1. Introduction
Many current manufactured products are highly reliable because of competitiveness between manufacturers. Therefore, experimenters exploring different avenues of reliability and quality of such products face the issue of not having enough information about the products’ failures under normal operating conditions. Consequently, experimenters presented accelerated life tests (ALTs) in the literature as an approach to analyzing highly reliable products’ lifetimes efficiently. In such experiments, the test items are run at higher-than-usual levels of stress, including, but not limited to, temperature, voltage and weight, to actuate early failures. In ALTs, extreme stress levels are forced on the product to guarantee fast failures. There are several models under ALTs, and the foremost utilized models incorporate constant-stress and step-stress models. In a constant-stress accelerated life test model, each examined unit is operated at constant stress until the test ends or all units fail. Many authors discussed constant-stress ALT models in the literature. See, for example, Yin et al. [
1], Nassar and Dey [
2], Dey and Nassar [
3] and Sief et al. [
4].
On the other hand, in a step-stress ALT experiment, the stress is raised step by step at predetermined times or upon the event of a specified number of failures. A simple step-stress ALT model is obtained as a particular situation when the test contains just two stress levels. Many researchers in the literature considered this model; see, for example, Balakrishnan et al. [
5], Mohie El-Din et al. [
6] and Nassar et al. [
7], as well as the references therein. For more details about the ALTs, one can refer to Guan et al. [
8], Mohie El-Din et al. [
9] and Bagdonavicius and Nikulin [
10].
In the analysis of ALTs, one of the main focuses is utilizing the obtained information at accelerated stress stages to extrapolate the product performance at normal use conditions. To achieve this objective, one needs to know the life–stress model, which determines the connection between the lifetime and stress conditions. In some situations, the life–stress models cannot be known or assumed. Therefore, a partially accelerated life test (PALT) is one option to estimate the product reliability at normal use conditions. In PALT, items are tested at both normal and accelerated conditions. In a constant-stress PALT (CSPALT), each unit is operated at a constant stress, under either normal use conditions or accelerated conditions. Many authors have also investigated CSPALT. Mahmoud et al. [
11] considered the estimation problems of modified Weibull distributions based on CSPALT using Type-II censored samples. Dey et al. [
12] investigated the estimations of Nadarajah–Haghighi distribution parameters using CSPALT under progressively Type-II censored data. Ahmadini et al. [
13] estimated the unknown parameters and the acceleration factor of Fréchet distributions with Type-I censoring based on CSPALT. Li and Zheng [
14] studied CSPALT using Type-I censoring under the Gompertz distribution.
Recently, a new two-parameter distribution called the modified Kies exponential (MKE) distribution was considered by Al-Babtain et al. [
15] using the
family procedure. Almetwally et al. [
16] used the same approach to introduce the modified Kies inverted Topp–Leone distribution. This MKE distribution has many desirable properties in modeling lifetime data compared with traditional distributions, such as the Weibull and the gamma distributions. The MKE distribution has a significantly flexible probability density function (PDF); it can be negatively skewed, positively skewed and symmetric and can permit tremendous flexibility of the tails. Its hazard rate function (HRF) has different shapes, including increasing and bathtub-shaped. Besides the flexibility of the PDF and HRF of this distribution, one of the most desirable distributional properties is the simple closed-form cumulative distribution function (CDF). In this case, the distribution is suitable for use in different areas, such as life testing, reliability analysis, medical studies and survival analysis. In this context, Al-Babtain et al. [
15] employed two distinct kinds of real data to demonstrate that the MKE model is a useful alternative to numerous prevalent models, such as the exponential, gamma, Weibull, generalized exponential, Marshall–Olkin exponential, Kumaraswamy exponential and beta exponential models. Abd El-Raheem et al. [
17] studied the MKE distribution using multiple constant-stress testing based on progressive Type-II censored data with binomial removal. Aljohani et al. [
18] studied the estimation of the parameters of the MKE distribution based on ranked set sampling. Many authors applied the MKE distribution to analyze different data types, including precipitation, failure times of transformer insulation, failure times for a particular windshield device and time-to-failure of turbocharger data.
In practice, the researcher may not always obtain a complete sample of failure times for all examination units in life reliability analysis and testing investigations. Data gained from such tests are described as censored data. Sparing the time on a test and the cost associated with it are some of the leading reasons for censoring. There are many censoring schemes in life testing, and the foremost familiar censoring schemes are Type-I and Type-II censoring (see, for more details, Lawless [
19]). Motivated by such causes, as stated before, studying the MKE distribution under CSPALT in the presence of Type-II censored data is of considerable interest. To the best of our knowledge, the estimation of the MKE distribution parameters using CSPALT under the Type-II censoring scheme has not yet been studied. Therefore, in this work, two methods are used for this purpose: maximum likelihood (ML) and maximum product of spacing (MPS) methods. In addition to the point estimates of the unknown parameters, the approximate confidence intervals (ACIs) are also computed based on the two methods. It is important to mention here that this is the first time the MPS method is used to estimate the model parameters in the presence of CSPALT. In addition, two parametric bootstrap confidence intervals are considered based on both ML and MPS methods. The different point and interval estimates are examined via an extensive simulation study. In addition, two real data sets are explained to confirm the applicability of the various proposed estimators in real-life scenarios.
The remainder of this paper is designed as follows: In
Section 2, we explain the proposed model. The ML method is applied to obtain the point and interval estimates of the unknown parameters in
Section 3.
Section 4 discusses point and interval estimation for the parameters based on the MPS method. In
Section 5, two parametric bootstrap confidence intervals are presented. A Monte Carlo simulation study is implemented in
Section 6. Two real data sets are investigated in
Section 7. Finally, some outcomes are provided in
Section 8.
2. Model Description
Suppose that under normal conditions, the lifetime of an object, say,
Y, follows the MKE distribution. Then, the associated PDF according to Al-Babtain et al. [
15] is given by
where
a and
b are the shape and scale parameters, respectively. The CDF of the MKE distribution is
The reliability function (RF) and HRF are, respectively, given by
and
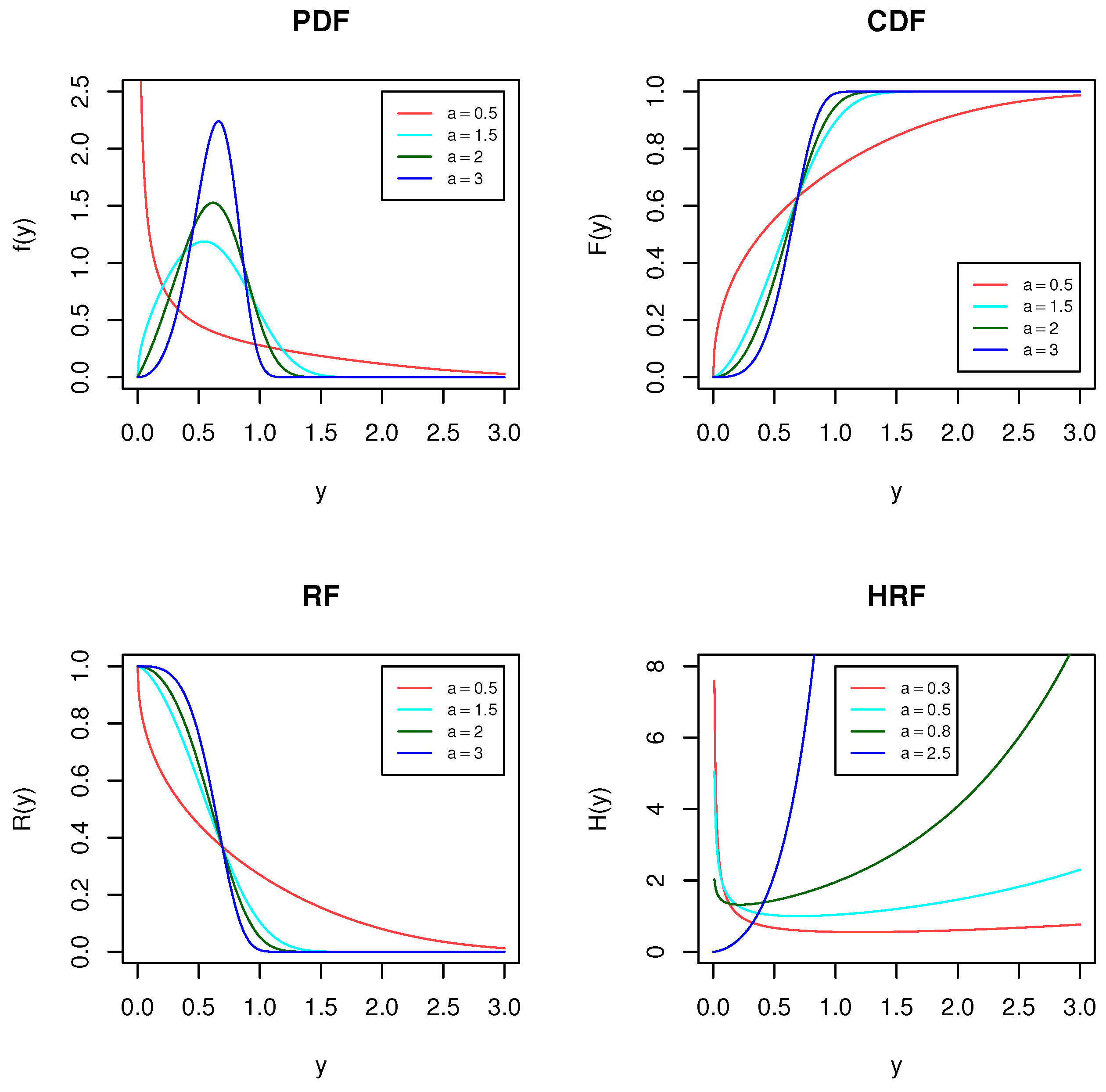
Figure 1 displays the different plots of the PDF, CDF, RF and HRF for some selected values of the shape parameter and assumes that the scale parameter is one in all the cases. Al-Babtain et al. [
15] mentioned that the PDF of the MKE distribution can be symmetric or positive- or negative-skewed, depending on the shape parameter value. In addition, they proved that the HRF of the MKE distribution is increasing for
and bathtub-shaped for
. According to Al-Babtain et al. [
15], the mean and median of the MKE distribution can be written, respectively, as
and
Now, suppose that we have
n units divided into two groups: the first group contains
units randomly chosen from
n test units at normal conditions, and the second group contains the remaining
units, which are subjected to an accelerated condition. For group
k, where
, the units are tested under the Type-II censoring scheme with prefixed sample size
, where
, are the observed number of failures at normal use and accelerated conditions, respectively. Once the experiment ends, one has the observations
. The lifetime of an item tested at normal conditions follows the MKE distribution, with PDF, CDF, RF and HRF given by (
1)–(
4). The hazard rate of a tested unit at accelerated condition is given by
, where
is given by (
4) and
c is an acceleration factor satisfying
. In this case, the HRF under the accelerated condition is given by
Using the relation
, we can obtain the RF under the accelerated condition as follows:
The corresponding CDF and PDF are, respectively, given by
and
It is of interest to mention here that one of the main advantages of the MKE distribution is that it contains only one scale and one shape parameter. Hence, this makes it a very flexible model when applied in the CSPALT because the number of parameters of the new model will be three, including the acceleration factor
c. On the other hand, when using models with three parameters, such as the exponentiated Weibull distribution, the model parameters increase to four parameters (due to the acceleration factor). Therefore, the resulting model will be very complicated with many parameters, which makes it not a practical choice to many researchers and reliability engineers. Based on the previous argument, the likelihood function (without constant terms) based on the realizations of the two censored samples is given by
where
. Cheng and Amin [
20] proposed the MPS estimation method as an alternative to the ML estimation method, especially for the distributions with unknown scale and shifted threshold. They pointed out that the MPS and ML estimators have similar asymptotic sufficiency, consistency and efficiency properties. Ranneby [
21] studied the mathematical properties of the MPS method as an approximation to the Kullback–Leibler information and observed that the MPS method gives unique and minimum variance unbiased estimators. In addition, Anatolyev and Kosenok [
22] investigated the invariance properties of the MPS estimators (MPSEs) and showed that they have the same properties as the MLEs. The MPSEs are obtained by maximizing the product of the differences between the values of the CDF at adjacent ordered points. Ng et al. [
23] extended the MPS method to estimate the parameters of a three-parameter Weibull distribution under progressively Type-II censored data. Following the same approach as Ng et al. [
23], we can write the product of spacing to be maximized under the CSPALT for Type-II censored data as
3. Maximum Likelihood Estimation
For
, let
be two Type-II censored samples from two populations with CDFs and PDFs given by (
2), (
1), (
7) and (
8), respectively. In this case, we can write the log-likelihood function, denoted by
, in the following form:
where
and
,
. The maximum likelihood estimates (MLEs) of the parameters
and
c can be obtained by maximizing the objective function (
11). This can be achieved by deriving (
11) with respect to
and
c, equating them to zero, and then solving the system of nonlinear equations simultaneously. Here, the likelihood equations are as follows:
and
where
. From (
14) and for fixed
a and
b, the MLE of the parameter
c can be obtained as follows:
Substituting
, given by (
15) in (
12) and (
13), the MLEs of
a and
b, denoted by
and
, can be obtained by solving the following two nonlinear equations:
and
It is observed that, from (
16) and (
17), there are no closed forms for
and
; therefore, any suitable numerical technique may be used to obtain these estimates. Upon obtaining
and
,
can be obtained from (
15) by replacing
a and
b with their corresponding estimates
and
. Based on the asymptotic properties of the MLEs, we can construct the ACIs of the unknown parameters and the acceleration factor
. From large sample theory, it is known that the asymptotic distribution of the MLEs
is a trivariate normal distribution with mean
and variance–covariance matrix
. Practically,
is used to estimate
, where
is the observed information matrix and
where
and
Now, the
ACIs of the unknown parameters
and
c can be obtained as follows:
where
and
are the main diagonal elements of (
18), respectively, and
is the upper
th percentile point of the standard normal distribution.
Clearly, maximizing the objective function (
11) with respect to
and
c to obtain the MLEs requires a numerical method using a statistical software such as R, which is an environment for statistical computing, see Reference [
24]. Typically, researchers use Newton’s method (i.e., Newton–Raphson) to solve (
12)–(
14), with respect to the model parameters, to numerically determine the MLEs. Furthermore, they sometimes transform the model parameters using a log-transformation to avoid constraints, as indicated by MacDonald [
25]. In R, the objective function (
11) can be maximized using built-in functions of R, such as
nlm() and
optim(). However, since there is a constraint on the acceleration parameter
c, namely,
, we could not apply any transformations on the model parameters to avoid constraints; thus, we considered the R built-in function
nlminb(), which implements a constrained quasi-Newton method. For details about this approach, see Fox et al. [
26].
4. Maximum Product of Spacing Estimation
In the maximum likelihood method approach, the values of the parameters are chosen to maximize the likelihood function. The MPSEs are computed instead by choosing the values of the parameters that maximize the product of the spaces between the values of the distribution function at adjacent ordered points. Anatolyev and Kosenok [
22] stated that for small sample sizes, the MPSEs demonstrate efficient small sample behaviour when compared with the MLEs, which makes the MPS method even more appealing in reliability studies. For more details about the MPS estimation method, see Nassar et al. [
27] and Basu et al. [
28]. Using the same notation as the previous sections and from (
2), (
7) and (
10), we can write the product of spacing to be maximized as follows:
Taking the natural logarithm of (
19), say,
, we have the following:
The MPSEs are obtained by maximizing the objective function (
20) with respect to the unknown parameters
and
c. These estimates can also be obtained by differentiating (
20) with respect to
and
c, equating the results to zero, and then solving the three nonlinear equations simultaneously. The three normal equations of (
20) are given by
and
where
,
,
and
. It is noted that the MPSEs denoted by
and
cannot be obtained in closed forms; therefore, numerical techniques can be used to solve Equations (
21)–(
23).
Using the same approach as the ML estimation method and from large sample theory, we constructed the ACI for the unknown parameters based on the MPSEs. The asymptotic distribution of the MPSEs
is a trivariate normal distribution with mean
and variance–covariance matrix
. It is beneficial to remark here that several authors have elicited the asymptotic equivalence of the MPS method and ML estimation method; Cheng and Amin [
20], Ghosh and Jammalamadaka [
29] and Anatolyev and Kosenok [
22] demonstrated that the MPS method exhibits asymptotic properties, like the ML method. One can also refer to Basu et al. [
30,
31]. In this case, we used
to estimate
as follows:
where
and
where
,
,
,
and
. Now, the
ACIs of the unknown parameters
and
c based on the MPSEs can be obtained:
where
and
are the estimated variances.
Similar to MLEs, maximizing the objective function (
20) with respect to
and
c to obtain MPSEs also requires a numerical method using R. We considered the same R built-in function
nlminb() that implements a constraint quasi-Newton method to obtain the MPSEs.
6. Simulation Studies
In this section, the outcomes of the analysis of a simulated data set from the described model are first presented in an illustrative example; afterwards, results from a Monte Carlo simulation study are reported. All results in this section are associated with proper discussions. It is important to mention that obtaining explicit estimators from the systems of nonlinear equations, which were mentioned in the previous sections, is typically not possible. In our case, we had three parameters; thus, we were dealing with three complicated nonlinear equations. That is why we obtained the desired estimators numerically.
Moreover, since we derived first- and second-order derivatives for the objective functions, we considered Newton’s method to find MLEs and MPSEs. Convergence problems might occur in any optimization process if the initial values are not chosen carefully by the researchers; we randomly generated initial values close to the actual model parameters. To optimize the objective function, we considered Newton’s method, which is known for its fast quadratic convergence. We do not provide details about this method for the sake of brevity.
6.1. Illustrative Example
Here, the MLEs and the MPSEs were determined numerically from a data set simulated from a CSPALT with
and
and
. The observations are reported in
Table 1.
Type-II censored data were derived from the data in
Table 1 under the assumption that
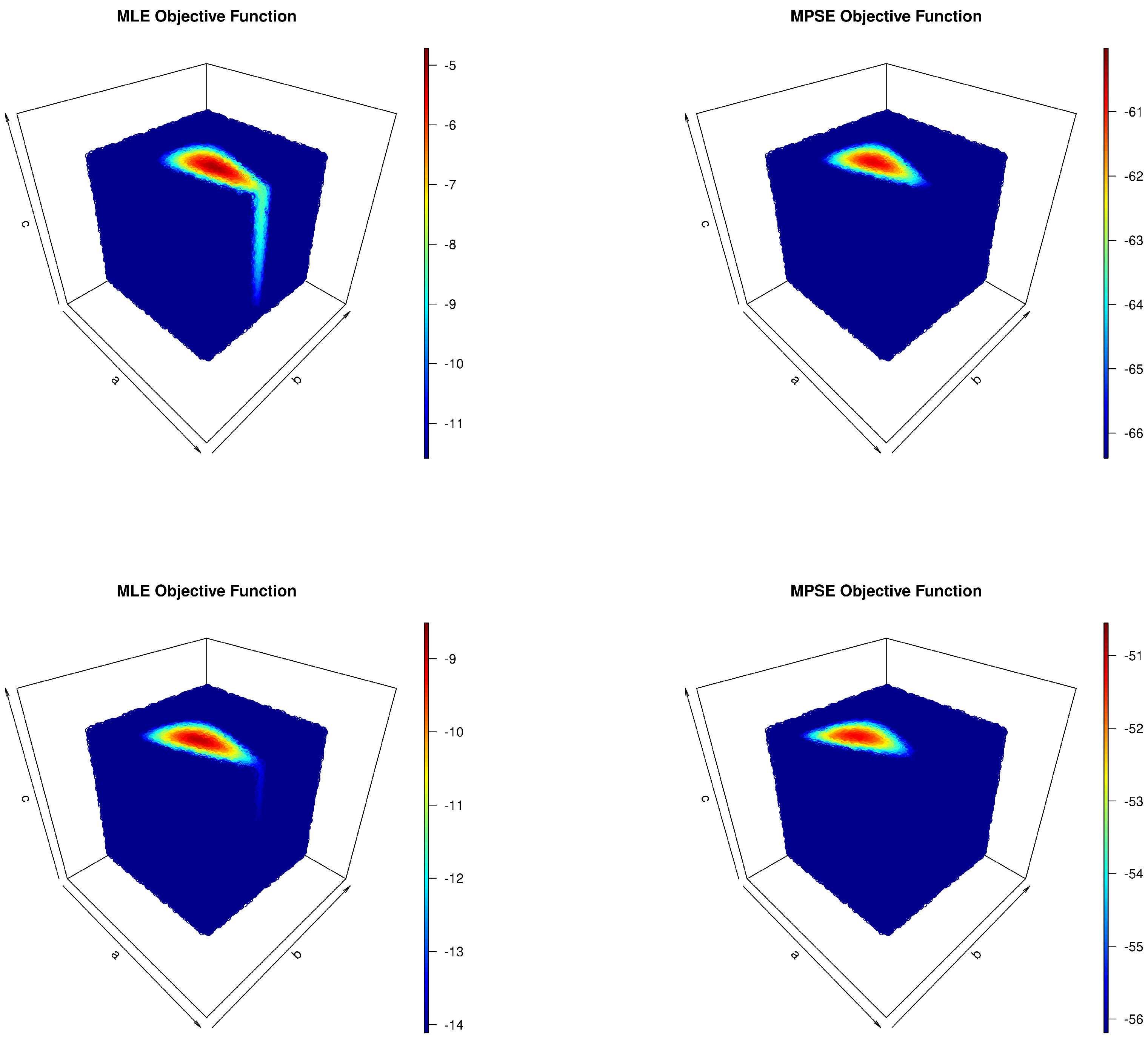
. Before proceeding to the calculation of the MLEs and the MPSEs for the model parameters, one must check their existence and uniqueness and whether the data are complete or not. Although proving these conditions is extremely important mathematically, it is beyond this study’s scope. However, one could still prove such requirements by using graphical means. In fact, by using extensive Monte Carlo simulations, a four-dimensional (4D) plot for the profiles of the objective functions of MLEs and MPSEs was established, as shown in
Figure 2, in the case of complete and censored data. The 4D charts clearly show regions, namely, the dark-red spots, in which global maxima exist and are unique for the objective functions. In addition, censoring caused the regions to slightly change their forms and shift from their original places when the data were uncensored. The starting values for the model parameters were obtained from the Monte Carlo simulations to optimize the objective function and are reported in
Table 2. The reason for having different initial values is that we were dealing with two different objective functions under two different data settings. The initial values that maximize the log-likelihood function might not necessarily maximize the maximum product of spacing objective function. Nevertheless, the initial values that maximize the log-likelihood function can still obtain the MPSEs. By using these initial values in
Table 2, the estimates of the model parameters and their asymptotic variances evaluated at these estimates are given in
Table 3. From this table, one can readily conclude that MLEs provided estimates close to the true values of the model parameters compared to the MPSEs when the data were complete or censored and that censoring increased the values of the approximated asymptotic variations of the estimates. Further comparisons are conducted in the upcoming subsection to investigate the performance of the MLEs and MPSEs.
6.2. Simulation Method and Outcomes
This subsection reports the results of a simulation study conducted based on Monte Carlo methods to examine the efficiency of the considered estimators numerically. The performance of the MLEs and MPSEs was assessed in terms of simulated biases and simulated root-mean-square errors (RMSEs). In this simulation study, the model parameters were considered to be , and . Furthermore, it was assumed that and for the sake of concision; moreover, the following Type-II censoring settings were considered in both normal use and accelerated stress stages:
and .
and .
and .
and .
and .
and .
and .
and .
and .
and .
By maximizing the objective functions (
11) and (
20) with respect to
and
c using
R, we obtained the MLEs and the MPSEs for the model parameters, as mentioned in the previous sections. Due to the fact that there is no information about the range of the estimates in practice, the starting values of the model parameters were randomly obtained around their true values, assuming independent uniform distributions. From a practical perspective, one should alternatively consider computational ranges for the model parameters and perform profiling on the objective functions to acquire the corresponding starting values. For more details about best practice optimization approaches in
R, see Nash [
34].
For each setting, the process was repeated 1000 times and the average values of biases and RMSEs for
and
c were obtained. These outcomes are displayed in
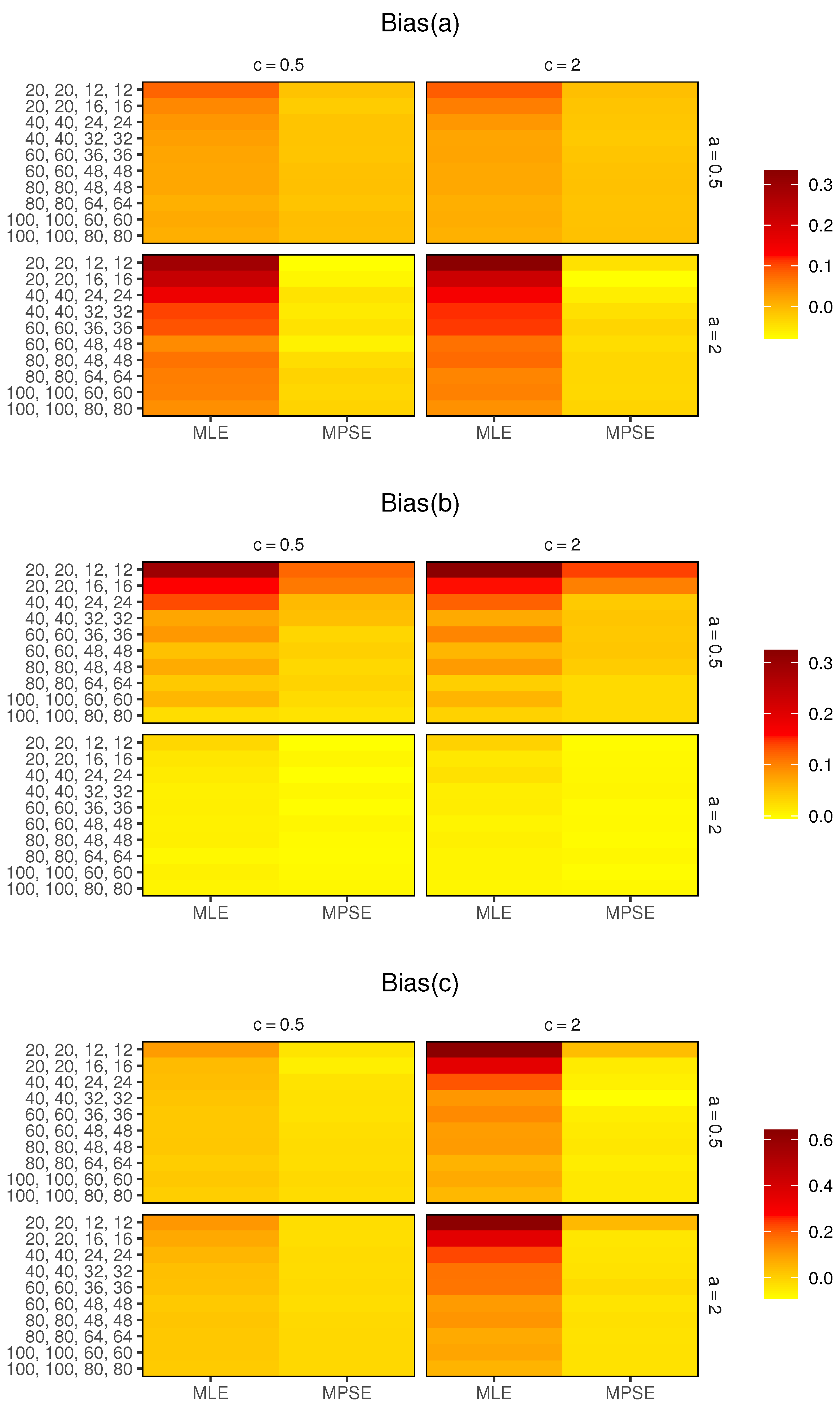
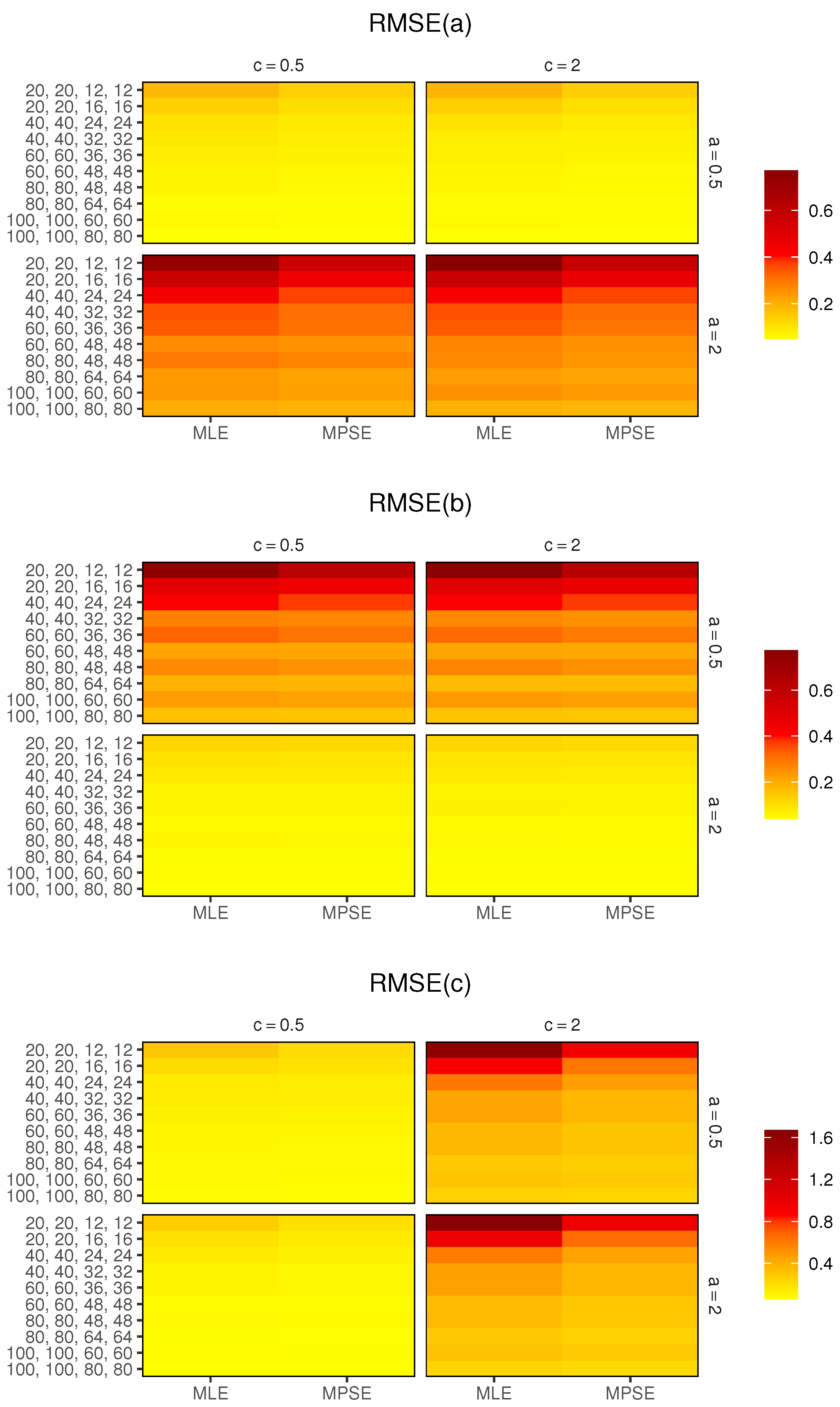
Figure 3 and
Figure 4, where
Figure 3 displays the heatmaps of biases and
Figure 4 presents the heatmaps of RMSEs. In addition, to compare the performance of the different proposed confidence intervals (CIs), the lengths (Lens) of the CIs were computed and are presented in
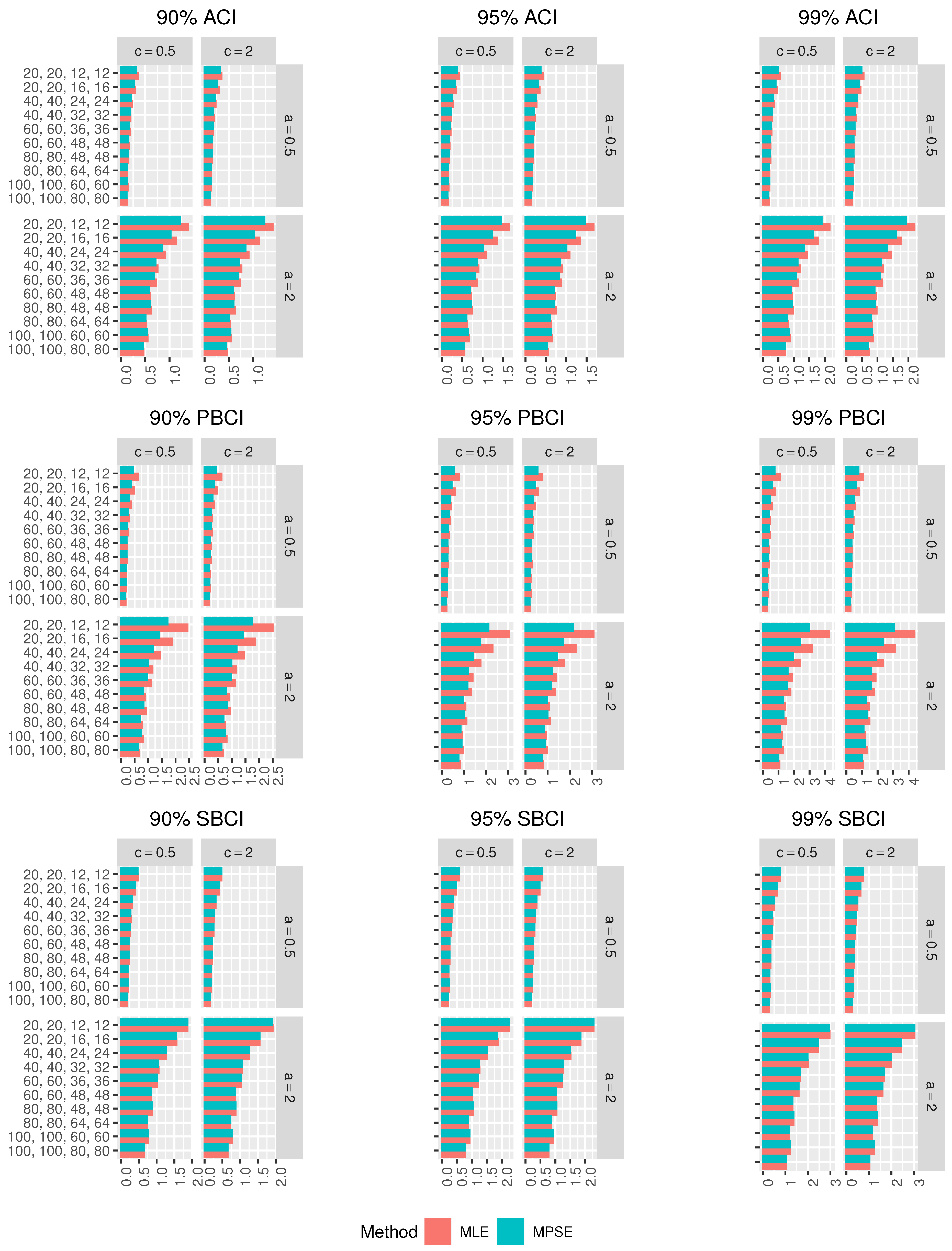
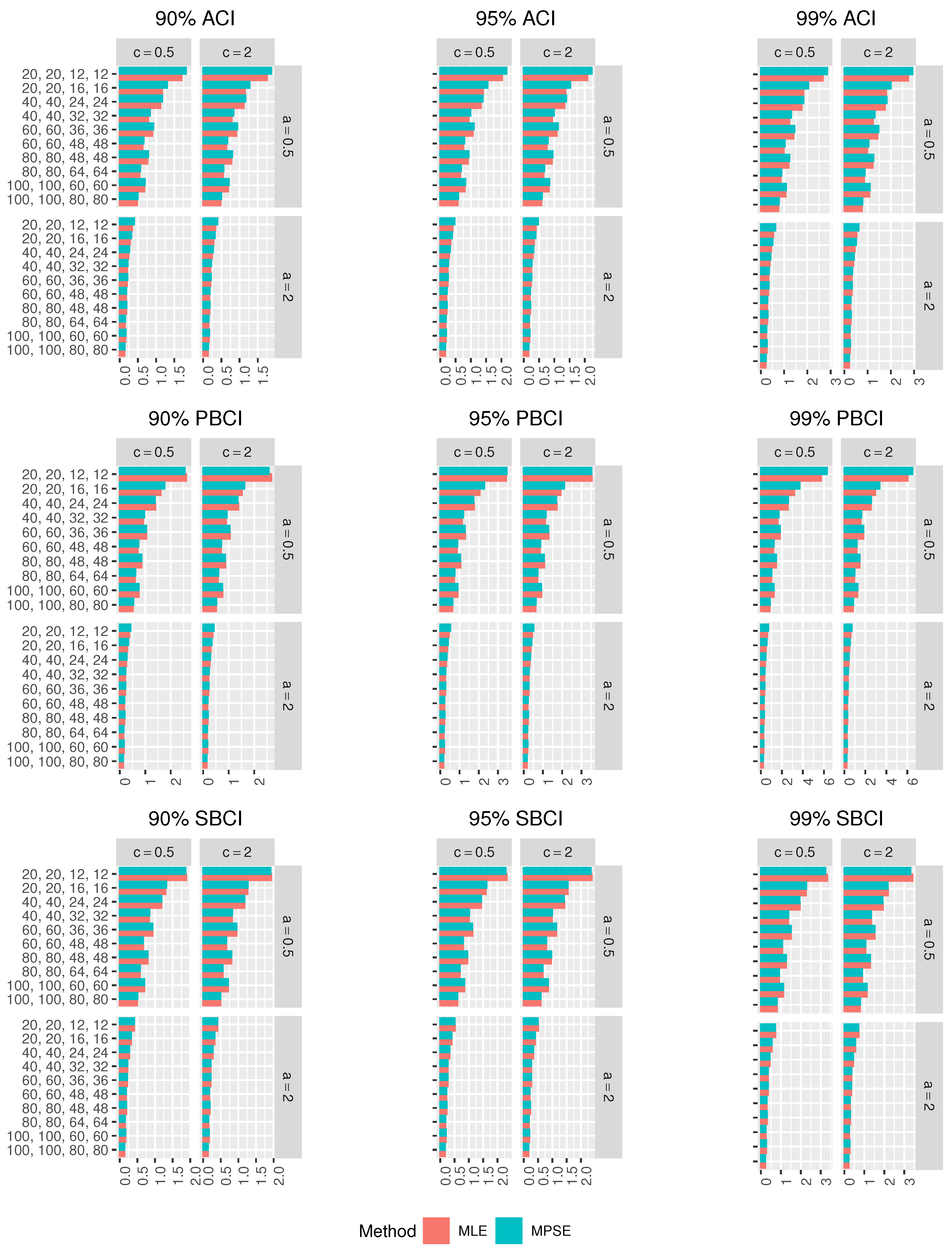
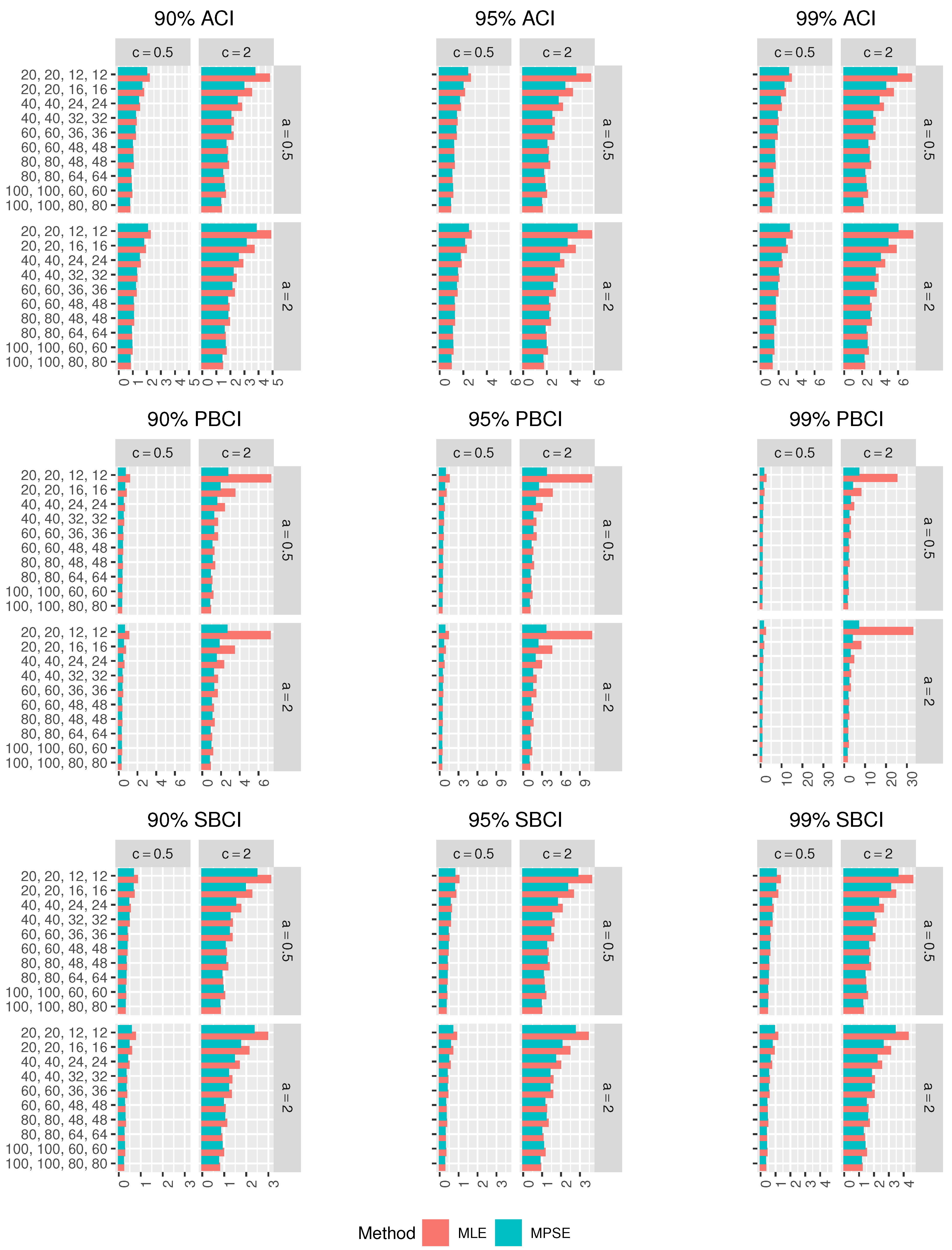
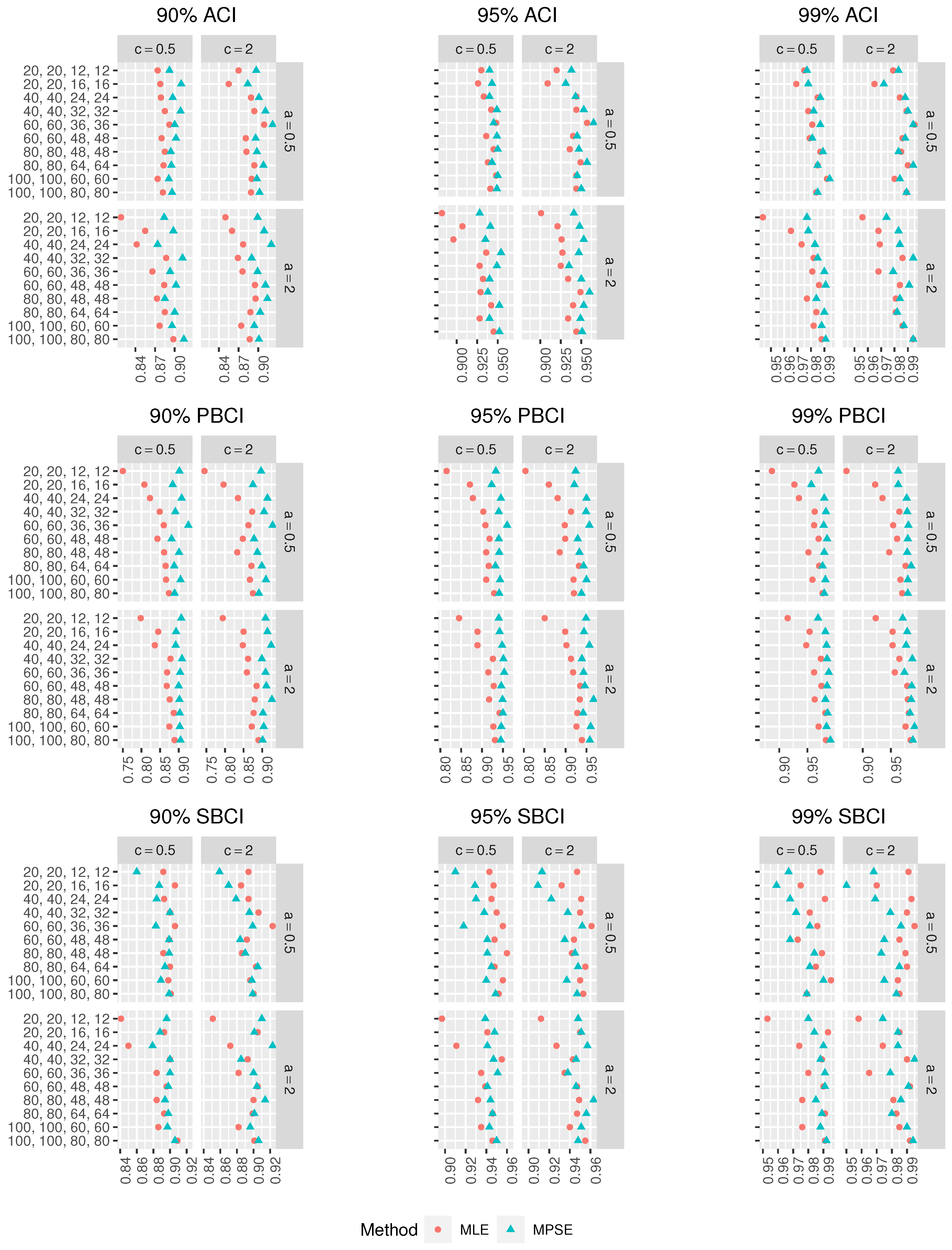
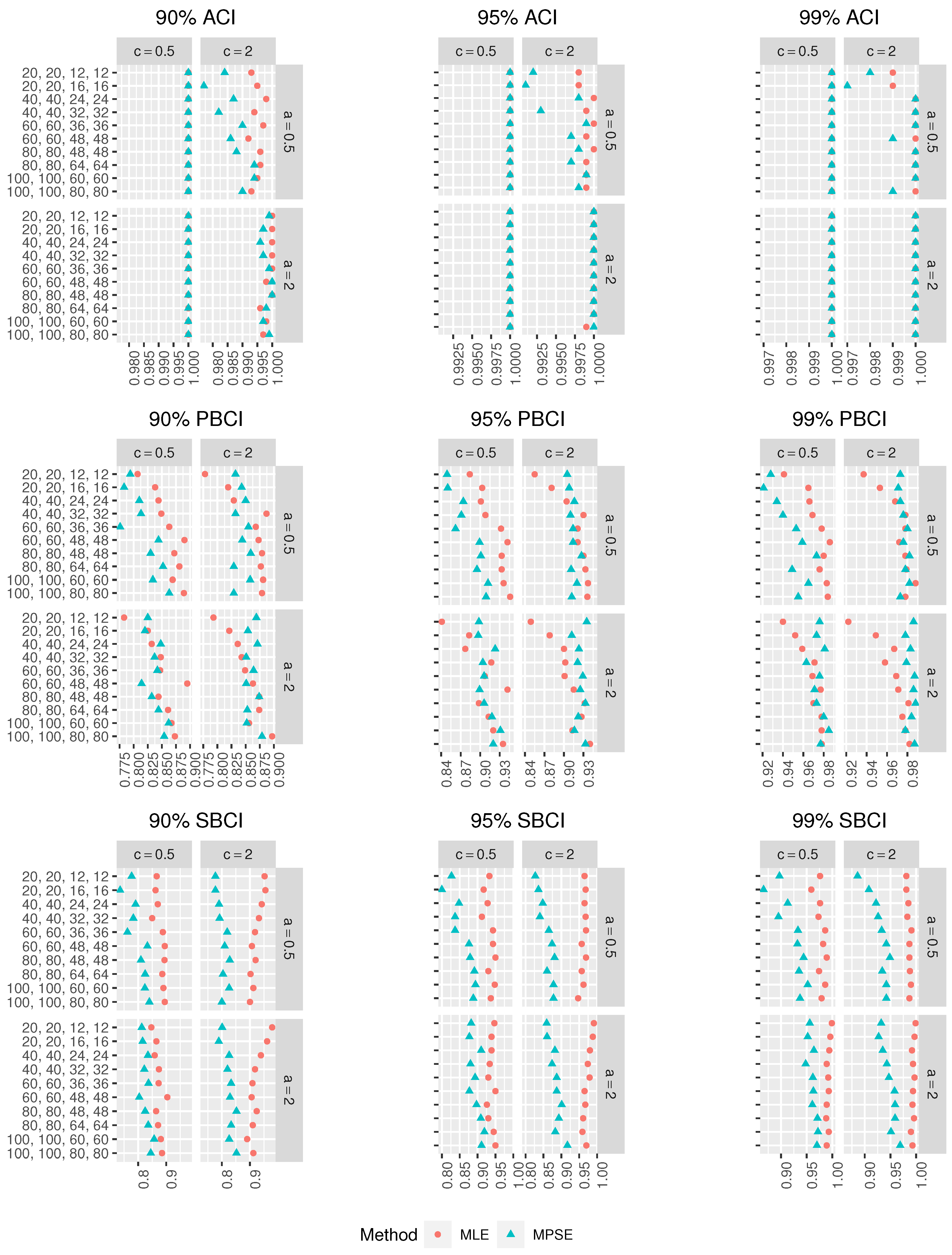
Figure 5,
Figure 6 and
Figure 7, respectively. In addition, the coverage probabilities (CPr) of the different CIs were obtained and are presented in
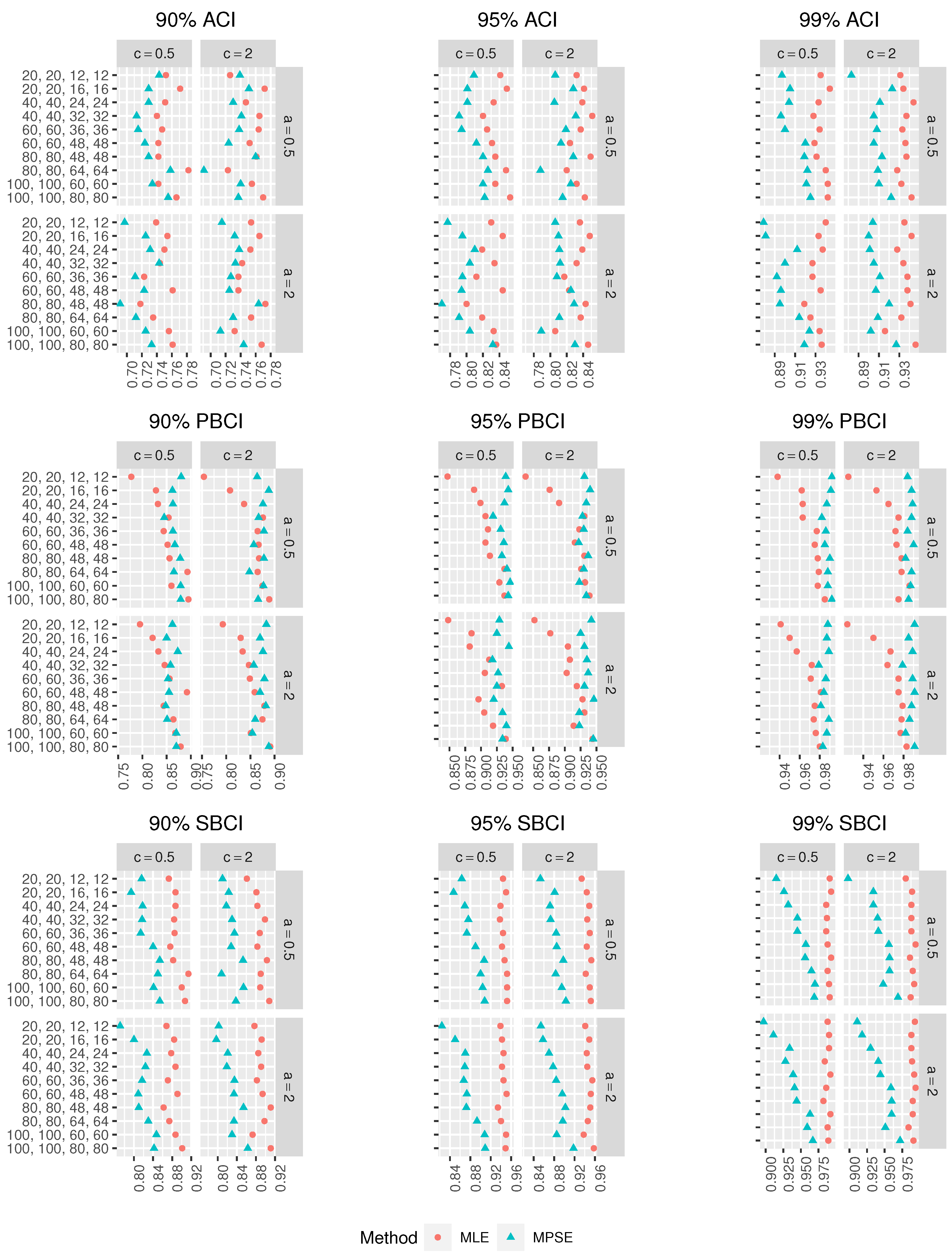
Figure 8,
Figure 9 and
Figure 10. From the simulation results in
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8,
Figure 9 and
Figure 10, one can draw the following observations:
For fixed , as increases, the biases of the MLEs and MPSEs decrease, which implies that the estimators are asymptotically unbiased.
For fixed , as rises, the RMSEs of the MLEs and MPSEs decrease, which infers that the estimators are consistent.
The MPSEs perform better than the MLEs based on minimum biases in all the cases.
The MPSEs have fewer RMSEs than the MLEs in all the cases.
For small , the MPSEs have smaller biases and RMSEs than the MLEs in all the cases.
In terms of minimum Lens, the different CIs based on the MPSEs perform better than those based on the MLEs.
For fixed , as increases, the Lens of the CIs using the MLEs and MPSEs decreases in all the cases.
The ACIs based on the MLEs and MPSEs have the smallest Lens among other CIs in most of the cases.
The ordering of performance for the CIs using the MLEs and MPSEs are the ACIs, SBCIs and PBCIs.
In all the cases, as , increases, the CPr of the different CIs tends to the nominal confidence level.
Merging all the earlier results, we suggest using the MPS estimation method to estimate the parameters of the MKE distribution based on CSPALT and Type-II censored data.
7. Data Analysis Illustrative Examples
In this part of the paper, two data analysis examples are considered to show practical application of the estimation methods discussed in the preceding sections.
Example 1 (Oil breakdown times of insulating fluid)
. The first data set to be analyzed is the oil breakdown times of insulating fluid subjected to different constant levels of high voltage. The main data set consists of additional observations since the tests were performed under different levels of stress, as reported in Nelson [35] and recently analyzed by many authors (see, for example, Nassar and Dey [2]). For the sake of illustration, the data set under stress level 30 kilo-volt (KV) was assumed to be the data under normal use conditions, while the observations under stress level 32 KV were considered to be the accelerated data set. The data sets of interest are provided in Table 4. To analyze the data in
Table 4, firstly, the goodness-of-fit of the MKE distribution was evaluated by using the one-sample Kolmogorov-Smirnov (K-S) test. The K-S statistic is obtained as follows:
The K-S distance and the corresponding
p-value based on the MLEs and MPSEs are summarized in
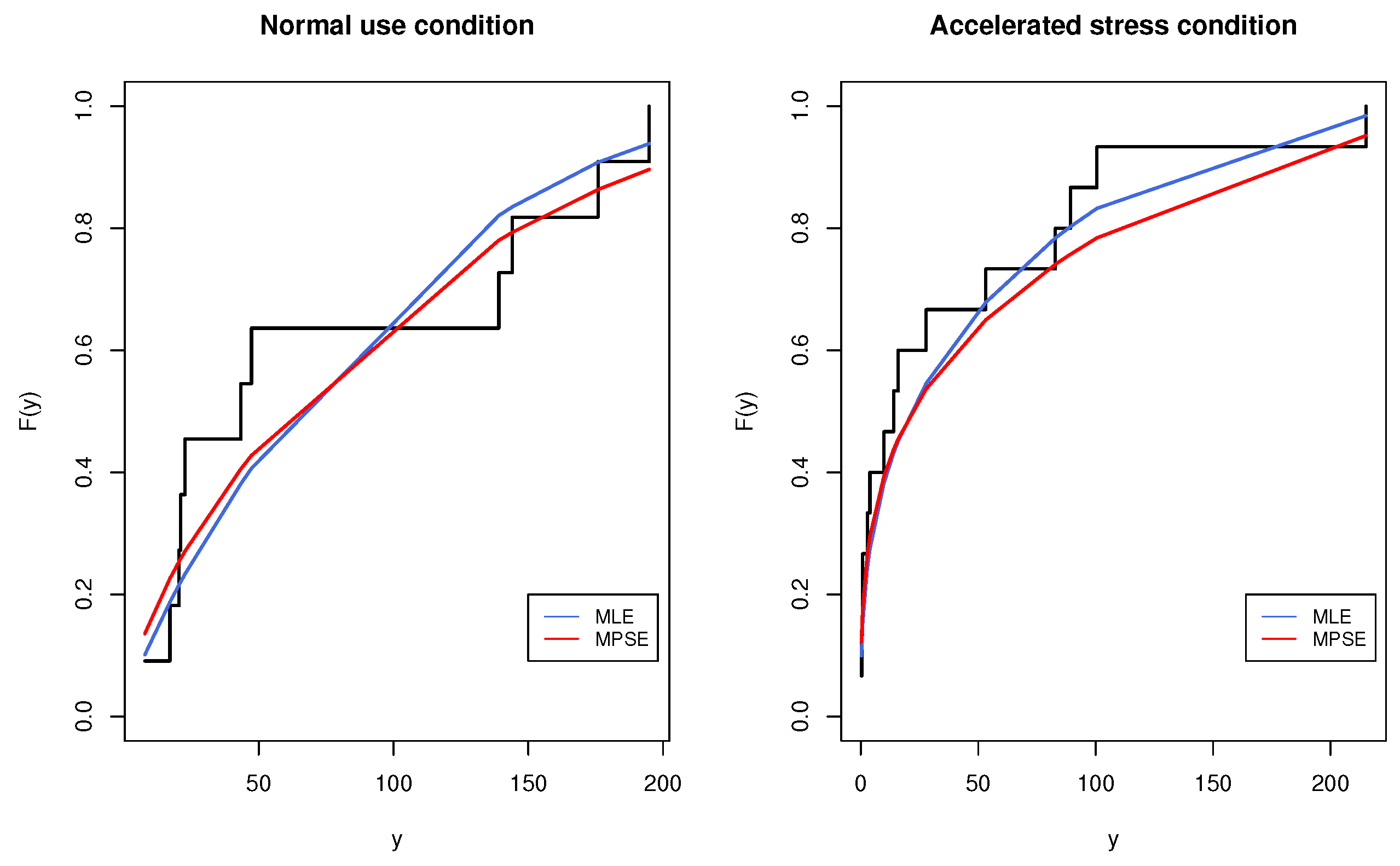
Table 5. Regardless of the considered estimator, the goodness-of-fit test indicates that the MKE distribution could be considered an adequate life model for the analyzed data set; nevertheless, MPSEs provided better goodness-of-fit outcomes. The empirical and fitted CDF plots of the MKE distribution for the data in
Table 4 are depicted in
Figure 11. For the sake of illustration, a Type-II censored CSPALT data set was obtained by considering
and
. Accordingly, the MLEs and MPSEs and the associated standard errors were acquired for the model parameters as well as the considered
CIs, as shown in
Table 6. Based on the outcomes of the latter table, one can observe that the MPSEs of the parameters
a and
c perform better than the MLEs in terms of minimum standard errors, while the MLE of the parameter
b has a smaller standard error than the MPSE. On the other hand, the CIs computed via the MPSEs have a slightly shorter interval Lens than those obtained based on the MLEs, and similarly, the ACIs have slightly smaller interval lengths among other CIs, except in some cases. Based on the MLEs and MPSEs displayed in
Table 6, the estimates of the mean time to failure (MTTF) and RF using some mission times under normal use conditions were obtained and are displayed in
Table 7.
Example 2 (Time to breakdown of steel specimens)
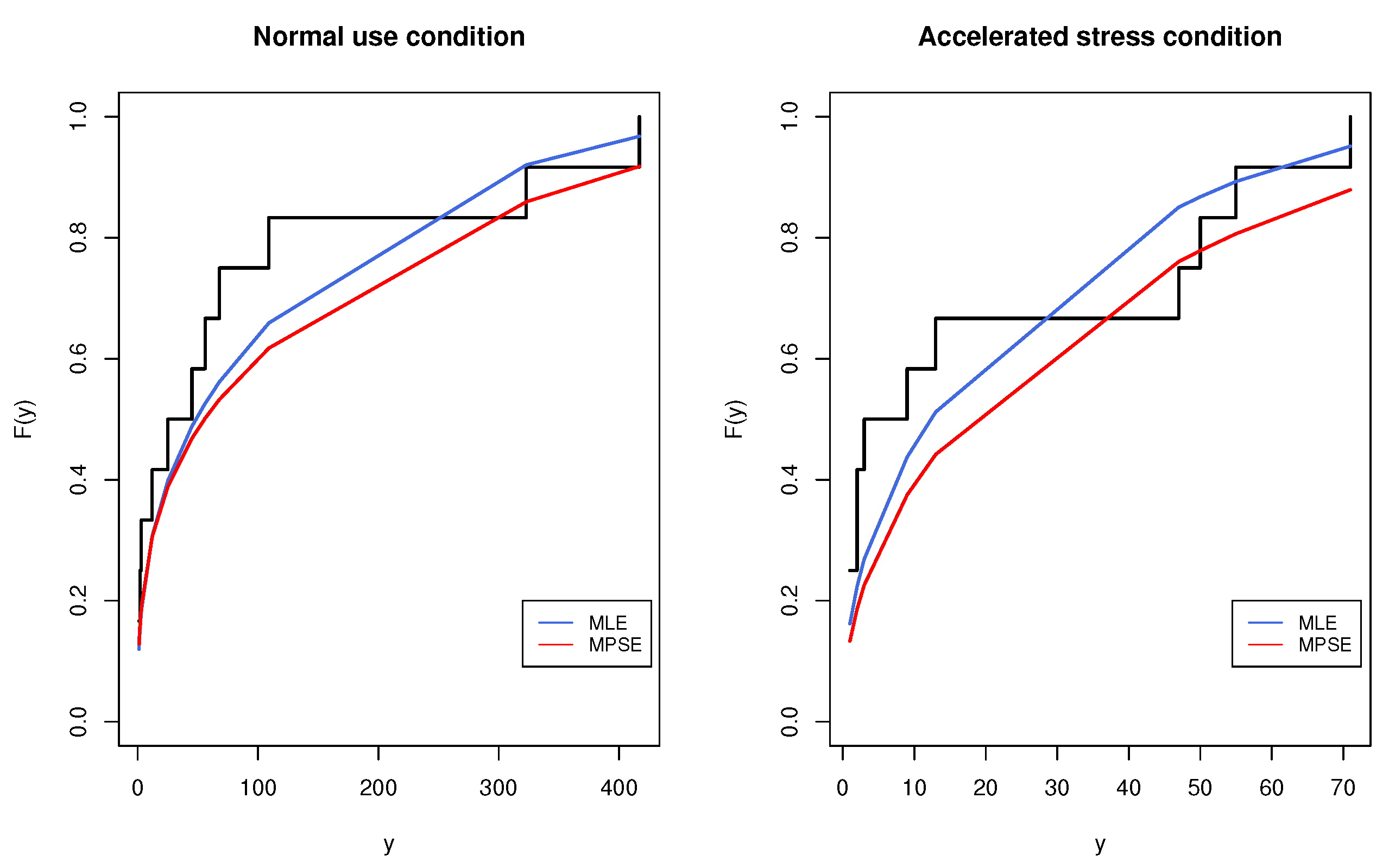
. The second data set was reported by Nelson [35]. The data consist of the time to breakdown of steel specimens under different stress levels. The data sets under stress levels of 40 KV (normal use) and 45 KV (accelerated stress), each containing 12 observations, are listed in Table 8. Before analyzing this data, we checked the validity of the MKE model to fit the two data sets. The MLEs, MPSEs and K-S and the corresponding p-value were obtained and are listed in Table 9. It is seen from the results in Table 9 that the MKE distribution could be accepted as a fit model for the given data sets. The empirical and fitted CDF plots of the MKE distribution for the data in Table 8 are displayed in Figure 12. From the complete data sets in
Table 8, a Type-II censored CSPALT data set was considered by choosing
. Consequently, the MLEs and MPSEs and the associated standard errors were obtained and are reported in
Table 10. In addition, the different
CIs of the unknown parameters were evaluated and are displayed in
Table 10. From the tabulated outcomes given in
Table 10, it is noted that CIs evaluated based on the MPSEs had the smallest Lens in most of the cases, especially when estimating the parameters
b and
c, and the bootstrap CIs based on the MPSEs performed better than the ACIs in terms of CIs Lens, except for in the case when estimating the parameter
a. Using the MLEs and MPSEs presented in
Table 10, the MLEs and MPSEs of the MTTF and RF using mission times under normal use conditions were obtained and are displayed in
Table 11.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}