
A Deep Neural Network Approach to Solving for Seal’s Type Partial Integro-Differential Equation

Abstract
1. Introduction
2. Preliminaries
3. Deep Neural Network (DNN) Approach
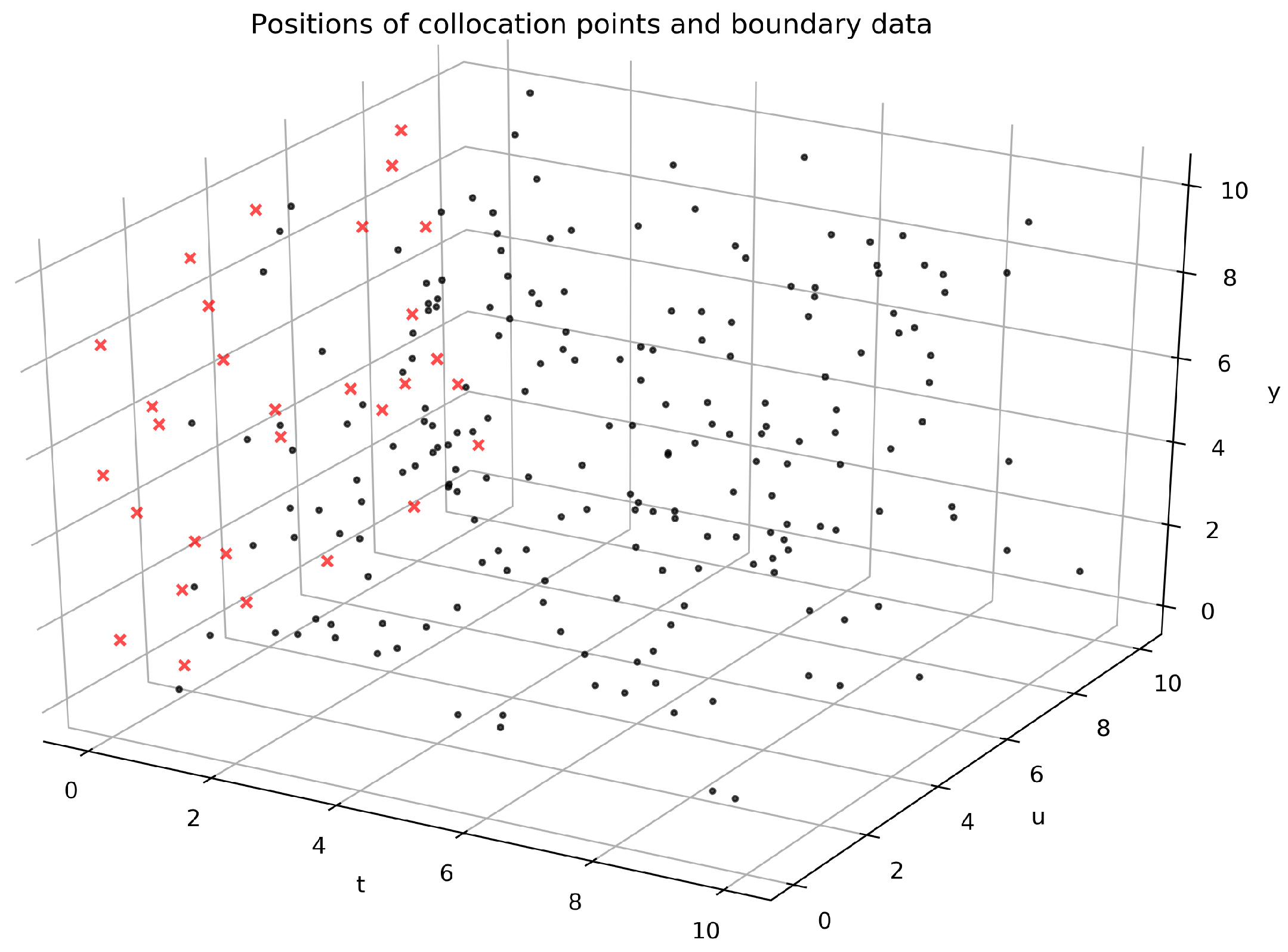
- The mean square error of the data points within the regionin a training data set .
- The mean squared error with respect to the initial conditionin a number of points , where is the neural network approximation of the solution . denotes the initial value function.
- Sigmoid functionThe output mapping of the sigmoid function is within the range of , the function is monotone continuous, and the output range is limited, so it is easy to differentiate. However, it is also easy to saturate, resulting in poor training effectiveness.
- Tanh functionThe shape of this function is similar to the sigmoid function, except that the tanh function is in the range of [−1,1]; thus, it has the advantage that it is more easily able to handle negative numbers. When the two functions are compared, the tanh function converges faster than the sigmoid function, and the data distribution is more even. However, its drawback is the disappearance of the gradient due to saturation.
- ReLU functionCompared with the previous two activation functions, the ReLU function can converge quickly in the stochastic gradient descent algorithm, and since its gradient is 0 or constant, it can alleviate the problem of gradient disappearance. However, as training goes on, the neurons may die; the weights cannot be renewed, so if this occurs, the gradient passing through those neurons is always 0 from that point onward.
| Algorithm 1 Framework of DNNs for solving finite-time survival probability. | |
| Input: | |
| 1: | Set the network structure: the number of hidden layers and the number of neurons in each hidden layer; |
| 2: | Select the type of activation function; |
| 3: | Generate the training data set ; |
| 4: | Set the iteration step size (learning rate) , the total number of iterations , and the error threshold ; |
| Output:; | |
| 5: | The initial parameter is randomly selected, ; |
| 6: | Calculate and the loss function ; |
| 7: | If the loss function , then evaluate ; |
| 8: | Update the network parameter: , and return to Step 6, ; |
| 9: | When or , stop the iteration; |
| 10: | return. |
4. General Case
4.1. The General Network Approach
4.2. Alternative Formulae
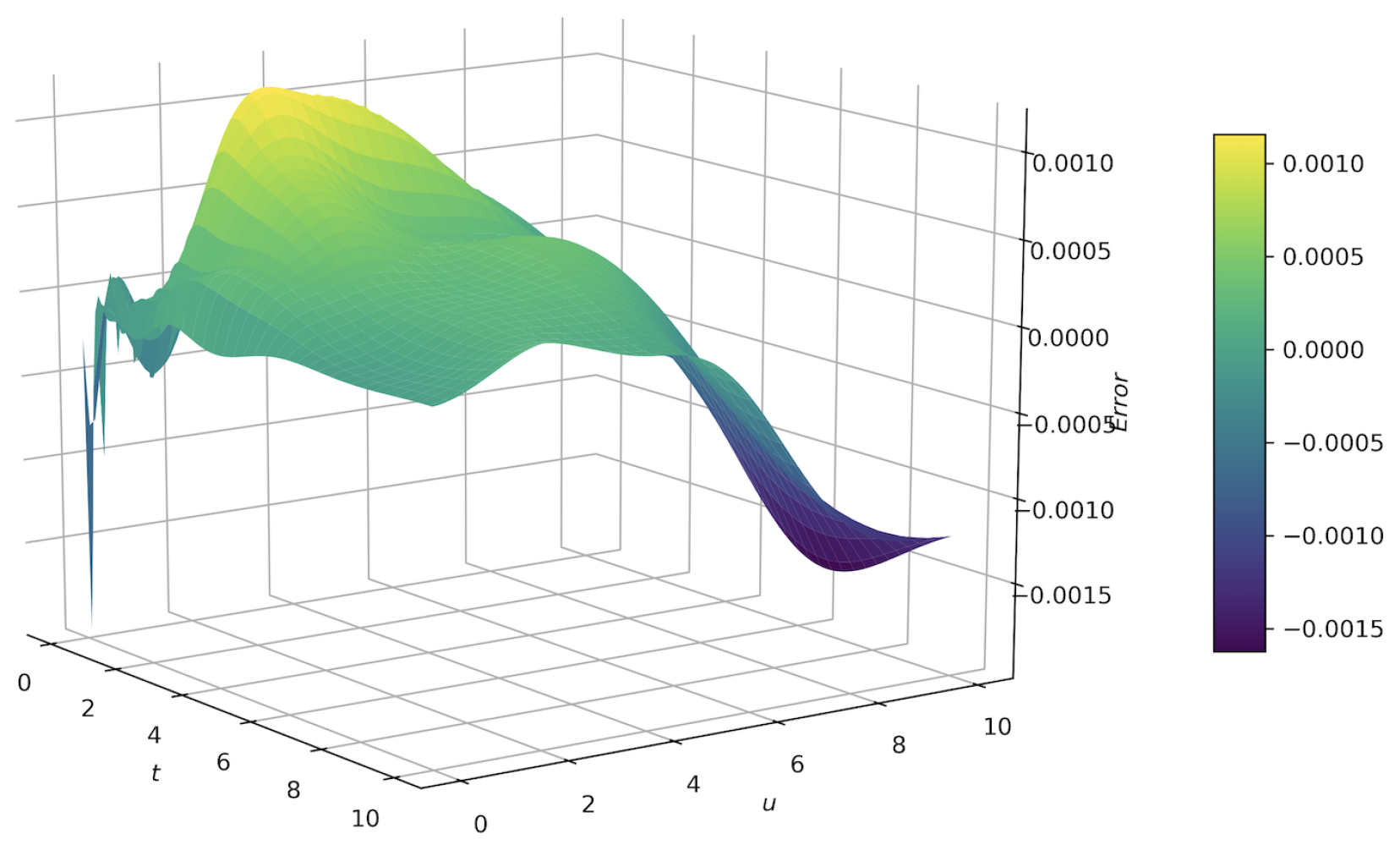
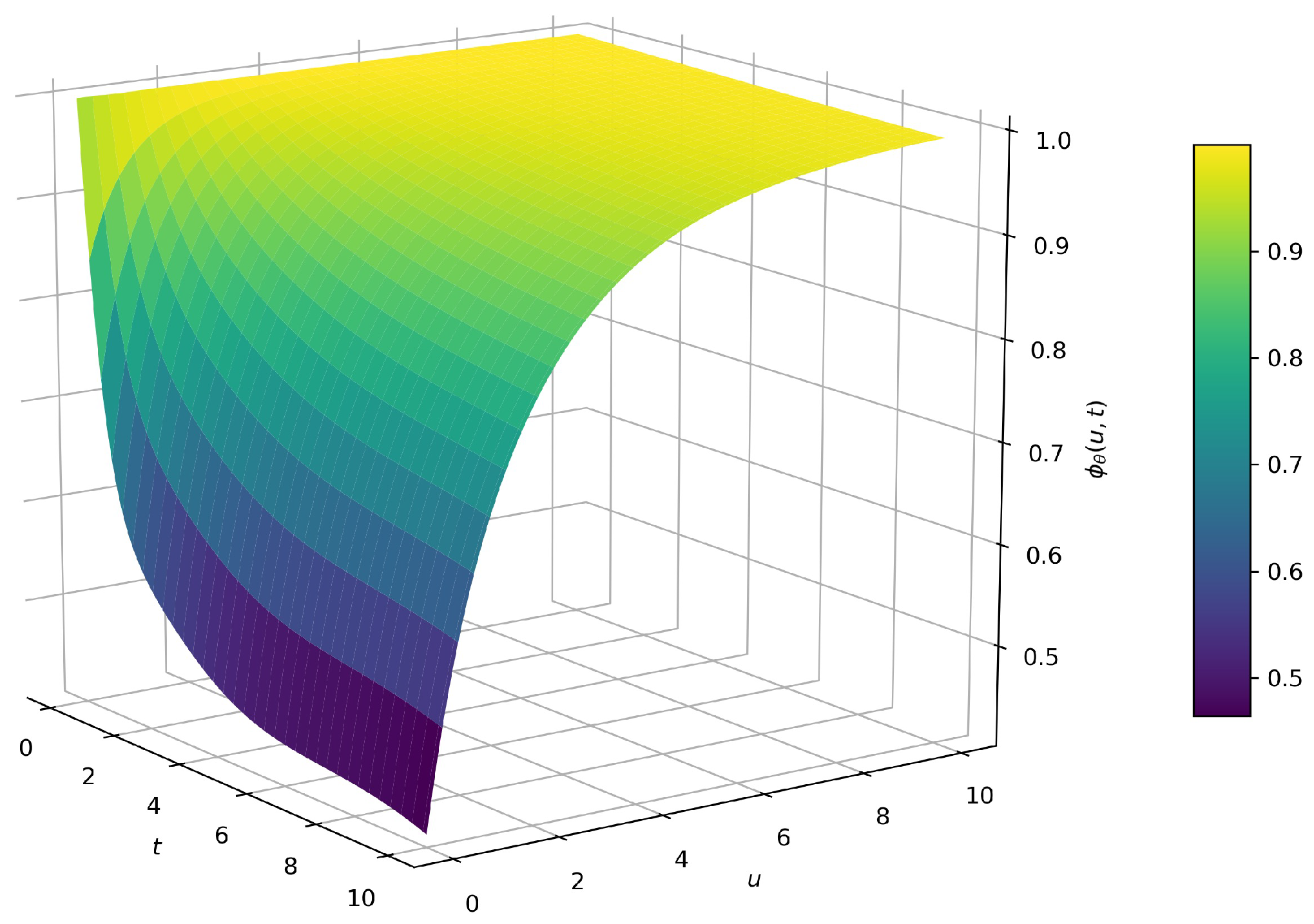
5. Numerical Results
5.1.
- Parameter 1: 4 hidden layers, each layer has 8 neurons, the activation function is the tanh function, and the times of training is 50,000;
- Parameter 2: 10 hidden layers, each layer has 20 neurons, the activation function is the tanh function, and the times of training is 50,000.
- (1)
- gives the exact values of the finite-time survival probabilities;
- (2)
- denotes the values of the survival probabilities computed by using the multinomial lattice approximate method proposed by [15] with ;
- (3)
- represents the values calculated by the Monte Carlo simulation with 10,000 path and ;
- (4)
- represents the values calculated by the nonparametric estimation (see [21]) with 10,000 data points;
- (5)
- denotes the values computed by using the DNN method with parameter 1;
- (6)
- denotes the values computed by using the DNN method with parameter 2.
- (1)
- denotes the values of the survival probabilities computed by using the multinomial lattice approximate method with ;
- (2)
- represents the values calculated by the Monte Carlo simulation with 10,000 path and ;
- (3)
- represents the values calculated by the nonparametric estimation with 10,000 data points;
- (4)
- denotes the values computed by using the DNN method with parameter 1;
- (5)
- denotes the values computed by using the DNN method with parameter 2.
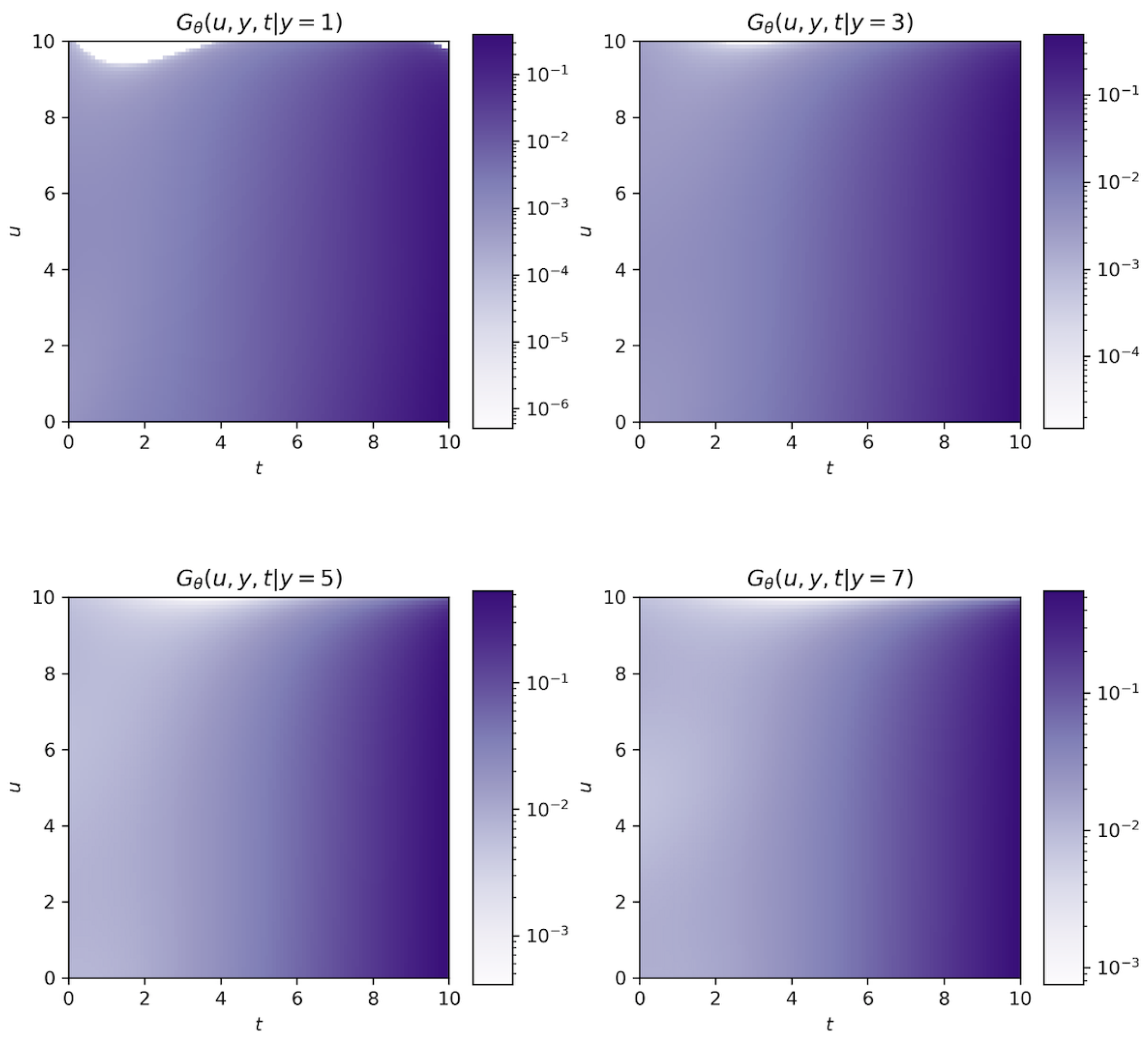
5.2.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Klafter, J.; Lim, S.C.; Metzler, R. Fractional Dynamics: Recent Advances; World Scientific: Singapore, 2011. [Google Scholar]
- Klages, R.; Radons, G.; Sokolov, I.M. Anomalous Transport; Wiley: New York, NY, USA, 2008. [Google Scholar]
- Shlesinger, M.F.; Zaslavsky, G.M.; Frisch, U. Lévy Flights and Related Topics in Physics; Springer: Berlin/Heidelberg, Germany, 1995. [Google Scholar]
- Dickson, D.C. The joint distribution of the time to ruin and the number of claims until ruin in the classical risk model. Insur. Math. Econ. 2012, 50, 334–337. [Google Scholar] [CrossRef]
- Dickson, D.C.; Willmot, G.E. The density of the time to ruin in the classical Poisson risk model. ASTIN Bull. J. IAA 2005, 35, 45–60. [Google Scholar] [CrossRef]
- Drekic, S.; Willmot, G.E. On the density and moments of the time of ruin with exponential claims. ASTIN Bull. J. IAA 2003, 33, 11–21. [Google Scholar] [CrossRef][Green Version]
- Li, S.; Lu, Y. Distributional study of finite-time ruin related problems for the classical risk model. Appl. Math. Comput. 2017, 315, 319–330. [Google Scholar] [CrossRef]
- Constantinescu, C.; Samorodnitsky, G.; Zhu, W. Ruin probabilities in classical risk models with gamma claims. Scand. Actuar. J. 2018, 7, 555–575. [Google Scholar] [CrossRef]
- Avram, F.; Usabel, M. Finite time ruin probabilities with one Laplace inversion. Insur. Math. Econ. 2003, 32, 371–377. [Google Scholar] [CrossRef][Green Version]
- Dickson, D.C. A note on some joint distribution functions involving the time of ruin. Insur. Math. Econ. 2016, 67, 120–124. [Google Scholar] [CrossRef]
- Willmot, G.E. On a partial integrodifferential equation of Seal’s type. Insur. Math. Econ. 2015, 62, 54–61. [Google Scholar] [CrossRef]
- DeVylder, F.E.; Goovaerts, M.J. Explicit finite-time and infinite-time ruin probabilities in the continuous case. Insur. Math. Econ. 1999, 24, 155–172. [Google Scholar] [CrossRef]
- Chen, M.; Yuen, K.C.; Guo, J. Survival probabilities in a discrete semi-Markov risk model. Appl. Math. Comput. 2014, 232, 205–215. [Google Scholar] [CrossRef]
- Lefevre, C.; Loisel, S. Finite-time ruin probabilities for discrete, possibly dependent, claim severities. Methodol. Comput. Appl. Probab. 2009, 11, 425–441. [Google Scholar] [CrossRef]
- Costabile, M.; Massabo, I.; Russo, E. Computing finite-time survival probabilities using multinomial approximations of risk models. Scand. Actuar. J. 2015, 5, 406–422. [Google Scholar] [CrossRef]
- Picard, P.; Lefevre, C. The probability of ruin in finite time with discrete claim size distribution. Scand. Actuar. J. 1997, 1997, 58–69. [Google Scholar] [CrossRef]
- Dickson, D.C.; Waters, H.R. Ruin probabilities with compounding assets. Insur. Math. Econ. 1999, 25, 49–62. [Google Scholar] [CrossRef]
- Cheung, E.C.; Zhang, Z. Simple approximation for the ruin probability in renewal risk model under interest force via Laguerre series expansion. Scand. Actuar. J. 2021, 2021, 804–831. [Google Scholar] [CrossRef]
- Shimizu, Y. Non-parametric estimation of the Gerber-Shiu function for the Wiener-Poisson risk model. Scand. Actuar. J. 2012, 2012, 56–69. [Google Scholar] [CrossRef]
- Zhang, Z. Estimating the Gerber-Shiu function by Fourier-Sinc series expansion. Scand. Actuar. J. 2017, 2017, 898–919. [Google Scholar] [CrossRef]
- Zhang, Z. Nonparametric estimation of the finite time ruin probability in the classical risk model. Scand. Actuar. J. 2017, 2017, 452–469. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics informed deep learning (part i): Data-driven solutions of nonlinear partial differential equations. arXiv 2017, arXiv:1711.10561. [Google Scholar]
- Beck, C.; Becker, S.; Grohs, P.; Jaafari, N.; Jentzen, A. Solving stochastic differential equations and Kolmogorov equations by means of deep learning. arXiv 2018, arXiv:1806.00421. [Google Scholar]
- Van der Meer, R.; Oosterlee, C.W.; Borovykh, A. Optimally weighted loss functions for solving pdes with neural networks. J. Comput. Appl. Math. 2022, 405, 113887. [Google Scholar] [CrossRef]
- Weinan, E.; Han, J.; Jentzen, A. Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations. Commun. Math. Stat. 2017, 5, 349–380. [Google Scholar]
- Chen, Y.; Yu, H.; Meng, X.; Xie, X.; Hou, M.; Chevallier, J. Numerical solving of the generalized Black-Scholes differential equation using Laguerre neural network. Digit. Signal Processing 2021, 112, 103003. [Google Scholar] [CrossRef]
- Blanka, H.; Muguruza, A.; Tomas, M. Deep learning volatility: A deep neural network perspective on pricing and calibration in (rough) volatility models. Quant. Financ. 2021, 21, 11–27. [Google Scholar]
- Salvador, B.; Oosterlee, C.W.; van der Meer, R. Financial option valuation by unsupervised learning with artificial neural networks. Mathematics 2021, 9, 46. [Google Scholar] [CrossRef]
- Huh, J. Pricing options with exponential Lévy neural network. Expert Syst. Appl. 2019, 127, 128–140. [Google Scholar] [CrossRef]
- You, H.; Yu, Y.; D’Elia, M.; Gao, T.; Silling, S. Nonlocal kernel network (nkn): A stable and resolution- independent deep neural network. arXiv 2022, arXiv:2201.02217. [Google Scholar]
- Chen, H.; Yu, Y.; Jaworski, J.; Trask, N.; D’Elia, M. Data-driven learning of Reynolds stress tensor using nonlocal models. Bull. Am. Phys. Soc. 2021, 66. Available online: https://meetings.aps.org/Meeting/DFD21/Session/E11.2 (accessed on 23 February 2022).
- Pang, G.; Lu, L.; Karniadakis, G.E. fPINNs: Fractional physics-informed neural networks. SIAM J. Sci. Comput. 2019, 41, A2603–A2626. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (1) | 0.5366 | 0.3448 | 0.2804 | 0.2457 | 0.2232 | 0.2146 | |
| (2) | 0.5343 | 0.3429 | 0.2785 | 0.2437 | 0.2212 | 0.2126 | |
| (3) | 0.5360 | 0.3385 | 0.2763 | 0.2457 | 0.2196 | 0.2174 | |
| (4) | 0.5401 | 0.3526 | 0.2876 | 0.2505 | 0.2257 | 0.2121 | |
| (5) | 0.5369 | 0.3450 | 0.2804 | 0.2458 | 0.2233 | 0.2147 | |
| (6) | 0.5364 | 0.3445 | 0.2803 | 0.2455 | 0.2226 | 0.2142 | |
| (1) | 0.7619 | 0.5740 | 0.4881 | 0.4365 | 0.4013 | 0.3874 | |
| (2) | 0.7625 | 0.5740 | 0.4876 | 0.4357 | 0.4001 | 0.3861 | |
| (3) | 0.7624 | 0.5798 | 0.4925 | 0.4341 | 0.4080 | 0.3849 | |
| (4) | 0.7644 | 0.5815 | 0.4926 | 0.4399 | 0.465 | 0.3891 | |
| (5) | 0.7591 | 0.5753 | 0.4881 | 0.4368 | 0.4017 | 0.3876 | |
| (6) | 0.7623 | 0.5738 | 0.4877 | 0.4361 | 0.4008 | 0.3871 | |
| (1) | 0.8803 | 0.7315 | 0.6456 | 0.5886 | 0.5475 | 0.5309 | |
| (2) | 0.8809 | 0.7318 | 0.6453 | 0.5880 | 0.5465 | 0.5297 | |
| (3) | 0.8798 | 0.7336 | 0.6383 | 0.5931 | 0.5460 | 0.5371 | |
| (4) | 0.8842 | 0.7374 | 0.6483 | 0.5943 | 0.5507 | 0.5322 | |
| (5) | 0.8801 | 0.7315 | 0.6452 | 0.5882 | 0.5472 | 0.5306 | |
| (6) | 0.8801 | 0.7315 | 0.6453 | 0.5884 | 0.5473 | 0.5308 | |
| (1) | 0.9997 | 0.9968 | 0.9908 | 0.9826 | 0.9731 | 0.9681 | |
| (2) | 0.9994 | 0.9968 | 0.9908 | 0.9827 | 0.9731 | 0.9681 | |
| (3) | 0.9999 | 0.9971 | 0.9921 | 0.9813 | 0.9742 | 0.9688 | |
| (4) | 0.9999 | 0.9986 | 0.9927 | 0.9846 | 0.9765 | 0.9713 | |
| (5) | 0.9999 | 0.9973 | 0.9916 | 0.9827 | 0.9753 | 0.9705 | |
| (6) | 0.9999 | 0.9964 | 0.9906 | 0.9823 | 0.9731 | 0.9679 |
| (1) | 0.6240 | 0.4977 | 0.4569 | 0.4361 | 0.4236 | 0.4191 | |
| (2) | 0.6260 | 0.5020 | 0.4460 | 0.4351 | 0.4283 | 0.4164 | |
| (3) | 0.6306 | 0.5061 | 0.4521 | 0.4326 | 0.4265 | 0.4206 | |
| (4) | 0.6258 | 0.5019 | 0.4518 | 0.4363 | 0.4246 | 0.4132 | |
| (5) | 0.6254 | 0.5016 | 0.4523 | 0.4358 | 0.4241 | 0.4146 | |
| (1) | 0.8701 | 0.7666 | 0.7212 | 0.6956 | 0.6793 | 0.6732 | |
| (2) | 0.8710 | 0.7709 | 0.7229 | 0.6999 | 0.6776 | 0.6774 | |
| (3) | 0.8732 | 0.7724 | 0.7219 | 0.6987 | 0.6761 | 0.6754 | |
| (4) | 0.8680 | 0.7652 | 0.7173 | 0.6933 | 0.6779 | 0.6692 | |
| (5) | 0.8692 | 0.7659 | 0.7187 | 0.6942 | 0.6773 | 0.6714 | |
| (1) | 0.9451 | 0.8788 | 0.8425 | 0.8199 | 0.8048 | 0.7990 | |
| (2) | 0.9430 | 0.8775 | 0.8397 | 0.8183 | 0.8075 | 0.8017 | |
| (3) | 0.9418 | 0.8793 | 0.8375 | 0.8214 | 0.8061 | 0.8028 | |
| (4) | 0.9431 | 0.8771 | 0.8398 | 0.8174 | 0.8029 | 0.7965 | |
| (5) | 0.9438 | 0.8774 | 0.8407 | 0.8186 | 0.8043 | 0.7987 | |
| (1) | 0.9989 | 0.9972 | 0.9952 | 0.9933 | 0.9916 | 0.9909 | |
| (2) | 0.9997 | 0.9987 | 0.9946 | 0.9941 | 0.9911 | 0.9902 | |
| (3) | 0.9995 | 0.9991 | 0.9968 | 0.9943 | 0.9897 | 0.9877 | |
| (4) | 0.9989 | 0.9967 | 0.9944 | 0.9925 | 0.9910 | 0.9904 | |
| (5) | 0.9989 | 0.9969 | 0.9947 | 0.9941 | 0.9924 | 0.9917 |
| 10,000 | 50,000 | 100,000 | |||
|---|---|---|---|---|---|
| Parameter 1 | 56 s | 248 s | 515 s | 2480 s | 4560 s |
| Parameter 2 | 146 s | 569 s | 1074 s | 5690 s | 10,456 s |
| Training Times | 10,000 | 50,000 | 100,000 | ||
|---|---|---|---|---|---|
| Parameter 1 | 2 s | 5 s | 9 s | 42 s | 81 s |
| Parameter 2 | 3 s | 14 s | 28 s | 135 s | 278 s |
| Path Number | 10,000 | 50,000 | 100,000 | ||
|---|---|---|---|---|---|
| 1 s | 6 s | 15 s | 83 s | 205 s | |
| 8 s | 36 s | 76 s | 452 s | 1104 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, B.; Xu, C.; Li, J. A Deep Neural Network Approach to Solving for Seal’s Type Partial Integro-Differential Equation. Mathematics 2022, 10, 1504. https://doi.org/10.3390/math10091504
Su B, Xu C, Li J. A Deep Neural Network Approach to Solving for Seal’s Type Partial Integro-Differential Equation. Mathematics. 2022; 10(9):1504. https://doi.org/10.3390/math10091504
Chicago/Turabian StyleSu, Bihao, Chenglong Xu, and Jingchao Li. 2022. "A Deep Neural Network Approach to Solving for Seal’s Type Partial Integro-Differential Equation" Mathematics 10, no. 9: 1504. https://doi.org/10.3390/math10091504
APA StyleSu, B., Xu, C., & Li, J. (2022). A Deep Neural Network Approach to Solving for Seal’s Type Partial Integro-Differential Equation. Mathematics, 10(9), 1504. https://doi.org/10.3390/math10091504