
A Two-Stage Hybrid Extreme Learning Model for Short-Term Traffic Flow Forecasting



Abstract
:1. Introduction
- We apply the perspective of a meta model to rethinking the amelioration of traffic flow forecasting models, with an example about a learning model optimized by a data-driven hybrid evolutionary algorithm.
- We establish a particle swarm optimization combining a gravitational search algorithm optimized extreme learning machine model for forecasting traffic flow in the short term.
- We demonstrate the practicability of our motivation of the data-driven meta model by sufficient experiments, whose results demonstrate the outperformance of the proposed model to state-of-the-art models.
2. Methodology
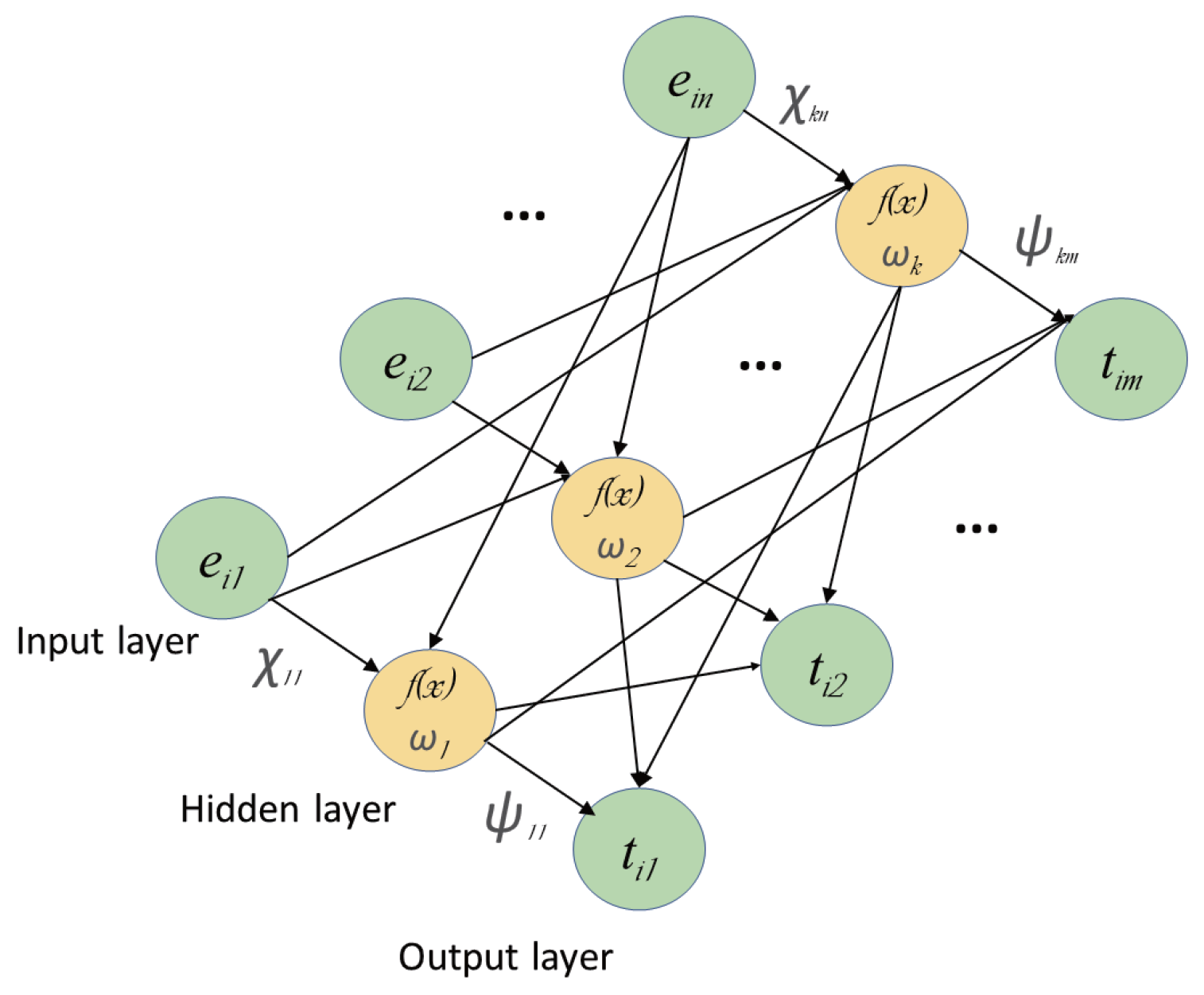
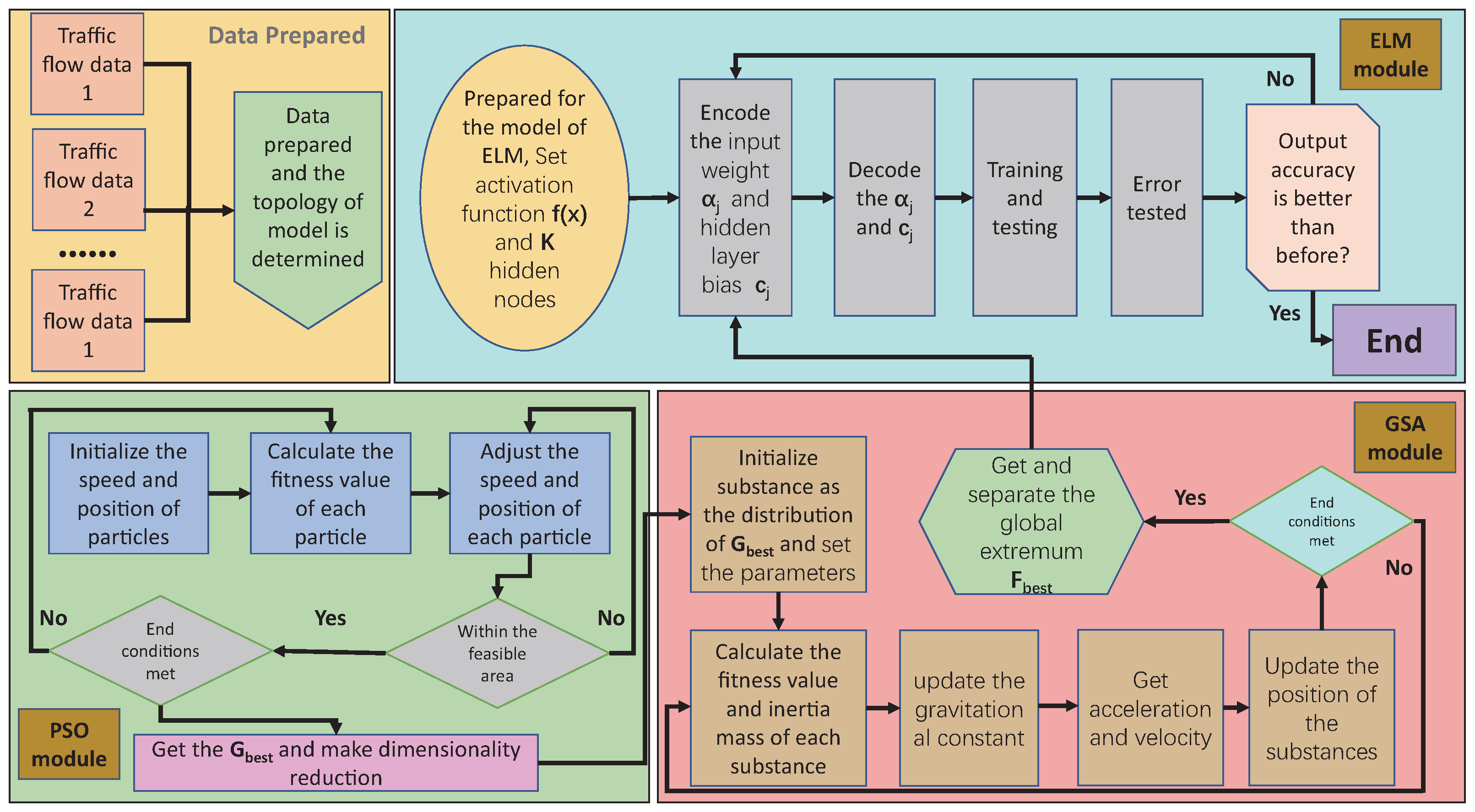
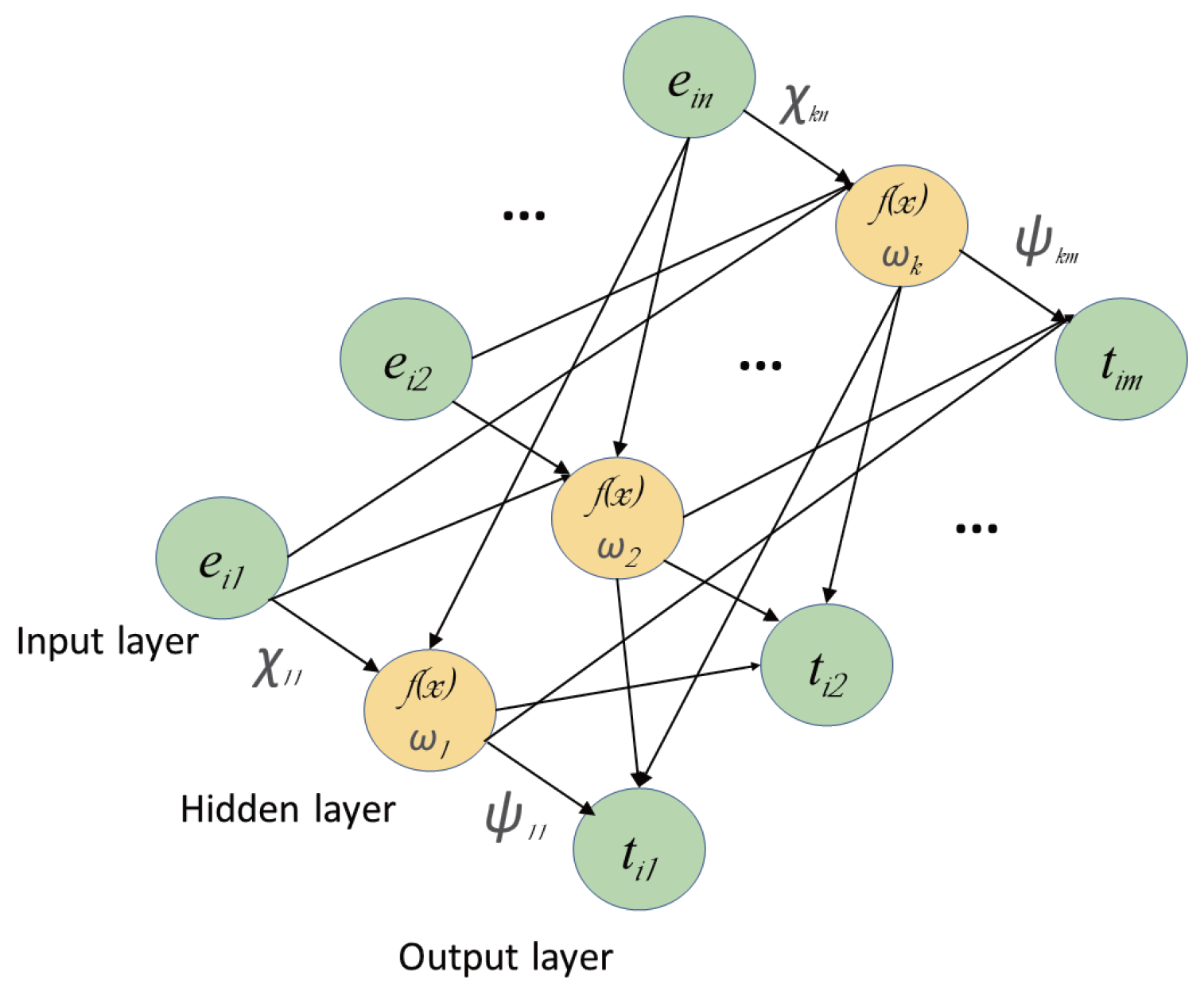
2.1. Extreme Learning Machine
2.2. Standard Gravitational Search Algorithm
2.3. Standard Particle Swarm Optimization
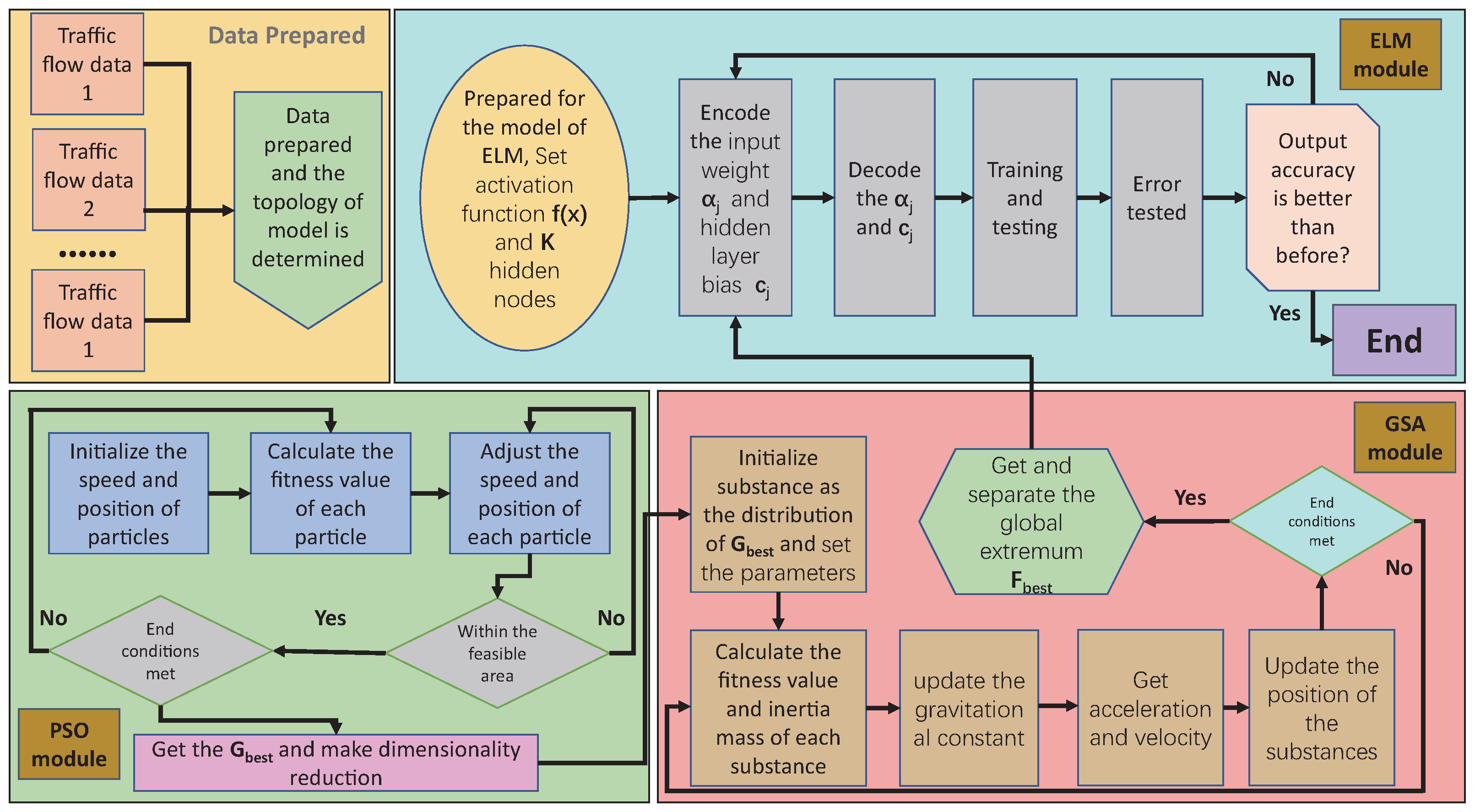
2.4. ELM Optimization Learning Based on Data Driven
3. Experiments
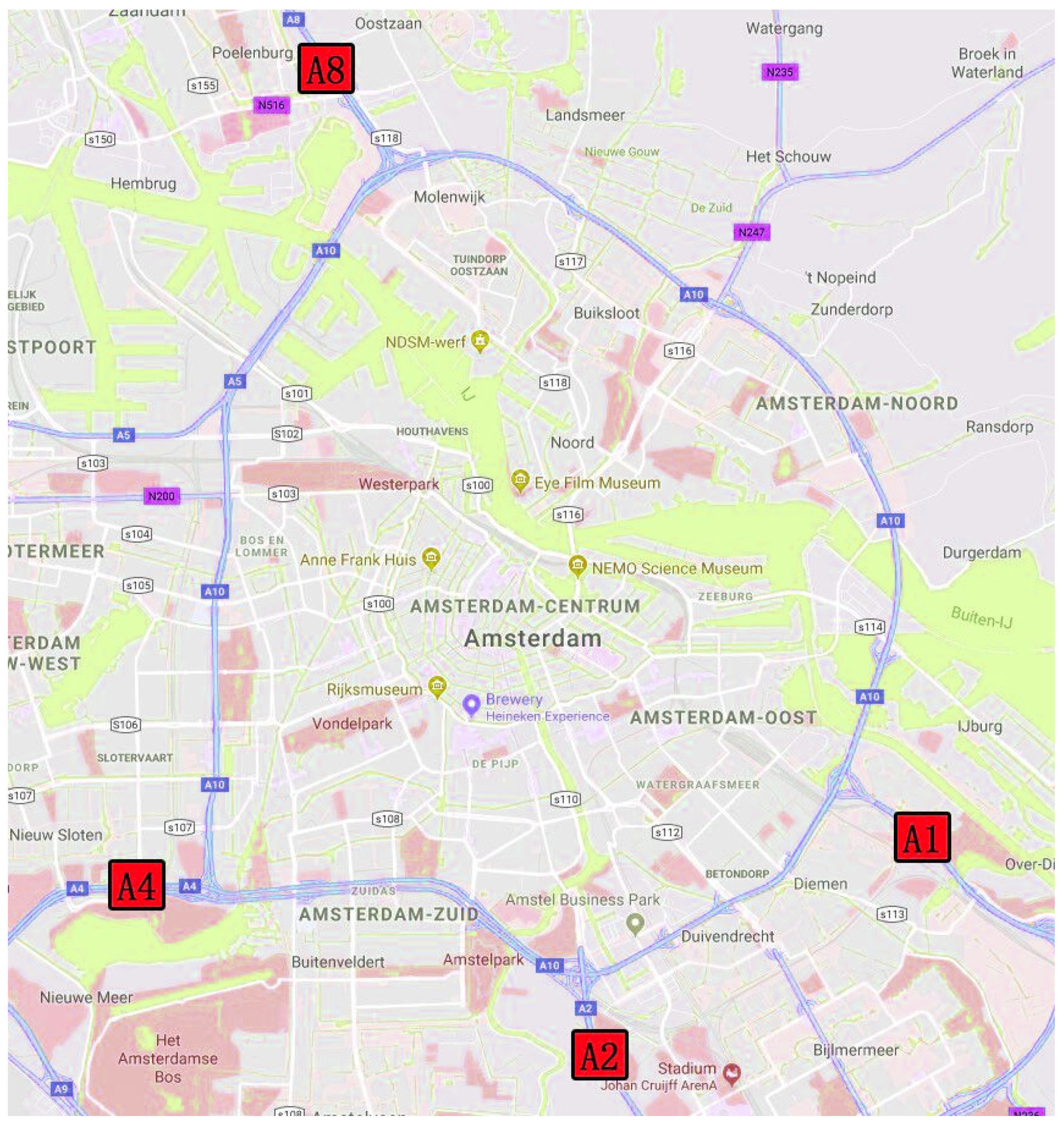
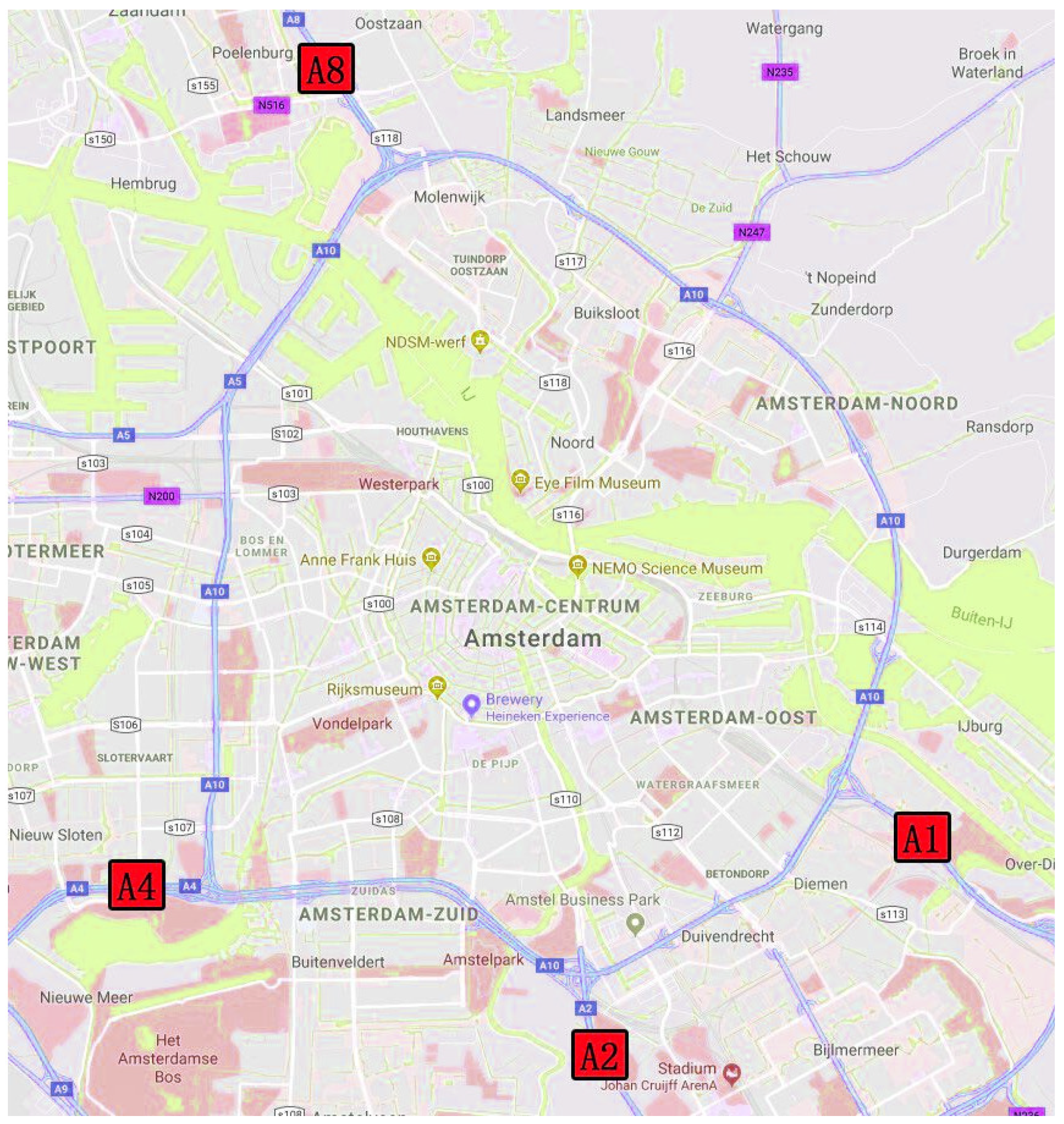
3.1. Data Description
- The A1 freeway is an extremely significant route in Europe whose extraordinary position is the link between the German border and Amsterdam. The first 3+ barrier-separated lanes with high-occupancy vehicle (HOV) in Europe is located on the A1 freeway. Therefore, forecasting traffic flow accurately is thrown down the gauntlet because the flow on an HOV vehicle lane changes dramatically over time.
- The A2 expressway links the Belgian border and the city of Amsterdam, which is one of the expressways with the highest traffic flow in the Netherlands. The data collected before the road widening in 2010 could be employed for evaluating the performance of the proposed framework when the road falls into traffic congestion in our research.
- As a section of the Rijksweg 4, the A4 expressway in the Netherlands is another high priority, starting from Amsterdam and ending at the Belgian border.
- A8 is the shortest of the four freeways, starting from the A10 motorway at interchange Coenplein to the Zaandijk, and the total length is less than 10 km.
3.2. Evaluation Criterion
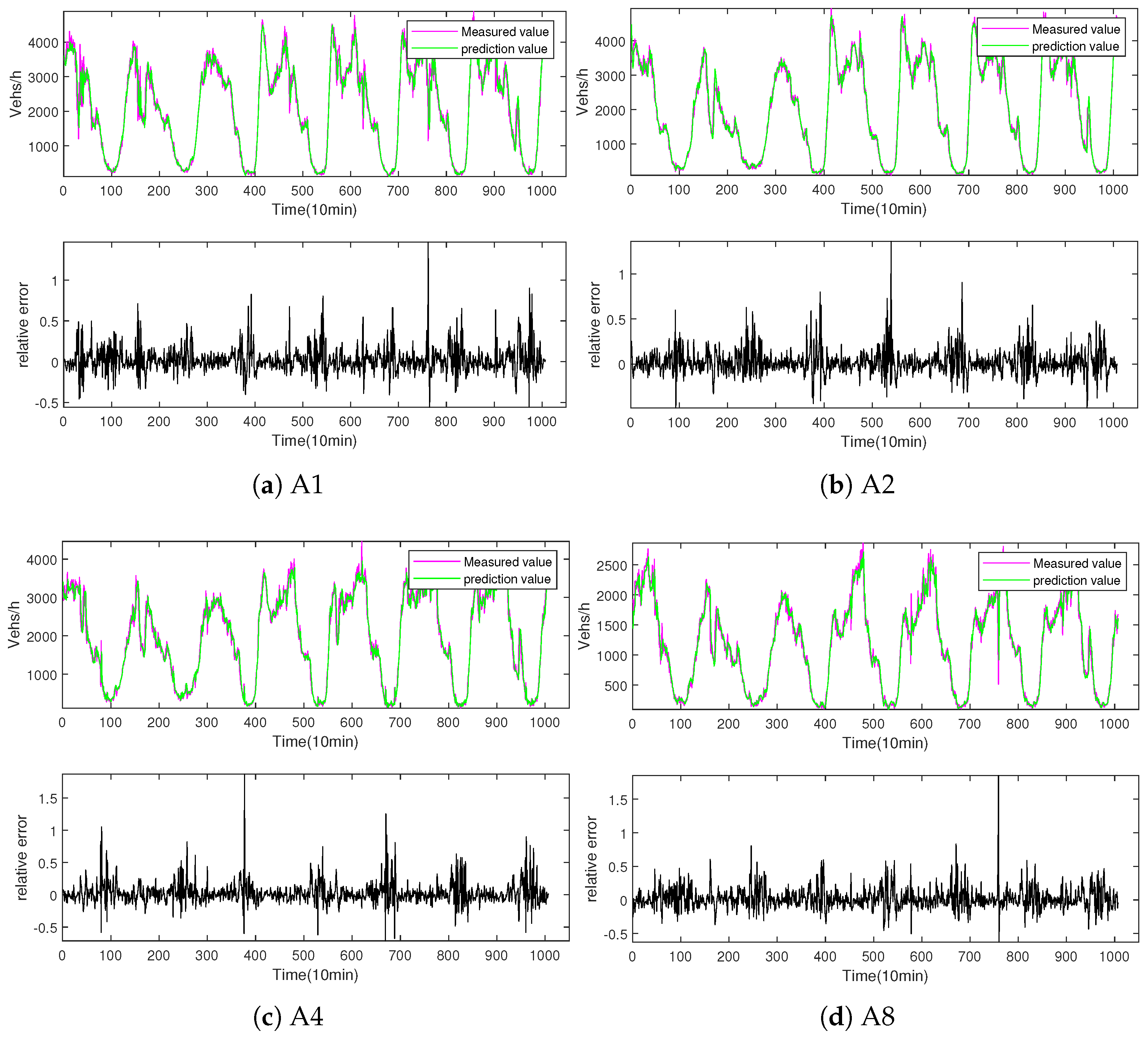
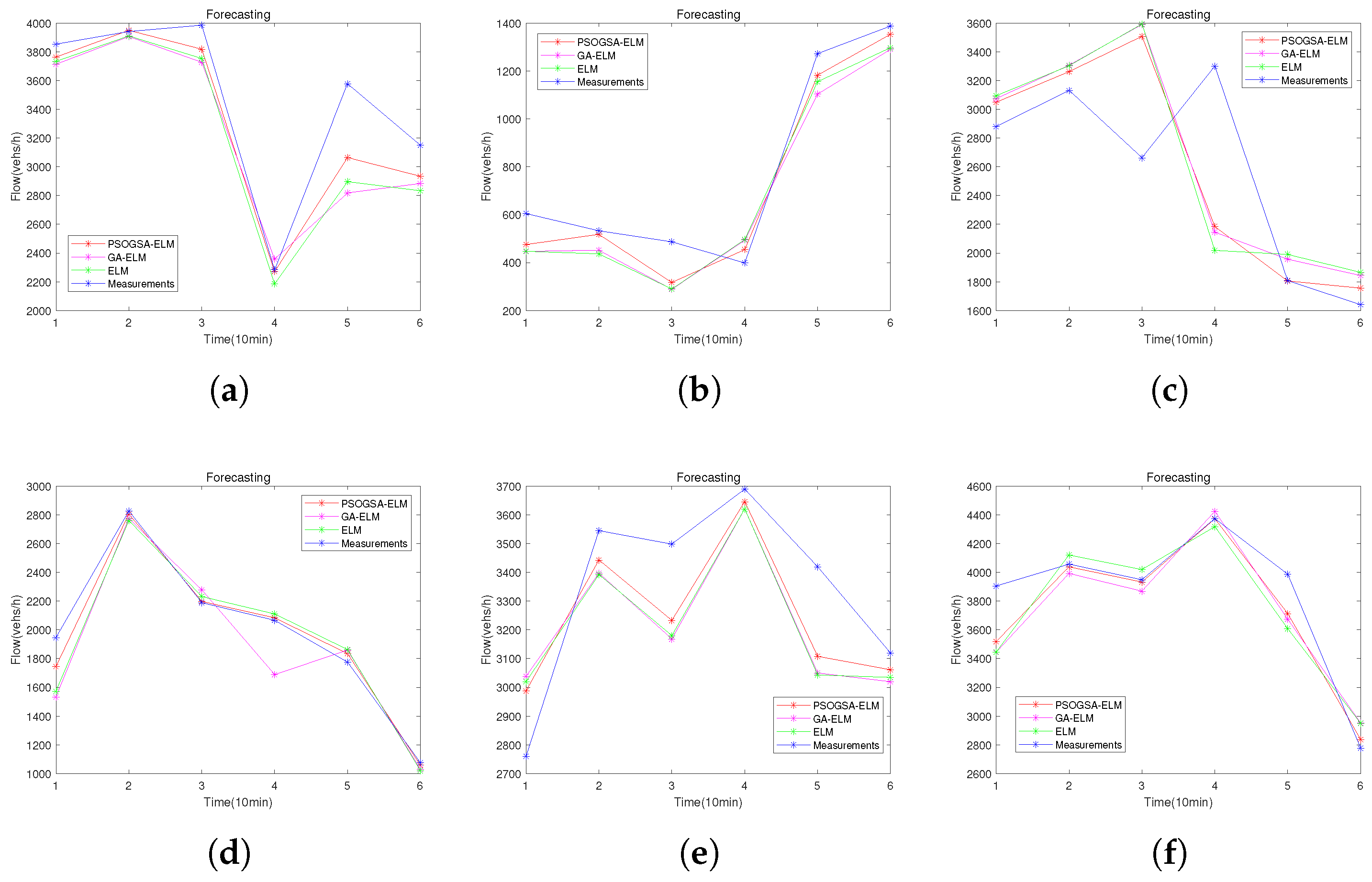
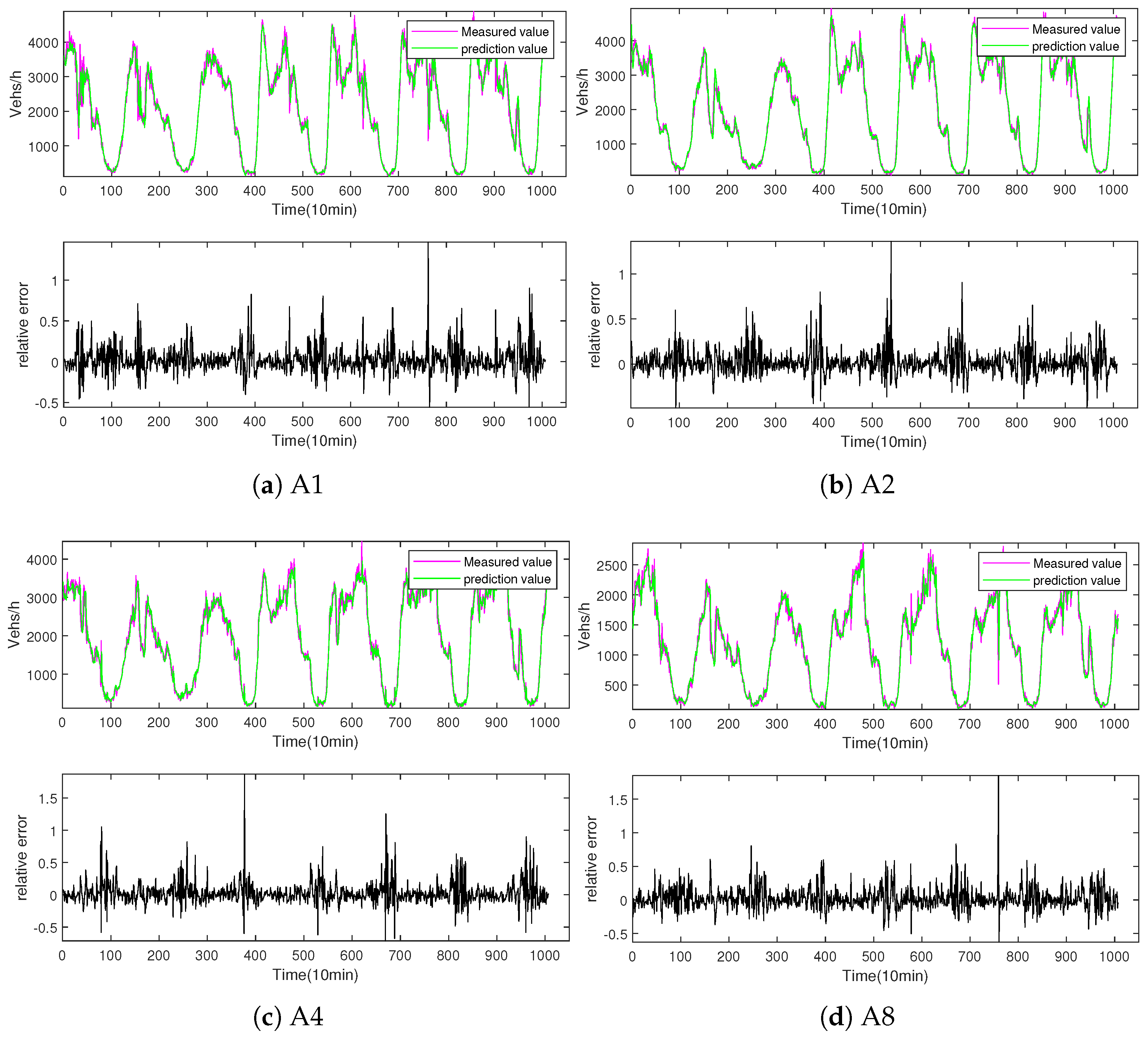
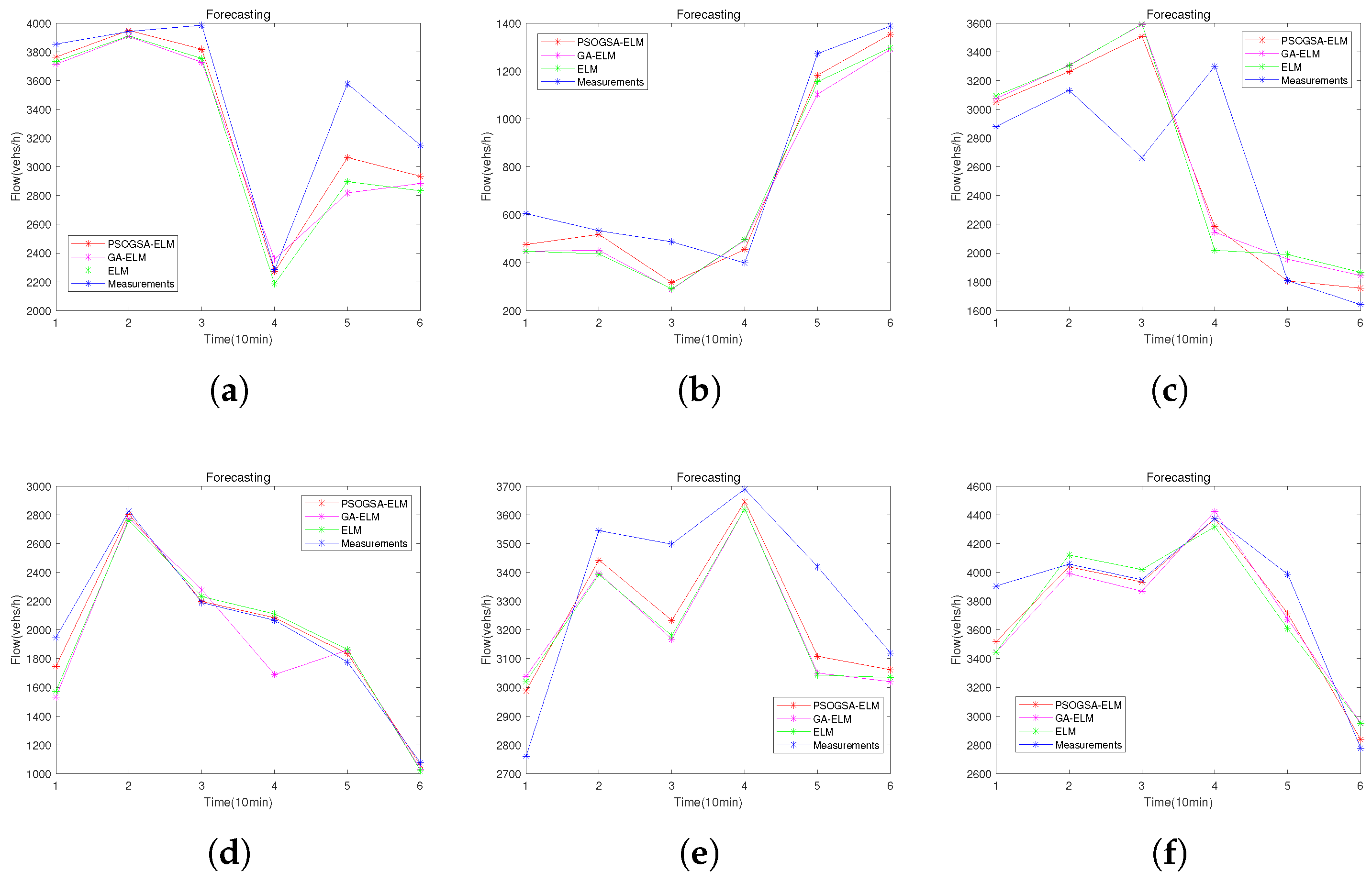
3.3. Performance Evaluation
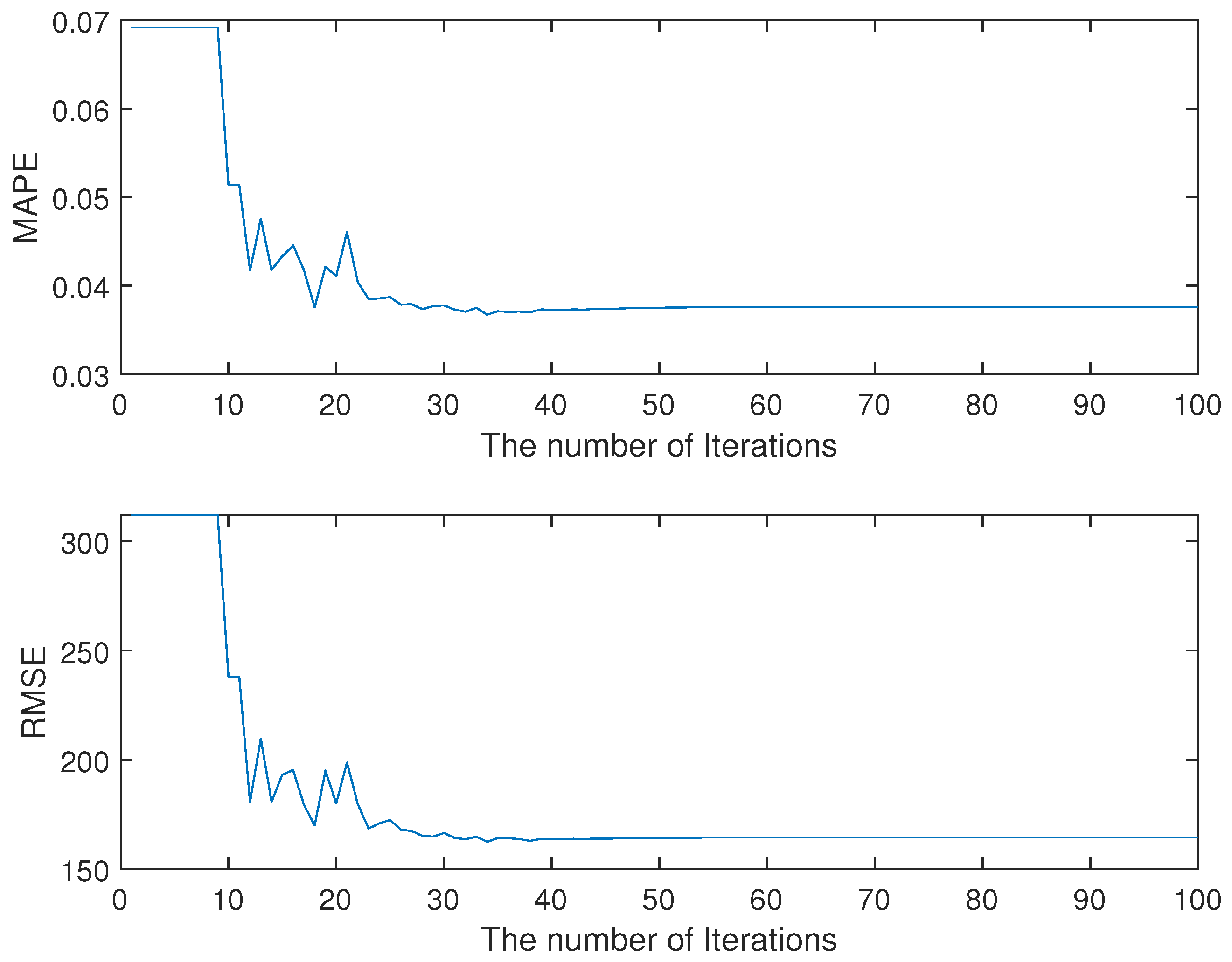
3.4. Ablation Study
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cai, L.; Lei, M.; Zhang, S.; Yu, Y.; Zhou, T.; Qin, J. A noise-immune lstm network for short-term traffic flow forecasting. Chaos Interdiscip. J. Nonlinear Sci. 2020, 30, 023135. [Google Scholar] [CrossRef] [PubMed]
- Olayode, I.O.; Tartibu, L.K.; Okwu, M.O.; Ukaegbu, U.F. Development of a hybrid artificial neural network-particle swarm optimization model for the modelling of traffic flow of vehicles at signalized road intersections. Appl. Sci. 2021, 11, 8387. [Google Scholar] [CrossRef]
- Li, Z.; Cao, Q.; Zhao, Y.; Zhuo, R. Signal cooperative control with traffic supply and demand on a single intersection. IEEE Access 2018, 6, 54407–54416. [Google Scholar]
- Li, Z.; Cao, Q.; Zhao, Y.; Tao, P.; Zhuo, R. Krill herd algorithm for signal optimization of cooperative control with traffic supply and demand. IEEE Access 2019, 7, 10776–10786. [Google Scholar]
- Chen, L.; Yang, D.; Zhang, D.; Wang, C.; Li, J. Deep mobile traffic forecast and complementary base station clustering for C-RAN optimization. J. Netw. Comput. Appl. 2018, 121, 59–69. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, M.S.; Cook, A.R. Analysis of Freeway Traffic Time-Series Data by Using Box-Jenkins Techniques. Number 722. 1979. Available online: https://trid.trb.org/view/148123 (accessed on 9 May 2022).
- Yang, H.; Li, X.; Qiang, W.; Zhao, Y.; Zhang, W.; Tang, C. A network traffic forecasting method based on SA optimized ARIMA–BP neural network. Comput. Netw. 2021, 193, 108102. [Google Scholar] [CrossRef]
- Cai, L.; Zhang, Z.; Yang, J.; Yu, Y.; Zhou, T.; Qin, J. A noise-immune Kalman filter for short-term traffic flow forecasting. Phys. A Stat. Mech. Appl. 2019, 536, 122601. [Google Scholar] [CrossRef]
- Zhou, T.; Jiang, D.; Lin, Z.; Han, G.; Xu, X.; Qin, J. Hybrid dual Kalman filtering model for short-term traffic flow forecasting. IET Intell. Transp. Syst. 2019, 13, 1023–1032. [Google Scholar] [CrossRef]
- Olayode, I.O.; Tartibu, L.K.; Okwu, M.O. Prediction and modeling of traffic flow of human-driven vehicles at a signalized road intersection using artificial neural network model: A South African road transportation system scenario. Transp. Eng. 2021, 6, 100095. [Google Scholar] [CrossRef]
- Olayode, I.O.; Severino, A.; Campisi, T.; Tartibu, L.K. Prediction of Vehicular Traffic Flow using Levenberg-Marquardt Artificial Neural Network Model: Italy Road Transportation System. Commun.-Sci. Lett. Univ. Zilina 2022, 24, E74–E86. [Google Scholar] [CrossRef]
- Cai, L.; Yu, Y.; Zhang, S.; Song, Y.; Xiong, Z.; Zhou, T. A sample-rebalanced outlier-rejected k-nearest neighbor regression model for short-term traffic flow forecasting. IEEE Access 2020, 8, 22686–22696. [Google Scholar] [CrossRef]
- Cai, L.; Chen, Q.; Cai, W.; Xu, X.; Zhou, T.; Qin, J. SVRGSA: A hybrid learning based model for short-term traffic flow forecasting. IET Intell. Transp. Syst. 2019, 13, 1348–1355. [Google Scholar] [CrossRef]
- Zheng, S.; Zhang, S.; Song, Y.; Lin, Z.; Jiang, D.; Zhou, T. A noise-immune boosting framework for short-term traffic flow forecasting. Complexity 2021, 2021, 5582974. [Google Scholar] [CrossRef]
- Cai, W.; Yang, J.; Yu, Y.; Song, Y.; Zhou, T.; Qin, J. PSO-ELM: A hybrid learning model for short-term traffic flow forecasting. IEEE Access 2020, 8, 6505–6514. [Google Scholar] [CrossRef]
- Cui, Z.; Huang, B.; Dou, H.; Tan, G.; Zheng, S.; Zhou, T. GSA-ELM: A hybrid learning model for short-term traffic flow forecasting. IET Intell. Transp. Syst. 2022, 16, 41–52. [Google Scholar] [CrossRef]
- Hu, X.; Xu, X.; Xiao, Y.; Chen, H.; He, S.; Qin, J.; Heng, P.A. SINet: A scale-insensitive convolutional neural network for fast vehicle detection. IEEE Trans. Intell. Transp. Syst. 2018, 20, 1010–1019. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Yu, T.; Hu, X.; Ng, W.W.; Heng, P.A. SALMNet: A structure-aware lane marking detection network. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4986–4997. [Google Scholar] [CrossRef]
- Li, L.; Lin, Y.; Du, B.; Yang, F.; Ran, B. Real-time traffic incident detection based on a hybrid deep learning model. Transp. A Transp. Sci. 2022, 18, 78–98. [Google Scholar] [CrossRef]
- Zhou, T.; Han, G.; Xu, X.; Lin, Z.; Han, C.; Huang, Y.; Qin, J. δ-agree AdaBoost stacked autoencoder for short-term traffic flow forecasting. Neurocomputing 2017, 247, 31–38. [Google Scholar] [CrossRef]
- Zhou, T.; Han, G.; Xu, X.; Han, C.; Huang, Y.; Qin, J. A learning-based multimodel integrated framework for dynamic traffic flow forecasting. Neural Process. Lett. 2019, 49, 407–430. [Google Scholar] [CrossRef]
- Li, L.; Qin, L.; Qu, X.; Zhang, J.; Wang, Y.; Ran, B. Day-ahead traffic flow forecasting based on a deep belief network optimized by the multi-objective particle swarm algorithm. Knowl.-Based Syst. 2019, 172, 1–14. [Google Scholar] [CrossRef]
- Qu, Z.; Li, H.; Li, Z.; Zhong, T. Short-term traffic flow forecasting method with MB-LSTM hybrid network. IEEE Trans. Intell. Transp. Syst. 2020, 23, 225–235. [Google Scholar]
- Lu, H.; Ge, Z.; Song, Y.; Jiang, D.; Zhou, T.; Qin, J. A temporal-aware lstm enhanced by loss-switch mechanism for traffic flow forecasting. Neurocomputing 2021, 427, 169–178. [Google Scholar] [CrossRef]
- Fang, W.; Zhuo, W.; Yan, J.; Song, Y.; Jiang, D.; Zhou, T. Attention meets long short-term memory: A deep learning network for traffic flow forecasting. Phys. A Stat. Mech. Appl. 2022, 587, 126485. [Google Scholar] [CrossRef]
- Luo, X.; Peng, J.; Liang, J. Directed hypergraph attention network for traffic forecasting. IET Intell. Transp. Syst. 2022, 16, 85–98. [Google Scholar] [CrossRef]
- Li, L.; He, S.; Zhang, J.; Ran, B. Short-term highway traffic flow prediction based on a hybrid strategy considering temporal–spatial information. J. Adv. Transp. 2016, 50, 2029–2040. [Google Scholar] [CrossRef]
- Lu, H.; Huang, D.; Song, Y.; Jiang, D.; Zhou, T.; Qin, J. St-trafficnet: A spatial-temporal deep learning network for traffic forecasting. Electronics 2020, 9, 1474. [Google Scholar] [CrossRef]
- Li, S.; Zhuang, C.; Tan, Z.; Gao, F.; Lai, Z.; Wu, Z. Inferring the trip purposes and uncovering spatio-temporal activity patterns from dockless shared bike dataset in Shenzhen, China. J. Transp. Geogr. 2021, 91, 102974. [Google Scholar] [CrossRef]
- Yang, S.; Li, H.; Luo, Y.; Li, J.; Song, Y.; Zhou, T. Spatiotemporal Adaptive Fusion Graph Network for Short-Term Traffic Flow Forecasting. Mathematics 2022, 10, 1594. [Google Scholar] [CrossRef]
- Dou, H.; Tan, J.; Wei, H.; Wang, F.; Yang, J.; Ma, X.G.; Wang, J.; Zhou, T. Transfer inhibitory potency prediction to binary classification: A model only needs a small training set. Comput. Methods Programs Biomed. 2022, 215, 106633. [Google Scholar] [CrossRef]
- Zhou, T.; Dou, H.; Tan, J.; Song, Y.; Wang, F.; Wang, J. Small dataset solves big problem: An outlier-insensitive binary classifier for inhibitory potency prediction. Knowl.-Based Syst. 2022. [Google Scholar] [CrossRef]
- Ahila, R.; Sadasivam, V.; Manimala, K. An integrated PSO for parameter determination and feature selection of ELM and its application in classification of power system disturbances. Appl. Soft Comput. 2015, 32, 23–37. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Lippi, M.; Bertini, M.; Frasconi, P. Short-term traffic flow forecasting: An experimental comparison of time-series analysis and supervised learning. IEEE Trans. Intell. Transp. Syst. 2013, 14, 871–882. [Google Scholar] [CrossRef]
- Hu, W.; Yan, L.; Liu, K.; Wang, H. A short-term traffic flow forecasting method based on the hybrid PSO-SVR. Neural Process. Lett. 2016, 43, 155–172. [Google Scholar] [CrossRef]
- Lv, L.; Wang, W.; Zhang, Z.; Liu, X. A novel intrusion detection system based on an optimal hybrid kernel extreme learning machine. Knowl.-Based Syst. 2020, 195, 105648. [Google Scholar] [CrossRef]
- Manoharan, J.S. Study of variants of Extreme Learning Machine (ELM) brands and its performance measure on classification algorithm. J. Soft Comput. Paradig. (JSCP) 2021, 3, 83–95. [Google Scholar]
- Rashedi, E.; Nezamabadi-Pour, H.; Saryazdi, S. GSA: A gravitational search algorithm. Inf. Sci. 2009, 179, 2232–2248. [Google Scholar] [CrossRef]
- Eappen, G.; Shankar, T. Hybrid PSO-GSA for energy efficient spectrum sensing in cognitive radio network. Phys. Commun. 2020, 40, 101091. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Wang, Y.; Van Schuppen, J.H.; Vrancken, J. Prediction of traffic flow at the boundary of a motorway network. IEEE Trans. Intell. Transp. Syst. 2013, 15, 214–227. [Google Scholar] [CrossRef]
- Li, Y.; Li, Z.; Li, L. Missing traffic data: Comparison of imputation methods. IET Intell. Transp. Syst. 2014, 8, 51–57. [Google Scholar] [CrossRef]
- Chan, K.Y.; Dillon, T.S.; Singh, J.; Chang, E. Neural-network-based models for short-term traffic flow forecasting using a hybrid exponential smoothing and Levenberg–Marquardt algorithm. IEEE Trans. Intell. Transp. Syst. 2011, 13, 644–654. [Google Scholar] [CrossRef]
- Zhu, J.Z.; Cao, J.X.; Zhu, Y. Traffic volume forecasting based on radial basis function neural network with the consideration of traffic flows at the adjacent intersections. Transp. Res. Part C Emerg. Technol. 2014, 47, 139–154. [Google Scholar] [CrossRef]
- Li, Y.; Guo, Z.; Yang, J.; Fang, H.; Hu, Y. Prediction of ship collision risk based on CART. IET Intell. Transp. Syst. 2018, 12, 1345–1350. [Google Scholar] [CrossRef]
- Moeeni, H.; Bonakdari, H.; Ebtehaj, I. Integrated SARIMA with neuro-fuzzy systems and neural networks for monthly inflow prediction. Water Resour. Manag. 2017, 31, 2141–2156. [Google Scholar] [CrossRef]
- Altinisik, Y.; Van Lissa, C.J.; Hoijtink, H.; Oldehinkel, A.J.; Kuiper, R.M. Evaluation of inequality constrained hypotheses using a generalization of the AIC. Psychol. Methods 2021, 26, 599. [Google Scholar] [CrossRef] [PubMed]
- Friedrich, M.; Pestel, E.; Schiller, C.; Simon, R. Scalable GEH: A Quality Measure for Comparing Observed and Modeled Single Values in a Travel Demand Model Validation. Transp. Res. Rec. 2019, 2673, 722–732. [Google Scholar] [CrossRef]
- Sinha, A.; Bassil, D.; Chand, S.; Virdi, N.; Dixit, V. Impact of Connected Automated Buses in a Mixed Fleet Scenario With Connected Automated Cars. IEEE Trans. Intell. Transp. Syst. 2021. early access. [Google Scholar] [CrossRef]
- Joseph, J.; Rao, A.M.; Velmuruganc, S.; Puwar, S.S. Analysis of Surrogate Safety Performance Parameters for an Interurban Corridor. J. Sci. Ind. Res. (JSIR) 2021, 80, 956–965. [Google Scholar]
- Krishnan, G.S.; Kamath, S. A novel GA-ELM model for patient-specific mortality prediction over large-scale lab event data. Appl. Soft Comput. 2019, 80, 525–533. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | A1 | A2 | A4 | A8 |
|---|---|---|---|---|
| HA | 404.84 | 348.96 | 357.85 | 218.72 |
| ES | 315.82 | 226.40 | 237.76 | 174.67 |
| ANN | 299.64 | 212.95 | 225.86 | 166.50 |
| DT | 316.57 | 224.79 | 243.19 | 238.35 |
| AR | 301.44 | 214.22 | 226.12 | 166.71 |
| SARIMA | 308.44 | 221.08 | 228.36 | 169.36 |
| SVR | 329.09 | 259.74 | 253.66 | 190.30 |
| ELM | 300.67 | 208.84 | 224.54 | 172.69 |
| GA-ELM | 291.42 | 211.43 | 228.57 | 169.25 |
| PSOGSA-ELM | 288.03 | 204.09 | 220.52 | 163.92 |
| Model | A1 | A2 | A4 | A8 |
|---|---|---|---|---|
| HA | 16.87 | 15.53 | 16.72 | 16.24 |
| ES | 11.94 | 10.75 | 11.97 | 12.00 |
| ANN | 12.61 | 10.89 | 12.49 | 12.53 |
| DT | 12.08 | 10.86 | 12.34 | 13.62 |
| AR | 13.57 | 11.59 | 12.70 | 12.71 |
| SARIMA | 12.81 | 11.25 | 12.05 | 12.44 |
| SVR | 14.34 | 12.22 | 12.23 | 12.48 |
| ELM | 11.92 | 10.32 | 12.09 | 12.58 |
| GA-ELM | 11.86 | 10.30 | 11.87 | 12.26 |
| PSOGSA-ELM | 11.53 | 10.16 | 11.67 | 12.02 |
| Model | A1 | A2 | A4 | A8 |
|---|---|---|---|---|
| ELM | 15.429 | 15.544 | 15.168 | 14.267 |
| GA-ELM | 15.416 | 15.522 | 15.136 | 14.161 |
| PSOGSA-ELM | 15.325 | 15.430 | 15.055 | 14.156 |
| Dataset | A1 | A2 | A4 | A8 |
|---|---|---|---|---|
| GEH | 6.13 | 4.48 | 4.88 | 4.81 |
| Algorithm | Paramater | Value |
|---|---|---|
| PSO | Range of inertia weights | [0.4,0.9] |
| Number of particles | 40 | |
| 1.7 | ||
| 1.3 | ||
| Maximum Iterations | 150 | |
| GSA | Population size | 300 |
| 100 | ||
| 20 | ||
| Maximum Iterations | 100 |
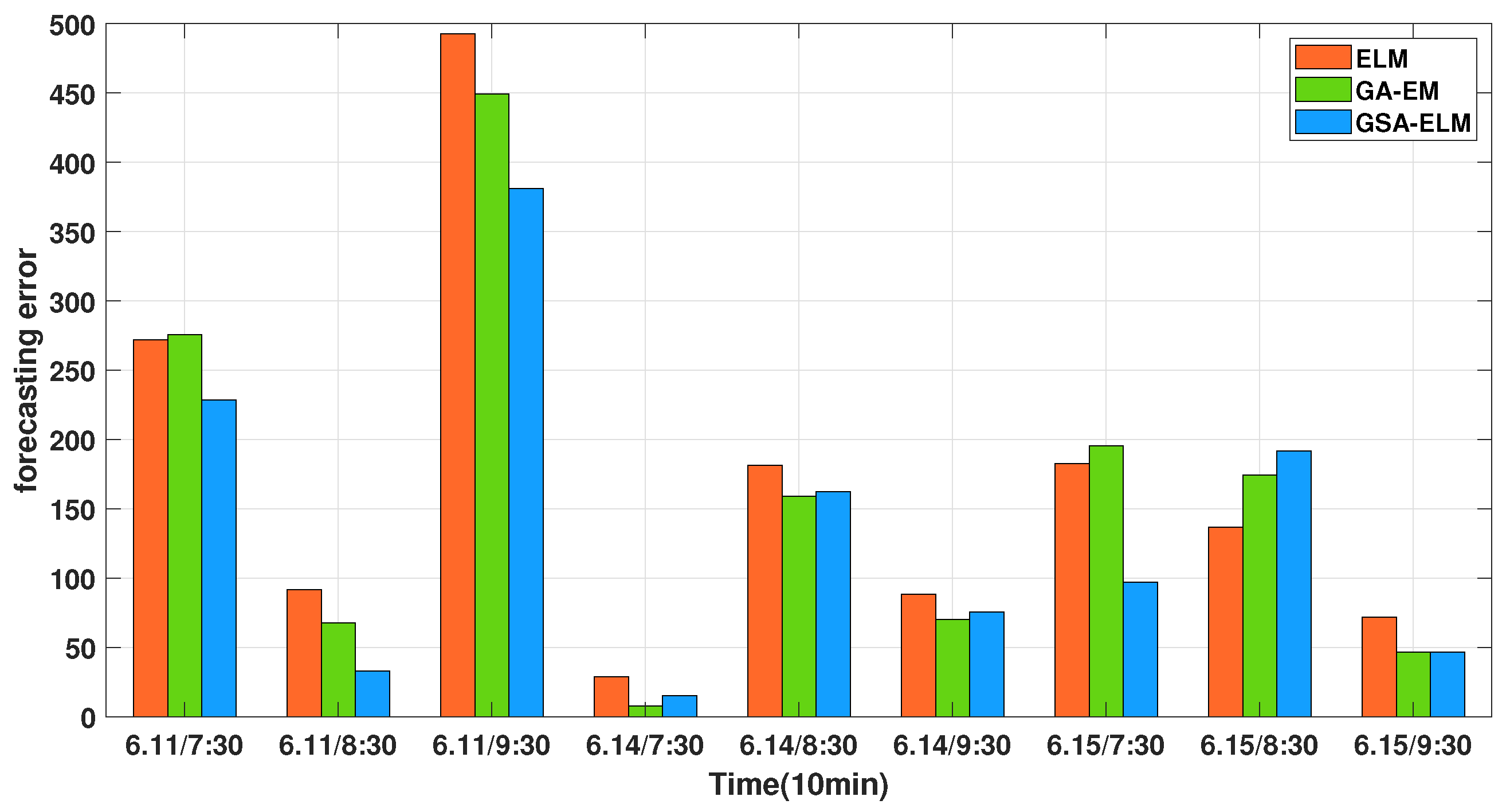
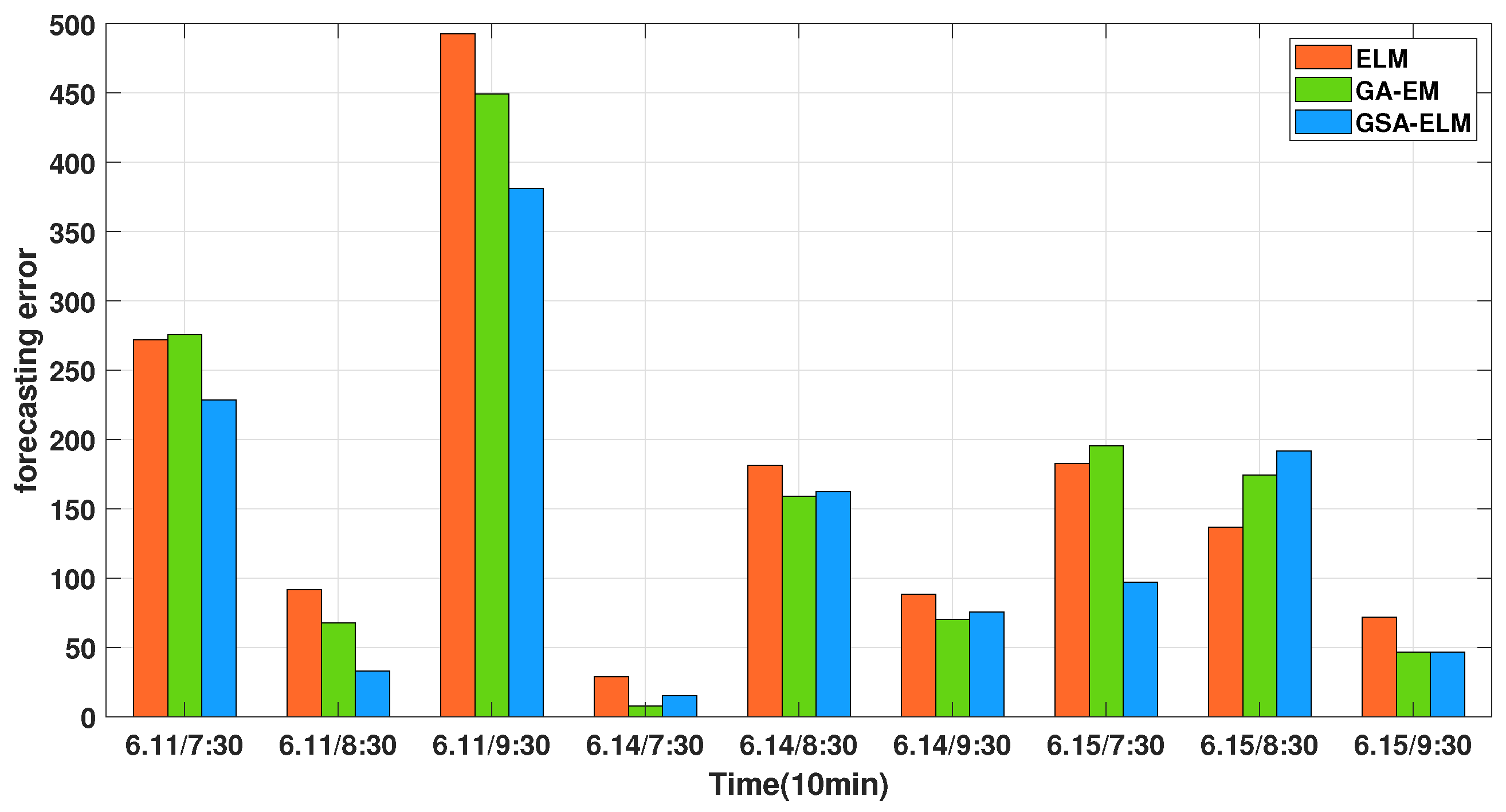
| The Morning Peak Period | Groundtruth | ELM | Prediction GA-ELM | PSOGSA-ELM |
|---|---|---|---|---|
| 6/11/7:30 | 3546 | 3274.033 | 3270.369 | 3392.933 |
| 6/11/8:30 | 3792 | 3700.290 | 3724.208 | 3756.983 |
| 6/11/9:30 | 4184 | 3691.265 | 3734.778 | 3801.143 |
| 6/14/7:30 | 2670 | 2641.334 | 2662.170 | 2649.311 |
| 6/14/8:30 | 3116 | 2934.568 | 2957.073 | 2976.761 |
| 6/14/9:30 | 3094 | 3005.691 | 3023.728 | 3033.094 |
| 6/15/7:30 | 2817 | 2999.734 | 3012.434 | 2920.417 |
| 6/15/8:30 | 2893 | 2846.403 | 2808.657 | 2807.973 |
| 6/15/9:30 | 3154 | 3225.806 | 3200.339 | 3239.240 |
| RMSE | 217.03 | 206.39 | 164.44 | |
| MAPE | 5.01 | 4.69 | 3.76 |
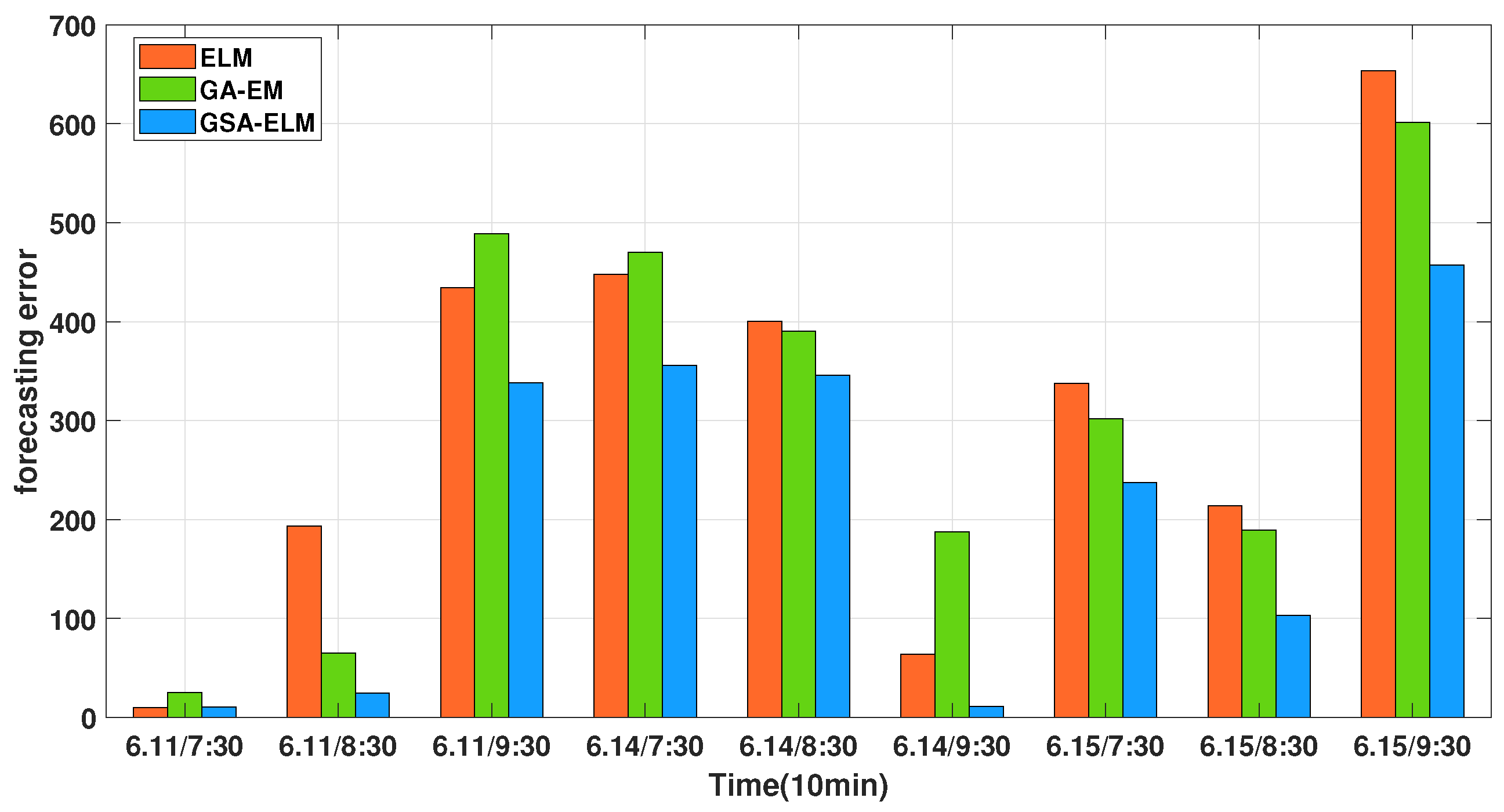
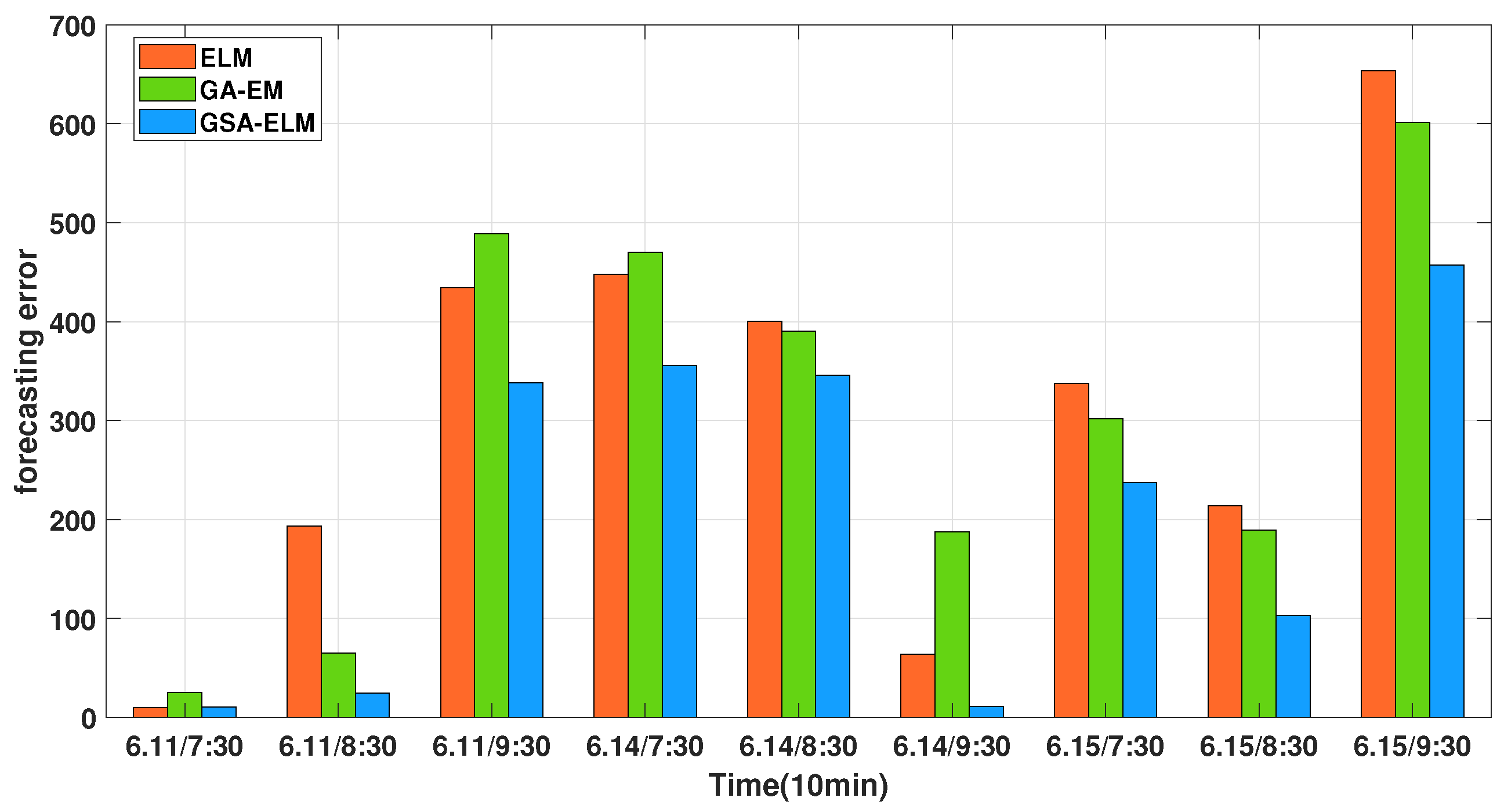
| The Afternoon Peak Period | Groundtruth | ELM | Prediction GA-ELM | PSOGSA-ELM |
|---|---|---|---|---|
| 6/11/13:30 | 3948 | 3957.867 | 3973.349 | 3956.204 |
| 6/11/14:00 | 4373 | 4179.630 | 4437.895 | 44,407.233 |
| 6/11/14:30 | 3542 | 3976.427 | 4030.626 | 3968.726 |
| 6/14/13:30 | 3817 | 3369.284 | 3346.841 | 3376.680 |
| 6/14/14:00 | 4135 | 3734.672 | 3744.345 | 3812.346 |
| 6/14/14:30 | 4197 | 4261.105 | 4384.840 | 4272.334 |
| 6/15/13:30 | 3732 | 3394.333 | 3430.046 | 3431.599 |
| 6/15/14:00 | 4032 | 3818.189 | 3842.358 | 3827.597 |
| 6/15/14:30 | 4549 | 3895.383 | 3947.706 | 3908.953 |
| RMSE | 361.78 | 356.10 | 338.08 | |
| MAPE | 7.62 | 7.57 | 6.82 |
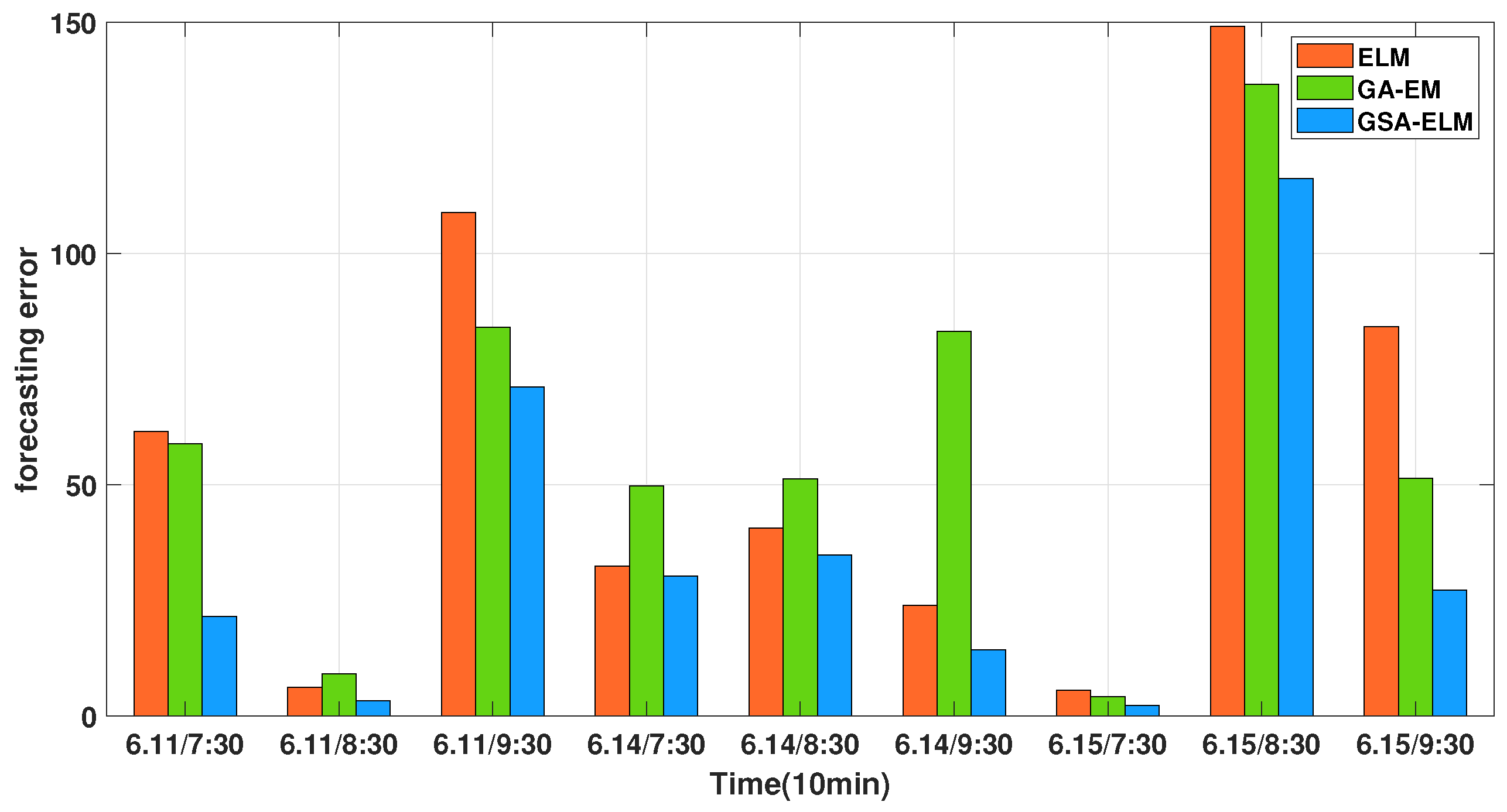
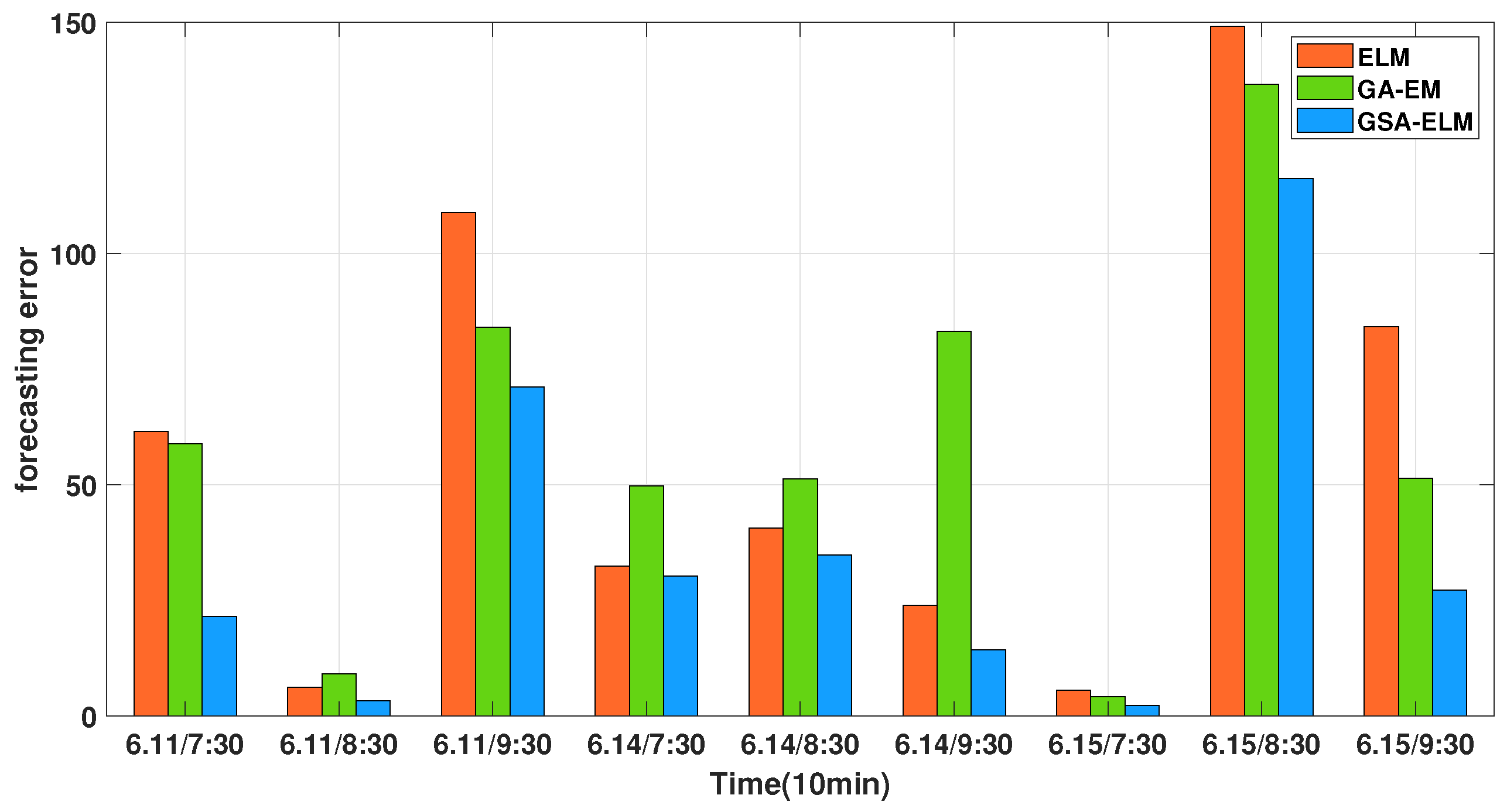
| The Midnight Period | Ground Truth | ELM | Prediction GA-ELM | PSOGSA-ELM |
|---|---|---|---|---|
| 6/11/23:30 | 297 | 235.481 | 238.125 | 238.980 |
| 6/12/00:00 | 243 | 236.766 | 233.857 | 241.629 |
| 6/12/00:30 | 229 | 337.797 | 313.061 | 309.774 |
| 6/12/23:30 | 297 | 264.544 | 247.249 | 259.573 |
| 6/13/00:00 | 192 | 232.681 | 243.316 | 212.192 |
| 6/13/00:30 | 426 | 402.075 | 342.899 | 374.851 |
| 6/13/23:30 | 241 | 246.560 | 236.844 | 236.777 |
| 6/14/00:00 | 187 | 336.153 | 323.598 | 261.377 |
| 6/14/00:30 | 284 | 368.125 | 335.396 | 316.246 |
| RMSE | 73.25 | 69.88 | 48.20 | |
| MAPE | 24.47 | 24.02 | 15.93 |
| Model | Computational Time (s) |
|---|---|
| ELM | 0.0516 |
| GA-ELM | 100.2139 |
| PSOGSA-ELM | 83.8456 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, Z.; Huang, B.; Dou, H.; Cheng, Y.; Guan, J.; Zhou, T. A Two-Stage Hybrid Extreme Learning Model for Short-Term Traffic Flow Forecasting. Mathematics 2022, 10, 2087. https://doi.org/10.3390/math10122087
Cui Z, Huang B, Dou H, Cheng Y, Guan J, Zhou T. A Two-Stage Hybrid Extreme Learning Model for Short-Term Traffic Flow Forecasting. Mathematics. 2022; 10(12):2087. https://doi.org/10.3390/math10122087
Chicago/Turabian StyleCui, Zhihan, Boyu Huang, Haowen Dou, Yan Cheng, Jitian Guan, and Teng Zhou. 2022. "A Two-Stage Hybrid Extreme Learning Model for Short-Term Traffic Flow Forecasting" Mathematics 10, no. 12: 2087. https://doi.org/10.3390/math10122087
APA StyleCui, Z., Huang, B., Dou, H., Cheng, Y., Guan, J., & Zhou, T. (2022). A Two-Stage Hybrid Extreme Learning Model for Short-Term Traffic Flow Forecasting. Mathematics, 10(12), 2087. https://doi.org/10.3390/math10122087