
How Do Curricular Design Changes Impact Computer Science Programs?: A Case Study at San Pablo Catholic University in Peru

 ,
,  ,
,  ,
,  and
and 
Abstract
:1. Introduction
2. Contextualization
- (a)
- Computer Science/Informatics. Undergraduate programs in computing in Latin America have been influenced since their inception by two trends, which have both emerged since the late 1940s: the Anglo-American with the term computer science and the European with the term Informatics. In practice, the international scientific community considers both terms synonymous. They refer to the study of computers, including the theory of computation, software design, and algorithms, and the way humans interact with technology. Computer science/informatics and six other branches of computing are currently regulated based on the world standard called Computing Curricula [15]. This standard was developed in cooperation with institutions such as the Association for Computing Machinery (ACM) and the Computer Society from the Institute of Electrical and Electronics Engineers (IEEE-CS) and propose guidelines to undergraduate programs in computing-based areas. Other institutions such as the International Federation for Information Processing (IFIP, Europe) also support this standard. This trend in computer science has a strongly marked presence in Brazil. On the other hand, there is also a significant presence of computer science programs in Argentina, Chile, and Mexico, although they still maintain a diversity of nomenclatures. In the rest of the Latin American countries, this trend is not very significant or is in an initial stage.
- (b)
- Systems engineering in English-speaking countries. Another essential factor to be considered in this context is the term Systems Engineering that emerged in the 1940s in the USA and was defined as the engineering discipline that deals with complex engineering problems requiring multidisciplinary approaches, including management aspects. This trend is currently regulated by the International Council on System Engineering (INCOSE) and exists mainly in English-speaking countries.
- (c)
- Systems engineering in Latin America. In addition to establishing Systems Engineering (in the 1960s), the activity generated by companies such as IBM emerged. To manage its installed computing solutions, IBM created a job position called a Systems Engineer, which a person of any professional background could fill. Then, from this required position in the market, several Latin American countries such as Colombia, Peru, Ecuador, and Venezuela, among others, began to create undergraduate programs under the name Systems Engineering. This regional version of Systems Engineering consists of topics related to Business, Marketing, Accounting, Administration, Economics, Organizational behavior, Indus- trial Engineering, Electronic Engineering, and the content of some parts of the seven standards of Computing Curricula (ACM, CS-IEEE).
- (d)
- Computer Engineering in Spain. As in Latin America, the terminology of Systems Engineering is common; in Spain, this convergence led to “Ingeniería Informática” (informatics engineering). However, after adhering to the Bologna agreement (in 1999), the need to standardize and internationalize the content of these careers arose. At present, for historical reasons, this denomination is still maintained. Still, each computer-related program is being built or aligned based on one of the seven programs proposed in the Computer Science Study Plans (ACM, CS-IEEE).
3. Related Work
4. Research Questions
5. Materials and Methods
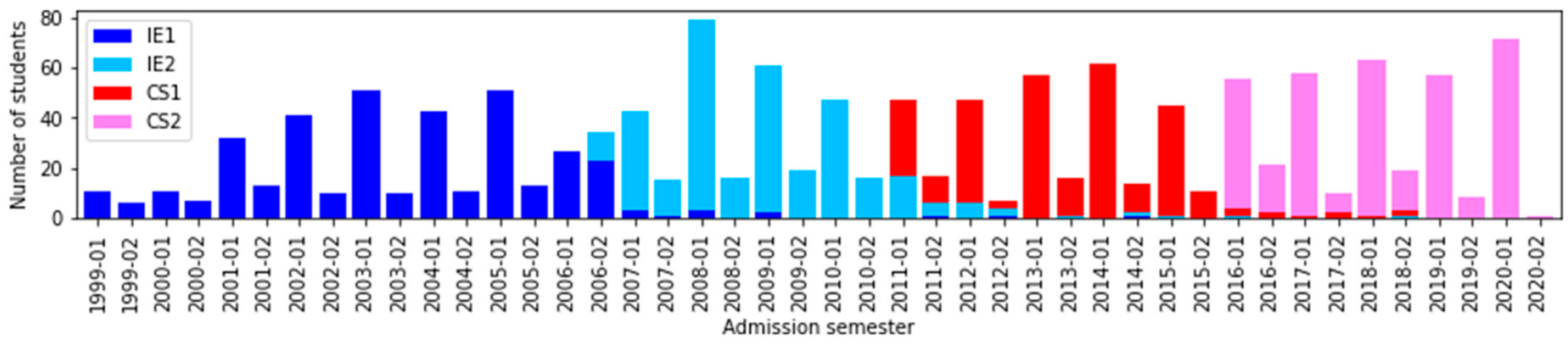
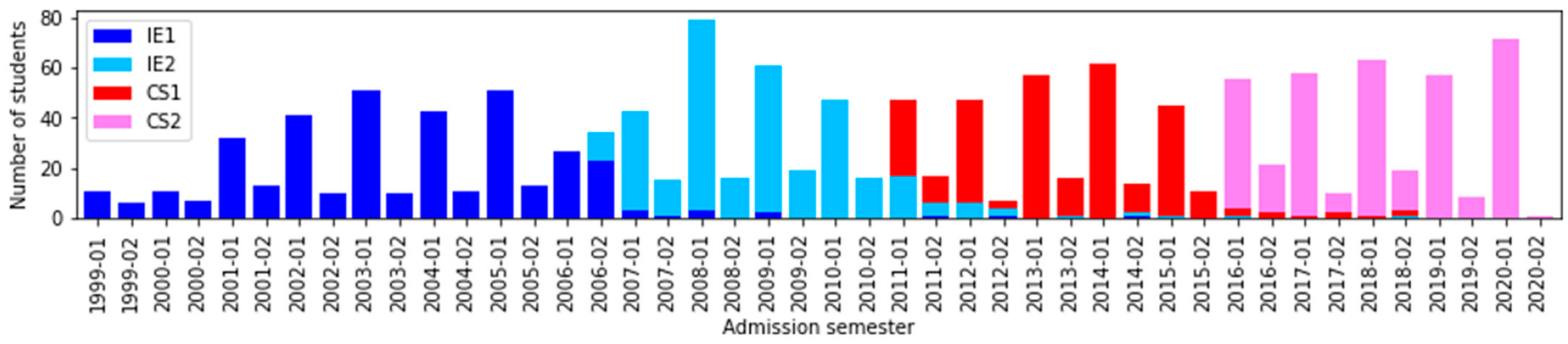
5.1. Data Set
- (a)
- Demographic data consists of general information about students, such as person identifier, gender, marital status, date of birth, age, provenance location, residence location, and high school type.
- (b)
- General academic data are data linked to universities. One variable is the name of the curriculum design, which assumes values of IE1, IE2, CS1, and CS2. Additionally, we have the admission semester. In the same vein, we have the name of the enrolled semester, which can be regular or not. For example, 2001–01 and 2001–02 are regular semesters, and other configurations are non-regular semesters. They are resources that satisfy the number of hours and credits as summer courses. The completed semester represents the practical semester of study, assuming a unique value between 1 and 10. For example, a student may have enrolled in five periods and have only two semesters completed; this occurs because the student failed some courses. The scholarship represents the state of whether or not it has financial funding. Finally, student status assumes the following values: graduated, regular, reserved, separated, retired, and transferred.
- (c)
- Academic data by course is related to the enrolled courses. Based on the courses, we have attributes of course code, course name, type of course (compulsory or elective), course grade (on a scale from 0 to 20), weekly hours per course, number of credits per course, hours of absence per course, and reservation status per course.
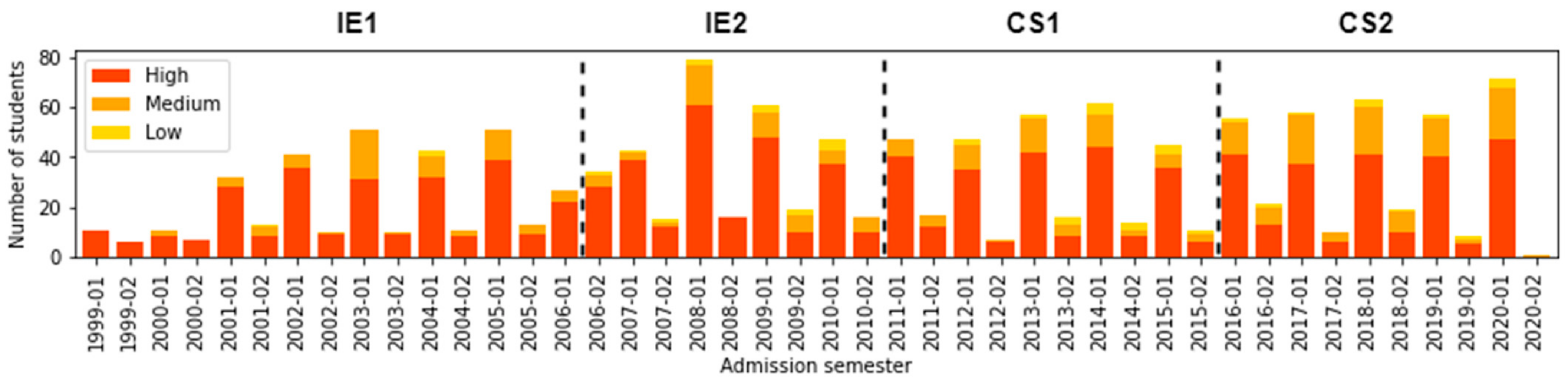
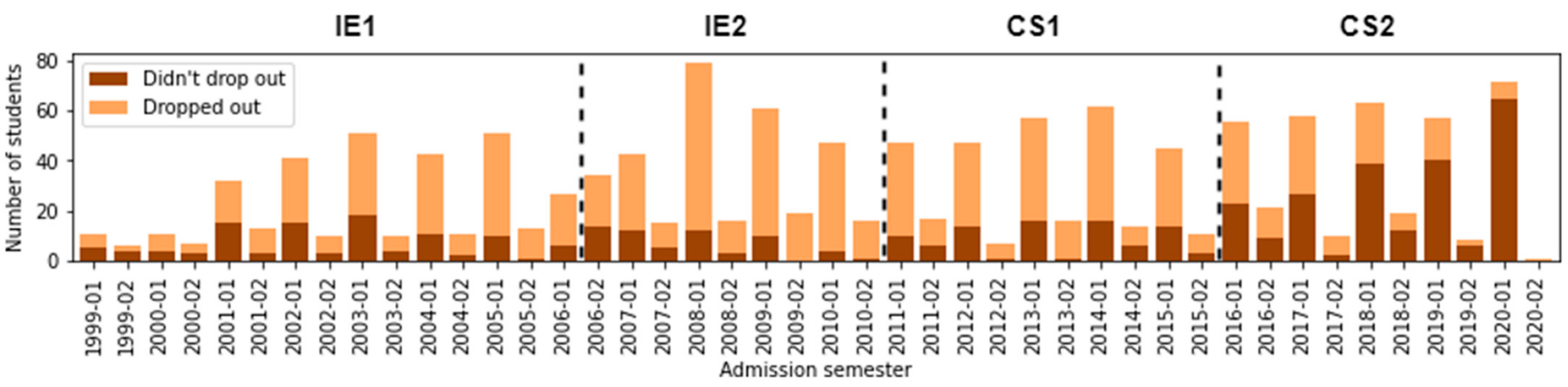
5.2. Exploratory Data Analysis
6. Results
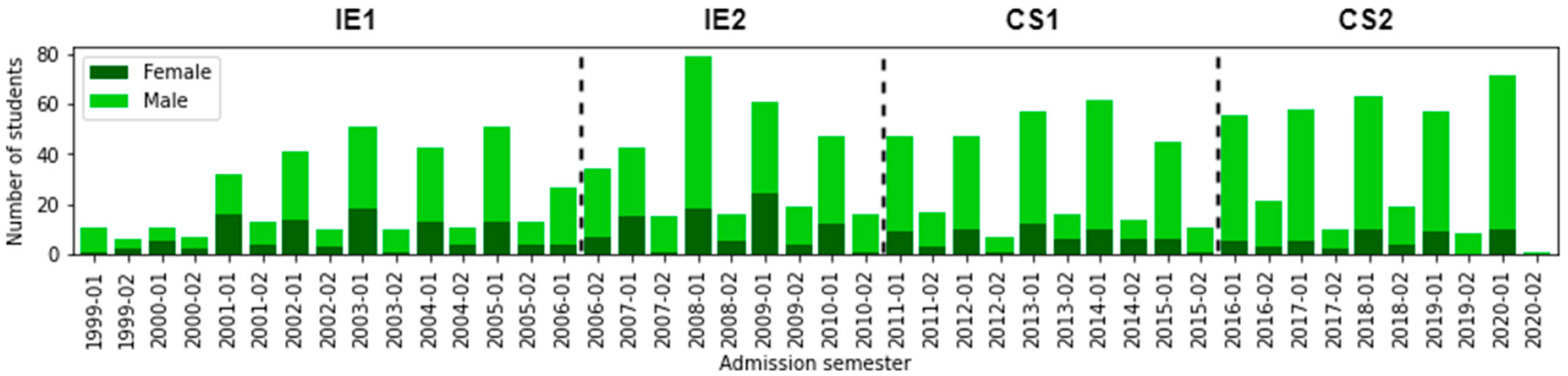
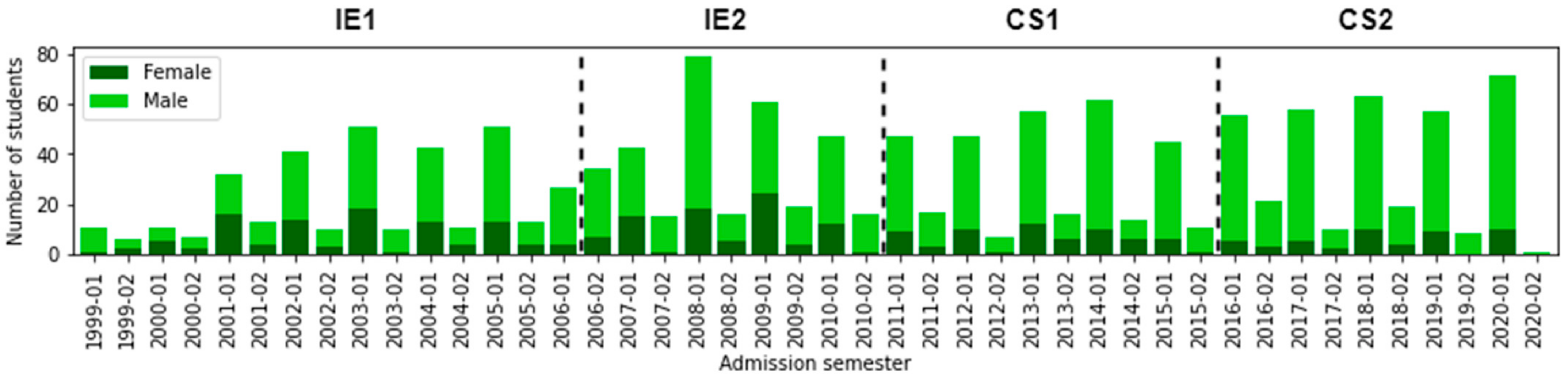
6.1. (RQ1) Did the Different Curricular Designs Have an Impact on Students’ Gender Proportion?
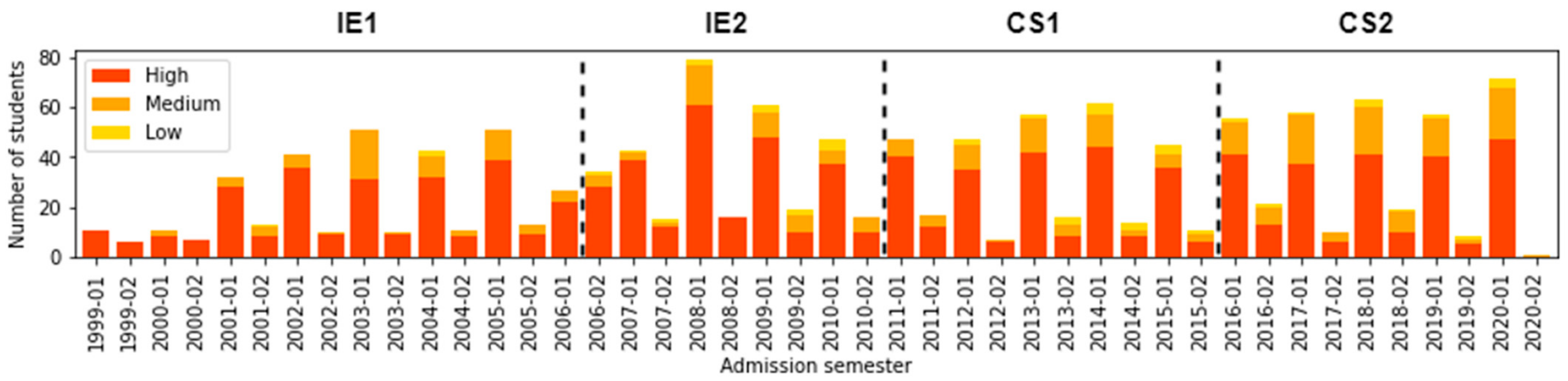
6.2. (RQ2) Did the Different Curriculum Designs Impact the Proportion of Students According to Provenance Location Socioeconomic Level?
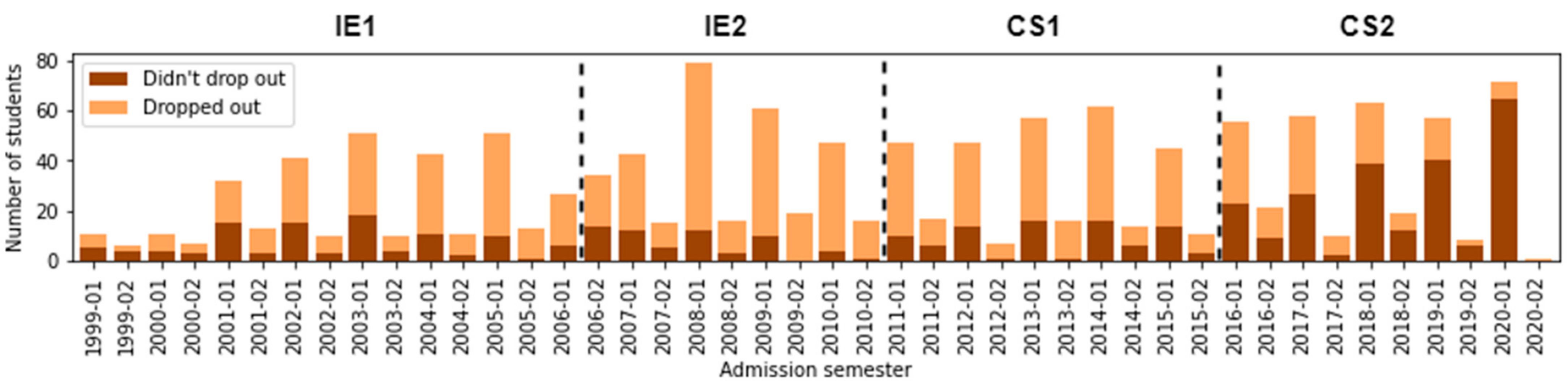
6.3. (RQ3) Did the Different Curriculum Designs Have an Impact on Students’ Dropout Rates?
6.4. (RQ4) What Was the Impact of Gender and Provenance Location Socioeconomic Level on Student Dropout Rates?
- Dropout students according to Gender: Applying the Chi-square test, we obtain a value of p < 0.001, suggesting a dependence on curricular changes in dropout students grouped by gender. We note that there is not much difference between them. The most significant percentage difference occurs in IE1, i.e., the dropout rate for men was 71.26%, while the dropout rate for women was 61.26%. In CS1, both dropout rates coincide (70.4% for male and female students). So, in dropout students, the curricular design impacted the gender balance. We concluded that although the dropout rates are very high for both genders, we find a minor percentage difference in computer science (CS1 and CS2) than informatics engineering (IE1 and IE2).
- Dropout students according to Socioeconomic_Prov. We obtain a p < 0.001 and demonstrate dependence between these variables. In most cases, the higher the provenance location socioeconomic level, the lower the dropout rate. The opposite case occurs in CS2. This phenomenon may be due to several reasons. For instance, we highlight the recent improvement of economic support promoted by the Peruvian government—allowing low-income students to continue their studies thanks to financial aid. Based on this, we can say that poor performance in studies is not always the only reason for dropping out. It is a phenomenon that is much more complex. Analyzing the dropout rates in students of low socioeconomic origin shows that, in IE1 and IE2, all students dropped out, while in CS1, there is a slight improvement, with only 85% of them dropping out. Currently, in CS2, the dropout percentage is 23.08%, which presents better results than students from a better provenance location socioeconomic level.
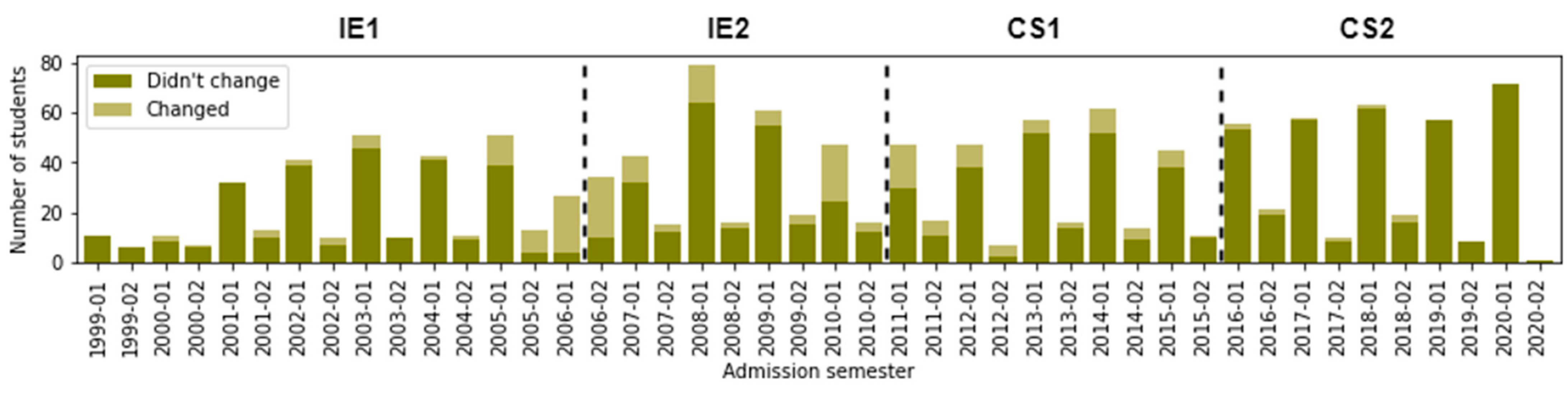
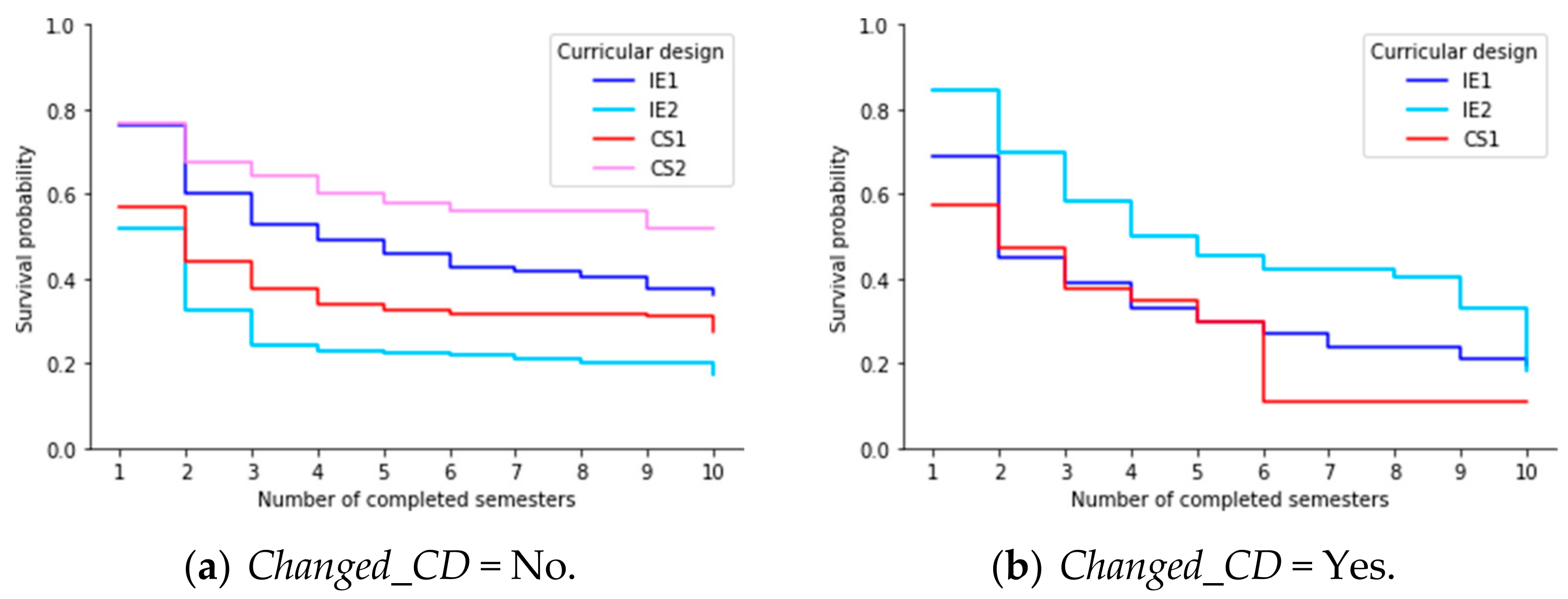
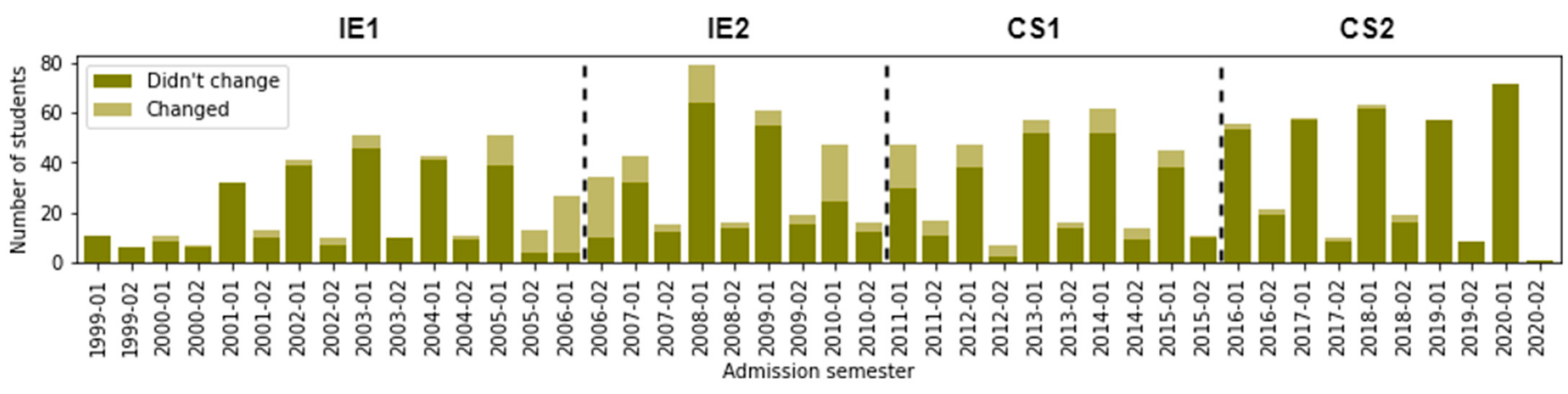
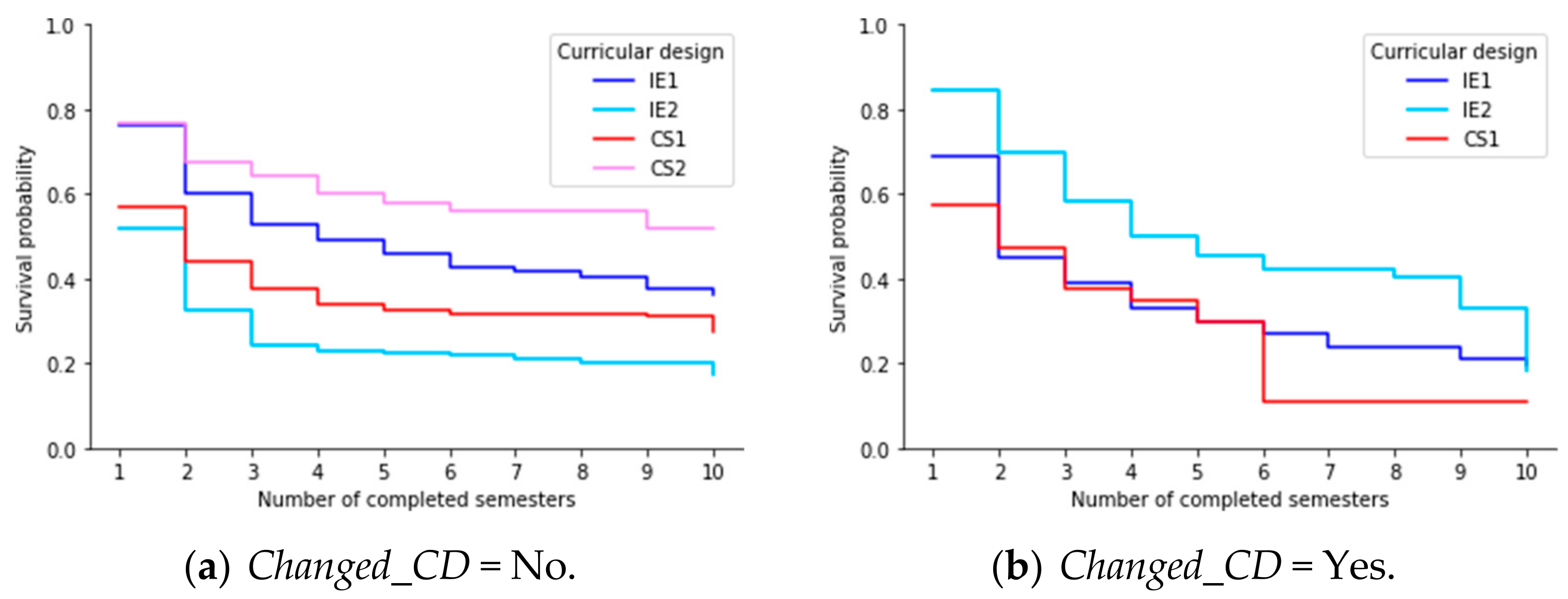
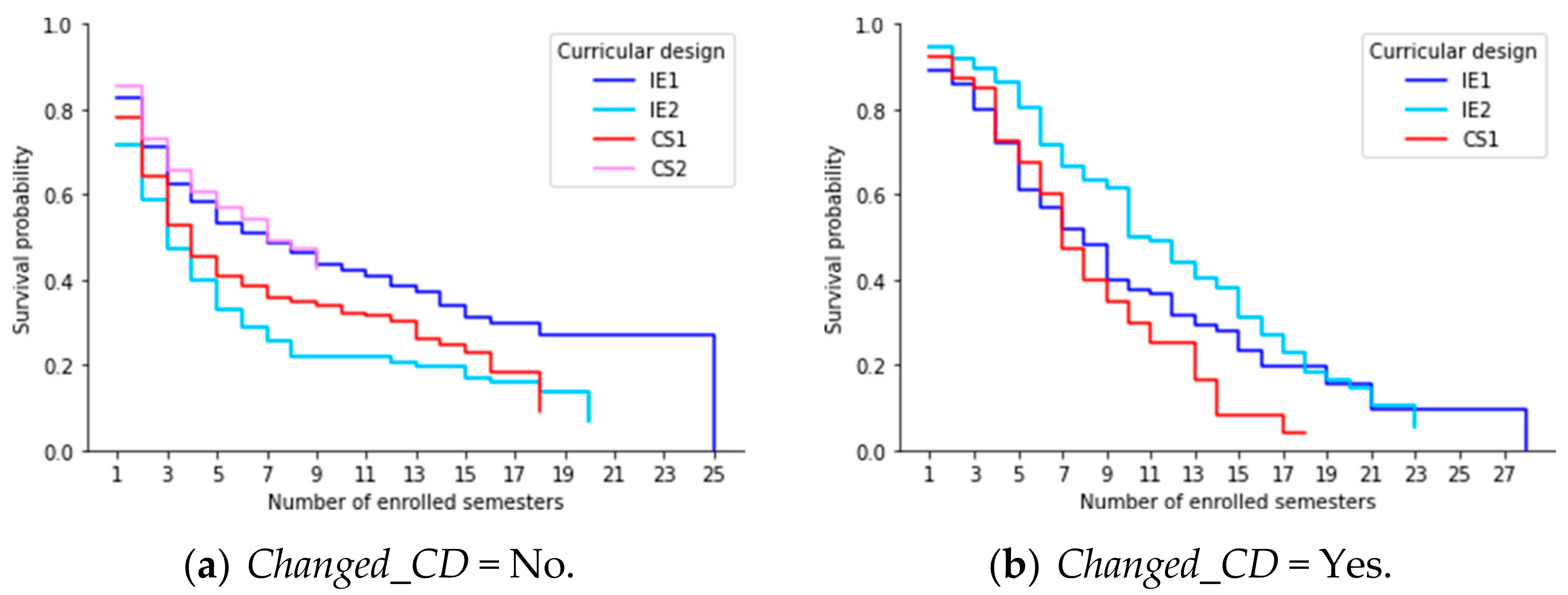
6.5. (RQ5) Did the Different Curriculum Designs Have an Impact on Students’ Permanence Time?
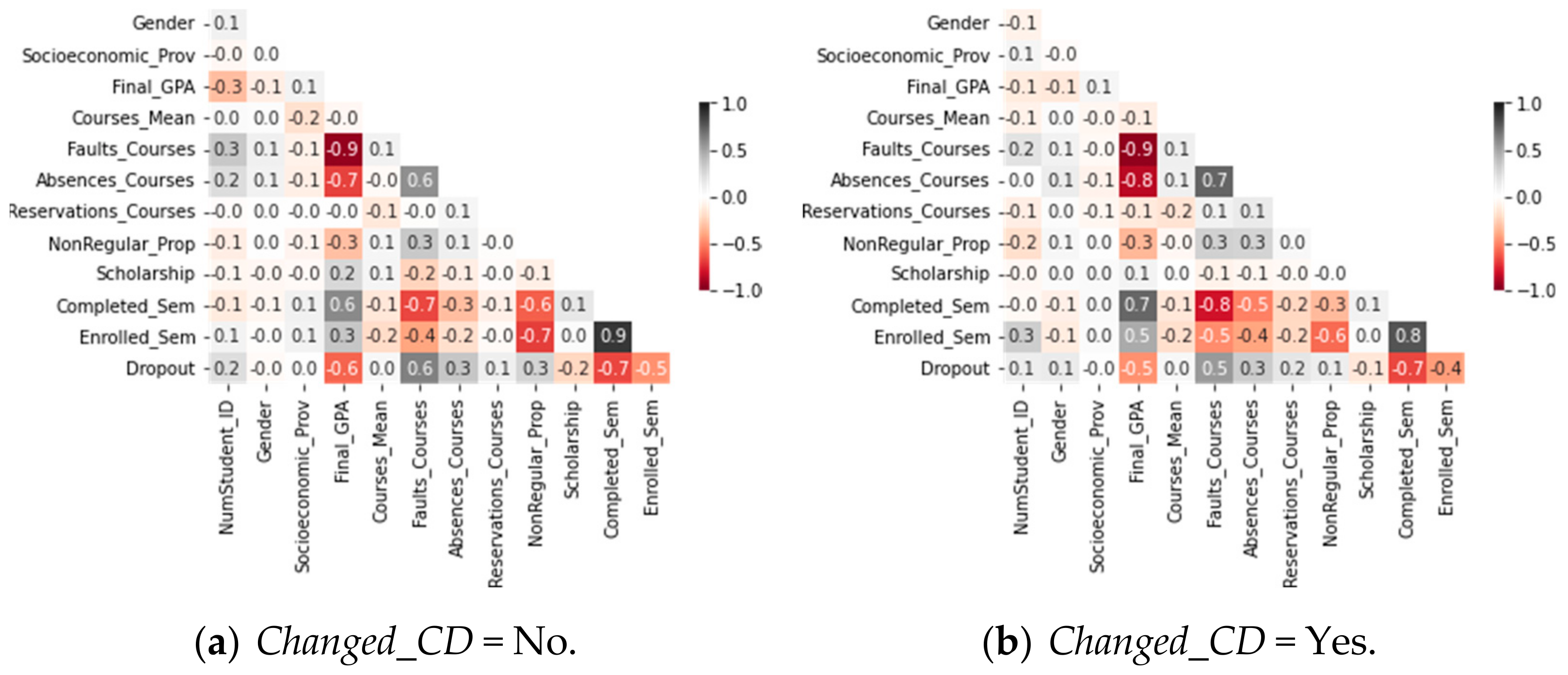
- (a)
- Students who did not change their curricular design (Changed_CD = No).
- (b)
- Students who changed their curricular design (Changed_CD = Yes).
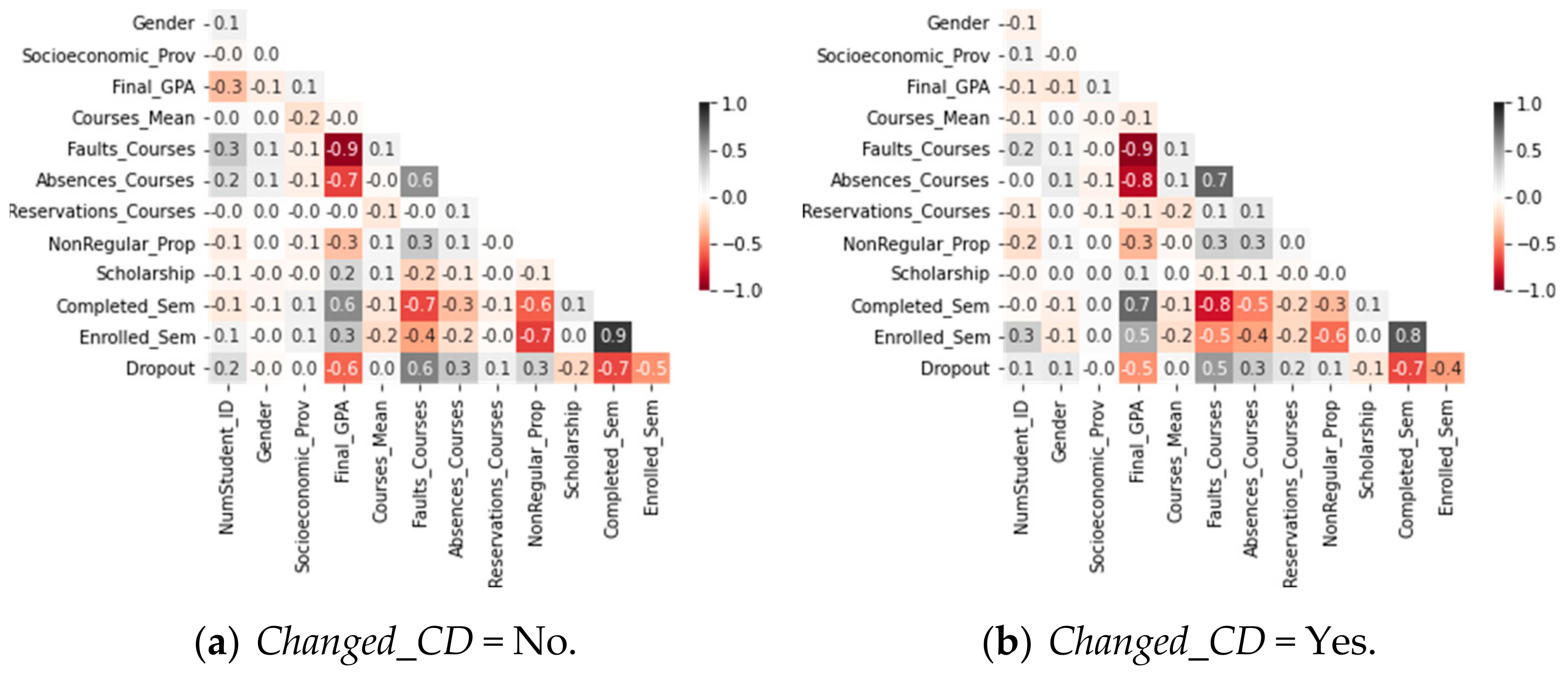
6.6. (RQ6) What Variables Are Most Decisive in Predicting the Permanence Time before Dropping Out?
- C-index of 0.5 denotes a random model;
- C-index of 1.0 denotes a perfect model;
- C-index of 0.0 denotes a perfectly wrong model.
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fraser, S.P.; Bosanquet, A.M. The curriculum? That’s just a unit outline, isn’t it? Stud. High. Educ. 2006, 31, 269–284. [Google Scholar] [CrossRef]
- Biggs, J. What the student does: Teaching for enhanced learning. High. Educ. Res. Dev. 1999, 18, 57–75. [Google Scholar] [CrossRef] [Green Version]
- Vergel, J.; Quintero, G.A.; Isaza-Restrepo, A.; Ortiz-Fonseca, M.; Latorre-Santos, C.; Pardo-Oviedo, J.M. The influence of different curriculum designs on students’ dropout rate: A case study. Med. Educ. Online 2018, 23, 1432963. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barbosa, A.; Santos, E.; Pordeus, J.P. A machine learning approach to identify and prioritize college students at risk of dropping out. In Proceedings of the SBIE 2017, Natal, Brazil, 30 October–2 November 2017; Volume 28, p. 1497. [Google Scholar]
- Rovira, S.; Puertas, E.; Igual, L. Data-driven system to predict academic grades and dropout. PLoS ONE 2017, 12, e0171207. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Palmer, S. Modelling engineering student academic performance using academic analytics. IJEE 2013, 29, 132–138. [Google Scholar]
- Gitinabard, N.; Khoshnevisan, F.; Lynch, C.F.; Wang, E.Y. Your actions or your associates? Predicting certification and dropout in MOOCs with behavioral and social features. arXiv 2018, arXiv:1809.00052. [Google Scholar]
- Aulck, L.; Aras, R.; Li, L.; L’Heureux, C.; Lu, P.; West, J. STEM-ming the Tide: Predicting STEM attrition using student transcript data. arXiv 2017, arXiv:1708.09344. [Google Scholar]
- Solís, M.; Moreira, T.; Gonzalez, R.; Fernandez, T.; Hernandez, M. Perspectives to predict dropout in university students with machine learning. In Proceedings of the 2018 IEEE—IWOBI, San Carlos, Costa Rica, 18–20 July 2018; IEEE: Piscatway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Iputo, J.E.; Kwizera, E. Problem-based learning improves the academic performance of medical students in South Africa. Med. Educ. 2005, 39, 388–393. [Google Scholar] [CrossRef] [PubMed]
- Quintero, G.A.; Vergel, J.; Arredondo, M.; Ariza, M.C.; Gómez, P.; Pinzon-Barrios, A.M. Integrated medical curriculum: Advantages and disadvantages. J. Med. Educ. Curric. Dev. 2016, 3, 133–137. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ioannis, B.; Maria, K. Gender and Student Course Preferences and Course Performance in Computer Science Departments: A Case Study. Educ. Inf. Technol. 2019, 24, 1269–1291. [Google Scholar] [CrossRef]
- Baer, A.; DeOrio, A. A Longitudinal View of Gender Balance in a Large Computer Science Program. In Proceedings of the 51st ACM Technical Symposium on Computer Science Education, Portland, OR, USA, 11–14 March 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 23–29. [Google Scholar]
- Parker, M.C.; Solomon, A.; Pritchett, B.; Illingworth, D.A.; Marguilieux, L.E.; Guzdial, M. Socioeconomic Status and Computer Science Achievement: Spatial Ability as a Mediating Variable in a Novel Model of Understanding. In Proceedings of the 2018 ACM Conference on International Computing Education Research, Espoo, Finland, 13–15 August 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 97–105. [Google Scholar]
- Force, C.T. Computing Curricula 2020: Paradigms for Global Computing Education; Association for Computing Machinery: New York, NY, USA, 2020. [Google Scholar]
- Savic, M.; Ivanovic, M.; Lukovic, I.; Delibasic, B.; Protic, J.; Jankovic, D. Students’ preferences in selection of computer science and informatics studies: A comprehensive empirical case studyStudents’ preferences in selection of computer science and informatics studies: A comprehensive empirical case study. Comput. Sci. Inf. Syst. 2021, 18, 251–283. [Google Scholar] [CrossRef]
- Ying, K.M.; Rodríguez, F.J.; Dibble, A.L.; Martin, A.C.; Boyer, K.E.; Thomas, S.V.; Gilbert, J.E. Confidence, Connection, and Comfort: Reports from an All-Women’s CS1 Class. In Proceedings of the 52nd ACM Technical Symposium on Computer Science Education, Virtual Event USA, 13–20 March 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 699–705. [Google Scholar]
- Pappas, I.O.; Giannakos, M.N.; Jaccheri, L. Investigating Factors Influencing Students’ Intention to Dropout Computer Science Studies. In Proceedings of the 2016 ACM Conference on Innovation and Technology in Computer Science Education, Arequipa, Peru, 11–13 July 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 198–203. [Google Scholar]
- Christoph, F.; Weimer, W.; Angstadt, K. The Early Bird Gets the Worm: Major Retention in CS3. In Proceedings of the 26th ACM Conference on Innovation and Technology in Computer Science Education V. 1, Virtual Event Germany, 26 June–1 July 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 422–428. [Google Scholar]
- Mendez, G.; Ochoa, X.; Chiluiza, K.; de Wever, B. Curricular Design Analysis: A Data-Driven Perspective. J. Learn. Anal. 2014, 1, 84–119. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Li, Y.; Reddy, C.K. Machine Learning for Survival Analysis: A Survey. ACM Comput. Surv. 2019, 51, 110. [Google Scholar] [CrossRef]
- Ameri, S.; Fard, M.J.; Chinnam, R.B.; Reddy, C.K. Survival Analysis Based Framework for Early Prediction of Student Dropouts. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 903–912. [Google Scholar]
- Gutierrez-Pachas, D.A.; Garcia-Zanabria, G.; Cuadros-Vargas, A.J.; Camara-Chavez, G.; Poco, J.; Gomez-Nieto, E. A comparative study of WHO and WHEN prediction approaches for early identification of university students at dropout risk. In Proceedings of the 2021 XLVII Latin American Computing Conference (CLEI), Cartago, Costa Rica, 25–29 October 2021; pp. 1–10. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label Name | Description | Type |
|---|---|---|
| MaskPerson_ID | Masked person identifier | Nominal |
| MaskStudent_ID | Masked student identifier | Nominal |
| NumStudent_ID | Number of student identities | Discrete numeric |
| Initial_CD | Initial enrolled curricular design | Nominal (IE1 or IE2 or CS1 or CS2) |
| Final_CD | Final enrolled curricular design | Nominal (IE1 or IE2 or CS1 or CS2) |
| Number_CD | Number of enrolled curricular designs | Discrete numeric |
| Changed_CD | Whether the student changedcurricular design | Nominal (Yes or No) or not |
| Admission_Sem | Admission semester to the university | Nominal (from 1999–01 to 2020–02) |
| Gender | Gender of student | Nominal (Male or Female) |
| Socioeconomic_Prov | Provenance location socioeconomic level | Nominal (High or Medium or Low) |
| Final_GPA | Final Grade Point Average | Continuous numeric |
| Courses_Mean | Mean of enrolled courses per semester | Continuous numeric |
| Faults_Courses | Proportion of faulted courses in relation to the total number of enrolled courses | Continuous numeric |
| Absences_Courses | Proportion of faulted courses by absence | Continuous numeric |
| Reservations_Courses | Proportion of reservations in relation to the total number of enrolled semesters | Continuous numeric |
| NonRegular_Prop | Proportion of non–regular semesters in relation to the total number of enrolled semesters | Continuous numeric |
| Scholarship | Whether the student has a scholarship or not | Nominal (Yes or No) |
| Completed_Sem | Number of completed semesters | Discrete numeric (from 1 to 10) |
| Enrolled_Sem | Number of enrolled semesters | Discrete numeric |
| Student_Status | Student’s current status | Nominal (Graduated or Regular or Reserved or Separated or Retired or Transferred) |
| Dropout | Dropout status | Nominal (Yes or No) |
| Initial_CD | Number of Students | Changed_CD | |
|---|---|---|---|
| No (%) | Yes (%) | ||
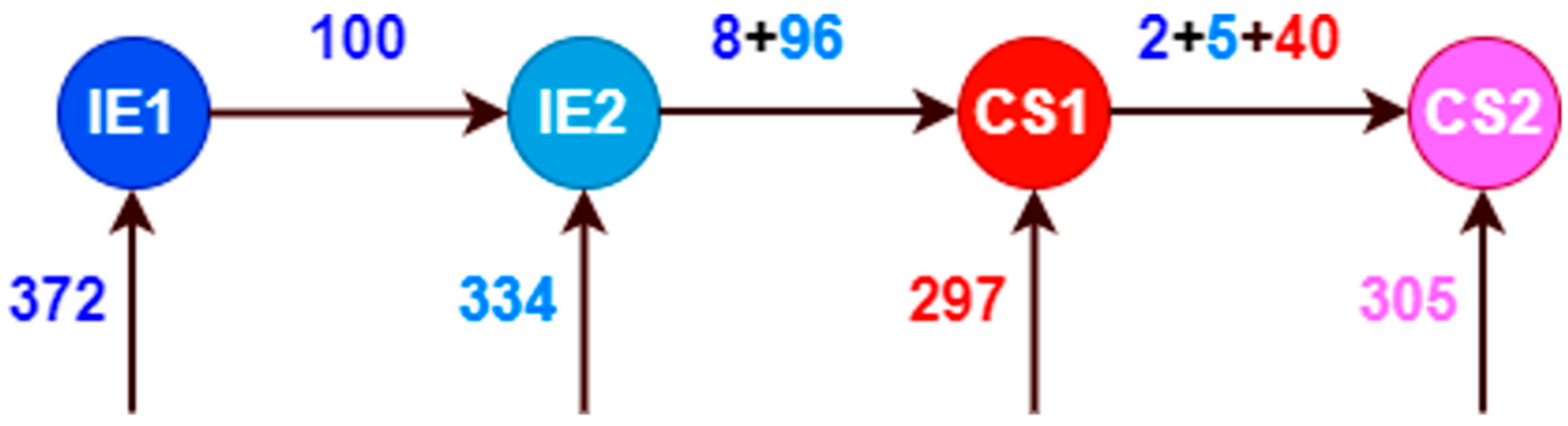
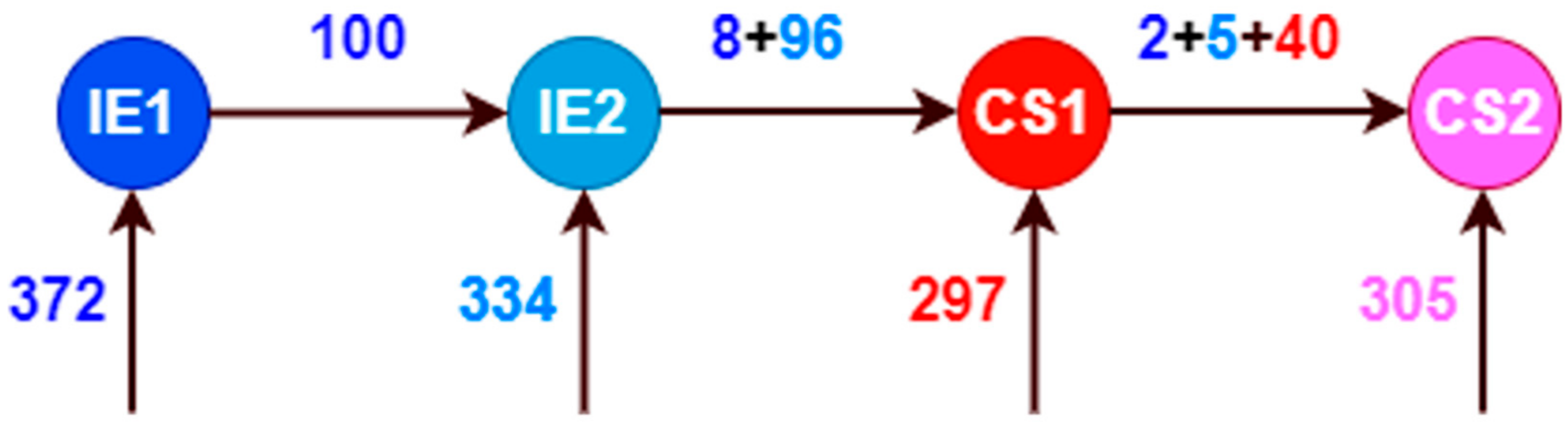
| IE1 IE2 | 372 334 | 272 (73.12%) 238 (71.26%) | 100 (26.88%) 96 (28.74%) |
| CS1 CS2 | 297 352 | 257 (86.53%) 352 (100%) | 40 (13.47%) – |
| Initial_CD | Gender | Socioeconomic_Prov | |||
|---|---|---|---|---|---|
| Male (%) | Female (%) | High (%) | Medium (%) | Low (%) | |
| IE1 IE2 | 261 (70.16%) 243 (72.75%) | 111 (29.84%) 91 (27.25%) | 294 (79.03%) 260 (77.84%) | 74 (19.89%) 59 (17.66%) | 4 (1.08%) 15 (4.5%) |
| CS1 CS2 | 243 (81.82%) 305 (86.65%) | 54 (18.18%) 47 (13.35%) | 214 (72.05%) 233 (66.19%) | 63 (21.21%) 106 (30.11%) | 20 (6.74%) 13 (3.7%) |
| Initial_CD | Gender = Female | Gender = Male | ||
|---|---|---|---|---|
| No (%) | Yes (%) | No (%) | Yes (%) | |
| IE1 IE2 | 93 (83.78%) 66 (72.53%) | 18 (16.22%) 25 (27.47%) | 179 (68.58%) 172 (70.78%) | 82 (31.42%) 71 (29.22%) |
| CS1 CS2 | 53 (98.15%) 47 (100%) | 1 (1.85%) – | 204 (83.95%) 305 (100%) | 39 (16.05%) – |
| Initial_CD | Socioeconomic_Prov = High | Socioeconomic_Prov = Medium | Socioeconomic_Prov = Low | |||
|---|---|---|---|---|---|---|
| No (%) | Yes (%) | No (%) | Yes (%) | No (%) | Yes (%) | |
| IE1 IE2 | 210 (71.43%) 184 (70.77%) | 84 (28.57%) 76 (29.23%) | 58 (78.38%) 41 (69.49%) | 16 (21.62%) 18 (30.51%) | 4 (100%) 13 (86.67%) | 0 (0%) 2 (13.33%) |
| CS1 CS2 | 190 (88.79%) 233 (100%) | 24 (11.21%) – | 52 (82.54%) 106 (100%) | 11 (17.46%) – | 15 (75%) 13 (100%) | 5 (25%) – |
| Initial_CD | Dropout = No | Dropout = Yes | ||
|---|---|---|---|---|
| No (%) | Yes (%) | No (%) | Yes (%) | |
| IE1 IE2 | 98 (83.05%) 42 (68.85%) | 20 (16.95%) 19 (31.15%) | 174 (68.50%) 196 (71.79%) | 80 (31.50%) 77 (28.21%) |
| CS1 CS2 | 72 (93.51%) 219 (100%) | 5 (6.49%) – | 185 (84.09%) 133 (100%) | 35 (15.91%) – |
| Initial_CD | Gender | Socioeconomic_Prov | |||
|---|---|---|---|---|---|
| Male (%) | Female (%) | High (%) | Medium (%) | Low (%) | |
| IE1 IE2 | 186 (71.26%) 199 (81.89%) | 68 (61.26%) 74 (81.32%) | 204 (69.39%) 209 (80.38%) | 46 (62.16%) 49 (83.05%) | 4 (100%) 15 (100%) |
| CS1 CS2 | 180 (74.07%) 118 (38.69%) | 40 (74.07%) 15 (31.91%) | 157 (73.36%) 88 (37.77%) | 46 (73.02%) 42 (39.62%) | 17 (85%) 3 (23.08%) |
| Initial_CD | Number of Non-Dropout Students | Regular (%) | Graduated (%) | Reserved (%) |
|---|---|---|---|---|
| IE1 IE2 | 120 68 | 1 (0.83%) 8 (11.76%) | 118 (98.34%) 59 (86.76%) | 1 (0.83%) 1 (1.48%) |
| CS1 CS2 | 77 219 | 29 (37.66%) 210 (95.89%) | 45 (58.44%) 1 (0.46%) | 3 (3.90%) 8 (3.65%) |
| Initial_CD | Completed_Sem | Enrolled_Sem | ||
|---|---|---|---|---|
| No (%) | Yes (%) | No (%) | Yes (%) | |
| IE1 IE2 | 5.3 3.9 | 3.8 4.2 | 10 6.3 | 8.6 10.3 |
| CS1 CS2 | 5.3 6.8 | 3.4 – | 7.2 5.3 | 6.3 – |
| Attribute Name | Changed_CD = No | Changed_CD = Yes | |||||
|---|---|---|---|---|---|---|---|
| IE1 | IE2 | CS1 | CS2 | IE1 | IE2 | CS1 | |
| NumStudent_ID | 0.57 | 0.55 | 0.51 | 0.54 | 0.52 | 0.54 | 0.52 |
| Gender | 0.52 | 0.59 | 0.51 | 0.54 | 0.62 | 0.53 | – |
| Socieconomic_Prov | 0.52 | 0.47 | 0.51 | 0.52 | 0.58 | 0.61 | 0.50 |
| Final_GPA | 0.80 | 0.84 | 0.87 | 0.90 | 0.87 | 0.77 | 0.79 |
| Courses_Mean | 0.71 | 0.60 | 0.66 | 0.49 | 0.52 | 0.65 | 0.52 |
| Faults_Courses | 0.83 | 0.85 | 0.86 | 0.90 | 0.88 | 0.77 | 0.90 |
| Absences_Courses | 0.58 | 0.60 | 0.66 | 0.72 | 0.76 | 0.75 | 0.71 |
| Reservations_Courses | 0.52 | 0.60 | 0.50 | 0.52 | 0.51 | 0.57 | 0.58 |
| NonRegular_Prop | 0.77 | 0.79 | 0.83 | 0.66 | 0.68 | 0.52 | 0.60 |
| Scholarship | – | 0.52 | 0.50 | 0.55 | – | – | 0.50 |
| Attribute Name | Changed_CD = No | Changed_CD = Yes | |||||
|---|---|---|---|---|---|---|---|
| IE1 | IE2 | CS1 | CS2 | IE1 | IE2 | CS1 | |
| NumStudent_ID | 0.54 | 0.56 | 0.52 | 0.47 | 0.60 | 0.62 | 0.64 |
| Gender | 0.54 | 0.56 | 0.51 | 0.55 | 0.58 | 0.53 | – |
| Socieconomic_Prov | 0.51 | 0.52 | 0.52 | 0.51 | 0.55 | 0.61 | 0.48 |
| Final_GPA | 0.76 | 0.65 | 0.71 | 0.77 | 0.75 | 0.64 | 0.48 |
| Courses_Mean | 0.74 | 0.61 | 0.43 | 0.52 | 0.59 | 0.67 | 0.69 |
| Faults_Courses | 0.78 | 0.66 | 0.70 | 0.77 | 0.75 | 0.63 | 0.60 |
| Absences_Courses | 0.53 | 0.53 | 0.55 | 0.62 | 0.64 | 0.62 | 0.73 |
| Reservations_Courses | 0.49 | 0.57 | 0.52 | 0.50 | 0.46 | 0.63 | 0.56 |
| NonRegular_Prop | 0.82 | 0.87 | 0.87 | 0.80 | 0.80 | 0.63 | 0.69 |
| Scholarship | – | 0.51 | 0.50 | 0.54 | – | – | 0.50 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gutierrez-Pachas, D.A.; Garcia-Zanabria, G.; Cuadros-Vargas, A.J.; Camara-Chavez, G.; Poco, J.; Gomez-Nieto, E. How Do Curricular Design Changes Impact Computer Science Programs?: A Case Study at San Pablo Catholic University in Peru. Educ. Sci. 2022, 12, 242. https://doi.org/10.3390/educsci12040242
Gutierrez-Pachas DA, Garcia-Zanabria G, Cuadros-Vargas AJ, Camara-Chavez G, Poco J, Gomez-Nieto E. How Do Curricular Design Changes Impact Computer Science Programs?: A Case Study at San Pablo Catholic University in Peru. Education Sciences. 2022; 12(4):242. https://doi.org/10.3390/educsci12040242
Chicago/Turabian StyleGutierrez-Pachas, Daniel A., Germain Garcia-Zanabria, Alex J. Cuadros-Vargas, Guillermo Camara-Chavez, Jorge Poco, and Erick Gomez-Nieto. 2022. "How Do Curricular Design Changes Impact Computer Science Programs?: A Case Study at San Pablo Catholic University in Peru" Education Sciences 12, no. 4: 242. https://doi.org/10.3390/educsci12040242
APA StyleGutierrez-Pachas, D. A., Garcia-Zanabria, G., Cuadros-Vargas, A. J., Camara-Chavez, G., Poco, J., & Gomez-Nieto, E. (2022). How Do Curricular Design Changes Impact Computer Science Programs?: A Case Study at San Pablo Catholic University in Peru. Education Sciences, 12(4), 242. https://doi.org/10.3390/educsci12040242