

Syntactically Enhanced Dependency-POS Weighted Graph Convolutional Network for Aspect-Based Sentiment Analysis


Abstract
:1. Introduction
- We propose to weight dependencies with different types in dependency trees according to their contribution to ABSA task by capturing the correlations between dependency types and POS labels.
- We propose DPGCN to weight different dependencies with a graph attention mechanism which incorporates dependency information and POS information. SynFE and SemFE are developed to extract more feature information for elevating model performance.
- We conduct extensive experiments on five benchmark datasets, and the results prove the effectiveness of our model.
2. Related Work
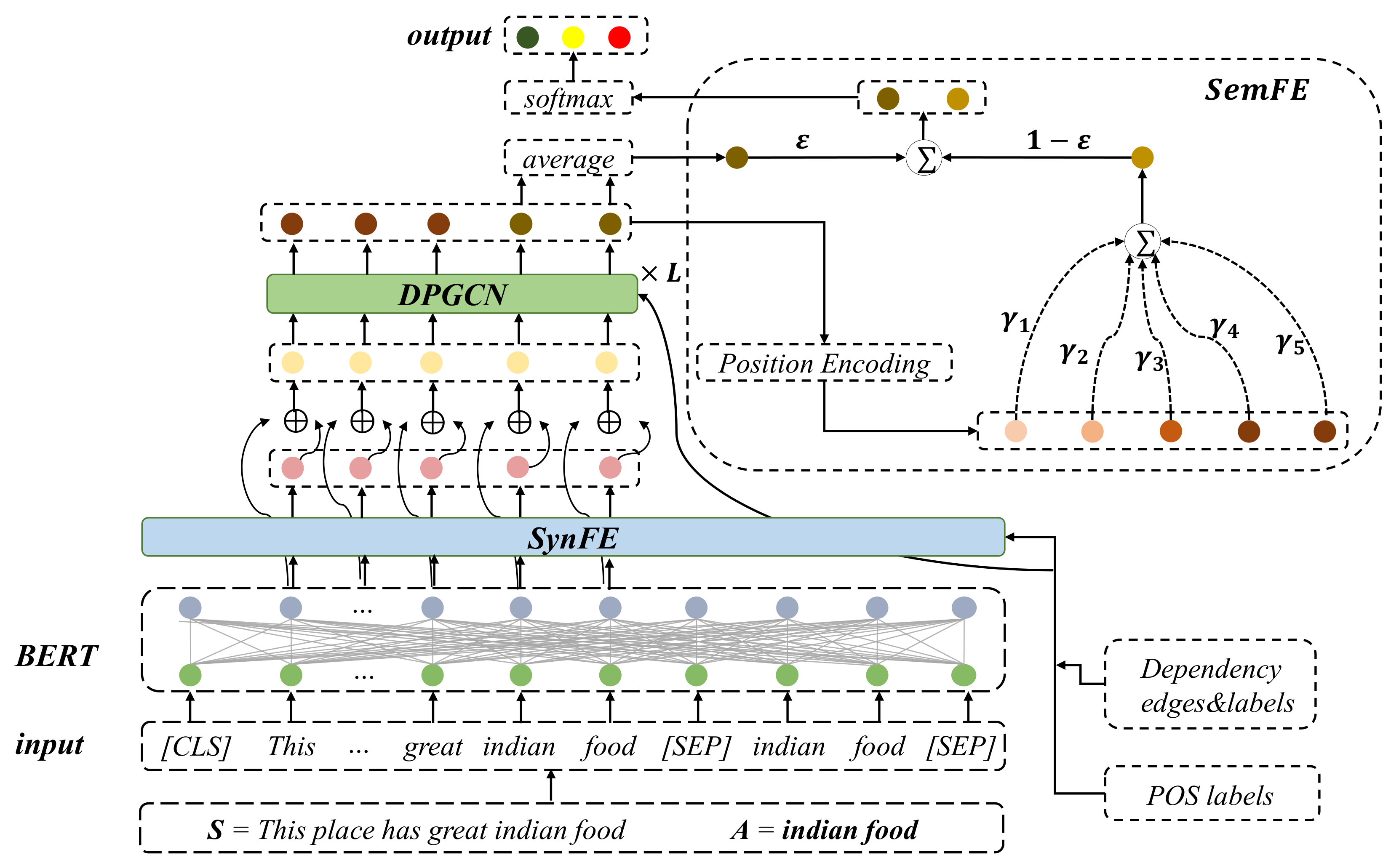
3. Method
3.1. Problem Definition (ABSA)
3.2. Initial Embedding Module
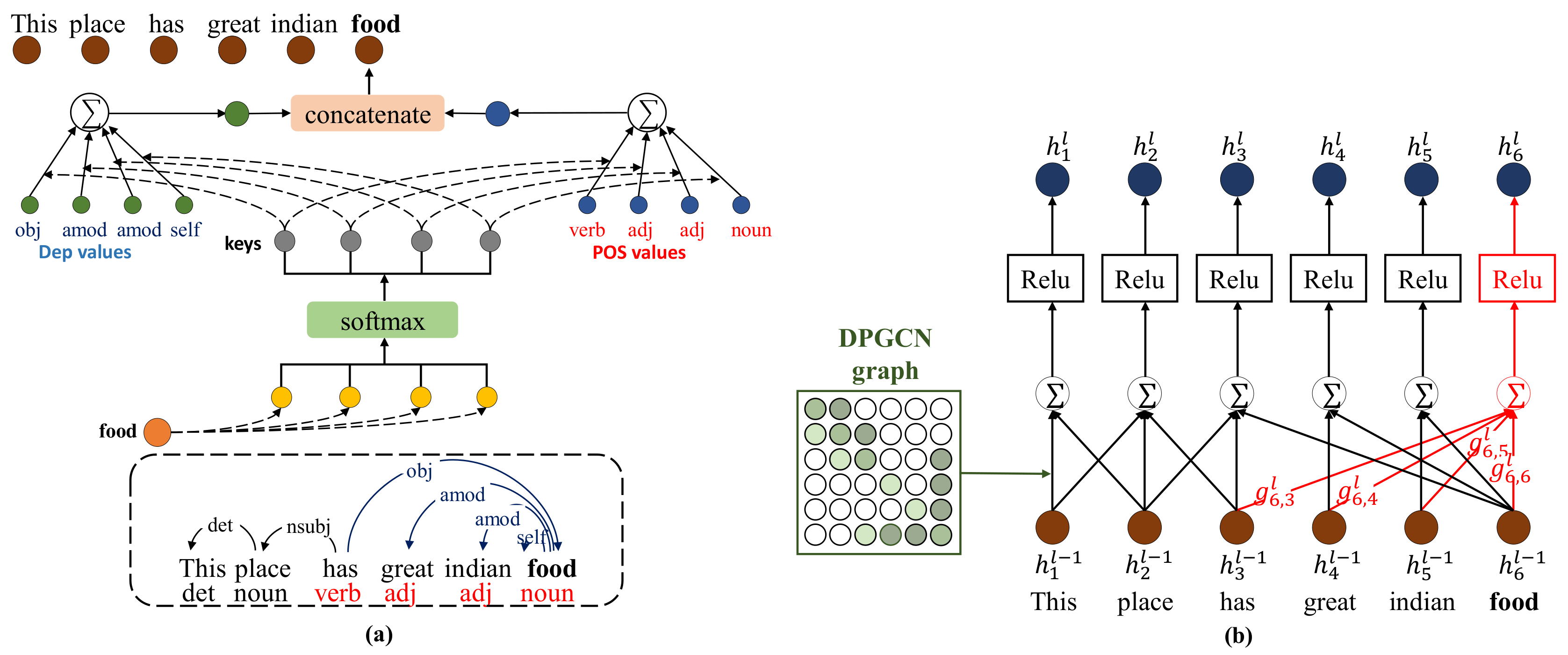
3.3. Syntactic Feature Encoder (SynFE)
3.4. Dependency-POS Weighted Graph Convolutional Network (DPGCN)
3.5. Semantic Feature Extractor (SemFE)
3.6. Model Training
4. Experiments
4.1. Datasets
4.2. Experimental Settings
4.3. Baselines
4.4. Results and Analysis
4.5. Ablation Study
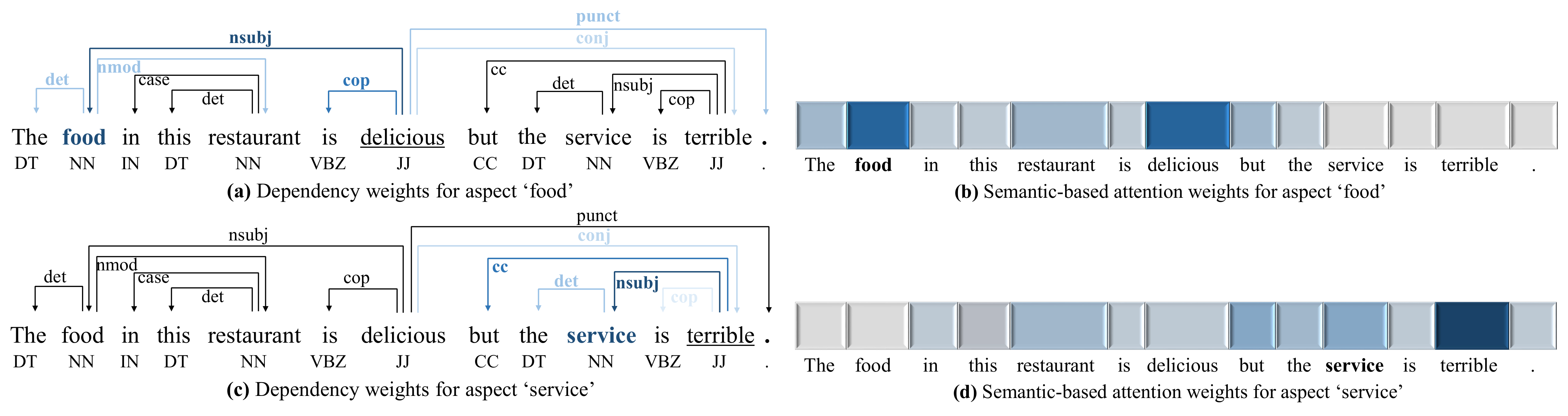
4.6. Case Study
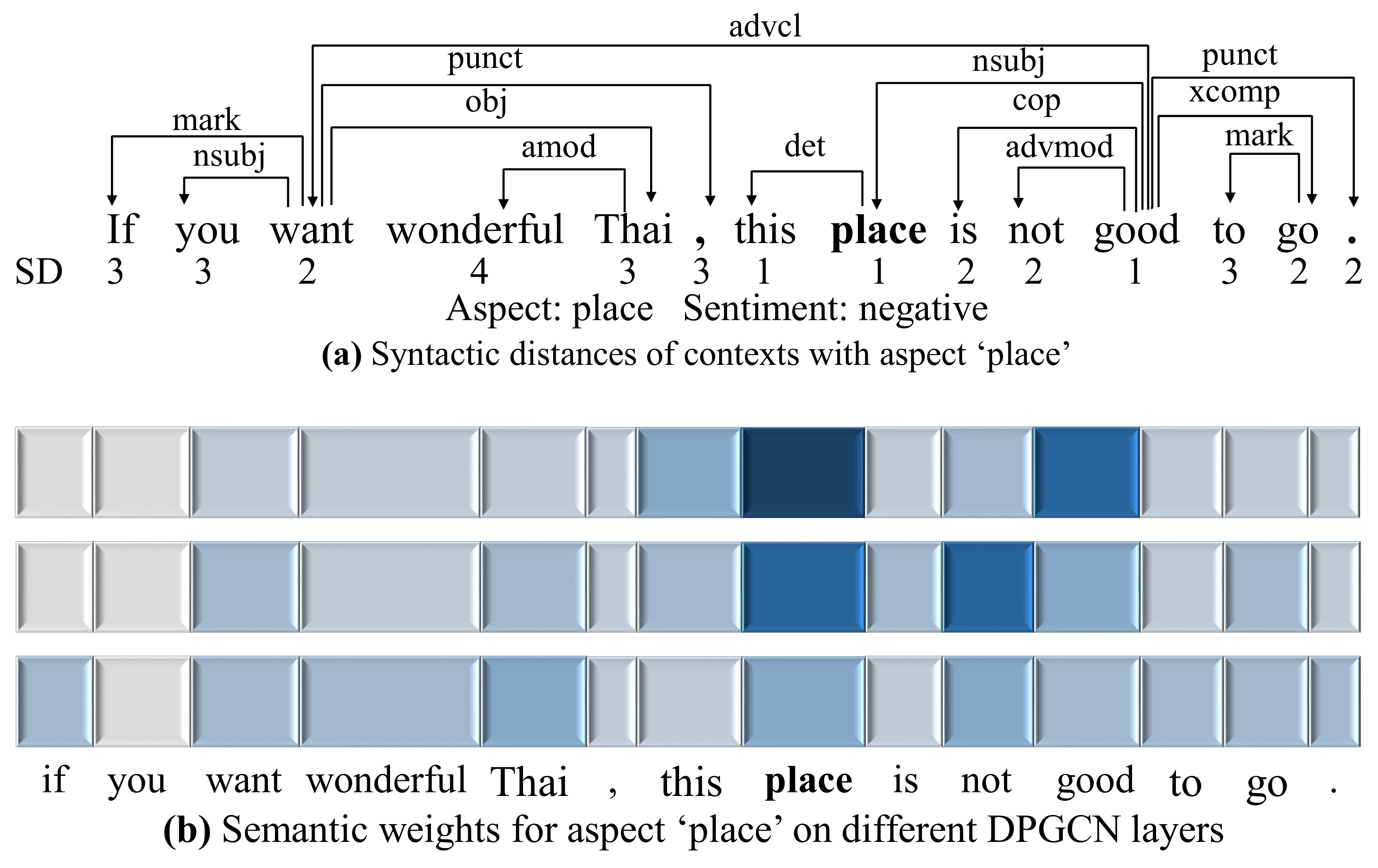
4.6.1. Weights Visualization
4.6.2. Probability Distribution Visualization
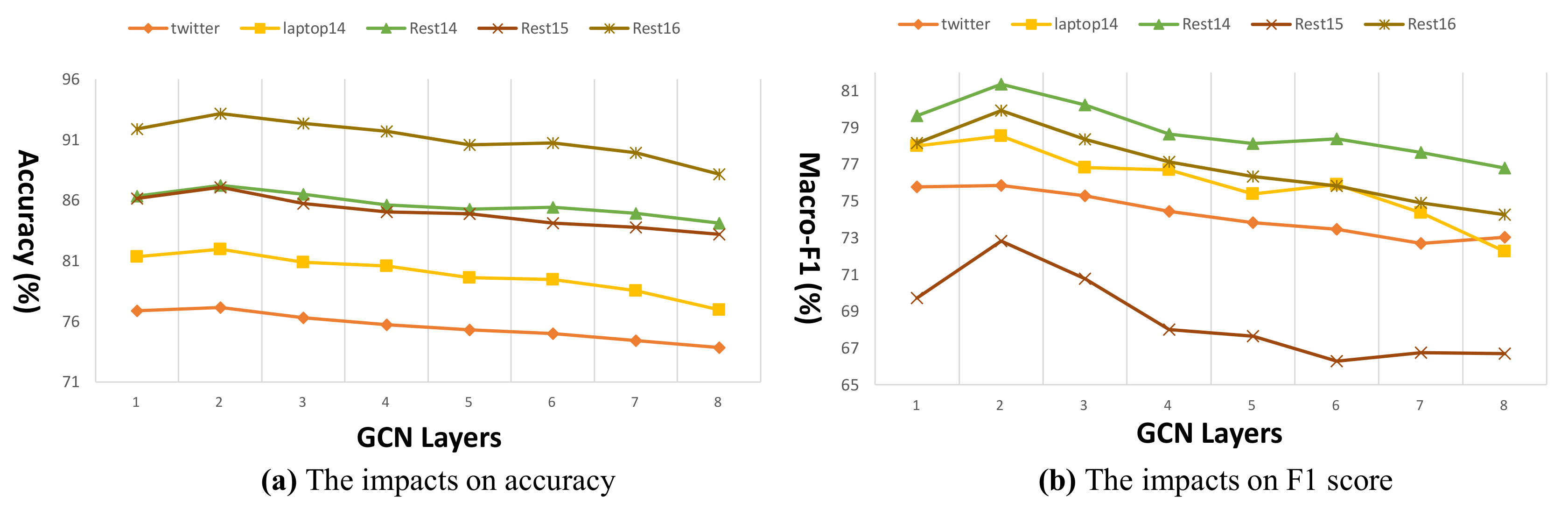
4.7. Impacts of DPGCN Layer Number
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, Y.; Huang, M.; Zhu, X.; Zhao, L. Attention-based LSTM for aspect-level sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 606–615. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Aspect level sentiment classification with deep memory network. arXiv 2016, arXiv:1605.08900. [Google Scholar]
- Chen, P.; Sun, Z.; Bing, L.; Yang, W. Recurrent attention network on memory for aspect sentiment analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 452–461. [Google Scholar]
- Fan, F.; Feng, Y.; Zhao, D. Multi-grained attention network for aspect-level sentiment classification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3433–3442. [Google Scholar]
- Huang, B.; Ou, Y.; Carley, K.M. Aspect level sentiment classification with attention-over-attention neural networks. In Proceedings of the International Conference on Social Computing, Behavioral-Cultural Modeling and Prediction and Behavior Representation in Modeling and Simulation, Washington, DC, USA, 10–13 July 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 197–206. [Google Scholar]
- Zhang, C.; Li, Q.; Song, D. Aspect-based sentiment classification with aspect-specific graph convolutional networks. arXiv 2019, arXiv:1909.03477. [Google Scholar]
- Sun, K.; Zhang, R.; Mensah, S.; Mao, Y.; Liu, X. Aspect-level sentiment analysis via convolution over dependency tree. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5679–5688. [Google Scholar]
- Zhang, M.; Qian, T. Convolution over hierarchical syntactic and lexical graphs for aspect level sentiment analysis. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 3540–3549. [Google Scholar]
- Chen, C.; Teng, Z.; Zhang, Y. Inducing target-specific latent structures for aspect sentiment classification. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 5596–5607. [Google Scholar]
- Liang, B.; Yin, R.; Gui, L.; Du, J.; Xu, R. Jointly learning aspect-focused and inter-aspect relations with graph convolutional networks for aspect sentiment analysis. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 150–161. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Sun, C.; Huang, L.; Qiu, X. Utilizing BERT for aspect-based sentiment analysis via constructing auxiliary sentence. arXiv 2019, arXiv:1903.09588. [Google Scholar]
- Nguyen, H.T.; Le Nguyen, M. Effective attention networks for aspect-level sentiment classification. In Proceedings of the 2018 10th International Conference on Knowledge and Systems Engineering (KSE), Ho Chi Minh City, Vietnam, 1–3 November 2018; pp. 25–30. [Google Scholar]
- Phan, M.H.; Ogunbona, P.O. Modelling context and syntactical features for aspect-based sentiment analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3211–3220. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Wang, K.; Shen, W.; Yang, Y.; Quan, X.; Wang, R. Relational graph attention network for aspect-based sentiment analysis. arXiv 2020, arXiv:2004.12362. [Google Scholar]
- Li, R.; Chen, H.; Feng, F.; Ma, Z.; Wang, X.; Hovy, E. Dual graph convolutional networks for aspect-based sentiment analysis. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing; Volume 1: Long Papers; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 6319–6329. [Google Scholar]
- Dong, L.; Wei, F.; Tan, C.; Tang, D.; Zhou, M.; Xu, K. Adaptive Recursive Neural Network for Target-dependent Twitter Sentiment Classification. In Proceedings of the ACL, Baltimore, MD, USA, 22–27 June 2014; pp. 49–54. [Google Scholar]
- Pontiki, M.; Papageorgiou, H.; Galanis, D.; Androutsopoulos, I.; Pavlopoulos, J.; Manandhar, S. SemEval-2014 Task 4: Aspect Based Sentiment Analysis. SemEval 2014, 2014, 27. [Google Scholar]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Manandhar, S.; Androutsopoulos, I. Semeval-2015 task 12: Aspect based sentiment analysis. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; pp. 486–495. [Google Scholar]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S.; Al-Smadi, M.; Al-Ayyoub, M.; Zhao, Y.; Qin, B.; De Clercq, O.; et al. Semeval-2016 task 5: Aspect based sentiment analysis. In Proceedings of the International Workshop on Semantic Evaluation, San Diego, CA, USA, 16–17 June 2016; pp. 19–30. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Ma, D.; Li, S.; Zhang, X.; Wang, H. Interactive attention networks for aspect-level sentiment classification. arXiv 2017, arXiv:1709.00893. [Google Scholar]
- Gao, Z.; Feng, A.; Song, X.; Wu, X. Target-dependent sentiment classification with BERT. IEEE Access 2019, 7, 154290–154299. [Google Scholar] [CrossRef]
- Tang, H.; Ji, D.; Li, C. Dependency graph enhanced dual-transformer structure for aspect-based sentiment classification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6578–6588. [Google Scholar]
- Tian, Y.; Chen, G.; Song, Y. Aspect-based Sentiment Analysis with Type-aware Graph Convolutional Networks and Layer Ensemble. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 2910–2922. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Positive | Negative | Neutral | |||
|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | |
| 1561 | 173 | 1560 | 173 | 3127 | 346 | |
| Lap14 | 994 | 341 | 870 | 128 | 464 | 169 |
| Res14 | 2164 | 728 | 807 | 196 | 637 | 196 |
| Res15 | 912 | 326 | 256 | 182 | 36 | 34 |
| Res16 | 1240 | 469 | 439 | 117 | 69 | 30 |
| Model | Lap14 | Rest14 | Rest15 | Rest16 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc | F1 | Acc | F1 | Acc | F1 | Acc | F1 | Acc | F1 | |
| IAN | 72.50 | 70.81 | 72.05 | 67.38 | 79.26 | 70.09 | 78.54 | 52.65 | 84.74 | 55.21 |
| MGAN | 72.54 | 70.81 | 75.39 | 72.47 | 81.25 | 71.94 | 79.36 | 57.26 | 87.06 | 62.29 |
| ASGCN | 72.15 | 70.40 | 75.55 | 71.05 | 80.77 | 72.02 | 79.89 | 61.89 | 88.99 | 67.48 |
| CDT | 73.29 | 72.02 | 75.63 | 72.01 | 83.10 | 73.01 | 79.42 | 61.68 | 86.24 | 67.62 |
| BIGCN | 74.16 | 73.35 | 74.59 | 71.84 | 81.97 | 73.48 | 81.16 | 64.79 | 88.96 | 70.84 |
| BERT | 73.27 | 71.52 | 77.59 | 73.28 | 84.11 | 76.68 | 83.48 | 66.18 | 90.10 | 74.16 |
| TD | 76.69 | 74.28 | 78.87 | 74.38 | 85.10 | 78.35 | – | – | – | – |
| R-GAT | 76.15 | 74.88 | 78.21 | 74.07 | 86.60 | 81.35 | – | – | – | – |
| DGEDT | 77.9 | 75.4 | 79.8 | 75.6 | 86.3 | 80.0 | 84.0 | 71.0 | 91.9 | 79.0 |
| LCFS | – | – | 80.52 | 77.13 | 86.71 | 80.31 | – | – | – | – |
| TGCN | 76.45 | 75.25 | 80.88 | 77.03 | 86.16 | 79.95 | 85.26 | 71.69 | 92.32 | 77.29 |
| DualGCN | 77.40 | 76.02 | 81.80 | 78.10 | 87.13 | 81.16 | – | – | – | – |
| Ours | 76.88 | 75.01 | 82.13 | 78.86 | 87.23 | 81.38 | 85.61 | 73.03 | 92.69 | 80.25 |
| Models | Lap14 | Rest14 | Rest15 | Rest16 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc | F1 | Acc | F1 | Acc | F1 | Acc | F1 | Acc | F1 | |
| -SynFE | 76.01 | 74.02 | 81.03 | 77.76 | 86.79 | 80.07 | 85.06 | 71.88 | 92.05 | 77.65 |
| DPGCN -dep | 76.16 | 74.54 | 80.56 | 77.12 | 86.16 | 79.11 | 84.87 | 70.24 | 91.88 | 77.98 |
| DPGCN -POS | 76.45 | 74.75 | 81.19 | 77.52 | 86.60 | 78.82 | 85.24 | 72.22 | 92.21 | 78.85 |
| DPGCN -both | 75.87 | 73.57 | 80.25 | 76.13 | 85.62 | 78.21 | 84.69 | 69.92 | 91.56 | 76.02 |
| SemFE -PE | 76.45 | 74.82 | 81.50 | 77.92 | 86.96 | 80.48 | 85.42 | 71.95 | 92.37 | 78.76 |
| -SemFE | 76.01 | 74.30 | 80.88 | 77.36 | 86.16 | 79.57 | 85.24 | 71.42 | 92.05 | 76.61 |
| ours | 76.88 | 75.01 | 82.13 | 78.86 | 87.23 | 81.38 | 85.61 | 73.03 | 92.69 | 80.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Dai, A.; Xue, Y.; Zeng, B.; Liu, X. Syntactically Enhanced Dependency-POS Weighted Graph Convolutional Network for Aspect-Based Sentiment Analysis. Mathematics 2022, 10, 3353. https://doi.org/10.3390/math10183353
Yang J, Dai A, Xue Y, Zeng B, Liu X. Syntactically Enhanced Dependency-POS Weighted Graph Convolutional Network for Aspect-Based Sentiment Analysis. Mathematics. 2022; 10(18):3353. https://doi.org/10.3390/math10183353
Chicago/Turabian StyleYang, Jinjie, Anan Dai, Yun Xue, Biqing Zeng, and Xuejie Liu. 2022. "Syntactically Enhanced Dependency-POS Weighted Graph Convolutional Network for Aspect-Based Sentiment Analysis" Mathematics 10, no. 18: 3353. https://doi.org/10.3390/math10183353
APA StyleYang, J., Dai, A., Xue, Y., Zeng, B., & Liu, X. (2022). Syntactically Enhanced Dependency-POS Weighted Graph Convolutional Network for Aspect-Based Sentiment Analysis. Mathematics, 10(18), 3353. https://doi.org/10.3390/math10183353