
A Traffic Event Detection Method Based on Random Forest and Permutation Importance


Abstract
:1. Introduction
2. Related Work
3. Proposed Method
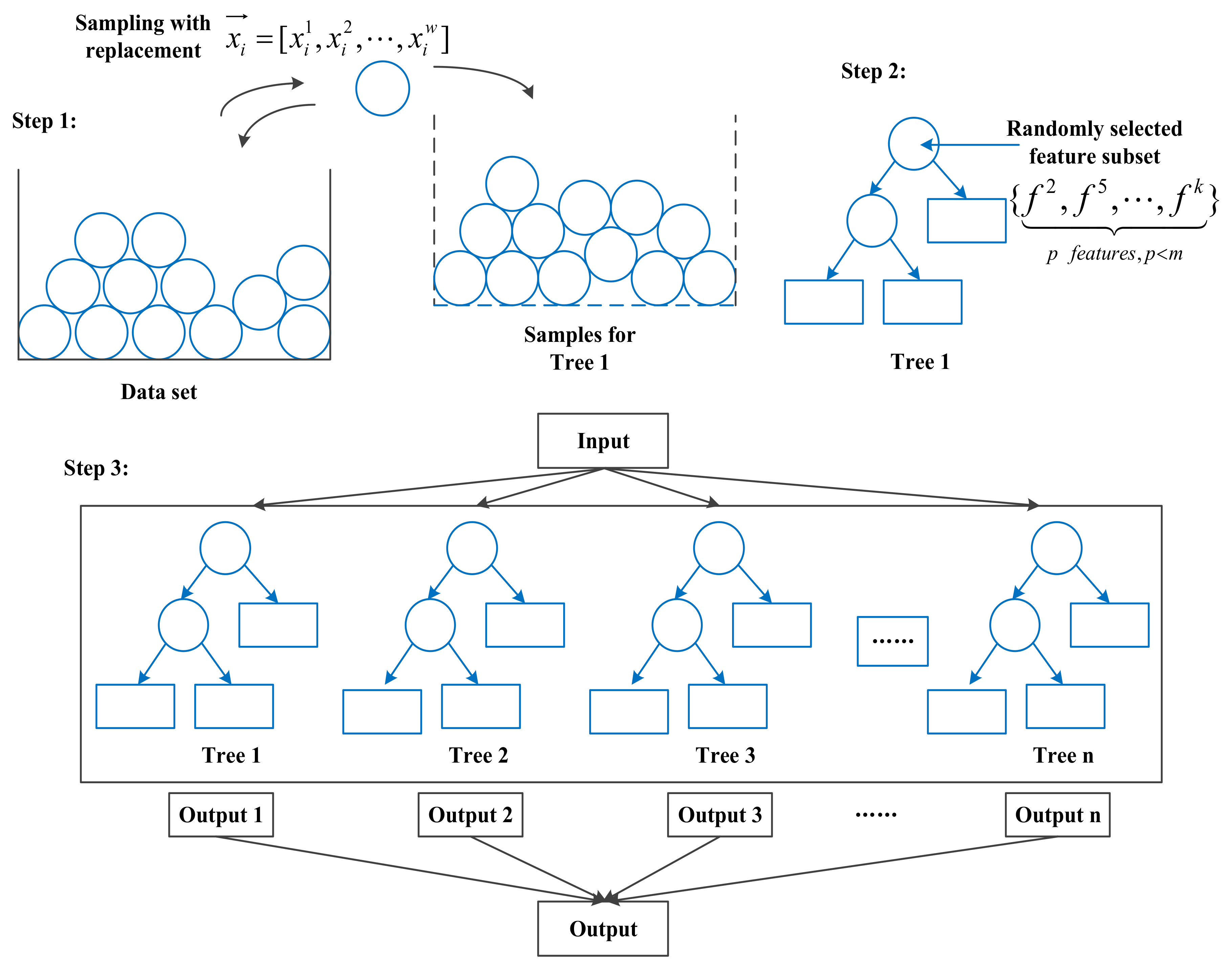
3.1. Improved Random Forest Method for Traffic Event Detection
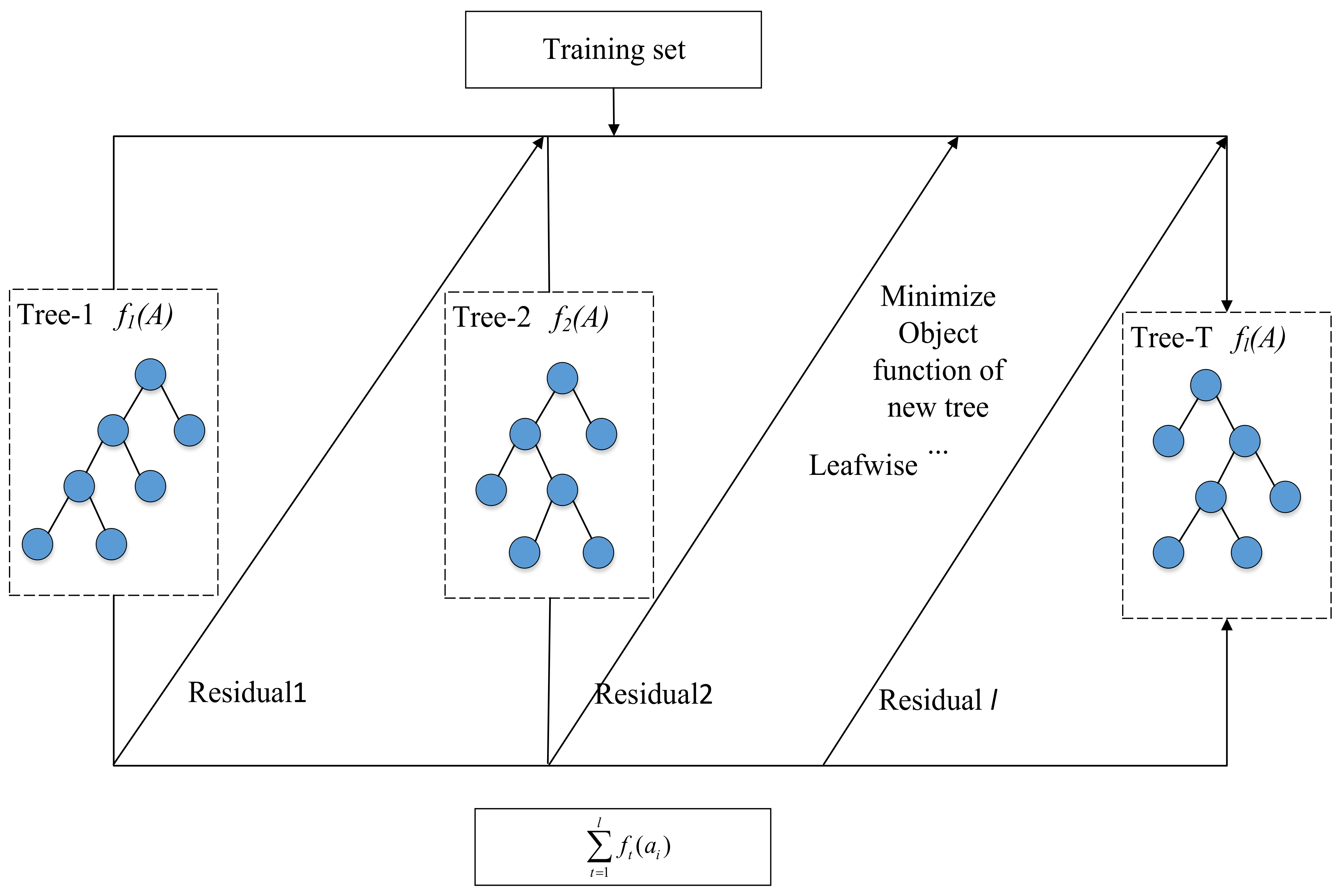
3.2. A Traffic Event Detection Method Based on PI
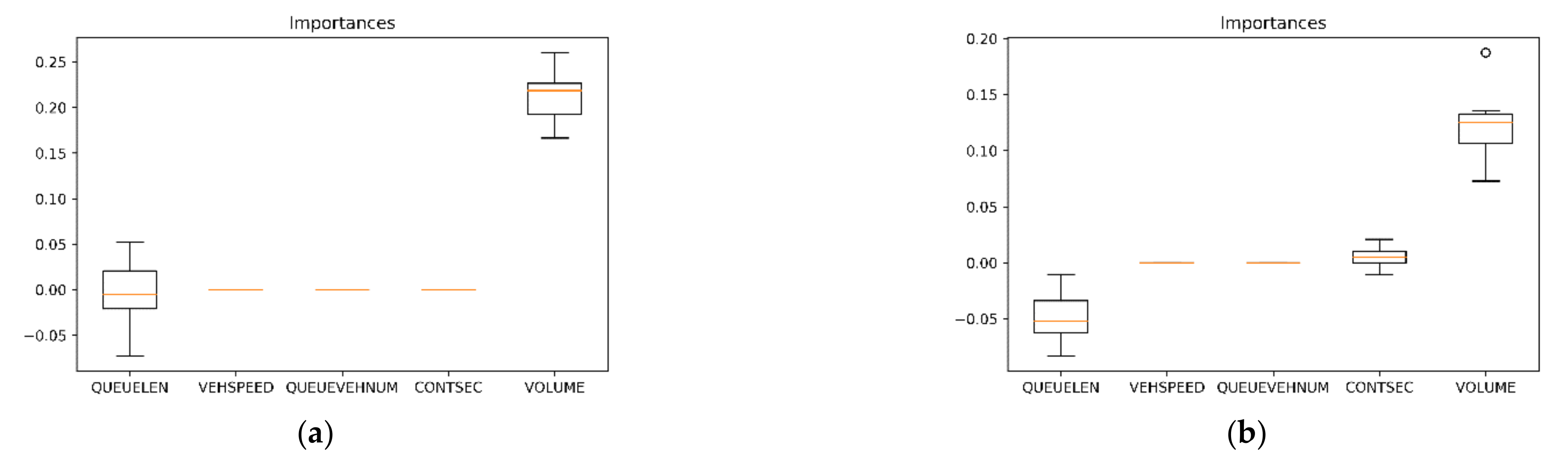
3.3. Choose PI Parameters
3.4. Algorithm Evaluation
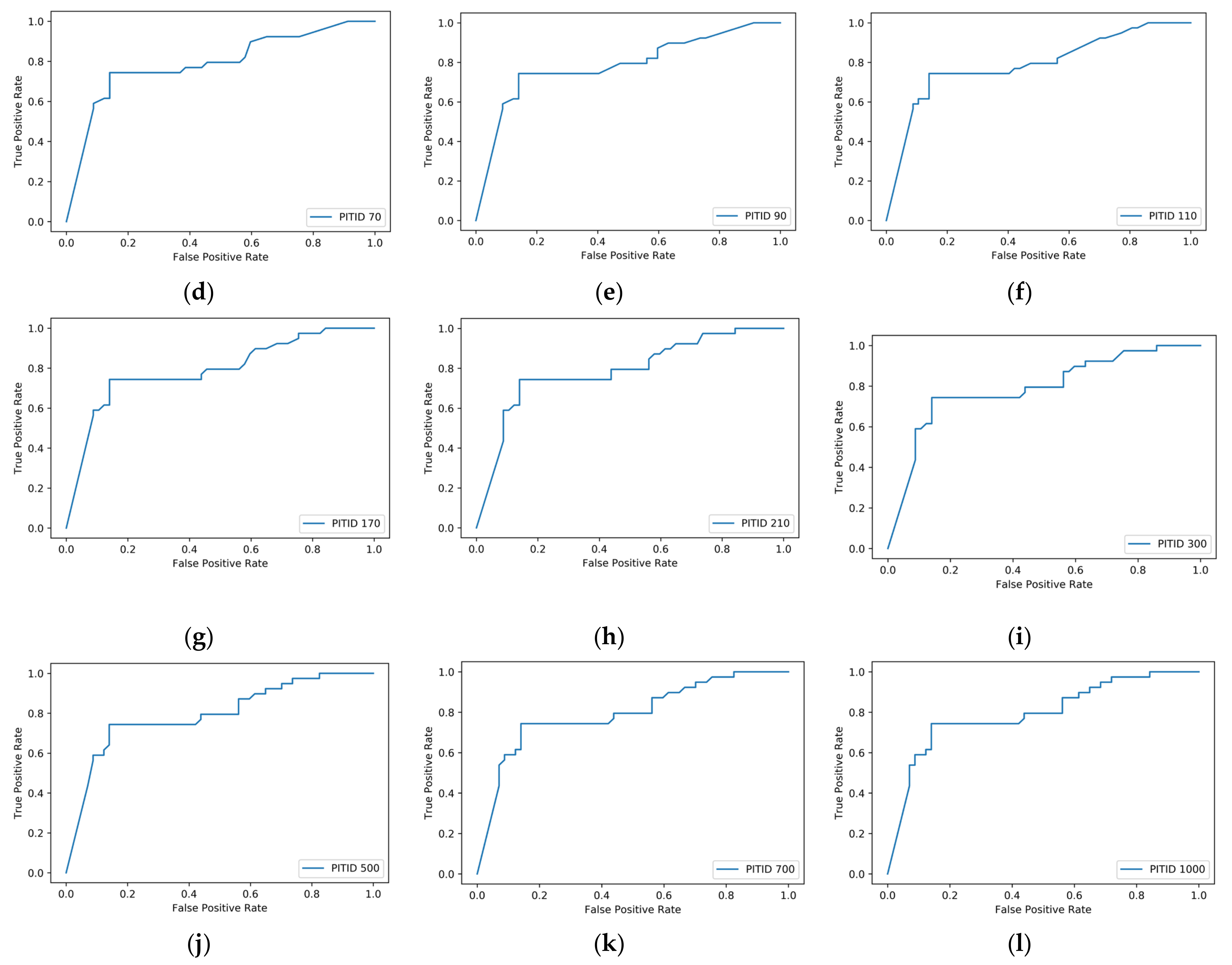
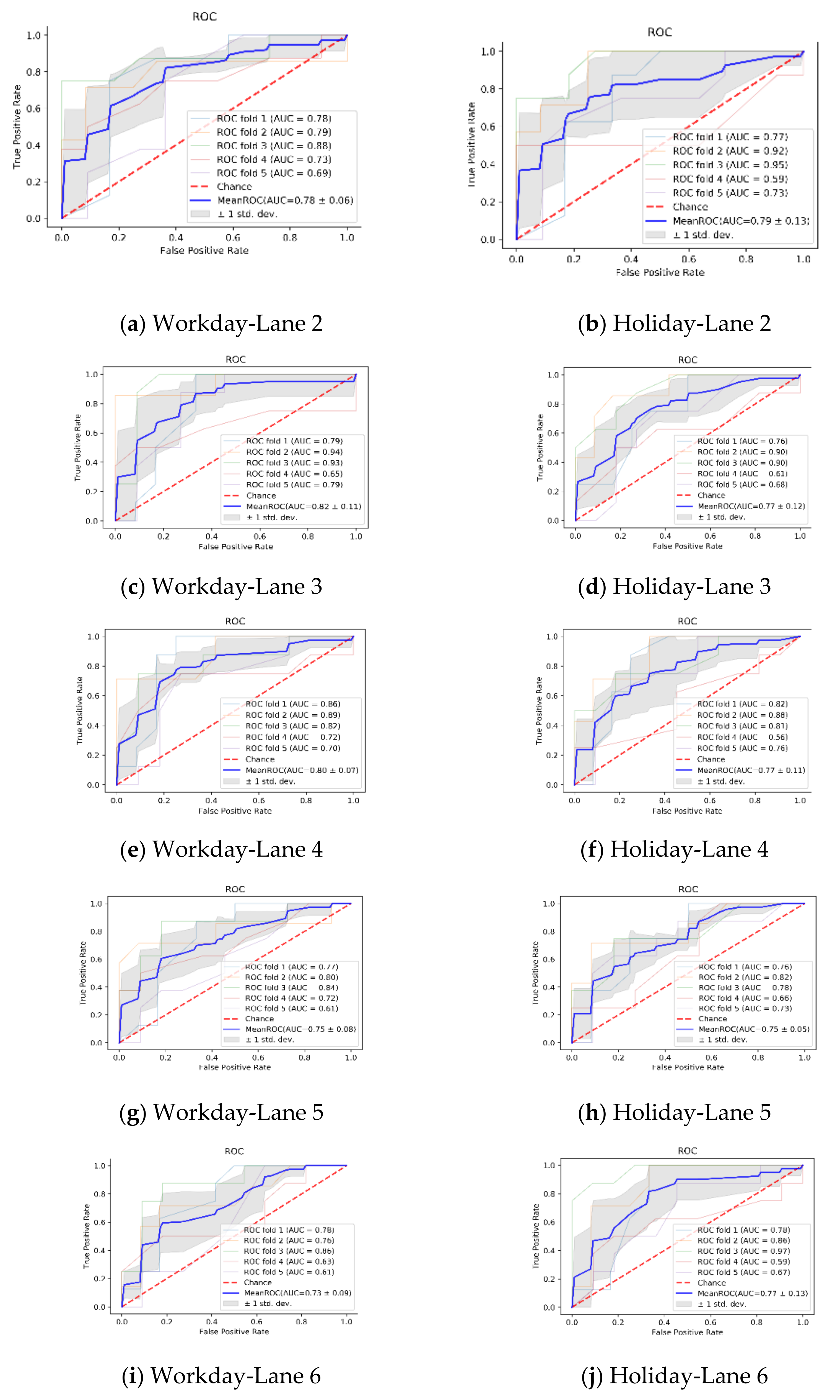
4. Experiments
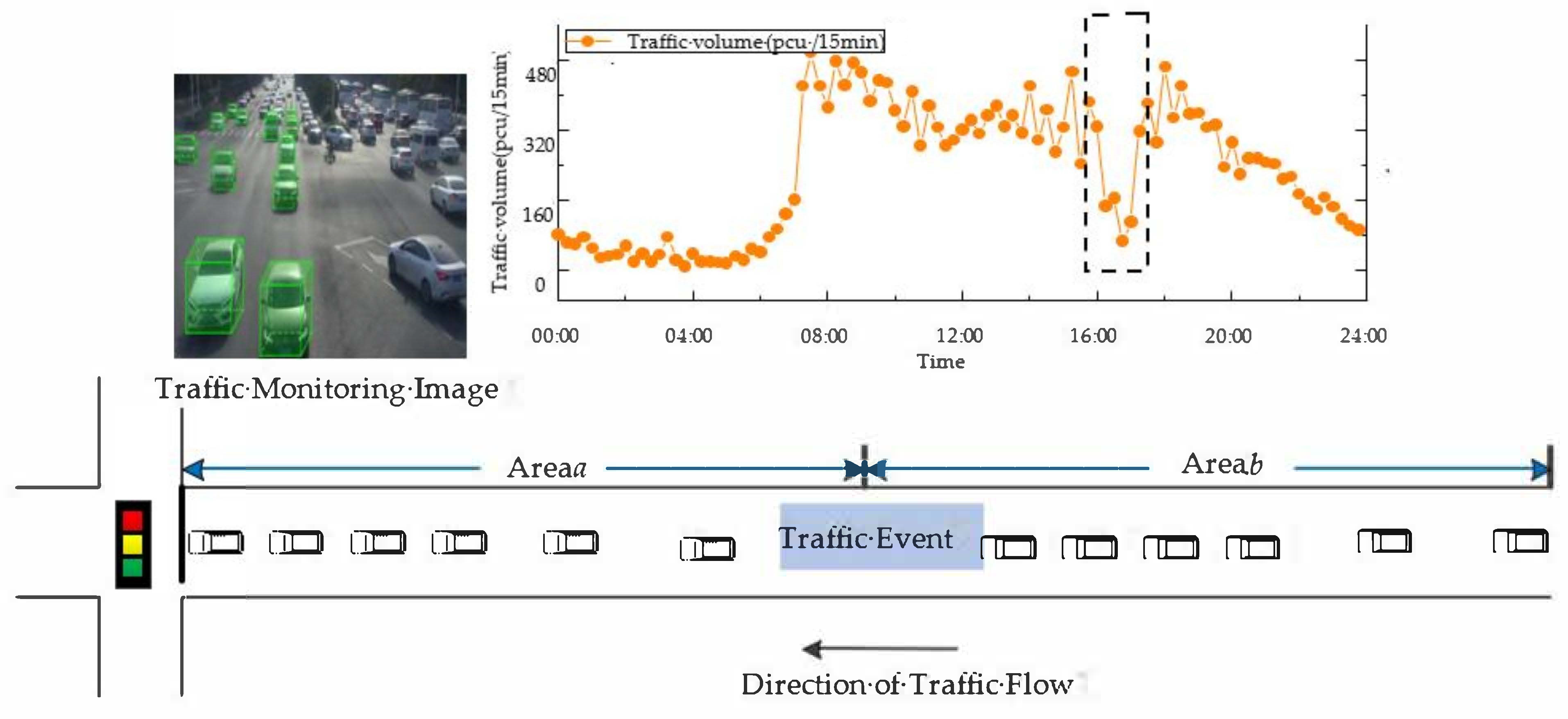
4.1. Video Monitoring at Intersections
4.2. DT Quantitative Impact Analysis
4.3. K-Fold Cross Validation Analysis
4.4. Comparative Analysis of Different Algorithms
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Buch, N.; Velastin, S.A. A Review of Computer Vision Techniques for the Analysis of Urban Traffic. IEEE Trans. Intell. Transp. Syst. 2011, 12, 920–939. [Google Scholar] [CrossRef]
- Hu, X.W.; Xu, X.M.; Xiao, Y.J.; Chen, H.; He, S.F.; Qin, J.; Heng, P.A. SINet: A Scale-Insensitive Convolutional Neural Network for Fast Vehicle Detection. IEEE Trans. Intell. Transp. Syst. 2019, 20, 1010–1019. [Google Scholar] [CrossRef] [Green Version]
- Jalali, A.; Nejad, H.T. Event Detection in Freeway Based on Autocorrelation Factor of GPS Data. Int. J. Intell. Transp. Syst. Res. 2020, 18, 174–182. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. A survey of recent advances in CNN-based single image crowd counting and density estimation. Pattern Recognit. Lett. 2018, 107, 3–16. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.P.; Wang, F.Y.; Wang, K.F.; Lin, W.H.; Xu, X.; Chen, C. Data-Driven Intelligent Transportation Systems: A Survey. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1624–1639. [Google Scholar] [CrossRef]
- McCall, J.C.; Trivedi, M.M. Video-based lane estimation and tracking for driver assistance: Survey, system, and evaluation. IEEE Trans. Intell. Transp. Syst. 2006, 7, 20–37. [Google Scholar] [CrossRef] [Green Version]
- Meng, Q.; Song, H.S.; Zhang, Y.; Zhang, X.Q.; Li, G.; Yang, Y.N. Video-Based Vehicle Counting for Expressway: A Novel Approach Based on Vehicle Detection and Correlation-Matched Tracking Using Image Data from PTZ Cameras. Math. Probl. Eng. 2020, 2020, 1969408. [Google Scholar] [CrossRef] [Green Version]
- Rettore, P.H.L.; Santos, B.P.; Lopes, R.R.F.; Maia, G.; Villas, L.A.; Loureiro, A.A.F. Road Data Enrichment Framework Based on Heterogeneous Data Fusion for ITS. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1751–1766. [Google Scholar] [CrossRef]
- Huang, T.T.; Wang, S.; Sharma, A. Highway crash detection and risk estimation using deep learning. Accid. Anal. Prev. 2020, 135, 105392. [Google Scholar] [CrossRef] [PubMed]
- Sheikh, M.S.; Liang, J.; Wang, W.S. An Improved Automatic Traffic Event Detection Technique Using a Vehicle to Infrastructure Communication. J. Adv. Transp. 2020, 2020, 9139074. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.; Li, L.; Jing, H.; Ran, B.; Sun, D. Automated traffic incident detection with a smaller dataset based on generative adversarial networks. Accid. Anal. Prev. 2020, 144, 105628. [Google Scholar] [CrossRef] [PubMed]
- Davis, N.; Raina, G.; Jagannathan, K. A framework for end-to-end deep learning-based anomaly detection in transportation networks. Transp. Res. Interdiscip. Perspect. 2020, 5, 100112. [Google Scholar] [CrossRef]
- Evans, J.; Waterson, B.; Hamilton, A. A Random Forest Event Detection Algorithm that Incorporates Contexts. Int. J. Intell. Transp. Syst. Res. 2020, 18, 230–242. [Google Scholar]
- Han, X.; Shi, Y. Online Traffic Congestion Prediction Based on Random Forest; Atlantis Press: Paris, France, 2018. [Google Scholar]
- Duan, Y.J.; Lv, Y.S.; Liu, Y.L.; Wang, F.Y. An efficient realization of deep learning for traffic data imputation. Transp. Res. Part C-Emerg. Technol. 2016, 72, 168–181. [Google Scholar] [CrossRef]
- Chen, Z.H.; Ling, X.Y.; Feng, X.X.; Zheng, H.F.; Xu, Y.W. Short-term Traffic State Prediction Approach Based on FCM and Random Forest. J. Electron. Inf. Technol. 2018, 40, 1879–1886. [Google Scholar] [CrossRef]
- Liu, X.Z.; Cai, H.X.; Zhong, R.X.; Sun, W.L.; Chen, J.Z. Learning Traffic as Images for Event Detection Using Convolutional Neural Networks. IEEE Access 2020, 8, 7916–7924. [Google Scholar] [CrossRef]
- Kee, C.Y.; Wong, L.; Khader, A.T.; Hassan, F.H. Multi-label classification of estimated time of arrival with ensemble neural networks in bus transportation network. In Proceedings of the 2017 2nd IEEE International Conference on Intelligent Transportation Engineering (ICITE), Singapore, 1–3 September 2017; pp. 150–154. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4 December 2017; Volume 30. [Google Scholar]
- Sun, L.B.; Lin, Z.T.; Li, W.N.; Xiang, Y.Q. Freeway event detection based on set theory and short-range communication. Transp. Lett.-Int. J. Transp. Res. 2019, 11, 558–569. [Google Scholar] [CrossRef]
- Ou, J.; Xia, J.; Wu, Y.-J.; Rao, W. Short-Term Traffic Flow Forecasting for Urban Roads Using Data-Driven Feature Selection Strategy and Bias-Corrected Random Forests. Transp. Res. Rec. 2017, 2645, 157–167. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial Number | Variable | Specific Meaning | Unit |
|---|---|---|---|
| 1 | VEHSPEED | 15 min average vehicle speed | km/h |
| 2 | QUEUELEN | 15 min Cumulative queue length of vehicles | m |
| 3 | QUEUEVEHNUM | 15 min Cumulated queue number of vehicles | veh |
| 4 | CONTSEC | 15 min Cumulative duration of vehicle | s |
| 5 | VOLUME | 15 min Cumulative traffic flow | veh/15 min |
| Parameters | Description | Default | Our |
|---|---|---|---|
| Num_leaves | Number of leaf nodes per tree | 31 | 31 |
| Learning_rate | Learning rate | 0.1 | 0.05 |
| Max_depth | Maximum depth of tree | −1 | 8 |
| Min_data_in_leaf | Minimum records of leaves | 20 | 20 |
| Feature_fraction | Scale of feature selection | 1.0 | 0.5 |
| Bagging_fraction | Select the scale of the data | 1.0 | 0.5 |
| min_split_gain | Minimum segmentation gain | 0.1 | 0.1 |
| bagging_freq | The number of bagging times. 0 means disabled | 0 | 0 |
| Num_class | Number of categories | / | 2 |
| Method | DR (%) | FAR (%) | MTTD (min) | CR (%) | AUC (%) |
|---|---|---|---|---|---|
| NN | 79.53 | 3.63 | 0.56 | 84.35 | 69.43 |
| SVM | 80.21 | 3.96 | 0.47 | 82.76 | 70.29 |
| DT | 78.62 | 3.57 | 0.26 * | 83.25 | 71.54 |
| RF-OOB | 83.65 | 3.79 | 0.83 | 91.72 | 76.23 |
| PITED | 89.23 * | 2.81 * | 0.92 | 93.48 * | 87.95 * |
| Average | 82.25 | 3.55 | 0.61 | 87.11 | 75.09 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, Z.; Liu, Q.; Zhao, C.; Sun, F. A Traffic Event Detection Method Based on Random Forest and Permutation Importance. Mathematics 2022, 10, 873. https://doi.org/10.3390/math10060873
Su Z, Liu Q, Zhao C, Sun F. A Traffic Event Detection Method Based on Random Forest and Permutation Importance. Mathematics. 2022; 10(6):873. https://doi.org/10.3390/math10060873
Chicago/Turabian StyleSu, Ziyi, Qingchao Liu, Chunxia Zhao, and Fengming Sun. 2022. "A Traffic Event Detection Method Based on Random Forest and Permutation Importance" Mathematics 10, no. 6: 873. https://doi.org/10.3390/math10060873
APA StyleSu, Z., Liu, Q., Zhao, C., & Sun, F. (2022). A Traffic Event Detection Method Based on Random Forest and Permutation Importance. Mathematics, 10(6), 873. https://doi.org/10.3390/math10060873