1. Introduction
Firms, companies, and economic institutions are nowadays highly interconnected in networks of different kinds. The role or the ranking of a firm within such networks can be evaluated in several ways.
There is a variety of indicators that allow us to assess the ranking, exposure and reliability of a company in the national and international context (see, e.g.,
Tosyali et al. 2021). Among them, centrality measures have assumed a prominent role in the analysis of local properties of a network (see, e.g., the following most up-to-date papers
Bloch et al. 2023;
Bowater and Stefanakis 2023;
Cao et al. 2024;
Chebotarev 2023;
Raj and Bhattacharya 2023). The importance of these measures in the economic and financial network analysis is also widely supported by the most recent literature. For example,
Alkan et al. (
2023) compare different centrality scores for the economic policy uncertainty indices of 21 countries and
Strielkowski et al. (
2023) studied the role of regional innovation systems (RISs) in shaping up the national innovation systems (NISs), uncovering emerging trends, most influential agents, and domains of intensive research activity. A local perspective in financial network analysis is also adopted by
Alamsyah et al. (
2022), who studied the effect of shifts in the network triadic motifs on the propagation of shocks in a transaction network. Our paper fits into this research framework.
In network theory, many classical centrality measures have been introduced and used to rank institutions (see, e.g.,
Belik 2022;
Borgatti 2005;
Freeman 1978;
Rajeh et al. 2021;
Scott 1991;
Wasserman and Faust 1994). Regardless of the nature of the ties and links that characterize the network, among the most used we mention the degree centrality, which quantifies the number or weight of these ties, the betweenness, which evaluates the key role of a company as a bridge between two or more groups of companies, the closeness (see, e.g.,
Bavelas 1950;
Sabidussi 1966), which quantifies the proximity to other institutions and the promptness with which it is possible to reach them from the node under examination. A remarkable role is played by the well-known eigenvector centrality (
Bonacich 1972), particularly in contexts where the authority of an institution or its governing bodies is to be determined. In this case, in fact, the score assigned to an institution is not defined by the internal parameters of the institution itself; rather, it is inherited from the scores of its immediate neighbors. In a sense, we can say that its reliability is established on the basis of the level of reliability of the institutions with which it cooperates. It is clear that this centrality measure, more than others, strongly weights the overall contribution of the network in which the institution is nested and from which it cannot be considered separate. Lastly, there is a broad class of centrality measures that emerge as the asymptotic result of diffusive processes internal to the network. These measures assign rankings to nodes that are updated at each step of an iterative process until it converges, under appropriate conditions, to stable final values. This is the case of PageRank (see, e.g.,
Brin and Page 1998;
Page et al. 1999), used to define the ranking of web pages in Google, which can be considered as the stationary state of a linear conservative diffusion process. Another case is DebtRank (
Battiston et al. 2012), which assesses the additional stress that each institution’s default can generate in a linear shock propagation framework, on directed networks of financial interdependence through interbank lending.
The centrality measure proposed in this paper combines two of the aspects described above. It quantifies the importance of an institution by assigning it a score resulting from nonlinear feedback between its own score and that of all the elements immediately connected to it, nodes and links. Furthermore, it emerges as the asymptotic non null steady state of an iterative process that involves two suitably coupled contagion mechanisms. In this way, we fill a gap in the literature on centrality measures, since the scheme behind the definition of eigenvector centrality has never been extended to all elements connected to a node and has never been interpreted as the steady state of an appropriate diffusive process involving both nodes and links.
To illustrate the main idea behind our proposal, consider the following example. Suppose we have a network of firms in which the ties are due to having a common director on the respective boards (see, e.g.,
Giglio and Lux 2021;
Takes and Heemskerk 2016). This is a typical framework for analyzing corporate networks as projections of the bipartite network of companies and directors. Suppose that such a network during a period of market turbulence is the site of dissemination of important business information that may lead directors to make appropriate choices or not. Of course, we may consider two different propagation processes on the network of corporate boards (nodes) and on the network of directors (edges) and the reciprocal effect each process in one network has on the other. The processes are coupled and mutually reinforcing. The higher the likelihood that directors in common between two companies have at their disposal a given piece of information, the greater the likelihood that it will affect business choices and may determine the behavior of other companies in the network. We design a unified dynamic process that converges, under appropriate conditions, to asymptotic steady states of both firms and directors. These states are then interpreted as their centrality scores and are the result of a complex reciprocal action between nodes and edges. In this way, we can view the ranking of a node not as the consequence of mere and static local properties, but of its complex interactions arising from its deep embedding in the network.
Another example can be provided referring to a correlation network (see, e.g.,
Kukreti et al. 2020;
Onnela et al. 2003;
Mantegna 1999;
Masuda et al. 2023;
Gkatzoglou et al. 2024) obtained from the returns of a basket of securities in a given portfolio. Linear correlation coefficients can be interpreted as the result of a series of complex interactions and exchanges of information that have occurred in the past between these securities and that have led to their behavior being more or less correlated. As such, they can change over time and be subject to a shock that propagates from other correlations perturbations, i.e., from other neighboring links, which in turn will influence the future behavior of stock returns.
The previous examples suggest not separating the propagation of a shock on the network of actual nodes from that on the network of their edges. The idea of a reciprocal action in which node and edge attributes are mutually dependent has recently been used to propose a static nonlinear eigenvector centrality for nodes and edges in
Tudisco and Higham (
2021) in the wider context of hypergraphs.
The novelty of our approach is that we implement a similar idea through a specific non-conservative diffusion model on both the networks of nodes and edges and let them interact by means of a coupling coefficient, which we call the reinforcement factor. The actual dynamical system will be described by an SIS-like epidemiological model. In particular, to obtain the new centrality measure we adopt the self-adaptive model introduced in
Bartesaghi et al. (
2024). The node incidence, which is the instantaneous increase or decrease of the individual score, is determined by that associated with all its neighboring elements (connected edges and neighbor nodes); similarly, the edge incidence is determined by that of all its neighboring elements (adjacency edges and end nodes).
Since the edge weight generally conveys how effective that edge is in transmitting information, we are assuming that this weight is not independent of the information content of its end nodes. In other words, we assume that these weights can be updated to account for the changing information content of the nodes, just as this content depends on the edge weights themselves in any diffusion process on networks. Therefore we consider a secondary, or dual process, in which the shock propagates
among edges through the nodes, that is, a process that occurs in the so-called line graph
Gross et al. (
2013) in which the role of nodes and edges are reversed. The two processes evolve simultaneously over time using one of the scores yielded by the other. The asymptotic non null steady state of the two coupled processes is interpreted as the new self-adaptive eigenvector centrality.
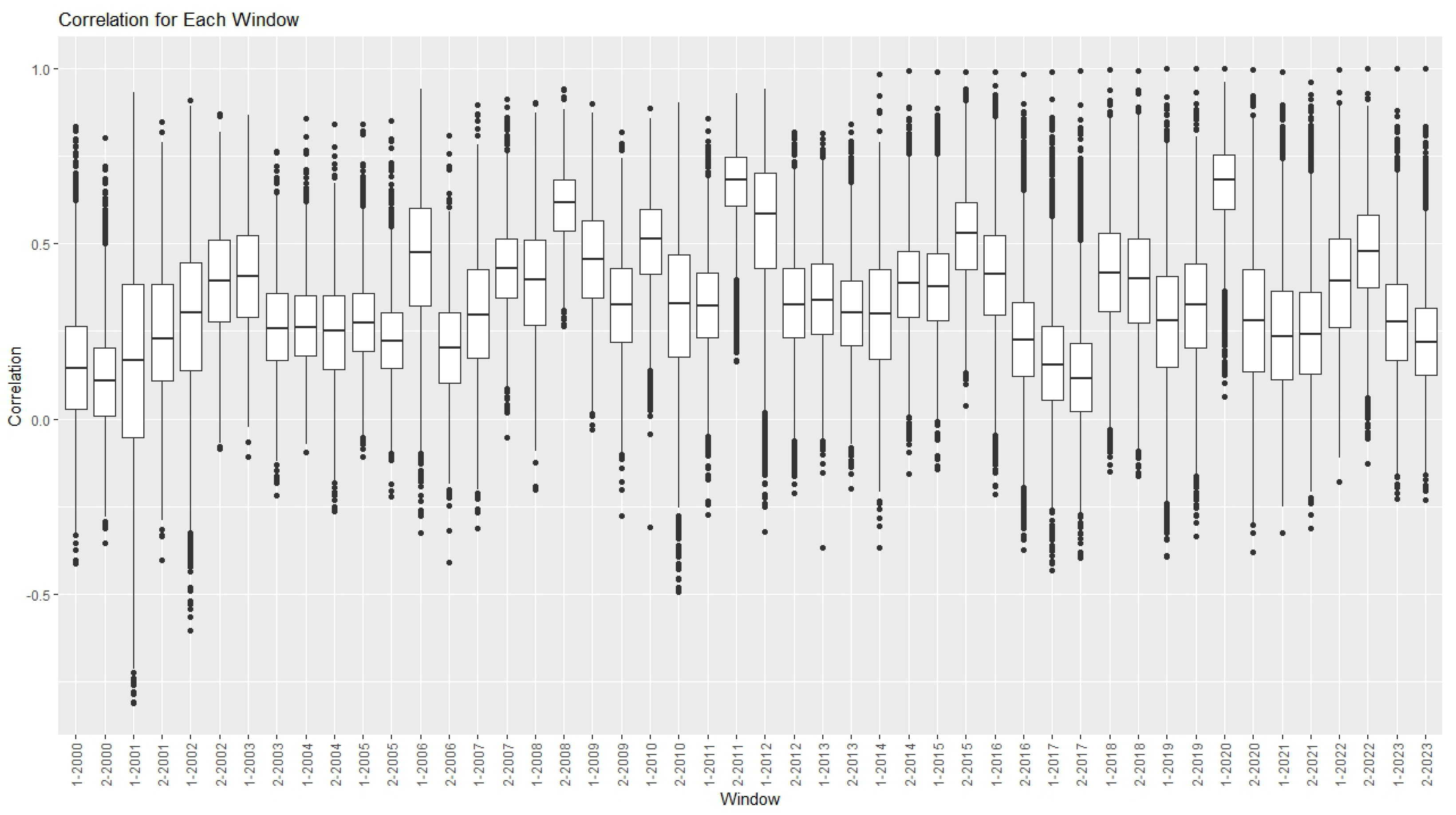
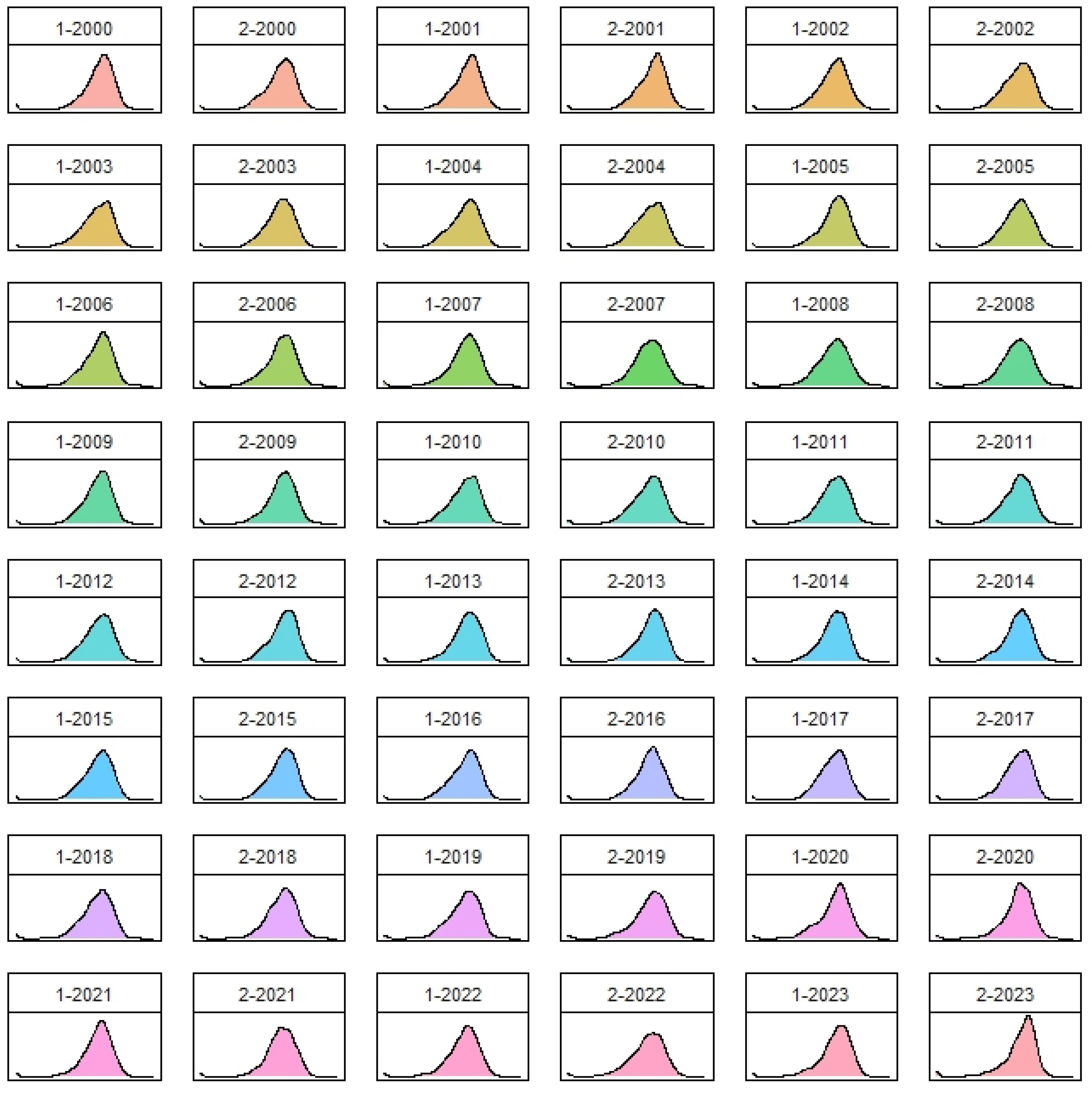
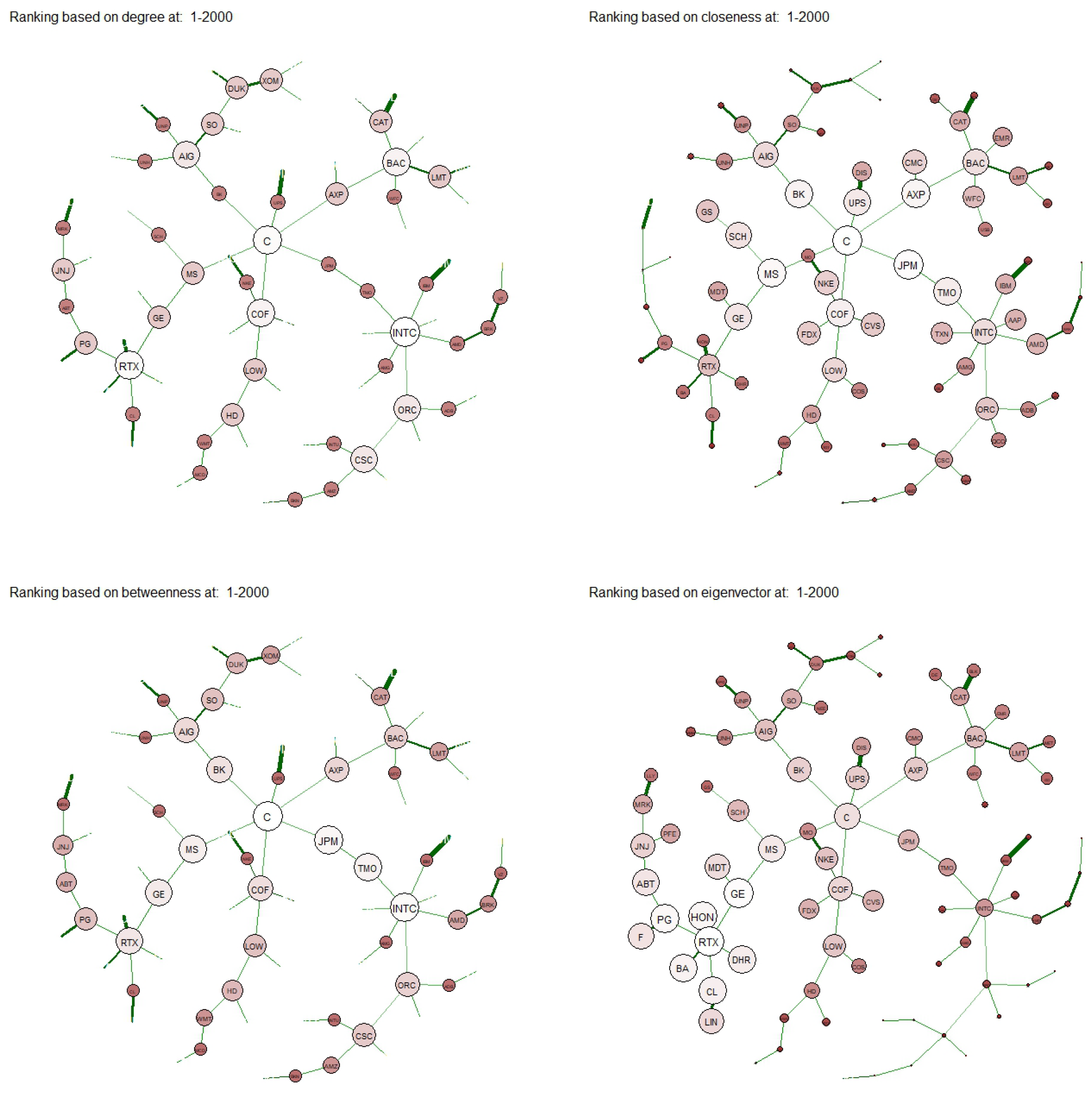
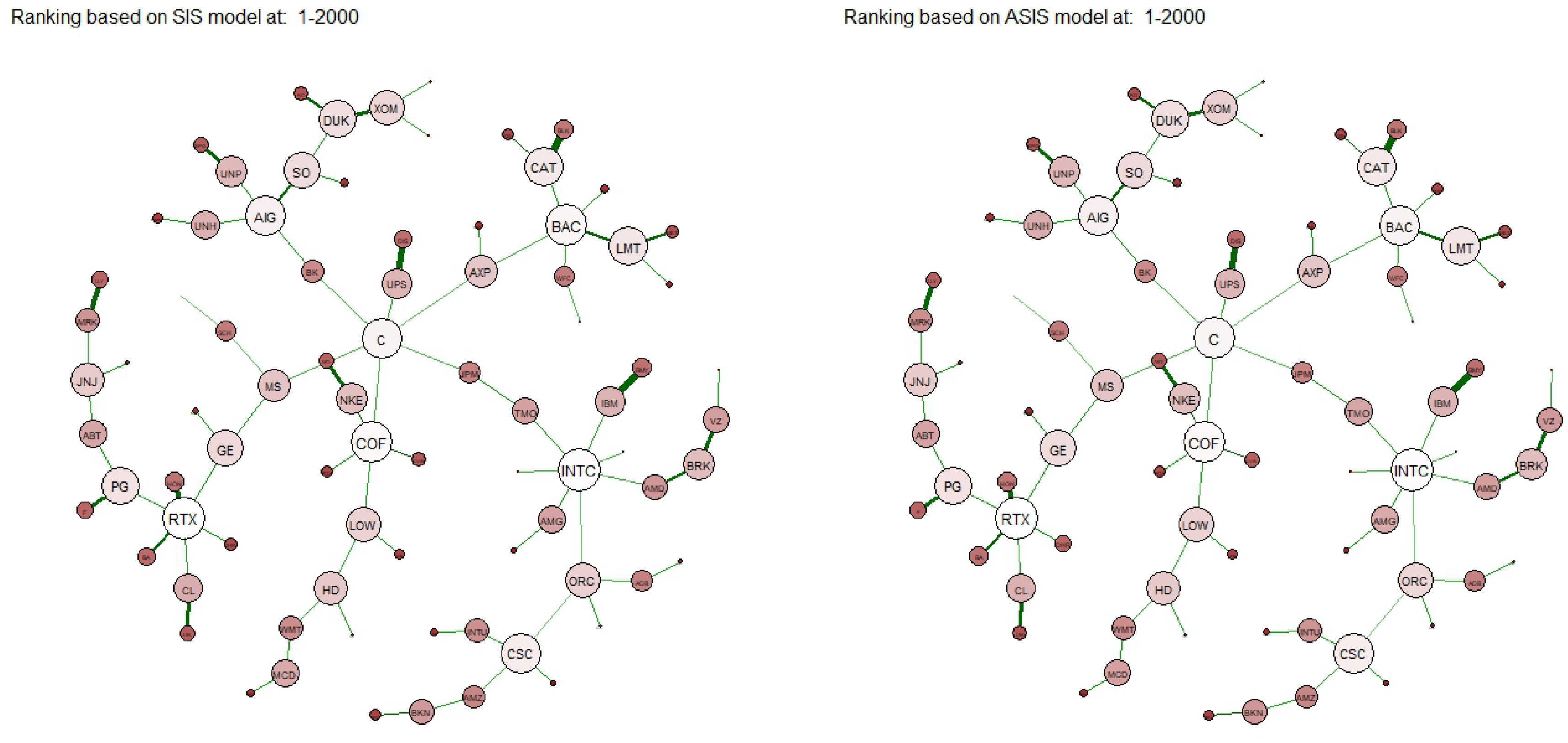
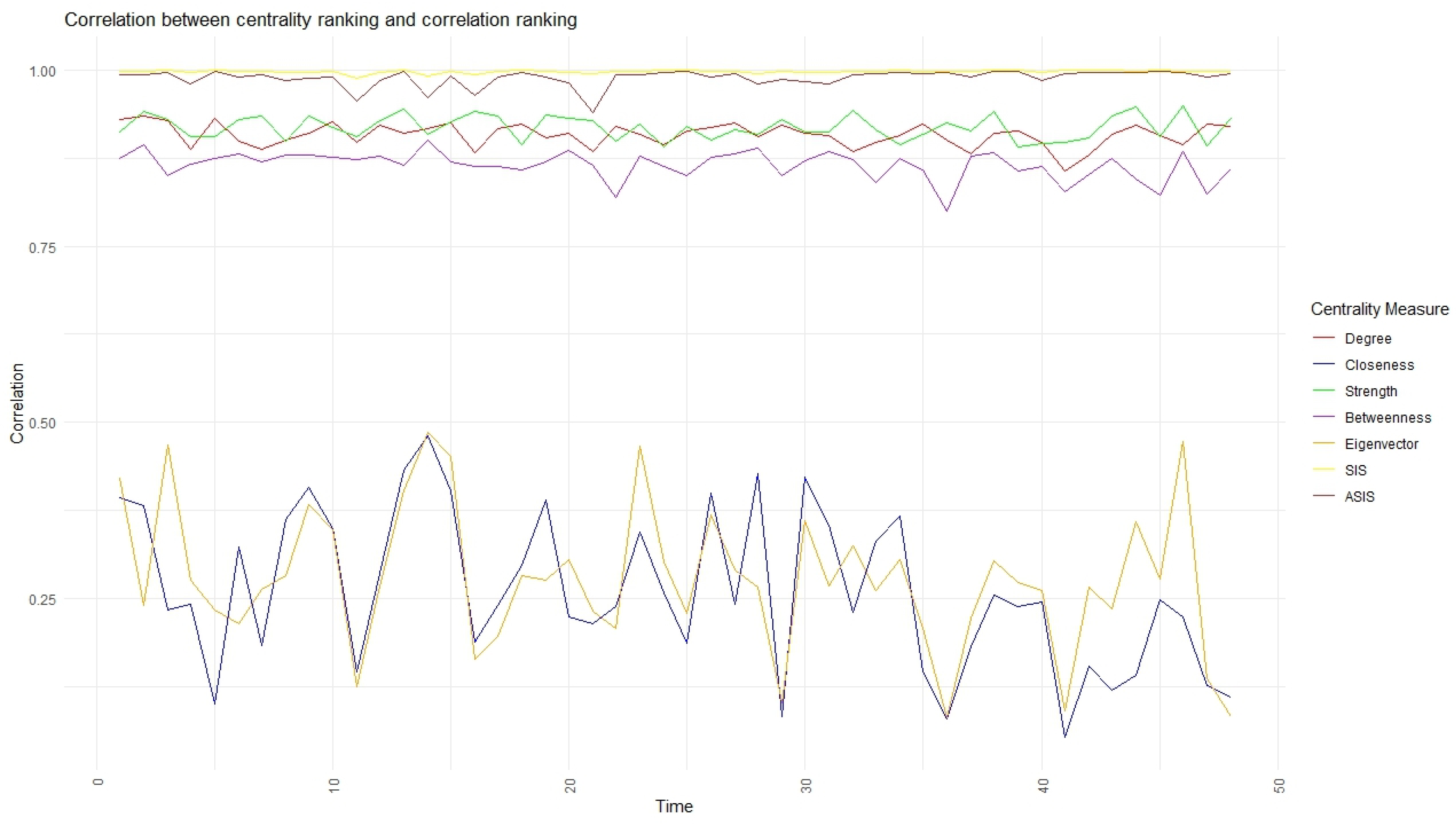
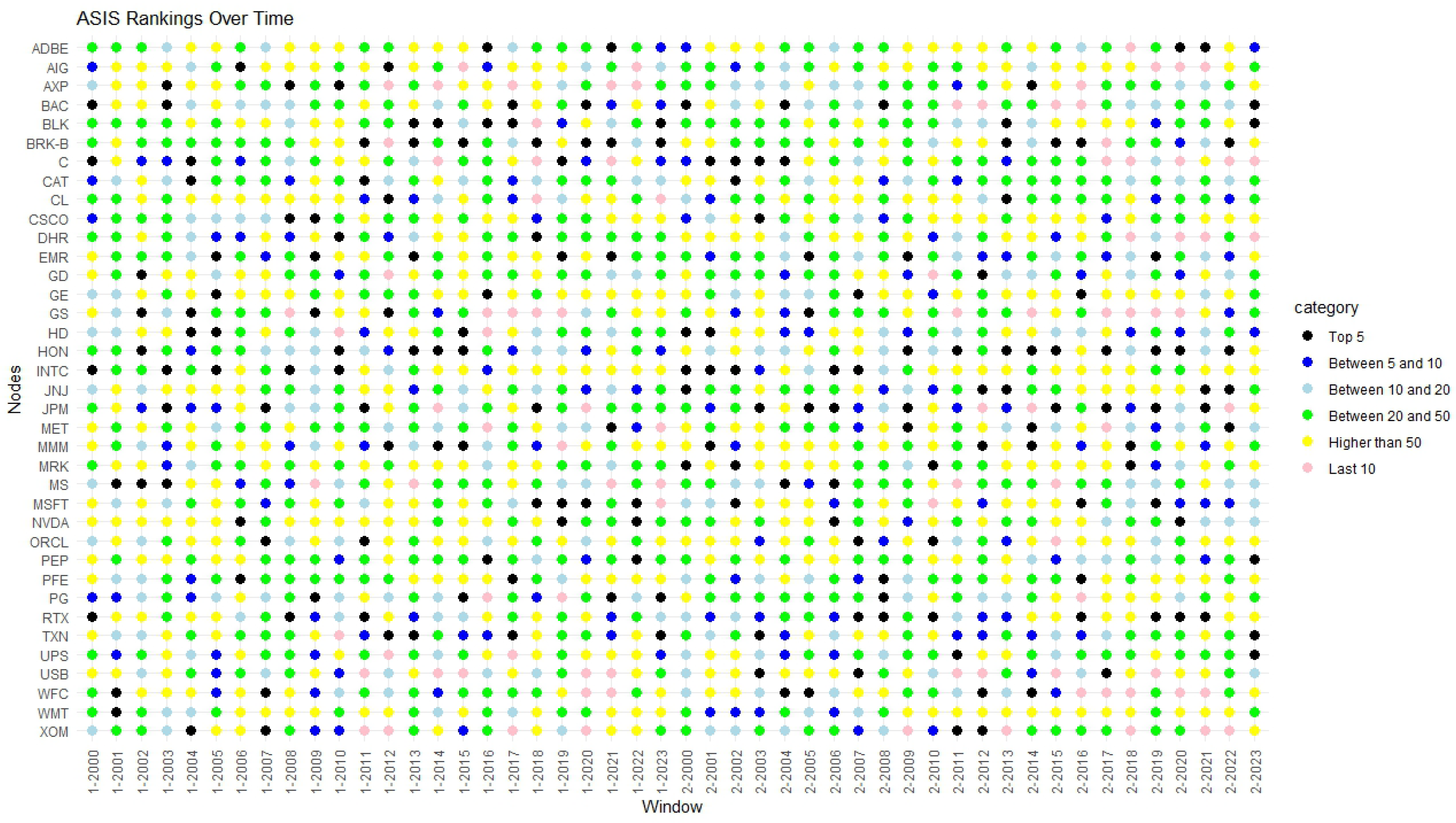
Numerical analyses have been developed to test the proposed approach on the networks built using the returns constituent of the SP100 index at the end of 2003. Specifically, we analyzed returns’ correlation spanning from the inception of 2000 to the end of 2023 and we divided the whole period in different windows. In each interval, we have compared nodes’ rankings based on traditional unweighted and weighted centrality measures with the ones obtained by the proposed approach. We noticed that the performance of non-linear centralities remains robust in identifying highly correlated assets within networks, even in periods of heightened volatility and turbulence. Consequently, these measures present themselves as promising alternatives for identifying central or diversifiable assets in optimal portfolio allocation strategies (see, e.g.,
Clemente et al. 2021;
Olmo 2021; and
Peralta and Zareei 2016). The financial and economic implications of this proposal are significant. By identifying and quantifying central nodes within financial networks, stakeholders can better understand the propagation of defaults, thereby enhancing risk management strategies. This approach provides a more nuanced view of asset interdependencies, leading to more informed investment decisions and regulatory measures. Additionally, the ability to assess the interaction intensity between nodes and edges offers insights into the systemic risk posed by highly interconnected assets, facilitating more robust financial stability assessments. Ultimately, this method can contribute to more resilient financial systems by enabling the early detection of potential vulnerabilities and the implementation of preemptive measures to mitigate systemic risks. This proposal is in line with the current literature. Recent studies (see, e.g.,
Raddant and Di Matteo 2023) showed that central nodes in financial networks are pivotal in understanding market dynamics and systemic risks. By leveraging these findings, we show how our analysis aligns with established research indicating that central assets can significantly influence market behavior. Additionally,
Bardoscia et al. (
2016) highlights the benefits of using advanced centrality measures in portfolio management. Their findings suggest that portfolios constructed with an understanding of network centrality are better diversified and exhibit lower risk. This supports our claim that identifying central assets helps in precise diversification and risk reduction.
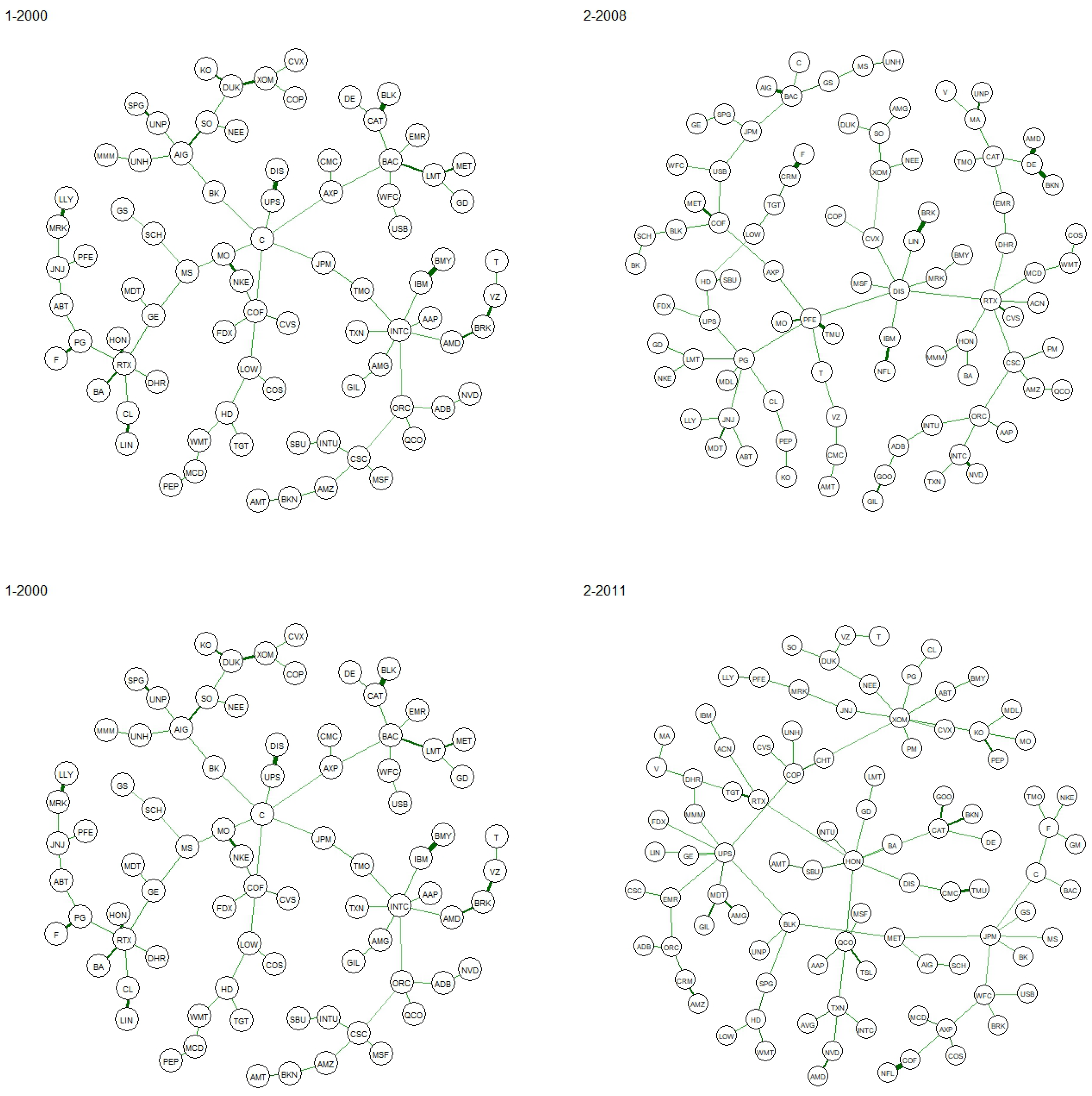
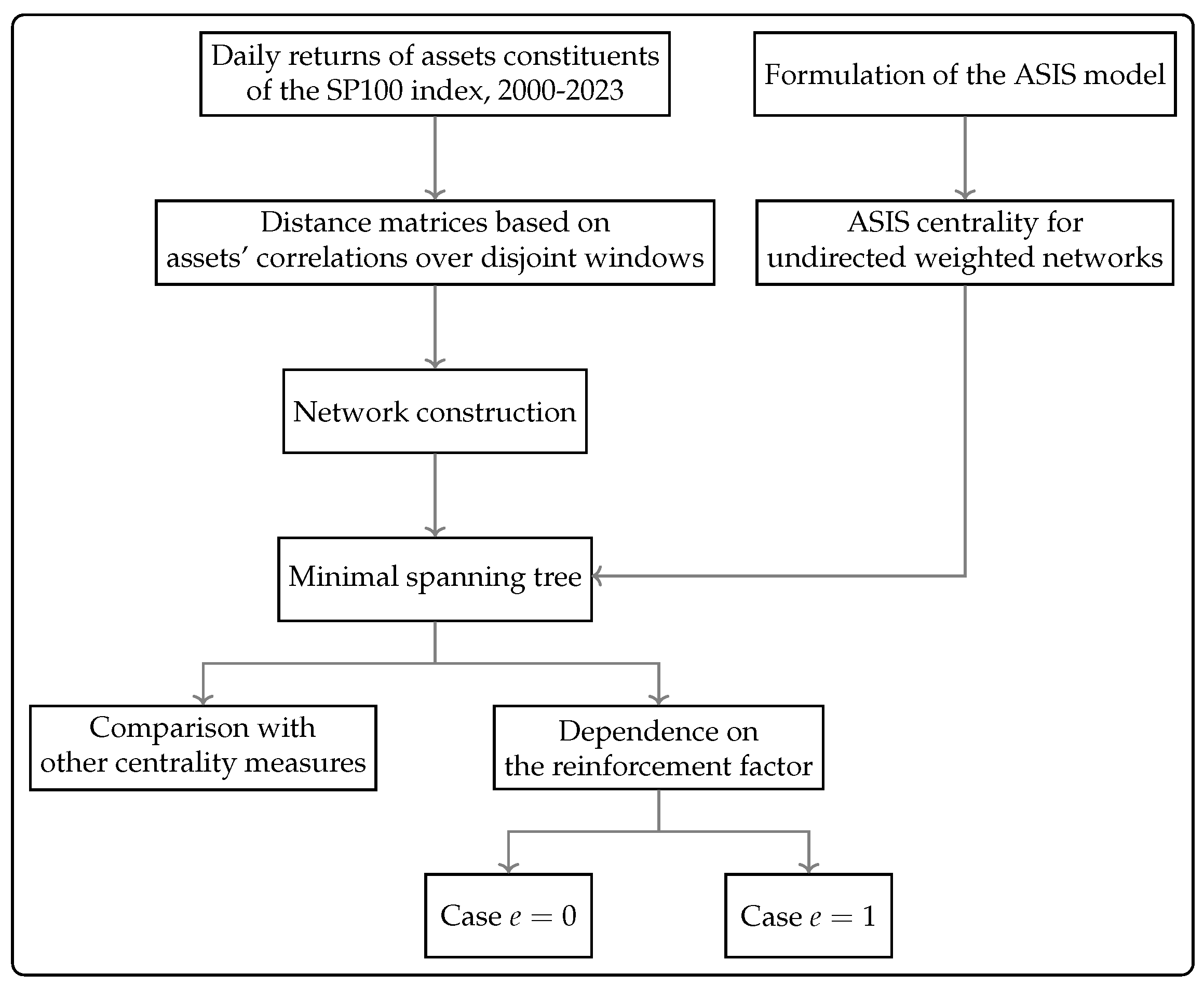
In summary, the contributions of the present paper to the literature in this area can be identified in three different aspects. First, in having provided a strategy to assign to nodes a centrality score that depends, in an eigenvector centrality scheme, on that of all the elements of the network connected to it, nodes and edges, thus incorporating the importance of edges. Second, by parameterizing this score as a function of a reinforcement factor, which for the first time implements the intensity of the interaction between the network of nodes and that of the edges. Third, showing how this new indicator, when applied to the minimal spanning tree of a correlations network between assets, allows highlighting more central and therefore riskier assets from a financial default propagation perspective.
The paper is organized as follows. In
Section 2, we recall some basic notions about centrality measures and establish the notation. In
Section 3, we give a brief overview of the self-adaptive model introduced in
Bartesaghi et al. (
2024), from which the new centrality measure originates. In
Section 4, we define the self-adaptive centrality measure. In
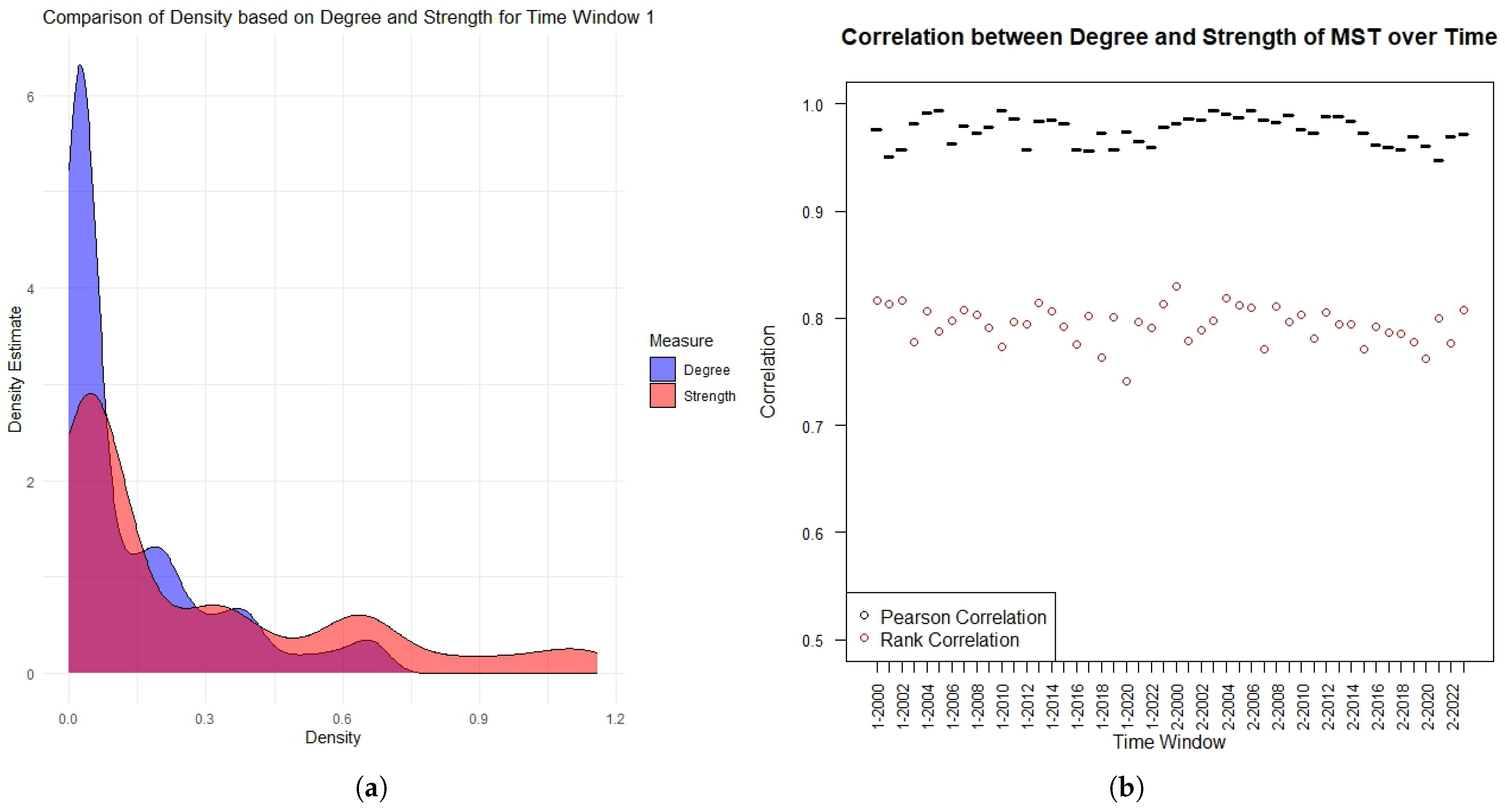
Section 5, we apply this measure to a financial dataset, we describe the data and the procedure used to construct the networks and, finally, we compare the results obtained with other centrality measures. We conclude with some further remarks in
Section 6.
2. Networks and Centrality Measures
The mathematical structures behind networks are graphs. We briefly recall here the basic graph definitions, as well as the most known vertex centrality measures. For more details the reader can refer to
Brandes and Erlebach (
2005);
Harary (
1969). From now on, we will use the words “networks” and “graphs” interchangeably.
Let be a graph, where V is the set of n vertices, or nodes, and E is the set of m edges, or links. For undirected graphs, if then . In this case, i and j are adjacent. The degree of the vertex i is the number of its adjacent nodes, and we denote by the whole degree vector. A -path is a sequence of distinct vertices and edges between i and j. If a -path exists, then i and j are connected. G is connected if every pair of vertices is connected. The shortest -path is said -geodesic. We define the distance between nodes i and j as the number of edges of the -geodesic.
The adjacency relations between nodes are represented by a n-square binary matrix , called adjacency matrix, whose entries if , 0 otherwise. As the network is undirected, is symmetric and its eigenvalues are real. Let be the eigenvalues of , the eigenvector associated with and an eigenpair of . Graphs considered in this work are without loops and multiple links. A network is weighted if a weight is assigned to the link . In the case of a weighted network, we denote the weighted adjacency matrix by . The line graph of a graph G is a graph whose nodes are the edges of G and in which two nodes are connected if the corresponding edges in G have a common vertex.
Centrality is one of the key issues in network analysis. In general, any element (i.e., nodes, edges or groups of nodes) of the network can be important in terms of the overall structure, but the most studied aspect is the assignment of a centrality score to the vertices of the network, indicating their relevance and influence in terms of connections. Among the different centrality measures existing in the literature, we focus on the most well-known and used in the weighted version.
The most intuitive centrality measure is the degree centrality of a node i, which counts the number of nodes adjacent to i, and it is formally represented by the degree . For a weighted graph, we can consider weights defining the strength , and collecting the strength values in a vector, .
As degree and strength centralities, the eigenvector centrality (
Bonacich 1972) is based on the adjacency relations, but with a more refined interpretation. A node
i is central if connected to nodes that are central themselves. In other words, the node
i’s centrality
is proportional to the sum of the centralities of its neighbors, that is:
where
is a constant.
Using the vector of centralities
, this expression can be rewritten in matrix form as
so that
is an eigenvector of the adjacency matrix
with eigenvalue
. As the centralities have to be nonnegative, by the Perron–Frobenius theorem (
Horn and Johnson 1985),
must be the largest eigenvalue of
and the centrality vector is the corresponding principal eigenvector
, whose components are all positive. The normalized (with Euclidean norm) eigenvector score is
. Also, in this case, it is easy to generalize to weighted networks defining the vector of weighted eigenvector centralities as the vector
s.t.
being
the weighted adjacency matrix.
Two measures related to paths are betweenness and closeness (
Freeman 1977;
Sabidussi 1966). The shortest-path betweenness centrality quantifies how often a node is located on a shortest path between all other nodes. Formally, it is the percentage of geodesics between pairs of vertices
, passing through
i:
where
is the number of geodesics from node
j to node
k, and
is the number of those geodesics that pass through
i. The measure is normalized by dividing the betweenness value
by its maximum value
.
Closeness of a node
i is defined as the reciprocal of the sum of the distance between
i and all other nodes:
The normalized version is and it allows us to compare networks of different sizes.
Unlike degree and eigenvector centrality, which are based on the adjacency relationships, the generalization to the weighted case is not immediate for the path-based measures. A famous algorithm was proposed by
Brandes (
2001). It extends the betweenness centrality to the weighted case by using the Dijkstra algorithm and reverting the edge weights. We refer to this algorithm in computing the betweenness in
Section 5.
3. Self-Adaptive SIS Model Overview
The self-adaptive centrality measure on which this paper focuses was introduced as a direct consequence of the nonlinear dynamic process described in
Bartesaghi et al. (
2024) and called the ASIS model. Here, we briefly recall the basic features of such a model and then expand on the discussion of the centrality measure.
The ASIS model is based on the continuous interaction between a graph (primal network) and its line graph (dual network). It is assumed that both the primal and dual networks are home to a dynamic process that sees the attributes or scores of the nodes evolve over time according to an iterative scheme based on an SIS-like (Susceptible–Infected–Susceptible) compartmental framework. The model provides for a step-wise update of the edge weights in one of the two networks based on the evolution of the dynamic process in its counterpart. In particular, in a discrete setting, it proves that the weights attributed to the edges in the primal network at time t are updated by the values of the scores associated with the nodes of the dual network at time . These scores, originally conceived as the probability of being infected or having adopted a certain behavior, are here interpreted as the node score and take on real values in .
The ASIS centrality measure is provided by the non null asymptotic state of the probability distribution on the nodes in the two networks and is computed as the outcome of a nonlinear iterative process that allows the process to be modeled over discrete times. The interaction between the primary network and the dual one can be appropriately calibrated by a coupling factor, called the reinforcement factor, which defines the intensity with which one process influences the other. In this way, it is possible to evaluate the effect of the coupling between the processes on their asymptotic values, i.e., on the endemic stationary states, and as a consequence on the centrality measures we are interested in.
The mathematical structure of the model is the following. Let us assume that the primary network
is represented by an undirected graph with adjacency matrix
and incidence matrix
and the dual network
by an adjacency matrix
. Suppose that both the nodes and the edges of the network
are assigned numerical attributes represented by vectors
and
, respectively. Variables
and
evolve in time and their values are used to update the entries in the adjacency matrices according to the rules
where
,
and
is the diagonal matrix having diagonal entries given by
.
The model is then entirely described by the following nonlinear system
where
and
are the infection and recovery rates, assumed common to both the primary and dual networks,
is the
n-square identity matrix, and where we used
and
to simplify the expression. The initial conditions of the problem are set to
and
, where
and
,
represents the initial probability of being infected, uniformly distributed across nodes in network
and nodes in network
.
Let us observe that, by the rule in Equation (
4), edges in the network
are assigned weights equal to the node probabilities in the network
to produce an updated version of the adjacency matrix
at time
t. Similarly, for
, by assigning
to the edges of the dual network, the probabilities of the corresponding nodes in
at time
t in a non one-to-one correspondence.
The intensity of the coupling between the two processes can be modulated by an appropriate convex combination between the fully updated adjacency matrix at time
t and the fixed adjacency matrix at time
:
where
. In this way, we calibrate the weights of the adjacency matrices from the initial probabilities
p (
) and the actual probabilities of the nodes and edges at time
t (
). For
, the model reduces to two disentangled standard SIS processes on the primary and dual networks. For
, it returns the fully self-adaptive SIS model. For any
, we obtain the more general partially coupled model.
Finally, by introducing the variable
, the model can be given the compact form
, where
and
4. Self-Adaptive Eigenvector Centrality
The above model can lead to an evolution of the process towards extinction or towards endemic non-zero steady states, depending on the values of the parameters involved. In particular, when non-zero steady states exist, they can be obtained as solutions to the following system of nonlinear eigenproblems:
where
is the effective infection rate. The eigenvectors
and
of the problem (
9) are identified with the steady state solution of the diffusion model, when they exist. An iterative procedure to obtain the eigenvectors
and
can be summarized in the following Algorithm 1.
| Algorithm 1: Self-adaptive eigenvector centrality |
![Economies 12 00164 i001]() |
We stress that this algorithm, when it converges to non-null vectors, returns the final asymptotic values of the diffusive process described in Equation (
5), but that the intermediate values at step
k do not coincide with the time evolution of the processes
and
.
We call the component of asymptotic value Self-adaptive nonlinear eigenvector centrality of node i in the network . Specifically, we compute the Perron eigenvectors and of the diagonally perturbed adjacency matrices of the graph and of the line graph and interpret their positive components as eigenvector scores for the nodes and the edges, respectively.
There are two key aspects that set apart Equation (
9) from a typical equation defining eigenvector centrality. Firstly, it is a nonlinear eigenproblem as it involves matrices that depend on the eigenvectors themselves. Secondly, there is a trade-off between the centralities of the nodes and the centralities of the edges. Essentially, this equation suggests that the centrality of a node is determined by both the centrality of the edges it belongs to and the centrality of its neighbors, and conversely, the centrality of an edge is influenced by the centrality of its extreme nodes and the centrality of its adjacent edges.
Let us note that in
Tudisco and Higham (
2021), the authors define a node and edge score such that the importance
of an edge is a nonnegative number proportional only to the importance of the nodes in the same edge, and the importance
of a node is a nonnegative number proportional only to the importance of the edges in which it participates. They neglect the influence of neighbors’ scores on the centrality of a node and the influence of edges adjacent to the centrality of an edge. In a sense, our centrality measure more evenly encompasses the characteristics of an ordinary eigenvector centrality and the characteristics of the measure introduced in
Tudisco and Higham (
2021). In fact, focusing, for instance, on the node
i in the network
, its score is proportional to
, that is the sum of the products between the score of its neighboring nodes and the score of the corresponding edges connecting them to the node
i. Hence, in our model, the importance of a node does not depend on the importance of neighboring nodes alone or adjacent edges individually, but on the combined impact of these factors.
6. Conclusions and Future Perspectives
Centrality measures hold a pivotal role in the literature of network theory, offering crucial insights into the structure, dynamics, and functionality of complex systems. By quantifying the relative importance or influence of nodes within a network, centrality measures provide a fundamental framework for understanding various real-world phenomena. Through centrality analysis, researchers can identify key actors, pathways, and vulnerabilities, facilitating targeted interventions, optimal resource allocation, and robust network design. Classical centrality measures are specifically concentrated on only one structural aspect of the network—i.e., nodes or links. In contrast, our proposal globally incorporates all structural neighbor elements at once. Moreover, it emerges as the outcome of a dynamic process taking place in the network. Indeed, the ASIS centrality measure proposed in this paper integrates peculiar characteristics of traditional indicators, taking into account the reciprocal interaction between nodes and edges in a dynamic setting. By employing a non-conservative diffusion model and a reinforcement factor, we designed a self-adaptive eigenvector centrality that reflects the complex interplay between network elements.
Numerical analyses, conducted on financial networks derived from the SP100 index returns, validate the efficacy of our approach. The proposed non-linear centrality indicators reliably identify highly correlated assets, offering valuable insights for portfolio allocation strategies. Indeed, by integrating these advanced centrality measures into financial analyses, investors and portfolio managers can enhance their decision-making processes. The ability to pinpoint highly correlated and central assets enables more precise diversification, potentially reducing portfolio risk and improving returns. Furthermore, regulators and policymakers can leverage these insights to monitor systemic risks more effectively, ensuring financial stability. The adaptability of our model to various market conditions also suggests its utility in dynamic and volatile financial environments, providing a robust tool for continuous risk assessment and strategic planning. In addition, our research could foster a more resilient financial ecosystem by equipping stakeholders with a suitable method for identifying riskier assets.
Ultimately, it is noteworthy that the centrality measure proposed in this paper is limited to the study of the interplay between nodes and edges of the same network, interpreted as two distinct graphs. However, it could be extended to general bipartite networks, assuming that the two coupled processes described above run on the two different projections. In this way, it may prove useful in the analysis of economic and financial networks of a broader nature, thus offering promising avenues for future research in portfolio optimization and risk management.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}