1. Introduction
It is well established that a language learners’ first language (L1) influences the perception and production of speech sounds when learning second or additional languages (L2)
1, particularly in adulthood. This influence is not limited to the L1 sound system. It is importantly connected to literacy experience in the orthographic scripts of the known and target languages, as well as the relationship between the representation of sounds in the different orthographies (
Hayes-Harb and Barrios 2021;
Bassetti 2023). Due to the ubiquity of early exposure to writing in instructed language-learning settings, there is a need to understand how simultaneous written and spoken language learning impacts the development of L2 phonology.
In the last few years, both a comprehensive review (
Hayes-Harb and Barrios 2021) and the first monograph (
Bassetti 2023) dedicated to the effects of orthography on the acquisition of L2 phonology have been published. These important contributions present evidence of the persistent and pervasive influence of orthography across perception, production, lexical processing, and metalinguistic awareness, even after minimal exposure and into high levels of proficiency. These reviews demonstrate the ways that researchers are increasingly turning their attention to the varied manifestations of orthographic influence and what they reveal about underlying language learning mechanisms. Where earlier studies ask whether written input helps or hinders phonological acquisition, more recent efforts seek to understand the circumstances which determine positive, negative, and null effects.
Despite growing evidence that orthographic input is an influential factor in L2 phonological development, theoretical accounts of L2 speech learning and processing tend to focus on naturalistic contexts and infrequently reference written input. Where orthographic influence is mentioned, predictions assume alphabetic literacy in a shared script (
Tyler 2019). Similarly, empirical research has focused on investigating orthographic effects when both known and target languages share the same script, where references to the Latin alphabet
2 and English as the L1 or L2 dominate the existing literature (
Bassetti n.d.). In related fields, attention has been drawn to the lack of research into reading in languages other than English (
Share 2008,
2021) and bi-scriptal bilinguals (
Vaid 2022;
Vaid et al. 2022), who make up a large proportion of language learners and users around the world (
Cook and Bassetti 2005;
Pae and Wang 2022).
For example,
Vaid (
2022) highlights that China and India account for around 36% of the global population. Around 97% and 76% of these populations, respectively, are reported to be literate
3 and both countries employ bi-scriptal language education (e.g., the use of Romanised Pinyin for beginning literacy and digital communication in Mandarin Chinese). In fact, in India, there is a three-language policy, where children are educated in the regional language, as well as the national languages of Hindi and English (
Mishra 2019). Regional languages, such as Tamil, may be written in a different script from that of Hindi, meaning that many people are multi-scriptal. Thus, the number of bi- and multi-scriptal literate individuals from these two countries alone is likely to outnumber the combined populations of Europe and North America, which account for only 15% of the global population.
These global statistics mostly refer to literacy development in different writing systems during childhood. However, childhood multi-scriptal language and literacy development differs in numerous ways from that of adult L2 contexts. While the impact of acquiring multiple orthographic scripts in childhood also deserves greater academic attention (
Share 2021;
Vaid 2022), it is beyond the scope of the present discussion. The relevance of these global statistics here is to highlight biases in second language research and challenge assumptions related to the literacy experience adults bring from their known languages to additional language learning. For example, over 1 million people in China and around 35,000 people in India were reported to be learning Japanese in 2021 (
Japan Foundation 2023). Thus, from this small example, it is clear many individuals, with diverse literacy experiences, are learning languages across distinct scripts and writings systems.
The importance of addressing the underrepresentation of diverse spoken and written languages relates to theoretical, ethical, and pedagogical concerns, increasingly articulated within the second language research community. For example, researchers are questioning the extent to which predominantly university student samples, often from Linguistics or Psychology programmes in North America and Europe, can offer insight into adult language learning more broadly (
Plonsky 2023;
Andringa and Godfroid 2020;
Shepperd 2022;
Leung n.d.). The urgency of addressing such biases relates to the generalisability and validity of both empirical findings and theoretical constructs.
Calls have also been made for more just and equitable research, particularly in psycholinguistics where a focus on “normality” has led to entrenched ideals around monolingualism and native-speakerism, with marginalising effects on large language communities (
Kutlu and Hayes-Harb 2023). Additionally, while not at all recent, it is acknowledged that under-researched learners are likely to be underserved, and potentially harmed, by the inappropriate application of overgeneralised findings (
Ortega 2005;
Bigelow and Tarone 2004). Therefore, it is important to look beyond language learning involving English and the Latin alphabet, to broaden our understanding of orthographic effects on L2 phonology, and to develop appropriate pedagogical approaches for learners from diverse language and literacy backgrounds.
The purpose of the present paper is to draw together the limited, but increasing, research exploring cross-scriptal orthographic influence on L2 phonology, with the intention of inspiring a higher quantity and quality of research on this topic. In particular, theoretical and methodological innovation is called for. The theoretical grounding for the field of orthographic influence on L2 phonology is broadly underdeveloped. Further, issues mentioned relating to sampling bias, monolingual norms, and the underrepresentation of large groups of language learners are prevalent. As such, novel approaches are needed to move the field forward and establish a robust evidence base.
Initially, dominant models of L2 speech learning are outlined, highlighting speculative insights into predicted orthographic effects. Key concepts relevant to L2 acquisition across writing systems are then defined, followed by an introduction to current understandings of orthographic influence on L2 phonology. The focus of the paper is a review of empirical research investigating L2 phonological acquisition across diverse orthographic scripts. Studies investigating orthographic effects with entirely unfamiliar written input are discussed separately from those with experienced language learners, to better understand the influence of proficiency and literacy experience. The discussion centres around preliminary findings, the need to refine terms, methodological limitations across the field, and routes for future research.
2. Models of L2 Speech Learning
Adult L2 learning is characterised by a variability in ultimate attainment that is strikingly distinct from language learned in typically developing children. This is particularly pronounced regarding phonological development, where mastering foreign sounds is notoriously problematic for those learning languages outside of childhood (
Flege et al. 1999;
Moyer 2013;
Singleton and Ryan 2004). Well-known difficulties include the “rocket” and “locket” distinction for Japanese speakers (
Aoyama et al. 2004) or “bet” and “bat” for Dutch speakers (
Broersma 2005). It is not suggested that the ideal outcome of adult language learning is to entirely lose an accent or achieve native-like proficiency (
Bialystok 2001;
Cook 1999). However, sufficiently precise phonological representations are crucial for effective communication, to both comprehend and be comprehended (
Flege 1991;
Flege et al. 2003;
Gathercole and Baddeley 1993;
Hamada and Koda 2008).
Several theoretical models have been proposed to account for the factors and mechanisms involved in L2 speech learning, typically focusing on perception or production at different stages of language development. The two most widely cited models are the Perceptual Assimilation Model (PAM) (
Best and Tyler 2007;
Tyler 2019;
Best 1995) and the Speech Learning Model (SLM) (
Flege and Bohn 2021;
Flege 1995), which have been revised in the form of PAM-L2 and SLM-r, respectively. These models both emphasise the perceptual basis of L2 speech learning and make predictions about the difficulty of categorising L2 phonological segments based on cross-linguistic influence from L1 categories. However, they differ in their assumptions, aims, and predictions.
The Perceptual Assimilation Model (
Best 1995;
Best and Tyler 2007) focuses on the earliest points in language exposure, investigating naïve listeners’ perception of nonnative speech and taking a direct realist perspective. The principal predictions of PAM relate to different assimilation patterns and their associated difficulties, depending on the relationship between the L1 and the target phonological contrasts. For example, the easiest contrast to acquire would follow a two-category (TC) assimilation pattern, where each sound within a target phonological contrast assimilates clearly to two sounds within an existing contrast in the L1. Single-category (SC) assimilation is then predicted to cause the most problems for perception, occurring when two target categories are perceived to be equally good or poor examples of the same L1 category. For example, L1 English learners of a language which contrasts the nasal stops /m/ and /n/ face little difficulty with this distinction, as each sound is assimilated to two separate L1 categories. Meanwhile, distinguishing the bilabial plosive-implosive contrast /b/ and /ɓ/, found in several languages, causes far more difficulty, as English speakers assimilate both to the L1 /b/ category.
Assimilation patterns and their predicted difficulties are also detailed for category-goodness (CG), uncategorised–uncategorised (UU), uncategorised–categorised (UC), and non–assimilable patterns. The CG fit can be exemplified by English learners of the /t-tˤ/ distinction in Arabic, where both are assimilated to the L1 /t/ category, but /t/ is perceived to be a better fit than /tˤ/. The Arabic /ћ-h/ contrast illustrates a UC scenario, where /ћ/ does not easily assimilate to existing L1 categories, whereas /h/ is assimilated to the equivalent category in English. Then, the distinction between /ћ/ and /χ/ would be an example of UU contrast, where neither of the sounds are perceived to be a good fit for any L1 categories. The discrimination of CG contrasts is predicted to be moderate to very good, whereas UC contrasts are predicted to be very well discriminated. UU contrasts, then, prove more or less difficult depending on their proximity to partially similar L1 phonemes. PAM-L2 then extended model predictions from naïve listeners to L2 learners (
Best and Tyler 2007), highlighting differences in attentional focus based on learner proficiency, context, and goals.
The Speech Learning Model (
Flege 1995) focuses on L2 production and the developmental trajectory of language learning across the lifespan, particularly ultimate attainment. Similarly to PAM, SLM proposes a cross-linguistic equivalence classification, where the L1 and L2 categories exist in a shared phonological space and L2 speech errors relate to perceptual bias. However, SLM focuses on individual sounds rather than contrasts, and their representations in long-term memory. Additionally, this equivalence classification is based on statistical distributional properties of the L2 input. Overall, SLM predicts that, as phonetic dissimilarity increases between L1 and L2 sounds, the easier it will be to perceive a cross-linguistic distinction and form a new target-like category. Accordingly, the easiest sounds to perceive are
old or existing sounds, which require no additional learning to perceive or produce. The most challenging scenario would involve learning
similar sounds to those of the L1 categories (e.g., /u/ for English learners of French), where L1–L2 composite phonetic categories are predicted to develop. Better outcomes are predicted for
new sounds, which are understood to be perceptually dissimilar from the closest L1 category (e.g., /y/ for English learners of French).
Several researchers have drawn attention to the lack of reference to orthographic influence within these models (
Mok et al. 2018;
Nimz and Khattab 2020;
Bassetti 2017;
Bassetti et al. 2018;
Rafat and Stevenson 2018). The focus on naturalistic language learning partially explains the absence of any formalised role of orthography in PAM and SLM, as the large quantity and early exposure to written language is supposedly less of a central concern. However, naturalistic language learning studies have also demonstrated orthographic effects on L2 phonology (
Young-Scholten and Langer 2015;
Stoehr and Martin 2022). It is likely that, both inside and outside of classroom settings, literate adult L2 learners draw heavily on written sources of linguistic input throughout their language development. However, there is limited evidence to draw upon to understand differences in the quantity and modality of input for adult learners in instructed versus immersion L2 settings.
A preliminary contribution to address the theoretical gap has been offered by
Tyler (
2019), who speculatively explored PAM-L2 in relation to instructed environments, including the mention of alphabetic written input. Tyler states that alphabets may help learners tune into acoustic distinctions, when they are clearly signalled. However, when orthography does not systematically and congruently signal a phonological difference, it may reinforce incorrect perceptions of equivalence. Thus, the difficulty posed by an SC assimilation pattern is likely to be exacerbated. Tyler offers a starting point for understanding how L2 speech learning models can be extended to include orthographic effects. Still, formalised accounts and empirical testing are required, including the consideration of a greater variety of writing systems.
3. Writing Systems, Scripts, and Orthographies
While there are around 7000 spoken languages in use, there are only a few hundred orthographic scripts currently recorded (
“Languages of the World” n.d.)
4. This is partly because one script may be used to represent numerous spoken languages (e.g., the Latin alphabet). Additionally, there are many languages that are exclusively spoken, without written representation. Despite written communication being one of the most celebrated human inventions (
Brookes 2023), it has been the focus of surprisingly limited linguistic investigation. Compelling arguments have been made by linguists, such as Saussure and Bloomfield, emphasising that writing and speech should not be conflated and that speech should constitute the primary object of study (
Coulmas 2013). Indeed, Bloomfield is often cited in textbooks, arguing “writing is not language, but merely a way of recording language by means of visible marks” (
Bloomfield 1933, p. 21). However, it was partly because of the influence of writing on spoken language and the importance often attributed to written representation that these thinkers were driven to disentangle modalities. It was not the case that they believed writing to be entirely separate or unimportant.
More recently, applied- and psycho-linguists, particularly in the field of reading research, have made substantial contributions to knowledge around written languages, including specific references to L2 acquisition (
Cook and Bassetti 2005). Before further discussing the relationship between spoken and written languages in L2 contexts, it is necessary to define what is meant by a writing system, an orthographic script, and an orthography. Writing systems here refer to the way in which the units of a language are represented by graphic elements. For example, alphabets and syllabaries are distinct writing systems, each connecting different units of language to a visual symbol. Scripts refer to the particular graphic representations of a writing system, such as the Latin, Greek and Cyrillic alphabets. Orthographies are then the language-specific mappings of a script, where the same graph in a shared script may map distinctly for individual languages (e.g., Dutch and Spanish orthographies, which are both in the Latin alphabet). Other important considerations include spacing, punctuation, and the direction of writing.
Alphabetic languages represent individual consonants and vowels with graphemes, and vary by level of consistency. The consistency between grapheme–phoneme correspondences (GPCs) in alphabetic orthographies is often described with reference to the Orthographic Depth Hypothesis (
Katz and Frost 1992). An orthography with one-to-one GPCs is considered to be ‘shallow/transparent’, while one-to-many GPCs would indicate a ‘deep/opaque’ orthography. For example, English has a notoriously deep orthography
5 (<thought>—/θɔːt/, <though>—/ðəʊ/
6), whereas Spanish has a shallow orthography (‘to think’ <pensar>—/pensaɾ/). To further illustrate the differences between systems, scripts, and orthographies, English and Spanish are both represented with alphabetic writing systems, and share the Latin script. However, the orthographies of the languages differ in their GPCs. Not only do they vary in the consistency of their representations, but a symbol shared by both orthographies can represent a different sound in each language (e.g., <v> corresponds to /v/ in English but /b/ in Spanish).
Examples of other writing systems include morphemic
7 scripts, such as Chinese characters, which denote units of meaning through combined semantic and phonetic components. Syllabaries, like Japanese hiragana and katakana, visually denote syllables. Abjads, such as those found in Arabic, Hebrew, and Persian languages, predominantly represent consonants. Meanwhile, abugidas or alphasyllabaries, which are common in South and Southeast Asian languages, represent a consonant and vowel together with a single written unit. The Korean hangul script is debatably alphabetic and syllabic, in the sense that individual phonemes are represented with individual graphemes, but these letters are then spatially displayed in units corresponding to syllables. Thus, writing systems vary in the level of phonology that they represent, as well as mix levels and vary in their consistency of representation (
Verhoeven and Perfetti 2017). These varying grainsizes and consistencies of written representations are then said to influence the rate and processes of developing literacy in both L1 and L2 acquisition, as well as levels of phonological awareness (
Seymour et al. 2003;
Ziegler and Goswami 2005;
Goswami and Bryant 2016;
Koda 1989;
Cook and Bassetti 2005).
It is important to acknowledge that orthography does not fully represent phonology. Alphabetic scripts can offer good insight into the phonemic repertoire of a language, yet arguably “the rest of the phonological information that L2 learners need to acquire is hardly available from reading at all” (
Cutler 2015, p. 123). While there are exceptions, languages rarely denote sentence prosody, lexical prosody, phonotactics, casual speech processes, and lexical tone orthographically, with most of this information needing to be encoded based on listening experience. This is of little concern when initially learning languages as children. For hearing individuals, the first point of contact with language is typically auditory, and language-specific perception is attuned early in development (
Piske and Young-Scholten 2008;
Werker and Tees 1984), before literacy is acquired. In stark contrast, learning languages later in life involves making sense of novel linguistic input through established knowledge of both the phonology and orthography of known languages. Additionally, orthography represents more than phonology, reflecting linguistic, historical, and cultural contexts (
Venezky 2005;
Huettig et al. 2018). With these points in mind, the need to consider the role of written input and literacy, specifically in L2 contexts, is underscored by the quantity and timing of written input dominating instructed settings.
4. Orthographic Influence on L2 Phonological Acquisition
In the introduction to this paper, two significant publications were highlighted for their comprehensive reviews of the growing research into orthographic influence on L2 phonology, namely those by
Hayes-Harb and Barrios (
2021) and
Bassetti (
2023). This section outlines the key contributions from each publication and uses them to draw together the existing evidence base, in order to provide context for the subsequent discussion of cross-scriptal orthographic effects on L2 phonology.
Both publications draw attention to the dominance of research into orthographic influence on phonology with alphabetic languages. Reflecting the majority of research to date,
Bassetti (
2023, n.d.) intentionally focuses on languages written in an alphabetic writing system and predominantly where English is being acquired as a second language. Her research offers an overview of the established types and causes of orthographic effects across shared scripts and emphasises findings from active L2 learners and users over naïve participants, who have never previously encountered the target language. This work is complemented by that of
Hayes-Harb and Barrios (
2021), who focused on four key variables which appear to moderate the effects of written input, namely systematicity, congruence, familiarity, and perceptibility. These factors are detailed below, drawing on evidence from both active L2 learners and naïve participants. While the overrepresentation of alphabetic languages and the inclusion of English remains apparent, a wider variety of writing systems and languages are found in the reported studies by Hayes-Harb and Barrios.
Additions, otherwise known as epenthesis, occur when a sound is added based on the orthographic form, either because a learner pronounces a ‘silent’ letter (e.g., learners of English pronouncing the <e> at the end of <make>), or by adding vowels to facilitate the production of all graphically represented sounds in a complex consonant cluster (
Young-Scholten 2002;
Detey and Nespoulous 2008). Learners also omit, or delete, sounds from the phonological form when they are not orthographically represented (
Bassetti 2006;
Pytlyk 2017) (e.g., the deletion of the vowel from /iou/ when not represented in Pinyin <iù> for learners of Mandarin). Substitutions occur when the orthography leads learners to replace a sound based on the spelling (e.g., English learners of Spanish pronouncing <v> as [v], rather than [b]), which is the most frequently reported example of orthographic interference (
Young-Scholten 2002;
Young-Scholten and Langer 2015;
Bassetti and Atkinson 2015;
Bassetti et al. 2018,
2020;
Han and Kim 2017;
Hayes-Harb et al. 2010;
Hayes-Harb et al. 2018).
Notably, several studies report both facilitative and inhibitory effects, such as faster word learning but less accurate production (
Bürki et al. 2019;
Cerni et al. 2019;
Uchihara et al. 2022), as well as varying accuracy depending on the sound (
Escudero and Wanrooij 2010;
Escudero et al. 2014) or different dimensions of the same sound (
Nimz and Khattab 2020). Ultimately, these effects of orthography manifested in perception and production are understood to reflect the influence of orthography on the L2 phonological representations of learners and the co-activation of orthographic representations during L2 spoken-word processing.
Approaching the topic from an alternative perspective, the mediating variables proposed by
Hayes-Harb and Barrios (
2021) echo the types and causes of orthographic effects on L2 phonology outlined by (
Bassetti n.d.). However, their approach offers greater clarity and relevance for the present discussion of cross-scriptal orthographic influence. First, systematicity refers to the extent to which a learner can rely on orthographic information to make accurate inferences about the phonological form of words, including the ideas related to orthographic depth outlined in the previous section (
Katz and Frost 1992). Systematic written representations can facilitate the acquisition of confusable L2 phonological contrasts (e.g., the <e-a> spelling of the confusable /ɛ-æ/ distinction for Dutch learners of English) (
Escudero et al. 2008). Meanwhile, unreliable mappings can lead to non-target productions, such as the various pronunciations of <ough> in English, as in ‘cough’, ‘tough’, ‘though’, ‘thought’, and ‘through’. Systematicity also relates to a learner’s existing linguistic experience and orthographic knowledge, where the effects of written input can differ depending on the orthographic depth of the learner’s first language (
Erdener and Burnham 2005).
While systematicity captures the reliability of written representations within a single orthographic system, congruence relates to the consistency of GPCs between different languages sharing the same script. When shared letters congruently map to the same sounds across languages, this can facilitate the acquisition of the phonological form of a novel lexical item. Meanwhile, incongruent mappings of a shared letter to distinct sounds is one of the most widely reported negative influences of orthographic input (
Hayes-Harb et al. 2010;
Escudero et al. 2014;
Rafat 2016). This relates to the substitution example given above, where <v> is a shared letter between English and Spanish, but maps to /v/ in English and /b/ in Spanish, often leading to non-target production for L2 learners.
The familiarity of the L2 orthography is a related consideration, defined as graphemes which are familiar to learners from the L1. Unsurprisingly, the facilitative effects reported for congruent orthographic input are found where learners are already familiar with the target script. The idea of familiarity is easily applied to studies with shared scripts or naïve participants, with no experience in the target language or its writing system (
Showalter and Hayes-Harb 2015;
Jackson 2016;
Hayes-Harb and Cheng 2016;
Showalter and Hayes-Harb 2013). However, it is less clear how this concept relates to learners with varying script familiarity and literacy experiences across writing systems. Some studies have looked at degree of familiarity, based on similarity between L1 and L2 graphemes in Latin and Cyrillic scripts (
Mathieu 2016;
Showalter 2018) and L1 English speakers’ L2 experience in Russian and Mandarin (
Showalter 2020;
Hao and Yang 2021;
Hayes-Harb and Hacking 2015). However, it continues to be difficult to tease apart script familiarity from broader L2 proficiency, and the overrepresentation of L1 English monolingual samples is noteworthy.
The final variable to consider is the perceptibility of the target L2 phonology. There is evidence that orthographic input can provide visual analysis to aid the discernment of contrasts that are difficult to acoustically perceive. For example, a nonnative contrast may be lexically encoded with the support of written forms where it would otherwise be encoded as homophonous (
Escudero et al. 2008). Additionally, orthography can promote more target-like productions of difficult nonnative sounds (
Rafat 2015). However, there is also evidence that orthographic input only enhances what learners are already able to perceive (
Escudero et al. 2014). Indeed,
Cutler (
2015) claims that, even if orthographic input facilitates the establishment of a phonological contrast in lexical representations, there may be other difficulties depending on perceptual development, as stored forms may not map well to the perceptual processing of the speech signal. Thus, orthographically encoded distinctions in lexical representations do not necessarily improve a learner’s ability to perceptually detect the phonemic distinction within an unfolding acoustic signal. With the key variables of systematicity, congruence, familiarity, and perceptibility in mind, the next section discusses empirical evidence of cross-scriptal orthographic influence in more detail.
5. Cross-Scriptal Orthographic Influences
Despite the global prevalence of L2 learning across different writing systems and scripts, there is limited research on the topic in relation to phonological learning. Considering the evidence discussed so far, the widely-reported inhibitory effects of written input related to incongruence between shared scripts are unlikely to extend to learning across distinct scripts. It stands to reason that cross-scriptal orthographic input may hold additional benefits for L2 phonological learning, assuming that written input systematically represents the target phonology. However, it is unclear to what extent learners need to be familiar with a new script in order to take advantage of its visual cues, and how this then relates to the perceptibility of the target language.
Preliminary insights are offered from a growing collection of empirical studies, with a focus on learners’ experience with the target language. Acknowledging that active L2 learners and naïve participants’ motivations, processes, and strategies likely differ (
Bassetti n.d.), these two groupings are discussed separately in the subsequent sections. This distinction is also crucial for understanding the role of proficiency and how to operationalise ‘familiarity’ as a variable in this emerging line of enquiry. The studies from both groups are summarised in below, including their methods and key findings. Effect sizes are provided where they are reported or where it is feasible to calculate them from other reported statistics. They are not further analysed, such as in the form of a meta-analysis, due to the heterogeneity of the studies, particularly with experienced learners. Thus, caution is recommended when comparing studies and interpreting general findings. However, two central points of discussion are illustrated by reporting these values. Firstly, strong cross-scriptal orthographic effects on L2 phonology are evidenced and deserve further investigation. Secondly, methodological rigour and innovation are needed in future research to assess whether the strength of these effects can be replicated with larger and more diverse samples.
Throughout the discussion of these studies, the terms ‘shared’ and ‘distinct’ are used to express the extent to which scripts overlap, and are likely to activate GPCs from a learner’s first or known languages. To illustrate the application of these terms and their relation to other constructs, such as congruence,
Figure 1 provides an example of Ukrainian words in the Cyrillic script. English spelling is used as a point of comparison here, as it is an assumed common language of the readership of this article. These words demonstrate that, while the Cyrillic and Latin alphabet are overarchingly distinct scripts, there is overlap in visually similar graphemes. These overlapping graphemes may then be congruent or incongruent with L1 GPCs, across shared scripts, which is not the case for visually distinct graphemes. For example, the Cyrillic letter <т> visually overlaps with the capital letter <T> in the Latin alphabet, which commonly and congruently maps to /t/ across languages that use both scripts. In contrast, the Cyrillic letter <p> visually overlaps with <p> in the Latin alphabet, but maps to the phoneme /r/ rather than /p/, thus introducing an incongruence between GPCs.
Figure 2 presents an example from Mandarin, demonstrating how different orthographic representations may be shared or distinct from L1 orthography, both in a script and a writing system. Mandarin is commonly denoted using traditional or simplified Chinese characters, depending on the region (e.g., simplified characters are used in Mainland China, whereas traditional characters are used in Taiwan). Additionally, transparent phonographic representations of Mandarin have been developed to support both L1 and L2 beginner learners of Mandarin. As mentioned in the introduction, one script is Romanised Pinyin, which is widely used in Mainland China and Singapore. Another script is Zhuyin (also known as ‘Bopomofo’), which is used in Taiwan and is an alpha-syllabary based on Chinese character components.
In this scenario, English learners of Mandarin may be negatively impacted by Pinyin graphemes, which are shared but incongruent with English GPCs. Issues around incongruence are avoided with distinct Zhuyin and characters, which then differ in the systematicity of their mappings to Mandarin phonology. Zhuyin offers a transparent phonological representation, whereas morphemic characters are considered more phonologically opaque. Instead, the characters offer more cues about the meaning of words (e.g., <知>—“to know” and <觉>—“feelings” in
Figure 2 (
Hao and Yang 2021)
8), which can be particularly useful considering the amount of homophony in Mandarin. The extent to which learners are likely to be influenced by distinct script inputs is then anticipated to depend on L2 proficiency and how familiar learners are with the script of the target language. The following sections first present findings with naïve participants, followed by experienced learners.
6. Naïve Participants
Initial psycholinguistic explorations into cross-scriptal orthographic influence focus on early exposure studies with naïve participants, often L1 English speakers. The aim of these studies is to discover whether entirely unfamiliar written input influences the lexical encoding of nonnative phonological contrasts. Intuitively, it seems unlikely that written input in an unfamiliar script would provide a useful visual aid when developing mental representations of a nonnative phonological contrast. These studies test this assumption, particularly in comparison to audio-only input and familiar-incongruent written input, in order to understand both the direction and extent of any influence.
Much of this work has been conducted by Hayes-Harb and colleagues, investigating the role of script familiarity on the lexical encoding of nonnative contrasts, across Arabic, Russian, and Mandarin Chinese. The first series of studies investigated orthographic influence on the lexical encoding of nonnative contrasts by naïve L1 English learners of Arabic pseudowords (
Showalter and Hayes-Harb 2015;
Mathieu 2016;
Jackson 2016). These studies followed the same basic word learning procedure, involving around six minimal pairs of Arabic pseudowords. Participants were presented with the auditory form of the word, matched with a familiar image, and the written form of the word, depending on the written input group. After four randomised exposures to each of the items, participants completed a criterion test. During the criterion test, participants heard the words accompanied by the images they had learned, and had to indicate whether the word and image matched. Half of the items matched and half mismatched with a non-minimal pair word (e.g., [kubu] vs. [qaʃu]). If participants scored above 90% correct, they moved on to the testing phase. The testing phase was identical to the criterion task, except the mismatch trials involved the audio from the minimal pair item (e.g., [kubu] vs. [qubu]), to test whether the target contrast had been encoded or whether participants had encoded items as homophonous.
These studies have yielded mixed results (see
Table 1).
Showalter and Hayes-Harb (
2015) found no significant difference between audio-only and Arabic script input groups, including additional testing with explicit instruction, or comparing training and testing with one or two different speakers. Partial eta-squared (η
p2) effect sizes from the ANOVA results, reported in
Table 1, indicate that effect sizes are also generally small. For reference, common benchmarks for interpreting partial eta-squared values are 0.01, 0.06, and 0.14 to indicate small, medium, and large effects, respectively (
Cohen 1988;
Norouzian and Plonsky 2018;
Richardson 2011). There was a large effect for the improved performance with the unfamiliar Arabic script when items were taught and tested with the same single speaker, rather than with two different speakers. Although, this was only the case for speaker-1 and not speaker-2. Overall, there was no evidence that unfamiliar written input was advantageous in comparison to audio-only input when encoding the nonnative contrasts. These findings may reflect the low perceptibility of the velar-uvular /k-q/ contrast for L1 English speakers, or could be related to the small sample sizes.
A significant difference between groups, with a large effect size, was found when comparing familiar Roman script inputs to Arabic and audio-only groups. Due to comparison between unequal sample sizes, a Mann–Whitney U test was conducted for this comparison, without reporting effect size. Therefore, a probability of superiority (Ps) value was calculated to estimate the effect size based on the reported sample sizes and the U statistic in R. Ps values closer to 1 or 0 indicate larger effects, whereas values closer to 0.5 indicate overlaps and smaller effects. Against predictions that the Roman script group would have less difficulty with the task, this group performed worse than the other orthographic condition groups. As well as the difficulty of the target contrast, the authors consider it likely that there was L1 orthography-induced transfer, as <k> and <q> can both map onto /k/ in English (e.g., “king” and “queen”), encouraging spurious homophony.
Mathieu (
2016) went on to explore the effect of varying degrees of script familiarity. This was measured by comparing audio-only, Arabic script, Cyrillic script, and hybrid (Cyrillic + Roman) script conditions, when learning pseudowords differing by the Arabic uvular-pharyngeal /χ—ћ/ contrast (e.g., [χal]—<خال>, <xaл>, <жal>). As with the design of
Showalter and Hayes-Harb (
2015), it is useful to attend to d-prime (
d′) scores, which measure the ability to distinguish a signal from noise and clarifies the extent to which participants are able to detect the nonnative phonological contrast (e.g., by both accepting match trials and rejecting mismatches). Comparison of the different script condition
d′ scores revealed that performance was significantly worse with the entirely unfamiliar Arabic script and the partially unfamiliar Cyrillic script compared to audio-only input, where the effect was large and moderate for each input condition, respectively. The difference between the audio-only and hybrid-script input conditions was only approaching significance but was still accompanied by a moderate effect size. Thus, it appears that degree of unfamiliarity and overlap with L1 scripts deserves greater exploration, as well as evidence that entirely unfamiliar written input may have an inhibitory influence.
A positive influence of unfamiliar written input was suggested by
Jackson (
2016), who reported a strong advantage for learning pseudowords differing by the /k-q/ contrast with a novel grapheme (<k-л
9>) over an additional diacritic (<k-̣k>). The strength of this effect may relate to the visual similarity in the diacritic condition, especially for English speakers who are not used to attending to diacritics for lexical distinctions. The significant influence of instruction for the diacritic group may further indicate that participants needed attention to be explicitly drawn to the diacritic. Despite the advantage of a novel grapheme over a diacritic, as there is no audio-only condition for comparison, it remains unclear the extent to which these findings reflect a broadly supportive role of unfamiliar written input. Indeed, the novel grapheme accuracy in this study is comparable to the results reported in
Showalter and Hayes-Harb (
2015) for the Arabic script input and audio-only condition with a single speaker, thus offering limited evidence of a real advantage.
Issues of perceptibility and the compounded difficulty of simultaneously encoding unfamiliar phonological and orthographic information inspired an additional adaptation of this study design.
Shepperd (
2018) investigated the acquisition of 16 Arabic pseudowords, differing by either native (/s-z/ and /m-n/) or nonnative (/k-q/ and /x-ɣ/) L2 contrasts, across audio-only, English script, and Arabic script conditions. This study aimed to discover whether the previously reported null or inhibitory influence of entirely unfamiliar written input would be evidenced in the lexical-encoding of both native and nonnative L2 contrasts. The matching task also integrated a visual world eye-tracking element, as well as additional perception and production tasks.
In line with
Mathieu (
2016), lexical encoding accuracy was worse with any orthographic input compared to no orthographic input, and this effect was particularly strong for the nonnative contrast items. Further, no advantage was found for the Arabic script condition, for either lexical encoding or production accuracy. Meanwhile, familiar–congruent orthographic input improved lexical-encoding accuracy with the native contrast words, and generally supported target-like productions for both native and nonnative contrast items. Eye-movement data also implied a disadvantage for Arabic orthographic input, through less-focused visual attention. The high discrimination accuracy of both native and nonnative contrasts suggested that perceptual difficulty associated with the nonnative contrasts likely reflected the quality of the phonological representation rather than the ability to discriminate the sounds.
Showalter (
2018) also sought to understand the influence of cross-scriptal orthographic influence as separate from issues of perceptibility. Her research examined L1 English speakers learning Russian pseudowords, differing only by native contrasts, accompanied by Cyrillic script input. The script input was either unfamiliar, familiar–congruent, or familiar–incongruent with L1 GPCs. As demonstrated in
Figure 1, Cyrillic offers the opportunity to manipulate both familiarity and congruence, as some letters overlap with the Latin alphabet, while others are entirely different.
Showalter (
2018) found that L1 English speakers were able to perform with near-ceiling accuracy in an audio–image-matching task, except with familiar–incongruent items (e.g., <PAT>—[rɑt]). Thus, incongruence was a pervasive effect, regardless of perceptibility, whereas the unfamiliarity of orthographic input did not pose additional challenges.
Showalter (
2020) extended this study to compare naïve, beginner, and experienced learners, as well as the impact of explicit instruction. Interference effects from incongruent GPCs were particularly evident with the naïve participants, which did not improve with instruction, but these interference effects reduced with increased language experience. The role of experience is further discussed in the next section.
The effect of familiarity and congruence across scripts has been further investigated by looking at learning Mandarin words with Pinyin or Zhuyin
10 (see
Figure 2).
Hayes-Harb and Cheng (
2016) assigned L1 English speakers to a Pinyin (familiar) and Zhuyin (unfamiliar) group, who were taught and tested on 16 Mandarin pseudowords, with both native and nonnative target phonemes. Stimuli presented to the Pinyin group were either congruent or incongruent with L1 GPCs (e.g., [nai]-<nai> or [ɕiou]-<xiu>). Three experiments were conducted with the same participants. The first taught and tested the novel words with auditory and written input, where participants decided whether the auditory and written form matched or mismatched. The second additionally included line drawings during teaching, and required participants to decide whether the auditory form matched the image. The third assessed consonant discrimination, to aid in the interpretation of findings. It was predicted that unfamiliar and familiar–congruent items would promote improved performance, while the familiar–incongruent items would be more difficult.
As expected, the Pinyin and Zhuyin groups both performed at ceiling level in the congruent trials. While the Zhuyin group outperformed the Pinyin group overall, this was only significant for the incongruent trials. The size of this effect was particularly strong when learning the phonological form of novel words, illustrated through the auditory–image-matching task. There was no difference between groups in their perceptual discrimination, as they all performed with ceiling-level accuracy across all items. Taken together, this was interpreted to show the advantage of avoiding L1 interference through unfamiliar graphemes, in comparison to that of familiar–incongruent GPCs. However, it is noteworthy that the tasks did not involve differentiating between confusable contrasts, there was no audio-only condition, and the design differences involved different amounts of exposure to both auditory and written forms than in the other studies mentioned above. Primarily,
Hayes-Harb and Cheng (
2016) contribute to evidence that the negative influence of familiar–incongruent written input on L2 phonological learning is of greater concern than entirely unfamiliar written input.
Further insight has been offered into unfamiliar orthographic influence by using a distributional learning approach (
Alarifi and Tucker 2023). This approach involves using probabilistic distributional information available in the input to form sound categories. L1 English participants were assigned to six learning groups, where they were trained to detect the Arabic singleton–geminate contrast for /m/ and /n/. They were exposed to either unimodal or bimodal auditory input, with accompanying orthographic stimuli in the Roman or Arabic script. The orthographic input then varied in terms of compatibility with the auditory input (e.g., unimodal audio spelled with <m> or <م> = compatible, unimodal audio spelled <mm> or <مّ>
11 = incompatible). It was predicted that participants would rely more on orthographic cues over auditory distributional information to support their learning of the length distinction, and that this reliance would be less evident with unfamiliar written inputs.
When tested on an AX discrimination task, participants who were exposed to bimodal audio and compatible familiar written cues were more successful in inferring the geminate length contrast than with bimodal audio alone. However, the bimodal audio with compatible unfamiliar written cues did not significantly improve discrimination scores. Speculatively, the lack of influence with the Arabic geminate written cue may be related to the reduced salience of a diacritic compared to a double-letter, rather than to the general unfamiliarity. Focusing on the findings related to unfamiliar script input exposure, participants were reportedly 191 times less likely to discriminate the length contrast if they were exposed to unimodal audio and compatible written cues, than with unimodal audio alone. Meanwhile, those exposed to bimodal audio with incompatible unfamiliar spelling were 98 times less likely to discriminate the geminate contrast, than with bimodal audio only. These findings demonstrate the ability of orthography to override auditory input, even when entirely unfamiliar. The lack of support provided by the Arabic geminate written cue casts doubt on the extent to which unfamiliar written input is able to promote the perception of a nonnative length contrast over distributional information in the audio. This study points to novel methodological routes of enquiry for the field and raises important questions around implicit and explicit processing in relation to orthographic input and phonological learning. However, the extraordinarily large odds ratios suggest that these effects may be overestimated, potentially due to the small sample size in each group (
Greenland et al. 2016). Thus, findings should be interpreted with caution and further exploration is warranted.
Summarising the findings reported in this section, these studies demonstrate that even minimal exposure to an entirely unfamiliar script can influence L2 phonology. There is little evidence to suggest that entirely unfamiliar orthographic input supports the encoding of confusable L2 contrasts during novel word learning, over audio-only input. However, as anticipated, unfamiliar written input does not lead to inhibitory effects to the same extent as familiar–incongruent written input does (
Hayes-Harb and Cheng 2016;
Showalter and Hayes-Harb 2015;
Showalter 2018). While initial experiments by
Showalter and Hayes-Harb (
2015) suggested a null influence of unfamiliar orthographic input, later studies indicate a more complex picture, where orthographic effects are variably evidenced depending on L1 script overlap (
Mathieu 2016), the perceptibility of the target phonology (
Hayes-Harb and Cheng 2016;
Shepperd 2018;
Showalter 2018), and the systematic written representation of auditory cues (
Alarifi and Tucker 2023).
Further research is needed to interpret the sizable effects reported in the emerging research on this topic. In particular, it is clear that methodological limitations need to be addressed, including small sample sizes, the predominantly monolingual Anglophone university student participants, and single-session experiments. Larger and more diverse samples would offer greater insight into the extent to which findings are robust and generalisable. Additionally, multi-session experiments would better indicate how input relates to longer-term learning. With developmental trajectories in mind, the next section presents evidence of cross-scriptal orthographic influence on the phonological development of experienced L2 learners.
7. Experienced Learners
The studies reviewed in this section all investigate the influence of L1-distinct orthographic input on developing L2 phonology across different levels of proficiency and literacy experience. These studies seek to understand whether, as familiarity increases with proficiency and literacy experience, distinct script input can support phonological learning. In contrast to naïve learners, these participants are not faced with the same challenges, as both L2 sounds and symbols are more familiar. In this case, learners may be better able to take advantage of distinct written input, which does not promote L1 transfer to the same extent as shared script input.
In comparison to the previous section, these studies involve a wider range of methods and more diverse samples. Additionally, varied analytical approaches were used and effect sizes were less consistently reported. Where feasible, effects sizes have been calculated from reported statistics and are indicated in the footnotes of
Table 2. In addition to the partial eta squared (η
p2) and probability of superiority (Ps) values mentioned in the previous section, the effects reported below are measured using Cohen’s
d, from Wilcoxon Signed-Rank test scores, and odds ratios in relation to logistic mixed effects models. The commonly used benchmarks for interpreting Cohen’s
d are 0.2, 0.5, and 0.8 for small, medium, and large effect sizes, respectively. As there is controversy around the interpretation of odds ratios, particularly with small to moderate samples, the
β coefficient is also reported in the table. The findings in
Table 2 demonstrate that large effects are commonly reported across these studies. However, results should be interpreted with caution and take into account the sample sizes and number of experimental trials.
The first study to mention is from
Pytlyk (
2011), who conducted a multi-session study with L1 English speakers, involving Mandarin instruction with Pinyin, Zhuyin, or no orthographic input. Strictly speaking, this study was conducted with naïve participants, like the studies in the previous section. However, the addition of language classes and learning over several weeks offers a stepping stone from complete unfamiliarity to the initial decoding of a distinct script. Mandarin consonants were chosen where L1-shared Pinyin symbols were incongruent with English GPCs and mapped to nonnative Mandarin sounds (e.g., <c>—[tsʰ]). An oddity discrimination task was conducted before and after receiving 4.5 h of Mandarin instruction over three lessons, focused on teaching all Mandarin phonemes, amongst other introductory language content. The hierarchy of perception accuracy in the posttest was predicted to be Pinyin < no orthography < Zhuyin. The perceptual performance of all three groups did not differ significantly, which the author speculatively connects to the limited amount of instruction and small sample size. It may also be the case that orthographic influence is evidenced to a lesser degree in perceptual discrimination tasks, compared to testing the lexically-encoded phonological form (
Hayes-Harb and Cheng 2016).
In another study looking at the earliest stages of L2 learning,
Al Azmi (
2019) investigated the influence of orthographic input and L1 literacy experience on rates of epenthesis and deletion in the production of L2 English consonant clusters. As mentioned, a known orthographic effect on L2 phonology is increased vowel epenthesis to simplify complex consonant clusters, rather than consonant deletion, which is more commonly evidenced in L1 acquisition (
Young-Scholten 2002;
Detey and Nespoulous 2008). For example, when producing the word ‘text’- /tɛkst/, do learners simplify the consonant cluster as [tɛks] (deletion) or [tɛkist] (epenthesis)? Al Azmi investigated whether increased epenthesis is found with written input in an L1-distinct script, and reduced in the context of L1 low-literacy. Beginner English classes were given to 60 L1 Arabic speakers, which involved learning 26 target words with different English onset and coda clusters. Participants were taught in ten 20 min lessons over five weeks, and were divided into three groups: non-literate, Arabic literate audio-only, and Arabic literate audio + Roman script input groups. As anticipated, the non-literate group had a higher rate of deletion in picture naming productions than the literate groups, and the audio-only group had a higher rate of deletion than the audio + Roman script group. These results align with shared script research, demonstrating that orthographic input promotes epenthesis and the importance of producing all visually represented units (
Young-Scholten et al. 1999;
Bassetti 2007;
Bassetti and Atkinson 2015), even across distinct scripts with limited L2 script familiarity. Importantly, these findings also highlight that (a lack of) L1 literacy experience affects developing L2 phonology.
Extending insights into higher levels of proficiency,
Hao and Yang (
2021) compared naïve, intermediate, and advanced L1 English learners of L2 Mandarin and their lexical encoding of segmental and tonal contrasts. Participants were taught 16 low-frequency Mandarin words through the presentation of (1) auditory forms, (2) English translation, and (3) the written form in either L1-shared Pinyin or distinct Chinese characters. In a subsequent audio–meaning-matching task, tonal encoding, but not segmental encoding, was facilitated by exposure to Chinese characters for both intermediate and advanced learners, more than Pinyin. Meanwhile, the naïve participants were more accurate with Pinyin input, adding to evidence that entirely unfamiliar graphemes do not support phonological learning. The authors propose that, as tonal information is not separated from segmental information in characters, sufficiently proficient learners may benefit from the more holistic representation of a syllable. In comparison, Pinyin separates the tone from the segment by representing it as a diacritic. With increased script literacy experience, learners may also benefit from the reduced L1 interference with distinct script inputs compared to shared written forms. Additionally, the authors connect the apparent shift in preferred script input with experience and the prevalent literacy practices of learners, inside and outside the classroom, as proficiency increases.
Mok et al. (
2018) also investigated the difference between learning L2 Mandarin tones with characters and Pinyin, but with L1 Cantonese speakers. Both Mandarin and Cantonese are tonal languages, but have different tonal systems. Mandarin has four tones, meanwhile Cantonese has six tones. Due to the historical relationship between these languages, there are certain regularities in their tonal correspondence. For example, Mandarin tone 1 maps to Cantonese tone 1 most often (84%), whereas Mandarin tone 2 usually maps to Cantonese tone 4 (76%) or tone 6 (12%). Therefore, the authors predicted that exposure to Chinese characters would promote increased L1 transfer of tonal mappings, compared to Pinyin. In particular, they predicted that the systematicity of tone diacritics in Pinyin would support L2 speech perception and production. In this study, Chinese characters were the shared script and Pinyin was distinct for the L1 Cantonese speakers, who were experienced learners of Mandarin. In contrast to the use of Pinyin in Mainland China, Hong Kong students are not taught Cantonese with a Romanised system. However, while it is not discussed in the article, biliteracy and proficiency in English is likely, based on the use and prevalence of English in Hong Kong. Therefore, neither script is unfamiliar but the tonal diacritics in Pinyin are not found in English orthography and should not introduce issues around incongruence.
All 49 participants heard 16 monosyllabic words in Mandarin and had to choose from four written forms on the screen, where one block presented two quartets of the items in Pinyin and another two quartets in characters (e.g., <yīn yín yǐn yìn> and <翻 反 犯 凡>). A subset of 38 participants also completed two further orthographic blocks of 192 trials with bisyllabic words, where participants chose between minimal pairs in Pinyin and characters (e.g., <gǔ shī—gǔ shí> and <剪刀—尖刀>). Bisyllabic words were formed for six possible tone-pair contrasts, such as TIT2, T3T4, but not T1T1. A further subset of 16 participants (8 high and 8 low performance) went on to complete production tasks. For the monosyllabic words, participants were presented with 8 words in Pinyin and 32 in characters, while 96 bisyllabic items were presented in Pinyin and a further 96 in characters. Participants were then recorded reading each word aloud three times. Due to the differences between sample sizes, materials, and procedures, it is difficult to interpret and directly compare the tasks. However, findings add to evidence of orthographic influences across scripts and the importance of considering task demands.
As predicted, Pinyin was found to facilitate the perception and production of tones over characters, but only in monosyllabic words. While Pinyin accuracy remained high, characters proved more beneficial when testing the perception of disyllabic words. Unsurprisingly, high performers were more accurate than low performers in their tonal productions. It then appeared that high performers were better able to take advantage of the Pinyin forms with both monosyllabic and disyllabic items. Additionally, the difficulty of the contrast between tone 2-tone 3 appeared to be exacerbated when presented alongside Pinyin. This was evidenced across perception and production, both syllable lengths, and most pronounced for low-performance participants. Overall, some evidence is provided for the benefits of distinct script input. However, this likely depends on task complexity, individual aptitudes, proficiency, and script literacy experience, all of which deserve further investigation. These findings also align with other reports that systematic distinct input holds limited benefit if the perceptibility of the target language is too low (
Showalter and Hayes-Harb 2015;
Shepperd 2018).
Looking at the relationship between phonology and orthography from a different angle,
Ota et al. (
2009) used a semantic-relatedness task to demonstrate the effects of L1 phonology on L2 lexical representations during visual word recognition. They tested L1 Arabic, Japanese, and English speakers to see whether English near-homophones would be perceived as homophonous when differing by a nonnative contrast. For example, Japanese lacks the /l-r/ distinction between <lock> and <rock>, which is likely to influence the judgement that <key> and <rock> are related. This contrast is established in Arabic, which then lacks the /p-b/ contrast found in English and Japanese. Participants in each language group, all with high proficiency in English, were asked to judge the relatedness of 20 homophone pairs, 20 /l-r/ minimal pairs, and 20 /p-b/ minimal pairs, based on their spelling, without audio. As predicted, all participants were less accurate and slower when judging real homophones. Furthermore, the Japanese group was less accurate and slower with /l-r/ items, while the same was true of the Arabic group with the /p-b/ items. These findings show that cross-linguistic transfer occurs at the level of phonological representation, not misperception or production, which is striking in the context of the clear visual distinction in the spelling. Thus, this study further underscores that the disambiguating benefits of systematic, distinct written forms (e.g., <l-r> and <p-b>) are limited by the L1 influence on phonological representations of L2 lexical entries, even in the context of high L2 proficiency.
Several studies have also looked at cross-scriptal orthographic effects on L2 allophonic variation.
Lu and Lee (
2023) conducted an imitation production task with experienced L1 Mandarin learners of L2 English. They found that the accurate production of allophonic unaspirated stops was impeded by exposure to distinct Roman script input, in comparison to audio-only imitation. However, this effect was stronger for pseudowords, indicating that increased exposure to real lexical items reduced the effects of written input.
The effect of distinct script input on L2 allophonic production and lexical-encoding was also demonstrated by
Han and Kim (
2017). They taught and tested Korean pseudowords with allophonic variants of /h/ over three learning sessions to beginner and advanced L1 Mandarin learners of L2 Korean. In the final learning session, participants of both proficiency levels were either shown the <ㅇ> spelling indicating a deleted consonant, the <ᄒ> spelling for the [ɦ] segment, or audio-only presentation. In both a picture-naming and a spelling-recall task, the orthographic exposure during learning had a strong influence on the extent to which participants produced or deleted [ɦ], with a limited effect of proficiency. Thus, the authors argue that L2 learners restructure phonological representations according to orthographic input, including allophonic variation. Considering the large effect sizes and the recent findings from
Lu and Lee (
2023), it would be of interest to further investigate these effects with a larger sample per group, and compare real and pseudowords.
Finally,
Han and Kim (
2022) looked again at Mandarin learners of Korean phonological variants, but, this time, looking at the activation of orthography during the spoken-word processing of bisyllabic words featuring Korean obstruent nasalisation. Intermediate to advanced learners of Korean, and a control group of L1 Korean speakers, completed a cross-modal priming task with 16 sets of real words and pseudowords in Korean, differing by cross-modal (written prime—auditory target) and within-modal (auditory prime and target) conditions. The analysis of the real word trials revealed both L1 and L2 Korean speakers were more accurate when prime and target words were repeated in the cross-modal condition compared to the within-modal condition. The advantage of cross-modal primes was more pronounced for L2 learners when the written form reflected the underlying phonological form and mismatched with the phonetic forms (e.g., pseudo-repetition trials, <식물>—/sik.mul/—[siŋ.mul]), rather than when written and phonetic forms matched (e.g., repetition trials, <식당>—/sik.taŋ/—[sik.taŋ]). Even though L2 learners were less accurate than the L1 speakers, these findings suggest that L2 learners can benefit from orthographic input in a distinct script during the spoken word recognition of regular phonological variants.
Claims by (
Veivo et al. 2015,
2018;
Veivo and Jarvikivi 2013) may offer additional context for the facilitative effect of cross-modal priming with the mismatching of written and audio forms involving phonological alternations. For example, they argue that there is often a bias towards orthographic information in L2 lexical representations, where instructional learning can lead to written forms being more established than phonological forms. Further they provide evidence that the activation of orthographic information and facilitative orthographic effects in the context of spoken word recognition are more evident for advanced learners, who are better able to suppress misleading information. While Han and Kim did not find the length of Korean acquisition to be a significant predictor of spoken word recognition errors, further studies looking at orthographic effects on spoken word recognition at different proficiency levels would be valuable. Additionally, as Korean is a transparent alpha-syllabary system, it would be of interest to see if these facilitative effects extend to more opaque, distinct script input. Finally, for comparison with other shared script (
Young-Scholten and Langer 2015;
Hayes-Harb et al. 2018) and distinct script (
Lu and Lee 2023) studies investigating orthographic input and phonological alternations, the integration of production tasks would prove insightful.
Drawing together the findings of studies with experienced learners, there is compelling evidence that distinct script input influences L2 phonology, particularly with increasing L2 proficiency and literacy experience. The only study reporting null effects was conducted with naïve participants with limited instruction (
Pytlyk 2011), indicating that L1 English participants were not sufficiently familiar with the Zhuyin after 4.5 h of instruction to take advantage of the systematic, distinct written forms. Indeed,
Hao and Yang (
2021) demonstrated that L1 English speakers only benefited from distinct Chinese characters over Pinyin forms for Mandarin tonal contrasts with intermediate to advanced proficiency.
Mok et al. (
2018) also reported that higher-performance L1 Cantonese learners of Mandarin were better able to take advantage of systematic, distinct Pinyin written input when perceiving and producing Mandarin tones. However, as proficiency was not measured in this study, these group differences draw attention to other individual differences that may be relevant, such as auditory or cognitive processing abilities. One study, from
Al Azmi (
2019), did find evidence of cross-scriptal orthographic effects with beginner L2 learners, where exposure to distinct script orthography promoted the use of epenthesis over deletion when simplifying complex consonant clusters. Relatedly,
Han and Kim (
2017) found that learners were more likely to produce or omit allophonic variants depending on the written cues they were given. These orthographic effects of epenthesis and deletion align with those found across shared scripts (
Bassetti n.d.;
Bassetti 2006;
Young-Scholten 2002). Additionally, the inclusion of lexical tone and allophonic distinctions in these studies demonstrates that cross-scriptal orthographic influence is not limited to segmental phonology.
Overall, there is little to suggest that distinct script written forms introduce additional interference for experienced learners, as is the case with shared–incongruent written input. The studies in this section indicate that distinct script input can support the lexical encoding (
Hao and Yang 2021) and the perception and production of nonnative contrasts (
Mok et al. 2018), as well as the spoken word recognition of rule-governed phonological variants (
Han and Kim 2022). The only study to indicate that distinct script input had an inhibitory effect for experienced learners was in the context of producing allophones in pseudowords, and this effect did not extend to real words (
Lu and Lee 2023). However, it may be the case that the benefits of distinct script inputs are limited by various factors, such as lack of familiarity, systematicity, and perceptibility of the target phonology. In the context of confusable nonnative contrasts,
Ota et al. (
2009) demonstrated that even with high levels of proficiency and experience with a distinct script, L1 phonological interference persists. This is also reflected in the findings of
Mok et al. (
2018), where particularly poor performance with the distinct script input was reported for the confusable tone 2–tone 3 contrast. Additionally, the increased difficulty with items where the tonal correspondence between Mandarin and Cantonese was irregular suggests that distinct script input may hold limited benefit outside of dominant L1–L2 phonological correspondences.
As demonstrated in the overview of the studies in
Table 2, the research reported in this section is highly varied in terms of aims, language combinations, proficiency levels, sample sizes, methods, and analytical approaches. While it would be beneficial to see a clearer line of enquiry emerge in the field, especially with greater theoretical direction, the evidence of cross-scriptal orthographic effects across perception, production, lexical encoding and spoken word recognition is welcomed. As expected, orthographic influence on L2 phonology persists across writing systems, specifically where the L1 and L2 are represented by distinct scripts, and this influence appears to be moderated by L2 proficiency and literacy experience. The language and script literacy combinations in these studies also bring educational backgrounds and a range of individual differences into focus. However, the extent and nature of cross-scriptal orthographic effects mediated by these variables is yet to be fully explored.
8. Discussion
Over the last ten years, research into cross-scriptal orthographic influences on L2 phonology has been gradually increasing, but the topic remains largely unexplored. This means that there is little to guide both research and pedagogy relevant to the large number of adults around the world learning languages in an orthographic script that differs from that of their first or known languages. Even less is known about the effects of written input on the phonological development of those with diverse literacy profiles, including multi-script literate adults, or those lacking literacy in any or all their spoken languages. Based on the emerging evidence presented here, it is likely that L2 phonological learning is impacted by written input in a distinct script, even in contexts of minimal exposure with entirely unfamiliar orthographic input. As such, research would benefit from continuing to systematically investigate what type of effects are found when, and why.
Preliminary insights from studies with naïve participants indicate that the additional challenges posed by visually processing unfamiliar written forms are less of a hindrance than interference from familiar but incongruent orthographic input (
Showalter 2018;
Hayes-Harb and Cheng 2016;
Showalter and Hayes-Harb 2015). Some studies go further to suggest that even entirely unfamiliar orthographic input can be beneficial for L2 phonological learning (
Jackson 2016;
Alarifi and Tucker 2023); however, more research is required to assess these claims. Overall, the small collection of presented studies investigating entirely unfamiliar orthographic effects suggest that the variables outlined by
Hayes-Harb and Barrios (
2021) (systematicity, familiarity, congruence, and perceptibility) are relevant to understanding orthographic effects in both shared and distinct written input contexts. These studies benefit from a broadly shared methodological approach, one that is now well-established by Hayes-Harb and colleagues. As such, comparable discussions of findings highlight the need to better understand orthographic effects in relation to the perceptibility and phonological representation of the target language, to then shed light on the influence of script familiarity. The replication of these studies with larger sample sizes and measures of both perception and production would be highly beneficial to clarify varied findings. Additionally, the near-exclusive testing of L1 English student samples is a clear methodological point to address.
Research investigating cross-scriptal orthographic influences on the phonological development of active and experienced learners includes a wider range of language backgrounds and combinations, as well as methodological approaches, offering inevitably diverse findings. However, three points are apparent. Firstly, the construct of familiarity, as originally outlined by
Hayes-Harb and Barrios (
2021), must be amended to account for varying levels of familiarity with a script that is not shared with first or known languages. For this reason, script overlap has been proposed as an additional factor, to capture the way in which shared vs. distinct script inputs may variably influence orthographic effects on L2 phonology, separate from the level of familiarity. Secondly, individual differences, including L2 proficiency, L1 and L2 literacy experience, and auditory processing ability, deserve greater attention when seeking to tease apart the complexities of cross-scriptal orthographic effects. Thirdly, cross-scriptal orthographic effects on L2 phonology appear to be pervasive across phonemes and allophones; perception, production, and priming; alphabetic, abjad, and morphemic writing systems; and into high levels of L2 proficiency. While further research is needed to assess how robust and replicable initial findings are, these studies offer several launching points for future research in this area.
In order to propel research forward and disentangle the many and varied influences of orthography on L2 phonology across scripts and writing systems, more theoretically driven and methodologically innovative routes are required. To address the first point, it is noteworthy that there is little to no mention of how the methods and findings within the presented studies relate to theoretical accounts of L2 phonology. Several of the studies mentioned in this article focus on the encoding of confusable contrasts, where there is clear scope to refer to the predictions of PAM (
Best and Tyler 2007;
Best 1995). Additionally, the speculative predictions made by
Tyler (
2019), in relation to shared alphabetic script input, could be further explored. Indeed, broad claims that written input can be supportive of phonological learning if cues are systematic and congruent relate to the findings discussed here, as does the suggestion that reliance on written forms may exacerbate the difficulty of encoding confusable contrasts.
As an example,
Shepperd (
2018) chose /k-q/ and /x-ɣ/ as examples of a single category (SC) and an uncategorised (UU) contrast for naïve L1 English learners of L2 Arabic pseudowords, respectively. Predictions for perceptual discrimination difficulty were then made available for testing, in comparison to two category (TC) contrasts of /s-z/ and /m-n/. Aligning with
Tyler’s (
2019) suggestions, the difficulty associated with the nonnative contrasts increased with both shared and distinct script input. Clarification and discussion of the assumed perceptual assimilation patterns for /χ-ћ/ and singleton–geminate contrasts with a similar population (
Mathieu 2016;
Alarifi and Tucker 2023) could shed light on how to interpret varied findings and the mediating variable of perceptibility, in relation to orthographic effects. Similarly, there is scope to explore SLM predictions (
Flege 1995;
Flege and Bohn 2021) for L2 speech production in the context of studies with experienced learners, such as those reviewed above.
With regard to addressing the methodological limitations noted throughout the paper, sample diversity and sample size are recurring issues to highlight. Innovation is called for here, as both rigorous and novel approaches are required to meet these sampling challenges. Even once it is accepted that more diverse participant samples are worth actively considering when designing and conducting research, the overrepresentation of university student samples is largely related to convenience. Designing research which is inclusive and accessible to a wider variety of people can require far more time, energy, and resources on the part of the researcher. One promising route is through the use of internet-based methods. Online approaches can facilitate the inclusion of larger and more diverse samples in psycholinguistic research, and have been used to investigate orthographic influences on L2 phonology (
Shepperd 2022). However, this is by no means a silver bullet for issues around sampling and recruitment, and it is critically important to consider ways to conduct cross-linguistic and cross-cultural (online) research well.
The dearth of mixed methods research is also notable. Qualitative approaches are well-suited to exploratory research, generating theory, and shedding light on complex socio-cultural phenomena (
De Costa et al. 2017), all of which would be beneficial for future research exploring orthographic influence, particularly research across writing systems. Writing is a human invention and a tool connected to social history and diverse cultural practices across communities. We know that adult language learners bring their existing knowledge of the world with them to new language learning. However, the question of how the learners themselves understand the relationship between orthography and phonology when learning additional languages remains relatively unexplored (
Bassetti et al. 2020). Thus, there is much to be gained from combining qualitative and behavioural insights within this field.
To conclude, a few pedagogical considerations are offered in light of the evidence discussed in this paper. Due to the limited and complex findings related to cross-scriptal orthographic influence on L2 phonology, concrete recommendations for instructed settings are not possible. That being said, further evidence has been given of well-established interference effects related to shared and overlapping–incongruent orthographic input in the context of language learning across distinct writing systems. Additionally, the lack of clear benefit associated with unfamiliar and distinct script input for lower-level learners aligns with broader calls for caution against an overreliance on written input during the earliest stages of adult additional language learning (
Tyler 2019;
Hayes-Harb et al. 2018;
Rafat and Stevenson 2018;
Sokolović-Perović et al. 2019). Such caution does not appear to be necessary for higher-proficiency learners, who are better able to take advantage of distinct written cues in relation to developing L2 phonology. Future research would benefit from considering the ways in which cross-scriptal orthographic effects are relevant to the learning and teaching of L2 phonology, alongside offering practical implementations of recommendations in instructed settings.




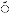 > diacritic in Arabic.
> diacritic in Arabic.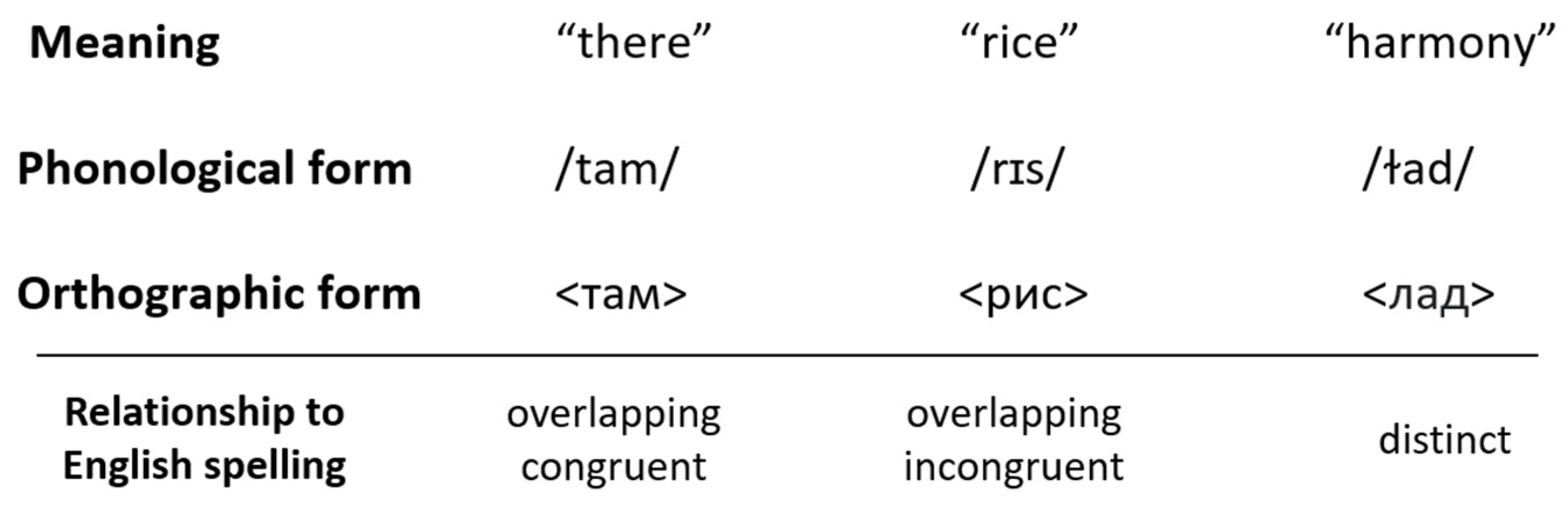

{kind=link}
{kind=link}