Abstract
Discrete-valued time series modeling has witnessed numerous bivariate first-order integer-valued autoregressive process or BINAR(1) processes based on binomial thinning and different innovation distributions. These BINAR(1) processes are mainly focused on over-dispersion. This paper aims to propose new bivariate distributions and processes based on a recently proposed over-dispersed distribution: the Poisson 2S-Lindley distribution. The new bivariate distributions, denoted by the abbreviations BP2S-L(I) and BP2S-L(II), are then used as innovation distributions for the BINAR(1) process. Properties are investigated for both distributions as well as for the BINAR(1) processes. The distribution parameters are estimated using the maximum likelihood method, and the BINAR(1)BP2S-L(I) and BINAR(1)BP2S-L(II) process parameters are estimated using the conditional least squares and conditional maximum likelihood methods. Monte Carlo simulation experiments are conducted to study large and small sample performances and for the comparison of the estimation methods. The Pittsburgh crime series and candy sales datasets are then used to compare the new BINAR(1) processes to some other existing BINAR(1) processes in the literature.
Keywords:
Poisson 2S-Lindley distribution; binomial thinning; over-dispersion; moments; maximum likelihood estimation; simulation; BINAR(1) process MSC:
62E15; 62E20; 62E17
1. Introduction
Count data, or the number of times an event occurs over a set period of time, are becoming ever more abundant in all spheres of human life. In medicine, biology, ecology, economics, demography, and other fields, modeling of these data is becoming pivotal. Real-world situations frequently involve discrete bivariate data that are typically highly related. Some of the examples include counting the number of COVID-19 cases reported in a hospital and the number of deaths among them or counting the number of traffic accidents and the corresponding number of deaths. As a result, bivariate discrete models may be ideal for the statistical analysis of such data.
To this aim, multiple strategies for establishing bivariate random variables have been reported in the literature. Most of them are addressed in [1]. The use of mixed methods to construct discrete and continuous bivariate random variables is often explored in the statistical literature. For instance, see [2,3,4]. The key advantage of this approach is that its marginal probability density function (pdf) or even its moments, correlation, and certain other properties will have simple expressions. A further possibility is to construct it using a new family of distributions. The Sarmanov family of distributions (see [5]) can be used to create bivariate distributions with a variable covariance structure, both discrete and continuous. The authors of [6] looked into several generic approaches to the family formation that took into account different types of marginal distributions. A specific member of the Sarmanov family is the famous Farlie–Gumbel–Morgenstern (FGM) copula.
The expanding number of applications involving time series of counts has necessitated the development of more appropriate integer-valued time series models that can manage the most common phenomena of over-dispersion while also taking into account the cases where two related series are assembled. Since the authors of [7,8] have performed pioneering research on the first-order integer-valued autoregressive (INAR(1)) process with Poisson innovations, plenty of relevant papers with univariate innovation distributions have appeared in the literature. See, for instance, [9,10,11,12,13]. For the bivariate setting, the authors of [14] introduced the concept of BINAR(1) processes to consider cross-correlations in integer-valued time series models.
On the other hand, a discrete univariate, one-parameter mixture distribution, the Poisson 2Sum-Lindley (P2S-L) distribution, was introduced in [15] by mixing the Poisson distribution with the 2Sum-Lindley (2S-L) distribution (see [16]). A count regression model, as well as an INAR(1) process having the P2S-L distribution, as an innovation distribution is effectively established in [15]. The superior model selection criteria of the P2S-L distribution and the INAR(1)P2S-L process are demonstrated through simulation studies and real-data analysis.
In this paper, we construct two bivariate distributions based on the P2S-L distribution and, motivated by their improved performance; we apply them as innovations to the BINAR(1) process. To be more precise, discrete bivariate distributions based on the P2S-L distribution are framed in this paper using the mixture methodology (the basic bivariate P2S-L, the bivariate Poisson 2S-Lindley I (BP2S-L(I) distribution) as well as the Sarmanov family of distributions (the Sarmanov bivariate P2S-L, bivariate Poisson 2S-Lindley II (BP2S-L(II)) distribution) and both distributions are mounted as innovation distributions in the BINAR(1) process. Hence, the BINAR(1)BP2S-L(I) and BINAR(1)BP2S-L(II) processes are created. Both the processes are then compared with some other recently proposed BINAR(1) processes, as well as those discussed in [14].
We first review the development of the P2S-L distribution and the associated INAR(1) process. Then, bivariate versions are constructed and adapted to the BINAR(1) process with bivariate P2S-L distribution innovations (BP2S-L(I) and BP2S-L(II) distributions) by inducing a cross-correlation between the counting series by assuming the paired P2S-L innovations are jointly distributed.
The remaining parts of the paper are organized as follows: Section 2 reviews the P2S-L distribution and associated INAR(1) process. The construction of the BP2S-L(I) and BP2S-L(II) distributions is discussed in Section 3. Estimation of the unknown parameters and its simulation study are given in Section 4. Both the bivariate distributions are used as innovation distributions for the BINAR(1) process, which is given in Section 5. Estimation of the unknown parameters of the BINAR(1) processes and their simulation is given in Section 6. The empirical importance of the proposed BINAR(1) processes is studied in Section 7. The concluding remarks are given in Section 8.
2. Poisson 2S-Lindley and its Associated INAR(1) Process
The 2S-Lindley (2S-L) distribution was comprehensively defined in [16] as the sum of two independent Lindley random variables (see [17]). Take and as two independent random variables with the same parameter , and Y as the 2S-L random variable defined by . Then, Y has the pdf given by
with . With the same number of parameters (one), the 2S-L distribution has direct stochastic ordering properties with the Lindley distribution, making it a viable alternative. Based on the 2S-L distribution, the authors of [15] recently proposed a discrete distribution by mixing the Poisson and 2S-L distributions, called the Poisson 2S-Lindley (P2S-L) distribution. A random variable X having the P2S-L distribution is characterized by the following stochastic structure:
where is a random variable that follows , , denotes “conditionally on , X has the D distribution”, P() denotes the Poisson distribution with parameter , and 2S-L() denotes the 2S-L distribution with parameter . One can establish that the unconditional probability mass function (pmf) of X is
Some of the important properties related to moments of X are discussed below:
The probability-generating function (pgf) of X is determined as
for . The moment-generating function (mgf) of X is derived as
for . From the function above, the mean and variance of X are easily obtained as
and
respectively. In addition, the Fisher index of dispersion (DI) of X is
One can remark that DI(X) can be less than or greater than 1, since is greater than 0. Thus, the P2S-L distribution can have under or over-dispersed properties. However, the study in [15] focuses on the over-dispersed case more deeply. Hence, the P2S-L distribution is effective in using it as an innovation distribution in an INAR(1) process based on binomial thinning, creating the INAR(1)P2S-L process. Such innovation distribution defined the process, its properties, and its effectiveness based on estimation and real data.
3. Construction of the Bivariate Distributions
In [18], the authors mentioned two methods for the construction of bivariate distributions based on the Poisson-Lindley distribution. That is, one used the basic method of bivariate construction, and the other used the Sarmanov family. In this section, we make use of those two methods for the construction of bivariate distributions: the BP2S-L(I) and BP2S-L(II) distributions.
3.1. The BP2S-L(I) Distribution
Here, a basic method is used for the construction of the BP2S-L(I) distribution.
Definition 1.
Let be a bivariate random vector such that
with and . That is, conditionally on , the random variables and are independent, and the conditional distribution of , is univariate Poisson with parameters , denoted by Then, we can say that has the BP2S-L(I) distribution. In this case, the unconditional pmf of is
where and .
Proof.
The pmf of the BP2S-L(I) distribution is obtained via the following integral development:
The stated pmf is obtained. □
Now, a bivariate random vector having the BP2S-L(I) distribution is denoted as BP2S-L(I)().
If BP2S-L(I)(), the marginal pmf of , , can be obtained by the usual procedure, and we have
Now, the conditional pmf of with can be easily derived as
for . The pmf of can also be derived in a similar manner.
The joint pgf of is
Now, the mean, variance, and covariance of , , are computed as follows:
The mean of is
The moment of order two of is given by
Hence, the variance of can be derived as
and the covariance of and as
It should be noted that is always positive, implying that the BP2S-L(I) distribution is only appropriate for modeling bivariate data with positive correlations.
3.2. The BP2S-L(II) Distribution
The second distribution is based on the scheme characterized by the Sarmanov family of distributions. Indeed, in [5], the Sarmanov family of bivariate distributions based on specific density definitions was introduced. Here, we stress discrete bivariate densities based on the Sarmanov approach. Let us first define how the Sarmanov bivariate density can be formed. Let and be two discrete random variables having the supports and , respectively. Further, let us consider two functions, denoted by , and defined as bounded non-constant functions such that
Then the joint pmf of for the Sarmanov family can be written as
where is a real number, and is a measure of the departure of and from independence such that the following condition is satisfied:
Different choices for the functions , , can give different cases. Here, following the spirit of [6], we use , where is the value of the Laplace transform of evaluated at . We recall that the Laplace transform of is given by
The pmf of the Sarmanov-based bivariate P2S-L or BP2S-L(II) distribution having the P2S-L distribution as a marginal distribution is derived below. First, the Laplace transform for the P2S-L distribution is
and, at ,
Then the joint pmf associated with a Sarmanov bivariate distribution takes the form
Definition 2.
The joint pmf of having the Sarmanov bivariate distribution with the P2S-L distribution as a marginal distribution is indicated as
where , with and ω satisfies (15).
The bivariate random vector , having the joint pmf (20), is hereafter denoted as BP2S-L(II)(). Hence, if BP2S-L(II)(), the mean and variance of , are
and
respectively. The covariance between and is computed as
where . More precisely, for the BP2S-L(II) distribution, we get
Further, note that the sign of Cov() depends on the sign of .
4. Estimation and Simulation of the Bivariate Distributions
In this section, the estimation of the corresponding parameters of the BP2S-L(I) and BP2S-L(II) distributions, as well as some Monte Carlo experiments for the simulation of parameters, are carried out in detail. The method of maximum likelihood (ML) is used for the estimation of parameters. For both distributions, two sets of parameter values for the sample sizes and number of replications are considered.
4.1. Estimation for the BP2S-L(I) Distribution
Suppose that , are the observations of a n random sample from BP2S-L(I)(). Then the log of the likelihood function satisfies
where . The ML estimate (MLE) of or, equivalently, the MLEs of , , and , are obtained by maximizing (25) using numerical methods. Here, the nlminb function in the R software is used (via the optimization PORT routines) to obtain the MLEs of the parameters in the BINAR(1)BP2S-L(I) process.
4.2. Simulation of Parameters of the BP2S-L(I) Distribution
The MLEs of the BP2S-L(I) distribution parameters are analyzed using a simulation study. The following two sets of parameter values are considered: () and (). The bias and mean square errors (MSEs) of the MLEs of the parameters are computed, and the results are reported in Table 1.

Table 1.
Simulation results for the BP2S-L(I) distribution.
Table 1 makes it clear that as the sample size increases, bias and MSE corresponding to each parameter decrease.
4.3. Estimation for BP2S-L(II) Distribution
Let , be the observations of a n random sample from BP2S-L(II)(). Then the log of the likelihood function is
where and is the pmf of the BP2S-L(II) distribution defined in (20). Then, (26) had to be maximized to find estimates for . Here also, the optimization technique PORT routines into the nlminb function in the R software is used to obtain the MLEs of the parameters in the BINAR(1)BP2S-L(I) process.
4.4. Simulation of Parameters of the BP2S-L(II) Distribution
In this part, the MLEs of the BP2S-L(II) distribution parameters are analyzed using a simulation study. The two following sets of parameter values are used: () and (). The bias and MSEs of the estimates of the parameters are computed, and the results are reported in Table 2.
Table 2.
Simulation results for the BP2S-L(II) distribution.
5. The Bivariate INAR(1) Processes with Paired P2S-L Innovation Distributions
This section deals with the model development of BINAR(1) processes with the BP2S-L(I) and BP2S-L(II) distributions as innovation distributions.
5.1. General Definition
Let , , define a BINAR(1) process, such that
where ∘ in (27) denotes the binomial thinning operator introduced in [19], which is described as
where is a sequence of independent and identically distributed Bernoulli random variables with parameter p. We assume that the innovation vector in (27) is and that is independent of , for each t and s, . In addition, let the innovation vector be independent of the counting series in thinning operator ∘. Now, we proceed by assuming has both of the discussed distributions, and then we develop the corresponding BINAR(1) processes.
5.2. BINAR(1) Process with BP2S-L(I) Innovation Distributions
For the BINAR(1) process discussed in (27), we suppose that the innovation vector satisfies BP2S-L(I)(). Then the resulting , , is a BINAR(1) process with BP2S-L(I) innovation denoted by BINAR(1)BP2S-L(I).
Suppose that the process , , is a BINAR(1)BP2S-L(I) process. In this case, the mean, variance, and DI of , , are given by
and
respectively. Note that the DI for the BINAR(1)BP2S-L(I) process is over-dispersed marginally, even though the P2S-L distribution shows under and over-dispersion properties. Now, the conditional mean and variance of components of the process are, for ,
and
respectively. The covariance of and is
The conditional joint pmf of the process is given by
where , , ,
and is given by substituting with and with in (5).
5.3. BINAR(1) Process with BP2S-L(II) Innovation Distributions
Here, we describe the BINAR(1)BP2S-L(II) process. To this aim, based on the BINAR(1) process, we suppose the innovation vector satisfies: BP2S-L(II)(). Further, we assume the assumptions made for the construction of the BINAR(1)BP2S-L(I) process hold too. Then, if , for the mean, variance and DI of , , are obtained as
and
respectively. In particular, based on the DI, we note that the BINAR(1)BP2S-L(II) process is marginally over-dispersed here also. Now, one step ahead gives the conditional expectation and variance of components of the process for as
and
respectively. Furthermore, we have
where
The conditional joint pmf of the BINAR(1)BP2S-L(II) process can be determined by using (34), with the exception that is swapped by (20).
In addition, under the stationary condition (see [20]), for both of the models, for and do not depend on t, and is finite.
6. Estimation and Simulation of Parameters of the BINAR(1) Processes
The estimation of the parameters and hence the simulation procedures of both the BINAR(1) processes discussed above are studied in detail. For the estimation, the methods of conditional maximum likelihood (CML) and conditional least squares (CLS) are applied.
6.1. Estimation and Simulation of the BINAR(1)BP2S-L(I) Process
Suppose that , is a n random sample from the BINAR(1)BP2S-L(I) process, and consider observations of this sample denoted as . This subsection explains the methods used for the estimation procedure for the parameters of the BINAR(1)BP2S-L(I) process. For this objective, we set as the parameter vector.
6.1.1. Method of Conditional Least Squares Estimation
The CLS estimate (CLSE) of for the BINAR(1)BP2S-L(I) process is obtained by minimizing the following equations with respect to : for ,
Here, we used the quasi-Newton approach (BFGS algorithm in particular) available in the optim function of R software for obtaining the CLSE.
6.1.2. Method of Conditional Maximum Likelihood Estimation
The CML estimate(CMLE) of for the BINAR(1)BP2S-L(I) process is computed using the conditional log-likelihood function of the BINAR(1)BP2S-L(I) process. The conditional log-likelihood can be obtained by substituting (34) in the following equation:
The CMLE is obtained by maximizing (42) with respect to . Furthermore, the consistency and asymptotic normality of the random version of the CMLE under standard regularity conditions are demonstrated in [21,22]. Further, the covariance is obtained as the inverse of Hessian (see [23]), and standard errors (SEs) are the square root of diagonal elements of the covariance matrix. Here, the optimization routines in the nlminb function and fdHess function in the R software are used to obtain the CMLE, observed information matrix, and SEs of the estimates of the parameters in the BINAR(1)BP2S-L(I) process.
6.1.3. Simulation Study for BINAR(1)BP2S-L(I) Process
The estimates obtained for the unknown parameters of the BINAR(1)BP2S-L(I) process via the two methods discussed above are assessed through a simulation study. Here, samples, each of sizes are taken for the two following sets of parameter values: () and (). For each n, bias and MSEs were calculated and are reported in Table 3 and Table 4.
Table 3.
Simulation results for the BINAR(1)BP2S-L(I) process for the set of parameter values: .
Table 4.
Simulation results for the BINAR(1)BP2S-L(I) process for the set of parameter values: .
Table 3 and Table 4 show that as the sample size increases, the bias and MSE corresponding to each parameter decrease for both methods. Although the CLS method performs slightly better than the CML method for the second set of parameters, we further proceed with the CML method since the model comparison is effective with it.
6.2. Estimation and Simulation of the BINAR(1)BP2S-L(II) Process
Suppose that , is a n random sample from the BINAR(1)BP2S-L(II) process, and consider observations of this sample denoted as . This subsection explains the methods used for the estimation procedure for the parameters of the BINAR(1)BP2S-L(II) process. We consider as the parameter vector.
6.2.1. Method of Conditional Least Squares Estimation
The CLSE of for the BINAR(1)BP2S-L(II) process is obtained by minimizing , , with respect to , where, for ,
and
Here also, we used the BFGS algorithm available in the optim function of the R software for obtaining the CLSE.
6.2.2. Method of Conditional Maximum Likelihood Estimation
The CMLE of for the BINAR(1)BP2S-L(II) process utilizes the conditional log-likelihood function indicated as
where is obtained via the joint pmf of () by (20). The CMLE is obtained by maximizing (45) according to . Moreover, the consistency and asymptotic normality of the random version of the CMLE under standard regularity conditions can be proven as given by referring to [21,22]. The covariance is obtained as the inverse of the Hessian matrix, and SEs is the square root of diagonal elements of the covariance matrix. Here also, the optimization routines in the nlminb function and the fdHess function in R software is used to obtain the CMLE, observed information matrix, and hence the SEs of estimates of the parameters in the BINAR(1)BP2S-L(II) process.
6.3. Simulation Study for the BINAR(1)BP2S-L(II) Process
The estimates obtained for the unknown parameters of the BINAR(1)BP2S-L(II) process by the CLS and CML methods are assessed through a simulation study. Thus, samples each of sizes are taken for the two following sets of parametric values: () and (). For each n, bias and MSEs were calculated and are reported in Table 5 and Table 6.
Table 5.
Simulation results for the BINAR(1)BP2S-L(II) process for the set of parameter values: .
Table 6.
Simulation results for the BINAR(1)BP2S-L(II) process for the set of parameter values: .
7. Empirical Study
The results of the suggested BINAR(1) processes are presented in this section using two real, over-dispersed time series count datasets.
7.1. Methodology
Model adequacy criteria are used to compare the proposed BINAR(1) processes to some existing BINAR(1) processes. To that end, we compare the BINAR(1)BP2S-L(I) and BINAR(1)BP2S-L(II) processes to the BINAR(1) bivariate Poisson weighted exponential (BINAR(1)BPWE) process, the BINAR(1) Sarmanov Poisson weighted exponential (BINAR(1)SPWE) process by [24], the BINAR(1) bivariate Poisson (BINAR(1)BP) and BINAR(1) bivariate negative binomial (BINAR(1)BNB) processes by [14], and the BINAR(1)Poisson-Lindley (BINAR(1)PL) process by [20]. The BINAR(1)BPWE and BINAR(1)SPWE processes were chosen since the Poisson-weighted exponential distribution is closely related to the Poisson-Lindley distribution, and the rest of the others were chosen since they have the same number of parameters as that of the BINAR(1)BP2S-L(I) and BINAR(1)BP2S-l(II) processes. Further, the P2S-L distribution is introduced as an alternative to the Poisson-Lindley distribution. Hence, the BINAR(1)PL process is particularly chosen. The BINAR(1)BNB process is commonly used to model over-dispersed count datasets. As we focus here on over-dispersion, we use the BINAR(1)BNB process for comparison.
The estimates of the parameters using the CML method (we used CLS estimates as initial values) along with their SEs and confidence intervals (CIs), -Log-Likelihood (-L), Akaike information criterion (AIC), Bayesian information criterion (BIC), and the root MSE (RMSE) of both the series for all the models described above are calculated. The RMSE represents the sum of squared differences between true values and one-step conditional expectations. Further, as the authors of [25] suggested, the standardized Pearson residuals are calculated to check the accuracy of the BINAR(1)BP2S-L(II) process for both datasets. They are calculated with the following formula:
where and are given in (38) and (39), respectively. Note that the fitted model is an adaptable choice if the mean and variance of are closer to 0 and 1, respectively. The residuals’ autocorrelation function (ACF) is then plotted to see if they are uncorrelated, and the cumulative periodograms (cpgrams) of Pearson residuals for both series are plotted to see if the BINAR(1)BP2S-L(II) process is random for both datasets.
7.2. Crime Series Data
The first data we used are the crime series data from the Pittsburgh police agencies in the file PghCarBeat.csv for the monthly period January 1990 to December 2001. The dataset consists of criminal records of drug activities (CDRUGS) and shooting activities (CSHOTS) in the 12th police car beats in Pittsburgh, with a sample size of 144 each, downloaded from the website www.forecastingprinciples.com. The average CDRUGS and CSHOTS data values are 5.1736 and 5.7569, respectively, with corresponding variances of 13.1794 and 14.2412, indicating a clear over-dispersion. The plots of the time series, ACF, partial ACF (PACF) of the CDRUGS and CSHOTS data are given in Figure 1, Figure 2 and Figure 3, respectively.
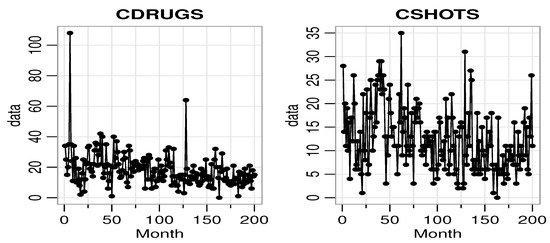
Figure 1.
The time-series plot of CDRUGS and CSHOTS data.
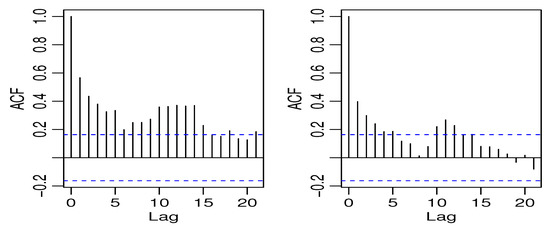
Figure 2.
The ACF plot of CDRUGS and CSHOTS data.
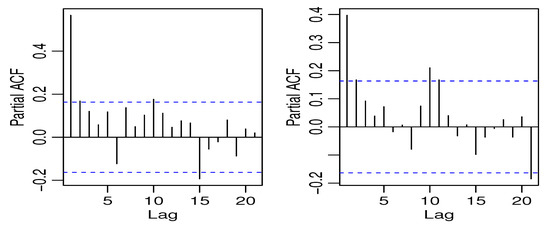
Figure 3.
The PACF plot of CDRUGS and CSHOTS data.
The PACF plots make it clear that the data can be used since only the first lag is significant. Further, Figure 4 displays the cross-correlation function (CCF) plot.
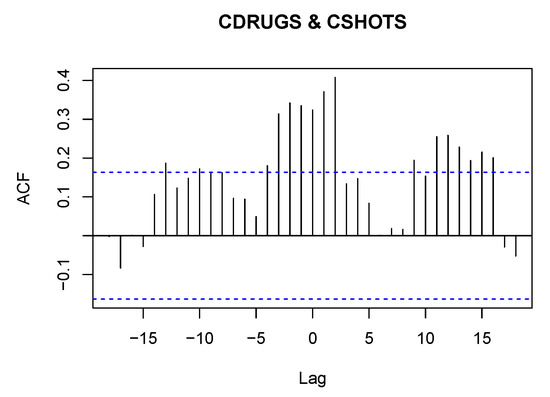
Figure 4.
CCF plot of the CDRUGS and CSHOTS datasets.
From Figure 4, we observe that there is a significant cross-correlation in lag 2 between the two time series, which displays positive autocorrelation among both series, which is obvious since after drug use there is a tendency to shoot and vice versa.
Table 7 consists of the CMLEs, AIC, BIC, and RMSEs for the BINAR(1) processes considered here for the crime series dataset.
Table 7.
Estimates with SEs and CIs, AIC, BIC, and RMSEs of the considered BINAR(1) processes for the crime series dataset.
From Table 7, we observe that the BINAR(1)BP2S-L(II) process performs well for the data because it has the smallest values for the AIC and BIC. The Pearson standardized residuals were calculated for the BINAR(1)BP2S-L(II) process, and we found out that they have the means and , and variances and , respectively. The ACF plots for standardized residuals for both time series are plotted in Figure 5.

Figure 5.
ACF of standardized residuals of CDRUGS and CSHOTS data for the BINAR(1)BP2S-L(II) process.
It clearly indicates that they are uncorrelated, which clearly shows that the BINAR(1)BP2S-L(II) process is accurate and gives a good fit to the crime series dataset. The cpgrams of Pearson residuals of both the series for the crime series dataset are plotted in Figure 6.

Figure 6.
Cpgrams of standardized residuals of CDRUGS and CSHOTS data for BINAR(1)BP2S-L(II) process.
From Figure 6, we can infer that the residuals exhibit randomly and without trend distribution.
7.3. Sales Data of Candies
The second dataset is related to some sales data of products on the market. The data are provided by the Kilts Center for Marketing, Graduate School of Business of the University of Chicago. Approximately nine years (1989–1997) of store-level data on the sales of 3500+ UPCs are available in this database (available on the website: http://research.chicagobooth.edu/marketing/databases/dominicks.) Here, we choose two products of candies, which are chewing gum from store ‘56’. The first product, named Candies1, is the ‘CHICLETS TINY PACK’, the UPC of which is ‘1254612128’ and the second product, named Candies2, is the ‘TIC TAC WINTERGREEN’, the UPC of which is ‘980000007’. The sales of these two products from week 1 to week 200 are recorded as the bivariate count time series data. The average Candies1 and Candies2 data values are 18.145 and 12.385, respectively, with corresponding variances of 122.7276 and 45.645, indicating a clear over-dispersion. The plots of the time series, ACF, and PACF of Candies1 and Candies2 data are given in Figure 7, Figure 8, and Figure 9, respectively.
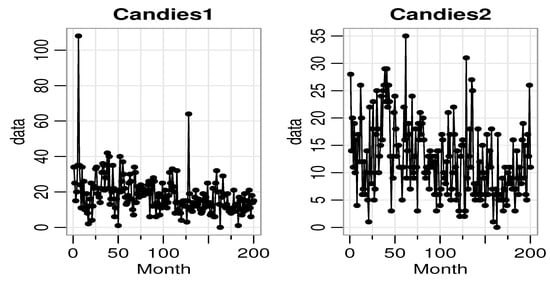
Figure 7.
The time series plot of Candies1 and Candies2 data.
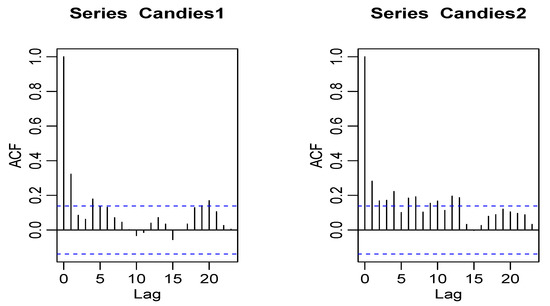
Figure 8.
The ACF plot of Candies1 and Candies2 data.

Figure 9.
The PACF plot of Candies1 and Candies2 data.
The PACF plots make it clear that the data can be used since only the first lag is significant. Further, Figure 10 displays the CCF plot for candies datasets.
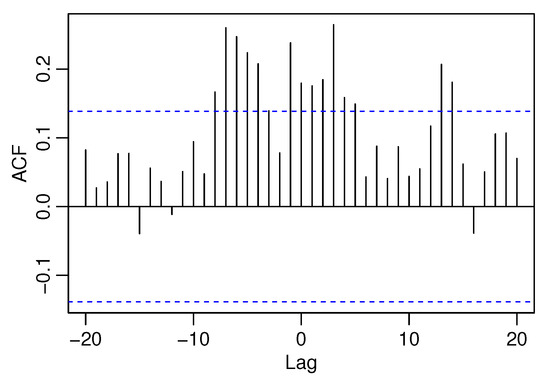
Figure 10.
The CCF plot of Candies1 and Candies2 datasets.
The CCF plot shows that the coefficient of lag 0 deviates significantly from 0, which implies the occurrence of cross-correlation. Table 8 consists of the CMLEs, AIC, BIC, and RMSEs for the BINAR(1)s considered here for the sales of candies dataset.
Table 8.
Estimates with SEs and CIs, AIC, BIC, and RMSEs of the considered BINAR(1) processes for the sales of candies dataset.
From Table 8, we observe that the BINAR(1)BP2S-L(II) process performs well for the data because it has the smallest values for the AIC and BIC. The Pearson standardized residuals were calculated for the BINAR(1)BP2S-L(II) process, and we found out that they have the means and , and variances and , respectively. The ACF plots for standardized residuals for both time series are plotted in Figure 11.
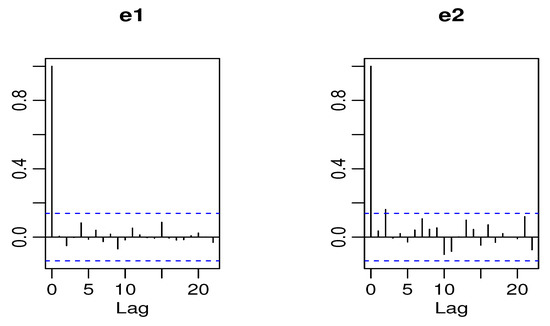
Figure 11.
ACF of standardized residuals of Candies1 and Candies2 data for the BINAR(1)BP2S-L(II) process.
It clearly indicates that they are uncorrelated, which clearly shows that the BINAR(1)BP2S-L(II) process is accurate and gives a good fit to the sales of candies dataset. The Pearson residual coefficients of both series for the candies sales dataset are plotted in Figure 12.
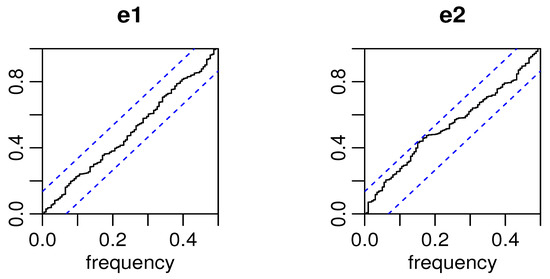
Figure 12.
Cpgrams of standardized residuals of Candies1 and Candies2 data for the BINAR(1)BP2S-L(II) process.
From Figure 12, we can also infer that the residuals exhibit randomly and without trend distribution.
8. Concluding Remarks
In this paper, bivariate distributions, namely the BP2S-L(I) and BP2S-L(II) distributions, are constructed based on two different approaches. Both distributions are studied in detail, and the main mathematical properties are derived. The unknown parameters of these distributions were estimated using the ML method. Simulation studies were carried out, and the results show consistent estimates under both distributions. Most importantly, the BINAR(1)BP2S-L(I) and BINAR(1)BP2S-L(II) processes were created with these paired innovation distributions. The unknown parameters of these BINAR(1) processes were estimated by employing the CML and CLS techniques. Both techniques were compared using simulation studies. The crime series and candy sales datasets are then analyzed using these BINAR(1) processes, and the results show that the BINAR(1)BP2S-L(II) process outperforms some other newly proposed BINAR(1) processes in terms of model adequacy metrics. As a result, the BINAR(1) process with various BP2S-L innovation distributions can be regarded as meritorious bivariate time series models that compete with those already published.
Author Contributions
Conceptualization, M.R.I., C.C., V.D., N.M.K. and R.M.; methodology, M.R.I., C.C., V.D., N.M.K. and R.M.; software, M.R.I., C.C., V.D., N.M.K. and R.M.; validation, M.R.I., C.C., V.D., N.M.K. and R.M.; formal analysis, M.R.I., C.C., V.D., N.M.K. and R.M.; investigation, M.R.I., C.C., V.D., N.M.K. and R.M.; data curation, M.R.I., C.C., V.D., N.M.K. and R.M.; writing—original draft preparation, M.R.I., C.C., V.D., N.M.K. and R.M.; writing—review and editing, M.R.I., C.C., V.D., N.M.K. and R.M.; All authors have read and agreed to the published version of the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Data Availability Statement
The sources of the data used in this study are provided.
Acknowledgments
We would like to thank the three referees for the thorough and constructive remarks on the first submitted version of the paper.
Conflicts of Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
- Balakrishnan, N.; Lai, C.D. Construction of bivariate distributions. In Continuous Bivariate Distributions; Springer: Berlin/Heidelberg, Germany, 2009; pp. 179–228. [Google Scholar]
- Karlis, D.; Xekalaki, E. Mixed Poisson distributions. Int. Stat. Rev. 2005, 73, 35–58. [Google Scholar] [CrossRef]
- Lai, C.-D. Constructions of discrete bivariate distributions. In Advances in Distribution Theory, Order Statistics, and Inference; Springer: Berlin/Heidelberg, Germany, 2006; pp. 29–58. [Google Scholar]
- Sarabia Alegría, J.M.; Gómez Déniz, E. Construction of multivariate distributions: A review of some recent results. Stat. Oper. Res. Trans. 2008, 32, 3–36. [Google Scholar]
- Sarmanov, O.V. Generalized normal correlation and two-dimensional Fréchet classes. In Doklady Akademii Nauk; Russian Academy of Sciences: Moscow, Russia, 1966; Volume 168, pp. 32–35. [Google Scholar]
- Ting Lee, M.-L. Properties and applications of the Sarmanov family of bivariate distributions. Commun. Stat.-Theory Methods 1996, 25, 1207–1222. [Google Scholar] [CrossRef]
- Al-Osh, M.A.; Alzaid, A.A. First-order integer-valued autoregressive (INAR(1)) process. J. Time Ser. Anal. 1987, 8, 261–275. [Google Scholar] [CrossRef]
- McKenzie, E. Some simple models for discrete variate time series 1. JAWRA J. Am. Water Resour. Assoc. 1985, 21, 645–650. [Google Scholar] [CrossRef]
- Altun, E. A new generalization of geometric distribution with properties and applications. Commun. Stat.-Simul. Comput. 2020, 49, 793–807. [Google Scholar] [CrossRef]
- Altun, E.; Khan, N.M. Modelling with the novel INAR (1)-PTE process. Methodol. Comput. Appl. Probab. 2022, 24, 1735–1751. [Google Scholar] [CrossRef]
- Eliwa, M.S.; Altun, E.; El-Dawoody, M.; El-Morshedy, M. A new three-parameter discrete distribution with associated INAR(1) process and applications. IEEE Access 2020, 8, 91150–91162. [Google Scholar] [CrossRef]
- Irshad, M.R.; Chesneau, C.; D’cruz, V.; Maya, R. Discrete pseudo Lindley distribution: Properties, estimation and application on INAR(1) process. Math. Comput. Appl. 2021, 26, 76. [Google Scholar] [CrossRef]
- Lívio, T.; Khan, N.M.; Bourguignon, M.; Bakouch, H.S. An INAR(1) model with Poisson–Lindley innovations. Econ. Bull. 2018, 38, 1505–1513. [Google Scholar]
- Pedeli, X.; Karlis, D. A bivariate INAR (1) process with application. Stat. Model. 2011, 11, 325–349. [Google Scholar] [CrossRef]
- Chesneau, C.; D’cruz, V.; Maya, R.; Irshad, M.R. A novel discrete distribution based on the mixture of Poisson and sum of two Lindley random variables with regression and an application on INAR(1) process. 2022; Preprint. [Google Scholar]
- Chesneau, C.; Tomy, L.; Gillariose, J. On a sum and difference of two Lindley distributions: Theory and applications. REVSTAT-Stat. J. 2020, 18, 673–696. [Google Scholar]
- Lindley, D. Fiducial distributions and Bayes’ theorem. J. R. Stat. Soc. Ser. B (Methodol.) 1958, 20, 102–107. [Google Scholar] [CrossRef]
- Gomez-Deniz, E.; Sarabia, J.M.; Balakrishnan, N. A multivariate discrete Poisson-Lindley distribution: Extensions and actuarial applications. ASTIN Bull. J. IAA 2012, 42, 655–678. [Google Scholar]
- Steutel, F.; van Harn, K. Discrete analogues of self-decomposability and stability. Ann. Probab. 1979, 7, 893–899. [Google Scholar] [CrossRef]
- Khan, N.M.; Oncel Cekim, H.; Ozel, G. The family of the bivariate integer-valued autoregressive process (BINAR (1)) with Poisson–Lindley (PL) innovations. J. Stat. Comput. Simul. 2020, 90, 624–637. [Google Scholar] [CrossRef]
- Andersen, E.B. Asymptotic properties of conditional maximum-likelihood estimators. J. R. Stat. Soc. Ser. B (Methodol.) 1970, 32, 283–301. [Google Scholar] [CrossRef]
- Bu, R.; McCabe, B. Model selection, estimation and forecasting in INAR (p) models: A likelihood-based Markov chain approach. Int. J. Forecast. 2008, 24, 151–162. [Google Scholar] [CrossRef]
- Freeland, R.K.; McCabe, B.P. Analysis of low count time series data by Poisson autoregression. J. Time Ser. Anal. 2004, 25, 701–722. [Google Scholar] [CrossRef]
- Sajjadnia, Z.; Sharafi, M.; Khan, N.M.; Soobhug, S. The bivariate INAR(1) model with paired Poisson-weighted exponential distributions. 2021; Preprint. [Google Scholar]
- Ristic, M.M.; Popovic, B. A new bivariate binomial time series model. Markov Process. Related Fields 2019, 25, 1–26. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).