
Single-Sample Face Recognition Based on Shared Generative Adversarial Network

Abstract
:1. Introduction
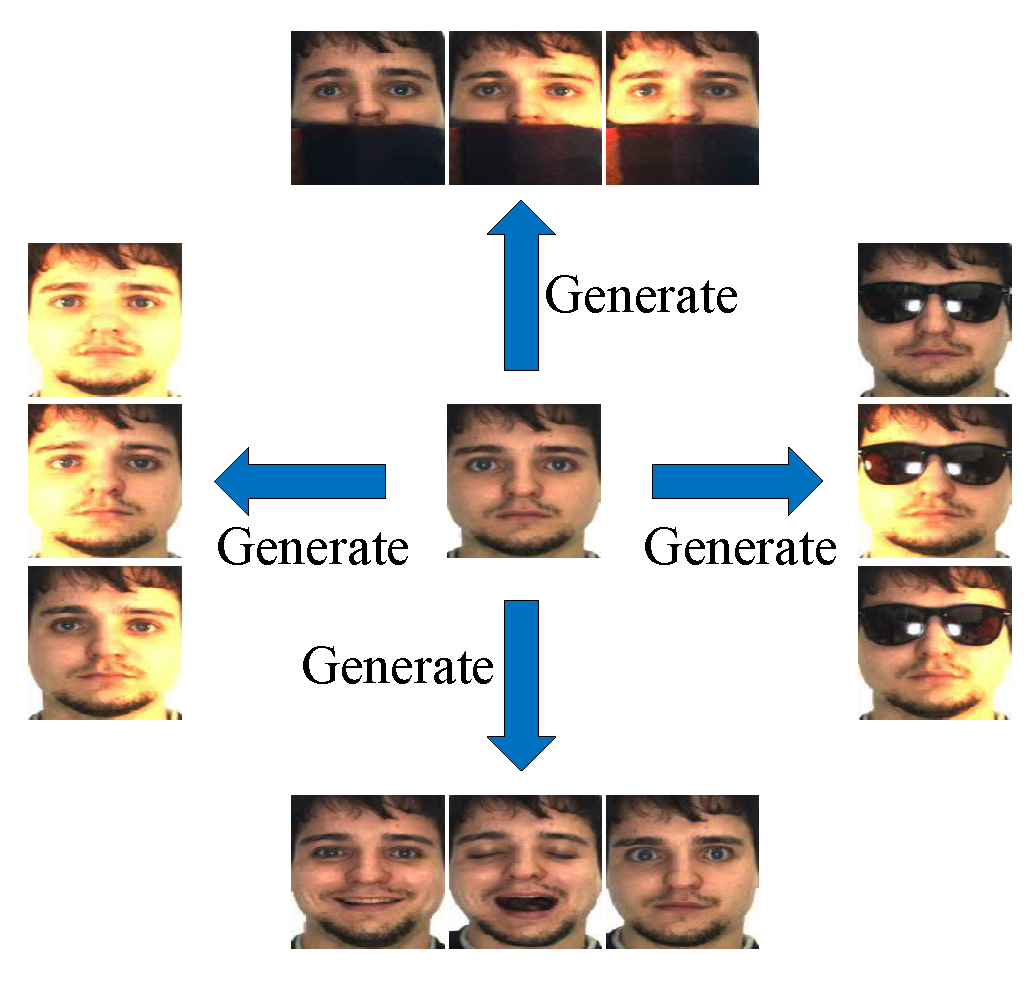
- We propose a shared generative adversarial network (SharedGAN) to expand the gallery dataset. SharedGAN is trained on the generic dataset and copies the variations in the generic dataset into the gallery samples. Compared with the methods [7,8,9], the proposed SharedGAN introduces enough variation information into the generated samples. Regarding the difficulty of collecting the generic dataset, the proposed SharedGAN requires only a small number of training samples.
- We add the generated samples and the generic dataset to a large public dataset, and then we train a deep convolutional neural network on the new dataset. We use the well-trained model for feature extraction.
- We propose a simple classification method and employ the features of the gallery and generated samples to train the classification model. Then, we classify the probe samples. Experiments on three public face databases are performed to demonstrate the effectiveness of our method.
2. Related Work
2.1. Single Sample Face Recognition
2.2. Generative Adversarial Networks
2.3. Image-to-Image Translation
3. Shared Generative Adversarial Network
3.1. Network Architecture
3.2. Multi-Domain Image-to-Image Translation Model
3.3. Image Generation Model
4. Classification Method
5. Experimental Results and Discussion
5.1. Evaluation for SharedGAN
5.1.1. Experiments on AR Dataset
5.1.2. Experiments on CMU-PIE Dataset
5.1.3. Experiments on FERET Dataset
5.2. Evaluation for Single Sample Face Recognition
5.2.1. Experiments on AR Dataset
5.2.2. Experiments on CMU-PIE Dataset
5.2.3. Experiments on FERET Dataset
5.2.4. Evaluation of the Proposed Classification Algorithm
5.2.5. Parameter Selection for the Proposed Classification Algorithm
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- He, X.; Niyogi, P. Locality preserving projections. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2004; pp. 153–160. [Google Scholar]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 210–227. [Google Scholar] [CrossRef] [Green Version]
- Lu, J.; Tan, Y.P.; Wang, G. Discriminative multimanifold analysis for face recognition from a single training sample per person. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 39. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.; Tang, J.; Song, Y.; Zhang, L.; Tang, Z. Local Structure-Based Sparse Representation for Face Recognition. ACM Trans. Intell. Syst. Technol. 2015, 7, 2:1–2:20. [Google Scholar] [CrossRef]
- Pang, M.; Cheung, Y.; Wang, B.; Liu, R. Robust heterogeneous discriminative analysis for face recognition with single sample per person. Pattern Recognit. 2019, 89, 91–107. [Google Scholar] [CrossRef]
- Zhang, D.; Chen, S.; Zhou, Z. A new face recognition method based on SVD perturbation for single example image per person. Appl. Math. Comput. 2005, 163, 895–907. [Google Scholar] [CrossRef] [Green Version]
- Gao, Q.X.; Zhang, L.; Zhang, D. Face recognition using FLDA with single training image per person. Appl. Math. Comput. 2008, 205, 726–734. [Google Scholar] [CrossRef]
- Chu, Y.; Zhao, L.; Ahmad, T. Multiple feature subspaces analysis for single sample per person face recognition. Vis. Comput. 2019, 35, 239–256. [Google Scholar] [CrossRef]
- Deng, W.; Hu, J.; Guo, J. Extended SRC: Undersampled Face Recognition via Intraclass Variant Dictionary. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1864–1870. [Google Scholar] [CrossRef] [Green Version]
- Zhu, P.; Yang, M.; Zhang, L.; Lee, I.Y. Local Generic Representation for Face Recognition with Single Sample per Person. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 34–50. [Google Scholar]
- Gu, J.; Hu, H.; Li, H. Local robust sparse representation for face recognition with single sample per person. IEEE/CAA J. Autom. Sin. 2017, 5, 547–554. [Google Scholar] [CrossRef]
- Hong, S.; Im, W.; Ryu, J.; Yang, H.S. Sspp-dan: Deep domain adaptation network for face recognition with single sample per person. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 825–829. [Google Scholar]
- Min, R.; Xu, S.; Cui, Z. Single-Sample Face Recognition Based on Feature Expansion. IEEE Access 2019, 7, 45219–45229. [Google Scholar] [CrossRef]
- Ding, Z.; Guo, Y.; Zhang, L.; Fu, Y. Generative One-Shot Face Recognition. arXiv 2019, arXiv:1910.04860. [Google Scholar]
- Zhu, P.; Zhang, L.; Hu, Q.; Shiu, S.C. Multi-scale patch based collaborative representation for face recognition with margin distribution optimization. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 822–835. [Google Scholar]
- Chen, S.; Liu, J.; Zhou, Z.H. Making FLDA applicable to face recognition with one sample per person. Pattern Recognit. 2004, 37, 1553–1555. [Google Scholar] [CrossRef]
- Zhang, P.; You, X.; Ou, W.; Chen, C.P.; Cheung, Y. Sparse discriminative multi-manifold embedding for one-sample face identification. Pattern Recognit. 2016, 52, 249–259. [Google Scholar] [CrossRef]
- Deng, W.; Hu, J.; Wu, Z.; Guo, J. From One to Many: Pose-Aware Metric Learning for Single-Sample Face Recognition. Pattern Recognit. 2018, 77, 426–437. [Google Scholar] [CrossRef]
- Tu, H.; Duoji, G.; Zhao, Q.; Wu, S. Improved Single Sample Per Person Face Recognition via Enriching Intra-Variation and Invariant Features. Appl. Sci. 2020, 10, 601. [Google Scholar] [CrossRef] [Green Version]
- Su, Y.; Shan, S.; Chen, X.; Gao, W. Adaptive generic learning for face recognition from a single sample per person. In Proceedings of the Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; IEEE: Manhattan, NY, USA, 2010; pp. 2699–2706. [Google Scholar]
- Yang, M.; Van, L.; Zhang, L. Sparse Variation Dictionary Learning for Face Recognition with a Single Training Sample per Person. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 689–696. [Google Scholar]
- Ji, H.; Sun, Q.; Ji, Z.; Yuan, Y.; Zhang, G. Collaborative probabilistic labels for face recognition from single sample per person. Pattern Recognit. 2017, 62, 125–134. [Google Scholar] [CrossRef]
- Deng, W.; Hu, J.; Guo, J. In Defense of Sparsity Based Face Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 399–406. [Google Scholar]
- Deng, W.; Hu, J.; Zhou, X.; Guo, J. Equidistant prototypes embedding for single sample based face recognition with generic learning and incremental learning. Pattern Recognit. 2014, 47, 3738–3749. [Google Scholar] [CrossRef] [Green Version]
- Pang, M.; Cheung, Y.; Wang, B.; Lou, J. Synergistic Generic Learning for Face Recognition From a Contaminated Single Sample per Person. IEEE Trans. Inf. Forensics Secur. 2019, 15, 195–209. [Google Scholar] [CrossRef]
- Yang, M.; Wang, X.; Zeng, G.; Shen, L. Joint and collaborative representation with local adaptive convolution feature for face recognition with single sample per person. Pattern Recognit. 2017, 66, 117–128. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Zhao, J.; Mathieu, M.; LeCun, Y. Energy-based generative adversarial network. arXiv 2016, arXiv:1609.03126. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Zhang, Z.; Song, Y.; Qi, H. Age progression/regression by conditional adversarial autoencoder. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5810–5818. [Google Scholar]
- Yoo, S.; Bahng, H.; Chung, S.; Lee, J.; Chang, J.; Choo, J. Coloring with limited data: Few-shot colorization via memory augmented networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 11283–11292. [Google Scholar]
- Lee, J.; Kim, E.; Lee, Y.; Kim, D.; Chang, J.; Choo, J. Reference-based sketch image colorization using augmented-self reference and dense semantic correspondence. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5801–5810. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8789–8797. [Google Scholar]
- He, Z.; Zuo, W.; Kan, M.; Shan, S.; Chen, X. Attgan: Facial attribute editing by only changing what you want. IEEE Trans. Image Process. 2019, 28, 5464–5478. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to discover cross-domain relations with generative adversarial networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 1857–1865. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar]
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 700–708. [Google Scholar]
- Almahairi, A.; Rajeshwar, S.; Sordoni, A.; Bachman, P.; Courville, A. Augmented cyclegan: Learning many-to-many mappings from unpaired data. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 195–204. [Google Scholar]
- Huang, X.; Liu, M.Y.; Belongie, S.; Kautz, J. Multimodal unsupervised image-to-image translation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 172–189. [Google Scholar]
- Zhao, Y.; Wu, R.; Dong, H. Unpaired image-to-image translation using adversarial consistency loss. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 800–815. [Google Scholar]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Martinez, A.M.; Benavente, R. The AR face database: CVC Technical Report, 24; Universitat Autònoma de Barcelona: Barcelona, Spain, 1998. [Google Scholar]
- Sim, T.; Baker, S.; Bsat, M. The CMU pose, illumination, and expression database. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1615–1618. [Google Scholar]
- Phillips, P.J.; Wechsler, H.; Huang, J.; Rauss, P.J. The FERET database and evaluation procedure for face-recognition algorithms. Image Vis. Comput. 1998, 16, 295–306. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 October 2015; pp. 3730–3738. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Park, T.; Efros, A.A.; Zhang, R.; Zhu, J.Y. Contrastive Learning for Unpaired Image-to-Image Translation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2020. [Google Scholar]
- Seitzer, M. Pytorch-Fid: FID Score for PyTorch. Version 0.2.1. 2020. Available online: https://github.com/mseitzer/pytorch-fid (accessed on 11 January 2022).
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A discriminative feature learning approach for deep face recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 499–515. [Google Scholar]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Learning face representation from scratch. arXiv 2014, arXiv:1411.7923. [Google Scholar]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the COMPSTAT’2010, Paris, France, 22–27 August 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 177–186. [Google Scholar]
- Kumar, R.; Banerjee, A.; Vemuri, B.C.; Pfister, H. Maximizing all margins: Pushing face recognition with kernel plurality. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 2375–2382. [Google Scholar]
- Liu, F.; Yang, S.; Ding, Y.; Xu, F. Single sample face recognition via BoF using multistage KNN collaborative coding. Multimed. Tools Appl. 2019, 78, 13297–13311. [Google Scholar] [CrossRef]
- Zhou, D.; Yang, D.; Zhang, X.; Huang, S.; Feng, S. Discriminative probabilistic latent semantic analysis with application to single sample face recognition. Neural Process. Lett. 2019, 49, 1273–1298. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | V01 | V02 | V03 | V04 | V05 | V06 |
|---|---|---|---|---|---|---|
| CycleGAN | 44.4 | 36.4 | 51.5 | 39.2 | 45.6 | 52.7 |
| StarGAN | 91.1 | 89.1 | 115.0 | 83.9 | 81.5 | 102.4 |
| CUT | 34.6 | 32.9 | 46.7 | 33.5 | 32.2 | 48.9 |
| SharedGAN | 65.6 | 62.1 | 73.0 | 61.2 | 62.2 | 73.0 |
| Method | V07 | V08 | V09 | V10 | V11 | V12 |
| CycleGAN | 58.1 | 206.0 | 62.8 | 70.0 | 205.3 | 186.7 |
| StarGAN | 69.3 | 178.0 | 74.7 | 90.5 | 219.1 | 206.5 |
| CUT | 31.1 | 182.5 | 32.5 | 27.9 | 164.0 | 148.8 |
| SharedGAN | 45.0 | 130.8 | 42.0 | 37.4 | 161.5 | 141.6 |
| Method | V01 | V02 | V03 | V04 | V05 | V06 |
|---|---|---|---|---|---|---|
| Network (a) + (c) | 65.3 | 76.6 | 78.7 | 69.5 | 66.1 | 107.1 |
| SharedGAN | 65.6 | 62.1 | 73.0 | 61.2 | 62.2 | 73.0 |
| Method | V07 | V08 | V09 | V10 | V11 | V12 |
| Network (a) + (c) | 47.9 | 149.0 | 51.0 | 52.2 | 182.7 | 169.0 |
| SharedGAN | 45.0 | 130.8 | 42.0 | 37.4 | 161.5 | 141.6 |
| Pose | Method | V01 | V02 | V03 | V04 | V05 | V06 | V07 | V08 |
|---|---|---|---|---|---|---|---|---|---|
| C05 | CycleGAN | 101.5 | 66.3 | 75.5 | 63.6 | 75.3 | 57.1 | 69.7 | 70.9 |
| StarGAN | 248.7 | 125.1 | 107.8 | 139.0 | 105.4 | 111.5 | 127.5 | 197.9 | |
| CUT | 83.8 | 67.7 | 49.7 | 85.1 | 71.2 | 47.2 | 43.6 | 55.9 | |
| SharedGAN | 77.2 | 42.9 | 45.0 | 49.7 | 40.6 | 40.0 | 49.6 | 71.9 | |
| C07 | CycleGAN | 69.8 | 56.6 | 79.8 | 61.1 | 59.6 | 52.7 | 54.8 | 64.8 |
| StarGAN | 187.5 | 104.7 | 112.3 | 110.4 | 108.8 | 115.7 | 112.3 | 119.4 | |
| CUT | 68.0 | 54.7 | 45.4 | 58.5 | 51.2 | 40.9 | 38.4 | 53.0 | |
| SharedGAN | 78.3 | 43.6 | 49.8 | 47.7 | 44.8 | 43.2 | 51.0 | 71.6 | |
| C09 | CycleGAN | 121.9 | 68.1 | 74.4 | 69.0 | 64.5 | 54.7 | 59.1 | 72.8 |
| StarGAN | 216.3 | 140.8 | 137.4 | 148.8 | 147.4 | 148.2 | 159.9 | 251.7 | |
| CUT | 95.8 | 45.9 | 46.4 | 46.4 | 62.9 | 46.1 | 48.6 | 57.0 | |
| SharedGAN | 99.3 | 58.9 | 52.6 | 62.0 | 63.1 | 57.0 | 62.7 | 113.9 | |
| C27 | CycleGAN | 66.7 | 75.0 | 44.9 | 52.9 | - | 47.3 | 53.4 | 63.7 |
| StarGAN | 142.8 | 78.6 | 78.3 | 85.2 | - | 71.9 | 85.6 | 157.7 | |
| CUT | 57.1 | 45.8 | 40.3 | 49.7 | - | 35.9 | 34.8 | 50.5 | |
| SharedGAN | 63.4 | 39.3 | 52.3 | 38.4 | - | 35.8 | 38.9 | 62.6 | |
| C29 | CycleGAN | 89.1 | 70.2 | 70.9 | 83.3 | 68.4 | 67.2 | 62.8 | 83.6 |
| StarGAN | 263.6 | 141.4 | 132.6 | 152.1 | 129.3 | 112.7 | 122.4 | 234.1 | |
| CUT | 95.5 | 62.0 | 77.2 | 74.9 | 51.6 | 75.6 | 75.2 | 75.6 | |
| SharedGAN | 100.0 | 60.7 | 57.4 | 68.9 | 52.0 | 53.1 | 71.6 | 117.5 |
| Method | V01 | V02 | V03 | V04 | V05 | V06 |
|---|---|---|---|---|---|---|
| CycleGAN | 48.4 | 40.8 | 35.4 | 47.1 | 32.8 | 57.1 |
| StarGAN | 128.4 | 118.0 | 123.8 | 131.2 | 131.3 | 181.4 |
| CUT | 43.2 | 46.8 | 40.5 | 50.6 | 44.2 | 42.1 |
| SharedGAN | 48.4 | 48.7 | 47.4 | 49.0 | 44.7 | 73.8 |
| Method | Illumination | Expression | Disguise | Disguise + Illumination | Average |
|---|---|---|---|---|---|
| AGL | 86.3 | 75.0 | 54.4 | 47.8 | 65.3 |
| FLDA-single | 85.8 | 83.8 | 38.8 | 32.8 | 59.8 |
| LRA-GL | 96.7 | 77.5 | 85.6 | 72.2 | 81.9 |
| SRC | 75.4 | 85.8 | 53.8 | 22.8 | 56.9 |
| PSRC | 90.4 | 87.5 | 96.3 | 78.8 | 86.8 |
| PCRC | 95.4 | 87.5 | 95.0 | 80.0 | 88.2 |
| PNN | 85.4 | 86.7 | 88.8 | 72.2 | 81.9 |
| BlockFLDA | 72.9 | 50.4 | 60.0 | 45.6 | 56.0 |
| ESRC | 98.8 | 93.8 | 77.5 | 75.3 | 86.2 |
| SVDL | 97.9 | 93.3 | 81.3 | 75.6 | 86.6 |
| LGR | 99.2 | 97.9 | 98.1 | 96.6 | 97.8 |
| RHDA * | - | - | - | - | 96.4 |
| JCR-ACF * | 99.2 | 100 | 100 | 99.4 | 99.6 |
| MKCC-BoF * | 100 | 99.6 | 100 | 99.1 | 99.6 |
| DpLSA * | 100 | 100 | 100 | 99.8 | 99.9 |
| Ours | 99.6 | 97.9 | 98.8 | 98.8 | 98.8 |
| Method | Illumination | Expression | Disguise | Disguise + Illumination | Average |
|---|---|---|---|---|---|
| AGL | 55.4 | 44.2 | 31.3 | 26.6 | 39.0 |
| FLDA-single | 47.1 | 53.3 | 18.1 | 17.5 | 34.0 |
| LRA-GL | 85.4 | 65.4 | 61.3 | 50.9 | 64.9 |
| SRC | 45.8 | 70.4 | 25.0 | 11.9 | 37.2 |
| PSRC | 82.1 | 70.4 | 81.9 | 59.1 | 71.5 |
| PCRC | 87.1 | 69.2 | 83.1 | 63.4 | 74.1 |
| PNN | 75.0 | 74.6 | 71.3 | 50.9 | 66.3 |
| BlockFLDA | 56.7 | 35.8 | 45.0 | 29.7 | 40.5 |
| ESRC | 87.5 | 80.4 | 56.3 | 47.8 | 67.3 |
| SVDL | 84.6 | 80.4 | 59.4 | 50.6 | 68.0 |
| LGR | 97.1 | 84.6 | 93.8 | 86.9 | 90.0 |
| JCR-ACF * | 95.0 | 94.2 | 96.3 | 92.8 | 94.3 |
| MKCC-BoF * | 97.9 | 95.4 | 96.3 | 92.8 | 95.3 |
| DpLSA * | 97.7 | 97.0 | 100 | 97.0 | 97.7 |
| Ours | 99.2 | 95.4 | 93.8 | 92.8 | 95.2 |
| Method | C05 | C07 | C09 | C27 | C29 | Average |
|---|---|---|---|---|---|---|
| AGL | 28.2 | 50.8 | 64.0 | 86.9 | 55.9 | 57.1 |
| FLDA-single | 24.7 | 25.5 | 34.8 | 53.5 | 21.5 | 34.0 |
| LRA-GL | 61.7 | 54.7 | 68.4 | 86.5 | 52.4 | 67.4 |
| SRC | 32.1 | 36.6 | 38.8 | 58.2 | 27.3 | 40.4 |
| PSRC | 48.0 | 55.1 | 57.3 | 77.6 | 40.9 | 57.7 |
| PCRC | 51.4 | 57.2 | 59.9 | 81.5 | 44.4 | 61.0 |
| PNN | 42.4 | 45.3 | 51.6 | 71.9 | 42.5 | 52.5 |
| BlockFLDA | 12.3 | 16.0 | 15.1 | 55.9 | 12.0 | 25.6 |
| ESRC | 65.7 | 65.5 | 71.1 | 90.0 | 63.8 | 73.1 |
| SVDL | 63.4 | 64.8 | 70.8 | 89.6 | 62.9 | 72.0 |
| LGR | 64.8 | 66.1 | 74.8 | 88.6 | 61.2 | 72.7 |
| Ours | 93.6 | 94.5 | 95.6 | 93.6 | 94.9 | 94.2 |
| Method | Accuracy | Method | Accuracy |
|---|---|---|---|
| AGL | 69.5 | ESRC | 72.5 |
| FLDA-single | 31.0 | SVDL | 73.0 |
| LRA-GL | 49.2 | LGR | 46.9 |
| SRC | 47.6 | RHDA * | 69.8 |
| PSRC | 34.6 | DpLSA * | 92.4 |
| PCRC | 33.2 | KCFT * | 93.2 |
| PNN | 41.9 | EIVIF * | 96.4 |
| BlockFLDA | 19.8 | Ours | 99.5 |
| Method | AR | CMU-PIE | FERET | |||||
|---|---|---|---|---|---|---|---|---|
| Session 1 | Session 2 | C05 | C07 | C09 | C27 | C29 | ||
| LRA-GL | 95.4 | 93.2 | 80.3 | 85.6 | 88.4 | 85.2 | 83.7 | 97.9 |
| SRC | 97.4 | 93.3 | 92.7 | 90.3 | 94.3 | 92.7 | 92.0 | 98.6 |
| ESRC | 97.5 | 93.7 | 92.6 | 92.4 | 95.6 | 93.3 | 93.8 | 99.2 |
| Ours with | 98.3 | 94.0 | 93.2 | 93.0 | 96.2 | 92.8 | 93.9 | 98.2 |
| Ours | 98.8 | 95.2 | 93.6 | 94.5 | 95.6 | 93.6 | 94.9 | 99.5 |
| Session 1 | Session 2 | Session 1 | Session 2 | ||||
|---|---|---|---|---|---|---|---|
| 98.3 | 94.1 | 97.9 | 95.5 | ||||
| 98.3 | 94.2 | 98.1 | 95.3 | ||||
| 98.4 | 94.6 | 98.5 | 95.3 | ||||
| 98.5 | 94.7 | 98.8 | 95.2 | ||||
| 98.8 | 95.0 | 98.8 | 94.9 | ||||
| 98.8 | 95.2 | 98.4 | 94.7 | ||||
| 98.5 | 95.0 | 98.4 | 94.5 | ||||
| 98.4 | 95.0 | 98.2 | 94.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, Y.; Tang, Z.; Wang, F. Single-Sample Face Recognition Based on Shared Generative Adversarial Network. Mathematics 2022, 10, 752. https://doi.org/10.3390/math10050752
Ding Y, Tang Z, Wang F. Single-Sample Face Recognition Based on Shared Generative Adversarial Network. Mathematics. 2022; 10(5):752. https://doi.org/10.3390/math10050752
Chicago/Turabian StyleDing, Yuhua, Zhenmin Tang, and Fei Wang. 2022. "Single-Sample Face Recognition Based on Shared Generative Adversarial Network" Mathematics 10, no. 5: 752. https://doi.org/10.3390/math10050752
APA StyleDing, Y., Tang, Z., & Wang, F. (2022). Single-Sample Face Recognition Based on Shared Generative Adversarial Network. Mathematics, 10(5), 752. https://doi.org/10.3390/math10050752