

Joint Semantic Intelligent Detection of Vehicle Color under Rainy Conditions

Abstract
:1. Introduction
- contains far fewer parameters than previous two-stage methods since its subnets, and share the same feature extracting layers. This is of high practical value as the size of outdoor mobile equipment can be substantially reduced.
- In , the multi-scale fusion information obtained by cascading feature maps of original rainy images and recovered images are fed into the subsequent class-box subnet. In so doing, multi-scale information across domains is crucially beneficial for fine vehicle color recognition.
- The joint processing of low-level and high-level tasks can be mutually beneficial. Embedding the image restoration module can help improve the performance of subsequent high-level tasks under severe weather; conversely, the performance of subsequent high-level tasks as evaluation metrics can, in turn, fine-tune the image restoration algorithms.
- Comprehensive experiments show that our proposed methods outperform basic detection networks and two-stage network and transfer learning methods for the task of color recognition under rainy conditions. Further, our training and testing times are shortened.
2. Related Work
2.1. Vehicle Color Recognition under Normal Weather Conditions
2.2. Object Detection under Adverse Weather Conditions
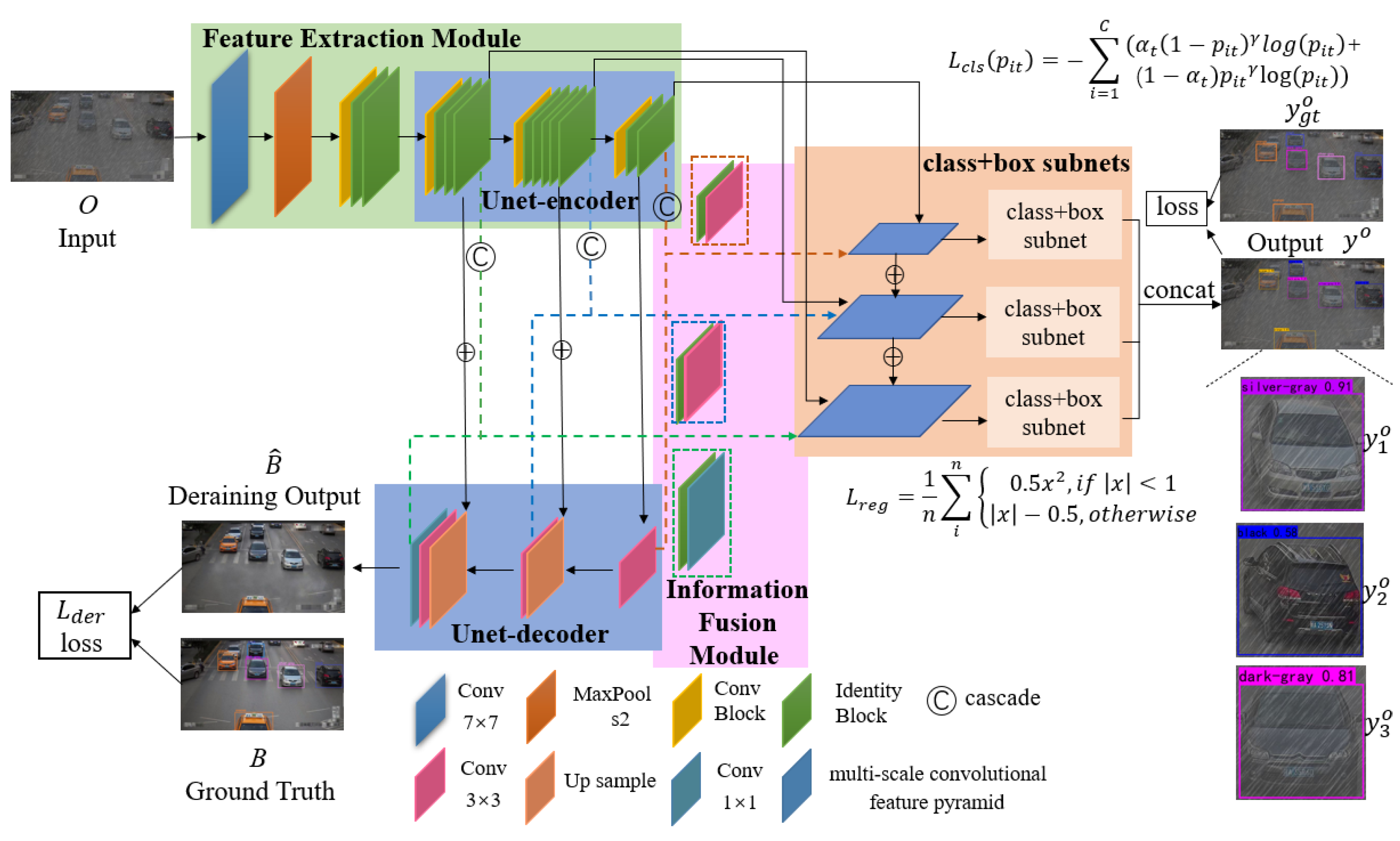
3. JADAR Algorithm
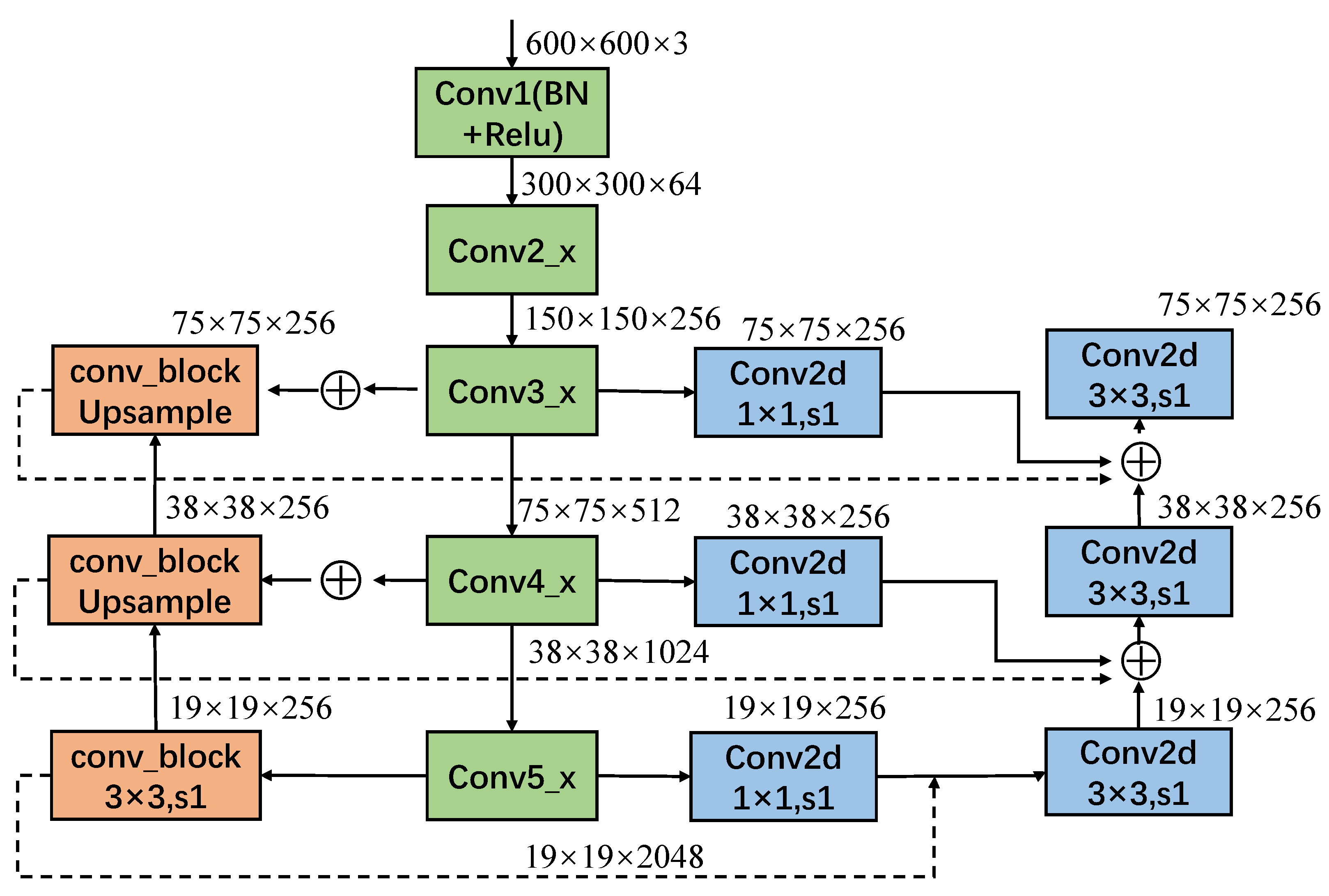
3.1. Fusion Network Design
3.2. Model Formulation and Model Optimization
4. Experiments
4.1. Experimental Setup
4.2. Datasets
4.2.1. Synthetic Dataset Rain Vehicle Color-24
4.2.2. Real Rain Vehicle Datasets: and
4.3. Ablation Study
4.4. Experiments and Analysis
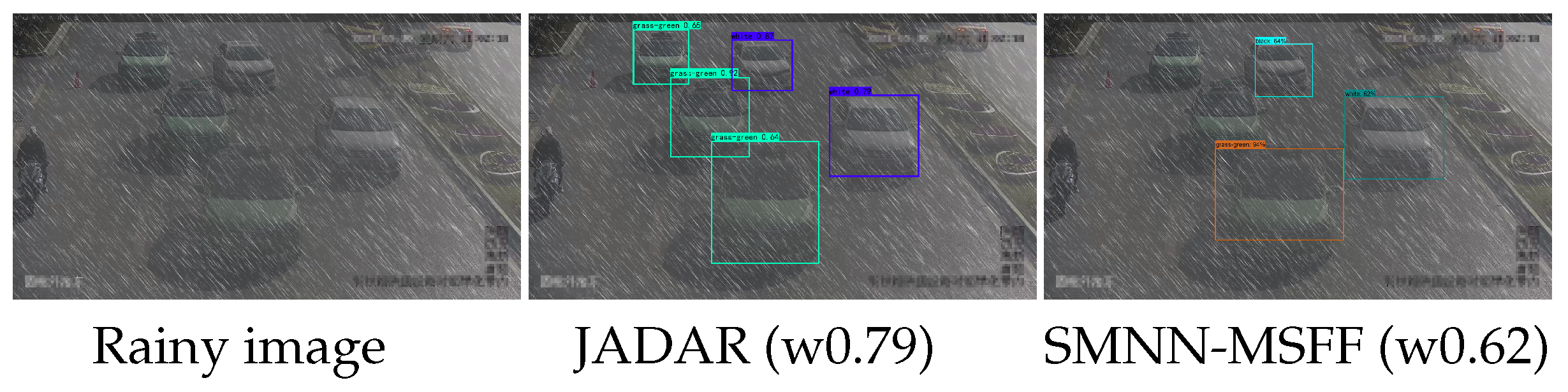
4.4.1. Results on Synthetic Datasets
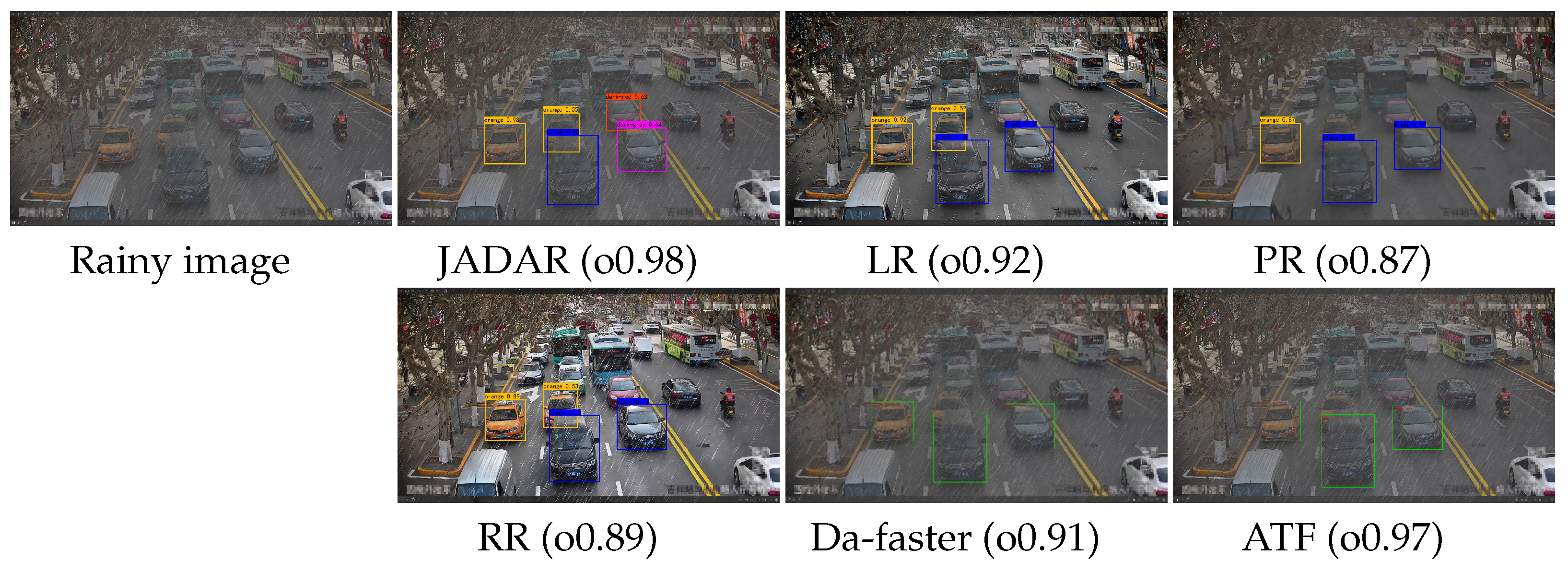
4.4.2. Results on Real Datasets
4.5. Inference Time
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tang, J.; Zeng, J. Spatiotemporal gated graph attention network for urban traffic flow prediction based on license plate recognition data. Comput.-Aided Civ. Infrastruct. Eng. 2022, 37, 3–23. [Google Scholar] [CrossRef]
- Rajavel, R.; Ravichandran, S.K.; Harimoorthy, K.; Nagappan, P.; Gobichettipalayam, K.R. IoT-based smart healthcare video surveillance system using edge computing. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 3195–3207. [Google Scholar] [CrossRef]
- Wang, Z.; Zhan, J.; Duan, C.; Guan, X.; Lu, P. A review of vehicle detection techniques for intelligent vehicles. IEEE Trans. Neural Netw. Learn. Syst. 2022, 23, 1–21. [Google Scholar] [CrossRef]
- Wang, J.; Gao, J.; Zhao, S.; Zhu, R.; Jiang, Z. From Model to Algorithms: Distributed Magnetic Sensor System for Vehicle Tracking. IEEE Trans. Ind. Inform. 2022, 33, 1. [Google Scholar] [CrossRef]
- Lee, S.; Park, S.H. Concept drift modeling for robust autonomous vehicle control systems in time-varying traffic environments. Expert Syst. Appl. 2022, 190, 116–206. [Google Scholar] [CrossRef]
- Khan, M.A.; Sayed, H.E.; Malik, S.; Zia, T.; Khan, J. Level-5 Autonomous Driving—Are We There Yet? A Review of Research Literature. ACM Comput. Surv. 2022, 55, 1–38. [Google Scholar] [CrossRef]
- Custers, B. AI in Criminal Law: An Overview of AI Applications in Substantive and Procedural Criminal Law. In Law and Artificial Intelligence; Asser Press: The Hague, The Netherlands, 2022; pp. 205–223. [Google Scholar]
- Chen, P.; Bai, X.; Liu, W. Vehicle color recognition on urban road by feature context. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2340–2346. [Google Scholar] [CrossRef]
- Jeong, Y.; Park, K.H.; Park, D. Homogeneity patch search method for voting-based efficient vehicle color classification using front-of-vehicle image. Multimed. Tools Appl. 2019, 78, 28633–28648. [Google Scholar] [CrossRef]
- Tilakaratna, D.S.; Watchareeruetai, U.; Siddhichai, S.; Natcharapinchai, N. Image analysis algorithms for vehicle color recognition. In Proceedings of the 2017 International Electrical Engineering Congress, Pattaya, Thailand, 8–10 March 2017; pp. 1–4. [Google Scholar]
- Dule, E.; Gokmen, M.; Beratoglu, M.S. A convenient feature vector construction for vehicle color recognition. In Proceedings of the 11th WSEAS International Conference on Nural Networks and 11th WSEAS International Conference on Evolutionary Computing and 11th WSEAS International Conference on Fuzzy Systems, Iasi Romania, 13–15 June 2010; pp. 250–255. [Google Scholar]
- Hu, C.; Bai, X.; Qi, L.; Chen, P.; Xue, G. Vehicle color recognition with spatial pyramid deep learning. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2925–2934. [Google Scholar] [CrossRef]
- Rachmadi, R.F.; Purnama, I.K. Vehicle color recognition using convolutional neural network. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–10 June 2015. [Google Scholar]
- Zhuo, L.; Zhang, Q.; Li, J.; Zhang, J.; Li, X. High-accuracy vehicle color recognition using hierarchical fine-tuning strategy for urban surveillance videos. J. Electron. Imaging 2018, 27, 1–9. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhuo, L.; Li, J.; Zhang, J.; Zhang, H. Vehicle color recognition using Multiple-Layer Feature Representations of lightweight convolutional neural network. Signal Process. 2018, 147, 146–153. [Google Scholar] [CrossRef]
- Fu, H.; Ma, H.; Wang, G.; Zhang, X.; Zhang, Y. Mcff-cnn: Multiscale comprehensive feature fusion convolutional neural network for vehicle color recognition based on residual learning. Neurocomputing 2020, 395, 178–187. [Google Scholar] [CrossRef]
- Nafzi, M.; Brauckmann, M.; Glasmachers, T. Vehicle shape and color classification using convolutional neural network. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–21 June 2019. [Google Scholar]
- Hu, M.; Bai, L.; Li, Y.; Zhao, S.R.; Chen, E.H. Vehicle Color Recognition Based on Smooth Modulation Neural Network with Multi-Scale Feature Fusion. arXiv 2021, arXiv:2107.09944. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S. Ssd: Single shot multi-box detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y. Yolov4: Optimal speed and accuracy of object detection. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- Xu, M.; Wang, H.; Ni, B.; Tian, Q.; Zhang, W. Cross-domain detection via graph-induced prototype alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12355–12364. [Google Scholar]
- Zhang, Y.; Wang, Z.; Mao, Y. Rpn prototype alignment for domain adaptive object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12425–12434. [Google Scholar]
- Kim, T.; Jeong, M.; Kim, S.; Choi, S.; Kim, C. Diversify and match: A domain adaptive representation learning paradigm for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12456–12465. [Google Scholar]
- Dong, H.; Pan, J.; Xiang, L.; Hu, Z.; Zhang, X.; Wang, F.; Yang, M.H. Multi-scale boosted dehazing network with dense feature fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2157–2167. [Google Scholar]
- Xu, C.D.; Zhao, X.R.; Jin, X.; Wei, X.S. Exploring categorical regularization for domain adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11724–11733. [Google Scholar]
- Vs, V.; Gupta, V.; Oza, P.; Sindagi, V.A.; Patel, V.M. Mega-cda: Memory guided attention for category-aware unsupervised domain adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4516–4526. [Google Scholar]
- Sindagi, V.A.; Oza, P.; Yasarla, R.; Patel, V.M. Prior-based domain adaptive object detection for hazy and rainy conditions. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 763–780. [Google Scholar]
- Wang, T.; Zhang, X.; Yuan, L.; Feng, J. Few-shot adaptive faster r-cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7173–7182. [Google Scholar]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van, G.L. Domain adaptive faster rcnn for object detection in the wild. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3339–3348. [Google Scholar]
- Liu, W.; Ren, G.; Yu, R.; Guo, S.; Zhu, J. Image-adaptive yolo for object detection in adverse weather conditions. In Proceedings of the AAAI Conference on Artificial Intelligence, Arlington, VA, USA, 17–19 November 2022; pp. 1792–1800. [Google Scholar]
- Fu, X.; Liang, B.; Huang, Y.; Ding, X.; Paisley, J. Lightweight pyramid networks for image deraining. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1794–1807. [Google Scholar] [CrossRef]
- Fan, Z.; Wu, H.; Fu, X.; Hunag, Y.; Ding, X. Residual-guide feature fusion network for single image deraining. arXiv 2018, arXiv:1804.07493. [Google Scholar]
- Jiang, K.; Wang, Z.; Yi, P.; Chen, C.; Huang, B. Multi-scale progressive fusion network for single image deraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8346–8355. [Google Scholar]
- Li, S.Y.; Araujo, I.B.; Ren, W.Q.; Wang, Z.Y.; Tokuda, E.K. Single image deraining: A comprehensive benchmark analysis. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3833–3842. [Google Scholar]
- Tremblay, M.; Halder, S.S.; De Charette, R.; Lalonde, J.F. Rain rendering for evaluating and improving robustness to bad weather. Int. J. Comput. Vis. 2021, 129, 341–360. [Google Scholar] [CrossRef]
- Zhang, H.; Sindagi, V.; Patel, V.M. Image de-raining using a conditional generative adversarial network. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3943–3956. [Google Scholar] [CrossRef]
- Huang, S.C.; Le, T.H.; Jaw, D.W. DSNet: Joint semantic learning for object detection in inclement weather conditions. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2623–2633. [Google Scholar] [CrossRef]
- Hu, M.; Yang, J.; Lin, N.; Liu, Y.; Fan, J. Lightweight single image deraining algorithm incorporating visual saliency. IET Image Process. 2022, 16, 3190–3200. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Jose, H.; Vadivukarasi, T.; Devakumar, J. Extraction of protein interaction data: A comparative analysis of methods in use. EURASIP J. Bioinform. Syst. Biol. 2007, 43, 53096. [Google Scholar] [CrossRef] [PubMed]
- Hu, M.; Wang, C.; Yang, J.; Wu, Y.; Fan, J.; Jing, B. Rain Rendering and Construction of Rain Vehicle Color-24 Dataset. Mathematics 2022, 10, 3210. [Google Scholar] [CrossRef]
- Hu, M.; Wu, Y.; Song, Y.; Yang, J.B.; Zhang, R.F. The integrated evaluation and review of single image rain removal based datasets and deep methods. J. Image Graph. 2022, 27, 1359–1391. [Google Scholar]
- Ren, D.; Zuo, W.; Hu, Q.; Zhu, P.; Meng, D.Y. Progressive image deraining networks: A better and simpler baseline. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3937–3946. [Google Scholar]
- Wang, H.; Xie, Q.; Zhao, Q.; Meng, D.Y. A model-driven deep neural network for single image rain removal. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3100–3109. [Google Scholar]
- He, Z.; Zhang, L. Domain adaptive object detection via asymmetric tri-way faster-rcnn. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 309–324. [Google Scholar]
- Liang, R.; Zhang, X. Interval-valued pseudo overlap functions and application. Axioms 2022, 11, 216. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, X. A novel multi-criteria decision-making method based on rough sets and fuzzy measures. Axioms 2022, 11, 275. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, J.; Zhan, J.; Dai, J. Fuzzy measures and Choquet integrals based on fuzzy covering rough sets. IEEE Trans. Fuzzy Syst. 2021, 30, 2360–2374. [Google Scholar] [CrossRef]
- Sheng, N.; Zhang, X. Regular partial residuated lattices and their filters. Mathematics 2022, 10, 2429. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, X.; Hu, Q. Three-way fuzzy sets and their applications (II). Axioms 2022. under review of the second version. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | mAP | |
|---|---|---|
| 0.1 | 70.69% | |
| 0.5 | 72.07% | |
| 1.0 | 63.78% |
| Category (R, G, B) | SM | FR | Yolo | SSD | RN | JADAR |
|---|---|---|---|---|---|---|
| white (255, 255, 255) | 0.60 | 0.96 | 0.95 | 0.95 | 0.97 | 0.97 |
| black (0, 0, 0) | 0.69 | 0.69 | 0.92 | 0.93 | 0.93 | 0.95 |
| orange (237, 145, 33) | 0.77 | 0.90 | 0.93 | 0.95 | 0.97 | 0.94 |
| silver-gray (128, 138, 135) | 0.31 | 0.81 | 0.86 | 0.86 | 0.86 | 0.85 |
| grass-green (0, 255, 0) | 0.82 | 0.93 | 0.95 | 0.96 | 0.96 | 0.96 |
| dark-gray (128, 128, 105) | 0.43 | 0.69 | 0.63 | 0.67 | 0.64 | 0.73 |
| dark-red (156, 102, 31) | 0.48 | 0.79 | 0.75 | 0.88 | 0.91 | 0.91 |
| gray (192, 192, 192) | 0.31 | 0.41 | 0.15 | 0.31 | 0.27 | 0.36 |
| red (255, 0, 0) | 0.44 | 0.56 | 0.60 | 0.76 | 0.77 | 0.83 |
| cyan (0, 255, 255) | 0.62 | 0.82 | 0.81 | 0.87 | 0.87 | 0.93 |
| champagne (255, 227, 132) | 0.28 | 0.74 | 0.58 | 0.73 | 0.66 | 0.69 |
| dark-blue (25, 25, 112) | 0.52 | 0.79 | 0.77 | 0.75 | 0.86 | 0.81 |
| blue (0, 0, 255) | 0.56 | 0.69 | 0.55 | 0.69 | 0.67 | 0.69 |
| dark-brown (94, 38, 18) | 0.35 | 0.18 | 0.40 | 0.47 | 0.37 | 0.50 |
| brown (128, 128, 42) | 0.35 | 0.10 | 0.22 | 0.34 | 0.30 | 0.21 |
| yellow (255, 255, 0) | 0.35 | 0.83 | 0.74 | 0.92 | 0.86 | 0.81 |
| lemon-yellow (255, 215, 0) | 0.57 | 0.99 | 0.73 | 0.75 | 0.75 | 0.94 |
| dark-orange (210, 105, 30) | 0.32 | 0.28 | 0.44 | 0.47 | 0.90 | 0.53 |
| dark-green (48, 128, 20) | 0.59 | 0.18 | 0.00 | 0.34 | 0.44 | 0.55 |
| red-orange (255, 97, 0) | 0.38 | 0.07 | 0.00 | 0.52 | 0.00 | 0.05 |
| earthy-yellow (184, 134, 11) | 0.68 | 0.45 | 0.00 | 0.28 | 0.93 | 1.00 |
| green (0, 255, 0) | 0.18 | 0.85 | 0.00 | 0.97 | 0.60 | 0.33 |
| pink (255, 192, 203) | 0.84 | 0.54 | 0.00 | 0.52 | 0.77 | 0.75 |
| purple (160, 32, 240) | 0.22 | 0.03 | 0.00 | 0.06 | 0.00 | 1.00 |
| mAP | 48.58% | 60.65% | 49.88% | 66.33% | 67.77% | 72.07% |
| Category (R, G, B) | LR | PR | RR | Da-Faster | ATF | JADAR |
|---|---|---|---|---|---|---|
| white (255, 255, 255) | 0.88 | 0.86 | 0.95 | 0.74 | 0.93 | 0.97 |
| black (0, 0, 0) | 0.75 | 0.75 | 0.92 | 0.61 | 0.87 | 0.95 |
| orange (237, 145, 33) | 0.91 | 0.92 | 0.96 | 0.73 | 0.90 | 0.94 |
| silver-gray (128, 138, 135) | 0.71 | 0.66 | 0.82 | 0.63 | 0.63 | 0.85 |
| grass-green (0, 255, 0) | 0.84 | 0.88 | 0.95 | 0.73 | 0.92 | 0.96 |
| dark-gray (128, 128, 105) | 0.55 | 0.44 | 0.73 | 0.38 | 0.65 | 0.73 |
| dark-red (156, 102, 31) | 0.67 | 0.75 | 0.87 | 0.54 | 0.66 | 0.91 |
| gray (192, 192, 192) | 0.27 | 0.20 | 0.37 | 0.19 | 0.27 | 0.36 |
| red (255, 0, 0) | 0.74 | 0.70 | 0.87 | 0.46 | 0.63 | 0.83 |
| cyan (0, 255, 255) | 0.81 | 0.78 | 0.92 | 0.75 | 0.93 | 0.93 |
| champagne (255, 227, 132) | 0.42 | 0.43 | 0.62 | 0.18 | 0.67 | 0.69 |
| dark-blue (25, 25, 112) | 0.58 | 0.30 | 0.67 | 0.16 | 0.89 | 0.81 |
| blue (0, 0, 255) | 0.33 | 0.48 | 0.53 | 0.44 | 0.92 | 0.69 |
| dark-brown (94, 38, 18) | 0.44 | 0.32 | 0.56 | 0.37 | 0.75 | 0.50 |
| brown (128, 128, 42) | 0.33 | 0.25 | 0.45 | 0.06 | 0.00 | 0.21 |
| yellow (255, 255, 0) | 0.79 | 0.77 | 0.89 | 0.39 | 1.00 | 0.81 |
| lemon-yellow(255, 215, 0) | 0.77 | 0.78 | 0.97 | 0.06 | 0.00 | 0.94 |
| dark-orange (210, 105, 30) | 0.56 | 0.18 | 0.90 | 1.00 | 0.00 | 0.53 |
| dark-green (48, 128, 20) | 0.65 | 0.50 | 0.95 | 0.22 | 0.07 | 0.55 |
| red-orange (255, 97, 0) | 0.00 | 0.00 | 0.00 | 0.39 | 1.00 | 0.05 |
| earthy-yellow (184, 134, 11) | 0.05 | 0.67 | 0.25 | 0.01 | 0.40 | 1.00 |
| green (0, 255, 0) | 0.06 | 0.13 | 0.00 | 1.00 | 1.00 | 0.33 |
| pink (255, 192, 203) | 0.44 | 0.67 | 0.67 | 0.92 | 0.93 | 0.75 |
| purple (160, 32,240) | 1.00 | 0.00 | 1.00 | 0.00 | 0.00 | 1.00 |
| mAP | 56.51% | 51.70% | 70.01% | 46.12% | 62.93% | 72.07% |
| Algorithm | RN | LR | PR | RR | Da-Faster | ATF | JADAR |
|---|---|---|---|---|---|---|---|
| Speed (s) | 1.7 | 23.5 | 2.8 | 6.1 | 2.5 | 2.6 | 1.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, M.; Wu, Y.; Fan, J.; Jing, B. Joint Semantic Intelligent Detection of Vehicle Color under Rainy Conditions. Mathematics 2022, 10, 3512. https://doi.org/10.3390/math10193512
Hu M, Wu Y, Fan J, Jing B. Joint Semantic Intelligent Detection of Vehicle Color under Rainy Conditions. Mathematics. 2022; 10(19):3512. https://doi.org/10.3390/math10193512
Chicago/Turabian StyleHu, Mingdi, Yi Wu, Jiulun Fan, and Bingyi Jing. 2022. "Joint Semantic Intelligent Detection of Vehicle Color under Rainy Conditions" Mathematics 10, no. 19: 3512. https://doi.org/10.3390/math10193512
APA StyleHu, M., Wu, Y., Fan, J., & Jing, B. (2022). Joint Semantic Intelligent Detection of Vehicle Color under Rainy Conditions. Mathematics, 10(19), 3512. https://doi.org/10.3390/math10193512