1. Introduction
Fama and French (
1993) introduced the three-factor asset pricing model (
Fama and French (
1992)), which expanded the traditional capital asset pricing model (CAPM) by identifying three systematic risk factors in stock returns. They constructed these risk factors based on the constructions of portfolios by sorting on stock characteristics. However, subsequent studies, e.g.,
Titman et al. (
2004) and
Novy-Marx (
2013), suggest that the three-factor model might not be sufficiently comprehensive. In response,
Fama and French (
1995) extended the model to incorporate profitability and investment factors, resulting in the five-factor model. They found that the five-factor model explains 71%–94% of the cross-sectional variance in expected returns concerning size, book-to-market, profitability, and investment.
Further examination of the Five-Factor Model by
Fama and French (
2015) across four regions—North America, Europe, Japan, and Asia Pacific—reveals that, while the global model may not provide entirely satisfactory results, regional models, constructed with local data from each area, do a better job in terms of explaining return variance.
The expanding array of potential risk factors in asset pricing has led to the colloquial term “Factor Zoo”. One of the earliest mentions of the Factor Zoo comes from
Cochrane (
2011), while
Harvey et al. (
2015),
McLean and Pontiff (
2016), and more recently,
Hou et al. (
2017), discuss how the proliferation of new risk factors can influence the risk pricing procedures.
But even with this growing number of new factors, the Fama–French model with 3, 4, and 5 factors continues to be an essential benchmark in risk pricing applications. This is due to the widespread availability of these factors and the interpretability of the associated risk premiums for each factor in the model. However, the existence of many other risk factors highlights the challenges faced when estimating models based on three, four, or five factors derived from the Fama–French framework. These estimations may face difficulties due to the omission of significant risk factors, rendering the risk premium estimates for the incorporated factors unreliable due to the bias generated by variable omission in the econometric estimation.
Recognizing the significance of omitted factors in risk premium estimation,
Giglio and Xiu (
2021) (referred to as GX) introduced a three-step method for estimating the risk premium of an observable factor. This method remains valid even in the presence of omitted risk factors in the model. It also accounts for possible measurement errors in the observable factors and identifies factors that may be spurious or “useless” in influencing the estimation.
In our study, we analyzed the performance of the Fama–French five-factor pricing model in pricing risk in the Brazilian financial market. The Brazilian financial market exhibits distinctive characteristics when compared to other developing economies. One notable aspect is its technological advancement, stemming from periods of hyperinflation witnessed in the 1980s and 1990s. This tumultuous economic backdrop spurred the development of a sophisticated banking and financial infrastructure. Innovative financial products, including indexed accounts and pioneering instruments like future contracts tied to one-day interbank interest rate fluctuations, emerged as a response to daily price variations. Another significant feature is the market’s size and banking concentration. As of 2021, the five largest banks command over 75% of the market share, exemplifying considerable dominance within the sector.
A unique aspect is the consolidation of operations within the Brazilian financial market. Since the early 2000s, various regional stock exchanges—such as São Paulo (BOVESPA), Rio de Janeiro (BVRJ), Minas-Espírito Santo-Brasília (BOVMESB), among others—were integrated. This led to the concentration of share trading in Brazil, culminating in the merger of BM&F (Bolsa de Commodities and Futures) and Bovespa in 2008, creating BM&FBovespa. This merger unified stock, derivatives, and futures operations under one exchange. Subsequently, the 2017 merger between BM&FBovespa and CETIP, responsible for electronic custody systems and financial settlement in public and private securities markets, further centralized operations. As a result, trading shares, derivatives, futures, and custody and financial settlement systems became centralized under a single market operator. B3 (Bolsa Brasil Balcão), the current name of BM&Fbovespa, stands as Latin America’s largest stock exchange, both in total market capitalization and the number of listed companies.
An integral aspect of the Brazilian financial market is its susceptibility to both political dynamics and the broader global financial landscape. For instance, notable outliers emerged in March 2016 following the exposure of recordings implicating President Luiz Inácio Lula da Silva in the Lava-Jato operation. Similarly, the market experienced significant upheaval in May 2017 when revelations from the JBS partners’ plea bargain involving President Michel Temer rattled investor confidence. Moreover, periods of systemic crises, such as the substantial fluctuations in returns witnessed between September and November 2008, were directly linked to the global financial crisis. Similarly, the onset of the COVID-19 pandemic in March 2023 marked another phase of market turbulence, underlining the interconnectedness between global events and the Brazilian financial landscape.
The Brazilian market also stands out for its sophisticated portfolio and risk management practices, boasting a substantial number of portfolio managers. For instance, as of November 2023, there are 36,255 active registered funds, encompassing 1418 fixed-income funds and 3418 actively managed multi-market funds. Many of these multimarket funds operate on quantitative strategies rooted in factor investing, using multifactor pricing models to create trading strategies, with a central role of models based on risk factors built from characteristics using the Fama–French framework.
We study two ways of using the five-factor model to price stocks with Brazilian data. The Fama–French factors are widely used in risk pricing in the Brazilian market, even in the presence of models with alternative risk factors, as discussed in
Varga and Brito (
2016), but as we discussed, the risk premium estimates derived from this specification may be biased by the omission of relevant factors in the model.
First, we focused our study on testing possible factor omission, and thus the existence of bias in the risk premium estimation. For this, we propose a test for factor omission exploring the panel data structure of asset returns. We apply two estimators for panel data to estimate the risk premium of the factors: the Mean Group (MG), proposed by
Pesaran and Smith (
1995), and the common correlated effects estimator (CCE), introduced by
Pesaran (
2006). The MG estimator is defined as an average of OLS estimators, while the CCE estimator is an extension of the MG estimator that assumes an unobserved common factor structure for the errors. Thus, we can interpret the MG estimator as an estimator that is not robust to the presence of omitted risk factors using a panel data structure, while the CCE estimator would be robust to this problem.
If there are factors omitted in the Fama–French five-factor model, the CCE estimator for the parameters of observed factor must be robust for the omission of relevant factors, and therefore, their coefficients would be different from the estimated coefficients for the MG estimator, and we can use the parameter difference between the two estimations to implement a test for factor omission exploring the panel data structure of asset returns.
The second way of studying the relevance of the five factors was to test whether they are sufficient to correctly price the assets, that is, whether these factors can estimate an approximately correct price for the set of assets in question. For this, we estimate the risk premium using the
Giglio and Xiu (
2021) method, denoted by GX, which theoretically also corrects the estimation for the possible omission of variables and the presence of measurement error using an alternative methodology incorporating the specific aspects of the risk pricing structure, and we use this estimate to predict returns. Finally, we compare which model best fits the observed returns, the MG, CCE, or the GX estimators.
We noticed significant differences in the estimated coefficients for the model when using the MG and CCE estimators, which indicated the potential omission of factors in the model. We also assessed the number of factors that the estimator introduced by
Giglio and Xiu (
2021) using four penalty functions. Although all penalty functions approached zero as the sample size and time period increased, we were unable to identify a suitable penalty function that ensured accurate factor estimation. Nevertheless, the
Giglio and Xiu (
2021) estimator performed well with three of the penalty functions, particularly in simulations involving one or three factors.
In comparing the residuals generated by the Fama–French model estimated by the MG, CCE, and GX estimators, the CCE estimator, it was expected that the estimator that the GX three-step estimator would yield superior results. However, it did not perform as well as we had expected in terms of fitting the expected returns. We believe that this might be due to the presence of weak latent factors in the cross-section of the returns, violating one of the main assumptions of the
Giglio and Xiu (
2021) method.
This study contributes to the field of asset pricing by introducing a novel approach for factor omission testing using panel data, comparing the mean group and common correlated effect estimators to identify the potential missing risk factors in the model. Additionally, the study assesses the sufficiency of the Five-Factor Model in accurately pricing assets, providing insights into its ability to estimate expected returns using the MG, CCE, and GX methods. These contributions are particularly relevant in the Brazilian market, where accurate risk premium estimation is vital for investment decisions, and the study’s methodologies offer valuable insights for researchers and practitioners in finance.
This work has the following structure: a brief literature review is presented in
Section 2; the methodology is reviewed in
Section 3. In
Section 4, we will present the data used.
Section 5 presents the main results obtained. Final conclusions are presented in
Section 6.
2. Literature Review
The field of asset pricing has witnessed significant advancements in recent years, driven by the emergence of various factors and factor models aimed at understanding how specific characteristics influence asset prices. The foundational work in this domain can be traced back to the portfolio selection problem initially introduced by
Markowitz (
1952). This work laid the groundwork for optimal portfolio selection, emphasizing the mean variance principle and the creation of efficient mean-variance combinations. Building upon this,
Sharpe (
1964) proposed a market equilibrium theory of asset prices under risk, revealing a linear relationship between expected returns and the standard deviation of returns for efficient asset combinations. Additionally,
Sharpe (
1964) highlighted the consistent relationship between expected returns and systematic risk, measured by market beta, which quantifies a stock’s volatility relative to the market.
Similar to Sharpe’s work,
Lintner (
1965) and
Black (
1972) also studied the relationship between average returns and risk. Like the Sharpe model, the
Lintner (
1965) and
Black (
1972) models concluded that expected returns are positive linear functions of market betas. They also found that market betas absorb the effect of leverage on prices and are sufficient to describe the cross-section of expected returns.
Similarly,
Lintner (
1965) and
Black (
1972) explored the connection between average returns and risk, confirming that expected returns exhibit a positive linear relationship with market beta. They also noted that market beta encapsulates the effects of leverage on asset prices and effectively describes the cross-section of expected returns. Meanwhile,
Fama and Macbeth (
1973) investigated the relationship between dividend yields and expected stock returns, discovering that dividend yields explain a substantial portion of variance in long-term returns but less in monthly or quarterly returns.
Fama and French (
1988) delved into the relationships between expected returns, market beta, size, leverage, book-to-market equity (BE/ME), and earnings/price (E/P), concluding that leverage is well captured by book-to-market equity, and the combination of size and book-to-market equity accounts for the relationship between E/P and expected returns.
Fama and French (
1992) expanded on their previous research using the time series regression approach to construct two risk factors related to size and BE/ME for stocks, and two risk factors related to the term structure for bonds. The factors related to size and BE/ME are known as SMB and HML, respectively. To build these factors, they sorted the stocks by size (big and small) and BE/ME (low, medium, and high). This classification by BE/ME is based on dividing the stock population into three groups, with the lower 30% classified as low, the middle 40% as medium, and the upper 30% as high. From this classification, six portfolios are created based on the intersections between the size and BE/ME classifications: Small/Low (S/L), small/medium (S/M), small/high (S/H), big/low (B/L), big/medium (B/M), and big/high (B/H). These six portfolios provide returns on the large- (B) and small- size (S) portfolios.
From these two portfolio returns shown above, with
and
representing the returns of big stocks and the returns of small stocks, respectively, the returns
of zero SMB net investment factors (small minus big, i.e., long position in low capitalization stocks and short position in high capitalization stocks), are constructed:
Similarly, the returns of the high (
H) and low (
L) portfolios are:
From these two portfolios, the zero HML net investment factor is created (high minus low, that is, a long position in high BE/ME and short position in low BE/ME):
They also created two portfolios to measure the common risk related to unexpected changes in interest rates for bonds, called TERM and DEF. These five factors were found to effectively explain the common variation in bond and stock returns.
In a subsequent study,
Fama and French (
1993) sought to identify the economic foundations for their empirical findings and rationalize asset pricing. They hypothesized that common risk factors associated with size and BE/ME influenced returns, which should be explicable by the earning behavior. However, they did not find evidence supporting the idea that returns respond to the BE/ME factor in earnings, leaving questions open regarding the economic variables influencing earnings and returns related to size and BE/ME.
Despite the popularity of the three-factor model, studies such as those by
Titman et al. (
2004) and
Novy-Marx (
2013) revealed its inadequacy in explaining the variations in average returns related to factors like profitability and investment. To address these limitations,
Fama and French (
1995) introduced the five-factor asset pricing model. This extended model incorporates profitability and investment factors, represented by the Robust Minus Weak (RMW) and conservative minus aggressive (CMA) portfolios, which capture the differences in returns between companies with strong and weak profitability and between conservative and aggressive firms, respectively. This model has demonstrated a superior performance in explaining the average returns compared to the previous three-factor model. However, the potential for omitted variable bias and measurement errors poses challenges, leading to inconsistent estimates and less accurate asset pricing predictions.
To confront these issues, researchers have explored new factors for asset pricing, resulting in a proliferation of potential factors, often referred to as the “Factor Zoo”.
Cochrane (
2011) was among the first to draw attention to this phenomenon, and subsequent studies, including those by
Harvey et al. (
2015),
McLean and Pontiff (
2016), and
Hou et al. (
2017), have further explored the impact of these factors on pricing models.
Other examples of six-factor models include those of
Roy (
2021) and
Zhou et al. (
2022), and the applications of arbitrage-based pricing models with seven or more risk factors are discussed in
Bhatti and Mirza (
2014);
Maharani and Narsa (
2023);
Malhotra et al. (
2023) and
Fang and Almeida (
2019), for example. All of these references indicate the need to use a greater number of factors than the usual five factors of the Fama–French structure, indicating that models with a reduced number of factors may be incorrectly specified, requiring the type of corrections for omitted factors discussed in our article.
These works underscore the challenge of omitting relevant factors in risk premium estimation. In response,
Giglio and Xiu (
2021) proposed a three-step methodology that incorporates rotation invariance and principal component analysis (PCA) to provide consistent risk premium estimates for observed factors, even in the presence of omitted factors and model mis-specification. This approach addresses critical issues in risk premium estimation and offers a path towards more robust asset pricing models.
4. Database
We use risk factors and portfolio return data constructed by NEFIN
Núcleo de Estudos em Finanças, Finance Studies Center (acessed on 20 December 2020) from University of São Paulo (USP) for the period from January 2001 to December 2020 using a daily frequency. The sample contains 4950 observations. It would be possible to work with monthly or quarterly returns, and in some aspects, the use of monthly or quarterly data facilitates the estimation of factor models. For example, the impact of measurement errors on factors would be reduced by greater aggregation. If we consider the variance of the measurement error constant, the signal-to-noise ratio would increase with temporal aggregation, reducing the impact of the measurement errors. However, this could impact the estimators used in the article, since both the panel-based MG and CCE estimators and the estimator proposed in
Giglio and Xiu (
2021) depend on asymptotic properties in relation to the sample size, and thus the greater temporal aggregation should affect these estimators, indicating the use of the daily frequency returns.
The one-year risk-free factor (
) was calculated from the 360-day DI-Swap instrument, deflated by expected inflation measured by the IPCA index (data available on the website of the Central Bank of Brazil). The DI-Swap are futures contracts in the interbank deposit rates, being the main reference for risk-free interest rates in Brazil. The market factor (
) is the difference between the daily value-weighted return of the market portfolio and the daily risk-free rate, which is calculated from the 30-day DI-Swap.
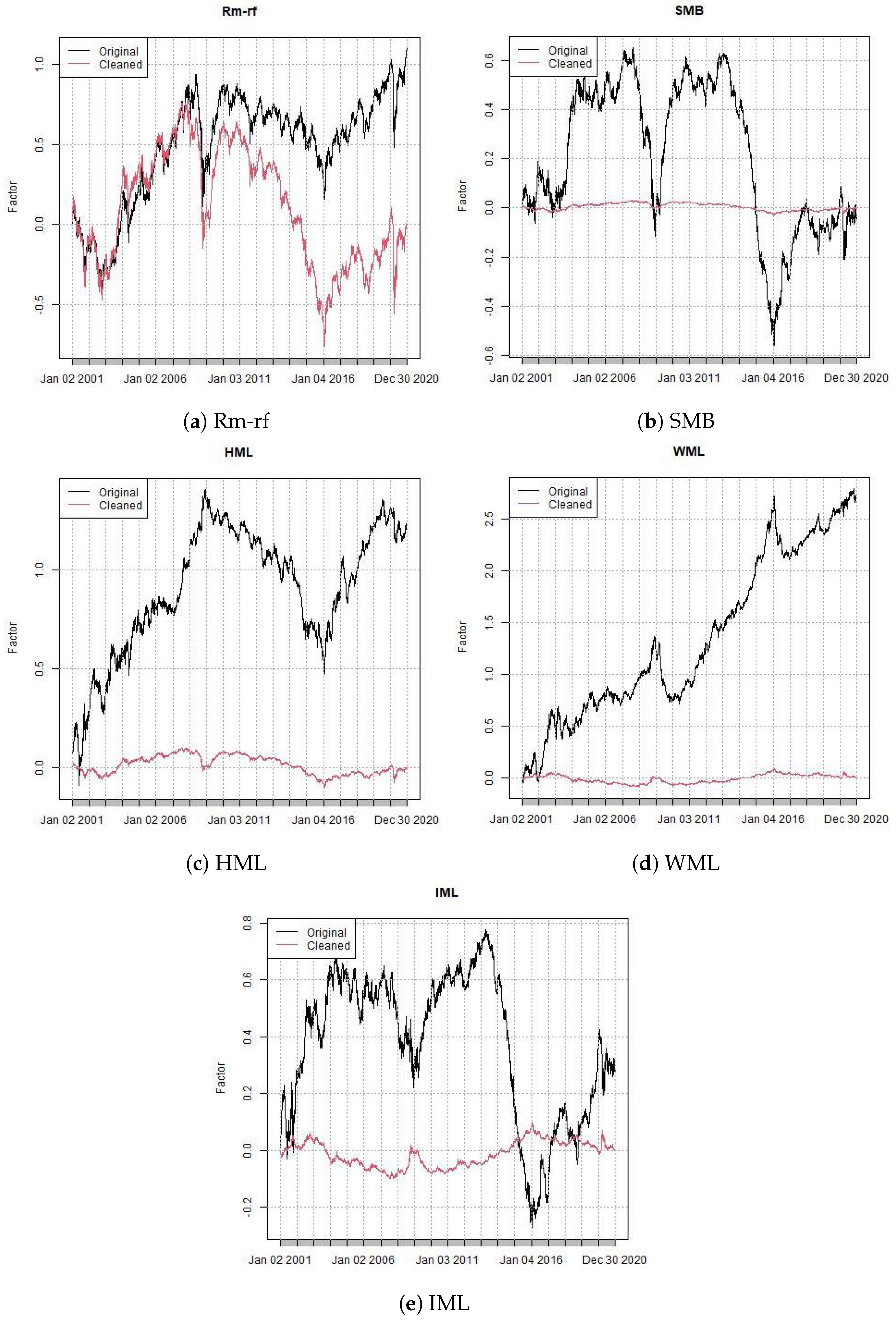
Figure 1 shows the market factor returns.
The size factor
(small (− big) is the return of a portfolio long on stocks with low market capitalization (smal) and short stocks with high market capitalization (big’). Every January of the year
t, the shares are classified as eligible according to the market capitalization of December of the year
, and are sorted and separated into three quantiles (portfolios). Then, the returns of the first portfolio (small’) and the third portfolio (big’) are calculated with equal weight. The
factor is the return of the small portfolio minus the return of the big’ portfolio.
Figure 2 shows the size factor returns.
The factor related to BE/ME is the
factor (high minus low). This return is the return of a portfolio long on stocks with a high book-to-market ratio (high) and short on a low book-to-market ratio (low’). Every January of the year
t, the shares are classified as eligible and sorted into three quantiles (portfolios) according to the firm’s book-to-market ratio in June of the year
. Again, equal weighted returns of the high portfolio minus the returns of the low portfolio are constructed.
Figure 3 presents the book-to-market factor returns.
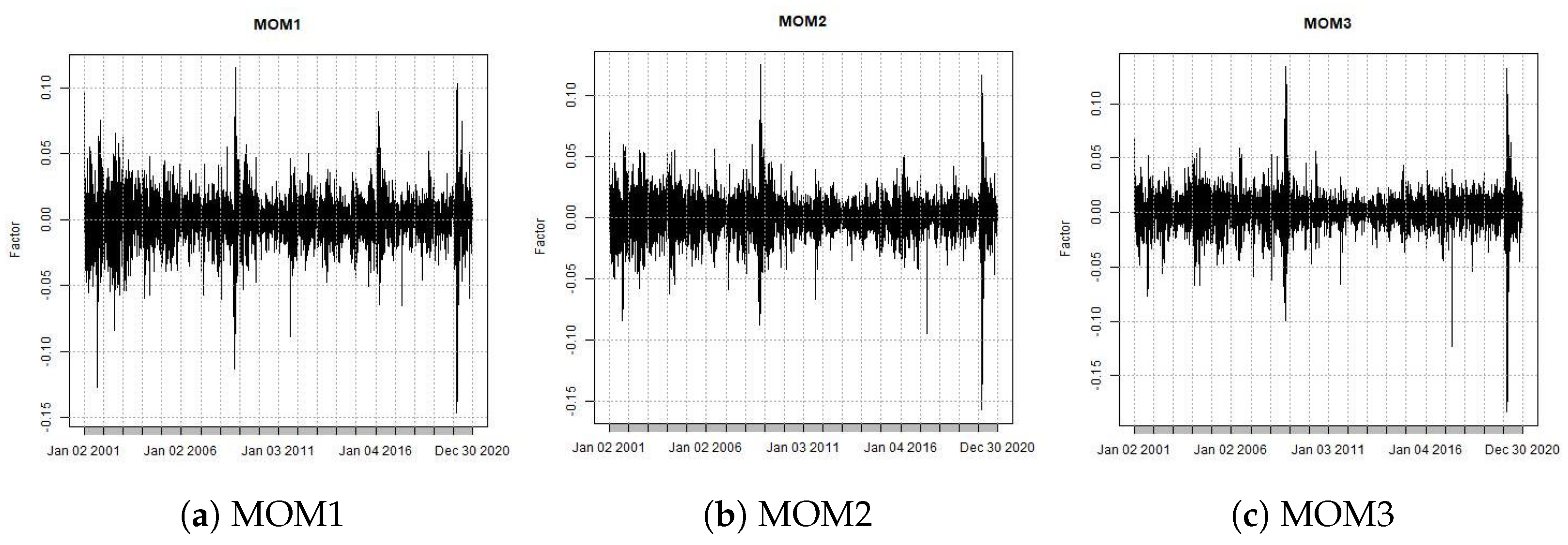
The
factor (winners minus losers) is the return of a portfolio long on stocks with high past returns (winners) and short on low past returns (losers). Every month,
t shares are classified as eligible and divided into three quantiles (portfolios) according to their cumulative returns between the months
and
, with equal weighted returns of the first portfolio (losers) and the third portfolio (winners’). The
factor is the return of the winners’ portfolio minus the return of the losers’ portfolio. The returns of
factor are shown in
Figure 4.
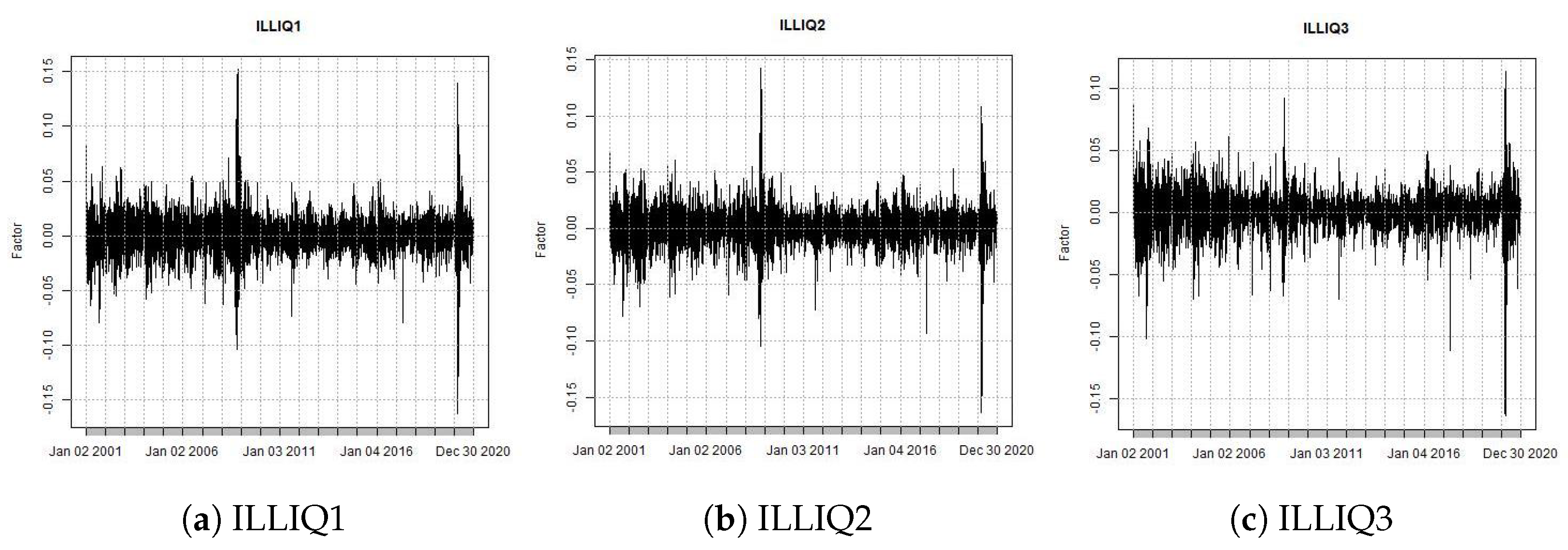
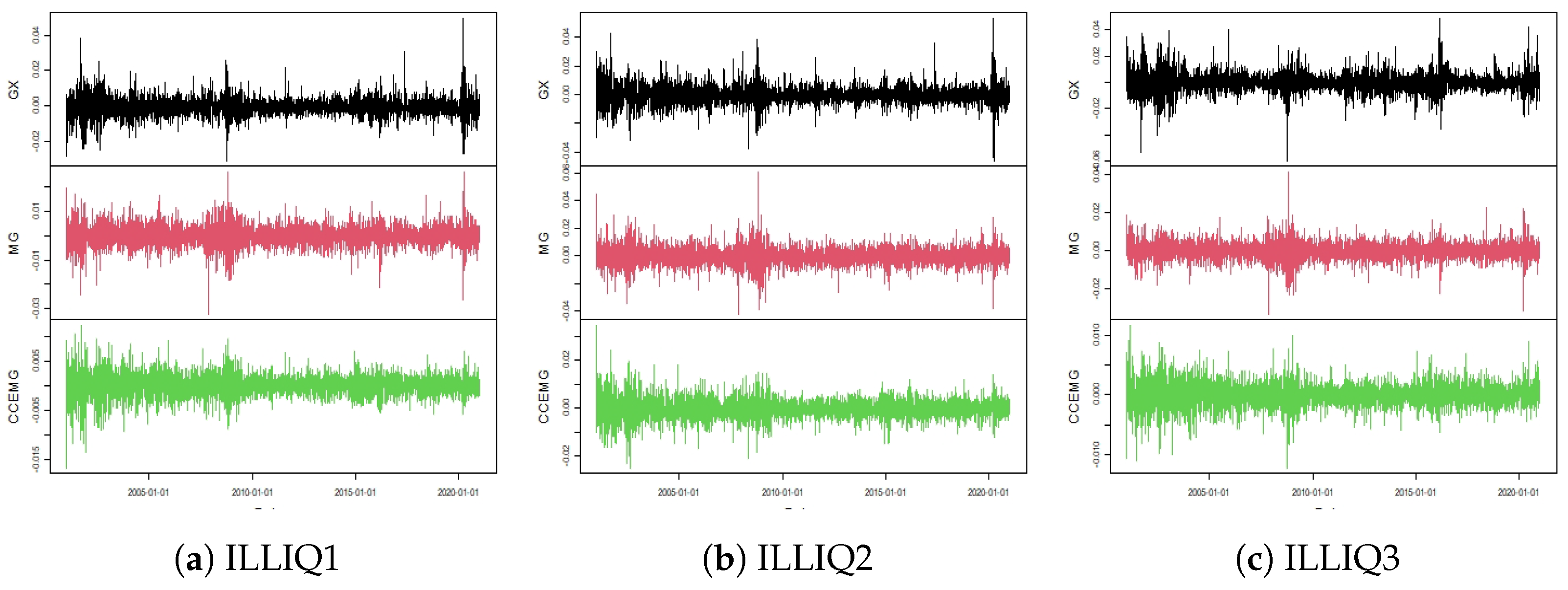
The
factor (illiquid minus liquid) is the return of a portfolio long on highly illiquid stocks (Illiquid’) and short on low illiquid (Liquid’). Every
t month, we sort eligible stocks (in ascending order) into three quantiles (portfolios) according to the moving average of illiquidity over the previous twelve months (stock illiquidity is calculated according to
Acharya and Pedersen (
2002) method). As with the previous factors, we calculated with equal weight the returns of the first portfolio (liquid) and the third portfolio (illiquid). The factor
is the return on the illiquid’ portfolio minus the return on the liquid’ portfolio.
Figure 5 presents the book-to-market factor returns.
The dependent variables in our analysis are asset portfolios constructed using sorting by asset characteristics. The use of portfolios as dependent variables is a way of summarizing the heterogeneity observed in market assets, eliminating the idiosyncratic effects observed in individual assets by the diversification mechanism. The 12 portfolios returns analyzed are divided into four groups:
Three portfolios sorted by size;
Three portfolios classified by book-to-market;
Three portfolios sorted by momentum;
Three portfolios classified by illiquidity.
Portfolios sorted by size are obtained as follows: every January of year t, eligible stocks are sorted in ascending order into terciles according to their market capitalization in December of year . Then, the portfolios are held for the year t. Portfolios sorted by book-to-market are similar: every January of the year t, eligible stocks are sorted in ascending order in terciles, according to the ratio between the book value and market value in June of the year . Then, the portfolios are held for the year t.
Momentum sorted portfolios are constructed in a similar way: every month
t, eligible stocks are sorted in ascending terciles according to their cumulative returns for month
and month
, and are held for the month
t. Finally, the portfolios sorted by illiquidity are sorted in ascending terciles according to the moving average of the illiquidity of the twelve previous months, according to
Acharya and Pedersen (
2002), and again are held for the year
t.
In order to be considered eligible, the stock shares traded on BOVESPA had to meet three criteria: The share is the company’s most traded share (that is, the one with the highest volume traded during the last year); the shares were traded in more than of the days of the year , with a volume greater than BRL 500,000.00 per day, and if the share was listed in the year , the period considered runs from the day of listing to the last day of the year; the shares were initially listed before December of the year .
6. Conclusions
In this study, we investigate the applicability of the Fama–French five-factor model in explaining expected returns within the Brazilian asset market. Our analysis takes into account the potential consequences of omitting relevant factors in the model specification. To address this concern, we employ two distinct analytical approaches. Firstly, we construct a Wald test to assess the presence of omitted factors, examining both the temporal and cross-sectional dimensions of the data. To achieve this, we utilize two panel data estimators. Specifically, we compare the parameter estimates from the mean group (MG) estimator (
Pesaran and Smith 1995), which does not correct for omitted factors, with those from the common correlated effects (CCE) estimator (
Pesaran 2006), which accounts for omitted factors/variables in panel data estimations. Our findings reject the null hypothesis of parameter equality between the two estimations, strongly suggesting the existence of omitted factors in our estimation of the Fama–French five-factor model within the Brazilian stock market data.
With the identification of these omitted factors, we adopt the estimator introduced by
Giglio and Xiu (
2021). This approach enables us to estimate the risk premium associated with the observed factors while considering the potential presence of omitted factors and measurement errors. Subsequently, we compare the risk premiums for the included factors estimated using this correction with those derived from the uncorrected Fama–MacBeth estimation. This comparison reveals substantial differences between the parameters estimated under these two specifications, further emphasizing the significance of omitted factors in risk premium estimation.
Furthermore, we conduct a comparative analysis of three models: MG, CCE, and GX. We assess their predictions for the expected returns of the portfolios under scrutiny by calculating predicted returns and evaluating the residuals generated by each model. Our results indicate that the CCE estimator offers the most accurate predictions for expected returns, as it exhibits the lowest mean squared error. Additionally, this suggests that the correction proposed by
Giglio and Xiu (
2021) is less precise in estimating the expected returns compared to the panel estimation based on common correlated effects.
The core premise of the
Giglio and Xiu (
2021) approach hinges on the belief that the underlying data-generating process (DGP) for returns is influenced by latent but strong factors, and the PCA can uncover all the pivotal pricing factors. They posit that these latent factors can be discovered through principal component analysis (PCA). This issue carries significant weight, especially in light of the extensive assortment of factors and test assets found in financial literature, as it is quite plausible that within any cross-section of the test assets, some factors may prove to be weak rather than strong. The prevalence of this weak factor problem is evident in empirical data.
Lettau and Pelger (
2020) shows that employing weak factors in addition to those identified by PCA yields significantly better out-of-sample performance compared to models that solely rely on PCA-identified factors, and show that PCA-based factors often overlook low volatility components with high Sharpe ratios, a crucial aspect in asset pricing.
Onatski (
2012) explores the utilization of principal component estimation in the context of large-factor models featuring weak factors. He emphasizes a crucial point: when a factor does not explain a substantial portion of the variance in the data, PCA cannot detect it. Additionally,
Pesaran and Smith (
2019) delve into the ramifications of factor strength and pricing errors when estimating risk premiums. They observe that the conventional two-pass risk premium estimation method exhibits a slower convergence as factors lose their strength. Even if all factors are robust, the presence of highly correlated factors can introduce the challenge of the weak factor problem.
The superior performance of the CCE estimator compared to the GX estimator can be attributed to the findings of
Chudik et al. (
2011), who demonstrated that, when weak or semi-strong factors are present, the principal component estimates of factors may lack consistency. In contrast, the CCE estimator exhibits good performance and minimal size distortions. Notably, this issue does not impact the CCE estimator, as its objective does not revolve around achieving consistent factor estimation. Instead, it addresses error cross-section dependence more broadly by employing cross-section averages to mitigate such effects. A similar interpretation of the relative performance of estimators based on cross-sectional averages compared to principal component-based estimators can be found in
Westerlund and Urbain (
2015) and
Kapetanios et al. (
2021), which is in violation of the assumptions necessary for estimating principal components, whilst CCE estimators tend to have better performance and the robustness properties of CCE analyzed by
Chudik and Pesaran (
2015) are valid.
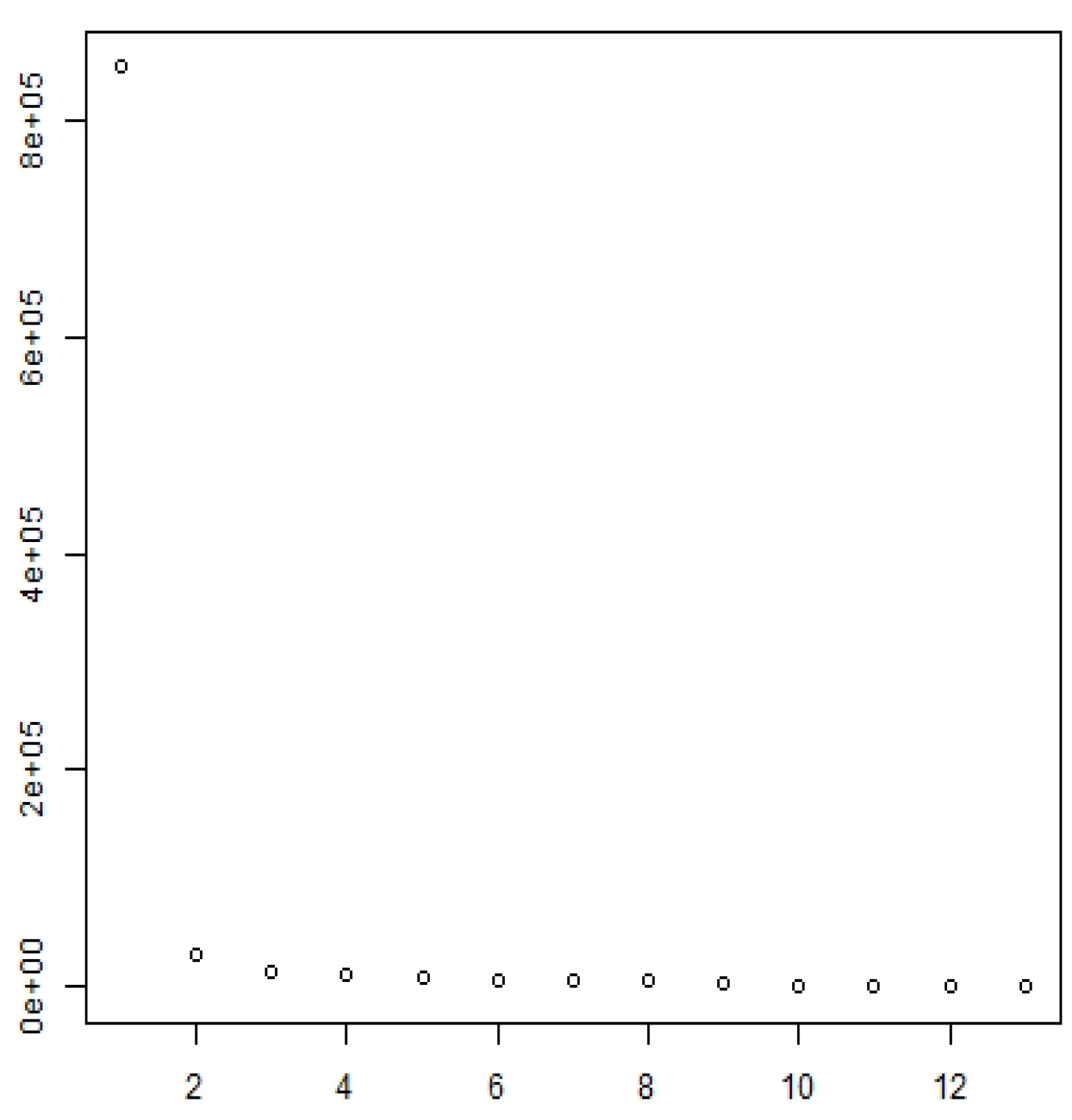
We also evaluated in the Appendix of the work in which the estimator of the number of factors proposed by
Giglio and Xiu (
2021) uses four penalty functions. Although all penalty functions approach zero as
N and
T increase, we were unable to identify a penalty function that satisfies the second condition and accurately estimates the factors in our simulations. Despite this limitation, we found that the
Giglio and Xiu (
2021) estimator performed well with three of the penalty functions, particularly in simulations with one or three factors.
It is important to emphasize that our analysis and the estimation methods used depend on some important assumptions that may be violated. An essential assumption for the application of the panel estimators (MG and CCE) used as well as the GX estimator is a linear structure of dependence between the assets. We are assuming a linear pricing model based on the arbitrage price structure theory and a stochastic discount factor with a linear structure. Although it is a common assumption in this literature and especially in practical applications, it is important to note that there may be evidence contrary to this assumption.
For example, a non-linear dependence structure may occur in periods of market stress, where the occurrence of an extreme event in a series is non-linearly related to extremes in other processes, which would be a violation of the linear dependence between assets. Although the use of portfolios both in defining dependent variables and in constructing portfolio risk factors minimizes this problem through diversification, it is important to note that we may still be subject to problems such as nonlinear tail dependencies and other similar dependency structures. As we can observe the occurrence of extreme events and outliers both in the original series and in the estimation residuals, we cannot guarantee the existence of a multivariate normality structure, which would guarantee a linear dependence structure between assets. In this aspect, the estimators used implicitly depend on the assumption of linearity and/or joint multivariate normality. Similarly, other violations, for example, the non-sphericity in the covariance matrix (see, e.g.,
Baltagi et al. 2015), can also affect the finite sample properties of our estimators, since the existence of conditional volatility in financial time series generates heavy-tailed distributions, and harms the efficiency properties of estimators in finite samples.
Although there is a literature on estimating nonlinear panel models using the general structure of common correlated effects and mean group estimators (e.g.,
Hacıoğlu Hoke and Kapetanios 2021;
Chen and Zhang 2023) and similar corrections to principal component-based estimators (
Chen et al. 2014), these estimators require the nonlinear functional form linear is known, which is not the case in our problem. An alternative approach would be, for example, to use a copula structure, where we could define the nonlinear dependence function through some copula function with nonlinear tail dependence, which would be a very interesting extension of our analysis. We recognize that our analysis depends on a linear pricing structure, and that specification issues such as the rejection of normality, nonlinear dependence, and problems with extreme values can affect our results and conclusions. An analysis of the robustness properties of the Wald tests for factor sufficiency and MG, CCE, and GX estimators analyzed in the present paper in relation to these mis-specification problems in the estimation of risk premia is an interesting extension of the analyses carried out in our work.
As a general conclusion, our analyses show that the use of econometric corrections for omitted factors is important for estimating the risk premium in the Brazilian financial market, and that the correction method used is also relevant.
All factor sufficiency tests performed conclusively indicate the presence of omitted factors when using the five factors constructed by NEFIN to estimate risk premiums for portfolios constructed using sortings. As these portfolios serve as proxies for general stock portfolios in Brazil, we have relevant evidence about the need for additional risk factors and the use of robust econometric methods in estimating risk premiums in the Brazilian stock market.
Investment strategies and portfolio selection using factors depend directly on the accurate estimation of the risk premium associated with each factor, as discussed in
Alles Rodrigues and Casalin (
2022);
Brière and Szafarz (
2020);
Caldeira et al. (
2013), and thus the econometric properties of risk premium estimators are relevant in practical market applications. Our results indicate that the CCE estimator, which corrects the presence of omitted factors by exploring the averages through a panel structure, appears to estimate the risk premium structure for the analyzed portfolios in a less biased and accurate way, obtaining residuals with less variability and bias, and thus better performance in predicting the expected returns, an essential property in portfolio selection and risk measurement procedures.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}