
Continuous Emotion Recognition for Long-Term Behavior Modeling through Recurrent Neural Networks †





Abstract
:1. Introduction
- Enhanced continuous emotion recognition performance, employing recurrent neural network (RNN) architectures instead of the DNN ones;
- Competitive recognition results compared with the state-of-the-art approaches in the field, following the more strict and realistic leave-one-speakers-group-out (LOSGO) evaluation protocol [35];
- Implementation of an efficient and user-friendly human behavior modeling tool based on the experience gained through interaction.
2. Materials and Methods
2.1. Database
2.2. Face Detection Tool
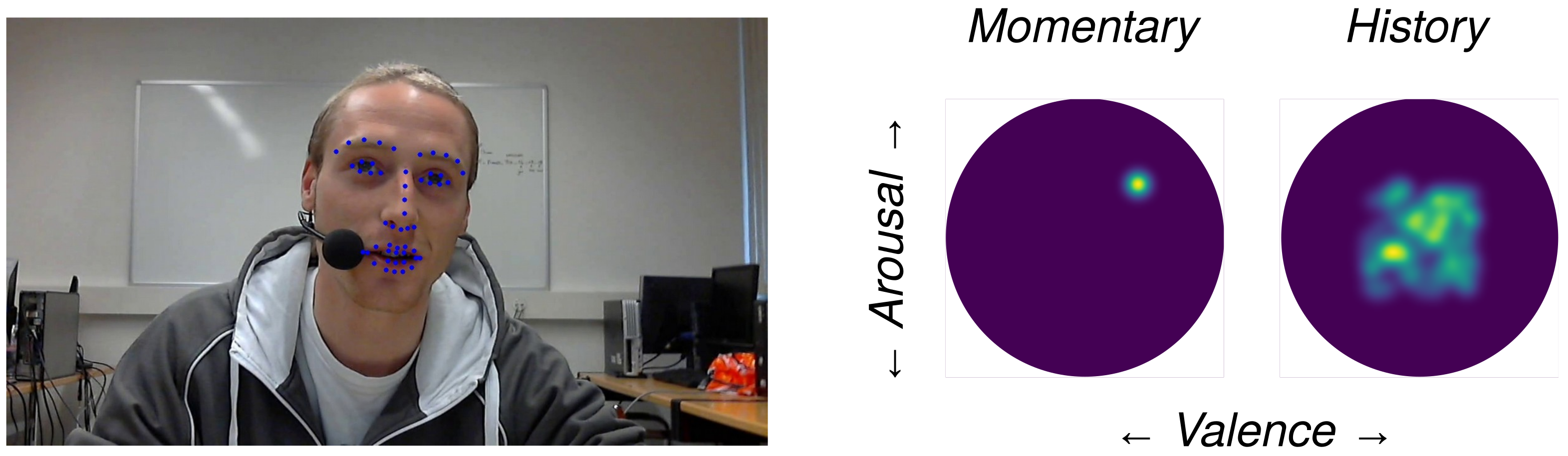
2.3. Facial Landmark Extraction Tool
2.4. Continuous Emotion Recognition Tool
2.5. Validation Strategy
3. Results
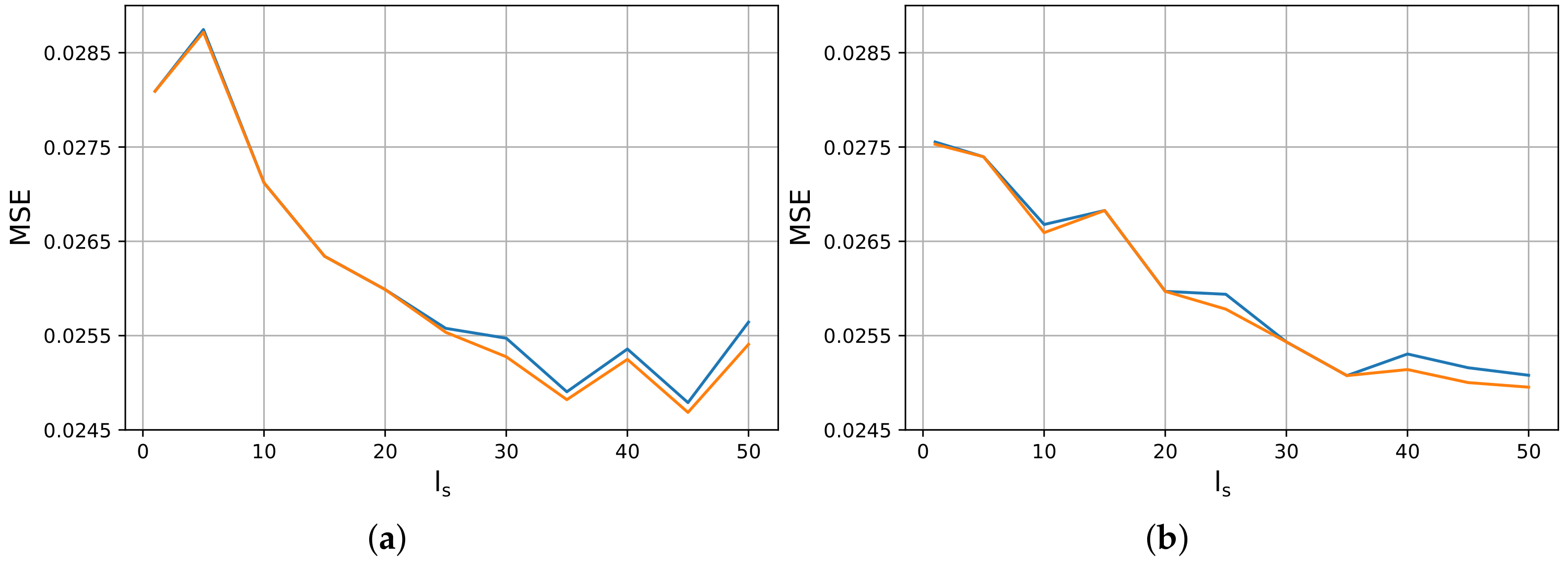
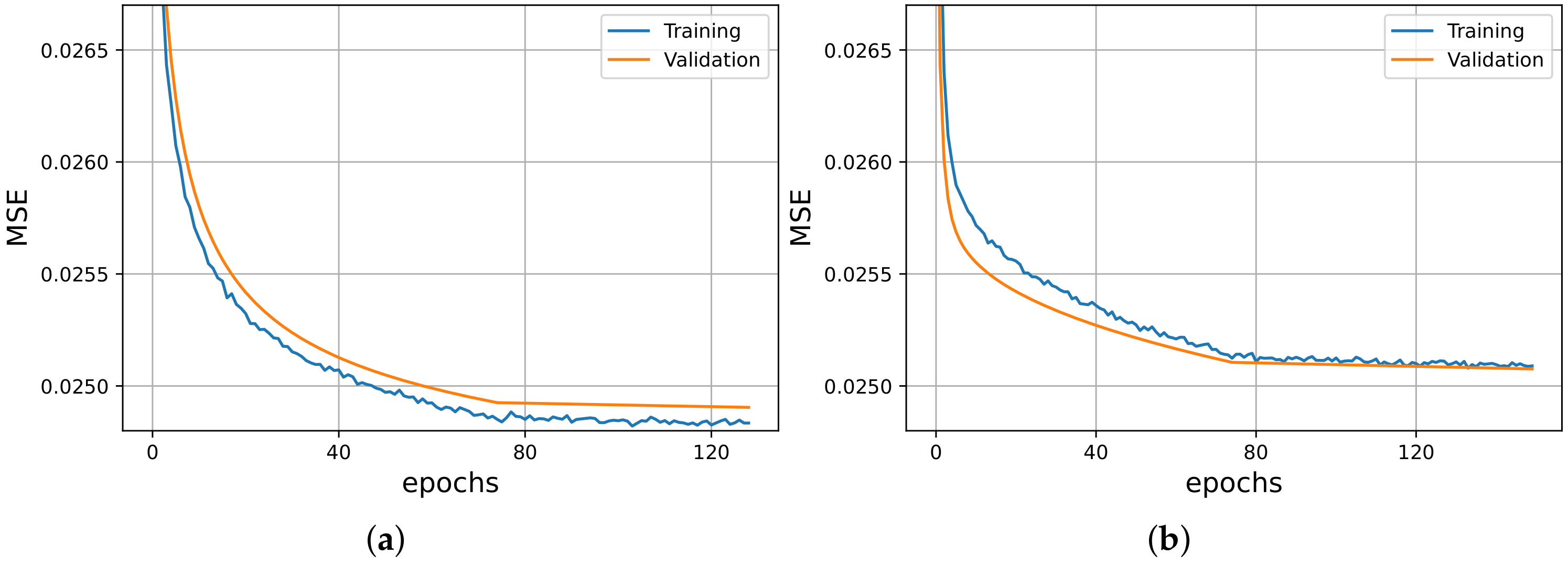
3.1. Ablation Study
3.2. Sequence Length Configuration
3.3. Architecture Configuration
3.4. Comparative Results
3.5. Continuous Speaker Estimation
4. Discussion
5. Conclusions
6. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| DNN | deep neural network |
| RNN | recurrent neural network |
| LSTM | long short-term memory |
| CERT | continuous emotion recognition tool |
References
- Breaban, A.; Van de Kuilen, G.; Noussair, C.N. Prudence, Emotional State, Personality, and Cognitive Ability. Front. Psychol. 2016, 7, 1688. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rossi, S.; Ferland, F.; Tapus, A. User profiling and behavioral adaptation for HRI: A survey. Pattern Recognit. Lett. 2017, 99, 3–12. [Google Scholar] [CrossRef]
- Charalampous, K.; Kostavelis, I.; Gasteratos, A. Recent trends in social aware robot navigation: A survey. Robot. Auton. Syst. 2017, 93, 85–104. [Google Scholar] [CrossRef]
- Nocentini, O.; Fiorini, L.; Acerbi, G.; Sorrentino, A.; Mancioppi, G.; Cavallo, F. A survey of behavioral models for social robots. Robotics 2019, 8, 54. [Google Scholar] [CrossRef] [Green Version]
- Čaić, M.; Avelino, J.; Mahr, D.; Odekerken-Schröder, G.; Bernardino, A. Robotic versus human coaches for active aging: An automated social presence perspective. Int. J. Soc. Robot. 2020, 12, 867–882. [Google Scholar] [CrossRef] [Green Version]
- Avelino, J.; Gonçalves, A.; Ventura, R.; Garcia-Marques, L.; Bernardino, A. Collecting social signals in constructive and destructive events during human-robot collaborative tasks. In Proceedings of the Companion of the 2020 ACM/IEEE International Conference on Human-Robot Interaction, Cambridge, UK, 23–26 March 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 107–109. [Google Scholar]
- Cambria, E.; Das, D.; Bandyopadhyay, S.; Feraco, A. Affective computing and sentiment analysis. In A Practical Guide to Sentiment Analysis; Springer: Cham, Switzerland, 2017; pp. 1–10. [Google Scholar]
- Ekman, P.; Friesen, W.V.; O’sullivan, M.; Chan, A.; Diacoyanni-Tarlatzis, I.; Heider, K.; Krause, R.; LeCompte, W.A.; Pitcairn, T.; Ricci-Bitti, P.E.; et al. Universals and cultural differences in the judgments of facial expressions of emotion. J. Personal. Soc. Psychol. 1987, 53, 712. [Google Scholar] [CrossRef]
- Jacobs, E.; Broekens, J.; Jonker, C. Emergent dynamics of joy, distress, hope and fear in reinforcement learning agents. In Proceedings of the Adaptive Learning Agents Workshop at AAMAS2014, Paris, France, 5–6 May 2014. [Google Scholar]
- Tzirakis, P.; Trigeorgis, G.; Nicolaou, M.A.; Schuller, B.W.; Zafeiriou, S. End-to-end multimodal emotion recognition using deep neural networks. IEEE J. Sel. Top. Signal Process. 2017, 11, 1301–1309. [Google Scholar] [CrossRef] [Green Version]
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H. Affectnet: A database for facial expression, valence, and arousal computing in the wild. IEEE Trans. Affect. Comput. 2017, 10, 18–31. [Google Scholar] [CrossRef] [Green Version]
- Russell, J.A.; Barrett, L.F. Core affect, prototypical emotional episodes, and other things called emotion: Dissecting the elephant. J. Personal. Soc. Psychol. 1999, 76, 805. [Google Scholar] [CrossRef]
- Ko, B.C. A brief review of facial emotion recognition based on visual information. Sensors 2018, 18, 401. [Google Scholar] [CrossRef]
- Nonis, F.; Dagnes, N.; Marcolin, F.; Vezzetti, E. 3D Approaches and challenges in facial expression recognition algorithms—A literature review. Appl. Sci. 2019, 9, 3904. [Google Scholar] [CrossRef] [Green Version]
- Palestra, G.; Pettinicchio, A.; Coco, M.D.; Carcagnì, P.; Leo, M.; Distante, C. Improved performance in facial expression recognition using 32 geometric features. In International Conference on Image Analysis and Processing; Springer: Cham, Switzerland, 2015; pp. 518–528. [Google Scholar]
- Murugappan, M.; Mutawa, A. Facial geometric feature extraction based emotional expression classification using machine learning algorithms. PLoS ONE 2021, 16, e0247131. [Google Scholar]
- Akçay, M.B.; Oğuz, K. Speech emotion recognition: Emotional models, databases, features, preprocessing methods, supporting modalities, and classifiers. Speech Commun. 2020, 116, 56–76. [Google Scholar] [CrossRef]
- Marín-Morales, J.; Higuera-Trujillo, J.L.; Greco, A.; Guixeres, J.; Llinares, C.; Scilingo, E.P.; Alcañiz, M.; Valenza, G. Affective computing in virtual reality: Emotion recognition from brain and heartbeat dynamics using wearable sensors. Sci. Rep. 2018, 8, 13657. [Google Scholar] [CrossRef]
- Picard, R.W.; Vyzas, E.; Healey, J. Toward machine emotional intelligence: Analysis of affective physiological state. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1175–1191. [Google Scholar] [CrossRef] [Green Version]
- Ali, S.; Wang, G.; Riaz, S. Aspect based sentiment analysis of ridesharing platform reviews for kansei engineering. IEEE Access 2020, 8, 173186–173196. [Google Scholar] [CrossRef]
- Zhang, J.; Yin, Z.; Chen, P.; Nichele, S. Emotion recognition using multi-modal data and machine learning techniques: A tutorial and review. Inf. Fusion 2020, 59, 103–126. [Google Scholar] [CrossRef]
- Ahmed, F.; Sieu, B.; Gavrilova, M.L. Score and rank-level fusion for emotion recognition using genetic algorithm. In Proceedings of the 2018 IEEE 17th International Conference on Cognitive Informatics & Cognitive Computing (ICCI*CC), Berkeley, CA, USA, 16–18 July 2018; pp. 46–53. [Google Scholar]
- Daneshfar, F.; Kabudian, S.J. Speech emotion recognition using discriminative dimension reduction by employing a modified quantum-behaved particle swarm optimization algorithm. Multimed. Tools Appl. 2020, 79, 1261–1289. [Google Scholar] [CrossRef]
- Tsai, H.H.; Chang, Y.C. Facial expression recognition using a combination of multiple facial features and support vector machine. Soft Comput. 2018, 22, 4389–4405. [Google Scholar] [CrossRef]
- Kansizoglou, I.; Bampis, L.; Gasteratos, A. Deep Feature Space: A Geometrical Perspective. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef]
- Tsintotas, K.A.; Bampis, L.; Gasteratos, A. Probabilistic appearance-based place recognition through bag of tracked words. IEEE Robot. Autom. Lett. 2019, 4, 1737–1744. [Google Scholar] [CrossRef]
- Allognon, S.O.C.; De S. Britto, A., Jr.; Koerich, A.L. Continuous Emotion Recognition via Deep Convolutional Autoencoder and Support Vector Regressor. In Proceedings of the 2020 International Joint Conference on Neural Networks, Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Lee, H.S.; Kang, B.Y. Continuous emotion estimation of facial expressions on JAFFE and CK+ datasets for human–robot interaction. Intell. Serv. Robot. 2020, 13, 15–27. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Kansizoglou, I.; Bampis, L.; Gasteratos, A. An active learning paradigm for online audio-visual emotion recognition. IEEE Trans. Affect. Comput. 2019. [Google Scholar] [CrossRef]
- Zhang, K.; Li, Y.; Wang, J.; Cambria, E.; Li, X. Real-time video emotion recognition based on reinforcement learning and domain knowledge. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1034–1047. [Google Scholar] [CrossRef]
- Li, W.; Shao, W.; Ji, S.; Cambria, E. BiERU: Bidirectional emotional recurrent unit for conversational sentiment analysis. Neurocomputing 2022, 467, 73–82. [Google Scholar] [CrossRef]
- Stylios, I.; Kokolakis, S.; Thanou, O.; Chatzis, S. Behavioral biometrics & continuous user authentication on mobile devices: A survey. Inf. Fusion 2021, 66, 76–99. [Google Scholar]
- Kansizoglou, I.; Misirlis, E.; Gasteratos, A. Learning Long-Term Behavior through Continuous Emotion Estimation. In Proceedings of the 14th PErvasive Technologies Related to Assistive Environments Conference, Corfu, Greece, 29 June–2 July 2021; pp. 502–506. [Google Scholar]
- Zhalehpour, S.; Onder, O.; Akhtar, Z.; Erdem, C.E. BAUM-1: A spontaneous audio-visual face database of affective and mental states. IEEE Trans. Affect. Comput. 2016, 8, 300–313. [Google Scholar] [CrossRef]
- Ringeval, F.; Sonderegger, A.; Sauer, J.; Lalanne, D. Introducing the RECOLA multimodal corpus of remote collaborative and affective interactions. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–8. [Google Scholar]
- Valstar, M.; Gratch, J.; Schuller, B.; Ringeval, F.; Lalanne, D.; Torres Torres, M.; Scherer, S.; Stratou, G.; Cowie, R.; Pantic, M. Avec 2016: Depression, mood, and emotion recognition workshop and challenge. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge, Amsterdam, The Netherlands, 16 October 2016; pp. 3–10. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; p. I. [Google Scholar]
- Zhang, S.; Zhang, S.; Huang, T.; Gao, W.; Tian, Q. Learning affective features with a hybrid deep model for audio–visual emotion recognition. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 3030–3043. [Google Scholar] [CrossRef]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar]
- Vonikakis, V.; Winkler, S. Identity-invariant facial landmark frontalization for facial expression analysis. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 2281–2285. [Google Scholar]
- Bottou, L. Stochastic gradient learning in neural networks. Proc. Neuro-Nımes 1991, 91, 12. [Google Scholar]
- Huang, Z.; Stasak, B.; Dang, T.; Wataraka Gamage, K.; Le, P.; Sethu, V.; Epps, J. Staircase regression in OA RVM, data selection and gender dependency in AVEC 2016. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge, Amsterdam, The Netherlands, 16 October 2016; pp. 19–26. [Google Scholar]
- Weber, R.; Barrielle, V.; Soladié, C.; Séguier, R. High-level geometry-based features of video modality for emotion prediction. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge, Amsterdam, The Netherlands, 16 October 2016; pp. 51–58. [Google Scholar]
- Somandepalli, K.; Gupta, R.; Nasir, M.; Booth, B.M.; Lee, S.; Narayanan, S.S. Online affect tracking with multimodal kalman filters. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge, Amsterdam, The Netherlands, 16 October 2016; pp. 59–66. [Google Scholar]
- Brady, K.; Gwon, Y.; Khorrami, P.; Godoy, E.; Campbell, W.; Dagli, C.; Huang, T.S. Multi-modal audio, video and physiological sensor learning for continuous emotion prediction. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge, Amsterdam, The Netherlands, 16 October 2016; pp. 97–104. [Google Scholar]
- Wiles, J.L.; Leibing, A.; Guberman, N.; Reeve, J.; Allen, R.E.S. The Meaning of “Aging in Place” to Older People. Gerontologist 2011, 52, 357–366. [Google Scholar] [CrossRef]
- Mitchell, J.M.; Kemp, B.J. Quality of life in assisted living homes: A multidimensional analysis. J. Gerontol. Ser. B Psychol. Sci. Soc. Sci. 2000, 55, 117–127. [Google Scholar] [CrossRef] [Green Version]
- Payr, S.; Werner, F.; Werner, K. Potential of Robotics for Ambient Assisted Living; FFG Benefit: Vienna, Austria, 2015. [Google Scholar]
- Christoforou, E.G.; Panayides, A.S.; Avgousti, S.; Masouras, P.; Pattichis, C.S. An overview of assistive robotics and technologies for elderly care. In Proceedings of the Mediterranean Conference on Medical and Biological Engineering and Computing, Coimbra, Portugal, 26–28 September 2019; pp. 971–976. [Google Scholar]
- Rashidi, P.; Mihailidis, A. A survey on ambient-assisted living tools for older adults. IEEE J. Biomed. Health Inf. 2012, 17, 579–590. [Google Scholar] [CrossRef]
- ElHady, N.E.; Provost, J. A systematic survey on sensor failure detection and fault-tolerance in ambient assisted living. Sensors 2018, 18, 1991. [Google Scholar] [CrossRef] [Green Version]
- Mitzner, T.L.; Chen, T.L.; Kemp, C.C.; Rogers, W.A. Identifying the potential for robotics to assist older adults in different living environments. Int. J. Soc. Robot. 2014, 6, 213–227. [Google Scholar] [CrossRef]
- Pirhonen, J.; Tiilikainen, E.; Pekkarinen, S.; Lemivaara, M.; Melkas, H. Can robots tackle late-life loneliness? Scanning of future opportunities and challenges in assisted living facilities. Futures 2020, 124, 102640. [Google Scholar] [CrossRef]
- Kansizoglou, I.; Bampis, L.; Gasteratos, A. Do neural network weights account for classes centers? IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Tian, J.; Yung, D.; Hsu, Y.C.; Kira, Z. A geometric perspective towards neural calibration via sensitivity decomposition. Adv. Neural Inf. Process. Syst. 2021, 34, 1–12. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4690–4699. [Google Scholar]
- Kansizoglou, I.; Santavas, N.; Bampis, L.; Gasteratos, A. HASeparator: Hyperplane-Assisted Softmax. In Proceedings of the 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 14–17 December 2020; pp. 519–526. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | ||||
| Output |
| Final MSE | ||||
| Best MSE |
| Final MSE | |||||||
| Best MSE |
| Method | Features | Arousal | Valence |
|---|---|---|---|
| Baseline [37] | Geometric | ||
| RVM [43] | Geometric | ||
| Weber et al. [44] | Geometric | ||
| Somandepalli et al. [45] | Geometric | ||
| Baseline [37] | Appearance | ||
| RVM [43] | Appearance | ||
| Weber et al [44] | Appearance | ||
| Somandepalli et al. [45] | Appearance | ||
| Brady et al. [46] | Appearance | ||
| Tzirakis et al. [10] | Raw image | ||
| Ours | Geometric |
| Subject 1 | Subject 2 | Subject 3 | Subject 4 | Subject 5 | Subject 6 | Subject 7 | Subject 8 | Subject 9 | |
|---|---|---|---|---|---|---|---|---|---|
| Valence | |||||||||
| Arousal |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kansizoglou, I.; Misirlis, E.; Tsintotas, K.; Gasteratos, A. Continuous Emotion Recognition for Long-Term Behavior Modeling through Recurrent Neural Networks. Technologies 2022, 10, 59. https://doi.org/10.3390/technologies10030059
Kansizoglou I, Misirlis E, Tsintotas K, Gasteratos A. Continuous Emotion Recognition for Long-Term Behavior Modeling through Recurrent Neural Networks. Technologies. 2022; 10(3):59. https://doi.org/10.3390/technologies10030059
Chicago/Turabian StyleKansizoglou, Ioannis, Evangelos Misirlis, Konstantinos Tsintotas, and Antonios Gasteratos. 2022. "Continuous Emotion Recognition for Long-Term Behavior Modeling through Recurrent Neural Networks" Technologies 10, no. 3: 59. https://doi.org/10.3390/technologies10030059
APA StyleKansizoglou, I., Misirlis, E., Tsintotas, K., & Gasteratos, A. (2022). Continuous Emotion Recognition for Long-Term Behavior Modeling through Recurrent Neural Networks. Technologies, 10(3), 59. https://doi.org/10.3390/technologies10030059