1. Introduction
In this paper, we are interested in designing a proximal point procedure to solve the following optimization problem
where
is a continuously differentiable matrix function and
denotes the identity matrix. The feasible set of Problem (
1), denoted by
, is known as the
Stiefel manifold [
1]. Actually, this set constitutes an embedded Riemannian sub-manifold of the Euclidean space
with dimensions equal to
(see [
1]). Notice that (
1) is a well-defined optimization problem because
is a compact set and
is a continuous function; therefore, the Weierstrass theorem ensures the existence of at least one global minimizer (and even a global maximizer) for
on the Stiefel manifold.
The orthogonality-constrained minimization problem (
1) is widely applicable in many fields, such as the nearest low-rank correlation matrix problem [
2,
3], the linear eigenvalue problem [
4,
5,
6], sparse principal component analysis [
5,
7], Kohn–Sham total energy minimization [
4,
6,
8,
9], low-rank matrix completion [
10], the orthogonal Procrustes problem [
8,
11], maximization of sums of heterogeneous quadratic functions from statistics [
4,
12,
13], the joint diagonalization problem [
13], dimension reduction techniques in pattern recognition [
14], and deep neural networks [
15,
16], among others.
In the Euclidean setting, given
, a closed proper convex function, the proximal operator
is defined by
where
is the standard norm of
and
is the proximal parameter [
17].
The scalar
plays an important role controlling the magnitude by which the proximal operator sends the points towards the optimum values of
f. In particular, larger values of
are related to mapped points near the optimum, while smaller values of this parameter promote a smaller movement to the minimum. It can design iterative optimization procedures that use the proximal operator to define the recursive update scheme. For example, the proximal minimization algorithm [
17], minimizes the cost function
f by consecutively applying the proximal operator
, similar to fixed-point methods, to some given initial vector
.
Several researchers have proposed generalizations of the proximal minimization algorithm in the Riemannian context. This kind of method was first considered in the Riemannian context by Ferreira and Oliveira [
18] in the particular case of Hadamard manifolds. Papa Quiroz and Oliveira [
19] adapted the proximal point method for quasiconvex functions and proved full convergence of the sequence
to a minimizer over Hadamard manifolds. In addition, Souza and Oliveira [
20] introduced a proximal point algorithm to minimize DC functions on Hadamard manifolds. Wang et. al. [
21] established linear convergence and finite termination of this type of algorithm on Hadamard manifolds. For this same type of manifold, in [
22], the authors proved global convergence of inexact proximal point methods. Recently, Almeida et. al. [
23] developed a modified version of the proximal point procedure for minimization over Hadamard manifolds. For the specific case of optimization on the Stiefel manifold, in [
7], the authors proposed a proximal gradient method to minimize the sum of two function
over
, where
f is smooth and its gradient is Lipschitz continuous, and
g is convex and Lipschitz continuous. Another proximal-type algorithm is proposed in [
24], where the authors developed a proximal linearized augmented Lagrangian algorithm (PLAM) to solve (
1). However, the PLAM algorithm does not build a feasible sequence of iterates, which differs from the rest of the Riemannian proposals.
To minimize a function
defined on a Riemannian manifold
, all the approaches presented in [
18,
19,
20,
21,
23,
25] consider the following generalization of (
2)
where
is the Riemannian distance [
1]. The main disadvantage of all these works is that the authors proposed methods and theoretical analyses based on the exponential mapping, which requires the construction of geodesics on
. However, it is not always possible to find closed expressions for geodesics over a given Riemannian manifold, since geodesics are defined through a differential equation, [
1,
26]. Even in the case when we have available a closed formula for the corresponding geodesics on
, the computational cost of calculating the exponential mapping over a matrix space is too high, which is an obstacle to solving large-scale problems.
In this paper, we introduce a very simple proximal point algorithm to tackle Stiefel-manifold-constrained optimization problems. The proposed approach replaces the term
in (
3) with the usual matrix distance
in order to avoid purely Riemannian concepts and techniques such as Riemannian distance and geodesics. The proposed iterative method tries to solve the optimization problem (
1) by repeatedly applying our modified proximal operator to a given starting point. We prove (without imposing the Lipschitz continuity hypothesis) that our method converges to critical points of the restriction of the cost function to the Stiefel manifold. Our preliminary computational results suggest that our proposal presents competitive numerical performance against several feasible methods existing in the literature.
The rest of this manuscript is organized as follows.
Section 2 summarizes a few well-known notations and concepts of linear algebra and Riemannian geometry that will be exploited in this paper. Afterwards,
Section 3 introduces a new proximal point algorithm to deal with optimization problems with orthogonality constraints.
Section 4 provides a concise convergence analysis for the proposed algorithm.
Section 5 presents some illustrative numerical results, where we compare our approach with several state-of-the-art methods for the solution of linear eigenvalue problems and the minimization of sums of heterogeneous quadratic functions. Finally, the paper ends with a conclusion in
Section 6.
2. Preliminaries
Throughout this paper, we say that
is skew-symmetric if
. Given a square matrix
,
denotes the skew-symmetric part of
A; that is,
. The trace of
X is defined as the sum of the diagonal elements, which we denote as
. The standard inner product between two matrices
is given by
. The Frobenius norm is defined by
. Let
be an arbitrary matrix in the Stiefel manifold; the tangent space of the Stiefel manifold at
X is given by [
1]
Let
; the canonical metric [
6] associated with the tangent space of the Stiefel manifold is defined by
Let
be a differentiable function; we denote as
the matrix of partial derivatives of
(the Euclidean gradient of
). Let
be a smooth function defined on the Stiefel manifold; then the Riemannian gradient of
at
, denoted as
, is the unique vector in
satisfying
where
is any curve that verifies
and
.
The Riemannian gradient of
under the canonical metric has the following closed expression [
4,
6]
In addition, based on Formula (
5), we can define the following projection operator over
It can be easily shown that the operator (
6) effectively projects matrices from
to the tangent space
. This projection operator was also considered in [
27].
Similar to the case of smooth unconstrained optimization,
is a critical point of
if it satisfies [
1,
28]
Therefore, the critical points of the restriction of the cost function
to the Stiefel manifold are candidates to be local minimizers of Problem (
1). Here, we clarify that the objective function
that appears in (
1) has both a Euclidean gradient and a Riemannian gradient. In the rest of this paper, we will denote by
the Riemannian gradient of the restriction of
to the set
under the canonical metric.
3. Proximal Point Algorithm on
In this section, we propose an implicitly defined curve on the Stiefel manifold. We also validate that the proposed curve verifies analogous properties that Riemannian gradient methods have. Using this curve, we further present in detail the proposed proximal point algorithm.
As we mentioned in the introduction, we consider an adaptation of the exact proximal point method to the framework of minimization over the Stiefel manifold: given a feasible point
, we compute the new iterate
as a point on the curve
defined by
Observe that the argmin set in (
7) is never empty since
is a continuous function on a compact domain. In addition, note that this proximal optimization problem is obtained from (
3) by substituting the Riemannian distance with the standard metric associated with the matrix space
. Additionally,
satisfies that
. Thus,
is a curve on
that connects the consecutive iterates
X and
. This is an analogous property to that which the retraction-based line-search curves verify (see [
1,
29]). Here it is important to remark that (
7) can have multiple global solutions; in this situation,
would not be a curve since it would not be a well-defined function.
The lemma below establishes that is a descent iterative process.
Lemma 1. Given , consider the curve (7). Then, Proof of Lemma 1. Let
be a positive real number. In view of the optimality of
in (
7), we have
Post-multiplying both sides of (
9) by
and rearranging, we obtain
completing the poof. □
Lemma 1 guarantees that the proposed approach is a descent iterative process. Therefore, by executing an iterative process based on the proximal curve (
7), we can minimize the objective function and at the same time move towards stationarity. Taking into account this fact, we propose our proximal point algorithm on
, the steps for which are described in Algorithm 1 (PPA-St).
| Algorithm 1 PPA-St |
- 1:
, , is a sequence such that for all , . - 2:
while do - 3:
- 4:
If then stop the algorithm. - 5:
, - 6:
end while
|
Notice that the proposed PPA-St algorithm can be interpreted as a Euclidean proximal point algorithm with respect to the cost function
where
is the indicator function given by
and
is defined by
Thus the PPA-St process can be seen as a special case of the proximal alternating linearized descent (PALM) algorithm developed in [
30] by selecting the functions
and
(in the notation of [
30]). Particularly, PALM has a rich convergence analysis and was already applied to the Stiefel manifold in [
31,
32]. Nonetheless, the main differences between PALM and PPA-St are that our proposal does not require linearizing the function
to solve the problem, and PPA-St does not involve inertial steps.
On the other hand, there are some cost functions for which the proxy (
7) can be solved analytically. For example, if
, where
is a data matrix, then the proximity operators are
with
constant. Since
, the optimization problem above is equivalent to
which has a closed-form solution (see Proposition 2.3 in [
8]). Additionally, let
be two constant matrices and
. Let us consider the objective function
given by
. In this special case, the proximal operator is reduced to
The above constrained optimization problem can be reformulated as
which is an orthogonal Procrustes problem with an analytical solution (see [
33]). However, in general the proximal operator (
7) does not have a closed-form expression for its solutions. Therefore, in the implementation of PPA-St, we will use an efficient Riemannian gradient method based on the QR-retraction mapping (see Example 4.1.3 in [
1]) in order to solve the optimization subproblem (
10).
By introducing the notation
, we propose to use the following feasible line-search method, starting at
and
,
where
is the Riemannian gradient under the canonical metric of
evaluated at
Y; that is,
, where
is the Euclidean gradient of
, i.e.,
. In addition,
denotes the Cholesky factor obtained from the Cholesky factorization of
, i.e., let
be a symmetric and positive definite matrix (PSD) and suppose that
is its Cholesky decomposition; then
. Observe that this function is well-defined due to the uniqueness of Cholesky factorization for PSD matrices. Additionally, notice that in the recursive scheme (
15), we are projecting
over the Stiefel manifold using its QR factorization obtained from the Cholesky decomposition (see Equation (1.3) in [
34]). We now present the inexact version of our Algorithm 1 based on the Riemannian gradient scheme (
15).
It is well-known that if we endow the iterative method (
15) with a globalization strategy to determine the step-size
, such as the Armijo’s rule [
1,
35] or a non-monotone Zhang–Hager type condition [
36,
37], then the Riemannian line-search method (
15) is globally convergent (please see [
1,
36]). This means that the while loop between Steps 3 and 6 of Algorithm 2 does not take infinite time, i.e., there must exist an index
such that
for all
. In addition, it is always possible to determine a step-size
such that Armijo’s rule (
16) holds. For practical purposes, we implement our Algorithm 2 using the well-known
backtracking strategy to find such a step-size (see [
35]). Furthermore, to reduce the number of line searches performed in each inner iteration (the iterations in terms of the index
i), we incorporate the Barzilai–Borwein step-size, which typically improves the performance of gradient-type methods (see [
38]).
| Algorithm 2 Inexact PPA-St |
- 1:
, , , is a sequence such that for all , is a sequence of positive real numbers such that , . - 2:
while do - 3:
Set and . - 4:
while do - 5:
, where is selected in such a way that the Armijo condition is satisfied, i.e.,
- 6:
, - 7:
end while - 8:
, - 9:
, - 10:
end while
|
4. Convergence Results
In this section, we establish the global convergence of Algorithms 1 and 2. Here, we say that an algorithm is globally convergent if, for any initial point , the generated sequence satisfies that . Thus, global convergence does not refer to convergence towards global optima. Firstly, we analyze the convergence properties of Algorithm 1 by revealing the relationships between the residuals , and .
Since
is continuously differentiable over
, then its derivative
is continuous. Hence,
is bounded on
due to the compactness of the Stiefel manifold. Then, there exists a constant
such that
Consequently, the Riemannian gradient of
satisfies
for all
.
The following proposition states that Algorithm 1 stops at Riemannian critical points of .
Proposition 1. Let be a sequence generated by Algorithm 1. Suppose that Algorithm terminates at iteration ; then .
Proof of Proposition 1. The first-order necessary optimality condition associated with Subproblem (
10) leads to
but since Algorithm 1 terminates at the
k-th iteration, we have that
, which directly implies that
. By substituting this fact in (
19), we obtain the desired result. □
The rest of this section is devoted to study the asymptotic behavior of Algorithm 1 for infinite sequences
generated by our approach, since otherwise, Proposition 1 says that Algorithm 1 returns a stationary point for Problem (
1). The lemma below provides us two key theoretical results.
Lemma 2. Let be an infinite sequence generated by Algorithm 1. Then, we have
- 1.
is a convergent sequence.
- 2.
The residual sequence converges to zero.
Proof of Lemma 2. It follows from Lemma 1 that
Therefore, is a monotonically decreasing sequence. Now, since the Stiefel manifold is a compact set and is a continuous function, we obtain that has a maximum and minimum on . Therefore, is bounded, and then is a convergent sequence, which proves the first part of the lemma.
On the other hand, by rearranging Inequality (
20), we arrive at
Applying limits in (
21) and using the first part of this lemma, we obtain
□
Now we are ready to prove the global convergence of Algorithm 1, which is established in the theorem below.
Theorem 1. Let be an infinite sequence generated by Algorithm 1. Then Proof of Theorem 1. Firstly, let us denote by
. Now, notice that
By applying Lemma 2 in (
22), we obtain
It follows from (
24), (
7), the Cauchy–Schwarz inequality, and (
18) that
which implies that
Finally, taking limits in (
26) and considering (
23) and Lemma 2, we obtain
which completes the proof. □
We now turn to proving the convergence to stationary points of the inexact version of the PPA-St approach.
Theorem 2. Let be an infinite sequence generated by Algorithm 2. Then Proof of Theorem 2. From the Armijo condition (
16), Step 7, and the definition of
, we have
Additionally, the Armijo condition (
16) clearly implies that, for fixed
k,
is a non-increasing sequence. Combining this result with inequality (
27) and Step 2, we arrive at
which leads to
Therefore, the sequence of objective values is convergent. Moreover, we get that .
On the other hand, notice that
The second term on the right-hand side of (
28) verifies that
By rearranging (
28), we get
Applying the norm to both sides of the above equality and considering that
and (
29), we arrive at
Taking limits in the above relation, we conclude that
proving the theorem. □
Corollary 1. Let be an infinite sequence of iterates generated by Algorithm 1 or Algorithm 2. Then every accumulation point of is a critical point of in the Riemannian sense.
Proof. Let
be an infinite sequence generated by Algorithm 1 (or Algorithm 2). Clearly, the set of all accumulation points of the sequence
is non-empty since
and
is bounded. Let
be an accumulation point of
; that is, there is a subsequence
converging to
. Since
is compact and
is feasible, for all
, we have
. Applying Theorem 1 (or Theorem 2) and considering that
is a continuous function, we arrive at
proving the corollary. □
5. Computational Experiments
In this section, we present some numerical results to verify the practical performance of the proposed algorithm. We test our Algorithm 2 on academic problems, considering linear eigenvalue problems and minimization of sums of heterogeneous quadratic functions. We coded our simulations in MATLAB (version 2017b) with double precision on a machine with an Intel(R) Core(TM) i7-4770 CPU@3.40 GHz, a 1TB HD, and 16 GB RAM. We compare our approach with the Riemannian gradient method based on the Cayley transform [
6] (OptStiefel) and with three Riemannian conjugate gradient methods—RCG1a, RCG1b, and RCG1b+ZH—developed in [
13]. (The OptSt MATLAB code is available at
https://github.com/wenstone/OptM, accessed on 10 May 2023, and the Riemannian conjugate gradient methods—RCG1a, RCG1b, and RCG1b + ZH—can be downloaded from
http://www.optimization-online.org/DB_HTML/2016/09/5617.html, accessed on 10 May 2023). In addition, we stop all the methods when the algorithms find a matrix
such that
−4. In all the tests, we consider Algorithm 2 with
for all
. The implementation of our algorithm is available at
https://www.mathworks.com/matlabcentral/fileexchange/128644-proximal-point-algorithm-on-the-stiefel-manifold, accessed on 10 May 2023.
In the rest of this section, we use the following notation: Time, Nitr, Grad, Feasi, and Fval denote the average total computing time in seconds, average number of iterations, average residual , average feasibility error , and average final cost function value, respectively. In all experiments presented below, we solve ten independent instances for each pair , and then we report all of these mean values. For all of the computational tests, we randomly generate the starting point using the MATLAB command .
5.1. The Linear Eigenvalues Problem
In order to illustrate the numerical behavior of our method in computing some eigenvalues of a given symmetric matrix
, we present a numerical experiment taken from [
8]. Let
be the eigenvalues of
A. The
p-largest eigenvalue problem can be mathematically formulated as
Firstly, we illustrate the numerical behavior of Algorithm 2 via varying the proximal parameter
. Specifically, we conduct an experiment where we choose
constant throughout the iterations process and solve an instance of Problem (
30) with
for different values of
. We randomly generate the matrix
A as follows:
using MATLAB’s commands, and we solve the problem for each
. In
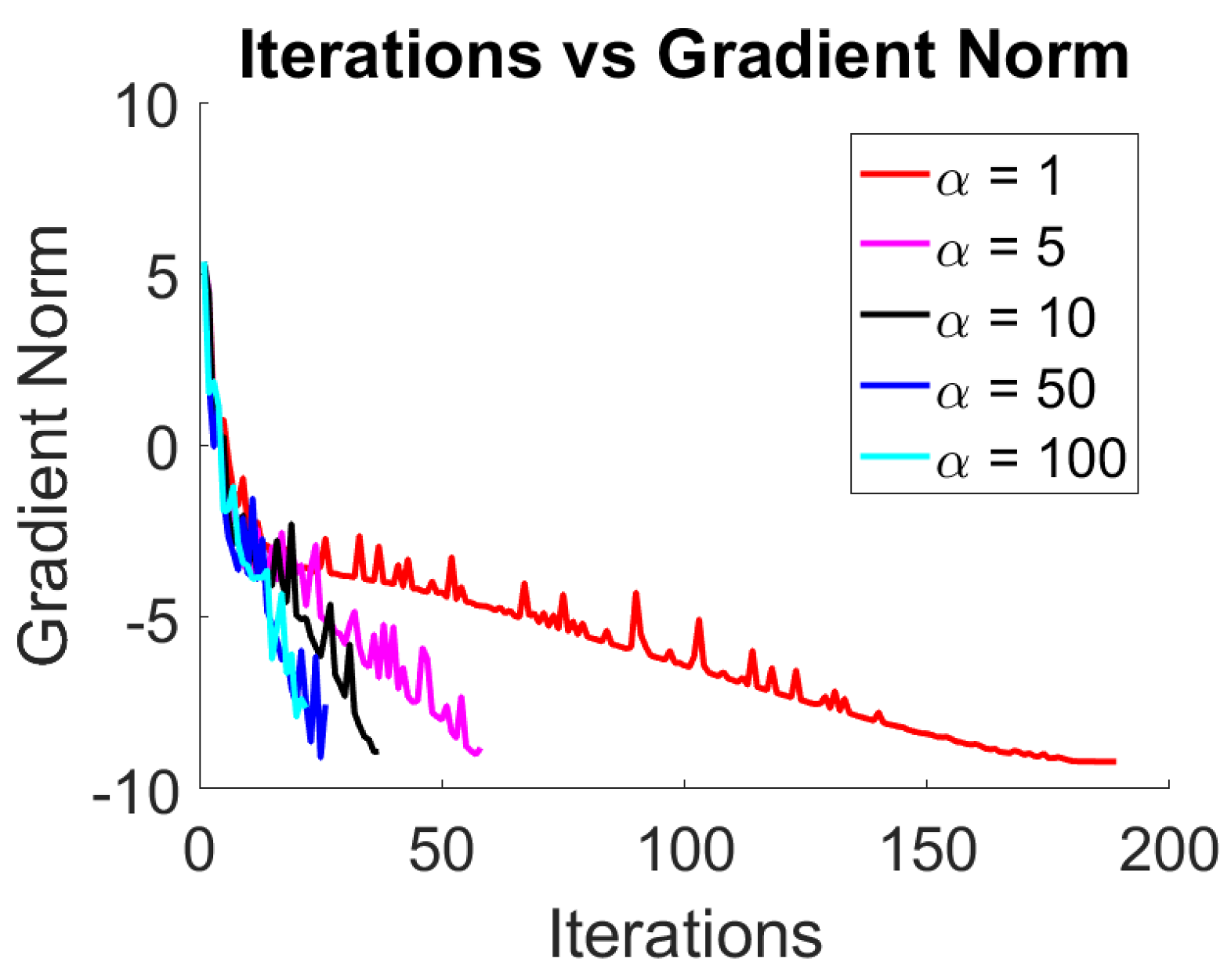
Figure 1, we present the convergence history of Algorithm 2 for all considered values of
. In addition,
Table 1 contains the numerical results associated with each value of
. From
Figure 1 and
Table 1, we clearly see that Algorithm 2 requires a larger number of iterations to achieve the desired accuracy in the gradient norm for small values of
.
Now, we consider the following experiment design: given
, we randomly generate dense matrices assembled as
, where
is a matrix whose entries are sampled from a standard Gaussian distribution.
Table 2 contains the computational results associated with varying
but fixed
. As shown in
Table 2, all of the methods obtained estimates of a solution of Problem (
30) with the required precision. Furthermore, we clearly observe that as
p approaches
n, our proposal converges more quickly, even in terms of computational time, than the rest of the methods.
5.2. Heterogeneous Quadratic Minimization
In this subsection, we consider the minimization of sums of heterogeneous quadratic functions over the Stiefel manifold; this problem is formulated as
where
are
n-by-
n symmetric matrices and
denotes the
i-th column of
X. For benchmarking, we consider two structures for the data matrices
obtained by using the following MATLAB commands:
Structure I: , for all .
Structure II: , for all ,
where
are random matrices generated by
. This experiment design was taken from [
13]. The numerical results concerning Structures I and II are contained in
Table 3 and
Table 4, respectively. From
Table 3, we see that the most efficient method both in terms of the number of iterations and in total computational time was our procedure. The second most efficient method was OptStiefel. However, the numerical performance of PPASt and OptStiefel is very similar.
On the other hand, the results related to Structure II show that OptStiefel is slightly superior to PPASt in terms of computational time. However our PPASt approach was much more efficient than the three Riemannian conjugate gradient methods and took fewer iterations to reach the desired tolerance than the rest of the methods. In addition, to illustrate the numerical efficiency of our proposal, we designed two randomized experiments where the initial points were built using the following MATLAB commands,
and generated the heterogeneous quadratic minimization problems according to Structures I and II described above. In
Figure 2 and
Figure 3, we show the convergence history in terms of iterations and time (in seconds) of all the methods for these specific experiments. From these figures, we clearly see that our proximal point method converges faster (in terms of iterations) to a local minimizer than the rest of the methods, while in terms of computational time, the proposal achieves competitive results with respect to the other methods. Particularly, PPASt is the most efficient method for problems with Structure I.
5.3. The Joint Diagonalization Problem
Now, we evaluate the performance of our method on non-quadratic objective functions. Particularly, we consider the joint diagonalization problem [
39], mathematically formulated as
where the data
s are
n-by-
n symmetric matrices and
is the diagonal matrix obtained from
M by replacing the non-diagonal elements of
M with zero. In order to test all the algorithms, we randomly generate the matrices
s as follows
where
is a random matrix whose entries are generated independently from a Gaussian distribution, and, given a vector
,
denotes the diagonal matrix of size
n-by-
n whose
i-th diagonal entry is exactly the
i-th element of the vector
v. This experiment was taken from [
13]. We include in the numerical comparisons the Riemannian proximal gradient method (ManPG) developed in [
7]. For this experiment, we generate ten independent instances for different values of
n and
p and report the mean values of Time, Nitr, Grad, Feasi, and Fval for each method. Additionally, we use
as the maximum number of iterations allowed for all the algorithms and we use
as the tolerance for the termination rule associated with the gradient norm. The numerical results associated with this numerical test are presented in
Table 5.
From
Table 5, we see that the ManPG method obtains very poor performance, which is possibly due to the step-size used to initialize the backtracking process being set to
in each iteration, which can lead to the method carrying out many re-orthogonalizations and function evaluations per iteration. Furthermore, we notice that our proposal was the most efficient both in terms of total computational time and in the number of iterations. In fact, in terms of CPU time, the OptStiefel method is better than PPASt only for instances with
, while for the rest of the instances, our PPASt outperforms the other methods.







{kind=link}
{kind=link}
{kind=link}