
A Modified γ-Sutte Indicator for Air Quality Index Prediction




Abstract
1. Introduction
2. Preliminary
2.1. Air Quality Index (AQI)
2.2. Related Work on AQI
2.3. Sutte Indicator
2.4. α-Sutte Indicator
2.5. β-Sutte Indicator
2.6. Autoregressive Integrated Moving Average (ARIMA)
2.7. Ensemble Model
3. Materials and Methods
3.1. Data Collection
3.2. The α-Sutte and Proposed γ-Sutte Indicator
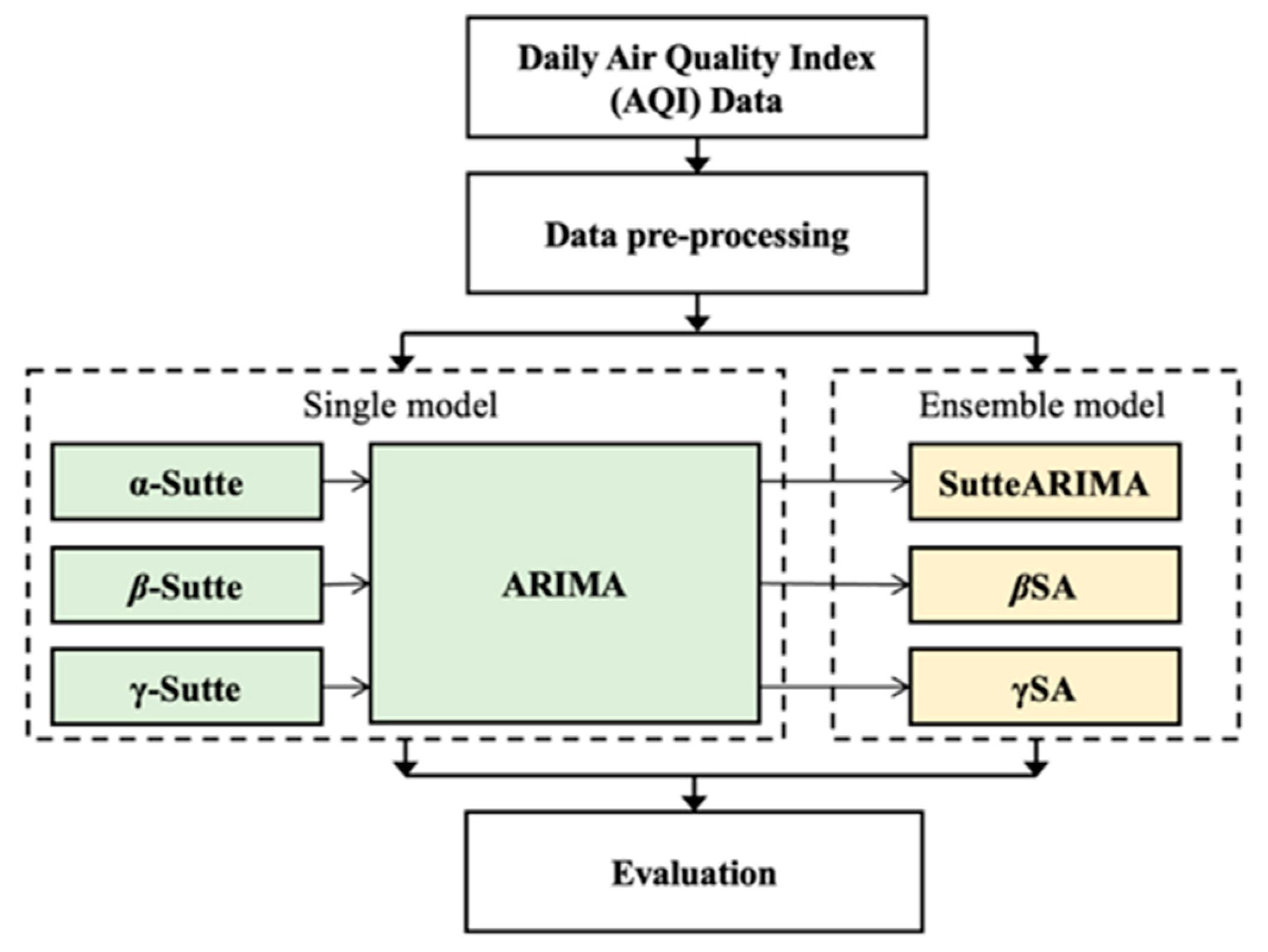
3.3. Overall Experimental Process
3.3.1. Evaluation Process of Time Series Single Models
- Data pre-processing: To ensure the authenticity of the data, the negative value and outliers were removed during the preprocessing;
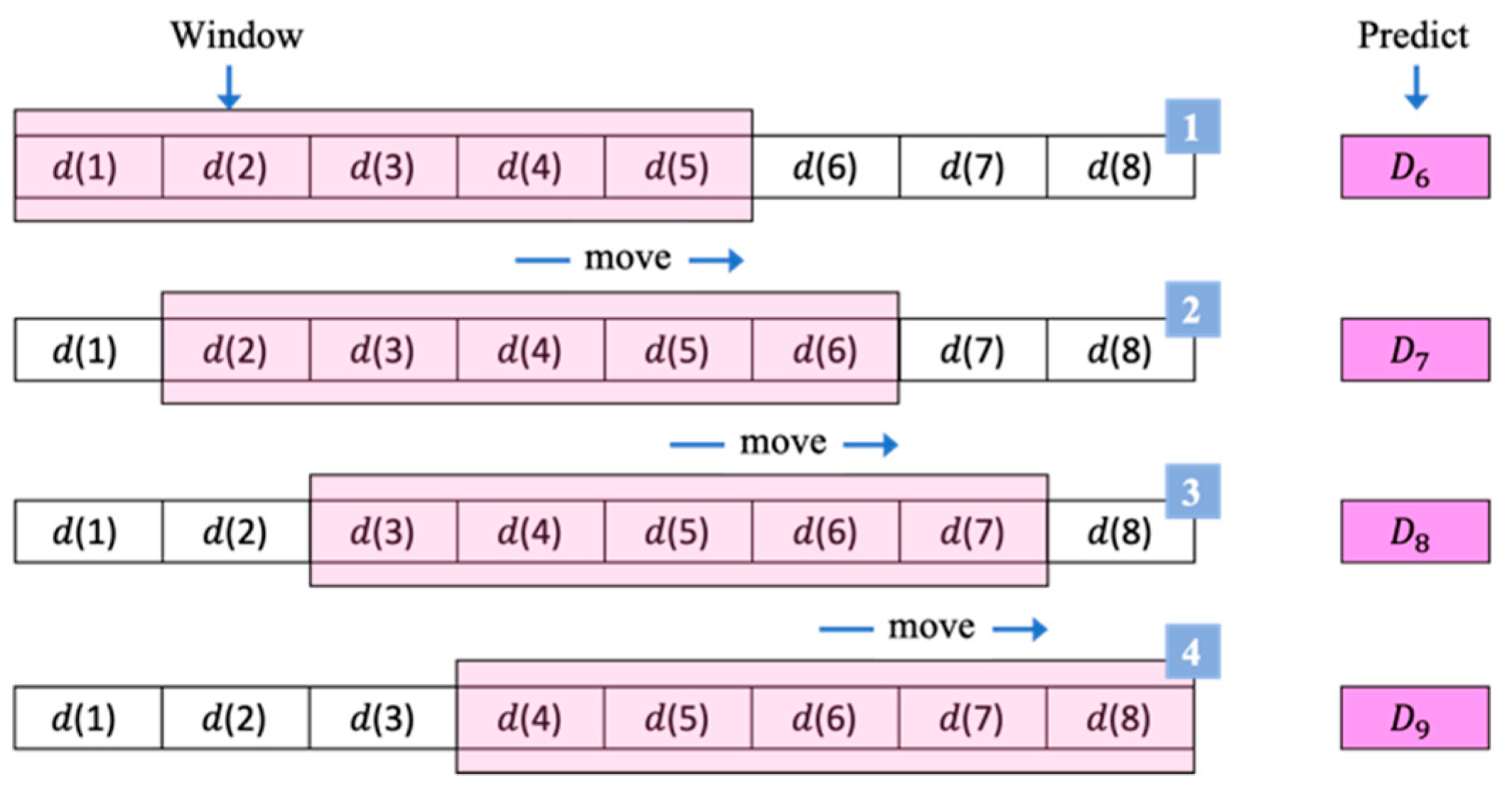
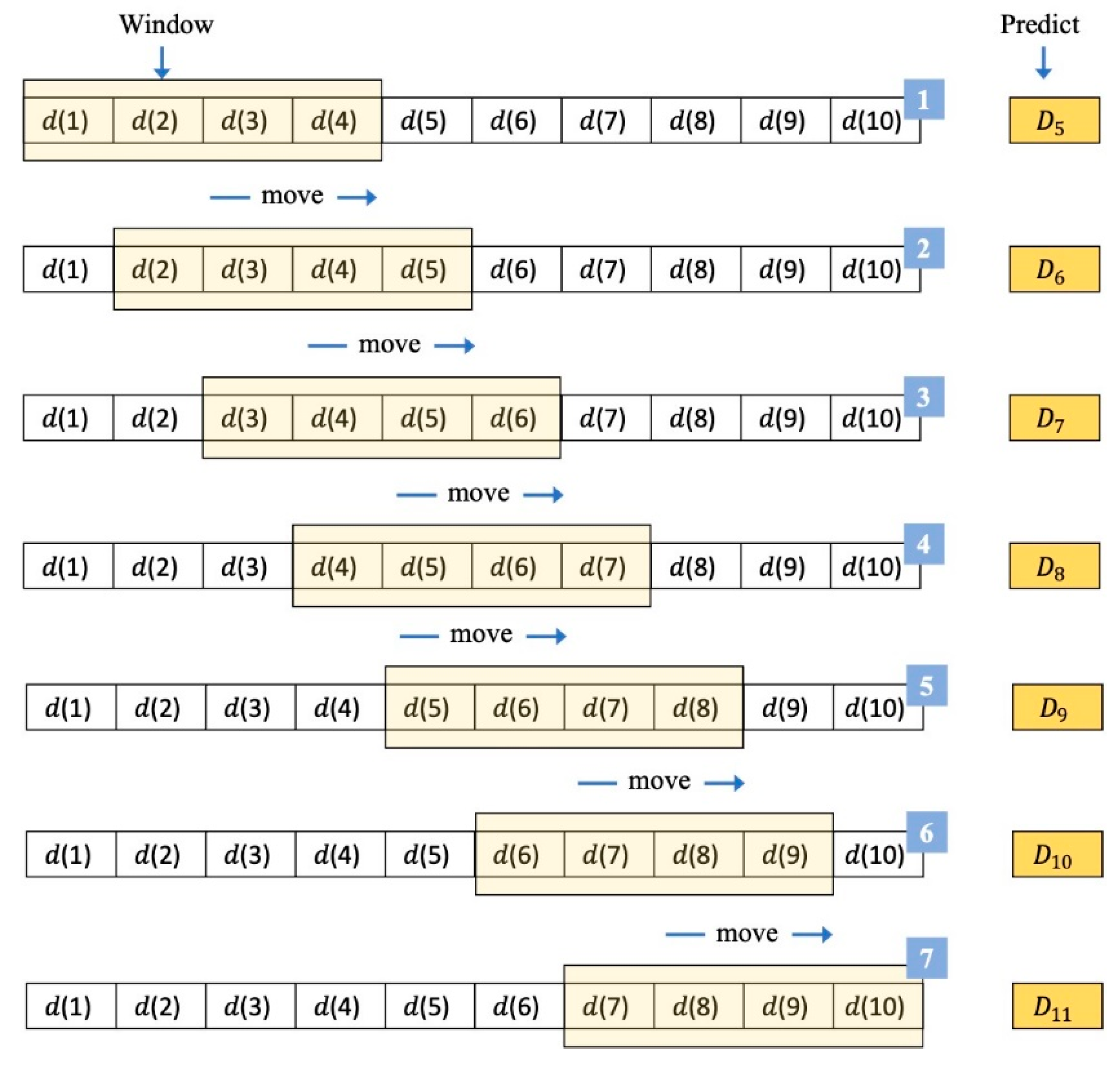
- The γ-Sutte indicator used a sliding window size of 5 to make the prediction as shown in Figure 2. For example, the γ-Sutte indicator used , , , , and to predict , then used , , , , and to predict , and so on;
- The sliding window size of the γ -Sutte indicator proposed in this study was set to 5, and took , , , , and , and used Equation (3) to calculate the variation of {, , , };
- After the calculation, three error values {} of , , and were calculated using Equation (5);
- The results from Step 4: were adopted to Equation (4) to calculate the dynamic weights {};
- The weight obtained in Step 5 was put into Equation (2) to calculate the predicted value ;
- The four methods (α-Sutte indicator, β-Sutte indicator, γ-Sutte indicator, and ARIMA) of the time series single model were all evaluated using evaluation metrics.
3.3.2. The Evaluation Process of the Ensemble Models
- Data pre-processing: To ensure the authenticity of the data, the negative value and outliers were removed during the preprocessing;
- The ARIMA method used the same dataset, then averaged the results of the α-Sutte indicator and ARIMA, to become the final result of the SutteARIMA;
- The results of the other two methods, the β-Sutte indicator, and the γ-Sutte indicator, were averaged with the ARIMA results to form the results of the βSA, and the γSA ensemble models;
- The results of the three ensemble models were evaluated using the evaluation metrics.
3.4. Evaluation Metrics
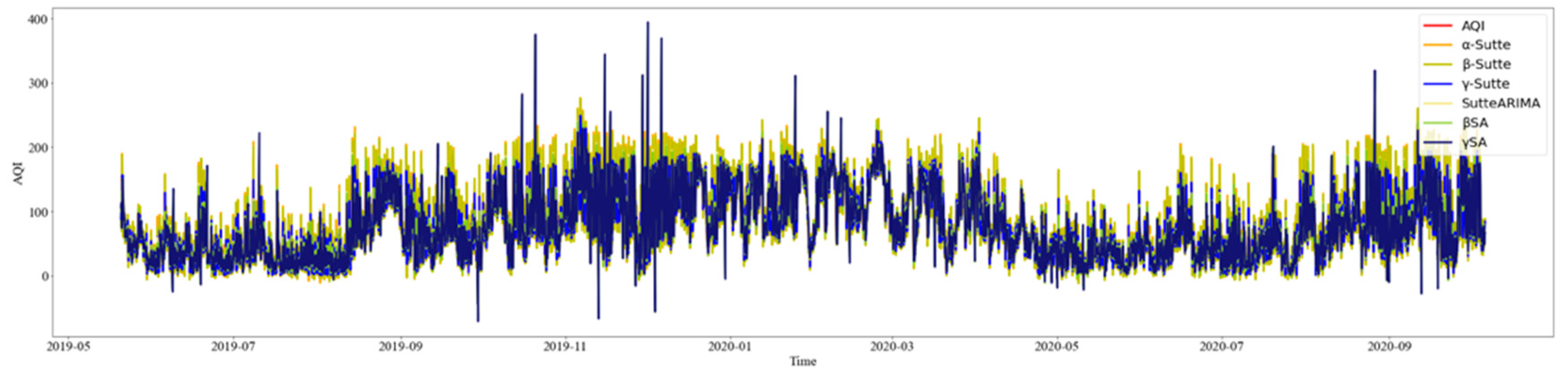
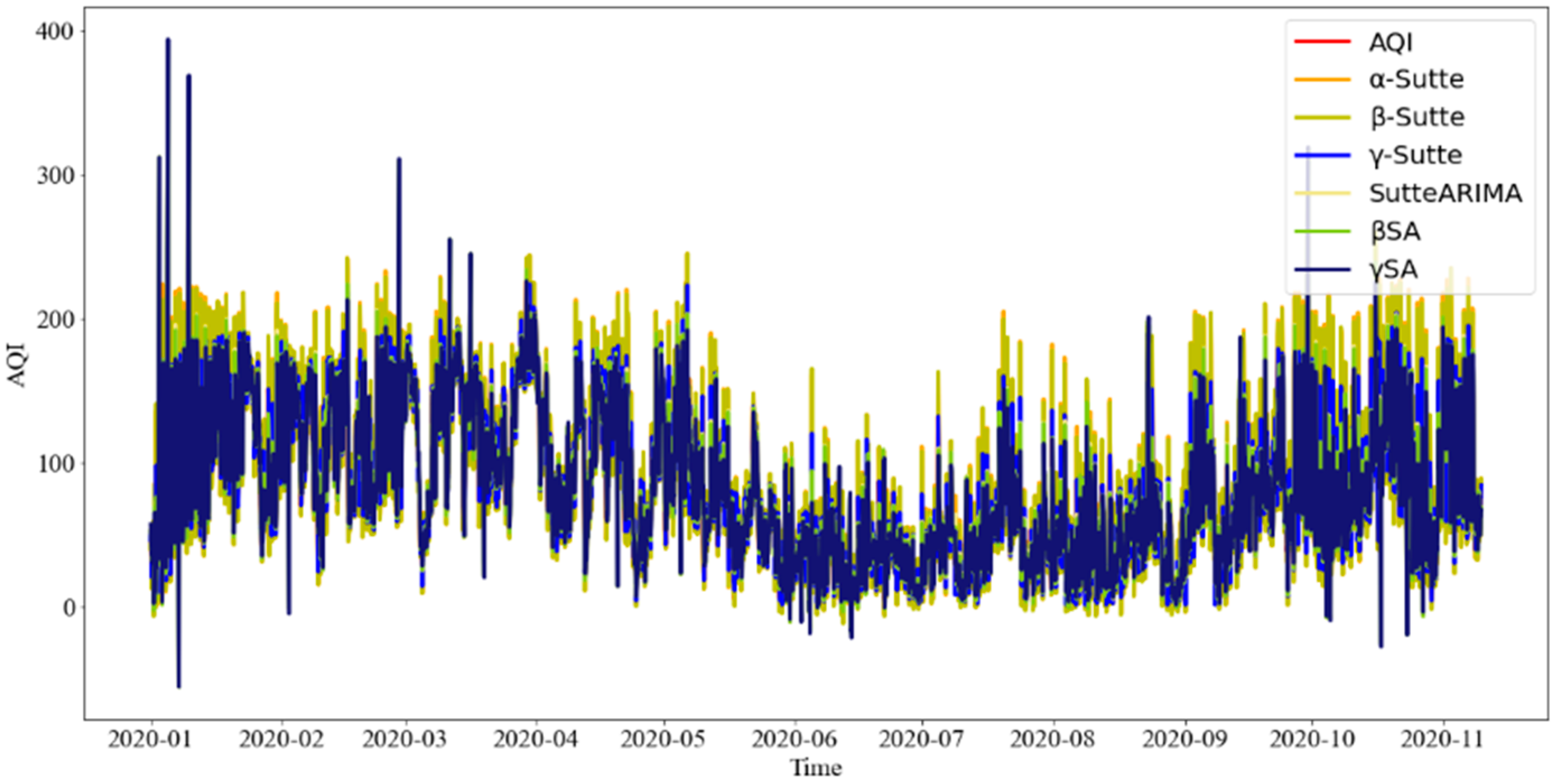
4. Results
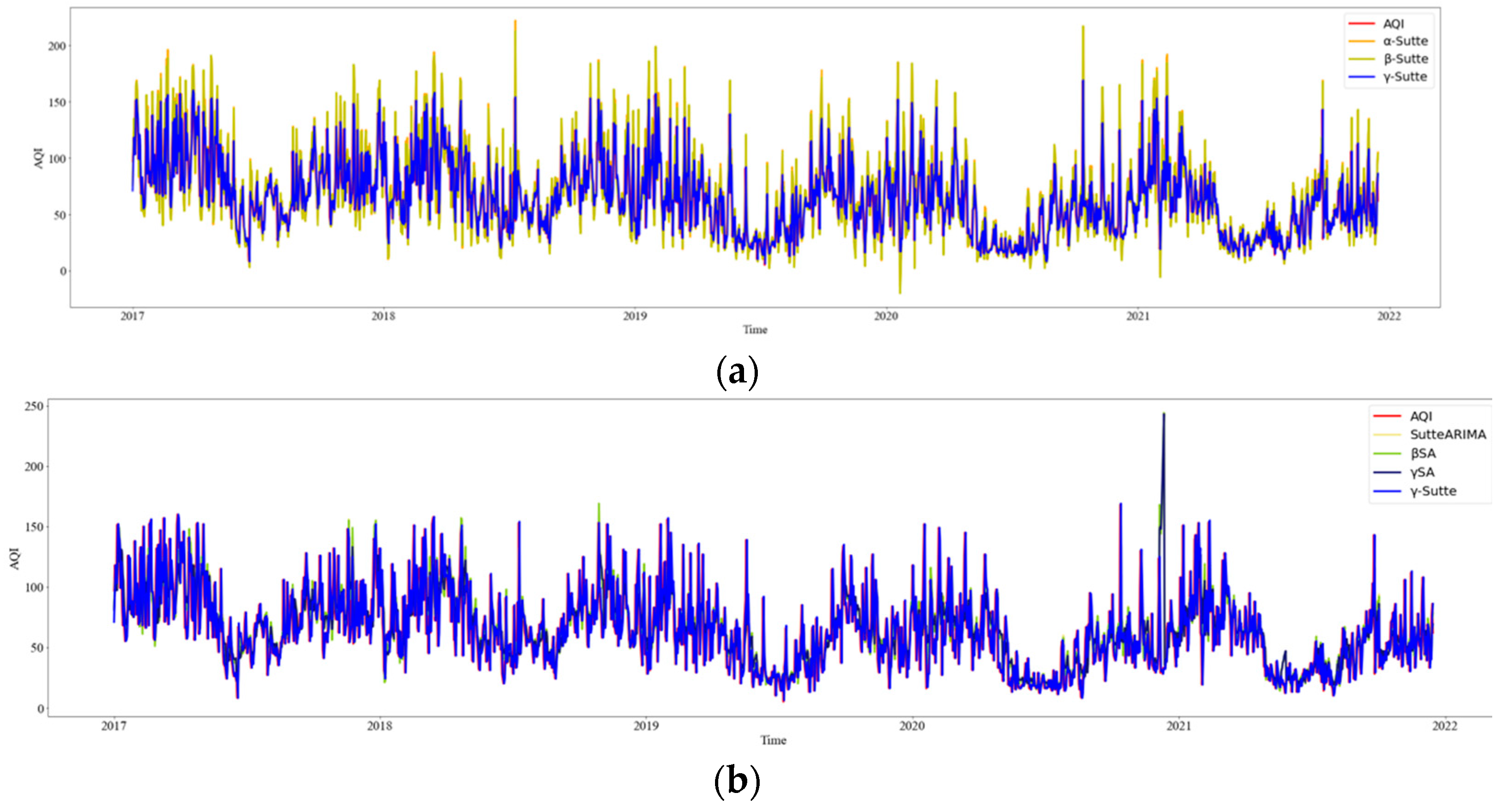
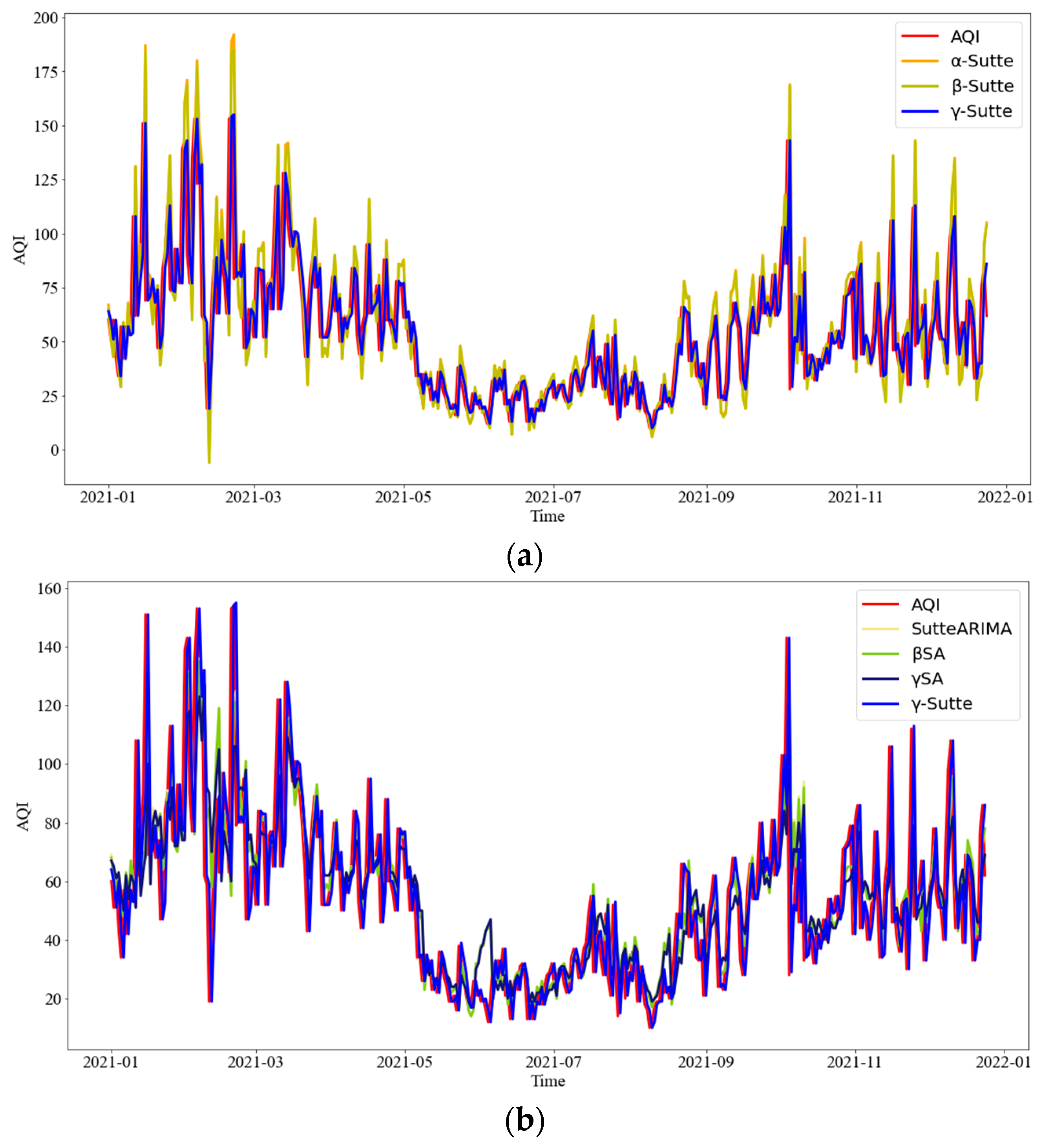
4.1. Time Series Single Model Evaluation
4.2. Ensemble Model Evaluation
5. Discussion
5.1. Transferable
5.2. Discussion
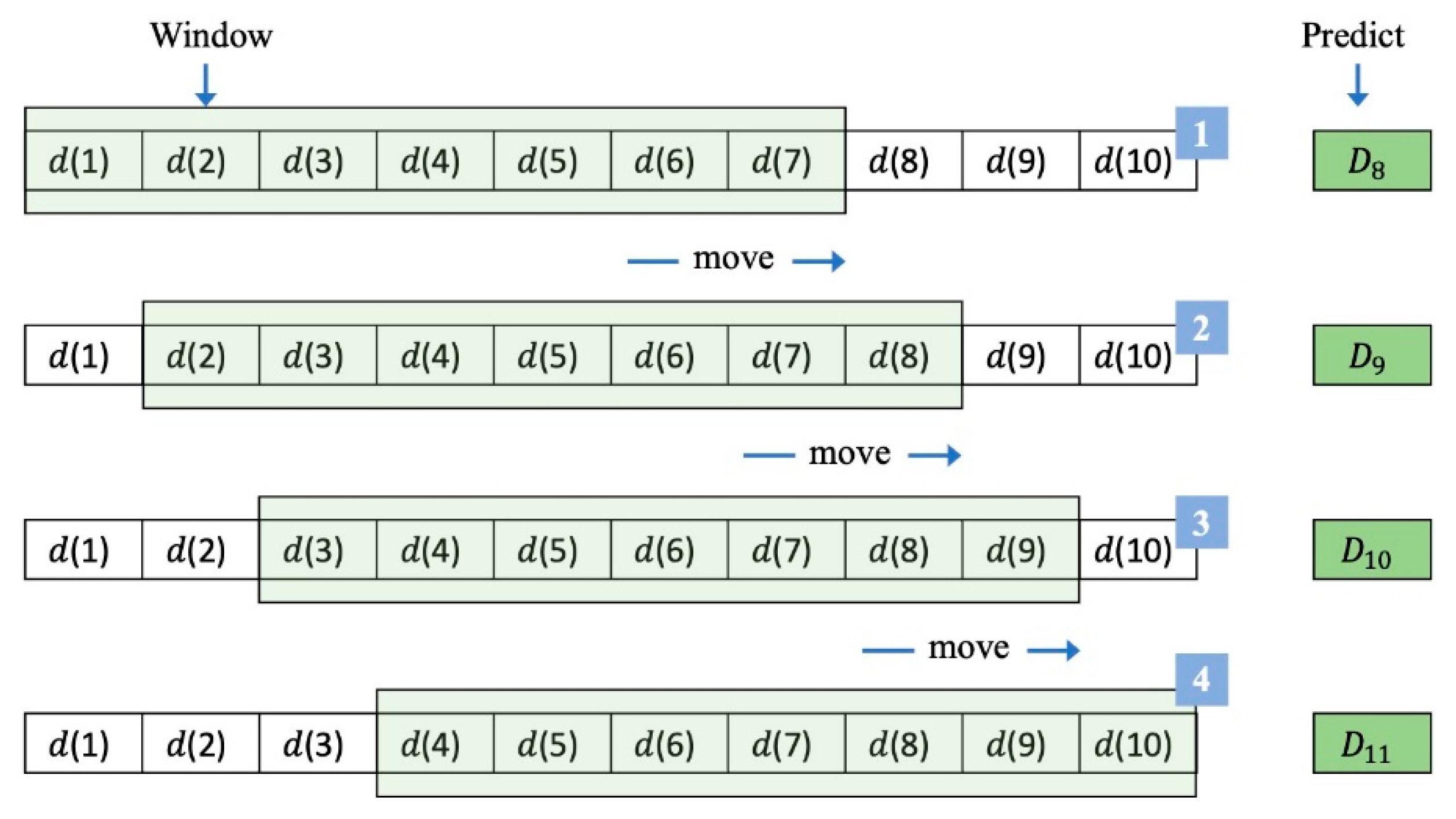
- The α-Sutte indicator [8] uses fixed weight, while the γ-Sutte indicator proposed in this study used dynamic weight to make predictions. The effect of dynamic weight on prediction was better than fixed weight because the weight was adjusted at all times according to the sliding window. Therefore, the prediction results of the β-Sutte indicator [9] in another study was also better than the α-Sutte indicator; this was verified in this study. Figure 7 and Figure 8 show the operation of the sliding window of the α-Sutte indicator and the β-Sutte indicator. Although the prediction results of the β-Sutte indicator were slightly better than that of the α-Sutte indicator, the required time window size was much larger than that of the α-Sutte indicator.
- The β-Sutte indicator [9] used the dynamic error weight and the sliding window size of 7 (in Figure 8), while the γ-Sutte indicator proposed in this study also used a different error dynamic weight to make predictions, with a sliding window size of only 5 (in Figure 3). In addition, the computational complexity of the α-Sutte indicator, the β-Sutte indicator, and the γ-Sutte indicator were O(1), O(2n), and O(n), respectively. The computational cost of the γ-Sutte indicator was relatively low compared to the β-sutte indicator. Nevertheless, the prediction results of the γ-Sutte indicator were better than the β-sutte indicator, indicating that the prediction results may be better if an appropriate error function and sliding window size are selected.
- Although the prediction results of the ARIMA model, which had a relatively high calculation time, was not better than that of the γ-Sutte indicator proposed in this study, the prediction results of ARIMA were still better than that of other time series models, indicating that the ARIMA prediction model is still feasible to use in time series analysis.
- Traditionally, the prediction results of the ensemble model were better than those of the single model. However, if the prediction results of the single model selected are not very good, then they will weaken the advantages of the ensemble model; this was verified in the experiment of this study.
6. Conclusions
- To calculate dynamic weight, the training calculation time of the γ-Sutte indicator proposed in this study was higher than that of the α-Sutte indicator which uses a fixed weight. The calculation cost was lower than that of the β-Sutte indicator with dynamic weight. However, the prediction results of the γ-Sutte indicator was among the best. Nevertheless, if the prediction results are arbitrary and with acceptable accuracy, the α-Sutte indicators may be the best option.
- In addition to the daily AQI prediction in the Mailiao district, this study also conducted the hourly AQI prediction experiment in the Vientiane district. The results showed that the γ-Sutte Indicator also had good prediction ability in different periods, representing this method’s transferability and generalization.
- The main reason why the modified γ-Sutte indicator was proposed is that although the prediction abilities of the β-Sutte indicator established by Shih [9] were slightly better than those of the α-Sutte indicator, the calculation cost was higher than that of α-Sutte. Therefore, this study proposed a more efficient modified γ-Sutte indicator.
- In the prediction of AQI, other variables should be considered in the future, such as wind direction, nearby stations, climate, etc.
- For the ensemble model, combinations of the γ-Sutte indicator with other time series methods in the future to form a better model should be explored, such as the Holt-Winters Model.
- In addition, perhaps deep learning and artificial neural networks can be compared together in the future. Wang [33] proposed an optimized echo state network for effective time series prediction. Compared with other artificial neural networks, the most apparent advantage of echo state network (ESN) is its more straightforward network structure and lower computational cost. Two real-time series datasets were used for prediction experiments, and the experimental results of the optimized ESN were also quite excellent. Xu [34] proposed multi-variable LSTM (MV-LSTM) to better capture the different temporal dynamics of multivariate sequences in an interpretable form. This model dramatically improves the prediction model’s performance and has a good effect on the housing load prediction. By evaluating each variable’s contribution to the prediction, the multi-quantile prediction of multiple time steps in the future can be generated.
Author Contributions
Funding
Conflicts of Interest
References
- World Health Organization. Ambient (Outdoor) Air Quality and Health, Fact Sheet No. 313. Available online: http://www.who.int/mediacentre/factsheets/fs313/en/ (accessed on 1 August 2022).
- International Agency for Research on Cancer (IARC). Outdoor Air Pollution. In IARC Monographs on the Evaluation of Carcinogenic Risks to Humans; International Agency for Research on Cancer: Lyon, France, 2013; Volume 109. [Google Scholar]
- Zhu, S.; Lian, X.; Liu, H.; Hu, J.; Wang, Y.; Che, J. Daily air quality index forecasting with hybrid models: A case in China. Environ. Pollut. 2017, 231, 1232–1244. [Google Scholar] [CrossRef]
- Wu, Q.; Lin, H. A novel optimal-hybrid model for daily air quality index prediction considering air pollutant factors. Sci. Total Environ. 2019, 683, 808–821. [Google Scholar] [CrossRef]
- Wang, J.; Li, J.; Wang, X.; Wang, J.; Huang, M. Air quality prediction using CT-LSTM. Neural Comput. Appl. 2021, 33, 4779–4792. [Google Scholar] [CrossRef]
- Han, Y.; Li, V.O.; Lam, J.C.; Pollitt, M. How BLUE is the sky? Estimating air qualities in Beijing during the Blue-Sky Day period (2008–2012) by Bayesian multi-task LSTM. Environ. Sci. Policy 2021, 116, 69–77. [Google Scholar] [CrossRef]
- Zhang, L.; Na, J.; Zhu, J.; Shi, Z.; Zou, C.; Yang, L. Spatiotemporal causal convolutional network for forecasting hourly PM2.5 concentrations in Beijing, China. Comput. Geosci. 2021, 155, 104869. [Google Scholar] [CrossRef]
- Ahmar, A.S.; Rahman, A.; Mulbar, U. Implementation of α-Sutte Indicator to Forecasting Consumer Price Index in Turkey. In Proceedings of the International Conference On Mathematics and Natural Sciences, Bali, Indonesia, 6–7 September 2017; pp. 1–4. [Google Scholar]
- Shih, D.-H.; Wu, T.-W.; Shih, M.-H.; Yang, M.-J.; Yen, D.C. A Novel βSA Ensemble Model for Forecasting the Number of Confirmed COVID-19 Cases in the US. Mathematics 2022, 10, 824. [Google Scholar] [CrossRef]
- Cheng, W.-L.; Chen, Y.-S.; Zhang, J.; Lyons, T.; Pai, J.-L.; Chang, S.-H. Comparison of the revised air quality index with the PSI and AQI indices. Sci. Total Environ. 2007, 382, 191–198. [Google Scholar] [CrossRef]
- Benchrif, A.; Wheida, A.; Tahri, M.; Shubbar, R.M.; Biswas, B. Air quality during three covid-19 lockdown phases: AQI, PM2.5 and NO2 assessment in cities with more than 1 million inhabitants. Sustain. Cities Soc. 2021, 74, 103170. [Google Scholar] [CrossRef]
- Li, Y.; Chiu, Y.-h.; Lu, L.C. Energy and AQI performance of 31 cities in China. Energy Policy 2018, 122, 194–202. [Google Scholar] [CrossRef]
- Ren, Y.-S.; Narayan, S.; Ma, C.-q. Air quality, COVID-19, and the oil market: Evidence from China’s provinces. Econ. Anal. Policy 2021, 72, 58–72. [Google Scholar] [CrossRef]
- Li, X.; Hu, Z.; Cao, J.; Xu, X. The impact of environmental accountability on air pollution: A public attention perspective. Energy Policy 2022, 161, 112733. [Google Scholar] [CrossRef]
- Sethi, J.K.; Mittal, M. Analysis of air quality using univariate and multivariate time series models. In Proceedings of the 2020 10th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 29–31 January 2020. [Google Scholar]
- Phruksahiran, N. Improvement of air quality index prediction using geographically weighted predictor methodology. Urban Clim. 2021, 38, 100890. [Google Scholar] [CrossRef]
- Yan, R.; Liao, J.; Yang, J.; Sun, W.; Nong, M.; Li, F. Multi-hour and multi-site air quality index forecasting in Beijing using CNN, LSTM, CNN-LSTM, and spatiotemporal clustering. Expert Syst. Appl. 2021, 169, 114513. [Google Scholar] [CrossRef]
- Liu, H.; Yan, G.; Duan, Z.; Chen, C. Intelligent modeling strategies for forecasting air quality time series: A review. Appl. Soft Comput. 2021, 102, 106957. [Google Scholar] [CrossRef]
- Ahmar, A.S. Sutte Indicator: A technical indicator in stock market. Int. J. Econ. Financ. Issues 2017, 7, 223–226. [Google Scholar]
- Ahmar, A.S. A comparison of α-Sutte Indicator and ARIMA methods in renewable energy forecasting in Indonesia. Int. J. Eng. Technol. 2018, 7, 20–22. [Google Scholar] [CrossRef][Green Version]
- Lippi, M.; Bertini, M.; Frasconi, P. Short-term traffic flow forecasting: An experimental comparison of time-series analysis and supervised learning. IEEE Trans. Intell. Transp. Syst. 2013, 14, 871–882. [Google Scholar] [CrossRef]
- Rekhi, J.K.; Nagrath, P.; Jain, R. Forecasting Air Quality of Delhi Using ARIMA Model. In Advances in Data Sciences, Security and Applications; Springer: Berlin/Heidelberg, Germany, 2020; pp. 315–325. [Google Scholar]
- Aladağ, E. Forecasting of particulate matter with a hybrid ARIMA model based on wavelet transformation and seasonal adjustment. Urban Clim. 2021, 39, 100930. [Google Scholar] [CrossRef]
- Gopu, P.; Panda, R.R.; Nagwani, N.K. Time Series Analysis Using ARIMA Model for Air Pollution Prediction in Hyderabad City of India. In Soft Computing and Signal Processing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 47–56. [Google Scholar]
- Li, Y.; Pan, Y. A novel ensemble deep learning model for stock prediction based on stock prices and news. Int. J. Data Sci. Anal. 2022, 13, 139–149. [Google Scholar] [CrossRef]
- Ahmar, A.S.; Del Val, E.B. SutteARIMA: Short-term forecasting method, a case: COVID-19 and stock market in Spain. Sci. Total Environ. 2020, 729, 138883. [Google Scholar] [CrossRef]
- Ejohwomu, O.A.; Shamsideen Oshodi, O.; Oladokun, M.; Bukoye, O.T.; Emekwuru, N.; Sotunbo, A.; Adenuga, O. Modelling and Forecasting Temporal PM2.5 Concentration Using Ensemble Machine Learning Methods. Buildings 2022, 12, 46. [Google Scholar] [CrossRef]
- Executive Yuan. Environmental Information Open Platform of the Environmental Protection Department. Available online: https://data.epa.gov.tw/dataset/detail/AQX_P_434 (accessed on 8 January 2022).
- Kumar, A.; Goyal, P. Forecasting of daily air quality index in Delhi. Sci. Total Environ. 2011, 409, 5517–5523. [Google Scholar] [CrossRef] [PubMed]
- Shahid, N.; Shah, M.A.; Khan, A.; Maple, C.; Jeon, G. Towards Greener Smart Cities and Road Traffic Forecasting Using Air Pollution Data. Sustain. Cities Soc. 2021, 72, 103062. [Google Scholar] [CrossRef]
- Korstjens, I.; Moser, A. Series: Practical guidance to qualitative research. Part 4: Trustworthiness and publishing. Eur. J. Gen. Pract. 2018, 24, 120–124. [Google Scholar] [CrossRef]
- Air Quality Data of the United States Consulate in Laos. Available online: https://www.airnow.gov/ (accessed on 8 January 2022).
- Wang, Z.; Zeng, Y.R.; Wang, S.; Wang, L. Optimizing echo state network with backtracking search optimization algorithm for time series forecasting. Eng. Appl. Artif. Intell. 2019, 81, 117–132. [Google Scholar] [CrossRef]
- Xu, C.; Li, C.; Zhou, X. Interpretable LSTM Based on Mixture Attention Mechanism for Multi-Step Residential Load Forecasting. Electronics 2022, 11, 2189. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Definition |
|---|---|
| siteid | station number |
| sitename | station name |
| monitordate | monitoring date |
| aqi | AQI Value |
| so2subindex | Sulfur dioxide sub-index |
| cosubindex | Carbon monoxide sub-index |
| o3subindex | Ozone sub-index |
| pm10subindex | suspended particulates sub-index |
| no2subindex | Nitrogen dioxide sub-index |
| o38subindex | Ozone 8-h sub-index |
| pm25subindex | fine suspended particulates sub-index |
| Notation | Definition |
|---|---|
| Observations at day | |
| Observations at day | |
| The predicted value of day | |
| Observations on day | |
| , | Observations on day |
| Observations on day | |
| Observations on day | |
| Observations on day | |
| Error function | |
| Dynamic weighting function |
| Evaluation Metrics | α-Sutte | β-Sutte | -Sutte | ARIMA |
|---|---|---|---|---|
| MAPE | 35.52503 | 35.33326 | 28.15433 | 44.45941 |
| MAE | 20.40166 | 20.35359 | 16.3663 | 16.3663 |
| RMSE | 28.86724 | 28.69002 | 23.18071 | 34.22783 |
| R2 | 0.4682005 | 0.4660149 | 0.5347211 | 0.1757319 |
| Evaluation Metrics | SutteARIMA | βSA | SA | -Sutte |
|---|---|---|---|---|
| MAPE | 32.60922 | 32.29693 | 32.1901 | 28.15433 |
| MAE | 17.25304 | 17.18177 | 17.10884 | 16.3663 |
| RMSE | 24.52663 | 24.45834 | 24.21541 | 23.18071 |
| R2 | 0.4643722 | 0.4633891 | 0.4499986 | 0.5347211 |
| Variables | Definitions |
|---|---|
| Site | name of the station |
| Date.LT. | date of monitoring |
| AQI | air quality index |
| AQI.Category | Categories of air quality index |
| Raw.Conc. | - |
| QC.Name | - |
| Evaluation Metrics | α-Sutte | β-Sutte | -Sutte | ARIMA | SutteARIMA | βSA | SA |
|---|---|---|---|---|---|---|---|
| MAPE | 22.78845 | 22.61683 | 19.79801 | 63.85786 | 35.03214 | 34.90172 | 38.71741 |
| MAE | 10.90479 | 10.77376 | 9.059488 | 29.66419 | 15.5703 | 15.54959 | 17.72079 |
| RMSE | 16.08355 | 15.8108 | 13.76311 | 45.62253 | 23.58507 | 23.58148 | 26.33336 |
| R2 | 0.9175967 | 0.9200563 | 0.9286815 | 0.4358475 | 0.7988707 | 0.7991491 | 0.7499707 |
| Area | Metrics | α-Sutte | β-Sutte | -Sutte | ARIMA | SutteARIMA | βSA | SA |
|---|---|---|---|---|---|---|---|---|
| Mailiao | MAPE | 35.52503 | 35.33326 | 28.15433 | 44.45941 | 32.60922 | 32.29693 | 32.1901 |
| MAE | 20.40166 | 20.35359 | 16.3663 | 16.3663 | 17.25304 | 17.18177 | 17.10884 | |
| RMSE | 28.86724 | 28.69002 | 23.18071 | 34.22783 | 24.52663 | 24.45834 | 24.21541 | |
| R2 | 0.4682005 | 0.4660149 | 0.5347211 | 0.1757319 | 0.4643722 | 0.4633891 | 0.4499986 | |
| Vientiane | MAPE | 22.78845 | 22.61683 | 19.79801 | 63.85786 | 35.03214 | 34.90172 | 38.71741 |
| MAE | 10.90479 | 10.77376 | 9.059488 | 29.66419 | 15.5703 | 15.54959 | 17.72079 | |
| RMSE | 16.08355 | 15.8108 | 13.76311 | 45.62253 | 23.58507 | 23.58148 | 26.33336 | |
| R2 | 0.9175967 | 0.9200563 | 0.9286815 | 0.4358475 | 0.7988707 | 0.7991491 | 0.7499707 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shih, D.-H.; Hien, T.T.; Nguyen, L.S.P.; Wu, T.-W.; Lai, Y.-T. A Modified γ-Sutte Indicator for Air Quality Index Prediction. Mathematics 2022, 10, 3060. https://doi.org/10.3390/math10173060
Shih D-H, Hien TT, Nguyen LSP, Wu T-W, Lai Y-T. A Modified γ-Sutte Indicator for Air Quality Index Prediction. Mathematics. 2022; 10(17):3060. https://doi.org/10.3390/math10173060
Chicago/Turabian StyleShih, Dong-Her, To Thi Hien, Ly Sy Phu Nguyen, Ting-Wei Wu, and Yen-Ting Lai. 2022. "A Modified γ-Sutte Indicator for Air Quality Index Prediction" Mathematics 10, no. 17: 3060. https://doi.org/10.3390/math10173060
APA StyleShih, D.-H., Hien, T. T., Nguyen, L. S. P., Wu, T.-W., & Lai, Y.-T. (2022). A Modified γ-Sutte Indicator for Air Quality Index Prediction. Mathematics, 10(17), 3060. https://doi.org/10.3390/math10173060