1. Introduction
In the teaching-learning process under the competency-based educational model, the instructor plays the role of a facilitator in the classroom. Following this paradigm, a flexible and adaptable environment is generated to support student learning. The learner becomes the center in the teaching process, seeking to acquire competencies. From the operational perspective, competencies require skills and behaviors that go from the simple to the complex. According to Westera, the individual’s cognitive structure contains theory and practical knowledge [
1].
Knowledge can be used in everyday activities, although some tasks require strategic thinking. In more complex situations, the competencies combine the acquired skills with specific attitudes. Under this approach, the student must grasp the theoretical knowledge (knowing), practical experience (knowing how to do it), and strategic thinking.
Preparation of didactic planning is one of the initial tasks to carry out in the competency-based approach. Didactic planning is a documented process that provides the instructor and the student with a guide to the teaching process in the classroom [
2]. For the preparation of didactic planning, some instructors reflect on their experience to choose the didactic material supporting the course syllabus, or they try to replicate previous approaches. We propose a framework based on natural language processing techniques with the support of an ontology grounded in the experience of instructors and university level course plans in the information systems area. We employ the original Bloom taxonomy [
3] in the ontology design, producing an ascending structure for didactic planning, which allows the student to learn gradually.
An experiment with students and teachers for the development of a product in six stages (planning, concept development, system-level, design, detailed design, implementation and testing, and production) for the engineering discipline was undertaken. This showed how the levels of Bloom’s taxonomy appear gradually and allow students to reflect as they solve the problem [
4]. In the early stages of development, the knowledge level of the taxonomy reaches the highest peak, while in the final stages of product development, the level of analysis and evaluation reach a high value. Furthermore, the experiment provided evidence of the link between engineering design and Bloom’s taxonomy. In this study, the inclusion of verbs in Bloom’s taxonomy led to a positive perception of the students. This research provided the motivation to consider Bloom’s taxonomy as a guide for instructors to develop didactic planning.
Below, we present the elements of didactic planning:
Learning strategies: activities carried out by students to participate in the training process to reinforce the instructor’s knowledge or acquire new knowledge in an autodidactic way.
Teaching strategies: activities, techniques, methods, or procedures that the facilitator uses to conduct the teaching process in the classroom.
Evidence of learning: products of individual or group activities that demonstrate the student’s learning process.
Evaluation instruments: tools used by the instructor to assess student performance evidence in the teaching process.
In this study, the developed framework has two main components, the first is intended to manage the created ontology, and the second performs several text analyses. These two components are detailed in corresponding sections later on. The framework can analyze the didactic planning section-by-section from this combined interaction of the two components, as shown in
Table 1.
There is little reported use of methods based on natural language processing for textual analysis in the formulation and writing of teaching and learning activities. To fill this gap, we developed the present framework. Our work is particularly helpful for novice instructors who are starting to write learning activities as they can receive an automatic analysis of their writing based on prior knowledge of the ontology and NLP methods. The framework can automatically validate if a given learning activity has the structure of verb + activity + topic—if any component is missing, the instructor is immediately given feedback. With this, a more complete and structured set of learning and teaching activities is obtained, since several rules, relations and inferences are verified or enforced. For example, in the case of the teaching activity “Explain examples about the use of vectors in programming”, for this sentence the framework detects the absence of the topic which must be related to data structures according to the competence “Identify the different data structures, their classification, and how to manipulate them to find the most efficient way to solve problems through their classification and memory management”.
Our framework’s evaluation was carried out with 715 elements to produce an analysis report applying our approach and then this was compared it against the results of expert analysis. For the assessment, a Cohen’s kappa agreement analysis was performed. The framework comprises nine analysis processes: competence, learning activities, teaching activities, learning evidence, evaluation instruments, competence-learning relationship, learning-evidence relationship, evidence-learning relationship, and evidence-instruments relationship.
Contributions:
A framework that applies the knowledge managed in an ontology, combined with natural language processing (NLP) techniques to identify deficiencies in didactic planning, either in learning strategies, teaching strategies, evidence of learning, or evaluation instruments.
Our study seeks to potentiate the ontology by implementing methods based on NLP as a complement. Previous related studies explored are mainly based on the use of ontologies.
A framework designed to analyze text in Spanish, which can be equally adapted to other languages.
The article is structured as follows:
Section 2 describes recent studies related to ontologies for designing and evaluating didactic planning.
Section 3 provides an overview of the developed framework.
Section 4 details the created ontology, including a binary relation scheme taking Bloom’s taxonomy as a reference. The text analysis component is detailed in
Section 5, including the four modules: text segmenter, match process, evidence-learning, and instrument-evidence. The statistical results are shown in
Section 6.
Section 7 focuses on the results of analysis on the test set. Finally,
Section 8 addresses conclusions and discusses future research.
2. Related Work
In the educational environment, the design of learning objectives, teaching methods, techniques, and pedagogical approaches are part of the process called learning design (LD) [
5]. The concept of learning design refers to the “process of designing effective learning experiences with the use of technological innovations and resources” [
5]. In our work, didactic plan refers to a document that fits within the LD process, specifically in the competency model, to help the instructor organize the course plan. The use of educational data mining and learning analytic approaches to help improve LD has evolved with different computational techniques. Educational data mining (EDM) refers to creating methods to explore data that has an origin in educational environments. Learning analytics (LA) is defined as measuring, collecting, and analyzing data from students to understand and improve learning environments. Among the main areas closely related to EDM/LA are: computer science, computer-based education, education, educational statistics, data mining/machine learning, and statistics [
6].
In [
7], we reviewed recent trends in educational technology in the Computers & Education Journal, from 1976 to 2018. The authors performed a topic-based bibliometric analysis of 3963 articles. We observe that our research is aligned with topics such as assessment, teacher training, technology acceptance models, E-learning, and policy, which correspond to increasing trends identified by [
7]. Another study that supports the importance of artificial intelligence in education is [
8] which highlights the relevance of using data-driven learning to personalize and deliver immediate feedback in real-time. Our framework using AI techniques offers immediate feedback to the instructor.
Educational Data Mining and Learning Analytics
The design of strategies to improve student learning in online courses is approached using different algorithms [
9], for example, longitudinal k-means cluster analysis. For this purpose, student groups were characterized using measurable features, such as the percentage of reading, instructional videos watched, the number of times task guides were viewed, the number of times task instructions were viewed, and the order of completed assignments. On this basis, the authors defined several groups: novice careful, confident traditional, knowledgeable confident, and no main group. Then a pattern was created for each kind of student. These groups represent the strategies developed by the students. For example, 21% of students were grouped under the novice careful strategy, so these students would have to read more text and watch many more videos. Analysis of this data helps instructional designers to focus their efforts.
Student performance prediction through clustering was analyzed in [
10]. The authors grouped students with the objective that students with the same performance were placed together; thus, three groups were defined according to lecture materials, activity description, source, and the IP address of the student who accessed the e-course. To obtain a prediction, the authors built three decision trees, one for each group; in this way, they produced a general profile for each group. The smallest group contained the best-performing students. The result was that teachers could identify student behavior and design better techniques to encourage them to improve their reading time before tests.
The authors of [
11] proposed monitoring of students to identify variables affecting student productivity. The authors focused on learning analytics, and using statistical tools, such as non-parametric tests and multivariate regression. They found five variables were related to student learning behaviors: total time spent, off-task behavior, the closeness of the first attempt to the due date, number of attempts, and the spacing of the study sessions. These variables provided instructors with valuable information to design and implement activities that could improve student learning.
PLATON is a system focused on stimulating self-reflection and providing support to teachers for understanding planned activities, asking questions such as, “How much time is scheduled for action—is that realistic?” [
12]. In contrast, our framework seeks to computationally analyze the text and provide suggestions to instructors to improve teaching planning. Research-related work addresses aspects of ontologies and competency-based models.
Studies have also been undertaken using ontologies as a resource to organize expert knowledge. In some cases, this architecture is combined with other methods. For instance, in [
13], we identified an ontology for designing competency-based learning applications that combines the concepts of knowledge, skill, attitudes, and performance. The ontology provides ways to semantically annotate resources to define individual actors’ competencies, prerequisites, and goals for activities and resource content, evaluation criteria, and personalization capabilities for e-learning and knowledge management applications. The author also presents a competency management framework with an evaluation grid tool used by facilitators to assess learners’ actual competencies. The author suggests that it can be used to adapt the learning environments to the learners’ characteristics. In the same way, our framework utilizes an ontology to manage the information of the competencies. However, our ontology is based on Bloom’s taxonomy and incorporates natural language processing (NLP) techniques for the analysis of new unprocessed texts.
The design of activities and assessment instruments are relevant for the student to understand his/her progress. In [
14], the authors propose creating five ontologies to conceptualize the e-assessment domain to support the semi-automatic generation of assessment. They present an ontologies course domain specification, an educational resource specification, a learning object, assessment, and assessment instruments. The ontologies are connected through membership relationships. First, the course’s domain incorporates the education resource, which, in turn, integrates the assessment ontology. This provides a means of ensuring that the suggested assessment instrument is appropriate for the course domain.
In [
15], the authors introduce a pedagogic model within an ontology, placing the levels around the student, including learning style, learning objective learning domain, tag, and emotion, which are intended to provide better feedback to the student. In our work, all relationships revolve around the competence of didactic planning. However, we only have one ontology organized hierarchically according to Bloom’s taxonomy. In the ontology of assessment, a deep hierarchy is observed, including three types of evaluation: formative, diagnostic, and summative.The ontology for evaluation includes a battery of assessment instruments, for example, essays and conceptual maps.
Under the competencies model, we found an ontology to support the teacher in designing a didactic sequence [
16]. The ontology includes five elements: competence, resources (communication tools and digital resources), integrative tasks (learning scenarios), learning activities, and evaluation criteria (evaluation instruments and evidence). The authors employed the methontology [
17] approach for the design of the ontology. We follow the same approach. One feature of their approach is the systematic creation of learning activities. However, the authors did not consider any text analysis as has been proposed and applied in our work.
In [
18], the authors proposed an evaluation instrument for competencies using a rubric applied to a didactic sequence. The rubric considers the aspects of planning, intervention, and reflection. Experts who reviewed the consistency of the instrument analyzed the rubric. The authors performed a pilot test to validate its applicability. However, the aspects considered in the rubric require the interpretation of an expert for the rubric’s application. Therefore, it is advantageous to have an approach, such as our framework, which employs a method to automatically evaluate the didactic planning document based on the ontology and language processing techniques.
One key difference between our work and the previously mentioned study is that most of the analyses focus on the English language, while our didactic planning framework was developed for the Spanish language. A closely related work [
19] used ontology and NLP techniques but was oriented to the evaluation of essays. We found that the authors employed the same processes, including tokenization and identification of grammatical class as a verb. These authors used only cosine similarity, while we employed two metrics, cosine similarity and Levenshtein distance. The inclusion of NLP techniques to link the text, according to the ontology rules for didactic planning assessment, is also one of our main contributions.
3. Framework Overview
A framework based on natural language processing techniques to analyze college-level subjects’ didactic planning is presented below. In addition, we create an ontology considering the information from didactic plans that an evaluation committee had previously approved. The basic assumptions of the competency learning model are:
The instructor must be a facilitator of the learning process, motivating the learner to develop skills and aptitudes in a self-taught way. The teacher must prepare the learning environment with teaching strategies that consider the context.
According to the desired graduate profile, the teaching process must focus on developing competencies, emphasizing actual problems and context applications.
Depending on the established competencies, the formative assessment takes into account the student’s achievements and development of their abilities during the course.
The goal was to develop a framework capable of detecting the key elements that each of the planning sections should contain and identifying the inter-related sections. Below, we describe the framework architecture.
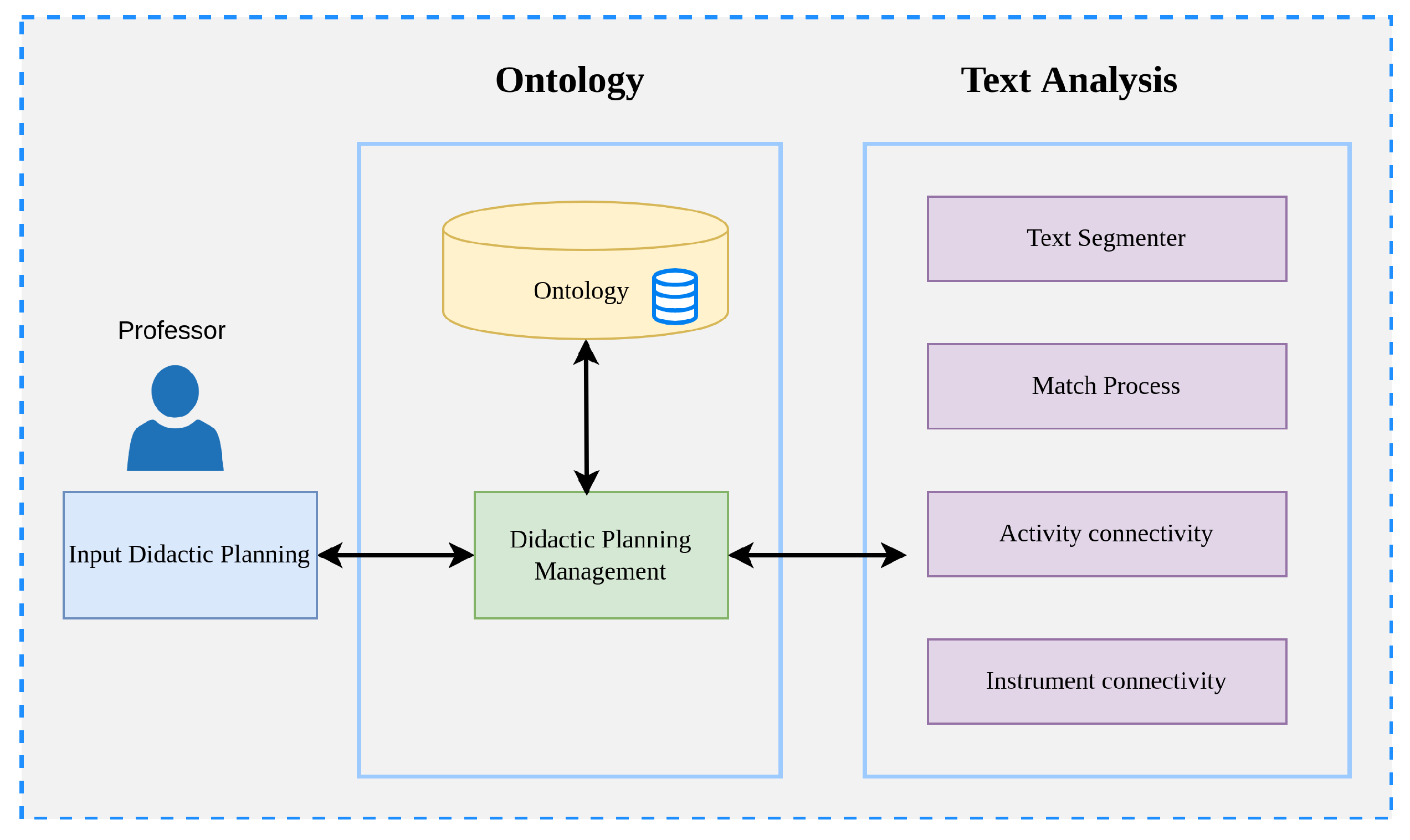
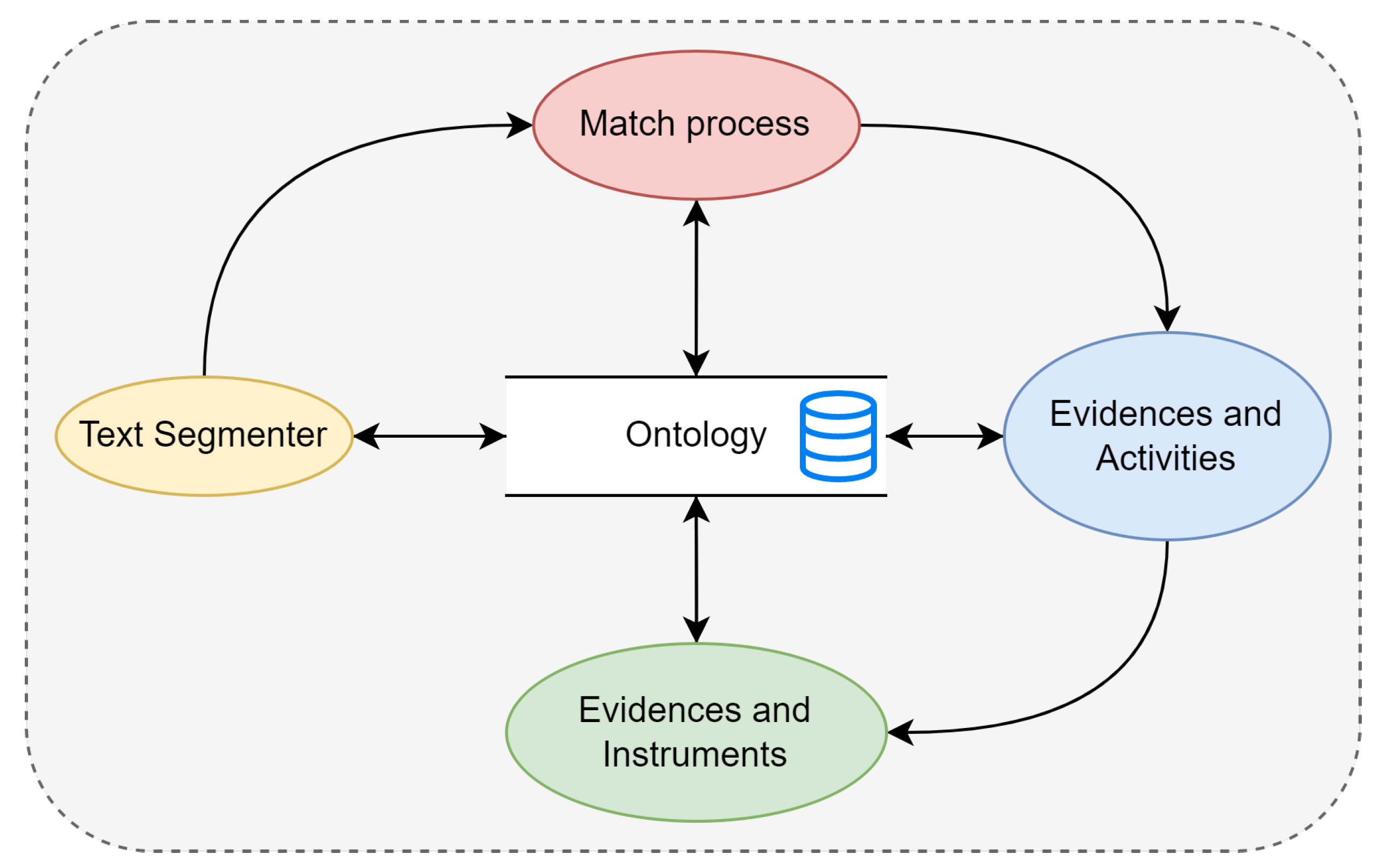
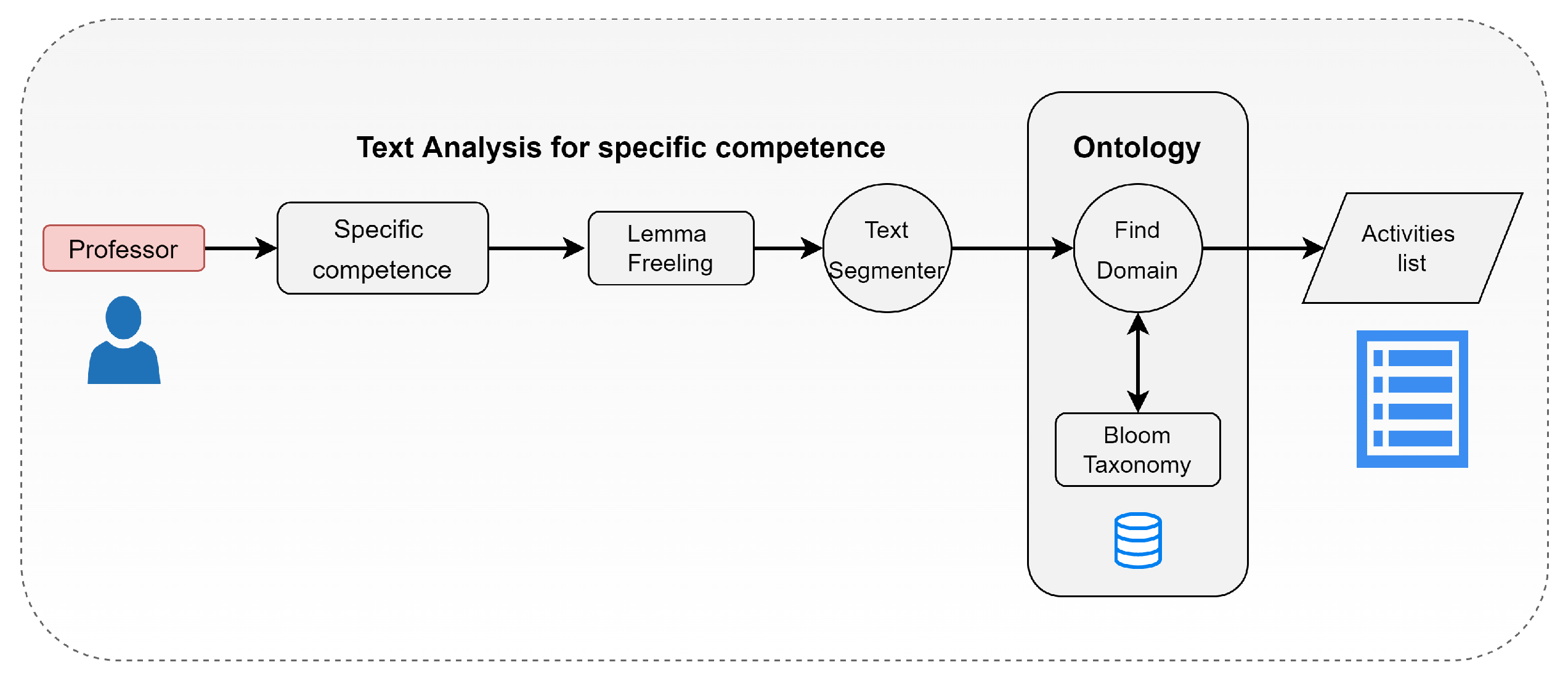
In
Figure 1, we can observe two components: the first focuses on ontology, while the second shows the methods employed for the extraction and analysis of text in free format. Both components maintain inter-communication for the retrieval and extraction of information. One of the first steps in this model is to segment competence into three elements, the verb, object, and purpose, where the main verb of the competence is analyzed under Bloom’s taxonomy. It is essential to note that when the didactic planning is designed, there is a gradual increase in the student’s activities and expected results. For instance, it is commonly observed that, in the first unit of planning, the concepts of the main topics are established and activities are defined for the student to appropriate that knowledge. Later, in subsequent units, the subject is deepened, and the learning evidence requires further elaboration by the student.
Bloom’s taxonomy, proposed by Benjamin Bloom, is a six-part cognitive model focused on a person’s thinking skills. This model increases in complexity as one progresses from higher-order to lower-order thinking skills [
3]. Bloom sought to order the cognitive processes of the students hierarchically. For example, the ability to evaluate is based on the assumption that the student must have the necessary information, understand that information, apply it, analyze it, synthesize it and, finally, evaluate it. The six levels are knowledge, comprehension, application, analysis, synthesis, and evaluation. In Anderson’s work [
20], a review of Bloom’s taxonomy is presented, redefining some of the levels. At the highest level of the original taxonomy is assessment, while in the revised taxonomy this is before the creation level. The six levels established in the revised taxonomy are: memorize, understand, apply, analyze, evaluate, and create. In addition, the definitions of the levels was changed from using nouns to verbs. Our work employs the original taxonomy as a reference, since we found it to be more suitable for the engineering discipline of our research.
This taxonomy leads the instructor to use appropriate verbs in each thematic unit of planning in our work. In this way, when the instructor carries out the planning, this gradually influences the student’s learning level upwards.
The framework’s input data to perform the analysis are: competence, syllabus, learning activities, teaching activities, the learning evidence, and assessment instruments. These elements are part of the didactic planning.
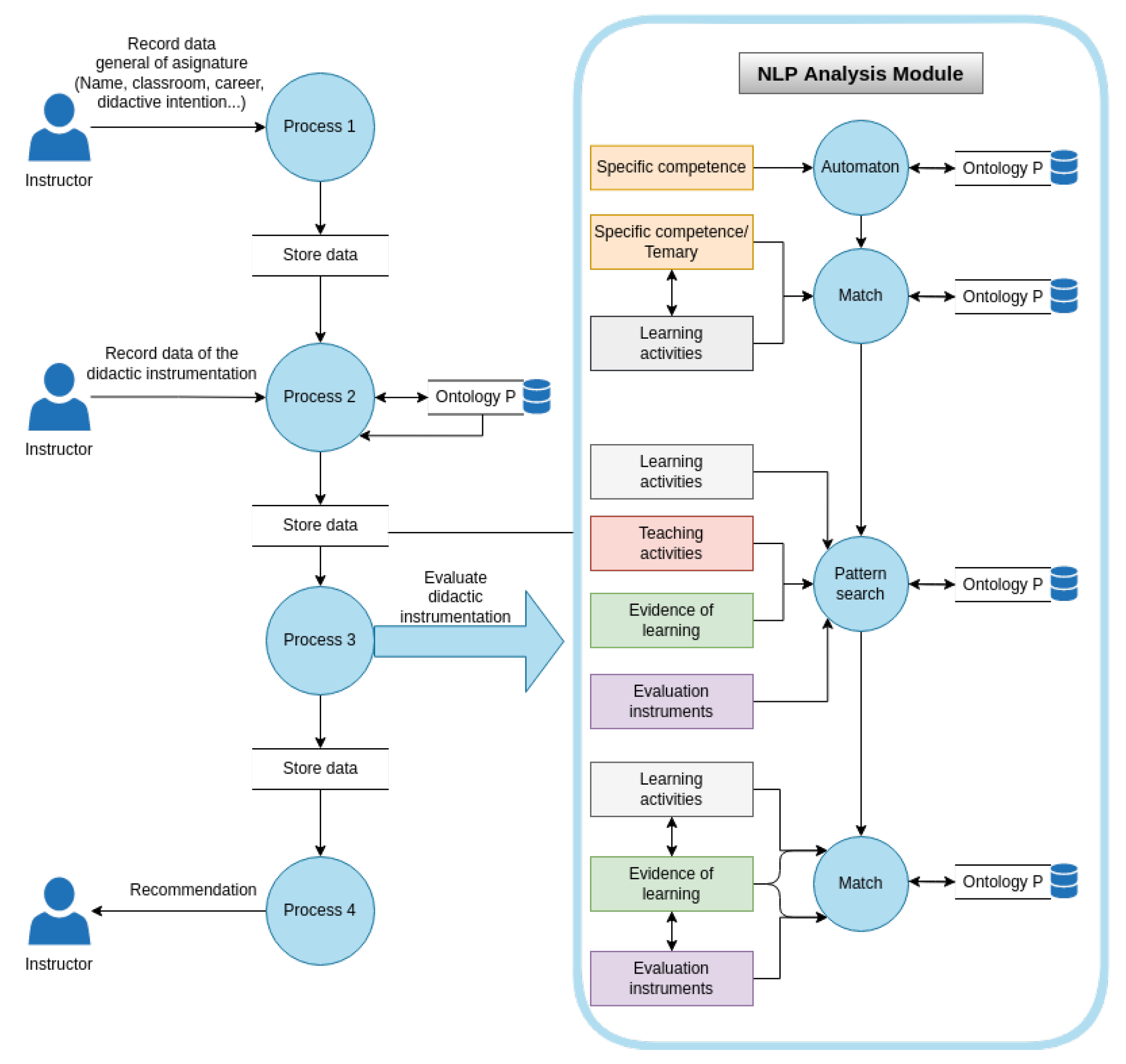
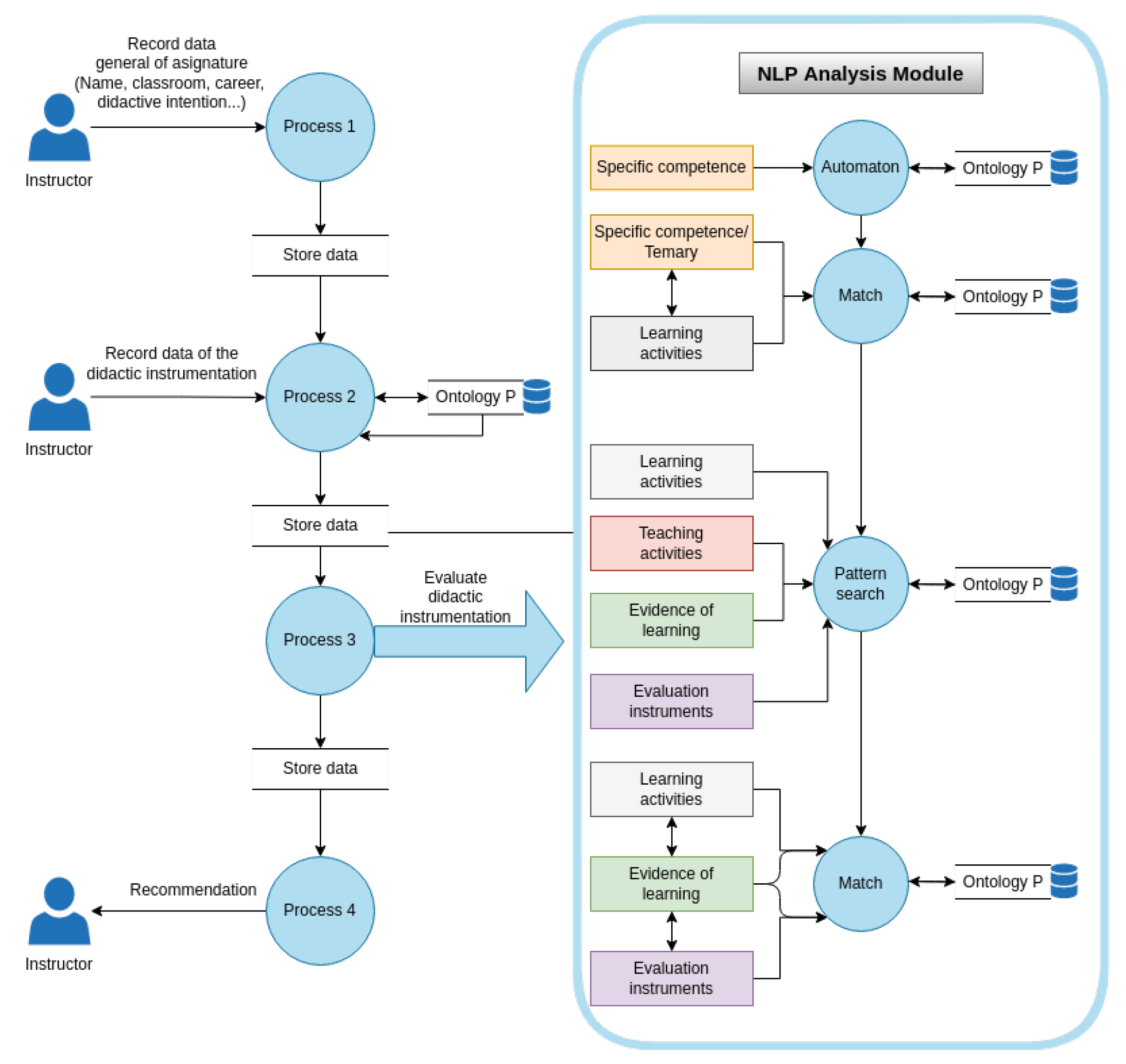
Figure 2 shows a flow diagram of the processes that are carried out to evaluate didactic planning.
Process 1: As a first step, the instructor submits the general course data for the didactic planning, such as the name, the course code, degree level, and the didactic intention, among other data contained in the official document of the course.
Process 2: In this process, the instructor writes (in his/her own words) the data that will be analyzed by the algorithm presented in this article, as shown in
Table 1. Starting from a specific competence and the course syllabus, the instructor will plan which learning and teaching activities to apply during the course, considering the student’s evidence to deliver, and the instruments to evaluate the course results.
Process 3: Subsequently, an evaluation of the sections that make up the didactic instrumentation registered by the teacher is carried out. The evaluation sequence involves four stages:
- -
Automaton: the specific competence segmentation is carried out to identify if it complies with the three elements that it must contain and determine the verb level in Bloom’s taxonomy. The correct wording of this sentence is essential to improve the probability of a match in the following process.
- -
Match: In the first match process, the aim is to identify a relationship between the learning activities and the specific competence of the unit, considering that the activities must be planned to comply with the competence.
- -
Search for patterns: an activity or evidence has a pattern, i.e., a verb followed by an activity and a topic associated with the current unit.
- -
Evidence of activities: As a result of a learning activity, there must be at least one piece of evidence expected from the student. Three different evaluations were employed to find the connection: a match between the learning activity and the evidence activity, a fuzzy match to find a paraphrase in its counterpart, and finally, an unsupervised clustering technique. Based on the three evaluations, an estimate is obtained to determine whether there is evidence for each proposed activity.
- -
Evidence evaluation: Finally, whether the instructor’s evaluation instrument is adequate for the learner’s evidence is judged.
In each of the steps just described, the algorithm relies on the relationships inferred by the knowledge model to increase the probability of finding patterns between the analyzed sections.
Process 4: Finally, the results obtained by the NLP method and the knowledge model are sent to a recommendation module that, based on the metrics, indicates to the instructor whether its didactic planning complies with the grammatical structures and relationships necessary to move on to the final phase: the human review. In this work, we focus on the didactic planning analysis method. However, in an advanced version of this project, the system sends thirteen types of recommendations because two kinds of advice are given for each of the elements: verb, infinitive verb, the relationship between competence and learning activities, the relationship between learning activities and learning evidence, and the connection between learning evidence and assessment instruments. The first time an error is found, a list of recommended learning objects is displayed for each specific case. For example, if the competence does not have a verb and it is the first attempt, the recommendation will be displayed: “Remember that competence requires a verb that indicates what the student will do to demonstrate its performance. It is recommended that you review the following learning objects and try again”.
4. Ontology Component
The ontology design was based on the methontology methodology [
17], which integrates five tasks: specification, conceptualization, formalization, implementation, and maintenance. The domain of the proposed ontology is limited to the elements of didactic planning of academic program subjects at the undergraduate level in information systems in the Spanish language.
The acquisition of knowledge was carried out with experts in the area to create a glossary. The ontology was fed from the knowledge of two instructors of the computing area. Both instructors had completed graduate studies, with around 20 years experience of teaching, lecturing, and doing didactic planning. One of the instructors had also completed speciality studies in education. In addition, we followed recommendations of teachers in the design of didactic sequences based on high school education competencies [
16].
Table 2 shows a partial view of the results for the concepts of teaching activities and generic competencies. There were 83 classes (21 main classes and 69 subclasses) and 486 previously defined individuals, representing the most used didactic material in the domain and corresponding to those described in Bloom’s taxonomy. The organization of tacit (empirical) knowledge is complemented with explicit (theoretical) knowledge regarding the methodology to elaborate correct didactic plans. The main elements are related to a specific competence that determines what goal should be met at each thematic unit’s end.
Based on the experts’ information, a relationship was identified between the unit’s specific competences and Bloom’s taxonomy, indicating the level of cognitive ability to be achieved in the thematic unit. A competency can belong to more than one level of the six that make up the taxonomy. The learning and teaching activities must consider the maximum level of competence and include activities for the previous levels until reaching it. For example, if the application level (level 3) is chosen, then activities at the knowledge, comprehension, and application levels must be considered to comply with the methodology.
Consequently, the ontology makes sense of the different classifications needed and the relationships established between the individuals that belong to more than one cognitive level. Therefore, it is not necessary to establish all the relationships in the model. Employing the inference engine, it is possible to deduce some correlations that generate knowledge.
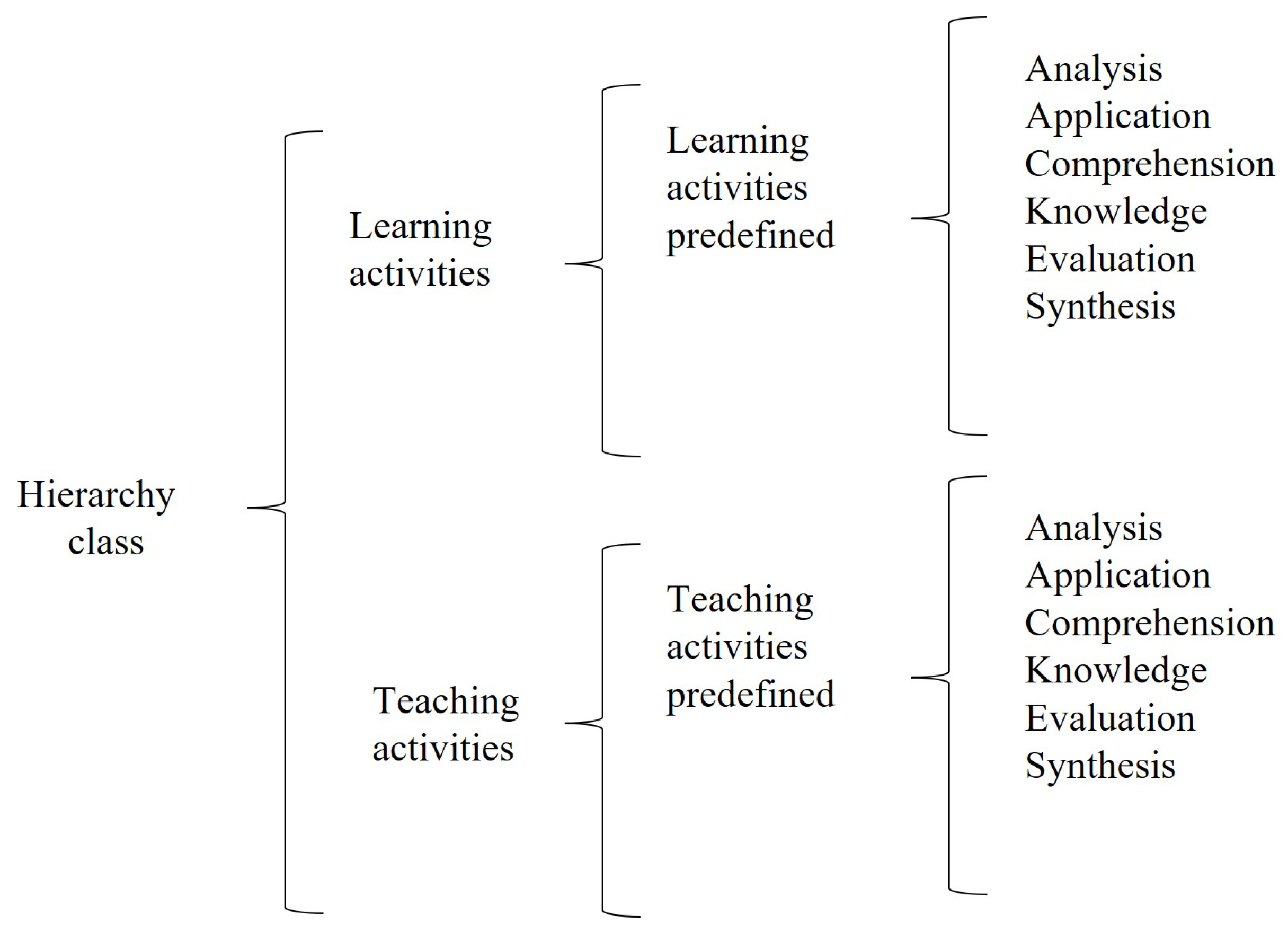
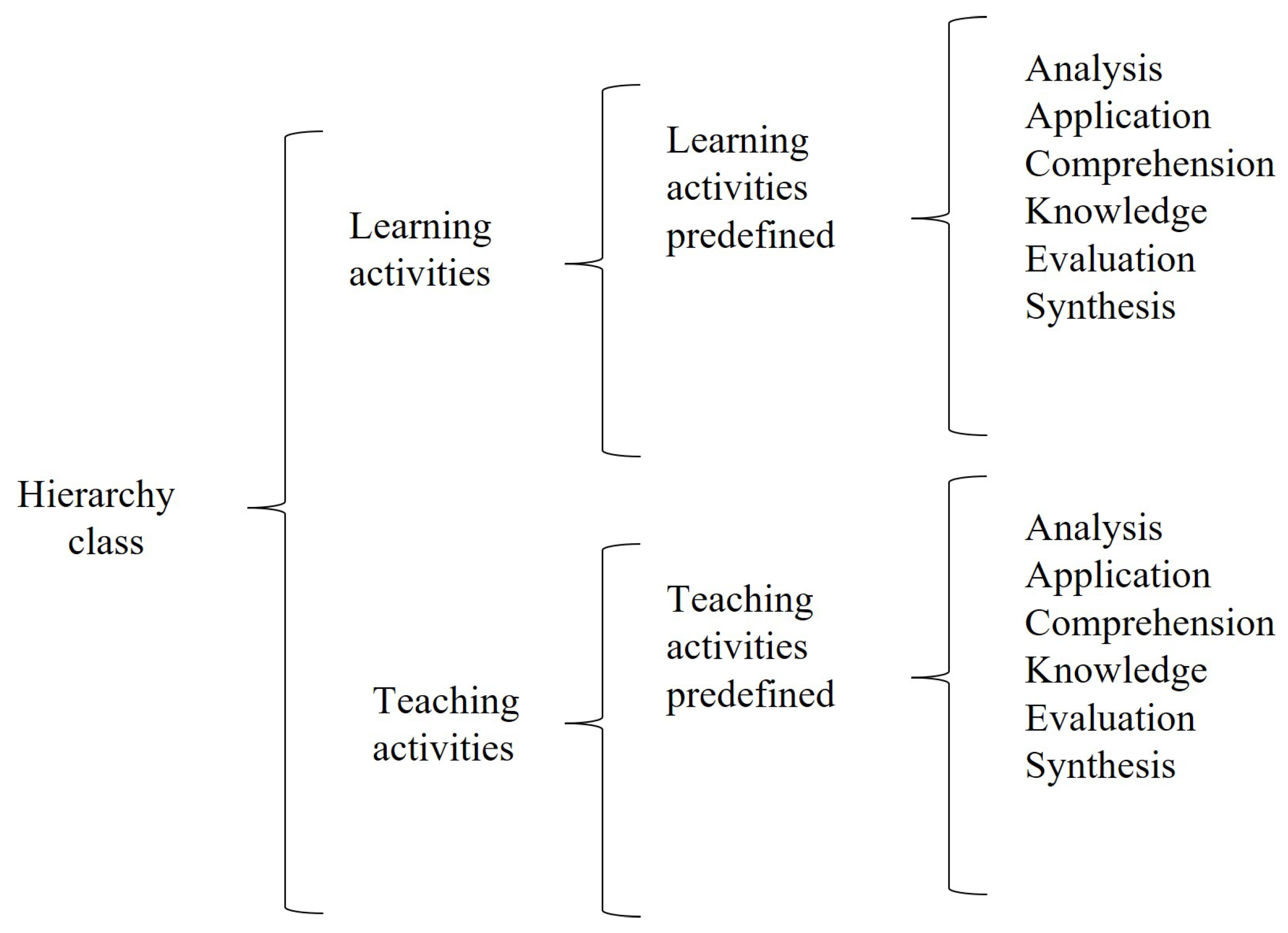
Figure 3 shows a partial diagram of the class hierarchy. This hierarchy is defined based on Bloom’s taxonomy. Within each concept, there are six levels of verbs of the taxonomy.
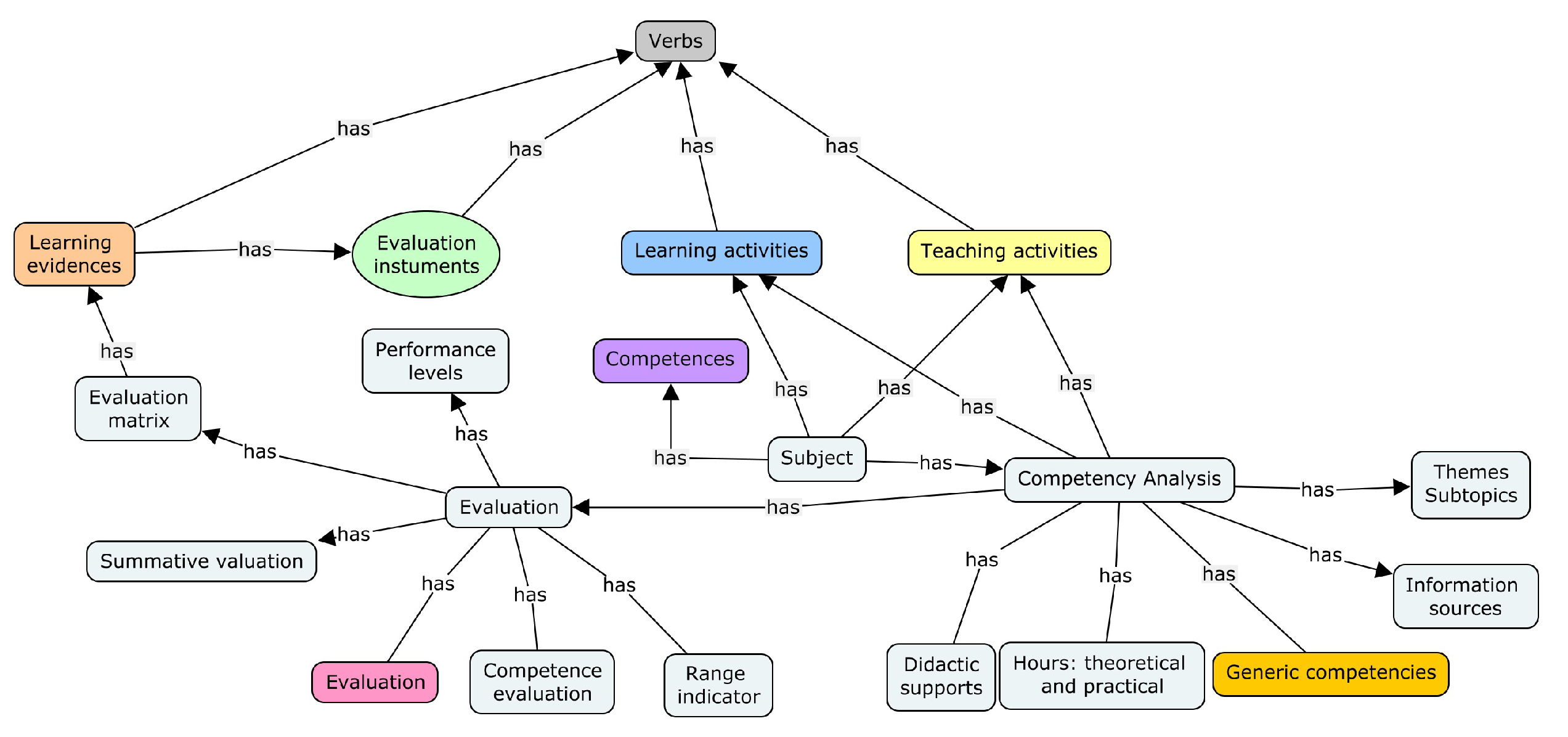
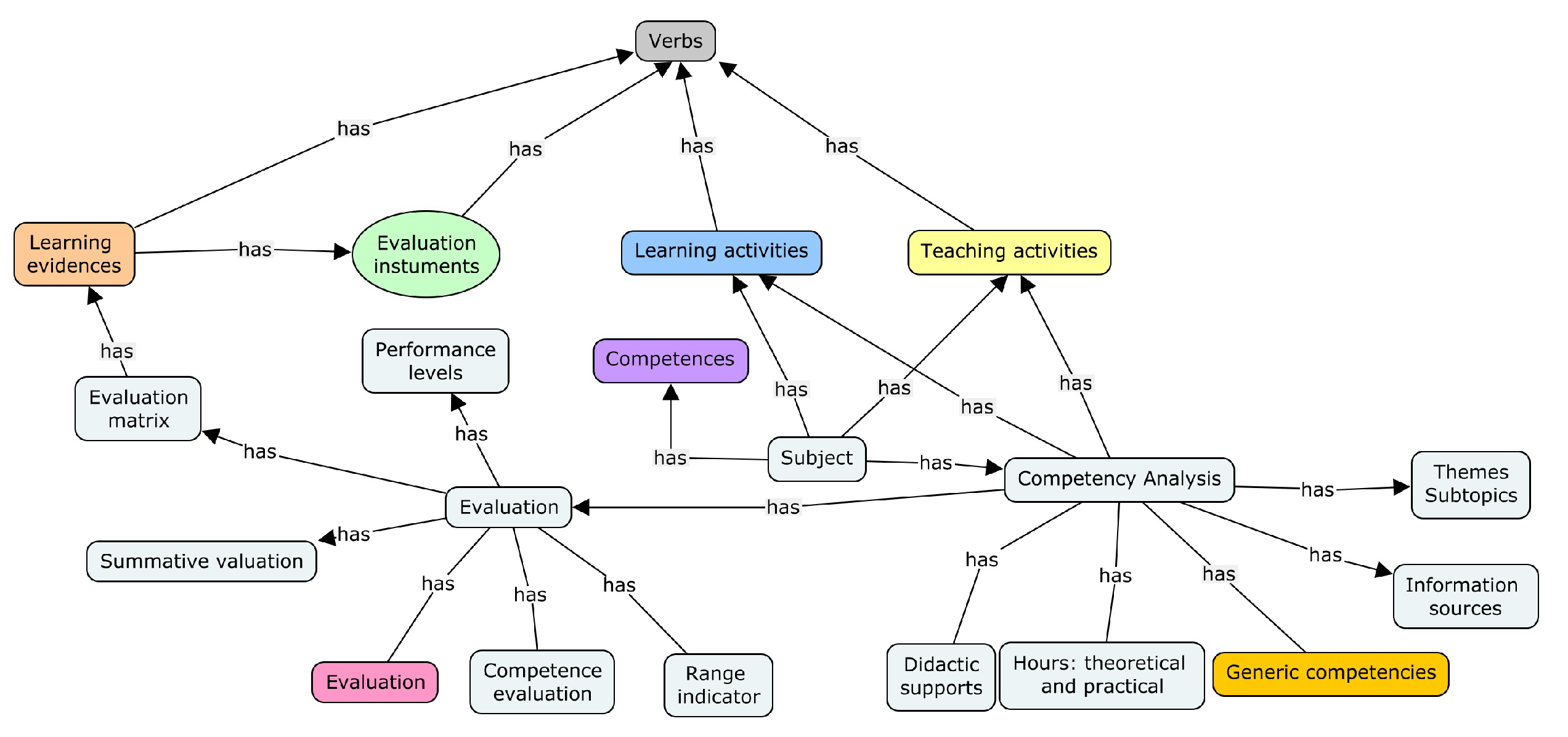
Figure 4 shows the general diagram of the existing binary relationships between the main classes of the ontology, where the categories that are classified based on Bloom’s taxonomy are “Learning evidence”, “Evaluation instruments”, “Learning activities”, and “Teaching activities”. The competence class is directly related to the learning activities, the teaching activities, and the evaluation method. Teaching and learning activities should consider a domain verb, while the evidence may omit it. Ontology super classes are those whose levels have subclasses, and are shown in a dark color tone.
To implement the ontological model, the open-source ontology editor Protege was employed. The ontology is involved in several processes; one of them is when component two extracts the main verb. The first step is to identify the verb in the ontology, the related verbs, and their activities with respect to Bloom’s taxonomy. If the verb is applicable, then the levels of knowledge and comprehension are considered, alongside the inference engine’s activities. The ontology is also in charge of finding similar concepts. For instance, from the sentence “make a PowerPoint presentation with slides on NLP”, three activities are detected: “presentation”, “PowerPoint”, and “slides”. A query is submitted to the ontology to find similar concepts—if any activity corresponds to a verb, this is removed. Subsequently, which activity is accompanied by a verb is sought (in this case, PowerPoint). Therefore, the “slides” activity is discarded.
An example of learning activities and evidence is given below:
In this case, the algorithm does not identify that C# is a programming language but identifies that the synoptic table is a diagram. Using the synonyms, it is possible to identify that a synoptic table can be a comparative table. This knowledge is inferred, since both elements are related to the word diagram’s knowledge model (ontology). Therefore, the relationship is valid. Finally, each piece of evidence has associated instruments, and then it is identified which activity is the evidence. After that, a query is submitted to the ontology with that activity, and the possible evaluation instruments are retrieved. The ontology’s function is to facilitate the classification based on Bloom’s taxonomy of activities and verbs and to infer the relationships to obtain synonyms and relationships between words.
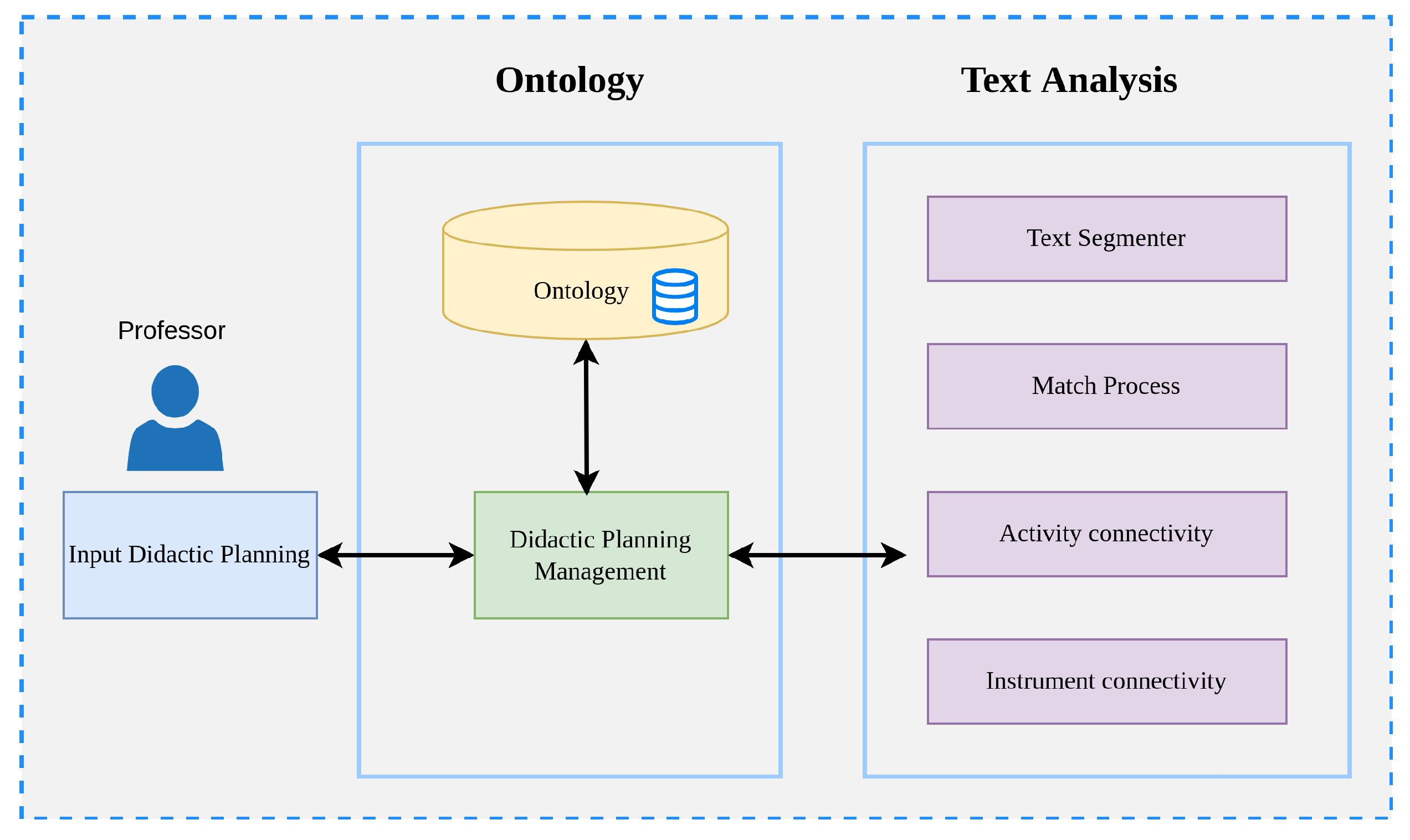
5. Text Analysis Component
The second component of our framework focuses on the application of natural language processing techniques. The search for existing patterns in the sections that make up the didactic planning involves evaluating the text in free format.
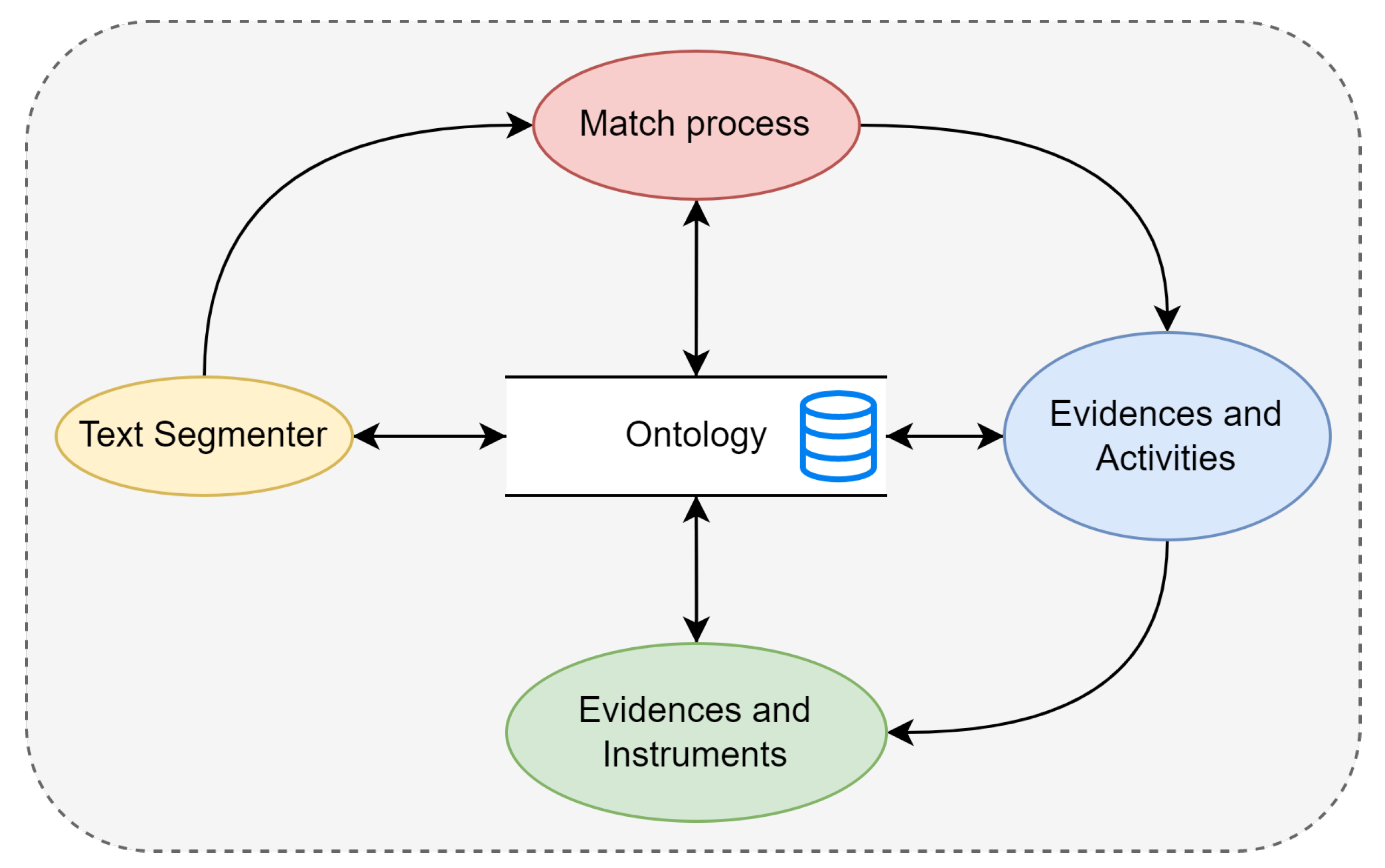
Figure 5 shows the general design, starting from the segmentation of the unit’s specific competence to finding the competence’s linguistic structure and its main components. Afterwards, a lexical-syntactic comparison is performed between the filtered elements to determine their similarity (match process). The evidence and activities process identifies whether the learning activities are connected for at least one evidence example. Finally, the last process matches the evidence with the instruments to determine whether the selected instrument is adequate, based on the evidence. Each process can be carried out separately and gives an evaluation result, but they need to maintain the sequence since each depends on the previous one.
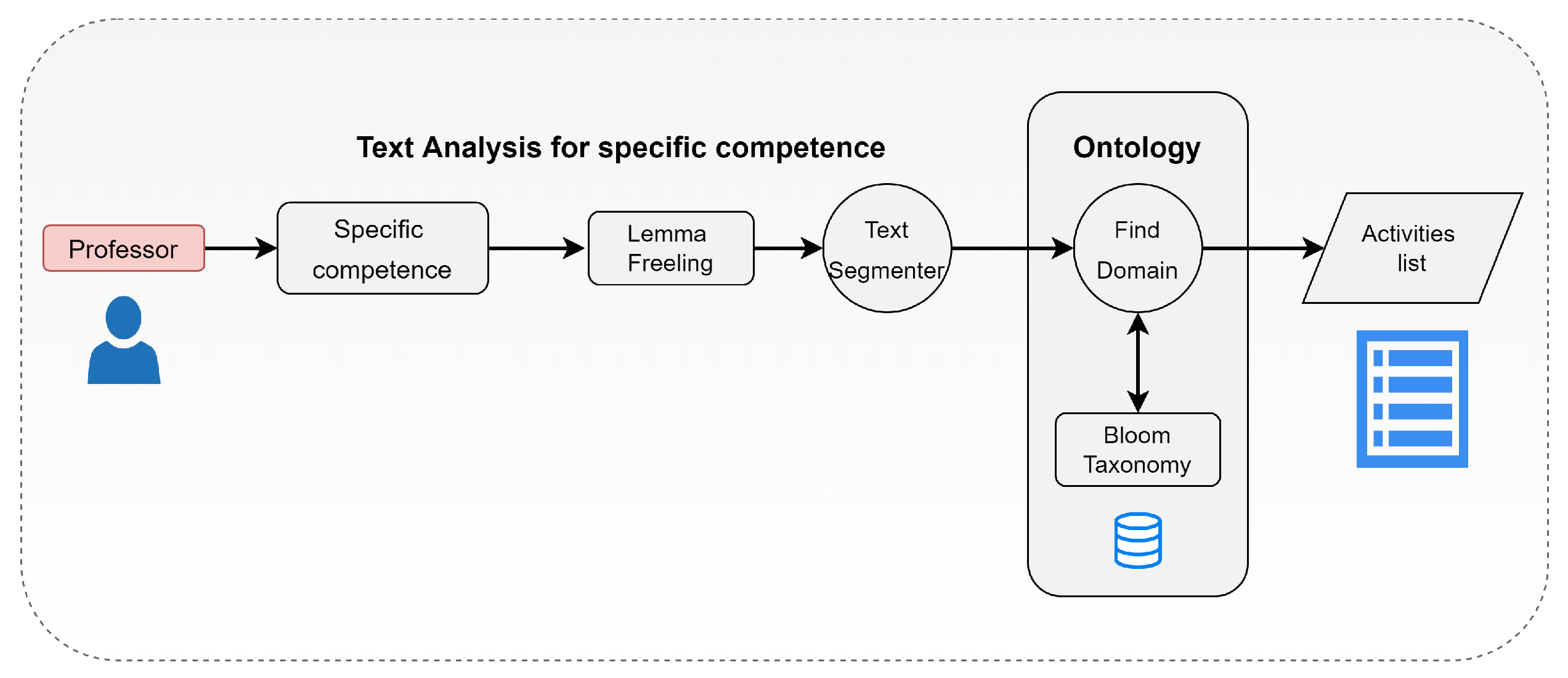
5.1. Text Segmenter
In this process, the component considers that a specific competence must contain a verb that identifies the domain to which it pertains, based on Bloom’s taxonomy. Competence is composed of three sections:
Competence = verb + object + purpose or performance condition
We designed a method to carry out the segmentation, using morpho-syntactic analysis to find the words’ root (lemma) and identify each grammatical role of the terms (tokens) in the sentence. We used the Freeling Library [
21], that returns the base form of words and POS tagging (part of speech category tagging).
Figure 6 illustrates how the segmentation process works. The verb that accompanies the learning object allows retrieval of the information stored in the ontology, establishing a filter dependent on the cognitive level for the written competence. Identifying the third element is also essential because it must maintain a relationship with the unit’s learning activities.
The morphological analysis by Freeling allows generation of the label of the grammatical category of a sentence’s words, providing a nomenclature depending on its classification, such as category, type, or gender, among others. The segmenter uses the words whose label indicates that it is a verb (V), conjunction (C), a noun (N), a pronoun (P), a preposition (S), or punctuation mark (F). For example, when the competence “Comprehends and applies linear data structures for problem-solving” is analyzed, the result of the competence segmentation process is the following:
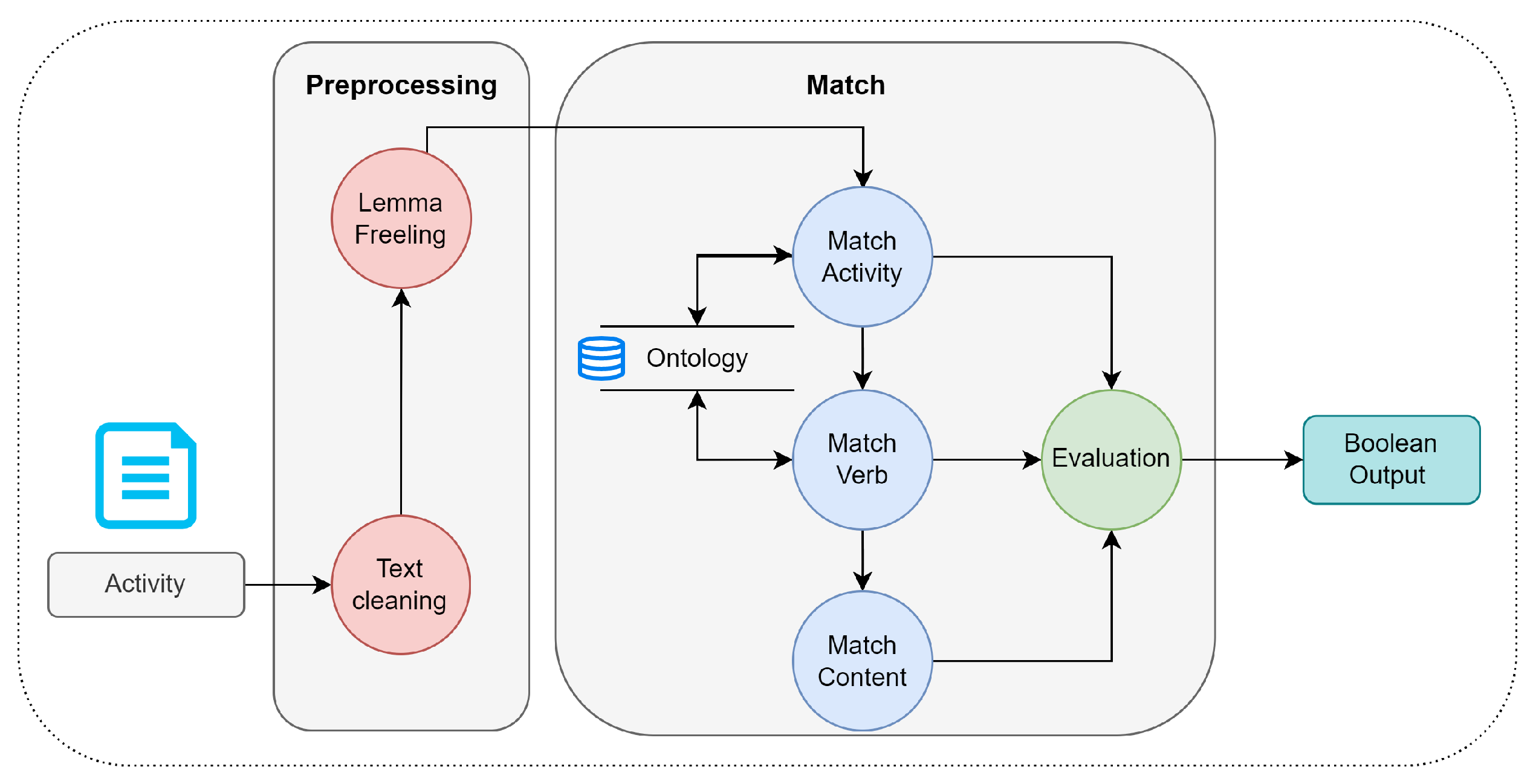
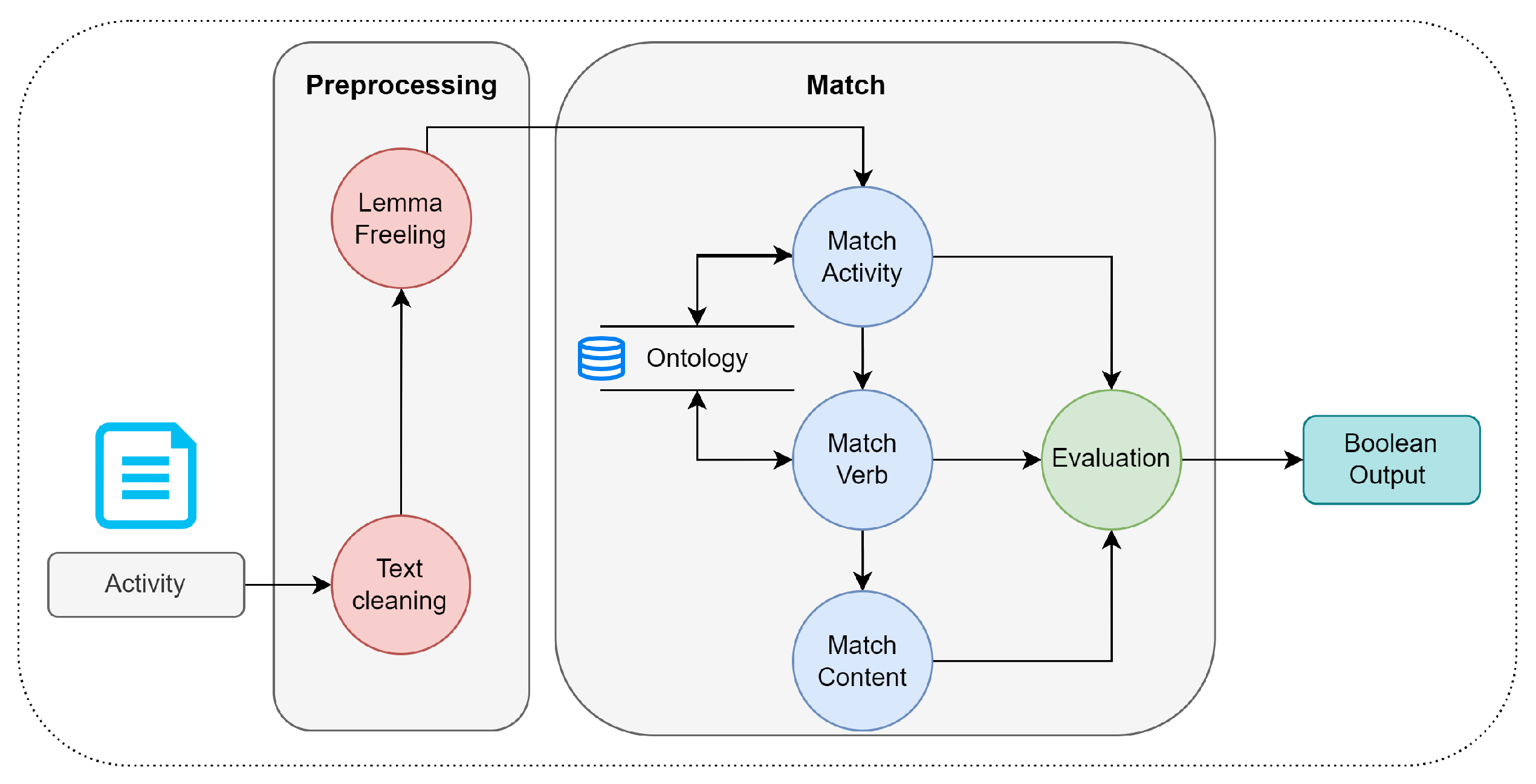
5.2. Match Process
The matching process consists of two parts. First, the unit’s specific competence and learning activities are compared, so the different activities (learning, teaching, evidence, and instruments) have to be recovered and formulated by the instructor. Similar to a competence, an activity has a structure, as shown below:
Activity = verb + activity + topic
Figure 7 indicates the flow of information from the written activity to the result. The first step performs a pre-processing of the text, eliminating functional words (such as connectors and prepositions), and normalizing (eliminating capital letters, punctuation marks, word stemming), leaving only the words that provide relevant information for the analysis. Subsequently, the main activity is identified to detect later if there is a verb that accompanies it. Note that the activity and verb must belong to the catalogue available in the ontology. Later, it was identified if the activity is related to any subtopic of the current unit, to finally perform a joint evaluation of the three elements, resulting in a Boolean value that indicates whether the structure of the activity has been met.
The instrumentation elements analyzed in this process are teaching activities, learning activities, learning evidence, and assessment instruments. Within the match process, it is defined that the evidence may lack a verb, and, even if it does, its wording is considered adequate. The instruments lack a verb and subject, so the activity is only searched in the match process.
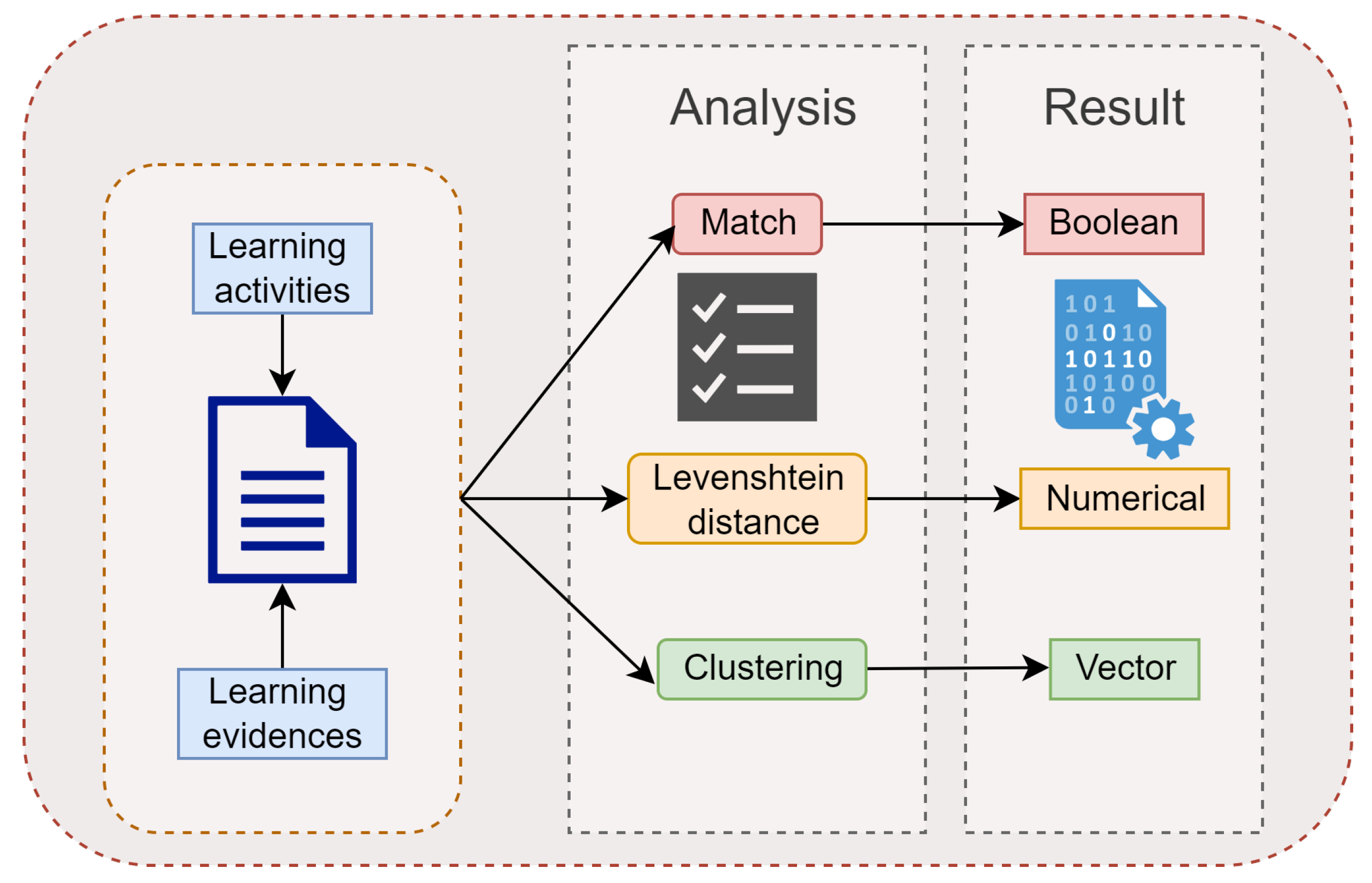
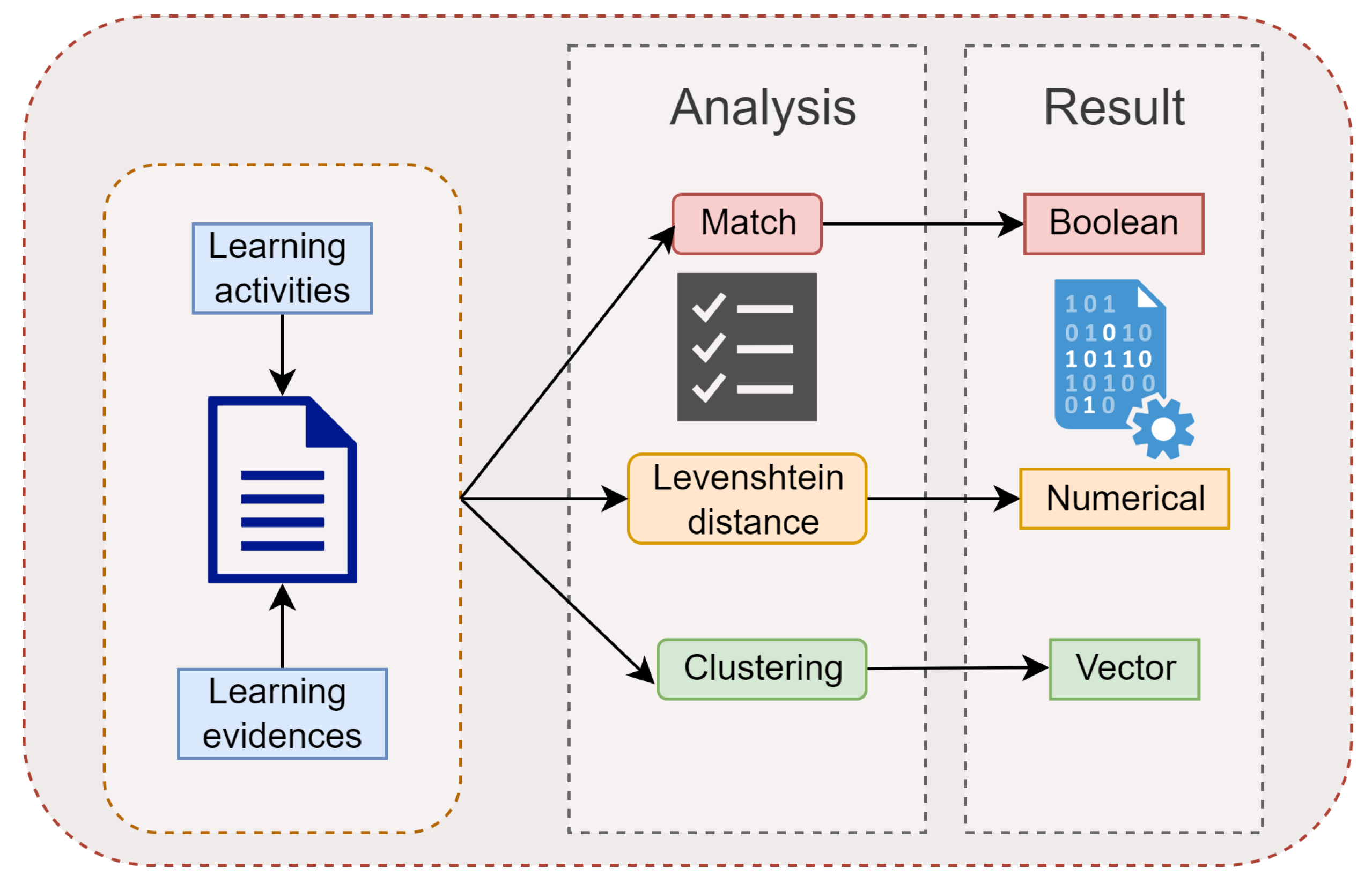
5.3. Evidence-Learning Activity Connection
This process seeks to identify the existence of evidence for each learning activity.
Figure 8 includes the diagram corresponding to this process, where three different methods can be identified that together produce a single correspondence value.
Match: The activity found in the previous process must appear in both texts. In addition, the synonyms stored in the ontology are considered, increasing the probability of a match. From this analysis, a Boolean value is obtained that indicates the existence or not of the relation.
Fuzzy match: This comparison is based on the Levenshtein distance that reflects the editing distance to determine the difference between two sentences. The writing of the evidence is considered a paraphrase of the proposed activity. When doing a partial analysis of the texts, their similarity should be high concerning the rest of the group, determining their similarity level by considering an acceptance threshold, which results in a numerical value.
Unsupervised clustering [
22]: Clustering organizes elements that share particularities, finding patterns using feature extraction techniques and the cosine similarity metric. TF-IDF (frequency of term-inverse document frequency) allows evaluation of the relevance of a word within a text by converting the strings into a vector representation of n components, where the angle between the vectors is measured through the cosine function, resulting in their degree of similarity. Finally, we obtain a vector with similar elements grouped. This was performed employing the library sklearn.cluster.KMeans.
The results obtained from the three methods give higher relevance to the match method since it was clear that the activity must appear in both texts. The other two processes allow for confirmation of the relationship and establish the degree dependent on its values. When combining the methods, a correlation threshold was obtained, classifying the relationship as acceptable, under review, or non-existent. For instance, suppose that the didactic planning contains the learning activity: “Develop a conceptual map to explain artificial intelligence”, and it also contains the evidence: “Develop a presentation that allows you to explain artificial intelligence”. If we employ the Levenshtein distance and clustering functions with the above learning activity and evidence as inputs, then the output will be a high similarity score. However, the relationship between the concept map and presentation is non-existent, so that it would be considered as “under review”.
The existence of the activity is not enough. For example, if the didactic planning has “Create a conceptual map to explain artificial intelligence”, and, as evidence, “Create a conceptual map on mobile devices”, the predicates do not correspond to each other, leading to low similarity, that, according to the threshold, would not be enough to be considered suitable (even when the learning object is available). For this, the fuzzy match and clustering process are pertinent to identify if the sentence predicates match.
5.4. Instrument-Evidence Connection and a Short Example
The last process is intended to evaluate whether the instructor’s instrument is appropriate, based on the evidence that the learner has requested. The didactic planning document contains a table, called the evaluation matrix, that indicates a direct relationship between both elements, unlike the previous process, where the correlation does not follow an order. Within the ontology, the match process’s activity for the current evidence is validated and is identified if the instrument is adequate for its evaluation. The learning activities are the nucleus of the process as they have to be related to the specific competence, the teaching activities, and the learning evidence. Therefore, the result of the relationships is dependent on the correct writing of this element.
In
Table 3, we provide a short output example of evaluation for the didactic planning by our framework. In the first step, we identify the following elements of the competence using the method in the text segmenter scheme: “Verb”: Identify, “Competence Object”: different data structures, their classification, and how to manipulate them, “Purpose”: to find the most efficient way to solve problems, “Condition”: through their classification and memory management.
Next, we show the output of three processes of the didactic planning analysis.
Table 4 shows the result of evaluating the teaching activities looking for a match between the activities retrieved from the ontology and those written by the instructor. In this process, we consider whether the domain verb has been used and the topic to be addressed. The method is described in
Section 5.2 Match process.
We can observe in
Table 4 the phrase under review, which means that the absence of a topic (course outline) allows identification of the vectors as data structures. In this case, the instructor has to review the activity. This match process is repeated with the learning activities, learning evidence, and assessment instruments.
In
Table 5, an evaluation of the evidence and learning activities is carried out. In this analysis, the match, Levenshtein distance, and clustering methods are employed, that were detailed in a previous section. There is no associated element in the example below for the first learning activity (under review). Therefore, the instructor must review the learning evidence.
Finally, in the third evidence of
Table 6, the identified activity “exercise” is not related to the evaluation instrument. It is incorrect to evaluate “exercises” with a checklist, so the framework generates a recommendation to the instructor, to review such activity.
5.5. Framework as a Feedback System
Our framework is responsible for evaluating the didactic planning of college-level subjects using PLN techniques and a knowledge model. The framework belongs to a system dedicated to instructor training and education.
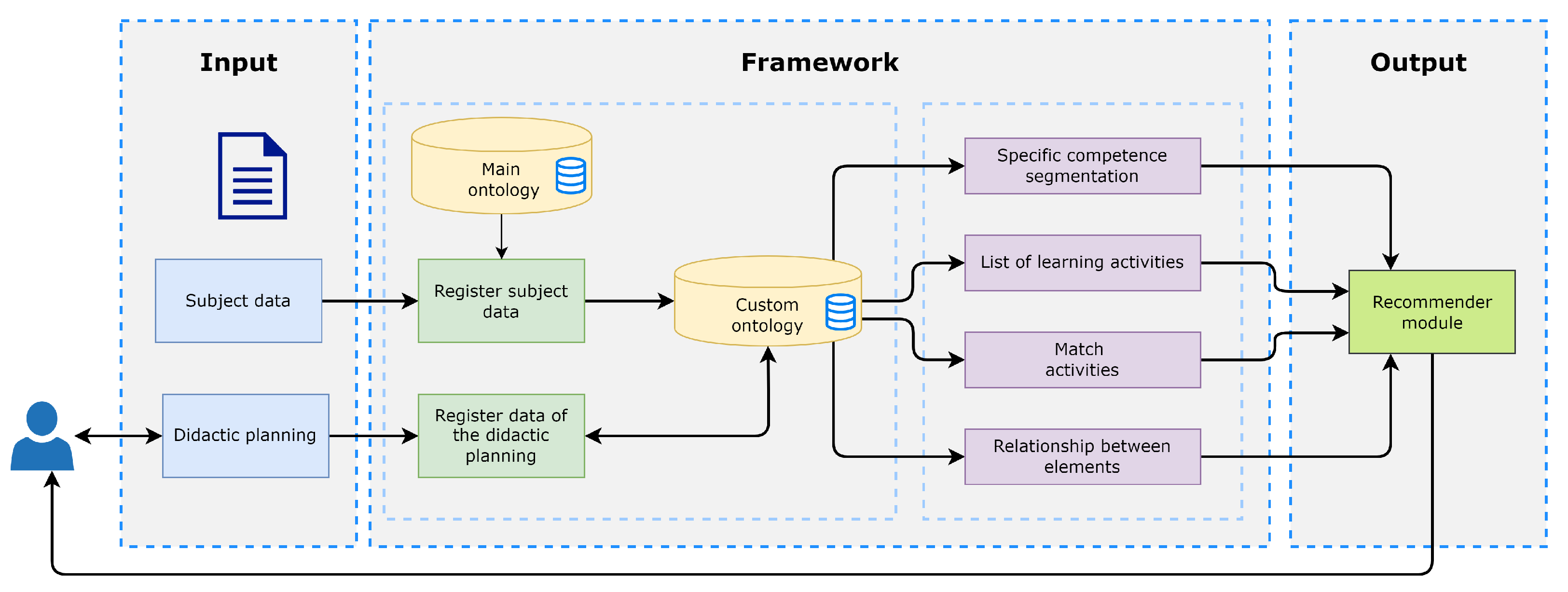
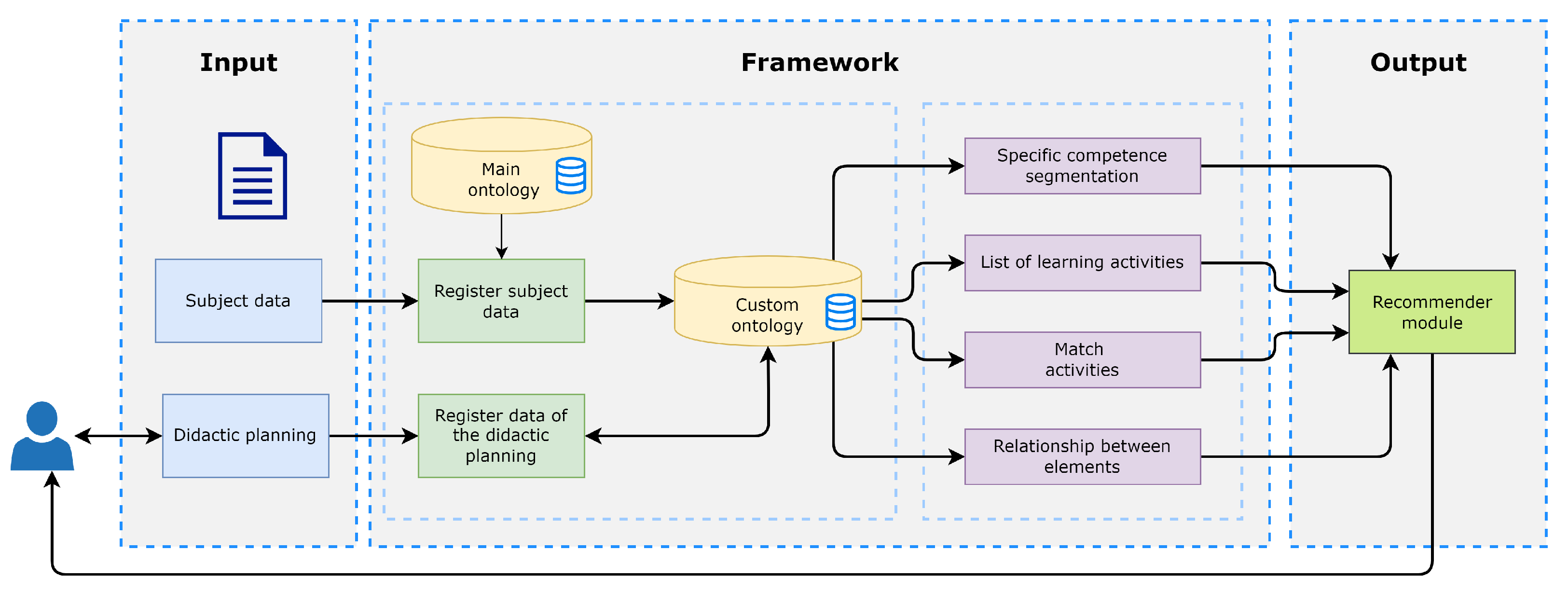
Figure 9 shows the main components of the recommender system.
Input: In this section, the instructor can specify (write) his/her didactic planning, and is able to consult the available material related to the course and the suggestions made by the recommendation module.
Framework: The function of the framework is to examine the didactic planning data using the components described in
Section 3. As a result of the analysis, metadata is obtained and sent to the recommendation module.
Output: Finally, this module receives the data from the analysis module to provide feedback. In the event of detecting deficiencies in the didactic planning, the system sends the instructor the pertinent recommendations. For example, suppose the competence does not correspond to the type of learning activities, and it is the first attempt. In that case, the recommendation will be displayed: “Remember that the learning activity must reflect the action indicated in the verb and the object on which that action is executed on”. In addition, a list of learning objects linked to the competence is displayed. If the instructor requires a second attempt, a list of learning activities is displayed.
The analysis time for didactic planning lasted 30 to 40 s. Each planning contained four to five planning units. This time covered the following:
If the competition was well written using the automaton
Comparison between competence and learning activities
Analyze if each activity is well-written
Analyze the relationship between learning activities and evidence of learning (Using ontology, fuzzy logic, and clustering)
Analyze the relationship between learning activities and evaluation instruments.
6. Statistical Results
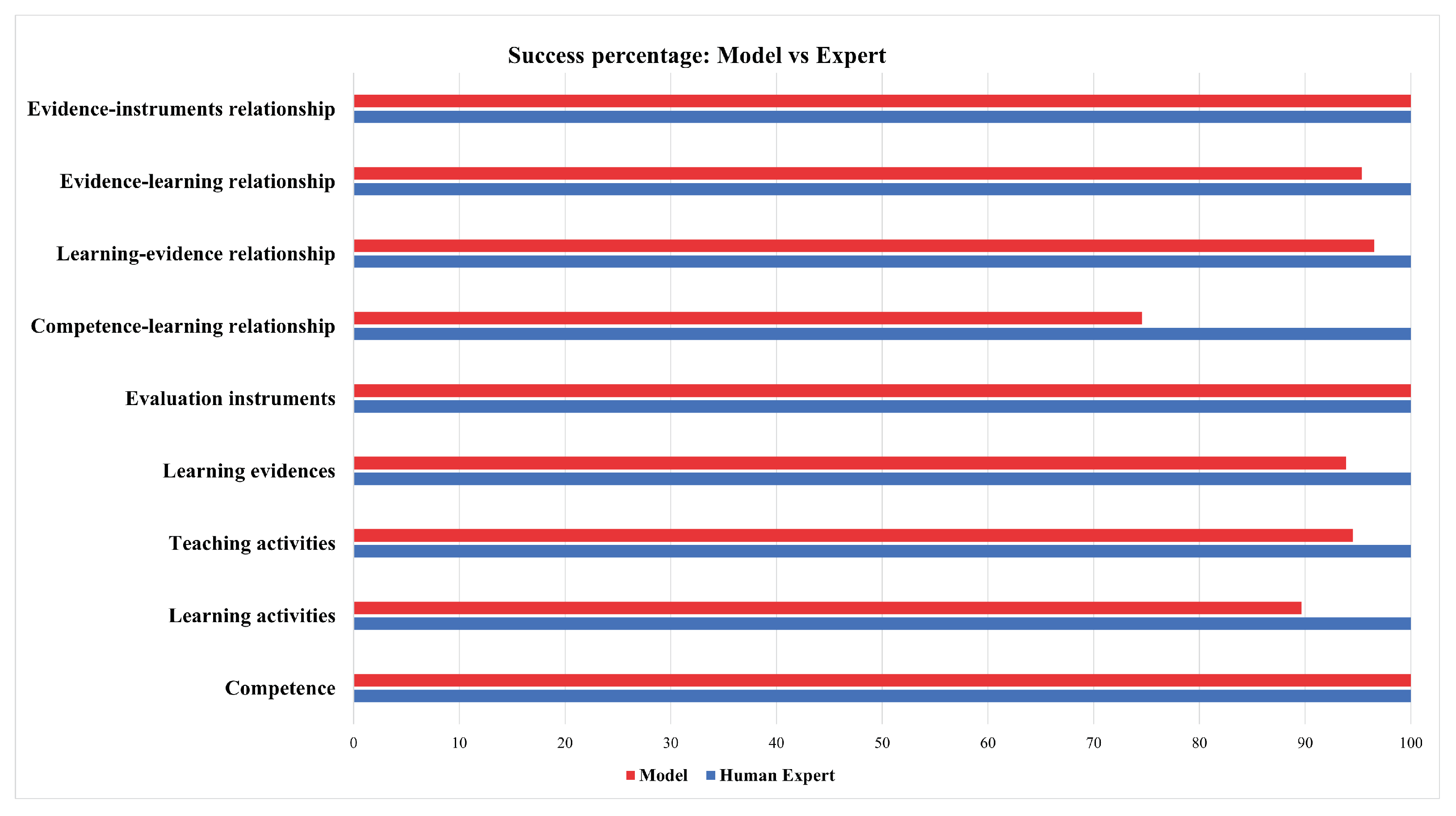
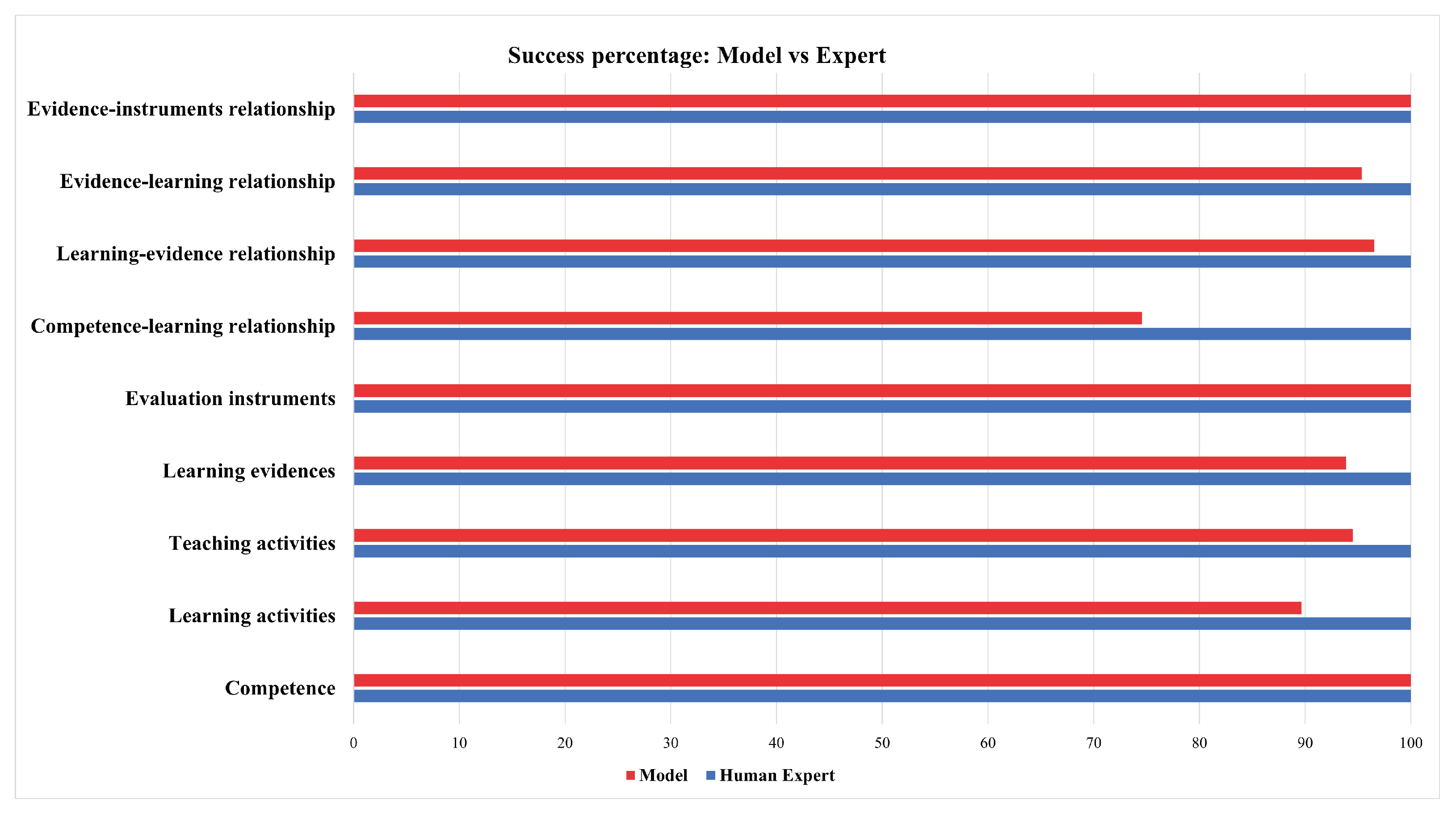
For the analysis of the results of the nine processes, we found the following: Out of the 715 elements, 658 elements had a match between the human expert and our framework. The rest were non-matches (57). These descriptive results indicate that the percentage of agreement between the expert and our framework was 92%.
Below, in
Figure 10, we detail the percentages in each of the nine processes. We can observe that the “Competence-learning relationship” process obtained the least correct answers, i.e., 75%. Competence-learning is a match of the competence with the activities to verify if the activities that the teacher is planning will help fulfill the unit’s specific competence. Reviewing the didactic plan, we observe that the teacher paraphrased the competence in an activity or placed complementary activities that were not directly related to the competence. Our algorithm does not detect this paraphrasing phenomenon and this is an improvement to include in a further version. However, reaching human performance at this point will be difficult, as it requires a process of understanding, possibly with additional costly processing (such as parsing) or resources (e.g., sentence embeddings). In the work of [
23], an analysis of classification tasks between humans and methods that used NLP was carried out; one of the conclusions was that humans will calibrate the learning results, and the algorithms will focus on refining the structure of the text. In contrast, the relationship between evidence instruments, evaluation instruments, and competence relationships reached 100% of correct answers. The complexity was lower since, at this stage, the instruments were already established, and the instructor only performed the selection. In this way, the match was facilitated for the computational algorithm.
We calculated Cohen’s kappa to obtain a result that would minimize randomness in the measurement. This coefficient reflects the level of agreement reached between our framework and the expert (instructor). Kappa is a statistical measure that adjusts for the effect of chance on the relationships involved [
24].
Pr(a) are those elements in which both experts have had a relative agreement, while
Pr(e) is the hypothetical probability of agreement by chance. Considering the results of this calculation,
Table 7 shows the 715 elements evaluated and the levels achieved.
The Cohen’s kappa scale for a value under 0 indicates that there is no agreement and in the interval from 0.01 to 0.20 is null or very slight. A regular agreement, is considered between 0.21 and 0.40, while 0.41 to 0.60 is a moderate agreement. At a higher acceptance level, a value of 0.61 to 0.80 is a substantial agreement, and, finally, between 0.81 and 1.00 is an almost perfect agreement. The lowest value of agreement obtained was 0.48 in the comparison between specific competence and learning activities. This was because in the set of elements analysed (114 items) there were cases where the learning activity did not appear in the competence. However, the expert was able to identify it based on his experience. The match between evaluation instruments reached the almost perfect level because the instructor only selected the instrument from an established list. The agreement analysis of learning evidences and learning activities obtained a value of 0.91; we believe that in this section the use of natural language processing with synonyms, in addition to clustering and Levenshtein distance, helped to obtain an almost perfect level. Regarding the first evaluation that was analysed, it managed to obtain an almost perfect level of agreement for the task of identifying the competence.
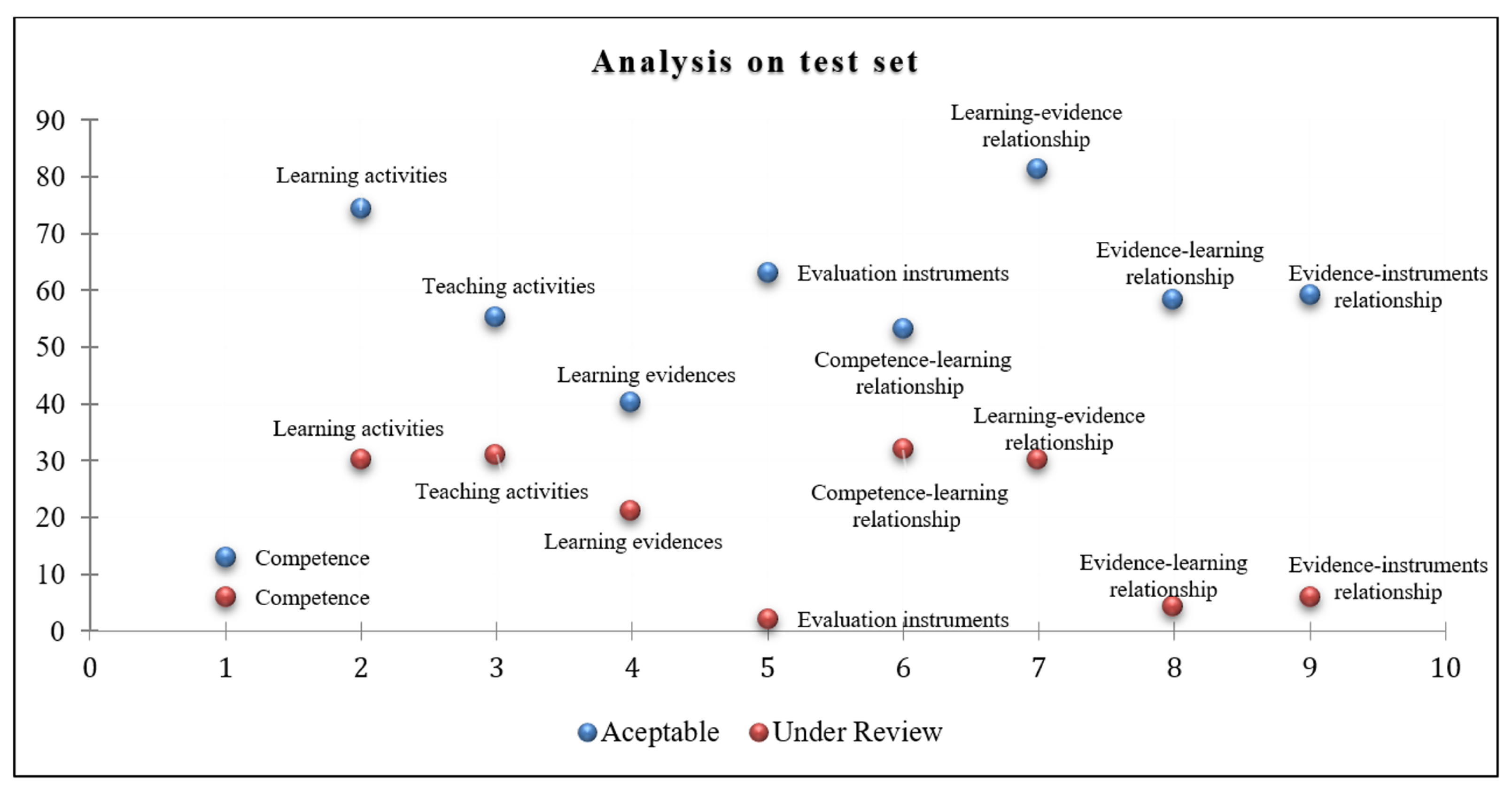
7. Analysis on Test Set
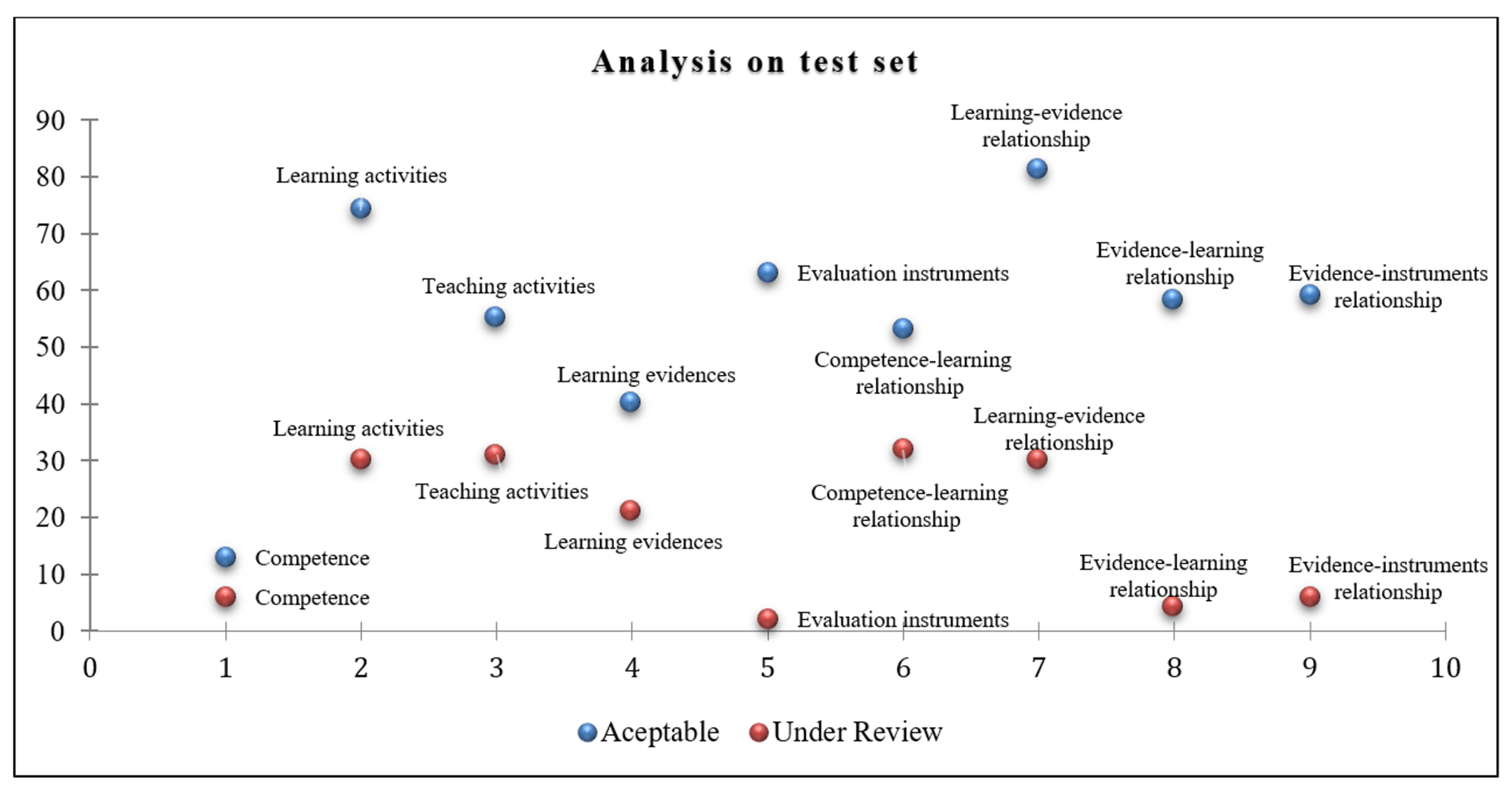
The number of elements where the expert and the framework obtained an “Acceptable” prediction was also counted, i.e., the content of the didactic planning document elaborated by the instructor fitted correctly with the knowledge of the ontology and the text analysis component. The number of elements was counted where the expert and our framework sent “Under review” (this indicates that a phrase revision was necessary). In the figure below, the nine processes are represented on the X-axis and the test set on the Y-axis.
Figure 11 depicts in blue the frequency where the expert and the framework achieved an “Acceptable” prediction, while in red, it depicts those contents that were sent for review. That is, both points (in blue and red) represent coincidences. We can infer that instructors have a lower frequency of errors or failures when writing the didactic plan. It was observed that most of the framework’s errors were due to the lack of a verb that accompanies the learning activity. The objective of this graph is to show that the failures of the designed method will be less than the successes. In the previous section, the kappa level was computed for each component. However, we sought to identify if this behavior could be supported statistically. Although there are no definitive results through a pilot test, this result indicates that the method is feasible to implement and put into practice. We performed a non-parametric correlation test to generalize the behaviour between the predictions “Acceptable” and “Under review”. After running the Spearman test, we obtained r (s) = 0.033, p (2-tailed) = 0.93, which indicates that it is very likely that this behaviour is present in most of the didactic planning that instructors develop. We might think that most learning and teaching activities will be appropriate for students to perform better. Finally, our framework’s precision depends on the handling of requirements indicated by the rubrics that the experts use to determine if planning complies with the competency-based model’s indications. However, it may be feasible for the framework to be used as a tool that assists the instructor in writing the didactic plan document. We do not intend to replace the instructor, and we intend to provide support to improve their planning, and therefore impact students at undergraduate level. However, an interesting issue is that our framework takes from an ontology the expert’s previous knowledge without training some learning model, for example, a neural network. Our approach helps a great deal in implementation processing because we require fewer resources. Our framework could, however, be complemented with a learning model, such as the BERT (bidirectional encoder representations from transformers) [
25], which would allow identifying relationships between conceptually connected words. BERT has multilingual-trained models that would serve our purposes. For instance, in
Table 3, the word “Android” was not linked to the word “mobile”, but using the BERT models, we will probably find a relationship between both words.
8. Conclusions
The evaluations performed in the didactic planning of instructors of high technological education identified deficiencies in the writing of the learning objects, which for the most part corresponded to the omission of a verb that identifies the maximum cognitive domain that was expected to be achieved when carrying out the activity, considering the levels of Bloom’s taxonomy. In a detailed results analysis, we observed that those elements where the algorithm and the expert did not coincide in the evaluation were due to the empirical knowledge resulting from years of experience in the evaluation of didactic plans, which allows human evaluators to infer relationships between elements, even when they are written implicitly. Therefore, modeling this knowledge and incorporating an infinity of possible options would imply having new rules and relationships that could harm the knowledge inference of the current framework, although they benefit it on some occasions.
Our framework’s results show that it is feasible to use NLP techniques and knowledge models for the analysis of didactic plans of higher education instructors. It is also vital to understand that the framework is not intended to impersonate certified evaluators but to be a support for them and for the instructor, who will benefit from obtaining immediate feedback. We observe that our method’s time to evaluate didactic planning was approximately 25 s against the more than 30 min that a human evaluator would invest in performing the same task. In light of this, we consider that the use of the proposed framework can reduce the workload of instructors.
The designed knowledge model, based on experts’ knowledge from the department, is another contribution of this research since it contains properties that allow inferring knowledge, given the predetermined relationships. However, it is not possible to consider all the possible situations presented in didactic planning, so its viability depends on the experts’ evaluation perspectives who were the source of the modeled knowledge.
We expect to integrate the framework into a platform dedicated to instructor training and education based on the competency-based model in future work. We plan to carry out a pilot test with new didactic plans that follow the methodology to obtain a new evaluation comparison that helps determine if the instructor has improved in the writing of his/her activities and the relationship between the sections, starting from the specific competence up to the evaluation instruments.
The knowledge model designed is limited to the technological domain, so evaluating other knowledge areas is beyond its scope. That is the reason we plan to increase the number of predetermined elements of the framework to provide higher coverage.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}