Author Contributions
M.S.E.: review and editing, validation, writing the original draft preparation, conceptualization, data curation, formal analysis, project administration, software; M.E.-M.: review and editing, methodology, conceptualization, software; H.M.Y.: review and editing, software, validation, writing the original draft preparation, conceptualization, supervision. All authors have read and agreed to the published version of the manuscript.
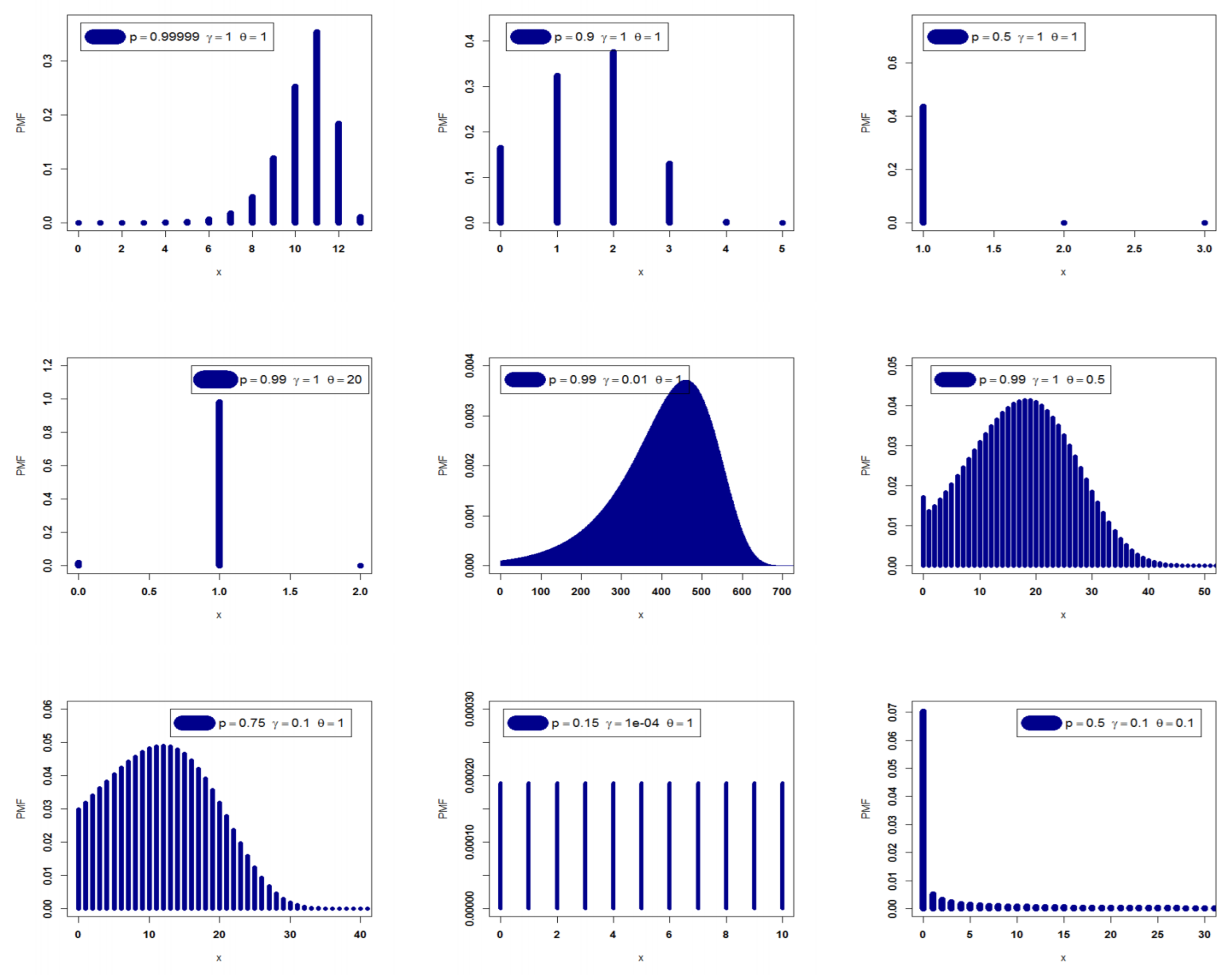
Figure 1.
The PMF of the DEGW model.
Figure 1.
The PMF of the DEGW model.
Figure 2.
The HRF of the DEGW model.
Figure 2.
The HRF of the DEGW model.
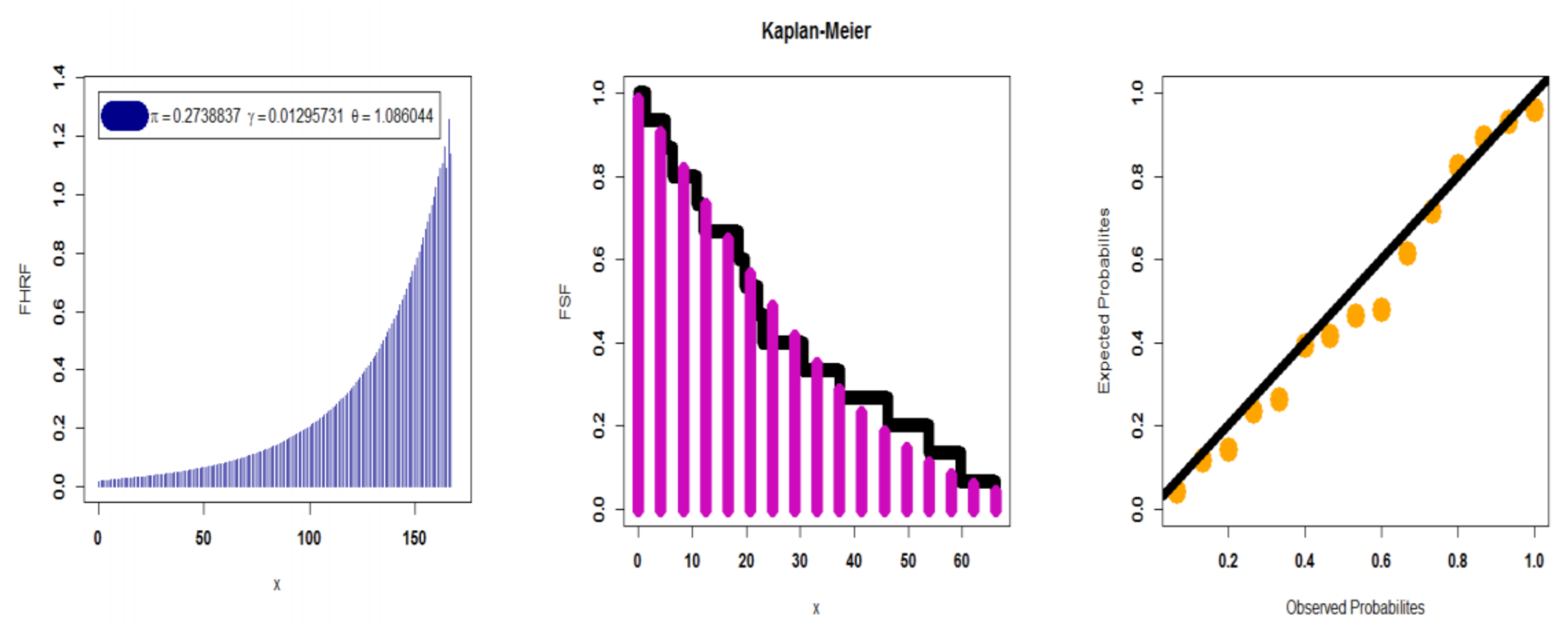
Figure 3.
Kaplan–Meier plots based on dataset I.
Figure 3.
Kaplan–Meier plots based on dataset I.
Figure 4.
Kaplan–Meier plots under dataset II.
Figure 4.
Kaplan–Meier plots under dataset II.
Figure 5.
Kaplan–Meier plots according to dataset III.
Figure 5.
Kaplan–Meier plots according to dataset III.
Figure 6.
Kaplan–Meier plots for dataset IV.
Figure 6.
Kaplan–Meier plots for dataset IV.
Figure 7.
Box, Q-Q, and TTT plots for dataset I.
Figure 7.
Box, Q-Q, and TTT plots for dataset I.
Figure 8.
The FHRF, ESF, and P–P plots for dataset I.
Figure 8.
The FHRF, ESF, and P–P plots for dataset I.
Figure 9.
Boxplot, Q-Q plot, and TTT plot for dataset II.
Figure 9.
Boxplot, Q-Q plot, and TTT plot for dataset II.
Figure 10.
The FHRF, ESF, and P–P plots for dataset II.
Figure 10.
The FHRF, ESF, and P–P plots for dataset II.
Figure 11.
Boxplot, Q-Q plot, and TTT plot for dataset III.
Figure 11.
Boxplot, Q-Q plot, and TTT plot for dataset III.
Figure 12.
The FPMF, FSF, FHRF, and FCDF plots for dataset III.
Figure 12.
The FPMF, FSF, FHRF, and FCDF plots for dataset III.
Figure 13.
Boxplot, Q-Q plot, and TTT plot for dataset IV.
Figure 13.
Boxplot, Q-Q plot, and TTT plot for dataset IV.
Figure 14.
The FPMF, FSF, FHRF, and FCDF plots for dataset IV.
Figure 14.
The FPMF, FSF, FHRF, and FCDF plots for dataset IV.
Table 1.
Some new sub-models.
Table 1.
Some new sub-models.
| Baseline Model | | Sub Model |
|---|
| LL | | DEG LL |
| W | | DEGW |
| IW | | DEGIW |
| E | | DEGE |
| IE | | DEGIE |
| Lx | | DEGLx |
| R | | DEGR |
| IR | | DEGR |
Table 2.
, , , and of the DEGW distribution.
Table 2.
, , , and of the DEGW distribution.
| | | | |
|---|
| (0.10, 1.0, 1.0) | 0.0191306 | 0.0191314 | 0.019133 | 0.0191363 |
| (0.50, 1.0, 1.0) | 0.3158439 | 0.3397145 | 0.387467 | 0.4830028 |
| (0.99, 1.0, 1.0) | 3.5744810 | 14.246690 | 60.28199 | 266.46120 |
| (0.10, 0.5, 1.5) | 0.2253027 | 0.2268436 | 0.2299255 | 0.2360891 |
| (0.50, 0.5, 1.5) | 0.7535885 | 0.9854351 | 1.4502100 | 2.3830030 |
| (0.99, 0.5, 1.5) | 3.4971860 | 13.014480 | 50.312590 | 200.27770 |
| (0.75, 0.1, 1.0) | 0.9713452 | 0.9736408 | 0.9782321 | 0.9874147 |
| (0.75, 0.5, 1.0) | 0.8297544 | 0.8297544 | 0.8297544 | 0.8297544 |
| (0.75, 1.0, 1.0) | 0.6099862 | 0.6099862 | 0.6099862 | 0.6099862 |
| (0.75, 1.5, 1.0) | 0.3672841 | 0.3672841 | 0.3672841 | 0.3672841 |
| (0.1, 0.1, 1.0) | 2.7581690 | 14.269410 | 94.86910 | 745.4975 |
| (0.1, 0.1, 2.0) | 1.1419800 | 1.9259440 | 3.704110 | 7.893829 |
| (0.1, 0.1, 3.0) | 0.8444187 | 0.9634029 | 1.2013710 | 1.677308 |
| (0.1, 0.1, 4.0) | 0.7850381 | 0.7852609 | 0.7857066 | 0.786598 |
| (0.1, 0.1, 5.0) | 0.7849267 | 0.7849267 | 0.7849267 | 0.7849267 |
Table 3.
Numerical results for , , , and of the DEGW distribution.
Table 3.
Numerical results for , , , and of the DEGW distribution.
| p | γ | θ | E(Z) | V(Z) | S(Z) | K(Z) | Disp-Ix(Z) |
|---|
| 0.99999 | 1 | 1 | 10.43584 | 1.726577 | −1.053185 | 5.105638 | 0.1654468 |
| 0.9999 | | | 8.134137 | 1.719510 | −1.025913 | 4.907183 | 0.2113943 |
| 0.999 | | | 5.837383 | 1.673887 | −0.929210 | 4.331043 | 0.2867530 |
| 0.99 | | | 3.574481 | 1.469777 | −0.645338 | 3.230067 | 0.4111861 |
| 0.75 | | | 0.773245 | 0.510106 | 0.430022 | 2.279438 | 0.6596955 |
| 0.5 | | | 0.315844 | 0.239957 | 1.093988 | 2.899762 | 0.7597332 |
| 0.1 | | | 0.019131 | 0.018765 | 7.021297 | 50.30325 | 0.9809121 |
| 0.99999 | 10 | 5 | 0.802314 | 0.158607 | −1.518194 | 3.304912 | 0.1976864 |
| 0.9999 | | | 0.110509 | 0.098297 | 2.484605 | 7.173261 | 0.8894908 |
| 0.999 | | | 2.6895 × 10⁻¹⁰ | 2.6895 × 10⁻¹⁰ | 60976.45 | ≈∞ | 1 |
| 0.99 | | | 7.2967 × 10⁻⁹⁷ | 7.2967 × 10⁻⁹⁷ | ≈∞ | ≈∞ | 1 |
| 0.5 | 0.001 | 2.5 | 12.741380 | 18.070030 | −0.3936527 | 2.605803 | 1.4182170 |
| | 0.01 | | 4.771435 | 2.934613 | −0.3801066 | 2.62509 | 0.615038 |
| | 0.1 | | 1.5940780 | 0.5300682 | −0.2989435 | 2.847207 | 0.3325235 |
| | 0.25 | | 0.9368591 | 0.2902798 | −0.0505357 | 3.385981 | 0.3098437 |
| | 0.5 | | 0.6378616 | 0.2310265 | −0.5732478 | 1.329823 | 0.3621891 |
| | 0.65 | | 0.5301451 | 0.2490913 | −0.1208001 | 1.014593 | 0.4698549 |
| | 0.75 | | 0.4610516 | 0.2484830 | 0.1562686 | 1.02442 | 0.5389484 |
| | 1.5 | | 0.08951734 | 0.08150398 | 2.875646 | 9.269339 | 0.9104827 |
| | 2.5 | | 0.00043026 | 0.00043009 | 48.17843 | 2322.161 | 0.9995697 |
| | 5 | | 4.21 × 10⁻⁴⁵ | 4.21 × 10⁻⁴⁵ | ≈∞ | ≈∞ | 1 |
| 0.15 | 0.5 | 0.1 | 471.2272 | 47392362 | 51.07037 | 4085.929 | 100572.2 |
| | | 0.5 | 0.5872831 | 1.464822 | 3.011574 | 15.06166 | 2.494234 |
| | | 1 | 0.3318428 | 0.3039623 | 1.477674 | 4.494878 | 0.9159829 |
| | | 5 | 0.2920874 | 0.2067724 | 0.9144595 | 1.836236 | 0.7079126 |
| | | 20 | 0.2920874 | 0.2067724 | 0.9144595 | 1.836236 | 0.7079126 |
| | | 150 | 0.2920874 | 0.2067724 | 0.9144595 | 1.836236 | 0.7079126 |
Table 4.
Results of the MSEs where .
Table 4.
Results of the MSEs where .
| n | | MLE | OLS | WLS | CVM | Bayesian | L-mom | KE | Bootst | AD2LE |
|---|
| 50 | | 0.00111 | 0.00116 | 0.00178 | 0.00126 | 0.00069 * | 0.00140 | 0.00120 | 0.00155 | 0.00178 |
| | | 0.00160 * | 0.02066 | 0.01452 | 0.01760 | 0.00430 | 0.00211 | 0.00885 | 0.00258 | 0.02066 |
| | | 0.00113 | 0.00080 | 0.00112 | 0.00071 | 0.00042 * | 0.00144 | 0.00066 | 0.00130 | 0.00095 |
| 100 | | 0.00058 | 0.00068 | 0.00106 | 0.00072 | 0.00052 * | 0.00082 | 0.00066 | 0.00096 | 0.00094 |
| | | 0.00067 * | 0.00886 | 0.00508 | 0.00816 | 0.00415 | 0.00094 | 0.00456 | 0.00255 | 0.01008 |
| | | 0.00058 | 0.00040 | 0.00063 | 0.00038 | 0.00036 * | 0.00083 | 0.00033 | 0.00076 | 0.00051 |
| 200 | | 0.00026 | 0.00036 | 0.00065 | 0.00037 | 0.00022 * | 0.00037 | 0.00032 | 0.00032 | 0.00050 |
| | | 0.00030 * | 0.00401 | 0.00186 | 0.00385 | 0.00254 | 0.00039 | 0.00221 | 0.00065 | 0.00493 |
| | | 0.00026 | 0.00020 | 0.00037 | 0.00020 | 0.00014 * | 0.00037 | 0.00017 | 0.00028 | 0.00028 |
| 300 | | 0.00019 * | 0.00025 | 0.00043 | 0.00025 | 0.00021 | 0.00024 | 0.00022 | 0.00023 | 0.00033 |
| | | 0.00020 * | 0.00248 | 0.00118 | 0.00243 | 0.00078 | 0.00024 | 0.00154 | 0.00040 | 0.00315 |
| | | 0.00020 | 0.00013 | 0.00025 | 0.00013 | 0.00009 * | 0.00024 | 0.00011 | 0.00017 | 0.00018 |
Table 5.
Results of the MSEs where .
Table 5.
Results of the MSEs where .
| n | | MLE | OLS | WLS | CVM | Bayesian | L-mom | KE | Bootst | AD2LE |
|---|
| 50 | | 0.00336 * | 0.00403 | 0.00400 | 0.00391 | 0.00503 | 0.01825 | 0.00382 | 0.00679 | 0.00396 |
| | | 0.00468 | 0.03063 | 0.03013 | 0.01105 | 0.00613 | 0.01639 | 0.00448 * | 0.00448 * | 0.01126 |
| | | 0.00380 * | 0.01173 | 0.01155 | 0.01050 | 0.02408 | 0.02421 | 0.01026 | 0.01313 | 0.01065 |
| 100 | | 0.00166 * | 0.00194 | 0.00193 | 0.00190 | 0.00198 | 0.01294 | 0.00173 | 0.00204 | 0.00192 |
| | | 0.00178 | 0.00688 | 0.00524 | 0.00530 | 0.00099 * | 0.01224 | 0.00140 | 0.00212 | 0.00548 |
| | | 0.00171 * | 0.00543 | 0.00537 | 0.00513 | 0.00392 | 0.01420 | 0.00438 | 0.00243 | 0.00520 |
| 200 | | 0.00081 * | 0.00101 | 0.00102 | 0.00100 | 0.00162 | 0.00930 | 0.00090 | 0.00135 | 0.00101 |
| | | 0.00083 | 0.00287 | 0.00175 | 0.00248 | 0.00039 * | 0.00919 | 0.00067 | 0.00083 | 0.00259 |
| | | 0.00082 * | 0.00274 | 0.00275 | 0.00268 | 0.00297 | 0.00944 | 0.00221 | 0.00220 | 0.00271 |
| 300 | | 0.00056 * | 0.00066 | 0.00067 | 0.00065 | 0.00068 | 0.00649 | 0.00057 | 0.00134 | 0.00065 |
| | | 0.00057 | 0.00159 | 0.00080 | 0.00143 | 0.00035 * | 0.00649 | 0.00049 | 0.00065 | 0.00151 |
| | | 0.00058 * | 0.00177 | 0.00180 | 0.00173 | 0.00148 | 0.00650 | 0.00137 | 0.00214 | 0.00175 |
Table 6.
Results of the MSEs where .
Table 6.
Results of the MSEs where .
| n | | MLE | OLS | WLS | CVM | Bayesian | L-mom | KE | Bootst | AD2LE |
|---|
| 50 | | 0.00241 * | 0.00333 | 0.00498 | 0.00312 | 0.01159 | 0.00347 | 0.00308 | 0.00320 | 0.00480 |
| | | 0.00242 | 0.00289 | 0.00189 * | 0.00250 | 0.00442 | 0.00339 | 0.00299 | 0.00327 | 0.00499 |
| | | 0.00240 | 0.00119 | 0.00225 | 0.00105 * | 0.00316 | 0.00337 | 0.00106 | 0.00322 | 0.00202 |
| 100 | | 0.00129 | 0.00175 | 0.00314 | 0.00170 | 0.00339 | 0.00181 | 0.00160 | 0.00111 * | 0.00265 |
| | | 0.00130 | 0.00139 | 0.00074 | 0.00130 | 0.00042 * | 0.00180 | 0.00149 | 0.00218 | 0.00248 |
| | | 0.00129 | 0.00059 | 0.00135 | 0.00056 | 0.00038 * | 0.00180 | 0.00053 | 0.00116 | 0.00108 |
| 200 | | 0.00058 * | 0.00084 | 0.00195 | 0.00082 | 0.00063 | 0.00083 | 0.00079 | 0.00067 | 0.00132 |
| | | 0.00059 | 0.00062 | 0.00032 | 0.00059 | 0.00019 * | 0.00082 | 0.00071 | 0.00056 | 0.00111 |
| | | 0.00058 | 0.00027 | 0.00082 | 0.00026 | 0.00014 * | 0.00082 | 0.00026 | 0.00056 | 0.00053 |
| 300 | | 0.00040 | 0.00049 | 0.00131 | 0.00049 | 0.00039 * | 0.00055 | 0.00048 | 0.00043 | 0.00078 |
| | | 0.00040 | 0.00037 | 0.00018 | 0.00036 | 0.00014 * | 0.00055 | 0.00045 | 0.00043 | 0.00065 |
| | | 0.00040 | 0.00016 | 0.00055 | 0.00016 | 0.00009 * | 0.00055 | 0.00015 | 0.00043 | 0.00031 |
Table 7.
Results of the MSEs where .
Table 7.
Results of the MSEs where .
| n | | MLE | OLS | WLS | CVM | Bayesian | L-mom | KE | Bootst | AD2LE |
|---|
| 50 | | 0.00026 | 0.00028 | 0.00060 | 0.00026 | 0.00022 * | 0.00023 | 0.00030 | 0.00268 | 0.00046 |
| | | 0.00041 | 0.00625 | 0.00578 | 0.00547 | 0.00271 | 0.00030 * | 0.00428 | 0.01436 | 0.00725 |
| | | 0.00034 | 0.00342 | 0.01019 | 0.00318 | 0.00252 | 0.00026 * | 0.00463 | 0.01624 | 0.00783 |
| 100 | | 0.00012 * | 0.00015 | 0.00035 | 0.00014 | 0.00012 * | 0.00012 * | 0.00016 | 0.00021 | 0.00023 |
| | | 0.00012 * | 0.00337 | 0.00270 | 0.00308 | 0.00269 | 0.00014 | 0.00264 | 0.00053 | 0.00435 |
| | | 0.00012 * | 0.00189 | 0.00653 | 0.00181 | 0.00161 | 0.00013 | 0.00246 | 0.00097 | 0.00375 |
| 200 | | 0.00006 * | 0.00007 | 0.00020 | 0.00007 | 0.00010 | 0.00006 * | 0.00007 | 0.00006 | 0.00011 |
| | | 0.00006 * | 0.00155 | 0.00107 | 0.00147 | 0.00105 | 0.00006 * | 0.00132 | 0.00019 | 0.00222 |
| | | 0.00006 * | 0.00091 | 0.00412 | 0.00090 | 0.00096 | 0.00006 * | 0.00114 | 0.00018 | 0.00171 |
| 300 | | 0.00004 * | 0.00004 * | 0.00014 | 0.00004 * | 0.00009 | 0.00004 * | 0.00005 | 0.00006 | 0.00007 |
| | | 0.00004 * | 0.00084 | 0.00059 | 0.00082 | 0.00103 | 0.00004 * | 0.00084 | 0.00007 | 0.00138 |
| | | 0.00004 * | 0.00055 | 0.00325 | 0.00055 | 0.00093 | 0.00004 * | 0.00072 | 0.00012 | 0.00110 |
Table 8.
Comparing methods using dataset I.
Table 8.
Comparing methods using dataset I.
| Method | p | γ | θ | K.S | P.V |
|---|
| MLE | 0.8450441207 | 0.1248812582 | 0.6840750167 | 0.163038 | 0.15266 |
| OLS | 0.9115300723 | 0.4505403055 | 0.4249120961 | 0.16907 | 0.11468 |
| WLS | 0.9273026987 | 0.4467200744 | 0.4572149891 | 0.20003 | 0.03659 |
| CVM | 0.9183256058 | 0.4514888661 | 0.4288501393 | 0.17538 | 0.09231 |
| * Bayesian | 0.8344024241 | 0.0987677765 | 0.7294684266 | 0.14712 | 0.22927 |
| L-mom | 0.8883682738 | 0.1303778446 | 0.7019449219 | 0.16801 | 0.11884 |
| KE | 0.0173097899 | 0.1619946274 | 0.0000203909 | 0.51000 | <0.0001 |
| Bootst | 0.8465409851 | 0.1275235069 | 0.6948444678 | 0.21355 | 0.02092 |
| AD2LE | 0.6215684527 | 0.1341556153 | 0.5297912271 | 0.22093 | 0.01518 |
Table 9.
Comparing methods using dataset II.
Table 9.
Comparing methods using dataset II.
| Method | p | γ | θ | K.S | P.V |
|---|
| MLE | 0.2738836678 | 0.012957314 | 1.0860441145 | 0.11998 | 0.98219 |
| OLS | 0.1985257104 | 0.0168180005 | 0.9854823405 | 0.11603 | 0.98761 |
| WLS | 0.2398746891 | 0.0180291436 | 0.9944931716 | 0.11229 | 0.99153 |
| CVM | 0.1327154712 | 0.0103680076 | 1.0482619245 | 0.10679 | 0.99553 |
| Bayesian | 0.3038462428 | 0.0199252587 | 0.9928028081 | 0.09937 | 0.99843 |
| L-mom | 0.5901252129 | 0.0522561583 | 0.8582513340 | 0.12438 | 0.97446 |
| KE | 0.0000033106 | 0.0586353219 | 0.0001265448 | 0.53331 | 0.00039 |
| Bootst | 0.2244536022 | 0.0101742641 | 1.3246956780 | 0.31898 | 0.09447 |
| * AD2LE | 0.0070230912 | 0.0024977558 | 1.2480067543 | 0.09885 | 0.99855 |
Table 10.
Comparing methods using dataset III.
Table 10.
Comparing methods using dataset III.
| Method | p | γ | θ | K.S | P.V |
|---|
| MLE | 0.4459431905 | 0.7342772117 | 0.3800575939 | 0.35698 | 0.83653 |
| OLS | 0.3572219176 | 0.623814996 | 0.3861454942 | 0.33875 | 0.84419 |
| WLS | 0.3351236932 | 0.5963314357 | 0.3977530334 | 0.38168 | 0.82627 |
| CVM | 0.3559783727 | 0.616701488 | 0.3850433614 | 0.28412 | 0.86757 |
| Bayesian | 0.4334316130 | 0.6761278712 | 0.4033948113 | 0.61746 | 0.73438 |
| L-mom | 0.6508195705 | 1.0129827319 | 0.3676423109 | 1.69547 | 0.42838 |
| KE | 0.09858974996 | 0.5052793233 | 0.0933711548 | 134.915 | <0.0001 |
| Bootst | 0.4502907161 | 0.7658835657 | 0.3892316532 | 1.15192 | 0.56216 |
| * AD2LE | 0.3560565879 | 0.6169232134 | 0.383446173 | 0.28323 | 0.86796 |
Table 11.
Comparing methods for dataset IV.
Table 11.
Comparing methods for dataset IV.
| Method | p | γ | θ | K.S | P.V |
|---|
| MLE | 0.0421915321 | 0.1441660755 | 0.8986850359 | 2.07337 | 0.35463 |
| OLS | 0.207451888 | 0.2600860974 | 0.9026929140 | 2.06132 | 0.35677 |
| WLS | 0.0328021927 | 0.1224019888 | 1.0741417897 | 2.57368 | 0.27614 |
| CVM | 0.2560193547 | 0.2955407600 | 0.8642332727 | 2.00076 | 0.36774 |
| Bayesian | 0.0388192223 | 0.1299953255 | 0.9335014673 | 2.21687 | 0.33007 |
| * L-mom | 0.0000162586 | 0.0427720724 | 1.0054904684 | 1.34090 | 0.51148 |
| KE | 0.0268390486 | 0.2732464266 | 7.22789×10⁻⁶ | 8.69×10⁶ | <0.0001 |
| Bootst | 0.0305812278 | 0.0787811852 | 1.0371758772 | 117.888 | <0.0001 |
| AD2LE | 0.4094146417 | 0.4016848541 | 0.8725794897 | 4.33318 | 0.11457 |
Table 12.
The competitive models.
Table 12.
The competitive models.
| Discrete Model | Abbreviations |
|---|
| Exponential | DE |
| Inverse Rayleigh | DIR |
| Weibull | DW |
| Lindley-II | DLy-II |
| Rayleigh | DR |
| Inverse Weibull | DIW |
| Generalized exponential-II | DGE-II |
| Burr type XII | DBXII |
| Lindley | DLi |
| Log-logistic | DLL |
| Lomax | DLx |
| Poisson | Poisson |
| Exponentiated Lindley | EDLy |
| Pareto | DPa |
| Exponentiated Weibull | EDW |
| Negative binomial (see Dougherty [27]) | NB |
Table 13.
The MLEs (and their corresponding St.Ers) for dataset I.
Table 13.
The MLEs (and their corresponding St.Ers) for dataset I.
| Model | p | γ | θ |
|---|
| DEGW | 0.84504 | 0.12488 | 0.68408 |
| | (0.1316) | (0.1337) | (0.1787) |
| EDW | 0.98914 | 1.13934 | 0.78444 |
| | (0.1644) | (3.2274) | (3.0535) |
| DW | 0.98126 | 1.02342 | |
| | (0.0114) | (0.1322) | |
| DIW | 0.01832 | 0.58244 | |
| | (0.0131) | (0.063) | |
| DLy-II | 0.96934 | 0.0585 | |
| | (0.00504) | (0.0274) | |
| EDLy | 0.97222 | 0.48020 | |
| | (0.0053) | (0.0873) | |
| DLLc | 1.00010 | 0.43941 | |
| | (0.3213) | (0.0623) | |
| DPa | 0.73922 | | |
| | (0.03212) | | |
Table 14.
The goodness-of-fit test statistics for comparing the competitive models for dataset I.
Table 14.
The goodness-of-fit test statistics for comparing the competitive models for dataset I.
| | DEGW | EDW | DW | DIW | DLy-II | EDLy | DLLc | DPa |
|---|
| −l | 233.47 | 240.24 | 241.65 | 261.94 | 240.67 | 240.38 | 294.99 | 275.99 |
| AICR | 472.93 | 486.76 | 487.25 | 527.89 | 485.23 | 484.69 | 593.84 | 553.74 |
| CAICR | 473.46 | 487.29 | 487.59 | 528.18 | 485.44 | 484.88 | 594.0 | 553.84 |
| K–S | 0.1630 | 0.1957 | 0.1872 | 0.2587 | 0.1868 | 0.1954 | 0.5354 | 0.3354 |
| P.V | 0.1527 | 0.0457 | 0.0619 | 0.0036 | 0.06499 | 0.045 | <0.001 | <0.0013 |
Table 15.
The MLEs (and their corresponding St.Ers) for dataset II.
Table 15.
The MLEs (and their corresponding St.Ers) for dataset II.
| Model | p | γ | θ |
|---|
| DEGW | 0.27388 | 0.01296 | 1.08604 |
| | (0.83537) | (0.0426) | (0.48154) |
| DGE-II | 0.9561 | 1.4912 | |
| | (0.0133) | (0.535) | |
| DIW | 2.3 × 10⁻⁴ | 0.8752 | |
| | (7.8 × 10⁻⁴) | (0.164) | |
| DLx | 0.0123 | 104.506 | |
| | (0.039) | (84.409) | |
| DBXII | 0.9753 | 13.367 | |
| | (0.051) | (27.785) | |
| DR | 0.9992 | | |
| | (2.58 × 10⁻⁴) | | |
| DIR | 1.832 × 10⁻⁷ | | |
| | (0.055) | | |
| DPa | 0.7201 | | |
| | (0.061) | | |
Table 16.
The goodness-of-fit test statistics for comparing the competitive models for dataset II.
Table 16.
The goodness-of-fit test statistics for comparing the competitive models for dataset II.
| | DEGW | DE | DGE-II | DR | DIR | DIW | DLo | DB-XII |
|---|
| −l | 63.7911 | 65.002 | 64.423 | 66.390 | 89.0964 | 68.703 | 65.864 | 75.724 |
| AICR | 133.581 | 134.02 | 134.88 | 134.83 | 180.191 | 141.413 | 135.728 | 155.45 |
| CAICR | 135.763 | 136.34 | 135.81 | 136.11 | 180.501 | 142.412 | 136.728 | 156.45 |
| K–S | 0.11998 | 0.1777 | 0.1291 | 0.2161 | 0.6982 | 0.20923 | 0.20524 | 0.3889 |
| P.V | 0.98219 | 0.6734 | 0.9373 | 0.4333 | <0.0001 | 0.4821 | 0.4912 | 0.0159 |
Table 17.
The MLEs (and their corresponding St.Ers) for dataset III.
Table 17.
The MLEs (and their corresponding St.Ers) for dataset III.
| Model | p | γ | θ |
|---|
| DEGW | 0.44594 | 0.73428 | 0.38006 |
| | (0.9079) | (1.3168) | (0.2637) |
| DW | 0.7503 | 0.43143 | |
| | (0.084) | (0.3402) | |
| DIW | 0.5813 | 1.0492 | |
| | (0.0483) | (0.1463) | |
| DLy-II | 0.5814 | 0.0011 | |
| | (0.0455) | (0.058) | |
| DLx | 0.1505 | 1.8303 | |
| | (0.0980) | (0.9513) | |
| DR | 0.90133 | | |
| | (0.0093) | | |
| DE | 0.5814 | | |
| | (0.0304) | | |
| DLi | 0.4363 | | |
| | (0.0263) | | |
| Poi | 1.3903 | | |
| | (0.1124) | | |
Table 18.
The goodness-of-fit test statistics for comparing the competitive models for dataset III.
Table 18.
The goodness-of-fit test statistics for comparing the competitive models for dataset III.
| Z | OF | DEGW | DW | DIW | DR | DEx | DLi | DLy-II | DLx | Poi |
|---|
| 0 | 65 | 64.163 | 59.01 | 63.91 | 11.00 | 46.09 | 40.25 | 46.03 | 61.89 | 27.42 |
| 1 | 14 | 15.626 | 19.84 | 20.70 | 26.83 | 26.78 | 29.83 | 26.77 | 21.01 | 38.08 |
| 2 | 10 | 9.184 | 10.78 | 8.050 | 29.55 | 15.56 | 18.36 | 15.57 | 9.650 | 26.47 |
| 3 | 6 | 6.038 | 6.260 | 4.230 | 22.23 | 9.040 | 10.35 | 9.050 | 5.240 | 12.26 |
| 4 | 4 | 4.169 | 4.190 | 2.60 | 12.49 | 5.250 | 5.530 | 5.270 | 3.170 | 4.260 |
| 5 | 2 | 2.955 | 2.010 | 1.750 | 5.420 | 3.050 | 2.860 | 3.060 | 2.060 | 1.180 |
| 6 | 2 | 2.127 | 1.990 | 1.260 | 1.850 | 1.770 | 1.440 | 1.780 | 1.420 | 0.270 |
| 7 | 2 | 1.545 | 1.320 | 0.950 | 0.520 | 1.030 | 0.710 | 1.040 | 1.020 | 0.050 |
| 8 | 1 | 1.128 | 0.990 | 0.740 | 0.110 | 0.600 | 0.350 | 0.600 | 0.760 | 0.010 |
| 9 | 1 | 0.827 | 0.860 | 0.590 | 0.020 | 0.350 | 0.170 | 0.350 | 0.580 | 0.000 |
| 10 | 1 | 0.606 | 0.760 | 0.480 | 0.000 | 0.200 | 0.080 | 0.200 | 0.460 | 0.000 |
| 11 | 2 | 0.445 | 1.990 | 4.740 | 0.000 | 0.280 | 0.070 | 0.280 | 2.740 | 0.000 |
| −l | | 167.047 | 170.14 | 172.93 | 277.78 | 178.77 | 189.1 | 178.8 | 170.48 | 246.21 |
| AICR | | 340.094 | 344.28 | 349.87 | 557.56 | 359.53 | 380.2 | 361.5 | 344.96 | 494.42 |
| CAICR | | 340.321 | 344.39 | 349.98 | 557.59 | 359.57 | 380.3 | 361.6 | 345.07 | 494.46 |
| | 0.35698 | 3.125 | 6.463 | 321.07 | 22.88 | 43.48 | 22.89 | 3.316 | 294.10 |
| d.f | | 2 | 3 | 3 | 4 | 4 | 4 | 3 | 3 | 4 |
| P.V | | 0.83653 | 0.373 | 0.091 | <0.0001 | 0.0001 | <0.0001 | <0.0001 | 0.345 | <0.0001 |
Table 19.
The MLEs (and their corresponding St.Ers) for dataset IV.
Table 19.
The MLEs (and their corresponding St.Ers) for dataset IV.
| Model | p | γ | θ | λ |
|---|
| DEGW | 0.04222 | 0.14417 | 0.89869 | |
| | (0.12268) | (0.13283) | (0.1634) | |
| DGW | 0.04503 | 2.539324 | 2.1593 | 0.47933 |
| | (0.4293) | (4.70345) | (2.6988) | (0.4655) |
| DIW | 0.34523 | 1.54132 | | |
| | (0.0433) | (0.1564) | | |
| DBXII | 0.51933 | 2.35811 | | |
| | (0.0513) | (0.3663) | | |
| NB | 0.87013 | 9.95623 | | |
| | (0.0364) | (0.09623) | | |
| DIR | 0.31923 | | | |
| | (0.0422) | | | |
| DR | 0.86721 | | | |
| | (0.01244) | | | |
| DPa | 0.3299 | | | |
| | (0.0344) | | | |
| Poi | 1.48344 | | | |
| | (0.0254) | | | |
Table 20.
The goodness-of-fit test statistics for comparing the competitive models for dataset IV.
Table 20.
The goodness-of-fit test statistics for comparing the competitive models for dataset IV.
| Z | OF | DEGW | DIW | DBXII | DIR | DR | NB | DPa | Poi | DEGW |
|---|
| 0 | 43 | 46.551 | 41.37 | 43.84 | 38.28 | 15.92 | 30.12 | 64.45 | 27.23 | 46.551 |
| 1 | 35 | 28.238 | 41.85 | 39.61 | 51.90 | 36.17 | 38.87 | 20.15 | 40.38 | 28.238 |
| 2 | 17 | 18.318 | 15.42 | 15.62 | 15.51 | 34.58 | 27.61 | 9.690 | 29.95 | 18.318 |
| 3 | 11 | 11.588 | 7.170 | 7.200 | 6.040 | 21.03 | 14.26 | 5.650 | 14.81 | 11.588 |
| 4 | 5 | 7.030 | 3.940 | 3.910 | 2.910 | 8.890 | 5.990 | 3.680 | 5.490 | 7.030 |
| 5 | 4 | 4.052 | 2.420 | 2.370 | 1.610 | 2.700 | 2.170 | 2.580 | 1.630 | 4.052 |
| 6 | 1 | 2.202 | 1.610 | 1.560 | 0.980 | 0.600 | 0.700 | 1.900 | 0.400 | 2.202 |
| 7 | 2 | 1.120 | 1.130 | 1.090 | 0.640 | 0.090 | 0.210 | 1.460 | 0.090 | 1.120 |
| 8 | 2 | 0.530 | 5.090 | 4.800 | 2.140 | 0.020 | 0.060 | 10.44 | 0.020 | 0.530 |
| −l | | 200.956 | 204.810 | 204.293 | 208.440 | 235.23 | 211.52 | 220.63 | 219.19 | 200.956 |
| AICR | | 407.912 | 413.621 | 412.587 | 418.881 | 472.45 | 427.05 | 443.24 | 440.38 | 407.912 |
| CAICR | | 408.119 | 413.723 | 412.689 | 418.915 | 472.49 | 427.14 | 443.27 | 440.41 | 408.119 |
| | 2.07337 | 5.511 | 4.664 | 14.274 | 70.688 | 20.367 | 32.462 | 38.478 | 2.07337 |
| d.f | | 2 | 3 | 3 | 4 | 4 | 3 | 4 | 4 | 2 |
| P.V | | 340.321 | 344.39 | 349.98 | 557.59 | 359.57 | 380.3 | 361.6 | 345.07 | 494.46 |


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}