1. Introduction
As a kind of securities with both bond and equity attributes, convertible bond has attracted the attention of the industry and academia since its birth in 1993. Comparing with A-shares, the convertible bond has developed more slowly and is still in an emerging market. The deep learning technology has the technology of mining the nonlinear laws in the data and the strict assumptions in the traditional pricing of convertible bonds. Some scholars began to carry out pricing of convertible bonds from another new perspective, that is, to introduce the relevant algorithm of deep learning to the valuation and pricing of convertible bonds, so as to reduce the pricing error. Though, the traditional convertible bond pricing theory can be roughly divided into four categories: B–S (Black–Scholes) option pricing model, tree graph pricing model, finite difference method and least square Monte Carlo pricing model (LSM).
However, due to the differences between the terms of domestic and foreign convertible bonds and the limitations of traditional models, it is found empirically that directly applying these methods to the pricing of domestic convertible bonds is not a good way to price convertible bonds. Considering some defects of the above models, this paper adopts a data-driven method (including the LSTM model and GAN model) to price convertible bonds, so as to solve the pricing imprecision problem of traditional methods. This method can discard some strict restrictions in traditional models and include more influential factors. According to the characteristics of different industries, reasonable influence factors can be selected for scientific pricing.
This paper also uses the method mentioned in
Wiese et al. (
2020) and
Tan et al. (
2022) for reference, and uses the GAN model instead of Monte Carlo to generate simulation data. It is put into the traditional LSM model to form the LSM improvement model, so as to overcome the defects caused by the assumptions of LSM, so as to improve the pricing power of the traditional model and promote the traditional pricing model to keep pace with the times. Therefore, the focus of this paper is to put forward two kinds of pricing methods (including the data-driven pricing method and LSM improved model) to solve the problem of low precision and difficult pricing of convertible bonds.
Theoretically, the study of this paper enriches the existing pricing theory, and discusses the shortcomings, what needs to be improved, and applies the new method to the traditional pricing model, so that it can overcome the pre-defect, and then better complete its pricing task. In practice, a new financial data generation method is adopted, and it is applied to the traditional least square pricing model to price the convertible bond, in order to enrich the pricing function in the financial field and provide empirical evidence for strategic investment of financial assets. The research framework is shown in the following (
Figure 1).
2. Literature Review
This paper summarizes the traditional pricing methods of convertible bonds according to the first division way. Among them, the analytical method is mainly the Black–Scholes option pricing method, and the numerical method includes the tree graph method, finite difference method and least square Monte Carlo simulation method. Secondly, because the machine learning algorithm can skip the overly strict assumptions in the traditional pricing methods, many scholars at home and abroad began to introduce machine learning methods to study the pricing of convertible bonds.
2.1. Pricing Method of Convertible Bonds Based on B–S Option Pricing Model
The application of the B–S option pricing method to the pricing of convertible bonds can be dated back to the studies of
Brennan and Schwartz (
1977) and
Ingersoll (
1977), who believed that convertible bonds were affected by three factors: interest payment, cash dividend and redemption terms. Since the volatility of the stock price of convertible bonds is an important factor in the B–S model, foreign scholars have made many improvements around it. Stochastic volatility (
Hull and White (
1988)), mean recovery Gaussian motion described volatility (
Kalotay et al. (
1993)) and GARCH option pricing theory (
Duan 1995) were applied to the pricing of convertible bonds, and more accurate pricing results were obtained. In recent years, many new statistical methods have been applied to the valuation of convertible bonds. In 2018, the concept of index variance gamma model was applied to the valuation of convertible bonds (CB), which is a new attempt by
Yang et al. (
2018). This differs from the standard Black–Scholes approach to valuing derivatives by using the VG process to describe the dynamic underlying asset logarithm price.
Domestic scholars have done a lot of improvement research on the basis of the mature theoretical achievements abroad.
Zheng and Lin (
2004) proved that the B–S model could be applied to the pricing of Chinese convertible bonds by adding some special clauses (downward revision clauses of convertible bonds).
Xie (
2021) took the Opai convertible bond as an example and conducted a pricing study by using the B–S pricing model that considered sell-back clauses and redemption clauses, and found that the pricing effect of the model was more complete after considering the two clauses.
2.2. Pricing Method of Convertible Bonds Based on Tree Graph Method
It can be seen from the previous study that the pricing effect of the analytical method on the convertible bond is not very good, so scholars began to conduct in-depth research on the numerical method of pricing. Since
Cox et al. (
1979) proposed the binary tree pricing model in 1979, scholars at home and abroad began to use it for pricing convertible bonds.
Hung and Wang (
2002) used the binary tree method to derive the value of convertible bonds after considering the two factors of random interest rate and default risk. On this basis,
Das and Sundaram (
2007) added stochastic volatility as the third factor, in which CEV model was used to predict stochastic volatility.
Ma et al. (
2019) priced Chinese convertible bonds by using the willow model that included stock price and interest rate. Although the willow model is similar to the classical binary tree, the nodes in the willow model do not increase over time.
2.3. Pricing Method of Convertible Bonds Based on Finite Difference Method
Brennan and Schwartz (
1977) first established the finite difference method to solve the structural model, and provided the convenient conditions of partial differential equations under some special conditions in 1980.
Takahashi et al. (
2001) applied the idea of investment fund recovery in the event of default of convertible bonds to the pricing model, adopted the credit risk model and obtained the value of convertible bonds through the finite difference method.
Lau and Kwok (
2004) verified the impact of two redemption clauses on the value of convertible bonds. Domestic scholars
Xie et al. (
2013), under the assumption that the discovery of the credit risk of underlying stocks will not decline to zero, found similar pricing effects when constructing a trinomial tree and a finite difference method for comparative analysis of pricing. In recent years,
Chang and Wang (
2020), based on the premise of Tsallis entropy distribution and instantaneous default risk, obtained the partial differential equation satisfied by the price of convertible bonds by applying the principle of no arbitrage, so as to derive the numerical solution of the price of convertible bonds (finite element method).
2.4. Pricing Method of Convertible Bonds Based on Least Square Monte Carlo Simulation Method
Since
Longstaff and Schwartz (
2001) first applied the least square Monte Carlo simulation method (LSM) to solve the American option problem,
Lvov et al. (
2004) used the CIR stochastic interest rate model to compare the accuracy of the LSM method and the finite difference method for convertible bonds.
Yang et al. (
2010) introduced the dilution effect of downward correction of convertibility and found through LSM model pricing that random interest rates could affect the pricing of convertible bonds, which was suggested to be included in the model, which was also verified by
Batten et al. (
2018).
Feng et al. (
2018) conducted an in-depth study on the impact of redemption clauses and sell-back clauses on the pricing of convertible bonds based on the LSM method.
2.5. Debentable Pricing Method Based on Machine Learning Model
It can be seen that traditional convertible bond pricing models are based on the displayed mathematical formula for pricing, but it is difficult for these models to reproduce the unique statistical characteristics of financial series, such as leverage effect, coarse-fine volatility correlation and the gain/loss asymmetry of financial time series (
Takahashi et al. (
2019);
Dogariu et al. (
2021)).
Zhou et al. (
2007) compared the pricing effect of the B–S model, the binary tree model and the artificial neural network model on convertible bonds and found that the estimation effect of the artificial neural network model is better.
Niu and Ba (
2021) used 31 factors of convertible bonds as input variables to predict the price of convertible bonds and found that the support vector regression model could well complete the prediction task.
2.6. Review of GAN Model Applications in Various Fields
Deep learning, especially GAN proposed by
Goodfellow et al. (
2014), has the potential to conduct dynamic modeling of complex data. Therefore, in this paper, we choose to use GAN as the generation model of stock price. In the financial field, GAN architecture also shows advantages in stock price prediction (
Dogariu et al. (
2021)), separation of market behavior from stock price movements (
Hadad et al. (
2017)), and systematic trading strategies (
Koshiyama et al. (
2021)). The application of the GAN model by domestic scholars mainly focuses on image generation and natural language processing, and a few of them are involved in the financial field. In the field of image generation,
Yang and Jiao (
2021) adopted a new structure, Retina-GAN, integrating the attention mechanism and RU-Net structure into the generator node, generating the adantagonistic network (GAN) for automatic vascular segmentation of fundus images. In the financial field,
Yao et al. (
2022) conducted a study on credit bond default data based on the WGAN model and the SMOTE sampling technique. The research results show that the generation technique of the GAN model can improve the predictive ability of related algorithms on bond default risk and provide a new way to study bond default risk forecast under non-balanced sample conditions.
2.7. Overview
Through the review of the relevant research literature, it is found that the research on pricing of convertible bonds in China started relatively late. Although compared with the development lag of foreign countries, domestic scholars pay more attention to exploring pricing methods of convertible bonds suitable for the Chinese market.
In the study of convertible bond pricing, domestic and foreign scholars have experienced the evolution from the B–S formula to the tree graph method and finite difference method, and then to the least square Monte Carlo method, which gradually takes more terms and situations into account, thus improving the applicability and accuracy of the pricing model. With the development of machine learning, scholars at home and abroad have also begun to explore the application of relevant models to the pricing of convertible bonds, and found that the machine learning model can improve the pricing effect of convertible bonds.
It can be seen that existing research mainly revises and improves the mainstream pricing model, but lacks the innovative application of convertible bond pricing and the pricing accuracy of traditional pricing methods is poor. Therefore, this paper uses the traditional pricing model, LSTM model, GAN model and LSM improved model to price convertible bonds, and compares and analyzes the pricing effects and application scenarios of different models.
3. Research Design
Convertible bonds, referred to as convertible bonds, can be converted into a certain percentage of the underlying stocks in accordance with the agreed terms during the conversion period, or held until maturity to obtain all interest, or sold directly for earnings. Due to its complex structure and characteristics, this chapter mainly elaborates related background concepts of convertible bonds from the development history and basic concepts of convertible bonds. In addition, while discussing the traditional pricing theory of convertible bonds, this paper also expounds the deep learning models used in this paper. Finally, the evaluation index of the model pricing effect and the authenticity evaluation index theory, which needed to be used in the generation sequence of the LSM improved model, are analyzed.
3.1. Pricing Theory of Convertible Bonds
3.1.1. Traditional Convertible Bond Pricing Theory
- (1)
B–S option pricing theory
The Black–Scholes formula was put forward by Black and Scholes in April 1973, and later perfected by Morton, which became the classic algorithm in the option pricing model. Subsequently,
Ingersoll (
1977) and other scholars introduced it to analyze the pricing of domestic convertible bonds. As an analytical method, the B–S model mainly decomposed the intrinsic value of convertible bonds into two parts: pure bond value and option value, and then directly calculated the value of the two parts of convertible bonds through the B–S option pricing model. Finally, the total value of pure bond and option was added to obtain the analytical solution of convertible bonds, namely:
The value of the pure debt part of the convertible bond can be obtained through the classical discounted cash model, as for the meaning of each letter in the model please refer to the following formular and
Table 1, namely:
The value of the option part of the convertible bond is obtained through the B–S formula, which is derived as follows:
In the case of risk neutral, the intrinsic option of a convertible bond is simplified into a European call option. The exercise price of a convertible bond is the price of the equity transfer, denoted as
X; 100 (par value)/
X is the conversion ratio; the stock price at the current time
t is
, and the stock price at the expiration time
T is
,
, indicating the partial value of the convertible bond option.
According to the B–S formula, the logarithmic return rate of the stock price follows the normal distribution, and is as follows:
where
represents the cumulative probability distribution function of the standard normal distribution variable with a mean of 0 and a standard deviation of 1;
,
, and
represent stock price volatility.
Therefore, with the B–S option pricing method, the value of the convertible bond is
- (2)
Binary tree pricing method
Specifically, the option validity period of the convertible bond is divided into several time intervals
. Suppose that the stock price of the company at the current moment rises or falls from moment
, and the stock price at the next moment
is
or
, where
u represents the rising range and
d represents the falling range. Suppose that the probability of rising is
P, the probability of falling is
P − 1 and the number of rising probabilities is m, then:
According to the risk-neutral pricing theory, , is the risk-free interest rate and is the volatility of the stock price.
- (3)
Finite difference method
The application of the finite difference method to the pricing of convertible bonds was first proposed by scholars such as
Brennan and Schwartz (
1977). In the model of
Tsiveriotis and Fernandes (
1998), the value of convertible bonds (V) is divided into debt part value (B) and stock part value (E). The specific formula is as follows:
where S is the stock price of the underlying asset;
is the risk-free interest rate;
is credit risk spreads;
is the volatility of stock prices.
In this model, the impact of redemption clauses and sell-back clauses on convertible bonds can also be taken into account. Based on the above partial differential equation,
Lai et al. (
2005) took into account the downward revision clause and modified the terminal conditions and boundary conditions to make the model more suitable for Chinese market conditions.
3.1.2. Least Square Monte Carlo (LSM) Model
Basic principles
The idea of the LSM model is to discretize the duration of convertible bonds [0,T] into {
}. The optimal exercise time in each simulated path is obtained by backward pushing. There are two main considerations in choosing the optimal exercise time: (1) the holding value of delayed exercise is less than the immediate conversion value; (2) the return of immediate stock conversion is greater than 0. According to the method proposed by
Longstaff and Schwartz (
2001) in 2001, the conditional expected income of the next exercise is
, taken as the holding value of the delayed exercise in a risk-neutral scenario. Specific conditions for exercising the right are as follows:
where the conditional expected return
,
refers to the parameter to be estimated of the Laguerre polynomial at time
i,
is the basis function at time
i. The common linear combination of the basis function is
.
In order to more intuitively show the pricing process of LSM and combine with the path classification method of stock prices proposed by
Feng et al. (
2016),
Figure 2 and
Figure 3 are drawn as the pricing situation in the simulation path, and path1 represents the path where early redemption occurs. path2 and path3 represent the path of in-price and out-of-price American options.
3.1.3. Comparison of Traditional Pricing Methods
The above two sections discuss the basic principles and specific steps of traditional pricing methods. In order to intuitively compare the three pricing methods, the advantages and disadvantages of the above four technologies are summarized (
Table 2):
Based on the above analysis, the least square Monte Carlo simulation is used as the pricing comparison group, compared with the deep learning pricing model alone, and the deep learning financial data generation technology is applied to the least square Monte Carlo pricing, so as to overcome the situation that the assumptions of traditional pricing methods are divorced from the real situation.
3.2. Theoretical Analysis of Neural Network Model
Considering the difficulties of existing pricing methods, this paper adopts two pricing ideas. One is to learn from the neural network model adopted by
Yang et al. (
2020) as the pricing model to price convertible bonds at any time within the duration. The other is to learn from the in-depth pricing method adopted by
Tan et al. (
2022) for the traditional pricing framework of convertible bonds. This method has the stylized fact of high real data reproducibility and can skip many overly stringent assumptions.
3.2.1. LSTM Model
The Long short-term memory network LSTM (Long short-term memory) is a variant of RNN, whose core concept lies in cell state and “gate” structure. Its essence is an improved version of RNN. On the basis of the original RNN, a cell state c is added for long-term state storage. The structure diagram is as follows
Figure 4 (where
represents the memory state at time t and
represents the hidden layer state at time T − 1):
- (1)
Forget the door
The function of the forgetting gate is to control the degree to which the cellular state of the previous moment is retained, that is, the degree of previous memory. The principle is to take the hidden state and input value at the moment t − 1 as input, and convert it into a probability value with the interval between 0 and 1 through Sigmoid activation. The closer to 1, the more important it is, that is, the more important the past information is. represent the weight and bias of the forgetting door, respectively.
- (2)
Input door
The main function of the input gate, also known as the memory gate, is to update the cell state, and the forgetting gate input method; first of all, the hidden state and the input value at t − 1 moment are taken as the input, and converted into a probability value with the interval between 0 and 1 through Sigmoid activation, which is used to control the updating degree of the new information. Both inputs are passed into the Tanh layer at the same time to activate, creating a new cell state .
- (3)
Cell state
The function of the cell state structure is mainly used to generate the cell state at the current moment. The work flow is to take the output of the forgetting gate and memory gate as the input to update the cell state, so as to obtain the cell state at the moment t.
- (4)
Output gate
3.2.2. Generative Adversarial Network (GAN)
- (1)
The basic principle of generating adversarial network model.
Since the GAN model was proposed by
Goodfellow et al. (
2014) in 2014, it has become one of the most popular generation task algorithms at present. The function of a large number of seeds is to ensure the diversity of the generated images. In the most original GAN papers, a multi-layer perceptron (i.e., MLP) was used to build generation models and discriminant models, and the specific structure is shown in
Figure 5.
The distribution of the generator and discriminator in the training process is shown in
Figure 6 (the generated data distribution is the blue line, and the real data distribution is the green line).
As shown in the figure above, the line trains the discriminator so that it can distinguish the real data from the generated data, and then trains the discriminator so that the distance between the generated data and the real data becomes smaller. After several rounds of training of the discriminator generator, we hope that the distribution of the generated sample and the real sample has been completely consistent. And the discriminator cannot tell them apart anymore.
As shown in
Figure 4, random noise
(each element of z is generally set as independent and equally distributed and subject to standard normal distribution or uniform distribution [0, 1]) is passed into generator
to obtain output distribution
. The distribution of real data is represented by
, and then the output distribution data
and real distribution data
are passed into discriminator 7
, respectively, to obtain the probability value of sample generation and the probability value of the real sample. The specific optimization objective function is as follows
where
represents the data distribution derived from real data, and
is equivalent to a sampling of noise data.
represents the discriminator’s expectation of the judgment result of the real sample. For the optimal discriminator D, the judgment result D(x) for the real sample should be 1, that is, log(D(x)) is 0; similarly,
represents the discriminator’s expectation of the spurious sample judgment result.
3.2.3. Wasseratein Generated Network Model (WGAN)
WGAN is the Wasseratein generation network model proposed by
Arjovsky and Bottou (
2017), whose core idea is to measure the distance between beam parts by Earth-Mover distance (also known as Wasseratein distance). Its advantage is that compared with KL divergence and JS divergence, even if the two distributions do not overlap, Wasserstein distance can still reflect their distance, which is exactly what will really happen under the condition of high dimension and insufficient sample sampling. Based on this, the loss function of the generator and discriminator in WGAN can be rewritten as:
where
represents a series of functions f that depend on the parameter w, which can be any function chosen, or a network model, where the parameter w is the set of parameters in the network.
satisfies the Lipschiz condition (a condition of smoothness stronger than uniformly continuous), namely
, where K is the Lipschiz constant and generally takes a value of 1.
Later,
Gulrajani et al. (
2017) added a penalty term to the discriminator loss function on the basis of WGAN to replace weight clipping in WGAN, which was widely adopted to overcome the situation of the poor weight clipping effect, and then obtained the discriminator loss function in the WGan-GP model, namely
where
represents the gradient penalty, which is used to constrain function
to meet the Lipschiz condition, and
represents the penalty distribution composed of the region of the generated data set, the region of the real data set and the region between them.
3.2.4. LSM Improved Model
Consistent with the discussion in the previous two chapters, the improved model of LSM mainly refers to the method mentioned in
Wiese et al. (
2020) and
Tan et al. (
2022), and uses the GAN model instead of the Monte Carlo method to generate simulation data and put it into the traditional LSM model, thus forming the improved model of LSM. The generator and discriminator of the GAN model both use the TCN model, so this part mainly analyzes the theory of time convolutional network.
4. Data and Empirical Analysis
4.1. LSM Pricing Model
4.1.1. Model Description
The research samples selected in this paper are bank convertible bonds. It can be seen from the issuance announcement of each sample that the trigger condition of call-back is the following: Only the holders of convertible bonds can trigger the call-back clause when they are identified by China Securities Regulatory Commission as changing the use of raised funds, so it cannot be quantified, so call-back clause is not considered in the model. Secondly, according to the inference in the literature of
Zhou and Wu (
2013),
Zheng and Lin (
2004) and the downward revision conditions of the special downward revision clause, it is found that the downward revision clause is equivalent to transferring the old shareholders’ equity to the investors of convertible bonds, which directly affects the original shareholders’ equity.
4.1.2. Sample Data and Descriptive Statistics
As can be seen from the total issuance volume in chapter one, the largest convertible bonds issuing scale in our country are usually banks. In addition, convertible bonds with a higher rating are usually issued by banks. Therefore, the sample mainly selects the existing bank convertible bonds on 20 January 2023, whose pricing date is the first day of listing, and conducts multi-node pricing on the Shanghai Pudong Development convertible bonds (through analysis of pricing results with other models), with the pricing range from 20 January 2022 to 20 January 2023, every 30 days as a node. The convertible bond price of each node is estimated, respectively.
4.1.3. Parameter Estimation
The first step of the LSM pricing model is to estimate the volatility of the risk-free interest rate and stock price. The following is the estimation process and results of the two parameters. In addition to that, other input parameters are set as follows: Monte Carlo simulation compensation is 252 trading days in a year, the number of simulations is 5000 times and the initial stock price selected is recorded as S0 on the day before the listing of convertible bonds.
- (1)
Risk-free interest rate
In the selection of risk-free interest rate, the maturity yield of ordinary bonds of China commercial banks with the same rating as the issuing subject is selected as the risk-free interest rate, which can consider the credit risk of enterprises on the basis of the risk-free interest rate, namely, credit spread.
- (2)
Stock price volatility
For the estimation of stock price volatility, the academic circle generally adopts the historical volatility estimation method and the GRACH model estimation method. The former uses the closing price data of the 252 trading days before the pricing date to estimate, while the latter uses the GARCH model to solve the unconditional stock price volatility, which is generally divided into four steps:
Descriptive statistics of the logarithmic rate of return of stock price;
Test the stationarity of logarithmic rate of return;
Autocorrelation and ARCH effect test;
GARCH model is used to estimate stock price volatility, and unconditional stock price volatility is obtained.
This paper refers to the research results of
Zhao and Zhao (
2009) and uses the GARCH model to solve stock price volatility. Next, take the Jiangbank Convertible Bond (128034.SZ) for example to illustrate the process of estimating stock price volatility as the following chart:
First of all, the logarithmic yields of the first 252 trading days of the CB were selected and visualized, as shown in
Figure 7, and the descriptive statistics were carried out, as shown in
Table 3 and
Table 4.
As can be seen from
Table 5, the Jarque-Bera statistic is 38.85,
p value is 3.7 × 10
−9, and H0 hypothesis is rejected, indicating that the return rate of logarithm of stock does not obey the normal distribution.
Then the second step is the ADF unit root test. The specific results are shown in
Table 6. It can be seen from the table that, at the significance level of 1%, the null hypothesis of the existence of unit root can be rejected, that is, the time series of logarithmic return rate of positive shares of unit root does not exist and is stable.
Furthermore, the ARCH effect test was conducted on the square sequence of residual errors in the mean value equation (see
Table 7). It can be seen that the Lagrange multiplier statistic is 27.649, the
p value is zero and the ARCH effect exists.
Finally, the GARCH (1,1) model is used to correct the volatility of stocks. According to the results of Stata, the GARCH (1,1) model of the stock volatility of the convertible bonds of Jiangbank can be obtained as follows:
Thus, according to the estimation formula
of the unconditional variance formula, the estimated value
of daily volatility can be obtained as 0.001145, which is converted into an annual volatility of 0.5372, shown in
Table 8.
4.1.4. Empirical Results
- (1)
Pricing results on the first day of listing
We use the pricing error rate formula mentioned in
Section 2 to evaluate the pricing results of the model, namely
Based on the LSM model and combined with the above estimated parameters as input values, the estimated first-day price, actual price and error rate of 17 sample convertible bonds simulated in Python are shown in
Table 9.
From
Table 9, we can see that the traditional pricing method has a certain deviation without considering the revised terms, and the maximum value of the error is within 20%. Among them, the deviation rate of the first day estimated price of five convertible bonds is more than 10%, with a maximum value of 19.42% and a minimum value of 0.52% of Nanyin convertible bonds. The overall mean absolute percentage error (MAPE) was 8.41%. In summary, these results show that the estimated results of the model are higher than the first-day prices of convertible bonds, indicating that the pricing function of the model needs to be improved.
- (2)
Multi-node pricing results within the duration
Consistent with the above, this paper compared with the pricing model in the following paper and selected the Pudong Development convertible bond with a relatively low error rate as an example to conduct multi-node pricing analysis. The pricing range was from 20 January 2022 to 20 January 2023, and the price of each node was estimated every 30 days, namely 12 nodes. Among them, stock price volatility and stock transfer price are updated every 30 days, shown
Table 10 below:
Figure 8 describes the LSM pricing results of the multi-node duration of Shanghai Pudong Development CB. It can be seen that the trend of estimated price and actual price is basically the same, and the trend of inflection point is earlier than the real situation. The deviation of pricing results is also mostly maintained within plus or minus 3%, meeting the pricing accuracy of the pricing error rate within 95%, and MAPE is 2.26%. Duration pricing results are excellent.
4.2. Long and Short-Term Memory Network (LSTM) Pricing Model
4.2.1. Model Description
The LSTM model is one of the most frequently used neural network models among the current series prediction models, and has excellent effects in natural language processing, series prediction and other aspects. This paper will use the modified model to predict the price of convertible bonds. The LSTM’s model super parameters are set as follows:
Step size in LSTM refers to the length of input sequence in the model, that is, the sequence length to be considered by the model during prediction. However, since LSTM is a supervised neural network model, a reasonable time step cannot be known before training, so it is necessary to set this parameter. The main task of the predictive pricing model of convertible bonds in this paper is to predict the price of the fifth trading day in the future, so as to avoid large errors in the future. In this paper, the experimental time step is set as 5 consecutive trading days.
- (2)
Hidden layer
In the process of multiple hyperparameter adjustment, it is found that the number of hidden layers and neurons of LSTM is set to 1 and 128, respectively, and the number of neurons in the two fully connected layers between the input layer and gate structure and the LSTM gate structure and output layer is set to 16 and 128, respectively.
- (3)
Activation function
In the neural network model, in order to improve the effect of the model, learn some nonlinear factors and prevent the neural network from falling back into a perceptron model after training for many times, an activation functions need to be added between layers. The activation function adopted in this paper is the ReLU function, whose expression is , representing the input value, and f(x) representing the output result.
4.2.2. Sample Data and Descriptive Statistics
As the data-driven modeling approach is inconsistent with traditional thinking, another modeling approach is adopted in this paper, that is, daily data of all maturing and unmaturing bank convertible bonds from 1 January 2010 to 20 January 2023 are selected for pricing analysis of convertible bonds. There are 25 convertible bonds in total, with a total of 18,134 sample values. Twenty-three of them were selected as training sets and the remaining two as test sets to test the pricing ability of the model (all data came from Choice financial data terminal).
In the test set, samples Zhongpu convertible bond and Jiangyin convertible bond were selected. The former had a total issuance of CNY 50 billion, was rated AAA at the time of issuance, and the issuance period was 6 years. The latter issued a total of CNY 2 billion, with a rating of AA+ at the time of issuance and a maturity of six years.
4.2.3. Data Preprocessing
In the following section, the input characteristic variables are preprocessed and converted into daily data that can be input.
- (1)
Quarterly financial data/monthly macro indicators
Generally speaking, the financial data referred by investors is delayed, and the financial data of the last quarter is generally released in the next quarter, so the data of this quarter adopts the data of the last quarter and adjusts the value at the beginning of each quarter. The same is true for the monthly macro indicators.
- (2)
Debt rating and subject rating
For debt rating and subject rating, AAA and AA+ in the sample are mapped as 1 for AAA and 2 for AA+ in this paper.
- (3)
Normalization
In order to increase the stability of model training and solve the dimensional problem between indexes, this paper carries out dimensionless processing on the original data. Generally speaking, dimensionless processing includes regularization, zero-mean standardization and min-max normalization. Referring to the method of previous scholars (
Tang et al. (
2020)), min-max normalization is adopted to de-dimensionalize data, namely
where
represents the feature data after normalization processing, min(
x) represents the minimum value of the feature data set, and max(
x) represents the maximum value of the feature set.
4.2.4. Empirical Results
There were 25 convertible bonds in the sample interval. In the experiment, Shanghai Development convertible bonds and Jiangbank convertible bonds were selected as test sets to verify the model pricing results. All the data in the training set were divided into several single samples with characteristics and label values according to the input sample requirements of LSTM, that is, the characteristic values of a single sample were 33 characteristic values of the past five trading days as the input of the model. The closing price of the convertible bond on the sixth trading day is used as the output of the model. Then, the samples from all training sets were divided into a training set and verification set in a ratio of about 3:1 (the number of training set samples was 10,000, and the verification set was 3670).
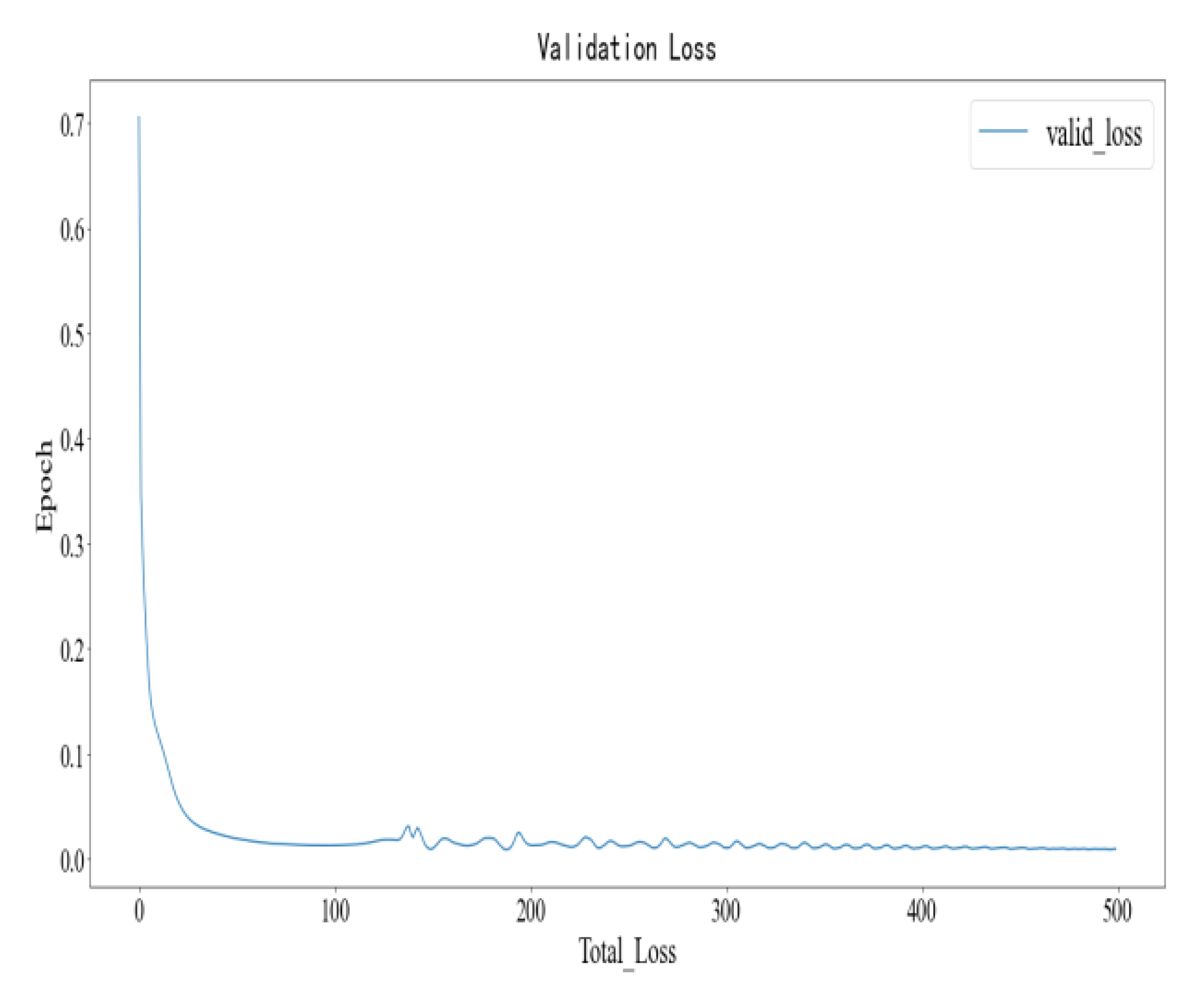
Figure 9 and
Figure 10, respectively, describe the loss change process of each round of LSTM in the training set and verification set, where the abscx axis represents the epoch of training rounds, with a total of 500 rounds of training; the ordinate represents the total training error of each round, namely the summary value of the mean square error of each round. It can be seen that when the training reaches about 20 rounds, the model can simulate the samples in the training set very well, that is, better parameters are obtained in the training set.
4.3. WGAN Pricing Model
4.3.1. Model Description
As explained in the theory part of
Section 2, WGAN, as a derivative model of basic GAN, inherits the advantages of the former, strengthens the training stability of the model and is widely used in the industry. Due to the special structure of the dual training model of WGAN, this paper refers to the modeling method of
Kang (
2019). It intends to use its discriminator to enhance the pricing effect of the generator model. The structure of the model is shown as follows in
Figure 11:
- (1)
Generator structure
As LSTM has many parameters, this section adopts the gated cycle unit structure (GRU) with faster computing performance as WGAN’s generator model, and uses Leaky ReLU as the activation function. The specific parameters are listed in the following table:
- (2)
Discriminator structure
Compared with traditional GAN, the discriminator of WGAN cancels the Sigmoid activation function of the output layer, resulting in the final output not being a value between 0 and 1. Instead, the W distance between the generated distribution and the real distribution is fitted, thus making the training of the model more stable. This paper chooses a multi-layer perceptron as the discriminator of the WGAN model and Leaky ReLU as the activation function. The specific parameters are shown in the following table:
Where
represents the function satisfying the Lipschiz condition, which is replaced by the discriminator network model in this paper,
represents the price sequence formed after adding the price generation result and
represents the real price sequence. In particular, according to the practice of
Arjovsky and Bottou (
2017), the training frequency ratio of generator and discriminator is 1:5, that is, the discriminator model trains the generator model once every five times.
4.3.2. Empirical Results
In this empirical study, it can be seen that the pricing effect of test sample 1 (Jiangbank CB) is better in the first 1000 trading days, but higher in the last 150 trading days. On the whole, the MAPE of sample 1 is 0.806%, which is slightly higher than the 0.763% of the LSTM pricing model. However, for test sample 2 (SPD CB), the results of
Figure 12,
Figure 13 and MAPE (0.231%) are both better than the LSTM pricing model (0.3% MAPE) and the traditional LSM model (2.25% MAPE for multi-node duration), indicating that the application of WGAN helps to improve the pricing effect of the model.
As can be seen from the above empirical results, the LSTM model and WGAN model have a better pricing effect, and the average absolute error of the two training samples in the test set is less than 1%, which fully meets the pricing requirements. In addition, both of the two models are data-driven pricing models, mainly based on the sample data to be learned, rather than relying on the preconditions in other models. They are able to mine the nonlinear relationship in the data and adapt to the real market environment.
Next, this paper takes the method mentioned by
Takahashi et al. (
2019) as reference and
Wiese et al. (
2020) and
Tan et al. (
2022) as reference, and uses Quant GANs proposed by
Wiese et al. (
2020) to replace Monte Carlo as the generation model of stock price series. In order to improve the pricing effect of the model, it avoids the premise assumptions in the traditional model and reuses the unique statistical characteristics of financial data, such as leverage effect, coarse-fine volatility correlation and the gain/loss asymmetry of financial time series.
4.4. Improved Model of LSM
4.4.1. Model Description
The improved model of LSM in this paper adopts the Quant GANs model proposed by
Wiese et al. (
2020) as the generation model of stock price series, thus avoiding the assumptions in the traditional model, and then prices the convertible bonds according to the traditional LSM pricing method. Quant GANs is a financial time series generation model proposed by
Wiese et al. (
2020) in 2019.
4.4.2. Empirical Results
The selection of samples is consistent with the traditional LSM pricing model, and the first-day pricing of 17 samples of continued bonds is carried out. Among them, the training sample of the Quant GANs model adopts the stock price data of 17 samples of bonds, and the sample interval is from 1 January 2010 to 20 January 2023, which is representative after several bull and bear markets.
In order to make a horizontal comparison with the pricing results of other models, this paper also adopts the Shanghai Pudong Development convertible bond for multi-node pricing. The pricing method is consistent with the above, and the node selection method is consistent with that described in
Section 4.1.4.
- (1)
Generate sequence authenticity evaluation index
From the comparison of the following groups of figures, it can be intuitively seen that, except for the leverage effect, the generated sequence reproduces the style characteristics of the real sequence. In addition, it can be seen from
Figure 14,
Figure 15,
Figure 16 and
Figure 17 that the Quant GANs model can generate a return sequence basically consistent with the real sequence.
- (2)
Pricing results of multi-node pricing within the duration
Consistent with the above, the multi-node pricing range of Shanghai Pudong Development convertible bonds is from 20 January 2022 to 20 January 2023, with 12 nodes every 30 days. The price of convertible bonds at each node is estimated, respectively, and the stock price volatility and stock price are updated every 30 days. Pricing results are shown in
Figure 18 below:
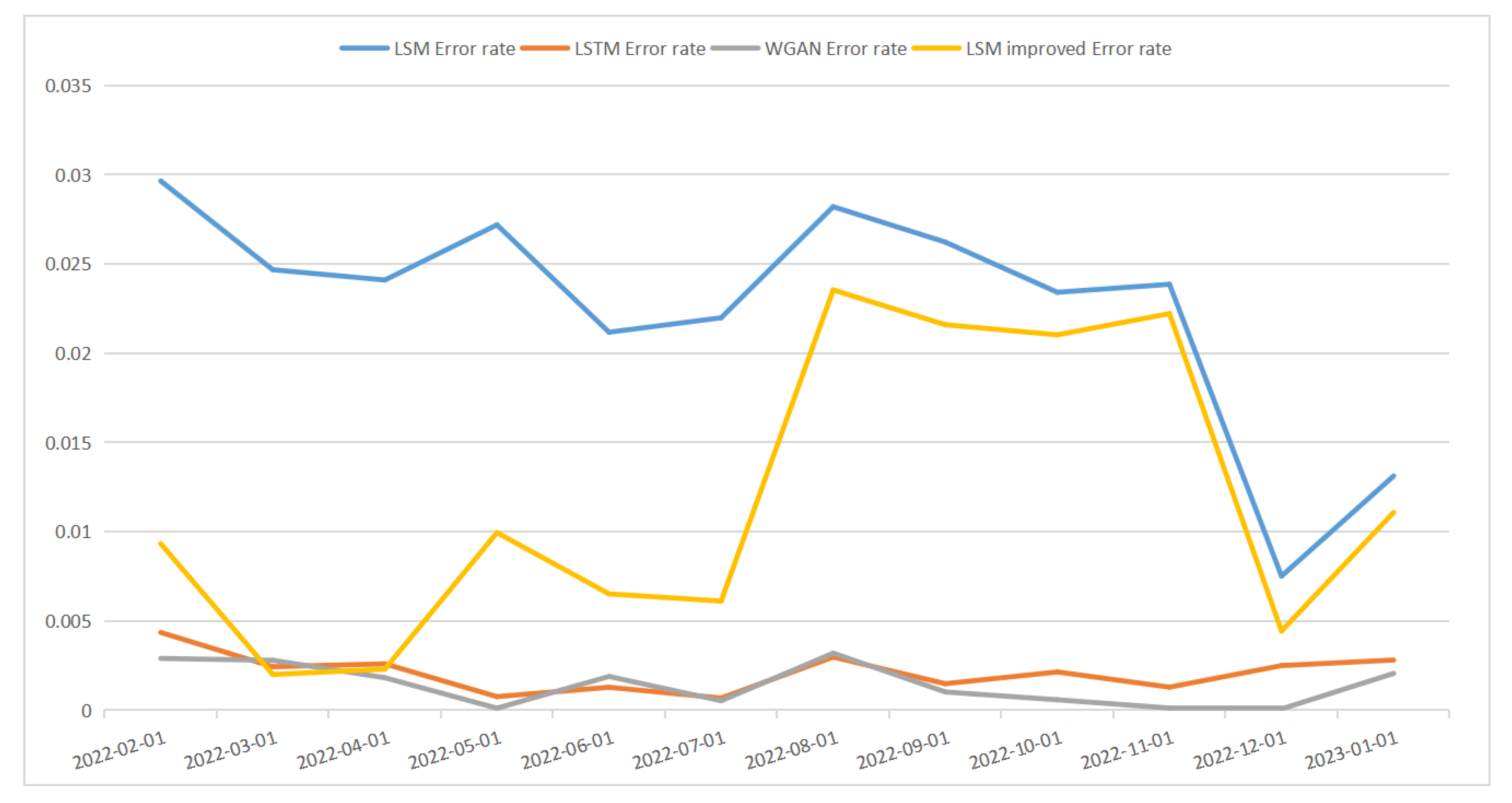
Table 11 and
Figure 19 show the pricing error rate of the four models, and the best pricing effect is the two deep learning models. From the perspective of the mean error rate, the pricing effect of WGAN (0.10%) is better than that of LSTM (0.13%), and the pricing effect of LSM’s improved model (−0.98%) is better than that of the traditional LSM model (−2.26%).
4.5. Comparative Analysis of Pricing Effect of Each Model
Due to the different pricing methods of each model, the scope of application of the model is also different. The traditional LSM can price convertible bonds at any time point, but the efficiency is low and the presupposition is not in line with the reality. The pure data-driven pricing model can achieve the purpose of improving the pricing effect by adding multiple characteristic variables describing the real situation. However, due to the model input problem, the price of the first day of listing of convertible bonds cannot be predicted. The improved model of LSM uses a data-driven approach to replace the generation of stock price trend sequence, so as to avoid the assumptions in the traditional model and meet the requirements that the generation sequence should meet the reality, but there are still requirements on the sample data of the underlying stock price of the convertible bond.
To sum up, this paper takes Shanghai Pudong Development Co., LTD as an example and uses error rate, MAPE and RMSE to evaluate the pricing effect of each model, as shown in
Table 12.
Table 12 summarizes the MAPE value of each pricing model and describes the overall pricing effect of the model. It can be seen that the two deep learning models still have the best overall pricing effect, and the pricing effect of WGAN (MAPE 0.14%, RMSE 0.1902) is better than that of LSTM (MAPE 0.21%, RMSE 0.2463), and the pricing effect of LSM’s improved model (MAPE 1.17%, RMSE 1.4895) is better than that of the traditional LSM model (MAPE 2.26%, RMSE 2.4699).
5. Conclusions
This paper adopts the traditional LSM pricing model, and selects 17 bank convertible bonds that still exist on 20 January 2023 as pricing samples. The pricing method is the first day of listing pricing. In addition, in order to compare with other models, the Shanghai Pudong Development convertible bonds with higher pricing accuracy on the first day of listing are selected as the pricing samples of multi-node pricing within the duration. The pricing range is from 20 January 2022 to 20 January 2023, and there are 12 pricing nodes every 30 days. In the two data-driven models, the daily data of all maturing and unmaturing bank convertible bonds from 1 January 2012 to 20 January 2023 were selected as the sample data, with a total of 25 samples, totaling 18,134 sample values. Among them, 23 were selected as training sets, and the remaining two were selected as test sets (Jiangbank convertible bonds and Shanghai Pudong Development convertible Bonds) to test the pricing power of the model. It is worth noting that the characteristic variables of each sample point are obtained from the macro environment, the fundamentals of listed companies, bond base, options, convertible bond trading data and clause design according to the existing literature.
The improved LSM model mainly uses the Quant GANs model proposed by previouse researcher and scholoars as the generation model of stock price series, thus avoiding the assumptions in the traditional model, and then prices the convertible bond according to the traditional LSM pricing method. The pricing sample is consistent with the traditional LSM pricing model. The first day of listing pricing of 17 sample bonds and the multi-node pricing of Shanghai Development convertible bonds within the duration were all conducted. Among them, the training sample of the Quant GANs model adopted the stock price data of 17 sample bonds. The sample interval was from 1 January 2010 to 20 January 2023, after several bull and bear markets; the samples were representative.
By sorting out the empirical results of each model, we reach the following conclusions:
- (1)
The traditional LSM pricing model has a large error in the first-day pricing, indicating that the pricing function of this model needs to be further improved;
- (2)
Among the four pricing models, the LSTM pricing model and WGAN pricing model have the best pricing effect. From the perspective of the MAPE index, the pricing effect of the WGAN pricing model (0.14%) is better than that of the LSTM pricing model (0.21%), and the pricing effect of the LSM improved model (1.17%) is better than that of the traditional LSM model (2.26%);
- (3)
Applying the generative deep learning model GAN to the pricing of convertible bonds can avoid strict assumptions and significantly improve the pricing effect of the traditional model.
Though there are some limitations of the existing research in this paper, the prospects for the future research direction are put forward also:
- (1)
The factors affecting the pricing of convertible bonds can be selected more accurately and the prediction accuracy of the model can be improved;
- (2)
Improve the Quant GANs model in the future, so that the generated samples can better reproduce the statistical characteristics of real sequences;
- (3)
In order to avoid model failure on new data, we need to update the model in time and adjust and improve it according to new market conditions.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}