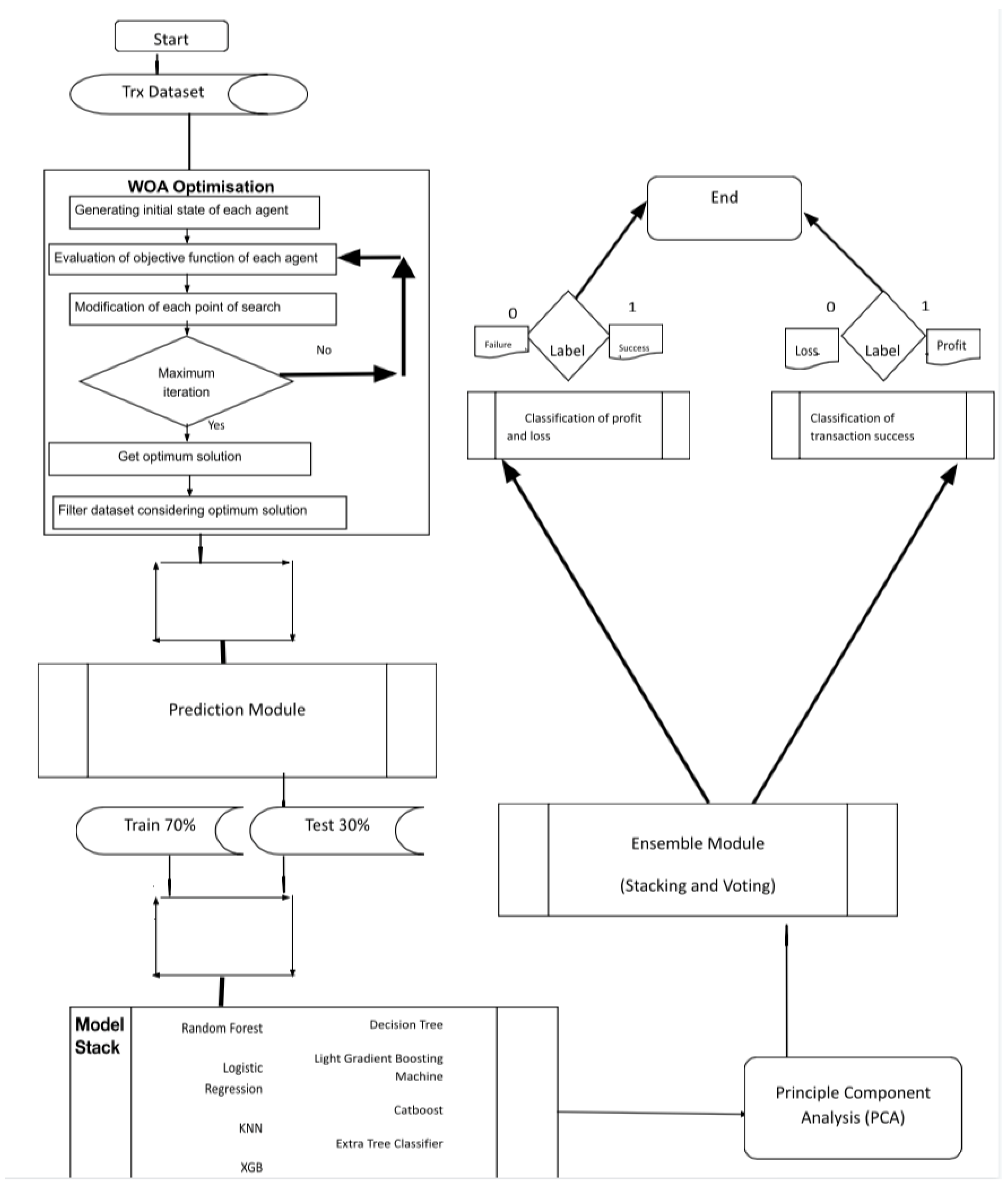
3. Materials and Methods
A lot of money goes into it from people investing on their own, from large institutions, and corporations. However, in contrast to more established commodities exchanges, the cryptocurrency market is more volatile. It is unstable and gains are uncertain, and unexpected because of the various technological, emotional, and legal aspects that might affect it. Therefore, the quantities in the columns have shown to increase in the long term, but have shown ups and downs at short intervals of time, often unrelated, due to external market circumstances and/or market sentiments over the years. The dataset is prepared from the data provided by Tronscan [
46] website which manages the entire data of Tron cryptocurrency and ecosystem. We use the daily price which has high, low, and, day prices and the data containing the volumes of trades. We scale all our data to make the data of the same order (say between 1 to 10) using the standard scaler standardization technique. We use python to merge the uniform data for the same days for transaction success prediction. We chose the data carefully to obtain a better correlation and use relevant features that are useful in a market-based analysis. Features relevant to regression are concatenated, and a new dataset is created, merging the price dataset and the related dataset.
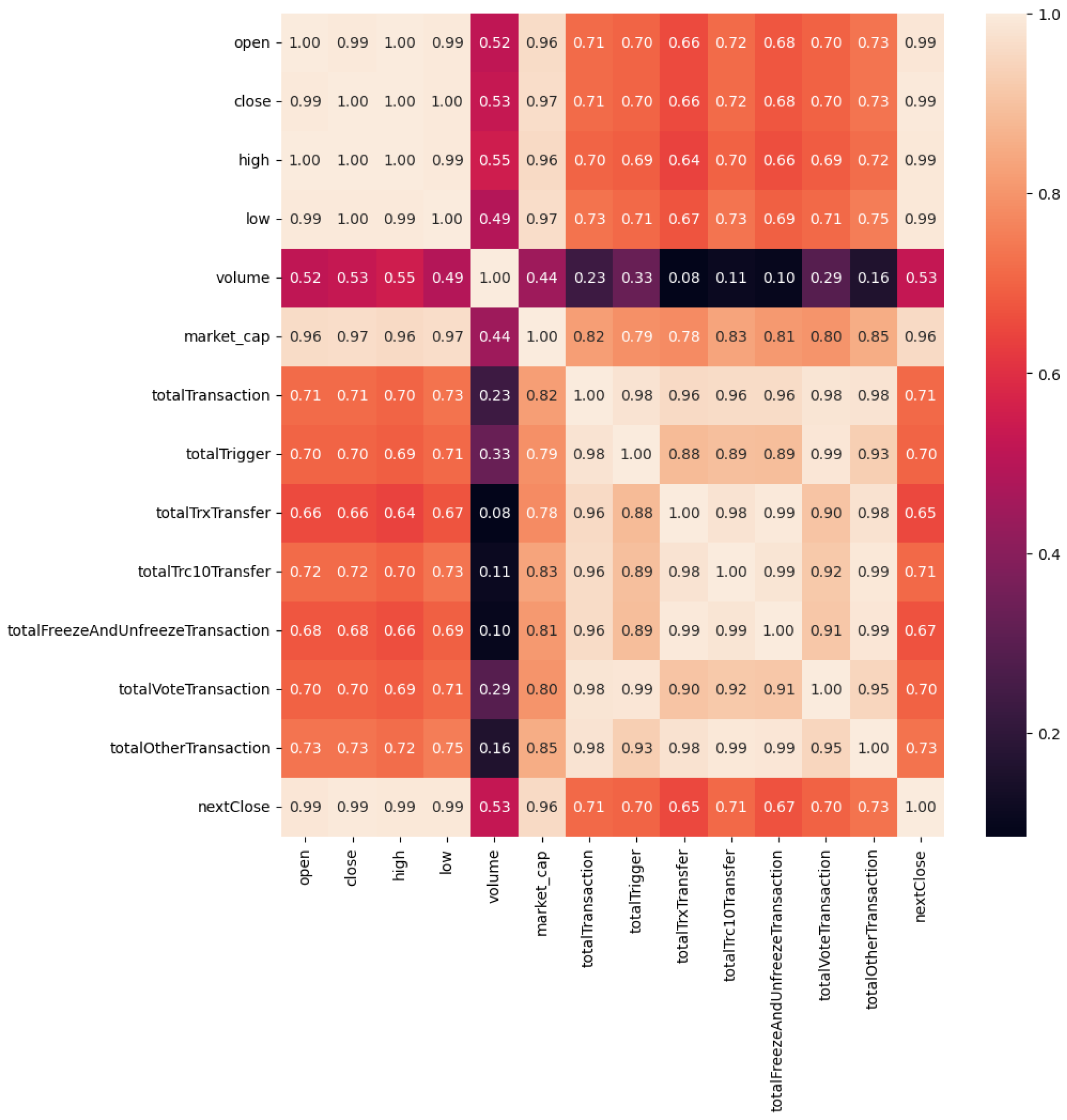
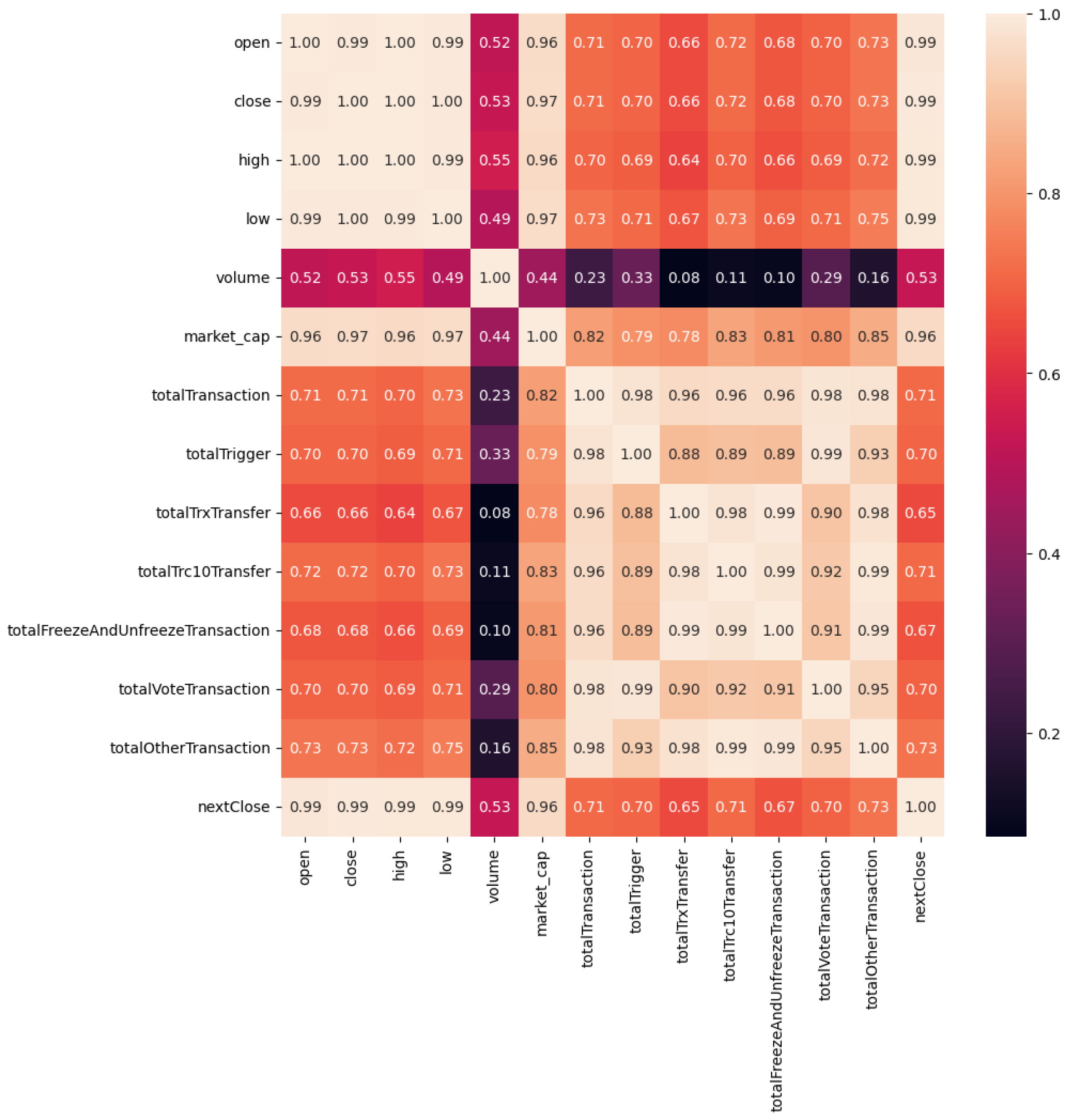
Figure 1 shows the heatmap showing the feature correlation. Some of the features show significant growth of the cryptocurrency and directly relate to strengthening the feature mentioned above and the scope of TRON. The daily price provides insights to the TRX coin market trends in short-term and prevailing market sentiments. The features such as ‘totalTrxTransfer’ and ‘totalTransactions’ refer to the transactions within the TRON environment, similar to the other features in
Figure 1. In regression analysis, these features are useful in establishing correlation between different variables.
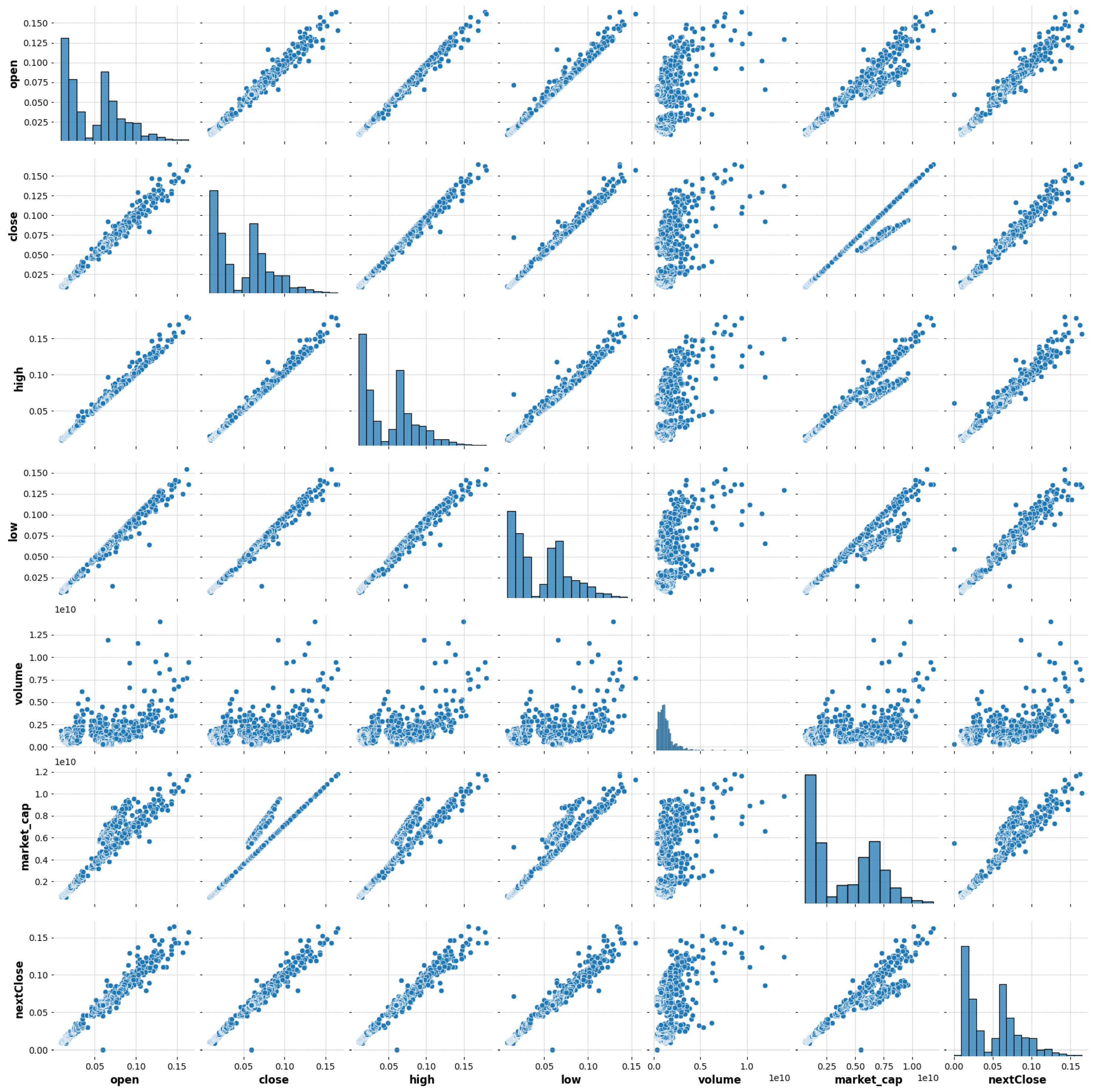
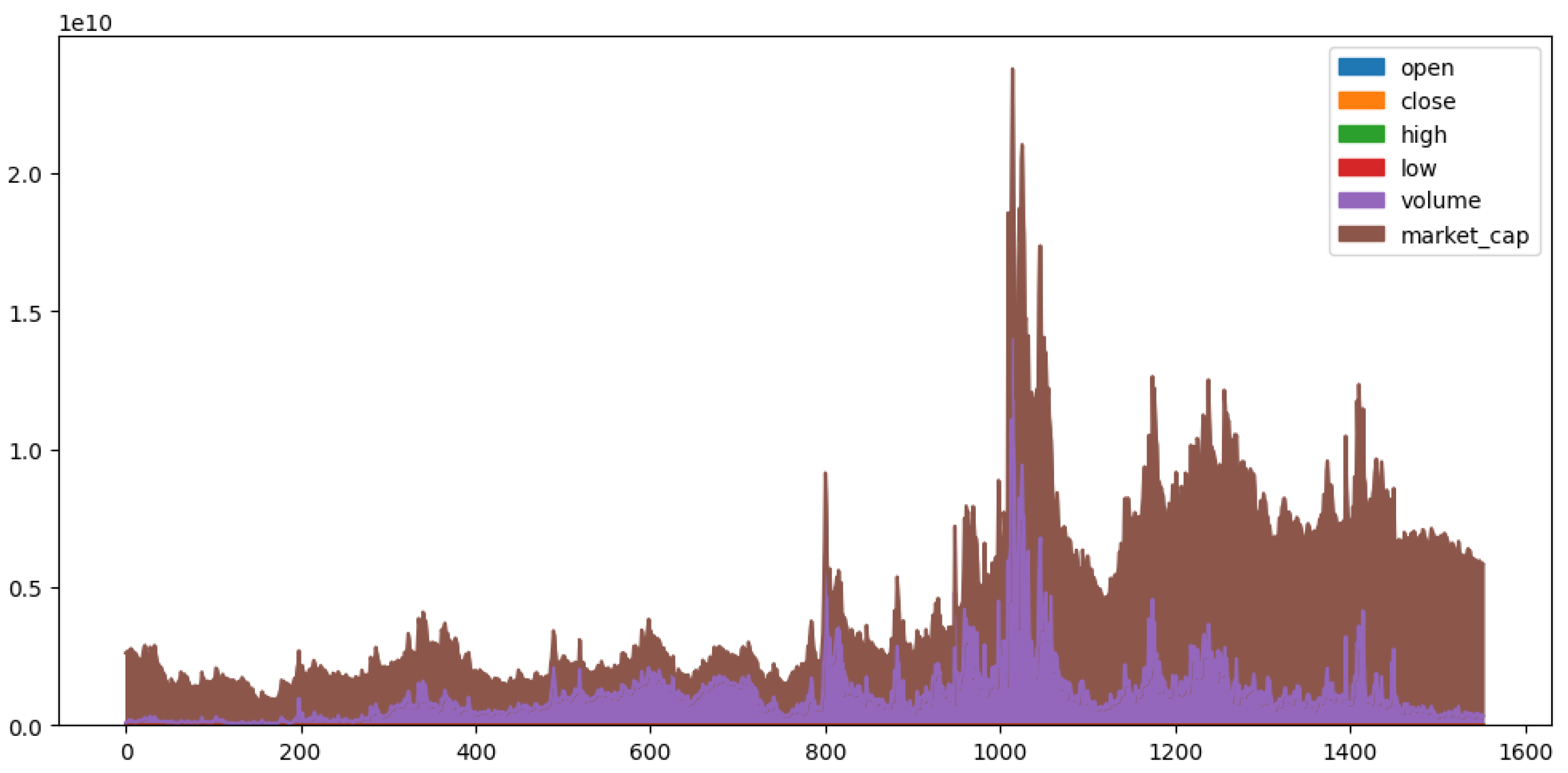
The relation between the values are plotted for the different features relating to the amount of Tron transferred from mid-2018 to mid-2022 and it is represented in
Figure 2 and
Figure 3. In
Figure 2 the
x-axis represents number of days and
y-axis represents the numerical values of these features. This shows that market cap and volume have really high values compared to the rest of the features. Though there is a wealth of literature on cryptocurrency price prediction, only some methods are practical for use in real-time. Independent validation is therefore seen at a time of unexpected upheaval, but little difference in prices occurs during a period of bearish markets; this allows us to evaluate the accuracy of the predictions regardless of whether or not the market trend reverses between the two periods.
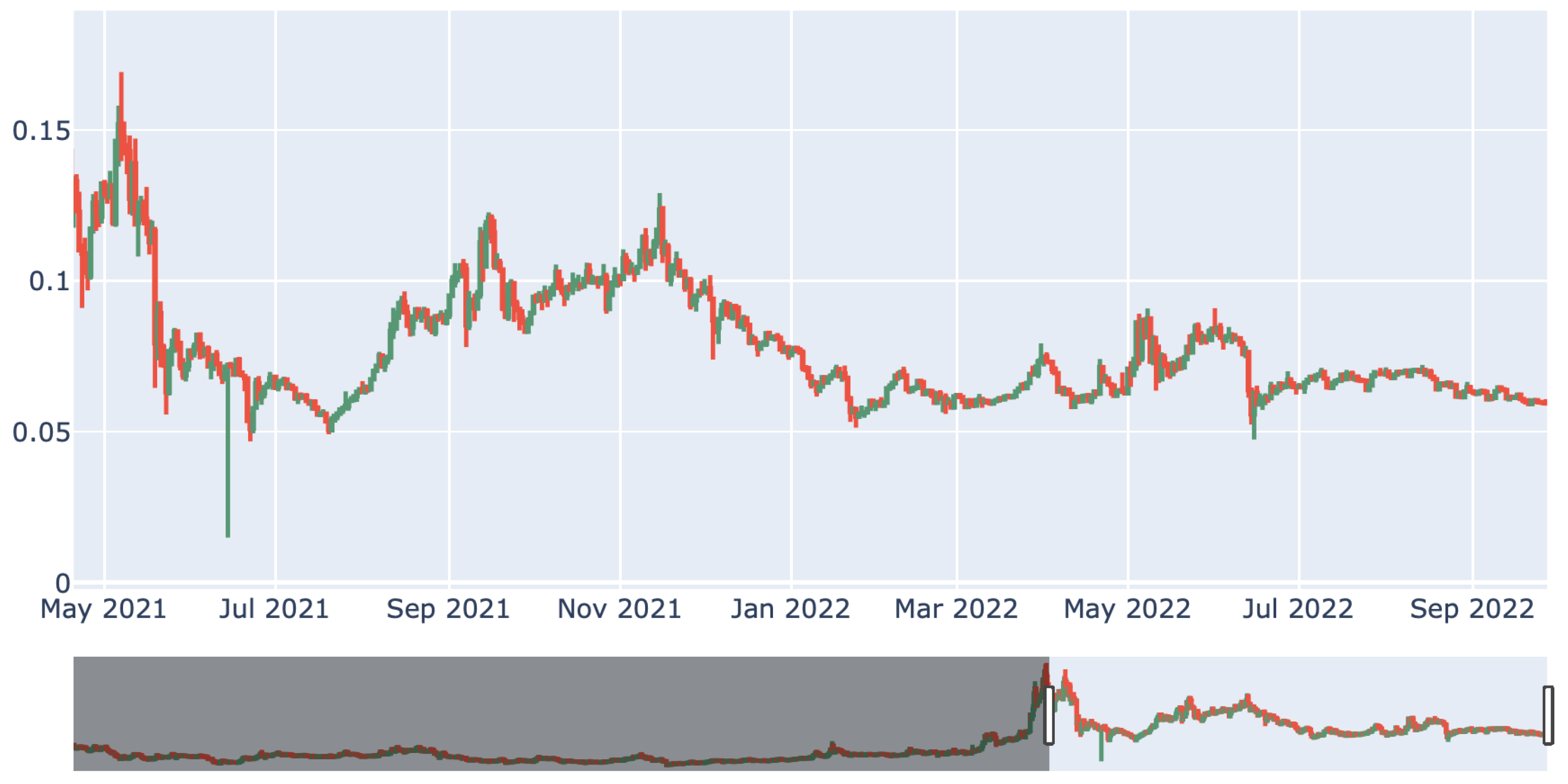
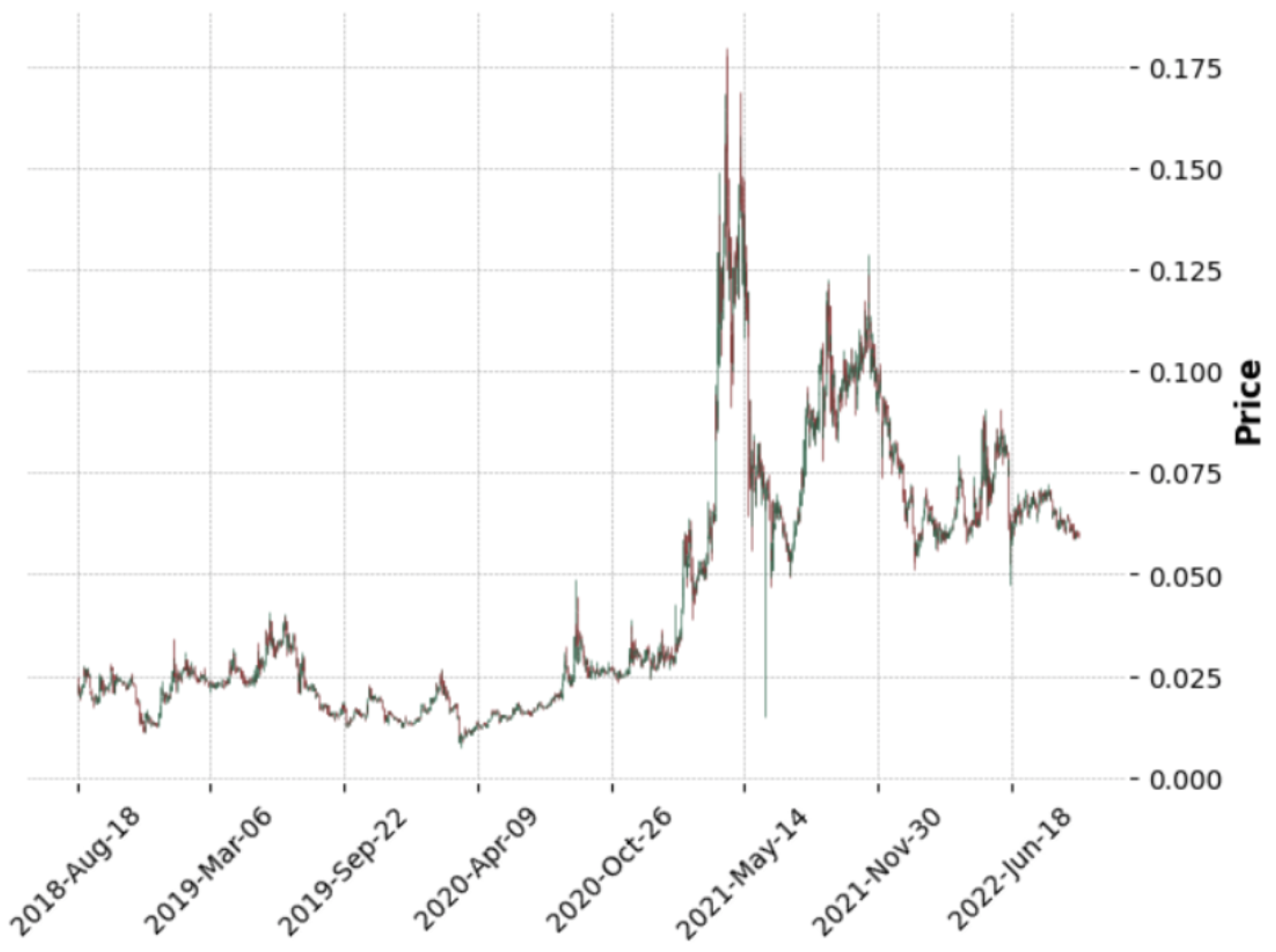
The use of cryptocurrencies as a novel medium for executing secure monetary transactions and storing value has grown in prominence in recent years. Due to the transparency of cryptocurrency transactions, quantitative analyses of many characteristics of virtual currencies are feasible. A candlestick chart condenses data from many time frames into a uniform price bar. They are, therefore, more beneficial than conventional open, high, low, and close (OHLC) bars or straight lines that connect closing price dots. The red candles represent fall in price and green candles represent the rise in prices. The candlestick chart for TRON is shown in
Figure 4.
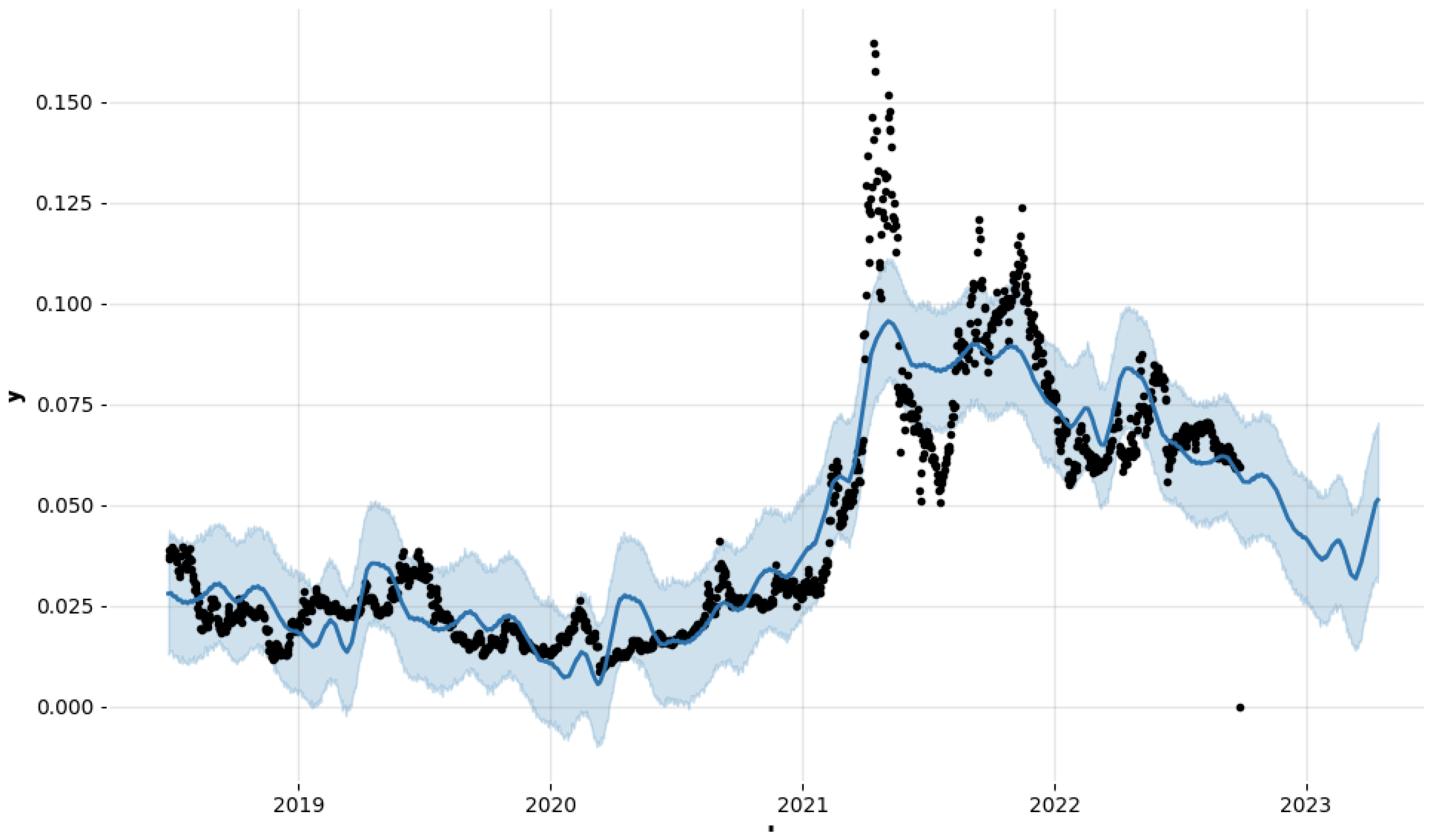
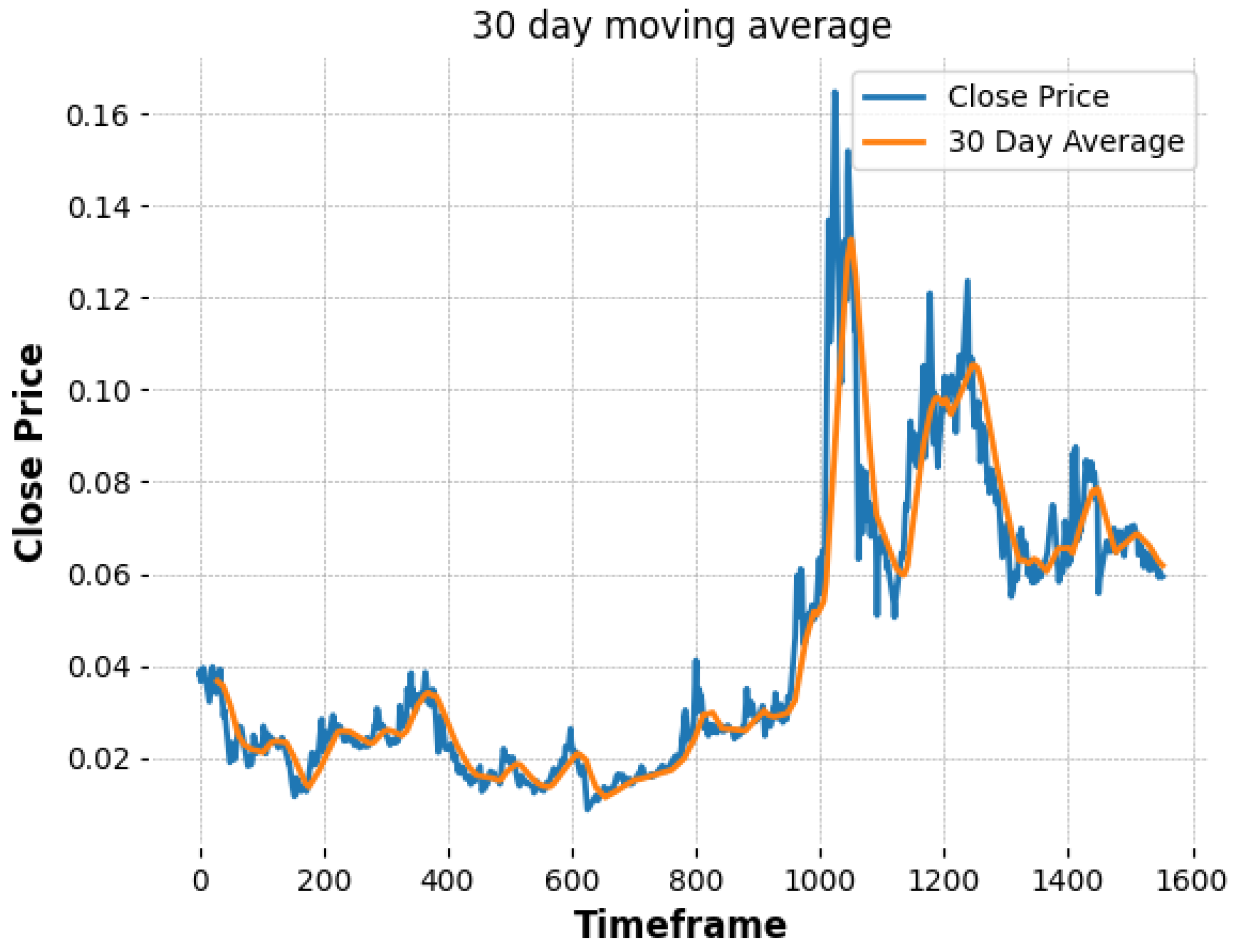
Figure 5 shows a 30-day moving average, which represents the closing price and the 30-day average price for four years. It is very clear from the plot that cryptocurrency, and in our case TRON has shown significant volatility over the 30 day average in the past, therefore we wish to help users make informed decisions for the long term but analysis would be beneficial to make these decisions (
Figure 6 and
Figure 7).
We propose an effective framework for potentially predicting future prices given the wide scope of TRON cryptocurrency and discuss aspects that have been neglected before. The aim a of studies such as this is to adapt to changing circumstances of the volatile nature of cryptocurrencies and the financial risks involved. The whale-optimized algorithm (WOA) is introduced along with ensemble classifiers, which can be called to train the models and more often results in improved accuracy and performance. The WOA algorithm is applied to obtain the optimized value and make a prediction on the transaction values. The Whale optimization algorithm is used for selecting the most optimal features for both of the predictions along with principal component analysis to potentially reduce the dimensionality of the data if applicable for the given scenario. The Returns (4) column indicates the percentage increase in the invested capital.
A crucial parameter is the dayChange, which represents the fluctuations in the market on a day-to-day basis. Essentially, it is the difference between the closing prices of two consecutive days. Under certain circumstances, it may be given approximately by the modulus of difference of closing and opening prices. This is relevant for the closing price of the next day, calculating which is essential for price prediction.
Changes in the daily prices can be expressed as shown in Equation (
6). A binary variable CallOrder represents if trading on a specific day would result in a gain or loss, which can be derived by applying the unit step function to the DayChange.
Likewise, the Equation (
8) gives closing price of a cryptocurrency for a complex OHLC dataset.
Now coming to the WOA optimization, we assume the actual best solution to be near the target fish (the solution) in an ocean and the other objects update their positions across the most optimal agent,
In this context, “
t” represents the current cycle, and the position vector of the humpback whale during its hunting strategy is denoted by
. The best solution is represented by
, while coefficient vectors are denoted by
and
. Essentially,
refers to the location of the humpback whale. This phase is often called encircling the fish.
represents the coefficient vector, which is used to control the exploration and exploitation rates of the algorithm, and
is the updated coefficient vector.
Regarding the bubble-net attack stage, which is sometimes referred to as the exploitation stage, we utilize the process of shrinking to demonstrate how humpback whales surround their prey. As the iterations progress, the value of a certain variable, denoted as
, is gradually reduced from 2 down to 0.
Here,
and
are random vectors in the range of [0, 1]. Variable
m is used in the cosine function. Its value affects the direction and magniture of the steps taken towards the best solution. For the spiral updating position, the following functions are incorporated,
In order for the humpbacks to update their position, the whales randomly search with respect to the position of their counterparts.
Equation (
17) calculates the coefficient
as iteration
progresses from 1 to
.
Equation (
18) computes the center of the search space
by averaging positions of agents
.
Equation (
19) calculates the distance
between the current position
of agent
i and the best position
A found so far, scaled by the coefficient
a.
Equation (
20) computes the parameter
used for updating the position of agents based on the random values
and
.
Equation (
21) updates the position of agent
i by moving it towards the best position
A using a spiral-shaped movement when
.
Equation (
22) updates the position of agent
by moving it away from the best position
A using a spiral-shaped movement when
.
Equation (
23) calculates the R-squared score
as the final performance metric for the optimized regression model.
refers to the test data.
Equation (
24) calculates the distance between each agent and the best solution found so far.
Equation (
25) updates the position of each agent according to the Whale Optimization Algorithm.
Equation (
26) predicts the class labels
for the test data
using the optimized classifier
.
The Equation (
27) calculates the accuracy of the classifier by dividing the number of correct predictions by the total number of predictions made.
Equation (
28) calculates the precision of the classifier, which is the proportion of true positive predictions out of all positive predictions made.
Equation (
29) calculates the recall of the classifier, which is the proportion of true positive predictions out of all actual positive instances in the dataset.
Equation (
30) computes the F1 score, which is the harmonic mean of precision and recall. The F1 score is a popular metric used to evaluate classifiers when dealing with imbalanced datasets.
In Equation (
31)
C is the confusion matrix,
are the true class labels, and
are the predicted class labels. The confusion matrix
C is a square matrix of size
, where
k is the number of classes. Each element
represents the number of instances of class
i that were classified as class
j.
In Algorithm 1, first, the population of profit classifications, denoted as
, is initialized. The training sets are split into n folds using Repeated Stratified K-fold cross-validation. The first n-1 folds are used as the base model, and the predictions are made for the n-th fold. The predictions from steps 1, 2, and 3 are concatenated into the x1_train list. The list is the converted to its binary representation and the fitness of each solution in the population is computed followed by initialisation of best solution as
. After processing each solution, the algorithm checks if any search agent has moved beyond the search space and corrects the position if necessary. The list is again converted to its binary representation and the fitness of each search agent is computed. The iteration counter t is incremented. Finally, the algorithm returns the best solution
. All the relevant equations are explained in Equations (9)–(16) related to this algorithm. This is the general algorithm for implementation of Whale optimization algorithm and is applicable for similar cryptocurrency datasets (or a retrieved OHLC data). It is worth noting that using A = 1 can lead to slower convergence to the global optimum, as it does not allow for larger jumps in the search space. It may be beneficial to use larger values of A to allow for more exploration of the search space. At each iteration of the algorithm, a new set of candidate parameter values is generated using a combination of random mutation and cross-over (i.e., taking the best parts of two or more candidate solutions and combining them). These new solutions are then evaluated using the objective function, and the best ones are kept as the basis for the next iteration. This gives us the best value of the hyper-parameters to then train our model. The algorithm converges on a set of parameter values that produce a high-performing classification model, as measured by the objective function. The algorithm may need to be run several times with different starting parameters in order to find the best possible solution. A good number of iterations is 100 in general, though the algorithm in itself is very complex, and more almost always lead to having a higher probability of finding a better solution.
| Algorithm 1 Optimal Global Position Vector |
- 1:
procedure OptimalGlobalPosition() - 2:
Initialize the population of profit classification. - 3:
Split the training sets into n folds using Repeated Stratified K-fold. - 4:
Take the first fold of the base model as , n-th folds are to be predicted. - 5:
The predictions using steps 1, 2, and 3 are concatenated to the list. - 6:
Convert the list to binary representation. - 7:
Compute the fitness of each solution. - 8:
Set the best solution as . - 9:
while do - 10:
for each solution do - 11:
if then - 12:
if then - 13:
The particle position is updated by - 14:
else - 15:
if then - 16:
Select a random particle . - 17:
Update the particle position by . - 18:
end if - 19:
end if - 20:
end if - 21:
end for - 22:
Investigate whether any search agent moves beyond space and correct the sample. - 23:
Convert the list to binary representation. - 24:
Compute the fitness of every search agent. - 25:
Update if there is a better solution. - 26:
. - 27:
end while - 28:
return . - 29:
end procedure
|
Algorithm 2, titled “Whale Optimization Algorithm for Regression”, aims to optimize the regression models (e.g., LightGBM, XGBoost, CatBoost) for achieving the best R-squared score using the Whale Optimization Algorithm. The algorithm takes as input the training data , testing data , a set of regression models , a search space , the number of agents , and the number of iterations . The main objective of the algorithm is to find the best combination of hyperparameters for the chosen regression model.
The FitnessFunction is defined to measure the performance of a solution by fitting the model to the training data and predicting the target variable on the test data. The fitness function returns the negative R-squared score to guide the optimization process. All the equations related to Algorithm 2 are explained in Equations (17)–(23) and (32)–(34).
| Algorithm 2 Whale Optimization Algorithm for Regression |
Require: Training data , testing data , regression models M (e.g., LightGBM, XGBoost, CatBoost), search space S, number of agents N, number of iterations T
Ensure: Best R-squared score found
- 1:
function FitnessFunction() - 2:
DataFrame(X, columns = .columns) - 3:
M.fit(, .target) - 4:
.predict() - 5:
return .target, - 6:
end function - 7:
RandomUniform() - 8:
None - 9:
- 10:
for to T do - 11:
- 12:
- 13:
for to N do - 14:
Clip to S - 15:
FitnessFunction() - 16:
if then - 17:
- 18:
- 19:
end if - 20:
- 21:
RandomUniform(0, 1) - 22:
- 23:
if then - 24:
- 25:
else - 26:
- 27:
end if - 28:
end for - 29:
end for - 30:
DataFrame(A, columns = .columns) - 31:
M.fit(, .target) - 32:
.predict() - 33:
.target, - 34:
return
|
The algorithm initializes the positions of agents in the search space and iterates for a given number of iterations . In each iteration, the algorithm updates the agents’ positions according to the Whale Optimization Algorithm equations, which involve calculating the distance between each agent and the best solution found so far. The agents’ positions are updated based on random variables and the distances calculated. The agents’ positions are clipped to the search space to ensure they remain within the search space boundaries. The fitness of each agent is evaluated, and the best solution is updated if a better one is found. The R-squared score is calculated for the best solution at the end of the algorithm, and the best R-squared score is returned.
The Algorithm 3 uses various variables, including
and
, which represent the training and testing data, respectively. The variable
represents a set of classification models, such as Logistic Regression and Random Forest. The search space for the optimization process is denoted by
, while the number of agents in the search space is represented by
. The algorithm runs for a specified number of iterations, indicated by
T. The positions of agents within the search space are stored in
. The position of the best solution found so far is represented by
, and the best accuracy score achieved is denoted by
. The equations used in Algorithm 3 are explained in Equations (17), (18), (24), (25) and (32)–(34).
refers to the dimensions of the desired output shape for the array generated by the ‘RandomUniform’ function, containing uniformly distributed numbers between 0 and 1. The notation “:-1” is a slicing notation which means “all elements from the start to one before the end”.
| Algorithm 3 Whale Optimization Algorithm for Classification using Stacking and Voting Classifiers |
Require: Training data , testing data , classification models M (e.g., Logistic Regression, Random Forest, K-Nearest Neighbors, Gaussian Naive Bayes, Stochastic Gradient Descent, Decision Tree, Extra Trees), search space S, number of agents N, number of iterations T
Ensure: Best accuracy score found for the classifiers
- 1:
function FitnessFunction() - 2:
DataFrame(.iloc[:, :-1], columns = .columns[:-1]) - 3:
DataFrame(.iloc[:, :-1], columns = .columns[:-1]) - 4:
.target - 5:
[] - 6:
for do - 7:
Pipeline([(m, )]) - 8:
.append((m, )) - 9:
end for - 10:
VotingClassifier(estimators = estimators, voting = ‘soft’) - 11:
StackingClassifier(estimators = estimators, final_estimator = voting) - 12:
- 13:
stacking.score(, .target) - 14:
return - 15:
end function - 16:
RandomUniform() - 17:
None - 18:
- 19:
for to T do - 20:
- 21:
- 22:
for to N do - 23:
Clip to S - 24:
FitnessFunction() - 25:
if then - 26:
- 27:
- 28:
end if - 29:
end for - 30:
RandomUniform() - 31:
- 32:
- 33:
end for - 34:
DataFrame(A, columns = .columns[:-1]) - 35:
.fit(, .target) - 36:
.target) - 37:
return
|
The methodology of applying the algorithm consists of three steps:
Applying the Regression Techniques; Gradient boosting regressors have been very successful in price prediction-based regression. XGBoost, CATBoost, and LGBM regressors are used for dynamic pricing estimation and we compare the efficiency of these regressors for our prepared TRX dataset. The tree-based regressors such as XGBoost, CatBoost, and LightGBM are useful in regressors have feature selection capabilities built-in that help identify the most important features for the regression task. The libraries are useful regularization techniques to prevent overfitting. XGBoost, CatBoost, and LightGBM can still be significantly faster than other algorithms when used along with a meta-heuristic.
Classification using standard classifiers; After the regression, we move on to the classification of profit and loss using different classifiers. We divide the data into training and testing sets and the training data are used to train each model simultaneously.
Classification using an ensemble of classifiers; The next stage is to analyze the forecasts of the models. Accuracy may be improved by ensemble techniques with XGBoost when dealing with asymmetric data. We first focus on classifying profits and losses to check if there is a profit, followed by an inspection of the accuracy of transaction success & failure considering TRX transactions over Blockchain. Equations (27)–(31) give more explanation about the evaluation metrics used.
XGBoost, CATBoost, and LGBM regressors are used for the regression.
Table 1 shows the different metrics for regressions performed by the models.
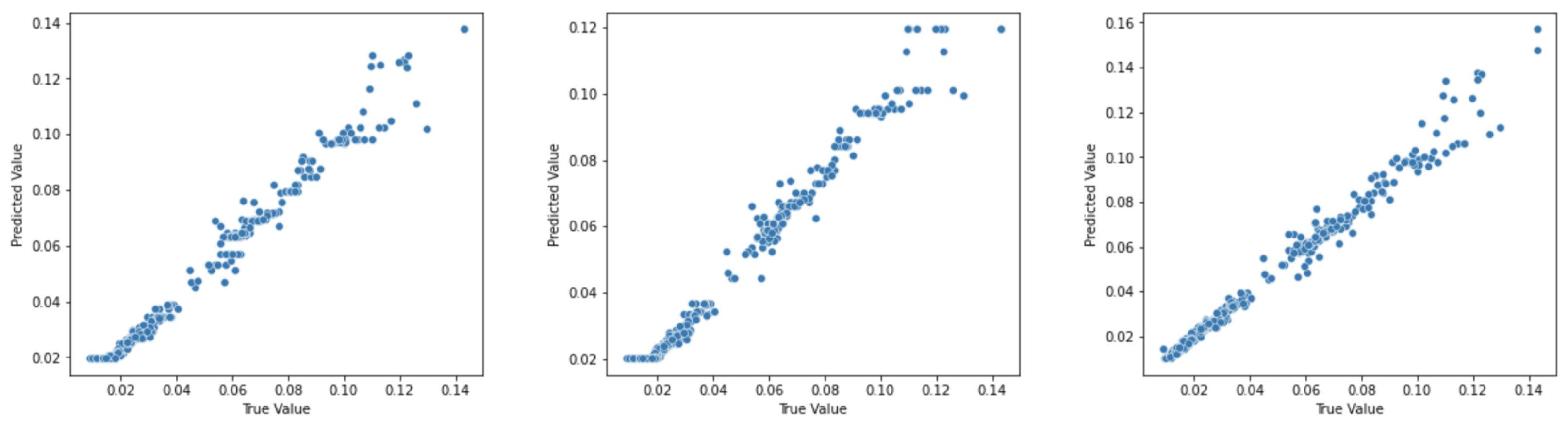
Figure 8 shows the scatter plots for corresponsing (a). XGBoost regressor, (b). LGBM regressor and (c). CATBoost Regressor. A higher R2 score generally indicates that the model is a better fit to the data. It is given by
where SSres is the squared residuals (the difference between the predicted and actual values) and SStot is the total sum of squares (i.e., the differences between the actual values and the mean of the target variable).
4. Results and Discussion
The x-axis of each scatterplot shows the true values of the next day’s closing price, while the y-axis shows the predicted values of the next day’s closing price. The scatterplots are useful for visualizing how well the models perform in predicting the next day’s closing price of Tron. The closer the scatterplot points are to the line of perfect predictions (y = x), the better the model is at predicting the next day’s closing price of Tron.
We then move to the classification problem, which helps with determining whether the cryptocurrency is going to make a profit or loss the next day based on the historical performance of the TRX coin. It is essential to consider that the price of any cryptocurrency, as noted in the literature review, can fluctuate significantly depending on factors that impact the market and factors inherent to the nature of the blockchain technology. For our classification problems, we analysed the performance of several models and observed that tree based models perform the best when it comes to smaller datasets. It is reflected in our analytics by the XGBoost classifier, which uses a tree-based gradient boosting algorithm. It is important to reduce its complexity to minimize any overfitting, which is effectively performed using L2 regularization and manual tuning while not including these hyper-parameters when defining the search space. The voting classifier takes several tree-based classifiers as inputs along with the other models, similar to stacking the classifier but in a more effective way.
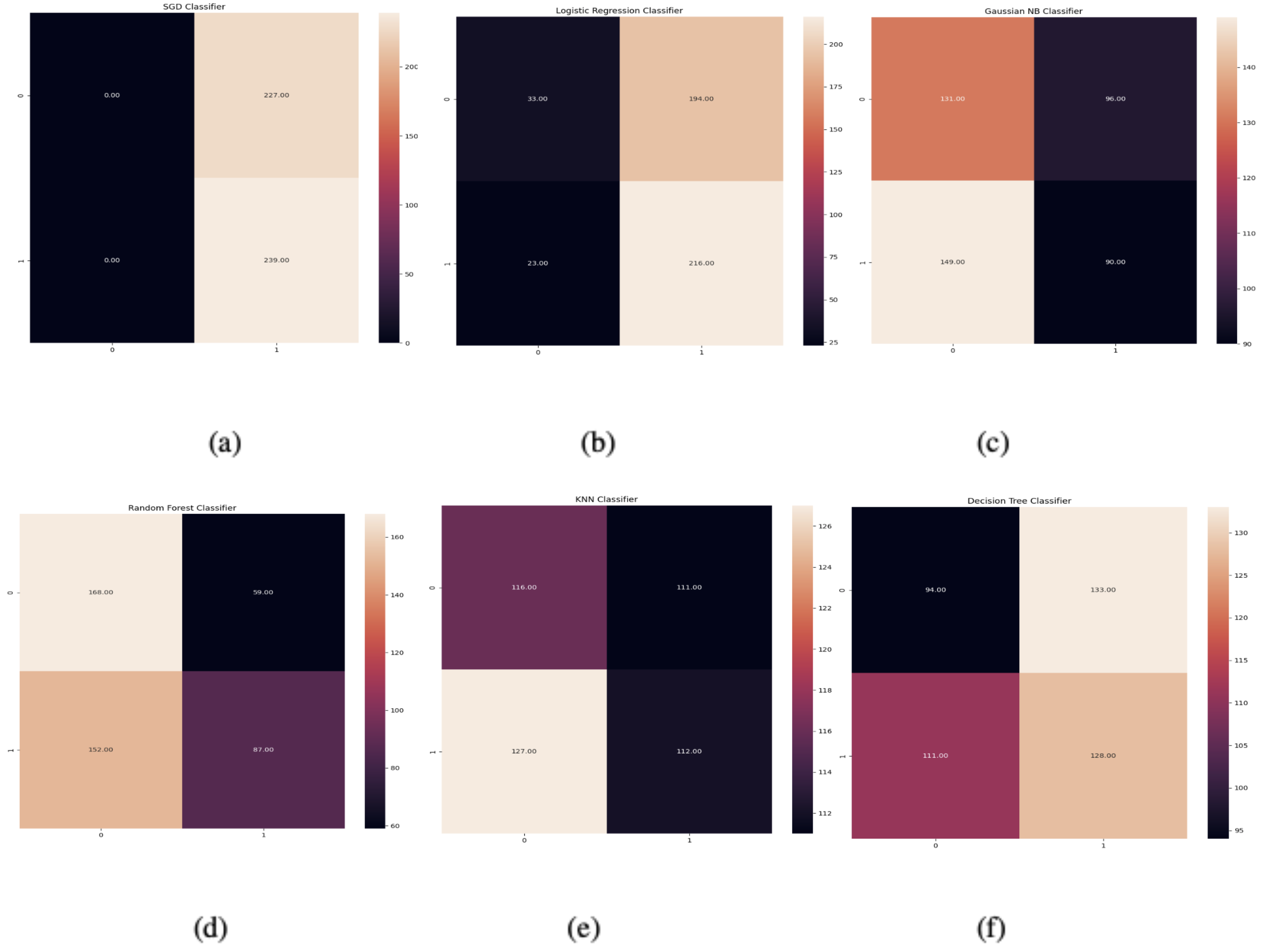
We found that the accuracy of the models such as Random Forest, Decision Tree, Gaussian Naive Baise, Logistic Regression, K-Nearest Neighbors, Scholastic Gradient Descent is on the lower end when compared to these ensemble techniques. The stacking classifier uses all these models plus the gradient boosters as pipelines with the final estimator being the voting classifier. Hyperparameter optimization then sets the ideal settings for learning rate, booster type, maximum depth, number of estimators, and other factors classifiers in our tabular dataset. From the standard techniques, XGBoost provides the best accuracy because of its superior performance in tabular datasets and tree-based structures. The corresponding confusion matrix before applying WOA is shown in
Figure 9. The use of a meta-heuristic whale optimization algorithm with staking classifier tends to bypass local optima.
In Algorithm 1, Equation (
32) initializes the positions of the agents in the search space
with random values uniformly distributed between the lower and upper limits of the search space
and
, and with a size of
.
Similarly, Equation (
33) gives random numbers in the range [0, 1] used for updating the positions of agents.
Equation (
34) creates a new DataFrame named
using the best agent’s position
. The DataFrame is created with the same column names as the training data
. This is performed to ensure that the data structure is consistent with the input format required by the regression models.
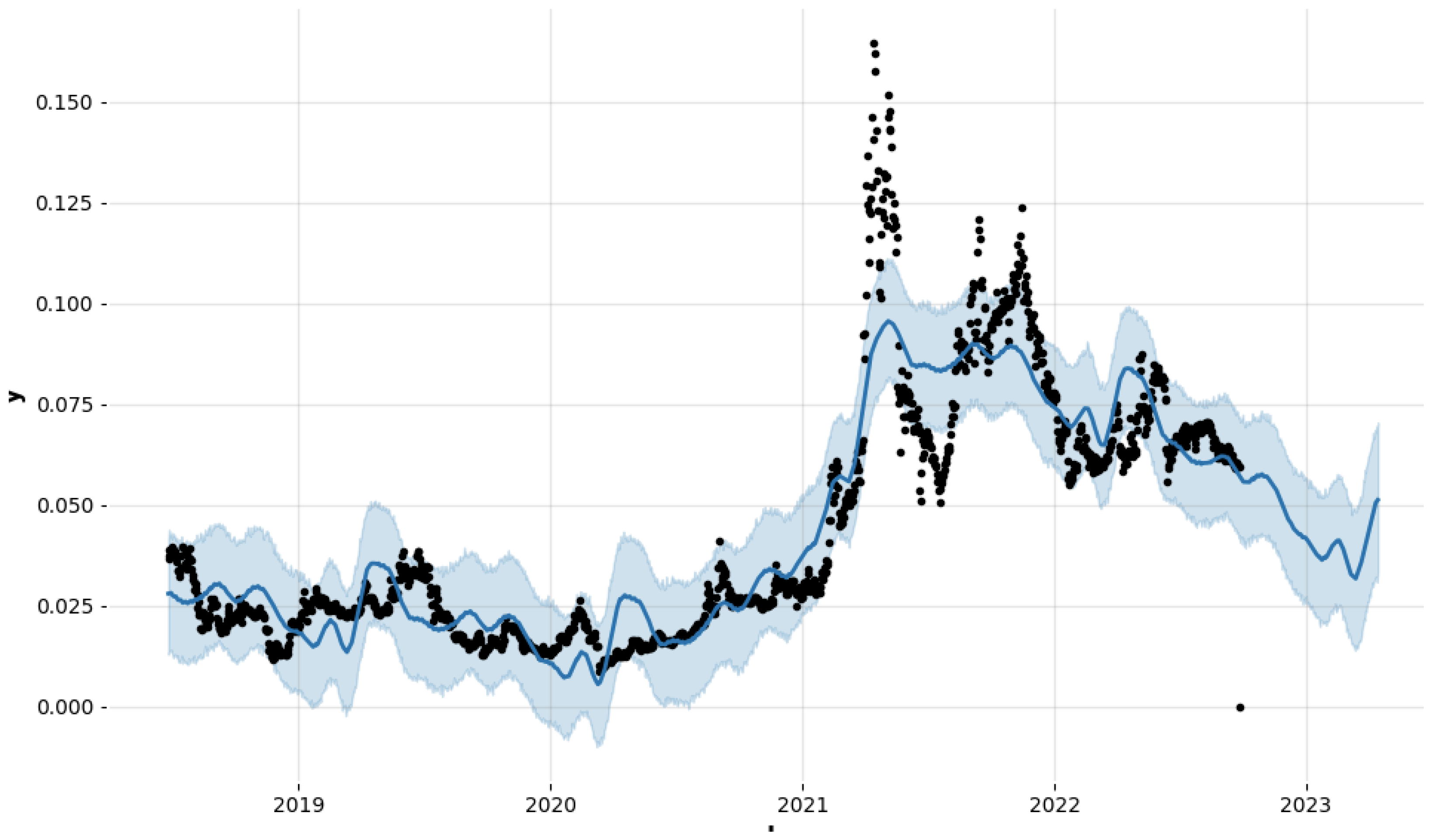
Comparing the models, CatBoost seems to perform slightly better than the other two models, with the highest R-squared value, lowest MSE and RMSE, and a slightly higher median absolute error (MedAE) than LGBM. However, the differences in performance are relatively small, and all of the models perform quite well. Techniques such as regularization or early stopping are useful and help prevent overfitting to a certain extent. The optimization algorithm does a good job in training the model in a more efficient and effective manner, which could indirectly help in reducing overfitting. However, reducing the complexity of the model by not considering the parameters which lead to a more complex model is a good approach to tackle the problem of overfitting along with regularization and cross-validation. Although the SGD classifier gets no true positive or false negative. This situation often arises when the model predicts only one class for all instances. The WOA addressed this by correct hyperparameters, with the results as shown in graphs and tables. Now, the prophet forecaster shows the prediction for future dates based on the current dates in the dataset. It is depicted in
Figure 10.
Table 2 shows some of the hyper-parameters that are included in the search to be tuned during the training of these models. It is important to note that n_estimators, reg_alpha or reg_lambda, min_data_in_leaf, min_gain_to_split should be preferred to be manually tuned to avoid overfitting, and any other hyperparameter should be accessed for overfitting on a case by case basis. Cross-validation (5, 8 or 10 folds) must be performed for accessing if there is overfitting and lower performance on testing data with respect to the corresponding training data.
We then move to the classification problem, which helps with determining whether the cryptocurrency is going to make a profit or loss the next day based on the historical performance of the TRX coin. It is essential to consider that the price of any cryptocurrency, as noted in the literature review, can fluctuate significantly depending on factors that impact the market and factors inherent to the nature of the blockchain technology.
For our classification problems, we analysed the performance of several models and observed that tree based models perform the best when it comes to smaller datasets. It is reflected in our analytics by the XGBoost classifier, which uses a tree-based gradient boosting algorithm. It is important to reduce its complexity to minimize any overfitting, which is effectively performed using L2 regularization and manual tuning while not including these hyper-parameters when defining the search space. The voting classifier takes several tree-based classifiers as inputs along with the other models, similar to stacking the classifier but in a more effective way. We found that the accuracy of the models such as Random Forest, Decision Tree, Gaussian Naive Baise, Logistic Regression, K-Nearest Neighbors, Scholastic Gradient Descent is on the lower end when compared to these ensemble techniques. The stacking classifier uses all these models plus the gradient boosters as pipelines with the final estimator being the voting classifier. Hyperparameter optimization then sets the ideal settings for learning rate, booster type, maximum depth, number of estimators, and other factors classifiers in our tabular dataset. From the standard techniques, XGBoost provides the best accuracy because of its superior performance in tabular datasets and tree-based structures. The corresponding confusion matrix of the model is shown in
Figure 11. The use of a meta-heuristic whale optimization algorithm with staking classifier tends to bypass local optima.
This is evident from the results that the base model has distinct performance over the dataset for the next day prediction. The dataset is relatively small, so the accuracy of these base models is found to be quite close to each other. The dataset for price prediction is quite balanced; however, the test set does not have many values to make accurate predictions. This is not much of a problem since tree-based models perform well even on this small dataset and perform exceedingly well when used in stacking and voting modules. The training and testing are first carried out using different machine learning classifiers with a test-train split of 30–70; next, we use it with the proposed stacking and the voting-based ensemble models. Random Forest, Support Vector Classifier, Decision Tree Classifier, ExtraTrees Classifier, Light Gradient Boosting Classifier, XGBoost, and Logistic Regression Classifier are some of the classifiers used by the stacking model. Each of these models provided appreciable accuracy when used alone, but the number of false negatives and false positives varied greatly. This is subsequently reflected in the recall graph.
Each of these individual classifiers may have a unique approach or strategy for analyzing the dataset, which can be seen from from the results. However, simply taking the majority decision may not always be the best approach, because some classifiers may give more false-positives or true-negatives in classification c others. In such cases, it might be better to consider all the factors related to a classifier and the algorithm behind it before using it for predictions In a general sense, the WOA algorithm found a set of hyperparameters that increase the number of trees in the ensemble model, (n_estimators) and limit the depth of each tree (max_depth) to avoid overfitting. It also adjusts the learning rate (learning_rate) to optimize the trade-off between the speed of convergence and the accuracy of the model.
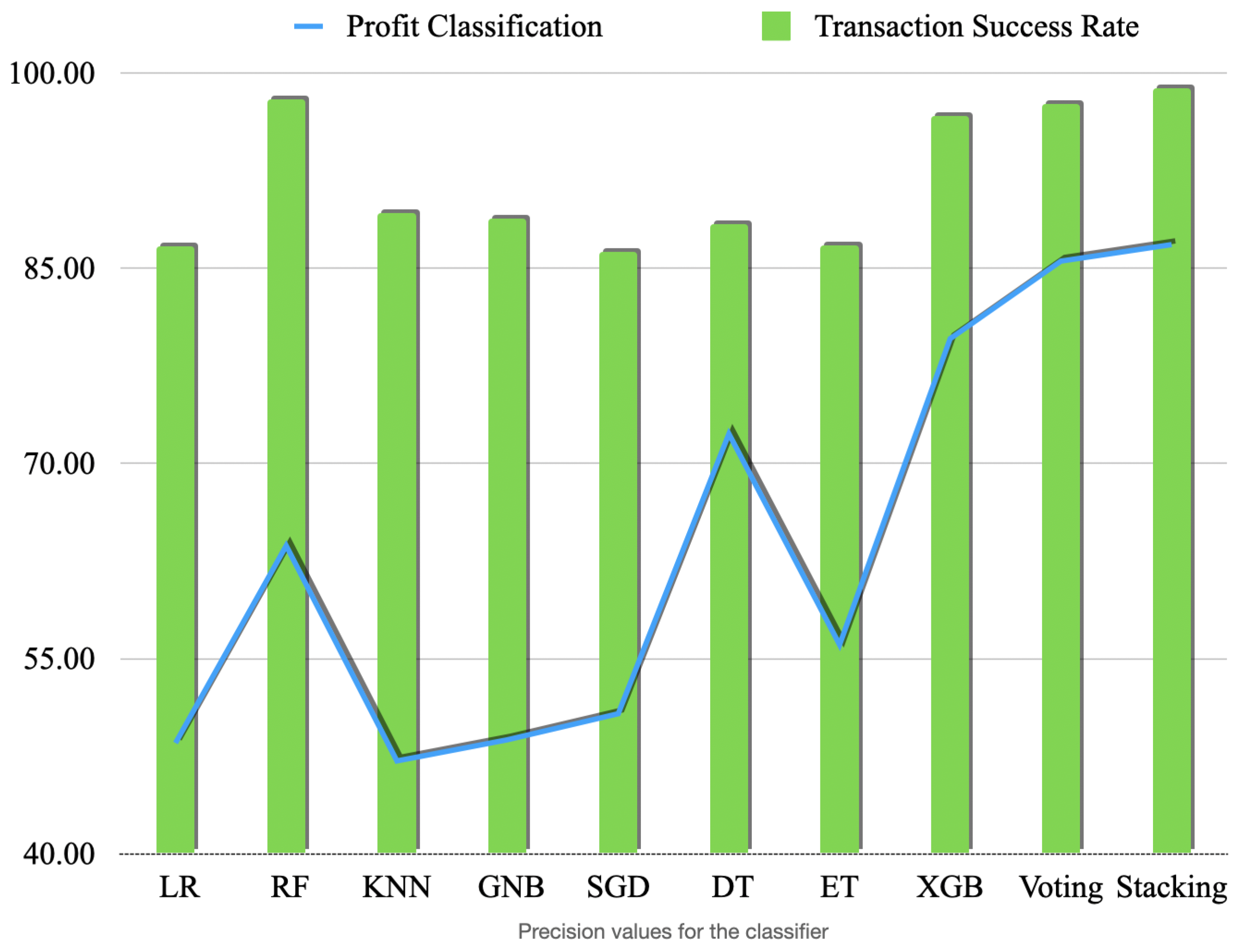
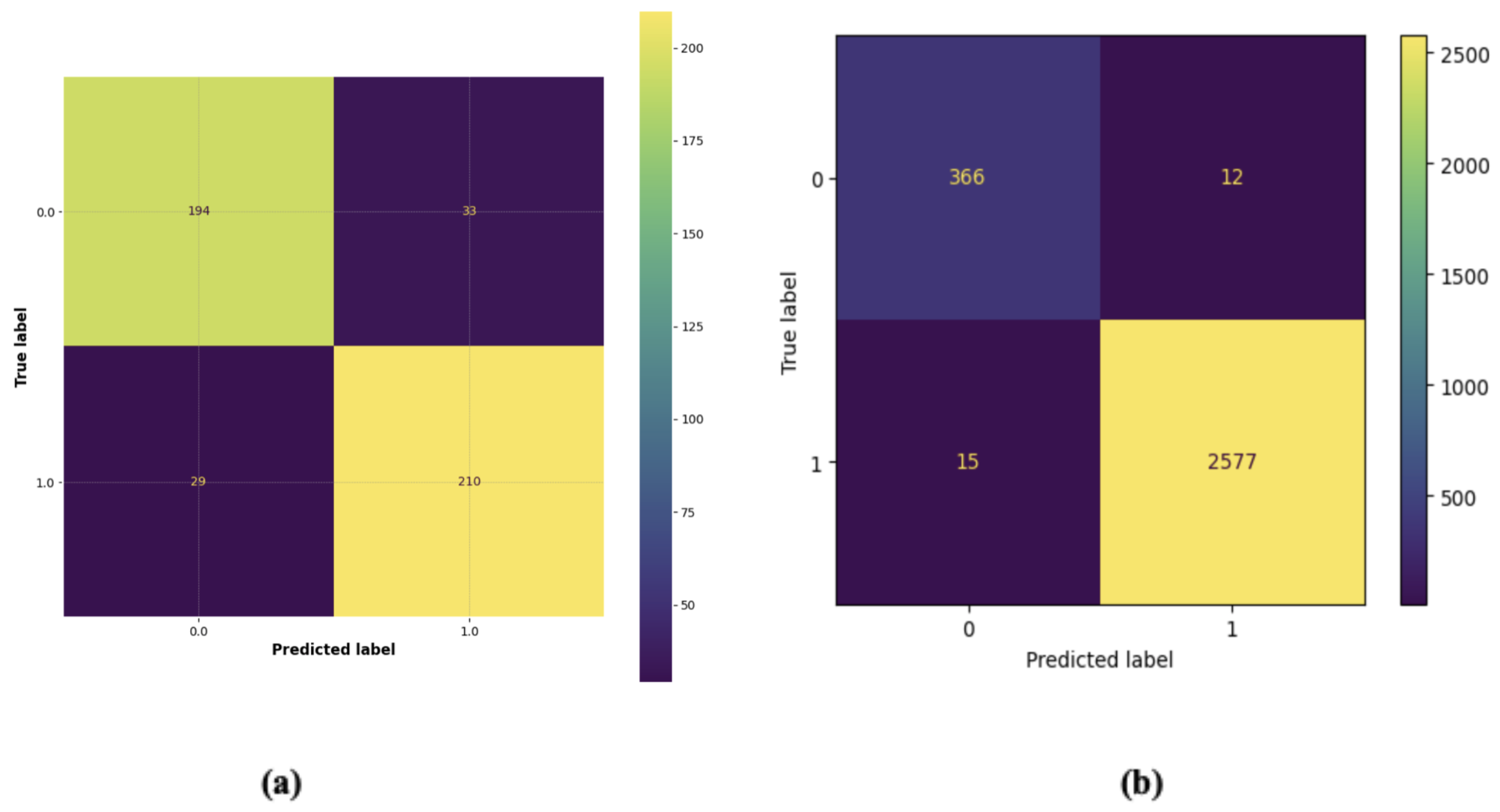
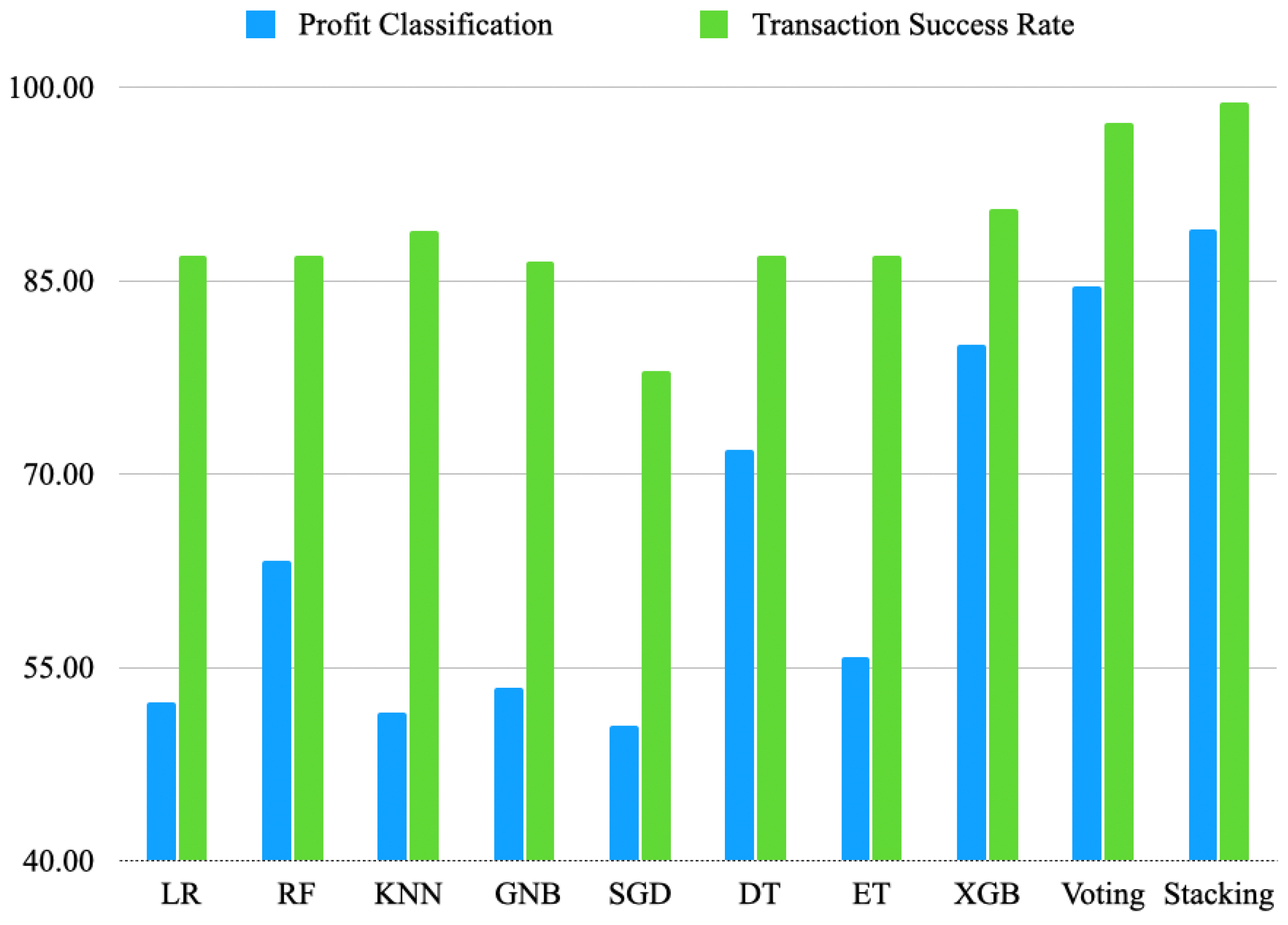
Figure 12 shows the accuracies obtained by the models for both of our classification problems where we use whale optimization algorithms. The confusion matrices for the stacking classifier are shown in
Figure 11 for both the tasks i.e., profit and success rate prediction.
The other classification system is used to determine if machine learning can predict success and failure rates along with the profits to cover another aspect of the real-world scenario for the cryptocurrency with good accuracy. In this case, we consider data such as sender, receiver, transaction type, status, amount and token type. The Status could be confirmed and unconfirmed in this case to address records as SUCCESS or FAILED (
Table 3).
The proposed work focuses on enhancement in deployment mechanisms and superior optimization techniques to predict the success and failure of transactions in a TRON environment. All the reported values are mean values for 5 runs, and this is performed to ensure reduced bias of the models towards optimized solutions. One thing to note, however, is that it’s best to reset the environment after each run in order to reduce re-fitting towards optimal values in a particular run.
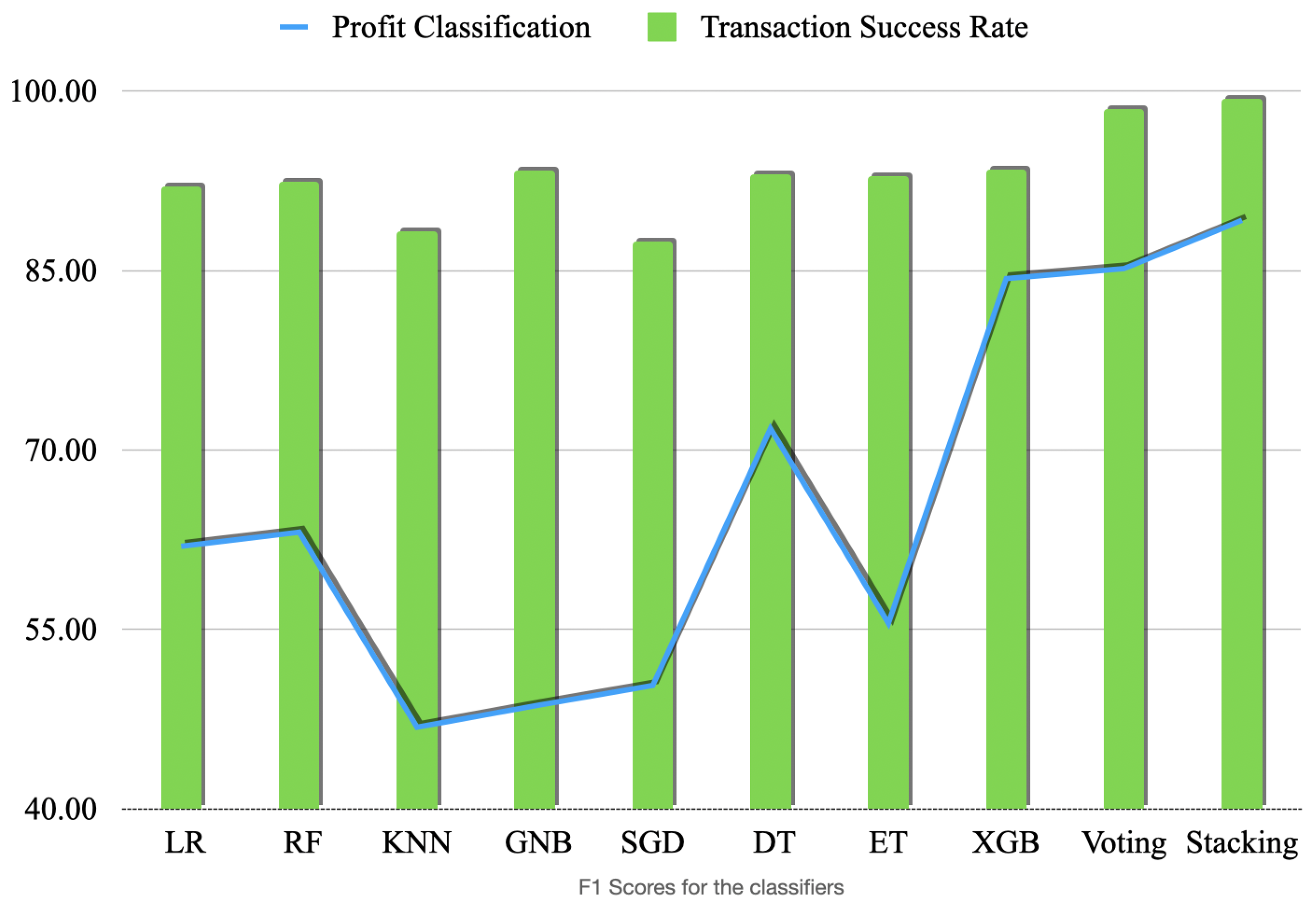
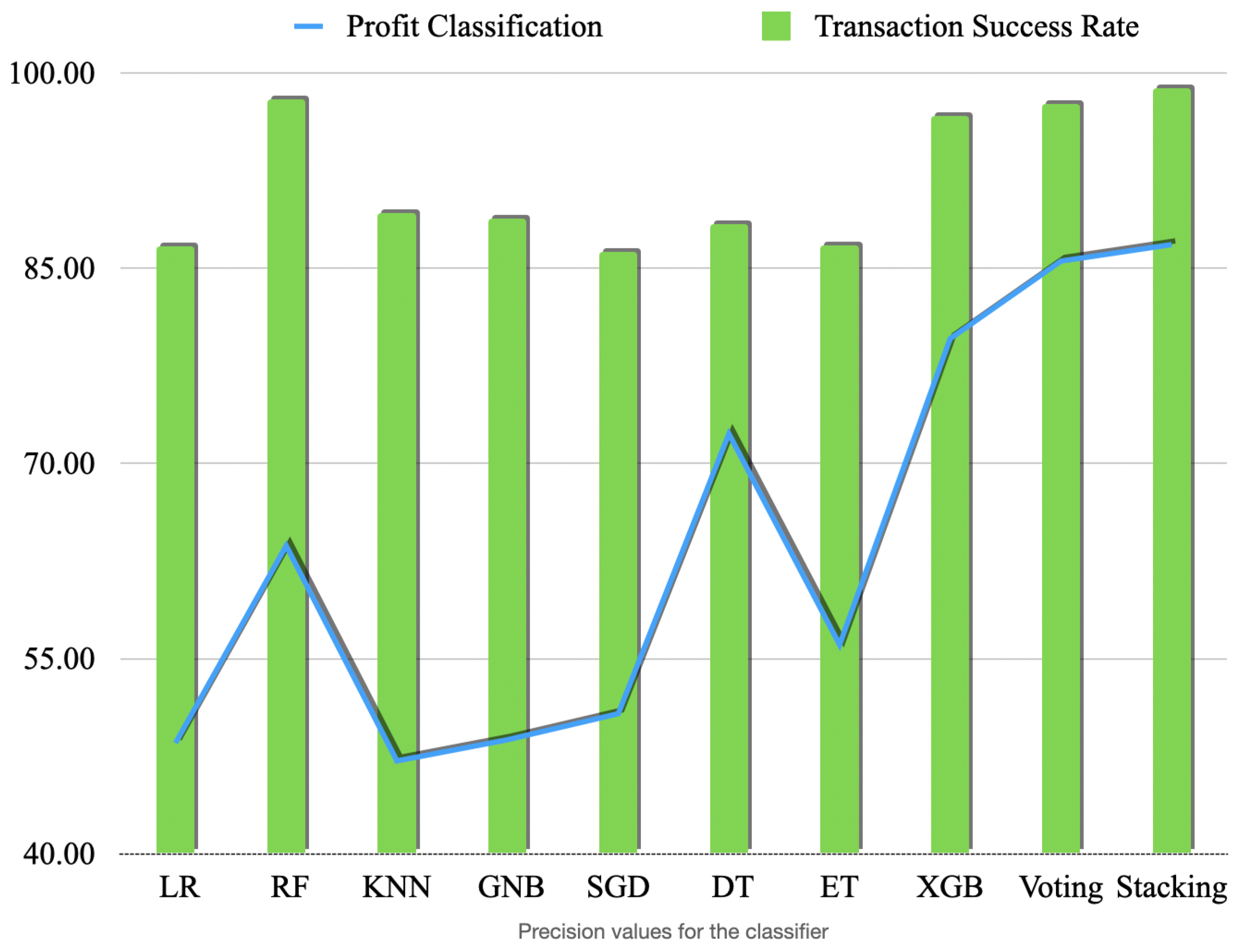
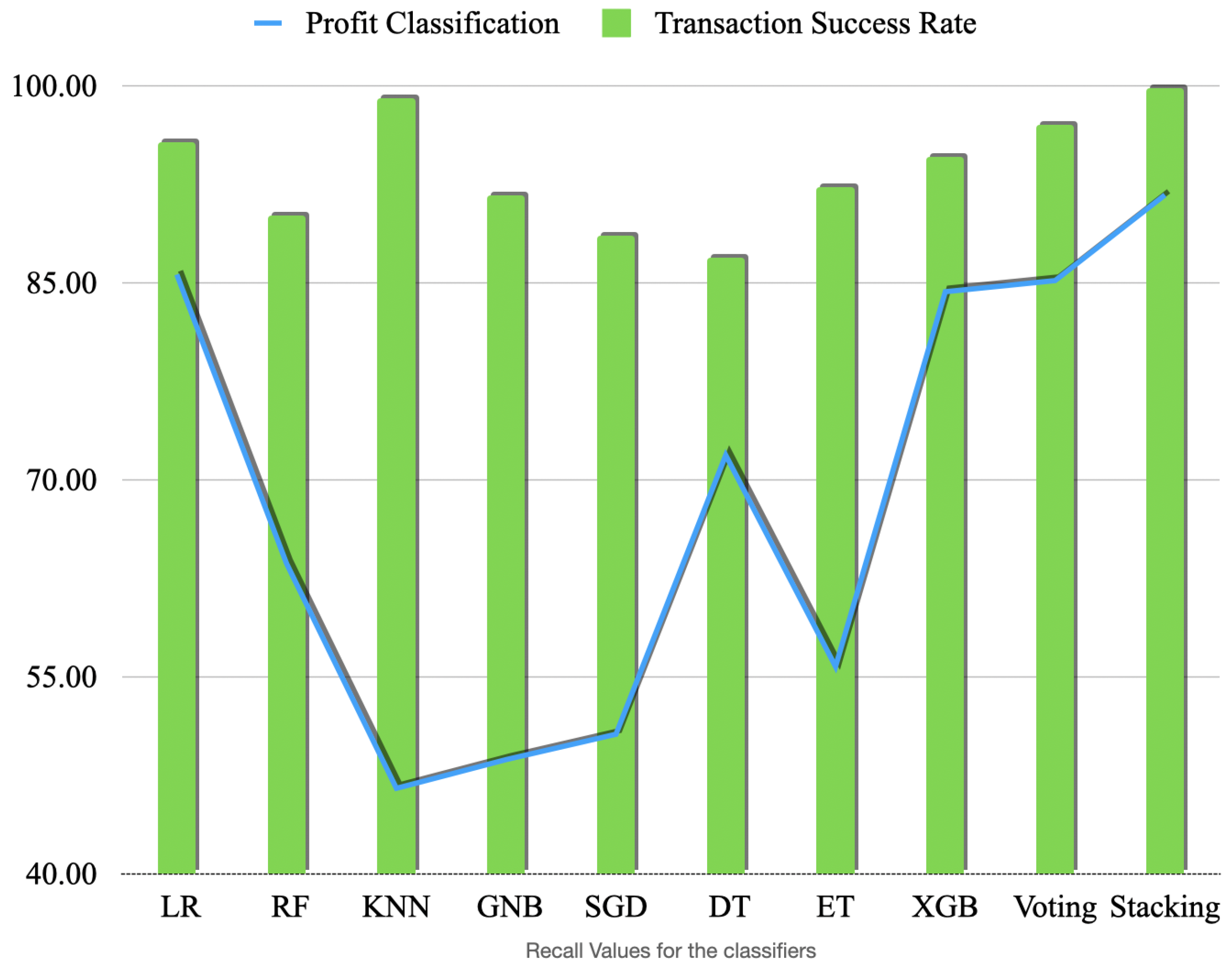
Figure 13,
Figure 14 and
Figure 15 show the F1, scores (the harmonic mean of precision and recall), precision and recall values, respectively. These scores show that some models consistently better than the others and have higher scores than the others for all the metrics. Stacking classifier has the best overall performance across all the metrics. Ensemble models should always be assessed for any overfitting at all times when used for unbalanced and smaller dataset and regularisation techniques that we applied are useful of avoiding overfitting to a certain extent.
There is very limited research on TRON to compare our results and specifically on the dataset that we use. It is concluded in the research work by Yadav et al. [
47] in 2021 that TRON performs the best out of five cryptocurrencies in their analysis. Similarly, research by Malsa et al. [
48] shows that theTRX coin has a promising future based on their qualitative and quantitative analysis of the parameters of the coin. From recent research performed for 10 different cryptocurrencies on a time-series dataset [
49], TRON shows promising results compared to similar tokens, obtaining an MSE value ranging from 0.0007 to 0.0009, RMSE ranging from 0.0081 to 0.0094 and MAE value ranging from 0.0052 to 0.0061.
Our models perform better for most of the values, potentially due to a robust hyperparameter tuning methodology combined with using tree-based regressors which perform significantly better on smaller datasets [
50]. It is important to note that even time series data may contain similar OHLC data that have significant overlap with our dataset. One important analysis from the literature on crypto price prediction is that the newer cryptocurrencies tend to show better performance when compared to their established counterparts in terms of MAE, R squared, and RSME values. Our findings show similar results and they reflect in other research works as well.
The models with the highest precision values for this binary classification problem are Stacking and Voting, with precision values ranging from 85.19% to 99.84%. Logistic Regression (LR) and XGBoost (XGB) also performed consistently well, achieving high precision values in addition to high overall accuracy.
Interestingly, LR and KNN show abnormally high values of recall for transaction success rate classification. Another possibility is that it is due to the imbalanced dataset itself, meaning that there are more negative cases than positive cases. One possibility is that the model is able to learn relevant patterns in the data that distinguish positive cases from negative cases. For example, in a binary classification problem, the model may learn to recognize specific features or combinations of features that are more likely to be present in positive cases. If these patterns are strong and consistent across the dataset, the model may be able to correctly identify a high proportion of the actual positive cases, leading to a high recall value.
For all the algorithms executed, a pipeline is created using StandardScaler(), PCA(), and the corresponding classifier. The StandardScaler is used to normalize the input data, and PCA is used for dimensionality reduction. The Stacking classifier takes the pipelines as input, and the final estimator is a Voting Classifier that takes the classifiers as input. In this case, the regression models are trying to predict the next closing price of TRON based on historical data. The input data includes various features (such as the opening price, high price, low price, and volume) from past trading periods, and the output is the next closing price of TRON.
Since we want to optimize the hyperparameters of the voting and stacking classifiers, we treat this as a continuous optimization problem. In the algorithm for optimal global position vector, the position of each agent represents a solution in the search space. The algorithm starts by initializing the population of agents randomly in the search space. Then, for each agent in the population, the position is updated based on the agent’s current position and the position of the best agent found so far. The updated equations for the position depends on the current iteration, which determines the type of search being performed (exploration or exploitation). The fitness of each agent is evaluated using the fitness function. If the fitness of an agent is better than the fitness of the best agent found so far, the best agent is updated. The step size is also updated in each iteration. The algorithm stops after a maximum number of iterations is reached, and the position of the best agent found is returned as the optimal solution.
For the regression, The XGBRegressor and LightGBM models use similar boosting algorithms but differ in their implementation. The XGBRegressor uses a pre-sorted algorithm to build trees, while the LightGBM uses a histogram-based algorithm. The CatBoostRegressor is another gradient-boosting model that uses ordered boosting and a random permutation to train the decision trees. Once trained, the models can be used to make predictions on new data (in this case, the test data) by taking in the input features and outputting a predicted closing price. The accuracy of the model is typically measured using a performance metric such as mean squared error or R-squared, which is best to use in our case. The hyperparameters that tuned for the XGBoost, LightGBM, and CatBoost regressors include but are not limited to the learning rate, number of estimators, maximum depth, gamma, subsample ratio, and regularization parameters. The search space for the WOA can be defined by setting the bounds for each hyperparameter to be tuned. The fitness function for the WOA is set to evaluate the performance of the model with the given hyperparameters. This is performed by training the model with the given hyperparameters and evaluating its performance on a validation set. The validation set can be used to prevent overfitting during hyperparameter tuning.
The voting classifier uses these XGB, LGBM, and CatBoost models for voting, with 6 other models as estimators. These models are: XGBClassifier with n_estimators = X[0] and max_depth = int(X[1]), CatBoostClassifier with learning_rate = X[2], and LGBMClassifier with learning_rate = X[3]. The three models are combined in an ensemble model using a VotingClassifier with a ‘soft’ voting strategy. The accuracy of the model is computed as the mean of the accuracy scores across all folds. The search space is defined as a NumPy array that contains four rows, each corresponding to one of the four hyper-parameters to optimize. A similar approach is used for the stacking classifier, while the final estimator used for the stacking classifier is the voting classifier. It is to be noted that for the problem of classification, the XGBoost model performs or another set of models does not influence the accuracy to a great length, however, to obtain the best possible accuracies, it is best to use the voting classifier as the final estimator. The first column of each row specifies the minimum value for the hyperparameter, and the second column specifies the maximum value. The WOA algorithm is run with the fitness_function and search_space defined above, as well as the number of agents and iterations specified. We used the Nvidia K80 GPU based on cloud for our evaluations on google cloud with 32 GB of usable ram. Three different models are created using the hyperparameters specified in the input parameter X. Limitations of our work include working on an unbalanced and small dataset. Future research should focus on improving the overall effectiveness and security of the framework

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}