
Dynamic Re-Weighting and Cross-Camera Learning for Unsupervised Person Re-Identification



Abstract
:1. Introduction
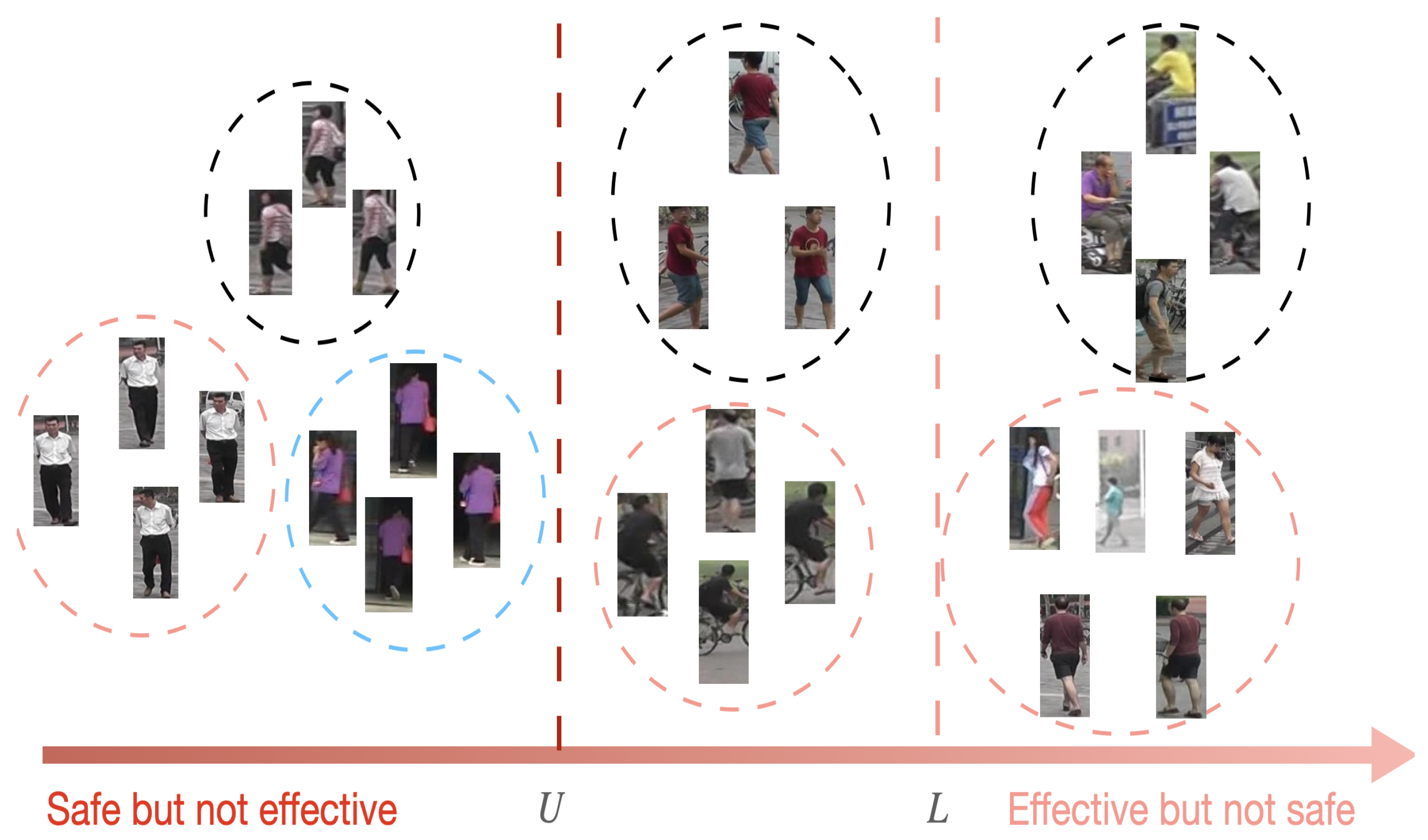
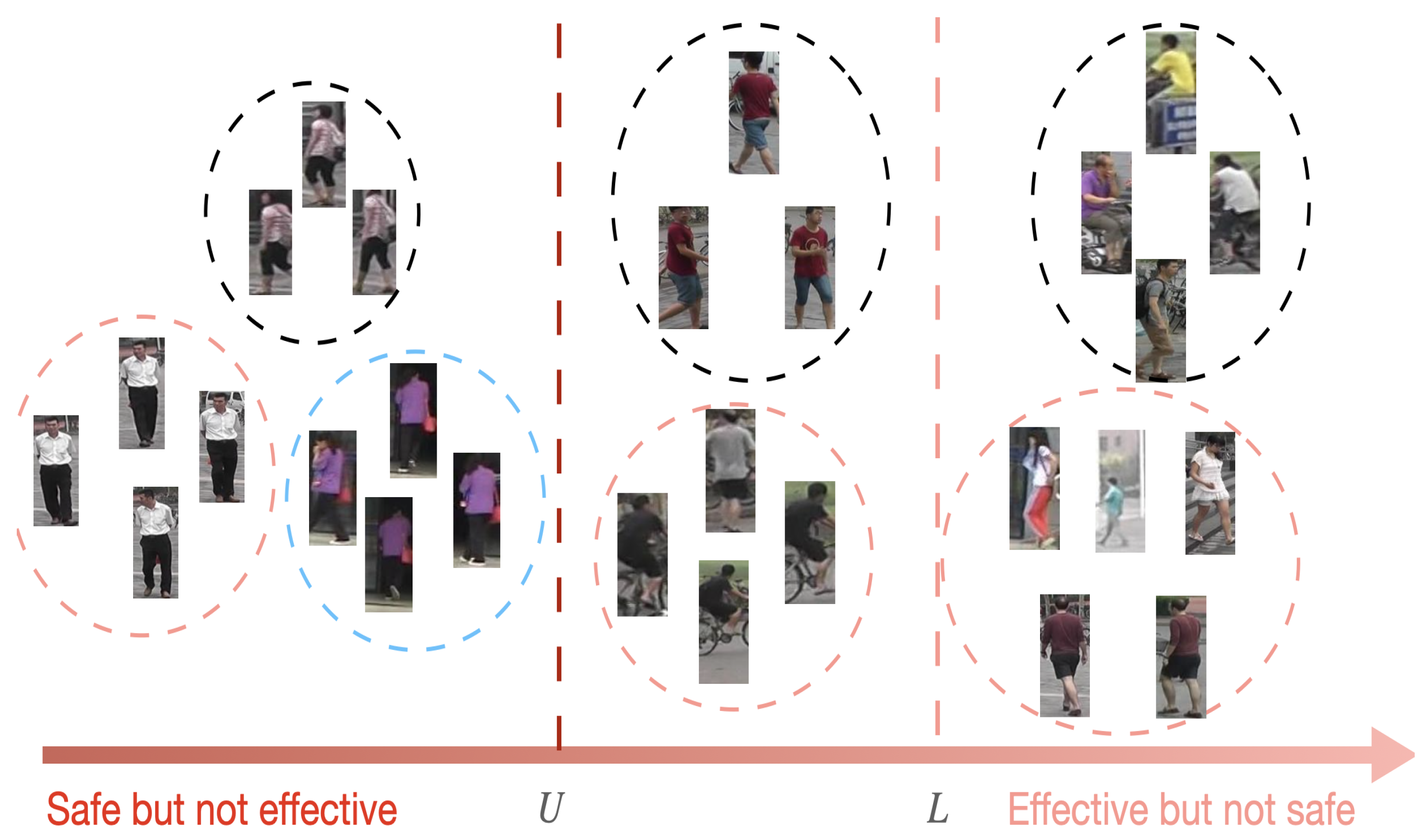
- Case 1 (top row): different people in the same camera, since pictures that belong to the same camera have the same background.
- Case 2 (middle row): pictures belong to the same person and same camera. These pictures can be easily merged into the same center. They are safe for training but cannot improve the cross-camera retrieval ability.
- Case 3 (bottom row): different people with similar appearances.
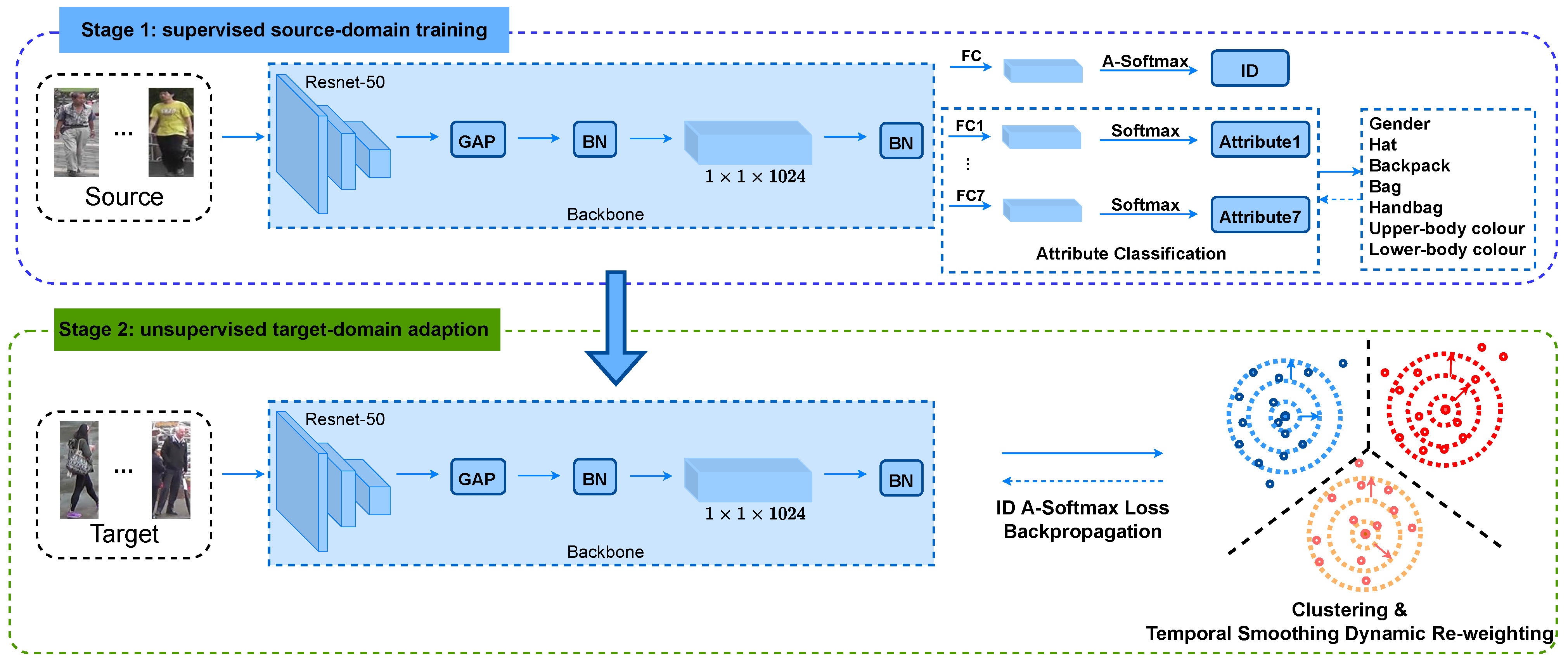
- We propose a novel temporal smoothing dynamic re-weighting and cross-camera learning (TSDRC) scheme to improve the training of the target domain with a person re-identification temporal smoothing constraint.
- We design a dynamic re-weighting (DRW) strategy to achieve a trade-off of selecting safe clustering samples and cross-view samples. To further improve the cross-view retrieval ability, we propose cross-camera triplet loss (CCT) for the target domain training.
- Comprehensive experiments on the Market-1501 and DukeMTMC-reID datasets demonstrate that the proposed method vastly improves the existing unsupervised person ReID methods.
2. Materials and Methods
2.1. Source Domain Training
2.2. Target Domain Training
| Algorithm 1: TSDRC |
Require: source dataset pre-trained model ; unlabeled dataset X; target dataset classifier ; threshold lower bound L and upper bound U; relaxing rate . Ensure: Optimized model ; 1: Initial ; 2: repeat 3: Extracting feature: for all ; 4: -normalization for feature ; 5: K-means clustering; 6: Updating cluster center C and pseudolabels ; 7: for i = 1 to N do 8: Calculate the nearest cluster center of ; 9: Re-weighting each cluster result as in Equation (4) 10: end for 11: Training with selected samples as in Equation (10) 12: Updating : 13: until () |
3. Results
3.1. Datasets
3.2. Implementation Details
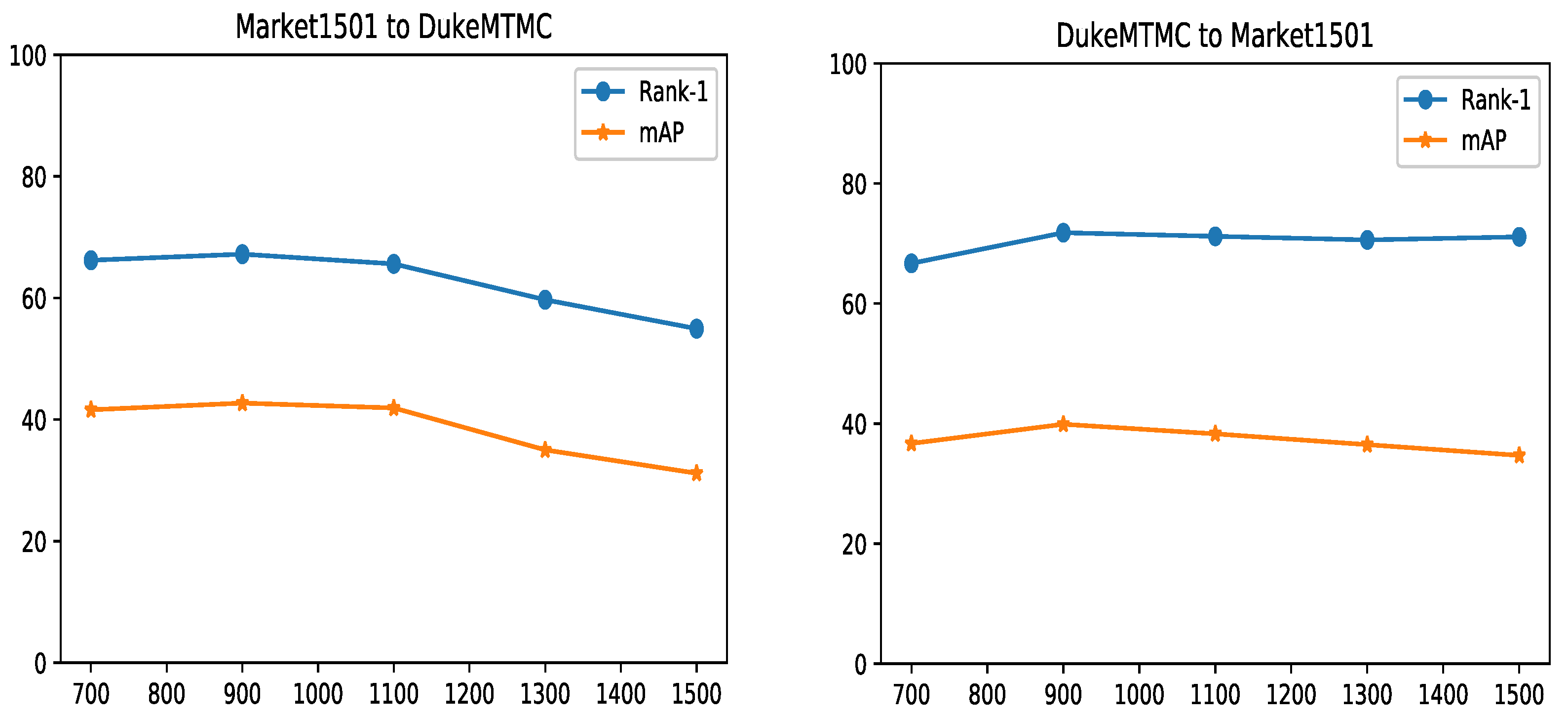
3.3. Ablation Experiments
3.4. Comparing with the State-of-the-Art Approaches
4. Discussion and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Subramanyam, A.V.; Gupta, V.; Ahuja, R. Robust Discriminative Subspace Learning for Person Reidentification. IEEE Signal Process. Lett. 2019, 26, 154–158. [Google Scholar] [CrossRef]
- Lin, Y.; Zheng, L.; Zheng, Z.; Wu, Y.; Hu, Z.; Yan, C.; Yang, Y. Improving person re-identification by attribute and identity learning. Pattern Recognit. 2019, 95, 151–161. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Zhang, L.; Wang, W.; Wu, X. AsNet: Asymmetrical Network for Learning Rich Features in Person Re-Identification. IEEE Signal Process. Lett. 2020, 27, 850–854. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, Y.; Wang, S. Open-World Person Re-Identification with Deep Hash Feature Embedding. IEEE Signal Process. Lett. 2019, 26, 1758–1762. [Google Scholar] [CrossRef]
- Chang, X.; Hospedales, T.M.; Xiang, T. Multi-level Factorisation Net for Person Re-identification. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2109–2118. [Google Scholar]
- Chen, D.; Xu, D.; Li, H.; Sebe, N.; Wang, X. Group Consistent Similarity Learning via Deep CRF for Person Re-identification. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8649–8658. [Google Scholar]
- Chen, Y.; Li, Y.; Du, X.; Wang, Y. Learning resolution-invariant deep representations for person re-identification. Proc. AAAI 2019, 33, 8215–8222. [Google Scholar] [CrossRef] [Green Version]
- Cheng, D.; Gong, Y.; Zhou, S.; Wang, J.; Zheng, N. Person Re-identification by Multi-Channel Parts-Based CNN with Improved Triplet Loss Function. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1335–1344. [Google Scholar]
- Kalayeh, M.; Basaran, E.; Gokmen, M.; Kamasak, M.; Shah, M. Human Semantic Parsing for Person Re-identification. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1062–1071. [Google Scholar]
- Liu, J.; Ni, B.; Yan, Y.; Zhou, P.; Cheng, S.; Hu, J. Pose Transferrable Person Re-identification. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4099–4108. [Google Scholar]
- Jean, G.I.J.P.; Mehdi, M.; Xu, B.; David, W.; Sherjil, O.; Yoshua, B. Generative Adversarial Nets. In Proceedings of the NIPS, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Chen, Y.; Hsu, W. Saliency Aware: Weakly Supervised Object Localization. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1907–1911. [Google Scholar]
- Chen, Y.; Huang, P.; Yu, L.; Huang, J.; Yang, M.; Lin, Y. Deep Semantic Matching with Foreground Detection and Cycle-Consistency. In Proceedings of the Asian Conference on Computer Vision (ACCV), Perth, Australia, 2–6 December 2018. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Y.; Yang, M.; Huang, J. Show, Match and Segment: Joint Weakly Supervised Learning of Semantic Matching and Object Co-Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3632–3647. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liao, S.; Hu, Y.; Zhu, X.; Li, S.Z. Person re-identification by local maximal occurrence representation and metric learning. In Proceedings of the Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2197–2206. [Google Scholar]
- Farenzena, M.; Bazzani, L.; Perina, A.; Murino, V.; Cristani, M. Person re-identification by symmetry-driven accumulation of local features. In Proceedings of the Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2360–2367. [Google Scholar]
- Gray, D.; Tao, H. Viewpoint Invariant Pedestrian Recognition with an Ensemble of Localized Features. In Proceedings of the ECCV, Marseille, France, 12–18 October 2008; pp. 262–275. [Google Scholar]
- Ma, B.; Su, Y.; Jurie, F. Covariance Descriptor based on Bio-inspired Features for Person Re-identification and Face Verification. Image Vis. Comput. 2014, 32, 379–390. [Google Scholar] [CrossRef] [Green Version]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.; Isola, P.; Saenko, K.; Efros, A.; Darrell, T. CyCADA: Cycle-Consistent Adversarial Domain Adaptation. In Proceedings of the ICML, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Chen, Y.; Lin, Y.; Yang, M.; Huang, J. CrDoCo: Pixel-level Domain Transfer with Cross-Domain Consistency. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Deng, W.; Zheng, L.; Kang, G.; Yang, Y.; Ye, Q.; Jiao, J. Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person reidentification. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 994–1003. [Google Scholar]
- Fan, H.; Zheng, L.; Yan, C.; Yang, Y. Unsupervised person re-identification: Clustering and fine-tuning. TOMM 2018, 14, 83. [Google Scholar] [CrossRef]
- Li, M.; Zhu, X.; Gong, S. Unsupervised person re-identification by deep learning tracklet association. In Proceedings of the ECCV, Munich, Germany, 8–10 September 2018; Volume 11208. [Google Scholar]
- Wang, J.; Zhu, X.; Gong, S.; Li, W. Transferable Joint Attribute-Identity Deep Learning for Unsupervised Person Re-identification. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2275–2284. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhong, Z.; Zheng, L.; Li, S.; Yang, Y. Generalizing a person retrieval model hetero-and homogeneously. In Proceedings of the ECCV, Munich, Germany, 8–10 September 2018; pp. 172–188. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.-W.; Kim, S.; Choo, J. StarGAN: Unified Generative Adversarial Networks for Multi-domain Image-to-Image Translation. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8789–8797. [Google Scholar]
- Lin, S.; Li, H.; Li, C.; Kot, A. Multi-task Mid-level Feature Alignment Network for Unsupervised Cross-Dataset Person Re-Identification. In Proceedings of the BMVC 2018, Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Kodirov, E.; Xiang, T.; Gong, S. Dictionary Learning with Iterative Laplacian Regularisation for Unsupervised Person Re-identification. In Proceedings of the BMVC, Swansea, UK, 7–10 September 2015; Volume 3, p. 8. [Google Scholar]
- Zhao, R.; Ouyang, W.; Wang, X. Unsupervised Salience Learning for Person Re-identification. In Proceedings of the Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3586–3593. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable Person Re-identification: A Benchmark. In Proceedings of the ICCV, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled Samples Generated by GAN Improve the Person Re-identification Baseline in Vitro. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, Y.; Yang, F.; Liu, Y.; Yeh, Y.; Du, X.; Wang, Y. Adaptation and Re-Identification Network: An Unsupervised Deep Transfer Learning Approach to Person Re-Identification. In Proceedings of the CVPRW, Salt Lake City, UT, USA, 18–22 June 2018; pp. 285–2856. [Google Scholar]
- Peng, P.; Xiang, T.; Wang, Y.; Massimiliano, P.; Gong, S.; Huang, T.; Tian, Y. Unsupervised cross-dataset transfer learning for person re-identification. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1306–1315. [Google Scholar]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person Transfer GAN to Bridge Domain Gap for Person Re-identification. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 79–88. [Google Scholar]
- Chen, S.; Fan, Z.; Yin, J. Pseudo Label Based on Multiple Clustering for Unsupervised Cross-Domain Person Re-Identification. IEEE Signal Process. Lett. 2020, 27, 1460–1464. [Google Scholar] [CrossRef]
- Lv, J.; Chen, W.; Li, Q.; Yang, C. Unsupervised Cross-dataset Person Re-identification by Transfer Learning of Spatial-Temporal Patterns. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7948–7956. [Google Scholar]
- Fu, Y.; Wei, Y.; Wang, G.; Zhou, Y.; Shi, H.; Huang, S. Self-Similarity Grouping: A Simple Unsupervised Cross Domain Adaptation Approach for Person Re-Identification. In Proceedings of the ICCV, Seoul, Korea, 27 October–3 November 2019. [Google Scholar]
- Lin, Y.; Dong, X.; Zheng, L.; Yan, Y.; Yang, Y. A bottom-up clustering approach to unsupervised person re-identification. In Proceedings of the AAAI, Honolulu, HI, USA, 27 January–1 February 2019; Volume 2, pp. 1–8. [Google Scholar]
- Song, L.; Wang, C.; Zhang, L.; Du, B.; Zhang, Q.; Huang, C.; Wang, X. Unsupervised Domain Adaptive Re-Identification: Theory and Practice. arXiv 2018, arXiv:1807.11334. [Google Scholar] [CrossRef] [Green Version]
- Yang, F.; Li, K.; Zhong, Z.; Luo, Z.; Sun, X.; Cheng, H.; Guo, X.; Huang, F.; Ji, R.; Li, S. Asymmetric Co-Teaching for Unsupervised Cross-Domain Person Re-Identification. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020; pp. 12597–12604. [Google Scholar]
- Zhang, X.; Cao, J.; Shen, C.; You, M. Self-training with progressive augmentation for unsupervised cross-domain person re-identification. In Proceedings of the ICCV, Seoul, Korea, 27 October–3 November 2019; pp. 8222–8231. [Google Scholar]
- Yin, Q.; Wang, G.; Ding, G.; Gong, S.; Tang, Z. Multi-View Label Prediction for Unsupervised Learning Person Re-Identification. IEEE Signal Process. Lett. 2021, 28, 1390–1394. [Google Scholar] [CrossRef]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Bhiksha, R.; Song, L. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 1. [Google Scholar]
- Wu, J.; Liao, S.; Lei, Z.; Wang, X.; Yang, Y.; Li, S.Z. Clustering and Dynamic Sampling Based Unsupervised Domain Adaptation for Person Re-Identification. In Proceedings of the ICME, Shanghai, China, 8–12 July 2019; pp. 886–891. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Yu, H.; Wu, A.; Zheng, W. Cross-View Asymmetric Metric Learning for Unsupervised Person Re-Identification. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017; pp. 994–1002. [Google Scholar]
- Zhou, K.; Yang, Y.; Qiao, Y.; Xiang, T. Domain generalization with mixstyle. In Proceedings of the ICLR, Virtual, 25–29 April 2022. [Google Scholar]
- Li, X.; Dai, Y.; Ge, Y.; Liu, J.; Shan, Y.; Duan, L. Uncertainty Modeling for Out-of-Distribution Generalization. arXiv 2022, arXiv:2202.03958. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Strategy | Market->Duke | Duke->Market | |||
|---|---|---|---|---|---|
| mAP | Rank-1 | mAP | Rank-1 | ||
| Attributes | no | 15.8 | 31.0 | 19.4 | 47.3 |
| yes | 19.9 | 37.2 | 22.4 | 50.1 | |
| Re-weighting | 0.85 | 33.0 | 57.3 | 32.9 | 64.6 |
| 0.8 | 39.6 | 64.3 | 37.3 | 67.3 | |
| 0.7 | 35.6 | 58.8 | 34.4 | 64.8 | |
| 0.6 | 29.71 | 49.8 | 36.12 | 63.18 | |
| DS | 42.7 | 67.2 | 39.9 | 71.8 | |
| TSDRW | 43.0 | 68.3 | 40.3 | 72.2 | |
| CCT | no | 42.7 | 67.2 | 39.9 | 71.6 |
| yes | 44.3 | 70.3 | 41.2 | 73.5 | |
| Frequency | Market->Duke | Duke->Market | ||
|---|---|---|---|---|
| mAP | Rank-1 | mAP | Rank-1 | |
| One epoch | 1.9 | 5.2 | 1.7 | 6.6 |
| Two epochs | 7.8 | 12.7 | 7.2 | 16.7 |
| Five epochs | 31.0 | 55.1 | 30.2 | 52.1 |
| 10 epochs | 44.3 | 70.3 | 41.2 | 73.5 |
| 20 epochs | 46.1 | 75.2 | 43.6 | 77.3 |
| Market->Duke | Duke->Market | |||
|---|---|---|---|---|
| mAP | Rank-1 | mAP | Rank-1 | |
| 21.9 | 35.2 | 19.7 | 36.6 | |
| 41.8 | 68.7 | 37.2 | 70.7 | |
| 44.3 | 70.3 | 41.2 | 73.5 | |
| 43.0 | 69.1 | 39.2 | 72.1 | |
| Methods | Market-1501 ->DukeMTMC-reID | |||
|---|---|---|---|---|
| mAP | Rank-1 | Rank 5 | Rank-10 | |
| LOMO [16] | 4.8 | 12.3 | 21.3 | 26.6 |
| UMDL [35] | 7.3 | 18.5 | 31.4 | 37.4 |
| PTGAN [36] | - | 27.4 | - | 50.7 |
| PUL [23] | 16.4 | 30.0 | 43.4 | 48.5 |
| CAMEL [48] | - | - | - | - |
| SPGAN+LMP [22] | 26.2 | 46.4 | 62.3 | 68.0 |
| TJAIDL [25] | 23.0 | 44.3 | 59.6 | 65.0 |
| HHL [27] | 27.2 | 46.9 | 61.0 | 66.7 |
| ARN [34] | 33.4 | 60.2 | 73.9 | 79.5 |
| CDS [46] | 42.7 | 67.2 | 75.9 | 79.4 |
| MixStyle [49] | 28.2 | 46.7 | - | - |
| DSU [50] | 32.0 | 52.0 | - | - |
| TSDRC | 44.3 | 70.3 | 79.7 | 82.2 |
| Methods | DukeMTMC-reID ->Market-1501 | |||
|---|---|---|---|---|
| mAP | Rank-1 | Rank 5 | Rank-10 | |
| LOMO [16] | 8.0 | 27.2 | 41.6 | 49.1 |
| UMDL [35] | 12.4 | 34.5 | 52.6 | 60.3 |
| PTGAN [36] | - | 38.6 | - | 66.1 |
| PUL [23] | 20.5 | 45.5 | 60.7 | 66.7 |
| CAMEL [48] | 26.3 | 54.5 | - | - |
| SPGAN+LMP [22] | 26.7 | 57.7 | 75.8 | 82.4 |
| TJAIDL [25] | 26.5 | 58.2 | 74.8 | 81.1 |
| HHL [27] | 31.4 | 62.2 | 78.8 | 84.0 |
| ARN [34] | 39.4 | 70.3 | 80.4 | 86.3 |
| CDS [46] | 39.9 | 71.6 | 81.2 | 84.7 |
| MixStyle [49] | 28.1 | 56.6 | - | - |
| DSU [50] | 32.4 | 63.7 | - | - |
| TSDRC | 41.2 | 73.5 | 83.1 | 86.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, Q.; Wang, G.; Wu, J.; Luo, H.; Tang, Z. Dynamic Re-Weighting and Cross-Camera Learning for Unsupervised Person Re-Identification. Mathematics 2022, 10, 1654. https://doi.org/10.3390/math10101654
Yin Q, Wang G, Wu J, Luo H, Tang Z. Dynamic Re-Weighting and Cross-Camera Learning for Unsupervised Person Re-Identification. Mathematics. 2022; 10(10):1654. https://doi.org/10.3390/math10101654
Chicago/Turabian StyleYin, Qingze, Guan’an Wang, Jinlin Wu, Haonan Luo, and Zhenmin Tang. 2022. "Dynamic Re-Weighting and Cross-Camera Learning for Unsupervised Person Re-Identification" Mathematics 10, no. 10: 1654. https://doi.org/10.3390/math10101654
APA StyleYin, Q., Wang, G., Wu, J., Luo, H., & Tang, Z. (2022). Dynamic Re-Weighting and Cross-Camera Learning for Unsupervised Person Re-Identification. Mathematics, 10(10), 1654. https://doi.org/10.3390/math10101654