1. Introduction
Most traditional algorithms are built on closed-world assumptions and use fixed training and test sets, which makes it difficult to cope with changeable scenarios, including the streaming data issue. However, most data in practical applications are provided as data streams. One of their common characteristics is that the data will continue to grow over time, and the uncertainty introduced by the new data will influence the original model. As a result, learning from streaming data has become more essential [
1,
2,
3] in machine learning and data mining communities. In this article, we employ the online gradient descent (OGD) framework proposed by Zinkevich [
4]. It is a real-time, streaming online technique that updates the model on top of the trained model once per piece of data, making the model time-sensitive. In this article, we will provide a novel noise-resistant variable selection approach for handling noisy data streams with multicollinearity.
Since the 1960s, the variable selection issue has been much research literature. Since Hirotugu Akaike [
5] introduced the AIC criterion, variable selection techniques have advanced, including more classic methods such as subset selection and coefficient shrinkage [
6]. Variable selection methods based on penalty functions were developed to optimize computational efficiency and accuracy. Using a multivariate linear model as an illustration, e.g.,
where the parameter vector is
, the parameters are estimated by methods such as OLS and Maximum Likelihood. The penalty function that balances the complexity of the model is added to this to construct a new penalty objective function. This penalty objective function is then optimized (maximized or minimized) to obtain parameter estimates. Its general framework is:
where
is loss function and
is a penalty function. This strategy enables the S/E (selection/Estimation) phase of the subset selection method to be done concurrently by compressing part of the coefficients to zero, significantly lowering computing time and minimizing the chance of the subset selection method becoming unstable. The most often employed of these are bridge regression [
7], ridge regression [
8], and lasso [
9], with bridge regression having the following penalty function:
where
is an adjustment parameter, since the ridge regression model introduces the
-norm, it has a more stable regression effect and outperforms OLS in prediction. While the lasso method is an ordered, continuous process, it offers the advantages of low computing effort, quick calculation, parameter estimation continuity, and adaptability to high-dimensional data. However, lasso has several inherent disadvantages, one being the absence of the Oracle characteristic [
10]. The adaptive lasso approach was proposed by Zou [
11]. Similar to ADS (adaptive Dantzig selector) [
12] for DS (Datnzig selector) [
13] the adaptive lasso is an improvement on the lasso method with the same level of coefficient compression. The adaptive lasso has Oracle properties [
11]. According to Zou [
11], the greater the least squares estimate of a variable, the more probable it is to be a variable in the genuine model. Hence, the penalty for it should be reduced. The adaptive lasso method’s penalty function is specified as:
where
and
are adjustment parameters.
With several sets of explanatory variables known to be strongly correlated, the lasso method is powerless if the researcher wants to keep or remove a certain group of variables. Therefore, Yuan and Lin [
14] proposed the group lasso method in 2006. The basic idea is to assume that there are
J groups of strongly correlated variables, namely
, and the number of variables in each group is
, and
as the corresponding element of the sub-variables. The penalty function for the group Lasso method:
where
is the elliptic norm determined by the positive definite matrix
.
Chesneau and Hebiri [
15] proposed the grouped variables lasso method and investigated its theory in 2008. They proved this bound is better in some situations than the one achieved by the lasso and the Dantzig selector. The group variable lasso exploits the sparsity of the model more effectively. Percival [
16] developed the overlapping groups lasso approach, demonstrating that permitting overlap does not remove many of the theoretical features and benefits of lasso and group lasso. This method can encode various structures as collections of groups, extending the group lasso method. Li, Nan, and Zhu [
17] proposed the MSGLasso (Multivariate Sparse Group Lasso) method. The method can effectively remove unimportant groups and unimportant individual coefficients within important groups, especially for the
problem. It can flexibly handle a variety of complex group structures, such as overlapping, nested, or multi-level hierarchies.
The prediction accuracy of the lasso drastically reduces when confronted with multi-collinear data. A novel regularisation approach dubbed elastic net [
18] has been presented to address these issues. Elastic net estimation may be conceived as a combination of lasso [
9] and ridge regression [
8] estimation. Compared to lasso, the elastic net approach performs better with data of the kind
with several co-linearities between variables. However, a basic elastic net is incapable of handling noisy data. To address the difficulties above, we propose canal-adaptive elastic net method in this article. This technique offers four significant advantages:
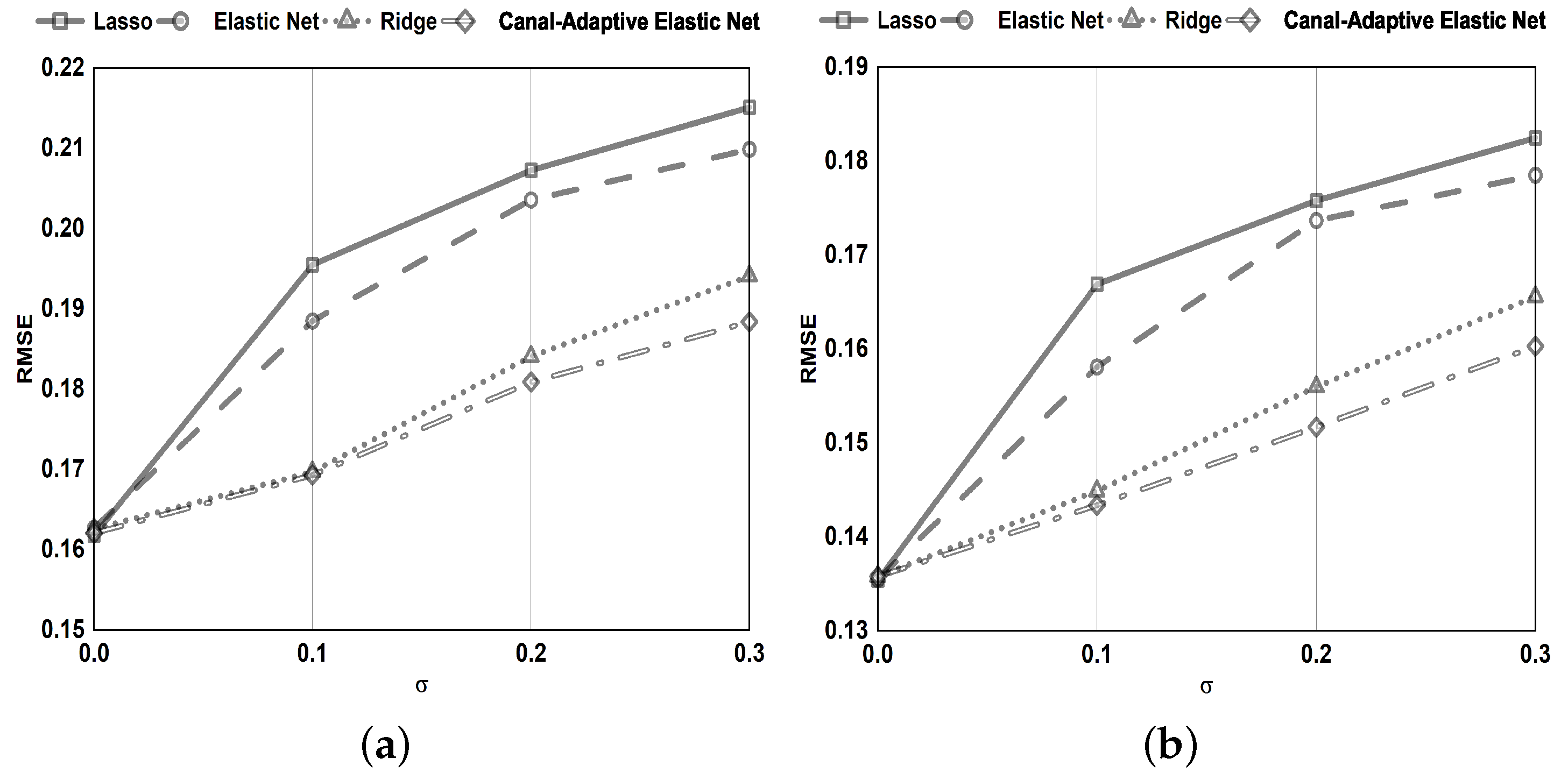
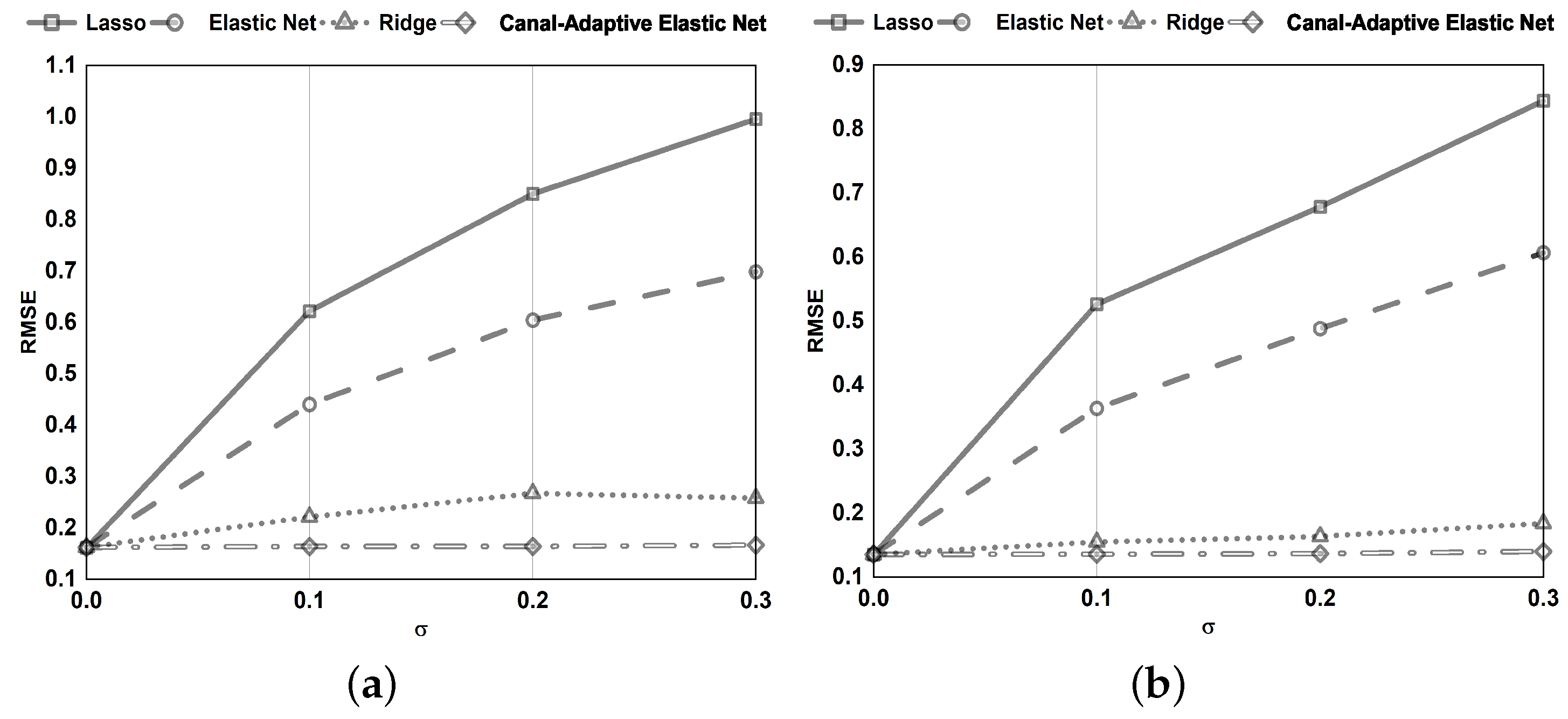
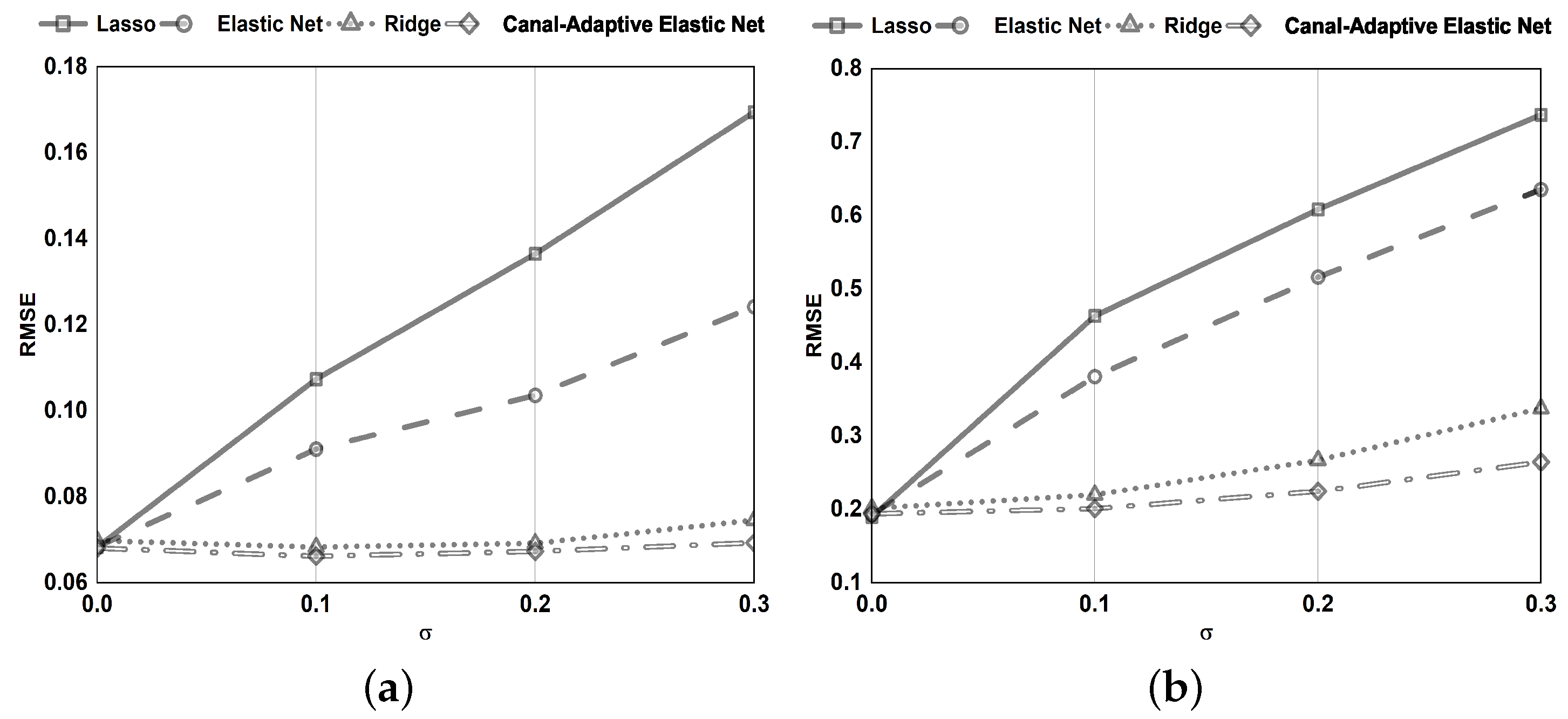
This model is efficient at handling streaming data. The suggested canal-adaptive elastic net dynamically updates the regression coefficients for regularised linear models in real-time. Each time a batch of data is fetched, the OGD framework enables updating the original model. Can handle stream data more effectively.
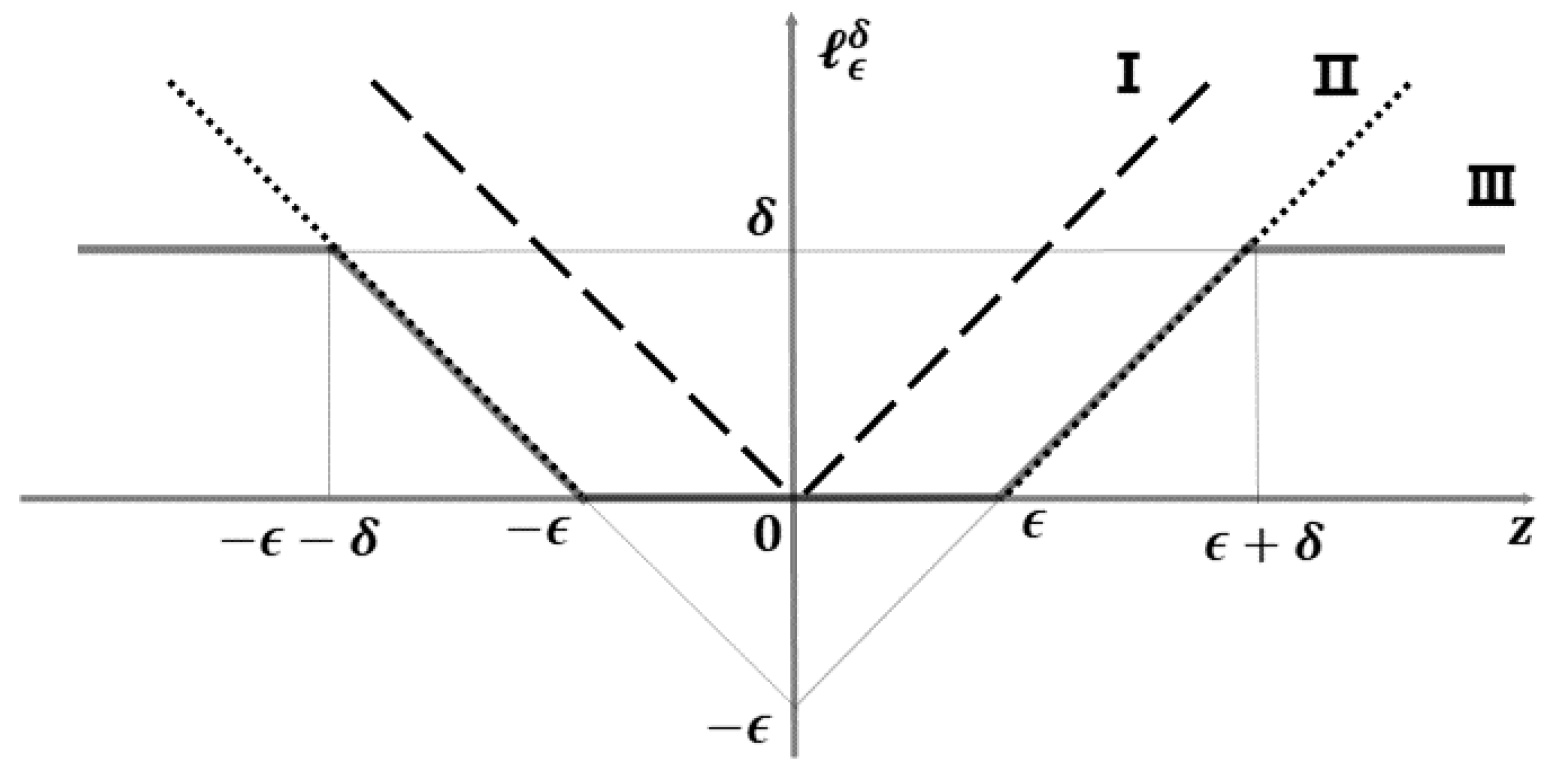
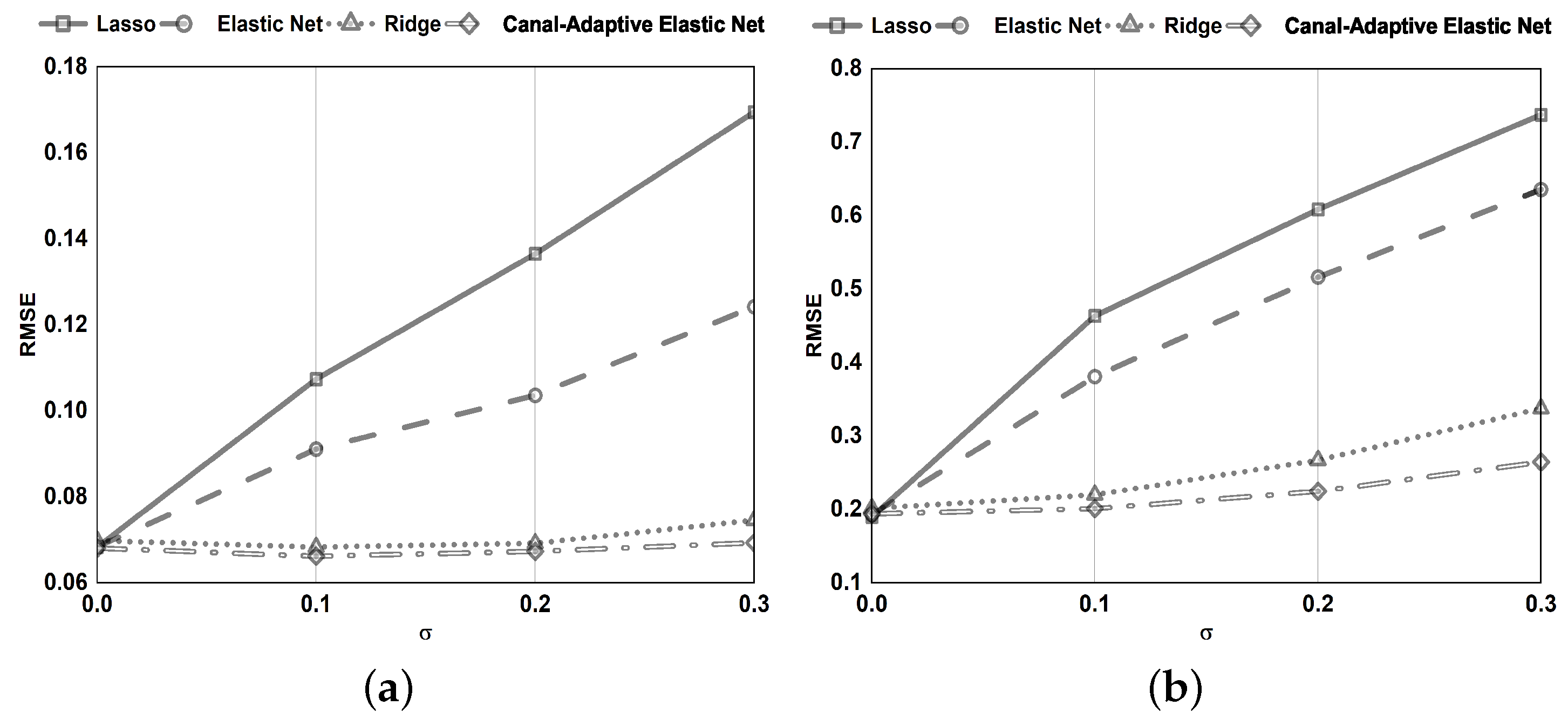
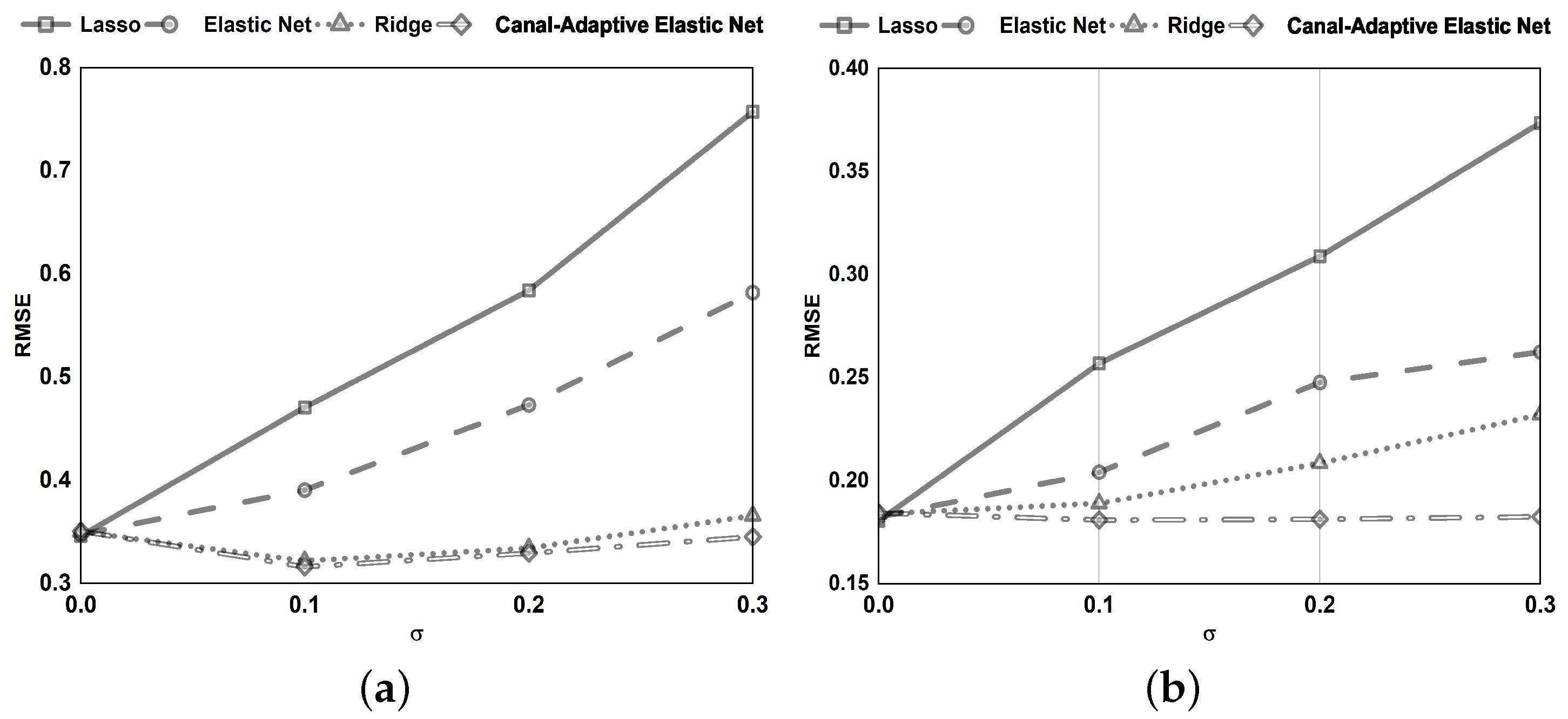
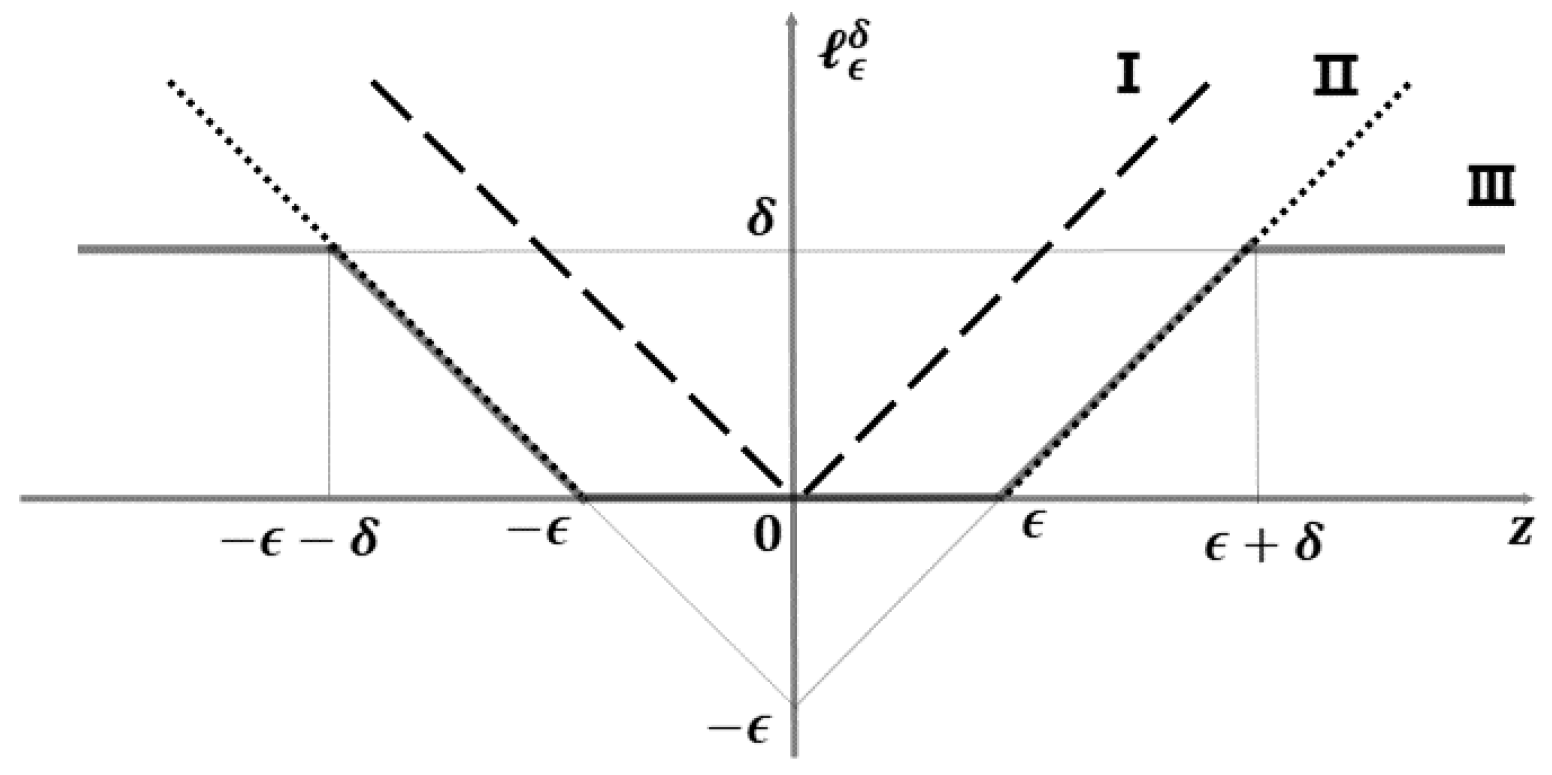
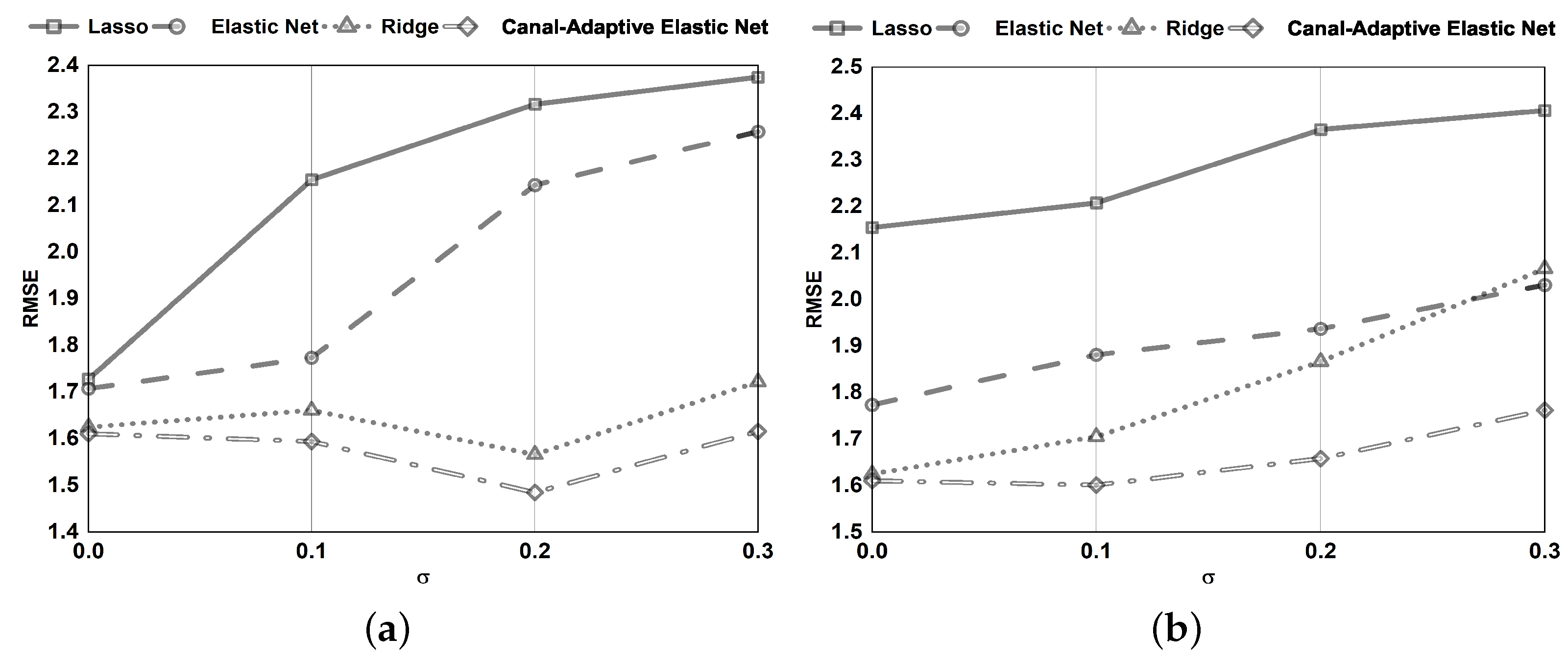
The model has a sparse representation. As illustrated in
Figure 1, only a tiny subsection of samples with residuals in the ranges
and
are used to adjust the regression parameters. As a result, the model has perfect scalability and decreases computing costs.
The improved loss function confers on the model a significant level of noise resistance. By dynamically modifying the parameter, noisy data with absolute errors (bigger than the threshold parameter ) are recognized and excluded from being employed to alter the regression coefficients.
The -norm and -norm are employed. Can handle the scenario of in the data more effectively. Simultaneous automatic variable selection and continuous shrinkage and can select groups of related variables. Overcoming the effects of data multicollinearity.
The rest of this paper is structured in the following manner.
Section 2 reviews some studies on variable selection, noise-tolerant loss functions, data multicollinearity, and streaming data.
Section 3 summarizes previous work on the penalty aim function and then introduces the linear regression noise-resistant online learning technique. In
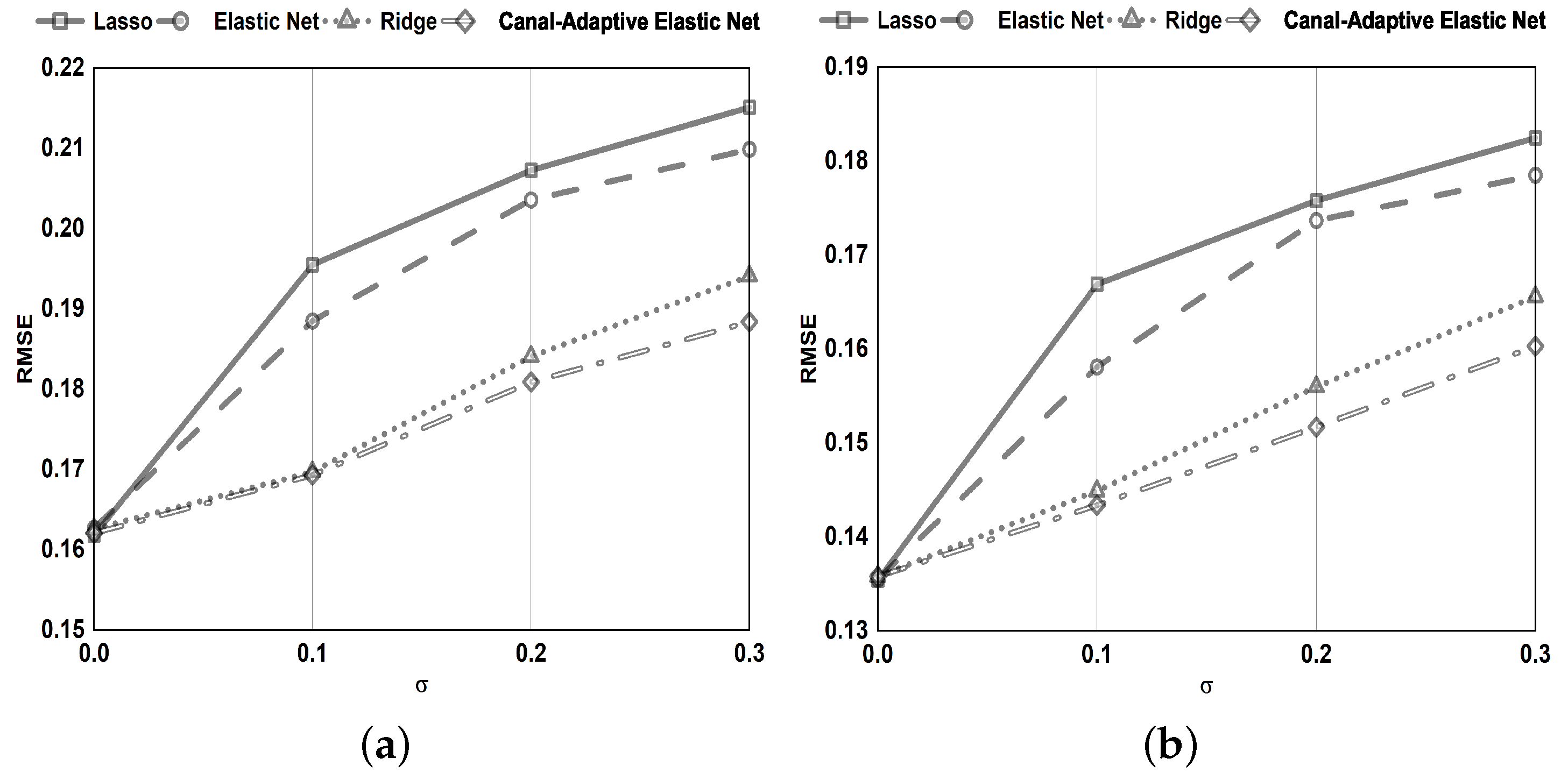
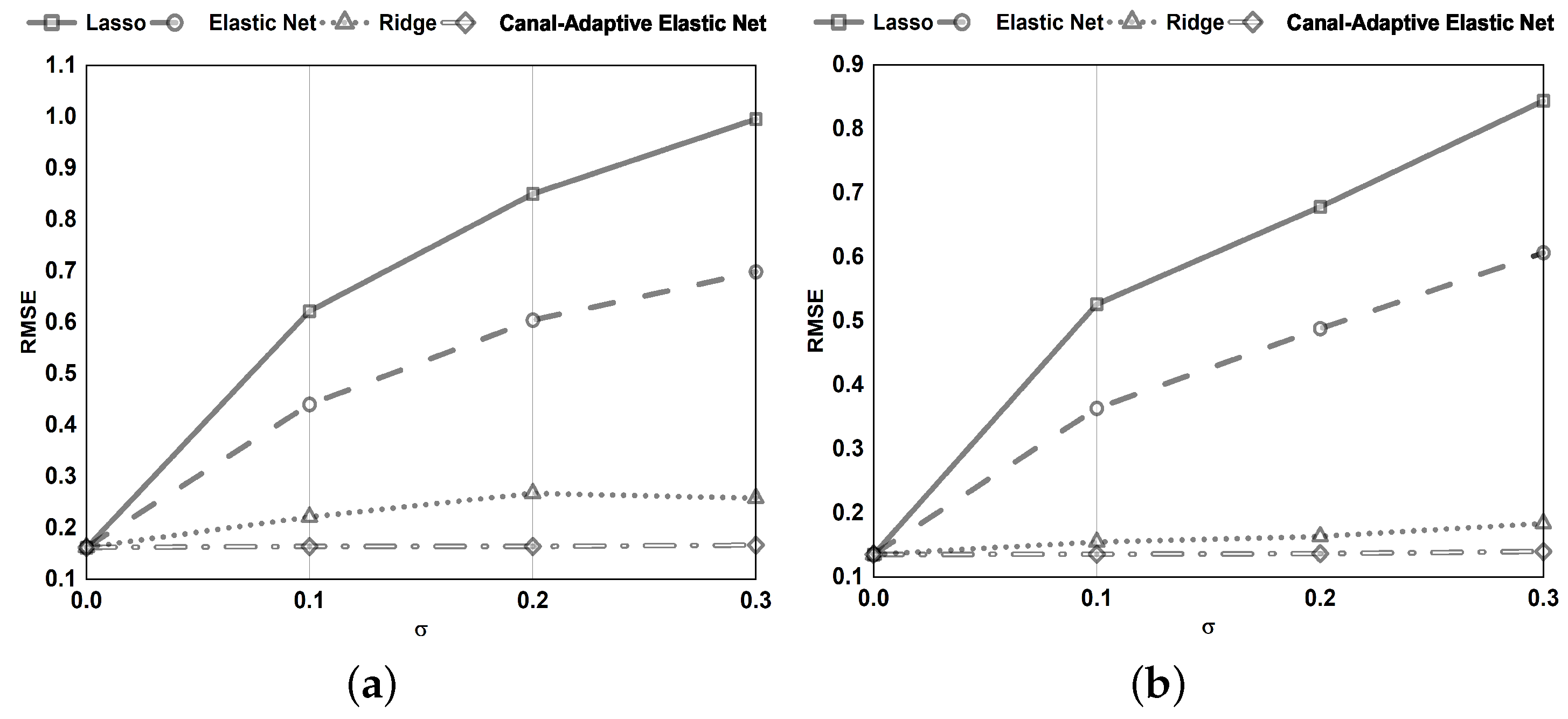
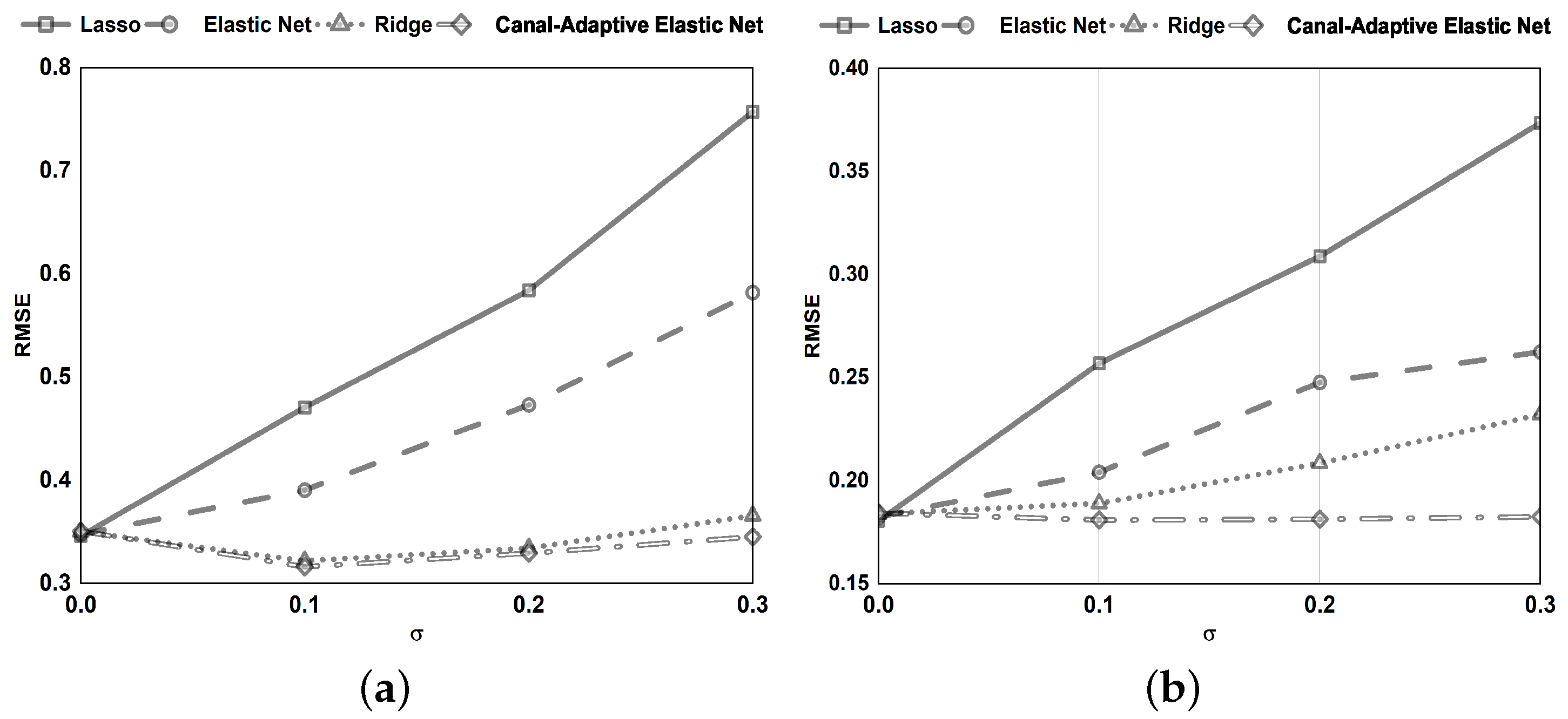
Section 4, we conduct numerical simulations and tests on benchmark datasets to compare the canal-adaptive elastic net presented in this research to lasso, ridge regression, and elastic net. Finally,
Section 5 presents a concise discussion to conclude the paper.
2. Related Works
Variable selection has always been an important issue in building regression models. It has been one of the hot topics in statistical research since it was proposed in the 1960s, generating much literature on variable selection methods. For example, the Japanese scholar Akaike [
5] proposed the AIC criterion based on the maximum likelihood method, which can be used both for the selection of independent variables and for setting the order of autoregressive models in time series analysis. Schwarz [
19] proposed the BIC criterion based on the Bayes method. Compared to AIC, BIC strengthens the penalty and thus is more cautious in selecting variables into the model. All the above methods achieve variable selection through a two-step S/E (Selection/Estimation) process, i.e., first selecting a subset of variables in an existing sample according to a criterion. A subset of variables is selected from the existing sample according to a criterion (Selection). Then the unknown coefficients are estimated from the sample (Estimation). Because the correct variable is unknown in advance, the S-step is biased, which increases the risk of the E-step. To overcome this drawback, Seymour Geisser [
20] proposed Cross-validation. Later on, variable selection methods based on penalty functions emerged. Tibshirani [
9] proposed LASSO (Least Absolute Shrinkage and Selection Operator) inspired by the NG (Nonnegative Garrote) method. The lasso method avoids the drawback of over-reliance on the original least squares estimation of the NG method. As Fan and Li [
21] pointed out that lasso does not possess the Oracle property, they thus proposed a new variable selection method, the SCAD (Smoothly Clipped Absolute Deviation) method, and proved that it has the Oracle property. Zou [
11] proposed the adaptive lasso method based on the lasso. The variable selection methods with structured penalties (e.g., features are dependent and/or there are group structures between features) have become more popular because of the ever-increasing need to handle complex data, such as elastic net and group lasso [
14].
While investigating noise-resistant loss functions, we generated interest in the truncated loss function. The losses generate learning models that are robust to substantial quantities of noise. Xu et al. [
22] demonstrated that truncation could tolerate much higher noise for enjoying consistency than without truncation. The robust variable selection is a novel concept that incorporates robust losses from the robust statistics area into the model. Formed models that perform well empirically in noisy situations [
23,
24,
25].
The concept of multicollinearity refers to the linear relationships between the independent variables in multiple regression analysis. Multicollinearity occurs when the regression model incorporates variables that are highly connected not only with the dependent variable but also to each other [
26]. Some research has explored and discussed the challenges associated with multicollinearity in regression models, emphasizing that the primary issue of multicollinearity is uneven and biased standard errors and unworkable interpretations for the results [
27,
28]. There are many strategies for handling multicollinearity, one of which is ridge regression [
29,
30].
Many studies have been conducted over the last few decades on inductive learning approaches such as lasso [
9], artificial neural networks [
31,
32]. Support vector regression [
33], among others. These methods have been applied successfully to a variety of real-world problems. However, their usual implementation causes the simultaneous availability of all training data [
34], making them unsuitable for large-scale data mining applications and streaming data mining tasks [
35,
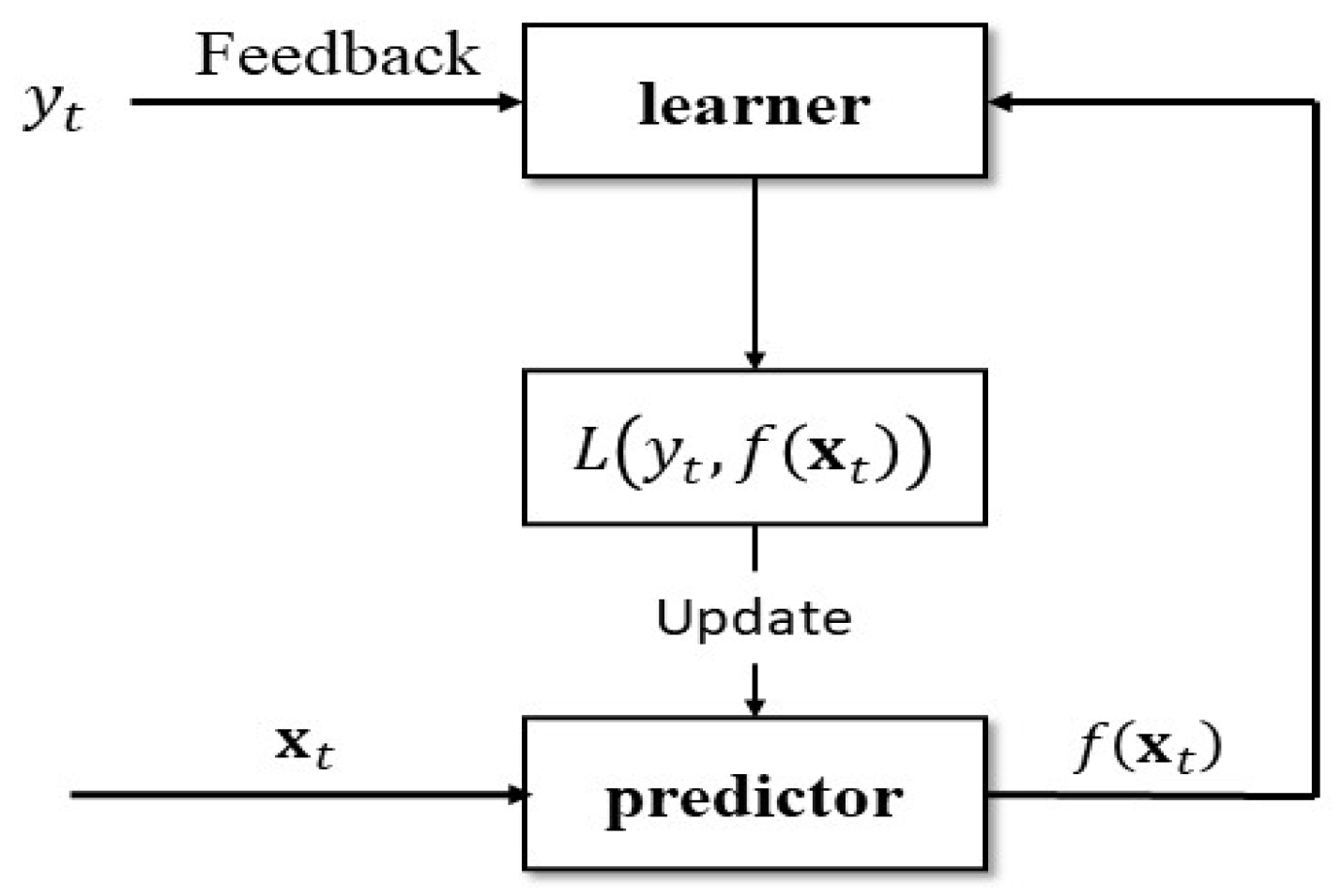
36]. Compared to the traditional batch learning framework, the online learning algorithm (shown in
Figure 2) is another framework for learning samples in a streaming fashion, which has the advantage of scalability and real-time. In recent years, great attention has been paid to developing online learning methods in the machine learning community, such as online ridge regression [
37,
38], adaptive regularization for lasso [
39], projection [
40] and bounded online gradient descent algorithm [
41].






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}