
Integrating AI-Driven Wearable Metaverse Technologies into Ubiquitous Blended Learning: A Framework Based on Embodied Interaction and Multi-Agent Collaboration

 ,
, 
 ,
,  and
and
Abstract
1. Introduction
2. Literature Review
2.1. Wearable Devices in Ubiquitous Blended Learning
2.2. Embodied Interaction in Ubiquitous Blended Learning
2.3. AI Agents in Metaverse
3. A Conceptual Framework for Wearable Metaverse Environments
3.1. The Overall Framework of the Model
3.2. Embodied Interaction Module
3.2.1. Data Collection and Sensor Integration
3.2.2. Embodied Interaction Strategies
3.3. Multi-Agent Collaboration Module
3.3.1. Functions of Multi-Agent Module
3.3.2. Intelligent Interaction Mechanisms
3.3.3. Collaboration Using CrewAI and ST-GNNs
3.4. Multi-Source Data Fusion Module
3.5. Low-Computation-Cost Strategy Module
- High fidelity in gaze-sensitive areas: Regions closer to the gaze point are rendered at higher resolutions to ensure high-fidelity viewing in the user’s focus area;
- Optimized peripheral rendering: Regions further away from the viewpoint are rendered at lower resolutions, reducing the computational demands while maintaining acceptable visual quality.
4. Technical Approaches for Implementing Wearable Metaverse Environments
4.1. Enhancing Precision Through Multi-Source Data Fusion
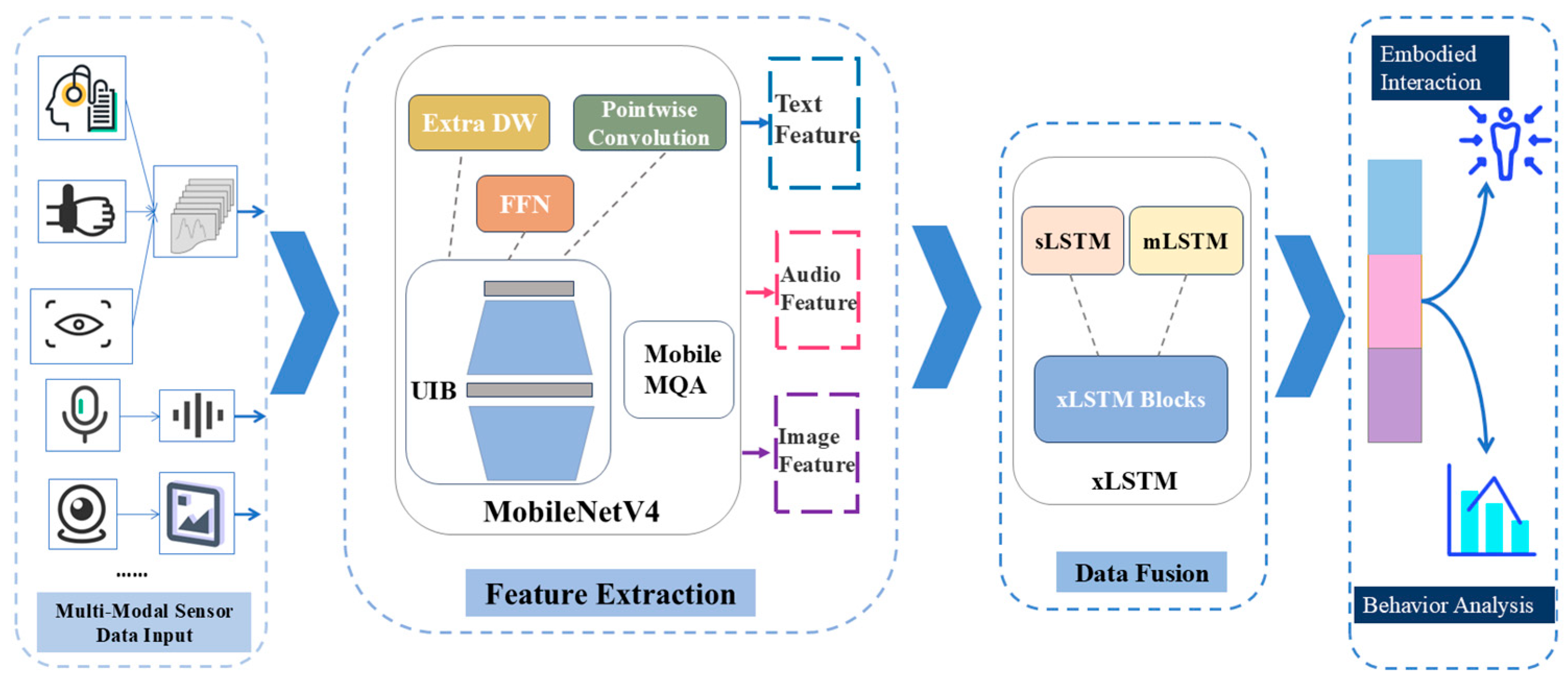
4.1.1. Feature Extraction with MobileNetV4
- Text Data: Discrete text data is transformed into continuous low-dimensional semantic vectors using an embedding layer. These vectors are then processed through modified UIB blocks, specifically adapted for text data, to extract high-level semantic features.
- Image and Video Data: MobileNetV4’s depthwise separable convolution, as a key element of the UIB block, is leveraged to efficiently extract spatial features from image data. For video data, these spatial features are temporally aggregated using temporal modeling layers, such as the Mobile MQA attention block, enabling the capture of dynamic temporal dependencies.
- Speech Data: High-level acoustic features are initially extracted using a pre-trained acoustic model (e.g., Wav2Vec or HuBERT). These features are subsequently compressed using MobileNetV4’s UIB blocks, which are fine-tuned for speech data, to reduce the dimensionality without losing essential information. The Mobile MQA attention block is then applied to capture long-range dependencies within the speech sequences.
4.1.2. Dynamic Cross-Modality Fusion with xLSTM
- Input Transformation: The extracted feature maps are pre-processed (e.g., normalization, dimensionality alignment) to ensure compatibility across the modalities.
- Temporal Alignment Using Modality Interaction Units (MIUs): MIUs in xLSTM explicitly model the temporal relationships between the modalities.
- Dynamic Modality Weighting: At each time step, xLSTM calculates the relative importance of each modality using learned weighting parameters.
- Output Fusion for Downstream Tasks: The fused multi-modal representation is passed to task-specific layers (e.g., classification, regression, or decision-making modules).
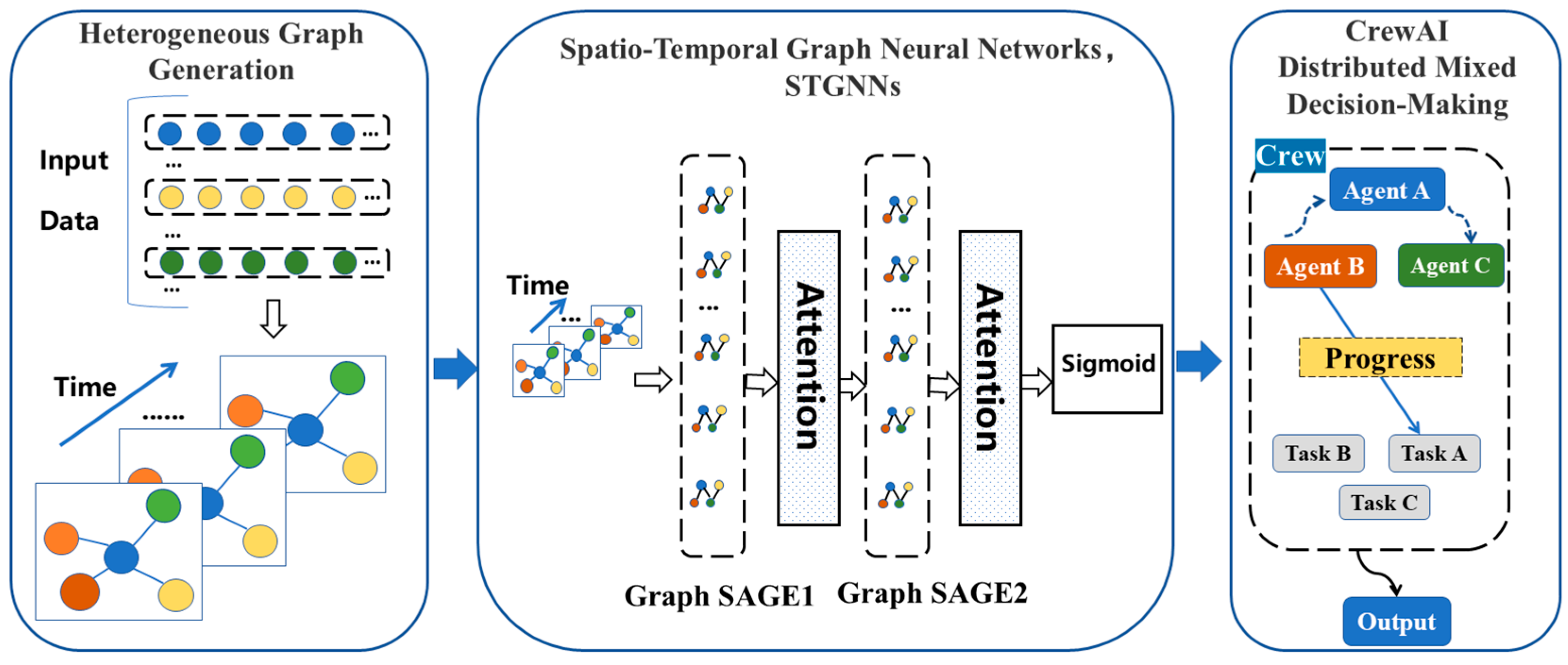
4.2. Agents’ Collaboration Based on Multi-Agent Framework and Graph Neural Networks
4.2.1. Spatio-Temporal Collaboration Modeling with ST-GNNs
4.2.2. Distributed and Hybrid Decision-Making with CrewAI
- Macro-Level Coordination: A central platform agent serves as a global coordinator, aggregating information from all the agents and generating high-level decisions using graph neural networks. The platform agent evaluates the states of learners, virtual environments, and real-world contexts to identify optimal task–agent matches. For example, it might assign a specific virtual tutor to a struggling student or coordinate collaborative tasks among urban and rural students.
- Micro-Level Distributed Decisions: Individual agents (e.g., virtual tutors, learning companions, or environment agents) independently generate localized decisions based on their private states. Using deep reinforcement learning, the agents express personalized preferences for scheduling or task execution, which are communicated back to the platform agent through CrewAI’s interaction mechanisms. This two-way communication ensures that global decisions are informed by local needs while maintaining the overall system coherence.
4.3. Optimization of Visual Experiences Based on Low Computation Cost
4.3.1. Low-Computation-Cost Environment Perception and Modeling
4.3.2. Gaze Prediction Using Visual Attention Models
- Visual Attention Models: Inspired by the human visual system, lightweight convolutional neural networks (e.g., boundary attention models) are used to predict potential regions of interest in images or videos (Polansky et al., 2024). These predictions guide rendering optimizations by focusing computational resources on areas the user is likely to attend to.
- Real-Time Gaze Tracking: The system utilizes low-computation-cost gaze-tracking algorithms to identify the learner’s gaze position in real time, ensuring that the rendering priorities align with the user’s visual attention.
4.3.3. Gaze Prediction and Dynamic Rendering Cache Mechanism
- Dynamic Resolution Adjustment: Based on gaze prediction, the rendering engine dynamically adjusts the resolution of different regions. Higher resolutions are prioritized for gaze-sensitive areas, while peripheral regions are rendered at lower resolutions. Techniques such as the Level of Detail (LOD) method and frustum culling (Su et al., 2017) are used to allocate resources effectively.
- Rendering Cache Mechanism: Leveraging temporal coherence, previously rendered frames are stored and reused to avoid redundant computations. Frame difference encoding and result compression techniques are further applied to reduce the computational cost for static or minimally changing regions.
- Predictive Gaze Modeling: Recurrent neural networks (e.g., RNNs) predict potential gaze shifts, allowing the system to pre-render areas of future interest and minimize the latency.
4.3.4. Visual Perception Optimization
- Image Quality Evaluation: Algorithms such as CrossScore (Z. Wang et al., 2025) and GR-PSN (Ju et al., 2024) are used to assess the visual quality of the rendered frames in real time. These evaluations guide adjustments to the rendering parameters, such as the resolution and texture detail, to balance visual fidelity and computational efficiency.
- Perceptual Mapping Techniques: Techniques like VDP (Visual Difference Prediction) (Mantiuk et al., 2023) are employed to identify areas of higher visual importance, ensuring that the system resources are allocated in a way that maximizes the perceptual quality.
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abrahamson, D., Nathan, M. J., Williams-Pierce, C., Walkington, C., Ottmar, E. R., Soto, H., & Alibali, M. W. (2020). The future of embodied design for mathematics teaching and learning. Frontiers in Education, 5, 147. [Google Scholar] [CrossRef]
- Alharthi, M., & Mahmood, A. (2024). xLSTMTime: Long-term time series forecasting with xLSTM. AI, 5(3), 1482–1495. [Google Scholar] [CrossRef]
- Amirkhani, A., & Barshooi, A. H. (2022). Consensus in multi-agent systems: A review. Artificial Intelligence Review, 55(5), 3897–3935. [Google Scholar] [CrossRef]
- Arslan, M., Munawar, S., & Cruz, C. (2024). Sustainable digitalization of business with multi-agent RAG and LLM. Procedia Computer Science, 246, 4722–4731. [Google Scholar] [CrossRef]
- Ba, S., & Hu, X. (2023). Measuring emotions in education using wearable devices: A systematic review. Computers & Education, 200, 104797. [Google Scholar] [CrossRef]
- Barbarroxa, R., Gomes, L., & Vale, Z. (2025). Benchmarking large language models for multi-agent systems: A comparative analysis of AutoGen, CrewAI, and TaskWeaver. In P. Mathieu, & F. De La Prieta (Eds.), Advances in practical applications of agents, multi-agent systems, and digital twins: The PAAMS collection (Vol. 15157, pp. 39–48). Springer Nature. [Google Scholar] [CrossRef]
- Beck, M., Pöppel, K., Spanring, M., Auer, A., Prudnikova, O., Kopp, M., Klambauer, G., Brandstetter, J., & Hochreiter, S. (2024). xLSTM: Extended long short-term memory. arXiv, arXiv:2405.04517. [Google Scholar] [CrossRef]
- Cárdenas-Robledo, L. A., & Peña-Ayala, A. (2018). Ubiquitous learning: A systematic review. Telematics and Informatics, 35(5), 1097–1132. [Google Scholar] [CrossRef]
- Chakma, A., Faridee, A. Z. M., Khan, M. A. A. H., & Roy, N. (2021). Activity recognition in wearables using adversarial multi-source domain adaptation. Smart Health, 19, 100174. [Google Scholar] [CrossRef]
- Chen, H. R., Lin, W. S., Hsu, T. Y., Lin, T. C., & Chen, N. S. (2023). Applying smart glasses in situated exploration for learning English in a national science museum. IEEE Transactions on Learning Technologies, 16(5), 820–830. [Google Scholar] [CrossRef]
- Cheng, Y., Zhang, C., Zhang, Z., Meng, X., Hong, S., Li, W., Wang, Z., Wang, Z., Yin, F., Zhao, J., & He, X. (2024). Exploring large language model based intelligent agents: Definitions, methods, and prospects. arXiv, arXiv:2401.03428. [Google Scholar] [CrossRef]
- Closser, A. H., Erickson, J. A., Smith, H., Varatharaj, A., & Botelho, A. F. (2022). Blending learning analytics and embodied design to model students’ comprehension of measurement using their actions, speech, and gestures. International Journal of Child-Computer Interaction, 32, 100391. [Google Scholar] [CrossRef]
- Crowell, C., Mora-Guiard, J., & Pares, N. (2018). Impact of interaction paradigms on full-body interaction collocated experiences for promoting social initiation and collaboration. Human–Computer Interaction, 33(5–6), 422–454. [Google Scholar] [CrossRef]
- Di Mitri, D., Schneider, J., & Drachsler, H. (2022). Keep me in the loop: Real-time feedback with multimodal data. International Journal of Artificial Intelligence in Education, 32(4), 1093–1118. [Google Scholar] [CrossRef]
- Feng, L., Jiang, X., Sun, Y., Niyato, D., Zhou, Y., Gu, S., Yang, Z., Yang, Y., & Zhou, F. (2025). Resource allocation for metaverse experience optimization: A multi-objective multi-agent evolutionary reinforcement learning approach. IEEE Transactions on Mobile Computing, 24(4), 3473–3488. [Google Scholar] [CrossRef]
- Fleury, M., Lioi, G., Barillot, C., & Lécuyer, A. (2020). A survey on the use of haptic feedback for brain-computer interfaces and neurofeedback. Frontiers in Neuroscience, 14, 528. [Google Scholar] [CrossRef] [PubMed]
- Foglia, L., & Wilson, R. A. (2013). Embodied cognition. WIREs Cognitive Science, 4(3), 319–325. [Google Scholar] [CrossRef] [PubMed]
- Frisoli, A., & Leonardis, D. (2024). Wearable haptics for virtual reality and beyond. Nature Reviews Electrical Engineering, 1(10), 666–679. [Google Scholar] [CrossRef]
- Gao, C., Lan, X., Li, N., Yuan, Y., Ding, J., Zhou, Z., Xu, F., & Li, Y. (2024). Large language models empowered agent-based modeling and simulation: A survey and perspectives. Humanities and Social Sciences Communications, 11(1), 1259. [Google Scholar] [CrossRef]
- Gatto, L., Fulvio Gaglio, G., Augello, A., Caggianese, G., Gallo, L., & La Cascia, M. (2022, October 19–21). MET-iquette: Enabling virtual agents to have a social compliant behavior in the Metaverse. 2022 16th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS) (pp. 394–401), Dijon, France. [Google Scholar] [CrossRef]
- González-Briones, A., De La Prieta, F., Mohamad, M. S., Omatu, S., & Corchado, J. M. (2018). Multi-agent systems applications in energy optimization problems: A state-of-the-art review. Energies, 11(8), 1928. [Google Scholar] [CrossRef]
- Hazarika, A., & Rahmati, M. (2023). Towards an evolved immersive experience: Exploring 5G-and beyond-enabled ultra-low-latency communications for augmented and virtual reality. Sensors, 23(7), 3682. [Google Scholar] [CrossRef] [PubMed]
- Heikenfeld, J., Jajack, A., Rogers, J., Gutruf, P., Tian, L., Pan, T., Li, R., Khine, M., Kim, J., Wang, J., & Kim, J. (2018). Wearable sensors: Modalities, challenges, and prospects. Lab on a Chip, 18(2), 217–248. [Google Scholar] [CrossRef] [PubMed]
- Janbi, N., Katib, I., & Mehmood, R. (2023). Distributed artificial intelligence: Taxonomy, review, framework, and reference architecture. Intelligent Systems with Applications, 18, 200231. [Google Scholar] [CrossRef]
- Johnson-Glenberg, M. C., & Megowan-Romanowicz, C. (2017). Embodied science and mixed reality: How gesture and motion capture affect physics education. Cognitive Research: Principles and Implications, 2(1), 24. [Google Scholar] [CrossRef] [PubMed]
- Johnson-Glenberg, M. C., Yu, C. S. P., Liu, F., Amador, C., Bao, Y., Yu, S., & LiKamWa, R. (2023). Embodied mixed reality with passive haptics in STEM education: Randomized control study with chemistry titration. Frontiers in Virtual Reality, 4, 1047833. [Google Scholar] [CrossRef]
- Ju, Y., Shi, B., Chen, Y., Zhou, H., Dong, J., & Lam, K. M. (2024). GR-PSN: Learning to estimate surface normal and reconstruct photometric stereo images. IEEE Transactions on Visualization and Computer Graphics, 30(9), 6192–6207. [Google Scholar] [CrossRef] [PubMed]
- Kang, J., Chen, J., Xu, M., Xiong, Z., Jiao, Y., Han, L., Niyato, D., Tong, Y., & Xie, S. (2024). UAV-assisted dynamic avatar task migration for vehicular metaverse services: A multi-agent deep reinforcement learning approach. IEEE/CAA Journal of Automatica Sinica, 11(2), 430–445. [Google Scholar] [CrossRef]
- Kosmas, P., & Zaphiris, P. (2023). Improving students’ learning performance through Technology-Enhanced Embodied Learning: A four-year investigation in classrooms. Education and Information Technologies, 28(9), 11051–11074. [Google Scholar] [CrossRef]
- Li, J., Wang, S., Zhang, M., Li, W., Lai, Y., Kang, X., Ma, W., & Liu, Y. (2024). Agent hospital: A simulacrum of hospital with evolvable medical agents. arXiv, arXiv:2405.02957. [Google Scholar] [CrossRef]
- Lin, L. (2015). Exploring collaborative learning: Theoretical and conceptual perspectives. In L. Lin (Ed.), Investigating Chinese HE EFL classrooms (pp. 11–28). Springer. [Google Scholar] [CrossRef]
- Lindgren, R., Tscholl, M., Wang, S., & Johnson, E. (2016). Enhancing learning and engagement through embodied interaction within a mixed reality simulation. Computers & Education, 95, 174–187. [Google Scholar] [CrossRef]
- Liu, J., Zheng, Y., Wang, K., Bian, Y., Gai, W., & Gao, D. (2020). A real-time interactive tai chi learning system based on VR and motion capture technology. Procedia Computer Science, 174, 712–719. [Google Scholar] [CrossRef]
- Liu, Y., & Fu, Z. (2024). Hybrid intelligence: Design for sustainable multiverse via integrative cognitive creation model through human–computer collaboration. Applied Sciences, 14(11), 4662. [Google Scholar] [CrossRef]
- López-Belmonte, J., Pozo-Sánchez, S., Moreno-Guerrero, A.-J., & Lampropoulos, G. (2023). Metaverse in education: A systematic review. Revista De Educación a Distancia (RED), 23(73), 2252656. [Google Scholar] [CrossRef]
- Manawadu, M., & Park, S. Y. (2024). 6DoF object pose and focal length estimation from single rgb images in uncontrolled environments. Sensors, 24(17), 5474. [Google Scholar] [CrossRef] [PubMed]
- Mantiuk, R. K., Hammou, D., & Hanji, P. (2023). HDR-VDP-3: A multi-metric for predicting image differences, quality and contrast distortions in high dynamic range and regular content. arXiv, arXiv:2304.13625. [Google Scholar] [CrossRef]
- Mills, K. A., & Brown, A. (2023). Smart glasses for 3D multimodal composition. Learning, Media and Technology, 50(2), 156–177. [Google Scholar] [CrossRef]
- Mira, H. H., Chaker, R., Maria, I., & Nady, H. (2024). Review of research on the outcomes of embodied and collaborative learning in STEM in higher education with immersive technologies. Journal of Computing in Higher Education, 1–38. [Google Scholar] [CrossRef]
- Nahavandi, D., Alizadehsani, R., Khosravi, A., & Acharya, U. R. (2022). Application of artificial intelligence in wearable devices: Opportunities and challenges. Computer Methods and Programs in Biomedicine, 213, 106541. [Google Scholar] [CrossRef] [PubMed]
- Nascimento, T. H., Fernandes, D., Vieira, G., Felix, J., Castro, M., & Soares, F. (2023, October 9–11). MazeVR: Immersion and interaction using google cardboard and continuous gesture recognition on smartwatches. 28th International ACM Conference on 3D Web Technology (pp. 1–5), San Sebastian, Spain. [Google Scholar] [CrossRef]
- Palermo, F., Casciano, L., Demagh, L., Teliti, A., Antonello, N., Gervasoni, G., Shalby, H. H. Y., Paracchini, M. B., Mentasti, S., Quan, H., Santambrogio, R., Gilbert, C., Roveri, M., Matteucci, M., Marcon, M., & Trojaniello, D. (2025). Advancements in context recognition for edge devices and smart eyewear: Sensors and applications. IEEE Access, 13, 57062–57100. [Google Scholar] [CrossRef]
- Pan, A. (2024). How wearables like apple vision pro and orion are transforming human interactions with interfaces—…. Medium. Available online: https://medium.com/@alexanderpanboy/how-wearables-like-apple-vision-pro-and-orion-are-transforming-human-interactions-with-interfaces-95f3c390a77d (accessed on 10 December 2024).
- Park, J. S., O’Brien, J. C., Cai, C. J., Morris, M. R., Liang, P., & Bernstein, M. S. (2023). Generative agents: Interactive simulacra of human behavior. arXiv, arXiv:2304.03442. [Google Scholar] [CrossRef]
- Phakamach, P., Senarith, P., & Wachirawongpaisarn, S. (2022). The metaverse in education: The future of immersive teaching & learning. RICE Journal of Creative Entrepreneurship and Management, 3(2), 75–88. [Google Scholar] [CrossRef]
- Polansky, M. G., Herrmann, C., Hur, J., Sun, D., Verbin, D., & Zickler, T. (2024). Boundary attention: Learning curves, corners, junctions and grouping. arXiv, arXiv:2401.00935. [Google Scholar] [CrossRef]
- Qin, D., Leichner, C., Delakis, M., Fornoni, M., Luo, S., Yang, F., Wang, W., Banbury, C., Ye, C., Akin, B., Aggarwal, V., Zhu, T., Moro, D., & Howard, A. (2025). MobileNetV4: Universal models for the mobile ecosystem. In A. Leonardis, E. Ricci, S. Roth, O. Russakovsky, T. Sattler, & G. Varol (Eds.), Computer vision—ECCV 2024 (Vol. 15098, pp. 78–96). Springer Nature. [Google Scholar] [CrossRef]
- Reiniger, J. L., Domdei, N., Holz, F. G., & Harmening, W. M. (2021). Human gaze is systematically offset from the center of cone topography. Current Biology, 31(18), 4188–4193.e3. [Google Scholar] [CrossRef] [PubMed]
- Sahili, Z. A., & Awad, M. (2023). Spatio-temporal graph neural networks: A survey. arXiv, arXiv:2301.10569. [Google Scholar] [CrossRef]
- Song, T., Tan, Y., Zhu, Z., Feng, Y., & Lee, Y. C. (2024). Multi-agents are social groups: Investigating social influence of multiple agents in human-agent interactions. arXiv, arXiv:2411.04578. [Google Scholar] [CrossRef]
- Su, M., Guo, R., Wang, H., Wang, S., & Niu, P. (2017, July 18–20). View frustum culling algorithm based on optimized scene management structure. 2017 IEEE International Conference on Information and Automation (ICIA) (pp. 838–842), Macau, China. [Google Scholar] [CrossRef]
- Sun, J. C. Y., Ye, S. L., Yu, S. J., & Chiu, T. K. F. (2023). Effects of wearable hybrid AR/VR learning material on high school students’ situational interest, engagement, and learning performance: The case of a physics laboratory learning environment. Journal of Science Education and Technology, 32(1), 1–12. [Google Scholar] [CrossRef]
- Sun, Z., Zhu, M., Shan, X., & Lee, C. (2022). Augmented tactile-perception and haptic-feedback rings as human-machine interfaces aiming for immersive interactions. Nature Communications, 13(1), 5224. [Google Scholar] [CrossRef] [PubMed]
- Suo, J., Zhang, W., Gong, J., Yuan, X., Brady, D. J., & Dai, Q. (2023). Computational imaging and artificial intelligence: The next revolution of mobile vision. Proceedings of the IEEE, 111(12), 1607–1639. [Google Scholar] [CrossRef]
- Vrins, A., Pruss, E., Prinsen, J., Ceccato, C., & Alimardani, M. (2022). Are you paying attention? The effect of embodied interaction with an adaptive robot tutor on user engagement and learning performance. In F. Cavallo, J.-J. Cabibihan, L. Fiorini, A. Sorrentino, H. He, X. Liu, Y. Matsumoto, & S. S. Ge (Eds.), Social robotics (Vol. 13818, pp. 135–145). Springer Nature. [Google Scholar] [CrossRef]
- Wang, X., Wang, Y., Yang, J., Jia, X., Li, L., Ding, W., & Wang, F. Y. (2024). The survey on multi-source data fusion in cyber-physical-social systems: Foundational infrastructure for industrial metaverses and industries 5.0. Information Fusion, 107, 102321. [Google Scholar] [CrossRef]
- Wang, Z., Bian, W., & Prisacariu, V. A. (2025). CrossScore: Towards multi-view image evaluation and scoring. In A. Leonardis, E. Ricci, S. Roth, O. Russakovsky, T. Sattler, & G. Varol (Eds.), Computer vision—ECCV 2024 (Vol. 15067, pp. 492–510). Springer Nature. [Google Scholar] [CrossRef]
- Wu, X., Chen, X., Zhao, J., & Xie, Y. (2024). Influences of design and knowledge type of interactive virtual museums on learning outcomes: An eye-tracking evidence-based study. Education and Information Technologies, 29(6), 7223–7258. [Google Scholar] [CrossRef]
- Xi, Z., Chen, W., Guo, X., He, W., Ding, Y., Hong, B., Zhang, M., Wang, J., Jin, S., Zhou, E., Zheng, R., Fan, X., Wang, X., Xiong, L., Zhou, Y., Wang, W., Jiang, C., Zou, Y., Liu, X., … Gui, T. (2023). The rise and potential of large language model based agents: A survey. arXiv, arXiv:2309.07864. [Google Scholar] [CrossRef]
- Xia, Y., Shin, S.-Y., & Lee, H.-A. (2024). Adaptive learning in AI agents for the metaverse: The ALMAA framework. Applied Sciences, 14(23), 11410. [Google Scholar] [CrossRef]
- Yu, D. (2023, September 18–20). AI-empowered metaverse learning simulation technology application. 2023 International Conference on Intelligent Metaverse Technologies & Applications (iMETA) (pp. 1–6), Tartu, Estonia. [Google Scholar] [CrossRef]
- Zhai, X., Xu, J., Chen, N. S., Shen, J., Li, Y., Wang, Y., Chu, X., & Zhu, Y. (2023). The syncretic effect of dual-source data on affective computing in online learning contexts: A perspective from convolutional neural network with attention mechanism. Journal of Educational Computing Research, 61(2), 466–493. [Google Scholar] [CrossRef]
- Zhai, X. S., Chu, X. Y., Chen, M., Shen, J., & Lou, F. L. (2023). Can edu-metaverse reshape virtual teaching community (VTC) to promote educational equity? An exploratory study. IEEE Transactions on Learning Technologies, 16(6), 1130–1140. [Google Scholar] [CrossRef]
- Zhao, G., Liu, S., Zhu, W. J., & Qi, Y. H. (2021). A lightweight mobile outdoor augmented reality method using deep learning and knowledge modeling for scene perception to improve learning experience. International Journal of Human–Computer Interaction, 37(9), 884–901. [Google Scholar] [CrossRef]
- Zhao, Z., Zhao, B., Ji, Z., & Liang, Z. (2022). On the personalized learning space in educational metaverse based on heart rate signal. International Journal of Information and Communication Technology Education (IJICTE), 18(2), 1–12. [Google Scholar] [CrossRef]
- Zhou, X., Yang, Q., Zheng, X., Liang, W., Wang, K. I. K., Ma, J., Pan, Y., & Jin, Q. (2024). Personalized federated learning with model-contrastive learning for multi-modal user modeling in human-centric metaverse. IEEE Journal on Selected Areas in Communications, 42(4), 817–831. [Google Scholar] [CrossRef]
- Zhu, L., Li, Y., Sandström, E., Huang, S., Schindler, K., & Armeni, I. (2024). LoopSplat: Loop closure by registering 3D gaussian splats. arXiv, arXiv:2408.10154. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Interaction Dimension | Contents | Description |
|---|---|---|
| Learner-to-Learner | Gesture Recognition | Capturing natural gestures for non-verbal communication and object manipulation in virtual spaces. |
| Synchronized Activities | Mapping shared physical activities (e.g., virtual sports) in real time to foster collaboration. | |
| Haptic Feedback | Simulating remote physical touch, enhancing social presence and emotional connection. | |
| Learner-to-Metaverse | Immersive Operations | Enabling direct and intuitive interaction with virtual objects through body movements. |
| Multisensory Feedback | Providing rich experiences through integrated visual, auditory, and haptic feedback. | |
| Spatial Navigation | Allowing for natural navigation of virtual spaces using physical movements to enhance exploration. | |
| Learner-to-Real-Environment | AR Annotations | Overlaying real-world objects with contextual learning information. |
| Interaction Mapping | Mapping real-world actions to virtual environments for seamless learning. | |
| Environmental Adaptation | Dynamically adjusting learning content based on environmental data. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, J.; Zhai, X.; Chen, N.-S.; Ghani, U.; Istenic, A.; Xin, J. Integrating AI-Driven Wearable Metaverse Technologies into Ubiquitous Blended Learning: A Framework Based on Embodied Interaction and Multi-Agent Collaboration. Educ. Sci. 2025, 15, 900. https://doi.org/10.3390/educsci15070900
Xu J, Zhai X, Chen N-S, Ghani U, Istenic A, Xin J. Integrating AI-Driven Wearable Metaverse Technologies into Ubiquitous Blended Learning: A Framework Based on Embodied Interaction and Multi-Agent Collaboration. Education Sciences. 2025; 15(7):900. https://doi.org/10.3390/educsci15070900
Chicago/Turabian StyleXu, Jiaqi, Xuesong Zhai, Nian-Shing Chen, Usman Ghani, Andreja Istenic, and Junyi Xin. 2025. "Integrating AI-Driven Wearable Metaverse Technologies into Ubiquitous Blended Learning: A Framework Based on Embodied Interaction and Multi-Agent Collaboration" Education Sciences 15, no. 7: 900. https://doi.org/10.3390/educsci15070900
APA StyleXu, J., Zhai, X., Chen, N.-S., Ghani, U., Istenic, A., & Xin, J. (2025). Integrating AI-Driven Wearable Metaverse Technologies into Ubiquitous Blended Learning: A Framework Based on Embodied Interaction and Multi-Agent Collaboration. Education Sciences, 15(7), 900. https://doi.org/10.3390/educsci15070900