1. Introduction
In many real-world vision tasks, it is an inevitablity that researchers conduct analyses on degraded versions of the original scene. Blurring is a common type of image degradation that usually occurs in imperfect imaging, e.g., out of focus, camera or object motion. In this paper, the blur is formalized as the following simple but reasonably accurate model [
1]. The blurred image
is the result of ideal scene
f convolved by a Point-Spread Function (PSF)
h, i.e.,
. Moreover, the modern image processing software, e.g., Photoshop, can simulate blurring effects based on the above formalization, with potential use in general image retouching and even malicious adversary attacks against automatic systems. Therefore, an efficient and secure vision algorithm naturally requires the robustness to blur.
1.1. Current Solutions
Robust visual algorithms heavily rely on robust data representations [
2]. In this regard, current typical deep-learning representations [
3], mainly Convolutional Neural Networks (CNN), are not designed to be robust to blurring at the architectural level. As a remedy, there are two popular data-level ideas to improve the robustness of learning representations:
Data augmentation which includes blurred image samples in the training phase for boosting the CNN to adapt to blurred patterns;
Deblurring as data pre-processing, which attempts to restore an ideal scene from blurred images for the regular (without blur augmentation) CNN inference.
However, the above two ideas face issues such as inefficiency, instability, and lack of explainability:
Regarding the efficiency, data augmentation and pre-processing clearly increase the computational cost of the training and inference phases, respectively;
Regarding the stability, blind deblurring is an ill-posed inverse problem, and the introduced recovery artifacts also strongly disturb the CNN representations [
4];
Regarding the explainability, neither of these ideas can achieve a guaranteed robustness with respect to a given class of blurs—their effectiveness is somewhat empirical.
On the non-learning path, moments and moment invariants have been well established, towards the
in-form robustness with respect to various forms of image distortion [
5].
In particular, orthogonal moments and moment invariants may be the most popular class for real-world tasks. They provide geometric invariance while providing a certain robustness to signal loss (including blurring) due to the orthogonality. However, such robustness is restricted from a Fourier perspective: only a few low-order moments capturing low-frequency information are stable while the rest remain sensitive to signal loss. One will have to face a tricky contradiction between discriminability and robustness in the design of the algorithm.
Recently, such moments and invariants have been extended to a fractional domain of orders, yielding new time-frequency discriminability and hence somewhat alleviating the above contradiction. However, both integer and fractional moment invariants still lack the guaranteed robustness to blurring.
To address above issue, the researchers have specifically designed blur invariants, formed in Fourier domain by special
projection operator [
6]. As a key theoretical contribution, such projection-based methods are recently integrated and generalized into a unified theorem, General Theorem of Blur Invariants (GTBI) [
7], which does not require any prior knowledge of the blur type.
1.2. Motivations
On the other hand, such Fourier-domain blur invariants are not robust to geometric transformations. With this lack, the existing ideas expand above blur invariants via integer geometric/complex moments, and then introducing combined invariance by Substitution Theorem (ST) based on corresponding geometric invariants. However, this expanded version has a quite complicated explicit form, and it is even more complicated after introducing the combined invariance.
1.3. Contributions
In this paper, we explore a simple but effective way to define combined invariants, which are designed from Fractional Moments under Projection operators (FMP).
Theoretically, the blur invariance and rotation invariance of FMP are guaranteed by the GTBI and the Fourier-domain rotation equivariance, respectively. From a statistical perspective, the proposed FMP representations can be considered as flexible and orthogonal statistics in frequency domain, where both properties are beneficial for the discriminability.
In summary, the proposed FMP not only has a simpler explicit definition, but also has useful representation properties including orthogonality, statistical flexibility, as well as the combined invariance of blurring and rotation.
1.4. Organizations
The rest of this paper is organized as follows. We first briefly review the studies of blur invariants and fractional moments in the following
Section 2. As the core of this paper, we formulate the basic definitions of FMP and the derived important properties in
Section 3 and
Section 4, respectively. Furthermore,
Section 5 reports the comparative results of our FMP with state-of-the-art orthogonal moments and deep learning representations with data augmentation or deblurring. In
Section 6, we give the conclusion of this paper and point out future work on stability.
2. Related Works
In this section, we briefly review the relevant studies on blur invariants and fractional moments, which are linked to the proposed methodology.
2.1. Blur Invariants
In the community of moment and moment invariants, the blur invariants are a recent idea compared to the geometric invariants, where geometric ones can even be traced back to David Hilbert (1890s) [
8].
In pioneer papers (1990s) [
9], Flusser et al. achieved heuristic blur invariance by restricting the definition of PSF. Such problem modeling and solving ideas have been adopted by many later researchers. Therefore, a series of blur invariants are derived with respect to centrosymmetric blur [
10], axially symmetric blur [
11], motion blur [
12], circularly symmetric blur [
13], arbitrary
N-fold symmetric blur [
6], and arbitrary (anisotropic) Gaussian blur [
14]. In the last two works, the authors developed projection-based invariants in the Fourier domain, and the restrictions on the PSF were greatly relaxed.
Recently, the above projection-based approach was extended to a very strong theorem, i.e., General Theorem of Blur Invariants (GTBI) [
7], where the construction of invariants occurs regardless of the specific form of the PSF and the dimensionality of the image. This remarkable work moves blur invariants from being constructed heuristically to being constructed by a unified theory.
Turning to the topic of combined invariants for image representation, i.e., geometric invariance is further introduced into the above blur invariants. A typical solution in this regard is to expand the Fourier-domain blur invariants by means of classical moments, e.g., geometric moments and complex moments. Then, the combined invariance is introduced in the expanded version by Substitution Theorem (ST) [
7] with geometric/complex moment invariants.
Note that such expanded blur invariants as well as the corresponding combined invariants exhibit quite complicated explicit forms. Therefore, this paper attempts to give an alternative path for the construction of combined invariance with respect to blurring and rotation, without going through the tricky moment expansion.
2.2. Fractional Moments
We start the topic of fractional moments with the information suppression problem [
15]. Indeed, the regional information of the image represented by the moments is closely related to the distribution of zeros of basis functions [
15]. The suppression is a unnecessary bias of zeros toward certain non-discriminative regions, causing the information in other more discriminative regions to be ignored.
This information suppression problem was first analyzed in Zernike Moments (ZM), both theoretically and empirically [
16]. Here, the solution suggested by the authors is to use the moments with uniformly distributed zeros, e.g., Orthogonal Fourier–Mellin Moments (OFMM).
As a more systematic idea, Hoang et al. [
17] proposed a class of fractional moments with adjustable zeros, i.e., Generic Polar Harmonic Transforms (GPHT). From a classical signal processing perspective, such fractional moments are time-frequency analysis methods. Its apparent ability to resolve the phenomenon of information suppression and, more generally, to alleviate the inherent contradiction between robustness and discriminability of classical moments. In this path, many classical moments are extended to the fractional domain of orders, e.g., fractional Legendre moments [
18], fractional OFMM [
19], fractional ZM [
20], fractional Chebyshev moments [
21], and Fractional Jacobi–Fourier Moments (FJFM) [
22]. As unified mathematical tools, GPHT and FJFM are more general definitions covering other fractional moments.
Note that the above fractional moments are all designed in the original image domain and robustness/invariance to blurring is not discussed. Therefore, this paper focus on fractional moments in transformation domains, for satisfying both blurring invariance and rotation invariance.
3. Fractional Moments under Projection: Definition
In this section, we formulate the most basic components in this paper, covering the general definition of FMP and two kinds of radial basis functions.
Definition 1. (Fractional moments under projection). For an image function f, the fractional moments under projection are defined as the following inner product:where is of blur invariance
and is defined in the Fourier domain by GTBI [7]:with orthogonal projector , mapping the image space into a given class (which we want to design the invariants) of PSFs , where and the P is called orthogonal when . The is the basis function of order parameter and fractional parameter over the domain , where * is the complex conjugate. Here, orthogonality
and rotation invariance
structures are imposed on the definition of basis functions [5]:with angular basis function () and radial basis function satisfying the weighted orthogonality condition: over a unit-disk domain . In the Definition 1,
can be considered as the blur-invariant part of
f in the Fourier domain. Here, its invariance derives from the equivariance of projector
P with respect to blurring, i.e.,
for any
. Furthermore, this equivariance is in fact ensured by the orthogonality of projector
P. For more details on the proof, we refer the reader to the GTBI by Flusser et al. [
7].
Note that the explicit definition of
is not yet given and bears numerous potential forms (see [
5] for a survey). Considering the representation capability and discussion generality, we introduce two classes of radial basis functions based on harmonic and polynomial functions, respectively.
Definition 2. (Harmonic radial basis function). The complex exponential functions
[23] in Fourier analysis can satisfy the weighted orthogonality condition in Definition 1, leading to an explicit form:where the orthogonality holds for all possible α. Definition 3. (Polynomial radial basis function). A class of classical orthogonal polynomials
, Jacobi polynomials [22], can satisfy the weighted orthogonality condition in Definition 1, leading to an explicit form:where and the polynomial parameters must fulfill: , ; similarly, the orthogonality holds for all possible α, p, and q. Here, we have specified the FMP of Definition 1 into harmonic and polynomial versions, corresponding Definitions 2 and 3, respectively. As to be discussed later, the proposed harmonic/polynomial FMP is a generic and flexible representation in Fourier domain, with in-form blurring and rotation invariance.
4. Fractional Moments under Projection: Property
In this section, we give some important properties derived from above definitions, covering the generic/flexible nature, rotation invariance, and blurring robustness.
Property 3. (Generic and flexible nature). By changing the parameter value of α, a specific class of FMP representations can be obtained from the generic Definitions 1∼3. Note that members of this class share beneficial Properties 2 and 3, while also being complementary in discriminative information since the distribution of zeros of is flexible depending on α.
Remark 1. As can be seen from the above property, the fractional parameter α in Definitions 2 and 3 allows a generic and flexible representation, meaning potential discriminability for various vision tasks. Mathematically, the number and location of zeros of the basis functions determine the frequency and spatial properties of the represented information, respectively, [15]. In our FMP, and α explicitly encode the number and location of zeros of the basis functions: The number of zeros in the radial and angular directions is proportional to n and m, respectively.
The location of zeros in the radial direction is biased towards 0 or 1 corresponding to or , where means a uniformly distributed zeros.
Property 3. (Rotation invariance). Suppose is a rotated version of image f by an angle φ about the center, when projector P is rotation equivariance, there must be a function other than constant functions such that:i.e., satisfying the rotation invariance, for all possible input images and FMP parameters. Proof. The proof of (6) is based on the 2D-Fourier rotation equivariance for and the 1D-Fourier translation theorem for .
For convenience, we denote the rotation operator about the center as
, i.e.,
. Firstly, the Fourier transform
is widely known to have equivariance to rotations in the classical literature as
. Secondly, we have assumed the equivariance of projector
P to rotation, i.e.,
. With the above properties, it is easy to derive:
We introduce a polar form of the frequency domain: . Then (7) can be rewritten as .
With the above rotation equivariance of
, it can be derived that the FMP representations before and after image rotation will differ by only a phase term (with respect to the rotation angle):
with
, where the second pass holds due to Fourier translation theorem of
.
Here, a naive definition of
is the magnitude operator:
hence
. For the more generalized definition of
, interested readers are referred to [
24]. □
Property 3. (Blurring robustness). Suppose is a blurred version of image f convolved by a function h: , the FMP is more robust than the counterpart in the original image domain [22,23] under the sense of l-norm distance of representation variations:and the equality holds if and only if . Proof. The proof of (10) is based on the blur invariance of , the linearity of inner product, the positive definiteness of norm, as well as the completeness and orthogonality of the basis functions V.
For the left side of (10), i.e., the variation of FMP representation, we can rewrite it as:
where the first pass holds due to the linearity of inner product and the second pass holds as the blur invariance of (2) is guaranteed by GTBI.
For the right side of (10), i.e., the variation of the image-domain counterpart representation, we can rewrite it as:
where
can be considered as image residual. Here, we assert that
and the equality holds if and only if
, i.e.,
.
Without loss of generality, we assume that there exists , such that . Based on this assumption, it is known that , due to if . Taken together, the above assumption means that d is a nonzero element that does not belong to the set of basis functions, while being orthogonal to any element in this set for guaranteeing . This obviously conflicts with the completeness and orthogonality of the basis functions in a Hilbert space. Therefore, this assumption does not hold.
It can be noted that the correctness of (11) and (12) implies in fact the correctness of the original property (10). □
Note that the ideal identities in Properties 2 and 3 may no longer hold for the discrete domain, which involve resampling and requantization errors. Interested readers can access our symmetrical work on noise-invariant representation in [
25].
5. Experiments
In this section, we will evaluate the robustness and discriminability of the proposed FMP, by intuitive feature histogram and quantitative pattern recognition on challenging blurred images.
5.1. Implementation Details
Before giving the results, we first specify the implementation details of our FMP. In fact, the Definition 1 of FMP is a very broad formulation that does not rely on the specific type of image blurring.
Throughout the experimental section, we take the
centrosymmetric blurring as an example and form a specific practice of FMP accordingly. Hence, the set of centrosymmetric PSFs is
. With the relevant papers on GTBI [
7], we define the orthogonal projector as
, yielding a special form of (2) as
.
Note that the is of a fractional form (2), with certain numerical instability when the denominator is small. In our implementation, we evade this issue by restricting the frequency range with the natural image prior: .
5.2. Feature Histogram
For this part, we evaluate the robustness by visualizing the FMP representation with different blurring conditions, which will also demonstrate the non-trivial nature of the representation.
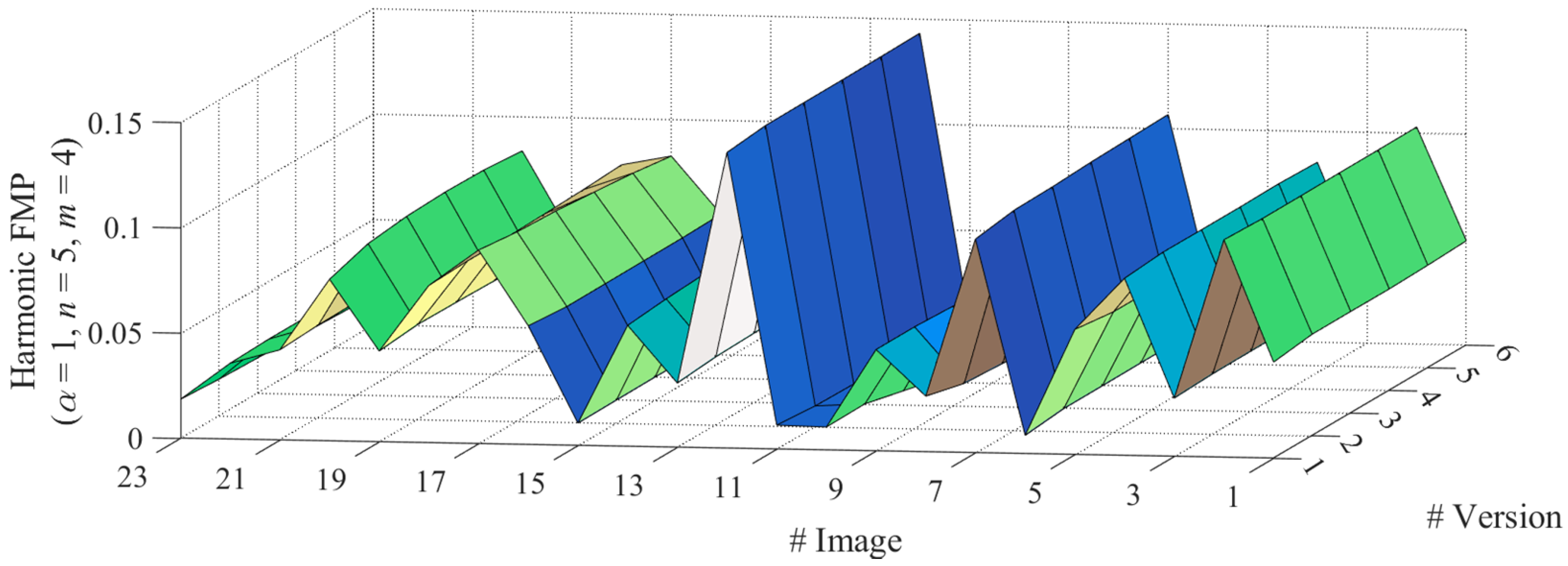
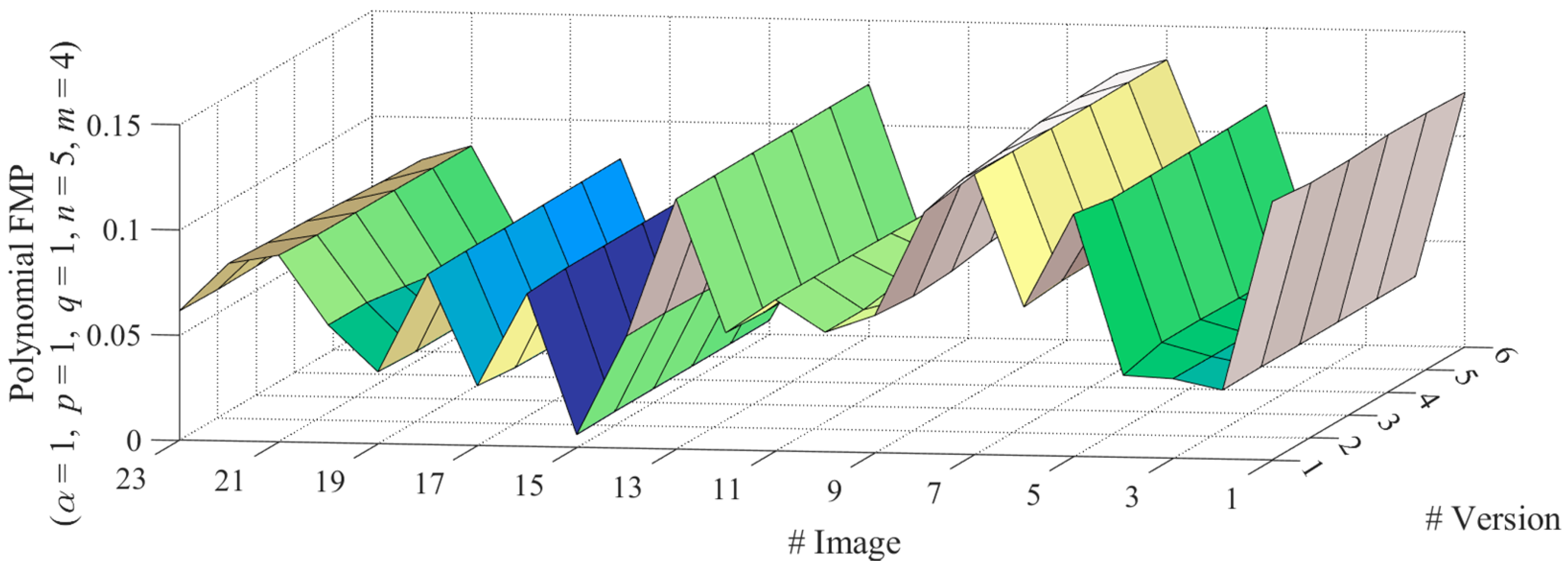
As shown in
Figure 1, the experiment is executed on the well-known degraded image dataset CIDIQ [
26] involving centrosymmetric Gaussian blurring. Here, the CIDIQ includes 23 clean images, each one corresponds to 5 blurred versions at different levels, for a total of 115 images.
As shown in
Figure 2 and
Figure 3, we present the magnitude of harmonic/polynomial FMP over clean and blurred images, where the harmonic FMP is of
,
, and
, and the polynomial FMR is of
,
,
,
, and
. Note that the value is always almost constant within each individual blurring series (regardless of blurring level) while significantly different for distinct images. This phenomenon means that our FMP has ideal blurring robustness as well as sufficient discriminability for distinct images (i.e., non-trivial nature of such invariants).
5.3. Pattern Recognition
For this part, we directly verify the robustness to rotation and blurring as well as the discriminability to distinct images, by employing pattern recognition with different blurring and orientation conditions.
The testing images are derived from the COREL dataset [
27], with four orientations and also with blurring of:
Gaussian: G1 (, , , and ), G2 (same as G1 except ), and G3 (same as G1 except and );
Disc: D1 () and D2 ();
Motion: M1 ( and ) and M2 ( and ).
The comparison methods involved in this experiment include:
In
Table 1, we list the correct classification percentages for non-learning representations, i.e., classical moment representations, FM representations, and FMP representations.
In
Table 2, we list the correct classification percentages for learning representations with rotation and blur data augmentation or deblurring as data preprocessing.
With only rotation data augmentation, learning representations cannot yet achieve satisfactory classification accuracy, where the additional cost is an 8-fold increase in training size.
Concerning both rotation and blur data augmentation, learning representations perform significantly better but still do not achieve >90% accuracy for any blurring types, where the additional cost is a 16-fold increase in training size.
With rotation data augmentation and deblurring, learning representations perform even worse than without the blur data augmentation, potentially due to the recovery error introduced by the deblurring algorithm [
37], where the additional cost is the preprocessing for each testing image. Note that such a performance gap was also observed in [
4].
Further, our FMP achieves significantly better scores with respect to the state-of-the-art learning representations, meaning FMP is competitive for small-scale robust vision problems even in the deep-learning era.
6. Conclusions
In this paper, we have provided a simple but effective way to define robust image representation for blur and orientation variants. We refer to this approach as “Fractional Moments under Projection operators (FMP)”, which is characterized by orthogonality, generality, flexibility, as well as the combined invariance of blurring and rotation.
The definitions and properties of FMP have been well formalized through the general theorem of blur invariants and the general theorem of in-/equi-/co-variance. Moreover, simulation experiments validate the beneficial properties of FMP, revealing the potential for small-scale robust vision problems.
Since the GTBI definition involves a fractional form, the direct discrete implementation exhibits a certain numerical instability when the denominator is small. Therefore, our future work will address numerical issues related to the discrete implementation of FMP.
Author Contributions
Conceptualization, S.Q., Y.Z. and C.W.; methodology, S.Q.; software, S.Q. and C.W.; validation, S.Q. and C.W.; formal analysis, S.Q.; writing—original draft preparation, S.Q.; writing—review and editing, Y.Z. and R.L.; visualization, C.W.; supervision, Y.Z. and R.L.; project administration, Y.Z. and R.L.; funding acquisition, Y.Z. and R.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded in part by the Postgraduate Research & Practice Innovation Program of Jiangsu Province under Grant KYCX22-0383 and in part by the Basic Research Program of Jiangsu Province under Grant BK20201290. We would also like to thanks the editors for the APC waiver.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhang, K.; Ren, W.; Luo, W.; Lai, W.S.; Stenger, B.; Yang, M.H.; Li, H. Deep image deblurring: A survey. Int. J. Comput. Vis. 2022, 130, 2103–2130. [Google Scholar] [CrossRef]
- Qi, S.; Zhang, Y.; Wang, C.; Zhou, J.; Cao, X. A principled design of image representation: Towards forensic tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 5337–5354. [Google Scholar] [CrossRef]
- Dong, S.; Wang, P.; Abbas, K. A survey on deep learning and its applications. Comput. Sci. Rev. 2021, 40, 100379. [Google Scholar] [CrossRef]
- VidalMata, R.G.; Banerjee, S.; RichardWebster, B.; Albright, M.; Davalos, P.; McCloskey, S.; Miller, B.; Tambo, A.; Ghosh, S.; Nagesh, S.; et al. Bridging the gap between computational photography and visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4272–4290. [Google Scholar] [CrossRef] [PubMed]
- Qi, S.; Zhang, Y.; Wang, C.; Zhou, J.; Cao, X. A survey of orthogonal moments for image representation: Theory, implementation, and evaluation. ACM Comput. Surv. 2021, 55, 1. [Google Scholar] [CrossRef]
- Flusser, J.; Suk, T.; Boldys, J.; Zitova, B. Projection operators and moment invariants to image blurring. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 786–802. [Google Scholar] [CrossRef]
- Flusser, J.; Lebl, M.; Pedone, M.; Sroubek, F.; Kostkova, J. Blur invariants for image recognition. arXiv 2023, arXiv:2301.07581. [Google Scholar]
- Hilbert, D. Theory of Algebraic Invariants; Cambridge University Press: Cambridge, UK, 1993. [Google Scholar]
- Flusser, J.; Suk, T.; Saic, S. Image features invariant with respect to blur. Pattern Recognit. 1995, 28, 1723–1732. [Google Scholar] [CrossRef]
- Flusser, J.; Suk, T. Degraded image analysis: An invariant approach. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 590–603. [Google Scholar] [CrossRef]
- Flusser, J.; Suk, T.; Saic, S. Recognition of blurred images by the method of moments. IEEE Trans. Image Process. 1996, 5, 533–538. [Google Scholar] [CrossRef]
- Zhong, S.H.; Liu, Y.; Liu, Y.; Li, C.S. Water reflection recognition based on motion blur invariant moments in curvelet space. IEEE Trans. Image Process. 2013, 22, 4301–4313. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.; Shu, H.; Zhang, H.; Coatrieux, G.; Luo, L.; Coatrieux, J.L. Combined invariants to similarity transformation and to blur using orthogonal Zernike moments. IEEE Trans. Image Process. 2010, 20, 345–360. [Google Scholar] [CrossRef] [PubMed]
- Kostkova, J.; Flusser, J.; Lebl, M.; Pedone, M. Handling Gaussian blur without deconvolution. Pattern Recognit. 2020, 103, 107264. [Google Scholar] [CrossRef]
- Abu-Mostafa, Y.S.; Psaltis, D. Recognitive aspects of moment invariants. IEEE Trans. Pattern Anal. Mach. Intell. 1984, 6, 698–706. [Google Scholar] [CrossRef]
- Kan, C.; Srinath, M.D. Invariant character recognition with Zernike and orthogonal Fourier-Mellin moments. Pattern Recognit. 2002, 35, 143–154. [Google Scholar] [CrossRef]
- Hoang, T.V.; Tabbone, S. Fast generic polar harmonic transforms. IEEE Trans. Image Process. 2014, 23, 2961–2971. [Google Scholar] [CrossRef]
- Xiao, B.; Li, L.; Li, Y.; Li, W.; Wang, G. Image analysis by fractional-order orthogonal moments. Inf. Sci. 2017, 382, 135–149. [Google Scholar] [CrossRef]
- Zhang, H.; Li, Z.; Liu, Y. Fractional orthogonal Fourier-Mellin moments for pattern recognition. In Pattern Recognition. CCPR 2016; Springer: Singapore, 2016; pp. 766–778. [Google Scholar]
- Chen, B.; Yu, M.; Su, Q.; Shim, H.J.; Shi, Y.Q. Fractional quaternion Zernike moments for robust color image copy-move forgery detection. IEEE Access 2018, 6, 56637–56646. [Google Scholar] [CrossRef]
- Benouini, R.; Batioua, I.; Zenkouar, K.; Zahi, A.; Najah, S.; Qjidaa, H. Fractional-order orthogonal Chebyshev moments and moment invariants for image representation and pattern recognition. Pattern Recognit. 2019, 86, 332–343. [Google Scholar] [CrossRef]
- Yang, H.; Qi, S.; Tian, J.; Niu, P.; Wang, X. Robust and discriminative image representation: Fractional-order Jacobi-Fourier moments. Pattern Recognit. 2021, 115, 107898. [Google Scholar] [CrossRef]
- Yang, H.; Qi, S.; Niu, P.; Wang, X. Color image zero-watermarking based on fast quaternion generic polar complex exponential transform. Signal Process.-Image Commun. 2020, 82, 115747. [Google Scholar] [CrossRef]
- Flusser, J. On the independence of rotation moment invariants. Pattern Recognit. 2000, 33, 1405–1410. [Google Scholar] [CrossRef]
- Qi, S.; Zhang, Y.; Wang, C.; Xiang, T.; Cao, X.; Xiang, Y. Representing noisy image without denoising. arXiv 2023, arXiv:2301.07409. [Google Scholar]
- Liu, X.; Pedersen, M.; Hardeberg, J.Y. CID:IQ—A new image quality database. In Image and Signal Processing. ICISP 2014; Springer: Cham, Switzerland, 2014; pp. 193–202. [Google Scholar]
- Wang, J.Z.; Li, J.; Wiederhold, G. SIMPLIcity: Semantics-sensitive integrated matching for picture libraries. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 947–963. [Google Scholar] [CrossRef]
- Manjunath, B.S.; Salembier, P.; Sikora, T. Introduction to MPEG-7: Multimedia Content Description Interface; John Wiley & Sons: Hoboken, NJ, USA, 2002. [Google Scholar]
- Zhang, D.; Lu, G. Shape-based image retrieval using generic Fourier descriptor. Signal Process.-Image Commun. 2002, 17, 825–848. [Google Scholar] [CrossRef]
- Teague, M.R. Image analysis via the general theory of moments. J. Opt. Soc. Am. 1980, 70, 920–930. [Google Scholar] [CrossRef]
- Sheng, Y.; Shen, L. Orthogonal Fourier-Mellin moments for invariant pattern recognition. J. Opt. Soc. Am. A 1994, 11, 1748–1757. [Google Scholar] [CrossRef]
- Ping, Z.; Ren, H.; Zou, J.; Sheng, Y.; Bo, W. Generic orthogonal moments: Jacobi-Fourier moments for invariant image description. Pattern Recognit. 2007, 40, 1245–1254. [Google Scholar] [CrossRef]
- Hu, H.; Zhang, Y.; Shao, C.; Ju, Q. Orthogonal moments based on exponent functions: Exponent-Fourier moments. Pattern Recognit. 2014, 47, 2596–2606. [Google Scholar] [CrossRef]
- Yap, P.T.; Jiang, X.; Kot, A.C. Two-dimensional polar harmonic transforms for invariant image representation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1259–1270. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Biggs, D.S.; Andrews, M. Acceleration of iterative image restoration algorithms. Appl. Opt. 1997, 36, 1766–1775. [Google Scholar] [CrossRef] [PubMed]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).









{kind=link}
{kind=link}
{kind=link}