1. Introduction
Recently, with the rapid development of computer technology, fifth-generation technology, communication technology, artificial intelligence, and other high-tech, various industries’ intelligence has been improved to different degrees. Among them, the intelligent development of construction machinery (CM) has attracted considerable attention [
1]. The development strategy of “Made in China 2025” indicated the direction for the future development of various industries at present as well as the pathway for the intelligent development of CM. CM covers national defense construction, transportation construction, energy industry construction, mining, and other important national fields, and its intelligent development has become one of the hot research directions. As the pioneer of modern construction, CM is mainly used in the construction sites of large-scale projects. However, the working conditions are often accompanied by vibration, high temperatures, dust, volatile gas, bad smells, radiation, and other harsh environments; these harsh environments pose severe threats to the personal safety and health of machine operators. Furthermore, longterm exposure to these environments is extremely harmful to workers. Therefore, the development of intelligent and unmanned engineering machinery and equipment is crucial. In this study, we address the current application needs of harsh working conditions and improve the ability of a loader to independently determine the category of CM and materials by exploring material intelligence recognition technology under complex scenes to realize the intelligent level of the loader. As such, the loader can sense the surrounding environment and make its own decisions as well as operate under the condition of protecting the personal safety of workers, thereby minimizing risk while improving work efficiency.
At present, mainly two types of target detection methods exist: traditional manual feature extraction (FE)- and convolutional neural network (CNN)-based visual detection methods. The traditional manual FE-based detection method has been mainly used for classifying and recognizing images in recent years. For example, Haralick et al. [
2] proposed a classification technique based on texture features using a grayscale co-occurrence matrix to describe image textures and hence classify them. Lazebnik et al. [
3] proposed a classification technique based on spatial relationship features using a spatial pyramid model to enhance the feature description capability and achieve target classification. Chai et al. [
4] used a sliding window detector to obtain local features and then fed them into a support vector machine classifier for classification; this algorithm obtained 67% classification accuracy.
In the last decade, the target detection field developed with the development of deep learning techniques. In particular, target detection techniques within the deep learning field developed rapidly after the advent of AlexNet. [
5] AlexNet is a network proposed by Hinton and his student Alex Krizhevsky in 2012, which won the ILSVRC competition for classification. In 2014, Simonyan et al. [
6] proposed a deeper network model, VGGNet. Szegedy et al. [
7] also proposed GoogleNet in 2014 and won the championship of ILSVRC-2014. K. He [
8] proposed ResNet in 2015, which uses a residual module to achieve constant mapping to solve the degradation problem of networks as the number of layers increases. Girshick et al. [
9] proposed the region-based CNN (RCNN) model to apply CNN to the target detection field; afterward, the Fast RCNN [
10] and Faster RCNN [
11] models were developed to improve the detection accuracy of targets. The emergence of you only look once (YOLO) [
12] realized end-to-end real-time detection, and the detection speed was significantly improved; however, accuracy was sacrificed.
Currently, applying improved YOLO versions to specific topics has become a mainstream idea. Wang et al. [
13] applied YOLO version 4 (YOLOv4) to the multitarget detection of aerial images to improve the generalizability of YOLO for problems of many small and easily obscured targets in unmanned aerial vehicle (UAV) images, complex detection scenes, and low detection accuracy due to large-scale variability. Yu et al. [
14] employed the YOLOv4-Tiny algorithm for target detection of pigs; compared with YOLOv4, the algorithm compressed the model size by 80% and improved the detection speed by 11 frames/s without sacrificing accuracy. Huang et al. [
15] applied the YOLOv4 algorithm to remote sensing target detection, thereby improving the detection accuracy for remote sensing image targets. Li et al. [
16] employed an improved YOLOv4 algorithm for surface defect detection; compared with the original YOLOv4 algorithm, the improved YOLOv4 algorithm increased the mean average precision (mAP) and detection speed on a test set by 2.17% and 1.58 fps, respectively, solving the problems of low accuracy and slow detection speed of surface defects of aero-engine components to a certain extent. Guo et al. [
17] applied the improved YOLOv4 algorithm to detect mixed pedestrian–vehicle traffic at complex intersections; compared with YOLOv4, the detection accuracy of pedestrians and vehicles with severe occlusion and overlap improved in complex intersection scenarios. Wang et al. [
18] applied the improved YOLOv4-Tiny algorithm to recognize and detect blueberry ripeness; the algorithm could achieve an average accuracy of 96.24% in complex scenes, such as occlusion and uneven illumination. Jing et al. [
19] applied the improved YOLOv4-Tiny algorithm to UAV photography target detection using a bottom-up fusion of deep and shallow semantic information to enrich the feature information about small targets; the average accuracy rate improved by 5.09% compared with the original YOLOv4-Tiny algorithm, with better comprehensive performance. Andriyanov et al. designed an apple position estimation system based on YOLOv3 and depth cameras [
20], which can calculate the relative distance of all coordinates based on the distance of the target and the positioning of the target in the image. Kuznetsova et al. used the YOLOv3 algorithm to develop a machine vision system for orchard apple detection [
21], which can be used not only on an apple harvesting robot, but also on an orange harvesting robot. The approach from multilayer artificial neural networks to pattern recognition and CNN designed by Kamyshova et al. is inspiring [
22]. Osipov et al. used a deep learning approach to solve the problem of recognition and classification under severe weather conditions [
23], which has significant advantages over the classical convolutional neural network approach. Yan et al. applied the improved YOLOv5 algorithm to apple detection [
24], which met the requirements of realtime apple detection. Zhao et al. applied the improved YOLOv5 algorithm to wheat spike detection [
25] with a mAP of 94.1%, which is 10.8% better than the standard YOLOv5. In recent years, an image annotation algorithm using convolutional features from the middle layer of deep learning proposed by Chen et al. [
26] and the idea of processing images based on the attention mechanism (AM) [
27] motivated this study; we believe incorporating the AM into CNN can be helpful for accuracy improvement. Li et al. incorporated the AM into the YOLOv3 algorithm to solve the imbalance in the distribution of detection frames in the edge region problem [
28]. Mo et al. improved an image restoration algorithm using multiscale adversarial networks and neighborhood models to improve the accuracy of image coloring and to apply to many types of images [
29].
To promote the rapid development of intelligent unmanned loaders, studying the intelligent recognition algorithms of loaders is essential. Inspired by the above studies, we propose a target detection algorithm for problems faced by loaders in daily operations, such as variable environments, complex working conditions, and large jitter amplitude. The algorithm enables the loader to detect and classify materials and CM accurately in real time in both normal and complex environments and demonstrates high real-time performance while ensuring high recognition accuracy.
The main contributions of this study are as follows.
(1) For the complex and variable environments faced by loader operations, we employ the technical means of style migration and sliding window segmentation to expand the dataset, which significantly improves the recognition rate of the loader in a low-contrast environment and vehicle jittering situation;
(2) We use VGG19, a network with strong FE ability, and a YOLOv4-Tiny streamlined network to realize a high recognition rate for loaders under complex working conditions, making the proposed algorithm exhibit a high recognition rate under various working conditions;
(3) In this study, an improved FE network is integrated with an AM to effectively balance the relationship between detection speed and accuracy. Compared with the previous network, the recognition accuracy increased to a certain extent while ensuring almost constant detection speed and training time;
(4) The final target detection algorithm is significantly improved compared with the traditional algorithm, and the final proposed network demonstrates the characteristics of high recognition accuracy and fast recognition speed, with mAP and detection speed reaching 96.82% and 134.4 fps, respectively.
2. Dataset
CM operating in the construction site scene, along with vehicle movement, environmental changes, and other circumstances, will cause image blurring problems. Similarly, extreme environments and weather will also affect images to a certain extent. Therefore, we need to enhance the adaptability of the detection models to complex working conditions and reduce the impact of external factors on recognition accuracy by enhancing the underlying dataset.
According to our research objectives, the proposed target detection algorithm needs to demonstrate a high recognition rate and fast recognition speed in low-contrast environments; also, the algorithm should not be computationally intensive. During the image acquisition, we captured images under different angles, distances, clarities, weathers, times, etc. To increase the ability to realize a high recognition rate in extreme environments, we use the technical means of style migration to migrate the feature information about extreme weather, such as fog, rain, and snow, and enhance the image by replacing the original image background. In addition, we use the technique of sliding window to convert a single image into multiple images, including part of the target image, to expand the sample size and enhance the detail features of the target simultaneously. At this point, we acquired a total of 14,349 images.
2.1. Image Acquisition
In this study, we used a Canon SX280 HS camera to capture images of seven types of targets, including loaders, excavators, trucks, stones, rocks, loess, and fine sand, in the early morning, midday, and evening under rainy, clear, and high sunlight weather conditions, respectively. The images captured under normal weather are shown in
Figure 1. The images were collected during the shooting process for targets with different rotation angles, different distances, different clarities, and different exposure values. These images were captured at the R&D experiment site of Guangxi LiuGong Machinery Co. The images were taken over a large time span in order to acquire images under different weather conditions [
30].
When capturing images, the exposure value of the camera and the shooting angle were artificially adjusted to acquire low-contrast images. This image enhancement method not only expands the variety of images, but also increases the adaptability and robustness of the proposed target detection algorithm in complex environments, which makes the model’s algorithm exhibit a high recognition rate in low-contrast environments and effectively solves the interference problem faced by loaders in actual operations [
31,
32]. The schematic diagram is shown in
Figure 2.
2.2. Data Augmentation
To ensure the proposed algorithm is robust and adaptive, we use image enhancement to augment the dataset. In addition, an overfitting problem caused by insufficient samples is avoided to some extent due to an increase in the sample size of the dataset. We mainly use style migration and sliding window segmentation for the image enhancement process.
2.2.1. Style Transformation
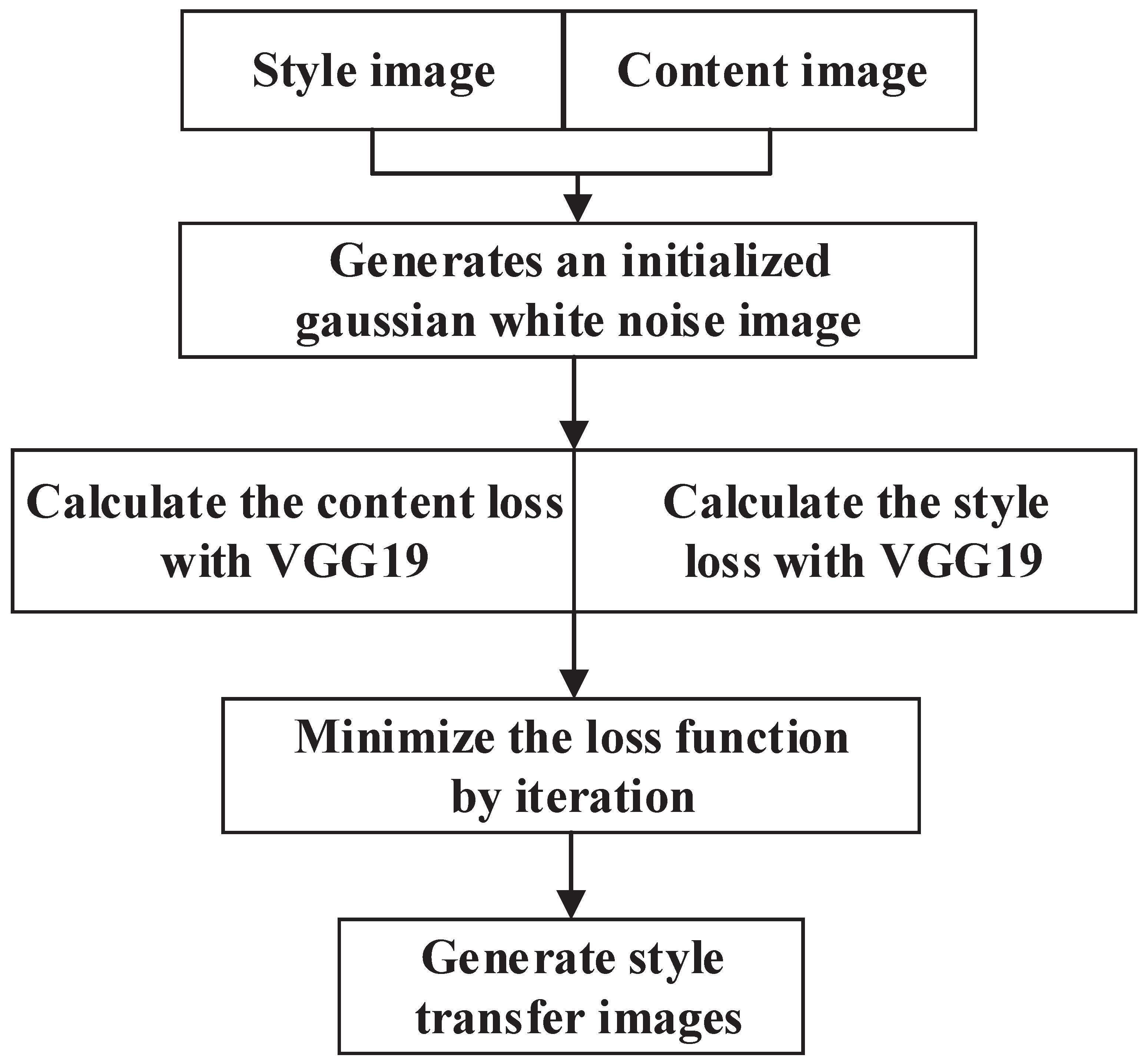
Style migration is a method to make the original image acquire the style of other images. The specific process is to make one image the style image and the other image the content image. After preprocessing the two images, a Gaussian white noise image is generated, and then, after VGG19 or VGG16 is employed, the deep features of the two images are extracted, and the feature maps of each convolution layer are obtained. The covariance matrix of the feature maps obtained after the images have been convolved can well characterize the texture features of the images [
33].
Because VGG19 exhibits a stronger FE capability than VGG16, we choose VGG19 as our FE network. To achieve the best results for the final style-migrated image, a loss function is defined to specify the desired goal and minimize loss (see Equations (1)–(4)). The content loss not only captures the global and abstract image content in the convolution layer but also calculates the L2 parity between the target and generated images at the same layer’s activation function, which ensures that the generated image looks similar to the original target image. Style loss refers to maintaining the internal correlation between different layers between the stylized reference image and the generated stylized feature image, which effectively ensures that the texture styles of the reference image and the generated image do not differ significantly on different scale spaces. The loss functions of the content and style images are assigned with different weights, which constitute the final style migration image loss, and a gradient descent process is set to minimize this loss function to ensure the accuracy of VGG19 in extracting features from the content and style images. Finally, the image texture is captured using feature correlation, and the texture features of the content and style images are fused to form the final migrated image. The flowchart of style migration implementation is shown in
Figure 3.
The loss calculation formula for style migration is as follows:
Generate style migration images:
where
denotes the content loss at layer
r;
and
denote the content and generated images, respectively;
and
denote the content and background images, respectively, at layer
r;
and
denote the
k-th element of the
i-th and
j-th channels, respectively, at layer
r of the feature map;
is the weighting factor of each layer’s contribution to the total loss;
denotes the product of the length and width of the feature map (i.e., the feature size); and
is the Gram matrix of the style migration image.
In this study, the expansion of the dataset’s sample size and that of the types of complex scene images are achieved using an image style migration method. The content map is mainly the seven types of target images captured above, and the style map uses three types of backgrounds: rainy, foggy, and snowy days. By this method, the problem of not easily obtaining meteorological conditions, such as snowy and foggy days, in southern China is solved, and the dataset’s diversity is increased. The results are presented with an excavator as the representative of CM and loess as the representative of material (
Figure 4).
2.2.2. Sliding Window Segmentation
Sliding window processing is a technique to capture a complete image at a certain size and cut the image at a fixed step from the beginning to the end of the original image. The sliding window processing allows us to obtain a partial feature map of the original image, and we select the generated image with distinct features in the generated image to expand the dataset. The dataset obtained as such can enhance the adaptability of the training model so that the model can obtain more information, demonstrate higher detection accuracy, and better adapt to the real CM operating environment. The calculation formula is shown in Equation (
5), and the graph of the sliding window processing results is shown in
Figure 5.
where
and
d represent the original image, its height, width, and bit depth, respectively;
h and
w represent the height and width of the sliding window;
represents the step size;
i and
j represent the rows and columns of the original image, respectively;
represents rounding; and
represents the generated image.
2.3. Image Annotation and Dataset Production
We use professional labeling software, LabelImg, to create image labels and produce the dataset. To ensure a more accurate recognition rate, we balanced the number of images in each category more. Each category includes both captured original images and image enhanced images. The breakdown of the dataset categories and quantities is shown in
Table 1.
3. Method
3.1. YOLO (You Only Look Once)
YOLO is a one-stage detection and recognition integrated algorithm, which can obtain the location and category of the target directly from the image and achieve two major tasks of classification and localization simultaneously, with high real-time performance. Several versions of YOLO exist, including YOLOv1, YOLOv2 [
34], YOLOv3 [
35], and YOLOv4 [
36]. YOLOv4 is the best comprehensive algorithm among the YOLO series algorithms; particularly, YOLOv4 adds more tricks to YOLOv3, making YOLOv4 exhibit better accuracy in handling small targets. YOLOv4 exhibits better accuracy for small targets. In the design of the CNN, YOLOv4 adds CSPNet to the Darknet53 structure. CSPNet can enhance the learning ability of the CNN, which can increase the accuracy, reduce the computational bottleneck, and lower the memory cost while maintaining its lightweight qualities.
YOLOv4-Tiny is a simplified version of YOLOv4, which removes some feature layers based on YOLOv4 and keeps only two independent prediction branches of sizes 13 × 13 and 26 × 26 for predicting large- and medium-sized objects, respectively, and the accuracy is reduced compared with YOLOv4. The reason for the low detection accuracy is that the YOLOv4-Tiny backbone network is relatively shallow and cannot extract higher-level semantic features. The proposed target detection algorithm requires high detection speed and detection accuracy. After the speed and detection accuracy tradeoff, we improve YOLOv4-Tiny. The principle of YOLOv4 is described as follows.
The image is divided into grid cells of size
S ×
S by YOLOv4 before entering the neural network in which grid the center of the object is in the image, and the corresponding mesh is only responsible for predicting the object. Predict B bounding boxes per grid and give the confidence of that box [
37]; each box contains five variables, as defined in Equation (
6).
where x and y are the target prediction frame centroid position; w and h are the prediction frame’s width and height, respectively; confidence is the confidence of the prediction category, and its calculation formula is given by Equation (
7).
In addition, there is Class information;
denotes the class of its own dataset, which is represented in Equation (
8).
This yields the final tensor output, which is calculated as shown in Equation (
9).
where
B is generally taken as 2, and
is the number of categories in the dataset.
YOLOv4 characterizes the corresponding loss function based on the squared sum of the errors between the predicted and true borders and the crossentropy of the probabilities between the target prediction and true categories. In YOLOv4, the loss is divided into three parts: one is the error brought by the x, y, w and h, which is the loss brought by the bounding box location; another is the error brought by the category; the third is the error brought by the confidence level. Unlike YOLOv3, YOLOv4 uses CIOU. CIOUconsiders the scale information on the overlap, center distance, and aspect ratio of borders based on IOU; the formula of the loss function is given by (10)–(14).
where
S represents the grid size;
represents the detection box size;
B denotes the number of bounding boxes;
indicates that if a target is found in the bounding box at
, the value is 1, and it is 0 otherwise; and
indicates that if no target is found in the bounding box at
, the value is 1, and it is 0 otherwise. To balance the influence of too many “nonobject” bounding boxes, the penalty weight coefficient
is added, which is generally taken as 0.5, to balance too many “nonobject” cells;
is the IOU (confidence score) of the predicted and labeled boxes;
is the confidence score generated by the network;
and
are the width and height of the real frame, respectively;
is the intersection ratio between the predicted frame
X and the real frame
Y;
is the Euclidean distance between the center point of the predicted frame and real frames;
m is the diagonal distance of the minimum closed region containing both the predicted and real frames;
u is the balance adjustment parameter; and
v is the parameter measuring the consistency of the aspect ratio [
38].
With the development of target detection algorithms, the latest algorithm in the YOLO family is currently YOLOv5. Studies have shown that YOLOv5 has faster execution efficiency and is higher than YOLOv4 in terms of training speed. YOLOv4 uses the Darknet-based framework to acquire targets with higher accuracy and execution efficiency than other target detection algorithms [
39]. To further evaluate the advantages of both, the two algorithms are analyzed from the activation function and loss perspectives. YOLOv4 uses the Mish activation function with higher complexity and outperforms the activation function of YOLOv5 in the benchmark test. Comparing the two algorithms from the loss perspective, the bounding box loss in YOLOv5 uses GIoU in the early stage and CIoU in the later stage, and CIoU is used in YOLOv4. Compared with other methods, CIoU brings faster convergence and better performance, and the prediction box is more in line with the real box [
40]. In general, YOLOv4 is stronger in performance and YOLOv5 is more efficient in execution. In this paper, we are more concerned with the recognition accuracy of targets in complex scenarios, and we choose YOLO v4 for improvement and optimization from the perspective of compromise between accuracy and execution efficiency.
3.2. Attention Model
The AM in deep learning is similar to the attention mechanism in human vision, which is to focus attention on the target area that needs to be focused in a large amount of information, and the core goal is to select the information that is more critical to the current task goal from a large amount of information to obtain more detailed information. This enables humans to use limited attentional resources to quickly obtain high-value information from a large amount of information, which greatly improves the efficiency of the brain in processing information. Algorithmically, we can analogize the attention mechanism to pooling, i.e., pooling in convolutional neural networks is seen as a special average weighted attention mechanism, or the attention mechanism is a general pooling method with preferences for input assignment. The attention mechanism is the attention to the input weight assignment, which was first used in encoder-decoder, where the attention mechanism obtains the input variables of the next layer by weighting the hidden states of the encoder over all time steps. The addition of the attention model allows neural networks to automatically learn the region of interest in images, thereby achieving the goal of saving resources and quickly obtaining the most effective information, improving recognition accuracy without significantly increasing the training difficulty [
41]. Currently, the common attention model is the channel, spatial, and convolutional block attention models. The channel attention model generates and scores the mask for the channel, represented by SE-Net and CAM; the spatial attention model generates and scores the mask for the space, represented by SAM; the hybrid domain attention model evaluates and scores both the channel and spatial attention, represented by BAM and CBAM [
42].
3.3. The Proposed Algorithm
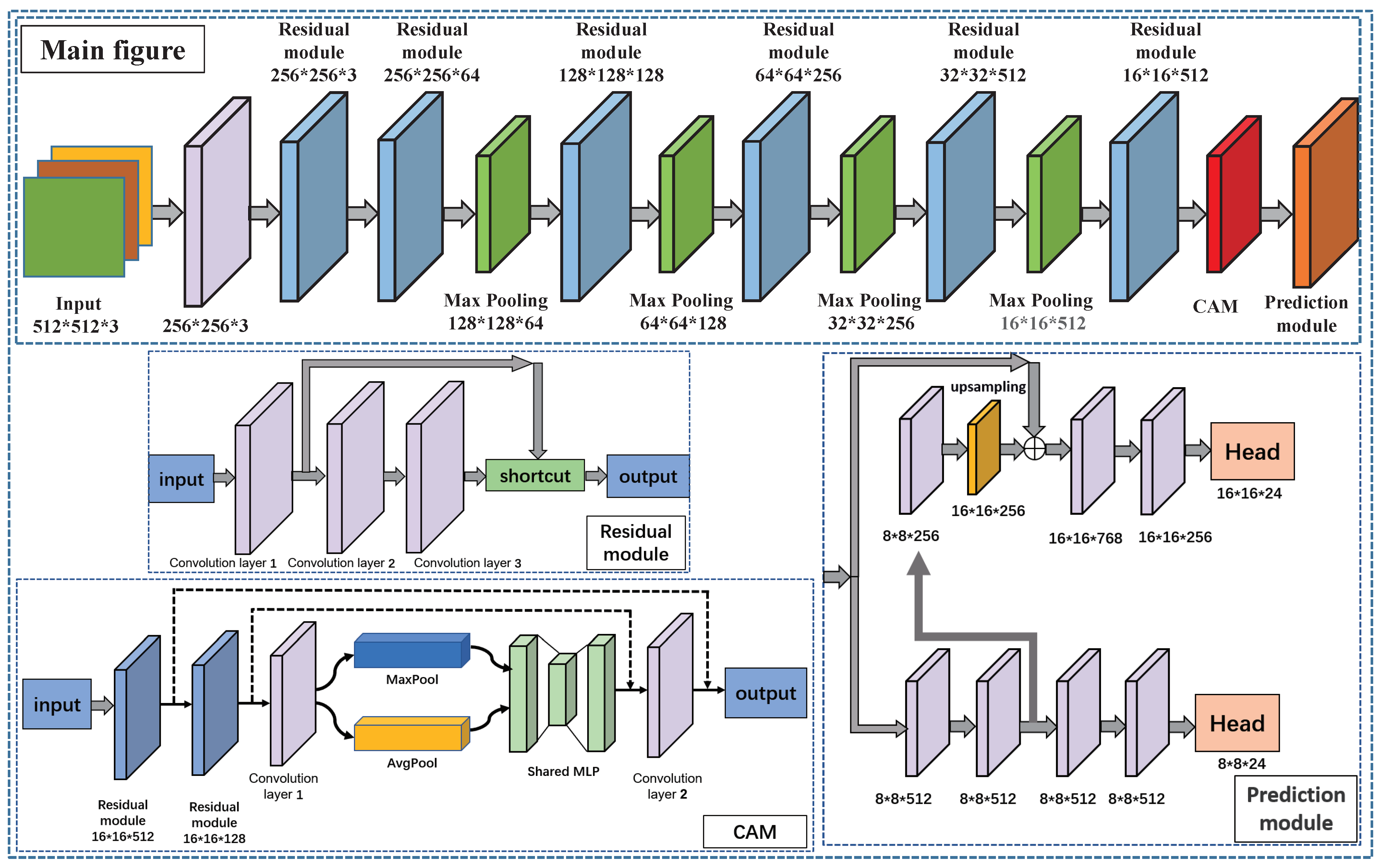
YOLOv4 is not perfectly adapted to our dataset because the CNN of YOLOv4 is more complex and the training time is longer; in addition, the prediction module of YOLOv4 targets three sizes of objects, whereas our targets are mainly CM and materials as the detection targets, which are large and small in size, respectively, and the features are distinct. We choose the corresponding simplified version for improvement, aiming to make the trained model achieve a higher recognition rate, faster recognition speed, and shorter training time.The CNN designed in this paper for CM and materials in low contrast is derived from the improved fusion of VGG19, CAM, and YOLOV4-Tiny improvements with the following details.
In the selection of the FE network, we choose to optimize and improve the network structure of VGG19. VGG19’s network structure is deep, robust to extract deep features of a target, and mature, with a high recognition accuracy, which meets the improvement requirements of this study. In addition, we incorporate the idea of a residual network to suppress the phenomenon of network degradation and use jump connections in the residual blocks inside the network to alleviate the problem of gradient disappearance brought by increasing depth in deep neural networks.
In order to make the trained model with high robustness, this paper adopts style migration and sliding window segmentation to increase the diversity of the dataset; firstly, considering that the YOLOv4-Tiny base network framework only adopts the form of layer-by-layer connection, which has insufficient feature extraction ability, the paper makes use of the VGG19 network idea to deeply connect the low-level information with the high-level information. Meanwhile, in order to achieve recognition of targets at different scales, the detection head of YOLOv4-Tiny and the backbone FE layer of VGG19 are selected and fused as the prediction module. The detection head size of YOLOv4-Tiny is changed from 13 × 13 and 26 × 26 to 8 × 8 and 16 × 16, respectively, for our dataset. The 8 × 8 and 16 × 16 detection heads are used to detect large- and medium-sized targets, respectively. Finally, to make the designed network demonstrate higher accuracy and efficiency, we add CAM between the backbone and prediction module of CNN. The correlation of features between different channels is learned by assigning weights to the features of each channel to enhance the transmission of deep information of the network structure, thereby reducing the interference of a complex background on target recognition. The detection network exhibits fewer network layers, occupies low memory, and demonstrates little impact on the training speed, which can effectively reduce the interference of low-contrast environmental background information on the target and improve the recognition accuracy of the target.
We optimize the network structure by changing the size of some convolutional layers and adding the residual mesh structure, so that the three network structures of the backbone, CAM, and prediction module are smoothly connected. Through the experimental comparison, the effect of this step can increase the training speed and detection accuracy of the network to some extent. Because the anchor size of YOLOv4 is obtained by clustering on the COCO dataset, which is not consistent with the target material size needed in this study, to improve the model recognition accuracy and make the proposed algorithm suitable for this dataset, the anchor box size needs to be reclustered. We use the K-means++ clustering algorithm to recluster the dataset, and the anchor sizes obtained are 94, 115, 250, 69, 172, 157, 311, 133, 170, 319, 373, and 322. The block diagram of the proposed improved algorithm is shown in
Figure 6.
An image is automatically scaled to 512 × 512 × 3 in size before entering the algorithm; it first passes through a convolutional layer for size transformation and initial FE, and then, it passes through six residual modules for depth FE, cascading the low- and high-level information. After the second residual module, the maximum pooling layer is added between each interval to enhance the extraction effect on image features. The final extracted result enters CAM for secondary filtering of feature information in the region of interest at each scale, filtering the redundant feature information and retaining the important feature information. Finally, the information is further extracted into the prediction module, and the detection results of large targets are output through an 8 × 8 × 24 convolution kernel, whereas part of the feature information is upsampled through a 16 × 16 × 24 convolution kernel, and the detection results of medium targets are output. The algorithm pseudocode is shown in
Table 2.
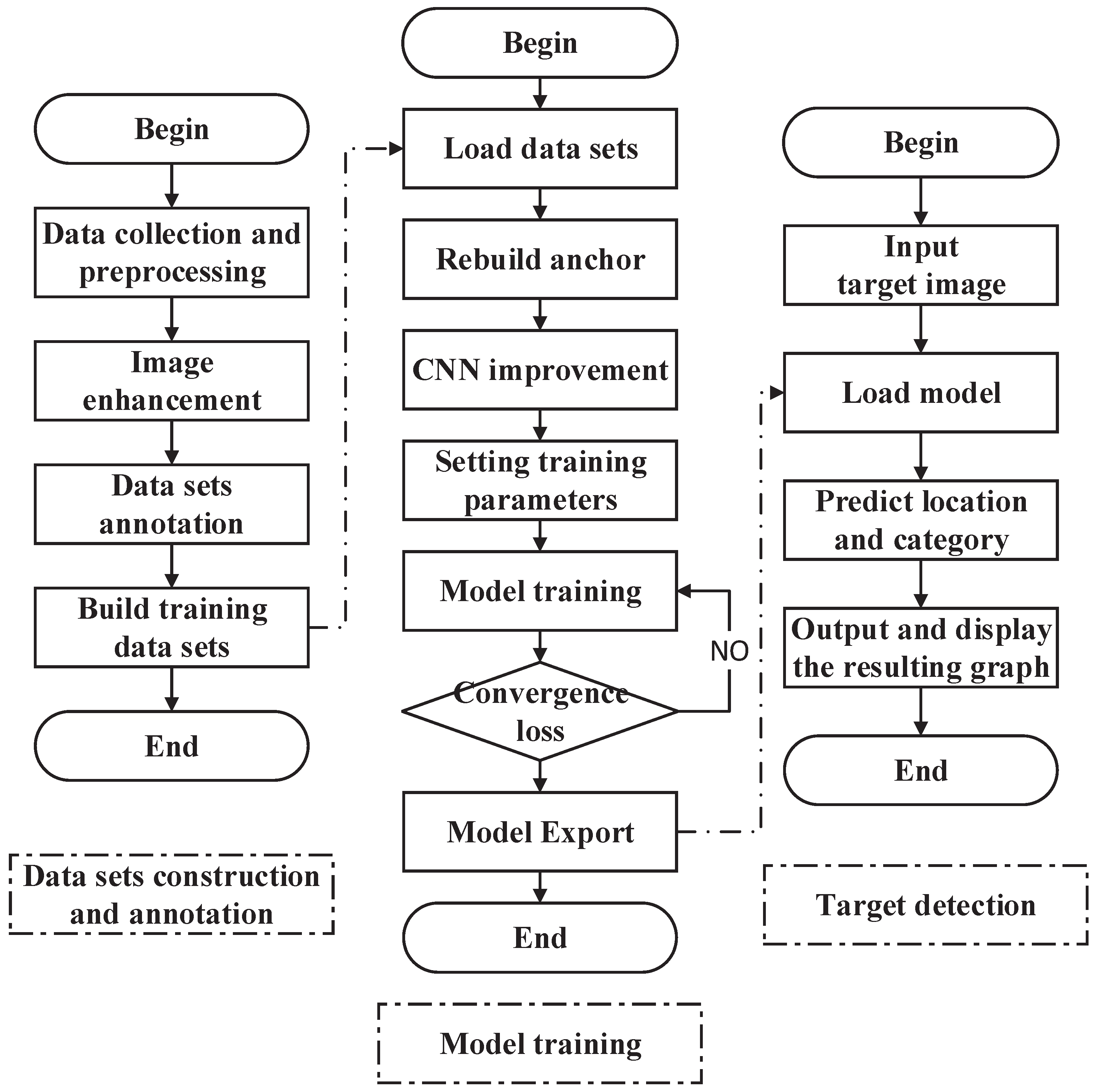
3.4. Algorithm Summary
To improve the recognition accuracy of the loader for CM and materials in normal and low-contrast environments, a YOLOv4-Tiny improved CM and material recognition algorithm is proposed. In this study, first, a diverse dataset is constructed by adopting manual shooting and image enhancement; second, a CNN is constructed by fusing VGG19 with YOLOv4-Tiny and incorporating CAM into it. We use the K-means++ algorithm to recluster on the labeled sample set to obtain the new anchor box size. Then, the constructed network is used to train its sample dataset until the loss function does not converge. Finally, the trained model is used to predict the static or dynamic target image, and the class and location of the target are labeled in the recognition image. The flowchart of the proposed algorithm is shown in
Figure 7.






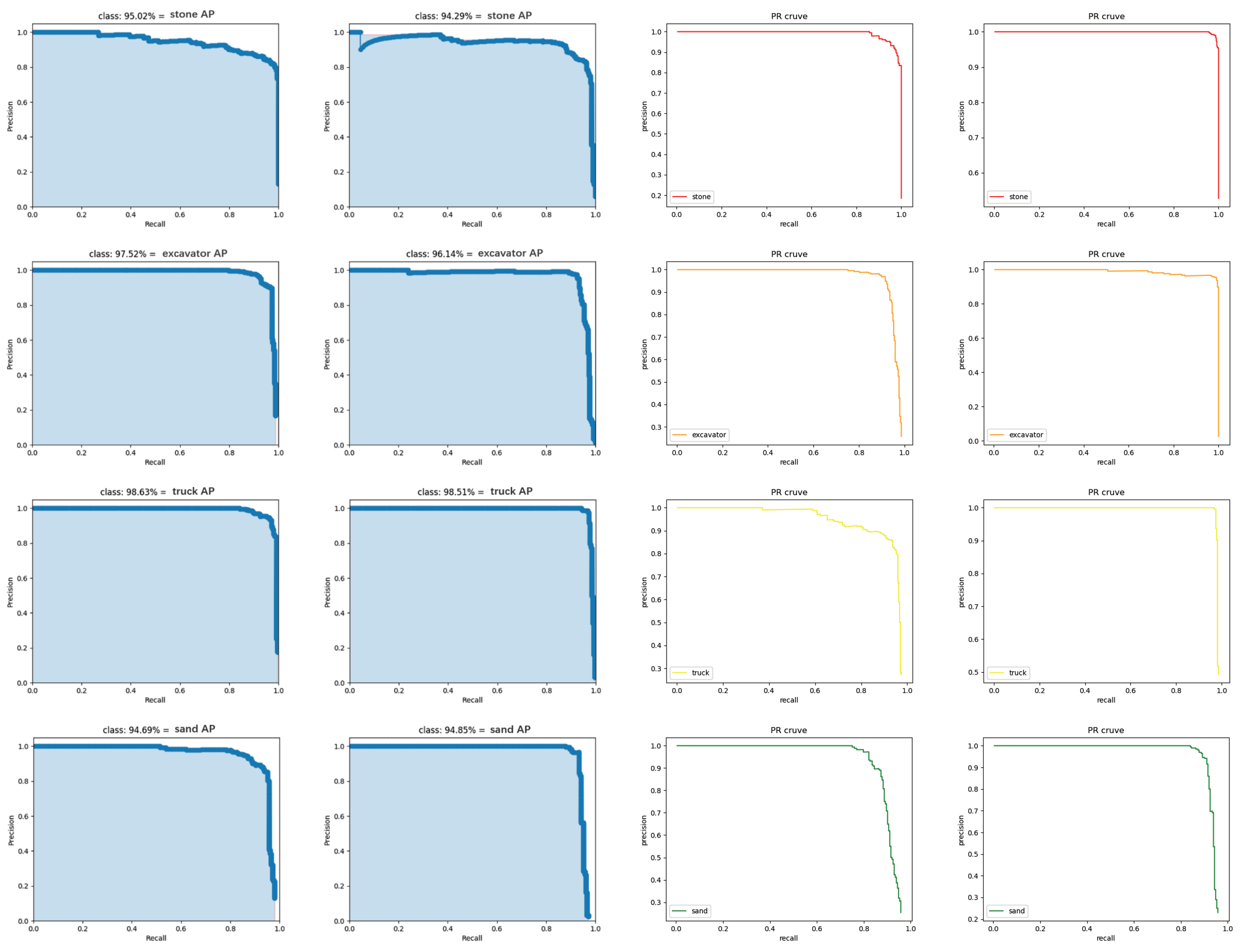
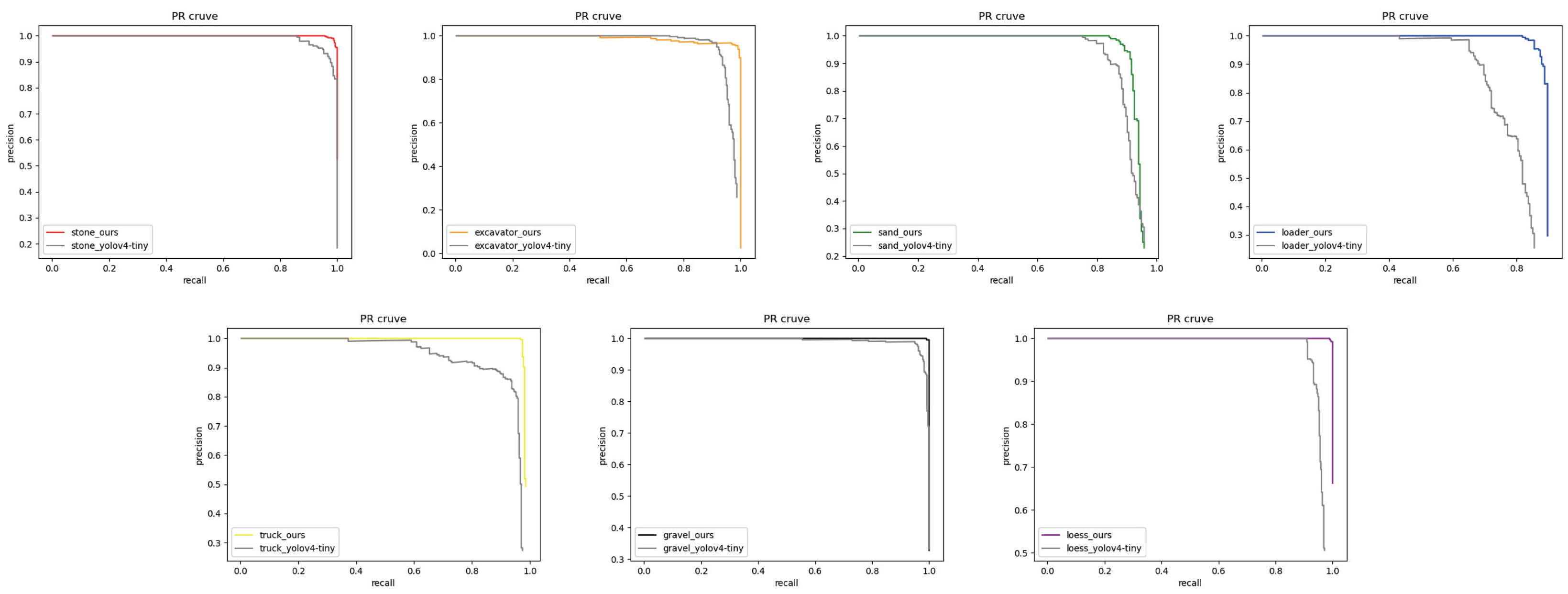



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}