
Optimizing the Neural Structure and Hyperparameters of Liquid State Machines Based on Evolutionary Membrane Algorithm

Abstract
:1. Introduction
- There are few studies on evolutionary algorithms for optimizing the hyperparameters of liquid state machines.
- For the first time, an improved evolutionary membrane algorithm is used as a learning algorithm for a liquid state machine.
- According to the hyperparameters of the liquid state machine, three elements of an evolutionary membrane algorithm are implemented, including objects, reaction rules and membrane structures.
- In our experiments, we demonstrate that the results of the proposed algorithm are highly competitive with those of the experimental algorithms. Simulation results verify the effectiveness of the proposed algorithm as a learning algorithm for the hyperparameters of a liquid state machine.
2. Theoretical Background
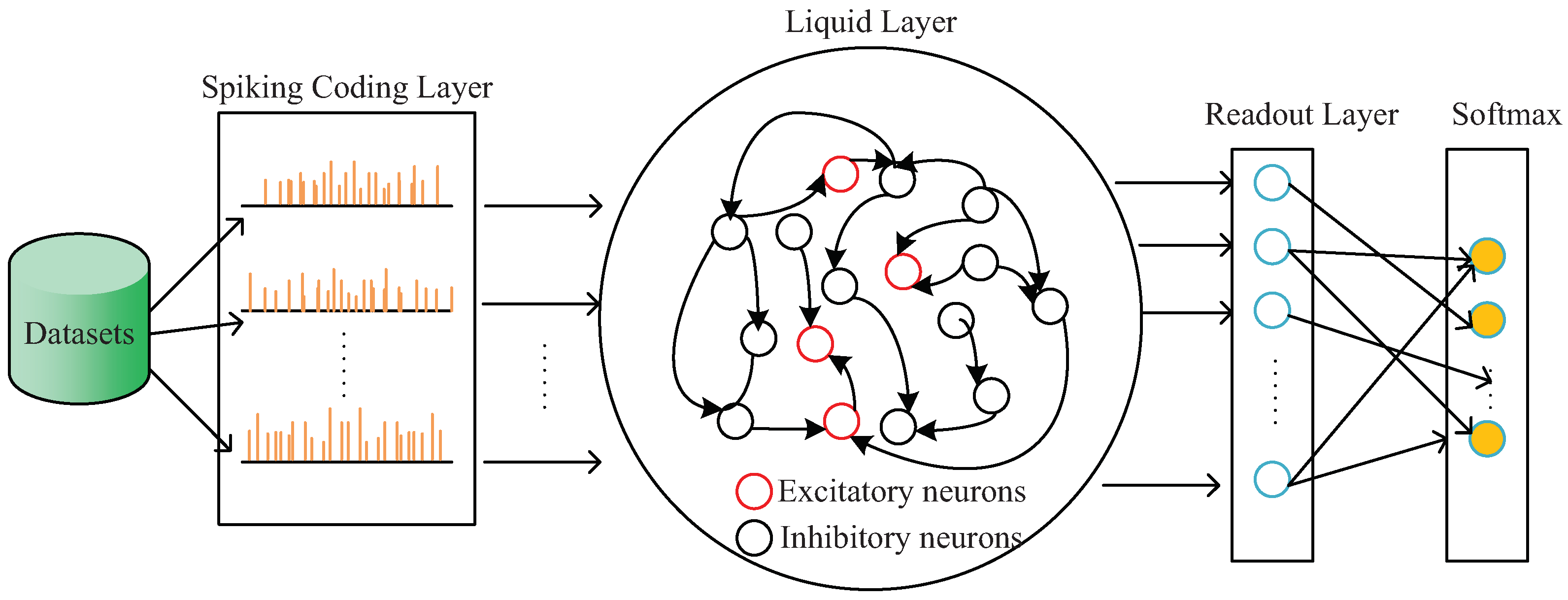
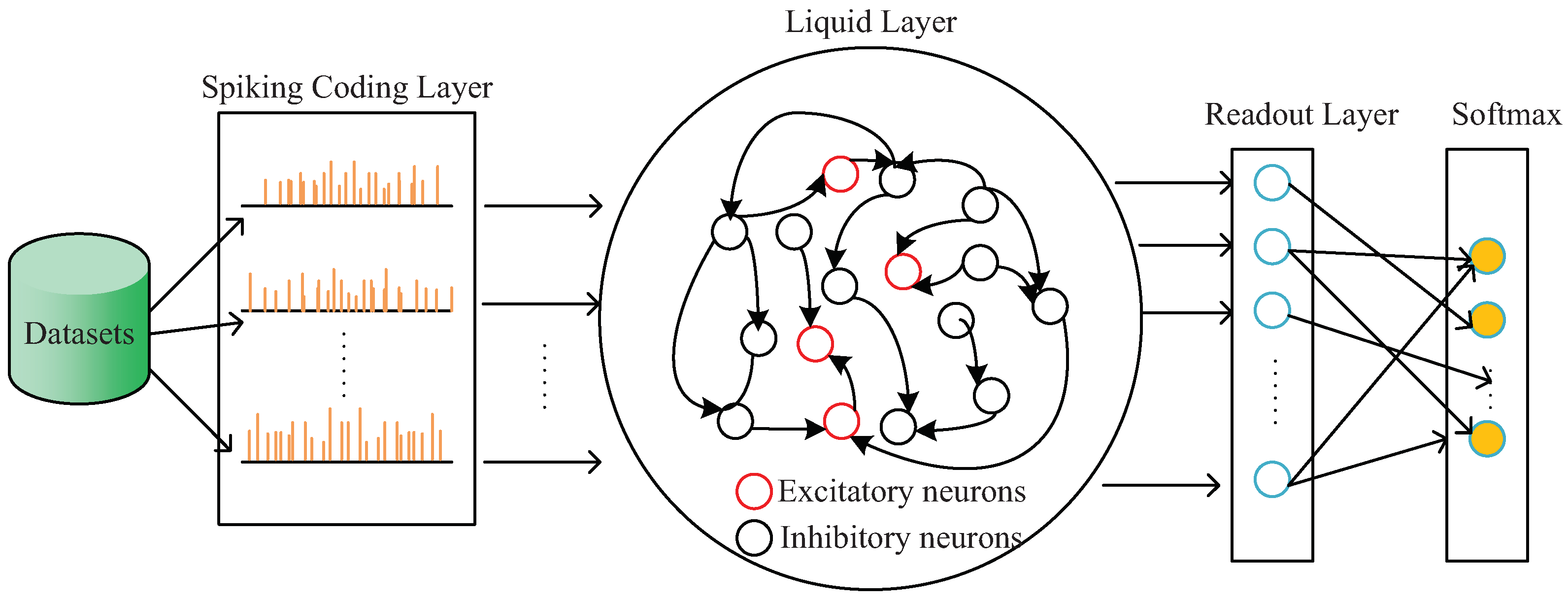
2.1. Liquid State Machine
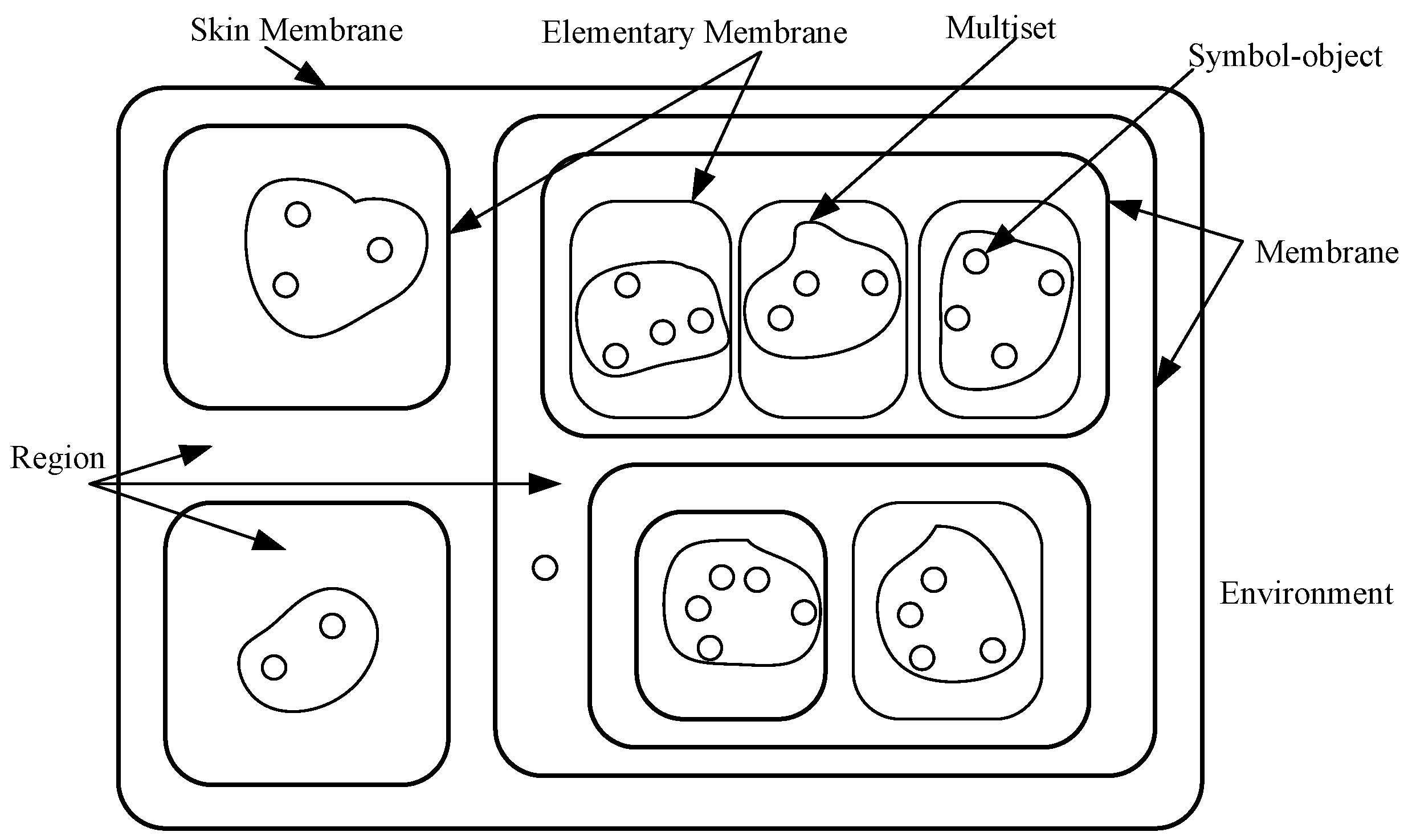
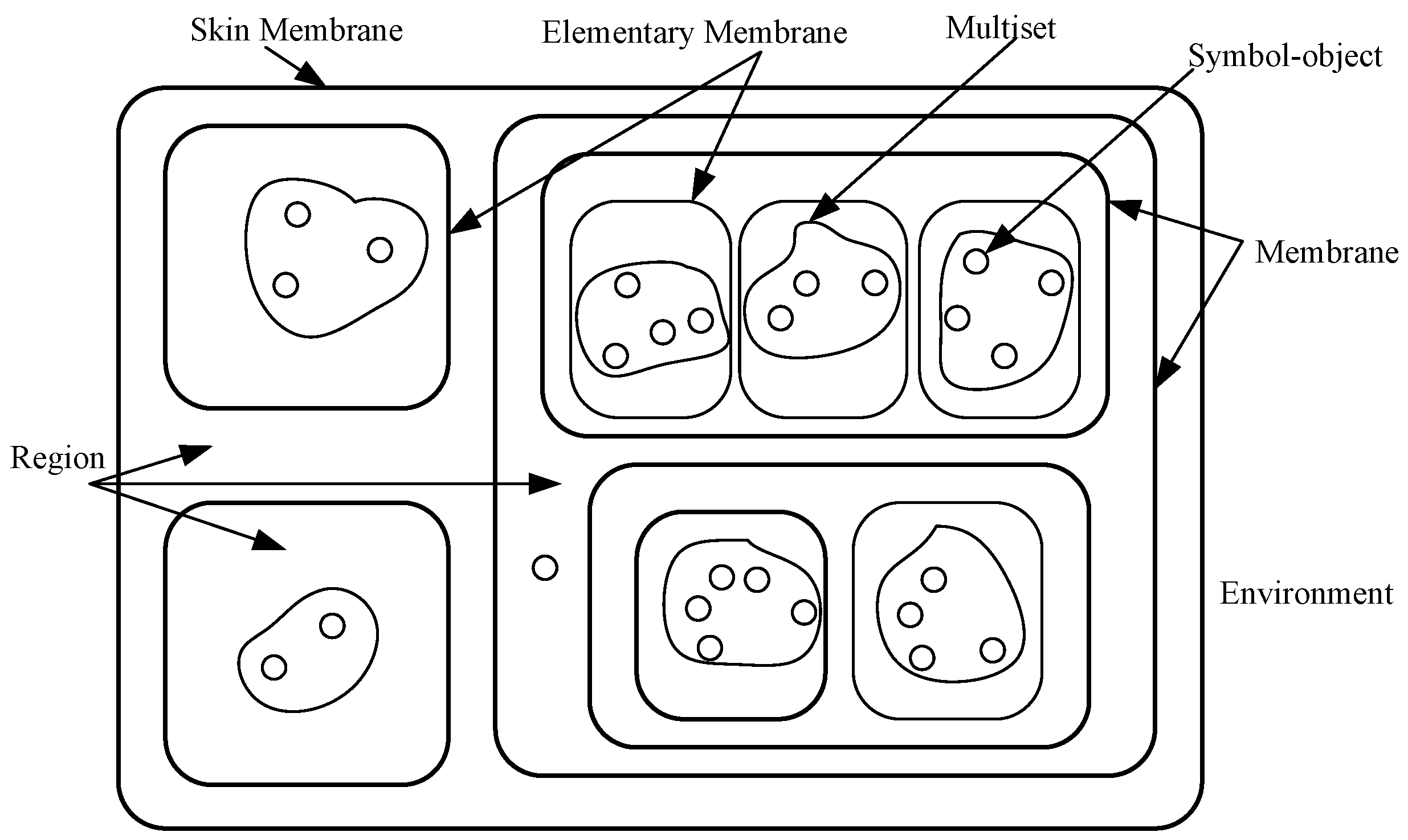
2.2. Evolutionary Membrane Algorithm
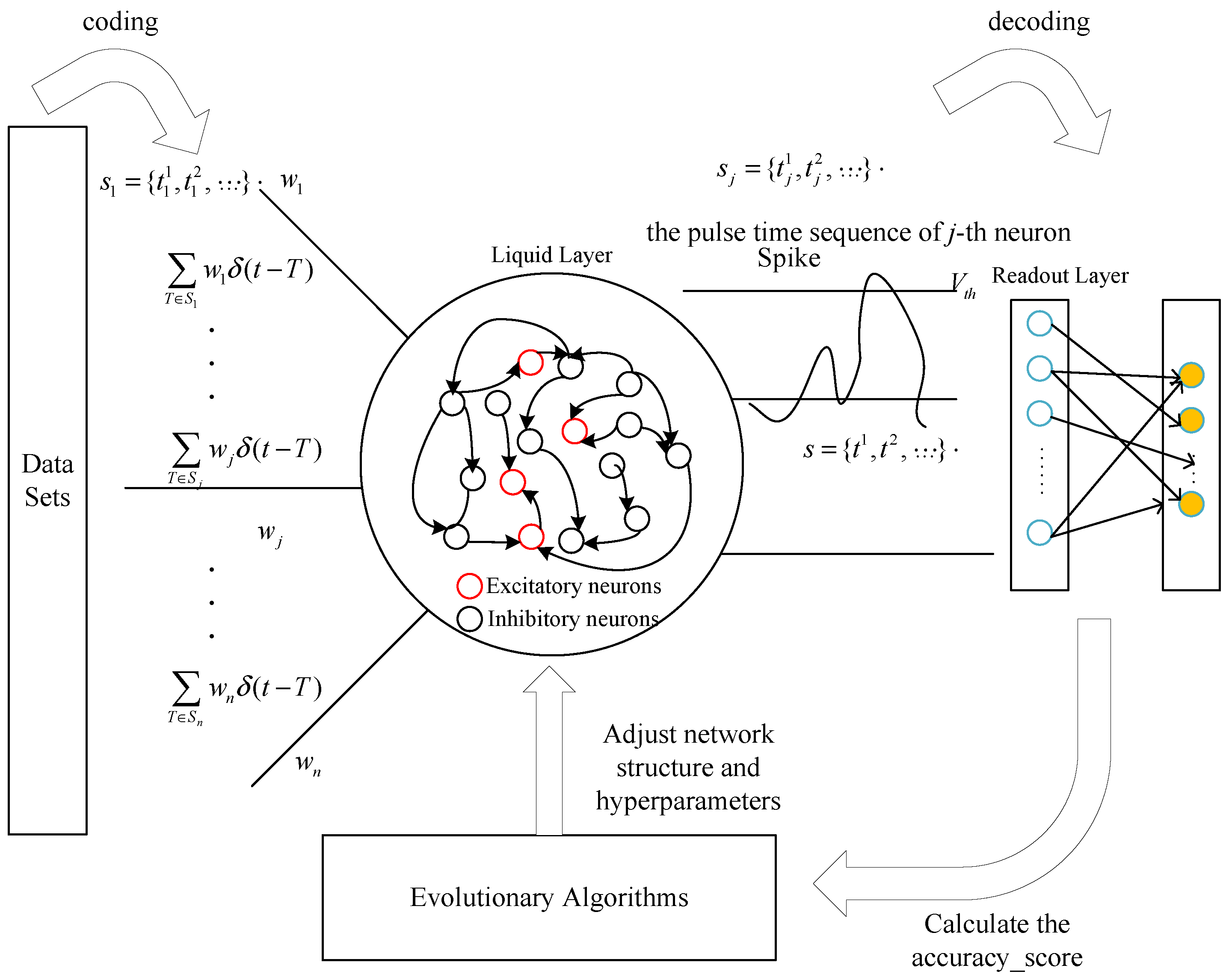
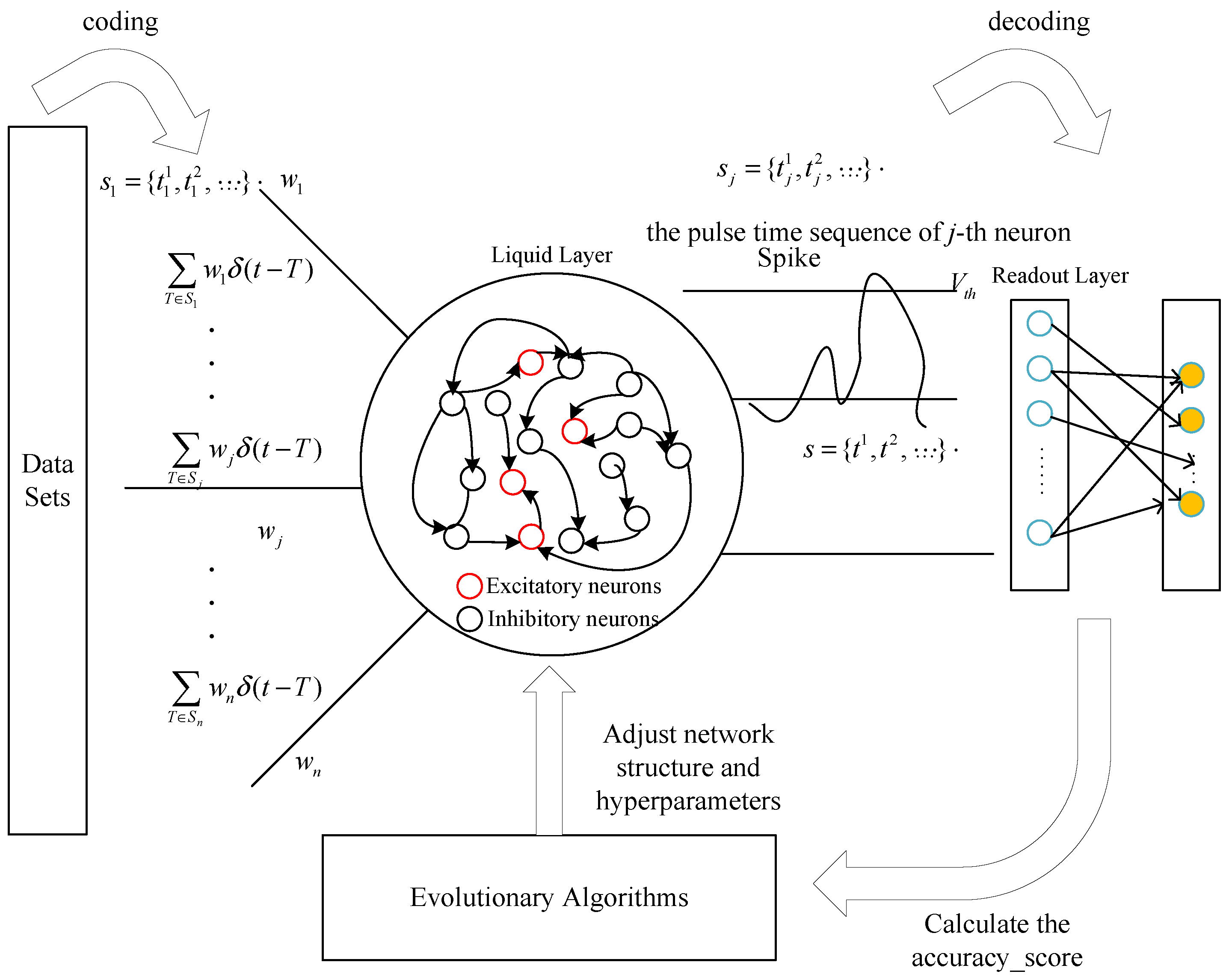
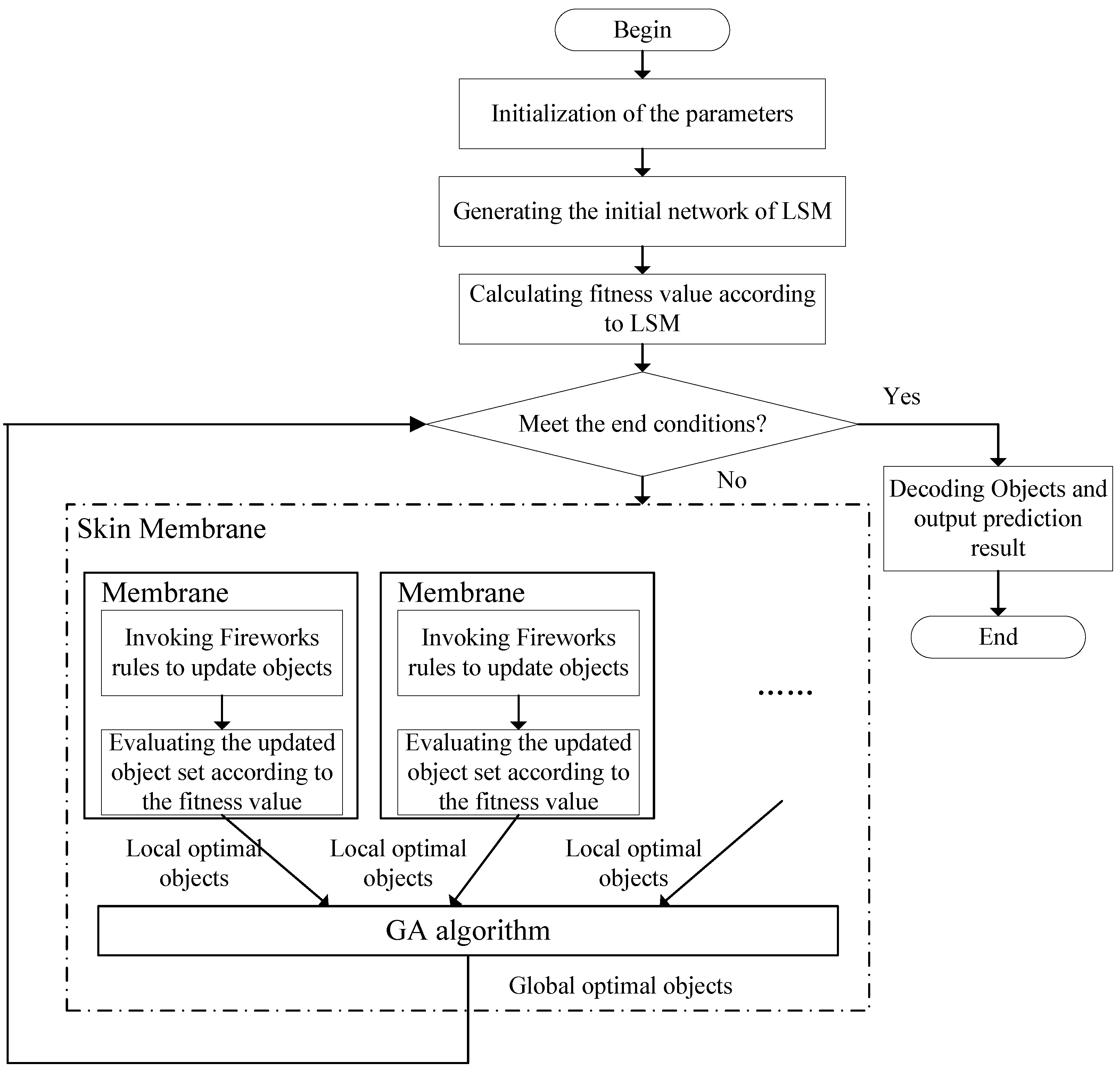
3. Proposed Framework
- The datasets need to be coded as the spiking input sequence of the liquid state machine;
- The hyperparameters and the neural structure of the liquid state machine are coded as the decision variables of the proposed algorithm;
- The optimum for the design of the liquid state machine is found by the constant searching of the proposed algorithm;
- The output spiking of the liquid state machine is loaded into the Readout layer, and the Readout layer will transfer the spiking sequence into the prediction results;
- According to the accuracy_score between the prediction results and the actual results, the proposed algorithm is called to generate new hyperparameters and the neural structure of the liquid state machine until the optimal prediction result is obtained
3.1. Membrane Structure
3.2. Reaction Rules
| Algorithm 1 Pseudocode for the calling logic of fireworks algorithm. |
|
4. Experimental Studies
4.1. Benchmark Datasets and Evaluation Indicators
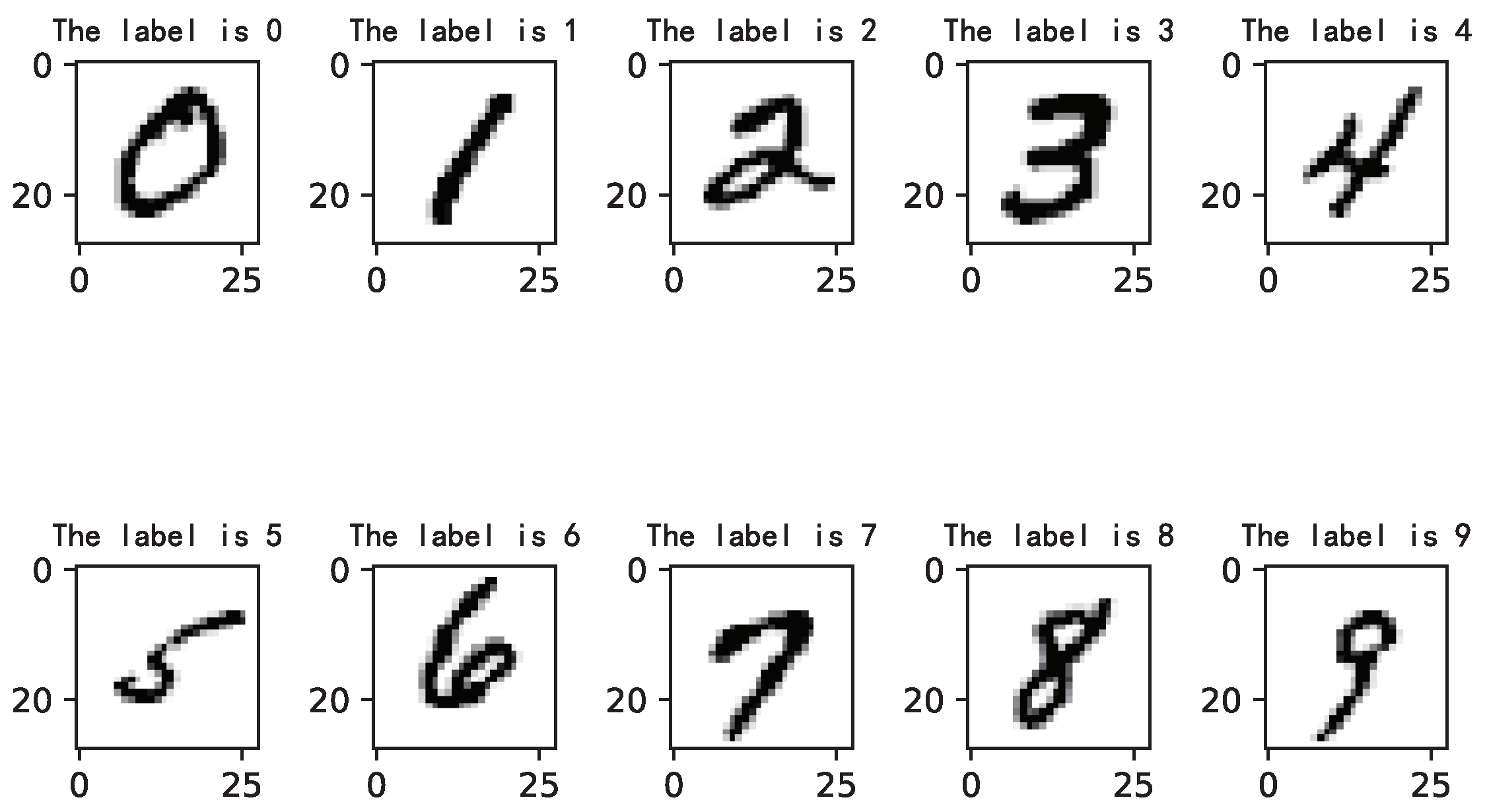
4.1.1. Benchmark Datasets
- The compressed file name of the training set images is train-images-idx3-ubyte.gz, the file size is 9.9 MB and the file contains 60,000 samples.
- The compressed file name of the training set labels is train-labels-idx1-ubyte.gz, the file size is 29 KB and the file contains 60,000 labels.
- The compressed file name of the test set images is t10k-images-idx3-ubyte.gz, the file size is 1.6 MB and the file contains 10,000 samples.
- The compressed file name of the test set labels is t10k-labels-idx1-ubyte.gz, the file size is 5 KB and the file contains 10,000 labels.
4.1.2. Evaluation Indicators
4.1.3. Experimental Conditions
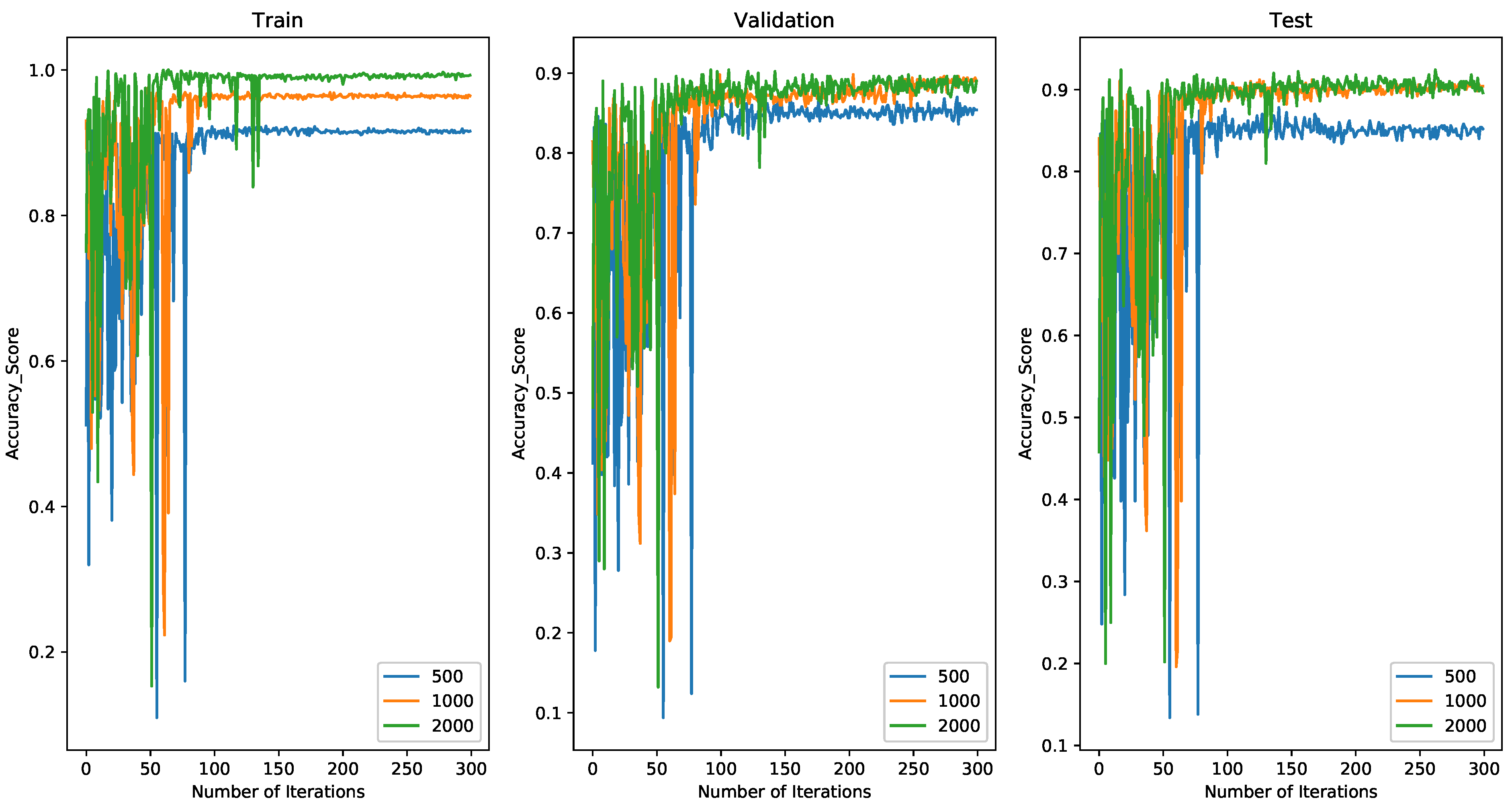
4.2. Comparing the Results of All Experimental Algorithms on MINIST
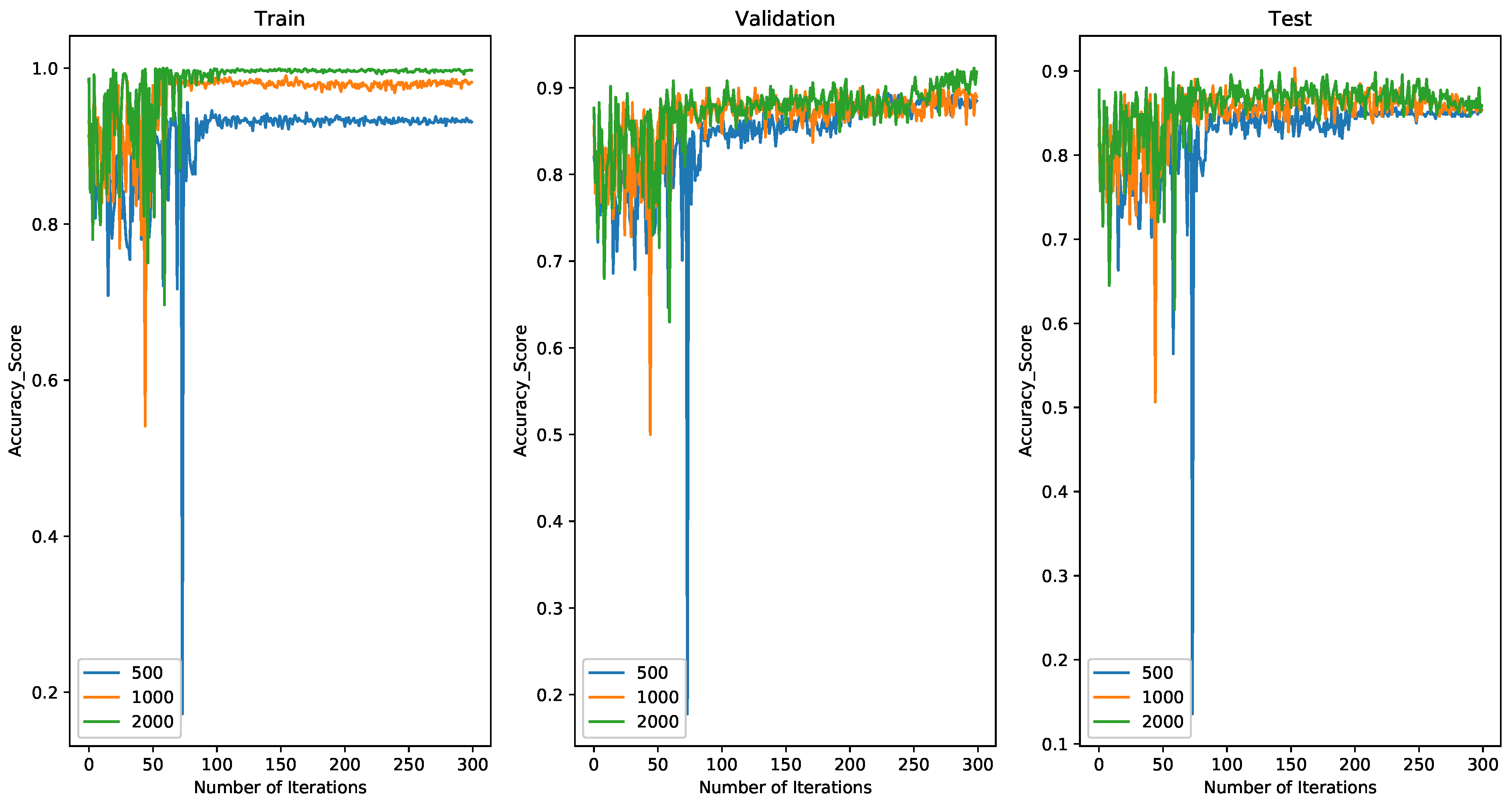
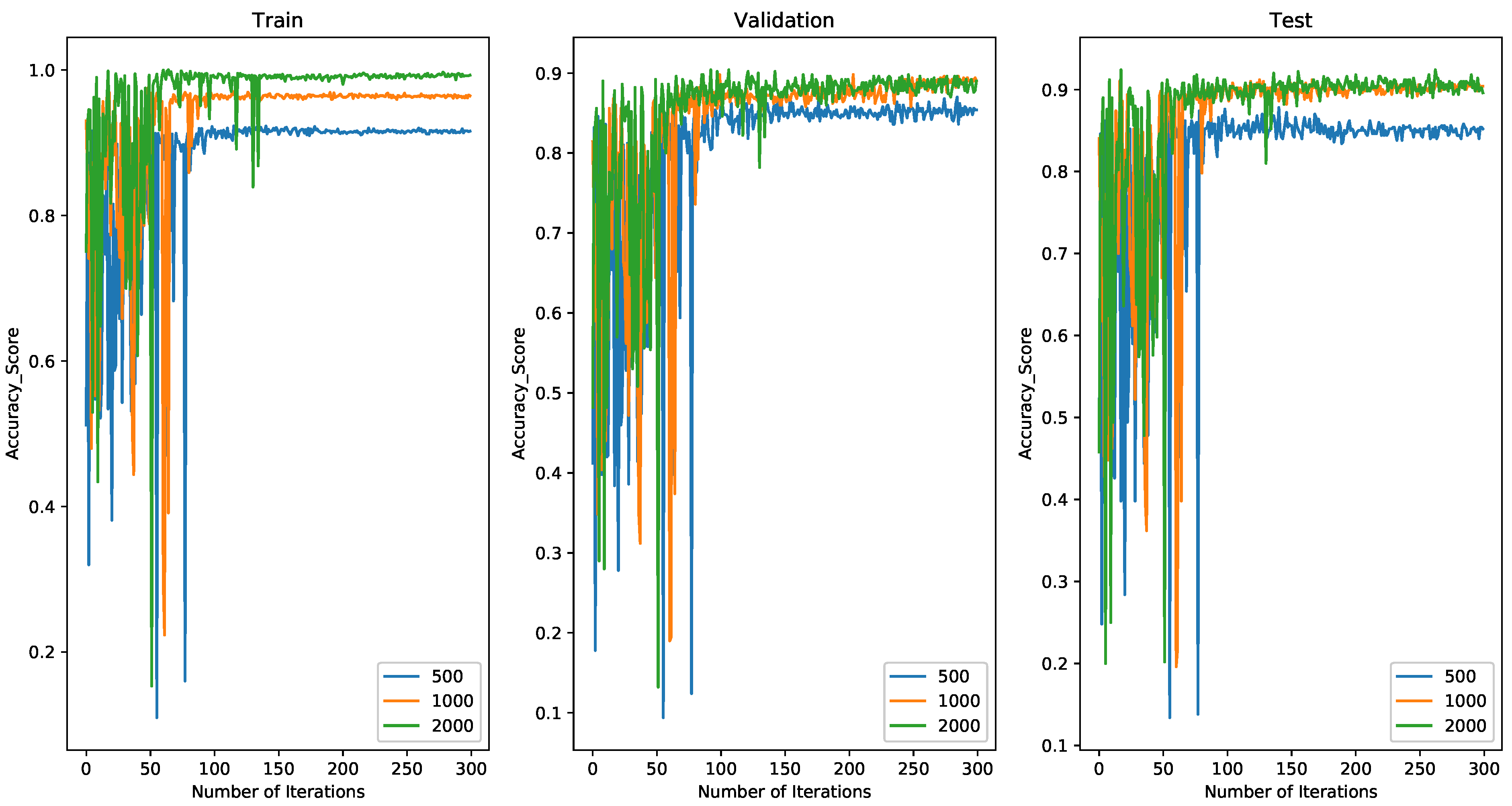
4.2.1. Comparing Results with 500 Spiking Neurons on MINIST
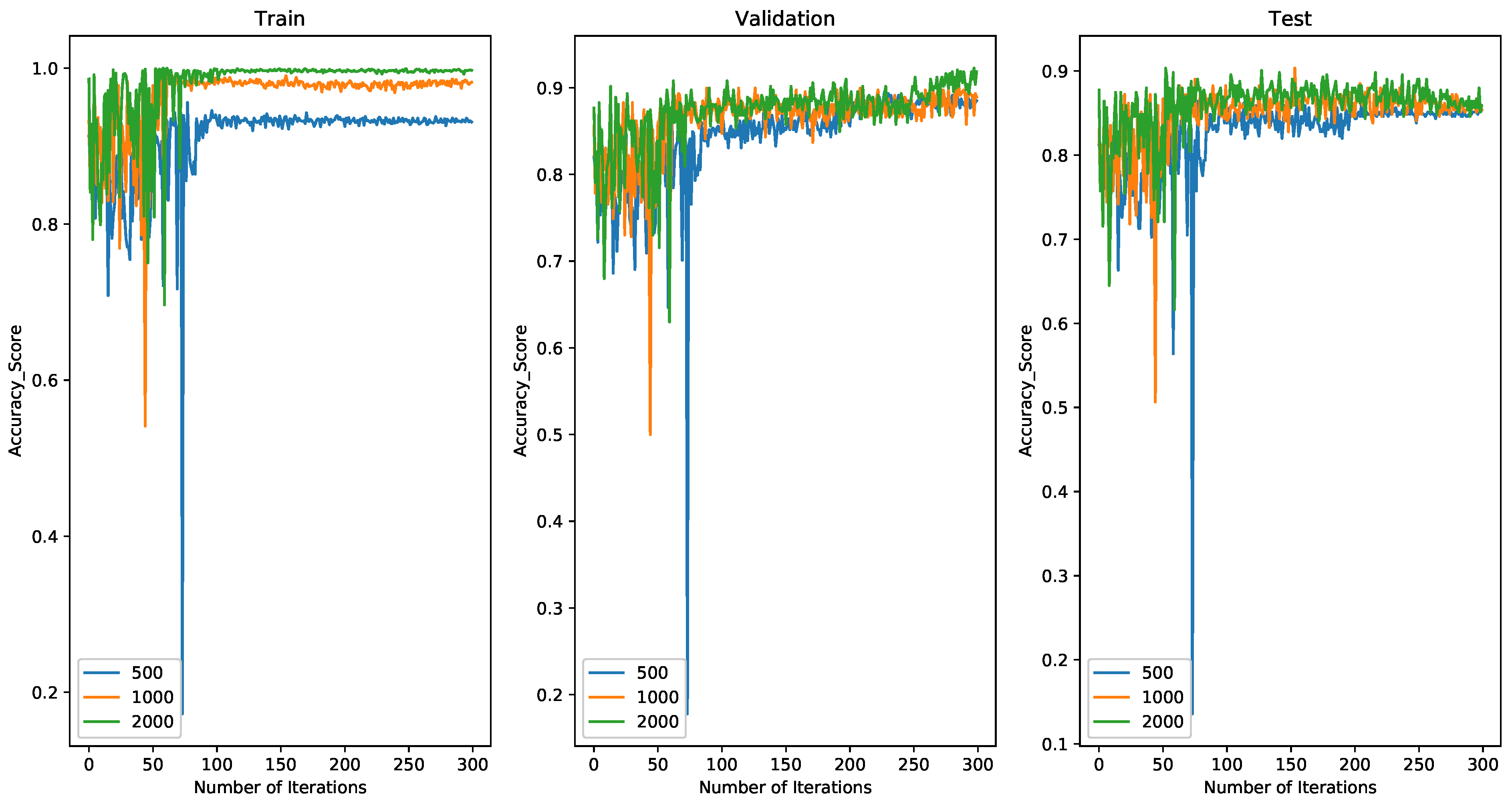
4.2.2. Comparing Results with 1000 Spiking Neurons on MINIST
4.2.3. Comparing Results with 2000 Spiking Neurons on MINIST
4.3. Comparing the Results of All Experimental Algorithms on KTH
4.3.1. Comparing Results with 500 Spiking Neurons on KTH
4.3.2. Comparing Results with 1000 Spiking Neurons on KTH
4.3.3. Comparing Results with 2000 Spiking Neurons on KTH
4.4. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, Y.; Mai, Y.; Feng, R.; Xiao, J. An adaptive threshold mechanism for accurate and efficient deep spiking convolutional neural networks. Neurocomputing 2022, 469, 189–197. [Google Scholar] [CrossRef]
- Doborjeh, M.; Doborjeh, Z.; Merkin, A.; Bahrami, H.; Sumich, A.; Krishnamurthi, R.; Medvedev, O.N.; Crook-Rumsey, M.; Morgan, C.; Kirk, I.; et al. Personalised predictive modelling with brain-inspired spiking neural networks of longitudinal MRI neuroimaging data and the case study of dementia. Neural Netw. 2021, 144, 522–539. [Google Scholar] [CrossRef] [PubMed]
- Jamshidi, M.B.; Lalbakhsh, A.; Talla, J.; Peroutka, Z.; Roshani, S.; Matousek, V.; Roshani, S.; Mirmozafari, M.; Malek, Z.; Spada, L.L.; et al. Deep learning techniques and covid-19 drug discovery: Fundamentals, state-of-the-art and future directions. In Emerging Technologies during the Era of COVID-19 Pandemic; Springer: Cham, Switzerland, 2021; pp. 9–31. [Google Scholar]
- Petro, B.; Kasabov, N.; Kiss, R.M. Selection and Optimization of Temporal Spike Encoding Methods for Spiking Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 358–370. [Google Scholar] [CrossRef] [PubMed]
- Khalaj, O.; Jamshidi, M.B.; Saebnoori, E.; Mašek, B.; Štadler, C.; Svoboda, J. Hybrid Machine Learning Techniques and Computational Mechanics: Estimating the Dynamic Behavior of Oxide Precipitation Hardened Steel. IEEE Access 2021, 9, 156930–156946. [Google Scholar] [CrossRef]
- Jamshidi, M.B.; Talla, J.; Peroutka, Z. Deep learning techniques for model reference adaptive control and identification of complex systems. In Proceedings of the 2020 19th International Conference on Mechatronics-Mechatronika (ME), Prague, Czech Republic, 2–4 December 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Zhang, A.; Niu, Y.; Gao, Y.; Wu, J.; Gao, Z. Second-order information bottleneck based spiking neural networks for sEMG recognition. Inf. Sci. 2022, 585, 543–558. [Google Scholar] [CrossRef]
- Liu, J.; Lu, H.; Luo, Y.; Yang, S. Spiking neural network-based multi-task autonomous learning for mobile robots. Eng. Appl. Artif. Intell. 2021, 104, 104362. [Google Scholar] [CrossRef]
- Lobo, J.L.; Del Ser, J.; Bifet, A.; Kasabov, N. Spiking neural networks and online learning: An overview and perspectives. Neural Netw. 2020, 121, 88–100. [Google Scholar] [CrossRef]
- Wang, J.; Hafidh, B.; Dong, H.; Saddik, A.E. Sitting Posture Recognition Using a Spiking Neural Network. IEEE Sens. J. 2021, 21, 1779–1786. [Google Scholar] [CrossRef]
- Norton, D.; Ventura, D. Improving liquid state machines through iterative refinement of the reservoir. Neurocomputing 2010, 73, 2893–2904. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Li, P.; Jin, Y.; Choe, Y. A Digital Liquid State Machine With Biologically Inspired Learning and Its Application to Speech Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2635–2649. [Google Scholar] [CrossRef]
- Florescu, D.; Coca, D. Learning with Precise Spike Times: A New Decoding Algorithm for Liquid State Machines. Neural Comput. 2019, 31, 1825–1852. [Google Scholar] [CrossRef] [PubMed]
- Rajan, K.; Abbott, L.F.; Sompolinsky, H. Stimulus-dependent suppression of chaos in recurrent neural networks. Phys. Rev. E 2010, 82, 011903. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wieland, S.; Bernardi, D.; Schwalger, T.; Lindner, B. Slow fluctuations in recurrent networks of spiking neurons. Phys. Rev. E 2015, 92, 040901. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beer, C.; Barak, O. One Step Back, Two Steps Forward: Interference and Learning in Recurrent Neural Networks. Neural Comput. 2019, 31, 1985–2003. [Google Scholar] [CrossRef] [Green Version]
- Iranmehr, E.; Shouraki, S.B.; Faraji, M.M.; Bagheri, N.; Linares-Barranco, B. Bio-Inspired Evolutionary Model of Spiking Neural Networks in Ionic Liquid Space. Front. Neurosci. 2019, 13, 1085. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Jin, Y.; Ding, J. Surrogate-Assisted Evolutionary Search of Spiking Neural Architectures in Liquid State Machines. Neurocomputing 2020, 406, 12–23. [Google Scholar] [CrossRef]
- Goel, L. An extensive review of computational intelligence-based optimization algorithms: Trends and applications. Soft Comput. 2020, 24, 16519–16549. [Google Scholar] [CrossRef]
- Mahafzah, B.A.; Jabri, R.; Murad, O. Multithreaded scheduling for program segments based on chemical reaction optimizer. Soft Comput. 2021, 25, 2741–2766. [Google Scholar] [CrossRef]
- Al-Shaikh, A.; Mahafzah, B.; Alshraideh, M. Metaheuristic approach using grey wolf optimizer for finding strongly connected components in digraphs. J. Theor. Appl. Inf. Technol. 2019, 97, 4439–4452. [Google Scholar]
- Ju, H.; Xu, J.X.; Chong, E.; VanDongen, A.M. Effects of synaptic connectivity on liquid state machine performance. Neural Netw. 2013, 38, 39–51. [Google Scholar] [CrossRef]
- Reynolds, J.J.M.; Plank, J.S.; Schuman, C.D. Intelligent Reservoir Generation for Liquid State Machines using Evolutionary Optimization. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Tian, S.; Qu, L.; Wang, L.; Hu, K.; Li, N.; Xu, W. A neural architecture search based framework for liquid state machine design. Neurocomputing 2021, 443, 174–182. [Google Scholar] [CrossRef]
- Li, S.; Tian, S.; Kang, Z.; Qu, L.; Wang, S.; Wang, L.; Xu, W. A multi-objective LSM/NoC architecture co-design framework. J. Syst. Archit. 2021, 116, 102154. [Google Scholar] [CrossRef]
- Wang, X.; Lin, X.; Dang, X. Supervised learning in spiking neural networks: A review of algorithms and evaluations. Neural Netw. 2020, 125, 258–280. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Du, Y. A membrane algorithm based on chemical reaction optimization for many-objective optimization problems. Knowl.-Based Syst. 2019, 165, 306–320. [Google Scholar] [CrossRef]
- Liu, C.; Shen, W.; Zhang, L.; Du, Y.; Yuan, Z. Spike Neural Network Learning Algorithm Based on an Evolutionary Membrane Algorithm. IEEE Access 2021, 9, 17071–17082. [Google Scholar] [CrossRef]
- García-Victoria, P.; Cavaliere, M.; Gutiérrez-Naranjo, M.A.; Cárdenas-Montes, M. Evolutionary game theory in a cell: A membrane computing approach. Inf. Sci. 2022, 589, 580–594. [Google Scholar] [CrossRef]
- Dong, J.; Stachowicz, M.; Zhang, G.; Cavaliere, M.; Rong, H.; Paul, P. Automatic Design of Spiking Neural P Systems Based on Genetic Algorithms. Int. J. Unconv. Comput. 2021, 16, 201–216. [Google Scholar]
- Casauay, L.J.; Macababayao, I.C.H.; Cabarle, F.G.C.; Cruz, R.T.D.L.; Adorna, H.N.; Zeng, X.; Martínez del Amor, M.Á. A Framework for Evolving Spiking Neural P Systems. In Proceedings of the ACMC 2019: The 8th Asian Conference on Membrane Computing, Xiamen, China, 14–17 November 2019; pp. 271–298. [Google Scholar]
- Nishida, T. Membrane algorithms: Approximate algorithms for NP-complete optimization problems. In Applications of Membrane Computing; Springer: Berlin/Heidelberg, Germany, 2006; pp. 303–314. [Google Scholar]
- Zhang, G.; Cheng, J.; Gheorghe, M.; Meng, Q. A hybrid approach based on differential evolution and tissue membrane systems for solving constrained manufacturing parameter optimization problems. Appl. Soft Comput. 2013, 13, 1528–1542. [Google Scholar] [CrossRef]
- Niu, Y.; Wang, S.; He, J.; Xiao, J. A novel membrane algorithm for capacitated vehicle routing problem. Soft Comput. 2015, 19, 471–482. [Google Scholar] [CrossRef]
- Peng, H.; Shi, P.; Wang, J.; Riscos-Núñez, A.; Pérez-Jiménez, M.J. Multiobjective fuzzy clustering approach based on tissue-like membrane systems. Knowl.-Based Syst. 2017, 125, 74–82. [Google Scholar] [CrossRef]
- Orozco-Rosas, U.; Picos, K.; Montiel, O. Hybrid path planning algorithm based on membrane pseudo-bacterial potential field for autonomous mobile robots. IEEE Access 2019, 7, 156787–156803. [Google Scholar] [CrossRef]
- Orozco-Rosas, U.; Montiel, O.; Sepúlveda, R. Mobile robot path planning using membrane evolutionary artificial potential field. Appl. Soft Comput. 2019, 77, 236–251. [Google Scholar] [CrossRef]
- Song, Q.; Huang, Y.; Lai, W.; Han, T.; Xu, S.; Rong, X. Multi-membrane search algorithm. PLoS ONE 2021, 16, e0260512. [Google Scholar] [CrossRef] [PubMed]
- Tian, X.; Liu, X. Improved Hybrid Heuristic Algorithm Inspired by Tissue-Like Membrane System to Solve Job Shop Scheduling Problem. Processes 2021, 9, 219. [Google Scholar] [CrossRef]
- Niu, Y.; Zhang, Y.; Cao, Z.; Gao, K.; Xiao, J.; Song, W.; Zhang, F. MIMOA: A membrane-inspired multi-objective algorithm for green vehicle routing problem with stochastic demands. Swarm Evol. Comput. 2021, 60, 100767. [Google Scholar] [CrossRef]
- Liu, C.; Shen, W.; Zhang, L.; Yang, H.; Du, Y.; Yuan, Z.; Zhao, H. Improved Membrane Algorithm Under the Framework of P Systems to Solve Multimodal Multiobjective Problems. Int. J. Pattern Recognit. Artif. Intell. 2021, 35, 2159024. [Google Scholar] [CrossRef]
- Peng, H.; Wang, J.; Shi, P.; Riscos-Nunez, A.; Perez-Jimenez, M.J. An automatic clustering algorithm inspired by membrane computing. Pattern Recognit. Lett. 2015, 68, 34–40. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, W.; Sun, M.; Liu, X. An Improved Consensus Clustering Algorithm Based on Cell-Like P Systems With Multi-Catalysts. IEEE Access 2020, 8, 154502–154517. [Google Scholar] [CrossRef]
- Bergstra, J.; Yamins, D.; Cox, D. Making a Science of Model Search: Hyperparameter Optimization in Hundreds of Dimensions for Vision Architectures. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Dasgupta, S., McAllester, D., Eds.; PMLR: Atlanta, GA, USA, 2013; Volume 28, pp. 115–123. [Google Scholar]
- Tan, Y.; Zhu, Y. Fireworks Algorithm for Optimization. In Proceedings of the International Conference in Swarm Intelligence, Beijing, China, 12–15 June 2010; Tan, Y., Shi, Y., Tan, K.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 355–364. [Google Scholar]
- Eriksson, D.; Pearce, M.; Gardner, J.; Turner, R.D.; Poloczek, M. Scalable Global Optimization via Local Bayesian Optimization. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Hansen, N.; Müller, S.D.; Koumoutsakos, P. Reducing the Time Complexity of the Derandomized Evolution Strategy with Covariance Matrix Adaptation (CMA-ES). Evol. Comput. 2003, 11, 1–18. [Google Scholar] [CrossRef]
- Khattab, H.; Mahafzah, B.A.; Sharieh, A. A hybrid algorithm based on modified chemical reaction optimization and best-first search algorithm for solving minimum vertex cover problem. Neural Comput. Appl. 2022, 1–29. [Google Scholar] [CrossRef]
- Al-Shaikh, A.; Mahafzah, B.A.; Alshraideh, M. Hybrid harmony search algorithm for social network contact tracing of COVID-19. Soft Comput. 2021, 1–23. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy_Score | BO [46] | GA [44] | CMA-ES [47] | GP-Assisted CMA-ES [18] | Proposed Algorithm |
|---|---|---|---|---|---|
| Train | 91.2% | 90.2% | 90.8% | 91.5% | 92.2% |
| Validation | 85.1% | 84.4% | 84.6% | 85.2% | |
| Test | 86.2% | 81.2% | 85.2% | 85.4% | 86.8% |
| Accuracy_Score | BO [46] | GA [44] | CMA-ES [47] | GP-Assisted CMA-ES [18] | Proposed Algorithm |
|---|---|---|---|---|---|
| Train | 96.5% | 97.3% | 91.6% | 96.5% | 98.6% |
| Validation | 87.1% | 87.6% | 82.1% | 89.4% | 89.6% |
| Test | 89.6% | 89.8% | 88.2% | 90.4% | 90.6% |
| Accuracy_Score | BO [46] | GA [44] | CMA-ES [47] | GP-Assisted CMA-ES [18] | Proposed Algorithm |
|---|---|---|---|---|---|
| Train | 98.9% | 99.8% | 99.5% | 99.2% | 99.9% |
| Validation | 88.1% | 88.8% | 88.2% | 89.1% | 88.6% |
| Test | 89.6% | 90.6% | 91.4% | 89.6% | 90.8% |
| Accuracy_Score | BO [46] | GA [44] | CMA-ES [47] | GP-Assisted CMA-ES [18] | Proposed Algorithm |
|---|---|---|---|---|---|
| Train | 89.8% | 90.1% | 86.3% | 91.1% | 91.7% |
| Validation | 81.9% | 82.1% | 78.9% | 84.4% | 84.7% |
| Test | 80.1% | 80.4% | 77.4% | 82.5% | 82.9% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Wang, H.; Liu, N.; Yuan, Z. Optimizing the Neural Structure and Hyperparameters of Liquid State Machines Based on Evolutionary Membrane Algorithm. Mathematics 2022, 10, 1844. https://doi.org/10.3390/math10111844
Liu C, Wang H, Liu N, Yuan Z. Optimizing the Neural Structure and Hyperparameters of Liquid State Machines Based on Evolutionary Membrane Algorithm. Mathematics. 2022; 10(11):1844. https://doi.org/10.3390/math10111844
Chicago/Turabian StyleLiu, Chuang, Haojie Wang, Ning Liu, and Zhonghu Yuan. 2022. "Optimizing the Neural Structure and Hyperparameters of Liquid State Machines Based on Evolutionary Membrane Algorithm" Mathematics 10, no. 11: 1844. https://doi.org/10.3390/math10111844
APA StyleLiu, C., Wang, H., Liu, N., & Yuan, Z. (2022). Optimizing the Neural Structure and Hyperparameters of Liquid State Machines Based on Evolutionary Membrane Algorithm. Mathematics, 10(11), 1844. https://doi.org/10.3390/math10111844