Abstract
Classification using linear discriminant analysis (LDA) is challenging when the number of variables is large relative to the number of observations. Algorithms such as LDA require the computation of the feature vector’s precision matrices. In a high-dimension setting, due to the singularity of the covariance matrix, it is not possible to estimate the maximum likelihood estimator of the precision matrix. In this paper, we employ the Stein-type shrinkage estimation of Ledoit and Wolf for high-dimensional data classification. The proposed approach’s efficiency is numerically compared to existing methods, including LDA, cross-validation, gLasso, and SVM. We use the misclassification error criterion for comparison.
Keywords:
classification; linear discriminant analysis; high-dimensional data; Ledoit and Wolf shrinkage method; Stein-type shrinkage; misclassification error MSC:
62H30; 68T09
1. Introduction
As one of the most widely used classification techniques, linear discriminant analysis (LDA) is still interesting because of its simplicity, stability, and prediction accuracy. Consider X as a p-dimensional predictor vector and the response as the class labels. In LDA, it is assumed that , where and ; consequently, the Bayes decision rule involves . In the large sample setting, when , the sample covariance matrix is an unbiased estimator of . However, in a high-dimensional setting, or , will be singular, and the likelihood estimator has many weaknesses such as inaccuracy (see [1,2]).
Many studies have been conducted using factor methods, sparse, graphical, and shrinkage methods for estimating . Srivastava [3] examined multivariate theory in a high-dimensional state and used the Moore–Penrose inverse of the covariance matrix to solve the singularity problem of . However, when some covariance matrix values are zero or close to zero, this idea does not work well.
The idea of estimating the precision matrix using a sparse method was first proposed by Dempster [4], and later, Meinshausen and Bühlmann [5] proposed the use of least absolute shrinkage and selection operator (Lasso) regression to identify the zeros of the inverse covariance matrix. Banerjee et al. [6] performed a penalized maximum likelihood estimation with the lasso penalty for sparse estimation of the inverse of the covariance matrix. Friedman et al. [7], proposed the graphical Lasso method, under the sparsity assumption of by using coordinate descent for the lasso penalty, through the objective function
where , denotes the trace of matrix , and is the norm one operator. Bickel and Levina [8] used the hard thresholding estimator for the sparse estimation of the covariance matrix . Furthermore, Cai and Zhang [9] developed an optimality theory for LDA in the high-dimensional setting by considering a different approach to solve the problem of LDA. Instead of estimating , and separately, they proposed a data-driven and tunning free classification rule called AdaLDA by directly estimating the discriminant direction through solving an optimization problem. As the hard threshold estimator in regression provides inflexible estimators, Ratman et al. [10] refined a generalized threshold law by using the combination of the threshold method and the shrinkage method. Bin and Tibshirani [11] generalized the estimate of a sparse covariance matrix by simultaneously estimating the nonzero covariance and the graph structure (location of zeros). Refer to Fan et al. [12] for more related studies.
Apart from sparse covariance matrix estimation, a common approach to improve the estimation of is the use of the class of shrinkage estimators, which was initially proposed by James and Stein [13] to define bias estimation in order to reduce the variance of (see [14,15,16] for extensive reviews). Di Pillo [17] and Campbell [18] improved the estimate of using the ridge idea. Peck and Van Niss [2] proposed another type of shrinkage estimator of by reducing the Fisher’s classification error. Mkhadri [19] used the cross-validation (CV) method to estimate the shrinkage parameter for the estimation of in classification rule. However, Choi et al. [20] demonstrated that the use of the CV method may not lead to a positive definite estimate for the high-dimensional case .
In the shrinkage method and graphical and factor models, additional information is needed in the estimation process (e.g., Beckel and Levina [21]; Khare and Rajaratnam [22]; Cai and Zhou [23]), whereas this surplus knowledge is not always available (Maurya [24]). Therefore, Ledoit and Wolf [25] proposed the rule of the optimal linear shrinkage estimator with optimal asymptotic properties by using the analysis of covariance matrix eigenvalues. For estimating the inverse covariance matrix (precision matrix) when , other studies have been conducted such as Wang et al. [26], Hong and Kim [27], and Lee et al. [28].
This paper aims to classify high-dimensional observations using the LDA, where the inverse sample covariance matrix is singular and not invertible. We apply Lediot and Wolf’s shrinkage method to estimate and efficiently classify new observations in a high-dimensional regime. Thus, the plan for the rest of this paper is as follows. In Section 2, the proposed methodology, along with some theory, is given. Section 3 includes extensive numerical assessments for performance analysis and compares the proposed discriminant rule with other existing methods. We conclude with the significant results in Section 4; Appendix A is allocated for the proofs.
2. Materials and Methods
In discriminant analysis, a set of observations are classified into predetermined categories using a function called the decision function or discriminant function. In other words, discriminant analysis seeks to identify linear or nonlinear combinations of independent variables that are best able to separate groups of observations using the discriminant rule.
Consider distinct populations with density function and prior probabilities . An observation is classified into if
In the simplest case, , it is assumed that , so that is independent of , , and . In the LDA, it is also assumed . According to Equation (2), if ; so, the discriminant function is obtained as follows
where and are unknown, and we estimate them using the training sample by the mean vector and the pooled sample covariance matrix , respectively, where , and
Hence, an observation is classified into if , and it is classified into the population otherwise. Therefore, the probability of misclassification (PMC) depends on the sample values , , and . If the estimate is weak, the PMC will not be minimized and in high-dimension (); either cannot be calculated or it is not efficient. In this case, we use the approach of shrinkage methods.
2.1. Ledoit and Wolf Shrinkage Estimators
The James and Stein shrinkage estimator [13] is a convex combination of a sample covariance matrix and a target matrix as follows
where is the shrinkage parameter and is positive definite. The target matrix should be chosen to have several properties. The target matrix must be structured, positive definite, and well-conditioned, representing our application’s true covariance matrix. The matrix may be biased; however, with its well-defined structure, it has a low variance. Given that the matrix is predetermined, determining the shrinkage parameter is important and should be chosen in such a way that the variance of the shrinkage estimator is less than the variance of . If , the variance must be less than the variance of the target matrix, i.e., , and if , the target matrix must have less variance than the variance , i.e., . Therefore, the values have a significant effect on the degree of the misclassification error.
In the category of Stein-type shrinkage estimators; Ledoit and Wolf [25] proposed the estimation of the shrinkage parameter using the following result, when .
Theorem 1.
Suppose is a random sample from , , , and ; and ; then,
- 1.
- ;
- 2.
- assuming , the optimal shrinkage parameter that minimizes the risk value of is equal to , wherein which, based on Srivastava [29],
See Ledoit and Wolf [25] for details.
2.2. Improved Linear Discriminant Rules
Since the shrinkage parameter, in the Ledoit and Wolf’s approach is obtained using the optimization method, in contrast to the CV method used by Mkhaderi [19], it will always lead to a positive definiteness of the sample covariance matrix. It also does not require additional information about explanatory variables and their independence. As a result, it has an advantage over other shrinkage estimation methods (Ledoit and Wolf [30]); therefore, the proposed method for reducing the misclassification error and the discriminant analysis in the high-dimensional case leads to the following classification rule
where can be obtained from the Equation (5), and
2.3. Properties of the Improved Discriminant Rule
Given that in the discriminant problem, has a normal distribution with the mean
and variance of
we have the following results.
Lemma 1.
Under the assumptions of Section 2.2, has a p-dimensional normal distribution with mean
and variance
Proof.
Refer to Appendix A. □
Theorem 2.
Proof.
Refer to Appendix A. □
3. Numerical Studies
To assess the performance of the estimator (5) in classification, we conducted a simulation study and analyzed some real data.
3.1. Simulation Study
Data were generated from two populations and , with in which is a p-dimensional zero vector, is a p-dimensional desired vector, and is a p-dimensional square matrix. When the covariance matrix is almost singular, discriminant analysis is likely to be sensitive to different choices of the mean vector; so in this paper, two different forms for the mean vector are selected, namely, and (named Mod1 and Mod2, respectively). The values of and m were chosen so that the Mahalanobis distance, , was the same for each case, and the were chosen using different values of (, and ). The covariance matrix was also considered as , where , is the identity matrix, and is the unit matrix of dimension . In order to determine the correlation role of the explanatory variables in the estimator, two values and for were considered. For each population and different combinations of and , we generated 10 p-dimensional training and 50 p-dimensional test data vectors. We chose the target matrix as , so the sample covariance matrix shrank to the identity matrix. This target imposed no variance to the shrinkage estimator. This simulation was repeated 1000 times, and the performance of proposed methodology LW was compared with linear discriminant analysis (LDA), the Mkhaderi method [19] (CV), the graphic lasso method (gLasso), and support vector machine (SVM).
The results for each case , i.e., Mod1 and Mod2, are summarized in Table 1 and Table 2. The column ‘Test’ shows the average value of the misclassification test errors for each parameter value of . Further, in these tables, the mean value of the shrinkage parameter for each discriminant rule is shown. The quantities in parentheses are the standard deviations of the respective means. Bold values are the smallest among all, showing the best method.

Table 1.
Misclassification error and shrinkage parameter values for Mod1.
Table 2.
Misclassification error and shrinkage parameter values for Mod2.
The improvement of the shrinkage algorithm strongly depends on the Mahalanobis distance between two populations. When the Euclidean distance between the means is small, the mean estimation error caused by the poor estimate of is very damaging to the classification. Therefore, as the Euclidean distance increases, the means move further apart, and it does not have much relative effect on the classification.
According to Table 1, by increasing , the misclassification error decreased. Apparently, for each , the shrinkage method LW had a lower classification error compared to the LDA, CV, gLasso, and SVM methods. This means that the Ledoit and Wolf method had better performance in determining and assigning new observations to populations.
On the other hand, according to Table 2, by changing the strategy and considering Mod2, the results obtained in Mod1 were still valid. Thus, changing all the values of the mean vector was established (better efficiency and performance of the proposed method of this research than the studied methods). Figure 1 simply shows the results stated in Table 1 and Table 2. Bold values are the smallest among all, showing the best method.
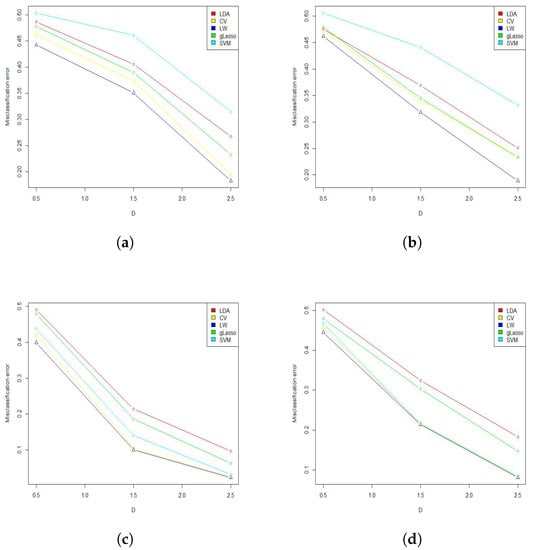
Figure 1.
Misclassification error by increasing the Mahalanobis distance. (a) Mod1, ; (b) Mod1, ; (c) Mod2, ; (d) Mod2, .
Figure 2 depicts the misclassification error for varying sample sizes. Not surprisingly, as n increased, the misclassification error decreased for all the methods in this study, but surprisingly, none of the methods had a smaller error compared to the LW. As shown in Figure 2, with the increasing sample size, the misclassification error in all methods was higher than the proposed method. Moreover, as the Mahalanobis distance increased, it became easier to identify which population the new observation belonged to, which improved the classification in the proposed method.
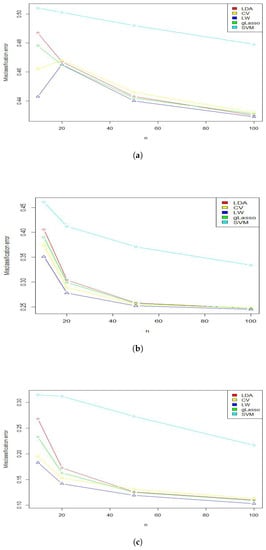
Figure 2.
Misclassification error by increasing sample size and . (a) Mod1, ; (b) Mod1, ; (c) Mod1, .
To evaluate the efficiency of the LW method, simulations were performed using values. These results are summarized in Table 3. As the dimension increased, the classical method of linear discriminant analysis as well as the proposed cross-validation method of Mkhaderi [19] could not be used due to the singularity of the covariance matrix. With an increase in the value of , the misclassification error decreased, and for each value , the shrinkage method of LW was significantly better than the other methods.
Table 3.
Misclassification error and shrinkage parameter values for in Mod1 state.
3.2. Real Data Analyses
In this section, we assess the performance of the five methods in classification for the datasets in Table 4.
Table 4.
Datasets (Accessed on 30 November 2022).
As shown in Table 5, the LW shrinkage method for classification was superior comparatively (marked as bold). In Data 4, the execution time in the system with specifications : and : for the gLasso method took more than 10 h, and for the LW method it was less than 5 min, which was a sign of the rapidity of the shrinkage method in the classification of high-dimensional data.
Table 5.
Misclassification error for the real datasets in Table 4.
Figure 3 depicts the average of misclassification errors for the five methods, discussed in the paper.
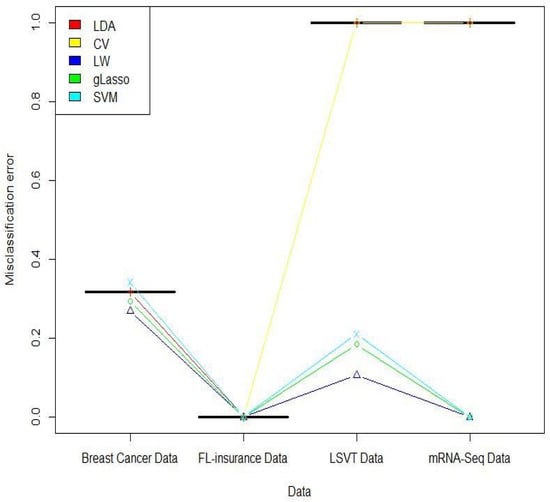
Figure 3.
Misclassification error for the four real datasets.
4. Discussion and Conclusions
In the present paper, we aimed to improve the efficiency of the LDA classification method in high-dimensional situations, where the singularity of the inverse covariance matrix produced problems. We proposed to estimate the precision matrix with the shrinkage approach of Ledoit and Wolf (LW) [25], where the sample covariance matrix and a target matrix were linearly combined through a penalty factor in LDA classification.
The implementation of the suggested method on simulation data showed that for different scenarios, the proposed approach was superior to two powerful competitors, gLasso and SVM, in the sense of misclassification error. By increasing the Mahalanobis distance and using and , we became more confident that the LW method could be considered as an alternative to some well-known methods for better classification.
In the real data analyses, three results were considerable. First, the analysis of Data1 and Data2 showed that LW was as good as the other competitors or much better when . Second, the misclassification of Data3 () exhibited that our method was more reliable than the others in high-dimensional regimes (). Third, the LW method had the same misclassification error for Data4 when , compared to others. However, the execution time of the LW method was much shorter. In addition to high accuracy, the LW method was strongly recommended from the computation burden point of view, especially in a high-dimensional setting, where computing precision matrix estimation is challenging.
Lastly, if the covariance matrices of the populations are not the same (), instead of LDA, it is possible to use the quadratic discriminant analysis (QDA). Friedman [31] proposed the method of regularized discriminant analysis (RDA) by using the trace estimator, , and applying twice the shrinking sample covariance matrix. Since the trace estimator pools the diagonal elements of sample covariance matrices and ignores off-diagonal elements, Wu et al. [32] introduced the ppQDA estimator, which pools all elements in the covariance matrix, and it does not need to impose sparse assumptions. Although the ppQDA method has good asymptotic properties, it may not have a good performance for data classification. Therefore, considering (5) and Friedman’s [31] method as follows
where , are tuning parameters, and , it seems that by using the shrinkage method presented in this article, estimation of can be improved and it is possible to reduce the misclassification error of high-dimensional data in the quadratic discriminant analysis mode.
Author Contributions
Conceptualization, R.L., D.S. and M.A.; Funding acquisition, M.A.; Methodology, R.L., D.S. and M.A.; Software, R.L.; Supervision, D.S. and M.A.; Visualization, R.L., D.S. and M.A.; Formal analysis, R.L., D.S. and M.A.; Writing—original draft preparation, R.L.; Writing—review and editing, R.L., D.S. and M.A. All authors have read and agreed to the published version of the manuscript.
Funding
This work was based upon research supported in part by the National Research Foundation (NRF) of South Africa, SARChI Research Chair UID: 71199, the South African DST-NRF-MRC SARChI Research Chair in Biostatistics (Grant No. 114613), and STATOMET at the Department of Statistics at the University of Pretoria, South Africa. The third author’s research (M. Arashi) is supported by a grant from Ferdowsi University of Mashhad (N.2/58266). The opinions expressed and conclusions arrived at are those of the authors and are not necessarily to be attributed to the NRF.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data are publicly available.
Acknowledgments
The authors would like to sincerely thank the anonymous reviewers for their constructive comments, which helped to improve the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Here, we give the sketch of the proofs of Lemma 1 and Theorem 2.
Proof of Lemma 1.
According to (3), replacing with , the decision function is given by
On the other hand, since ∼ is independent of , , and , the conditional distribution given has the following mean and variance
The proof is complete. □
Proof of Theorem 2.
Considering and in Equations (8) and (9), we have
Let , where is a nonsingular matrix, and b are considered in such a way that ; , ; ; and ; we also define the variables and as follows
Using the Taylor’s series expansion, we have
and
Using Ledoit and Wolf [25] and , we obtain
where .
Moreover,
in which . Since , we obtain , and the proof is complete. □
References
- Clemmensen, L.; Hastie, T.; Witten, D.; Ersbøll, B. Sparse discriminant analysis. Technometrics 2011, 53, 406–413. [Google Scholar] [CrossRef]
- Peck, R.; Van Ness, J. The use of shrinkage estimators in linear discriminant analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1982, 5, 530–537. [Google Scholar] [CrossRef] [PubMed]
- Srivastava, M.S. Multivariate theory for analyzing high dimensional data. J. Jpn. Stat. Soc. 2007, 37, 53–86. [Google Scholar] [CrossRef]
- Dempster, A.P. Covariance selection. Biometrics 1972, 28, 157–175. [Google Scholar] [CrossRef]
- Meinshausen, N.; Bühlmann, P. High-dimensional graphs and variable selection with the lasso. Ann. Stat. 2006, 34, 1436–1462. [Google Scholar] [CrossRef]
- Banerjee, O.; El Ghaoui, L.; d’Aspremont, A. Model selection through sparse maximum likelihood estimation for multivariate Gaussian or binary data. J. Mach. Learn. Res. 2008, 9, 485–516. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. Sparse inverse covariance estimation with the graphical lasso. Biostatistics 2008, 9, 432–441. [Google Scholar] [CrossRef]
- Bickel, P.J.; Levina, E. Covariance regularization by thresholding. Ann. Stat. 2008, 36, 2577–2604. [Google Scholar] [CrossRef]
- Cai, T.T.; Zhang, L. High dimensional linear discriminant analysis: Optimality, adaptive algorithm and missing data. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2019, 89, 675–705. [Google Scholar]
- Rothman, A.J.; Levina, E.; Zhu, J. Generalized thresholding of large covariance matrices. J. Am. Stat. Assoc. 2009, 104, 177–186. [Google Scholar] [CrossRef]
- Bien, J.; Tibshirani, R. Sparse estimation of a covariance matrix. Biometrika 2011, 98, 807–820. [Google Scholar] [CrossRef] [PubMed]
- Fan, J.; Liao, Y.; Liu, H. An overview of the estimation of large covariance and precision matrices. Econom. J. 2016, 19, C1–C32. [Google Scholar] [CrossRef]
- Stein, C.; James, W. Estimation with quadratic loss. In Proceedings of the Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 20–30 June 1961; Volume 1, pp. 361–379. [Google Scholar]
- Efron, B. Biased versus unbiased estimation. Adv. Math. 1975, 16, 259–277. [Google Scholar] [CrossRef]
- Efron, B.; Morris, C. Data analysis using Stein’s estimator and its generalizations. J. Am. Stat. Assoc. 1975, 70, 311–319. [Google Scholar] [CrossRef]
- Efron, B.; Morris, C. Multivariate empirical Bayes and estimation of covariance matrices. Ann. Stat. 1976, 4, 22–32. [Google Scholar] [CrossRef]
- Di Pillo, P.J. The application of bias to discriminant analysis. Commun. Stat. Theory Methods 1976, 5, 843–854. [Google Scholar] [CrossRef]
- Campbell, N.A. Shrunken estimators in discriminant and canonical variate analysis. J. R. Stat. Soc. Ser. (Appl. Stat.) 1980, 29, 5–14. [Google Scholar] [CrossRef]
- Mkhadri, A. Shrinkage parameter for the modified linear discriminant analysis. Pattern Recognit. Lett. 1995, 16, 267–275. [Google Scholar] [CrossRef][Green Version]
- Choi, Y.-G.; Lim, J.; Roy, A.; Park, J. Fixed support positive-definite modification of covariance matrix estimators via linear shrinkage. J. Multivar. Anal. 2019, 171, 234–249. [Google Scholar] [CrossRef]
- Bickel, P.J.; Levina, E. Regularized estimation of large covariance matrices. Ann. Stat. 2008, 36, 199–227. [Google Scholar] [CrossRef]
- Khare, K.; Rajaratnam, B. Wishart distributions for decomposable covariance graph models. Ann. Stat. 2011, 39, 514–555. [Google Scholar] [CrossRef]
- Cai, T.; Zhou, H. Minimax estimation of large covariance matrices under ℓ1-norm. Stat. Sin. 2012, 22, 1319–1349. [Google Scholar]
- Maurya, A. A well-conditioned and sparse estimation of covariance and inverse covariance matrices using a joint penalty. J. Mach. Learn. Res. 2016, 17, 4457–4484. [Google Scholar]
- Ledoit, O.; Wolf, M. A well-conditioned estimator for large-dimensional covariance matrices. J. Multivar. Anal. 2004, 88, 365–411. [Google Scholar] [CrossRef]
- Wang, C.; Pan, G.; Tong, T.; Zhu, L. Shrinkage estimation of large dimensional precision matrix using random matrix theory. Stat. Sin. 2015, 25, 993–1008. [Google Scholar] [CrossRef][Green Version]
- Hong, Y.; Kim, C. Recent developments in high dimensional covariance estimation and its related issues, a review. J. Korean Stat. Soc. 2018, 47, 239–247. [Google Scholar] [CrossRef]
- Le, K.T.; Chaux, C.; Richard, F.; Guedj, E. An adapted linear discriminant analysis with variable selection for the classification in high-dimension, and an application to medical data. Comput. Stat. Data Anal. 2020, 152, 107031. [Google Scholar] [CrossRef]
- Srivastava, M.S. Some tests concerning the covariance matrix in high dimensional data. J. Jpn. Stat. Soc. 2005, 35, 251–272. [Google Scholar] [CrossRef]
- Ledoit, O.; Wolf, M. Nonlinear shrinkage estimation of large-dimensional covariance matrices. Ann. Stat. 2012, 40, 1024–1060. [Google Scholar] [CrossRef]
- Friedman, J.H. Regularized discriminant analysis. J. Am. Stat. Assoc. 1989, 88, 165–175. [Google Scholar] [CrossRef]
- Wu, Y.; Qin, Y.; Zhu, M. Quadratic discriminant analysis for high-dimensional data. Stat. Sin. 2019, 29, 939–960. [Google Scholar] [CrossRef]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).