
A Mathematical Perspective on Post-Quantum Cryptography


Abstract
:1. Introduction
2. Lattice-Based Cryptography
2.1. Lattice Fundamentals
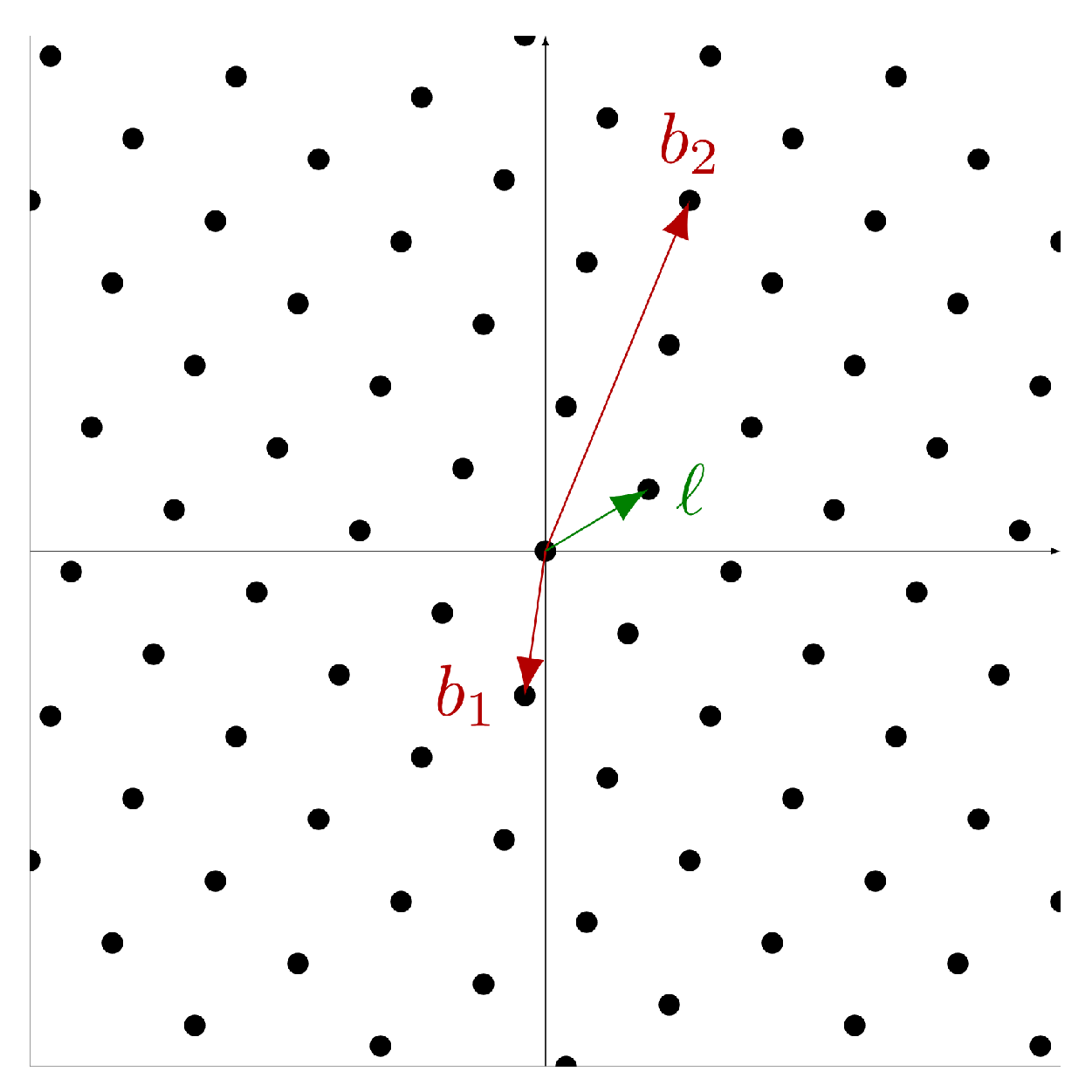
2.1.1. Lattices
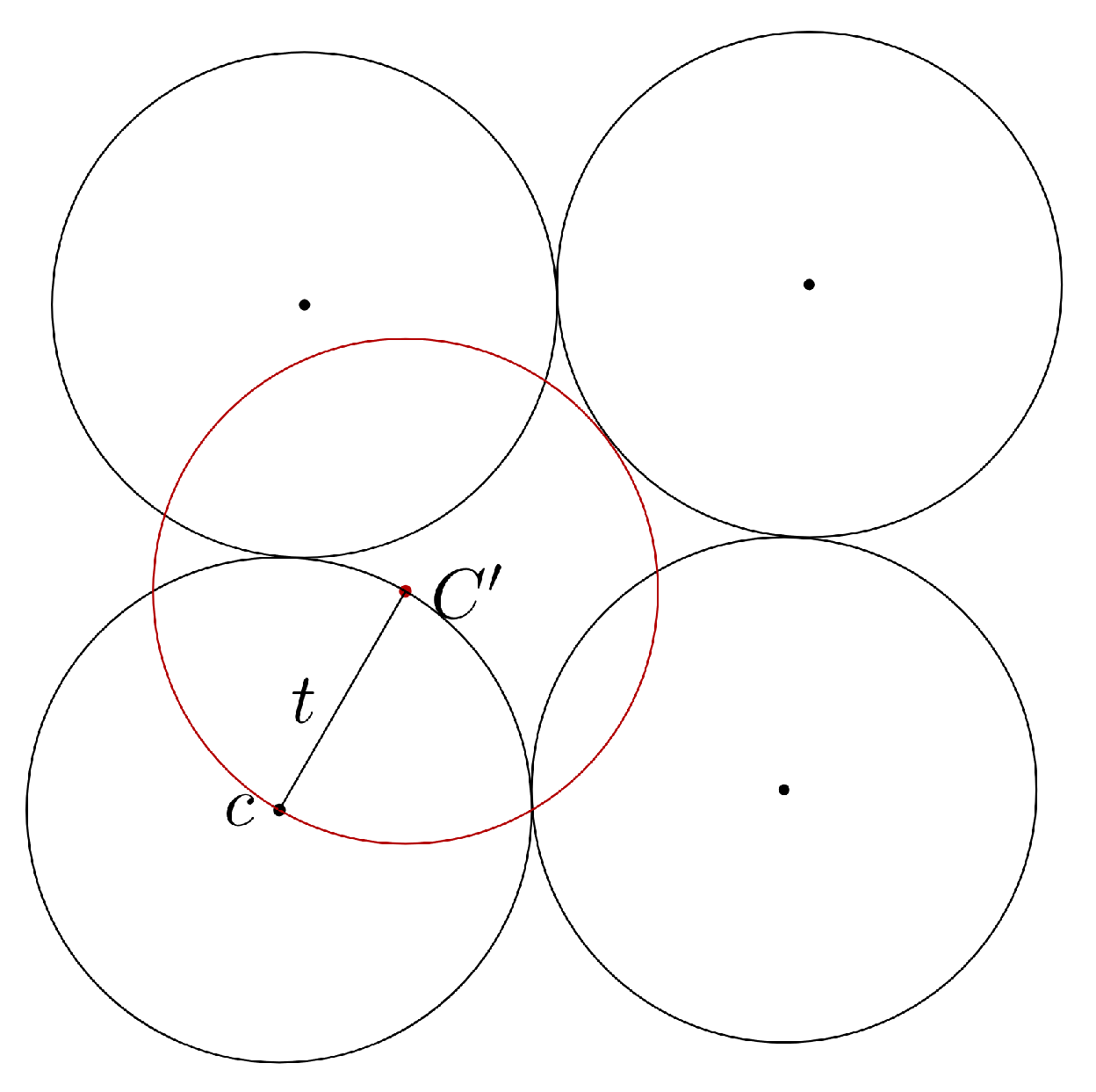
2.1.2. Computational Lattice Problems
- Let be a set of vectors generating the lattice L. Calculate a basis of L.
- Let L be a lattice. Evaluate whether a given vector c is an element of L.
Shortest Vector Problem
2.1.3. Closest Vector Problem
2.2. Cryptography Based on Learning with Errors (LWE)
2.2.1. LWE Fundamentals
Learning with Errors
Decisional LWE
Linking LWE to Computational Lattice Problems
LWE-Based Encryption Schemes
Flavors of LWE: Ring-LWE and Module-LWE
Learning with Rounding
2.2.2. Kyber
| Algorithm 1 Kyber PKE Key Generation: keyGen. |
Input: none
|
| Algorithm 2 Kyber PKE Encryption: enc, |
Input: public key , message
|
| Algorithm 3 Kyber PKE Decryption: dec |
Input: secret key s, ciphertext
|
| Algorithm 4 Kyber KEM Key Generation. |
Input: none
|
| Algorithm 5 Kyber KEM Encapsulation. |
Input: public key
|
| Algorithm 6 Kyber KEM Decapsulation. |
Input: public key pk, secret key , encapsulation c
|
2.2.3. Saber
| Algorithm 7 Saber PKE Key Generation: keyGen. |
Input: none
|
| Algorithm 8 Saber PKE Encryption: enc |
Input: public key , message
|
| Algorithm 9 Saber PKE Decryption: dec |
Input: secret key s, ciphertext
|
| Algorithm 10 Saber KEM Key Generation. |
Input: none
|
| Algorithm 11 Saber KEM Encapsulation. |
Input: public key
|
| Algorithm 12 Saber KEM Decapsulation. |
Input: public key pk, secret key , encapsulation c
|
2.2.4. Dilithium
| Algorithm 13 Dilithium Key Generation: keyGen. |
Input: none
|
| Algorithm 14 Dilithium Signature generation. |
| Input: public key , secret key s, message Until z is valid:
|
| Algorithm 15 Dilithium Verification. |
Input: public key , message , signature
|
2.3. NTRU-Based Cryptography
2.3.1. NTRU Fundamentals
The NTRU Assumption
NTRU-Based Encryption Schemes
Linking NTRU to Computational Lattice Problems
2.3.2. NTRU
| Algorithm 16 NTRU PKE Key Generation: keyGen. |
Input: none
|
| Algorithm 17 NTRU PKE Encryption: enc. |
Input: public key h, message
|
| Algorithm 18 NTRU PKE Decryption: dec. |
Input: secret key sk = , ciphertext c
|
| Algorithm 19 NTRU KEM Key Generation. |
Input: none
|
| Algorithm 20 NTRU KEM Encapsulation. |
Input: public key h
|
| Algorithm 21 NTRU KEM Decapsulation. |
Input: secret key sk = , encapsulation c
|
2.3.3. Falcon
- 1.
- mod q;
- 2.
- for some boundary , i.e., s has to be short.
| Algorithm 22 Falcon Key Generation. |
Input: none
|
| Algorithm 23 Falcon Signature generation. |
Input: secret key sk = , message
|
| Algorithm 24 Falcon Verification. |
Input: public key h, message , signature
|
3. Code-Based Cryptography
3.1. Linear Code Fundamentals
3.1.1. Linear Codes
3.1.2. Binary Goppa Codes
3.1.3. Computational Linear Code Problems
3.2. Classic McEliece
| Algorithm 25 Classic McEliece PKE Key Generation: keyGen. |
Input: none
|
| Algorithm 26 Classic McEliece PKE Encryption: enc. |
Input: public key , message with weight t
|
| Algorithm 27 Classic McEliece PKE Decryption: dec. |
Input: ciphertext , Goppa code
|
| Algorithm 28 Classic McEliece KEM Key Generation. |
Input: none
|
| Algorithm 29 Classic McEliece KEM Encapsulation. |
Input: public key H
|
| Algorithm 30 Classic McEliece KEM Decapsulation. |
Input: secret key , encapsulation
|
4. Multivariate Cryptography
4.1. Multivariate Polynomial Fundamentals
4.1.1. Multivariate Polynomial Functions
4.1.2. MQ Problem
4.1.3. Multivariate Signature Schemes
4.1.4. IP Problem
4.2. Rainbow
- We randomly assign values to the vinegar variables (highlighted in red), thus reducing the product between two vinegar variables to constants and the product of an oil and a vinegar variable to a linear term:
- This results in a linear system of k equations in variables, namely, . By applying Gaussian elimination, we solve this system and thereby derive the remaining oil values . In case the system does not have a solution, we repeat the previous step by sampling some other random values for the vinegar variables.
- The secret central map consisting of polynomials of the formwith layer one vinegar indices , layer one oil indices , layer two vinegar indices and layer two oil indices .The coefficients are randomly chosen from .
- Two secret randomly chosen invertible affine maps and . Their coefficients are randomly sampled from which is repeated if the maps turn out not to be invertible.
- The public key .
| Algorithm 31 Rainbow Key Generation. |
Input: none
|
- We randomly assign values to the vinegar variables of layer one, i.e., :
- We solve the resulting linear system of equations to obtain concrete values for the oil variables of layer one;
- The resulting assignment of values for is substituted into the second layer:
- We solve the resulting linear system of equations to obtain concrete values for the remaining oil variables of layer two;
- In case one of the linear systems has no solution, we start from the beginning by choosing other random values for the vinegar variables of the first layer.
| Algorithm 32 Rainbow Signature generation. |
Input: secret key sk = , message
|
| Algorithm 33 Rainbow Verification. |
Input: public key , message , signature
|
4.2.1. Rainbow Security Considerations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, L.; Jordan, S.; Liu, Y.K.; Moody, D.; Peralta, R.; Perlner, R.; Smith-Tone, D. Report on Post-Quantum Cryptography; Technical Report NIST Internal or Interagency Report (NISTIR) 8105; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2016. [CrossRef]
- Fraunhofer AISEC: Crypto Engineering. Post-Quantum Database (pqdb). Available online: https://cryptoeng.github.io/pqdb/ (accessed on 1 July 2022).
- Regev, O. On lattices, learning with errors, random linear codes, and cryptography. J. ACM 2009, 56, 34:1–34:40. [Google Scholar] [CrossRef]
- Bos, J.; Costello, C.; Ducas, L.; Mironov, I.; Naehrig, M.; Nikolaenko, V.; Raghunathan, A.; Stebila, D. Frodo: Take off the Ring! Practical, Quantum-Secure Key Exchange from LWE. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 1006–1018. [Google Scholar] [CrossRef] [Green Version]
- Lyubashevsky, V.; Peikert, C.; Regev, O. On Ideal Lattices and Learning with Errors over Rings. In Advances in Cryptology—EUROCRYPT 2010, Proceedings of the 29th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Riviera, French, 30 May–3 June 2010; Gilbert, H., Ed.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1–23. [Google Scholar]
- Langlois, A.; Stehle, D. Worst-Case to Average-Case Reductions for Module Lattices. Cryptology ePrint Archive, Report 2012/090. 2012. Available online: https://ia.cr/2012/090 (accessed on 1 July 2022).
- Alkim, E.; Ducas, L.; Pöppelmann, T.; Schwabe, P. Post-Quantum Key Exchange—A New Hope. Cryptology ePrint Archive, Report 2015/1092. 2015. Available online: https://ia.cr/2015/1092 (accessed on 1 July 2022).
- Peikert, C.; Pepin, Z. Algebraically Structured LWE, Revisited. Cryptology ePrint Archive, Report 2019/878. 2019. Available online: https://ia.cr/2019/878 (accessed on 1 July 2022).
- Banerjee, A.; Peikert, C.; Rosen, A. Pseudorandom Functions and Lattices. Cryptology ePrint Archive, Report 2011/401. 2011. Available online: https://ia.cr/2011/401 (accessed on 1 July 2022).
- Avanzi, R.; Bos, J.; Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schanck, J.M.; Schwabe, P.; Seiler, G.; Stehlé, D. CRYSTALS-KYBER: Algorithm Specifications and Supporting Documentation. Version 3.02. Available online: https://pq-crystals.org/kyber/data/kyber-specification-round3-20210804.pdf (accessed on 1 July 2022).
- Fujisaki, E.; Okamoto, T. Secure Integration of Asymmetric and Symmetric Encryption Schemes. J. Cryptol. 2013, 26, 80–101. [Google Scholar] [CrossRef]
- Hofheinz, D.; Hövelmanns, K.; Kiltz, E. A Modular Analysis of the Fujisaki-Okamoto Transformation. In Theory of Cryptography; Kalai, Y., Reyzin, L., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2017; Volume 10677, pp. 341–371. [Google Scholar] [CrossRef]
- Basso, A.; Bermudo Mera, J.M.; D’Anvers, J.P.; Karmakar, A.; Roy, S.S.; Van Beirendonck, M.; Vercauteren, F. SABER: Mod-LWR Based KEM (Round 3 Submission). Available online: https://www.esat.kuleuven.be/cosic/pqcrypto/saber/files/saberspecround3.pdf (accessed on 1 July 2022).
- Bai, S.; Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schwabe, P.; Seiler, G.; Stehlé, D. CRYSTALS-Dilithium: Algorithm Specifications And Supporting Documentation. Version 3.1. Available online: https://pq-crystals.org/dilithium/data/dilithium-specification-round3-20210208.pdf (accessed on 1 July 2022).
- Lyubashevsky, V. Lattice signatures without trapdoors. In Proceedings of the EUROCRYPT 2012—31st Annual International Conference on the Theory and Applications of Cryptographic Techniques, Lecture Notes in Computer Science, Cambridge, UK, 15–19 April 2012; Pointcheval, D., Schaumont, P., Eds.; Springer: Cambridge, UK, 2012; Volume 7237, pp. 738–755. [Google Scholar] [CrossRef] [Green Version]
- Bai, S.; Galbraith, S.D. An Improved Compression Technique for Signatures Based on Learning with Errors. In Topics in Cryptology – CT-RSA 2014, Proceedings of the Cryptographer’s Track at the RSA Conference 2014, San Francisco, CA, USA, 25–28 February 2014; Benaloh, J., Ed.; Springer International Publishing: Cham, Switzerland, 2014; pp. 28–47. [Google Scholar]
- Hoffstein, J.; Pipher, J.; Silverman, J. An Introduction to Mathematical Cryptography, 1st ed.; Springer Publishing Company, Incorporated: New York, NY, USA, 2008. [Google Scholar]
- Chen, C.; Danba, O.; Hoffstein, J.; Hülsing, A.; Rijneveld, J.; Schanck, J.M.; Schwabe, P.; Whyte, W.; Zhang, Z. NTRU: Algorithm Specifications and Supporting Documentation; Version September 2020. Available online: https://csrc.nist.gov/CSRC/media/Projects/post-quantum-cryptography/documents/round-3/submissions/NTRU-Round3.zip (accessed on 1 July 2022).
- Fouque, P.A.; Hoffstein, J.; Kirchner, P.; Lyubashevsky, V.; Pornin, T.; Prest, T.; Ricosset, T.; Seiler, G.; Whyte, W.; Zhang, Z. Falcon: Fast-Fourier Lattice-Based Compact Signatures over NTRU. Version 1.2. Available online: https://falcon-sign.info/falcon.pdf (accessed on 1 July 2022).
- Gentry, C.; Peikert, C.; Vaikuntanathan, V. Trapdoors for Hard Lattices and New Cryptographic Constructions. Cryptology ePrint Archive, Report 2007/432. 2007. Available online: https://ia.cr/2007/432 (accessed on 1 July 2022).
- Ajtai, M. Generating Hard Instances of the Short Basis Problem; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Babai, L. On Lovász’ lattice reduction and the nearest lattice point problem. Combinatorica 1986, 6, 1–13. [Google Scholar] [CrossRef]
- Ducas, L.; Prest, T. Fast Fourier Orthogonalization. Cryptology ePrint Archive, Report 2015/1014. 2015. Available online: https://ia.cr/2015/1014 (accessed on 1 July 2022).
- Lint, J.H.V. Introduction to Coding Theory, 3rd ed.; Number 86 in Graduate Texts in Mathematics; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- McEliece, R.J. A Public-Key Cryptosystem Based on Algebraic Coding Theory; National Aeronautics and Space Administration: Washington, DC, USA, 1978.
- Marcus, M. White Paper on McEliece with Binary Goppa Codes. 2019. Available online: https://www.hyperelliptic.org/tanja/students/m_marcus/whitepaper.pdf (accessed on 1 July 2022).
- Engelbert, D.; Overbeck, R.; Schmidt, A. A Summary of McEliece-Type Cryptosystems and their Security. 2006. Available online: https://ia.cr/2006/162 (accessed on 1 July 2022).
- Albrecht, M.R.; Bernstein, D.J.; Chou, T.; Cid, C.; Gilcher, J.; Lange, T.; Maram, V.; von Maurich, I.; Misoczki, R.; Niederhagen, R.; et al. Classic McEliece: Conservative Code-Based Cryptography. Version October 2020. Available online: https://classic.mceliece.org/nist/mceliece-20201010.pdf (accessed on 1 July 2022).
- Niederhagen, R.; Waidner, M. Practical Post-Quantum Cryptography; Fraunhofer SIT: Darmstadt, Germany, 2017. [Google Scholar]
- Sardinas, A.; Patterson, C. A necessary sufficient condition for the unique decomposition of coded messages. IRE Internat. Conv. Rec. 1953, 104–108. [Google Scholar]
- Niederreiter, H.; Xing, C. Algebraic Geometry in Coding Theory and Cryptography; Princeton University Press: Princeton, NJ, USA, 2009. [Google Scholar]
- Ding, J.; Yang, B.Y. Multivariate Public Key Cryptography. In Post-Quantum Cryptography; Springer: Berlin/Heidelberg, Germany, 2009; pp. 193–241. [Google Scholar] [CrossRef] [Green Version]
- Tao, C.; Diene, A.; Tang, S.; Ding, J. Simple Matrix Scheme for Encryption. In Post-Quantum Cryptography; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; pp. 231–242. [Google Scholar] [CrossRef]
- Patarin, J. Hidden Fields Equations (HFE) and Isomorphisms of Polynomials (IP): Two New Families of Asymmetric Algorithms. In Advances in Cryptology—EUROCRYPT ’96, Proceedings of the International Conference on the Theory and Application of Cryptographic Techniques, Saragossa, Spain, 12–16 May 1996; Maurer, U., Ed.; Springer: Berlin/Heidelberg, Germany, 1996; pp. 33–48. [Google Scholar]
- Ding, J.; Chen, M.S.; Petzoldt, A.; Schmidt, D.; Yang, B.Y. Rainbow—Algorithm Specification and Documentation, The 3rd Round Proposal. Available online: https://csrc.nist.gov/CSRC/media/Projects/post-quantum-cryptography/documents/round-3/submissions/Rainbow-Round3.zip (accessed on 1 July 2022).
- Thomae, E. About the Security of Multivariate Quadratic Public Key Schemes. Ph.D. Thesis, Universitätsbibliothek, Ruhr-Universität Bochum, Bochum, Germany, 2013; pp. 84–85. [Google Scholar]
- Beullens, W. Breaking Rainbow Takes a Weekend on a Laptop. Cryptology ePrint Archive. 2022. Available online: https://ia.cr/2022/214 (accessed on 1 July 2022).
- Beullens, W. Improved Cryptanalysis of UOV and Rainbow. Cryptology ePrint Archive, Report 2020/1343. 2020. Available online: https://ia.cr/2020/1343 (accessed on 1 July 2022).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Plain LWE | Ring-LWE | Module-LWE | |
|---|---|---|---|
| · | matrix mult. | polynomial mult. | matrix mult. |
| n | k | q | ||
|---|---|---|---|---|
| Kyber512 | 256 | 2 | 3329 | |
| Kyber768 | 256 | 3 | 3329 | |
| Kyber1024 | 256 | 4 | 3329 |
| n | k | q | p | ||
|---|---|---|---|---|---|
| LightSaber | 256 | 2 | |||
| Saber | 256 | 3 | |||
| FireSaber | 256 | 4 |
| n | (k,l) | q | #reps | |
|---|---|---|---|---|
| Dilithium 2 | 256 | (4,4) | 8380417 | 4.25 |
| Dilithium 3 | 256 | (6,5) | 8380417 | 5.1 |
| Dilithium 5 | 256 | (8,7) | 8380417 | 3.85 |
| n | q | |
|---|---|---|
| Falcon-512 | 512 | 12,289 |
| Falcon-1024 | 1024 | 12,289 |
| n | k | d | t | |
|---|---|---|---|---|
| McEliece348864 | 3488 | 2720 | 129 | 64 |
| McEliece460896 | 4608 | 3360 | 193 | 96 |
| McEliece6688128 | 6688 | 5024 | 257 | 128 |
| McEliece6960119 | 6960 | 5413 | 239 | 119 |
| McEliece8192128 | 8192 | 6528 | 257 | 128 |
| Level I | GF(16) | 36 | 32 | 32 |
| Level III | GF(256) | 68 | 32 | 48 |
| Level V | GF(256) | 96 | 36 | 64 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Richter, M.; Bertram, M.; Seidensticker, J.; Tschache, A. A Mathematical Perspective on Post-Quantum Cryptography. Mathematics 2022, 10, 2579. https://doi.org/10.3390/math10152579
Richter M, Bertram M, Seidensticker J, Tschache A. A Mathematical Perspective on Post-Quantum Cryptography. Mathematics. 2022; 10(15):2579. https://doi.org/10.3390/math10152579
Chicago/Turabian StyleRichter, Maximilian, Magdalena Bertram, Jasper Seidensticker, and Alexander Tschache. 2022. "A Mathematical Perspective on Post-Quantum Cryptography" Mathematics 10, no. 15: 2579. https://doi.org/10.3390/math10152579
APA StyleRichter, M., Bertram, M., Seidensticker, J., & Tschache, A. (2022). A Mathematical Perspective on Post-Quantum Cryptography. Mathematics, 10(15), 2579. https://doi.org/10.3390/math10152579