1. Introduction
Online learning originated in the 19th century through correspondence education and has evolved significantly in today’s digital age through advances in computer and Internet technologies. The emergence of Open Education Resources (OER) and Massive Open Online Courses (MOOCs) has fundamentally transformed educational accessibility (
Saykili, 2018). While the trend toward online education was already growing, the COVID-19 pandemic accelerated this transformation to unprecedented levels, with UNESCO reporting approximately 862 million students, almost half of the world’s student population, affected by school closures across 107 countries (
Abuhammad, 2020). This global shift prompted higher education institutions worldwide to rapidly adopt online learning platforms. Even after the pandemic has subsided, most institutions continue to rely on widely adopted online learning platforms, making it increasingly important to enhance the accessibility and effectiveness of recorded lecture archives. Lecture archives are integral to blended learning, enabling students to combine in-person instruction with flexible online review. This study examines a practical blended learning scenario where students attend face-to-face lectures and selectively revisit key segments of unedited recordings to enhance learning efficiency.
Among these blended learning resources, lecture archives, which are complete recordings of face-to-face lectures without editing, have become an increasingly common practice in higher education institutions, especially in countries like the United Kingdom and the United States. For instance, lecture capture is now a common feature in UK universities (
Lamb & Ross, 2022), and earlier surveys already showed that a majority of institutions had deployed such solutions by 2014 (
Walker et al., 2014). Similarly, high adoption rates are reported in the US, where one study found 95% of responding medical schools regularly record lectures (
Khong et al., 2025). This popularity primarily stems from their cost-effectiveness and ease of distribution. In Japan, the Japan Advanced Institute of Science and Technology (JAIST) also exemplifies this trend, having systematically recorded face-to-face lectures through their Learning Management System since 2006, thereby creating an extensive archive for supplemental learning (
Hasegawa et al., 2007). However, the unedited, long-form nature of these recordings presents significant hurdles. Beyond the practical difficulties for instructors in manually editing and managing such large volumes of content, they often prove inefficient for student learning. For instance, students can find it difficult to maintain attention throughout extended viewing periods (
Guo et al., 2014;
Sablić et al., 2021), and contemporary research indicates that the key to enhancing learning with long-form material is not merely shortening it, but providing a meaningful, navigable structure (
Seidel, 2024).
This raises the practical question of how to identify which segments learners find most meaningful. While direct measures of cognitive engagement, such as eye tracking or user self-reporting, are often impractical in real-world educational environments, behavioral indicators derived from interaction data offer a promising alternative. Equating “meaningful” segments with “high-engagement” segments, inferred from viewing patterns, provides a scalable approach to improving the accessibility and effectiveness of lecture archives. For example, Guo et al. proposed the use of engagement time—the duration students spend watching a video—as a proxy for interest (
Guo et al., 2014).
Building upon this idea,
Bulathwela et al. (
2020) introduced the VLEngagement dataset, which estimates video-level engagement by computing a normalized viewing duration aggregated across large numbers of users. Specifically, they defined Engagement Score = Average Watch Time/Video Duration, providing a cost-effective and scalable labeling method for large collections of educational videos. However, the engagement labels in this dataset are defined at the whole-video level, resulting in a coarse granularity that limits its applicability to tasks such as segment-level attention modeling or highlight extraction.
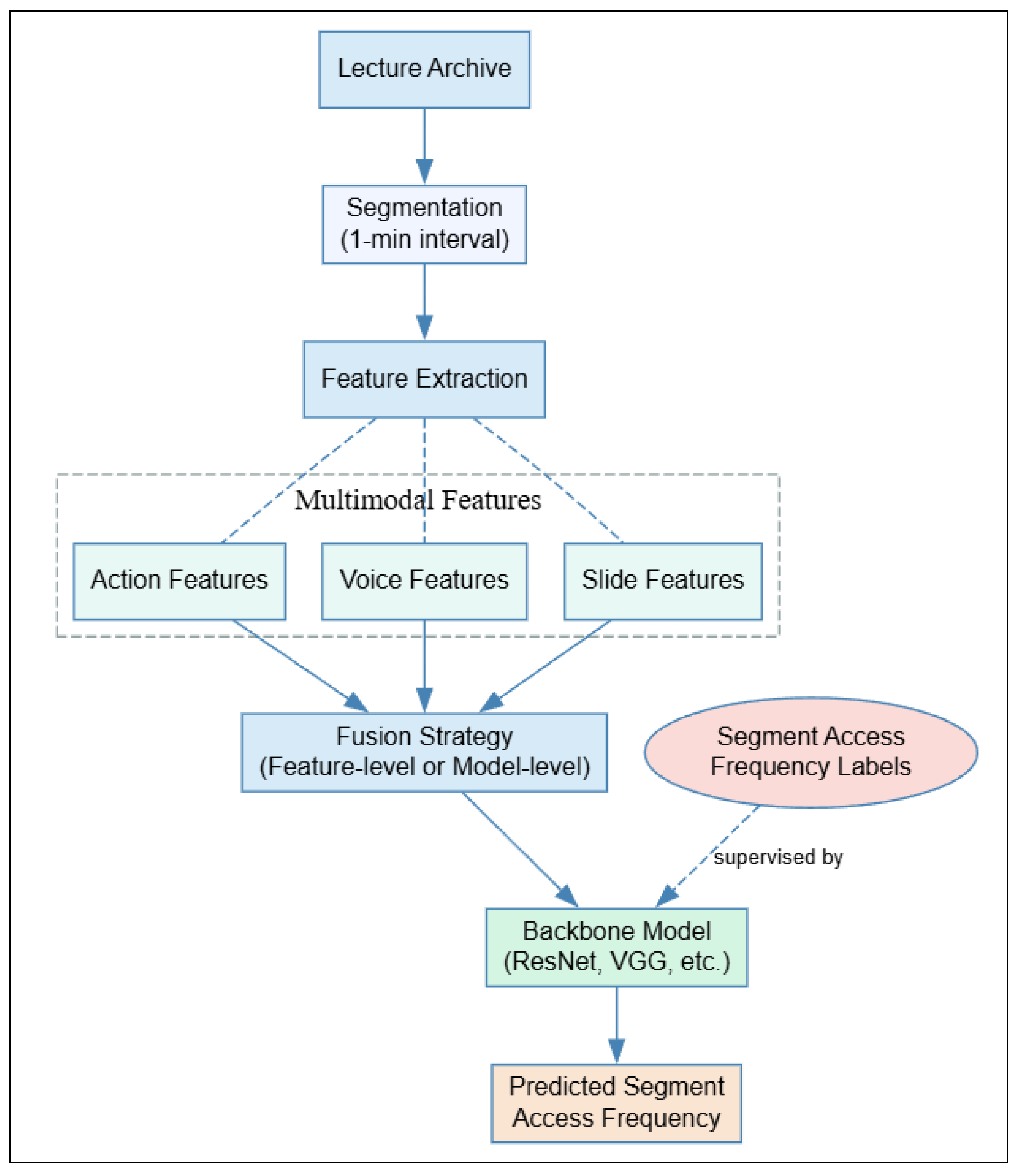
Inspired by these approaches, this study proposes to use segment access frequency (SAF) as a more fine-grained and context-appropriate measure of engagement. This metric, calculated from the number of playback events associated with each time segment, provides a practical and scalable solution that does not depend on semantic content or specialized hardware. It is particularly suitable for classroom lecture recordings, which typically lack rich annotations or auxiliary sensors.
This study focuses on lecture archives recorded in real classroom environments in higher educational institutions. These settings are often resource-constrained, which defines the core challenges we address. Specifically, the recordings themselves are typically unedited, capturing the instructor with a fixed, ceiling-mounted camera and microphone, which can result in audio quality that is too noisy or indistinct for reliable automatic transcription. Furthermore, the context of their use is also constrained: the archives serve a small number of learners from a single course, and the viewing data from these learners is collected without any auxiliary hardware such as eye-tracking devices. One representative example of such a setting is the video archive system accumulated at JAIST, where face-to-face lectures are routinely recorded and made available through the institutional LMS. Building on this setting, prior work by
Sheng et al. (
2022) presented at AIED 2022 initially explored the feasibility of predicting focal periods using access logs, based on a set of manually extracted features and relatively simple models. However, that study lacked systematic comparisons and did not incorporate advanced fusion strategies. Building upon this early validation, the present study significantly extends their prior work through improved feature design, structured fusion methods, and comprehensive model benchmarking.
This study aims to develop a lightweight and efficient prediction method based on non-semantic multimodal features to address the challenges of such resource-limited settings. This approach is designed to avoid semantic dependence, enable cross lingual adaptability, and minimize training costs for estimating durations with high SAF in lecture archives. Furthermore, by generating SAF labels automatically from aggregated playback data, the system is intended to support scalable deployment in practical educational contexts.
To systematically validate the feasibility and optimize the design of such a non-semantic framework, this study is therefore guided by the following research questions:
Main Research Question: Can segment access frequency (SAF) in lecture archives be accurately predicted using only non-semantic multimodal features, derived from real-world recordings without transcripts or semantic annotation?
Sub RQ1: Which non-semantic modality—action, voice, or slide—contributes most to SAF prediction accuracy, and how do combinations of these modalities affect performance?
Sub RQ2: Which fusion strategy and neural network backbone provide the optimal balance of prediction accuracy and computational efficiency in resource-constrained educational settings?
To address these research questions, this study makes the following contributions:
The proposal of a language-independent prediction framework for estimating Segment Access Frequency (SAF) based on non-semantic features. This lightweight framework functions without relying on semantic understanding or specialized equipment.
A comparative analysis of fusion strategies, which demonstrates the superiority of early feature fusion for achieving higher prediction accuracy and training efficiency in resource-limited scenarios.
A comprehensive ablation and backbone analysis that identifies the dominant contribution of instructor action features and confirms the effectiveness of ResNet-based architectures for this task.
4. Experiment
This section presents a series of experiments conducted to evaluate the effectiveness of the proposed prediction framework. First, the predictive capacity of instructor action features used in isolation is assessed. Then, two multimodal fusion strategies are investigated: one that combines features before input into the network (feature fusion), and another that processes each modality separately before combining outputs (model fusion). An ablation study is further conducted to examine the relative contribution of each modality. Finally, several backbone architectures are compared to identify the most effective configuration under resource constraints. All experiments are carried out using seven-fold cross-validation, and evaluated using both regression metrics and three-class accuracy.
4.1. Effectiveness of Action Features
Before introducing multimodal fusion, it was first evaluated whether action features alone could serve as a reliable predictor of student attention. As described in
Section 3.2.1, the instructor’s motion patterns were extracted from each lecture segment using OpenPose and optical flow, resulting in time-series visual representations. These action features were then used as the sole input to a ResNet50 model.
To enhance temporal stability, three smoothing strategies were applied to the predicted attention values: Moving Average, Savitzky–Golay filter, and Kalman filter. These were compared against unsmoothed (raw) predictions. For this experiment, a fixed data split was used: Lesson 1–5 for training, Lesson 6 for validation, and Lesson 7 for testing.
The results in
Table 2 confirm that the visual motion features extracted from the instructor’s body movements contain sufficient predictive signals. All four smoothing conditions achieved positive
values and moderate Pearson correlation coefficients (PCC), demonstrating that the model could learn meaningful patterns from the action features even without additional modalities.
Among the smoothing methods, the moving average performed best across all metrics, suggesting it effectively suppresses noise while preserving temporal trends. Compared to more complex alternatives such as the Savitzky–Golay filter and Kalman filter, the moving average has a significantly lower computational cost and is extremely simple to implement. Its robustness, interpretability, and real-time applicability make it a strong default choice for smoothing time-series predictions in practical educational settings.
4.2. Fusion Strategies
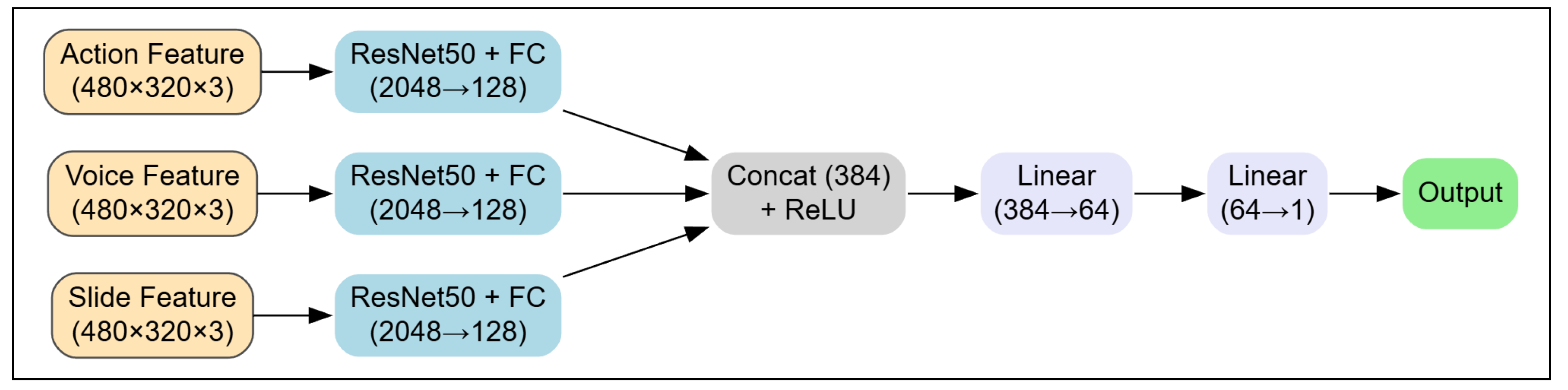
To evaluate how different fusion strategies impact model performance, two approaches were compared: feature-level fusion and model-level fusion. Both strategies utilized all three modalities—action, voice, and slide—and employed ResNet50 as the backbone to ensure fair comparison.
In the feature-level fusion strategy, all modality features were resized and stacked along the channel dimension to form a single RGB-like image (480 × 320 × 3), which was then passed through a single ResNet50 model. In contrast, the model-level fusion strategy assigned each modality its own dedicated ResNet50 network. The output features from each branch were concatenated and passed through a joint prediction head.
All models were trained using identical cross-validation protocols and evaluated using regression metrics (MSE, MAE, R
2, PCC).
Table 3 shows the results.
Table 3 shows that feature-level fusion outperforms model-level fusion across all regression metrics while requiring significantly less training time. This combination of higher accuracy and computational efficiency makes feature-level fusion a practical choice for real-time lecture archive analysis, enabling scalable deployment in educational platforms.
Despite model-level fusion’s theoretical advantages—preserving the full resolution of each feature map and enabling modality-specific encoding—it suffered from increased parameter count and training instability. These drawbacks outweigh its theoretical flexibility in this setting, where training data is limited and computational efficiency is an important consideration. Based on these comprehensive findings, feature-level fusion was adopted as the default strategy for all subsequent experiments.
4.3. Ablation Study
To further understand the contribution of each modality to the overall performance, an ablation study was conducted by systematically removing one or more modalities from the input. All experiments in this section were performed under the feature-level fusion setting using ResNet50 as the backbone model. The same cross-validation protocol and smoothing method (moving average) were applied across all conditions.
The tested combinations include the full model (A + V + S), all possible two-modality pairs (A + V, A + S, S + V), and individual modalities (A, V, S). The evaluation results are shown in
Table 4.
The results show that the full model using all three modalities (A + V + S) achieved the best performance across all metrics, indicating that each modality contributes complementary information to the prediction. Among the single-modality models, action features alone performed the best, while slide features showed the weakest predictive power when used in isolation. This suggests that instructor motion contains the most informative cues, consistent with the findings in
Section 4.1.
Interestingly, the combinations A + S and S + V both outperformed their constituent single-modality models, implying that even relatively weak features like slides can enhance the model when combined with stronger signals. These findings highlight the synergistic effect of multimodal fusion and support the inclusion of all three modalities in the final system design.
4.4. Backbone Model Comparison
Six backbone architectures were systematically evaluated to identify the most effective neural architecture for classroom attention prediction. All models were assessed under identical conditions: feature-level fusion with action, voice, and slide inputs, smoothing via moving average, and training with 7-fold cross-validation. The evaluated architectures span three model families: convolutional networks (VGG16, VGG19), residual networks (ResNet50, ResNet101), a transformer-based model (ViT), and a sequential hybrid (CNN + LSTM).
As shown in
Table 5, ResNet50 consistently outperformed all other architectures across metrics, demonstrating the best balance between prediction accuracy and training stability. VGG16 followed closely with good consistency across folds, while VGG19 showed slightly diminished performance. Interestingly, ResNet101 underperformed despite its greater depth, likely due to overfitting on the relatively small dataset. The ViT model exhibited promising regression metrics but slightly lower classification accuracy, suggesting its global attention mechanism may require more data to realize its full potential. The CNN + LSTM architecture provided no clear advantages over purely spatial models, indicating that explicit temporal modeling offers limited benefits at the one-minute feature resolution.
Given ResNet50’s superior performance, a more detailed analysis of its fold-wise behavior was conducted to assess reliability and generalization capabilities.
Table 6 reveals considerable performance variation across the seven validation folds for ResNet50. Fold 7 demonstrated exceptional performance with the lowest MSE (0.0145), MAE (0.0951), highest
(0.6376), and strongest correlation (PCC = 0.8491). However, some folds (particularly 2 and 5) yielded negative
values, indicating challenges in capturing variance for certain lesson contexts. Despite these variations, the average metrics across all folds show a moderate positive correlation (PCC = 0.5143), suggesting the model can capture meaningful attention patterns even with limited training data.
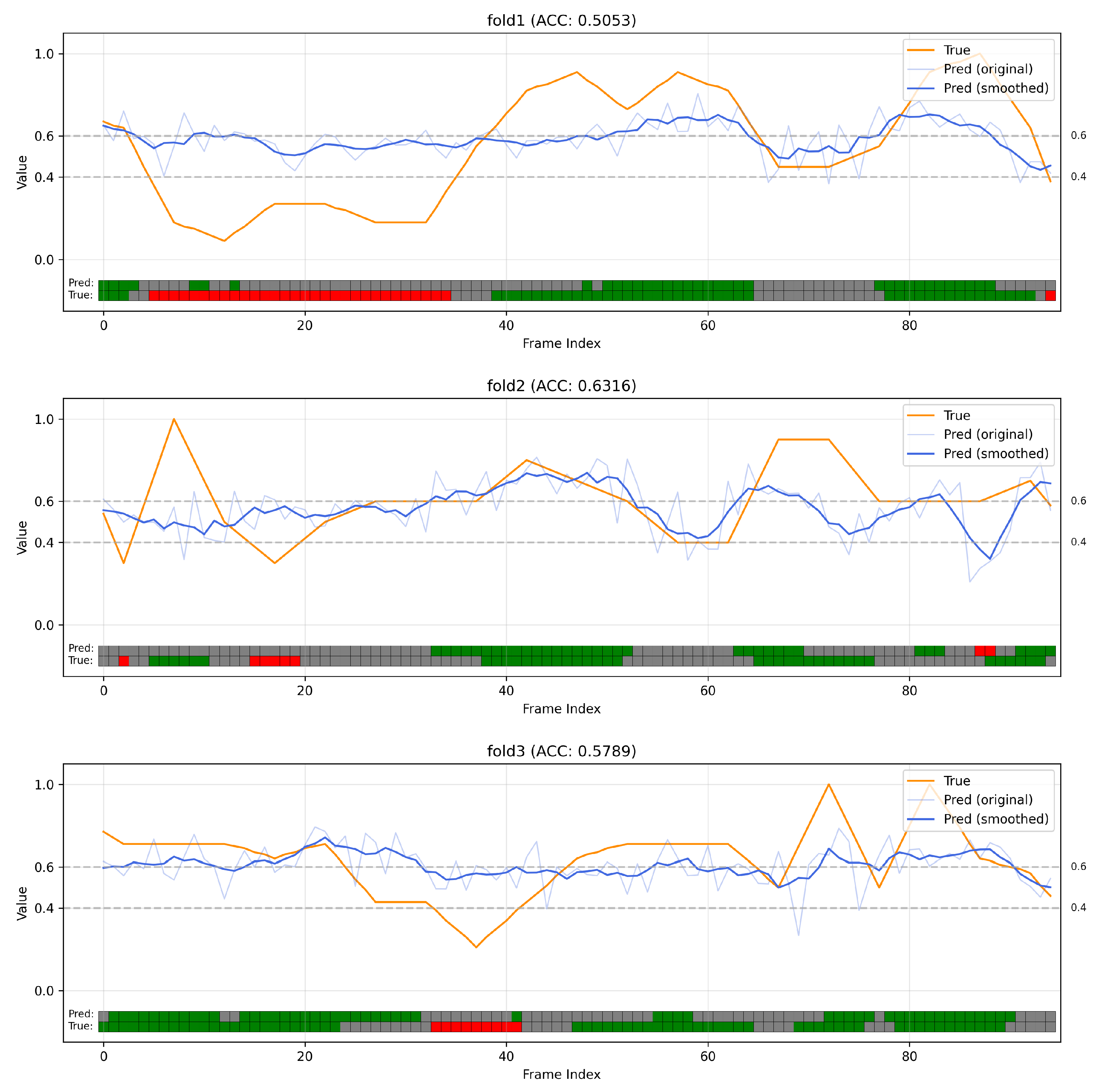
Figure 10 visually compares the predicted Segment Access Frequency (SAF) with the ground-truth labels across the seven validation folds. In each plot, the orange line represents the ground-truth SAF, the light blue line shows the raw predicted values, and the dark blue line indicates the smoothed predictions. Beneath the curves, the rectangular colored blocks display the three-class classification result for each one-minute segment: green for High-SAF, gray for Medium-SAF, and red for Low-SAF. A key observation is that the model’s predictions consistently capture the overall temporal trends of student attention—the rising and falling patterns—even when the absolute numerical accuracy varies. This is evident in folds with poor statistical metrics (e.g., Fold 5, with an
of −0.3305 and 3-class accuracy of 48.42%), where the predicted curve still mirrors the general shape of the ground-truth.
This trend-capturing capability, rather than absolute value precision, is the most critical quality for the intended application. It allows the system to reliably generate an `attention heatmap’ that guides students to conceptually dense segments. The practical utility of this non-semantic approach is underscored by its performance on lessons with known content peaks. For instance, the predicted peak in Fold 1 aligns with the ground truth for Lesson 1, corresponding to the explanation of the Version Space Algorithm, while the peak in Fold 4 correctly identifies the initial segment of Lesson 4, where the instructor demonstrates problem-solving steps. This alignment demonstrates that the model can effectively distinguish high-engagement segments from lulls in the lecture, which is the primary goal for enhancing archive navigation.
These results confirm that ResNet50 offers the most reliable foundation for the multimodal attention prediction framework, providing an optimal balance between prediction accuracy, generalization capability, and computational efficiency. Traditional convolutional architectures—particularly ResNet50 and VGG16—appear well-suited for this task, while more complex models showed no clear advantages under the experimental constraints.
5. Discussion
5.1. Addressing the Research Questions
In this section, we revisit the research questions introduced in the Introduction and evaluate how our findings address each.
Main Research Question: Can segment access frequency (SAF) in lecture archives be accurately predicted using only non-semantic multimodal features, derived from real-world recordings without transcripts or semantic annotation?
The results confirm that non-semantic features can effectively predict SAF despite limited data. The full multimodal approach achieved a Pearson correlation of 0.5143 and 61.05% three-class classification accuracy in 7-fold cross-validation (
Table 3 and
Table 5). Even using only instructor action features yielded a significant correlation (PCC = 0.5464,
Table 2). These findings validate the hypothesis that SAF can be meaningfully predicted without semantic content understanding, even with an extremely limited dataset averaging only 8.71 valid viewers per lecture (
Table 1).
Sub RQ1: Which non-semantic modality—action, voice, or slide—contributes most to SAF prediction accuracy, and how do combinations of these modalities affect performance?
The ablation study (
Table 4) revealed that instructor action features performed best in isolation, while slide features performed worst. However, any dual-modality combination outperformed its constituent single-modality models, with the full tri-modal fusion achieving optimal results. This confirms the complementary nature of the selected modalities and highlights the primary contribution of instructor actions.
Sub RQ2: Which fusion strategy and neural network backbone provide the optimal balance of prediction accuracy and computational efficiency in resource-constrained educational settings?
The experiments indicate that a combination of feature-level fusion and a ResNet50 backbone provides the optimal trade-off. Feature-level fusion significantly outperformed model-level fusion across all metrics while requiring only 23% of the training time (
Table 3). Among the tested backbone architectures, ResNet50 consistently outperformed alternatives across all metrics (
Table 5), providing the best balance between accuracy and computational efficiency. Deeper networks like ResNet101 showed worse performance due to overfitting. Similarly, the Vision Transformer (ViT) model did not realize its full potential, and the CNN + LSTM architecture’s explicit temporal modeling offered no significant advantages over purely spatial models at the feature resolution, demonstrating their unsuitability for the resource-constrained context.
These findings provide practical design guidelines for SAF prediction systems in educational environments with resource constraints, demonstrating the potential of non-semantic approaches for improving lecture archive accessibility. By identifying high-SAF segments, the framework enhances lecture archive usability in blended learning, supporting students’ self-directed review after face-to-face instruction and improving integration of online and in-person learning.
5.2. Practical Implications and Potential Applications
To concretely illustrate the practical utility of the framework in an authentic blended learning environment, an in-depth analysis of the results from fold 7 (corresponding to Lesson 7) is conducted, as shown in
Figure 10. This lecture exhibits three distinct phases: a high-SAF zone from 0–50 min, corresponding to the explanation of complex example problems; a medium-SAF zone from 50–70 min for conceptual review; and a low-SAF zone from 70–95 min, which features a live programming demonstration. By applying the system to this 95-min lecture, a highlight summary containing only the 22 min of high-SAF segments can be generated. This compresses the content to just 23.16% of its original length, demonstrating significant information compression efficiency.
From the students’ perspective, the system’s most direct value lies in the substantial improvement of learning efficiency. This 22-min summary enables students preparing for exams to bypass lengthy review and demonstration segments, allowing them to directly access the most critical parts of the example explanations for targeted and efficient review. Furthermore, having a clear learning map helps alleviate the sense of intimidation students often feel when confronted with long lecture videos, fostering a more positive and proactive learning experience.
From the instructor’s perspective, the framework serves as a powerful tool for pedagogical diagnosis and intervention. By analyzing the SAF heatmap of existing lectures, instructors can accurately identify common student difficulties and points of confusion. More importantly, the predictive capability of the framework transcends this retrospective analysis to address the cold-start problem in pedagogical feedback. For a new lecture without any viewing data, the model can proactively generate a predicted SAF heatmap. This helps instructors anticipate potential bottlenecks and adjust their teaching materials accordingly, transforming pedagogical assessment from a reactive response into a proactive planning process.
5.3. Limitations
While the approach demonstrates the feasibility of non-semantic multimodal prediction for SAF, several limitations should be acknowledged:
Dataset Scope and Diversity. The experiments relied on seven lectures from a single Machine Learning course taught by one instructor, leading to performance variability across validation folds (
Table 6). This constrained scope limits the model’s generalizability to diverse educational contexts, such as humanities courses or interactive teaching formats, posing challenges for broader applicability in real-world settings.
Engagement Measurement Indirectness. SAF serves as an indirect proxy for engagement, primarily capturing revisitation patterns rather than immediate engagement states. This metric may not fully represent the multifaceted nature of student engagement, particularly during first-time viewing, as it primarily reflects post-hoc revisitation behaviors.
Temporal Resolution Constraints. The one-minute segment resolution, adopted to balance granularity and computational efficiency, overlooks transient engagement peaks, such as those triggered by key explanations or student questions. This coarse temporal scale restricts the model’s precision in identifying brief, high-impact segments critical for applications like highlight extraction.
Non-semantic Feature Limitations. While the non-semantic approach offers cross-lingual applicability and low training costs, it inherently limits the model’s ability to capture content-driven factors that may influence segment access frequency but are not explicitly reflected in non-semantic features. For example, in the prediction results for Lesson 1 in
Figure 10, the model generated moderately high SAF predictions for the first 30 min. This likely occurred because during this segment, the instructor was introducing himself, explaining the course structure and schedule—activities involving continuous speaking, writing, and movement which, without semantic understanding, appear similar to the delivery of information-dense concepts. However, in reality, this portion held little importance for students’ review purposes, leading most students to skip it and resulting in consistently low actual SAF levels.
6. Conclusions
Building on the findings summarized in
Table 7, this study has successfully established a lightweight, non-semantic framework for predicting Segment Access Frequency (SAF) in real-world lecture archives. Our results confirm that it is feasible to estimate student engagement patterns from multimodal features without relying on semantic cues. The comprehensive analysis identified the optimal combination of features and model architecture for this task under resource-constrained conditions.
Compared to existing methods, the approach offers three key advantages, summarized as follows:
Language independence: The non-semantic feature design allows the model to be applied across different languages without requiring content understanding.
Suitability for educational settings with limited scale: The lightweight architecture achieves high computational efficiency and can be trained with limited dataset, such as university lecture archive.
Automatic label generation: SAF labels are automatically derived from access logs, eliminating the need for manual annotation or specialized hardware.
To further improve model generalization and practical value, future work will expand to more diverse instructional contexts, integrate fine-grained behavioral cues (e.g., facial expressions and gaze), and explore lightweight semantic augmentation such as OCR-based slide content. The development of downstream applications—such as SAF heatmaps and automated highlight extraction—is also aimed, which will support both learners and instructors by enhancing content navigability, instructional feedback, and lecture archive usability.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}